
Abstract
Unmanned aerial vehicles (UAVs) are extensively applied in military, rescue operations, and traffic detection fields, resulting from their flexibility, low cost, and autonomous flight capabilities. However, due to the drone’s flight height and shooting angle, the objects in aerial images are smaller, denser, and more complex than those in general images, triggering an unsatisfactory target detection effect. In this paper, we propose a model for UAV detection called DoubleM-Net, which contains multi-scale spatial pyramid pooling-fast (MS-SPPF) and Multi-Path Adaptive Feature Pyramid Network (MPA-FPN). DoubleM-Net utilizes the MS-SPPF module to extract feature maps of multiple receptive field sizes. Then, the MPA-FPN module first fuses features from every two adjacent scales, followed by a level-by-level interactive fusion of features. First, using the backbone network as the feature extractor, multiple feature maps of different scale ranges are extracted from the input image. Second, the MS-SPPF uses different pooled kernels to repeat multiple pooled operations at various scales to achieve rich multi-perceptive field features. Finally, the MPA-FPN module first incorporates semantic information between each adjacent two-scale layer. The top-level features are then passed back to the bottom level-by-level, and the underlying features are enhanced, enabling interaction and integration of features at different scales. The experimental results show that the mAP50-95 ratio of DoubleM-Net on the VisDrone dataset is 27.5%, and that of Doublem-Net on the DroneVehicle dataset in RGB and Infrared mode is 55.0% and 60.4%, respectively. Our model demonstrates excellent performance in air-to-ground image detection tasks, with exceptional results in detecting small objects.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, object detection has made significant progress in computer vision. This crucial task involves identifying and localizing different objects in digital images, including people, animals, and vehicles [1, 2]. With the development and popularity of drone technologies, they have been widely applied across various domains and generated massive aerial image data. Meanwhile, deep learning-based target detection techniques have also made great strides in effectively parsing image contents. Therefore, researching target detection algorithms tailored for drone aerial images enables the integration of both technologies to play an important role in intelligent transportation [3, 4], environmental monitoring [5, 6], emergency rescue, and disaster relief [7, 8].
One-stage and two-stage detectors are two distinct research paradigms in object detection. The former directly predicts the bounding boxes and corresponding class labels of objects, bypassing the need for a region proposal network. In contrast, the latter relies on a regional proposal network to perform object detection. R-CNN [9], a seminal work, ushers in the era of deep learning in object detection. Due to its computationally intensive nature and time-consuming algorithms, SPPNet [10] proposes shared convolutional calculations and pyramid pooling, significantly reducing storage requirements and training time. Faster R-CNN [11] further enhances performance by leveraging a Region Proposal Network to extract and integrate proposals into the overall network. On the other hand, the Feature Pyramid Network (FPN) [12] introduces a straightforward and efficient method for creating a feature pyramid, enabling object detection across multiple scales. One-stage detectors represent a class of object detection algorithms that employ convolutional neural networks to predict objects’ classes and locations directly. Among the various types of one-stage detectors, the YOLO series is a leading approach. YOLOv1-3 [13,14,15] stand out as groundbreaking algorithms within this series. Additionally, YOLOv4 [16] divides the network architecture into three components: the backbone, neck, and head. It leverages bag-of-freebies and bag-of-specials techniques to design a framework optimized for training on a single GPU. Other competitive one-stage object detector algorithms include YOLOv5-8 [17,18,19,20]. Recently, YOLOv9 [21] has also made its debut. Typically, one-stage algorithms excel in speed but may compromise some accuracy, whereas two-stage algorithms, while slower, can attain higher accuracy. Unmanned aerial vehicles (commonly known as drones) occupy a pivotal position in various applications. The application of object detection technology to drone-captured scenarios has garnered significant attention, primarily due to its vast array of practical uses. In recent years, object detection in drone-captured images has garnered widespread attention, with remarkable progress achieved by utilizing deep convolutional neural networks on prominent large-scale benchmark datasets.

