
Abstract
Linear programming is the core problem of various operational research problems. The dominant approaches for linear programming are simplex and interior point methods. In this paper, we show that the alternating direction method of multipliers (ADMM), which was proposed long time ago while recently found more and more applications in a broad spectrum of areas, can also be easily used to solve the canonical linear programming model. The resulting per-iteration complexity is O(mn) where m is the constraint number and n the variable dimension. At each iteration, there are m subproblems that are eligible for parallel computation; each requiring only O(n) flops. There is no inner iteration as well. We thus introduce the new ADMM approach to linear programming, which may inspire deeper research for more complicated scenarios with more sophisticated results.
Similar content being viewed by others
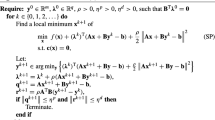

Avoid common mistakes on your manuscript.
1 Introduction
We consider the canonical linear programming (LP) model
where \(c, a_i, \, i=1, \cdots , m\) are given vectors in \(\mathbb {R}^n\) and \(b_i\in \mathbb {R}\). As one of the most fundamental mathematical problems in operational research, LP has been intensively studied in the literature. The simplex and interior point methods represent two most important categories among different methods for LP, we refer to, e.g., [1–3] for reviews. The purpose of this short note is to show that the alternating direction method of multipliers (ADMM), which was originally proposed in [4] and has recently found many impressive applications in a broad spectrum of areas, can be easily used for the LP model (1.1). We thus aim at proposing the new ADMM approach to LP, which is completely different from the major simplex and interior point approaches in the literature.
To introduce ADMM, we consider a convex minimization problem with linear constraints and its objective function is the sum of two functions without coupled variables:
where \(\mathcal{X}_i \subseteq \mathbb {R}^{s_i}\) are nonempty closed convex sets; \(\vartheta _i: \mathbb {R}^{s_i} \rightarrow \mathbb {R}\) are closed proper convex functions and \(\mathcal{A}_i \in \mathbb {R}^{t \times s_i}\) for \(i=1,2\); and \({\varvec{b}}\in \mathbb {R}^\mathrm{T}\). Note that we use bold letters in (1.2) because it may be in block-wise form. For example, \({\varvec{x}}_1\) may include more than one variable and \({\varvec{\vartheta }}_1\) may be the sum of more than one function.
Let \({\varvec{\lambda }}\in \mathbb {R}^\mathrm{T}\) and \(\beta \in \mathbb {R}\) denote the Lagrangian multiplier and penalty parameter of (1.2), respectively. Then, the augmented Lagrangian function of (1.2) is
When the ADMM proposed in [4] is applied to (1.2), the iterative scheme reads as
We refer the reader to [5–7] for some recent review papers on ADMM; in particular, its applications in various fields such as image processing learning, statistical learning, computer vision, wireless network, and cloud computing. It worths to mention that these application models usually have nonlinear objective functions, but they are in separable form and thus the decomposition over variables often makes the subproblems in (1.4) extremely easy.
Next, we will show that after an appropriate reformulation, the LP model (1.1) can be solved by the ADMM scheme (1.4); this application results in a per-iteration complexity of O(mn) where m is the constraint number and n is the variable dimension. Moreover, at each iteration, there are m subproblems that are eligible for parallel computation, and they all have closed-form solutions. Indeed, each of these subproblems only requires O(n) flops. We refer to [8] for some augmented Lagrangian-based efforts to LP.
2 Reformulation
In this section, we reformulate the LP model (1.1) as a more favorable form so that the ADMM scheme (1.4) can be used conveniently. Without loss of generality, we assume m is odd, i.e., \(m=2l+1\) where l is an integer. For the case where m is even, we can add a dummy constraint to make m odd (or vice versa if m is assumed to be even).
Clearly, if we introduce auxiliary variables \(x_i \in \mathbb {R}^n\) for \(i=1,\cdots ,m\) and define
the LP model (1.1) can be written as
Let us denote by A the coefficient matrix in (2.1). Then we have
where \(A_i\)’s denote the columns of A. For these columns \(A_i\)’s, we have
Further, let us regroup the variables, functions, and constraint sets in (2.1) as
and
Then, the model (2.1) is a special case of the block-wise model (1.2) with the specifications above and \({\varvec{b}}=0\). Thus, the ADMM scheme (1.4) is applicable. Note that we additionally have the following identities:
and
which are actually important facts that make the implementation of the ADMM scheme (1.4) extremely easy.
