
Abstract
Among the major causes of female mortality, breast cancer used to pose big challenges to the medical world. Currently, the most popular method of monitoring and diagnoses—in addition to mammography—is carrying out repeated biopsies to locate the tumor further, that may result in loss of breast tissues. This paper presents an effective method of classifying and detecting the masses in mammograms. In the proposed method, we first attain the feature vector pertaining to each mammography image based on Gabor wavelet transform. Then, we performed tenfold cross validation through several experiments, analyzing the data complexity on each fold. We also used some machine learning methods as decision-making stage and achieved mean accuracies above 0.939, mean sensitivities as high as 0.951, and the mean specificities greater than 0.92. Evaluations and comparisons witness the effectiveness of the proposed method for better diagnosis of breast cancer against the known classification techniques developed in mammography. Simplicity, robustness and high accuracy are advantages of the proposed method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Breast cancer is the most common malignancy among women and the second leading cause of death [1]. In 2012, a total of 1.7 million new breast cancer cases was diagnosed worldwide according to the Globocan project [2]. On the other hand, aging was found in a study by American Cancer Society in 2015 in relevance to the number of patients with breast cancer and thereby, the number of deaths [3]. However, the diagnosis of cancer occurs as late as the time that cancer cells start to grow uncontrollably and spread out, the point that the tumor is diagnosed to be malignant. Physicians use mammography as the most common tool to diagnose the disease. In many cases the difference in the breast tissue of patients, several biopsies are required in addition to mammography which may result in entire loss of breast tissue. Two main diagnosis methods, namely Breast Self-Examination (BSE) and Clinical Breast Exam (CBE) are normally employed for patients. However, these methods are not capable of detecting cancer at its earliest stage.
While mammography is the popular technique designed to image the breast [4], computer aided diagnosis (CAD) helps obtaining fast, consistent and reliable diagnosis [2]. Since the purpose of mammography images is to spot a mass, extracting appropriate features plays an important role in analyzing these images. Gabor wavelet transform is used in many studies for feature extraction from texture-based images, and its effectiveness is shown [5]. Using appropriate parameters for this transform minimizes the feature overlap. As far as accuracy of diagnosis concerned, data mining methods are believed to reduce the misdiagnosis [6,7,8]. In this paper, Gabor wavelet transform is used for feature extraction, due to the transform capabilities in analyzing and classifying the mammograms. Once feature extraction is complete, selecting a proper method for classification and identifying healthy images out of unhealthy ones is very important.
The rest of the paper is organized as follows. In Sect. 2, the work done in the past has been reviewed. Section 3 describes the proposed method and preliminaries. In Sect. 4, results and performance are described, and the results are compared with similar works. Finally, the results are analyzed, and the conclusion is described.
2 Review and background
Various data mining methods are used for classification, and due to producing understandable rules, the decision tree is the most common [9]. Wang et al. proposed a breast tumor detection algorithm in digital mammography based on extreme learning machine [10]. Hassanien et al. introduced a hybrid approach that combines the advantages of fuzzy sets, pulse coupled neural networks (PCNNs), and support vector machine, in conjunction with wavelet-based feature extraction [11].
Keles et al. applied an expert system to diagnose breast cancer tumors using neuro-fuzzy rules [12]. Elsayad used an ensemble of Bayesian networks for mammography data classification and compared its effectiveness to a multi-layer neural network classifier [13]. Salama et al. compared different classifiers on three different datasets from classification accuracy perspective. The classifiers included decision tree (DT), naïve bayes (NB) and multi-layer perception (MLP), sequential minimal optimization (SMO) and instance-based for K-nearest neighborhood (IBK) and their datasets were Wisconsin Breast Cancer (WBC), Wisconsin Diagnosis Breast Cancer (WDBC), and Wisconsin Prognosis Breast Cancer (WPBC). The fusion between MLP and J48 classifiers in addition to feature selection method achieved higher accuracy among others for WDBC dataset. The proposed SMO is better for WDBC dataset whereas fusion of MLP, DT, SMO, and IBK achieved higher accuracy for WPBC dataset. They, Afterwards, proposed a multi-classifier for each of these datasets by mixing the examined classifiers and finding out which multi-classifier works best for each dataset [14].
