
Abstract
In this paper, a backstepping controller with an adaptive neural states observer is proposed for MEMS (Micro-Electro-Merchanical-System) gyroscopes in the presence of model uncertainties and external disturbance. Gyroscope states are usually assumed to be available in controller design procedure. However, gyroscope states may be unavailable in some circumstances. In this paper, an adaptive neural states observer is employed to estimate gyroscope states without physical sensors and thus can help reducing complexity of the gyroscope system. A backstepping controller is utilized to control the vibrating amplitude and frequency of the mass proof and the control law is carried out with states estimation rather than actual gyroscope states. Adaptive laws are investigated in the Lyapunov stability framework to guarantee the stability of the observer. Numerical simulation results demonstrate the effectiveness of the proposed control scheme.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Gyroscopes are one of the most common sensors used to measure angular velocity and they are widely used in areas such as navigation, automobiles and so on. The principle of gyroscopes is that the device can transfer energy from driving axis to sensing axis by the Coriolis force when gyroscopes are rotating at some angular velocity. In practical situations, temperature change, manufacturing errors, quadrature errors are all factors that will deteriorate the performance of gyroscopes and will lead to false output; thus, it is necessary to use advanced control methods to control gyroscopes.
To handle the factors that will hinder the measurement and improve the performance of gyroscopes, many professionals have done much research in the field. Adaptive control, sliding mode control, intelligent control all have been used to improve the performance of gyroscopes. Juan et al. [1] introduced an adaptive fuzzy approach for the MEMS gyroscope where non-linear parts are compensated. Fazlyab et al. [2] applied fuzzy sliding mode control to a z-axis MEMS gyroscope and the parameters of the system can be estimated. Wang et al. [3] proposed a T-S fuzzy model based robust adaptive sliding mode control for the MEMS gyroscope. Besides, adaptive control and intelligent control [4–12] are commonly combined in control methods to improve control performances.
Usually, position and velocity signals are essential in the design of control force. Sometimes, it is difficult or even impossible to measure the states and adding physical sensors will add to the complexity of the system. So, states observer is a feasible method to solve the problem and it has been developed in many areas. Laurent et al. [13] derived an adaptive controller with observer for the magnetic guided microrobot. Kim et al. [14] investigated disturbance-observer-based position tracking controller and carried out the method in electrohydraulic actuators. Jiang et al. [15] proposed an adaptive neural observer-based backstepping fault tolerant control and applied the method in the near space vehicle under control effector damage. Chen et al. [16] proposed a direct adaptive neural control based on disturbance observer for a class of uncertain nonaffine nonlinear systems. Li et al. [17] presented an adaptive fuzzy backstepping control of static var compensator based on state observer. An adaptive observer backstepping control using neural networks was proposed for the single-input–single-output system by Choi [18]. Yao et al. [19] introduced extended-state-observer-based output feedback nonlinear robust control of hydraulic systems with backstepping. Tong et al. [20] derived an observer-based adaptive fuzzy backstepping output feedback control of uncertain multiple-input-multiple-output pure-feedback nonlinear systems. A novel SPR-filter approach using indirect adaptive fuzzy control scheme based on observer was investigated by Boulkroune [21]. An observer-based adaptive neural network control was derived by Zhou et al. [22] and was applied in nonlinear stochastic systems. Ting et al. [23] studied the model of linear stepping motor and derived an observer-based back-stepping control. Xu et al. [24] proposed an observer-based fuzzy adaptive control of nonlinear systems with actuator fault and unmodeled dynamics. An output feedback dynamic surface control was derived by Yoo et al. [25] in the application of flexible-joint robots. Na et al. [26] proposed an adaptive control for nonlinear pure-feedback systems with high-order sliding mode observer.
