
Abstract
Adjunct array token Petri net structure (AATPNS) is a recently introduced rectangular picture generating device which extends Array token Petri net structure. AATPNS generates some of the classical classes of picture languages namely Siromoney matrix languages and kolam array languages, and a recent, pure 2D context-free languages. In this paper we concentrate our attention on determining the generative power of AATPNS by comparing it with some expressive rectangular picture grammar models and also with the classes of languages recognizable by tiling systems. We also study certain closure properties with respect to basic array operations.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
Since seventies, the study of two dimensional languages generated by grammars or recognized by Automata have been found in the theory of formal languages with the motivation of picture processing and pattern recognition tasks (Giammarresi and Restivo 1997; Rosenfeld and Siromoney 1993; Siromoney 1987). With the quest of syntactic techniques on digital picture patterns, many array generating grammar devices have been proposed. Siromoney matrix grammars (SMG; Siromoney et al. 1972), controlled table L array grammars (T0LG/T1LG; Siromoney and Siromoney 1977), kolam array grammars (KAG; Siromoney et al. 1973, 1974) are some of the classical generating devices, which used sequential and parallel application of rewriting rules. Pure 2D context-free grammars (P2DCFG; Subramanian et al. 2009) and parallel contextual array grammars (Subramanian et al. 2008a, b) make use of only terminal symbols as in pure string grammars. Prusa grammars (PG; 2004) tile rewriting grammars (TRG) and regional tile rewriting (RTG) grammars (Crespi-Reghizzi and Pradella 2005; Cherubini et al. 2006; Pradella et al. 2011) are some of the more expressive context-free grammars. Tiling system (TS; Giammarresi and Restivo 1997; Cherubini et al. 2006) is a recognizing device for the class of recognizable picture languages (REC), which involves the projection of languages belonging to the class of local picture languages (LOC) defined by a finite set of tiles.
Recently another picture generating mechanism, array token Petri net structure (ATPNS; Lalitha et al. 2012b) has been evolved from string generating Petri nets (Baker 1972; Hack 1975). Petri net (Peterson 1981) is one of the formal models used for analyzing systems that are concurrent, distributed and parallel. In ATPNS, array tokens are used to simulate the dynamism of the net.
ATPNS model along with a control feature called inhibitor arcs generate the same family of languages as generated by KAG, T0LG and P2DCFG. To increase the generative power of this model, adjunction rules are introduced and adjunct array token Petri net structure (AATPNS; Lalitha et al. 2012a) is defined. This model generates the table 1L languages and strictly included ATPNS family of languages. In Kamaraj et al. (2013) AATPNS is also compared with extended forms of SMGs (Nivat et al. 1989; Subramanian et al. 1989), extended P2DCFGs (Subramanian et al. 2008b) and internal parallel contextual grammars (Subramanian et al. 2008a).
Several approaches have been proposed or attempted to find a Chomsky-like hierarchy for array grammars. To find a hierarchy it is very essential to compare generating capacities of various models. Recently, in Bersani et al. (2011) and Pradella et al. (2011) mutual relationship between various context-free array grammars has been established. In this paper, we compare AATPNS, with some expressive rectangular picture grammar devices and also with REC and LOC.
This paper is organized in the following manner. In Sect. 2, basic definitions of arrays, Petri nets and notions of Petri nets pertaining to arrays have been recalled. In Sect. 3, we recall the definition of adjunct array token Petri nets and provide some illustrative examples. In Sect. 4, some of the closure properties are discussed. In Sect. 5 we compare AATPNS with various array grammars and also with REC and LOC with respect to the generative capacity.
2 Preliminaries
The following notation and definitions are mainly from Giammarresi and Restivo (1997), Bersani et al. (2011) and Lalitha et al. (2012b). In this section, we review some of the definitions of arrays, array grammars, Petri nets and notions of Petri nets pertaining to arrays.
2.1 Arrays and languages
Definition 2.1.1
Let Σ be a finite alphabet. A rectangular arrangement of elements of Σ is called an array or a picture over Σ. The set of all non-empty arrays over Σ is denoted by Σ++.
For h, k ≥ 0, Σ(h,k) denotes the set of pictures of size (h, k) and Σ** = Σ++ ∪ {Λ} where Λ is the empty picture. We denote by |p|r and |p|c, the number of rows and columns of a picture p ∈ Σ**. The size of p is the pair |p| = (|p|r, |p|c). A picture (array) language is a subset of Σ**.
For 1 ≤ i ≤ |p|r, 1 ≤ j ≤ |p|c, the element of p in the ith row and jth column is called a pixel, denoted by p(i, j). The domain of a picture p, denoted by d(p), defined by d(p) = [1, |p|r] × [1, |p|c] ⊆ N2. Subdomain of d(p) is a set of the form {k, k + 1,…,k′} × {ℓ, ℓ + 1,…,ℓ′} where 1 ≤ k ≤ k′ ≤ |p|r and 1 ≤ ℓ ≤ ℓ′ ≤ |p|c also denoted as (k, ℓ; k′, ℓ′). The set of subdomains of p is denoted by Ds(p). Let ds = (k, ℓ; k′, ℓ′) ∈ Ds(p), then the subpicture pics(p, ds) ∈ \(\Upsigma^{{^{{{\text{k}}^{'} - {\text{k}} + 1,\ell^{'} - \ell + 1}} }}\) is defined as pics(p, ds)(i, j) = p(k + i − 1, ℓ + j − 1) for all 1 ≤ i ≤ k′ − k + 1, 1 ≤ j ≤ ℓ′ − ℓ + 1.