a–d are the object scale distribution, target center point distribution, and some image samples of the VisDrone, DroneVehicle, COCO, and VOC datasets, respectively
However, air-to-ground images differ significantly from natural images, posing numerous challenges for object detection in aerial images. The flight altitude of the drone is tens to hundreds of meters high, resulting in a large field of view, small target size, varied viewpoints, and dynamic environments. As shown in Fig. 1, the target scale distribution, target center point distribution, and some picture samples of the VisDrone, DroneVehicle, COCO, and VOC datasets are exhibited. Most objects in the aerial images are smaller than \(32 \times 32\) pixels, with targets throughout the image. This brings unique difficulties when designing deep learning-based target detection algorithms. It is imperative to thoroughly study the characteristics of UAV images, and devise detection frameworks that can handle small targets and varied viewpoints, for example, by utilizing multi-scale feature extraction, fusing high- and low-level semantic information, etc., to improve target detection performance on UAV images further.
In this study, we propose an object detection model for UAV images named DoubleM-Net, which is specially designed with a multi-scale spatial pyramid pooling-fast (MS-SPPF) module and multi-path adaptive feature pyramid network (MPA-FPN) module to effectively handle challenges like large scale variations and complex scenes in UAV images. Specifically, the backbone network first extracts multi-scale feature maps from the raw images. Then, the MS-SPPF module repeatedly conducts pooled operations at varied scales to form feature maps with rich multi-scale receptive fields, which can capture information on different-sized objects and enhance the model’s robustness to scale changes. Moreover, the MPA-FPN module first fuses semantic information between adjacent scale layers. Then, it enhances lower-level features by propagating top-level semantic features down in a multi-path manner to realize interaction and integration of multi-scale features. This retains fine-grained low-level features while sufficiently incorporating high-level semantics. By jointly utilizing MS-SPPF and MPA-FPN modules, DoubleM-Net can fully exploit multi-scale feature information to detect small objects in UAV images effectively and improve adaptability to complex scenes, achieving superior detection performance.
The main contributions of this paper are as follows:
-
We construct a novel plug-and-play feature extraction module MS-SPPF. The module incorporates the ideas of SPP and SPPF by using pooling kernels of different sizes (k = 5, 9, 13) for multiple pooling operations. This design enables MS-SPPF to capture spatial features at different scales simultaneously and enhance the richness of the features through multiple pooling operations. MS-SPPF further compensates for the shortcomings of traditional methods in multi-scale feature extraction and improves the accuracy of target detection.
-
In order to overcome the limitations of traditional feature pyramid networks in solving the scale change problem, we propose an original feature pyramid structure called MPA-FPN. By designing the feature fusion method, MPA-FPN effectively reduces the information contradiction between non-neighboring features and enhances the interaction between low-level and high-level semantic information. MPA-FPN not only improves the detection effect of the model on small targets but also provides new ideas and methods to cope with the scale change problem in target detection.
-
Based on MS-SPPF and MPA-FPN, we further construct a model called DoubleM-Net. It is validated on two challenging datasets, VisDrone and DroneVehicle, and its performance is comprehensively evaluated. The experimental results show that DoubleM-Net achieves a mAP50-95 of 27.5% on the VisDrone dataset and 55.0% and 60.4% on the DroneVehicle dataset in RGB and Infrared modes, respectively.
The structure of this paper can be outlined as follows. In Sect. 2, the related literature is discussed. Section 3 presents the design of the DoubleM-Net model, providing a comprehensive characterization. Section 4 elaborates on the implementation of the proposed method, including the setup and results. Finally, Sect. 5 concludes the paper, highlighting the findings, and proposes potential directions for future research.
2 Related work
This section provides an overview of notable techniques and methods in object detection, which serve as the foundation for developing our proposed DoubleM-Net model. Specifically, we discuss the YOLO series model, spatial pyramid pooling, feature pyramid-related technologies, and object detectors designed for aerial images.
2.1 YOLO-series model
The YOLO object detection framework achieves an excellent balance between speed and accuracy, making it stand out among various object detection algorithms for efficiently and accurately detecting objects in images. YOLOv1-v3 [13,14,15] establish the foundational YOLOs, introducing a single-stage detection architecture with backbone-neck-head components. It enabled multi-scale object detection through branches, becoming a prominent single-stage object detection model. YOLOv4 [16] utilizes CSPDarknet to improve computational efficiency. YOLOv5 [17] is the first PyTorch implementation, developing a new CSP-based backbone and decoupled classification and regression detection heads. Based on YOLOv5, Xu et al. [22] propose Lite-YOLOv5, an on-board SAR ship detection model that is both lightweight and high-performance. It introduces a lightweight cross stage partial (L-CSP) module combined with network pruning techniques to reduce the computational complexity. In addition, Lite-YOLOv5 has been successfully ported to the NVIDIA Jetson TX2 embedded platform, providing robust support for on-board evaluation. YOLOv6 v3.0 [18] simplifies the Spatial Pyramid Pooling-Fast (SPPF) module in YOLOv5 to SimSPPF, improving accuracy with negligible change in speed. YOLOv7 [19] proposes the E-ELAN module to accelerate convergence. Alibaba’s DAMO-YOLO [23] employs automatic neural architecture search to obtain an efficient backbone and designed a new Efficient RepGFPN neck structure to fuse multi-scale features through CSPSatge. DAMO-YOLO also utilize AlignOTA for dynamic label assignment and knowledge distillation for further speed improvements through model compression. YOLOv8 [20] incorporates the C2f component to enhance feature expression and applied a decoupled anchor-free head design for multi-task recognition. Subsequently, the Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN) architectures in YOLOv9 [21] introduces a new paradigm for network design and optimization. The PGI allows the model to adaptively regulate the gradient flow during training, potentially mitigating problems such as gradient vanishing or gradient explosion. The GELAN architecture, on the other hand, uses gradient-based path planning to efficiently aggregate features across multiple scales and resolutions, improving the model’s ability to detect targets of different sizes. Through continuous architectural evolution, YOLO series models have consistently optimized model efficiency and effectiveness, advancing single-stage real-time recognition technologies.
2.2 Spatial pyramid pooling
