
Abstract
With the breakthrough of deep learning in vibration-based damage detection, such methods have obtained high detection accuracy, especially supervised learning. However, the work of labelling data is tedious and challenging when facing complex structures and long-time monitoring. This paper proposes a damage detection method based on principal component analysis (PCA) and deep convolutional neural network (DCNN) with dynamic response measured by FBG (Fibre Bragg Grating) sensor arrays. Several FBG sensors are applied to form chainlike arrays along a steel beam and a reinforced concrete (RC) beam. The raw dynamic signal is recorded via FBG sensors in different damage states and analyzed by PCA-based method focusing on T2 and Q statistic as damage indices firstly. Then a priori knowledge of damage in each raw data is achieved according to calculated damage indices and the raw data are labelled. After the labelling procedure, DCNN-based models for steel beam and RC beam are constructed and trained. The DCNN models are evaluated and tested to predict the unknown damage levels. The results show that the DCNN-based damage detection method with the training data labelled by PCA-based model can accurately predict the damage levels.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In bridge engineering, structural damage is common in structures that already have been in service, such as fatigue and corrosion. Changing vehicle load and environmental conditions can lead to the extension of existing damage and the appearance of new damage, which can reduce structural performance and shorten the service life of structures. Therefore, it is very important to continuously monitor the structure and assess its condition, as well as to provide early warning of structural damage [1].
The traditional structural damage detection method relies on human vision and the professional knowledge of the inspectors to evaluate the structure. However, the general bridge structure is large in size, which makes conventional visual inspection time-consuming and labour-intensive. And in most cases, it is difficult to inspect all the load-bearing structural members due to the covering of the outermost members. With the continuous development of research in the field of Structural Health Monitoring (SHM), many structural damage detection technologies have been developed to detect, locate, and quantify structural damage, trying to make the detection process more systematic, objective and automatic [2,3,4]. Among these, many vibration-based damage detection methods have been proposed [5, 6], which collects and analyzes the vibration response of the target structure to evaluate the structural damage and make judgements about the health status of the structure [7].
The presence of damage alters the geometry or material properties of the structure, which means some inherent characteristics of the structure have changed. And any obvious changes in structural vibration characteristics are associated with varieties in the structural state (i.e. the expansion of old damage and the appearance of new damage). Vibration-based damage detection methods can detect structural damage by extracting vibration features from the structural vibration response and applying classification algorithms to identify the features of the unknown state based on those of the known state [8, 9].
Among the sensors that measure the vibration response of a structure, acceleration sensors are the most commonly used but they have some drawbacks in long-term monitoring of structures, such as vulnerability to electromagnetic interference and poor durability. As one of the potential instruments for long term monitoring, long-gauge Fibre Bragg Grating (FBG) sensors have been feasible in SHM. Several attempts on long-gauge FBG sensors have been made to break through the dilemma by measuring the average strain of the enlarged gauge region. Some researchers carried out relevant research earlier and obtained some productive achievements [10, 11]. Through analyzing the error in measurement induced by sensor gauge, Branko Glišić proposed the guiding suggestions for choosing the gauge length of sensors [12]. Wu and Li explored the damage identification method based on macro-strain modal by extracting structural modal parameters from distributed macro strain [13]. Also, FBG sensors have been extensively researched in vibration-based damage identification and demonstrated to be capable of monitoring high-frequency dynamic strains of structures [14]. However, in the long-term monitoring of structures, a large amount of vibration response data is generated. And it is a great challenge to get the damage information related to the structural condition from the massive data.
In recent years, machine learning for structural damage detection has been studied in SHM, such as support vector machine (SVM) [15, 16], principal component analysis (PCA) [17,18,19,20,21], artificial neural network [22,23,24,25,26] and so on. For instance, a pipeline leakage identification method based on SVM and support vector regression (SVR) was proposed by Jia[27]. And the damage levels of carbon fibre reinforced plastic (CFRP) structures was identified by means of FBG sensors and SVR model [28]. S. Z. Lu et al. used PCA to reduce the dimension of damage feature extracted from structural frequency response analyzed by the dynamic response of CFRP structure with FBG sensors [29]. B. T. Xu et al. employed back propagation (BP) neural network and FBG sensors to detect the damage location of the aluminium plate model [30]. Geng et al. presented a method, which integrates FBG sensors with BP neural network, to study the damage identification system of CFRP structure [31]. Julian Sierra-Perez et al. [32,33,34,35] developed a PCA model and used Q and T2 statistics as damage indicators for damage detection of wing structures. However, the method can only detect different damage states of the structure, and the research of damage localization and quantification needs to be further studied. In summary, the above researches have well demonstrated the effective integration of conventional machine learning algorithms with FBG sensors in damage identification, but with limited processing power in the face of large amounts of data.
Recently, deep learning (DL) has been broadly applied in many fields, such as image classification, speech recognition, and objection detection [36, 37], because of the development of DL algorithms and computational power. Furthermore, DL has more extraordinary learning capabilities than traditional machine learning, which can be proved with the fact that DL can extract high-dimensional features from the raw signal without hand-craft features [38]. Ahmed Ibrahim et al. compared the damage classification capability and noise reduction of several algorithms (SVM, K-nearest neighbour and CNN) and demonstrated the performance of CNN is remarkable [39]. Li et al. classified the damage state of cable bridge model respectively using deep CNN (DCNN), random forest algorithm, SVM, K-nearest neighbour algorithm, and decision tree algorithm, among which DCNN shows the best results [40]. Although CNN-based damage detection method has the ability to handle the big data and can achieve high accuracy, the manual labelling of long-term monitoring data will be cumbersome.
In view of the problems faced in the above vibration-based damage detection methods, a hybrid damage detection method is proposed. Several long-gauge FBG sensors are utilized to form chainlike arrays along a steel beam and a reinforced concrete (RC) beam with different damage states for measuring structural dynamic response. Based on the collected data, two conventional statistics of PCA-based model as damage indices enable to distinguish the pattern of raw data, which can be used as the labelling process of new sampled data for the training of DCNN. After that, DCNN-based models for steel beam and RC beam are constructed and trained based on labelled data. The models of DCNN are evaluated by training curve and confusion matrix, and then tested to predict the damage levels. All models are verified by the result of laboratory experiments.
2 Proposed damage detection method
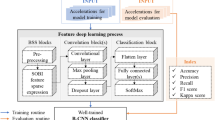
As shown in Fig. 1, supervised learning requires professional knowledge in setting up damage features so that data in different structural states are manually labelled. Then the labelled training dataset is fed to deep learning models to learn the mapping relationship and the trained model is tested to check its detection accuracy. The proposed self-supervised learning uses PCA to replace the manual data labelling. The proposed method has two steps, principal component analysis and supervised learning, to identify structural damage states. The unsupervised learning, PCA, aims to detect abnormal damage information in various elements of the structure based on the obtained statistics, which provides a priori information for the labelling of training data of CNN instead of the manual data labelling process relied on human expertise. CNN is trained and tested on labelled data to classify different damage states more intelligently and to predict the degrees of damage to various elements of the structure divided by long-gauge FBG sensors.

