
Abstract
Precise evaluations of climate model precipitation outputs are valuable for making decisions regarding agriculture, water resource, and ecosystem management. Many downscaling techniques have been developed in the past few years for projection of weather variables. We need to apply dynamical and statistical downscaling (DD and SD) to bridge the gap between the coarse resolution general circulation model (GCM) outputs and the need for high-resolution climate information over a semi-arid region. We compare the requirements of DD (RegCM4) and SD (Delta) approaches, evaluate the historical run of NNRP1 data in comparison with station data, and analyze the changes in wet days and precipitation values through both methods during 1990–2010. In this study, we did not want to use prediction data under different scenarios of climate change, and we have just applied observed data to assess the amount of precise of NNRP1 data, over the observed period. SD method requires less time and computing power than DD. The DD approach performs better over the evaluation period according to efficiency criteria. In general, the Pearson correlation in DD with observation data in evaluation period was higher than (r > 0.72 and R2 > 0.52) SD (r > 0.65 and R2 > 0.41) over three study stations. Similarly, MAE and NSE show better results from DD relative to SD. SD underestimates the number annual mean wet-days for all three stations examined. DD overestimates a number of annual mean wet-days, but with less deviation from the observed mean.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The Fifth Assessment Report of the Intergovernmental Panel on Climate Change describes the state of the science of climate change (IPCC AR5 2013). General circulation model (GCM) outputs often have global coverage, they do not provide high spatial resolution outputs on proper scales for management decision-making (Meehl et al. 2007; Ullah et al. 2018). For transforming these coarse outputs to a finer resolution, there are two broad fundamental approaches, namely Statistical Downscaling (SD) and Dynamical Downscaling (DD) (Abbasnia et al. 2016). Both approaches provide researchers with access to fine-scale resolution projections of drought, flood, and climate change impacts on hydrology, water resources, air pollution, and crop yields.
SD uses equations to associate the variables simulated well by GCMs (predictors) and surface climate variables based on observed records (predictands). This method does not model atmospheric dynamics (Ayar et al. 2016). The three most commonly used approaches for statistical downscaling are (1) transfer functions (Imbert and Benestad 2005), (2) weather typing (Huth et al. 2008), and (3) stochastic weather generator (Buishand et al. 2003). Several variations on a fourth approach Bias Correction (BC), have been developed to downscale climate variables from climate models (Li et al. 2010; Chen et al. 2011; Maraun 2016).
Dynamic downscaling, nesting a fine scale climate model in a coarse scale model to simulate higher spatial resolution by solving equations of motion and thermodynamics, lateral boundary conditions, parameterization, and physical processes (Giorgi et al. 2001). DD and SD approaches have their own advantages and disadvantages, but there is no consensus that one approach is superior in terms of reproducing the observed variability of local climates (Mearns et al. 1999; Gutowski et al. 2000). DD approaches have heavy computational costs, long runtime, and require convection schemes and input data (Benestad 2010; Kim et al. 2016a, b). SD approaches are simple, require less computational demand, time, cost, and are easily implemented, which explains their relative popularity of SD approaches (Souvignet and Heinrich 2011; Manzanas et al. 2017a, b; Nikulin et al. 2017).
Over the last two decades, dynamical and statistical downscaling approaches have been compared in New Zealand (Kidson and Thompson 1998), Europe (Murphy 1999; Manzanas et al. 2017a, b), eastern Nebraska (Mearns et al. 1999), Colorado (Wilby et al. 2000), Japan (Oshima et al. 2002), Romania (Busuioc et al. 2006), UK (Haylock et al. 2006), North America (Wang and Zhang 2008), southeastern United States (Lim et al., 2007), Philippines (Robertson et al. 2011), northeastern United States (Tryhorn and DeGaetano 2011), Spain (Casanueva et al. 2016), China (Su et al. 2017), and Eastern Africa (Nikulin et al. 2017). Several researchers point to the SD and DD differences in projected precipitation changes. Jang et al. (2013) assessed the difference in 100-year average precipitation changes over northern California region outputs from SD (BCSD (Bias-Correction and Spatial Downscaling)) vs DD (MM5 (the Fifth-Generation NCAR/Penn State Mesoscale Model)). The BCSD method of Wood et al. (2004) is an empirical statistical technique in which the monthly precipitation and temperature output from a GCM are downscaled. The MM5 model is a regional mesoscale model used for creating weather forecasts and climate projections. The most prominent features of the MM5 are multiple-nesting capability, availability of four-dimensional data assimilation (FDDA), and a large spectrum of physics options (Boo et al. 2004). The precipitation change from MM5 simulations and BCSD estimations show the opposite spatial patterns in many places over the study region. The BCSD method has limitations in projecting future precipitation values. Mehrotra et al. (2013) saw SD as providing better simulations of point rainfall, spell lengths, and amounts, but DD was well suited where regionally averaged rainfall is of primary concern.
