
Abstract
The Transmission welding using incremental scanning technique (TWIST) combines linear feed with an oscillating laser beam to enhance weld quality and expand the process window. However, TWIST welding is influenced by nonlinear process variables, and achieving multiple objectives concurrently is challenging due to conflicting performance attributes. In industrial practice, time constraints and project specifications limit the effectiveness of methodologies tailored to specific workpiece materials or single performance optimization. The present study employs an artificial neural network (ANN) to establish a correlation between TWIST welding parameters and desired performance attributes. Various ANN model architectures are evaluated, with the 5-11-6-2 architecture achieving the highest accuracy (correlation coefficient of 0.998). For multi-objective optimization, the non-dominated sorted genetic algorithm (NSGA-II) and non-dominated sorted teaching learning-based optimization (NSTLBO) algorithm are employed, utilizing the ANN model's fitness function as the objective. The newly developed two-step model provides operators with the flexibility to prioritize factors based on project requirements, resulting in improved outcomes. Comparative analysis of the algorithms using seven metrics demonstrates that NSGA-II outperforms NSTLBO in solution prediction, albeit with slightly increased computing time. NSGA-II offers a broader range of Pareto optimum solutions compared to NSTLBO, which converges narrowly and restricts non-dominated sets. Validation experiments confirm the adequacy of both algorithms, supporting the effectiveness of the two-step model. The proposed methodology enables practitioners to achieve better weld quality, accommodate conflicting performance attributes, and effectively optimize multiple objectives in industrial applications.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Polymers have a significant role in our daily life, which is difficult to comprehend. Nowadays, polymers are employed everywhere, from essential everyday items to very complicated industrial goods. The fabrication of well-designed electronic products and microfluidic devices is made possible by the wide variety of polymeric materials that are now readily available [1,2,3]. Polymers are widely used due to their low weight, durability, and ease of manufacturing and recycling. Increasing the use of polymer composites in the automotive and aviation sectors helps to improve fuel economy and thereby reduce greenhouse gas emissions, making it more fuel efficient and environmentally friendly [4]. For polymers and polymer composites to have a broader range of applications in many sectors, high-quality joining is necessary. Although there have been decades of traditional polymer welding options available, laser transmission welding (LTW) is gradually taking the place of friction, electromagnetic, and thermal traditional polymer welding processes in industrial applications due to its unique process advantages. LTW involves using a laser beam to join two thermoplastic parts with distinct optical properties in an overlap configuration, as shown in Fig. 1a. One of the parts is made to be transparent to the laser wavelength, while the other part is designed to absorb the laser radiation. When the laser beam is directed onto the absorbing part by transmitting through the top transparent part, the energy is absorbed in the absorbing part and converted into heat, depending on the thickness and absorption coefficient of the material. This heat is then transferred to the transparent part, causing both parts to melt at the interface where they are joined together. As a result, a strong joint is created at the weld seam [5]. LTW is not just restricted to the automotive and aviation sectors but is also found in other sectors such as textile, medical, packaging, and electronics [6]. This technology has a promising future and will continue to advance since using this method is far less expensive than other methods, including adhesive bonding. The widespread usage of LTW is still constrained by material issues, albeit [7]. TWIST (transmission welding using incremental scanning technique) is a promising technology for welding dissimilar polymers and the newest innovation in the field of LTW. In TWIST welding, the laser beam moves incrementally along the welding line while also making rapid circular oscillations, partly overlapping neighboring circles, at a high velocity [8], as shown in Fig. 1b. TWIST welding solves the drawbacks of LTW by allowing for micro-welding and enhanced joint strength [9, 10]. The wobbling modes used in TWIST welding cause turbulence inside the weld pool and increase weld strength by boosting material intermixing. In addition to the standard LTW process parameters like laser power, pulse frequency, scanning speed and clamping pressure, wobble amplitude and wobble frequency, which regulate the circular overlap, also impact the performance of TWIST welding [11]. The beam wobbling parameter may be adjusted to control the weld width. TWIST welding finds widespread industrial application in the automotive, aerospace, battery, micro components, and food packaging industries for seaming, sealing, and welding [12]. TWIST welding produces narrower heat affected zone and much more uniform welded zone [13]. Weld strength and weld width are two performance metrics that are commonly used to gauge the effectiveness of the TWIST process, while a defect-free seam, minimal distortion, and pleasing seam appearance are indicators of weld quality [14].