Using WDBC dataset, Christobel and Sivaprakasam, proposed a technique to achieve higher accuracy of breast cancer diagnosis. They compared DT, KNN, SVM and NB classifiers and studied their classification accuracy. The highest accuracy equivalent to 96.99% belonged to SVM. However, the proposed technique was limited to only one dataset and used single classifiers [15]. Lavanya and Usha Rani [7] examined the performance of decision tree classifier without feature selection for breast cancer datasets. It has achieved 69.23% classification accuracy without feature selection and 94.84% accuracy for WBC and 92.97% in WDBC dataset. The accuracies were increased to 70.63, 96.99, and 92.09% respectively by applying the feature selection method [16].
Maglogiannis and Zafiropoulos used NB, SVM, and artificial neural network as their classifiers and compared their classification accuracy. The results showed that NB got a rate of 97.54, SVM 92.80 and ANN achieved a rate of 97.90% as classification accuracy [17]. Lavanya and Rani [7] proposed an ensemble classifier for breast cancer data. The presented approach is a hybrid one and is also based on classification and regression tree (C&R) classifier and bagging technique. The preprocessing phase and feature selection have also enhanced the performance. Nonetheless, the classification accuracy can be refined by heterogeneous classifier ensemble model [18]. Tu et al. introduced bagging approach for decision tree and naïve bayes to make an ensemble classifier to predict disease. The enhancements are made using weighted voting scheme with heterogeneous classifiers [19].
A neural ensemble network-based framework for classification of benign and malignant lesions is offered by Mcleod et al. [20]. Jiang et al. presented a content-based image retrieval (CBIR) method for detection masses in mammograms [21]. Instead of using a single classifier, Choi et al. have proposed an ensemble classifier learning algorithm for detection of abnormalities in mammograms [22]. Ebrahimpour et al. improved breast cancer classification by reducing dimensions on mammograms. They used Digital Database For Screening Mammography (DDSM) and proposed three breast cancer classification via feature extraction (BCCFE), breast cancer classification via feature selection (BCCFS) and breast cancer classification without dimension reduction (BCCWDR) methods [23]. Halxia et al. used local contour features and classified breast masses in mammography. They proposed a new method to translate 2D contour of breast masses in mammography to 1D signature and extracted four local features. Finally, they used SVM, KNN, artificial neural network (ANN) classifier on 233 contours including 143 benign masses and 180 malignant ones from DDSM dataset [24]. A comprehensive review of the cutting-edge techniques reveals that considerable research is conducted in breast cancer diagnostics, yet there is still room for improvement which can be achieved using a novel combination of heterogeneous classifiers in an ensemble scheme.
As the state of the art, currently deep learning is used for classifying. Wenqing et al. developed a graph based semi-supervised learning scheme using deep convolutional neural network for breast cancer. They used a small labeled data for training and achieved 0.8243 accuracy [25]. By developing a computer aided diagnosis system based on deep convolutional neural networks Chougral et al. got 97.3 accuracy on the DDSM database [26].
3 Breast cancer detection based on Gabor wavelet transform
The current section enfolds the details of the proposed system, Breast Cancer Detection based on Gabor wavelet transform (BCDGWT). First, the feature extraction method from the images of DDSM database is explained. Next, the details of implementing the learning and testing processes are proposed.
3.1 Forming the feature vector
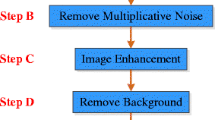
The images were cropped and then resized to 128 × 128 pixels to eliminate the noisy part. For cropping, 60 pixels from the right and 15 pixels from the up are deleted from right side mammograms. For the left side mammograms this is done for the left and up pixels. Figure 1 shows the preprocessing phase in a sample image. The images in the image database were classified by age.

Preprocessing phase on an example image
One of the signs of a cancerous tumor is tissue heterogeneity on both sides of the breast, and it rarely happens that the tumor in both tissues, happens to be at the same size and location. That’s why for each person there are four images in the database, two images from the above and the other two images from the side view. Though, if there was such a situation that the extracted features were incompatible with the characteristics of healthy tissue, then it will be recognized as unhealthy. Features were extracted from images using Gabor wavelet transform for each of the four left carino-caudal (CCL), Left medio lateral oblique (MLOL), right carino-caudal (CCR) and right medio lateral oblique (MLOR) views and finally a feature vector of length 194 was obtained with the following format:
where A and L denote age and label, respectively.