A subdomain is c-homogeneous (or homogeneous) when all pixels in the associated picture are identical to c ∈ Σ.
Let u, v ∈ Z, the translation of ds by (u, v) is the subdomain ds ⊕ (u, v) = (k + u, ℓ + v; k′ + u, ℓ′ + v).
An homogenous partition of a picture p is any partition \({\text{P}} = \{ {\text{d}}_{{{\text{s}}_{ 1} }} ,\;{\text{d}}_{{{\text{s}}_{ 2} }} , \ldots ,{\text{d}}_{{{\text{s}}_{\text{n}} }} \}\) of d(p) into homogeneous subdomains \({\text{d}}_{{{\text{s}}_{ 1} }} ,\;{\text{d}}_{{{\text{s}}_{ 2} }} , \ldots ,{\text{d}}_{{{\text{s}}_{\text{n}} }} .\) Then unit partition of p, written U(p), is the homogeneous partition of d(p) defined by single pixels. A homogeneous partition is called strong if adjacent subdomains have different labels and the partition is also unique in this case.
Let # ∉ Σ be a boundary symbol. If p ∈ Σ(h,k), \({\hat{\text{p}}}\) ∈ Σ(h+2,k+2) is the picture p surrounded by # as shown in Fig. 1.

A picture p and the corresponding picture \({\hat{\text{p}}}\)
A picture p of size (2, 2) is called a tile. Set of all tiles contained in a picture p is denoted by [[p]].
Let Γ and Σ be two finite alphabets and π: Γ → Σ a function called projection, if p ∈ Γ**, the projection of p by π is the picture p′ ∈ Σ** such that p′(i, j) = π(p(i, j)), for all 1 ≤ i ≤ |p|r, 1 ≤ j ≤ |p|c. Row and column catenations are partial operations on arrays denoted by ○ and □. If p, q ∈ \(\Upsigma^{{^{{({\text{k}},}} *^{)} }}\) (resp. p, q ∈ \(\Upsigma^{{^{{\left( {*,\ell } \right)}} }}\)) p □ q (resp. p ○ q) is the horizontal (resp. vertical) juxtaposition of p and q. With (p)n [resp. (p)n] is denoted the horizontal (resp. vertical) juxtaposition of n copies of p. If L1 and L2 are two array languages over Σ then the column catenation of L1, L2, denoted as L1 □ L2, is defined by
The row catenation of L1, L2 can be defined in the similar notion.
2.2 Pure 2D context-free grammars
P2DCFGs, unlike the SMGs, admit rewriting of any row or column of pictures by equal length strings involving only terminal symbols.
Definition 2.2.1
A P2DCFG is a four-tuple G = (Σ, Pc, Pr, ℳ0), where Σ is a set of symbols, Pc = {\({\text{t}}_{{{\text{c}}_{\text{i}} }}\) /1 ≤ i ≤ m}, Pr = {\({\text{t}}_{{{\text{r}}_{\text{j}} }}\) /1 ≤ j ≤ n}.
Each \({\text{t}}_{{{\text{c}}_{\text{i}} }}\) (1 ≤ i ≤ m), called a column table, is a set of context free rules of the form a → α, a ∈ Σ, α ∈ Σ* such that any two rules of the form a → α, b → β in \({\text{t}}_{{{\text{c}}_{\text{i}} }} ,\) have |α| = |β| where |α| denotes the length of α.
Each \({\text{t}}_{{{\text{r}}_{\text{j}} }}\) (1 ≤ j ≤ n), called a row table, is a set of context free rules of the form c → γT, c ∈ Σ, γ ∈ Σ* such that any two rules of the form c → γT, d → δT in \({\text{t}}_{{{\text{r}}_{\text{j}} }} ,\) have |γ| = |δ|.
ℳ0 ⊆ Σ++ is a finite set of axiom arrays.
Derivations are defined as follows. For any two arrays M1, M2, M1 ⇒ M2 denotes that M2 is obtained from M1 by either rewriting a column of M1 by rules of a column table \({\text{t}}_{{{\text{c}}_{\text{i}} }}\) in Pc or a row of M1 by rules of a row table \({\text{t}}_{{{\text{r}}_{\text{j}} }}\) in Pr. \(\mathop \Rightarrow \limits^ {*}\) is the reflexive transitive closure of ⇒.
The picture language L(G) generated by G is the set of rectangular picture arrays {M/M0 \(\mathop \Rightarrow \limits^ {*}\) M ∈ Σ**, for some M0 ∈ ℳ0}.
Definition 2.2.2
A P2DCFG with regular control [(R)P2DCFG] is a tuple Gr = <G, Γ, C > where G is a P2DCFG, Γ is the control alphabet, the set of labels of the rule tables in Pc ∪ Pr, C ⊆ Γ* is the regular control associated with the grammar.
