
Abstract
In this study, a new, model-free damage detection method is proposed and validated on a simple numerical experiment. The proposed algorithm used vibration data (deck accelerations) and bridge weigh-in-motion data (load magnitude and position) to train a two-stage machine learning setup to classify the data into healthy or damaged. The proposed method is composed in its first stage of an artificial neural network and on the second stage of a gaussian process. The proposed method is applicable to railway bridges, since it takes advantage of the fact that vehicles of known axle configuration cross the bridge regularly, that normally only one train is on the bridge at a time and that the lateral positioning of the loads does not change. The novelty of the proposed algorithm is that it makes use of the data on the load’s position, magnitude and speed that can be obtained from a Bridge Weigh-in-Motion system to improve the accuracy of the damage detection algorithm.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Damage detection in civil infrastructure is a very active field of research. There are many algorithms and techniques being developed, but they can generally be classified in two categories: model-based and model-free. In the model-based damage detection paradigm, an accurate finite element (FE) model of the structure is required. Unknown parameters are inferred from signals measured on the structure. In this way, eventual reduction in stiffness can be detected. One of the main advantages of this approach is that the damage detected has a direct physical interpretation. The largest obstacle with this approach is the need of an extremely accurate and detailed FE model. For structures of some complexity, this can be very difficult to achieve. Also the optimization procedure to find the updated variables is often ill-posed. On the other hand, model-free damage detection does away with the need of a FE model, at the price of not always having a direct physical interpretation of the damage. Most modern techniques for model-free damage detection involve artificial intelligence. In this type of approaches, a classification algorithm is trained on data acquired on the structure so that it is able to separate, based on data alone, the signals coming from a healthy structure from those in which damage is present. Depending on the nature of the training, this can be said to be supervised (when data from all possible states are used) or unsupervised (when only data from a base state are used). Obviously damage can take many forms in a civil structure, and one does not have access to a structure to which one can freely introduce different levels of damage to obtain the relevant data. Thus, supervised learning is seldom used. In unsupervised training only data from the assumed healthy structure are available and the algorithm used should ideally detect significant deviation from the observed ”normal” behavior. Thus, damage detection becomes an instance of novelty detection. Novelty detection implies that, in any model-free damage detection algorithm, damage will be always defined against a baseline status that is assumed to be undamaged.
The following paragraphs present recent developments within the area of damage detection using novelty detection.
In [1], data on the displacement and rotation along a beam frame subjected to an unknown moving load are gathered. The data are arranged in a matrix in which each column corresponds to a load passage and each raw corresponds to a fix position in the bridge. Principal component and Robust regression analysis are used to reduce the dimensionality of this matrix. Then, data gathered during an initial period assumed to be absent of damage are used to characterize the natural variation of the reduced parameters, so that subsequent variation beyond this ”natural” range can be flagged as damage. The method successfully detects stiffness reductions of 20 \({\%}\). Among the weaknesses of this method is that it assumed known load speed, quasistatic behavior and a single load, which are seldom the case in real bridges.
In [2], the time-derivative of the acceleration, here called the “jerk” is used to localize damage in a structure. The method is tested both numerically and in a laboratory experiment and compared to other methods. The method computes the curvature of the “jerk” energy (defined analogously to the kinetic energy) and compares it to that of a reference healthy measurement. The method is capable of successfully localizing the damage (20 \({\%}\) stiffness reduction), even in noisy multiple damage scenarios. The only load scenario considered was an impulse loading, which limits the applicability of the method.
In [3], an operational modal analysis (OMA) based in a quantity called the “cepstrum” is used to obtain the modal characteristics of a structure. These are compressed using principal components and classified into damaged or healthy by an artificial neural network (ANN). The cepstrum is used because it allows, under certain conditions, to relax the normal white-noise constrain in OMA. The damage is introduced in the laboratory experiment as an extra mass. The excitation is assumed to be single input, which constitutes a limitation of the suggested method.