3.2 Feature extraction using Gabor-wavelets
From an optimization perspective, feature extraction is known to be among the most crucial operations in any retrieval system [8]. Every image encompasses a number of extractable features, including mainly frequency domain characteristics and those related to frequency–time transformations. The characteristics of the Gabor wavelets, particularly the representations of frequency and orientation are based on the human visual system and have been proven to be suitable for representation and discrimination of texture information. A two-dimensional Gabor wavelet is essentially a Gaussian kernel function modulated by a sinusoidal plane wave and can be represented as follows [27].
3.3 Gabor transform and wavelet
The two-dimensional Gabor function and two-dimensional Fourier transform are acquired using the following equations [28].
where \({\sigma _u}=\frac{1}{2}\pi {\sigma _x}\) and \({\sigma _v}=\frac{1}{2}\pi {\sigma _y}\). As seen in the above equations, Gabor functions incur a complete non-orthogonal set. Once a signal decomposed using the Gabor transform, local frequency descriptors are created. Similar basis functions can be derived from the Gabor transform, called Gabor wavelet functions. Assume \(g(x.y)\) as basis Gabor wavelet transform, the functions or similar filters can be obtained through rotation and traversal of \(~g(x.y)\) in several stages:
where \(m\) and \(n\) are integers and \(a\) denotes a positive integer number. In the above equation:
Thus, in \(\theta =n\frac{\pi }{K}\), \(K\) represents the number of directions and the traversal parameter, \({a^{ - m}}\) implies that the energy generated by these transforms is independent of \(m\).
3.4 Calculating Gabor filter parameters
Filtering an image with non-orthogonal Gabor wavelet results in some duplicated samples in the created data. Choosing the right parameters for Gabor function can decrease the duplicate data to a great extent by reducing the wavelets’ overlay. Suppose that \({U_h}\) and \({U_l}\) be maximum and minimum of central frequencies respectively, \(K\) denoting the number of rotational directions and \(S\) denoting the number of traversals, then assuming \({U_h}=0.4,~{U_l}=0.05,~K=6\) and \(S=4\), Gabor wavelet filters the images with minimum number of duplicates. Figure 2 shows an example of the intervals between these wavelets [29].

Gabor Wavelets with \({U_h}=0.4,\;{U_l}=0.05,\;K=6\) and \(S=4\)
Figure 3 shows how image texture is concentrated based on wavelets.

Texture concentration based on wavelets
Assuming the values mentioned before for \({U_h}~,~{U_l}~,K\) and \(S\), the parameters \({\sigma _v}\), \({\sigma _u}\) and \(a\) can be computed for (1)–(3) equations using the following relations:
Also, in Eq. (1) assume the following values for \(m\) and \(W~\):
The coefficients mentioned in Eqs. (6)–(8) are computed to calculate the Gabor wavelets. Then, with \(K\) and \(n\) in hand, the \(x^{\prime}.~y^{\prime}.~\theta .~{\sigma _x}.~{\sigma _y}\) are determined. Similarly, using Eqs. (1)–(3), \({g_{mn}}(x^{\prime},y^{\prime})\) is obtained. Thus, the calculated \({g_{mn}}(x^{\prime},y^{\prime})\) with \(K=6\) and \(S=4\) is considered as Gabor wavelets with six rotational directions and four traversals. By applying the resulting relationships for these wavelets, proficient texture based features can be acquired for retrieval. The following shows how to determine the feature vector for an image based on Gabor wavelet transform.
3.4.1 Feature representation
With the image \(I(x.y)\), the corresponding Gabor wavelet transform is obtained using the Eq. (9).
After computing Gabor wavelet transform, the feature vector is obtained using the average and the variance of the transforms formed by rotating and traversing the Gabor basis function. The average and variance are obtained using the following.
