
Abstract
The power generalized Weibull distribution has been proposed recently by [24] as an alternative to the gamma, Weibull and the exponentiated Weibull distributions. The power generalized Weibull family is suitable for modeling data that indicate nonmonotone hazard rates and can be used in survival analysis and reliability studies. Usefulness and flexibility of the family are illustrated by reanalyzing Efron’s data pertaining to a head-and-neck cancer clinical trial. These data involve censoring and indicate unimodal hazard rate. For this distribution, some recurrence relations are established for the single and product moments of upper record values. Further, using these relations, we have obtained means, variances and covariances of upper record values from samples of sizes up to 10 for various values of the parameters and present them in figures. Real data set is analyzed to illustrate the flexibility and importance of the model.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Record values are used in many statistical applications, statistical modeling and inference involving data pertaining to weather, athletic events, economics, life testing studies and so on. For example, Guinness World Records, fastest time taken to recite the periodic table of the elements or shortest ever tennis matches both in terms of number of games and duration of time or fastest indoor marathon. There are lots of work published on value (see, [1, 9, 28, 30, 4, 5, 12]and [2, 3]).
[8] proposed the concept of record value and are widely used many real life situations such as industrial stress testing, meteorology, hydrology, sports and stock market analysis. For example, see [3] and [23, 25,26,27, 31, 13,14,15]. Recently, [16] and [29] obtained the relations for moments of record values for generalized Lindley and unit-Gompertz distributions, respectively.
The power generalized Weibull (PGW) distribution proposed by [24] with probability density function (pdf) of the form
and cumulative distribution function (cdf) is
The hazard function is given by

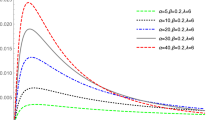
Means of record values for \(\tau =1(1)5\), \(\xi =1\) and \(\delta =0.5\)
The pdf of power generalized Weibull family is hight-tailed at the left end, similar to that of the Exponential distribution. The hazard rates of the power generalized Weibull family can be constant, monotone, unimodal, bathtub shaped . [24] pointed out PGW \((\tau , \delta , \xi )\) distribution can be used to model reanalyzing Efron’s data pertaining to a head-and-neck cancer clinical trial. Note that by setting \(\delta = 1\) and \(\tau =1\), \(\delta =1\), (1) reduces to the Weibull and exponential distributions, respectively. [24] obtained the first and second moments of this distribution are (Fig. 1)
and
Moreover, the quantile function of PGW \((\tau , \delta , \xi )\) distribution is found to be
The outline of this note is as follows. In Sect. 2, we describe the basic concept of record values. In Sect. 3, we derive relations for single and product moments of record values from PGW distribution. The maximum likelihood estimators and the asymptotic confidence intervals for the parameters based on asymptotic variance covariance matrix are provided in Sect. 4. In Sect. 5, the prediction of a future record value is discussed. In Sect. 6, we describe the computational procedure that will produce all the means and variances of record values as presented in Figs. 2–5. In Sect. 7, we present real data applications. Finally, in Sect. 8, we make some concluding remarks.

Means of record values for \(\tau =1(1)5\), \(\xi =1\) and \(\delta =1.0\)

Variance of record values for \(\tau =1(1)3\), \(\xi =1\) and \(\delta =0.5\)

Variance of record values for \(\tau =1(1)3\), \(\xi =1\) and \(\delta =1.0\)

Fitted densities for cancer data
2 Record Values
Let \(\{X_{n}, n\ge 1\}\) be a sequence of identically independently distributed (iid) random variables with pdf f(x) and cumulative distribution function (cdf) F(x). The \(j-\)th order statistics of a sample \((X_{1}, X_{2},\ldots , X_{n})\) is denoted by \(X_{j:n}\). For a fix \(k\ge 1\), we define the sequence \(\{U^{(k)}(n), n\ge 1\}\) of k upper record times of \(X_{1},X_{1},\ldots \) as follows:
The sequences \(\{Z_{n}^{(k)}, n\ge 1\}\) with \(Z_{n}^{(k)}=X_{k:U^{(k)}(n)+k-1}\), \(n=1, 2,\ldots ,\) are called the sequences of kth upper record values of \(\{X_{n}, n\ge 1\}\). For convenience, we shall also take \(Z_{0}^{(k)}=0.\) Note that \(k=1\) we have \(Y_{n}^{(1)}=X_{U(n)},~ n\ge 1\), i.e., record values of \(\{X_{n},~ n\ge 1\}\).