3 Application of ADMM for LP
Recall we assume \(m=2l+1\) in (1.1). Moreover, to implement the ADMM (1.4) to the reformulation (2.1), the Lagrange multiplier \({\varvec{\lambda }}\) can be denoted as
3.1 Algorithm
Now, let us elucidate the k-th iteration of the ADMM scheme (1.4) when it is applied to solve the model (2.1). More specifically, starting from given \({\varvec{x}}_2^k\) and \({\varvec{\lambda }}^k\), the new iterate \(({\varvec{x}}_1^{k+1},{\varvec{x}}_2^{k+1}, {\varvec{\lambda }}^{k+1})\) is generated by the following steps.
Step 1 With given \(({\varvec{x}}_2^k, {\varvec{\lambda }}^k)\), obtain
via
Step 2 With given \(({\varvec{x}}_1^{k+1}, {\varvec{\lambda }}^k)\), obtain
via
Step 3 Update the Lagrange multipliers \( {\varvec{\lambda }}^{k+1} = {\varvec{\lambda }}^k - \beta \left( \mathcal{A}_1{\varvec{x}}_1^{k+1} + \mathcal{A}_2{\varvec{x}}_2^{k+1}\right) \) via
3.2 An Illustrative Example
Let us take the particular example of (1.1) with \(m=5\) and see how to implement the ADMM (1.4). That is, we consider the specific case of (2.1):
For the coefficient matrix A in (3.2), we have
We suggest regrouping this model as
Then, using these notation:
and
the model (3.2) is reformulated as a special case of (1.2) with
To execute the k-th iteration of the ADMM (1.4) for the problem (3.4), we start with the given iterate
Below, let us explain how to solve the resulting subproblems (3.1a) and (3.1b).
(1) Obtain \( {\varvec{x}}_1^{k+1} = \mathrm{argmin} \bigl \{ \mathcal{L}_{\beta }({\varvec{x}}_1,{\varvec{x}}_2^k,{\varvec{\lambda }}^k)\; \big | \; {\varvec{x}}_1\in \mathcal{X}_1 \bigr \}. \)
The first step of (1.4) is
Note that we get the second equation in (3.6) by ignoring some constant terms in its objective function. Notice that the first-order optimality condition of the optimization problem (3.6) is
It follows from the orthogonal property (2.2) that \( (x_1^{k+1}, x_3^{k+1}, x_5^{k+1}) \in {X}_1\times {X}_3\times {X}_5\), and
According to the structure \(A_j\) in (3.3), we further have \( (x_1^{k+1}, x_3^{k+1}, x_5^{k+1}) \in {X}_1\times {X}_3\times {X}_5\) and
Based on these inequalities, the solution of (3.6) can be obtained via
This is just the concrete form of (3.1a) for the case where \(l=2\).
(2) Obtain \( {\varvec{x}}_2^{k+1} = \mathrm{argmin} \bigl \{ \mathcal{L}_{\beta }({\varvec{x}}_1^{k+1},{\varvec{x}}_2,{\varvec{\lambda }}^k)\; \big | \; {\varvec{x}}_2\in \mathcal{X}_2 \bigr \}. \)
The second step of the k-th iteration of (1.4) is
Again, we get the second equation in (3.8) by ignoring some constant terms in its objective function. Since the first-order optimality condition of the optimization problem (3.8) is
it follows from the orthogonal property (2.2) that \( (x_2^{k+1}, x_4^{k+1}) \in {X}_2\times {X}_4\), and
According to the structure \(A_j\) in (3.3), we further have \( (x_2^{k+1}, x_4^{k+1}) \in {X}_2\times {X}_4\), and
Thus, the solution of (3.8) can be obtained via
This is just the concrete form of (3.1b) for the case where \(l=2\).
3.3 Subproblems
Recall that when the LP model (1.1) is considered, we have
in (2.1). It is thus clear that when the ADMM scheme (1.4) is used to solve (1.1), the computation at each iteration is dominated by the subproblems in form of
where \(a_i, q_i\in \mathbb {R}^n\) are given vectors and \(b_i\in \mathbb {R}\) is a given scalar. In this subsection, we discuss how to solve these subproblems. The main result is summarized in the following theorem.
Theorem 3.1
For given \(a, q\in \mathbb {R}^n\) and \(b\in \mathbb {R}\), we have
Proof
First, for any \(q\in \mathbb {R}^n\), we know that
are the unique decompositions satisfying the following conditions:
Note that the Lagrangian function of the minimization problem in (3.10) is
The first-order optimality condition is
Left multiplying \(a^\mathrm{T}\) to (3.12a), we get
Using (3.12b) and (3.11), we get
and thus
Substituting it into (3.12a), we obtain the assertion (3.10) immediately.
