
Abstract
This paper introduces a new class of finite-time feedback controllers for rigid-body attitude dynamics subject to full actuation. The control structure is Lyapunov-based and is designed to regulate the configuration from an arbitrary initial state to any prescribed final state within user-specified finite transfer-time. A salient feature here is that the synthesis of the control structure is explicit, i.e., given the transfer-time time, the feedback-gains are explicitly stated to satisfy the convergence specifications. A major contrast between this work and others in the literature is that instead of resorting to feedback-linearization (to get to the so-called normal form), our approach efficiently marries the process of designing time-varying feedback gains with the logarithmic Lyapunov function for attitude kinematics based on the Modified Rodrigues Parameters representation. Saliently, this finite-time solution extends nicely for accommodating trajectory tracking objectives and possesses robustness with respect to bounded external disturbance torques. Numerical simulations are performed to test and validate the performance and robustness features of the new control designs.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
This work introduces a finite-time feedback controller for fully actuated rigid-body attitude dynamics. We make use of Lyapunov’s Direct Method to design a feedback law that regulates the configuration from an arbitrary initial state to any final state within a desired finite transfer-time tf. The control synthesis is explicit, i.e., given the transfer-time time tf, the feedback-gains are explicitly stated to satisfy the convergence specifications, even in the presence of bounded disturbances.
Several recent papers in literature address finite-time regulation problems for fully-controllable systems that are diffeomorphic to the so-called normal form representation. Some of these methods stem from non-smooth feedback, such as bang-bang [1], fractional-order systems, and/or sliding-mode controllers. These methods usually introduce discontinuous dynamics through feedback, which can lead to chattering and excitation of undesired frequencies [2]. Other methods are built on top of the “Lyapunov differential inequality” [3], and many recent results stem from this methodology (see Ref. [4] and references therein). Whereas many of existing methods provide results for finite-time control algorithms, the explicit synthesis of such feedback schemes is far from being fully resolved, especially when applied to nonlinear systems such as the attitude control problem.
In this work, we introduce a feedback control law whose feedback gains are time-varying and grow unbounded towards the terminal time tf. Although the notion of using unbounded feedback gains can be unsettling at a first glance, such an approach has certain strong theoretical underpinnings that are based upon variational calculus. Specifically, finite-horizon optimal control problems with terminal state constraints are known to produce unbounded feedback gains [5].
The major contributions of this paper are as follows. Our formulation introduces a feedback structure that is closely related to Ref. [4]. However, a major contrast is that our work does not seek to arbitrarily cancel out nonlinearities including those associated with the non-working terms within Euler’s rotational dynamics equations. Thus, instead of resorting to the traditional approach of feedback-linearization, our approach utilizes the unbounded gains in conjunction with the logarithmic Lyapunov function presented by Ref. [6] for the attitude kinematics based on the Modified Rodrigues Parameters (MRPs) representation.
This paper is structured along these following lines: Section “Control Design” presents our control design for attitude stabilization around the origin, while Section “Tracking Control” extends the result for trajectory tracking problems (such as slew maneuvers). Section “Practical Considerations” introduces some practical considerations for the implementation of the designed controller. Section “Simulation Results” presents numerical simulation results and Section “Conclusion” summarizes the paper by drawing some concluding remarks.
Control Design
Assume a rotation of an angle \(\psi \in \left (\begin {array}{llll}-2\pi , 2\pi \end {array}\right )\) rad around a unit-norm axis \(\hat {\boldsymbol {e}} \in \mathbb {R}^{3}\). The three-parameter MRP (Modified Rodrigues Parameters) representation \(\boldsymbol {\sigma } \in \mathbb {R}^{3}\) for the same rotation is defined as:
The kinematics of MRPs [7] is given by
where \(\boldsymbol {\omega }(t) \in \mathbb {R}^{3}\) is the angular velocity expressed in a body-fixed frame, and
where we denote v∗ as the skew-symmetric matrix associated with a vector \(\boldsymbol {v} \in \mathbb {R}^{3}\).
It should be noticed that the product σTB(σ) satisfies the property:
The composition rule between the MRPs σ1 and σ2 is given by [8]:
The direction cosine matrix associated with an MRP σ can be obtained by:
Defining the MRP inverse σ− 1 as the parameterization for the rotation matrix C(σ− 1) = CT(σ), then the relation between σ− 1 and σ is given by:
The body angular velocity ω(t) evolves according with Euler’s rotation equation:
where J = JT > 0 is the inertia tensor expressed in the body-fixed frame, u(t) is an input torque, and d(t) is an unknown bounded disturbance torque.