If p ∈ Σ** and S ∈ S′, p is derived from S in Gr by means of a control word
w = w1 w2··· ∈ C, in symbols S ⇒ w p, if p is obtained from S by applying the column/row rules in sequence of tables w1w2··· The language L(G) generated by (R)P2DCFG Gr is the set of pictures {p/ S ⇒w p ∈ Σ++ for some w ∈ C}.
While a P2DCFG allows rewriting any column or any row of a picture, a variant of P2DCFG investigated in Zbynek et al. (2014), allows rewriting of only the left most column or the upper most row. P2DCFG working under this derivation mode is known as (l/u) P2DCFG and the corresponding family of picture languages generated by them is denoted as (l/u) P2DCFL. It is shown that (Zbynek et al. 2014) (l/u) P2DCFL is incomparable with P2DCFL.
2.3 Tiling systems
TS define a ground level class of array languages known as recognizable languages (REC) by means of projection of pictures of a local language belonging to the class LOC. The local language is defined by means of a set of tiles.
Definition 2.3.1
Let Σ be a finite alphabet, θ a finite set of tiles over the alphabet Σ ∪ {#}. The local language defined by θ is the set L(θ) = {p ∈ Σ**/[[\({\hat{\text{p}}}\) ]] ⊆ θ}. The family of local languages is denoted by LOC.
Definition 2.3.2
A TS is a four-tuple T = (Σ, Γ, θ, π), where Σ and Γ are two finite alphabets, θ is a finite set of tiles over the alphabet Γ ∪ {#}, and π: Γ → Σ is a projection. A picture p ∈ Σ** is recognized by T if there exists p′ ∈ Γ** such that p′ ∈ LOC(θ) and =π(p′). The class of all languages recognized by some TS is denoted by REC.
2.4 Prusa grammars
PGs are the formalisms that admit parallel application of rules in which non-terminal symbols can be substituted with rectangular pictures.
Definition 2.4.1
PG is a tuple (J, N, R, S), where J is the finite set of terminal symbols, disjoint from the set N of non-terminal symbols; S ∈ N is the start symbol; and R ⊆ N × (N ∪ J)++ is the set of rules.
Let G = (J, N, R, S) be a PG. We define a picture language L(G, A) over J for every A ∈ N. The definition is given by the following recursive descriptions:
-
(1)
if A → w is in R, and w ∈ J++, then w ∈ L(G, A);
-
(2)
let A → w be a production in R, w = (N ∪ J)(m,n), for some m, n ≥ 1, and pi,j, with 1 ≤ i ≤ m, 1 ≤ j ≤ n, be pictures such that:
-
(a)
if w(i, j) ∈ J, then pi,j = w(i, j);
-
(b)
if w(i, j) ∈ N, then pi,j ∈ L(G, w(i, j));
-
(c)
if Pk = pk,1 □ pk,2 □···□ pk,n, for any 1 ≤ i ≤ m, 1 ≤ j ≤ n, |pi,j|c = |pi+1,j|c, and P = P1 ○ P2 ○···○ Pm; then P ∈ L(G, A).
-
(a)
The set L(G, A) contains exactly the pictures that can be obtained by applying a finite sequence of rules (i) and (ii). The language L(G) generated by grammar G is L(G, S).
2.5 Regional TRGs
TRGs (Crespi-Reghizzi and Pradella 2005) perform an isometric derivation process for which homogeneous sub pictures are replaced with isometric pictures of the local language defined by the right part of the rules.
Definition 2.5.1
A tile rewriting grammar (TRG) is a tuple (J, N, S, R), where J is the terminal alphabet, N is a set of non-terminal symbols, S ∈ N is the starting symbol, R is a set of rules. Let A ∈ N. There are two kinds of rules in R:
-
(1)
fixed size A → t, where t ∈ J;
-
(2)
variable size A → ω, ω is a set of tiles over N ∪ {#}.
At each step of the derivation, an A-homogeneous sub picture is replaced with an isometric picture of the local language defined by the right part α of a rule A → α, where α admits a strong homogeneous partition. The process terminates when all non terminals have been eliminated from the current picture.
Regional tile grammars (RTG; Pradella et al. 2011) are the TRGs with specified set of tiling called regional.
Definition 2.5.2
A homogeneous partition is regional (HR) iff distinct (not necessarily adjacent) subdomains have distinct labels. A picture p is regional if it admits a HR partition. A language is regional if all its pictures are so. A regional tile grammar (RTG) is a TRG (see Definition 2.5.1), in which every variable size rule A → ω is such that L(ω) ∈ LOC, is a regional language.
2.6 Petri nets
Definition 2.6.1
Petri Net is one of the mathematical modeling tools for the description of distributed systems involving concurrency and synchronization. It is a weighted directed bipartite graph consisting of two kinds of nodes called places (represented by circles) and transitions (represented by bars). Places represent conditions and transition represents events. The places from which a directed arc runs to a transition are called input places of the transition and the places to which directed arcs run from a transition are called output places. Places in Petri nets may contain a discrete number of marks called tokens. Any distribution of tokens over the places will represent a configuration of the net called a marking. In the abstract sense, a transition of a Petri net may fire if it is enabled; when there are sufficient tokens in all of its input places.
Definition 2.6.2
A Petri net structure is a four tuple C = (Q, T, I, O) where Q = {q1, q2,…,qn} is a finite set of places, n ≥ 1, T = {t1, t2,…,tm} is a finite set of transitions m ≥ 1, Q ∩ T = ϕ, I: T → Q∞ is the input function from transitions to bags of places and O: T → Q∞ is the output function from transitions to bags of places.
