
Abstract
In this paper, we extend the two-step matrix splitting iteration approach by introducing a new relaxation parameter. The main idea is based on the inner–outer iteration for solving the PageRank problems proposed by Gleich et al. (J Sci Comput 32(1): 349–371, 2010) and Bai (Numer Algebra Cont Optim 2(4): 855–862, 2012) and the two-step splitting iteration presented by Gu et al. (Appl Math Comput 271: 337–343, 2015). The theoretical analysis results show that the proposed method is efficient. Numerical experiments demonstrate that the convergence performances of the method are better than the existing methods.
Similar content being viewed by others
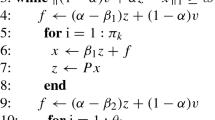
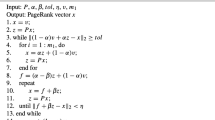

Avoid common mistakes on your manuscript.
1 Introduction
Consider the solution of the eigenvalue problem with the following form:
where P is the column-stochastic matrix with appropriate dimension, i.e., its entries are nonnegative real numbers and all its columns sum to one. \(\alpha \in (0,1)\) denotes the damping factor which determines the weight given to the Web link graph. e is a column vector with all the ones, and v is a personalization vector or a teleportation vector. x is the eigenvector to be determined.
The above linear system (1.1), the so-call PageRank problem, occurs when one determines the importance of the Web pages based on the graph of the Web. PageRank can be viewed as a stationary distribution of a Markov chain (Langville and Meyer 2005). The PageRank has been widely exploited by Google as part of its search engine technology with the rapid development of the Internet. Although the exact ranking techniques and calculation approaches used by Google have been improved gradually, the PageRank method still receives great attention and becomes a hot issue in the field of science and engineering calculation in the last years.
At present, the method for solving the model (1.1) can be classified as a direct method and iterative method. The direct method often involves a lot of storage of the filling elements; especially when the coefficient matrix and the condition number are very large, the stability of the direct method is weak. In view of the sparsity of the matrix P, one can take advantage of the sparse structure to reduce the storage space and computation. The iterative method has become a popular approach for solving the eigenvalue problem. Sauer developed the Power method to compute PageRank, as it converges for every choice of a nonnegative starting vector (Sauer 2005). But, when the damping factor \(\alpha \) is large, the Power method easily causes a low efficiency in the convergence performance. An extrapolation method was proposed, which speeds up the convergence by calculating and then subtracting off estimates of the contributions of the second and third eigenvectors (Kamvar et al. 2003). Also, Kamvar et al. (2004) proposed the adaptive methods to improve the computation of PageRank, in which the PageRank of pages that have converged are not recomputed per iteration. PageRank-type algorithms are used in application areas other than Web search (Morrison et al. 2005). Capizzano considered the Jordan canonical form of the Google matrix, which is a potential contribution to the PageRank computation (Capizzano 2005). The Krylov subspace methods have also been considered recently. Jia presented the restarted refined Arnoldi method (Jia 1997) which can be regarded as the variant of the Arnoldi-type algorithm proposed by Golub et al. in (2006). A lot of approaches have been given; see the book (Langville and Meyer 2006), which provides a more comprehensive description of the PageRank problem, the papers (Bai et al. 2004, 1996; Bai 2012; Berkhin 2005; Gleich et al. 2010; Langville and Meyer 2005, 2006; Page et al. 1999; Yin et al. 2012; Golub and Van Loan 1996; Wu and Wei 2007; Kamvar et al. 2003; Huang and Ma 2015; Fan and Simpson 2015; Skardal et al. 2015), which contain many additional results and useful references, and the book (Stewart 1994), which includes overviews of the Markov chains.
Gu et al. (2015) developed a two-step matrix splitting iteration (TSS) for computing PageRank which is based on the inter–outer iteration (IOI) approach proposed by Gleich et al. in (2010) and Bai in (2012). Inspired by these works, in this paper, we construct a new relaxed two-step splitting iteration method (RTSS) for computing PageRank, which can be showed as a more efficient and flexible technique for this problem.
The remainder of the paper is organized as follows. In Sect. 2, we first give a brief review of the inter–outer iteration and two-step matrix splitting iteration methods. Also, consider a new relaxed two-step splitting iteration method for computing PageRank (1.1). In Sect. 3, we provide the convergence analysis in detail. Some numerical experiments are given to illustrate that the new method is efficient in Sect. 4. Finally, we end the paper with some conclusions in Sect. 5.
2 The RTSS method
In this section, we review the inner–outer iteration and two-step matrix splitting iteration approaches for computing the PageRank problem.
It is obvious that the eigenvector problem (1.1) is equivalent to solve the following linear system
where I denotes the identity matrix with the corresponding dimension clear from the context.
By (2.1), it is known that the smaller the damping parameter \(\alpha \), the easier it is to solve the problem. In view of this consideration, Gleich et al. presented the inner–outer iteration approach for solving the system (2.1) (Gleich et al. 2010). Now, we give a brief review of this approach.
The coefficient matrix of (2.1) can be written as the following splitting:
where \(M_1=I-\beta P,~N_1=(\alpha -\beta )P.\) Then, the fixed point equation of (2.1) gives
So the stationary outer iteration scheme
where \(0<\beta <\alpha .\) Moreover, the inner Richardson iteration
is considered to speed up the outer iteration, where \(f=(\alpha -\beta )Px^k+(1-\alpha )v,~j=0,1,2\ldots ,l-1,~y^0=x^k.\) The l-th step inner solution \(y^l\) is assigned to be the next new \(x^{k+1}.\) The inner–outer iteration method is listed following Algorithm 2.1.