It can be found from [1] and [3] that the states of the gyroscope are assumed to be measurable and the states are directly used in the design of control forces. If the states are assumed to be unmeasurable and the states can not be used directly, the control forces can hardly be carried out, thus a states observer can be used to estimate system states and the states estimation can be used in the design process. This paper proposes a backstepping controller using states observer for z-axis gyroscopes. All the states are replaced by the states estimation. Adaptive laws in both states observer and controller are derived in framework of Lyapunov stability theory, so the stability of the entire system can be guaranteed. The contribution of the control scheme can be concluded as follows:
-
1.
In the presence of disturbances, an adaptive neural observer is proposed to estimate gyroscope states. The complexity of the gyroscope system will be reduced for not installing physical sensors. Lyapunov stability theorem guarantees bounded estimation error.
-
2.
A backstepping controller is carried out with states estimation rather than actual gyroscope states. This solves the problem when gyroscope states are essential in controller design procedure while they are unavailable in actual circumstances.
-
3.
The combination of backstepping controller and states observer is applied to MEMS gyroscopes for the first time.
The paper is organized by 5 parts in all. In Sect. 2, the dynamics of MEMS gyroscope are studied through non-dimensional transformation. The design of the states observer is presented in Sect. 3 where the stability of the observer is analyzed with Lyapunov stability theory as well. In Sect. 4, the backstepping controller using states estimation is proposed. Simulation results are shown in Sect. 5 to verify the effect of the control method and observer. Section 6 gives the conclusion.
2 Dynamics of MEMS gyroscope
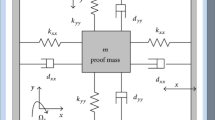
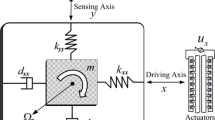
Generally, a vibratory gyroscope consists of a proof mass suspended by springs, the driving mechanism and the sensing mechanism. The proof mass is two-degree-free which means that the proof mass can only move on the plane of X–O–Y. The electrostatic driven mechanism is set to force the proof mass to oscillate while the sensing mechanism is set to sense the position and velocity of the proof mass. A z-axis vibratory gyroscope is shown in Fig. 1.

Schematic model of a z-axis vibratory gyroscope
We assume that the gyroscope is rotating about the z axis at a constant velocity over a long time interval. The dynamics of the Gyroscope can be described as:
where \( x \) and \( y \) are the coordinates of the proof mass in the direction of \( X \) and \( Y \),\( k_{xx} \), \( k_{yy} \) are the spring coefficients and \( d_{xx} \),\( d_{yy} \) are the damping coefficients along the \( X \) and \( Y \) axis. For the fabrication imperfection and the fact that the structure of the gyroscope is not totally symmetric and the asymmetric structure contributes mainly to the cross spring term \( k_{xy} \) and cross damping term \( d_{xy} \). \( m \) is the weight of the proof mass, and \( u_{x} \) and \( u_{y} \) are the control forces in the \( X \) and \( Y \) direction.
We can get the non-dimensional form of the dynamics by dividing both sides of (1) with \( m,q_{0} ,\omega_{0}^{2} \) where \( m,q_{0} ,\omega_{0}^{2} \) represent the reference mass, length and natural resonance frequency respectively. The dynamics of the gyroscope can be rewritten in non-dimensional form as:
where \( \frac{{d_{xx} }}{{m\omega_{0} }} \to d_{xx} \), \( \frac{{d_{xy} }}{{m\omega_{0} }} \to d_{xy} \), \( \frac{{d_{yy} }}{{m\omega_{0} }} \to d_{yy} \), \( \frac{{\varOmega_{z} }}{{\omega_{0} }} = \varOmega_{z} \), \( \sqrt {\frac{{k_{xx} }}{{m\omega_{0}^{2} }}} \to \omega_{x} \), \( \sqrt {\frac{{k_{yy} }}{{m\omega_{0}^{2} }}} \to \omega_{y} \), \( \frac{{k_{xy} }}{{m\omega_{0}^{2} }} \to \omega_{xy} \).