Overview of Proposed framework
2.1 An unsupervised PCA-based model
For a PCA-based model, an X matrix is used to rearrange the data information from the dynamic response of several FBG sensors (m) for many test trials (n). In this paper, two conventional statistics, T2 and Q statistics [41, 42] of PCA-based model as damage indices by the analysis of column vectors of X help to distinguish damage states. The Q statistic can be used to measure the change in projection of the sample vector on the residual space, which describes the deviation degree of the sample vector from the principal component model. If the structure is damaged, the Q statistic will be larger than its control limit. T2 statistic measures the variations of sample in the principal component space. It reflects the degree to which each principal component deviates from the PCA model in terms of trend and magnitude. Detailed descriptions can be found in the literature [43]. However they can’t achieve the information of damage location.
If the data of a single sensor along the time direction is processed by the two statistics in PCA only, the level of damage can be identified in the long-term monitoring process or whether the damage has deteriorated. But, the damage cannot be located. By rearranging the time-series data, the data are expanded along the time direction into data along the sensor number direction. So the two statistics are linked to the sensor number. Damage localization can therefore be achieved by sensor position and a closer damage level can be identified. A transformed PCA-based model is attempted to find out the current or new emerging damage location by the analysis of row vectors of X. During this process, XT, transposed matrix of X, will replace X for rearranging the data set as follows:
where \(x_{ji}\) is a vector related with time series measured from sensor j among arrays at test trial i.
For dynamic measurement, all gathered data should be rearranged into a 3D matrix as ‘D type unfolding’ mode [41] for further operation. After rescaling and upgrading XT matrix according to the references [41, 42], a new covariance matrix will be reformed and calculated by
In matrix, it is easy to find that the components located in diagonal represent the variances, while those located off diagonal represent the covariances between measurements from pairs of sensors. The variances also represent the magnitude of the change, yet the covariances have related with the redundancy, so that the object of PCA aims at interpreting the dynamic response along the direction of the largest variances and the least covariances. During the processing, a matrix P is used to implement a linear transformation to achieve the minimal redundancy and form T matrix.
The transformation matrix P is a set of eigenvectors by columns. Since the orders of the eigenvectors have correspondence with the amount of information, the dimensionality of X can be reduced if only part numbers of principal components related with eigenvectors are retained. The retained eigenvectors will form a new matrix Pr. At the same time, a baseline constructed by previous structure (healthy or damaged) and calculation from Pr, is needed to eliminate the confusion between the current and previous damage state when there is too much damage in the structure.
For X, the column vectors of matrix T are the projections of the dynamic response over the direction of the principal component. For XT, the meaning is defined as “the contribution of each sensor” to the direction of the principal component in this paper. T2 and Q statistics will be calculated again based on the matrix of XT and corresponding Pr to locate the new emerging damage state as follows:
where \(\tilde{x}_j\) is the projection into the residual subspace; \(\Lambda\) is a diagonal matrix constructed with eigenvalues of \(C_{X^T }\) but only for Pr and \(t_{sj}\) is the projection of \(x_j\), i.e. \(t_{sj} { = }x_j P_r\); I is an identity diagonal matrix.
In CNN damage detection, the data labels for the classification task are not the same as for the regression task. For the classification task, the training data and the PCA model are utilized to calculate the two statistics of each damage state and the range of the statistics is determined, which is the boundary of data labels in each damage state. Next, a model for automatic data labelling for the CNN damage classification task is obtained. Finally, the training data for the CNN classification task is fed into the model. If it meets the corresponding range of values for the two statistics, a pre-defined data label is added to the last row of the data sample.
For the regression task, the contribution of the statistics calculated for each sensor is used to label the data and the location with a relatively large contribution is considered to be where the damage occurs. The first step is the same as the classification task, calculating two statistics for each damage category. But the contribution of each sensor to the two statistics is separated out and compared to find the location of the sensor with the relatively high value of the statistics. Assuming that the data label of the previous state (e.g. healthy) is known, the values of the statistics for each sensor location are compared and the structural element with the larger value is coded, which the value "1" for the corresponding location of the damage label vector is increased and if the same location is damaged again, the value "1" is cumulatively added.
2.2 A supervised DCNN-based model
2.2.1 Convolutional neural networks (CNN)
Based on the damage information identified by PCA-based model, damage pattern will be labelled for supervised learning in a DCNN-based model. The convolutional layers, sub-sampling layers and fully connected layers are main parts of a CNN [44]. Among those layers, convolutional layer is a very significant component of CNN, including kernels and feature maps, the function of which is to extract the features of local area. Equation (6) shows the 2D convolution operation:
where I is the input matrix i.e. the dynamic response along time series from FBG sensors in this paper, K is kernel parameters. Multiple different kernels are added to each layer to improve the representation ability of CNN. Therefore, the data can be represented more ideally.
A significant problem faced by CNN is overfitting. A pooling layer added after convolutional layer enables to select features so that the dimensionality of features is reduced and overfitting is also mitigated to a certain extent. In general, the Max pooling is kept in step with the convolution layers to extract maximum value in the pooling area. After pooling, the characteristics of output remain unchanged. The last few layers of CNN are fully connected layers used to classify the features extracted from the previous layers and are common component of artificial neural networks such as multilayer perceptrons. The operation of fully connected layers is as follows:
where u is feature vector, w is weights, b is bias, and f is activation function. Leaky ReLU function will be used as the activation function in the proposed model following all convolutional layers and the first two fully connected layers to improve the capability of nonlinear expression in the networks.
For DL, batch normalization (BN) [45] can smooth the surface for optimization, decrease the sensitivity to the choice of hyperparameters and bring about faster convergence. Compared with general artificial neural networks, DCNN may easily lead to overfitting. As a training technique, Dropout [46] randomly inactivates a certain percentage of neuron nodes in hidden layers in the every training batch to obviously eliminate the interaction between nodes and mitigate overfitting.
2.2.2 Scenario of DCNN
The proposed DCNN structure is depicted in Fig. 2. Each data utilized to train CNN is a q × n matrix, which is constituted of dynamic response i.e. the time history of wavelength measured from FBG arrays, where q is the number of sampling points with duration and n is the number of sensors. Because q is much larger than n, square kernel applicable for image data are not considered but 5 × 1 and 3 × 1 are employed. To improve the accuracy of classification, each column of data in a sampling is normalized within the range of [0, 1].

