
Abstract
In this study, we mathematically demonstrate that heterogeneous networks accelerate the social learning process, using a mean-field approximation of networks. Network heterogeneity, characterized by the variance in the number of links per vertex, is effectively measured by the mean degree of nearest neighbors, denoted as \(\langle k_{nn}\rangle \). This mean degree of nearest neighbors plays a crucial role in network dynamics, often being more significant than the average number of links (mean degree). Social learning, conceptualized as the imitation of superior strategies from neighbors within a social network, is influenced by this network feature. We find that a larger mean degree of nearest neighbors \(\langle k_{nn}\rangle \) correlates with a faster spread of advantageous strategies. Scale-free networks, which exhibit the highest \(\langle k_{nn}\rangle \), are most effective in enhancing social learning, in contrast to regular networks, which are the least effective due to their lower \(\langle k_{nn}\rangle \). Furthermore, we establish the conditions under which a general strategy A proliferates over time in a network. Applying these findings to coordination games, we identify the conditions for the spread of Pareto optimal strategies. Specifically, we determine that the initial probability of players adopting a Pareto optimal strategy must exceed a certain threshold for it to spread across the network. Our analysis reveals that a higher mean degree \(\langle k \rangle \) leads to a lower threshold initial probability. We provide an intuitive explanation for why networks with a large mean degree of nearest neighbors, such as scale-free networks, facilitate widespread strategy adoption. These findings are derived mathematically using mean-field approximations of networks and are further supported by numerical experiments.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In reality, human decision-making often deviates from perfect rationality, with a tendency to imitate strategies from our neighbors. Research by [30] and [15] illustrates this through the gradual adoption of more productive hybrid corn in the U.S., following a distinct spatial pattern. This adoption process, characterized by an S-curve, exemplifies the diffusion of superior strategies via imitation within social networks.
Social networks possess intriguing characteristics that have prompted extensive research. Classic studies [20, 24, 33] reveal the ’small world’ phenomenon, where individuals in social networks are connected through a surprisingly small number of intermediaries. Contrary to previous assumptions of randomness, many social networks differ significantly from regular and random networks.
Scale-free social networks, typifying heterogeneous networks, include diverse real-world examples such as mathematical collaboration networks [16], citation networks [29], communication networks [6, 10, 13], and so forth. These networks often exhibit small-world properties, characterized by short path lengths and high clustering coefficients, a measure of local link density.
The relationship between network structure and the game highlights the importance of spatial or social structure of populations, represented as graphs, in shaping the evolution of cooperation and other strategies within evolutionary games. A comprehensive review can be found in the review by [3]. Population structure is modeled as a graph, where vertices represent individuals, and edges indicate interactions for game payoffs and competition for reproduction. This structural representation fundamentally influences evolutionary outcomes by determining the interactions and competitive dynamics among individuals. The conditions under which a strategy, such as cooperation, is evolutionarily successful are derived from the benefit-to-cost ratio of cooperative behavior and the degree of the graph, which represents the number of connections per individual. Different update rules, which govern the mechanisms by which individuals reproduce and replace others, can lead to different evolutionary outcomes on the same graph structure, highlighting the complexity of the dynamics. Furthermore, considering separate graphs for interactions and replacements reveals intricate dynamics where the evolution of cooperation can depend on both the structure of interactions (who plays the game with whom) and the structure of competition (who competes with whom for reproduction). The network structure plays a crucial role in evolutionary games by shaping the interaction and competition patterns among individuals, which, in turn, influence the evolutionary viability of different strategies. The specific outcomes depend on the network’s characteristics, the rules governing strategy update and the nature of the game itself. Comprehensive reviews on complex networks are available in [2, 8, 9, 12, 14, 17, 26, 34], and others. Studies [1, 5, 21, 25] have explored social learning processes. Our work adds a new dimension by considering complex network structures like degree distribution and network heterogeneity.
The structure of underlying networks significantly influences outcomes in network models. Scale-free networks, in particular, have substantial effects due to their heterogeneous nature. This paper focuses on how network heterogeneity impacts outcomes by studying scale-free networks.
We address key questions about the influence of social network structures on learning processes from neighbors and the role of network heterogeneity. Our study involves a game on a social network where each player interacts only with adjacent players. Our model, based on imitation, is social learning through social networks.
2 Scale-Free Networks Enhance Social Learning Process
2.1 The Model of Social Learning
We explore a learning process based on imitation within social networks, focusing on how different network structures influence the spread of effective strategies. We analyze a simple game where consistently choosing one strategy is more advantageous than the other. This choice is a result of the social learning process. In our game model, each player, located at a network vertex, interacts only with adjacent players. The payoff matrix for this game is:

assuming \(a+c> b\) and \(a\ge b\). All parameters are not necessarily positive. Here, choosing strategy H is always more beneficial than E by a constant c. Players earn their total payoff G from these games, and the overall payoff T combines a baseline payoff and the game-derived payoff, scaled by a factor w.
The strategy update follows an imitation dynamic, where players are likely to adopt the majority strategy of their neighbors or a strategy yielding a better payoff. This dynamic ensures that the more effective strategy gradually but consistently spreads over time.
2.2 The Update Rule of the Strategies
Initially, a fraction r of players adopt strategy H, while the rest choose E. Strategy updates occur at each time step, where a randomly selected player imitates the strategy of adjacent players based on their total payoffs. Figure 1 illustrates this update rule, demonstrating how the strategy spread can be viewed as a learning process through local social interactions.
We aim to understand how the speed of strategy spread varies with different network structures.

Update rule of the game: the shaded circle represents a randomly chosen player who will adopt the strategy of adjacent players (H or E) based on a probability proportional to their total payoffs
2.3 Notations Used
We define the network size as N, the mean degree as \(\langle k \rangle \), and the mean degree of nearest neighbors as \(\langle k_\text {nn}\rangle \). The latter is crucial for network dynamics and differs from the mean degree in non-regular networks. We apply the mean-field approximation from our previous studies [18, 19], where the degree of a randomly chosen vertex is approximated by \(\langle k\rangle \), and that of its nearest neighbor by \(\langle k_\text {nn}\rangle \). Let \(q_{X|Y}(k_1,k_2)\) denote the conditional probability of finding an X-player, given that the adjacent vertex is occupied by a Y-player, and that the degrees of the X-player and the Y-player are \(k_1\) and \(k_2\), respectively. We define \(q_{X|Y}^\text {nn}:=q_{X|Y}(\langle k_\text {nn}\rangle ,\langle k_\text {nn}\rangle )\). Figure 2 schematically represents this approximation. We also introduce various probabilities and conditional probabilities to describe the network’s strategy distribution, using the pair approximation method [22]. Our approach extends the method developed in [18] to analyze the spread of strategies in general uncorrelated networks, leading to Eq. (38).