Based on the inner–outer iteration method, Gu et al. proposed a two-step splitting iteration (TSS) for PageRank which is closely related to the power method and Richardson iteration. It is shown in the following Algorithm 2.2

In fact, an iteration updating (2.3) was considered before the vector f can be computed in step 2 of the IOI method in Algorithm 2.1. It has been shown that the TSS method derived better performances than the IOI method. Inspired by Gleich et al. (2010), Gu et al. (2015), we further consider these methods by introducing a new relaxed parameter \(\gamma ,\) which can accelerate the TSS method to a certain extent. Specially, the TSS method only involves the stationary outer iteration scheme, namely, the inner iteration must be a precise iteration. In Algorithm 2.2, the inner loop is an inaccurate iteration. The convergence of the TSS method was shown by Theorem 2 in Gu et al. (2015); however, the inner loop that leads to Algorithm 2.2 is a non-stationary iteration, which has been ignored. So, in the paper, we will discuss the situation in detail.
Now, we consider the coefficient matrix \(\mathcal {A}\) in the following splitting:
where \(M_2=\gamma I-\beta P, N_2=(\gamma -1)I+(\alpha -\beta )P,\) \(\gamma >0\). The relaxed two-step splitting iteration is described in the Algorithm 2.3.

Remark 2.1
In fact, if we set \(\gamma =1\), the RTSS is reduced to the TSS, so the RTSS approach is a generalized version of the TSS method. The flexible choice of the relaxation parameter \(\gamma \) of the RTSS generates excellent convergence performances than the TSS method, which can be seen in our numerical test parts.
Remark 2.2
Algorithm 2.3 is generated by the stationary iteration scheme, so it can be extended to study the absolute value equation (AVE) \(Ax+|x|=b\) (Mangasarian and Meyer 2006; Rohn 2012; Moosaei et al. 2015; Yong 2016; Yong et al. 2011), which can also be expressed in the form of a stationary equation. The importance of the AVE derives from the fact that quadratic programs, linear programs, bimatrix games and many other problems can all be reduced to a linear complementarity problem (LCP) (Cottle and Dantzig 1968; Cottle et al. 1992) which is equivalent to the AVE. Furthermore, we know that the AVE is NP-hard. It was testified in (Mangasarian 2007) by reducing the LCP corresponding to the NP-hard knapsack feasibility problem to an AVE. Under suitable hypotheses, such as when the singular values of the coefficient matrix A exceed 1, some efficient approaches can be utilized to solve the problem, for instance, generalized Newton method. In our future work, we will devote ourselves to investigate the AVE by the proposed method or its improved version.
3 The convergence properties
In this section, we discuss the convergence property of Algorithm 2.3 in detail. To this end, we rewrite Algorithm 2.3 as follows:
Theorem 3.1
Let parameters \(0<\beta <\alpha <\gamma \le 1\) and \(1-\alpha <\gamma \), \(m_k\) be the inner loop numbers for the k-th outer iteration. Algorithm 2.3 generates the iteration scheme
where
Then, the iteration solution \(x^k\) generated by Algorithm 2.3 converges to the exact solution \(x^*\) of the PageRank problem (1.1).
Proof
From (3.1), we obtain
Note that \(x^{k,0}=\alpha Px^k+(1-\alpha )v;\) moreover, we get
and therefore (3.2) holds.
It follows from (3.2)–(3.3) and the exact solution \(x^*\) that
where \(T^k\) denotes the k-th step iteration matrix. Combined with (3.2) and (3.5), we have
Then, one gives
if and only if
If \(\Vert T^k\Vert _1<\eta \) (\(0<\eta <1\)), then
Now, we will show the existence of the upper bound parameter \(\eta ^k\).
By (3.3), we get
It follows from \(e^TP=e^T\) that