Architecture of DCNN
In the model, the large kernels are used to extract features firstly, and then gradually reduce the size of kernel in the following convolutional layers. The Max pooling is added to the first four convolutional layers, whose sizes are respectively 3 × 1 and 2 × 1. Especially, A kernel 1 × 1[47] is utilized in the network to play a role in exchanging cross-channel information and decreasing parameters when the feature dimensionality is too large. The output of networks is a vector indicating the damage levels.
2.2.3 Training and test
Once a DCNN model is constructed, the training process is essential to adjust some inner parameters to a proper value. There are two main tasks for DCNN: classification task and regression task. In this study, the training curve and confusion matrix in classification task, and the average output value in regression task, i.e. the evaluation criterion for the performance, are used to determine whether the training process has met the accuracy requirements.
For classification task, the cross entropy function is utilized as loss function:
where L1 is the value of cross-entropy loss function, p and q are respectively true output and predicted output as probability, M is the number of categories for classification. In addition, the loss function of regression task is mean square error function:
where L2 is the value of mean square error loss function, N is the number of the batch size of samplings, \(y_i\) is the true label vector, and \(\overline{y_i }\) is the predicted vector.
Gradient of network parameters is calculated by Adam optimizer [48] and stochastic gradient descent for each task, which backpropagates to previous layers. When training is complete and the inner parameters are adjusted properly, the model can be tested for target task without the need of gradient descent process.
3 Experiment process
3.1 Long-gauge FBG sensor
In the experiment, long gauge length FBG sensors are used to measure the structural vibration response and the structure is divided into several elements to better detect structural damage. The changes in strain or temperature can cause the variation of grating period or effective refractive index of fibre, resulting in a shift of centre wavelength. The strain calculated from the shift of centre wavelength of FBG is the average within preset gauge length due to only two pre-stressed ends (preset gauge length) are fixed on the measured structure. Long-gauge FBG enlarge the measured area, however, which may lead to the reduction of sensitivity in measuring tensile or compression strain. In practical engineering, the selection of preset gauge length is essential considering the geometry, potential deformation of the structures. Further details on the long-gauge FBG sensor can be found in the literature [49].
3.2 Experimental details of small scale I-shaped steel beam
I-shaped steel beam is simply supported. As shown in Fig. 3, at one side on the bottom flange plate, 10 FBG sensors with gauge length of 30 cm are distributed (S1–S10); at another side, 6 FBG sensors with gauge length of 50 cm are distributed (S11–S16). The flange plate is damaged by cutting one slit with length of 30 mm and width of 2 mm per time at different locations (D1–D4) in Fig. 3 to simulate four level damage states. D1 and D2 are located at the conjunction of S13 and S14 (S5 and S6); D3 is located at the conjunction of S12 and S13 and within S7; D4 is located at the conjunction of S11 and S12 and within S9. The whole experimental system is shown in Fig. 4. An electromagnetic exciter at 6 locations in Fig. 3 is used to generate sine sweep signal with the frequency range from 1 to 100 Hz in each damage state. The exciter will bring about vibration 30 times at one location as test trials. During each exciting vibration, a sampling proceeds with the duration of 120 s and the frequency of 250 Hz by Micron Optics SM130 for FBG sensors seen in Figs. 5 and 6.