Definition 2.6.3
An inhibitor arc from a place q l to a transition tk has a small circle in the place of an arrow in regular arcs. This means the transition tk is enabled only if q l has no tokens in it. In other words a transition is enabled only if all its regular arc input places have required number of tokens and all its inhibitor arc (if exists) input places have zero tokens.
2.7 Array token Petri nets
In the array generating Petri Net structure, arrays over an alphabet J are used as tokens in some input places.
Definition 2.7.1
Row (resp. column) catenation rules in the form of A ○ B (resp. A □ B) can be associated with a transition t as a label, where A is a m × n array in the input place and B is an array language whose number of columns (resp. rows) depends on the number of columns (resp. rows) of A. Three types of transitions can be enabled and fired
-
(i)
When all the input places of transition t (without label) having the same array as tokens.
-
Each input place should have at least the required number of tokens (arrays).
-
Firing t removes arrays from all its input places and moves the array to all its output places.
The graph in Fig. 2a represents position of arrays in the net before the transition t fires and Fig. 2b represents position of arrays in the net after the transition t fires.
Fig. 2 
Transition of type 1
-
-
(ii)
When all the input places of transition t have the different arrays as tokens.
-
The label of t designates one of its input places which has sufficient number of same arrays as tokens.
-
Firing t removes arrays from all its input places and moves the array from the designated input place to all its output places.
The graph in Fig. 3a shows the transition t with label before firing and Fig. 3b shows the transition t with label after firing.
Fig. 3 
Transition of type 2
-
-
(iii)
When all the input places of transition t (with row or column catenation rule as label) have the same array as tokens.
-
Each input place should have at least the required number of tokens (arrays).
-
Firing t removes arrays from all its input places and creates the catenated array as per the catenation rule, in all its output places.
The graph in Fig. 4a shows the transition t with catenation rule before firing and Fig. 4b shows the transition t with catenation rule after firing.
Fig. 4 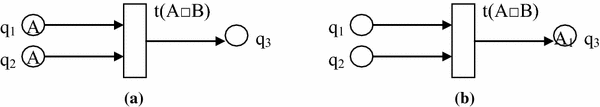
Transition of type 3
-



In all the three types, firing of a transition t is enabled only if all the input places corresponding to inhibitor arcs (if exist) does not have any tokens in it.
Definition 2.7.2
An ATPNS is a five tuple N = (J, C, M0, ρ, F) where J is a given alphabet, C = 〈Q, T, I, O〉 is a Petri net structure with tokens as arrays over J, M0: Q → J**, is the initial marking of the net, ρ: T → L, a mapping from the set of transitions to set of labels of transitions and F ⊂ Q, is a finite set of final places.
3 Adjunct ATPNS
In this section, we recall the notions of AATPNS (Lalitha et al. 2012a) in generalized form and give some examples.
Definition 3.1
Adjunction is a generalization of catenation. In the row catenation A ○ B, the array B is joined to A after the last row. But row adjunction can join the array B into array A after any row of A. Similarly column adjunction can join the array B into array A after any column of A. Let A be an m × n array in J** called host array; B ⊂ J** be an array language whose members, called adjunct arrays have fixed number of rows. A row adjunct rule (RAR) joins an adjunct array B into a host array A in two ways: by post rule denoted by (A, B, arj), array B is juxtaposed into array A after jth row and by pre rule denoted by (A, B, brj), array B is juxtaposed into array A before jth row. The number of columns of B is same as the number of columns of A. In the similar notion column adjunct rule (CAR) can also be defined in two ways: post rule (A, B, acj) and pre rule (A, B, bcj) joining B into A, after jth column of A and before jth column of A, respectively. It is obvious that a row catenation rule A ○ B in ATPNS is a post RAR rule (A, B, arm) and column catenation rule A □ B is a post CAR rule (A, B, acn). Transitions of a Petri net structure can also be labeled with RAR or CARs.
Definition 3.2
An AATPNS is a five tuple N = (J, C, M0, ρ, F) where J is a given alphabet, C = (Q, T, I, O) is a Petri net structure with tokens as arrays over J, M0: Q → J**, is the initial marking of the net, ρ: T → L, a mapping from the set of transitions to set of labels where catenation rules of the labels are either RAR or CAR and F ⊂ Q, is a finite set of final places.
In AATPNS, the types of transitions which can be enabled and fired are similar to that of Definition 2.7.1 except the type (iii) where labels of transitions may be RAR or CAR rules instead of row or column catenation rules.
When all the input places of a transition t (with RAR or CAR rule as label) have the same array as tokens.
-
Each input place should have at least the required number of tokens (arrays).
-
Firing t removes arrays from all its input places and creates the array through adjunction as per the RAR or CAR rule, in all its output places.
In all the three types, firing of a transition t is enabled only if all the input places corresponding to inhibitor arcs (if exists) does not have any tokens in it.
Definition 3.3
If P is an AATPNS then the language generated by P is defined as L(P) = {X ∈ J** / X is in the place q for some q in F}. Starting with arrays (tokens) over a given alphabet as initial marking, all possible sequences of transitions are fired. Set of all arrays created in final places F is called the language generated by AATPNS.