In [4], a two-stage damage detection algorithm is proposed. In the first stage, it uses Monte Carlo Markov Chain method to cluster the response of a structure, even under environmental variability. In the second stage the Mahalanobis distance is used to detect outliers that are then flagged as damage. The method is tested in data from the Z-24 bridge in Switzerland on which healthy and damaged data were available. The data used for clustering consisted on the three lowest eigenfrequencies and the air temperature on site. Using the clustered data to calculate the Mahalanobis distance false positives are minimized.
In [5], Principal component analysis is used to reduce the dimensionality of a matrix containing time signals from different sensors on a structure. The reduced data are then used for outlier detection using different regression tools that are compared against each other. Data gathered from numerically simulated truss bridge and concrete frame are used to validate the methods. Finally, the suggested methods are used in an existing concrete bridge in which data from the construction period are used in lieu of damaged data.
In [6], a method for location and estimation of damage using macro strains is proposed. The method uses data from distributed fiber optic sensors that measure strains along the whole structure. It used these data to estimate the distribution along a beam of the bending moments in the frequency domain calling it the modal bending moment. In several numerical experiments it is demonstrated that in the case of damage the modal bending moment spikes around the damaged elements, the magnitude of the spikes indicating the extent of the damage. The method is also tested in a multi-damage scenario in a laboratory experiment with a reinforced concrete beam. The damage is introduced progressively by reducing the cross-section’s width. The tested method detects and locates the damage successfully and is able to quantify it to some degree.
In [7], a reference free damage detection algorithm is proposed. The method is based on the increase of the information content of a signal measured close to a damage location. For this, the relative entropy of the signals in the wavelet domain is computed. The method was tested in a truss structure in a laboratory setup. To introduce damage bolts in the truss connections were loosened. The proposed method could successfully detect this type of damage when it occurred close to a sensor.
In [8], data are compressed using principal component analysis and interquantile intervals and several definitions of similarity are tested to detect outliers and cluster the monitoring data. The proposed method is tested on a numerical model of an existing cable stayed bridge, updated with data measured on the structure. Damage was applied to the model by introducing a change in a cable, simulating dead-weight redistribution. The simulations included the natural temperature variability of the structure. The proposed method was able to detect stiffness reduction in the cable equivalent to 1 \({\%}\).
As can be seen for the brief review above, novelty detection is a varied and rich field of research. Many of the proposed method are limited to a certain type of damage, to a specific loading scenario or to relatively simple structures, which limits their usability in real bridges. The load acting on a bridge at a given moment is rarely known, so assumptions in the load should be done carefully.
Lately several bridge weigh-in-motion (BWIM) methods have been suggested [9–13] and some applications have been used in the context of damage detection [14]. BWIM is normally implemented for their own sake, since there is a clear value in knowing the magnitude and frequency of loads crossing a structure. In this study, we suggest that BWIM can be of use also in damage detection. Particularly for railway bridges, where the vehicle configurations are limited and known, and where there is minutes of separation between consecutive trains, BWIM can be especially accurate [15–17].
The method proposed in this study presupposes a bridge instrumented with a dynamic monitoring system that includes BWIM capabilities. It uses an ANN to predict the value of the deck accelerations given values of previous deck accelerations and information on the load’s magnitude and position provided by the BWIM system. The ANN is trained with representative data recorded in the healthy structure, so that the prediction errors, the difference between the predicted and measured accelerations, are as little as possible. Once this has been achieved, any subsequent increase in the prediction errors can be attributed to changes in the way the structure behaves, i.e., damage.
Of course, the prediction errors have some variability, even under healthy conditions so a stochastic characterization is necessary to separate the outliers that will be flagged as damage. This is achieved by fitting a gaussian process to the prediction errors under healthy conditions.
By choosing data that come from only one vehicle of fixed axle configuration (but allowing for the natural variability of the axle loads and the vehicle speed) the variability of the data is reduced, resulting in a more successful damage detection. The chosen vehicle should be one that crosses the monitored bridge frequently to make the period necessary to accumulate sufficient training data shorter and to allow to evaluate the health of the bridge often.
The proposed method was tested in a simple numerical experiment as a first step towards a full validation.
