
Abstract
Data augmentation has played an important role in generalization capability and performance improvement for data-driven deep learning models in recent years. However, most of the existing data augmentation methods in NLP suffer from high manpower consumption or low promotion, which limits the practical applications. To this end, we propose a simple yet effective approach named Heuristic Masked Language Modeling(HMLM) to obtain high-quality data by introducing mask language modeling embedded in pre-trained models. More specifically, the HMLM method first identifies the core words of the sentence and masks some non-core fragments in the sentence. Then, these masked fragments will be filled with words created by the pre-trained model to match the contextual semantics. Compared with the previous data augmentation approaches, the proposed method can create more grammatical and contextual augmented data without a heavy cost. We conducted experiments on typical text classification tasks e.g., intent recognition, news classification and sentiment analysis separately. Experimental results demonstrate that our proposed method is comparable to state-of-the-art data augmentation approaches.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The superior performance of the deep neural network model is known for having heavy data dependence, which might not be available in resource-lean scenarios [1]. Data augmentation (DA) is a widely used technique to increase the size of the training data [2,3,4]. In data augmentation, new labeled instances are created by modifying the features of existing instances with transformations that do not change the label of an instance. Data augmentation methods for computer vision include image translation, flipping, scaling, separation, etc. However, these methods cannot be transferred to natural language processing tasks directly. The difference between the two can be attributed to the discreteness of text data. For the text data, every word plays an important role in expressing the whole meaning, and the order of words is also consequential to the semantics of sentences. Hence, inappropriate operations of augmentation on the text make changes to the semantic information, resulting in the failure to maintain the consistency of the label [5].
To address this issue, current text augmentation approaches such as back-translation [6, 7], word replacement [8], text augmentation based on contextual information [9, 10], and language generation method [11,12,13] have been attempted. The quality of the translation decoder determines the data generated by the back translation technique. The current issue is that not only are the majority of the translation decoding results inaccurate but also the usage of conversion models necessitates the utilization of extra computer resources. In terms of replacement methods, hey are primarily based on random substitution and dropping words. Although this kind of method has a minimal time cost, it may lose the semantic structure and order of the original training data, which brings about changes in the augmented semantic labels. Contextual information-based data augmentation is also called conditional data augmentation. This kind of method is based on the pre-trained language model and integrates the label information into the neural network for fine-tuning. In addition, language generation models are also used for data augmentation. However, when the language generation model performs text augmentation, it generates text without restriction and may not be good at saving label information.
As discussed, keeping the semantic structure and labels correct makes text augmentation more challenging. The text label is a word that highly generalizes the text content. Each token in the text sequence has different contributions to the generation of the label. We can keep the label correct if the word with the greatest contribution is reserved when conducting data augmentation operations. Therefore, this paper is motivated by the desire for the model to create augmented data with reserved labels at relatively low cost. As a result, we propose a simple and effective data augmentation method, Heuristic Masking Language Modeling (HMLM), the execution example is shown in Fig. 1.

HMLM data augmentation, when a sentence “the steak is great” is augmented by replacing only steak with words predicted based on the context, and the core word "great" is kept unchanged
In particular, we first conduct core word recognition(CWR) for the text. Because of the different targets of the tasks, the core word may be an intention, emotional attitude word, or a term necessary for classification. Following that, one of these non-core words in the text is randomly masked. And then, the pre-trained language model is allowed to make predictions to achieve the purpose of text augmentation. In a nutshell, our contribution can be summarized as follows:
-
(1)
We propose an effective and low-cost data augmentation approach to generate rich training data, which is according to the prior knowledge and contextual information to mask, and fill the masked words in the sentence heuristically through utilizing mask language modeling based on pre-trained language models.
-
(2)
We adopted different ways to conduct core word recognition (CWR) according to the characteristics of specific tasks, which guarantee the recognition accuracy of the core word, and make the created data keep the same distribution as the original data.
-
(3)
Experiments show that the method outperforms baseline methods in different natural language processing applications. In particular, it is a robust improvement on the problem of data label changes in the process of data augmentation compared to other methods. The rest of the paper is organized as follows. Section 2 introduces related work in the data augmentation methods. Section 3 introduces the method that we proposed. Section 4 describes the experiment setup. Section 5 introduces comparative experiment and discussion. Section 6 introduces the summary and future works.
2 Related work
2.1 Data augmentation
Deep learning has performed remarkably well on many natural language processing tasks recently. The superior performance of deep neural network models has heavy data dependence so a large amount of data is needed to minimize overfitting. However, the size and quality of labeled data for many real-world NLP (Natural Language Processing) applications are frequently constrained. Hence, data augmentation has become an effective way to augment the size and quality of the training data; even it is crucial to the successful application of deep learning models on data-driven projects. In addition to some existing traditional data augmentation techniques, with the emergence of a considerable amount of the work of pre-trained models, researchers are also attempting to employ pre-trained models to bring a new perspective to data augmentation.