Operational strategy of a LTW, and b TWIST welding processes
The manufacturing sector faces the significant challenge of balancing economic objectives like increased production rates, improved product quality, and lower production costs with environmental concerns by reducing industrial waste, maximizing material utilization, and conserving energy [15]. However, optimizing all these objectives simultaneously is practically unattainable, necessitating trade-offs to determine the overall best solution. Process modeling and optimization have therefore, grown in significance during the past few decades. However, optimizing process performance based on individual process features has limited applicability and impracticality. Furthermore, concurrently optimizing multiple objectives is challenging due to their frequent incompatibilities. This has led to extensive research on determining the ideal process variables for joining processes with conflicting objectives. Consequently, there has been a rise in interest in methods like machine learning and evolutionary algorithms for multi-objective optimization and data-driven process modeling [16].
Machine learning is a data analytics approach that enables computers to acquire the ability, akin to humans and animals, to learn from experience [17]. Machine learning, deep learning, and neural networks all fall under the category of artificial intelligence (AI) as sub-fields. Notably, within this framework, machine learning serves as the parent category, with neural networks as a sub-field, and further specialization is found in deep learning [18]. Commonly utilized machine learning algorithms encompass neural networks, linear regression, logistic regression, clustering, decision trees, and random forests [19]. Neural networks, emulating the intricate workings of the human brain, consist of numerous interconnected processing nodes. Their proficiency lies in pattern recognition, image recognition, speech recognition, natural language translation, etc. Linear regression algorithms find utility in predicting numerical values, leveraging a linear relationship among different variables. Conversely, logistic regression algorithms specialize in forecasting outcomes for categorical response variables, notably including "yes/no" answers to questions. Clustering algorithms exhibit the ability to identify patterns within data, enabling effective grouping. In this regard, computers play a significant role in assisting data scientists by uncovering overlooked distinctions between data items. Decision trees serve a dual purpose by predicting numerical values (regression) and categorizing data into distinct groups. These trees rely on a branching sequence of interconnected decisions, often depicted visually through tree diagrams. Lastly, the random forests algorithm predicts values or categories by amalgamating outcomes from multiple decision trees, thus enhancing predictive accuracy.
Artificial neural networks (ANN) have emerged as one of the most successful empirical modeling tools, particularly for nonlinear systems [20]. ANNs are highly flexible but powerful deep learning models inspired by biological neural networks that is used to approximate functions with several variables. Alakabri et al. [21] employed support vector regression with response surface methodology to accurately predict the critical total drawdown in sand production from gas wells. They also utilized AI techniques such as ANN and Fuzzy logic to develop a highly accurate model for predicting bubble point pressure (BPP) in the petroleum industry [22]. Ayoub et al. [23] took a different approach by using the group method data handling (GMDH) evolutionary algorithm to achieve a correlation coefficient of 0.995 when predicting the oil formation volume factor. GMDH, unlike ANN, does not require a predefined network structure and converges after a set number of trials. Ayoub et al. [24] further employed the adaptive neuro-fuzzy inference system (ANFIS) modeling method to accurately determine the solution gas-oil ratio, achieving a correlation coefficient of 0.9904. Baarimah et al. [25] optimized fuzzy logic parameters and developed a model for predicting BPP in the petroleum industry using published data. The accuracy of the model was evaluated using correlation coefficient, standard deviation, and absolute percentage relative error. Gaussian process regression (GPR) is found to be a powerful tool for modeling complex problems in the field of machine learning, outperforming existing models in various petrochemical engineering issues [26]. Hassan et al. [27] demonstrated the effectiveness of the ANN machine-learning algorithm in modeling and predicting the contact angle in oil and gas applications, specifically in the context of smart water-assisted foam technology. Jeng et al. [28] employed an ANN with back propagation and learning vector optimization to reliably predict weld quality, such as weld width, undercut, and distortion as a function of laser welding parameters with minimal error. Nagesh et al. [29] employed back propagation ANN to establish the relationship between weld geometry and process factors and showed that the resulting model accurately predicts bead and penetration geometry in shielded metal arc welding, which was confirmed by test data. Okuyucu et al. [30] employed ANN to estimate tensile strength, yield strength, weld zone hardness, and heat-affected zone as a function of process factors in friction stir welding of aluminum. Researchers used ANN for empirical modeling of several manufacturing process applications such as laser transmission welding [31], electro-discharge machining [32,33,34], etc., to predict intended responses as a function of process parameters, with excellent prediction accuracy recorded. When comparing prediction capability for non-linear process modeling, such as manufacturing processes, the ANN outperforms response surface methodology, the most extensively used conventional empirical modeling tool [31, 35].
The shortcomings of traditional optimization techniques such as the Taguchi method, desirability function analysis, iterative mathematical search technique, etc., as they frequently get stuck at the local optima, have increased interest in using heuristic search methods to reach the global optima in process optimization [36]. Evolutionary algorithms and, more broadly, nature-inspired metaheuristics are gaining popularity as computational intelligence approaches have been successfully used to address optimization issues in various disciplines, including manufacturing. Chandrasekaran et al. [37] reviewed the use of genetic algorithms (GA), ant colony optimization, and fuzzy sets in various manufacturing processes and showed their capacity to cope with complicated optimization issues. GA is a popular and well-tested optimization approach because it can handle both discrete and continuous variable objective functions and automatically searches for a non-linear relationship between process variables and responses [38, 39]. It is a simple optimization approach that uses a derivative-free method to find a point that is near to optimum [40, 41]. The teaching learning-based optimization (TLBO) algorithm is a novel metaheuristic algorithm whose superiority over simulated annealing and artificial bee colony in terms of accuracy and convergence rate is well-tested [42, 43]. The absence of method-specific tuning factors, such as acceleration constants in particle swarm optimization algorithms, and the absence of gradient computation are significant advantages of using the fast-converging TLBO algorithm [44]. Venkatarao [45] conducted experiments and numerical simulations to optimize weld bead geometry and reduce power consumption in wire arc additive manufacturing. The implementation of the TLBO technique successfully identified the optimal working conditions, resulting in improved bead geometry and reduced power usage. Figure 2 represents the general framework of the proposed method used in this paper in the form of a flow chart.

General framework of the proposed method in the form of a flowchart
The non-linear relationship between welding parameters and weld quality in TWIST welding presents a challenging task in predicting appropriate parameter values for desired weld quality attributes. Additionally, the contradicting nature of process outputs necessitates an effective multi-objective optimization approach that can provide trade-off solutions in a single simulation run for optimizing the TWIST welding process. To address these challenges, the utilization of non-linear empirical modeling tools like ANN and metaheuristic optimization algorithms such as GA and TLBO can be advantageous.
This research aims to develop and evaluate two distinct optimization strategies for the modeling and optimization of the TWIST welding process. The proposed approach involves the sequential integration of an ANN model, data-driven non-dominated sorting GA (NSGA-II), and a posteriori version of the non-dominated sorting TLBO algorithm (NSTLBO). An ANN-based surrogate model is employed as the objective function, and different ANN architectures, including single and multiple hidden layers, are evaluated to determine the optimal architecture with the lowest coefficient of variance. The developed ANN-NSGA-II and ANN-NSTLBO approaches are then compared to determine their relative superiority in handling the complexities of the TWIST welding process. The performance of these optimization strategies is assessed based on their ability to search for Pareto solutions in multi-objective optimization.
This research addresses the existing research gap in the utilization of advanced optimization techniques for TWIST welding, considering the highly non-linear nature of the process and conflicting objectives. The outcomes of this study will provide insights into the effectiveness and comparative performance of ANN-NSGA-II and ANN-NSTLBO, facilitating the selection of an appropriate optimization strategy for TWIST welding in industrial applications.
2 Methodologies
2.1 Artificial Neural Network
The artificial neural network is a soft computing technique that simulates the human brain in information processing functions such as reasoning, studying, and remembering. This is made possible by interconnected structures composed of several basic processing neurons capable of doing massive parallel computations for data processing and information representation. Figure 3 displays the architecture of an artificial neural network, which has three layers: an input layer, one or more hidden layers, and an output layer.

An ANN model architecture
The circle symbolizes the neurons that make up each layer, and the lines that link the neurons depict the flow of information. ANNs are taught by using a learning method like back-propagation with an optimization approach like gradient descent. Neurons in one layer are connected to those in the next layer via weighted connections. An activation function in one neuron combines and elaborates the signals from the incoming connections. The weights and biases of the architecture become stable after numerous presentations of the training data patterns to the ANN, and the ANN is considered to be trained [31]. The phases of ANN modeling are depicted in Fig. 4, including the steps for initializing the neural network and obtaining the best ANN architecture for this study. ANN emerged as a widely used deep learning tool due to its unique characteristics, including non-linearity, adaptability, feature learning, parallel processing, generalization, and the ability to handle high-dimensional and large datasets.

Schematic flow diagram of ANN
2.2 Genetic Algorithm
Genetic algorithms, originated from John Holland's research at the University of Michigan in the 1960s, surged in popularity during the 1990s owing to advancements in computing power and their effective application to diverse optimization problems. A genetic algorithm is a sort of evolutionary computing and the solutions it provides are subject to recombination and mutation processes, which produce new offspring and continue the process for numerous generations [46]. Consequently, the population's fitness improves over time as people inherit their parent generation's preferred designs. GA is implemented in three stages: selection, crossover, and mutation [47]. Figure 5 is a representative depiction of GA operations.

Representative depiction of GA operations
The schematic flow diagram of the GA is presented in Fig. 6, which includes the following operating paradigms.
-
i.
A simulation of the natural genetic process
-
ii.
Randomly generation of an initial population
-
iii.
Exploitation of parent solution
-
iv.
The survival of the fittest for the creation of the next generation
-
v.
Generation of better offspring

Schematic flow diagram of GA
2.3 Teaching Learning-Based Optimization Algorithm
The teaching–learning-based optimization (TLBO) algorithm is a relatively recent optimization method that was proposed by Rao in 2011 [42]. The TLBO algorithm is built upon the concept of classroom learning, specifically focusing on the interaction between teachers and learners and how teachers influence learner performance [45]. The algorithm consists of two key components: teachers and learners. Each learner is considered as a member of the population, with the subjects they learn representing distinct variables. The teacher is identified as the best solution among the entire population. The design variable is utilized to create the objective function for the optimization problem, and the optimal solution is determined based on the best value of the objective function. Figure 7 depicts the operating principle of non-dominated sorted TLBO in the form of a flow diagram employed in this study.

