
Abstract
To precisely represent bivariate continuous variables, this work presents an innovative approach that emphasizes the interdependencies between the variables. The technique is based on the Teissier model and the Farlie-Gumbel-Morgenstern (FGM) copula and seeks to create a complete framework that captures every aspect of associated occurrences. The work addresses data variability by utilizing the oscillatory properties of the FGM copula and the flexibility of the Teissier model. Both theoretical formulation and empirical realization are included in the evolution, which explains the joint cumulative distribution function \(\mathfrak {F}(z_{1}, z_{2})\), the marginals \(\mathfrak {F}(z_{1})\) and \(\mathfrak {F} (z_{2})\), and the probability density function (PDF) \(\mathfrak {f}(z_{1},z_{2})\). The novel modeling of bivariate lifetime phenomena that combines the adaptive properties of the Teissier model with the oscillatory characteristics of the FGM copula represents the contribution. The study emphasizes the effectiveness of the strategy in controlling interdependencies while advancing academic knowledge and practical application in bivariate modelling. In parameter estimation, maximum likelihood and Bayesian paradigms are employed through the use of the Markov Chain Monte Carlo (MCMC). Theorized models are examined closely using rigorous model comparison techniques. The relevance of modern model paradigms is demonstrated by empirical findings from the Burr dataset.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The implementation of classical probability models is hugely convenient in many practical study disciplines, along with reliability, economics, health sciences, and perhaps other cutting-edge domains. For analyzing life-time data, the exponential and gamma distributions are ubiquitously used throughout probability distributions. New flexible distribution families have been created as a consequence of the limitations that traditional distributions face when interacting with a diverse variety of real-world data [see Tyagi et al. (2022), Agiwal et al. (2023)]. Subsequently, numerous methodologies for converting traditional univariate distributions into bivariate distributions have been shown to work. For the analysis of bivariate data, a variety of distributions were put forward that extend numerous well-known univariate distributions, such as the exponential, Weibull, Pareto, gamma, and log-normal distributions. (see for example, Gumbel (1960), Marshall and Olkin (1967), Sankaran and Nair (1993), Kundu and Gupta (2009), Sarhan et al. (2011)). The incredible accomplishments of constructing bivariate distributions using conditional and marginal distributions have garnered a lot of attention in latest years. Following that, other outstanding approaches for building bivariate distributions using order statistics have been put forth and researched; these methods include both absolutely continuous and singular components and may be helpful when there are ties in the data. You may look at Dolati et al. (2014), Mirhosseini et al. (2015), and Kundu and Gupta (2017) for certain recent references. In addition to conventional methods, copula models have recently been utilized to characterize the dependence between random variables. The copula function, which links the marginals to the joint distribution, is frequently used in economics, biology, engineering, hydrology, and geophysics to illustrate the interdependence of random variables. A copula is a multivariate distribution function with uniform one-dimensional margins on the unit interval [0, 1]. In this paper, I focus only on a bivariate copula for our analysis. A formal definition of the bivariate copula is as follows:
A function \(\mathfrak {C}: [0,1]\times [0,1]\longrightarrow [0,1]\) is a bivariate copula if it satisfies the following properties:
-
(i)
For every \(y_{1}, y_{2}\in [0,1]\)
$$\begin{aligned} \mathfrak {C}(y_{1},0)=0=\mathfrak {C}(0,y_{2}) \end{aligned}$$and
$$\begin{aligned} \mathfrak {C}(y_{1},1)=1\;\; \text {and} \;\;\mathfrak {C}(1,y_{2})=y_{2} \end{aligned}$$ -
(ii)
For every \(y_{11}, y_{12}, y_{21}, y_{22}\in [0,1]\) such that \(y_{11}\le y_{12}\) and \(y_{21}\le y_{22}\)
$$\begin{aligned} \mathfrak {C}(y_{12}, y_{22})-\mathfrak {C}(y_{12}, y_{21})-\mathfrak {C}(y_{11}, y_{22})+\mathfrak {C}(y_{11}, y_{21})\ge 0. \end{aligned}$$
Let \((Z_1, Z_2)\) be random vector (RV) with joint DF \(\mathfrak {F}(.)\), and marginals \(\mathfrak {F}_{1}\) and \(\mathfrak {F}_{2}\), respectively, then Sklar (1959) says that there exists a copula function \(\mathfrak {C}\) which connects marginals to the joint DF via the relation \(\mathfrak {F}(z_1,z_2)=P(Z_1\in (0,z_1),Z_2\in (0,z_2))=\mathfrak {C}(\mathfrak {F}_{1}(z_{1}), \mathfrak {F}_{2}(z_{2}))\). If \(Z_1\) and \(Z_2\) are continuous, then the copula \(\mathfrak {C}\) is unique; otherwise it is uniquely determined on \(\text {Domain}(\mathfrak {F}_{1})\times \text {Domain}(\mathfrak {F}_{2})\). The associated joint density is \(\mathfrak {f}(z_1,z_2)=\mathfrak {c}(\mathfrak {F}_{1}(z_1), \mathfrak {F}_{2}(z_2))\mathfrak {f}_1(z_1)\mathfrak {f}_2(z_2)\), where \(\mathfrak {c}\) is copula density. A potent method of assessing a broad class of multivariate distributions based on marginals from several families is the copula approach. A copula with a separately stated dependence structure and marginals can be employed to depict any joint DF. For a good source on copulas, one may refer Nelsen (2006) and Joe (2014). Copula methodologies may offer a versatile strategy for creating a broad class of bivariate lifetime distributions that can handle various types of data and recognize the two lifetimes of a single patient. For instance, the study of human organs related to kidneys or eyes, as well as the intervals between the first and second hospitalization for a certain ailment, may be of interest (see Rinne (2008), Bhattacharjee and Misra (2016)).