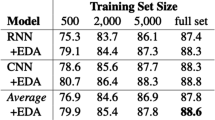
Word replacement The principle of word replacement is to create training data similar to the original data by injecting noise into the original data. Jason Wei and Kai Zou [14] proposed the EDA method to replace words randomly by thesaurus. Although EDA has made some achievements, it still has a few shortcomings that cannot be ignored. On the one hand, synonyms need to be defined manually, which takes a significant amount of time. On the other hand, the kind of selective substitution without emphasis may give rise to the loss of the semantic structure of the augmented data. UDA optimizes EDA’s random word processing strategy, which uses the probability of a negative correlation with TF-IDF to extract words in each text to determine whether to replace [1]. Dai et al. [15] proposed for sentence-level and sentence-pair NLP tasks, using binomial distribution to determine whether each token is replaced. The replacement method is to randomly select another token with the same label. Word replacement method also chooses words that share the same morphology [16, 17].
Other generic word replacement methods include word dropout, which randomly drops out any number of a word’s occurrences, and not just none or all words [18, 19]. Reward Augmented Maximum Likelihood (RAML) essentially replaces certain words in the target sentence with other words in the target vocabulary [20]. To the best of our knowledge, the performance of this method is relatively inferior to EDA in some respects.
Back-translation Back translation signifies that the original data is translated into other languages, and then back into the original language, the target language. If the intermediate languages are different, the final augmented data may be more diverse. Back translation technology was primarily employed by early researchers to increase the performance of the neural network translation model (NMT). Rico Sennrich et al. [21] proposed a general data augmentation method in machine translation (MT) that allows the system to incorporate monolingual training data. For instance, when training an English\(\rightarrow\)French system and the monolingual French text is translated to English using a French \(\rightarrow\) English system, the synthetic parallel data can be used for training subsequently. Back-translation can also be used for paraphrasing [22], and it has been used for data augmentation for QA [13]. Adams Wei Yu et al. [23]used the back-translation technology as a special data augmentation technology to optimize the performance of the question and answer model.
Contextual information-based This work was first proposed by Kobayashi and Sosuke [9], and they used a contextual information augmentation method based on a bidirectional language model. A contextualized language model usually captures the information of words and manages the morpho-syntactic variations typical of handwritten notes. In order to ensure the consistency of the label after the augmentation, the researchers embedded the label information in the LM hidden layer. Similar to Contextual augmentation, CBERT replaced the bidirectional LM with BERT and also fine-tuned the BERT, introducing the label information of the original text to make sure that augmented samples have the same label attributes as the original samples [10].
Language generation model LAMBADA used a method of synthesizing labeled data [2]. It was first pre-trained on a huge volume of the text so that the model can capture the structure of the language, which could produce coherent sentences. They fine-tuned the model on a small number of datasets for different tasks, and the new sentences were then generated using the fine-tuned model. Finally, training the classifier on the same small dataset and filtering it to ensure that the existing small data and the newly generated data have a similar distribution.
Other methods In addition to the popular approaches mentioned above, there are also alternative methods that contribute to text data augmentation. Yitong Li et al. [24] proposed a linguistically motivated method to text application customization, which is based on injecting noise into the input text. Michihiro et al. [25] proposed to generate samples by increasing the reverse disturbance at the input-end in the direction of significantly increasing the classifier’s loss function. Moustafa Alzantot et al. [26] utilized an unrestricted end-to-end solution to efficiently generate adversarial texts.
2.2 Pre-trained models for NLP
Recently, substantial work has shown that pre-trained models (PTMs) on the large corpus can learn universal language representations, which are beneficial for downstream NLP tasks and can avoid training a new model from scratch [27]. With the help of the representation extracted from the PTM in the large unannotated corpus, there was a significant performance improvement on many NLP tasks. Among them, self-encoding language models, like the BERT series, are developed by the transformer, which proves the importance of the attention mechanism. It discarded the traditional convolutional neural networks(CNNs) and recurrent neural networks(RNNs) in the encoder-decoder and consists of only attention mechanisms and Feed Forward Neural Networks.
BERT. It used a bidirectional transformer block connection and introduced Masked Language Modeling(MLM) pre-trained targets to enable it to obtain context-related bidirectional feature representations [28], introducing Next Sentence Prediction (NSP) pre-trained targets to make the model good at handling sentence or paragraph matching task.