Example 3.1
Consider the AATPNS P1 = (J, C, M0, ρ, F) where J = {0, 1}, C = (Q, T, I, O), Q = {q1, q2}, T = {t1, t2}, I(t1) = {q1}, I(t2) = {q2}, O(t1) = {q2}, O(t2) = {q1}, M0 is the initial marking: the array S is in q1 and there is no array in q2, ρ(t1) = (A, B1, acn) and ρ(t2) = (A, B2, arm) and F = {q1}. The arrays used in the net are defined as follows: S = \(\begin{array}{cc} 1& 0\\ 0& 1\\ \end{array}\) and B1 = (0)m and B2 = (0)n−1 1. The Petri net graph is given in Fig. 5.

Petri net for generating the picture language L1
Initially t1 is the only enabled transition. Firing of t1 adjoins a column of 0’s after the last column of array S and puts the derived array in q2, making t2 enabled. Firing t2 adjoins a row of 0’s ending with 1 after the last row of the array in q2 and puts the derived array in q1. When the transitions t1, t2 fire the array that reaches the output place q1 is shown as \(\begin{array}{cc} 1 & 0 \\ 0 & 1 \\ \end{array} \mathop \Rightarrow \limits^{{{\text{t}}_{1} }} \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ \end{array} \mathop \Rightarrow \limits^{{{\text{t}}_{2} }} \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ \end{array} .\) Firing the sequence (t1t2)2 generates the output array as \(\begin{array}{cccc} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ \end{array} .\) The language L1 generated by Petri net is set of square pictures over {0, 1} with 1’s in the main diagonal and other elements are 0’s.
Example 3.2
If in Example 3.1, J = {a}, S = a, B1 = (a)m, B2 = (a)n, then the language L2 of square pictures of a’s is generated.
Example 3.3
Consider the AATPNS P3 = (J, C, M0, ρ, F), where J = {a}, the Petri net structure is C = (Q, T, I, O) with Q = {p1, p2, p3, p4, p5, p6, p7}, T = {t1, t2, t3, t4, t5, t6}, I(t1) = {p1, p2}, I(t2) = {p3}, I(t3) = {p4}, I(t4) = {p1, p5}, I(t5) = {p5, p6}, I(t6) = {p1, p2}, O(t1) = {p3}, O(t2) = {p4}, O(t3) = {p2, p5}, O(t4) = {p6}, O(t5) = {p1}, O(t6) = {p7, p2}.
ρ: T → L is defined as follows: ρ(t1) = p2, ρ(t2) = (A, B1, acn), ρ(t3) = (A, B2, arm), ρ(t4) = λ, ρ(t5) = λ, ρ(t6) = λ, ρ(t7) = λ, F = {p7}. The Petri net graph is given in Fig. 6. The arrays used are S = \(\begin{array}{cc} {\text{a}} & {\text{a}} \\ {\text{a}} & {\text{a}} \\ \end{array} ,\) B1 = (a a)m, B2 = \(\left( {\begin{array}{c} {\text{a}} \\ {\text{a}} \\ \end{array} } \right)^{\text{n}} .\)

Petri net for generating the picture language L3
To start with only t1 is enabled. Firing of sequence of transitions t1t2t3 results in a square of a’s of size 4 × 4 in p2 and p5. At this stage both t6 and t4 are enabled. Firing the sequence t1t2t3t6 puts a square of size 4 × 4 in p7. Firing t4 pushes the array to p6, emptying p5. In this position t5 is enabled. Firing t5 puts two copies of same array in p1. Since at this stage there are two tokens in p1, the sequence t1t2t3 has to fire two times to empty p1. The firing of sequence t4t5 (t1t2t3)2 t6 puts a square of a’s of size 8 × 8 in p7. The inhibitor input p1 make sure that a square of size 6 × 6 does not reach p7. This AATPNS generates the language L3 of squares of a’s of size (2n, 2n), n ≥ 1.
Example 3.4
The AATPNS P4 = (J, C, M0, ρ, F) with J = {a, b}, F = {p} given in Fig. 7, where S ∈ \(\left\{ {\begin{array}{cccc} {\text{a}} & {\text{b}} & {\text{b}} & {\text{a}} \\ {\text{b}} & {\text{b}} & {\text{b}} & {\text{b}} \\ \end{array} ,\;\begin{array}{cccc} {\text{b}} & {\text{b}} & {\text{b}} & {\text{b}} \\ {\text{b}} & {\text{b}} & {\text{b}} & {\text{b}} \\ \end{array} ,\;\begin{array}{cccc} {\text{b}} & {\text{a}} & {\text{a}} & {\text{b}} \\ {\text{a}} & {\text{a}} & {\text{a}} & {\text{a}} \\ \end{array} ,\;\begin{array}{cccc} {\text{a}} & {\text{a}} & {\text{a}} & {\text{a}} \\ {\text{a}} & {\text{a}} & {\text{a}} & {\text{a}} \\ \end{array} } \right\} ,\) B1 = (aa)m, B2 = an, B3 = (bb)m, B4 = bn, generates the language L4 of pictures of symmetrical squares, where each square is composed by nested “L” shaped strings of the same character over the alphabet {a, b}.