Schematic flow diagram of NSTLBO
3 Experimental Work
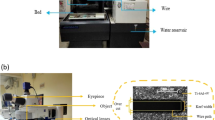
Laser transmission welding is conducted between clear acrylic and polycarbonate plaques measuring 80 mm × 40 mm × 4 mm, using an Nd:YVO4 laser (EMS 100; Electrox Ltd.) equipped with galvo scanning systems. The galvo mirror system employs mirror technology to manipulate the laser beam by rotating and adjusting mirror angles, causing the beam to wobble. Wobble welding is achieved by superimposing the laser beam's rapid circular motion along the welding contour. The laser operates at a wavelength of 1064 nm, with a pulse width of 4.2 ns. It has an average power output of 9.28 W and a beam spot diameter of 50 µm. A schematic representation of the experimental setup utilized in this study is shown in Fig. 8.

Schematic diagram of the experimental setup
The acrylic plaque is positioned on top in a lap joint configuration, while the polycarbonate plaque is placed at the bottom in the overlapping region. Since both parts are transparent to the laser's wavelength, a black strip is marked on the bottom plaque using a black marker pen. This black strip absorbs the laser beam at the interface, converting it into the necessary heat to melt the joint interface for welding purposes. The process parameters involved in this technique include laser power, pulse frequency, scanning speed, wobble width, and wobble frequency. Key factors for achieving desired weld quality include weld strength and weld seam width. Throughout the experiment, the laser spot diameter, pulse repetition rate, and stand-off distance remain consistent. To ensure proper alignment and prevent misalignment during the process, mechanical clamping is applied to secure the overlapping parts in close contact at the interface. Figure 9 provides both a pictorial view and a schematic representation of the welded sample.

a Pictorial view and b schematic diagram of the welded sample
The experimental plan is carried out using the central composite design of response surface methodology. The experimental scheme employs a five-factor three-level face-centered cubic form of the central composite design. The chosen experimental design required the execution of fifty experimental runs, consisting of 32 factorial points, 10-star points, and 8 center points. Based on the literature review and the limits of the machine, preliminary trial experiments are carried out to determine the suitable ranges of process parameters for experimental work, as shown in Table 1 [14]. The lap shear tests of the welded samples are performed using an Instron universal tensile testing equipment (Model 8801) (Fig. 10a). In this study, the strength of a welded joint is determined by the maximum load that a welded sample can bear before it fails in a lap shear test. This maximum load (N) is known as the joint strength and is specifically referred to as the weld shear strength. Figure 10b illustrates the stress–strain relationship, depicted as a load versus extension graph, obtained from the tensile testing of a welded sample. This graph portrays the material's deformation as the applied load increases, reaching a peak point that signifies the maximum load the material can endure.

a Lap shear testing of weld samples, and b load versus extension graph during ap shear testing (Exp. No. 34)
A 3-dimensional optical measuring microscope (STM-6, OLYMPUS) is used to measure the seam width of the welded sample. For all measurements, a 5X magnification objective lens is utilized. Multiple measurements of the weld width are taken at different locations along the weld line, ensuring a minimum of three measurements. The average weld width (mm) is then determined by calculating the mean value of these three measurements. Table 2 displays the experimentally measured values of weld shear strength and weld seam width in relation to the experimental design [14].
3.1 Performance Evaluation of TWIST Welding
Weld strength and weld width are critical performance metrics in TWIST welding, where their significance is underlined by their direct influence on joint reliability and load-carrying capacity. These metrics are intricately tied to the selection of process variables and experimental setup, further emphasizing the need for precise control and optimization to achieve superior weld quality. The graphs are plotted which serves as a visual representation of the intricate relationship between process variables and their impact on desired performance parameters in TWIST welding. It emphasizes the necessity for identifying the optimal range of process variables to ensure a defect-free seam with maximum weld strength, providing essential insights for achieving superior weld quality and mechanical integrity. Figure 11 depicts the influence of laser power on weld strength and weld seam width, as the scanning speed is varied. The dotted line showcases the behavior of weld strength, while the solid line captures the trends in weld seam width, providing insights into the complex interplay between laser power, scanning speed, and the resulting weld characteristics. It is evident that weld strength exhibits a discernible pattern with respect to the variation in laser power. Initially, as laser power increases, weld strength shows a progressive trend until reaching a mid-point. Beyond this critical threshold, however, weld strength begins to decline. The rationale behind this trend lies in the intricacies of heat input during TWIST welding. At the mid-range of laser power, the material experiences sufficient heat input, enabling proper interfusion and resulting in higher weld strength. Deviating from this mid-value, either towards lower or higher laser power, leads to adverse effects on the joint. Insufficient heat input at lower laser powers hampers proper material bonding, while excessively high laser powers degrade the material, leading to weakened joints. The observed phenomenon of weld width increasing with higher laser power can be attributed to the substantial increase in line energy delivered to the material. As the laser power is raised, a greater amount of energy is imparted to the material, resulting in increased heat input and a wider weld seam. The results reveal a decline in both weld strength and weld width as the scanning speed increases. These results can be attributed to the inverse relationship between line energy and scanning speed; higher scanning speeds result in reduced line energy, leading to insufficient heat input during the welding process [13]. Consequently, inadequate heat input adversely affects material fusion, contributing to diminished weld strength and narrower weld seams.

Effect of laser power on performance parameter at varying scan speed
Figure 12 shows the impact of varying pulse frequency on weld strength and weld seam width. The dotted line illustrates the variation in weld strength, while the solid line represents the changes in weld seam width, presenting insights into the interplay of pulse frequency and its effects on the mechanical properties and dimensions of the weld joint. A striking resemblance is observed between the trends of weld strength concerning the change in pulse frequency and laser power. In both cases, weld strength demonstrates an initial increase, reaching a critical threshold, beyond which it starts to decline. This intriguing similarity suggests a potential connection between pulse frequency and laser power in influencing the welding process and its impact on weld strength. Initially, as pulse frequency and laser power increase, the heat input to the material intensifies, resulting in improved material fusion and interfacial bonding, which contributes to higher weld strength. However, beyond a certain point, excessively high pulse frequency and laser power can lead to an overabundance of heat, causing adverse effects like increased material degradation, porosity, or overheating. These unfavorable conditions weaken the joint, leading to a decline in weld strength. The observed trend shows that at lower laser power, low pulse frequency results in higher weld width, while at higher laser power, higher pulse frequency leads to higher weld width. At lower laser power settings, low pulse frequencies provide longer pulse durations, resulting in greater heat input to the material, leading to a wider weld. Conversely, at higher laser power settings, higher pulse frequencies deliver shorter pulse durations but with higher energy per pulse. This concentrated and intense heat input facilitates more material melting, leading to wider welds.