ERNIE 2.0 This model introduced multi-task learning(interacting with a priori knowledge base) pre-trained so that the model could learn more language knowledge from different tasks [29]. The main method was to build an incremental learning model, which continuously updated the pre-trained model through multi-task learning. This continuous alternating learning paradigm will not make the model forget the previously learned language knowledge.
Chinese-Bert-wwm It utilized the whole word masking strategy for Chinese BERT, which improved the problem that BERT’s Word Mask mechanism may affect the meaning of words in Chinese [30].
RoBERTa It made some adjustments based on BERTFootnote 1. It removed the next predicted loss, dynamically adjusted the mask mechanism, and the training sequence was longer. In addition, it took longer to train and needed more training data. Such a change may introduce more prior knowledge for data augmentation.
Different from the previous data augmentation work using the pre-trained model and fine-tuning pattern. The proposed HMLM adopts the LM_mask function of the self-encoding language model to mask the non-core words randomly in text and uses the pre-trained model to predict the mask part of the original data directly to obtain the text, which maintains the consistent label with the original.
3 Heuristic Masked Language Modeling
3.1 Problem definition
Text classification refers to the process of assigning predefined labels to text and is an instance of the supervised learning problem for text data. By this definition, a training dataset is given:
D\(_{train}\)=\(\left\{ \left( x_{i}, y_{i}\right) \right\} _{i=1}^{n}\) containing \(\textit{n}\) labeled sentences. Here \(\textit{p(X,Y)}\) indecate the distribution over all training data pairs \((x_{i}, y_{i})\), and use a hat \({\hat{p}}({\hat{X}},{\hat{Y}})\) to denote distribution of augmented data. If \({f(\cdot )} \rightarrow {{\hat{p}}({\hat{X}},{\hat{Y}})} \simeq\) p(X,Y), which means this data augmentation fuction \({f(\cdot )}4\)ss is effective. There are differents ways to measure the quality of a data augmentation function, but the most straightforward way is to measure whether it improves the accuracy of the downstream tasks. If the augmented data can significantly improve the performance of the downstream tasks classifier, it can be considered that data augmentation improves the model robustness, making the model pay more attention to the semantic information of the text and to the local noise of the text no longer sensitive. In the text classification task, we use the cross-entropy [31] loss function to update the parameters. Its formula can be expressed as:
where \(p(x_i)\) denotes the true label distribution, and \(q(x_i)\) denotes the predicted label distribution.
3.2 Heuristic mask strategy
To the best of our knowledge, the concept of the heuristic was first proposed in the optimization algorithm. It means that in a random optimization process, individuals can use their own or global experience to formulate their own search strategies. In a nutshell, the emphasis of the heuristic is how to better use global or self-information. Similarly, we expect that the data augmentation model will be able to use global information with label information to maintain the correct semantic tags instead of embedding tags into the input for retraining.
In some conventional NLP tasks, their labels are determined by the core words, such as the sentiment analysis task, it is the emotional attitude words that determine their labels, so we regard the emotional attitude words as core words for sentiment analysis. When performing the mask decision, it is clear that improper mask positions will affect the model’s use of global information. The random mask strategy may mask the core word so that the pre-trained model may replace these significant words when filling the mask part, resulting in label variation. On the contrary, if core words are retained, the pre-trained model can make good use of the global information with core words, thus keeping the label invariant. In order to maintain the label correctness of the augmented data, the proposed approach conducts core word recognition to bypass core words before using the pre-trained model for mask-prediction. This strategy utilize the prediction function of the pre-trained model in the data augmentation stage, which does not require additional training at all, which means our approach is low-cost.
The procedure of the proposed approach is shown in Fig. 2. There are three subgraphs from bottom to top, which respectively illustrate the specific operation of each stage of the HMLM algorithm. Subgraph (a) shows the stage of CWR for the input sentence. The core word ”news” is picked as recognition results. Then, the subgraph (b) shows the mask operation; some non-core words are arbitrarily masked after we bypass the core word. Next, the subgraph (c) shows that the pre-trained model is used to predict some words to replace these masked words to make sure the context of the sentence is clear and coherent in the meantime. As shown in subgraph (b), due to the different positions of the mask words, more and different augmented data can be obtained by the predicting stage.