The Spatial Pyramid Pool is a network structure that handles objects at different scales and is designed to capture features at different scales. He et al. [24] introduce SPP into a deep convolutional neural network to solve the feature extraction problem and classify images with different input sizes. The core idea of SPP is to realize scale invariance by mapping features of different scales of the input image onto a fixed-size feature vector through the pyramid pooling layer. Motivated by SPP, the semantic segmentation model DeepLabv2 [25] proposes Atrous Spatial Pyramid Pooling. The module uses multiple parallel atrous convolution layers with different sampling rates. The convolution kernel of different receptive fields is constructed through different atrous rates to obtain multi-scale object information. From simulating the receptive field of human vision to enhancing the feature extraction capability of the network, Liu et al. [26] introduce Inception [27] into the proposed Receptive Field Block module. The main idea is to add an atrous convolution based on Inception, thus effectively increasing the receptive field. YOLOv5 [17] introduces a novel Spatial Pyramid Pooling-Fast method built upon SPP to improve speed. It will apply the maximum pooling of different scales on a feature layer of the network, and the pooling kernel is \(5\times 5\), \(9\times 9\), and \(13\times 13\), respectively. Finally, \(1\times 1\) convolution is applied to channel integration of the feature maps of different scales, and they are fused into one feature graph. Pooling at different scales can capture a more extensive range of content and enhance the multi-scale processing capability of the model. Based on the SPPF, YOLOv6 v3.0 [18] proposes that the Simplified SPPF. Although it only has one activation function from SPPF, it is much faster than SPPF. YOLOv7 [19] introduces the idea of a Cross Stage Partial (CSP) Network based on SPP and proposes the SPPCSPC module. CSP divides the features into two parts: routinely processed, and the SPP structure processes the other. Finally, the two parts are combined. Although the calculation amount and the number of parameters have been improved, they also gain accuracy. Overall, the development of SPP enables target detection networks to be more flexible and efficient in handling targets at different scales, laying the foundation for subsequent improvement and development.
2.3 Feature pyramid network
Feature pyramid is a crucial component utilized in various fields such as object detection, semantic segmentation, behavior recognition, etc. It plays a significant role in enhancing the performance of models. Prior to the introduction of Feature Pyramid Network [12], SSD [28] directly employs feature maps from different stages to detect objects of varying scales. FPN is designed as a top-down unidirectional fusion mechanism incorporating features extracted from the model’s backbone. In this process, due to the limitation of one-way feature fusion. PANet [29] adds a bottom-up path based on FPN to enable deep features to obtain detailed information in shallow features. BiFPN [30] is an advanced iteration of FPN. It further enhances its performance by eliminating nodes with a single input edge and introducing additional edges from the original input at the same level. Zhang et al. [31] propose a novel quad feature pyramid network (Quad-FPN) for SAR ship detection. Made up of four unique FPNs, They are Deformable Convolutional FPN, Content-Aware Feature Reassembly FPN, Path Aggregation Space Attention FPN, and Balance Scale Global Attention FPN. Generalized-FPN (GFPN) [32] introduces an innovative cross-scale connection method known as “queen-fusion”, which effectively incorporates hierarchical features from preceding and current layers. Additionally, the \(\log _{2}{n}\) skip-layer connections are integrated to facilitate enhanced information transmission and enable the scaling of deeper networks with greater effectiveness. Xu et al. [33] propose a new group-wise feature enhancement-and-fusion network (GWFEFNet) with dual-polarization feature enrichment. It contains four key modules: dual-polarization feature enrichment, group-wise feature enhancement, group-wise feature fusion, and hybrid pooling channel attention. This leads to better dual-polarized SAR ship detection. DOMO-YOLO [23] builds upon the foundation of GFPN and introduces an enhanced variant known as Efficient-RepGFPN, which empowers real-time object detection. Recently, the Asymptotic Feature Pyramid Network (AFPN) [34] has broken through the pattern of conventional FPN to avoid significant semantic gaps between non-adjacent levels. AFPN initiates fusion in the first phase for backbone bottom-up features by combining two shallow features at different scales. As we enter the later stage, the deep features are gradually integrated into the fusion process, and finally the complete fusion of the top features of the backbone is achieved.
2.4 UAV aerial images object detection methods
In recent years, the field of small object detection has garnered significant research interest, and numerous scholars have made notable advancements in this domain. Deep learning-based UAV object detection techniques are evaluated by Saqib et al. [35], who use the migration learning method to train a pre-trained model for the network with sparse training samples. Chen et al. [36] have incorporated adaptive resampling techniques and regression modules into their RRNet model. These integrations offer superior data augmentation and precise bounding boxes, effectively tackling the intricacies of detecting diminutive objects within dense environments. Khan et al. [37] propose a framework for satellite images with complex backgrounds, arbitrary viewpoints, and significant variations in object size. The framework comprises two phases: the first generates multi-scale object proposals, and the second categorizes each proposal into different classes. Furthermore, in GDF-Net [38], dilated convolutions are employed to refine density features, thereby broadening the network’s receptive field. This refinement bolsters the model’s efficacy and resilience. Tian et al. [39] introduce a double neural network verification approach, which secondarily identifies overlooked target regions, ensuring exceptional detection quality for small targets. DMF [40] model is a detection method based on difference depth, which solves the problem of low accuracy of long-distance small-object traffic detection by clustering the difference maps with different depths and mapping the different difference regions to two-dimensional candidate regions. Li et al. [41] propose a novel multi-scale detection network to reduce the redundant information transfer between scales. The network divides objects according to their distance from the viewpoint. A multi-branch architecture is constructed to provide specialized detection for each scale of objects separately. Ma et al. [42] propose an UAV tracking control algorithm based on incremental reinforcement learning. The algorithm achieves proper exploration and efficient learning in new environments by transforming into a Markov decision process and applying policy mitigation and importance weighting methods. Zhang et al. [43] develop an adaptive and dense pyramid network to address multi-scale challenges in UAV aviation images. The network integrates a pyramid density module and a target detection module to align density information and instance recognition features. This alignment improves network performance and detection accuracy. In PETNet [44], a novel Prior Enhanced Transformer (PET) module and One-to-Many Feature Fusion (OMFF) mechanism are introduced. The PET module is designed to capture enhanced global information, while the OMFF mechanism fuses multiple features. These advancements contribute to improved detection performance.
3 DoubleM-Net
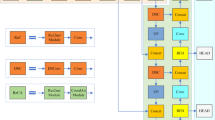
In this section, we thoroughly explain the DoubleM-Net model, including the process and setup information, as well as the relevant algorithms and expressions. We describe the MS-SPPF, ASFF, MPA-FPN, and the loss function, etc. The complete network architecture of the proposed DoubleM-Net can be seen in Fig. 2.