Experimental information of steel beam

The whole test system

Demodulation system

Interface from SM130 demodulator
3.3 Experimental details of large scale T-shaped RC beam
As shown in Fig. 7 from the section of T-shaped beam, 2 long-gauge FBG sensors are stuck with longitudinal reinforcing steel bar on the top of the beam. The structure is designed and built according to the T-shaped beam in the practical engineering. Due to the width of the bottom plate is relatively narrow, the rebar arrangement is along the beam height direction, which is in line with the reinforcement principle. It is also possible to place two reinforcement bars with larger diameters at the bottom of the beam when the reinforcement area is the same. However, according to the calculation of the bottom width of the T-beam, such a configuration cannot meet the minimum clear distance requirements of the steel bars to ensure the quality of concrete pouring. In contrast, the arrangement of multiple smaller-diameter steel bars side by side along the web can also increase the contact area of the steel bars and increase the bonding force between the steel bars and the concrete. The span of 4 m is equally divided into 8 elements along the longitudinal direction. Total 16 FBG sensors (S1–S16) with the gauge length of 50 cm are independently embedded and parallel to the natural axis.

Details of bending experiment
To produce different damage states with different location, two static loading methods are carried out to achieve hierarchical damage states in a self-balancing load system. As seen in Fig. 8 T-shaped RC beam is simply supported. A vertical load has been gradually applied by a mechanical jack on RC beam through a distributive beam. Then the load will be equally split into two concentrated forces, one in the conjunction of S2 and S3, and another in the conjunction of S6 and S7, so that the area between S3 and S6 (S11 and S14) is subjected to the same bending moment and has the same probability of damage. The loading process is end about 200 kN when dispersed and nearly vertical cracks are found at the bottom of the web plate mainly within S3 (S11) and S4 (S12). As seen in Fig. 8, RC beam is clamped supported. Two equal vertical forces with maximum load about 10 kN have been imposed on a rotatable system perpendicular and attach to beam in the mid-span, then a torque will exerted on the RC beam. Several inclined cracks are found on the surface of top flange plate almost within S8 (S16) and develop along the existing crack at the bottom surface within S3. Considering the safety during the experiment, the excitation and sampling for test trials is only carried out when the static loading process is end. The method of excitation and sampling for test trials is the same as that for steel beam.

Details of torsion experiment
3.4 Raw dynamic response
Due to the limited space, only dynamic response with 2 s duration of one sensors in each state is shown in Fig. 9. In fact, the whole set of all gathered dynamic response is a tridimensional matrix (180 Tests × 30,000 Samples × 16 Sensors) in each state for both steel beam and RC beam. The analysis of T2 statistic and Q statistic will be carried out based on the increment response of four states (‘State 1’ to ‘State 4’) with initial health state (‘State 0’) in Fig. 9a for steel beam and that of only two states (‘State 1’ and ‘State 2’) with initial health state (‘State 0’) in Fig. 9b.