The procedure of data augmentation using HMLM. For instance, the label of ”Give me the hot news” is ”News.” If the word ”news” is replaced, the label changes accordingly. As a result, the word ”news” is regarded as the core word, and the words in the sentence other than ”news” can be regarded as non-core words. We recommend data augmentation for any words that do not change the label to ensure label continuity
3.3 Core word recognition
The significance of ensuring the correctness of semantic tags for data augmentation has already been discussed. In common NLP tasks, semantic tags are usually determined by several core words. For example, the labels of intent recognition are determined by intent keywords. In news classification, it is determined by keywords, and in sentiment analysis, some emotional words determine the emotional direction. Ignoring core words and using random replacement words for data augmentation, such as EDA, may cause the expanded data to obtain wrong labels. In this paper, as shown in Fig. 2a, we first recognize the core words in the input text. In particular, the different ways are applied to distinguish the core words according to the characteristics of specific tasks, such as textrank, BiLSTM+Attention, etc. Non-core words of training data are masked to construct samples when using the pre-trained model, as shown in Fig. 2b.
3.4 Predicting using mask language modeling
The mask language model is not a rigorous language model, but a way to train a language model. It is an example of autoencoding language modeling that reconstructs the output from a corrupted input. We typically mask one or more words in a sentence and have the model predict those masked words given the context of the sentence. By training the model with such an objective, it can essentially learn certainly, but not all, statistical properties of word sequences. Mask language model (MLM) was first proposed by Tylor as a cloze task in literature [32], with the idea that the better readability of an article, the lesser people made mistakes in guessing the hidden word. Devlin et al. [28]adapted this task as a novel pre-trained task to overcome the drawback of the standard unidirectional language model. The main way is to supervise themselves, for example, removing several words in a paragraph and using their context to predict the masked words. Similar to BERT, it randomly replaces 15% of words of the sentence with mask tags and, after that, predicts the masked words. Generally speaking, modeling the probability of natural language generation is the goal of the preview model. In terms of the bidirectional language model, given a sequence of n words, X={x\(_{1}\),x\(_{2}\),...,x\(_n\)}, the probability that the forward language model [27] predicts the sequence is:
The backward language model predicts the probability of a sentence as:
In the training stage, the loss function is to allow the language model to attempt to restore its original input. Different from the training phase goal, we do not have to reconstruct the original input; on the contrary, we hope that the model’s prediction and the original input have a certain difference, and this difference enriches our input sentence, the flow chart of prediction phase is shown in Fig. 2c.
Some augmented examples are given by experimenting with our data augmentation algorithm on three tasks: (1)intent detection; (2)news classification; (3)sentiment analysis. For each task, perform the following steps: (1) core word recognition; (2) using the mask language modeling for data augmentation; (3) verifying that the augmented data improves the performance of the classifier. As shown in Fig. 3, we can see that in the core word recognition stage, we utilize different approaches to identify core words for these three tasks.

Examples of data augmentation process diagram where CWR means core word recognition
We mark all the recognized core words in red to visually observe the changes in the data. After that, we can see that the red words are avoided mask when the mask token is added. For each task, the examples given in the figure are derived from different mask positions under pre-trained language models G\(\{ BERT-base\}\). To obtain more diverse augmented data, with the mask position unchanged, only the pre-trained model needs to be changed. In addition, during the execution of mask-prediction, the original input may also be predicted. Such samples will be regarded as invalid augmented data.
Simultaneously, the pseudo-code demonstrates the process of data augmentation, as shown in Algorithm 1. It is necessary to interpret some of the notations in Algorithm 1. Given a training dataset D\(_{train}\), contain labeled sentences to generate augmented dataset D\(_{aug}\). For line 3, the variable s represents each sentence among in D\(_{train}\). For line 5, \(l_s\) denotes the sentence length of D\(_{train}\), and \(l_c\) indicates the length of the core word in each sentence. For line 11, \({\hat{s}}\) represents the sentence generated by the model.

4 Experiment
4.1 Tasks and datasets
Three type of text tasks are designed in experiments: intent recognition, news classification, and sentiment analysis. Three Chinese single-label multi-classification datasets description is shown in Table 1. The dataset for intent detection comes from the online data collected by the company’s dialogue system, we named it intent_news, which contains 600 news-type intent and 2000 non-news-type intent. We select toutiao_news of the public dataset for news classification, and judged whether the news is one of 15 categories such as news_fiance, news_culture, etc, a total of 73360 samples. It can be classified as a long text classification task. The sentiment dataset comes from user reviews collected by a takeaway platform, of which 4000 are positive and about 8000 are negative. we randomly take 80% of samples as the training set and the last 20% as the testing set.
4.2 Models and experimental setup
Baseline We consider five models as our baseline.
-
(1)
EDA [14] model is a random word replacement method based on the thesaurus, which has proved to be effective in augmenting scenarios with small data sets.
-
(2)
HDA [33] implemented a hierarchical data augmentation strategy by augmenting texts at word-level and sentence level respectively and utilizes attention mechanism to distill (crop) important contents from texts hierarchically as summaries of texts.