The goal of this work is to find a control law for u(t),t ∈ [0,tf), such that σ(tf) = ω(tf) = 0, for some specified final time 0 < tf < ∞, even in the presence of non-zero disturbance torques. We accomplish this through a backstepping design: first, we assume that ω(t) = ωr(t) is an “input” to Eq. 2. We find a Lyapunov candidate function that stabilizes the MRP in finite time (i.e., σ(tf) = 0) by applying the control law ωr(t),t ∈ [0,tf). Then, we use ωr(t) to find a new control law u that stabilizes both σ(t) and ω(t).
Section “MRP Stabilization” presents the procedure for stabilizing (2) assuming input ω(t) = ωr(t). Section “Attitude Stabilization” presents the backstepping formulation for designing the feedback law u(t) that stabilizes both (2) and (8).
MRP Stabilization
Assume that ωr(t) is the input to
Next, define the function μ(t) as:
One should note that μ(0) = 1, μ(t) > 1,∀t ∈ (0,tf), and \(\lim _{t \to t_{f}}\mu (t) = \infty \). In addition, the derivative of μ(t) with respect to time is given by:
The integral of μ2(t) with respect to time is given by:
where \(\bar {\mu }(t) \triangleq \mu (t) - 1\). The signal \(\bar {\mu }(t)\) satisfies the properties \(\bar {\mu }(0) = 0\), \(\bar {\mu }(t) > 0, \forall t \in (0, t_{f})\), \(\lim _{t \to t_{f}}\bar {\mu }(t) = \infty \), and \(\dot {\bar {\mu }}(t) = \dot {\mu }(t)\).
We define the following Lyapunov candidate function:
for some \(\lambda \in \mathbb {R}_{>0}\). Clearly, V (t) = 0 ⇔ ||σ(t)|| = 0, and V (t) > 0,∀t ∈ [0,tf), if ||σ(t)||≠ 0.
The time derivative of Eq. 13 is given by:
Using the property from Eq. 4 into Eq. 14 leads to:
Since ln(1 + η) ≤ η,∀η ≥ 0, then:
In addition, μλ+ 1(t)σT(t)σ(t) ≤ μλ+ 2(t)σT(t)σ(t),t ∈ [0,tf), leading to:
We can choose the control law:
for some constant gain k > 0, \(\phi \triangleq 2 \left (\begin {array}{llll} \frac {\lambda }{t_{f}} + k \end {array}\right ) > 0\) and t ∈ [0,tf), leading to:
Noticing again that − ln(1 + η) ≥−η,∀η ≥ 0, then:
Invoking the Comparison Lemma [9], we have that:
Using Eq. 12, we get:
Observing that \(\lim _{t \to t_{f}}\exp \left [\begin {array}{llll} -kt_{f}\cdot \bar {\mu }(t) \end {array}\right ] = 0\), then:
Therefore, if the control law in Eq. 20 is realizable (i.e. ωr ∈ L∞), then we have finite time convergence of σ to the origin. Also, it is desirable that \(\lim _{t \to t_{f}}\boldsymbol {\omega }_{r}(t) = 0\), which would imply that once the state σ reaches zero at t = tf, it will remain there for t > tf (i.e., soft-landing).
Taking the two-norm of the control law from Eq. 20, we get that:
Therefore, it is sufficient to say that if the product μ2σ ∈ L∞, then ωr ∈ L∞, implying that the control law is realizable. Appendix A proves that if Eq. 24 holds true, then \(\mu ^{\alpha _{1}} \boldsymbol {\sigma } \in L_{\infty }, \forall \alpha _{1} \in \mathbb {R}\), implying that:
Choosing α1 = 3, we have that:
Therefore, from Eq. 26 we get that \(\lim _{t \to t_{f}}||\mu ^{2}(t) \boldsymbol {\sigma }(t)|| = 0 \implies \lim _{t \to t_{f}}||\boldsymbol {\omega }_{r}(t)|| = 0\).
Attitude Stabilization
In the previous subsection, the variable ω(t) = ωr(t) was assumed to be a control variable. Now, we employ a backstepping design to stabilize σ(t) and ω(t) in finite time. The equations of motion are given by:
where \(\boldsymbol {g}(\sigma ) \triangleq \frac {1}{4}\boldsymbol {B}\left (\begin {array}{llll}\boldsymbol {\sigma }(t) \end {array}\right )\), and d(t) is a bounded disturbance input with \(||\boldsymbol {d}(t)|| \leq \bar {d}\).
The goal is to design u(t) such that u ∈ L∞ and \(\lim _{t \to t_{f}}[\boldsymbol {\sigma }(t), \boldsymbol {\omega }(t)] = 0\).