The bfwa398 matrix with \(\alpha =0.901\), \(\beta =0.9\) and \(\gamma =0.94\)

The rdb5000 matrix with \(\alpha =0.901\), \(\beta =0.9\) and \(\gamma =0.94\)

The cryg10000 matrix with \(\alpha =0.901\), \(\beta =0.9\) and \(\gamma =0.94\)

The bfwa398 matrix with \(\alpha =0.45\), \(\beta =0.4\) and \(\gamma =0.8\)

The rdb5000 matrix with \(\alpha =0.45\), \(\beta =0.4\) and \(\gamma =0.8\)

The cryg10000 matrix with \(\alpha =0.45\), \(\beta =0.4\) and \(\gamma =0.8\)
where
As
it holds that
Furthermore, we have
So,
By (3.8)–(3.11), it means that
Combining with (3.7), we immediately get the conclusion, that is, the iteration solution \(x^k\) generated by Algorithm 2.3 converges to the exact solution \(x^*\) of the PageRank problem (1.1). This completes the proof. \(\square \)
4 Numerical experiments
In this section, we report some numerical results to illustrate the effectiveness of the relaxed two-step iteration (RTSS) method for solving the linear system (1.1) arising from the Google PageRank problem. All examples have been carried out by MATLAB R2011b (7.13), Intel(R) Core(TM) i7-2670QM, CPU 2.20GHZ, RAM 8.GB PC Environment. We compare our algorithm to the IOI and TSS methods. We use the following examples to examine these approaches with different iteration performances from these aspects of the iteration numbers(denoted by ‘IT’), elapsed CPU time in seconds (denoted by ‘CPU’) and the residual (denoted as ’RES’) defined by
We compare three approaches by choosing different parameters \(\alpha \), \(\beta \), and \(\gamma \) in a reasonable interval. Three sparse matrices, bfwa398, rdb5000 and cryg10000, are selected from the University of Florida sparse matrix collection (available at http://www.cise.ufl.edu/research/sparse/mat/). All numerical tests are shown in Tables 1,2 and Figs. 1, 2, 3, 4, 5 and 6. These results illustrate that the convergence of the RTSS approach performs better than the TSS and IOI methods’ both CPU time and the numbers of the iteration step, which demonstrates that the introduced approach is efficient.
5 Conclusion
In this paper, we have furthermore improved the two-step splitting iteration by introducing an additional relaxation parameter \(\gamma \) and presented a relaxed two-step splitting iteration for solving the PageRank problem, which can be regarded as a type of generalization for the TSS method. If we choose \(\gamma =1\), the RTSS approach is reduced to the TSS method. It is readily seen that the selection of the proper parameters \(\gamma \) may generate better convergence performances than the TSS and IOI methods. Numerical experiments show the effectiveness of the proposed approach.
References
Bai Z-Z, Golub GH, Lu L-Z, Yin J-F (2004) Block triangular and skew-Hermitian splitting methods for positive-definite linear systems. SIAM J Sci Comput 26(3):844–863
Bai Z-Z (2012) On convergence of the inner-outer iteration method for computing PageRank. Numer Algebra Cont Optim 2(4):855–862
Bai Z-Z, Sun J-C, Wang D-R (1996) A unified framework for the construction of various matrix multisplitting iterative methods for large sparse system of linear equations. Comput Math Appl 32(12):51–76
Berkhin P (2005) A survey on PageRank computing. Internet Math 2(1):73–120
Capizzano SS (2005) Jordan canonical form of the Google matrix: a potential contribution to the PageRank computation. SIAM J Matrix Anal Appl 27(2):305–312
Cottle RW, Dantzig G (1968) Complementary pivot theory of mathematical programming. Linear Algebra Appl 1:103–125
Cottle RW, Pang J-S, Stone RE (1992) The linear complementarity problem. Academic Press, New York
Fan C, Simpson O (2015) Distributed algorithms for finding local clusters using heat kernel pagerank, algorithms and models for the web graph. Springer International Publishing, pp 177–189