The architecture of our proposed DoubleM-Net. It includes the backbone network extracting multi-scale feature graphs \(\left\{ {C1, C2, C3, C4}\right\}\) for air-to-ground images, MS-SPPF enhances the adaptability of the model to scale change, and MPA-FPN better allows high-low-level semantic information to interact and six detection heads
3.1 Extracting multi-resolution features
The aerial images captured by drones are first fed into the backbone network for feature extraction. In the first convolution layer of the backbone network, a \(3\times 3\) kernel is used with smaller receptive fields to extract low-level features from the images, such as edges, textures, and other detailed features. As the number of network layers increases, the convolution layers in the backbone network will gradually downsample the images, using different-sized receptive fields to perform convolution operations to extract features of different scales. They cover more expansive areas and can extract higher-level features, forming more abstract feature representations such as object parts, shapes, etc. These features contain more global information and provide rich and varied features for subsequent feature fusion. In our proposed model, the backbone networks of DoubleM-Net-p6 extract multi-scale features from images, which is denoted as \(\left\{ {C1, C2, C3, C4}\right\}\) as shown in Fig. 2.
3.2 Multi-scale spatial pyramid pooling-fast
Figure 3 shows the structures of SPP and SPPF in (a) and (b), respectively, while (c) shows our proposed MS-SPPF. In SPP, several pooling kernels of different sizes \(k = [5, 9, 13]\) capture spatial features at various scales. In contrast, SPPF, an evolved version of SPP, uses a single pooling kernel \(k=5\) and simulates the effect of multi-scale feature extraction by applying this pooling kernel multiple times. MS-SPPF fuses the ideas of SPP and SPPF by using numerous pooling kernels with different sizes \(k=[5, 9, 13]\) and applying multiple times to each pooling kernel to enrich multi-scale feature extraction further. First, MS-SPPF performs an initial transformation of the input feature maps through a SimConv layer. Subsequently, the original feature maps are spliced with the feature maps processed by different pooling kernels in the channel dimension to integrate the multi-scale information. Finally, the spliced feature maps are again passed through a SimConv layer for further feature extraction and integration to generate the final output feature maps.

The structure of the spatial pyramid pooling. c is our proposed multi-scale spatial pyramid pooling-fast module (MS-SPPF)
The backbone network extracts features at different scales in a bottom-up fashion. MS-SPPF enhances computational efficiency through SimConv and captures richer small objects and multi-scale features through repeated multi-scale pooling operations. Specifically, we apply SimConv to convolute the feature vector \(x\in {\mathbb {R}} ^{(c1,w,h)}\) extracted from the backbone network to obtain:
where \({\tilde{c}}=c1/2\). Compared with the traditional convolutional, SimConv adopts ReLU as the default activation function, and the rest remains unchanged.
Then maxpooling is performed on x1 with kernel sizes of \(k=5, 9, 13\), respectively. Three pooling operations are conducted on each branch to obtain feature maps of different scales. This results in features with different receptive fields:
where \(i=1,2,3\) and mp is maxpooling operation. Finally, all the pooled features \(p_{i}, q_{i}, r_{i}\) and the retaining original information x1 are concatenated, then the SimConv operation is performed to obtain the feature vector y:
The detailed procedure for the MS-SPPF structure is shown in Algorithm 1.

MS-SPPF algorithm
3.3 Adaptive spatial feature fusion
In the field of image processing and computer vision, multi-scale feature fusion has been a research direction that has attracted much attention. With the rapid progress of deep learning technology, how to efficiently integrate feature information of different scales to enhance the performance of complex tasks such as target detection and image segmentation has become a hotspot that researchers are competing to explore. Feature pyramid representation, as a typical means to solve the problem of scale variation in object detection, still has obvious limitations despite certain achievements. In particular, the inconsistency between different feature scales becomes a significant challenge for feature pyramid-based single-shot detectors. To solve this problem, Liu et al. [45] propose the adaptive spatial feature fusion (ASFF) method. ASFF effectively suppresses the inconsistency between different feature scales by learning spatial filtering of conflicting information, which significantly improves feature-scale invariance.
We introduce ASFF to fuse features from different spatial scales or levels to improve the performance of image analysis and understanding. During multi-scale feature fusion, ASFF assigns different spatial weights to features at different scales, enhancing the importance of key levels and alleviating the influence of information from features across scales. Let \(x_{ij}^{m\longrightarrow n}\) denote the feature vector at position (i, j) from level m to level n. The resulting feature vector is denoted as \(y_{ij}^{n}\), obtained by adaptive spatial fusion of multi-scale features, defined by a linear combination of feature vectors \(x_{ij}^{1\longrightarrow n}, x_{ij}^{2\longrightarrow n}, \ldots , x_{ij}^{m\longrightarrow n}\) as follows:
where \(\alpha _{1_{ij} }^{n}, \alpha _{2_{ij} }^{n}, \ldots , \alpha _{m_{ij} }^{n}\) represent the spatial weights of the m different scale features at level n, respectively, subject to the constraint by:
As shown in Fig. 4a and b, we integrated features from two and three scales, corresponding to the cases when \(m=2\) and \(m=3\) in Eq. 4. Considering the differences in the number of fused features at each stage, it is possible to implement an adaptive spatial fusion module for a specific stage based on the actual situation.