We rewrite (2) as:
where \(\boldsymbol {\omega }_{e}(t) \triangleq \boldsymbol {\omega }(t) - \boldsymbol {\omega }_{r}(t)\).
Then, we construct a new Lyapunov candidate function \(V:[0, t_{f})\to \mathbb {R}^{+}\):
The time derivative of Eq. 31 is given by:
From Eqs. 14–22 in the previous section, it follows that:
for some k > 0 and ωr(t) given by Eq. 20. Using Eq. 32 together with the property from Eq. 4, we get:
Focusing on the disturbance term, we have that:Footnote 1
In addition, using the fact \(\mu ^{5}(t)\boldsymbol {\omega }_{e}^{T}(t)\boldsymbol {J}\boldsymbol {\omega }_{e}(t) \leq \mu ^{6}(t)\boldsymbol {\omega }_{e}^{T}(t)\boldsymbol {J}\boldsymbol {\omega }_{e}(t)\), we get that:
We can choose the control law:
where \(\dot {\boldsymbol {\omega }}_{r}(t)\) can be obtained by differentiating Eq. 20:
Substituting Eq. 35 into Eq. 34 leads to:
Once again, invoking the Comparison lemma leads to:
where \({\Phi }(t_{1},t_{2}) = \exp \left [\begin {array}{llll} -k t_{f} \left (\begin {array}{llll} \mu (t_{1}) - \mu (t_{2}) \end {array}\right ) \end {array}\right ]\). Solving the integral in Eq. 38, we can show that:
We provide the analysis for the disturbance free case in Section “Disturbance-Free Analysis” and the analysis for the case with non-zero disturbance torques in Section “Disturbance Analysis”. We demonstrate that the control objectives are reached in the disturbance-free case for any λ > 0, while we require λ = 8 to satisfy complete disturbance rejection at terminal time tf.
Disturbance-Free Analysis
In the absence of disturbances, \(\bar {d} = 0\) and the following holds:
Since \(\lim _{t \to t_{f}}\boldsymbol {\omega }_{e}(t) = 0\) and \(\lim _{t \to t_{f}}\boldsymbol {\omega }_{r}(t) = 0\) (See Eqs. 26 and 28), then \(\lim _{t \to t_{f}}\boldsymbol {\omega }(t) = 0\). Also, the right-hand side of Eq. 39 is a bounded function, for t ∈ [0,tf), implying that:
where the last implication above holds true given that ωr = −ϕμ2σ ∈ L∞ (See Appendix A).
We need to ensure that the control torque u(t) is bounded. According with Eqs. 40 and 41, μ2ωe ∈ L∞, σ ∈ L∞, \(\lim _{t \to t_{f}}||\mu ^{2}(t)\boldsymbol {\omega }_{e}(t)|| = 0\), and \(\lim _{t \to t_{f}}||\boldsymbol {\sigma }(t)|| = 0\). Given that Eq. 40 holds, Appendix A shows that μ3σ ∈ L∞, \(\lim _{t \to t_{f}}||\mu ^{3}(t)\boldsymbol {\sigma }(t)|| = 0\), μ4σ ∈ L∞, \(\lim _{t \to t_{f}}||\mu ^{4}(t)\boldsymbol {\sigma }(t)|| = 0\). Since σ ∈ L∞, then g(σ) ∈ L∞.
Therefore, u(t) is composed as a sum of bounded signals, which implies that u ∈ L∞. In addition, since \(\lim _{t \to t_{f}}||\mu ^{2}(t)\boldsymbol {\omega }_{e}(t)|| = 0\), \(\lim _{t \to t_{f}}||\boldsymbol {\sigma }(t)|| = 0\), \(\lim _{t \to t_{f}}||\mu ^{3}(t)\boldsymbol {\sigma }(t)|| = 0\) and \(\lim _{t \to t_{f}}||\mu ^{4}(t)\boldsymbol {\sigma }(t)|| = 0\), then \(\lim _{t \to t_{f}}\boldsymbol {u}(t) = \boldsymbol {0}\).
Disturbance Analysis
Equation 39 can be upper bounded as:
Defining the constant \(\bar {V} \triangleq V(0) + \frac {\bar {d}^{2}}{2k}\), if follows that:
Starting from Eq. 44, it is possible to show that μλ/2σ ∈ L∞ and that \(\lim _{t \to t_{f}}\mu ^{\rho }(t)\boldsymbol {\sigma }(t) = 0, \forall \rho < \lambda /2\) (See Appendix B), which implies that \(\lim _{t \to t_{f}}\boldsymbol {\sigma }(t) = 0\), if λ > 0.