Numerous scholars in the statistical literature have constructed a vast amount of bivariate distributions to evaluate lifetime data employing copula mechanisms. Bivariate generalized exponential distributions constructed from FGM and Plackett copula functions were taken into consideration, and their uses were illustrated using actual data sets in the study Abd Elaal and Jarwan (2017). A FGM copula is used to embed a bivariate modified Weibull distribution in Peres et al. (2018). Using copula, Popović et al. (2018) studied the statistical characteristics of a bivariate Dagum distribution. Nair et al. (2018) illustrated a bivariate model through copula methodology for analyzing different lifetime data sets. Samanthi and Sepanski (2019) proposed a new bivariate extension of the beta-generated distributions using Archimedean copulas and discussed its applications in financial risk management. de Oliveira Peres et al. (2020) proposed bivariate standard Weibull lifetime distributions using different copula functions and utilized them in real applications. Several other bivariate distributions using copula were put forward. Promiscuous crucial literatures includes (Saraiva et al. 2018; Taheri et al. 2018; Najarzadegan et al. 2019; Almetwally et al. 2021; Abulebda et al. 2022, 2023; Tyagi 2022).
This research presents a bivariate Teissier (BT) model, and its different statistical features are investigated with an application to real data. The structure of this article is as follows: In Sect. 2, the fundamentals of the univariate Teissier model are explored. Utilizing the FGM copula with support from the univariate Teissier model, a family of the BT model is formulated. Expressions for the joint survival function (SF), joint hazard function (HF), and joint reversed hazard function (RHF) for the proposed BT model are provided in Sect. 3. Section 4 introduces concepts of dependence measures such as orthant dependence, hazard gradient function, Clayton-Oakes association measure, conditional probability measure, Spearman’s \(\rho \), and Kendall’s \(\tau \), along with their pertinent properties for the BT model. The estimation of BT model parameters is conducted in Sects. 5 and 6 using maximum likelihood estimation and Bayesian estimation paradigms. Confidence intervals for parameters are constructed under the respective estimation methods. Section 7 encompasses data generation and several numerical experiments, while Sect. 8 presents an application to real data. A comprehensive overview and reflection on the entire study are presented in Sect. 9.
2 Bivariate Teissier model
The Teissier model was postulated to visualize the frequency of mortality owing to ageing mainly by Teissier (1934). Laurent (1975) reviewed the model and its classification based on life expectancy and looked at how it may be used in demographic research. Muth (1977) used this model to conduct a reliability analysis. Jodrá Esteban et al. (2015), who referred to it as the Muth model, determined the statistical characteristics of the Teissier model. In order to apply the Teissier model to reliability data, Jodrá Esteban et al. (2017) proposed the power Muth, a two-parameter extension. The Teissier model can be characterized by the DF, PDF, and SF shown below:
respectively. Due to its convenient form, the FGM copula is one of the most well-known parametric families of copulas and has been extensively utilized in the literature. Morgenstern (1956) proposed the FGM family and was later studied by Gumbel (1958, 1960) using normal and exponential marginals, respectively. The FGM family of distributions was named after Farlie (1960), which expanded this family and established its correlation structure. The bivariate FGM copula is provided by
In order to achieve the wider implementations of the FGM copula in real applications, there have been several generalized FGM copulas constructed and explored in the literature. Some of the recent references includes Amblard and Girard (2009) and Pathak and Vellaisamy (2016).
The bivariate distribution determined by FGM copula is
A new family of BT model via FGM copula is given by
A RV \((Z_{1}, Z_{2})\) is said to have a BT model with parameters \(\xi _1\), \(\xi _2\), and \(\delta \) if, its distribution function is given by (2.5), and is denoted by BT(\(\xi _1, \xi _2, \delta \)).
The joint density of the BT model \(\mathfrak {f}(z_{1},z_{2})\) defined in (2.5) is
The PDF depicted in Fig. 1 exemplifies a combination of parameters, displaying positive skewness and alternating between heavy-tailed and light-tailed characteristics. The PDF effectively captures skewed, heavy-tailed distributions common in real-world phenomena such as financial returns, extreme weather events, and rare diseases.
3 Reliability properties
In determining if such a bivariate distribution can be employed to analyze a particular data format, statistical features are absolutely critical. The BT model developed in this study is important because it can be used to investigate how reliable a system is when its two components work together. It is important to formulate a variety of reliability functions, including the SF, HF and RHF. The next subsections determine the aforementioned reliability anatomical features for the bivariate distribution.
3.1 Survival function
There are numerous approaches to building the reliability function for the bivariate distribution, but I prefer to utilize the copula technique to describe the reliability function for the BT model by utilizing the marginal SF \(\phi (z_{1})\) and \(\phi (z_{2})\) where \(Z_{1}\) and \(Z_{2}\) the random variable and selection dependence structure.
Theorem 3.1
The joint SF for the copula is as following
where the marginal SF \(y_{1} = \phi (z_{1})\) and \(y_{2} = \phi (z_{2})\).
The reliability function of FGM-BT based on Eq. (3.1)
In Fig. 2, the structure of the SF is displayed for diverse parameter combinations. Notably, the SF shows a sharp decline in relation to the scrutinized variables \(z_1\) and \(z_2\), indicating a prominent heavy-tailed distribution.