Assuming \(S=4\) and \(K=6\) i.e. with 6 rotational direction and 4 traversal a feature vector with the length of 48 is formed and the elements are defined as follows:
3.5 Data-set
We used Digital Database For Screening Mammography (DDSM) dataset to perform our experiments. The dataset is comprised of 2604 cases, each including carino-caudal (CC) and medio lateral oblique (MLO) views for each breast [23]. Figure 4 shows an example of these views.

Four view of mammographic images in dataset
3.6 Machine learning techniques
We used several machine learning methods to categorize the images in the database. The methods include C5.0 decision tree, support vector machine (SVM), artificial neural networks, quest tree and CHAID algorithm. In the following, we provide a brief description of each technique, followed by how they are adopted to the case.
3.6.1 Decision trees
Among decision support tools, three decision trees are used in proposed method, that are described as follows.
3.6.1.1 C5.0
C5.0 is developed by Ross Quinlan and is based on decision tree classifier [30]. It is an extension of C4.5 and ID3 decision tree algorithms. C5.0 classifier automatically extracts classification rules from provided train data in the form of the decision tree. This classifier performs better over C4.5 regarding required time and memory space. The tree generated by C5.0 algorithm is quite small when compared to the one created by C4.5 and therefore enhances the classification accuracy.
3.6.1.2 CHAID tree
CHAID is a type of decision tree technique, based upon adjusted significance testing. The acronym CHAID stands for Chi-squared automatic interaction detector. It is one of the oldest tree classification methods originally proposed by Kass. CHAID will “build” non-binary trees based on a relatively simple algorithm that is particularly well suited for the analysis of larger datasets. Also, because the CHAID algorithm will often effectively yield many multi-way frequency tables, it has been particularly popular in marketing research, in the context of market segmentation studies. CHAID output is visual and easy to interpret. Because it uses multiway splits, it needs rather large sample sizes to work effectively as with small sample sizes the respondent groups can quickly become too small for reliable analysis [31].
3.6.1.3 QUEST tree
QUEST stands for quick, unbiased, and efficient statistical tree. It is a binary-split decision tree algorithm for classification and data mining developed by Loh [32]. It deals with split field selection and split point selection separately. The univariate split in QUEST performs approximately unbiased field selection, i.e., if all predictor fields are equally informative concerning the target field, QUEST selects any of the predictor fields with equal probability. QUEST affords many of the advantages of classification and regression (C&R) Tree but also has the disadvantage that your trees can become unwieldy. You can apply automatic cost-complexity pruning to a QUEST tree to cut down its size. QUEST uses surrogate splitting to handle missing values.
3.6.2 Support vector machine (SVM)
SVM is based on Vladimir N. Vapnik’s statistical learning theory [8]. SVM is a robust classification and regression technique that maximizes the predictive accuracy of a model and avoids overfitting the train data. It maps data to a high-dimensional feature space in a way that data points can be categorized, even when the data are not otherwise linearly separable. Support vector machine [7] transforms the original train data into a higher dimension using a nonlinear map. Within this new dimension, it searches for the linear optimal separating hyperplane. With a proper nonlinear mapping to a sufficiently high dimension, data from two classes can always get separated by a hyperplane. With the help of support vectors and margins, the SVM finds this hyperplane. The support vector machines are a general class of learning architectures, inspired by the statistical learning theory that performs structural risk minimization on a nested set structure of separating hyperplanes.
3.6.3 Artificial neural networks
For many years artificial neural network models have been studied in the hope of achieving performance similar to a human being, in several fields such as speech and image comprehension. The networks are consisted of many nonlinear computational elements operating in a parallel manner and arranged in patterns reminiscent of biological neural networks. Computational elements or nodes are known as “neurons” are connected in several layers (input, hidden and output) via weights that are typically adapted during the training phase to achieve high performance. Instead of performing a set of instructions sequentially as in a Von Neumann computer, neural network models explore simultaneously many hypotheses using parallel networks composed of many computational elements connected by links with variable weights. The back-propagation algorithm is an extension of the least mean square (LMS) algorithm that can be used to train multi-layer networks. Both LMS and back-propagation are approximate steepest descent algorithms that try to minimize the average squared error between the network’s output and the target value over all the example pairs. The only difference between them is in the way in which the gradient is calculated. The back-propagation algorithm uses the chain rule to compute the derivatives of the squared error with respect to the weights and biases in the hidden layers. It is called back-propagation because the derivatives are computed first at the last layer of the network, and then propagated backward through the network by using the chain rule to compute the derivatives in the hidden layers. For a multi-layer network, the output of one layer becomes the input of the next layer [33].