Mean-field approximation scheme: a shows a randomly chosen vertex with mean degree \(\langle k\rangle \), surrounded by vertices with degree \(\langle k_\text {nn}\rangle \). b depicts neighboring vertices with degree \(\langle k_\text {nn}\rangle \), also surrounded by vertices with the same degree in the mean-field model
2.4 The Case of a General Payoff Matrix
While our primary interest lies in the specific payoff matrix outlined in Eq. (1), we extend our analysis to a general payoff matrix involving strategies A and B, represented as:

2.5 The Change in the Probability of Strategy A
Following the approach in our previous work [18], we examine the scenario where a randomly chosen player, initially adopting strategy B, switches to strategy A. This change results in an increase in the probability of strategy A, denoted as \(p_A\), by 1/N. In the mean-field approximation, where the degrees of nearest neighbors are represented by \(\langle k_\text {nn}\rangle \), the payoffs \(f_A\) and \(f_B\) for neighboring A and B players are calculated as follows:
The probability of a configuration where a randomly chosen B-player is surrounded by \(k_A\) A-neighbors and \(k_B\) B-neighbors is given by:
In this configuration, the probability of the B-player switching to strategy A is:
Thus, the probability that a B-player is randomly chosen and updates their strategy from B to A, resulting in an increase in \(p_A\) by 1/N, is:
Conversely, when an A-player is randomly chosen and switches to strategy B, \(p_A\) decreases by 1/N. The payoffs \(g_A\) and \(g_B\) for neighboring A and B players in this case are:
The probability of a configuration where the randomly chosen A-player is surrounded by \(k_A\) A-neighbors and \(k_B\) B-neighbors is:
In this configuration, the probability of the A-player switching to strategy B is:
Therefore, the expected change in \(p_A\) per time step in the mean-field approximation is given by:
Similarly, considering the scenario where a player with degree \(\langle k_\text {nn}\rangle \) is randomly chosen to change their strategy, we derive the change in \(p_A^\text {nn}\) per time step in the mean-field approximation as:
2.6 The Change in Conditional Probabilities
The dynamics of the probabilities \(p_A\) and \(p_A^\text {nn}\), as outlined in Eqs. (12) and (13), are influenced by the conditional probabilities \(q_{A|A}\) and \(q_{A|A}^\text {nn}\). We explore the dynamics of these conditional probabilities.
First, we consider the scenario where \(q_{A|A}\) increases. This occurs when a B-player, chosen randomly with probability \(p_{B}\), updates their strategy to A. Let \(k_A\) and \(k_B\) represent the number of neighboring A-players and B-players to the chosen B-player, respectively, satisfying \(k_A+k_B=\langle k\rangle \). The likelihood of this configuration is:
The probability of the B-player switching to A is:
Thus, the increase in \(q_{A|A}\) is:
The expected increase in \(q_{A|A}\) per time step in the mean-field approximation is:
Conversely, when an A-player is randomly chosen (probability \(p_{A}\)) and switches to B, \(q_{A|A}\) decreases. The probability of this configuration is:
The probability of the A-player switching to B is:
Thus, the decrease in \(q_{A|A}\) is:
The expected decrease in \(q_{A|A}\) per time step in the mean-field approximation is:
Combining these cases, the expected change in \(q_{A|A}\) per time step in the mean-field approximation is:
For \(q_{A|A}^\text {nn}\), we consider the case where the degree of the randomly chosen vertex is \(\langle k_\text {nn}\rangle \). The expected change in \(q_{A|A}^\text {nn}\) per time step in the mean-field approximation is:
This analysis provides insights into the dynamics of conditional probabilities within the network, crucial for understanding the spread of strategies in social learning processes.
2.7 The Speed of the Spread of General Strategy A
Through detailed calculations and expansion of Eqs. (12), (13), (22) and (23), and considering the continuous time limit, we arrive at the following equations:
where
We confirm that \(E[\triangle p_A]\) is of the order O(w), while \(E[\triangle q_{A|A}]\) is of the order \(O(w^0)\).
To derive Eq. (24), we employed the mean-field relation \(q_{X|Y}p_Y=p_{XY}=p_{YX}=q_{Y|X}p_X\). This relation is justified as follows: In the mean-field approximation, the pair probability \(p_{XY}\) is given by:
where \(P(k_\text {nn},k)\) is the probability of a vertex pair having degrees k and \(k_\text {nn}\), p(k) is the probability of a vertex having degree k, \(p_Y(k)\) is the probability of a vertex with strategy Y and degree k, and \(q_{X|Y}(k_\text {nn},k)\) is the conditional probability of a vertex with strategy X and degree \(k_\text {nn}\) given a neighboring vertex with strategy Y and degree k.
Thus, \(p_{XY}=q_{X|Y}p_Y\) holds in the mean-field approximation, and similarly, \(p_{YX}=q_{Y|X}p_X\) holds. Therefore, the mean-field relation \(q_{Y|X}p_X=p_{YX}=p_{XY}=q_{X|Y}p_Y\) is valid.
Due to this relation, the \(O(w^0)\) term in Eq. (24) vanishes.