3.2 Hazard function
Theorem 3.2
Let \((Z_{1}, Z_{2})\) having joint PDF \(\mathfrak {f}(z_{1},z_{2})\) and SF \(\phi (z_{1},z_{2})=P(Z_{1}\in (z_{1}, +\infty ), Z_{2}>\in (z_{2}, +\infty ))\). Then the bivariate HF is defined as
respective conditional HF will be,
3.3 Reversed hazard rate function
Theorem 3.3
Let \((Z_{1}, Z_{2})\) having joint PDF \(\mathfrak {f}(z_{1},z_{2})\) and the DF \(\mathfrak {F}(z_{1},z_{2})=P(Z_{1}\in (0, z_{1}), Z_{2}\in (0, z_{2}))\). Then the bivariate RHF is defined as

PDF BT model

Survival BT model
4 Constructive dependence measure
4.1 Orthant dependence
In the existing research, there are already several formulations of positive and negative dependency for multivariate distributions of wide variations degrees of intensity; for instance, see, Joe (2014). Positive upper orthant dependent (PUOD) is a term used to describe a RV \((Z_1, Z_2)\), iff,
and negative upper orthant dependent (NUOD) iff,
Similar to the first, the second states that a RV \((Z_1, Z_2)\) is positive lower orthant dependent (PLOD) iff,
and negative upper orthant dependent (NLOD) iff,
The joint SF of the BT model, provided in Eq. (3.2), and the marginal SF given in Eq. (2.3) are already available. These equations facilitate the straightforward verification that \((Z_{1}, Z_{2})\) complies with (4.1). Additionally, with the joint DF of the BT model from Eq. (2.6) and the marginal DFs of \(Z_{1}\) and \(Z_{2}\), it can be easily confirmed that \((Z_{1}, Z_{2})\) adheres to (4.3). Consequently, the RV \((Z_{1}, Z_{2})\) exhibits the PUOD as well as the PLOD when \(\delta \in (0,1)\). Therefore, the RV \((Z_{1}, Z_{2})\) with the BT model is POD in the case where \(\delta \in (0,1)\). Similarly, if \(\delta \in (-1,0)\), the RV \((Z_{1}, Z_{2})\) is NUOD as well as NLOD. Thus, the BT model fulfills both NUOD and NLOD conditions, establishing that the BT model is NOD.
4.2 Hazard gradient function
Examining a bivariate RV \((Z_1, Z_2)\) with a joint PDF \(\mathfrak {f}(z_1, z_2)\) and SF \(\phi (z_1, z_2)\), the characteristics of the hazard aspects can be delineated, as expounded in Johnson and Kotz (1975).
and
The hazard gradient of \((Z_1, Z_2)\) is expressed by the vector \((\eta _1(z_1, z_2), \eta _2(z_1, z_2))\). Be circumspective that the failure rate of \(Z_1\) with the provided acquaintance \(Z_2>z_2\) is described by the expression \(\eta _1(z_1,z_2)\). The failure rate of \(Z_2\) provided that \(Z_1>z_1\) is \(\eta _2(z_1,z_2)\). Consequently, the hazard gradient for the BT model is
Proposition 4.1
The next section examines the monotonic aspects of the conditional hazard rate functions and the hazard component functions for the BTM distribution using the totally positive order 2 (TP2).
4.3 Local depandence
To understand how well the random variables \(Z_1\) and \(Z_2\) associate with one another, a local dependence function called \(\gamma (Z_1, Z_2)\) is established.
The characteristics of TP2 may be determined using \(\gamma (Z_{1}, Z_{2})\). One might see Holland and Wang (1987) and Balakrishnan and Lai (2009) for a further understanding of \(\gamma (Z_{1}, Z_{2})\).
Proposition 4.2
Let \((Z_{1},Z_{2})\sim BTM(\xi _{1},\xi _{2},\delta )\). Then
It is noteworthy to highlight that in the case of \(\delta =0\), the function \(\gamma (z_{1},z_{2})\) evaluates to zero. This implies that there is no statistically significant positive relationship between \(Z_1\) and \(Z_2\). As elucidated by Holland and Wang (1987), a bivariate joint probability density function (PDF) \(f(z_1, z_2)\) is classified as TP2 if and only if \(\gamma (z_1, z_2)> 0\).
The TP2 characteristic of the BT model is addressed in the findings that follow.
Proposition 4.3
Let \((Z_{1}, Z_{2})\sim BT(\xi _{1},\xi _{2},\delta )\) with the PDF \(f(z_{1},z_{2})\) as mentioned in (2.7). Then \(f(z_{1},z_{2})\) is TP2. Also, I have,
-
With increasing \(z_2\), \(H(z_1| Z_2=z _)\) is diminishing,
-
\(\eta _{1}(z_{1},z_{2})\) In \(z_2\), is declining.
Remark 4.1
TP2 is a broader idea of dependence, as is widely recognized. TP2, right-tail increasing (RTI), association, PQD, covariance, and right corner set increasing (RCSI) have unintended consequence (see Nelsen (2006) and Balakrishnan and Lai (2009)).
Also,
The BT model so possesses each of these qualities.
4.4 Clayton-Oakes association measure
A local dependence method through survival function was mentioned in Oakes (1989) and is described as:
where \( \phi _1(z_{1},z_{2}) = \displaystyle \frac{\partial }{\partial z_{1}}\phi (z_{1},z_{2})\) and \( \phi _2(z_{1},z_{2}) =\displaystyle \frac{\partial }{\partial z_{2}}\phi (z_{1},z_{2})\). The Clayton-Oakes association measure is valuable in bivariate data analysis by quantifying the strength and direction of dependence between two variables. It aids in assessing event associations, handling censoring in survival data, comparing survival processes, identifying dependencies, and evaluating model fit. Especially useful in survival analysis and epidemiology, this measure informs decision-making, risk assessment, and understanding correlations in various fields.