Schmidli et al. (2007) compared daily precipitation statistics obtained by using six SD and three DD approaches over the European Alps. Their result revealed that all SD approaches underestimate the magnitude of the interannual variations, but the DD approaches produce about the right amount of interannual variability. Vrac et al. (2012) analyzed the performance of SD and DD and compared the potential benefit of applying a SD model to different DD approaches. The evaluated the uncertainty in downscaling of wind, temperature, and rainfall cumulative distribution functions for eight stations in the French Mediterranean basin over 1991–2000. They showed that SD approach produces accurate results. Gutmann et al. (2012) investigated the amount of winter precipitation over complex terrain by SD and DD approaches. The results showed that there are regions of significant difference between the two methods. Ayar et al. (2016) compared six SD and five RCM models are used in terms of precipitation outputs. The stochastic and resampling-based SD approaches better modeled marginal properties of rain occurrence and intensity, while RCMs and resampling-based SD approaches well reproduced spatial and temporal variability.
The large year-to-year variation in precipitation amounts is key for water resources planning, hydrological and agricultural modeling, and environmental assessments, especially in arid and semi-arid regions. In this work, we (1) compare the requirements of DD (RegCM4) and SD (Delta) approaches, (2) compare local predictions against observations, and (3) evaluate the downscaled predictions results (obtained either with SD or with DD) against observations, across yearly and seasonal timescales.
2 Data and Methods
2.1 Downscaling Methods
In this study, we used both approaches for downscaling, namely SD and DD. In the SD approach, the Delta method was applied, and for DD, the RegCM4.1 model was run. These methods were run on the data of the NNRP1 (NCEP/NCAR Reanalysis Product version 1) model. The following sections (2.1.1 and 2.1.2) provide more details of the mentioned models and approaches. In addition, all the steps of this research were presented in Fig. 1.

The flowchart of different steps in this study
2.1.1 Statistical Downscaling
Statistical downscaling is based on the relationship between the local climate surface variables and large-scale (typically circulation) atmospheric variables. We utilize the Delta method of SD approaches, as it is the most widely used with RCM outputs (Maraun et al. 2010; Themeßl et al. 2012; Kang et al. 2016; Kim et al. 2016a, b; Manzanas et al. 2017a, b), easy to run, and it is a relatively simple method (Dessu and Melesse 2013). Wetterhall et al. (2012) called this method as a direct method. Maraun et al. (2010) revealed that Delta approach is not a bias correction of a climate model, but only employs the model’s response to climate change to modify observations, as it is a useful benchmark for bias correction. Whereas in a large number of climate change impact assessment studies have used a bias correction downscaling method which often referred as the delta change method (Eckhardt and Ulbrich 2003; Teutschbein and Seibert 2012; Sunyer et al. 2012; Sachindra et al. 2014). The delta-approach, add only the climate change signal from GCMs to observations (Hay et al. 2000). Delta method has the advantage of simplicity and modest data requirements. In this study, downscaled precipitation is calculated as follows (Eq. 1):
where \( {P}_{SD}^{Delta} \) is downscaled data of precipitation, \( {\overline{P}}_{Obs} \) is the mean observed precipitation, and \( {\overline{P}}_{Mod} \) denotes the NNRP1 mean precipitation data over the control period (GCM historical run). If we want to use future data then we should apply future period in the equation. In this study, we have developed a tool (AgriMetSoft SD-GCM 2017) for running the Delta technique. The SD-GCM (Statistical Downscaling of General Circulation Models) software is a useful tool for downscaling CMIP5 models under RCP Scenarios. In this tool, the observation data and output data would be in Excel format files and the order of data in the columns are not important, therefore user can easily load the input observation data. This tool has an option for the verification metrics, including Nash-Sutcliffe Efficiency (NSE), Spearman Correlation, RMSE (Root Mean Squared Error), d (index of agreement), and MAE (Mean Absolute Error). For further details, refer to the help file of the SD-GCM tool.
2.1.2 Dynamical Downscaling
We used the Regional Climate Model (RCM) version 4.1, RegCM4 (Giorgi et al. 2012), developed at the Abdus Salam International Centre for Theoretical Physics (ICTP). It is an improved version of RegCM3 (Pal et al. 2007), which is also an evolution of its previous version RegCM2 (Giorgi et al. 1993a, b). The dynamical core of the RegCM is essentially equivalent to the hydrostatic version of the NCAR/Pennsylvania State University mesoscale model MM5 (Grell et al. 1994). Lateral boundary conditions were obtained from the NCEP/NCAR Reanalysis 1 (NNRP1) dataset at 2.5° × 2.5° latitude-longitude horizontal resolution over the observed period of 1990–2010. NNRP1 data was produced by the National Centers for Environmental prediction (NCEP) in collaboration with the National Centre for Atmospheric Research (NCAR) and it covers the period from 1948 to present day. The data assimilation system uses a 3D-variational analysis scheme, with 28 sigma levels in the vertical and a triangular truncation of 62 waves that corresponds to a horizontal resolution of approximately 200 km. For more details refer to Kalnay et al. (1996).
Sea-surface temperature (SST) was taken from the National Oceanic and Atmospheric Administration (NOAA) Optimum Interpolation SST (OISST) dataset with a weekly temporal resolution and 1° × 1° spatial resolution (Reynolds et al. 2002). Global terrain 30 arc-seconds resolution global land cover characteristics (GLCC; Loveland et al. (2000)) were used. For land use, we used GTOPO topography data. Details of the model configuration are presented in Table 1.