We now have the following system of equations from Eqs. (24)–(27):
Since \({\dot{p}}_A\) and \({\dot{p}}_A^\text {nn}\) are of order O(w), while \({\dot{q}}_{A|A}\) and \({\dot{q}}_{A|A}^\text {nn}\) are of order \(O(w^0)\), the conditional probabilities \(q_{A|A}\) and \(q_{A|A}^\text {nn}\) converge much faster than \(p_{A}\) and \(p_{A}^\text {nn}\). Thus, we can assume that \({\dot{q}}_{A|A}=0\) and \({\dot{q}}_{A|A}^\text {nn}=0\) always hold. In other words, the system converges to the slow manifold given by \(F_{3}=0\) and \(F_{4}=0\). From \(F_{3}=0\) and \(F_{4}=0\), we have:
Using the mean-field relations and Eqs. (33), the probabilities of strategies \(p_A\), \(p_B\), \(p_A^\text {nn}\), \(p_B^\text {nn}\), and the conditional probabilities \(q_{A|A}\), \(q_{B|A}\), \(q_{B|B}\), \(q_{A|B}\), \(q_{A|A}^\text {nn}\), \(q_{B|A}^\text {nn}\), \(q_{B|B}^\text {nn}\), and \(q_{A|B}^\text {nn}\) can be expressed in terms of only \(p_A\) and \(p_A^\text {nn}\) as follows:
Proposition 1
The expected change of the probability \(p_A\) for the general payoff matrix in a unit time step \(\triangle t\) is derived using Eq. (24), (34)–(37):
where
This proposition outlines the speed \(E[\triangle p_A]\) of the spread of strategy A with the general payoff matrix given by Eq. (2).
2.8 The Speed of the Spread of the Better Strategy H
We have already derived the expected change \(E[\triangle p_A]\) in \(p_A\) per unit time step as Eq. (38) for a general payoff matrix. Now, we apply this to the specific payoff matrix of social learning in Eq. (1). Let \(p_H\) denote the probability that a randomly chosen player adopts strategy H. The expected change \(E[\triangle p_H]\) in the probability \(p_H\) per unit time step \(\triangle t\) is given by:
Here, \(m^\text {sl}(p_H,\langle k\rangle , \langle k_\text {nn}\rangle )\) represents the speed of spread of the better strategy H. The superscript sl in \(m^\text {sl}\) stands for social learning. This speed satisfies the following conditions:
Based on these conditions, we propose the following:
Proposition 2
The expected speed \(E[\triangle p_{H}]\) of the spread of the better strategy H increases with the mean degree \(\langle k\rangle \) and the mean degree of nearest neighbors \(\langle k_\text {nn}\rangle \) in the mean-field approximation.
Comparing two networks, network 1 and 2, with the same network size N, number of links L, and initial probability of strategy H, but different mean degrees of nearest neighbors \(\langle k_\text {nn}\rangle \), we find that the network with a greater \(\langle k_\text {nn}\rangle \) enhances social learning more effectively. This is captured by the difference in the speed of spread of strategy H between the two networks, denoted as \(\triangle m^\text {sl}_{12}\):
Given that \(\langle k_\text {nn}\rangle =\frac{\sigma ^2+\langle k\rangle ^2}{\langle k\rangle }\) in uncorrelated networks, where \(\sigma ^2\) is the variance of the degree distribution, we have:
Thus, we conclude with the following proposition:
Proposition 3
The more heterogeneous the network is, the more it enhances the speed of the social learning process in the mean-field approximation.
Considering three representative networks-a regular network, a random network, and a scale-free network-with the same mean degree, we find that scale-free networks enhance social learning the most, while regular networks do the least. This is summarized in the following lemma:
Lemma 1
Among three representative networks with the same mean degree, scale-free networks enhance social learning the most, and regular networks the least, in the mean-field approximation.
Furthermore, if the mean degree \(\langle k\rangle \) is large enough such that \((\langle k\rangle -2)/(\langle k\rangle -1)\approx 1\), the speed of the spread of the better strategy is primarily influenced by the mean degree of nearest neighbors \(\langle k_\text {nn}\rangle \), as stated in the following proposition:
Proposition 4
If the mean degree \(\langle k\rangle \) is sufficiently large, the speed \(m^\text {sl}\) of the spread of the better strategy H is approximately given by:
Therefore, in networks with a large mean degree \(\langle k\rangle \), the mean degree of nearest neighbors \(\langle k_\text {nn}\rangle \) becomes the critical factor influencing the speed of the spread of the better strategy in the mean-field approximation.
2.9 Numerical Simulation for Social Learning in Scale-Free Networks
To validate the theory that network heterogeneity enhances social learning, we conducted numerical simulations on scale-free networks. These networks were constructed using a preferential attachment mechanism, known as the Barabási–Albert (BA) model [7, 11]. The construction process is as follows:
1. We start with a complete network of K vertices, where every vertex is connected to every other vertex. 2. A new vertex with m links is added to the existing network. The probability of this new vertex connecting to an existing vertex i is proportional to \((k_i+A)/\sum _j( k_j +A)\), where \(k_i\) is the degree of vertex i. 3. This process is repeated until the network reaches the desired size.
For our simulations, we used \(m=5\), \(K=m+1\), and a network size of \(N=3000\). The mean degree across all networks was \(\langle k\rangle =10\). We varied the exponent \(\gamma \) of the scale-free network to be 2.1, 2.2, 2.4, and 3, respectively. Initially, 750 players were randomly assigned as H players, and the remaining 2250 were E players. Each player’s strategy was updated according to the rule described in Sect. 2.2. Each simulation ran for 15, 000 time steps, after which we recorded the number of H players. This process was repeated 100 times for each network to calculate the average number of H players and the average mean degree of nearest neighbors \(\langle k_\text {nn}\rangle \). The game’s payoff parameters were set as \(a=1.5\), \(b=1\), and \(c=10\), with \(w=5\times 10^{-4}\).
The results, illustrated in Fig. 3, confirm that network heterogeneity significantly enhances social learning, aligning with our theoretical predictions.

The spread of the better strategy: the graph demonstrates that a more heterogeneous network facilitates the spread of the better strategy. These numerical experiments also support Proposition 4 and Eq. (47). The network size is \(N=3000\), the mean degree is \(\langle k\rangle =10\), w=\(5\times 10^{-4}\), and the payoff parameters are \((a,b,c)=(1.5,1,10)\). The y-axis represents the number of H players at the end of the simulation, while the x-axis shows the mean degree of nearest neighbors \(\langle k_{nn}\rangle \), indicating the extent of network heterogeneity. Note that while \(\langle k_{nn}\rangle \) varies, the connection density \(\langle k \rangle \) remains constant across different networks
3 Understanding the Enhancement of Social Learning in Scale-Free Networks
In Sect. 2, we established that scale-free networks significantly enhance social learning. This section delves into the reasons behind this phenomenon, focusing on the role of hub players in these networks.