The joint pdf of kth upper record values \(Z_{1}^{(k)}, Z_{2}^{(k)},\ldots ,Z_{n}^{(k)}\) can be given as the joint pdf of kth upper record values of \(\{-X_{n}, n\ge 1\}\), [25]
The marginal pdf of \(X_{U(n)}^{(k)}\), \(n\ge 1\) is given by
and the joint pdf of \(X_{m}^{(k)}\) and \(X_{n}^{(k)}\), \(1\le m<n\), \(n>2\) is given by
where \(~~~\bar{F}(x)=1-F(x).\)
3 Moments of Record Values
Here, we provide the relations for single and product moments of upper record values from PGW distribution.
3.1 Relations for Single Moments
Theorem 3.2 gives a relation for single moments of kth upper record values and r a negative integer.
Theorem 3.1
For the fixed parameters \(\tau , \delta >0\), \(\xi >0\) \(k, n=1, 2, \ldots \), and \(r=0,1,2,\ldots \), we have
Proof
Using (1.4), we have
where \(z=k\left[ 1+(x/\xi )^{\tau }\right] ^{1/\delta }\). The mean and variance kth record values are
and
respectively. \(\square \)
Theorem 3.2
For the fixed parameters \(\tau , \delta >0\), \(\xi >0\), \(k, n=1, 2, \ldots \), and r a negative integer, we have
Proof
This proof is straightforward. \(\square \)
Theorem 3.3
Under the assumptions of equation (8), and convention \(\mu _{n:k}^{(0)}=1\), \(\mu _{0:k}^{(r)}=0,\) we have
Proof
Clearly, from (1.1) and (1.2) , we see that
Therefore, for \(r=0,~1,~2,\ldots \), we have
Integrating by parts, we get
\(\square \)
Corollary 3.4
If \(r=0\) in (3.5), we get
Corollary 3.5
If \(r=1\) in (3.5), we get
3.2 Relations for Product Moments
Here, we present the relation for product moments of record values.
Theorem 3.6
For the PGW distribution given in (1) and for \(1\le m < n\) and \(r, s = 0, 1, 2,\ldots \),
where \({}_2 F_1(a,b;~c;~x)\) denotes the Gauss hypergeometric function defined by
where \((e)_{k}=e(e+1)\ldots (e+k-1)\) denotes the ascending fractorial.
Proof
Using ( 1.5), we have
where \(z=k\left[ 1+(y/\xi )^{\tau }\right] ^{1/\delta }\) and \(w=k\left[ 1+(x/\xi )^{\tau }\right] ^{1/\delta }\). \(\square \)
Theorem 3.7
For \(1\le m < n\) and \(r = 0, 1, 2,\ldots \), and s a negative integer,
Proof
This proof is straightforward. \(\square \)
Theorem 3.8
For \(1\le m < n\) and \(s= 0, 1, 2,\ldots \), and and r a negative integer,
Proof
This proof is straightforward. \(\square \)
Theorem 3.9
For \(1\le m < n\) and and both r and s negative integers,
Proof
This proof is straightforward. \(\square \)
Theorem 3.10
For the PGW distribution given in (1) and \(1\le m\le n-2\),
Proof
For \(m\le n-1\), we have
where
Upon integration by parts, we get
The result follows. \(\square \)
Corollary 3.11
Upon setting \(r=0\) and \(s=1\), we have the following relation for simple product moments for \(m=1,2,\ldots ....,n-1\)
Specially for \(m=1\), we get
4 Estimation of Model Parameters
4.1 Maximum Likelihood Estimation
Here, we obtain the maximum likelihood estimators (MLEs) of the parameters \(\tau \), \(\delta \) and \(\xi \) of PGW distribution. Let \(X_{1}, X_{2},\ldots \) be a sequence of iid random variables with cdf F(x) and pdf f(x) on positive support. Let \(Y_{n}=max\{X_{1}, X_{2},\ldots , X_{n}\}\) for \(n\ge 1\). The observation \(X_{j},~ J\ge 1\), is a upper record values of this sequence, if it is greater than all preceding observations, that is \(Y_{j}<Y_{j-1}\) for \(j>1\).