Proposition 4.4
where \(A= e^{e^{\xi _{1} z_{1}}+\xi _{2} z_{2}+1}\); \(B= e^{e^{\xi _{1} z_{1}}+e^{\xi _{2} z_{2}}}\)
Remark 4.2
By using the formula \(H(z_1| Z_2=z_2)=l(z_1,z_2)\eta _1(z_1,z_2),\) it is possible to determine the conditional HF. To put it another way, \(H(z_2| Z_1=z_1)=l(z_1,z_2)\eta _2(z_1,z_2)\).
4.5 Conditional probability measure
Anderson et al. (1992) used conditional probability to establish the following measure of association:
\(Z_1\) and \(Z_2\) are considered to be independent iff \(\psi (z_1, z_2)=1\) and PQD if \(\psi (z_1, z_2)>1\) \(\forall \) \((z_1, z_2)\). The outcome for the BT model is as follows.
Proposition 4.5
Remark 4.3
Derived from (4.14), it is evident that when \(\delta =0\), the function \(\psi (z_{1},z_{2})\) yields a value of 1. Consequently, \(Z_{1}\) and \(Z_{2}\) exhibit independence. Similarly, in the range \(\delta \in (-1,0)\), \(Z_{1}\) and \(Z_{2}\) demonstrate PQD.
4.6 Spearman’s \(\rho \) and Kendall’s \(\tau \) measure of dependence
Spearman’s \(\rho \) and Kendall’s \(\tau \) measures of dependence are defined as
Although Spearman’s \(\rho \) and Kendall’s \(\tau \) dependency approaches for the BT model cannot be determined in closed form, certain numerical techniques can be utilized to find them. Table 1 displays Spearman’s \(\rho \) and Kendall’s \(\tau \) values for numerous BT model parameter pairings. It can be observed from the table that the sign of Spearman’s \(\rho \) and Kendall’s \(\tau \) measures of dependence values are depend on the value of \(\delta \). If the value of \(\delta \) is negative, the values of Spearman’s \(\rho \) and Kendall’s \(\tau \) measures of dependence will be negative. vice-versa is also true.
5 Estimation strategies
5.1 Maximum likelihood estimation
The estimate of the BT model’s unobserved parameters using the maximum likelihood technique is described in this section. Estimators are produced using MLE by maximising the log-likelihood function with respect to each parameter independently. Let consider \((z_{11}, z_{21}), (z_{12}, z_{22})\), \(\dots , (z_{1n}, z_{2n})\) be a bivariate random sample of size n from the BT model. Then, the likelihood function is given as
where \(\varsigma \in (\xi _{1},\xi _{2})\).
The MLE (\(\hat{\xi }_{1}, \hat{\xi }_{2}, \hat{\delta }\)) can be obtained by solving simultaneously the likelihood equations
Due to the non-standard form of estimators derived from likelihood equations, parameter estimation is conducted using a non-linear optimization algorithm implemented in R-software.
5.2 Bayesian estimation strategies via MCMC techniques
5.2.1 Methodology
In this exploration, the Bayesian framework is employed to address the unknown parameters of the proposed model, considering both informative and vague priors. The squared error loss function (SELF), modified (quadratic) squared error loss function (MQSELF), and precautionary loss function (PLF) are three distinct loss functions that are taken into consideration. These loss functions, priors, and credible intervals are briefly described as follows:
5.2.2 Squared error loss function
The symmetric loss function \(L(\varsigma ,\hat{\varsigma }) =(\hat{\varsigma }-\varsigma )^{2}\) is called SELF. The Bayes estimator of \(\varsigma \) under SELF is \(\hat{\varsigma }_{SELF} =E(\varsigma | Z_{1}, Z_{2})\), with risk \(Var(\varsigma | Z_{1}, Z_{2})\) where the posterior PDF is taken into account while computing the expectation and variance. When an unbiased estimator of \(\varsigma \) is being taken into consideration, it was initially used to estimation issues. The success of SELF is also attributed to its associations with the conventional least squares methodology. SELF is neither concave nor bound. Due to the significant penalties for major mistakes, the convexity is very upsetting. Due to its symmetrical character, the SELF gives equal weight to overestimation and underestimation, which is rarely appropriate. As a consequence, I take into account MQSELF and PLF, two asymmetric loss functions.
5.2.3 Modified quadratic squared error loss function
The MQSELF is a alternative loss function of SELF. with form,
The Bayes estimator of \(\varsigma \) under MQSELF is \(\varsigma \)
with risk
where the expectation is evaluated with respect to the posterior PDF.
5.2.4 Precautionary loss function
An alternate, asymmetric PLF was presented by Norstrom (1996), with a particular instance of the quadratic loss function. To avoid underestimation, this loss function approaches infinity close to the origin, providing a cautious estimate. When underestimating might have major repercussions, it is tremendously helpful. PLF is described as
The Bayes estimator of \(\varsigma \) under MQSELF is \(\varsigma \)
with risk
where the expectation is taken with respect to posterior PDF.
5.2.5 Flat prior
The preceding information available and the prior distribution selected often exhibit correlation. Utilizing a flat prior becomes necessary when the knowledge about the parameter is limited or unknown. Flat priors have been extensively employed by practitioners historically (Ibrahim et al. (2001) and Santos and Achcar (2010)). For the baseline parameters \(\hat{\varsigma }\) and \(\varsigma \), and a uniform distribution for \(\delta \), the gamma distribution serves as the choice for flat priors. In essence, the PDFs under evaluation remain consistent with previous assessments,
Here, \(\nu _{1}=\nu _{2}=0.0001\), \(b=1\), and \(a=-1\).