This theorem thus shows that when the ADMM scheme (1.4) is applied to (1.1), all the resulting subproblems have closed-form solutions. This ADMM application is thus easy to be implemented. Moreover, as shown, at each iteration, there are m subproblems that are eligible for parallel computation; each of them only requires O(n) flops. We summarize this complexity result in the following theorem.
Theorem 3.2
When the ADMM scheme (1.4) is applied to (1.1) via the reformulation (2.1), at each iteration, there are m subproblems that are eligible for parallel computation; each of them only requires O(n) flops.
4 Extension
We can easily extend our previous analysis to the LP model with equality constraints:
Indeed, we can reformulate (4.1) as
with \(\theta _i(x_i)=c^\mathrm{T}x_i\) for \(i=1,\cdots ,m\). Furthermore, (4.2) can be regrouped as
which is a special case of (1.2), and thus the ADMM scheme (1.4) can be applied. Note that for the case (4.2), \(\mathcal{A}_1\) is an identity matrix and \(\mathcal{A}_2\) can be viewed a “one column” matrix. Thus, as the analysis in Sect. 3, the resulting subproblems are all easy. Indeed, these subproblems have the forms of
whose closed-form solutions can be given by
respectively. Similarly as the analysis in Sect. 3, the ADMM scheme (1.4) for (4.1) also needs to solve m subproblems that are eligible for parallel computation, and each of them only requires O(n) flops.
Remark 4.1
Note that one can artificially treat each \(x_i \in \mathbb {R}\) as one block of variable and each \(c_ix_i\) as one function; thus the direct extension of ADMM for a multiple-block (more than two block) can be applied to solve (4.1). However, as proved in [9], the direct extension of ADMM is not necessarily convergent.
Finally, we mention that we can extend our techniques for the LP models (1.1) and (4.1) to a more general model
where \(\theta (x):\mathbb {R}^n\rightarrow \mathbb {R}\) is a convex (not necessarily linear) function and \(X_i\)’s are closed convex nonempty sets that are not necessarily polyhedrons given by linear equalities or inequalities. This model (4.3) includes more applications such as the feasibility set problems and some image restoration models. We omit the detail for succinctness.
5 Conclusions
We show that the ADMM can be used to solve the canonical LP model. The iteration is easy to implement; the resulting per-iteration complexity is O(mn) where m is the constraint number and n is the variable dimension. The ADMM approach is completely different from the dominating simplex and interior point approaches in the literature. This is also a new application of ADMM that is different from most of its known applications in the literature. To use the ADMM, we need to introduce auxiliary variables and reformulate the LP model. The storage for variables is thus increased by m times accordingly. But, the decomposed m subproblems at each iteration are eligible for parallel computation, and each of them has a closed-form solution which can be obtained by O(n) flops. Thus, this new ADMM approach is particularly suitable for the LP scenario where there are many constraints and parallel computing infrastructure is available.
References
Dantzig, G.B., Thapa, M.N.: Linear Programming 1: Introduction. Springer, New York (1997)
Karmarkar, N.: A new polynomial time algorithm for linear programming. Combinatorica 4(4), 373–395 (1984)
Wright, S.: Primal-Dual Interior-Point Methods. SIAM, Philadelphia (1997)
Glowinski, R., Marrocco, A.: Approximation par éléments finis d’ordre un et résolution par pénalisation-dualité d’une classe de problèmes non linéaires. R.A.I.R.O. R2, 41–76 (1975)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3, 1–122 (2010)
Eckstein, J., Yao, W.: Understanding the convergence of the alternating direction method of multipliers: theoretical and computational perspectives. Pac. J. Optim. 11, 619–644 (2015)
Glowinski, R.: On Alternating Direction Methods of Multipliers: A Historical persPective. Modeling. Simulation and Optimization for Science and Technology, pp. 59–82. Springer, Dordrecht (2014)
Wright, S.: Implementing proximal point methods for linear programming. J Optim. Theory Appl. 65(3), 531–554 (1990)
Chen, C.H., He, B.S., Ye, Y.Y., Yuan, X.M.: The direct extension of ADMM for multi-block convex minimization problems is not necessarily convergent. Math. Program. 155, 57–79 (2016)
Author information
Authors and Affiliations
Corresponding author
Additional information
Bing-Sheng He was supported by the National Natural Science Foundation of China (No.11471156). Xiao-Ming Yuan was supported by the General Research Fund from Hong Kong Research Grants Council (No.12302514).
Rights and permissions
About this article

Cite this article
He, BS., Yuan, XM. Alternating Direction Method of Multipliers for Linear Programming. J. Oper. Res. Soc. China 4, 425–436 (2016). https://doi.org/10.1007/s40305-016-0136-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40305-016-0136-0