-
(3)
UDA [1] model introduced TF-IDF to measure the importance of a word to a sentence. In essence, it can be regarded as introducing strong prior knowledge on the basis of EDA and then replacing synonyms according to determined keywords.
-
(4)
CBERT [10] model retrofitted BERT to conditional BERT by introducing extra label-conditional constraint to the mask language model.
-
(5)
AugSBERT [34] utilized the cross-encoder to label a larger set of input pairs to augment the training data for the bi-encoder.
Parameter settings We present the parameter settings. The model and experiment settings include two aspects: classification model parameters and augmentation model parameters. On the one hand, the augmentation model parameters include the proportion of selected data \(\beta\), the augmentation multiples \(\gamma\) for a single sentence, and the number of core words \(\tau\) in each sentence. Among them, we stipulate that the ratio \(\beta\) =\(\left\{ 10 \%, 30 \%, 50 \%, 100 \%\right\}\) of the three datasets are selected, and the augmentation multiples \(\gamma\)=\(\{1,2,3 \}\) is achieved by masking different positions of the non-core word parts; and the number of core word \(\tau\) in each sentence we set \(\tau\)=\(\{1,2\}\). Furthermore, the ratio of the mask in each sentence varies according to the length of the sentence. In general, only two consecutive characters are masked in a sentence at a time. In the predicting-filling stage, we also selected different pre-trained models to compare the filling effects, including BERT-base, ERNIE 2.0, BERT-wmm and RoBERTa. Finally, in order to explore the impact of data augmentation on the classifier, we feed the augmented data together with the original data into the classifier. On the other hand, for the three tasks, detailed parameters corresponding to the classification model are described below.
Intent detection Since intent recognition sentences are typically short, each sentence can reflect a strong intent. Hence, we generalized a batch of words related to intent according to the intent labels and took them as the core words for frecognition. In order to correspond to the realization of subsequent augmentation multiples, the number of core words is set to \(\tau\)=1. For the TextCNN [35] model, we set lr=0.0001, batch_size=128, dropout=0.5, epochs=10, max_length=16, kernel=100, filter_size=(2,3,4), embedding_sizeFootnote 2=200.
News classification Due to the long length of the news data, there may be multiple core words. Therefore, it is different from the intention detection, we have set \(\tau\) =2. In news classification, the core words may determined by keywords, thus we use TextRank [36] to recognize core words. In terms of the TextCNN model, we set filter_size=(3,4,5), kernel=256, lr=0.001, batch_size=128, epochs=20, dropout=0.5, max_length=32, embedding_size\({}^{1}\)=200.
Sentiment analysis For sentiment analysis, emotional attitude words are used as the criteria for selecting core words. Owing comment may contain different aspects, and the aspects may have opposite polarities. We expect to extract the emotional attitude words contained in each aspect so as to avoid the emotional attitude words in the subsequent masking. The number of the core word is set to \(\tau\)=1. For core word recognition, we employ the BiLSTM to represent the word vector and attention mechanism to determine the importance of every word to the label. There is an attention weight between each word and the label. The higher the weight, the greater the importance of the word to the label, the greater the probability of the word as a core word. For the parameters of BiLSTM+Attention, we set lr=0.001, batch_size=128, epochs=10, dropout=0.5, max_length=32, hinder_layers=128, embedding_size\({}^{1}\)=200.
5 Result and discussion
5.1 Results of intent detection
The final experimental results of intent detection are shown in Fig. 4, and the accuracy of the classifier improved by data augmentation is shown in Table 2. It can be seen from Fig. 4 that our method improves the accuracy of the classifier better than the baseline performance. It can also be seen from Table 2, both RoBERTa and BERT-base have the best performance, and BERT-wmm is somewhere in between. Besides, when using 10% data to expand 3 times, the accuracy of the classifier has increased by at least 0.2; using 30% data and 50% data to expand three times, the performance of the classifier is improved by about 0.1; when using the full data to increase three times, the performance of the classifier is only increased by 0.02. Such a situation indicates that the data augmentation effect is better under a small amount of data, but when the amount of data is relatively large, the change of the augmentation multiples more little effect on the classifier. However, all baselines except AugSBERT degrade classifier performance when using the full amount of data to get three times as much data. This shows that they may replace the intent words related to the classification in the process of randomly selecting alternative words, which cannot guarantee the correctness of the label.

The best model of HMLM and baselines respectively improve the accuracy on the intention detection task, where ”Original” means to use source data without data augmentation
5.2 Results of news classification
The final experimental results are shown in the Fig. 5. The accuracy of the TextCNN classifier is improved by data augmentation compared to the classifier trained with the original data.