Given that the control law of Eq. 35 is function of \(\dot {\boldsymbol {\omega }}_{r}(t)\), which depends on μ4(t)σ(t) (see Eq. 36), then we need that λ/2 ≥ 4 ⇒ λ ≥ 8 to satisfy μ4σ ∈ L∞. Additionally, the control law of Eq. 35 depends on μλ− 4(t)σ(t), implying that we need λ − 4 ≤ λ/2 ⇒ λ ≤ 8. Therefore, λ = 8 satisfies both μ4σ ∈ L∞ and μλ− 4σ ∈ L∞.
Equation 45 implies that μ2ωe ∈ L∞. Also, since \(\boldsymbol {\omega }_{e}^{T}(t)\boldsymbol {J}\boldsymbol {\omega }_{e}(t) \leq \mu ^{-4}(t)\bar {V}\), then \(\lim _{t \to t_{f}}\boldsymbol {\omega }_{e}^{T}(t)\boldsymbol {J}\boldsymbol {\omega }_{e}(t) = 0 \implies \lim _{t \to t_{f}}\boldsymbol {\omega }_{e}(t) = 0\).
Given that \(\lim _{t \to t_{f}}\boldsymbol {\omega }_{e}(t) = 0\) and \(\lim _{t \to t_{f}}\boldsymbol {\omega }_{r}(t) = \lim _{t \to t_{f}}-\phi \mu ^{2}(t)\boldsymbol {\sigma }(t) = 0\) (for λ = 8), then \(\lim _{t \to t_{f}}\boldsymbol {\omega }(t) = \lim _{t \to t_{f}}\boldsymbol {\omega }_{e}(t) + \lim _{t \to t_{f}}\boldsymbol {\omega }_{r}(t) = 0\).
Therefore, by choosing λ = 8 we have that the control law of Eq. 35 is a sum of bounded terms, implying that u ∈ L∞. In addition, \(\lim _{t \to t_{f}}\boldsymbol {\sigma }(t) = 0\) and \(\lim _{t \to t_{f}}\boldsymbol {\omega }(t) = 0\), accomplishing the desired control objectives. One should also note that there are no guarantees that \(\lim _{t \to t_{f}}\boldsymbol {u}(t) = 0\), as is the case for the disturbance-free control.
Tracking Control
In the previous section, we developed a stabilizing controller that takes the system to the origin. In this section, we generalize the solution for tracking a desired trajectory.
Assume a desired trajectory given by a desired orientation signal σd(t) and a desired angular velocity signal ωd(t). The objective is to reach the desired trajectory at time t = tf, i.e., δσ(tf) = 0 and δω(tf) = 0, where \(\delta \boldsymbol {\sigma }(t) \triangleq \boldsymbol {\sigma }(t) \otimes \boldsymbol {\sigma }_{d}^{-1}(t)\) is the reference attitude error and \(\delta \boldsymbol {\omega }(t) \triangleq \boldsymbol {\omega }(t) - \boldsymbol {C}(\delta \boldsymbol {\sigma })\boldsymbol {\omega }_{d}(t)\) is the angular velocity error expressed in the true orientation’s frame of reference. The matrix C(δσ) is the direction cosine matrix equivalent to the rotation δσ (see Eq. 6) and satisfies \(\dot {\boldsymbol {C}}(\delta \boldsymbol {\sigma }) = -\delta \boldsymbol {\omega }^{*}\boldsymbol {C}(\delta \boldsymbol {\sigma })\). We assume that the quantities σd(t), ωd(t), and \(\dot {\boldsymbol {\omega }}_{d}(t)\) are fully specified as part of the tracking control objective.
As in the previous section, we first assume that the error dynamics for \(\delta \dot {\boldsymbol {\sigma }}(t)\) is driven by a signal δωr(t) as follows:
where \(\boldsymbol {g}(\delta \boldsymbol {\sigma }) \triangleq \frac {1}{4}\boldsymbol {B}(\delta \boldsymbol {\sigma })\).
We can choose the control law
which was already shown to lead to \(\lim _{t \to t_{f}} \delta \boldsymbol {\sigma }(t) = 0\). Also, we’ve already proven that the control law given by Eq.47 is realizable and that \(\lim _{t \to t_{f}} \delta \boldsymbol {\omega }_{r}(t) = 0\).