Adaptive spatial feature fusion procedure. a Feature fusion at two different resolutions; b feature fusion at three different resolutions; but we can use the method with more levels as needed
3.4 Multi-path adaptive feature pyramid network
The paradigm framework of MPA-FPN is shown in Fig. 5. Like many feature pyramid network based object detection methods, multi-scale features are extracted from the backbone before feature fusion. The last layer features are extracted from each feature level of the backbone to obtain a set of multi-scale features denoted as \(\left\{ C_{1}, C_{2}, \ldots , C_{n} \right\}\).

The framework of our proposed MPA-FPN. For n multi-scale features, feature interaction is performed level by level, finally generating \(2n-2\) detection feature maps
For feature fusion, a set of features of different scales obtained in the previous step, each of the two adjacent features is integrated into two levels of adaptive spatial, generating \(X_{2n-2}\) feature representations:
where \(A_{2}\) is the case of the adaptive spatial teature fusion operation shown in Fig. 4a and n = 2 in Eq. 4. Then extract the \(\left\{ X_{1}, X_{2}, \ldots , X_{2n-2} \right\}\) feature to get \(Y_{i}\):
where Blackbox is a series of feature extraction operations, such as convolution, C3 and C2f, or an adaptive spatial feature fusion at the next level. Next, the feature fusion at level \(n-1\) is performed on \(Y_{i} (i=1,2,\ldots ,2n-2)\) to obtain feature maps \(L_{i} (i=1,2,\ldots ,2n-2)\):
It is obvious that \(\left\{ L_{1}, L_{2},\ldots ,L_{2n-2} \right\}\) contains all the features in \(\left\{ C_{1}, C_{2}, \ldots , C_{n} \right\}\), but it is not directly fused. Due to the semantic gap between non-adjacent hierarchical features being greater than between adjacent hierarchical features, especially for the bottom and top features, directly fusing non-adjacent hierarchical features leads to poor fusion effects. Therefore, we first fuse adjacent features from different scales, then gradually fuse the features in steps, and finally generate feature maps rich in semantic information. Some operations on the feature representations \(\left\{ L_{1}, L_{2},\ldots ,L_{2n-2} \right\}\) before detection finally yield \(P_{i}\):
where f is the method to perform the feature extraction, generating \(2n-2\) feature maps rich in high- and low-level semantic information. The detailed procedure of MPA-FPN is shown in Algorithm 2.

MPA-FPN algorithm
3.5 Loss function
Considering the characteristics of images from the UAV viewpoint, which often contain many small targets. We design six detection heads to improve the detection accuracy of these small targets. DoubleM-Net achieves accurate target detection by using the decoupling head to detect different scales of feature maps generated by the neck network. The decoupling head is delicately conceived to decompose the detection task into two mutually independent branches: one specializes in classification prediction to identify the target class accurately. In contrast, the other branch focuses on regression prediction to accurately locate the target’s position.
The loss function plays a crucial role in model training by quantifying the difference between the model predictions and the actual values, providing a clear guideline for model optimization. For the DoubleM-Net model, the loss calculation covers classification loss and regression loss. The classification loss is calculated using the binary cross entropy (BCE) loss function to ensure the model’s accuracy in the classification task. In contrast, the regression loss combines the complete IoU (CIoU) loss and the distribution focus loss (DFL), further improving the model’s target localization accuracy. The BCE loss function is defined as shown in Eq. (10),
where \(y_{i}\) denotes the label value of the i-th sample, which takes the value of 0 or 1. \(p_{i}\) denotes the predicted probability of the ith sample. Then the CIoU loss function is calculated by Eq. 11,
where \(\varepsilon\) is the weight coefficient. \(b^{p}\) and \(b^{gt}\) represent the centroids of the predicted and actual boxes. \(\rho\) is the Euclidean distance calculated between the two centroids, and c denotes the diagonal distance between the closed regions of the two rectangular frames. \(\nu\) is used to measure the similarity of the aspect ratios and is defined as in Eq. 12,
where \((w^{gt}, h^{gt})\) and \((w^{p}, h^{p})\) are the width and height of the actual and predicted boxes, respectively. Finally, Class imbalances in data sets are a common challenge. This can cause the model to favor more numerous categories over less numerous ones during training. To mitigate this problem, we introduce distributed focus loss (DFL) to optimize the classification task, as shown in Eq. 13,
where y is the target label. The global minimum solution of DFL, i.e, \(F_{i}=\frac{y_{i+1}-y}{y_{i+1}-y_{i}}\), \(F_{i+1}=\frac{y-y_{i}}{y_{i+1}-y_{i}}\), can guarantee the estimated regression target \({\bar{y}}\) infinitely close to the corresponding label y. DFL helps the model focus more quickly and accurately on the output distribution near the accurate label by explicitly enlarging the two probability values \(y_{i}\) and \(y_{i+1}\) adjacent to the target label y. This allows the model to give proper attention to the categories even when unbalanced.
The overall training loss is a weighted combination of these three losses, as shown in Eq. 14,
4 Experiments
In this section, we provide a comprehensive overview of the implementation steps and conduct a detailed analysis of the results obtained from our experiment. We evaluate the object detection performance using standard metrics, including average precision (AP) and the mean average precision (mAP). To present these results, we utilize graphs and tables. The experimental data presented in this section offer valuable insights into the performance and effectiveness of our proposed model.
4.1 Dataset and analysis
The VisDrone [46] and DroneVehicle [47] datasets contain many annotated UAV-view images and videos, providing strong support for algorithm performance evaluation and optimization. These datasets specifically focus on target detection and tracking in real-world environments with UAV viewpoints, providing an ideal testbed for researchers. By covering a wide range of environments, lighting conditions, and UAV models, these datasets are closer to real-world application scenarios, which helps to improve the algorithm’s generalization ability in real-world applications. In existing research, VisDrone and DroneVehicle datasets have been widely used in various fields such as intelligent transportation, disaster response, urban planning, etc., providing essential data support for developing related applications.
The VisDrone dataset is a comprehensive benchmark designed explicitly for visual object detection and tracking in UAV platforms. It consists of images captured from various UAV platforms across 14 cities in China. The dataset provides ten categories: pedestrian, people, bicycle, car, truck, tricycle, awning-tricycle, bus, and motor, and their instance proportions, as shown in Fig. 6b. These images showed a high object density, averaging 53 instance objects per image. This dataset contains 8629 images, of which 6471 are used for training, 548 for validation, and 1610 for testing.