Petri net for generating the picture language L4
A typical picture in this language is given in Fig. 8.

A typical picture of L4
4 Closure properties
In this section we discuss the closure property with respect to various standard array operations. The formal definitions of these operations are given in Siromoney et al. (1973). We omit some of the proofs as they are straight forward.
Theorem 4.1
The family of languages generated by AATPNS is closed under the following picture operations.
-
(i)
transpose,
-
(ii)
rotation through 90°,
-
(iii)
rotation through 180°,
-
(iv)
reflection about the rightmost vertical,
-
(v)
reflection about the base.
Theorem 4.2
If L 1 and L 2 are two array languages generated by AATPNSs then L 1 □ L 2 and L 1 ○ L 2 need not be generated by another AATPNS.
Proof
If we consider both L1 and L2 are same as the language L4 in Example 3.4, then it is easy to see that L1 □ L2 and L1 ○ L2 will contain arrays which do not have any pattern. Hence it is impossible to construct a Petri net with finite number of transitions to generate all the arrays.
Theorem 4.3
The family of languages generated by AATPNS is closed under union and intersection.
Proof
Let P1 be an AATPNS with start array S1 at a place p1 and let P2 be another AATPNS with start array S2 at a place p2. In the net to generate the union, have two extra places p, q with S1 and S2, respectively as tokens. Let the extra transitions be tp and tq in the net. Let the label of tp be p and the label of tq be q. Let the input places of both tp and tq be p, q. Output place of tp is p1 and output place of tq is p2. Rest of the net would be the combination of C1 and C2. Once tp fires, the Petri net P1 would become operational or if tq fires, P2 would become operational. Hence the union of the languages generated by P1 and P2 can also be generated by an AATPNS.
If we construct another Petri net with new transition, which fires if and only if the transitions in P1 and P2 which have same labeling rule and same input array fires, then the intersection of the languages generated by P1 and P2 can also be generated by an AATPNS.
5 Comparative results
In the following results we use the notation \(\mathcal{L}\)(X) to denote the family of all languages generated by the device X.
Theorem 5.1
(R)P2DCFL ⊂ L (AATPNS).
Proof
Let the picture array language be generated by the P2DCFG G = (Σ, Pc, Pr, ℳ0), where Σ is a set of symbols, Pc = \(\{ {\text{t}}_{{{\text{c}}_{\text{i}} }} /1 \le {\text{i}} \le {\text{m}}\}\) is a set of column tables, Pr = \(\{ {\text{t}}_{{{\text{r}}_{\text{j}} }} /1 \le {\text{j}} \le {\text{n}}\}\) is a set of row tables, ℳ0 ⊆ Σ++ is a finite set of axiom arrays, with a regular control language over the set of labels, say (ℓ1, ℓ2,…,ℓm). Application of column table is equivalent to a column adjunction. Hence for every column table \({\text{t}}_{{{\text{c}}_{\text{i}} }} ,\) a corresponding CAR(A, B, aci/bci) can be defined. Similarly for every row table \({\text{t}}_{{{\text{r}}_{\text{j}} }} ,\) a corresponding RAR(A, B, arj/brj) can be defined. If it is assumed that the derivation \({\text{M}}_{ 0} \mathop \Rightarrow \limits^{\text{w}} {\text{M}}\) yields an array M of the language, where w is a control word ℓ1, ℓ2,…,ℓm then the AATPNS P can be constructed as follows.
Let p0 be a place with array M0 as token. Let t1 be a transition with the adjunction rule corresponding to ℓ1 as a label; p0 being the input place and p1 as its output place. Have a transition t2 with the adjunction rule corresponding to ℓ2 as a label; p1 being the input place and p2 as its output place and so on. Have a transition tm with the adjunction rule corresponding to the table ℓm as label; pm−1 being the input place and p0 as its output place. Let F = {p0}.
The firing sequence t1t2···tm will have the same effect as applying the rules ℓ1, ℓ2,…,ℓm in that order once. The firing the sequence (t1t2···tm)n generates the same array which is obtained by applying the set of tables in the control word (ℓ1, ℓ2,…,ℓm)n. Thus the Petri net P constructed will generate the language generated by the (R)P2DCFG G. In other words, (R)P2DCFL ⊆ \(\mathcal{L}\) (AATPNS).
For the strict inclusion, we consider the language L3 in Example 3.3 which cannot be generated by any (R)P2DCFG (Bersani et al. 2011, Proposition 5.5).
Since P2DCFL ⊂ (R)P2DCFL (Subramanian, Theorem 7), we can state the following:
Corollary 5.1
P2DCFL ⊂ L (AATPNS).
Theorem 5.2
(R)(l/u)P2DCFL ⊂ L (AATPNS).