Gleich DF, Gray AP, Greif C, Lau T (2010) An inner-outer iteration for computing PageRank. SIAM J Sci Comput 32(1):349–371
Golub GH, Greif C (2006) An Arnoldi-type algorithm for computing PageRank. BIT 46(4):759–771
Golub GH, Van Loan C (1996) Matrix computations, 3rd edn. The Johns Hopkins University Press, Baltimore
Gu C-Q, Xie F, Zhang K (2015) A two-step matrix splitting iteration for computing PageRank. J Comput Appl Math 278(15):19–28
Huang N, Ma C-F (2015) Parallel multisplitting iteration methods based on M-splitting for the PageRank problem. Appl Math Comput 271:337–343
Jia Z-X (1997) Refined iterative algorithms based on Arnoldis process for large unsymmetric eigenproblems. Linear Algebra Appl 259(1):1–23
Kamvar S, Haveliwala T, Manning C, Golub GH (2003) Extrapolation methods for accelerating PageRank computations. In: Twelfth International World Wide Web Conference, Budapest, Hungary, pp 261–270
Kamvar S, Haveliwala T, Golub GH (2004) Adaptive methods for the computation of PageRank. Linear Algebra Appl 386(15):51–65
Kamvar S, Haveliwala T, Manning C, Golub GH (2003) Exploiting the block structure of the web for computing PageRank. Technical Report, Stanford
Langville AN, Meyer CD (2005) A survey of eigenvector methods for Web information retrieval. SIAM Rev 47(1):135–161
Langville A, Meyer C (2006) Googles PageRank and beyond: the science of search engine rankings. Princeton University Press, Princeton
Langville A, Meyer C (2006) A reordering for the PageRank problem. SIAM J Sci Comput 27(6):2112–2120
Mangasarian OL, Meyer RR (2006) Absolute value equations. Linear Algebra Appl 419(2):359–367
Mangasarian OL (2007) Absolute value programming. Comput Optim Appl 36(1):43–53
Morrison JL, Breitling R, Higham DJ, Gilbert DR (2005) GeneRank: using search engine technology for the analysis of microarray experiments. BMC Bioinform 6:233
Moosaei H, Ketabchi S, Noor MA (2015) Some techniques for solving absolute value equations. Appl Math Comput 268:696–705
Page L, Brin S, Motwani R, Winograd T (1999) The PageRank citation ranking: bringing order to the web, Stanford Digital Libraries SIDL-WP-1999-0120, Stanford
Rohn J (2012) An algorithm for computing all solutions of an absolute value equation. Optim Lett 6(5):851–856
Sauer T (2005) Numerical analysis. Addison Wesley Publication, USA
Skardal PS, Taylor D, Sun J, Arenas A (2015) Collective frequency variation in complex networks and Google’s PageRank, arXiv preprint arXiv:1510.02018
Stewart W (1994) Introduction to the numerical solution of Markov chains. Princeton University Press, Princeton
Wu G, Wei Y-M (2007) A power-Arnoldi algorithm for computing PageRank. Numer Linear Algebra Appl 14(7):521–546
Yin J-F, Yin G-J, Ng MK (2012) On adaptively accelerated Arnoldi method for computing PageRank. Numer Linear Algebra Appl 19(1):73–85
Yong L-Q (2016) A smoothing newton method for absolute value equation. Int J Control Autom 9(2):119–132
Yong L-Q, Liu S-Y, Zhang S-M (2011) A new method for absolute value equations based on harmony search algorithm. ICIC Express Lett Part B Appl 2:1231–1236
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Jinyun Yuan.
The Project was supported by the National Natural Science Foundation of China (Grant Nos. 11071041, 11201074), Fujian Natural Science Foundation (Grant Nos. 2016J01005, 2015J01578), and Outstanding Young Training Plan of Fujian Province universities (Grant No. 15kxtz13, 2015).
Rights and permissions
About this article

Cite this article
Xie, YJ., Ma, CF. A relaxed two-step splitting iteration method for computing PageRank. Comp. Appl. Math. 37, 221–233 (2018). https://doi.org/10.1007/s40314-016-0338-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40314-016-0338-4