a is the number of category labels in the training, validation and test datasets in the RGB and Infrared modes in the DroneVehicle dataset. b is the proportion of labels in a category in the VisDrone dataset
The DroneVehicle dataset comprises 56,878 images collected by the drone. Out of this total, 50% are RGB images, while the remaining 50% are infrared images. This dataset has five categories: car, truck, bus, van, freight car. The number of objects in the train, validation, and test dataset for both RGB and infrared images is displayed in Fig. 6a. The images in the DroneVehicle dataset are divided into three scenarios: day, night, and dark night, with 14,478, 5,468 and 8493 images, respectively. Since the infrared images have a higher contrast in low-light conditions, they have more annotation than the RGB images, as evident in Fig. 6a. The number of photos in this dataset for training, validation, and testing the dataset in RGB and infrared images is 17,990, 1469, and 8980, respectively. These images show a high density of objects, with an average of 17 instance objects per image, with a maximum number of 206.
As shown in Fig. 7, the VisDrone and DroneVehicle datasets have more than 95% of small (area \(< 32\times 32\)) and medium (\(32\times 32<\) area \(< 96\times 96\)) objects. On the contrary, large (area \(> 96\times 96\)) targets account for less than 5%. This data distribution score reflects the challenges of UAV target detection in practical applications, especially the urgent need for small and dense target detection. Therefore, these two datasets not only enrich the data resources in the field of UAV visual inspection but also provide strong support for the optimization of algorithms and practical applications, which is of great significance in promoting the development of UAV visual inspection technology.
4.2 Experimental parameters setting
This section presents an overview of the experimental parameters employed in our study. The experiments are performed on a system equipped with an NVIDIA GeForce RTX 3090 GPU and a 15 vCPU Intel(R) Xeon(R) Platinum 8358P CPU @ 2.60GHz processor. Table 1 summarizes the critical parameters for the DoubleM-Net model. All models in this paper are trained from scratch on the VisDrone and DroneVehicle datasets, with each model trained for 100 epochs.

VisDrone and DroneVehicle (RGB and infrared) datasets comprise objects categorized based on their sizes into small objects (area \(< 32\times 32\)), medium objects (\(32\times 32<\) area \(< 96\times 96\)), and large objects (area \(> 96\times 96\))
4.3 Evaluation criterion
The primary evaluation metric used in object detection is the average accuracy (AP), which is calculated based on four possible outcomes: true positive (TP), false positive (FP), true negative (TN), and false negative (FN). The classification of these outcomes is determined by the predicted category of the detection model and the actual category of the object being detected. The AP metric provides valuable insights into the performance and accuracy of object detection. The precision rate is calculated using the following equation:
The recall rate is defined as:
The AP metric plays a crucial role in assessing the effectiveness of a learned model for each category. The formula for calculating AP is shown in Eq. 17.
where P(R) is a curve based on recall and precision. The AP value indicates the performance of the model in a particular category. On the other hand, mAP is the average of all AP values in all categories. It provides an assessment of the overall learning performance of the model and can be defined as Eq. 18,
where n is the total number of classes or categories.
4.4 Main results
This section aims to verify the effectiveness of the proposed DoubleM-Net. We conduct model training and validation from scratch using the Visdrone and DroneVehicle datasets to accomplish this. All experimental results based on YOLOv5 in this paper are conducted under the framework of YOLOv8.
4.4.1 Experimental results on VisDrone dataset

The first two rows and the last two rows are some visualization results of DoubleM-Net(x) on the VisDrone-DET-test-dev and VisDrone-DET-test-challenge datasets, respectively

We compare the effects of DoubleM-Net and YOLOv8, where the red and green dashed boxes indicate some differences in the detection effects of these two models. a is the VisDrone dataset; b and c the RGB and infrared patterns of the DroneVehicle dataset, respectively. It is seen from the figure that there are some omissions in YOLOv8, but DoubleM-Net can be detected
To validate the object detection performance of DoubleM-Net technology in UAV scenarios, we compare several classical single-stage and two-stage object detection methods on the VisDrone dataset. It is worth noting that all models are trained from scratch without utilizing any pre-trained weights. The detection results of DoubleM-Net on the VisDrone dataset are shown in Fig. 8. The first two rows depict the visualization of detection results on the VisDrone-DET-test-dev dataset. In comparison, the last two rows represent the results on the VisDrone-DET-test-challenge dataset. From the figure, it can be observed that DoubleM-Net can accurately recognize and localize medium to large vehicles under different lighting and weather conditions. It also achieves satisfactory detection results for smaller objects that can be distinguished by the human eye, such as pedestrians and motors. DoubleM-Net also competes in challenging scenarios with targets occluded and densely areas. Figure 9a compares the detection performance between DoubleM-Net and YOLOv8 on the VisDrone dataset. The image shows that YOLOv8 fails to detect the densely packed motors indicated by the orange dashed box, while DoubleM-Net accurately recognizes them. Furthermore, the red dashed box highlights a false detection produced by YOLOv8, which DoubleM-Net avoids.

a–d are the Precision, Recall, mAP 50, and mAP 50-95 for YOLOv5, YOLOv8, and DoubleM-Net on the VisDrone dataset, respectively. It can be seen that our model achieves significant results on n, s, m, l, and x
Table 2 presents the comparative results of our proposed model with several classical single-stage and two-stage networks, demonstrating the advantages of DoubleM-Net in terms of accuracy across different categories. Moreover, the detection performance varies across different categories, with bicycle, tricycle, and awning-tricycle showing the most significant improvements. Hence, our method exhibits remarkable effectiveness in detecting small targets such as bicycles and tricycles. Although the results may not be the best for other categories, they still achieve competitive performance on par with the competing models. Table 3 compares the performance of YOLOv5, YOLOv8, and DoubleM-Net on five scales: n, s, m, l, and x. It is evident from the table that both large and small models achieve excellent results for small targets such as bicycles, tricycles, and motorcycles. DoubleM-Net’s n, s, and m models demonstrate respective improvements of 2.8%, 3.3%, and 2.3% in the mAP50 metric. Although the accuracy improvements for the l and x models are less significant, a slight enhancement is still observed. Overall, these findings highlight the effectiveness of DoubleM-Net in capturing small objects across different scales. In Fig. 10, we contrast the precision, recall, mAP50, and mAP50-95 of YOLOv5, YOLOv8, YOLOv8-p6, DoubleM-Net, and DoubleM-Net-p6 across five different scales. Our model demonstrates significant performance improvements at the n, s, and m scales, with slight improvements observed at the other two scales. Across these four metrics, our model exhibits noticeable enhancements at the n, s, and m scales, indicating its effectiveness in detecting small targets with higher precision and recall. While the improvements are less pronounced for the more significant l and x scales, some enhancement is still observed. Our model consistently performs well across different scales, showcasing good detection capability and performance levels.
4.4.2 Experimental results on DroneVehicle dataset