5.2.6 Informative prior
According to informative priors, the hyperparameters are determined so that the expectation of the prior distribution for each unenlightened parameter is identical to the actual value. Several scholars have employed this technique, Chacko and Mohan (2018) as one example.
The section covers Bayesian estimation for the BT model parameters. The significance of the maximum likelihood estimates (MLEs) becomes apparent, particularly in scenarios involving high-dimensional optimization. Bayesian estimates tend to offer greater accuracy than MLEs when dealing with such parameters. A three-dimensional optimization challenge arises within the BT model, making it infeasible to compute a closed-form posterior distribution. Consideration of parameter independence is pivotal in employing the Bayesian technique (Ibrahim et al. (2001) and Santos and Achcar (2010)). This presumption leads to the following calculation of the joint posterior density function of parameters for the supplied variables \(Z_1\) and \(Z_2\):
In Eq. (5.1), L denotes the likelihood function, and \(g_i(.)\) denotes the prior PDF with known hyperparameters for the relevant parameters. Considering improved results, both flat and informative priors are taken into account.
Integration becomes challenging due to the high-dimensional nature of joint posterior distributions. Hence, opting for the widely used MCMC paradigm is crucial. MCMC involves the utilization of Gibbs samplers and the Metropolis-Hastings algorithm. The Heidelberger-Welch test has been employed to identify the Markov chain’s convergence to a stationary distribution. In order to do so, it has been thought that complete conditional distributions, which are proportional to the joint distribution of the model parameter, may be generated. For parameter \(xi_1\), the complete conditional distribution is,
The same is applicable to different parameters, for which comprehensive conditional distributions may be derived.
6 Confidence intervals
6.1 Asymptotic confidence intervals
Despite the lack of compact structures in the MLEs of \(\varsigma \), obtaining accurate confidence intervals for \(\varsigma \) poses a challenge. Consequently, relying on the asymptotic behaviors of the maximum likelihood estimator becomes necessary to determine asymptotic confidence intervals (CIs) for the model parameters. Large sample theory is employed to construct asymptotic confidence intervals for the model parameters due to the inability to distinctly calculate the specific sampling distributions of the MLEs. The asymptotic distribution of \((\varsigma ,\hat{\varsigma })\) is \(N_{3}(0,\zeta ^{-1})\), according to the general theory of MLEs. \(\zeta (\varsigma )\) is Fisher’s information matrix, which contains the following components:
It is computable numerically. The approximate value of the Fisher information matrix \(\zeta (\Xi )\) is
6.2 Construction of highest posterior density credible interval
In Bayesian inference, a credible interval is a domain of values that falls inside the bounds of a posterior probability distribution. The suitable posterior distribution’s credible interval for the \(100 \times (1-\eta )\) equal tail may be calculated as Eberly and Casella (2003)
where (L, U) are the lower and upper limits of the credible interval and \(\pi (\xi _1| Z_1, Z_2)\) is the posterior density of \(\xi _1\). The parameters \(\xi _2\) and \(\delta \) may then be found together with credible intervals.
7 Simulation analysis
7.1 Classical simulation
In this section, a numerical simulation study for the BT model created using the FGM copula is discussed. Initially, description revolves around the random sample generation from the BT model. The conditional procedure for random sample generation, as reported in Nelsen (2006), is employed. Let \(Z_{1}, Z_{2}\) be a random sample having BT model determined by FGM copula \(\mathfrak {C}\). The copula \(\mathfrak {C}\) is a joint distribution of a bivariate vector \((Y_1, Y_2)\) with uniform U(0, 1) marginals. The conditional distribution of the vector \((Y_1, Y_2)\) is given as \(P(Y_2\le y_2|Y_1=y_1) =\frac{\partial }{\partial y_1} \mathfrak {C}_1(y_1,y_2) =y_2[1+\delta (1-y_2)(1-2y_1)]\). Using the conditional distribution approach, random numbers \((z_{1},z_{2})\) from the BT can be generated using the following algorithm:
-
1)
From uniform U(0, 1) generate two independent sample \(y_1\) and t.
-
2)
Set \(t=\frac{\partial }{\partial y_1} \mathfrak {C}(y_1,y_2)\) and solved for \(y_2\).
-
3)
Find \(z_1= \mathfrak {F}^{-1}(y_1;\xi _1)\) and \(z_2= \mathfrak {F}^{-1}(y_2;\xi _2)\); where \(\mathfrak {F}^{-1}\) is the inverse of Teissier distribution.
-
4)
Finally, the desired random sample is \((z_{1},z_{2})\).
In the process of parameter estimation, both maximum likelihood and Bayesian paradigm methods are employed. Based on the data below that were produced by the BT model, a simulation study was conducted. The value of the parameters \(\xi _1\) and \(\xi _2\) is chosen with different value of the copula parameter \(\delta \) and different sizes of sample \((n = 10, 20, 30, 40, 50, 60, 70, 80, 90, 100)\), as shown for the following scenarios for the randomly generated variables produced by the BT model:
-
Case 1:
(\( \xi _1 = 0.5,\xi _2 = 1.5, \delta = -0.1 \))
-
Case 2:
(\( \xi _1 = 1.5,\xi _2 = 0.5, \delta = 0.1 \))
-
Case 3:
(\( \xi _1 = 2,\xi _2 = 5, \delta = -0.6 \))
-
Case 4:
(\( \xi _1 = 5,\xi _2 = 2, \delta = 0.6 \)).