Proof
Let L be the picture language generated by a (l/u) P2DCFG G = (Σ, Pc, Pr, ℳ0), where Σ is a set of symbols, Pc = \(\{ {\text{t}}_{{{\text{c}}_{\text{i}} }} /1 \le {\text{i}} \le {\text{m}}\}\) is a set of column tables, Pr = \(\{ {\text{t}}_{{{\text{r}}_{\text{j}} }} /1 \le {\text{j}} \le {\text{n}}\}\) is a set of row tables, ℳ0 ⊆ Σ++ is a finite set of axiom arrays, with a regular control language over the set of labels, say (ℓ1, ℓ2,…,ℓm). Application of a column table under (l/u) mode of derivation is equivalent to a column adjunction before or after the first column of the host array. Hence for every column table \({\text{t}}_{{{\text{c}}_{\text{j}} }} ,\) a corresponding CAR(A, Bj, ac1/bc1) can be defined. Similarly for every row table \({\text{t}}_{{{\text{r}}_{\text{k}} }} ,\) a corresponding RAR(A, Bk, ar1/br1) can be defined. If it is assumed that the derivation \({\text{M}}_{ 0} \mathop \Rightarrow \limits^{\text{w}} {\text{M}}\) yields an array M of the language, where w is a control word ℓ1, ℓ2,…,ℓm then the AATPNS P can be constructed as in Theorem 5.2.
Thus the Petri net P constructed will generate the language generated by the (R)(l/u)P2DCFG G. In other words, (R)(l/u)P2DCFL ⊆ \(\mathcal{L}\) (AATPNS).
For the strict inclusion, we again consider the language L3 in Example 3.3 which is not present in (R)P2DCFL. The families (R)P2DCFL and (R)(l/u)P2DCFL coincide if we restrict to only a unary alphabet. Since there is a single symbol and the column rules and row rules can use only one symbol, rewriting any column (row) is equivalent to rewriting the leftmost column (uppermost row). Since L3 is over unary alphabet {a}, it is not in (R) (l/u) P2DCFL also.
Since (l/u)P2DCFL ⊂ (R)(l/u)P2DCFL (Zbynek et al. 2014, Theorem 4), we can state the following:
Corollary 5.2
(l/u)P2DCFL ⊂ L (AATPNS).
Theorem 5.3
\(\mathcal{L}\) (AATPNS) is incomparable with \(\mathcal{L}\) (RTG) and \(\mathcal{L}\) (PG) but not disjoint.
Proof
The language L2 of squares over {a}, in Example 3.2, can be generated by a PG, G = (N, T, P, S) where N = {S, H, V}, T = {a} and \({\text{P }} = \left\{ {{\text{S}} \to \begin{array}{cc} {\text{a}} & {\text{H}} \\ {\text{V}} & {\text{S}} \\ \end{array} ,\;{\text{H}} \to {\text{aH}}/{\text{a}},\;{\text{V}} \to \begin{array}{c} {\text{a}} \\ {\text{V}} \\ \end{array} /{\text{a}},\;{\text{S}} \to {\text{a}}} \right\}.\)
Since \(\mathcal{L}\) (PG) ⊂ \(\mathcal{L}\) (RTG; Pradella et al. 2011, Proposition 8), this language is also in \(\mathcal{L}\) (RTG).
The incomparability with \(\mathcal{L}\) (RTG) can be seen as follows: the AATPNS language L4 of Example 3.4, which consists of pictures of symmetrical squares, where each square is composed by nested “L” shaped strings of the same character. This language cannot be generated by any regional tile grammar and hence by PG. In order to define two square regions, a production of the grammar should define them in the first derivation: since the partition is strong, the two sub-pictures generated from two different non-terminals say A and B are regionally defined, i.e., the derivations of the one can not affect the derivation of other. So there does not exist a method to make them symmetric.
Now, the language L+b of pictures consists of a horizontal and a vertical string of b’s (not in border) in the background of a’s can be generated by a PG (Prusa 2004, Example 8) and hence by a RTG. A typical member of L+b is given in Fig. 9. This language cannot be generated by any AATPNS, as the number of transitions in the net cannot depend on the size of the array. In an m × n array of a’s a column of b’s can be adjuncted in n − 1 ways and a row of b’s can be adjuncted in m − 1 ways. To insert both a column of b’s and a row of b’s the net required (m − 1)(n − 1) transitions with corresponding adjunction rules. Hence it is not feasible to generate these arrays using AATPNS.

A typical picture in L+b
Theorem 5.4
\(\mathcal{L}\) (AATPNS) is incomparable but not disjoint with LOC and REC.
Proof
The AATPNS language L1 of square pictures over {0, 1} with 1’s in the main diagonal and other elements are 0’s in Example 3.1, is in LOC (Giammarresi and Restivo 1997, Example 7.1) and hence in REC, as LOC ⊂ REC (Giammarresi and Restivo 1997). So, \(\mathcal{L}\) (AATPNS) ∩ LOC ∩ REC ≠ ϕ.
The incomparability of \(\mathcal{L}\) (AATPNS) with REC and hence with LOC is shown as follows: the language L6 = {anbn/n ≥ 1} is not in REC (Prusa 2004, Theorem 11) but can be generated by a AATPNS, P5 = (J, C, M0, C, F) with J = {a, b}, F = {p} given in Fig. 10.

Petri net for generating the picture language L6
where S = ab, B = ab.
The language Ldiag of pictures containing arbitrary number of diagonals of 1 (no single 1 are admitted at corners) that are separated by at least one diagonal of 0’s is in LOC. But Ldiag cannot be generated by any AATPNS. The only 2 × 2 array in the language is \(\begin{array}{cc} 0 & 0 \\ 0 & 0 \\ \end{array} .\) But there are four 3 × 3 arrays with the property belonging to the language. To generate four 3 × 3 arrays from the start array we need eight transitions with different array languages involved in the labels of the transitions. Hence it is impossible to construct a net with finite number of transitions.