Effect of laser power on performance parameter at varying pulse frequency
In Fig. 13, the impact of scanning speed on weld quality characteristics in TWIST welding is investigated by varying the pulse frequency. The dotted line represents the weld strength, while the solid line represents the weld seam width. The trends for both weld strength and weld width exhibit a similar pattern, indicating a decrease in values with increasing scanning speed. This consistent behaviour suggests that higher scanning speeds are associated with reduced weld strength and narrower weld seams in TWIST welding [13]. The observed decrease in weld strength and weld width with increasing scanning speed can be attributed to the inverse relationship between scanning speed and laser heat input. The observed effect of increasing welding speed with higher pulse frequency is a reduction in weld strength. The combination of higher pulse frequency and faster welding speed leads to insufficient heat input, resulting in inadequate material fusion and weaker bonding at the weld interface. On the other hand, the impact on weld width varies when welding speed is combined with a higher pulse frequency. At lower welding speeds, increasing the pulse frequency results in wider welds due to a longer heat exposure time and more thorough material melting. However, at very high welding speeds, the heat input becomes insufficient to produce a wider weld, leading to a decrease in weld width.

Effect of scanning speed on performance parameter at varying pulse frequency
In Fig. 14, the relationship between wobble width and weld quality characteristics in TWIST welding is depicted through the variation of wobble frequency. The study explores how changes in wobble width and wobble frequency influence weld quality and provides valuable insights into the impact of these TWIST welding parameters on weld strength and weld width.

Effect of wobble width on performance parameter at varying wobble frequency
The observed trend in the effect of wobble width on weld strength and weld width follows a consistent pattern: an increase with wobble width up to a mid-point, beyond which both metrics decline. Wobble width contributes to widening the seam through the circular oscillation of the beam, promoting better material intermixing within an expanded turbulence zone in the weld pool, thereby enhancing weld shear strength. However, when the wobble width becomes too wide, it scatters the line energy, leading to a reduced heat input to the fusion zone, which subsequently affects both weld strength and width negatively. The observed trend where the mid value of wobble frequency consistently yields higher weld strength across the entire range of wobble width can be attributed to the synergistic effect of these parameters on the welding process. The mid value of wobble frequency ensures that the heat input to the fusion zone remains balanced and sufficient for proper material fusion without excessive scattering of line energy. This precise balance between heat input and material mixing at the mid-range of wobble frequency contributes to higher weld strength compared to both lower and higher wobble frequency values. The observations indicate that, at lower wobble width settings, increasing the wobble frequency results in more frequent oscillations of the laser beam, which in turn leads to a wider weld seam. On the other hand, at higher wobble width settings, lowering the wobble frequency allows for extended and spaced-out circular oscillations, providing sufficient time for the material to spread out and flow, resulting in a wider weld seam.
3.1.1 Microstructural Analysis
Conducting a microstructural study near the fusion zone can provide valuable insights into the process mechanics of the TWIST welding process, further enhancing the understanding. Figure 15 displays SEM micrographs that reveal the presence of numerous bubbles or voids on the weld's top surface. Remarkably, these bubbles play a crucial role in reinforcing the micromechanical joining at the interface, thereby contributing to the observed increase in weld strength. Furthermore, the formation of small bubbles can also initiate the creation of cracks and pits, as evident from the figures below, activating the micro-anchor mechanism. This mechanism significantly enhances the bonding strength at the joint interface, further improving the weld's overall mechanical integrity. A key aspect of the TWIST welding process lies in the fast oscillation of the laser beam during welding. The initial oscillations of the laser beam trigger the preheating of the polymers, thus preparing the material for subsequent oscillations. These subsequent oscillations augment the laser's absorptivity, resulting in the formation of a higher molten region in the weld zone that surpasses the laser spot diameter of 50 µm. This expansion of the molten region profoundly influences the material bonding and overall weld quality, playing a crucial role in achieving superior weld characteristics.

SEM micrograph of PMMA/PC weld zone at 100 × magnification
4 Modeling of TWIST Process Using ANN
The TWIST welding process is modeled using a multilayer feed-forward neural network with a back-propagation algorithm. In this study, a network with an input layer with five neurons, one or two hidden layers with varying numbers of neurons in each hidden layer, and an output layer with two neurons is employed. The number of hidden layers and the number of neurons in each layer both affect how well a neural network performs. As a result, several combinations are tested to select an optimum architecture, as shown in Table 3. The majority of the researchers utilized RMSE (Root mean square error) as a neural network performance metric to choose the optimum architecture.
However, as the output distribution values are completely different in terms of magnitude order and unit of measurement, a direct comparison of the RMSE values is inadequate. Because of this, the coefficient of variance (CV) is employed as a statistical indicator parameter for evaluating the error, which is independent of the distribution [48]. It is defined as the ratio of the standard deviation (\({\sigma }_{{RMSE}_{i}}\)) to the distribution's average value (\({\mu }_{{RMSE}_{i}}\)) multiplied by 100.
The lower total CV that results in the lowest error when comparing targets and outputs determines the best ANN architecture.
4.1 Definition of Input and Output Layers
The number of input nodes is the same as the number of process parameters. Using activation functions and weighted connections, the input layer processes information from external sources before adding it to and transmitting it to the neurons of the hidden layer. Eventually, the resulting signals are sent to the output layer, where the training phase assesses the difference between the expected and desired outputs (called targets). There is the same number of output nodes as response parameters. The number of output nodes is equal to the number of response parameters. Five process parameters are considered inputs, while weld shear strength and weld seam width are considered outputs in a single network to create the logical link between inputs and outputs.
4.2 Definition of Hidden Layers
Unlike input and output layers, the number of neurons and hidden layers may be changed. In ANNs, one or two hidden layers are often used to compute the best approximation. Given that having too many or too few hidden neurons might result in over-fitting or under-fitting problems, the number of hidden neurons needs to be determined with caution. This is achieved by changing the number of neurons in a range, with the upper and lower numbers chosen via a heuristic method. Here, four heuristic approaches are applied in order to define the upper and lower threshold.
The lower bound of hidden neurons is heuristically defined by Her Majesty’s Department of Trade and Industry (MTI) [49]:
where IN and ON denotes the input and output nodes. Furthermore, a hidden neuron (HN) is added in the hidden layer until the upper threshold of HN is reached. For this purpose, three alternative heuristic approaches are considered for determining the maximum number of HN.
The upper bound of hidden neurons is heuristically defined by Kolmogorov (KOL) [50]:
The upper bound of hidden neurons is heuristically defined by Lippmann (LIP) [51]:
The upper bound of hidden neurons is heuristically defined by Kudrycky (KUD) [52]:
The CV is determined by taking the lower (MTI = 3 nodes) and upper bounds (LIP = 12 nodes) into account in order to produce the optimal configuration, as shown in Table 3. The ANN model with 11 hidden neurons in the first hidden layer and 6 hidden neurons in the second hidden layer is found to produce the least error. The chosen architectural model is shown in bold, and it has the lowest CV of any architecture.
4.3 Training, Validation, and Test of the ANN Model
The experimental data are used to train the ANN for predicting weld shear strength and weld seam width. The ANN employs the Levenberg–Marquardt Learning Algorithm along with a feed-forward and back-propagation network. The architecture of the ANN model is shown in Fig. 16. The MATLAB 2019 platform is used for ANN modeling, training, validation, and testing. During training, the fifty experimental input–output datasets are divided into three sets: 70% for training, 15% for cross-validation, and 15% for testing. This division allows the network to learn from the majority of the data and evaluate its performance on separate validation and testing sets to assess its generalization abilities. A normalization technique is applied to standardize the input and output variables by scaling them between 0 and 1. This ensures that all variables fall within a consistent range, aiding in the convergence and stability of the training process.