2.2 Verification Metrics Used and Used Graphs
We used three performance and evaluation metrics: MAE (MacLean 2005), Pearson’s correlation coefficient (R), and NSE (Nash and Sutcliffe 1970). MAE was used to determine the average magnitude of the error. The R coefficient was used to measure the degree of agreement between observation data and simulation data. The NSE ranges from minus infinity to 1, with a value of 1 indicating perfect agreement between measured and model-estimated values. A value of 0 indicates that the measured mean is as good a predictor as the model, whereas negative values indicate that the measured mean is a better predictor than the model. These equations are defined as following, with O observed, \( \overline{O} \) mean observed, S simulated values, and N is the number of observations:
Box-Whisker plots presenting observation data versus the downscaling methods over (1990–2010) were drawn. In this graph, the horizontal line in the middle of the box represents the median, the upper edge of the box represents the 75th percentile (upper quartile, UQ), while the lower edge is the 25th percentile (lower quartile, LQ). The boxes extend between the 25th to the 75th percentiles refers to the Interquartile Range (IQR), and the whiskers show the 5th and 95th percentiles, points are values outside this range.
In addition, the Cumulative Distribution Function plot (CDF) was also depicted. In this graph, the horizontal axis is the allowable domain for the given probability function. Since the vertical axis is a probability, it must fall between zero and one. We applied CDF for comparing the changes in precipitation of observation, statistical, and dynamical total precipitation during 1990–2010.
2.3 Study Area
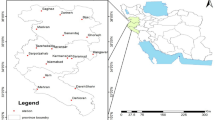
This study area (Fig. 2) was comprised of three different semi-arid locations: Mashhad, Sabzevar, and Torbat-e Heydarieh (Torbat), all located in Khorasan-e Razavi province, northeastern Iran. The study area province is located between 33° 52′ S and 37° 42′ N latitude and 56°19′ W and 61°16′ E longitude, with an area of 118,851 km2. Daily precipitation (mm) data were collected from the meteorological station at each location over 1990–2010 (Table 2). Homogenization and quality control of weather data were performed by the national meteorological organization of Iran (www.weather.ir) before the release of such data to users. The precipitation data in Table 2 refers to yearly mean total precipitation amounts during 1990–2010. Also, the number of wet days (#) were calculated from precipitation data via MATLAB programming language (R2017b, Version 9.1) for each day that the total precipitation was >0 .1mm (Buishand et al. 2003).

The study area location with three stations
3 Results and Discussion
3.1 Comparison of System Requirements
As seen in Table 3 and similar to other studies (Murphy 1999, 2000; Maurer and Hidalgo 2008), the DD method required more RAM (32GB) and hard drive space (150GB, due to precise settings such as boundary conditions and convection scheme) than the SD Delta method (RAM 3GB and hard 3GB). RAM is an acronym for Random Access Memory. The runtime for data loading and extracting in NC format file, applying the desired model for downscaling, and finally receive the downscaled weather data was also less intensive for SD (shown in Table 3).
3.2 SD and DD Methods Evaluation
DD method outputs performed better than SD method outputs overall for Mashhad and Torbat for all three efficiency metrics (Table 4 and Fig. 3). SD had better results at Sabzevar when performance was judged on NSE and MAE criteria. Figure 3 shows the relationships between monthly precipitation over each station (Mashhad, Sabzevar, and Torbat) and the corresponding values from the SD and DD precipitation. These results reveal that there is an acceptable agreement between the station-observed precipitation data and SD and DD precipitation data, with R2 > 0.52 for DD method and R2 > 0.41 for SD method (at 95% confidence level and p value<0.05). Overall, the SD method shows weaker correlations than the DD for precipitation, but the difference in the results of correlation in the two approaches is negligible. The highest R2 among three stations is achieved at the Sabzevar station for both SD and DD approaches.

Relationships of the monthly precipitation observed data vs. the SD and DD precipitation over the three stations
3.3 Precipitation and Wet-Days
Total annual precipitation (mm) and annual mean of the number of wet days (#) observation and simulated downscaled data over 1990–2010 are presented in Table 5. SD underestimates annual mean wet days for all stations, while the DD overestimates these values. Sabzevar is drier than the other stations in this study. Similar to wet days, SD underestimates total annual precipitation and DD overestimates these values Table 5. Tryhorn and DeGaetano (2011) found a similar overestimation of mean precipitation bias by the DD approach. DD precipitation bias is larger than SD for all stations. Frost et al. (2011) similarly found that SD approaches underestimated the number of wet-days. Wang et al. (2016) also found that the BC-based methods like our SD Delta method underestimated the wet-day frequency and the precipitation intensity. Our results confirm the findings of Maraun (2013) and Chen et al. (2011).