The likelihood function based on the random sample of size n is obtained as:
Using ( 1.1) and ( 1.2), then ( 3.4) can be rewritten as
The log likelihood function \(l(\tau , \delta , \xi |\underline{x})=log L(\tau , \delta , \xi |\underline{x})\), dropping terms that do not involve \(\tau \), \(\delta \) and \(\xi \), is
Differentiate (4.3) partially with respect to \(\tau \), \(\delta \) and \(\xi \) and equate to zero, we get
and
The solutions of the above equations are the maximum likelihood estimators of the parameters \(\tau \), \(\delta \) and \(\xi \), denoted \(\hat{\tau }_{MLE}\), \(\hat{\delta }_{MLE}\) and \(\hat{\xi }_{MLE}\), respectively. It may be noted that equations (4.4), (4.5) and (4.6) cannot be solved simultaneously to provide a nice closed form for maximum likelihood estimators. Therefore, we propose to use non-linear minimization method (nlm) through R software. For details about the proposed method, readers may refer [20,21,22].
4.2 Approximate Confidence Intervals
Since the MLEs of the unknown parameters \(\tau \), \(\delta \) and \(\xi \) cannot be derived in closed form, it is not easy to derive the exact distributions of the MLEs. Hence, we cannot obtain exact confidence intervals for the parameters. Using large sample approximation, the asymptotic distribution of the MLE is \([\sqrt{n}(\hat{\tau }_{MLE}-\tau ), \sqrt{n}(\hat{\delta }_{MLE}-\delta ), \sqrt{n}(\hat{\xi }_{MLE}-\xi )]\rightarrow N_{3}(0, \pi ^{-1}(\tau , \delta ,\xi ))\), (see [17]), where \(\pi ^{-1}(\tau , \delta , \xi )\), defined by
The derivatives in \(\pi (\Theta )\) are given in
where
and
The above approach is used to derive approximate \(100(1- \tau )\%\) confidence intervals of the parameters \(\tau \) and \(\delta \) of the forms
and
where \(z_{\tau /2}\) is the upper \((\tau /2)\)th percentile of the standard normal distribution.
5 Prediction of Future Record Values
5.1 Maximum Likelihood Prediction
The likelihood function of \(y=x_{U(m)}\) can be written (see Basak and Balakrishnan 2003) as
where
and
For the data set, we shall compare the fits of PGW model with other models.
The predictive likelihood function for the PGW distribution is
The log predictive likelihood is given by
Differentiating (33) partially with respect to \(\tau \) , \(\delta \), \(\xi \) and y and equate to zero, we get
and
6 Numerical Results
In Tables 1 and 2 , we have computed the values of means for \(n=1, 2, \cdots 10\) and \(\tau = 1(1)4\). One can see that the means are decreasing with respect to n but increasing with respect to \(\tau \). In Table 3, we have computed the variances and covariances for different values m and n and for different values of \(\tau \) and \(\delta \). We can see that variances and covariances are decreased for both \(\tau \) and \(\delta \) values increase.
7 Data Analysis
In this section, the PGW distribution is fitted to real data set and compared with other some competitive models to illustrate the potentiality of the PGW distribution.
We compare the PGW distribution with Burr type III (Burr-III) distribution [7], Marshall–Olkin generalized exponential (MOGE) distribution [19], exponentiated exponential (EE) distribution [10], Weibull (W) distribution [32] and complementary exponential geometric (CEG) distribution (Louzada et al. 2011). Their density functions (for \(x > 0\)) are given by
In order to compare the fits of the distributions, we consider some measures of goodness of fit statistics \(-2L\) (where L denotes the log-likelihood function evaluated at the maximum likelihood estimates), Kolmogorov–Smirnov (K-S) statistic and the corresponding p-value, Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC). The smaller these statistics are, the better the fit is.