The simulations in this study is repeated 1,00,000 times. Figures 3, 4 and 5 showcase the behaviour of the Mean Squared Error (MSE) in a simulation study. MSE, a pivotal metric in statistical analysis, reflects the average squared difference between estimated values and their true counterparts. The figures consistently illustrate that as the sample size increases, the MSE steadily decreases. This trend underscores a fundamental statistical principle: larger sample sizes lead to enhanced estimation accuracy. With more data points, the estimation process becomes more robust, resulting in smaller errors between estimated and actual values. These findings emphasize the importance of sample size in statistical analysis, highlighting the advantages of working with larger datasets when striving for precise and reliable parameter estimation. Figures 6, 7 and 8 delve into the behaviour of the CIs in the same simulation study. CIs quantify the uncertainty surrounding parameter estimates. The striking pattern observed in these figures is that as the sample size grows, the length of the CIs diminishes. This reduction in CI length signifies increased precision in parameter estimation with larger samples. This suggests that as the dataset becomes more extensive, confidence in determining the likely range within which the true parameter value lies also increases. These figures underscore the critical role of sample size in gauging the precision of statistical estimates and making informed decisions based on them. In general, the effect of marginal parameters has a little effect on estimating the copula parameters as shown in the table. The R programming language (R 3.5.3) was used to conduct the simulation analysis.
7.2 Bayesian simualtion
Assessing the effectiveness of the Bayesian estimation technique stands as the primary goal of the simulation study. Data \((Z_1, Z_2)\) is generated from the BT using the technique described in Sect. 7.1 for the simulation. Due to the lack of information about the parameters in the model, prior distributions are selected. Samples of various sizes are taken, and the chain of the Metropolis-Hasting algorithm and Gibbs sampling is iterated 1,00,000 times, disregarding the initial 10,000 iterations to eliminate initial value effects and prevent autocorrelation issues. Figures 3, 4 and 5 display the risk associated with \((\varsigma , \delta )\) under various error loss functions, including SELF, MQSELF, and PLF. These assessments are carried out with the inclusion of both informative and vague priors, providing a comprehensive view of the risk analysis. In parallel, Figs. 6, 7 and 8 present the HPD intervals for a range of parameter combinations. This allows for a detailed exploration of the uncertainty associated with different parameter settings, further enhancing the understanding of the studied phenomena.
The following information from these tables becomes noticeable:
-
1.
In comparison to estimates with vague priors, Bayes estimates based on informative priors perform better.
-
2.
All Bayes estimates have decreasing risks as n grows.
-
3.
The risk component of Bayes estimations under MQSELF outperformed.
-
4.
The HPD intervals for all Bayes estimates get relatively small as n increases.
The Bayesian technique with informative prior under MQSELF loss function is discovered to be the best strategy for point estimation across multifarious combinations of \((\underline{\varsigma }, \delta )\).

Simulation for parameter \(\xi _{1}\)

Simulation for parameter \(\xi _{2}\)

Simulation for parameter \(\delta \)

Confidence interval for parameter \(\xi _{1}\)

Confidence interval for parameter \(\xi _{2}\)

Confidence interval for parameter \(\delta \)
8 Illustration on real-life data
In this data analysis, there are 50 observations of the burr. The first component has a sheet thickness of 3.15 mm and a hole diameter of 12 mm. The thickness of the sheet and the hole diameter of the second component are both 9 mm. Two completely different computers create these two-component datasets. This data collection was used by Dasgupta (2011). Before even being processed, every data is multiplied by 10. These transitions will have no influence on our research and are entirely computational.
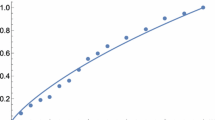
Figure 9 presents a comprehensive visual representation of the Bayesian analysis conducted on the Burr data set. This analysis focuses on estimating three crucial parameters—\(\xi _1\), \(\xi _2\), and \(\delta \)—under the assumption of vague priors, signifying minimal prior influence on the estimation process. The figure offers three types of plots for each parameter. Firstly, the posterior trace plots depict the evolution of parameter values throughout the Bayesian inference process. These plots are instrumental in evaluating the convergence of the Markov Chain Monte Carlo (MCMC) algorithm, aiming for stable and well-mixed traces devoid of discernible trends. Secondly, the density plots showcase the posterior probability density distributions for each parameter. They visually convey the shape and spread of these distributions, enabling an understanding of central tendencies and uncertainties. Wider distributions indicate greater parameter uncertainty. Lastly, the autocorrelation plots assess the degree of autocorrelation between successive samples drawn from the posterior distribution. High autocorrelation suggests less efficient sampling, while low autocorrelation signifies improved mixing and convergence. Figure 9 serves as a critical tool for researchers and analysts in the Burr data analysis, offering insights into MCMC sampler behaviour, posterior distribution shapes, and potential sampling issues. These visual cues enhance the reliability and accuracy of Bayesian parameter estimation for the Burr data set. Certainly, the table provides a comprehensive overview of parameter estimation for the BT model applied to the Burr data set. It presents estimates for the key parameters \(\xi _1\), \(\xi _2\), and \(\delta \) using two distinct approaches: Maximum Likelihood Estimation (MLE) and Bayesian methods. Under the Bayesian paradigm, the table differentiates between the NIP and the IP settings. For each estimation method, it includes various Bayesian techniques such as SELF(Risk), MQSELF(Risk) (Table 2), and PLF(Risk), accompanied by uncertainty measures and Bayesian credibility intervals (HPD Intervals). Additionally, the Heidelberg test results assess the fit of the Bayesian models. This table thus serves as a valuable resource for researchers and analysts to choose the most suitable estimation approach and gauge parameter uncertainty. Table 3 also computes Spearman’s \(\rho \) and Kendall’s \(\tau \), serving as indicators of the interdependency present within the Burr data set, thus revealing the existence of complex and interconnected relationships within the data. Table 4 illustrates the results of various model selection criteria for the BT model, including AIC, BIC, and AICc. It enables comparison of the BT model with other models available in the literature for the Burr data set. Notably, concerning AIC, BIC, and AICc, the BT model demonstrates superior performance compared to the bivariate generalized exponential (BGE) under FGM and Clayton copula, bivariate inverse Lindley (IL), bivariate Pareto (BP), and bivariate Gumbel (BG) distributions for the Burr data. In Fig. 10, Total Time Test (TTT) plots for both \(Z_1\) and \(Z_2\) unveil key characteristics of the Burr data set. These TTT plots exhibit a consistent concave shape and consistently position themselves above the \(45^{\circ }\) line, signifying an increasing hazard rate function over time. This observed behavior guides our modeling choice. Considering these characteristics, the Teissier distribution is selected to model the Burr data set. It aligns well with the data’s inherent features, especially its rising hazard rate, rendering it a suitable choice for robust statistical modeling and analysis.