For Mashhad station in winter, SD more closely matched observed (1990–2010) median precipitation and DD showed a bias toward overestimation (Fig. 4a). As you see in Fig. 4a (Mashhad), Delta method showed a wider range (from minimum to maximum) of the predicted precipitation values than RegCM4, also the maximum values of precipitation by Delta are greater than the RegCM4’s output, over winter and spring, whereas the highest IQR happened by RegCM4 over spring, summer, and autumn. Both downscaling approaches overestimate precipitation in spring over Mashhad and Sabzevar. For autumn, observation variability and median precipitation are better represented by DD and slightly underestimated by SD. In comparison with the median of observation and Delta method, RegCM4 had the largest variation of the median, and the highest median values predicted by the RegCM4 has occurred in winter (WD) and spring (SD).

Box plots for seasonal total precipitation (Pre.) values during 1990–2010 over three stations, that the first character of the word refers to W(Winter), S(Spring), SU(Summer), A(Autumn), and the second one refers to S(Statistical), D(Dynamical), and O(Observation)
At Sabzevar (Fig. 4b) SD performed fairly well with regard to the variability and median of precipitation in winter. DD overestimated variability and median precipitation in winter and spring, and strongly overestimates the percentile above 75th. The upper quartile of the seasonal precipitation distribution increases during winter and spring, in compare to observation data. At Torbat (Fig. 4c), both the SD and DD approaches underestimated the values of precipitation, but adequately capture median winter value. SD obtained the highest IQR in spring, and DD did relatively well for IQR in spring and autumn. Overall, in three stations, SD approach overestimated the precipitation’s values over spring; also, DD has the same behavior in spring, except for Torbat station. From the analysis for all stations, SD presented lower values of precipitation than DD, at summer and autumn.
At Mashhad station, the SD approach tends to underestimate the number of wet days in winter, spring, and summer. DD tends to overestimate wet days for these seasons (Fig. 5a). As illustrated in Fig. 5b, Sabzevar station shows trends similar to Mashhad: SD predictions are much closer to the observation station data and DD overestimates values for all seasons except summer. This may be because Sabzevar station is an arid area in contrast to the semi-arid climate of the other two sites. Torbat (Fig. 5c) shows similar results as Mashhad station; the SD approach underestimates wet days, and DD tends to overestimate for all seasons except summer. Mashhad and Torbat have similar climate and both of them are semi-arid. To summarize, for the four seasons of three data outputs (station, SD, and DD) in three locations, the number of wet days in a historical run versus observation data, are almost well captured by DD at autumn. Generally, the SD method tends to underestimate this value, while DD overestimates it, during winter, spring, and summer.

The average seasonal wet-days during 1990–2010 of observation, statistical, and dynamical data output, in the three locations
Figure 6 shows CDFs for observed versus SD and DD precipitation at three locations. For the observed precipitation at Mashhad (Fig. 6a), the probability of more than 40 mm of total precipitation is 20% ((1–0.80)*100 = 20%), but the values from SD and DD using historical data are 30% and 32%, respectively. At Mashhad, DD and SD show similar outputs of precipitation values greater than 50 mm of 20% probability. At Sabzevar DD significantly overestimates the probability of precipitation over 20 mm; SD only slightly overestimates this (Fig. 6b). The probability of total precipitation of more than 50 mm is 20% from DD, but this value is 10% from SD and 10% from observed data. DD outputs suggest a 60% probability of total precipitation less than or equal to 30 mm, but this value is 75% for SD and 80% for historical data. The historical probability for more than 25 mm of total precipitation at Torbat is 45% from the SD approach and 40% for DD. All three cases (observed, SD, and DD) agree on the probability of 120 mm or more of total precipitation (Fig. 6c). Overall, the DD approach more closely matches observed than SD at Torbat.

Cumulative distribution functions (CDF) of observed, statistical, and dynamical total precipitation in three locations
Average daily precipitation from 1990 to the end of 2010 from the dynamic simulation of the RegCM4 model in northeastern Iran is shown in Fig. 7. Precipitation simulations of the dynamic model in Sabzevar were 0.5–0.6, Torbat 0.7–0.8, and Mashhad, 0.8–0.9 mm / day, while observed values at these three stations have been reported 0.52, 0.73, and 0.67 mm / day, respectively. The simulated precipitation values in Torbat and Sabzevar are fully matched with observational values, but at Mashhad station, the dynamic model has a near 2 mm overestimate.

The result of average daily precipitation through DD method during 1990–2010
Both SD and DD approaches reproduced precipitation and wet days of the case study, but both represented biases with respect to observations as well. The statistical criteria show that the DD approach yielded better results than SD. This finding agrees with the results of Mearns et al. (1999), Gutowski et al. (2000), and Yarnal et al. (2001).