The best model of HMLM and baselines respectively improve the accuracy on the news classification task, where ”Original” means to use source data without data augmentation
As demonstrated in Fig. 5, of all the baselines, AugSBERT achieved the best performance. At the same time, it has been found that using data augmentation sometimes reduces the performance of the classifier. In particular, EDA makes this decline more pronounced. AugSBERT randomly selects two sentences that usually lead to a dissimilar (negative) pair; positive pairs are extremely rare. This skews the label distribution of the dataset heavily towards negative pairs. We can see that in all data ratios, the proposed method is better than baselines, and the BERT-base and RoBERTa model wins with an absolute advantage. As can be seen as Table 3, RoBERTa always has stable performance under different augmentation multiples, and the gap between it and other models becomes more obvious as the dataset increases and the augmentation multiples increase. By observing the improvement of the accuracy of the classifier, it can be found that when the classifier uses 10% data increased by two times, it is better than using 30% of the original data. The same result appears in 50% of the data. This may imply that, under certain circumstances, the data obtained using data augmentation methods have more training significance than the equivalent amount of data obtained in the real world.
5.3 Results of sentiment analysis
The experimental results are shown in Fig. 6, and the accuracy of the classifier improved by data augmentation is shown in Table 4.

The best model of HMLM and baselines respectively improve the accuracy on the sentiment analysis, where ”Original” means to use source data without data augmentation
It can be seen from Fig. 6 and Table 4 that all the data obtained after using the augmentation model have improved the accuracy of the classifier compared to the unaugmented. Under the requirement of doubling the augmentation, all of the augmentation models surpass baseline methods with a weak advantage, but this transcendence is amplified with the increasing of augmentation multiples. HDA performed better in sentiment analysis than the other two tasks. We argue that it is probably because there is an explicit relationship between the label and the sentiment in the sentence. Attention is also very good at identifying this kind of relationship. When there is an implicit relationship between label and text sequence, such as news classification, attention tend to select important words are more likely to make the text sequence lose its original semantic meaning. As a result, augmented data become noise for classifier. Besides, when the augmentation multiple is triple, the RoBERTa model makes the best performance. In the same situation, with the gradual increase in the data selection rate, the performance is significantly improved. Meanwhile, we also observed that the effect of using 10% to augment the two times is equivalent to directly using 30% of the original data for classification. When using 50% of the data, it needs to be augmented by three times to achieve the effect of classification under the total amount of data. This situation shows that for sentiment analysis, data augmentation has a higher cost-performance ratio when the amount of data is relatively small.
5.4 Analysis of \(\beta\) and \(\gamma\)
From the above experimental results, the augmentation benefits of the three tasks all follow the same trend. With the \(\beta\) keeping the invariant, the increase in \(\gamma\) improves the augmentation gain. With the \(\gamma\) keeping the invariant, the increase in \(\beta\) decreases the augmentation gain. The smaller the \(\beta\), the more significant the data augmentation gain, which can lead to an increase of up to 30 percentage points. For the entire data condition \(\beta\)=100%, the data augmentation may generate noise or even cause a negative gain, but this situation disappears with the increase of gamma.
5.5 Ablation study
So far, empirical outcomes have been favorable. In this section, we perform an ablation study to investigate the effect of the CWR procedure in HMLM. We can assume that the core word recognition will greatly increase the gain of the HLML algorithm; therefore, we isolate each CWR operation to determine its ability to boost performance. For three NLP tasks, we ran models using HMLM and HMLM w/o CWR separately on same augmentation multiples and data selection ratio. The detailed results are shown in Table 5. We find that with the same data selection ratio, merely utilizing HMLM w/o CWR can also improve the performance of the classifier, while the HMLM can improve more.
The experimental results reveal that the gain of the CWR has some discrepancies in different tasks. As shown in Table 5, for intent recognition and sentiment analysis, we received the best gain, indicating that the CWR method is suitable for these two tasks. Besides, when employing 10% and 30% data for data augmentation, the effect of CWR decreases with the increase of augmentation multiples. When more data are given, the effect of CWR begins to increase. It turns out that CWR operation contributes more to performance gain for intent recognition, news classification, and sentiment analysis, and the CWR method for news classification still has room for improvement.
5.6 The situation of conserving true labels
In text data augmentation, the key is to maintain class labels while modifying the input data. However, if sentences are significantly changed, then original class labels may no longer be valid. We take a sentence-matching approach to examine whether HMLM significantly changes the meanings of augmented sentences. We performed the experiment when \(\gamma\)=3 and \(\beta\)=100% and conducted mean pooling after using tencent embedding for original sentences and augmented sentences so that we could calculate the cosine similarity of the sentence pair. We have counted the data distribution of the semantic similarity, and the result is demonstrated in Fig. 7.