3.1 Model Overview
To elucidate this, we examine a model where players’ payoffs are independent of their neighbors’ strategies, yet a learning network exists to indicate who learns from whom. This scenario, essentially not a game in the traditional sense, represents a specific case of the general payoff matrix [Eq. (2)]. We consider two strategies, U and V, with U yielding a higher payoff (u) than V (v), assuming \(u>v\). If we express the payoff using the payoff matrix, it is

The strategy update rule remains the same as previously described, with players likely to adopt the majority strategy among neighbors or the one with a better payoff.
Initially, a fraction r of players adopt strategy U, while the rest opt for V. The network in this model lacks degree-degree correlation, similar to our earlier discussions.
3.2 Strategy Update Example
An example of strategy updating is depicted in Fig. 4. Here, the total payoff for players adopting strategy U around a randomly chosen player is denoted as \(T_U=2(1-w+w u)\), and similarly, \(T_V=2(1-w+w v)\) for strategy V. The probability of the randomly chosen player switching from V to U in the next step is \(T_U/(T_U+T_V)\).

Strategy update example: this figure illustrates how a player’s strategy is updated. The shaded circle represents a randomly chosen player, whose strategy change is influenced by the total payoffs of adjacent players adopting strategies U and V
3.3 Speed of Strategy Spread
Let \(p_U\) and \(p_V\) represent the probabilities of a randomly chosen player adopting strategies U and V, respectively. The speed of strategy U’s spread, denoted as \(E[\triangle p_U]\), is approximately given by Eq. (A.20) in the appendix as:
This equation indicates that the speed of social learning is independent of the mean degree of nearest neighbors \(\langle k_\text {nn}\rangle \) in this model, where only the learning network exists and payoffs depend solely on individual strategies. Conversely, when both the learning network and the game network exist, the speed of social learning is influenced by \(\langle k_\text {nn}\rangle \).
3.4 Proposition and Implications
We propose the following:
Proposition 5
In a learning network where payoffs depend only on individual strategies, the speed of spreading a superior strategy increases with the network’s mean degree \(\langle k\rangle \). However, this speed is not influenced by the mean degree of nearest neighbors \(\langle k_\text {nn}\rangle \) in the mean-field approximation.
This finding suggests that the enhancement of social learning in scale-free networks is not due to the learning network’s scale-free nature per se, but rather because the game network is scale-free. In such networks, hub players, who have a significant payoff difference between strategies, are more inclined to adopt the superior strategy. Consequently, their neighboring players are likely to follow suit, leading to a rapid spread of the better strategy through these influential hub players.
3.5 Numerical Validation of Proposition 5
To verify whether network heterogeneity impacts the social learning process, particularly when the learning network exists and payoffs depend solely on individual strategies, we conducted numerical simulations on scale-free networks.
3.5.1 Simulation Setup
The construction of scale-free networks and the parameters used are identical to those in Sect. 2.9. Specifically, we utilized networks with a mean degree of \(\langle k\rangle =10\) and a size of \(N=3000\). Four distinct networks were simulated, each characterized by different values of the exponent \(\gamma \): 2.1, 2.2, 2.4, and 3. Initially, 750 players were designated as U strategists, with the remaining 2250 adopting strategy V. Strategy updates followed the previously outlined rule, with simulations running for 15,000 time steps.
3.5.2 Simulation Parameters and Procedure
The payoff parameters were set at \(u=10\) and \(v=-10\), with \(w=5\times 10^{-3}\). Each simulation was repeated 100 times for every network to ensure reliability. The primary focus was on the final count of U players and the average mean degree of nearest neighbors \(\langle k_{nn}\rangle \) across these repetitions.
3.5.3 Results and Implications
The results, depicted in Fig. 5, demonstrate that network heterogeneity does not significantly influence the social learning process under the given conditions. This finding aligns with the expectations set forth in Proposition 5.

Impact of network heterogeneity on strategy spread: this figure illustrates the results of numerical simulations, supporting Proposition 5. It shows that the spread speed of the superior strategy is not significantly influenced by network heterogeneity. The scale-free networks used in the simulation have a consistent network size (\(N=3000\)) and mean degree (\(\langle k\rangle =10\)), with varying mean degrees of nearest neighbors \(\langle k_{nn}\rangle \). The y-axis represents the final count of U players, and the x-axis reflects the mean degree of nearest neighbors, indicating network heterogeneity
4 Coordination Game: Threshold Probability for Strategy Spread in Networks
In exploring a coordination game with imitation dynamics on networks, we first analyze the game with a general payoff matrix to determine the conditions under which a particular strategy, denoted as A, proliferates across the network.
Threshold Initial Probability for Strategy Spread.
We denote \(p_A^\text {nn}\) as the probability that a player adjacent to a randomly chosen player adopts strategy A. In the mean-field approximation, the degree of such a neighboring player is represented by \(\langle k_\text {nn}\rangle \). The expected change in the probability \(p_A^\text {nn}\) over a unit time step \(\triangle t\) is derived using Eqs. (25), (34)–(37). The detailed calculation, akin to Eq. (38), yields:
where \(\alpha _\textrm{nn}\), \(\beta _\textrm{nn}\), and \(\gamma _\textrm{nn}\) are defined based on the payoff matrix elements and \(\langle k_\textrm{nn}\rangle \).
Threshold Conditions for Strategy Spread.
We define \(r:=p_A(t=0)\) as the initial probability of adopting strategy A. The condition for strategy A to spread over the network is determined by whether \(m(r,r^\textrm{nn})>0\). The threshold conditions, depending on the payoff matrix elements, are as follows:
-
If \(x-y-z+s>0\), the threshold condition is:
$$\begin{aligned} r>\frac{-(x-y-z+s)-\langle k\rangle (x-y+(y-s)\langle k_\text {nn}\rangle )}{(x-y-z+s)[\langle k\rangle (\langle k_\text {nn}\rangle -1)-2]} , \end{aligned}$$(52)$$\begin{aligned} \langle k_\text {nn}\rangle (y-s)>y-x. \end{aligned}$$(53) -
If \(x-y-z+s=0\), the condition becomes:
-
If \(x-y-z+s<0\), the threshold condition is:
$$\begin{aligned} r<\frac{-(x-y-z+s)-\langle k\rangle (x-y+(y-s)\langle k_\text {nn}\rangle )}{(x-y-z+s)[\langle k\rangle (\langle k_\text {nn}\rangle -1)-2]}. \end{aligned}$$(54)
Proposition on Strategy Spread.