In order to control the tracking error dynamics, we need to stabilize the equations of motion below:
In order to achieve stability, we define the angular velocity error signal \(\delta \boldsymbol {\omega }_{e}(t) \triangleq \delta \boldsymbol {\omega }(t) - \delta \boldsymbol {\omega }_{r}(t)\). The derivative of Jδωe(t) is given by:
where \(\delta \dot {\boldsymbol {\omega }}_{r}(t)\) can be obtained by differentiating Eq. 47:
We choose the control law:
Replicating the same analysis as in the stabilization case, it is possible to show that the tracking error converges to zero: \(\lim _{t \to t_{f}}\delta \boldsymbol {\sigma }(t) = 0\) and \(\lim _{t \to t_{f}}\delta \boldsymbol {\omega }(t) = 0\). In addition, it is possible to use the same arguments as before to show that the control law from Eq. 51 is realizable (both in the presence and absence of disturbances).
Practical Considerations
We have proven in the previous sections that the control laws Eqs. 35 and 51 are bounded even in the presence of disturbances. Still, there are some practical aspects that have to be considered when utilizing these controller designs.
An important matter that arises in any real implementation concerns the feedback control using noisy measurements. Assuming a measurement model with zero-mean additive noise, the designed control laws cannot guarantee to drive the system to the origin anymore. As t approaches tf, μ(t) increases unboundedly and amplifies the measurement noise that is introduced into the system through Eqs. 35 or 51. Instead of being driven to the origin, the system states converge to a time-varying residual set whose extent changes as a function of μ(t).
A simple saturation heuristic that can be used to remedy the noise amplification is to bound μ(t) as follows:
for some user-chosen κ ∈ (0,1). This heuristic avoids μ(t) from becoming unbounded and thereby eliminating the possibility of increasingly amplifying the measurement noise.
A judicious choice of κ in Eq. 52 depends on the measurement noise characteristics, as well as the final time tf. As κ approaches 0, the risk is that the system might not reach an acceptably small residual set within the prescribed finite time. Alternatively, as κ approaches 1, the noise amplification might be too high, demanding too much on the actuators. Therefore, a rational choice of κ would be one that caps the signal μ(t) as soon as the system reaches to within a small enough residual set.
In order to identify whether or not the system trajectories are within the residual set, one can perform a rigorous analysis to characterize the measure of the residual set as a function of noise variance, initial states and final time. Alternatively, our experience based on extensive numerical simulations of the control laws Eqs. 35 and 51 shows that it is possible to determine whether the system has reached the residual set by analyzing the Fast Fourier Transform (FFT) of the measured angular velocity ω (δω for the tracking case) and identifying the instant when the high-frequencies (mostly noise) dominates the measured signal.
Finite-time (or even infinite time) convergence to the origin in the presence of noise is unattainable, given that the controller attempts to converge to a measured zero, which is not the true zero. Once the system states reach within a residual set, we cannot really claim that there is any advantage in using the control law from Eqs. 35 or 51 with respect to other works in the literature, including non-finite controllers. This means that one can run the finite-time controller until the system reaches the residual set, then switch to some other classical control law, such as a Proportional-Derivative controller [6, 10, 11] tuned with optimal feedback gains (minimizing actuation energy or residual set measure).
Simulation Results
This section presents some simulation results for the designed control laws. In the absence of measurement noise, we show that the designed control laws drive the system to zero error as expected. Section “Perfect Measurements” presents results for the control being applied in the absence of measurement noise, while Section “Noise Corrupted Measurements” shows the results for the control law with noisy measurements. Our simulations are performed for final time tf = 30s.
For all simulations, the initial orientation is given by a rotation of ψ(0) = π around the axis \(\hat {\boldsymbol {e}}(0) = 1/\sqrt {3}\left [\begin {array}{llll}1, & 1, & 1 \end {array}\right ]^{T}\), and the initial angular velocity is given by \(\boldsymbol {\omega }(0) = \left [\begin {array}{llll} -0.03, & 0.04, & -0.05 \end {array}\right ]^{T}\). The inertia matrix is given by:
Perfect Measurements
This section presents simulation results for attitude stabilization using noise-free measurements. We are able to demonstrate that the system converges to arbitrary final configurations for arbitrary initial conditions. We implement μ(t) with saturation as in Eq. 52 with κ = 0.995, avoiding the singularity at t = tf.
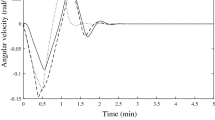
Figure 1 shows the result for the stabilization of the system to the origin using the control law from Eq. 35. Values below 2.20 ⋅ 10− 16 are considered zero and are not shown on the log plot. We can see that the system is being driven towards the origin increasingly faster until the machine zero is reached. Notice that the states (ω(t) and σ(t)) and the inputs (u(t)) all converge to zero. The log plots fade after 20 seconds, but one should have in mind that this is the double precision zero, not the mathematical zero. The mathematical zero should only happen at exactly t = tf as per our proofs.