The increment of each state to the initial state with the duration of 2 s
There is one health and four damage states in steel beam: (1) State 0: no damage; (2) State 1: one crack at the bottom of the midspan; (3) State 2: two cracks at the bottom of the midspan; (4) State 3: the damages in State 2 and one crack at the top of girder near the midspan; (5) State 4: the damages in State 3 and one crack at the top of girder near the one end point. There is one health and two damage states in RC beam: (1) State 0: no damage; (2) State 1: minor damage within S3 and S4; (3) State 2: severe damage within S8 and developed damage within S3. The labels for classification task in DCNN-based model are listed in Table 1.
According to the distribution of FBG sensors, two beams are respectively divides into 5 elements and 8 elements as seen in Figs. 3 and 7. Three damage levels with quantitative indicators ‘0’, ‘1’ and ‘2’ will be categorized into the elements of steel beam and RC beam for regression task: (1) 0: no damage; (2) 1: initial or not aggravated damage in the current state; (3) 2: accumulative damage over the previous state. The labels for regression task in DCNN-based model are listed in Table 2. Although in practical engineering applications, it is difficult to achieve very accurate damage quantification. However, the previous state is used as a baseline to identify whether the damage has deteriorated in the current state, which can also be used for long-term monitoring.
4 Analysis results and discussion
4.1 Data labelling by PCA-based model
4.1.1 I-shaped steel beam
The analysis of T2 and Q statistics will be implemented by MATLAB software. There are only part projections (first 80 left points along time series) into the PCA-based model at one test trial presented in Fig. 10. Seen from Fig. 10a and b, it is hard to distinguish some close damage states, such as ‘State 1’ and ‘State 2’ in T2 statistic or ‘State 2’ and ‘State 3’ in Q statistic, which means depending on one statistic is not enough to differentiate the damage states. The relationship between T2 statistic and Q statistic in Fig. 10c enables to clearly separate the states.

Part projections into the PCA-based model
The contribution of each sensor (S1–S16) to T2 statistic and Q statistic is presented in Fig. 11. Regarding 85% peak value as threshold, it is feasible to almost identify the damage location. The calculation of T2 statistic and Q statistic uses the health state as the baseline in Fig. 11a and b. The peak values of T2 statistic and Q statistic appears at two locations, one between the 5th sensor and the 6th sensor, and another side near the 13th sensor, in accordance with the damage state in Fig. 3. The previous damage state is proposed to be the baseline to find out the new damage in Fig. 11c and d. In Fig. 11c, the peak values of T2 statistic and Q statistic concurrently appears between the 7th sensor and the 8th sensor, i.e. here is a new damage state (D3) over the previous state (D2), so does ‘State 4’ over ‘State 3’ in Fig. 11d. The results also show that damage location in each state is almost accurately identified by the distributed sensors of S1 to S10, which demonstrates that the gauge length and the number of sensors in one array will have great effect on the sensitivity of measurement and analysis.

Projections of the contribution of each sensor into the PCA-based model
From the view of data labelling, the calculation based on the previous state is more conducive to highlighting new damage and it is easy to code on the basis of the data label of the previous state. When the difference in damage level is relatively large, the health status data can be used as the baseline and the identification of the damage level can be easily realized. It is consistent with the results obtained by using the health data as the baseline for the first damage state in the analysis of the steel beam test data. When several damage states are relatively close, using health data as the baseline can easily cause confusion among several states. Using the data of the previous level as the baseline ensures that some close, cumulative damage states are not lost during long-term monitoring.
4.1.2 T-shaped RC beam
There are also only part projections (first 80 left points along time series) into the PCA-based model presented in Fig. 12. Unlike the analysis of T2 statistic and Q statistic in steel beam, those in RC beam make a clear distinction among all states.

Part projections into the PCA-based model
The contribution of each sensor (S1–S16) to T2 statistic and Q statistic is presented in Fig. 13. Seen from Fig. 13a, the peak values of T2 statistic and Q statistic concurrently group at the 11th sensor and 12th sensor, in accordance with the damage state in Fig. 7. In Fig. 13b, the peak values of Q statistic indicates a new damage at the 16th sensor (C16) agreeing with the phenomenon in Fig. 8. The peak value and a larger value of T2 statistic appear near the 3rd and the 11th sensor, which reflects the propagation of the damage induced in ‘State 1’. It can also be seen that damage location in ‘State 1’ is hardly identified by the distributed sensors of S1–S8. In this regard, more sensors distributed in the same place are no helpful for damage identification in PCA-based model because the similar principal components will be eliminated as the redundancy of data.