We propose that a strategy spreads over the network as time progresses if the initial probability of a player adopting the strategy exceeds (or does not exceed) the threshold probabilities as outlined in Eqs. (52)–(54), within the framework of the mean-field approximation. Additionally, we explore the impact of network heterogeneity on these thresholds, particularly in the limit as \(\langle k_\text {nn}\rangle \rightarrow \infty \).
4.1 Coordination Game: Payoff Matrix and Strategy Spread Dynamics
In this section, we delve into a coordination game characterized by a specific payoff matrix and analyze the dynamics of strategy spread within network structures.
4.1.1 Payoff Matrix of the Coordination Game
The coordination game under consideration is defined by the following payoff matrix:

Players choose between strategies R and P, with the payoff parameters satisfying \(d+e>f\) and \(f>d>e>0\). This scenario corresponds to the case where \(x-y-z+s>0\). The optimal strategy pair is (P, P), with Nash equilibriums at (R, R) and (P, P). Strategy R is risk-dominant over P.
4.1.2 Threshold Initial Probability for Strategy Spread
The initial probability r for a player to adopt strategy R plays a crucial role. If r satisfies the following condition:
then strategy R proliferates over time. Conversely, if r is below this threshold, the Pareto optimal strategy P becomes dominant.
In the context of significant network heterogeneity (i.e., \(\langle k_\text {nn}\rangle \rightarrow \infty \)), the threshold condition simplifies to:
This implies that the expected payoffs for adopting strategies R and P become equivalent.
4.1.3 Impact of Network Heterogeneity on Strategy Spread
The relationship between network heterogeneity and the spread of the Pareto optimal strategy is influenced by the sign of \(e+(d-f)(1+\langle k\rangle )\). Specifically:
-
1.
If \(e+(d-f)(1+\langle k\rangle )>0\), increasing network heterogeneity lowers the threshold initial probability, favoring the spread of the Pareto optimal strategy.
-
2.
Conversely, if \(e+(d-f)(1+\langle k\rangle )<0\), the result is reversed, favoring the risk-dominant strategy.
Additionally, as the mean degree \(\langle k\rangle \) rises, the threshold for the Pareto optimal strategy’s spread decreases, regardless of the sign.
4.1.4 Proposition on Strategy Spread in Networks
We propose that the network’s heterogeneity plays a significant role in determining the spread of strategies. In networks with a sufficiently large mean degree \(\langle k \rangle \), the mean degree of nearest neighbors \(\langle k_{nn}\rangle \) predominantly influences the spread of the risk-dominant strategy R.
4.1.5 Scenario Where Risk Dominant Strategy is Also Pareto Optimal
In our previous discussions, we considered scenarios where the risk dominant strategy differed from the Pareto optimal strategy. We now turn our attention to a scenario where the risk dominant strategy is also the Pareto optimal. This situation arises under the conditions \(d+e>f\), \(d>f\), and \(d>e>0\), where strategy R is both risk dominant and Pareto optimal.
Threshold Initial Probability for Strategy Spread. In this unique scenario, the threshold initial probability for the spread of strategy R is governed by the same equation as before [Eq. (56)]. However, the condition \(e+(d-f)(1+\langle k\rangle )>0\) is always satisfied, leading to an interesting outcome: as network heterogeneity increases, the threshold initial probability for strategy R also rises. This indicates that network heterogeneity, in this case, acts as a barrier to the spread of strategy R, despite its dual status as both the risk dominant and Pareto optimal.
Impact of Mean Degree and Network Heterogeneity. The role of the mean degree \(\langle k\rangle \) is also noteworthy. Since \(\frac{\partial r_\text {th}}{\partial \langle k\rangle }>0\), an increase in the mean degree similarly raises the threshold initial probability for strategy R. This contrasts with scenarios where the risk dominant and Pareto optimal strategies are distinct, where the influence of the mean degree and the mean degree of nearest neighbors can diverge. In this unique case, however, both factors align in their impact on strategy spread.
In summary, when the risk dominant strategy also represents the Pareto optimal choice, both network heterogeneity and the mean degree of the network play a reinforcing role in determining the threshold for strategy proliferation. This highlights the nuanced interplay between network characteristics and strategy dynamics in coordination games.
4.2 Numerical Validation of the Theoretical Threshold in the Mean-Field Approximation
To validate the theoretical threshold derived in the mean-field approximation, we conducted numerical simulations of a coordination game. The game’s payoff matrix is defined as follows:

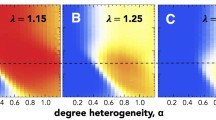
Simulation Setup. The simulations were executed on both a random network and a scale-free network, as illustrated in Figs. 6 and 7. The scale-free networks were constructed using the BA model, similar to the approach in Sect. 2.9. In each simulation step, a player is selected at random to update their strategy based on the defined rules. The simulation concludes after 40,000 time steps, at which point we record the proportion of players adopting strategy P.
Simulation Repetition and Averaging. Each simulation was repeated 100 times, and the results were averaged. A data point above the 45-degree line in the figures indicates that strategy P has successfully spread across the network over time. The simulations demonstrate that when the initial probability surpasses the theoretical threshold, the prevalence of strategy P is higher at the end of the simulation than at the beginning, confirming the validity of the mean-field approximation threshold.

Coordination game simulation on a random network: this figure validates the theoretical threshold [Eq. (56)] through numerical experiments on a random network. The network parameters are \(N=1000\), \(\langle k\rangle =10\), and \(w=5\times 10^{-4}\). The payoff matrix is as per Eq. (58). The y-axis represents the final probability of P players, while the x-axis shows the initial probability of adopting the Pareto optimal strategy P. The dashed line marks the theoretical threshold

Coordination game simulation on a scale-free network: this figure confirms the theoretical threshold [Eq. (56)] for a scale-free network. Parameters include \(N=1500\), \(\langle k\rangle =10\), \(w=5\times 10^{-4}\), and \(\gamma =3\). The payoff matrix follows Eq. (58). The y-axis shows the final probability of P players, and the x-axis represents the initial probability of adopting strategy P. The dashed line indicates the theoretical threshold
Figures and Interpretation These simulations corroborate the theoretical findings, demonstrating that the mean-field approximation provides an accurate prediction of the threshold for strategy spread in coordination games on both random and scale-free networks.