The data set represents the remission times (in months) of a random sample of 128 bladder cancer patients. The data are:
0.08, 2.09, 3.48, 4.87, 6.94, 8.66, 13.11, 23.63, 0.20, 2.23, 3.52, 4.98, 6.97, 9.02, 13.29, 0.40, 2.26, 3.57, 5.06, 7.09, 9.22, 13.80, 25.74, 0.50, 2.46, 3.64, 5.09, 7.26, 9.47, 14.24, 25.82, 0.51, 2.54, 3.70, 5.17, 7.28, 9.74, 14.76, 26.31, 0.81, 2.62, 3.82, 5.32, 7.32, 10.06, 14.77, 32.15, 2.64, 3.88, 5.32, 7.39, 10.34, 14.83, 34.26, 0.90, 2.69, 4.18, 5.34, 7.59, 10.66, 15.96, 36.66, 1.05, 2.69, 4.23, 5.41, 7.62, 10.75, 16.62, 43.01, 1.19, 2.75, 4.26, 5.41, 7.63, 17.12, 46.12, 1.26, 2.83, 4.33, 5.49, 7.66, 11.25, 17.14, 79.05, 1.35, 2.87, 5.62, 7.87, 11.64, 17.36, 1.40, 3.02, 4.34, 5.71, 7.93, 11.79, 18.10, 1.46, 4.40, 5.85, 8.26, 11.98, 19.13, 1.76, 3.25, 4.50, 6.25, 8.37, 12.02, 2.02, 3.31, 4.51, 6.54, 8.53, 12.03, 20.28, 2.02, 3.36, 6.76,12.07, 21.73, 2.07, 3.36, 6.93, 8.65, 12.63, 22.69.
This data set was studied by [18] in survival data analysis, but no one has discussed this data set in considered model under upper record values. From this data set, we have extracted 17 upper records 0.08, 2.09, 3.48, 4.87, 6.94, 8.66, 13.11, 23.63, 25.74, 25.82, 26.31, 32.15, 34.26, 36.66, 43.01, 46.12, 79.05 for our data analysis. The simulation results are presented in Table 1. Also, we have implemented prediction procedures as mentioned the earlier section of the paper. Here our goal is to predict 18-th upper record values based on the 17 records considered in the parameter estimation.
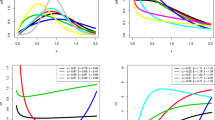
In Table 1, we compare the fits of the PGW model with the Burr III, MOGE, EE, We and CEG models. The figures in these tables indicate that the PGW distribution has the lowest values for all the goodness-of-fit statistics, for the data set, among all fitted models. The histogram and the fitted MOAP-Ex distribution of both the data sets are displayed in Figures 3 and 5. Also, the plots of the estimated cdfs of the two data sets are displayed in Figures 4 and 6, respectively. The fitted pdf, cdf, sf and Q-Q plots of the MOAP-Ex distribution are shown in Figure 7 (Fig. 8).

Fitted PP-plot for cancer data

Fitted QQ-Plot for cancer data

Fitted CDF plot and theoretical empirical plot for cancer data
8 Conclusion
In this paper, we considered the upper record values from power generalized Weibull distribution and obtained the relations for single and product moments of record values. We see that the moments of record values of the distribution are well behaved. However, we have only computed the means, variances and the covariances of the upper record values which are useful in determining best linear unbiased estimators (BLUEs) of location/scale parameters and best linear unbiased predictors (BLUPs) of censored failure times. This will encourage the study of the other properties of order statistics for a future research.