Projections of the contribution of each sensor into the PCA-based model
After the process of PCA, CNN-based damage detection method can utilize the results of PCA to label the training data of CNN more automatically. Although PCA can provide the damage information of a structure, some statistical knowledge is needed to understand the results of the analysis. However, CNN-based damage detection method is able to directly determine the damage state of the structure, which is more intuitive and makes up for the deficiencies of PCA-based method.
4.2 Damage identification by DCNN-based model
A DCNN-based model for steel beam will be constructed and trained firstly. The model is constructed with Python 3.7 language environment and Pytorch 1.5 DL framework. The NVIDIA GTX 850 m GPU is applied to accelerate training and obtain better results. Most hyperparameters are manually set by trial and error. Among the data set in 180 test trials, 80% of data will be used for training and the rest as the test set. During training, 25% of the training data is used for validation to monitor whether the model is overfitting and ensure the hyper-parameters to be adjusted in time.
4.2.1 Classification task
The accuracy and loss curves of model for steel beam are shown in Fig. 14. In the training phase, the accuracy of the DCNN models can finally stabilize between 99 and 100%. The training curve almost coincides with the validation curve between 0 and 300 epochs. The result of the verification shows that although the verification curve will oscillate during training, it follows the same trend as the training curve, which can indicate that there is no serious overfitting phenomenon in the training process of model. The convergence of training curves proves that the proposed model can effectively extract features and identify damage states. The model training result shown by the loss curve is roughly the same as the accuracy curve.

Evaluation of DCNN-based model for steel beam
The accuracy and loss curves of model for RC beam are shown in Fig. 15. Although there are some hop points, the training curve coincides with the validation curve roughly. Unlike the detection model of steel beams, the training curve of RC beams starts to converge after 20th epochs, which shows that the complexity of the task will affect the convergence speed of the DCNN model.

Evaluation of DCNN-based model for RC beam
Though high detection accuracy was acquired in the training phase, this does not indicate high generalization performance. Therefore, confusion matrix is used as another standard to assess the performance. As shown in Figs. 14 and 15, the test results of the trained models, confusion matrix, demonstrate that most of the samples can be accurately classified. However, there are a few samples that are not correctly classified in Fig. 14. There are two possible reasons for this: (1) the design of the model architecture or hyperparameters is not optimal for the dataset. (2) there is a few of bad (data with large errors in measurement) or insufficient samples in the dataset. The structure of the CNN model, the quality and quantity of samples in the dataset will affect the detection accuracy of the trained model. So the model with 100% detection accuracy is ideal. There are fewer classification categories for RC beam damage detection tasks and relatively more for steel beams. Therefore, it can be seen that the more types of damage, the more complex model structure is needed, which is difficult to adjust to the optimum. And the more training data is required. The increase in data can reduce the proportion of poor quality samples, thereby improving the generalization performance of the model.
Comparison with the results in the other study [40] reveals that the prediction performance of the DCNN in the proposed self-supervised learning method is superior, both in terms of the accuracy of the DCNN model during training and the prediction accuracy shown by the confusion matrix in the test results. It can be demonstrated that the proposed method can accurately identify different structural damage states.
4.2.2 Regression task
For regression task, only the loss curves are calculated as Fig. 16. The loss curve of steel beam in regression task is different to that in classification task because their optimization problems to be solved are diverse. The situation of RC beam is same. The loss curves of two models experienced a plateau at the beginning of training, indicating that the model encountered saddle points or local optima when it started to find the optimal solution to the optimization surface. Similarly, the validation curves of the two models demonstrate that the models were trained without overfitting.

Evaluation of DCNN-based model for regression task
The level of each damage state will be predicted and quantified by regression task with the average output value using the labels in Table 2. ‘Truth’ presents the predefined damage level and ‘Predication’ is the output value of test. Seen from Fig. 17, for each state, it is precise to predict the damage quantity of each element in steel beam as Fig. 3. For example, there is no damage in ‘State 0’ so that the average output value of each element is almost ‘0’. An initial damage occurs within ‘Element 3’ in ‘State 1’, the damage quantity of which is output close to ‘1’. And ‘Element 3’ is aggravated in ‘State 2’, hence it is output close to ‘2’. Then an initial damage occurs within ‘Element 4’ in ‘State 3’ and is output close to ‘1’ but the damage in ‘Element 3’ is not aggravated again, thus the label is unchanged, and so on.

The average output value for quantification of damage in steel beam
Similarly, seen from Fig. 18, the damage level of each element in RC beam as Figs. 7 and 8 can also be quantified accurately by the DCNN model. There is an initial damage within ‘Element 3’ and ‘Element 4’ in ‘State 1’ and the damage quantity of two element is output close to ‘1’. Then an accumulative damage occurs within ‘Element 3’ but not within ‘Element 4’ in ‘State 2’, hence the damage quantity of ‘Element 3’ is output close to ‘2’. At the same time, there is also an initial damage within ‘Element 8’ in ‘State 2’, thus the damage quantity of ‘Element 8’ is changed from ‘0’ to ‘1’. Other elements without damage are all output about ‘0’. The results show that DCNN-based model with finite elements divided by FBG sensors enables to predict damage quantity predefined by PCA-based model without considering any characteristic of the structure.