4.3 Facilitating the Spread of Pareto Optimal Strategy
Previously, we analyzed scenarios where the initial probability of adopting a strategy was independent of a player’s network degree. We now explore how the strategic positioning of players, particularly on hub vertices, can influence the spread of the Pareto optimal strategy. Specifically, we examine the impact when hub vertices are more likely to adopt strategy P initially.
Threshold Derivation for Differing Probabilities. To illustrate this, we derive the threshold condition for the case where \(r \ne r^\text {nn}\). Following a similar approach as before, we consider the general payoff matrix and establish the threshold r for different probabilities r and \(r^\text {nn}\), representing the likelihood of strategy R being adopted by vertices of varying degrees.
Threshold Conditions.
-
Positive Case: If \(x-y-z+s>0\), the threshold is defined as:
$$\begin{aligned} r&> \frac{-(x-y-z+s)\langle k\rangle (\langle k_\text {nn}\rangle )r^\text {nn}-(x-y-z+s)-(x-y)\langle k\rangle -(y-s)\langle k\rangle \langle k_\text {nn}\rangle }{(x-y-z+s)(\langle k\rangle -2)}\nonumber \\&=: r^\text {th}. \end{aligned}$$(59) -
Neutral Case: If \(x-y-z+s=0\), the condition becomes:
$$\begin{aligned} \langle k_\text {nn}\rangle (y-s) > y-x. \end{aligned}$$(60) -
Negative Case: If \(x-y-z+s<0\), the threshold is:
$$\begin{aligned} r < \frac{-(x-y-z+s)\langle k\rangle (\langle k_\text {nn}\rangle )r^\text {nn}-(x-y-z+s)-(x-y)\langle k\rangle -(y-s)\langle k\rangle \langle k_\text {nn}\rangle }{(x-y-z+s)(\langle k\rangle -2)}. \end{aligned}$$(61)
Impact of Hub Vertices. In scenarios where \(x-y-z+s>0\), a key relationship emerges:
This relationship implies that as the initial probability of hub vertices adopting strategy P increases, the overall threshold probability for strategy P to spread across the network decreases.
Proposition for Strategy Spread.
Proposition 6
In a coordination game, increasing the initial probability of hub vertices adopting the Pareto optimal strategy P leads to a lower threshold probability for the widespread adoption of strategy P across the network, as per the mean-field approximation.
This proposition suggests that strategically positioning players on hub vertices to adopt the Pareto optimal strategy can significantly enhance its spread across the network.
4.4 Numerical Validation of Proposition 6
To validate Proposition 6, we conducted a numerical simulation on a scale-free network, using the payoff matrix detailed in Eq. (58). The simulation results are depicted in Fig. 8. Initially, players adopting strategy P were strategically placed on vertices in descending order of their degree, until the ratio of P players to the total network size N matched the initial probability \(1-r\). The strategy updates continued for 40, 000 time steps.
Simulation Results. The outcomes of this simulation are represented by crosses in Fig. 8. For comparison, we also present results from a previous simulation (illustrated in Fig. 7) where the initial probability of adopting a strategy was not influenced by the players’ network degree. These results are indicated by dots in the figure.
Interpreting the Results. The crosses consistently appear above the dots, signifying that the simulation supports Proposition 6. This outcome suggests that when players on hub vertices initially adopt the Pareto optimal strategy, it significantly enhances the strategy’s spread across the network.

Comparison and confirmation of Proposition 6: the proposition is substantiated by the numerical simulations. The proposition implies that the spread of the Pareto optimal strategy is facilitated when players on hub vertices initially adopt this strategy. The dots represent the simulation results from Fig. 7, where the initial probability of adopting a strategy was independent of the players’ network degree. The crosses represent the simulation where hub players are more likely to be P players initially. The network parameters include a scale-free network with a size of \(N=1500\), a mean degree of \(\langle k\rangle =10\), \(w=5\times 10^{-4}\), and an exponent \(\gamma =3\). The payoff matrix follows Eq. (58). The y-axis shows the probability of players adopting strategy P at the end of the simulation, while the x-axis represents the initial probability of adopting strategy P. The 45-degree line is also included for reference
5 Understanding How a Large Mean Degree of Nearest Neighbors Facilitates Strategy Spread in Networks
This section aims to provide an intuitive understanding, using a mean-field perspective, of why networks with a large mean degree of nearest neighbors (\(\langle k_{\text {nn}}\rangle \)) are conducive to the spread of a strategy. This understanding is crucial for comprehending various phenomena observed in highly heterogeneous networks, such as scale-free networks.

Intuitive understanding and mean-field perspective: a Illustrates a randomly chosen vertex (representing ordinary vertices) and its nearest neighbors. The degree of the randomly chosen vertex is the mean degree \(\langle k\rangle \), while the degrees of the nearest neighbors are the mean degree \(\langle k_{\text {nn}}\rangle \). b Depicts neighboring vertices with degree \(\langle k_{\text {nn}}\rangle \), each surrounded by vertices also having a degree of \(\langle k_{\text {nn}}\rangle \), in the mean-field model
Understanding Ordinary Vertices. To comprehend network-wide phenomena, it is essential to first understand what occurs at ordinary vertices. The state of these vertices is influenced by their surrounding vertices. As shown in Fig. 9a, in the mean-field model, the degrees of vertices surrounding an ordinary vertex are represented by the mean degree of nearest neighbors, \(\langle k_{\text {nn}}\rangle \).
Regular Network of \(\langle k_{\text {nn}}\rangle \). In Fig. 9b, the vertices with a degree of \(\langle k_{\text {nn}}\rangle \) are also encircled by vertices of the same degree, forming a regular network. This setup allows for the resolution of states on vertices with degree \(\langle k_{\text {nn}}\rangle \), under the assumption that the expected values, such as the probability of adopting a certain strategy, are determined by the degree of the vertices in the mean-field model.
Strategy Spread Dynamics. Consider a scenario with two strategies, A and B. If it is determined that strategy A dominates in the regular network of degree \(\langle k_{\text {nn}}\rangle \) (as in Fig. 9b), then the vertices with degree \(\langle k_{\text {nn}}\rangle \) in Fig. 9a will likely adopt strategy A. Consequently, the strategy of ordinary vertices with degree \(\langle k\rangle \) is influenced by the strategies of their surrounding vertices with degree \(\langle k_{\text {nn}}\rangle \). Thus, the prevailing strategy in the entire network is essentially dictated by the dynamics within the regular network of degree \(\langle k_{\text {nn}}\rangle \).