Time histories of state trajectories for the set-point regulation case with perfect measurements
Figure 2 shows the result for the stabilization of a perturbed system to the origin using the control law from Eq. 35 with λ = 8. The disturbance is constant and given by \(d(t) = \left [\begin {array}{llll} 1, & 1, & 1 \end {array}\right ]^{T}\). The angular velocity ω(t) reaches zero before the terminal time, while ||σ(tf)|| = 3.62 ⋅ 10− 12. In steady state, the input torque compensates the disturbance signal \(\boldsymbol {u}(t) \to \left [\begin {array}{llll} -1, & -1, & -1 \end {array}\right ]^{T}\).

Time histories of state trajectories for the set-point regulation case with perfect measurements and applied disturbances
Figure 3 shows a result for the stabilization of the system to a tumbling configuration, using the control law from Eq. 51. The desired trajectory follows the differential equation:
with \(\boldsymbol {\sigma }_{d}(0) = -1/\sqrt {3}\left [\begin {array}{llll}1, & 1, & 1 \end {array}\right ]^{T}\), \(\boldsymbol {\omega }_{d}(0) = \left [\begin {array}{llll}0.01, & 0.01, & 0.01 \end {array}\right ]^{T}\). We can see that, for this scenario, the states of the error dynamics converge to “machine-zero” sometime after about 20s. The states (ω(t) and σ(t)) and the input torques u(t) all converge to zero.

Time histories of state trajectory errors for the trajectory tracking case with perfect measurements
Noise Corrupted Measurements
In order to test the presented algorithm in presence of noise, we add measurement noise that is typical for a spacecraft with a star tracker, a gyroscope, and is executing an onboard state estimation algorithm. We assume that the state estimator is executing at a rate of 100Hz, and that it produces angular velocity measurements with standard deviation σω = 0.002rad/s and attitude measurements with angular orientation error having standard deviation of σϕ = 2arcsec= 9.7 ⋅ 10− 6rad (in fact, commercial star tracker standard deviation is typically below 1.5arcsec [12]).
Figure 4 shows a result for the stabilization of the system to the origin using the two heuristics described in Section “Practical Considerations” for measurement noise accommodation. The blue plot implements μ(t) as in Eq. 52 with a fixed value of κ = 0.85 (Fixed Kappa Method - FKM). The red plot implements the FFT heuristic described in Section “Practical Considerations” by analyzing the FFT of ||ω|| over a window of 256 measurements, and tracking the instant at which frequencies above 10Hz dominate over frequencies below 10Hz.

System convergence to the origin with noisy measurements. The blue plot shows the controller that caps μ(t) at κ = 0.85, while the red plot shows the controller that detects the switching time through the FFT method
We can see in the blue plot of Fig. 4 that even though the state errors reach a residual set sometime after 13s, the controller gains keep increasing until t = 25.5s. Because of this, the FKM controller demands more control torque on average than the one using the FFT method, which capped the value of μ(t) at t = 12.22s. In average, the FKM results get to a narrower residual set for δσ than the FFT results, but the residual set for δω is larger in the FKM results than it is in FFT one.
Conclusion
In this paper, we have introduced a finite-time controller for fully-actuated rigid-body attitude dynamics. The feedback control law is stablished using Lyapunov’s direct method, regulating the system’s configuration from any arbitrary initial state to any final one within user-specified finite transfer time tf even in the presence of disturbances. In order to achieve finite-time regulation, the feedback gain grows unbounded as time approaches tf.
We have presented simulation results, demonstrating the efficacy of the controller in reaching the desired configuration within finite time. In presence of noise, the system trajectories are shown to converge within a residual set and we propose mechanisms to avoid unnecessary amplification of noise.
An interesting avenue for further work would be seeking the design of a finite-time controller for attitude dynamics without going through the backstepping process, as in the current work. An obvious downside of the backstepping design is that the designed control laws (35 and 51) are algebraically heavy due to the fact that they partially compensate for the “non-working” gyroscopic terms in the attitude dynamics equations (for example, the ω∗Jω term). On the other hand, the literature for asymptotic attitude stabilization (not finite-time) is abundant with control designs that can be obtained without gyroscopic compensation [6, 10].
Notes
We use the property \(a\boldsymbol {b}^{T}\boldsymbol {c} \leq \frac {1}{2}\left (\begin {array}{llll} a^{2} ||\boldsymbol {b}||^{2} + ||\boldsymbol {c}||^{2} \end {array}\right ), \forall a \in \mathbb {R}_{>0}, \boldsymbol {b} \in \mathbb {R}^{n}, \boldsymbol {c} \in \mathbb {R}^{n}, n \in \mathbb {Z}_{>0}\).