2 Method
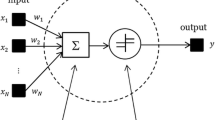
The proposed method is an implementation of a novelty detection algorithm and it is composed in its first stage of an ANN (to create predicted accelerations) and on the second stage of a gaussian process that classifies, based on the difference between predicted and measured accelerations, signals into damaged and undamaged. ANN are universal approximators [18] composed of simple computing units called neurons that are arranged in ordered layers. They are extensively used in the past for damage detection [19–21]. In its most typical layout each neuron takes as input the output of all the neurons in the previous layer and performs a relatively simple calculation to return a single real-value output. Thus, a single neuron can be modeled by:
where \(s_{1..N}\) is the output of each of the N neurons in the previous layer, \(w_{1..N}\) is a real-valued weight factor associated with each of the neurons on the previous layer, b is a real number called the neuron bias and \(S(\cdot )\) is some function, typically a sigmoid. It is plain to see that the predictive power of a single neuron is but small. But when enough neurons are interconnected in the right architecture they can be used to fit any data with arbitrary accuracy [22]. Typically an ANN is configured in 3 layers. The first one is called the input layer and does not receive input from any other layer, but directly from the independent variable of the data that is being fitted. This value is then output unchanged to the next layer. The second is called the hidden layer and takes as input the output of the input layer. Using this input and a predefined set of weights and bias it performs the computation described in Eq. 1 and passes the result as input to the next layer. The third layer, the output layer, takes its input from the hidden layer and performs an analogous operation. The output of the output layer is then treated as the output of the whole ANN, and constitutes the dependent variable. Because there is a weighing factor for each connection between neurons and each neuron is connected to all neuron in the previous and next layer an ANN architecture with 3 layers, namely an input layer with P neurons, a hidden layer with Q neurons and an output layer with R neurons, will have a total of \(PQ + QR\) weight factors w. Also, each neuron (except the input neurons) has its own bias b, for a total of \(Q + R\) biases. All in all the described architecture has a total of \(Q(P+R+1)+R\) parameters to be determined that can be gathered in a vector of parameters \(\theta\). To train an ANN is to find the optimal parameters \(\theta = \theta ^*\) so that ANN approximates the unknown function underlying the empirically obtain data pairs \((x_i, y_i)\), so that when evaluated at the independent variable \(x_i\) the ANN returns an approximation the matching dependent variable \(y_i\). This is achieved by minimizing the difference:
For all data points \((x_i, y_i)\) and for some norm \(|\cdot |\), usually the Euclidian norm, where \(ANN(\cdot )\) is composed of layers of neurons as described above. The most common algorithm to perform this optimization in Backpropagation, in this study the Levenberg–Marquardt backpropagation [23] was used. In the proposed method, an ANN is trained to be able to predict the deck acceleration during the passage of a vehicle of known axle configuration, based on the k previous values of the deck acceleration, measured at s sensors and information on the m axle loads magnitudes and position (because the vehicle is assumed to always have the same configuration, only the position of the leading axle is given). Let \(a_t^s\) be the acceleration measured at time t at sensor s. Let \(P_i\) be the magnitude of the load of the i-th axle of the vehicle. And let \(l_t\) be the position on the bridge of the leading axle of the vehicle at time t. Thus, the independent variable x is formed by the vector containing:
for all times t and sensors s. The dependent variable y becomes:
for all times t and sensors s. In this study, 4 sensors were used, and the 5 previous values of the acceleration were considered (meaning that k and s in Eq. 3 were set to 5 and 4, respectively). The vehicle was chosen to have 4 axles. These acceleration values (4 × 5) together with the magnitude of the 4 axle loads and the position of the leading axle make a input vector x with 25 components. In this way, the ANN is trained to estimate or “predict” the deck acceleration values for each sensor based on information on the live load and the previous values of the deck accelerations. For each passage of the chosen vehicle a prediction error can be calculated as:
For all sensors s, where \(pe_s\) is the prediction error for sensor s, \(x_t^s\) and \(y_t^s\) are as defined in Eqs. 3 and 4, \(\theta ^*\) is the optimized parameters of the ANN function. If the ANN is properly structured and trained with data from the undamaged structure the prediction errors \(pe_s\) should be fairly low, and will remain low as long as the structure continues to behave in its “undamaged” condition. If damage is introduced to the structure, the behavior of the structure will change. Because the ANN is trained to predict the behavior of the undamaged structure, the values of \(pe_s\) will increase, making it a suitable damage index. Now, the prediction errors \(pe_s\) will not be exactly the same for different vehicle passages, even if the condition of the structure remains unchanged, since the vehicle will cross at different speeds and with different axle loads (only the axle configuration is assumed to be unchanging, not the magnitude of the loads). Thus, the prediction errors \(pe_s\), even under the assumption of no damage, form a distribution that needs to be characterized stochastically. Values of \(pe_s\) that deviate from this distribution can be used as indicative of damage. It was found that the accuracy of the ANN at predicting the acceleration varied significantly with the speed of the crossing vehicle. Therefore, a gaussian process with the vehicle speed as independent variable was used to characterize the prediction errors \(pe_s\) for the healthy structure. A gaussian process [24] is a process whose realization is a normally distributed random variable for every point in its domain. Thus, for each vehicle speed v the prediction errors are normally distributed (but with different mean and standard deviation for each speed),
for each sensor s, where the dependence of the mean \(\mu _s\) and the standard deviation \(\sigma _s\) on the speed v have been made explicit.
The proposed method requires, therefore, an initiation period in which data are gathered on the structure under the assumption of no damage. These data are used to train the ANN and the gaussian process. In this study, the ANN was trained with data corresponding to either 150 or 300 vehicle passages. The gaussian process was trained with data corresponding to 100 vehicle passages. The proposed method uses passages of a single type of train to reduce the uncertainties. To ensure that enough data can be gathered a common train type should be chosen. For a heavy trafficked bridge, and for a common vehicle type, the necessary training data on 400 vehicle passages can be obtained in less than a week. Making it a realistic training period. To combine the four \(pe_s\) (one for each of the four sensor used in this study) into a single damage index DI the signed sum of the distance of the \(pe_s\) to the mean measured in standard deviations has been used, thus:
where \(pe_s\) is the prediction error for the sensor s, \(\mu _i(v)\) is estimated mean of the prediction errors for healthy condition at vehicle speed v and \(\sigma _i(v)\) is the estimated standard deviation of the prediction errors for healthy condition at vehicle speed v. In this way, a prediction error below the mean (corresponding to unusually good predictions) contributes negatively to the damage index, making it less likely that the system classifies it as damage. The whole method is schematically represented in Fig. 1.
The sensibility of the method to a number of parameters was also tested. This was done by comparing the results to a base-case and changing one parameter at a time. The base-case scenario had 5 % BWIM error introduced, vehicle speed varying from 20 to 23 m/s and 300 train passages as training dataset.

Schematic of the proposed method. The dashed line denotes relations that are only active during the initial training period
3 Case study
The numerical model used in this experiment consists of a simply supported Euler–Bernoulli beam discretized using 30 FE. Damage is represented as a 30 % stiffness reduction in element number 18. The geometric and material properties are detailed in Table 1.
The vehicle simulated is a 4-axle vehicle with inter-axle distances 2, 3 and 2 meters. Each of the axle’s load is obtained from an independent uniform random distribution in the range 100–120 kN. The speed of the vehicle is obtained from a uniform random distribution in the range 20–23 m/s. The numerical simulation is performed with Newmark’s beta method with \(\beta = 1/4\) and \(\gamma = 1/2\) with a time increment \(\Delta t = 1/300\) s and Rayleigh damping with a modal damping of 6 % for the first and second mode. The vehicle always cross from node 1 to node 31 (see Fig. 2). The vertical deck acceleration is recorded at nodes 6, 10, 15 and 23 (meaning 1.7, 3, 4.7 and 7.3 meters from the abutment, respectively). The acceleration data were corrupted with artificial white noise of 0 mean and standard deviation 0.1 mg, a value admittedly low, but by no means unrealistic for a high-quality accelerometer. The BWIM system was assumed to provide load magnitudes accurate to 5 % and exact load positions.