Impact of \(\langle k_{\text {nn}}\rangle \). The larger the degree \(\langle k_{\text {nn}}\rangle \) of this regular network, the more effectively a strategy propagates across the network. This insight explains why networks with a substantial mean degree of nearest neighbors, \(\langle k_{\text {nn}}\rangle \), are particularly effective in facilitating the spread of a strategy.
6 Conclusion
6.1 Summary
This paper has demonstrated that networks with heterogeneous degree distributions, particularly scale-free networks, significantly enhance social learning processes. The study focused on how network structures, perceived as social local interactions, influence social learning.
The model investigated players located at network vertices, engaging in games only with their immediate neighbors and deriving payoffs from these interactions. Players adopted strategies based on weak selection rules, leading to a gradual spread of more advantageous strategies across the network. This process, akin to the well-known S-curve, was analytically examined using the mean-field approximation of network structures, as introduced in previous works [18, 19].
Key findings include:
-
Networks with a larger mean degree of nearest neighbors (\(\langle k_{\text {nn}}\rangle \)) accelerate the spread of superior strategies, a phenomenon termed ’social learning’.
-
The mean degree (\(\langle k \rangle \)) also influences social learning, but its impact diminishes in networks with sufficiently high mean degrees.
-
Among various network types, scale-free networks most effectively enhance social learning, attributed to their high network heterogeneity.
The study also explored a coordination game on networks, deriving the threshold initial probability for the spread of Pareto optimal strategies. It was shown that networks with a high probability of hub vertices initially adopting Pareto optimal strategies are more conducive to the spread of these strategies.
6.2 More Discussion
We demonstrate how a scale-free network structure enhances social learning. Evolutionary games are viewed as social learning processes, where effective strategies spread through imitation dynamics. Foundational works like Maynard Smith and Price [23] show that spatial structures in these games can foster cooperative behavior. Studies [4, 28, 31, 32, 35] explore the interplay between evolutionary games, coevolution, and networks.
This paper mathematically derives the speed of strategy diffusion in evolutionary games with general payoff matrices and mean-field approximations of heterogeneous networks. We show that network heterogeneity facilitates the spread of effective strategies. We also examine coordination games, revealing the relationship between network heterogeneity, network structures, and the spread of Pareto optimal strategies. These findings are validated through numerical simulations.
We conclude that scale-free networks significantly enhance social learning. Additionally, we investigate coordination games on networks, examining how network structure influences outcomes. We identify the threshold initial probability for the spread of Pareto optimal strategies and demonstrate how network heterogeneity determines this threshold. Our analysis also shows that Pareto optimal strategies spread more effectively when players on hub vertices initially adopt these strategies. We employ mean-field approximations for networks, a crucial tool for approximate computations in complex network models.
The mean degree of nearest neighbors (\(\langle k_{\text {nn}}\rangle \)) emerges as a critical factor in network-based models, often overshadowing the influence of the mean degree. This paper emphasizes that \(\langle k_{\text {nn}}\rangle \) is a more significant determinant of network behavior than the mean degree. The concept of ’determining networks’ - virtual networks surrounding vertices with degree \(\langle k_{\text {nn}}\rangle \) - is introduced to illustrate this point. In the mean-field model, these determining networks, conceptualized as regular networks with degree \(\langle k_{\text {nn}}\rangle \), are pivotal in influencing network-wide phenomena.
6.3 Future Research Directions
While the mean-field approximation offers valuable insights, it does not account for degree-degree correlations known to exist in real networks. Future research should aim to incorporate these correlations into the mean-field model and extend the analysis to include pair approximations of game strategies. This advancement would provide a more comprehensive understanding of complex network dynamics and their implications for social learning and other network-based phenomena.
Data Availability
No datasets were generated or analysed during the current study.
References
Acemoglu D, Dahleh MA, Lobel I, Ozdaglar A (2011) Bayesian learning in social networks. Rev Econ Stud 78:1201–1236
Albert R, Barabási A (2002) Statistical mechanics of complex networks. Rev Mod Phys 74:47–97
Allen B, Nowak MA (2014) Games on graphs. EMS Surv Math Sci 1:113–151
Amaral MA, Wardil L, Perc M, da Silva JK (2016) Evolutionary mixed games in structured populations: cooperation and the benefits of heterogeneity. Phys Rev E 93:042304
Bala V, Goyal S (1998) Learning from neighbours. Rev Econ Stud 65:595–621
Barabasi A, Albert R (1999) Emergence of scaling in random networks. Science 286:509
Barabasi AL, Albert R (1999) Emergence of scaling in random networks. Science 286:509–512
Boccaletti S, Latora V, Moreno Y, Chavez M, Hwang D (2006) Complex networks: structure and dynamics. Phys Rep 424:175–308
Bornholdt S (2003) Handbook of graphs and networks: from the genome to the internet. Wiley-VCH, New York
Broder A, Kumar R, Maghoul F, Raghavan P, Rajagopalan S, Stata R, Tomkins A, Wiener J (2000) Graph structure in the web. Comput Netw 33:309–320
Dorogovtsev S, Mendes J, Samukhin A (2000) Structure of growing networks with preferential linking. Phys Rev Lett 85:4633–4636
Dorogovtsev SN, Goltsev AV, Mendes JFF (2008) Critical phenomena in complex networks. Rev Mod Phys 80:1275
Ebel H, Mielsch L, Bornholdt S (2002) Scale-free topology of e-mail networks. Phys Rev E 66:35103
Goyal S (2007) Connections: an introduction to the economics of networks. Princeton University Press, Princeton
Griliches Z (1957) Hybrid corn: an exploration in the economics of technological change. Econom J Econom Soc 25:501–522
Grossman J, Ion P (1995) On a portion of the well-known collaboration graph. In: Congressus Numerantium , pp 129–132