3.7 Implementation of train and test phases
Machine learning methods in SPSS Modeler software powered by IBM is used to analyze and classify images based on the extracted features. First, the features of all the images in the database were extracted and written in a text file. Then, the text file was used for training the models. After training models, test data were used in the testing phase. In this paper, 10-fold cross-validation was used, and accuracy of each fold was calculated after each training and testing phases.
The complexity of data is one of the parameters that the ability of classification prediction, strongly depends on it. One of these parameters is maximum Fisher’s discriminant ratio that computes how separated are two classes according to specific features. The range of this measure is \([0~,~+\infty ]\). Small values of this parameter represent strong overlapping [34]. Another parameter is maximum feature efficiency that measures the efficiency of individual features to describe how much each feature contributes to the separation of the two classes. The range in this case is \([0~,~1]\). Small values of this parameter indicate high overlap [34]. For each fold these parameters were calculated for test and train classes. Table 1 shows max Fisher’s discriminant ratio and maximum feature efficiency for each of 10 folds.
The volume of the overlap region is another parameter that indicates the overlap of the tails of the two class-conditional distributions. Small values of this parameter show small overlap volume [34]. The range of this metric is [0, 1] and for all of the folds, it is zero.
4 Results and discussions
The efficiency of each classification method is determined using three parameters including classification accuracy, sensitivity, and specificity. These parameters are computed using four regular measures namely true positive (TP), true negative (TN), false positive (FP) and false negative (FN). Classification accuracy is used for measuring the rate of cases that were correctly classified and can be calculated as follows.
where N denotes the number of records.
To measure the rate of cancerous images, the sensitivity of the classification is defined as follows.
Specificity is used for measuring the rate of non-cancerous images and also ensure the correctness of the classification. Specificity is defined as follows.
Tables 2 and 3 list the accuracy and specificity of each model for tenfolds, respectively. As seen from the tables, the proposed system using all five classification techniques incurs the acceptable level of performance regarding accuracy and specificity, with the mean values of no less than 0.939 and 0.92 for accuracy and specificity, respectively. Additionally, while SVM results the highest classification accuracy with the mean value of 0.968, C5.0 and CAHID TREE share the highest rate of specificity with the mean value of 0.947.
The trend of changes in the mean value during and after each fold is shown in Fig. 5. The graphs are demonstrated for all three metrics including accuracy, sensitivity, and specificity of each of the used machine learning methods.

Analyzing the obtained results via different classifiers
Once again in the figures, the SVM method is more accurate than the decision trees, and the accuracy of decision trees is higher than ANN. In decision trees, C5.0 results in better accuracy than CHAID, while CHAID causes more accuracy than QUEST. In general, the accuracy above 93% in the investigated methods, shows the good performance of the extracted features from the Gabor wavelet transform. One of the advantages of the proposed method is the simplicity of implementation, which, without segmentation, extracts useful features from the entire mammogram images.
4.1 Performance analysis
To provide more evaluations, the proposed method is compared with several methods including; Breast Cancer Classification via Feature Extraction (BCCFE), Breast Cancer Classification via Feature Selection (BCCFS), Breast Cancer Classification without Dimension Reduction (BCCWDR) [23], Breast Masses in Mammography Classification with Local Contour Features (BMMCLCF) [24], VocTree [21], Bag of Words (BoW) [21], and VocTree + AdaptWeight [21]. It is to be noted that the dataset used for all the methods mentioned above was DDSM. Table 4 lists the results of the comparisons. We also provided Fig. 6 to depict the trend of changes for more comparable case and clarity.