Sketch of the bridge used for the numerical experiment. The boxes represent the location of the accelerometers. The cross indicates the location of the damage. The axle loads are independently drawn from a uniform distribution, as is the speed
4 Results
Figure 3 shows the resulting prediction error for 300 simulated passages for all four sensors, plotted against train speed. The ones marked with a cross come from healthy condition and are used to fit the gaussian process that will function as a "baseline" for each sensor. Against this baseline subsequent measurements will be compared to discriminate whether they correspond to healthy or damaged condition. The thick line marks the mean of the fitted gaussian process and the gray area marks the two-standard-deviations limit.

Prediction errors (pe) for all four sensors from 300 train passages, plotted against speed. The 100 passages marked with + were used to stochastically characterize the pe by fitting a gaussian process. The mean of the gaussian process is shown as a thick line. The gray zone shows the \(\pm\) 2 standard deviations zone. The 100 passages marked with \(\circ\) correspond healthy conditions, not used for training. The 100 passages marked with asterick correspond to damaged conditions
The prediction errors marked with circles correspond to healthy conditions. As could be expected they lie generally within the two-standard-deviations limit.
The prediction errors marked with asterisks correspond to the damaged condition (30 % reduction in the stiffness of the 18th element). The difference is clearly observable for the naked eye. The sensors 2 and 3, which are located closer to the center of the span, show a clearer separation between the damaged and healthy conditions.

Schematic of how a ROC is constructed. The damage index DI is calculated for a number of damaged and healthy scenarios. Setting a threshold for the classification generates a point in the ROC. By sliding the threshold up and down the whole ROC is generated
For these data, the damage indexes DI can be calculated from Eq. 7, and the receiver operating characteristic (ROC) of the proposed method can be obtained. In a ROC, the percentage of true positive (correctly labeled damaged cases) is plotted against the percentage of false positives (healthy cases incorrectly labeled as damaged cases) as the critical DI that will work as a discriminating threshold is varied (see Fig. 4). A very low threshold will always warn for damage (resulting to 100 % true positives and 100 % false positives) while a very high threshold will never indicate damage (resulting in 0 % true positives and 0 % false positives). The ideal ROC has an “inverted L” shape.

Receiver operator curve based on the results shown in Fig. 3 (base-case)

Receiver operator curve based on the results shown in Fig. 9 (speed varied between 18 and 23 m/s)

Receiver operator curve based on the results shown in Fig. 10 (10 % BWIM error)

Receiver operator curve based on the results shown in Fig. 11 (reduced training set)
The ROC for the base-case described above is shown in Fig. 5. Besides the base-case, a sensitivity analysis was performed by varying some of the parameters used: namely, the estimation error of the loads’ magnitude, the range of speed of the crossing vehicles and the amount of data available for training. The ROCs for these cases are shown in Figs. 6, 7 and 8.
The ideal threshold should be set based on the probability of damage occurring, the associated costs of false positives (extra inspections, unnecessary repairs) and of false negatives (accumulation of undetected damage, eventual collapse), and should minimize the expected cost. The expected cost will be a linear combination of the costs of the four possible scenarios (true positive, false positive, true negative and false negative) weighed by their respective probabilities. These probabilities can be obtained from Bayes Theorem. For example, the probability of a true positive (i.e., the probability of damage present in the structure given that damage was detected) can be defined as follows: Let d denote damaged structure state, h denotes healthy structure state and det denotes detection
where the probabilities of detection given damage \(p(\text {det}|\text {d})\) and detection given a healthy condition \(p(\text {det}|\text {h})\) are obtained from the ROC (see Figs. 5 and 6) and depend on the threshold set. The probability of damage \(p(\text {d})\) should be known or at least estimated. The probability of no damage \(p(\text {h})\) is \(1-p(\text {d})\). The probabilities of the other three scenarios can be calculated in analogous way.
This case, with 5 % BWIM error, vehicle speed varying from 20 to 23 m/s and 300 train passages as training dataset was considered as a base against which to compare other combinations of parameters to study the sensibility of the proposed method.