Semantic similarity calculation of original sentences and augmented sentences. We performed the experiment when \(\gamma\)=3 and \(\beta\)=100%, and conducted mean pooling after using tencent embedding to calculate the cosine similarity. The higher the similarity between the augmented sentence and the original sentence, the more consistent the linguistic space is, suggesting that augmented sentences maintained their true class labels
We found that the original data representations and augmented sentences has highly similarity those of the original sentences, which suggests that, for the most part, sentences augmented with HMLM conserved the labels of their original sentences.
6 Conclusion
In the present work, we introduce a novel augmentation method by heuristic Masked Language Modeling. The proposed method explores the selection of core words for various tasks, after which non-core words are masked, and the masked fragments are predicted using the pre-trained language model. It provides a priori knowledge for data augmentation, which not only maintains label consistency but also enriches semantics. We have conducted experiments on intent recognition, news classification, and sentiment analysis, which demonstrated that our method could generate a variety of words appropriately with the semantic tags of the original text and improve the neural classifier more than the baseline. This method is simple, effective, and easy to implement, providing insight for practitioners and researchers to select use cases in data-starved research and applications. In future works, we will explore mixed augmentation methods based on more pre-trained models. Also, we will explore the application of our augmentation method for other natural language processing tasks to make continued progress in text data augmentation.
References
Xie Q, Dai Z, Hovy E.H, Luong T, Le Q (2020) Unsupervised data augmentation for consistency training. In: Advances in neural information processing systems 33: annual conference on neural information processing systems 2020, NeurIPS 2020, December 6-12,
Anaby-Tavor A, Carmeli B, Goldbraich E, Kantor A, Kour G, Shlomov S, Tepper N, Zwerdling N (2020) Do not have enough data? deep learning to the rescue! In: The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, New York, NY, USA, February 7-12, 2020, pp. 7383–7390
Wang J, Yang Y, Liu K, Xie P, Liu X (2022) Instance-guided multi-modal fake news detection with dynamic intra- and inter-modality fusion. In: Advances in knowledge discovery and data mining—26th Pacific-Asia conference, PAKDD 2022, Chengdu, China, May 16-19, 2022, pp. 510–521
Liu K, Li T, Yang X, Yang X, Liu D, Zhang P (2022) Wang J Granular cabin: an efficient solution to neighborhood learning in big data. Inform Sci 583:189–201
Tobin J, Fong R, Ray A, Schneider J, Zaremba W, Abbeel P (2017) Domain randomization for transferring deep neural networks from simulation to the real world. In: 2017 IEEE/RSJ International conference on intelligent robots and systems, IROS 2017, Vancouver, BC, Canada, September 24-28, 2017, pp. 23–30
Hoang C.D.V, Koehn P, Haffari G, Cohn T (2018) Iterative back-translation for neural machine translation. In: Proceedings of the 2nd workshop on neural machine translation and generation, NMT@ACL 2018, Melbourne, Australia, July 20, 2018, pp. 18–24
Edunov S, Ott M, Auli M, Grangier D (2018) Understanding back-translation at scale. In: Proceedings of the 2018 conference on empirical methods in natural language processing, Brussels, Belgium, October 31 - November 4, 2018, pp. 489–500
Fadaee M, Bisazza A, Monz C (2017) Data augmentation for low-resource neural machine translation. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, pp. 567–573
Kobayashi S (2018) Contextual augmentation: Data augmentation by words with paradigmatic relations. In: Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: human language technologies, NAACL-HLT, New Orleans, Louisiana, USA, June 1-6, 2018, pp. 452–457
Wu X, Lv S, Zang L, Han J, Hu S (2019) Conditional bert contextual augmentation. In: Computational Science—ICCS 2019—19th International Conference, Faro, Portugal, June 12-14, 2019, pp. 84–95
Liu T, Cui Y, Yin Q, Zhang W, Wang S, Hu G (2017) Generating and exploiting large-scale pseudo training data for zero pronoun resolution. In: Proceedings of the 55th annual meeting of the association for computational linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, pp. 102–111
Hou Y, Liu Y, Che W, Liu T (2018) Sequence-to-sequence data augmentation for dialogue language understanding. In: Proceedings of the 27th international conference on computational linguistics, COLING 2018, Santa Fe, New Mexico, USA, August 20-26, 2018, pp. 1234–1245
Dong L, Mallinson J, Reddy S, Lapata M (2017) Learning to paraphrase for question answering. In: Proceedings of the 2017 conference on empirical methods in natural language processing, EMNLP 2017, Copenhagen, Denmark, September 9-11, 2017, pp. 875–886