References
Ahsanullah, M.: Record Statistics. Nova Science Publishers, New York (1995)
Arnold, B.C., Balakrishnan, N., Nagaraja, H.N.: A First course in Order. John Wiley and Sons, New York (1992)
Arnold, B.C., Balakrishnan, N., Nagaraja, H.N.: Record. John Wiley and Sons, New York (1998)
Balakrishnan, N., Ahsanullah, M.: Relations for single and product moments of record values from exponential distribution, Open journal of Statistics. J. Appl. Statist. Sci. 2, 73–87 (1993)
Balakrishnan, N., Ahsanullah, M.: Recurrence relations for single and product moments of record values from generalized Pareto distribution. Comm. Statist. Theory Methods 23, 2841–2852 (1994)
Basak, P., Balakrishnan, N.: Maximum likelihood prediction of future record statistics. In: Mathematical and Statistical Methods in Reliability, 7, in Series on Quality, Reliability, and Engineering 578 Statistics, pp. 159-175. World Scientific Publishing, Singapore
Burr, I.W.: Cumulative frequency functions. Ann. Math. Statistics 13, 215–232 (1942)
Chandler, K.N.: The distribution and frequency of record values. J. Roy. Statist. Soc. Ser B 14, 220–228 (1952)
Glick, N.: Breaking records and breaking boards. Arner. Math. Monthly 85, 2–26 (1978)
Gupta, R.D., Kundu, D.: Exponentiated exponential family: an alternative to gamma and Weibull distributions. Biom. J. 43, 117–130 (2001)
Gradshteyn, I.S., Ryzhik, I.M.: Tables of Integrals. Academic Press, New York, Series of Products (2014)
Grunzien, Z., Szynal, D.: Characterization of uniform and exponential distributions via moments of the \(k\)-th record values with random indices Appl. Statist. Sci. 5, 259–266 (1997)
Kumar, D.: Explicit expressions and statistical inference of generalized rayleigh distribution based on lower record values. Math. Methods of Statistics 24, 225–241 (2015)
Kumar, D., Jain, N., Gupta, S.: The type I generalized half logistic distribution based on upper record values. J. Prob. Statistics 2015, 01–11 (2015)
Kumar, D.: \(kth\) lower record values from of Dagum distribution. Discussion Math. Prob. Statistics 36, 25–41 (2016)
Kumar, D., Dey, S., Ormoz, E., MirMostafaee, S.M.T.K.: Inference for the unit-Gompertz model based on record values and inter-record times with an application. Rendiconti del Circolo Matematico di Palermo 69, 1295–1319 (2020)
Lawless, J.F.: Statistical Models and Methods for Lifetime Data, 2nd edn. Wiley, New York (1982)
Lee and Wang: Statistical methods for survival data analysis. Annals of Statistics, John Wiley and Sons New York (2003)
Miroslav, M.R., Kundu, D.: Marshall-Olkin generalized exponential distribution. Metron 73, 317–333 (2015)
Nash, J.C.: On best practice optimization methods in R. J. Statistical Soft. 60, 1–14 (2014)
Nash, J.C.: Nonlinear parameter optimization using R tools. John Wiley and Sons, Chichester (2014)
Nash, J.C.: nlmrt: Functions for nonlinear least squares solutions. R package version 2014.5.4, URL http://CRAN.R-project.org/package=nlmrt (2014)
Nevzorov, V.B.: Records. Theo. Prob. Appl. 32, 201–228 (1987)
Nikulin, N., Haghighi, F.: On the power generalized Weibull family: model for cancer censored data, pp. 75–86. Metron, LXVII (2009)
Pawlas, P., Szynal, D.: Relations for single and product moments of \(k\)-th record values from exponential and Gumbel distributions. J. Appl. Statist. Sci. 7, 53–61 (1998)
Pawlas, P., Szynal, D.: Recurrence relations for single and product moments of \(k-\)th record values from Pareto, generalized Pareto and Burr distributions. Comm. Statist. Theory Methods 28, 1699–1709 (1999)
Pawlas, P., Szynal, D.: Recurrence relations for single and product moments of \(k-\)th record values from Weibull distribution and a characterization. J. Appl. Stats. Sci. 10, 17–25 (2000)
Resnick, S.I.: Extreme values, regular variation and point processes. Springer-Verlag, New York (1973)
Singh, S., Dey, S., Kumar, D.: Statistical inference based on generalized Lindley record values. J. Appl. Statistics 47(9), 1543–1561 (2020)
Shorrock, R.W.: Record values and inter-record times. J. Appl. Probab. 10, 543–555 (1973)
Sultan, K.S.: Record values from the modified Weibull distribution and applications. Int. Math. Forum 41, 2045–2054 (2007)
Weibull, W.: A statistical distribution function of wide applicability. J. Appl. Mech.-TransASME 18, 293–297 (1951)
Acknowledgements
The authors are grateful for the comments and suggestions by the referees and the editors. Their comments and suggestions have greatly improved the paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kumar, D., Kumar, M. & Saran, J. Power Generalized Weibull Distribution Based on Record Values and Associated Inferences with Bladder Cancer Data Example. Commun. Math. Stat. 12, 213–238 (2024). https://doi.org/10.1007/s40304-022-00286-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40304-022-00286-7