4 Conclusion
This analysis has focused on the performance of SD and DD approaches over NNRP1 precipitation historical data (1990–2010). We assessed their accuracy vs. observation data on precipitation amount and number of wet days, on annual and seasonal scales. DD is more complex and needs high frequency (6 hourly) GCM outputs and is associated with a heavy computational cost of RCMs. SD is computationally efficient, require less computational demand, time, cost, and are easily implemented. For this semi-arid area, the SD approach underestimates annual mean precipitation and number of wet days in all stations, whereas the DD overestimates these values. In all stations, the Pearson correlation coefficients for DD were greater than 0.72; for SD coefficients were more than 0.65 (p value<0.001). MAE results of DD for Mashhad and Torbat were 13.35 and 12.22, respectively; for SD they were 15.86 and 16.1. For Sabzevar station, MAE of DD was 12.96, whereas for SD it was 10.47. The Pearson correlation, NSE, and MAE values all point to the DD approach as more efficient. This finding agrees with other downscaling studies of precipitation and highlights the advantages of considering different downscaling methods (Hayhoe et al., 2006; Haylock et al. 2006; Maurer and Hidalgo 2008; Wang et al. 2016).
One of the limitations of this study was that it has been applied over a not very big region over the northeast of Iran. Better results may be obtained in different climates, with a further number of stations. Finally, according to the results of this research, we emphasize that the choice of most appropriate downscaling method depends on the user’s requirements (time and expense), time scale (seasonally, monthly or daily scale), and the climate of regions of interest.
References
Abbasnia, M., Tavousi, T., Khosravi, M.: Assessment of future changes in the maximum temperature at selected stations in Iran based on HADCM3 and CGCM3 models. Asia-Pacific J Atmos Sci. 52, 371 (2016). https://doi.org/10.1007/s13143-016-0006-z
AgriMetSoftn.d.: SD-GCM Tool [Computer software]. Available at: https://agrimetsoft.com/SD-GCM.aspx. (2017)
Ayar, P.V., Vrac, M., Bastin, S., Carreau, J., Déqué, M., Gallardo, C.: Intercomparison of statistical and dynamical downscaling models under the EURO-and MED-CORDEX initiative framework: present climate evaluations. Clim. Dyn. 46(3–4), 1301–1329 (2016). https://doi.org/10.1007/s00382-015-2647-5
Benestad, R.E.: Downscaling precipitation extremes: correction of analog models through PDF predictions. Theor. Appl. Climatol. 100, 1–21 (2010). https://doi.org/10.1007/s00704-009-0158-1
Boo, K., Kwon, W., Oh, J., Baek, H.: Response of global warming on regional climate change over Korea: an experiment with the MM5 model. Geophys. Res. Lett. 31, L21206 (2004). https://doi.org/10.1029/2004GL021171
Buishand, T.A., Shabaliva, M.V., Brandsma, T.: On the choice of the temporal aggregation level for statistical downscaling of precipitation. J. Clim. 17, 1816–1827 (2003)
Busuioc, A., Giorgi, F., Bi, X., Lonita, M.: Comparison of regional climate model and statistical downscaling simulations of different winter precipitation change scenarios over Romania. Theor. Appl. Climatol. 86, 101–120 (2006)
Casanueva, A., Herrera, S., Fernández, J., Gutiérrez, J.M.: Towards a fair comparison of statistical and dynamical downscaling in the framework of the EURO-CORDEX initiative. Clim. Chang. 137(3–4), 411–426 (2016). https://doi.org/10.1007/s10584-016-1683-4
Chen, J., Brissette, F.P., Leconte, R.: Uncertainty of downscaling method in quantifying the impact of climate change on hydrology. J. Hydrol. 401(3–4), 190–202 (2011). https://doi.org/10.1016/j.jhydrol.2011.02.020
Dessu, S.B., Melesse, A.M.: Evaluation and comparison of satellite and GCM rainfall estimates for the Mara River Basin, Kenya/Tanzania. Chapter Climate Change and Water Resources Volume 25 of the series The Handbook of Environmental Chemistry 29–45 (2013). https://doi.org/10.1007/698_2013_219
Eckhardt, K., Ulbrich, U.: Potential impacts of climate change on groundwater recharge and streamflow in a central European low mountain range. J. Hydrol. 284, 244–252 (2003)
Frost, A.J., Charles, S.P., Timbal, B., Chiew, F.H.S., Mehrotra, R., Nguyen, K.C., Chandler, R.E., McGregor, J.L., Fu, G., Kirono, D.G.C., Fernandez, E., Kent, D.M.: A comparison of multi-site daily rainfall downscaling techniques under Australian conditions. J. Hydrol. 408(1-2), 1–18 (2011)