Wei JW, Zou K (2019) EDA: Easy data augmentation techniques for boosting performance on text classification tasks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pp. 6382–6388
Dai X, Adel H (2020) An analysis of simple data augmentation for named entity recognition. In: Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020, pp. 3861–3867
Vania C, Kementchedjhieva Y, Søgaard A, Lopez A (2019) A systematic comparison of methods for low-resource dependency parsing on genuinely low-resource languages. In: Inui, K., Jiang, J., Ng, V., Wan, X. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pp. 1105–1116
Gulordava K, Bojanowski P, Grave E, Linzen T, Baroni M Colorless green recurrent networks dream hierarchically. In: Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, pp. 1195–1205
Sennrich R, Haddow B, Birch A Edinburgh neural machine translation systems for WMT 16. In: Proceedings of the first conference on machine translation, WMT 2016, colocated with ACL 2016, August 11-12, Berlin, Germany, pp. 371–376
Gal Y, Ghahramani Z A theoretically grounded application of dropout in recurrent neural networks. In: Advances in neural information processing systems 29: annual conference on neural information processing systems 2016, December 5-10, 2016, pp. 1019–1027
Norouzi M, Bengio S, Chen Z, Jaitly N, Schuster M, Wu Y, Schuurmans D Reward augmented maximum likelihood for neural structured prediction. In: Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, pp. 1723–1731
Sennrich R, Haddow B, Birch A Improving neural machine translation models with monolingual data. In: Proceedings of the 54th annual meeting of the association for computational linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany, pp. 86–96
Mallinson J, Sennrich R, Lapata M Paraphrasing revisited with neural machine translation. In: Proceedings of the 15th conference of the European chapter of the association for computational linguistics, EACL 2017, Valencia, Spain, April 3-7, 2017, pp. 881–893
Yu A.W, Dohan D, Luong M, Zhao R, Chen K, Norouzi M, Le Q.V Qanet: Combining local convolution with global self-attention for reading comprehension. In: 6th international conference on learning representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018
Li Y, Cohn T, Baldwin T Robust training under linguistic adversity. In: Proceedings of the 15th Conference of the European chapter of the association for computational linguistics, EACL 2017, Valencia, Spain, April 3-7, 2017, pp. 21–27
Yasunaga M, Kasai J, Radev D.R Robust multilingual part-of-speech tagging via adversarial training. In: Proceedings of the 2018 conference of the North American chapter of the association for computational linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, pp. 976–986
Alzantot M, Sharma Y, Elgohary A, Ho B, Srivastava M.B, Chang K Generating natural language adversarial examples. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pp. 2890–2896
Qiu X, Sun T, Xu Y, Shao Y, Dai N (2020) Huang X Pre-trained models for natural language processing: a survey. Sci China Technol Sci 63:1872–1897
Devlin J, Chang M, Lee K, Toutanova K BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, pp. 4171–4186
Sun WSLYFSTHWHWH Y Ernie 2.0: A continual pre-training framework for language understanding. In: The Thirty-fourth AAAI conference on artificial intelligence, AAAI 2020, New York, NY, USA, February 7-12, 2020, pp. 8968–8975
Cui Y, Che W, Liu T, Qin B, Yang Z Pre-training with whole word masking for chinese BERT. IEEE ACM Trans. Audio Speech Lang. Process. 29 3504–3514 (2021)
Xie Z, Huang Y, Zhu Y, Jin L, Liu Y, Xie L Aggregation cross-entropy for sequence recognition. In: IEEE conference on computer vision and pattern recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pp. 6538–6547
Taylor W.L “cloze procedure”: A new tool for measuring readability. Journalism quarterly 30(4), 415–433 (1953)
Yu S, Yang J, Liu D, Li R, Zhang Y (2019) Zhao S Hierarchical data augmentation and the application in text classification. IEEE Access 7:185476–185485
Thakur N, Reimers N, Daxenberger J, Gurevych I Augmented SBERT: data augmentation method for improving bi-encoders for pairwise sentence scoring tasks. In: Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, pp. 296–310
Kim Y Convolutional neural networks for sentence classification. In: Proceedings of the 2014 conference on empirical methods in natural language processing, EMNLP 2014, October 25-29, 2014, pp. 1746–1751
Mihalcea R, Tarau P Textrank: Bringing order into texts. In: Proceedings of the 2016 conference on empirical methods in natural language processing, EMNLP 2004,Barcelona, Spain, July
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, X., Zhong, Y., Wang, J. et al. Data augmentation using Heuristic Masked Language Modeling. Int. J. Mach. Learn. & Cyber. 14, 2591–2605 (2023). https://doi.org/10.1007/s13042-023-01784-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-023-01784-y