The case in which a wider range of vehicle speeds is considered was also studied. Figure 9 presents the prediction errors for 300 train passages under both healthy and damaged conditions, but for vehicle speeds in the wider interval 18–23 m/s. As expected the increased variability in the excitation leads to a wider spread in the results and a poorer performance in the detection (see Fig. 6), but still acceptable as a damage detection tool.

Prediction errors (pe) for all four sensors from 300 train passages, plotted against speed. See Fig. 3 for legend. In this case, the speed was varied between 18 and 23 m/s
If the inaccuracy of the load estimation of the BWIM system is increased to 10 % the result is still very good (see Fig. 7). In fact it is comparable to the result with 5 % error. This indicates that the system is fairly insensitive to BWIM inaccuracies. It can be mentioned that the only quantity in which error is introduced is the magnitude of the load. Information about the load position is still considered to be known exactly. Figure 10 presents the prediction errors for 300 train passages under both healthy and damaged conditions, for the case with increased BWIM error.
Figure 11 presents the prediction errors for 300 train passages under both healthy and damaged conditions, when the ANN is trained with only 150 train passages. The prediction capabilities are clearly diminished, but still acceptable as a damage detection tool (see Fig. 8).
As an example, one can see from Figs. 5, 6, 7 and 8 that for a threshold that correctly labels 90 % of the damaged cases one must accept a 6 % probability of false positives in the base-case, 8 % probability of false positives in the case with increased BWIM error, 17 % probability of false positives in the case with increased speed range and 24 % probability of false positives in the case with reduced training set.

Prediction errors (pe) for all four sensors from 300 train passages, plotted against speed. See Fig. 3 for legend. In this case, an error of 10 % was introduced in the BWIM data inputted to the ANN

Prediction errors (pe) for all four sensors from 300 train passages, plotted against speed. See Fig. 3 for legend. In this case, the ANN was trained with only 150 train passages
The proposed damage detection system works as a novelty detection, warning for changes in the behavior of the bridge under known loads interpreting them as damage. The baseline used to determine the novelty consists in a number of train passages recorded under healthy condition. It would be useful if the SHM system could tell if the damage is progressing or if it has stabilized. Figure 12 shows the damage index DI for a number of train passages (the same random four-axle vehicle used before) with variable damage severity (represented as a stiffness reduction in the x-axis). As can be seen the rate of change in DI increases with the severity of the damage, so the system can be expected to discriminate between stable damage and progressive damage.

Damage indices DI for a number of train passages for varying damage severities
5 Discussion and conclusions
In this study a new method for damage detection in railway bridges is presented and tested on numerically simulated data. The proposed method uses the information about the load provided by a BWIM system and the previously recorded deck accelerations as input to an ANN that predicts future values of the deck accelerations. Changes in prediction capabilities in the ANN are then linked to structural changes and damage.
The results from the presented experiment are very promising and give reason to explore this field further. The numerical data are admittedly generated from the simplest possible bridge, but since the ANN training is done on measured data, and thus is "model-free", the method is believed to work for more complex structures. Both the acceleration noise and BWIM error introduced are realistic enough.
The proposed method was found to be relatively insensitive to BWIM error, performing well with 5 and 10 % error introduced.
A case scenario with a four-axle vehicle was considered. This corresponds to the crossing of a single locomotive. While single locomotives do cross bridges with some regularity, the ideal would be to use the most common types of commuting trains. The number of axles in these is far higher.
It can be observed that the sensors located closest to the center of the bridge (sensors 2 and 3 located at nodes 10 and 15, respectively) are much more efficient in detecting damage. The spread of the prediction error is smaller for healthy condition and the difference between the means of healthy and damaged conditions is larger. This, even though sensor 4 (located in node 23) is closer to the damage than sensor 2. Therefore, it appears that further development is needed to be able to locate the damage.