ANN architecture used for predicting weld shear strength and weld seam width
The ANN architecture consists of different layers, including the input layer, hidden layers, and output layer. Neurons in the input layer do not use a transfer function, while neurons in the hidden layers and output layer employ a log-sigmoid transfer function. This choice of transfer function allows the neurons to produce outputs ranging from 0 to 1, which is appropriate for the prediction task. Figure 17 shows the performance convergence diagram of the ANN architecture after training. This diagram illustrates the progress of the network's performance during training epochs. The best validation performance achieved is 335.0634 at epoch 14, indicating that the network's performance, as evaluated on the validation set, is optimal at this stage of training. The utilization of the Levenberg–Marquardt Learning Algorithm, along with the specific ANN architecture and training methodology, enables the accurate prediction of weld shear strength and weld seam width.

Convergence diagram of the 5-11-6-2 network architecture
The regression plots shown in Fig. 18 are used to evaluate the fitness of the ANN model. Figure 18a shows a comparison of anticipated and actual data for the training patterns. It is evident from this figure that the predicted values have little error, demonstrating a remarkable level of accuracy in capturing the underlying patterns in the training dataset. Figure 18b and c present the comparison of actual and predicted data for the validation and testing patterns, respectively. These plots reveal a close agreement between the ANN predictions and the actual response values. The close agreement of the data points in both the validation and testing plots indicates the model's exceptional ability to generalize and yield precise predictions.

Actual and predicted data regression plots for weld shear strength and weld seam width
The efficacy of the developed ANN model is further assessed by an impressive R-squared value of 0.99, as shown in Fig. 18d. This confirms the predictability and robustness of the developed ANN, putting confidence in its capability to deliver precise predictions for both weld shear strength and weld seam width. Tables 4 and 5 supplement the regression plots by displaying the prediction error percentages for the chosen ANN architecture across all test samples. These tables give a summary of the prediction errors pertaining to weld shear strength and weld seam width, allowing for a thorough inspection of the model's performance. Together, the regression graphs, R-squared value, and prediction error percentages highlight the excellent prediction ability of the developed ANN model.
Figure 19a and b provides a comparison of actual and predicted weld shear strength and weld seam width for test data, respectively, and show that they are in good agreement.

Actual and ANN prediction of a weld shear strength and b weld seam width for test data
Figure 20a and b presents the comparison of actual and predicted weld shear strength, and actual and predicted weld seam width, respectively, for training patterns. It can be clearly observed from the line diagram that most of the predicted data points match with the actual fitted data points, which confirms the adequacy of the developed model.

Line diagram with best fit of actual and ANN prediction of a weld shear strength and b weld seam width, for training patterns
The weights and biases are now extracted from the trained model, and the predicted values are obtained. The inputs are normalized and fed into the mathematical equation for ANN. The outputs are then de-normalized to get the predicted values.
where bo is the output bias; wk is the weight of the connection between the kth of the hidden layer and the single output neuron; bhk is the bias in the kth neuron of the hidden layer; n is the number of neurons in the hidden layer; wik is the weight of connection between the ith input parameter and the hidden layer; Xi is the input variable, while Y is the response.
The de-normalized ANN value is plotted against the experimental value to perform a comparison analysis for weld shear strength and weld seam width, as illustrated in Fig. 21a and b.

Scatter diagram with the best fit of ANN prediction (de-normalized value) versus actual a weld shear strength and b weld seam width
Linear regression analysis is applied to find the correlation coefficient (CC) of the developed ANN model. CC is utilized to establish the relationship between actual and predicted output values. The developed ANN model for weld shear strength and weld seam width has a correlation coefficient near 1, which yields minimal error as shown in Fig. 21a and b. As a result, the developed neural network is found to be suitable for predicting the outputs of the TWIST process with significant accuracy.
5 Multi-objective Optimization of the TWIST Process
The selection of appropriate process parameters is critical in any welding process since it impacts weld quality, associated costs, and productivity. Multi-objective optimization of process parameters is pertinent to achieve overall desirability by simultaneously optimizing desired responses to produce better quality, enhanced productivity, and reduced costs. Both priori and posteriori methods can be used to solve a multi-objective optimization problem. In the priori method, a multi-objective problem is reduced to a single objective problem by weighting each goal, and then solved as a single objective optimization problem, yielding a unique optimum solution. The disadvantage of the priori technique is likewise solved by the posterior approach since the multi-objective problem is not reduced to a single objective problem, and hence no weighting is used. In this case, the Pareto optimum solution is obtained, which allows the freedom to choose one solution from the collection of Pareto points depending on the objective criterion. Due to its adaptability, the posteriori strategy is therefore considered to be more suited for tackling multi-objective optimization problems. Several optimization techniques based on genetic algorithms have been developed over the years. The non-dominated sorting algorithm, NSGA-II, is one of the finest genetic algorithm-based optimization algorithms ever developed. The non-dominated sorting TLBO algorithm has also emerged as a popular metaheuristic algorithm for multi-objective optimization due to its low computing cost and freedom from any algorithm parameters. The produced ANN model expression serves as the fitness function for the optimization algorithms.
The hyper-parameter values for both algorithms used are presented in Table 6.
5.1 Optimization Using NSGA–II
Deb et al. initially presented NSGA-II, which is frequently used to solve optimization problems because of its excellent performance and low computing cost [53]. Initially, multi-objective evolutionary algorithms based on non-dominated sorting lack computational complexity and a non-elitism approach. However, Multi-objective optimization based on NSGA-II overcomes the drawback associated with evolutionary algorithms. The Posteriori method is used for multi-objective optimization based on NSGA-II, which optimizes each objective simultaneously without being dominated by another solution. For most situations, NSGA-II can identify a significantly wider range of solutions and better convergence at the actual Pareto optimum front.
5.1.1 Objective Function Definition and NSGA–II Application
When employed as objectives in multi-objective optimization, the performance characteristics of the TWIST welding process, the weld shear strength and the weld seam width, are in conflict with one another. Weld shear strength must be increased while weld seam width must be reduced to achieve better weld quality. For the multi-objective NSGA-II, a posteriori strategy is employed to provide a collection of Pareto optimum solutions. The fitness function is derived from an artificial neural network [Eq. (8) and (9)] using five process variables. The problem space must be constrained by establishing upper and lower limits on each process variable, specified as inputs from Table 1. The bounds are defined in normalized units ranging from 0 to 1, and the population size is fixed at 50. The selection function is set to Tournament, with a reasonable crossover percentage of 0.8, and the mutation function is set to Adaptive Feasible. The NSGA-II algorithm is implemented in the MATLAB code to maximize and minimize the fitness function, which is derived based on the output values from the ANN. Table 7 shows the collection of Pareto optimum solutions produced by the NSGA-II algorithm. Among the obtained set of solutions, solutions no. 4 and 5 represent the maximum weld strength of 678.2 N at higher line energy (ratio of laser power to welding speed). Whereas, solution no. 1 and 2 represent the minimum weld seam width of 0.36 mm at lower heat input. Higher line energy can degrade the material and lower line energy leads to insufficient penetration. It is observed that better weld quality is achieved at the mid value of heat input (solution no. 7). The optimal parameter settings at which the highest weld shear strength and the minimum weld seam width are attained simultaneously are shown in bold. Depending on the proportional relevance of responses, the decision-maker can use any optimum option.
The collection of Pareto optimum solutions is depicted in Fig. 22. The graphic depicts several optimal points from which weld shear strength and weld seam width can be obtained based on the decision-maker's desired relevance of the response.