We present the visualization results of the DroneVehicle dataset. a–d are the results in the RGB and Infrared mode, respectively

Comparison of Precision, Recall, mAP 50, mAP 50-95 and F1 values for YOLOv5, YOLOv8 and DoubleM-Net, in both the RGB and Infrared modes of the DroneVehicle dataset
Now, we further showcase the detection performance of our model on the DroneVehicle dataset. All our models are trained from scratch without using any pre-trained weights. This ensures that our model can independently perform accurate object detection on the DroneVehicle dataset and validate its generalization capability across multiple datasets.
The detection results of DoubleM-Net on the DroneVehicle dataset are shown in Fig. 11. The figure showcases the detection visualizations of both RGB and infrared images from the dataset, represented as (a) and (c), and (b) and (d) respectively, corresponding to different modalities. It is evident from the images that DoubleM-Net can accurately identify and localize objects, regardless of whether it is day or night. Even for objects located at the images’ boundaries, DoubleM-Net can recognize them, albeit with relatively lower confidence scores. Furthermore, DoubleM-Net demonstrates impressive performance in challenging scenarios such as occluded targets and dense regions, showcasing its competitiveness. In Fig. 9b, we compare the detection performance between DoubleM-Net and YOLOv8 on the DroneVehicle dataset in RGB mode. By examining the image, it is evident that YOLOv8 exhibits false positive detections, as indicated by the orange dashed bounding box, while DoubleM-Net avoids such false positives. Additionally, we observe that YOLOv8 performs poorly when dealing with occluded targets, as demonstrated by the red dashed bounding box, whereas DoubleM-Net provides accurate detections with a confidence score of 0.25. As depicted in Fig. 9c, both models demonstrate comparable performance in Infrared mode. Table 4 presents a comparative analysis of YOLOv5, YOLOv8, and DoubleM-Net in terms of different scales, namely n, s, and m. The table demonstrates that in RGB and Infrared modes, these models achieve excellent results in detecting small objects such as cars and vans. Remarkably, the n, s, and m models of DoubleM-Net show a slight improvement in the mAP50-95 metric compared to the other models. Overall, these results highlight the capture capability and generalization performance of DoubleM-Net for small targets on different datasets. In the radar Fig. 12, a comparison is made between YOLOv5, YOLOv8, and DoubleM-Net for precision, recall, mAP50, mAP50-95, and F1 scores on three different scales (n, s, and m). The results demonstrate improvements in all five metrics for our model in the RGB mode, indicating its effectiveness in detecting air-to-ground images. In the Infrared mode, DoubleM-Net remains competitive with slight improvements in recall and precision for the s and m model sizes. Overall, our model consistently exhibits excellent detection capabilities and performance levels across different scales.
Through the discussion in the above two sections, we can state that DoubleM-Net demonstrates competitive detection performance on both datasets, thereby showcasing the superior capabilities of this model in the field of aerial image detection. DoubleM-Net proves its effectiveness in detecting small objects, adapting to scale variations, and performing well in RGB and infrared modes. These findings highlight the remarkable performance and generalization ability of DoubleM-Net in aerial image detection, providing strong support for its application in related domains.

Ablation visualization. The first row compares feature maps (visualization results) after SPP, SPPF, and MS-SPPF. The second row compares feature maps (visualization results) after PANet, AFPN, and MAP-FPN
4.5 Ablation studies
We systematically validated the contributions of the main modules included in DoubleM-Net to improve detection. The following experiments are conducted using the VisDrone dataset. To validate the performance of this method under different single-stage detectors, we conduct experiments based on YOLOv5 and YOLOv8.
4.5.1 Effect of MS-SPPF
The proposed MS-SPPF module in this paper leverages multi-scale pooling operations with repeated application of different-sized pooling kernels to extract critical information and multi-scale features of small targets. Ablation studies are conducted on the VisDrone dataset to evaluate the effectiveness of this module. Tables 5 and 6 present the advantages of MS-SPPF on baseline YOLOv8 and YOLOv5, respectively. According to the experimental results, both YOLOv8 and YOLOv5 showed a certain degree of improvement in mAP50-95 on different model sizes n, s, m, l, and x. These tables show that MS-SPPF outperforms SPP and SPPF in detecting small objects such as tricycles and awning-tricycles. Moreover, our model demonstrates competitive performance in other categories as well. These findings highlight the significant advantage of the MS-SPPF module in enhancing the detection of small objects and underscore the competitiveness of our model across multiple target categories. By comparing Tables 7 and 8, the influence of different pooling kernels (5, 5, 5), (9, 9, 9), (13, 13, 13), and (5, 9, 13) on precision, recall, mAP50, and mAP50-95 metrics in the MS-SPPF module can be observed. Tables 7 and 8 are based on YOLOv8 and YOLOv5, respectively. From the data in these tables, it can be concluded that, for different model sizes, the pooling kernel (5, 9, 13) exhibits a significant advantage. All four metrics improve using the (5, 9, 13) kernel. This highlights the crucial role of selecting an appropriate pooling kernel size in enhancing detection performance. The first row of Fig. 13 shows that the feature maps processed by MS-SPPF have a more significant effect in presenting the contours and shapes of the objects compared to SPP and SPPF. Even when facing objects of irregular size and shape, MS-SPPF can still effectively capture and emphasize their key features.
4.5.2 Effect of MPA-FPN
In this section, we similarly explore the effectiveness of the MPA-FPN module on the VisDrone dataset. Taking YOLOv8 as the baseline, we gradually introduce the MS-SPPF and MPA-FPN module, comparing their precision on the ten categories, as shown in Table 9. Encouragingly, we observe a significant improvement in precision after incorporating the MPA-FPN module. Whether it is for small objects such as tricycles or easily confusable objects like cars, vans, and buses, impressive detection results are achieved. Continuing with the YOLOv5 baseline, we repeat the process by introducing the MS-SPPF module first and then incorporating the MPA-FPN module. We analyze the precision, recall, mAP50, and mAP50-95 metrics at each step, as presented in Table 10. It is evident from the results that the integration of the MPA-FPN module led to substantial improvements in precision, recall, and mAP values. This underscores the significance of the MPA-FPN module in enhancing object detection performance. Based on the findings from these ablation experiments, it is evident that incorporating the MPA-FPN module, whether in YOLOv8 or YOLOv5, significantly improves the accuracy and effectiveness of object detection. This further substantiates the efficacy and competitiveness of the MPA-FPN module in multi-scale object detection. The second row of Fig. 13 shows that the feature maps processed by MPA-FPN show a more outstanding ability to highlight the contours and shapes of the objects compared with PANet and AFPN. MPA-FPN cannot only accurately locate the object’s exact position in the image but also effectively identify the size and shape features of the object. In addition, for small targets, the effect of MPA-FPN is superior and can capture and present their detailed features more accurately.
4.6 Limitation analysis
Although the DoubleM-Net model exhibits good detection performance on the VisDrone and DroneVehicle datasets, it is still insufficient in complex scenarios such as blur and nighttime, which is visualized in Fig. 14. Specifically, as shown in Fig. 14a, in the VisDrone dataset, DoubleM-Net’s recognition ability is significantly affected when dealing with images in blurred and nighttime environments, resulting in poor detection results; in Fig. 14b, when facing RGB-mode images in the DroneVehicle dataset, DoubleM-Net similarly faces the problem of poor processing in blur and nighttime environments. Figure 14c further shows that DoubleM-Net’s processing ability in blur and nighttime environments also appears to be stretched when confronted with the infrared mode of the DroneVehicle dataset. These limitations are clearly labeled in the red dashed box in Fig. 14.
The lack of information and unclear details in blurred images significantly challenge the model’s recognition. Due to the blurred images, the model is limited in extracting features and performing recognition, making it challenging to accurately capture essential information in the images. Meanwhile, images in nighttime environments often suffer from insufficient lighting, which leads to reduced image contrast and detailed information becoming difficult to distinguish, thus further increasing the difficulty of model processing. In addition, the noise and interference factors that may exist in nighttime environments can also adversely affect the model’s performance. Therefore, in-depth study and optimization of these limitations are needed in the following research work to improve further the DoubleM-Net model’s detection effect in complex environments such as blurred and nighttime environments.
Table 11 compares the DoubleM-Net model with other target detectors on key performance metrics, such as the number of parameters, GFLOPs, precision, recall, mAP50, mAP50-95, and inference time. By analyzing these data in depth, we can find that although the DoubleM-Net model exhibits notable detection performance, it is also accompanied by some significant limitations. First, the number of parameters of the DoubleM-Net model is relatively large, which means that the model requires more computational resources and storage space during training and deployment. Second, the increase in GFLOPs also indicates that the model requires higher computational effort in performing forward propagation, which may lead to slower inference in practical applications, especially in scenarios with high real-time requirements. In addition, the extended inference time further limits the application of the DoubleM-Net model in real-time scenarios.
Despite these limitations, the DoubleM-Net(m) model is still comparable to YOLOv8(l), YOLOv9, YOLOv9-c, and YOLOv9-e in terms of detection effectiveness, which to some extent proves the superiority of its detection performance. Nevertheless, while pursuing high detection accuracy, there is also a need to weigh the number of parameters and computational complexity. Reducing the number of parameters and computational complexity of the model under the premise of guaranteeing the detection accuracy is the current direction of further optimization and improvement of the DoubleM-Net model.