As can be seen from Fig. 12, the proposed damage index is sensitive not only to the presence of damage, but even to its extent. Thus, it can give a relative quantification of the damage. Relative because, from the time development of the damage index, it can be inferred whether the damage present is stable or exacerbating. The proposed method a model-free and thus, works as a novelty detecting algorithm. It detects changes in the dynamic behavior of the structure and interpret those changes as damage. As any other model-free method, it cannot relate the amount of change to a change in a physical quantity (such as a reduction in stiffness) and thus cannot provide an absolute damage quantification. To obtain an absolute damage quantification one will need train the algorithm with supervised learning, which is normally impossible for civil structures.
For damage location a similar argument holds. For the ANN to provide a direct estimation of the damage location it would need to be trained with data about the damage location for several damage scenarios. Because in Civil engineering one is as a rule limited to unsupervised learning this becomes an impossibility. An indirect damage location can be obtained by observing what sensors are more affected by the damage (i.e., which sensors register a larger change in pe). As a general rule, sensors closer to the location of the damage will detect the largest changes in the structures behavior. This general principle needs, nonetheless, to be balanced by the fact that, due to the quality and quantity of available data, the ANN will be inherently better at predicting some of the outputs compared to others. A measure of how good the ANN is at predicting each of the outputs can be easily obtained by the ANN’s fitness, i.e., the difference between the predicted and the target value for each of the output over a representative dataset.
It needs to be mentioned that the proposed method evaluates the health of the bridge every time the selected train type crosses it. Thus, the system can be made arbitrarily reliable over longer periods of time, even in the presence of false positives and false negatives. To illustrate this (using the base-case scenario), let us say we chose the threshold to give us a 90 % probability of detection in case of damage (true positive) and thus a 6 % probability of false detection (false positives) if damage is not present. Further let us say that we have estimated the a priori probability of damage to be one in a million or 1e-6. Let us say, we then evaluate 4 train passages and obtain that all 4 of them result in a ”damaged” classification. Then, the posterior probability of damage in the structure is only 4.8 % due to the overwhelmingly low a priori probability of damage occurring. If we continue to evaluate 5 more train passages and obtain a total of 8 "damaged" classifications and 1 "healthy" classification (the expected outcome if there was damage present in the structure), then the posterior probability of damage present in the structure rises to 99.6 %.
There are several important limitations for this work that should be considered in the future. One limitation of the proposed method is that it is assumed that damage introduced does not affect the performance of the BWIM system. It is possible to imagine scenarios in which this is not the case. However, the sensors used for the BWIM system are very local, so damage is unlikely to affect them. Further, at least two sensors in different cross-sections are needed for a BWIM system (to be able to infer the speed of the vehicle). Thus, sensor malfunctions can be discovered if the load estimations coming from the different BWIM sensors start to differ significantly ([12] has studied the case in which the very variation in the load estimation capabilities of the BWIM system is used as a damage sensitive feature).
A more complex structure should also be studied, now that the suggested method has proven to work in the simply supported beam case. A more realistic structure would have a richer behavior, with torsional, bending, lateral and longitudinal modes (and combinations thereof). This would, in turn, call for a more careful selection of the sensor locations.
Further, a bridge’s behavior can change dramatically from winter to summer. In ballasted railway bridges seasonal variation in eigenfrequencies of over 30 % has been observed [25]. For bridges located in regions with large yearly temperature variations, the temperature and other possible ambient loads (wind, solar radiation) should be inputted to the ANN so that normal changes due to environmental conditions are not mistakenly labeled as damage.
Finally, the prediction error was observed to depend heavily on the speed of the train. It is believed that this could be mitigated if the speed of the loads (and not only their position, as in this study) is provided as input to the ANN.