Pareto front obtained from NSGA-II
5.1.2 Validation Experiment
The confirmation experiment has been conducted at optimal parameter settings (solution no. 7) in order to validate the optimal solution obtained from the NSGA-II algorithm. Table 8 presents the confirmation test and shows that very minimal error has been found out.
5.2 Optimization Using the NSTLBO Algorithm
The NSTLBO algorithm is an extension of the TLBO algorithm, which solves multi-objective optimization problems using the posteriori method, yielding a diversified range of Pareto optimum solutions. The NSTLBO algorithm functions similarly to the TLBO algorithm and includes both a teacher and a learner phase. To solve multi-objective problems effectively, Rao et al. [14] presented the NSTLBO method, which employs a non-sorting technique and crowd distance computation. The NSTLBO algorithm's teacher and learner phases enable extensive exploration and exploitation of the search space, and the non-dominated sorting strategy assures that the selection process is always toward the best solutions and that the population is driven to the Pareto-front in each generation.
5.2.1 Objective Function Definition and the NSTLBO Algorithm Application
The fitness function for the NSTLBO algorithm is derived from the ANN model [Eq. (8) and (9)], and the lower and upper ranges of process variables in the design space act as constraints. A MATLAB code has been constructed to solve the optimization problem using the NSTLBO algorithm, with the learner population set to 50, with the number of subjects set to the number of input variables. The teaching factor can vary from one to two, and the number of iterations is decided to be 100. Table 9 shows the collection of Pareto optimum solutions obtained using the NSTLBO algorithm.
Among the obtained non-dominated set of solutions, all pareto optimal point represent the almost same response, such as maximum weld shear strength of 466.4 N and minimum weld seam width of 0.689 mm. Although, Solution no. 3 is selected because correct amount of heat input is required in order to obtain simultaneously the maximum weld shear strength and minimum weld seam width. The optimal parameter setting at which the maximum weld shear strength and the minimum weld seam width are attained simultaneously is shown in bold. The collection of Pareto-optimal solutions found by the NSTLBO algorithm is shown in Fig. 23. It is obvious that the majority of the optimum points converge at one value, and that value represents the most favorable result.

Pareto front obtained from NSTLBO
5.2.2 Validation Experiment
The confirmation experiment has been conducted at optimal parameter settings (solution no. 7) in order to validate the optimal solution obtained from the NSGA-II algorithm. Table 10 presents the confirmation test and shows that very minimal error has been found out.
5.3 Comparison of Performance of NSGA-II and NSTLBO
The multi-objective optimization algorithms, NSGA-II and NSTLBO, are put to the test to evaluate their effectiveness using a range of performance metrics. These metrics, namely computational time (CT), uniform distribution (UD), error ratio (ER), overall non-dominated vector generation (ONVG), maximum spread (MS), generational distance (GD), and maximum Pareto front error (MPFE) [54, 55], are carefully considered for the comparison. The comparisons are conducted across five independent trials, and the average values are used for the comparative study.
Computational time metric, which measures the time required by each algorithm to perform a computational process. In Fig. 24, it becomes evident that the NSGA-II algorithm takes more computational time compared to NSTLBO. This can be attributed to the intricate nature of NSGA-II's evolutionary process, which demands greater computational resources. However, lower CT generally indicates better performance when this is used as a metric for the evaluation of algorithm performance.

Comparison of NSGA-II and NSTLBO in terms of computational time
The uniform distribution metric evaluates how solutions are distributed along the approximation front within a predetermined parameter range. A higher UD value signifies a more evenly distributed set of solutions, indicating better algorithm performance. Figure 25 presents the comparison between NSGA-II and NSTLBO in terms of UD. Notably, NSGA-II exhibits a greater UD compared to NSTLBO. This suggests that NSGA-II is capable of generating a more uniformly distributed set of solutions across the Pareto front, enabling it to explore a broader range of trade-off solutions.

Comparison of NSGA-II and NSTLBO in terms of uniform distribution
The error ratio metric assesses the quality of the approximation front by considering the proportion of non-true Pareto points relative to the population size. A lower ER value indicates a superior non-dominated set, implying that a larger portion of the solutions in the front are truly Pareto-optimal. In Fig. 26, it becomes evident that NSGA-II boasts a lower ER value compared to NSTLBO, underscoring its superior performance in generating a higher proportion of non-dominated solutions. This showcases NSGA-II's ability to provide a more accurate representation of the Pareto front.

Comparison of NSGA-II and NSTLBO in terms of error ratio
The overall non-dominated vector generation metric refers to the number of non-dominated individuals found in the approximation front. It is crucial to strike a balance, avoiding an excessive or inadequate number of non-dominated solutions based on the specific problem and context. Figure 27 showcases an intriguing finding: while NSGA-II managed to discover a non-dominated set, NSTLBO failed to find any non-dominated individuals during its evolution. While ONVG alone does not guarantee algorithm performance, this outcome highlights NSGA-II's superiority in generating a diverse and well-balanced set of non-dominated solutions.

Comparison of NSGA-II and NSTLBO in terms of ONVG
The maximum spread metric evaluates how well the approximation set covers the true Pareto front. A higher MS value indicates better performance, as it signifies a broader coverage of the true Pareto front by the approximation set. Figure 28 presents the comparison between NSGA-II and NSTLBO in terms of MS, unveiling NSGA-II's achievement of a higher MS value relative to NSTLBO. This suggests that NSGA-II can cover a larger area of the true Pareto front, thereby providing a more comprehensive set of trade-off solutions.

Comparison of NSGA-II and NSTLBO in terms of maximum spread
The generational distance metric measures the distance between the evolved solution set and the true Pareto front. A lower GD value implies a closer approximation to the true front. As depicted in Fig. 29, NSGA-II outperforms NSTLBO with a lower GD value. This indicates NSGA-II's superior performance in terms of proximity to the true Pareto front. Consequently, NSGA-II excels at finding solutions that closely resemble the optimal solutions on the Pareto front.

Comparison of NSGA-II and NSTLBO in terms of generational distance
Lastly, we consider the maximum Pareto front error metric, which focuses on the largest distance between individuals on the evolved solution set from the true Pareto front. In Fig. 30, it becomes evident that NSGA-II exhibits a lesser MPFE compared to NSTLBO. This finding suggests that NSGA-II surpasses NSTLBO in terms of minimizing the error between the approximation front and the true Pareto front.