The average output value for quantification of damage in RC beam
5 Conclusions
In this paper, a novel method for structural damage detection combining unsupervised and supervised learning with dynamic response from FBG arrays is proposed to detect the damage of beam-like structures. This method directly analyzes the measured dynamic responses of the structure. Through several scenarios with many test trails on steel beam and RC beam, the method has been proved to perform well in structural damage detection.
The main conclusions are as follows:
As an unsupervised learning method, a PCA-based model using the gather projection of T2 statistic and Q statistic is used to get the damage information. A transformed PCA-based model by rearranging the data set and using the previous state as baseline is applied to identify the current state, which is useful when there are new data of increased damage states. The results displayed by PCA are consistent with the actual structural damage.
Damage information obtained from PCA can ease the work of labelled data in supervised learning, which is more intelligent than manual labelling procedure. Supervised learning can in turn better utilize and interpret the results of PCA to present the damage state of the structure more clearly.
As a supervised learning method, a proposed DCNN-based model using identified information and combining with the conception of finite element (FE) is applied to distinguish the damage categories by classification task and locate, quantify the damage by regression task. The results show that the DCNN model can accurately identify structural damage and roughly predict the degree of damage.
The methods open up a novel approach feasible for long term health monitoring. There are many uncertain damage states in engineering practice, so future work will focus on a variety of experiments to explore the effect of damage identification under sophisticated conditions. Meanwhile, the data of training and testing derives from FBG arrays distributed as chainlike line. Further work should also consider how to process the data from spatial distribution.
References
Celik O, Do NT, Abdeljaber O, Gul M, Avci O, Catbas FN (2016) Recent issues on stadium monitoring and serviceability: a review. In: Allen M, Mayes R, Rixen D (eds) Dynamics of coupled structures, Vol 4. Conference Proceedings of the Society for Experimental Mechanics Series, pp 411–416
Chesne S, Deraemaeker A (2013) Damage localization using transmissibility functions: a critical review. Mech Syst Signal Process 38(2):569–584
Amezquita-Sanchez JP, Adeli H (2014) Signal processing techniques for vibration-based health monitoring of smart structures. Arch Comput Methods Eng 23(1):1–15
Meruane V, Heylen W (2011) An hybrid real genetic algorithm to detect structural damage using modal properties. Mech Syst Signal Process 25(5):1559–1573
Magalhães F, Cunha A, Caetano E (2012) Vibration based structural health monitoring of an arch bridge: from automated oma to damage detection. Mech Syst Signal Process 28:212–228
Fugate ML, Sohn H, Farrar CR (2001) Vibration-based damage detection using statistical process control. Mech Syst Signal Process 15(4):707–721
Wu RT, Jahanshahi MR (2018) Data fusion approaches for structural health monitoring and system identification: past, present, and future. Struct Health Monitor 19(2):552–586
Mao Z, Todd MD (2016) A bayesian recursive framework for ball-bearing damage classification in rotating machinery. Struct Health Monit 2016:1475921716656123
Zhang W, Peng GL, Li CH (2017) Rolling element bearings fault intelligent diagnosis based on convolutional neural networks using raw sensing signal. In: Pan JS., Tsai PW, Huang HC (eds) Advances in intelligent information hiding and multimedia signal processing. Smart Innovation, Systems and Technologies, vol 64, pp 77–84
Ansari F (2005) Sensing issues in civil structural health monitoring. Springer, Dordrecht
Glišić B, Inaudi D (2007) Fibre optic methods for structural health monitoring. Wiley, Chichester
Glišić B (2011) Influence of the gauge length on the accuracy of long-gauge sensors employed in monitoring of prismatic beams. Meas Sci Technol 22:1–13
Wu ZS, Li SZ (2007) A non-baseline algorithm for damage locating in flexural structures using dynamic distributed macro-strain responses. Earthquake Eng Struct Dynam 36(9):1109–1125
Frieden J, Cugnoni J, Botsis J, Gmur T, Coric D (2010) High-speed internal strain measurements in composite structures under dynamic load using embedded FBG sensors. Compos Struct 92:1905–1912
Sajedi SO, Liang X (2020) A data-driven framework for near real-time and robust damage diagnosis of building structures. Struct Control Health Monit 27(3):e2488
Pan H, Azimi M, Yan F, Lin Z (2018) Time-frequency-based data driven structural diagnosis and damage detection for cable-stayed bridges. J Bridg Eng 23(6):04018033
Kourti T, MacGregor JF (1995) Process analysis, monitoring and diagnosis, using multivariate projection methods. Chemom Intell Lab Syst 28:3–21
Xia Q, Tian YD, Zhu XW, Xu DW, Zhang J (2015) Structural damage detection by principle component analysis of long-gauge dynamic strains. Struct Eng Mech 54(2):379–392
Wang X, Gao QF, Liu Y (2020) Damage detection of bridge under environmental temperature changes using a hybrid method. Sensors 20(14):3999
Jo BW, Khan RMA, Lee YS, Jo JH, Saleem N (2018) A Fiber Bragg Grating-based condition monitoring and early damage detection system for the structural safety of underground coal mines using the Internet of things. J Sens 201:9301873