Jackson M (2008) Social and economic networks. Princeton University Press, Princeton
Konno T (2011) A condition for cooperation in a game on complex networks. J Theor Biol 269:224–233. https://doi.org/10.1016/j.jtbi.2010.10.033
Konno T (2013) An imperfect competition on scale-free networks. Phys A Stat Mech Appl 392:5453–5460. https://doi.org/10.1016/j.physa.2013.06.017
Korte C, Milgram S (1970) Acquaintance networks between racial groups: application of the small world method. J Personal Soc Psychol 15:101–108
López-Pintado D (2006) Contagion and coordination in random networks. Int J Game Theory 34:371–381. https://doi.org/10.1007/s00182-006-0026-5
Matsuda H, Ogita N, Sasaki A, Sato K (1992) Statistical mechanics of population. Prog Theor Phys 88:1035–1049
Maynard Smith J, Price G (1973) The logic of animal conflict. Nature 246:15–18
Milgram S (1967) The small world problem. Psychol Today 2:60–67
Mueller-Frank M (2013) A general framework for rational learning in social networks. Theor Econ 8:1–40
Newman MEJ (2003) The structure and function of complex networks. SIAM Rev 45:167–256
Nowak MA, May RM (1992) Evolutionary games and spatial chaos. Nature 359:826–829
Perc M, Szolnoki A (2010) Coevolutionary games—a mini review. BioSystems 99:109–125
Redner S (1998) How popular is your paper? An empirical study of the citation distribution. Eur Phys J B 4:131–134
Ryan B, Gross N (1943) The diffusion of hybrid seed corn in two Iowa communities. Rural Sociol 8:15–24
Szolnoki A, Perc M (2009) Resolving social dilemmas on evolving random networks. EPL (Europhys Lett) 86:30007
Szolnoki A, Perc M, Danku Z (2008) Making new connections towards cooperation in the prisoner’s dilemma game. EPL (Europhys Lett) 84:50007
Travers J, Milgram S (1969) An experimental study of the small world problem. Sociometry 32:425–443
Vega-Redondo F (2007) Complex social networks. Cambridge Univerity Press, Cambridge
Wang Z, Wang L, Szolnoki A, Perc M (2015) Evolutionary games on multilayer networks: a colloquium. Eur Phys J B 88:1–15
Funding
It is not applicable.
Author information
Authors and Affiliations
Contributions
The author contributed to the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no Conflict of interest.
Ethical Approval
It is not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The author has studied this research since in Princeton University, the University of Tokyo, and in Waseda University.
Derivation of \(E[\triangle p_U]\) in Sect. 3
Derivation of \(E[\triangle p_U]\) in Sect. 3
1.1 Change in the Probability of Strategy U
We examine the dynamics of the mean-field probability \(p_U\), representing the likelihood of a player choosing strategy U. The analysis begins with scenarios where a V-player switches to strategy U, thereby increasing \(p_U\) by 1/N. In the mean-field model, a randomly chosen player has a degree of \(\langle k\rangle \).
Consider a V-player surrounded by \(k_U\) U-players and \(k_V\) V-players (\(\langle k\rangle =k_U+k_V\)). The probability of this V-player adopting strategy U in the next time step is:
The likelihood of encountering a V-player with \(k_U\) U-neighbors and \(k_V\) V-neighbors is:
Thus, the probability that \(p_U\) increases by 1/N in the next time step, under mean-field approximation, is:
Conversely, consider a U-player switching to strategy V, decreasing \(p_U\) by 1/N. The probability for this change, given a U-player with \(k_U\) U-neighbors and \(k_V\) V-neighbors, is:
The likelihood of this scenario is:
Therefore, the probability that \(p_U\) decreases by 1/N in the mean-field approximation is:
Combining these probabilities, the expected change in \(p_U\) in continuous time, under mean-field approximation, is:
1.2 Change in Conditional Probability
To understand the dynamics of the mean-field probability \(p_U\), we need to examine the behavior of the conditional probability \(q_{U|U}\) in the mean-field approximation.
Firstly, consider a scenario where a V-player, chosen randomly (with probability \(p_V\)), switches to strategy U. Let \(k_U\) and \(k_V\) denote the number of U-players and V-players, respectively, neighboring this V-player (\(k_U+k_V=\langle k\rangle \)). The probability of this V-player adopting strategy U is:
In this case, the conditional probability \(q_{U|U}\) increases by approximately \(\frac{k_U}{p_U \langle k\rangle N}\), as \(p_U\) changes by an order of O(w).
The likelihood of encountering this configuration is:
The probability of a V-player having \(k_U\) U-neighbors and \(k_V\) V-neighbors is:
Secondly, consider a U-player (chosen with probability \(p_U\)) switching to strategy V. The probability of this change, given \(k_U\) U-neighbors and \(k_V\) V-neighbors, is:
In this scenario, \(q_{U|U}\) decreases by approximately \(\frac{k_U}{p_U \langle k\rangle N}\).
The likelihood of this configuration is:
The probability of a U-player having \(k_U\) U-neighbors and \(k_V\) V-neighbors is:
Combining these scenarios, the expected change in \(q_{U|U}\) in continuous time, under mean-field approximation, is:
1.3 Speed of Spread of Better Strategy U
To determine the speed at which the better strategy U spreads across the network, we perform detailed calculations and expansions of Eqs. (A.7) and (A.14). In the continuous time limit and under the mean-field approximation, we derive the expected changes in \(p_U\) (the probability of choosing strategy U) and \(q_{U|U}\) (the conditional probability):
While \({\dot{p}}_U\) changes at the order of O(w), \({\dot{q}}_{U|U}\) does so at the order of \(O(w^0)\). Given the smallness of w, Eq. (A.16) converges much faster than Eq. (A.15). Therefore, we can assume that \({\dot{q}}_{U|U}=0\) is always true, leading to:
Using the mean-field relation \(p_{UV}=q_{U|V}p_V=q_{V|U}p_U\) (as detailed in Sect. 2.7) and Eq. (A.17), we derive:
Consequently, the expected change in the probability of adopting the better strategy U per unit time step, under the mean-field approximation, is:
This equation represents the speed at which strategy U spreads through the network.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Konno, T. Scale-Free Networks Enhance the Spread of Better Strategy. Dyn Games Appl (2024). https://doi.org/10.1007/s13235-024-00571-w
Accepted:
Published:
DOI: https://doi.org/10.1007/s13235-024-00571-w
Keywords
- Evolutionary games
- Imitation and learning
- Network heterogeneity
- Scale-free networks
- Coordination games
- Cooperation