Comparison of NSGA-II and NSTLBO in terms of maximum Pareto front error
The comprehensive analysis of multiple performance metrics highlights NSGA-II's superior performance over NSTLBO. NSGA-II excels in various aspects, including uniform distribution, error ratio, overall non-dominated vector generation, maximum spread, generational distance, and maximum Pareto front error. The only area where NSTLBO outperforms NSGA-II is computational time, with NSGA-II requiring more time to obtain optimal solutions. NSGA-II emerges as the stronger algorithm based on this thorough examination of performance metrics.
The study has limitations regarding the accuracy of model predictions and the confined search range within the experimental design space, which may result in errors when predicting beyond this space. Additionally, the employed modeling and optimization techniques, such as ANN, NSGA-II, and NSTLBO, have their inherent limitations. ANNs require a significant amount of labeled training data, are susceptible to overfitting, and can be computationally expensive. Selecting appropriate architecture and parameters for ANNs can be challenging and time-consuming. NSGA-II requires setting various parameters, and its reliance on Pareto dominance may not accurately capture the preferences of decision-makers. NSTLBO faces challenges in balancing exploration and exploitation of the search space, which may lead to premature convergence or inadequate exploration. However, the study mitigated these limitations by employing proper validation techniques and rigorous testing. Despite the limitations, the results obtained from the ANN, NSGA-II, and NSTLBO algorithms are excellent in terms of accuracy and precision, providing reliable outcomes.
6 Conclusion
This study proposed and evaluated two optimization strategies: an ANN-NSGA-II approach and an ANN-NSTLBO approach for modeling and optimizing the TWIST welding process. The following conclusions can be drawn from this study:
-
1.
ANN with double hidden layers yields lower variance and better predictability than single hidden layer.
-
2.
Graphical representation of actual vs. predicted weld shear strength and weld-seam width results shows good agreement between actual and predicted weld quality.
-
3.
NSGA-II achieves a wide range of optimal solutions, while NSTLBO converges at one point.
-
4.
NSGA-II outperforms NSTLBO in simultaneously maximizing weld strength and minimizing seam width.
-
5.
NSGA-II has better performance in terms of various metrics (uniform distribution, error ratio, overall non-dominated vector generation, maximum spread, generational distance, and maximum Pareto front error) despite slightly longer computational time.
-
6.
The implemented optimization approaches optimized process parameters effectively within specified constraints, improving quality and performance.
The presented work showcases the novelty and usefulness of the research findings by addressing the following aspects:
-
1.
The research addresses the challenges of predicting appropriate parameter values and optimizing conflicting objectives in TWIST welding.
-
2.
The outcomes of the study provide insights into the effectiveness and comparative performance of ANN-NSGA-II and ANN-NSTLBO, aiding the selection of an appropriate optimization strategy for TWIST welding in industrial applications.
The authors may expand on this work in the future to broaden the objectives of the current study to include the following aspects:
-
1.
Incorporate additional performance attributes and constraints into the multi-objective optimization framework.
-
2.
Investigate real-time optimization and control of TWIST welding for adaptive parameter adjustments.
-
3.
Extend the optimization strategies to other welding processes and refine the ANN model by exploring different training algorithms.
References
Ouellette, J.: A new wave of microfluidic devices. Ind. Phys. 9(4), 14–17 (2003)
Boglea, A.; Olowinsky, A.; Gillner, A.: Fibre laser welding for packaging of disposable polymeric microfluidic-biochips. Appl. Surf. Sci. 254(4), 1174–1178 (2007)
Mistry, K.: Tutorial plastics welding technology for industry. Assem. Autom. 17(3), 196–200 (1997)
Pervaiz, M.; Panthapulakkal, S.; Sain, M.; Tjong, J.: Emerging trends in automotive lightweighting through novel composite materials. Mater. Sci. Appl. 7(01), 26 (2016)
Acherjee, B.; Misra, D.; Bose, D.; Acharyya, S.: Optimal process design for laser transmission welding of acrylics using desirability function analysis and overlay contour plots. Int. J. Manuf. Res. 6(1), 49–61 (2011)
Kumar, D.; Acherjee, B.; Kuar AS: Laser transmission welding: a novel technology to join polymers. In: Reference module in materials science and materials engineering (2021)
Hopmann, C.; Weber, M.: New concepts for laser transmission welding of dissimilar thermoplastics. Progr. Rubber Plast. Recycl. Technol. 28(4), 157–172 (2012)
Acherjee, B.: Laser transmission welding of polymers–a review on welding parameters, quality attributes, process monitoring, and applications. J. Manuf. Process. 64, 421–443 (2021)
Samson, B.R.Y.C.E.; Hoult, T.O.N.Y.; Coskun, M.U.S.T.A.F.A.: Fiber laser welding technique joins challenging metals. J. Ind. Laser Solutions 32, 12–15 (2017)
Acherjee, B.: Laser transmission welding of polymers–a review on process fundamentals, material attributes, weldability, and welding techniques. J. Manuf. Process. 60, 227–246 (2020)
Mann, V.; Hofmann, K.; Schaumberger, K.; Weigert, T.; Schuster, S.; Hafenecker, J.; Schmidt, M.: Influence of oscillation frequency and focal diameter on weld pool geometry and temperature field in laser beam welding of high strength steels. Procedia CIRP 74, 470–474 (2018)
Acherjee, B.: State-of-art review of laser irradiation strategies applied to laser transmission welding of polymers. Opt. Laser Technol. 137, 106737 (2021)
Wang, Y.Y.; Wang, A.H.; Weng, Z.K.; Xia, H.B.: Laser transmission welding of Clearweld-coated polyethylene glycol terephthalate by incremental scanning technique. Opt. Laser Technol. 80, 153–161 (2016)
Kumar, D.; Sarkar, N.S.; Acherjee, B.; Kuar, A.S.: Beam wobbling effects on laser transmission welding of dissimilar polymers: Experiments, modeling, and process optimization. Opt. Laser Technol. 146, 107603 (2022)
Rao, R.V.; Rai, D.P.; Balic, J.: Multi-objective optimization of machining and micro-machining processes using non-dominated sorting teaching–learning-based optimization algorithm. J. Intell. Manuf. 29(8), 1715–1737 (2018)
Wu, P.; He, Y.; Li, Y.; He, J.; Liu, X.; Wang, Y.: Multi-objective optimisation of machining process parameters using deep learning-based data-driven genetic algorithm and TOPSIS. J. Manuf. Syst. 64, 40–52 (2022)
Alzubi, J.; Nayyar, A.; Kumar, A.: Machine learning from theory to algorithms: an overview. J. Phys. Confer. Series 1142, 012012 (2018)
Sick, B.: On-line and indirect tool wear monitoring in turning with artificial neural networks: a review of more than a decade of research. Mech. Syst. Signal Process. 16(4), 487–546 (2002)
Li, Y.; Yang, L.; Yang, B.; Wang, N.; Wu, T.: Application of interpretable machine learning models for the intelligent decision. Neurocomputing 333, 273–283 (2019)
Wu, D.; Jennings, C.; Terpenny, J.; Gao, R.X.; Kumara, S.: A comparative study on machine learning algorithms for smart manufacturing: tool wear prediction using random forests. J. Manuf. Sci. Eng. 139(7), 071018 (2017)