Yi J-H (2016) Laboratory tests on local damage detection for jacket-type offshore structures using optical FBG sensors based on statistical approaches. Ocean Eng 124:94–103
Tan ZX, Thambiratnam DP, Chan THT, Gordan M, Razak HA (2020) Damage detection in steel-concrete composite bridge using vibration characteristics and artificial neural network. Struct Infrastruct Eng 16(9):1247–1261
Eftekhar Azam S, Rageh A, Linzell D (2019) Damage detection in structural systems utilizing artificial neural networks and proper orthogonal decomposition. Struct Control Health Monit 26(2):e2288
Chang CM, Lin TK, Chang CW (2018) Applications of neural network models for structural health monitoring based on derived modal properties. Measurement 129:457–470
Chang MW, Kim JK, Lee JH (2019) Hierarchical neural network for damage detection using modal parameters. Struct Eng Mech 70(4):457–466
Jayasundara N, Thambiratnam D, Chan T, Nguyen A (2020) Damage detection and quantification in deck type arch bridges using vibration based methods and artificial neural networks. Eng Fail Anal 109:104265
Jia ZG, Ren L, Li HN, Jiang T, Wu WL (2019) Pipeline leakage identification and localization based on the fiber bragg grating hoop strain measurements and particle swarm optimization and support vector machine. Struct Control Health Monit 26(2):e2290
Lu SZ, Jiang MS, Wang XH, Yu HL, Su CH (2019) Damage degree prediction method of CFRP structure based on fiber bragg grating and epsilon-support vector regression. Optik-Int J Light Electr Opt 180:244–253
Lu SZ, Jiang MS, Wang XH, Yu HL (2019) Damage detection method of CFRP structure based on fiber Bragg grating and principal component analysis. Optik-Int J Light Electr Opt 178:858–867
Xu B, Zhang X, Jiang J, Liu K, Wang S, Fan X, Jiang L, Li Y, Chu Y, Liu T (2019) Method of damage location determination based on a neural network using a single fiber bragg grating sensor. Applied optics. 58(26):7251–7257
Geng XY, Lu SZ, Jiang MS, Sui QM, Lv SS, Xiao H, Jia YX, Jia L (2018) Research on FBG-based CFRP structural damage identification using BP neural network. Photonic Sens 2:168–175
Sierra-Pérez J, Güemes A, Mujica LE (2012) Damage detection by using FBGs and strain field pattern recognition techniques. Smart Mater Struct 22(2):025011
Sierra-Perez J, Guemes A, Mujica L, Ruiz M (2014) Damage detection in composite materials structures under variable loads conditions by using fiber Bragg gratings and principal component analysis, involving new unfolding and scaling methods. J Intell Mater Syst Struct 26(11):1346–1359
Sierra-Perez J, Arredondo MAT, Guemes A (2016) Damage and nonlinearities detection in wind turbine blades based on strain field pattern recognition. FBGs, OBR and strain gauges comparison. Compos Struct 135:156–166
Sierra-Perez J, Arredondo MAT, Alvarez-Montoya J (2017) Damage detection methodology under variable load conditions based on strain field pattern recognition using FBGs, nonlinear principal component analysis, and clustering techniques. Smart Mater Struct 27(1):015002
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521:436–444
Toğaçar M, Ergen B, Cömert Z (2020) Classification of flower species by using features extracted from the intersection of feature selection methods in convolutional neural network models. Measurement 158(1):107703
Fan J, Xu W, Wu Y, Gong Y (2010) Human tracking using convolutional neural networks. IEEE Trans Neural Networks 21(10):1610–1623
Ibrahim A, Eltawil A, Na YS, El-Tawil S (2020) A machine learning approach for structural health monitoring using noisy data sets. IEEE Trans Autom Sci Eng 17(2):900–908
Li S, Sun LZ (2020) Detectability of bridge-structural damage based on fiber-optic sensing through deep-convolutional neural networks. J Bridge Eng 25(4):04020012
Villez K, Steppec K, De Pauw DJW (2009) Use of Unfold PCA for on-line plant stress monitoring and sensor failure detection. Biosys Eng 103:23–34
Mujica LE, Rodellar J, Fernández A, Güemes A (2010) Q-statistic and T2-statistic PCA-based measures for damage assessment in structures. Struct Health Monit 10(5):539–553
Joe Qin S (2003) Statistical process monitoring: basics and beyond. J Chemom 17(8–9):480–502
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Ioffe S, Szegedy C (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv e-prints 1502.03167
Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov RR (2012) Improving neural networks by preventing co-adaptation of feature detectors. arXiv e-prints 1207.0580
Lin M, Chen Q, Yan S (2013) Network in network. arXiv e-prints 1312.4400
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv e-prints 1412.6980
Li SZ, Wu ZS (2009) Sensitivity enhancement of long-gage FBG sensors for macro-strain measurements. Struct Health Monit 8(6):415–423
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 51308369), A Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD) and an Enterprise graduate workstation ‘SUST-CCCC First Highway Two Engineering CO., LTD.’.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, D., Zhang, W. Damage detection combining principal component analysis and deep convolutional neural network with dynamic response from FBG arrays. J Civil Struct Health Monit 13, 101–115 (2023). https://doi.org/10.1007/s13349-022-00621-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13349-022-00621-0