References
Athans, M., Falb, P.L.: Optimal Control: An Introduction to the Theory and its Applications. Courier Corporation (2013)
Slotine, J.-J.E., Li, W., et al.: Applied Nonlinear Control, vol. 199. Prentice Hall, Englewood Cliffs (1991)
Bhat, S.P., Bernstein, D.S.: Finite-time stability of continuous autonomous systems. SIAM J. Control. Optim. 38(3), 751–766 (2000)
Song, Y., Wang, Y., Holloway, J., Krstic, M.: Time-varying feedback for regulation of normal-form nonlinear systems in prescribed finite time. Automatica 83, 243–251 (2017)
Bryson, A., Ho, Y.-C.: Applied Optimal Control: Optimization, Estimation, and Control (Revised Edition). Taylor & Francis, Levittown (1975)
Tsiotras, P.: New Control Laws for the Attitude Stabilization of Rigid Bodies. Automatic Control in Aerospace 1994 (Aerospace Control’94), pp. 321–326. Elsevier (1995)
Junkins, J.L., Akella, M.R., Robinett, R.D.: Nonlinear adaptive control of spacecraft maneuvers. J. Guid. Control Dyn. 20(6), 1104–1110 (1997)
Shuster, M.D.: A survey of attitude representations. Navigation 8(9), 439–517 (1993)
Khalil, H.K.: Nonlinear Systems. New Jewsey, Prentice Hall (2002)
Wen, J.-Y., Kreutz-Delgado, K.: The attitude control problem. IEEE Trans. Autom. control 36(10), 1148–1162 (1991)
Chatuverdi, N., Sanyal, A.K., McClamroch, N.H.: Rigid-body attitude control using rotation matrices for continuous, singularity-free control laws. IEEE Control. Syst. Mag. 31(8), 30–51 (2011)
Cemenska, J.: Sensor Modelling and Kalman Filtering Applied to Satellite Attitude Determination. University of California at Berkeley, PhD thesis (2004)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
In this section, we prove that if:
then \(\mu ^{\alpha _{1}} \boldsymbol {\sigma } \in L_{\infty }, \forall \alpha _{1} \in \mathbb {R}\).
Starting from Eq. 55, we use the definition \(\bar {\mu }(t) \triangleq \mu (t) - 1\) to get:
where \(\alpha _{2} \triangleq V_{0}(0)e^{kt_{f}} > 0\).
Defining \(\beta (t) \triangleq \exp \left [\begin {array}{llll} -kt_{f}\cdot \mu (t) \end {array}\right ]\), it follows that:
In order to show that the signal \(f(t) \triangleq ||\mu ^{\alpha _{1}}(t)\boldsymbol {\sigma }(t)||^{2}\) is bounded, we need to evaluate the limit as t → tf. Taking the limit on both sides:
The above limit can be rewritten as:
Assuming that λ < 2α1, Lemmas 1 and 2 are used to prove that the right-hand side of Eq. 59 is equal to zero, implying that \(||\mu ^{\alpha _{1}}(t)\boldsymbol {\sigma }(t)||^{2} \in L_{\infty }, \forall \alpha _{1} > \lambda /2\). In addition, since \(||\mu ^{\eta _{1}}(t)\boldsymbol {\sigma }(t)||^{2} \leq ||\mu ^{\eta _{2}}(t)\boldsymbol {\sigma }(t)||^{2}\), for η1 ≤ η2, then \(||\mu ^{\alpha _{1}}(t)\boldsymbol {\sigma }(t)||^{2} \in L_{\infty }, \forall \alpha _{1} \in \mathbb {R}\).
Lemma 1
For any finite real constantsα1≠ 0,α2 > 0,γ1 > 0,γ2 > 0, then:
Proof
Making the substitution \(y = x^{-\gamma _{2}}\), then:
where \(\gamma _{3} \in \mathbb {N} \triangleq \lfloor \gamma _{1}/\gamma _{2} \rfloor \) and \(\gamma _{4} \in [0, 1) \triangleq \gamma _{1}/\gamma _{2} - \gamma _{3}\).