Comparison between the proposed method and other methods
As figure and table show, regardless of the classifier used, the proposed system (BCDBGWT) incurs higher accuracy when compared to BOW, VocTree, and VocTree + AdaptWeight methods, presented in [21]. It was noted that although improved accuracy could occur using the methods BMMCLCFЅ and BMMCLCFS in the presence of SVM and KNN, respectively, the proposed method incurs high robustness with any of the classifiers, not seen with any of the other methods. Moreover, the proposed method comes with less complexity than those presented in [24]. Finally, the proposed method results in much higher accuracy when compared to the method reported in [3], besides, within the method in [23], BCCFS-SVM and BCCWDR-SVM cause rather lower accuracy than BCCFS-KNN, BCCFS-C45, and BCCFS-NB. As a result, the increased variance of changes caused lower robustness when compared to the proposed method. The same results are also present in the mean values. As for precision results, the proposed methods maintain an affordable level of precision with BCCWDR-KNN, BCCWDR-C45, and BCCWDR-NB, when compared to the other methods.
In parting, in contrast to BCCFS-SVM, BCCFE-SVM, and BCCWDR-SVM, the used SVM classifier in the proposed method results in higher precision, while decision trees maintain a similar level of accuracy with the studied methods. BCDBGWT-ANN incurs rather higher precision than with the majority of the studied methods. Other advantages of the proposed method are the simplicity of implementation, feature extraction from the whole image without the need for segmentation.
5 Conclusion
While the diagnosis of some diseases such as breast cancer has been a challenge for physicians ever since, extracting appropriate features of mammography and use of machine learning and data mining methods are believed to facilitate physicians in the diagnosis process. In many cases Gabor wavelet is used for feature extraction of texture images in content-based image retrieval systems and its efficiency is well illustrated in these systems. Through the current study, we used Gabor wavelet to extract features from mammography images and fed the extracted features into variant machine learning methods including artificial neural network, SVM, and decision trees. After training, many tests were performed on each of these methods. Accuracy, sensitivity, and specificity are calculated for each of the methods. Comparison with the similar methods and results show that physicians can use the features extracted using Gabor wavelet, alongside machine learning methods in breast cancer diagnosis.
References
Elsayad AM, Elsalamony HA (2013) Diagnosis of breast cancer using decision tree models and SVM 0975-8887. Int J Comput Appl 83(5):19–29
Raghavendra U et al (2016) Application of Gabor wavelet and locality sensitive discriminant analysis for automated identification of breast cancer using digitized mammogram images. Appl Soft Comput J. https://doi.org/10.1016/j.asoc.2016.04.036
Desantis C, Siegel R, Jemal A (2015) Breast cancer facts and figs. 2015–2016. Am Cancer Soc. https://doi.org/10.1016/B978-1-4377-1757-0.00028-7
Karabatak M, Cevdet M (2009) An expert system for detection of breast cancer based on association rules and neural network. Expert Syst Appl 36:3465–3469
Singh SM, Rajkumar R, Hemachandran K (2013) Comparative study on content based image retrieval based on Gabor texture features at different scales of frequency and orientations. Int J Comput Appl 78(7):1–7
Kovalerchuc B, Triantaphyllou E, Ruiz JF, Clayton J (1997) Fuzzy logic in computer-aided breast-cancer diagnosis: analysis of lobulation. Artif Intell Med 11:75–85
Lavanya D, Usha Rani K (2012) Ensemble decision making system for breast cancer data 0975-8887. Int J Comput Appl 51(17):19–23
Lim TS, Loh WY, Shih YS (2000) A comparison of prediction accuracy, complexity, and training time of thirty-three old and new classification algorithms. Mach Learn J 40:203–228
Floares A, Birlutiu A (2012) Decision tree models for developing molecular classifiers for cancer diagnosis. In: WCCI 2012 IEEE World congress on computational intelligence, 10–15 June, Brisbane, Australia
Wang Z, Yu G, Kang Y, Zhao Y, Qu Q (2014) Breast tumor detection in digital mammography based on extreme learning machine. Neurocomputing 128:175–184