Giorgi, F., Marinucci, M.R., Bates, G.T.: Development of a second-generation regional climate model (RegCM2). Part I: boundary-layer and radiative transfer processes. Mon. Weather Rev. 121(10), 2794–2813 (1993a). https://doi.org/10.1175/1520-0493(1993)121<2794:DOASGR>2.0.CO;2
Giorgi, F., Marinucci, M.R., Bates, G.T., De Canio, G.: Development of a second-generation regional climate model (RegCM2). Part II: convective processes and assimilation of lateral boundary conditions. Mon. Weather Rev. 121(10), 2814–2832 (1993b). https://doi.org/10.1175/1520-0493(1993)121<2814:DOASGR>2.0.CO;2
Giorgi, F., Hewitson, B., Christensen, J.H., Hulme, M., von Storch, H., Whetton, P., Jones, R., Mearns, L.O., Fu, C.: Regional climate information: evaluation and projections, in Climate Change 2001: The Scientific Basis, chap. 10, pp. 583–638. Cambridge Univ. Press, Cambridge (2001)
Giorgi, F., Coppola, E., Solmon, F., Mariotti, L., Sylla, M., Bi, X., Elguindi, N., Diro, G., Nair, V., Giuliani, G.: RegCM4: model description and preliminary tests over multiple CORDEX domains. Clim. Res. 52, 7–29 (2012). https://doi.org/10.3354/cr01018
Grell, G.A., J. Dudhia, and D.R. Stauffer, 1994: A description of the fifth-generation Penn State/NCAR mesoscale model (MM5)
Gutmann, E.D., Rasmussen, R.M., Liu, C., Ikeda, K., Gochis, D.J., Clark, M.P., Dudhia, J., Thompson, G.: A Comparison of Statistical and Dynamical Downscaling of Winter Precipitation over Complex Terrain. J. Clim. 25(1), 262–281 (2012)
Gutowski, W.J., Wilby, R.L., Hay, L.E., Anderson, C.J., Arritt, R.W., Clark, M.P., Leavesley, G.H., Pan, Z., Da Silva, R., Takle, E.S.: Statistical and dynamical downscaling of global model output for US national assessment hydrological analyses, Proceedings of the 11th Symposium on Global Change Studies, Long Beach, CA, January 9–14. (2000)
Hay, L.E., Wilby, R.L., Leavesley, G.H.: A comparison of delta change and downscaled GCM scenarios for three mountainous basins in the United States. J. Am. Water Resour. Assoc. 36(2), 387–397 (2000). https://doi.org/10.1111/j.1752-1688.2000.tb04276.x
Hayhoe, K., et al. : Past and future changes in climate and hydrological indicators in the U.S. northeast, Clim. Dyn. 28, 381– 407 (2006). https://doi.org/10.1007/s00382-006-0187-8
Haylock, M.R., Cawley, G.C., Harpham, C., Wilby, R.L., Goodess, C.M.: Downscaling heavy precipitation over the United Kingdom: a comparison of dynamical and statistical methods and their future scenarios. Int. J. Climatol. 26(10), 1397–1415 (2006). https://doi.org/10.1002/joc.1318
Huth, R., Beck, C., Philipp, A., Demuzere, M., Ustrnul, Z., Cahynov, M., Kysely, J., Tveito, O.E.: Classifications of atmospheric circulation patterns – recent advances and applications. Trends and directions in climate research: Ann. N.Y. Acad. Sci. 1146, 105–152 (2008). https://doi.org/10.1196/annals
Imbert, A., Benestad, R.: An improvement of analog model strategy for more reliable local climate change scenarios. Theor. Appl. Climatol. 82(3–4), 245–255 (2005). https://doi.org/10.1007/s00704-005-0133-4
IPCC: Climate change 2013: the physical science basis. Contribution of working group I to the fifth assessment report of the IPCC. Cambridge University Press, Cambridge, United Kingdom and NewYork, USA. 1535pp. (2013)
Jang, S., Kavvas, M.L., Asce, F.: Downscaling global climate simulations to regional scales: statistical downscaling versus dynamical downscaling. J. Hydrol. Eng. A4014006-1–A4014006-18 (2013). https://doi.org/10.1061/(ASCE)HE.1943-5584.0000939
Kalnay, E., Kanamitsu, M., Kistler, R., Collins, W., Deaven, D., Gandin, L., Iredell, M., Saha, S., White, G., Woollen, J.: The NCEP/NCAR 40-year reanalysis project. Bull. Am. Meteorol. Soc. 77(3), 437–471 (1996). https://doi.org/10.1175/1520-0477(1996)077<0437:TNYRP>2.0.CO;2
Kang, H.S., Tangang, F., Krishnan, R.: Regional climate downscaling over Asia-Pacific region. Asia-Pacific J Atmos Sci. 52, 77 (2016). https://doi.org/10.1007/s13143-016-0023-y
Kidson, J.W., Thompson, C.S.: A comparison of statistical and model-based downscaling techniques for estimating local climate variations. J. Clim. 11, 735–753 (1998)
Kim, Y., Jun, M., Min, S.K., Suh, M.S., Kang, H.S.: Spatial analysis of future east Asian seasonal temperature using two regional climate model simulations. Asia-Pacific J Atmos Sci. 52, 237 (2016a). https://doi.org/10.1007/s13143-016-0022-z
Kim, M.K., Kim, S., Kim, J., Heo, J., Park, J.S., Kwon, W.T., Suh, M.S.: Statistical downscaling for daily precipitation in Korea using combined PRISM, RCM, and quantile mapping: Part 1, methodology and evaluation in historical simulation. Asia-Pacific J Atmos Sci. 52, 79 (2016b). https://doi.org/10.1007/s13143-016-0010-3