9 Essence and deliberation
This study explored the BT model derived from the FGM copula by incorporating its univariate marginals of the Teissier model. Survival functions and reliability concepts linked to the BT model were formulated, alongside derived dependence measures indicating NOD for \(\delta \in (-1,0)\) and POD for \(\delta \in (0,1)\). Parameter estimation methodologies encompassed MLE and Bayesian inference techniques. The results of the investigation showed how important sample size is for improving estimation accuracy. With larger sample sizes, Bayesian estimates with informative priors performed better than other methods. This was especially true for the MQSELF loss function. The decrease in the intervals for the HPD that was found as sample sizes increased indicated increased accuracy in the estimation of Bayesian parameters, which reinforced the confidence in the predicted parameter ranges. Parameters estimation techniques, including MLE and Bayesian inference, were employed. In the Real Data Analysis, MLE played a pivotal role in estimating crucial parameters, such as \(\xi _1\), \(\xi _2\), and \(\delta \), from the Burr dataset. The MLE results provided fundamental insights into the distributional characteristics of the data, forming the basis for subsequent comparisons with alternative distributions. Comparison techniques, including AIC, BIC, and AICc, were instrumental in assessing the BT model’s performance against other candidate distributions available in the literature, such as BGE under FGM and Clayton copulas, IL, BP, and BG distributions for the Burr dataset. Notably, the BT model consistently demonstrated superior performance concerning AIC, BIC, and AICc criteria, indicating its favorable fit and better representation of the data compared to these alternative models. The selection of the Teissier distribution stemmed from its alignment with the inherent characteristics of the Burr data, as evidenced by TTT plots indicating an increasing hazard rate function over time. In summary, this study highlights the adaptability of the BT model in capturing diverse dependence structures and optimizing parameter estimation accuracy through empirical and simulation studies, showcasing its potential applications across various statistical domains.

Posterior Plots for the BT model Under Vague Priors for Burr data

TTT-plot of Burr data
References
Abd Elaal MK, Jarwan RS (2017) Inference of bivariate generalized exponential distribution based on copula functions. Appl Math Sci 11(24):1155–1186
Abulebda M, Pathak AK, Pandey A, Tyagi S (2022) On a bivariate XGamma distribution derived from Copula. Statistica (Bologna) 82(1):15–40
Abulebda M, Pandey A, Tyagi S (2023) On bivariate inverse Lindley distribution derived from Copula. Thailand Stat 21(2):291–304
Agiwal V, Tyagi S, Chesneau C (2023) Bayesian and frequentist estimation of stress-strength reliability from a new extended Burr XII distribution: Accepted: March 2023. REVSTAT-Statistical Journal
Almetwally EM, Sabry MA, Alharbi R, Alnagar D, Mubarak SA, Hafez EH (2021) Marshall–Olkin alpha power weibull distribution: different methods of estimation based on type-i and type-ii censoring. Complexity
Amblard C, Girard S (2009) A new extension of bivariate FGM copulas. Metrika 70(1):1–17
Anderson JE, Louis TA, Holm NV, Harvald B (1992) Time-dependent association measures for bivariate survival distributions. J Am Stat Assoc 87(419):641–650
Balakrishnan N, Lai CD (2009) Continuous bivariate distributions. Springer, Berlin
Bhattacharjee S, Misra SK (2016) Some aging properties of Weibull models. Electr J Appl Stat Anal 9(2):297–307
Chacko M, Mohan R (2018) Bayesian analysis of weibull distribution based on progressive Type-II censored competing risks data with binomial removals. Comput Statistics 34(4):233–252
Dasgupta R (2011) On the distribution of Burr with applications. Sankhya B 73:1–19
de Oliveira Peres MV, Achcar JA, Martinez EZ (2020) Bivariate lifetime models in presence of cure fraction: a comparative study with many different copula functions. Heliyon 6(6):e03961
Dolati A, Amini M, Mirhosseini SM (2014) Dependence properties of bivariate distributions with proportional (reversed) hazards marginals. Metrika 77(3):333–347
Eberly LE, Casella G (2003) Estimating Bayesian credible intervals. J Stat Plann Infer 112(1–2):115–32. https://doi.org/10.1016/S0378-3758(02)00327-0
Farlie DJ (1960) The performance of some correlation coefficients for a general bivariate distribution. Biometrika 47(3/4):307–323
Gumbel EJ (1958) Statistics of extremes. Columbia University Press, New York City
Gumbel EJ (1960) Bivariate exponential distributions. J Am Stat Assoc 55(292):698–707