Hassanien AE, Kim T, Hassanien AE, Kim T (2012) Breast cancer MRI diagnosis approach using support vector machine and pulse coupled neural networks. J Appl Log 10:277–284
Keles A, Keles A, Yavuz U (2011) Expert system based on neuro-fuzzy rules for diagnosis breast cancer. Expert Syst Appl 38:5719–5726
Elsayad A (2010) Predicting the severity of breast masses with ensemble of bayesian classifiers, J Comput Sci 6(5):576–584 (ISSN 1549-3636)
Salama GI, Abdelhalim MB, Zeid MA (2012) Breast cancer diagnosis on three different datasets using multiclassifiers. Int J Comput Inf Technol 01(01):764–2277
Angeline Christobel Y, Sivaprakasam P (2011) An empirical comparison of data mining classification methods. Int J Comput Inf Syst 3(2):24–28
Lavanya D, Rani KU (2011) Analysis of feature selection with classification: breast cancer datasets. Indian J Comput Sci Eng (IJCSE) 2(5):756–763
Maglogiannis I, Zafiropoulos E et al (2009) An intelligent system for automated breast cancer diagnosis and prognosis using SVM based classifiers. Appl Intel 30:24–36
Lavanya D, Rani KU (2012) Ensemble decision tree classifier for breast cancer data. Int J Inf Technol Converg Serv (IJITCS) 2(1):17–24
Tu MC, Shin D, Shin D (2009) Effective diagnosis of heart disease through bagging approach. In: 2nd international conference on biomedical engineering and informatics, pp 1–4
Leod PM, Verma B, Zhang M (2014) Optimizing configuration of neural ensemble network for breast cancer diagnosis. Proc Int Jt Conf Neural Netw. https://doi.org/10.1109/IJCNN.2014.6889707,
Jiang M, Zhang S, Li H, Metaxas DN (2015) Computer-aided diagnosis of mammographic masses using scalable image retrieval. IEEE Trans Biomed Eng 62(2):783–792. https://doi.org/10.1109/TBME.2014.2365494
Choi JY, Kim DH, Plataniotis KN, Ro YM (2016) Classifier ensemble generation and selection with multiple feature representations for classification applications in computer-aided detection and diagnosis on mammography. Expert Syst Appl 46:106–121. https://doi.org/10.1016/j.eswa.2015.10.014
Ebrahimpour MK, Mirvaziri H, Sattari-Naeini V (2017) Improving breast cancer classification by dimensional reduction on mammograms. Comput Methods Biomech Biomed Eng Imaging Vis 1163:1–11. https://doi.org/10.1080/21681163.2017.1326847
Li H, Meng X, Wang T, Tang Y, Yin Y (2017) Breast masses in mammography classification with local contour features. Biomed Eng Online 16(1):44. https://doi.org/10.1186/s12938-017-0332-0
Sun W, Tseng TLB, Zhang J, Qian W (2017) Enhancing deep convolutional neural network scheme for breast cancer diagnosis with unlabeled data. Comput Med Imaging Gr 57:4–9
Chougrad H, Zouaki H, Alheyane O (2018) Deep convolutional neural networks for breast cancer screening. Comput Methods Progr Biomed. https://doi.org/10.1016/j.cmpb.2018.01.011
Vinay A, Shekhar VS, Murthy KNB, Natarajan S (2015) Face recognition using Gabor wavelet features with PCA and KPCA—a comparative study. Proc Comput Sci 57:650–659
Shen L, Bai L (2006) A review on Gabor wavelets for face recognition. Pattern Anal Appl 9:273–292
Manjunath BS (1996) Texture features for browsing and retrieval of image data. IEEE Trans Pattern Anal Mach Intell 18:837–842
Wu X et al (2008) Top 10 algorithms in data mining. Knowl Inf Syst 14:1–37
Antipov E, Pokryshevskaya E (2010) Applying CHAID for logistic regression diagnostics and classification accuracy improvement. J Target Meas Anal Mark 18:109–117
Loh W (2008) Classification and regression tree methods. Encycl Stat Qual Reliab. https://doi.org/10.1002/9780470061572,
Ozyildirim BM, Avci M (2016) One pass learning for generalized classifier neural network. Neural Netw 73:70–76
Cano JR (2013) Analysis of data complexity measures for classification. Expert Syst Appl 40(12):4820–4831. https://doi.org/10.1016/j.eswa.2013.02.025
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
All authors have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ghasemzadeh, A., Sarbazi Azad, S. & Esmaeili, E. Breast cancer detection based on Gabor-wavelet transform and machine learning methods. Int. J. Mach. Learn. & Cyber. 10, 1603–1612 (2019). https://doi.org/10.1007/s13042-018-0837-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-018-0837-2