Li, H., Sheffield, J., Wood, E.F.: Bias correction of monthly precipitation and temperature fields from intergovernmental panel on climate change AR4 models using equidistant quantile matching. J. Geophys. Res. 115, D10101 (2010). https://doi.org/10.1029/2009JD012882
Loveland, T.R., Reed, B.C., Brown, J.F., Ohlen, D.O., Zhu, Z., Yang, L., Merchant, J.W.: Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data. Int. J. Remote Sens. 21(6–7), 1303–1330 (2000). https://doi.org/10.1080/014311600210191
MacLean, A.: Statistical Evaluation of WATFLOOD (Ms), University of Waterloo, Ontario, Canada, (2005)
Manzanas, R., Gutiérrez, J.M., Fernandez, J., van Meijgaard, E., Calmanti, S., Magariño, M.E., Cofiño, A.S., Herrera, S.: Dynamical and statistical downscaling of seasonal temperature forecasts in Europe: added value for user applications. Climate Services. 9, 44–56, ISSN 2405-8807 (2017a). https://doi.org/10.1016/j.cliser.2017.06.004
Manzanas, R., Lucero, A., Weisheimer, A., Gutiérrez, J.M.: Can bias correction and statistical downscaling methods improve the skill of seasonal precipitation forecasts? Clim. Dyn. (2017b). https://doi.org/10.1007/s00382-017-3668-z
Maraun, D.: Bias correction, quantile mapping, and downscaling: revisiting the inflation issue. J. Clim. 26(6), 2137–2143 (2013)
Maraun, D.: Bias correcting climate change simulations: a critical review. Curr. Clim. Change Rep. 2(4), 211–220 (2016). https://doi.org/10.1007/s40641-016-0050-x
Maraun D., Wetterhall, F., Ireson, A.M., Chandler, R.E., Kendon, E.J., Widmann, M., Brienen, S., Rust, H.W., Sauter, T., Themeßl, M., Venema, V.K.C., Chun, K.P., Goodess, C.M., Jones, R.G., Onof, C., Vrac, M., Thiele-Eich, I.: Precipitation downscaling under climate change: Recent developments to bridge the gap between dynamical models and the end user. Rev. Geophys. 48(3) (2010). https://doi.org/10.1029/2009RG000314
Maurer, E.P., Hidalgo, H.G.: Utility of daily vs. monthly large-scale climate data: an intercomparison of two statistical downscaling methods. Hydrol. Earth Syst. Sci. 12(2), 551–563 (2008). https://doi.org/10.5194/hess-12-551-2008
Mearns, L.O., Bogardi, I., Giorgi, F., Matyasovszky, I., Palecki, M.: Comparison of climate change scenarios generated from regional climate model experiments and statistical downscaling. J. Geophys. Res. 104, 6603–6621 (1999)
Meehl, G., Covey, C., Delworth, T., Latif, M., McAvaney, B., Mitchell, J., Stouffer, R., Taylor, K.: The WCRP CMIP3 multi-model dataset: a new era in climate change research. Bull. Am. Meteorol. Soc. 88, 1383–1394 (2007)
Mehrotra, R., Evans, J.P., Sharma, A., Sivakumar, B.: Evaluation of downscaled daily rainfall hindcasts over Sydney, Australia using statistical and dynamical downscaling approaches. Hydrol. Res. 45(2), 226–249 (2013)
Murphy, J.: An evaluation of statistical and dynamical techniques for downscaling local climate. J. Clim. 12, 2256–2284 (1999)
Murphy, J.: Predictions of climate change over Europe using statistical and dynamical downscaling techniques. Int. J. Climatol. 20, 489–501 (2000)
Nash, J.E., Sutcliffe, J.V.: River flow forecasting through conceptual models part 1 – a discussion of principles. J. Hydrol. 10, 282–290 (1970)
Nikulin, G., Asharaf, S., Magariño, M.E., Calmanti, S., Cardoso, R.M., et al.: Dynamical and statistical downscaling of a global seasonal hindcast in eastern Africa. Climate Services. 9, 72–85, ISSN 2405-8807 (2017). https://doi.org/10.1016/j.cliser.2017.11.003
Oshima, N., Kato, H., Kadokura, S.: An application of statistical downscaling to estimate surface air temperature in Japan. J. Geophys. Res. 107(D10), 4095 (2002). https://doi.org/10.1029/2001JD000762
Pal, J.S., Giorgi, F., Bi, X., Elguindi, N., Solmon, F., Rauscher, S.A., Gao, X., Francisco, R., Zakey, A., Winter, J.: Regional climate modeling for the developing world: the ICTP RegCM3 and RegCNET. Bull. Am. Meteorol. Soc. 88(9), 1395–1409 (2007). https://doi.org/10.1175/BAMS-88-9-1395
Reynolds, R.W., Rayner, N.A., Smith, T.M., Stokes, D.C., Wang, W.: An improved in situ and satellite SST analysis for climate. J. Clim. 15(13), 1609–1625 (2002). https://doi.org/10.1175/1520-0442(2002)015<1609:AIISAS>2.0.CO;2
Robertson, A.W., Qian, J.H., Tippett, M.K., Moron, V., Lucero, A.: Downscaling of seasonal rainfall over the Philippines: dynamical versus statistical approaches. Mon. Weather Rev. 140, 1204–1218 (2011). https://doi.org/10.1175/MWR-D-11-00177.1
Sachindra, D.A., Huang, F., Barton, A., Perera, B.J.C.: Statistical downscaling of general circulation model outputs to precipitation – part 2: bias-correction and future projections. Int. J. Climatol. 34, 3282–3303 (2014). https://doi.org/10.1002/joc.3915