References
Cavadas F, Smith FC, Figueiras J (2013) Damage detection using data-driven methods applied to moving-load responses. Mech Syst Signal Process 39(1):409–425
An Y et al (2014) A damage localization method based on the ‘jerk energy’. Smart Mater Struct 23(2):025020
Dackermann U, Smith WA, Randall RB (2013) Application of cepstrum analysis and artificial neural networks for the damage identification of a two-storey framed structure based on response-only measurements. Proceedings for the 6th international conference on structural health monitoring of intelligent infrastructure, Hong Kong, China, 9–11
Figueiredo E et al (2014) A Bayesian approach based on a Markov-chain Monte Carlo method for damage detection under unknown sources of variability. Eng Struct 80:1–10
Laory I et al (2013) ‘Combined model-free data-interpretation methodologies for damage detection during continuous monitoring of structures. J Comput Civil Eng 27(6):657–666
Tang Y et al (2013) A model-free damage identification method for flexural structures using dynamic measurements from distributed long-gage macro-strain sensors. J Intell Mater Syst Struct 25(13):1614–1630
Lee SG, Yun GJ, Shang S (2014) Reference-free damage detection for truss bridge structures by continuous relative wavelet entropy method. Struct Health Monit. doi:10.1177/1475921714522845
Santos JP, Cremona C, Orcesi AD, Silveira P, Calado L (2015) Static-based early-damage detection using symbolic data analysis and unsupervised learning methods. Fornt Struct Civil Eng. doi:10.1007/s117009-014-0277-3
Rowley C, O’Brien E, Gonzalez A, Zidaric A (2009) Experimental testing of a moving force identification bridge weigh-in-motion algorithm. Exp Mech 49(5):743–746
Deesomsuk Teerachai, Pinkaew Tospol (2010) Evaluation of effectiveness of vehicle weight estimations using bridge weigh-in-motion. IES J Part A 3(2):96–110
Deng Lu, Cai CS (2009) Identification of parameters of vehicles moving on bridges. Eng Struct 31(10):2474–2485
Carey Ciaran H, O’Brien Eugene J, Keenahan Jennifer (2013) Investigating the use of moving force identification theory in bridge damage detection. Key Eng Mater 569:215–222
Chen WZ, Xu J (2012) The theory and case study of axle load identification based on BWIM of orthotropic steel deck. Appl Mech Mater 204:1247–1254
Karoumi R, González A (2015) The virtual axle concept for detection of localised damage using bridge weigh-in-motion data. Eng Struct 89:26–36
Liljencrantz A, Karoumi R, Olofsson P (2007) Implementing bridge weigh-in-motion for railway traffic. Comput Struct 85(1):80–88
Ignacio G, Karoumi R (2013) Traffic monitoring using a structural health monitoring system. Proc ICE-Bridge Eng 168:13–23. doi:10.1680/bren.11.00046
Pimentel RMCD, Miguel R et al (2008) Hybrid fiber-optic/electrical measurement system for characterization of railway traffic and its effects on a short span bridge. Sens J IEEE 8(7):1243–1249
Braspenning PJ, Thuijsman F, Weijters AJMM et al (1995) Artificial neural networks: an introduction to ANN theory and practice. Springer, New York
Ko JM et al (2009) Investigation concerning structural health monitoring of an instrumented cable-stayed bridge. Struct Infrastruct Eng 5(6):497–513
Lin N, Qun C (2013) Structural health monitoring and damage detection using neural networks. Intelligent system design and engineering applications (ISDEA), 2013 3rd international conference on. IEEE
Shu J, Zhang Z, Gonzalez I, Karoumi R (2013) The application of a damage detection method using artificial neural network and train-induced vibrations on a simplified railway bridge model. Eng Struct 52:408–421
Cybenko G (1989) Approximation by superpositions of a sigmoidal function. Math Control Signals Syst 2(4):303–314
Marquardt DW (1963) An algorithm for least-squares estimation of nonlinear parameters. J Soc Ind Appl Math 11(2):431–441
Rasmussen CE, Nickisch H (2010) Gaussian processes for machine learning (GPML) toolbox. J Mach Learn Res 9999:3011–3015
Gonzales I, Ülker-Kaustell M, Karoumi R (2013) Seasonal effects on the stiffness properties of a ballasted railway bridge. Eng Struct 57:63–72
Acknowledgments
The authors are grateful for the funding provided by the Swedish Governmental Agency for Innovation Systems VINNOVA within the project IoT Bridge.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Gonzalez, I., Karoumi, R. BWIM aided damage detection in bridges using machine learning. J Civil Struct Health Monit 5, 715–725 (2015). https://doi.org/10.1007/s13349-015-0137-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13349-015-0137-4