6 Conclusion
In this paper we have considered a variant class of array token Petri nets with column and row adjunction rules as labels of transitions. We compared this model with some of the expressive grammar models: (R)P2DCFG, (R)(l/u)P2DFCG, RTG, PG and also with REC and LOC. We have shown that AATPNS have higher generative capacity than (R)P2DCFG and (R)(l/u)P2DCFG but incomparable with other models with non-empty intersection. The non-empty intersection clearly suggests that this model can generate a wide variety of digitized pictures and patterns. It will be of interest to allow the removal of a column or a row from the picture array, by the firing of transition in the Petri nets and examine the effect in the derivation of picture. The application of this model in picture processing tasks and Pattern recognition should be investigated further.
References
Baker HG (1972) Petri net languages. In: Computation structures group memo 68, Project MAC. MIT, Cambridge
Bersani MM, Frigeri A, Cherubini A (2011) On some classes of 2D languages and their relations. In: Aggarwal JK et al (eds) IWCIA 2011, LNCS, vol 6636, pp 222–234
Cherubini A, Crespi-Reghizzi S, Pradella M, Peitro PS (2006) Picture languages: tiling systems versus tile rewriting grammars. Theor Comput Sci 356:90–103
Crespi-Reghizzi S, Pradella M (2005) Tile rewriting grammars and picture languages. Theor Comput Sci 340:257–272
Giammarresi D, Restivo A (1997) Two-dimensional languages. In: Rozenberg G Salomaa A (eds) Handbook of formal languages, vol 3. Springer, Heidelberg, pp 215–267
Hack M (1975) Petri net languages. In: Computation structures group memo 124, Project MAC. MIT, Cambridge
Kamaraj T, Lalitha D, Thomas DG (2013) A Comparative study on adjunct array token Petri nets with some classes of array grammars. Appl Math Sci Hikari Publ 7(135):6705–6713
Kamaraj T, Lalitha D, Thomas DG (2014) A study on expressiveness of a class of array token Petri nets, In: M. Pant et al (eds.), SOCPROS 2013, Adv Intell Syst Comput Springer India 259:457–469
Lalitha D, Rangarajan K, Thomas DG (2012a) Adjunct array images using Petri nets. Indian J Math Math Sci 8(1):11–19
Lalitha D, Rangarajan K, Thomas DG (2012) Rectangular arrays and Petri nets. In: Barneva RP et al (eds) IWCIA 2012, LNCS, vol 7655, Springer, Heidelberg, pp 166–180
Nivat M, Saoudi A, Dare R (1989) Parallel generation of finite images. Int J Pattern Recognit Artif Intell 3(1989):279–294
Peterson JL (1981) Petri net theory and modeling of systems. Prentice Hall, Inc., Englewood Cliffs
Pradella M, Cherubini A, Crespi-Reghizzi S (2011) A unifying approach to picture grammars. Inf Comput 209:1246–1267
Prusa D (2004) Two-dimensional languages. PhD Thesis, Charles University, Faculty of Mathematics and Physics, Czech Republic
Rosenfeld A, Siromoney R (1993) Picture languages—a survey. Lang Des 1(3):229–245
Siromoney R (1987) Advances in array languages. In: Proceedings of the 3rd international workshop on graph grammars and their application to computer science, LNCS, vol 291. Springer, Heidelberg, pp 549–563
Siromoney R, Siromoney G (1977) Extended controlled table L-arrays. Inf Control 35:119–138
Siromoney G, Siromoney R, Krithivasan K (1972) Abstract families of matrices and picture languages. Comput Graph Image Process 1:284–307
Siromoney G, Siromoney R, Kamala K (1973) Picture languages with array rewriting rules. Inf Control 22:447–470
Siromoney G, Siromoney R, Kamala K (1974) Array grammars and kolam. Comput Graph Image Process 3(1):63–82
Subramanian KG et al (1989) Siromoney array grammars and applications. Int J Pattern Recognit Artif Intell 3(1989):333–351
Subramanian KG, Van DL, Helen Chandra P, Quyen ND (2008a) Array grammars with contextual operations. Fundam Inform 83(2008):411–428
Subramanian KG et al (2008b) Two-dimensional picture grammar models. In: Proceedings of the 2nd European modelling symposium, EMS2008. IEEE, Los Alamitos, pp 263–267
Subramanian KG, Rosihan M, Geethalakshmi M, Nagar AK (2009) Pure 2D picture grammars and languages. Discret Appl Math 157(16):3401–3411
Zbynek K et al (2014) A variant of pure two-dimensional context-free grammars generating picture languages. In: Barneva RP et al (eds) IWCIA 2014, LNCS, vol 8466. Springer, Heidelberg, pp 123–133
Author information
Authors and Affiliations
Corresponding author
Additional information
This work is an extension of a preliminary paper (Kamaraj et al. 2014).
Rights and permissions
About this article

Cite this article
Kamaraj, T., Lalitha, D. & Thomas, D.G. A formal study on generative power of a class of array token Petri net structure. Int J Syst Assur Eng Manag 9, 630–638 (2018). https://doi.org/10.1007/s13198-014-0304-8
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-014-0304-8