One can notice that the limit in Eq. 61 is a product of zero with ∞, which can be solved for by using L’Hospital’s rule. Defining \(\gamma _{5} \triangleq \gamma _{3} + \gamma _{4}\), we apply L’Hospital’s rule γ3 times, leading to:
If γ4 = 0, then the proof is complete. However, if γ4 ∈ (0, 1), then we need to use L’Hospital’s rule one more time:
Lemma 2
For any finite real constantsα1 > 0,α2 > 0, and0 < γ1 ≤ γ2 < γ3,then\(\lim _{x \to \infty }f(x) = 0\),where:
Proof
Defining \(y \triangleq x^{-\gamma _{3}}\), we have that \(y^{-\gamma _{4}} = x^{\gamma _{1}}\), and \(y^{\gamma _{5}} = x^{-\gamma _{2}}\), where \(\gamma _{4} \triangleq \frac {\gamma _{1}}{\gamma _{3}}\) and \(\gamma _{5} \triangleq \frac {\gamma _{2}}{\gamma _{3}}\). Since 0 < γ1 ≤ γ2 < γ3, then 0 < γ4 ≤ γ5 < 1. The limit can be rewritten as:
For notation simplicity, we define \(\beta (y) \triangleq \exp \left [\begin {array}{llll} -\alpha _{2} y^{-\gamma _{4}} \end {array}\right ]\), leading to:
It is straightforward to see that \(\lim _{y \to 0^{+}}\beta (y) = 0\) and that \(\lim _{y \to 0^{+}}e^{\alpha _{1} y^{\gamma _{5}} \beta (y)} = 1\). Since this limit is a ratio of zero with zero, we can use L’Hospital’s rule to show that the right-hand side of Eq. 66 converges to zero as y → 0+. We define the numerator signal as:
Clearly, it is sufficient to prove that if \(\lim _{y \to 0^{+}}\frac {dn(y)}{dy} = 0\), then
implying that \(\lim _{y \to 0^{+}}f(y) = 0\). Using the notation \(f^{\prime } \triangleq \frac {\partial f}{\partial y}\) the derivative of n(y) is given by:
where γ6 > 0 is defined as \(\gamma _{6} \triangleq 1 - \gamma _{5}\). Given that
for \(\gamma _{7} \triangleq 1 + \gamma _{4} > 1\), we can substitute Eq. 70 into Eq. 69:
One should note that since γ7 > 1 and 0 < γ5 < 1, then γ7 − γ5 > 0. Using Lemma 1 and the definition \(\beta (y) \triangleq \exp \left [\begin {array}{llll} -\alpha _{2} y^{-\gamma _{4}} \end {array}\right ]\), then:
Remembering that \(\lim _{y \to 0^{+}}\beta (y) = 0\), and that \(\lim _{y \to 0^{+}}e^{\alpha _{1} y^{\gamma _{5}}\beta (y)} = 1\), then \(\lim _{y \to 0^{+}} n^{\prime }(y) = 0\), which implies that \(\lim _{x \to \infty }f(x) = 0\).
Appendix B
In this section, we show that the inequality
for a constant \(\bar {V} > 0\), implies that μλ/2σ ∈ L∞ and that \(\lim _{t \to t_{f}}\mu ^{\rho }(t)\boldsymbol {\sigma }(t) = 0, \forall \rho < \lambda /2\).
Starting from Eq. 73, we have that:
In order to show that the signal \(f(t) \triangleq ||\mu ^{\lambda /2}(t)\boldsymbol {\sigma }(t)||^{2}\) is bounded, we need to evaluate the limit as t → tf. Taking the limit on both sides:
Assuming λ > 0, the above limit can be rewritten as:
Defining \(\xi (t) \triangleq \mu ^{-\lambda }(t)\), we have that:
Since the above limit is a ratio of zero with zero, we can use L’Hospital’s rule:
Therefore, \(f(t) \triangleq ||\mu ^{\lambda /2}(t)\boldsymbol {\sigma }(t)||^{2}\) is bounded, i.e., μλ/2σ ∈ L∞. Also, since \(||\mu ^{\lambda /2}(t)\boldsymbol {\sigma }(t)||^{2} \leq \bar {V}\), then for any 𝜖 > 0 and constant ρ such that 2𝜖 + ρ = λ/2 we have that \(||\mu ^{\rho }\boldsymbol {\sigma }(t)||^{2} \leq \mu ^{-\epsilon }(t)\bar {V}\), implying that \(\lim _{t \to t_{f}} ||\mu ^{\rho }\boldsymbol {\sigma }(t)||^{2} = 0\).
Rights and permissions
About this article

Cite this article
de Almeida, M.M., Akella, M.R. New Class of Attitude Controllers Guaranteed to Converge within Specified Finite-Time. J Astronaut Sci 67, 552–570 (2020). https://doi.org/10.1007/s40295-019-00180-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40295-019-00180-5