Schmidli, J., Goodness, C.M., Frei, C., Haylock, M.R., Hundecha, Y., Ribalaygua, J., Schmith, T.: Statistical and dynamical downscaling of precipitation: an evaluation and comparison of scenarios for the European Alps. J. Geophys. Res. 112, D04105 (2007). https://doi.org/10.1029/2005JD007026
Souvignet, M., Heinrich, J.: Statistical downscaling in the arid Central Andes: uncertainty analysis of multi-model simulated temperature and precipitation. Theor. Appl. Climatol. 106, 229 (2011). https://doi.org/10.1007/s00704-011-0430-z
Su, H., Xiong, Z., Yan, X., Dai, X., Wei, W.: Comparison of monthly rainfall generated from dynamical and statistical downscaling methods: a case study of the Heihe River Basin in China. Theor. Appl. Climatol. 129(1–2), 437 (2017). https://doi.org/10.1007/s00704-016-1771-4
Sunyer, M.A., Madsen, H., Ang, P.H.: 2010: a comparison of different regional climate models and statistical downscaling methods for extreme rainfall estimation under climate change. Atmos. Res. 103, 119–128 (2012). https://doi.org/10.1016/j.atmosres.2011.06.011
Teutschbein, C., Seibert, J: Bias correction of regional climate model simulations for hydrological climate-change impact studies: Review and evaluation of different methods. J. Hydrol. 456–457, 12–29 (2012)
Themeßl, M.J., Gobiet, A., Heinrich, G.: Empirical-statistical downscaling and error correction of regional climate models and its impact on the climate change signal. Clim. Chang. 112(2), 449–468 (2012)
Tryhorn, L., DeGaetano, A.: A comparison of techniques for downscaling extreme precipitation over the Northeastern United States. Int. J. Climatol. 31(13), 1975–1989 (2011). https://doi.org/10.1002/joc.2208
Ullah, A., Salehnia, N., Kolsoumi, S., Ahmad, A., Khaliq, T.: Prediction of effective climate change indicators using statistical downscaling approach and impact assessment on pearl millet (Pennisetum glaucum L.) yield through genetic algorithm in Punjab, Pakistan. Ecol. Indic. 90, 569–576 (2018). https://doi.org/10.1016/j.ecolind.2018.03.053
Vrac, M., Drobinski, P., Merlo, A., Herrmann, M., Lavaysse, C., Li, L., Somot, S.: Dynamical and statistical downscaling of the French Mediterranean climate: uncertainty assessment. Nat. Hazards Earth Syst. Sci. 12, 2769–2784 (2012). https://doi.org/10.5194/nhess-12-2769-2012
Wang, J.F., Zhang, X.B.: Downscaling and projection of winter extreme daily precipitation over North America. J. Clim. 21(5), 923–937 (2008)
Wang, L., Ranasinghe, R., Maskey, S., van Gelder, P.H.A.J.M., Vrijling, J.K.: Comparison of empirical statistical methods for downscaling daily climate projections from CMIP5 GCMs: a case study of the Huai River Basin, China. Int. J. Climatol. 36, 145–164 (2016). https://doi.org/10.1002/joc.4334
Wetterhall, F., Pappenberger, F., He, Y., Freer, J., Cloke, H.L.: Conditioning model output statistics of regional climate model precipitation on circulation patterns. Nonlin. Processes Geophys. 19, 623–633 (2012. www.nonlin-processes-geophys.net/19/623/2012/). https://doi.org/10.5194/npg-19-623-2012
Wilby, R.L., Hay, L.E., Gutowski, W.J., Arritt, R.W., Tackle, E.S., Leavesley, G.H., Clark, M.: Hydrological responses to dynamically and statistically downscaled general circulation model output. Geophys. Res. Lett. 27(8), 1199–1202 (2000)
Wood, A.W., Leung, L.R., Sridhar, V. et al.: Climatic Change 62–189 (2004). https://doi.org/10.1023/B:CLIM.0000013685.99609.9e
Yarnal, B., Comrie, A.C., Frakes, B., Brown, D.P.: Developments and prospects in synoptic climatology. Int. J. Climatol. 21, 1923–1950 (2001)
Acknowledgments
We would like to thank K. Grace CRUMMER (Institute for Sustainable Food Systems, University of Florida, USA) for editing and improving the language of the manuscript. The authors are grateful for the support of a grant of the Ferdowsi University of Mashhad, Iran. As well, the authors are grateful for the thoughtful comments provided by one the anonymous reviewers, which prompted significant improvements to the manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible Editor: Soon-Il An.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Salehnia, N., Hosseini, F., Farid, A. et al. Comparing the Performance of Dynamical and Statistical Downscaling on Historical Run Precipitation Data over a Semi-Arid Region. Asia-Pacific J Atmos Sci 55, 737–749 (2019). https://doi.org/10.1007/s13143-019-00112-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13143-019-00112-1