Holland PW, Wang YJ (1987) Dependence function for continuous bivariate densities. Commun Stat-Theory Methods 16(3):863–876
Ibrahim JG, Ming-Hui C, Sinha D (2001) Bayesian survival analysis. Springer, Berlin
Jodrá Esteban P, Jiménez Gamero MD, Alba Fernández MV (2015) On the Muth distribution. Math Model Anal 20(3):291–310
Jodrá Esteban P, Gómez HW, Jiménez Gamero MD, Alba Fernández MV (2017) The power Muth distribution. Math Model Anal 22(2):186–201
Joe H (2014) Dependence modeling with copulas. CRC Press, Cambridge
Johnson NL, Kotz S (1975) A vector multivariate hazard rate. J Multivar Anal 5(1):53–66
Kundu D, Gupta AK (2017) On bivariate inverse Weibull distribution. Brazil J Probabil Stat 31(2):275–302
Kundu Debasis, Gupta Rameshwar D (2009) Bivariate generalized exponential distribution. J Multivar Anal 100(4):581–593
Laurent AG (1975) Failure and mortality from wear and ageing. The Teissier model. In: A modern course on statistical distributions in scientific work. Springer, Dordrecht. pp. 301-320
Marshall AW, Olkin I (1967) A generalized bivariate exponential distribution. J Appl Probab 4(2):291–302
Mirhosseini SM, Amini M, Kundu D, Dolati A (2015) On a new absolutely continuous bivariate generalized exponential distribution. Stat Meth Appl 24(1):61–83
Morgenstern D (1956) Einfache beispiele zweidimensionaler verteilungen. Mitteilingsblatt fur Mathematische Statistik 8:234–235
Muth EJ (1977) Reliability models with positive memory derived from the mean residual life function. Theory Appl Reliabil 2:401–435
Nair NU, Sankaran PG, John P (2018) Modelling bivariate lifetime data using copula. Metron 76(2):133–153
Najarzadegan H, Alamatsaz MH, Kazemi I (2019) Discrete bivariate distributions generated By Copulas: DBEEW distribution. J Stat Theory Practice 13(3):1–30
Nelsen RB (2006) Springer series in statistics, An introduction to copulas
Norstrom JG (1996) The use of precautionary loss functions in risk analysis. IEEE Trans Reliab 45(3):400–403
Oakes D (1989) Bivariate survival models induced by frailties. J Am Stat Assoc 84(406):487–493
Pathak AK, Vellaisamy P (2016) Various measures of dependence of a new asymmetric generalized Farlie-Gumbel-Morgenstern copulas. Commun Stat-Theory Methods 45(18):5299–5317
Peres MVDO, Achcar JA, Martinez EZ (2018) Bivariate modified Weibull distribution derived from Farlie-Gumbel-Morgenstern copula: a simulation study. Electr J Appl Stat Anal 11(2):463–488
Popović BV, Genç Aİ, Domma F (2018) Copula-based properties of the bivariate Dagum distribution. Comput Appl Math 37(5):6230–6251
Rinne H (2008) The Weibull distribution: a handbook. CRC Press, Cambridge
Samanthi RG, Sepanski J (2019) A bivariate extension of the beta generated distribution derived from copulas. Commun Stat-Theory Method 48(5):1043–1059
Sankaran PG, Nair NU (1993) A bivariate Pareto model and its applications to reliability. Naval Res Logist (NRL) 40(7):1013–1020
Santos CA, Achcar JA (2010) A Bayesian analysis for multivariate survival data in the presence of covariates. J Stat Theory Appl 9:233–253
Saraiva EF, Suzuki AK, Milan LA (2018) Bayesian computational methods for sampling from the posterior distribution of a bivariate survival model, based on AMH copula in the presence of right-censored data. Entropy 20(9):642
Sarhan AM, Hamilton DC, Smith B, Kundu D (2011) The bivariate generalized linear failure rate distribution and its multivariate extension. Comput Stat Data Anal 55(1):644–654
Sklar M (1959) Fonctions de repartition an dimensions et leurs marges. Publ Inst Statist Univ Paris 8:229–231
Taheri B, Jabbari H, Amini M (2018) Parameter estimation of bivariate distributions in presence of outliers: An application to FGM copula. J Comput Appl Math 343:155–173
Teissier G (1934) Recherches sur le vieillissement et sur les lois de la mortalité. Annales de physiologie et de physicochimie biologique 10(1):237–284
Tyagi S (2022) Bivariate Inverse Topp-Leone Model to Counter Heterogeneous Data. arXiv preprint arXiv:2206.05798
Tyagi S, Kumar S, Pandey A, Saha S, Bagariya H (2022) Power xgamma distribution: properties and its applications to cancer data. Int J Stat Reliabil Eng 9(1):51–60
Funding
The study did not receive any grant from any organisation public or private.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have conflict of interest.
Human and animal rights
There is no involvement of human participation and/or animals.
Informed consent
Author has approved the manuscript and agree with its submission to the journal for publication.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tyagi, S. On bivariate Teissier model using Copula: dependence properties, and case studies. Int J Syst Assur Eng Manag 15, 2483–2499 (2024). https://doi.org/10.1007/s13198-024-02266-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-024-02266-2