Alakbari, F.S.; Mohyaldinn, M.E.; Ayoub, M.A.; Muhsan, A.S.; Abdulkadir, S.J.; Hussein, I.A.; Salih, A.A.: Prediction of critical total drawdown in sand production from gas wells: machine learning approach. Can. J. Chem. Eng. 101(5), 2493–2509 (2023)
Alakbari, F.S.; Elkatatny, S.; Baarimah, S.O.: Prediction of bubble point pressure using artificial intelligence AI techniques. In: SPE middle east artificial lift conference and exhibition. OnePetro (2016)
Ayoub, M.A.; Elhadi, A.; Fatherlhman, D.; Saleh, M.O.; Alakbari, F.S.; Mohyaldinn, M.E.: A new correlation for accurate prediction of oil formation volume factor at the bubble point pressure using group method of data handling approach. J. Petrol. Sci. Eng. 208, 109410 (2022)
Ayoub Mohammed, M.A.; Alakbari, F.S.; Nathan, C.P.; Mohyaldinn, M.E.: Determination of the gas-oil ratio below the bubble point pressure using the adaptive neuro-fuzzy inference system (ANFIS). ACS Omega 7(23), 19735–19742 (2022)
Baarimah, S.O.; Al-Gathe, A.A.; Baarimah, A.O.; Modeling yemeni crude oil reservoir fluid properties using different fuzzy methods. In: 2022 international conference on data analytics for business and industry (ICDABI), pp. 761–765. IEEE (2022)
Alakbari, F.S.; Mohyaldinn, M.E.; Ayoub, M.A.; Muhsan, A.S.; Hussein, I.A.: A robust Gaussian process regression-based model for the determination of static Young’s modulus for sandstone rocks. In: Neural computing and applications, 1–15 (2023)
Hassan, A.M.; Ayoub, M.A.; Mohyadinn, M.E.; Al-Shalabi, E.W.; Alakbari, F.S.: A new insight into smart water assisted foam SWAF technology in carbonate rocks using artificial neural networks ANNs. In: Offshore technology conference Asia. OnePetro (2022)
Jeng, J.Y.; Mau, T.F.; Leu, S.M.: Prediction of laser butt joint welding parameters using back propagation and learning vector quantization networks. J. Mater. Process. Technol. 99(1–3), 207–218 (2000)
Nagesh, D.S.; Datta, G.L.: Prediction of weld bead geometry and penetration in shielded metal-arc welding using artificial neural networks. J. Mater. Process. Technol. 123(2), 303–312 (2002)
Okuyucu, H.; Kurt, A.; Arcaklioglu, E.: Artificial neural network application to the friction stir welding of aluminum plates. Mater. Des. 28(1), 78–84 (2007)
Acherjee, B.; Mondal, S.; Tudu, B.; Misra, D.: Application of artificial neural network for predicting weld quality in laser transmission welding of thermoplastics. Appl. Soft Comput. 11(2), 2548–2555 (2011)
Andromeda, T.; Yahya, A.; Hisham, N.; Khalil, K.; Erawan, A.: Predicting material removal rate of electrical discharge machining (EDM) using artificial neural network for high I gap current. In: International conference on electrical, control and computer engineering 2011 (InECCE), pp. 259–262. IEEE (2011)
Pradhan, M.K.; Das, R.: Application of a general regression neural network for predicting radial overcut in electrical discharge machining of AISI D2 tool steel. Int. J. Mach. Mach. Mater. 17(3–4), 355–369 (2015)
Velpula, S.; Eswaraiah, K.; Chandramouli, S.: Prediction of electric discharge machining process parameters using artificial neural network. Mater. Today Proc. 18, 2909–2916 (2019)
Sewsynker-Sukai, Y.; Faloye, F.; Kana, E.B.G.: Artificial neural networks: an efficient tool for modelling and optimization of biofuel production (a mini review). Biotechnol. Biotechnol. Equip. 31(2), 221–235 (2017)
Mukherjee, I.; Ray, P.K.: A review of optimization techniques in metal cutting processes. Comput. Ind. Eng. 50(1–2), 15–34 (2006)
Chandrasekaran, M.; Muralidhar, M.; Krishna, C.M.; Dixit, U.S.: Application of soft computing techniques in machining performance prediction and optimization: a literature review. Int. J. Adv. Manuf. Technol. 46(5), 445–464 (2010)
Yusup, N.; Zain, A.M.; Hashim, S.Z.M.: Evolutionary techniques in optimizing machining parameters: review and recent applications (2007–2011). Expert Syst. Appl. 39(10), 9909–9927 (2012)
Zain, A.M.; Haron, H.; Sharif, S.: Application of GA to optimize cutting conditions for minimizing surface roughness in end milling machining process. Expert Syst. Appl. 37(6), 4650–4659 (2010)
Manolas, D.A.; Gialamas, T.P.; Frangopoulos, C.A.; Tsahalis, D.T.: A genetic algorithm for operation optimization of an industrial cogeneration system. Comput. Chem. Eng. 20, S1107–S1112 (1996)
Cus, F.; Balic, J.: Optimization of cutting process by GA approach. Robot. Comput. Integr. Manuf. 19(1–2), 113–121 (2003)
Rao, R.V.; Savsani, V.J.; Vakharia, D.P.: Teaching–learning-based optimization: a novel method for constrained mechanical design optimization problems. Comput. Aided Des. 43(3), 303–315 (2011)
Rao, R.V.; Kalyankar, V.D.: Parameter optimization of modern machining processes using teaching–learning-based optimization algorithm. Eng. Appl. Artif. Intell. 26(1), 524–531 (2013)
Ummidivarapu, V.K.; Voruganti, H.K.; Khajah, T.; Bordas, S.P.A.: Isogeometric shape optimization of an acoustic horn using the teaching-learning-based optimization (TLBO) algorithm. Comput. Aided Geom. Des. 80, 101881 (2020)
Venkatarao, K.: The use of teaching-learning based optimization technique for optimizing weld bead geometry as well as power consumption in additive manufacturing. J. Clean. Prod. 279, 123891 (2021)
Holland, J.H.: Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence. MIT press (1992)
Lambora, A.; Gupta, K.; Chopra, K.: Genetic algorithm-A literature review. In: 2019 international conference on machine learning, big data, cloud and parallel computing (COMITCon), pp. 380–384. IEEE (2019)
Quarto, M.; D’Urso, G.; Giardini, C.: Micro-EDM optimization through particle swarm algorithm and artificial neural network. Precis. Eng. 73, 63–70 (2022)
Garcia-Romeu, M.L.; Ceretti, E.; Fiorentino, A.; Giardini, C.: Forming force prediction in two point incremental forming using Backpropagation neural networks in combination with Genetic Algorithms. In: International manufacturing science and engineering conference, Vol. 49477, pp. 99–106 (2010)
Hecht-Nielsen, R.: Kolmogorov’s mapping neural network existence theorem. In: Proceedings of the international conference on neural networks, Vol. 3, pp. 11–14. New York, NY, USA: IEEE Press (1987)
Lippmann, R.: An introduction to computing with neural nets. IEEE ASSP Mag. 4(2), 4–22 (1987)
Maren, A.J.; Jones, D.; Franklin, S. (2014). Configuring and optimizing the back-propagation. Handbook of neural computing applications, 233.
Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T.A.M.T.: A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6(2), 182–197 (2002)
Yen, G.G.; He, Z.: Performance metric ensemble for multiobjective evolutionary algorithms. IEEE Trans. Evol. Comput. 18(1), 131–144 (2013)
Rabbani, M.; Navazi, F.; Farrokhi-Asl, H.; Balali, M.: A sustainable transportation-location-routing problem with soft time windows for distribution systems. Uncertain Supply Chain Manag. 6(3), 229–254 (2018)
Author information
Authors and Affiliations
Contributions
DK contributed to Methodology, Validation, Formal analysis, Writing—Original Draft; SG contributed to Software, Investigation; BA contributed to Conceptualization, Visualization, Writing—Review and Editing; ASK contributed to Resources, Supervision.
Corresponding author
Appendices
Appendix A: Pseudo Code of NSTLBO


Appendix B: Pseudo Code of NSGA-II

Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kumar, D., Ganguly, S., Acherjee, B. et al. Performance Evaluation of TWIST Welding Using Machine Learning Assisted Evolutionary Algorithms. Arab J Sci Eng 49, 2411–2441 (2024). https://doi.org/10.1007/s13369-023-08238-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-023-08238-1