DoubleM-Net has some limitations in its processing effectiveness in different datasets and modes. Specifically, a in the VisDrone dataset, DoubleM-Net is ineffective in processing images in blurred and nighttime environments; b in the RGB mode of the DroneVehicle dataset, DoubleM-Net also faces the problem of ineffective processing in blurred and nighttime environments; c for the infrared mode of the DroneVehicle dataset, DoubleM-Net also exhibits a lack of processing power in blurred and nighttime environments. These limitations are identified in the red dashed box in Fig.
5 Conclusion
Dynamic environments and numerous small targets often lead to low object detection accuracy in aerial scenes. In this paper, we propose an innovative approach called DoubleM-Net to optimize the detection performance in UAV scenarios. The method consists of two key modules we designed, MS-SPPF and MPA-FPN. Among them, MS-SPPF performs multiple pooling operations using pooling kernels of different sizes (k = 5, 9, 13), effectively capturing spatial features at different scales. Second, to overcome the limitations of feature pyramid networks in solving scale-varying problems, we construct an original MPA-FPN structure. By optimizing the feature fusion method, MPA-FPN effectively reduces the information contradiction between non-adjacent features and enhances the interaction between low-level and high-level semantic information. A new approach is provided to solve the scale change problem in object detection. The experimental results show that the mAP50-95 of DoubleM-Net is 27.5% on the VisDrone dataset. In contrast, on the DroneVehicle dataset, the mAP50-95 of DoubleM-Net is 55.0% and 60.4% in RGB and IR modes, respectively. In addition, our model performs well in the air-to-ground image detection task and excels in detecting small objects.
Improving the detection accuracy comes at the cost of significantly increasing the computational requirements. doubleM-Net puts pressure on computational resources, which will be a significant challenge for future work. Therefore, we will carry out the following work in the future:
-
1.
To maintain high accuracy, mitigate the number of detector parameters and computations.
-
2.
Explore distillation and pruning techniques to optimize the lightweight detector design.
-
3.
Explore the detection effect in complex situations such as blurring and nighttime.
Data availability and access
All data, models, and code generated and utilized in this study are available upon reasonable request from the corresponding author. The codes will upload on https://github.com/yangwygithub/PaperCode.git, Branch: DoubleM-Net_Zhongxu-Li2023.
References
Zou Z, Chen K, Shi Z, Guo Y, Ye J (2023) Object detection in 20 years: a survey. Proc IEEE 111(3):257–276
Wang X, Zhao Y, Pourpanah F (2020) Recent advances in deep learning. Int J Mach Learn Cybern 11:747–750
Cui J, Qin Y, Wu Y, Shao C, Yang H (2023) Skip connection yolo architecture for noise barrier defect detection using uav-based images in high-speed railway. IEEE Trans Intell Transp Syst 24(11):12180–12195
Li X, Wu J (2023) Developing a more reliable framework for extracting traffic data from a uav video. IEEE Trans Intell Transp Syst 24(11):12272–12283
Huang J, Jiang X, Jin G (2022) Detection of river floating debris in uav images based on improved yolov5. In: 2022 International Joint Conference on Neural Networks, pp 1–8
Sun L, Zhang Y, Ouyang C, Yin S, Ren X, Fu S (2023) A portable uav-based laser-induced fluorescence lidar system for oil pollution and aquatic environment monitoring. Opt Commun 527:128914–128928
Furusawa T, Premachandra C (2023) Innovative colormap for emphatic imaging of human voice for uav-based disaster victim search. In: 2023 IEEE Region 10 Symposium, pp. 1–5
Dorn C, Depold A, Lurz F, Erhardt S, Hagelauer A (2022) Uav-based localization of mobile phones for search and rescue applications. In: 2022 IEEE 22nd Annual Wireless and Microwave Technology Conference, pp. 1–4
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 580–587
He K, Zhang X, Ren S, Sun J (2015) Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell 37(9):1904–1916
Ren S, He K, Girshick R, Sun J (2017) Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39:1–14
Lin TY, Dollar P, Girshick R, He K, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2117–2125
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788
Redmon J, Farhadi A (2017) Yolo9000: better, faster, stronger. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7263–7271
Redmon J, Farhadi A (2018) Yolov3: an incremental improvement arXiv:1804.02767
Bochkovskiy A, Wang CY, Liao HYM (2020) Yolov4: optimal speed and accuracy of object detection arXiv:2004.10934
Jocher G (2020) YOLOv5 by Ultralytics
Li C, Li L, Geng Y, Jiang H, Cheng M, Zhang B, Ke Z, Xu X, Chu X (2023) Yolov6 v3.0: a full-scale reloading arXiv:2301.05586
Wang CY, Bochkovskiy A, Liao HYM (2022) Yolov7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors arXiv:2207.02696
Jocher G, Chaurasia A, Qiu J (2023) YOLO by Ultralytics
Wang CY, Yeh IH, Liao HYM (2024) Yolov9: learning what you want to learn using programmable gradient information arXiv:2402.13616
Xu X, Zhang X, Zhang T (2022) Lite-yolov5: a lightweight deep learning detector for on-board ship detection in large-scene sentinel-1 sar images. Remote Sens 14:1018–1030
Xu X, Jiang Y, Chen W, Huang Y, Zhang Y, Sun X (2023) Damo-yolo: a report on real-time object detection design arXiv:2211.15444
He K, Zhang X, Ren S, Sun J (2015) Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell 37(9):1904–1916
Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2018) Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans Pattern Anal Mach Intell 40(4):834–848
Liu S, Huang D, Wang a (2018) Receptive field block net for accurate and fast object detection. In: Proceedings of the European Conference on Computer Vision, pp. 385–400
Szegedy C, Ioffe S, Vanhoucke V, Alemi A (2016) Inception-v4, inception-resnet and the impact of residual connections on learning. Proc AAAI Conf Artif Intell 31:11231–11245
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, Berg AC (2016) Ssd: single shot multibox detector. In: Computer Vision—ECCV 2016: 14th European Conference, pp. 21–37
Liu S, Qi L, Qin H, Shi J, Jia J (2018) Path aggregation network for instance segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8759–8768
Tan M, Pang R, Le QV (2020) Efficientdet: scalable and efficient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10781–10790
Zhang T, Zhang X, Ke X (2021) Quad-fpn: a novel quad feature pyramid network for sar ship detection. Remote Sens 13:2771–2785
Jiang Y, Tan Z, Wang J, Sun X, Lin M, Li H (2022) Giraffedet: a heavy-neck paradigm for object detection arXiv:2202.04256
Xu X, Zhang X, Shao Z, Shi J, Wei S, Zhang T, Zeng T (2022) A group-wise feature enhancement-and-fusion network with dual-polarization feature enrichment for sar ship detection. Remote Sens 14:5276–5291
Yang G, Lei J, Zhu Z, Cheng S, Feng Z, Liang R (2023) Afpn: asymptotic feature pyramid network for object detection arXiv:2306.15988
Saqib M, Khan SD, Sharma N, Blumenstein M (2017) A study on detecting drones using deep convolutional neural networks. In: 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance, pp. 1–5
Chen C, Zhang Y, Lv Q, Wei S, Wang X, Sun X, Dong J (2019) Rrnet: a hybrid detector for object detection in drone-captured images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pp. 100–108
Khan SD, Alarabi L, Basalamah S (2022) A unified deep learning framework of multi-scale detectors for geo-spatial object detection in high-resolution satellite images. Arab J Sci Eng 47(8):9489–9504
Zhang R, Shao Z, Huang X, Wang J, Li D (2020) Object detection in uav images via global density fused convolutional network. Remote Sens 12(19):3140–3143
Tian G, Liu J, Yang W (2021) A dual neural network for object detection in uav images. Neurocomputing 443:292–301
Chen J, Wang Q, Peng W, Xu H, Li X, Xu W (2022) Disparity-based multiscale fusion network for transportation detection. IEEE Trans Intell Transp Syst 23(10):18855–18863
Li S, Chen J, Peng W, Shi X, Bu W (2023) A vehicle detection method based on disparity segmentation. Multimed Tools Appl 82(13):19643–19655
Ma B, Liu Z, Dang Q, Zhao W, Wang J, Cheng Y, Yuan Z (2023) Deep reinforcement learning of uav tracking control under wind disturbances environments. IEEE Trans Instrum Meas 72(5):1–13
Zhang R, Shao Z, Huang X, Wang J, Wang Y, Li D (2022) Adaptive dense pyramid network for object detection in uav imagery. Neurocomputing 489:377–389
Wang T, Ma Z, Yang T, Zou S (2023) Petnet: a yolo-based prior enhanced transformer network for aerial image detection. Neurocomputing 547:126384–126399
Liu S, Huang D, Wang Y (2019) Learning spatial fusion for single-shot object detection arXiv:1911.09516
Zhu P, Wen L, Du D, Bian X, Fan H, Hu Q, Ling H (2022) Detection and tracking meet drones challenge. IEEE Trans Pattern Anal Mach Intell 44(11):7380–7399
Sun Y, Cao B, Zhu P, Hu Q (2022) Drone-based rgb-infrared cross-modality vehicle detection via uncertainty-aware learning. IEEE Trans Circuits Syst Video Technol 32(10):6700–6713
Zhu C, He Y, Savvides M (2019) Feature selective anchor-free module for single-shot object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 840–849
Zhang S, Chi C, Yao Y, Lei Z, Li SZ (2019) Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection arXiv:1912.02424
Li Y, Chen Y, Wang N, Zhang Z (2019) Scale-aware trident networks for object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6054–6063
Zhou X, Wang D, Krähenbühl P (2019) Objects as points
Tian Z, Shen C, Chen H, He T (2019) Fcos: fully convolutional one-stage object detection arXiv:1904.01355
Chen Z, Yang C, Li Q, Zhao F, Zha ZJ, Wu F (2021) Disentangle your dense object detector. In: Proceedings of the 29th ACM International Conference on Multimedia, pp. 4939–4948
Feng C, Zhong Y, Gao Y, Scott MR, Huang W (2021) Tood: task-aligned one-stage object detection. In: 2021 IEEE/CVF International Conference on Computer Vision, pp. 3490–3499
Zhang H, Wang Y, Dayoub F, Sünderhauf N (2020) Varifocalnet: an iou-aware dense object detector arXiv:1200.81336
Cai Z, Vasconcelos N (2019) Cascade r-cnn: high quality object detection and instance segmentation. IEEE Trans Pattern Anal Mach Intell 43:1–15
Ge Z, Liu S, Wang F, Li Z, Sun J (2021) Yolox: exceeding yolo series in 2021 arXiv:2107.08430
Acknowledgements
The research is supported by the National Natural Science Foundation of China under Grant No. 62376114, the National Natural Science Foundation of China under Grant No.12101289, the Natural Science Foundation of Fujian Province under Grant Nos.2020J01821 and 2022J01891. And it is supported by the Institute of Meteorological Big Data-Digital Fujian, and Fujian Key Laboratory of Data Science and Statistics (Minnan Normal University), China.
Author information
Authors and Affiliations
Contributions
Zhongxu Li, Qihan He, Hong Zhao and Wenyuan Yang contribute equally to this work.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical and informed consent for data used
This article does not contain any research conducted by any author on human participants or animals and informed consent is obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, Z., He, Q., Zhao, H. et al. Doublem-net: multi-scale spatial pyramid pooling-fast and multi-path adaptive feature pyramid network for UAV detection. Int. J. Mach. Learn. & Cyber. (2024). https://doi.org/10.1007/s13042-024-02278-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13042-024-02278-1