The dynamics of the model can be rewritten in the vector form as
where \( q = \left[ {\begin{array}{*{20}c} x \\ y \\ \end{array} } \right] \), \( u = \left[ {\begin{array}{*{20}c} {u_{x} } \\ {u_{y} } \\ \end{array} } \right] \), \( D = \left[ {\begin{array}{*{20}c} {d_{xx} } & {d_{xy} } \\ {d_{xy} } & {d_{yy} } \\ \end{array} } \right] \), \( K = \left[ {\begin{array}{*{20}c} {\omega_{x}^{2} } & {\omega_{xy} } \\ {\omega_{xy} } & {\omega_{y}^{2} } \\ \end{array} } \right] \), \( \varOmega = \left[ {\begin{array}{*{20}c} 0 & { - \varOmega_{z} } \\ {\varOmega_{z} } & 0 \\ \end{array} } \right] \).
3 Adaptive neural observer design
In this section, an adaptive observer based on RBF (Radial Basis Function) neural network is proposed to estimate the states of the gyroscope. In order to avoid using the states in the design of control force, the states estimation from the observer is used to replace the position and velocity signals of the proof mass, thus the control force can be achieved without using gyroscope states. The nonlinear part in the model caused by parameter variation can be approximated by the neural network, and arbitrary small estimation error can be achieved.
Rewrite the dynamics in state space form as
where \( A = \left[ {\begin{array}{*{20}c} 0 & 1 & 0 & 0 \\ { - \omega_{x}^{2} } & { - d_{xx} } & { - \omega_{xy} } & { - (d_{xy} - 2\varOmega_{z} )} \\ 0 & 0 & 0 & 1 \\ { - \omega_{xy} } & { - (d_{xy} + 2\varOmega_{z} )} & { - \omega_{y}^{2} } & { - d_{yy} } \\ \end{array} } \right] \), \( B = \left[ {\begin{array}{*{20}c} 0 & 0 \\ 1 & 0 \\ 0 & 0 \\ 0 & 1 \\ \end{array} } \right] \), \( C = \left[ {\begin{array}{*{20}c} 1 & 0 \\ 0 & 0 \\ 0 & 1 \\ 0 & 0 \\ \end{array} } \right] \), \( u = \left[ {\begin{array}{*{20}c} {u_{x} } \\ {u_{y} } \\ \end{array} } \right] \) \( X = [x_{1} {\kern 1pt} {\kern 1pt} {\kern 1pt} \dot{x}_{1} {\kern 1pt} {\kern 1pt} {\kern 1pt} x_{2} {\kern 1pt} {\kern 1pt} {\kern 1pt} \dot{x}_{2} ]^{T} \).
By taking the parameters variation and external disturbance into account, the model can be rewritten as:
where \( X \in R^{n} \), \( y \in R^{m} \), \( A \in R^{n \times n} \), \( B \in R^{n \times m} \), \( u \in R^{m} \); \( \Delta A \) represents unknown parameters variation in \( A \),\( d(t) \) is an external disturbance.
Assumption 1
There exist some appropriate functions \( f_{m} \), \( d_{u} \) such that \( \Delta AX = Bf_{m} \) and \( d(t) = Bd_{u} \). Therefore, the dynamics can be expressed as
where \( f_{m} \), \( d_{u} \) represent the parameter uncertainties and external disturbance.
The observer is proposed as
where \( \hat{X} \) is the estimation of \( X \),\( \hat{y} \) is the estimation of the gyroscope output \( y \), \( \hat{f}_{m} \) is the estimation of the unknown function \( f_{m} \), \( u \) is the control force, the robust term \( v \) is set to address the parameter variation and disturbance, \( K \) is the gain vector.
Define the states estimation error as
The derivative of the states estimation error becomes
Substitute the gyroscope model (6) and the observer (7) into the derivative of the states estimation error gives
Define the output estimation error as \( \tilde{y} = y - \hat{y} \), then the states estimation error and output estimation error become
where \( \tilde{f}_{m} \) is the nonlinear function approximation error, which is expressed as
The Laplace transform of \( \dot{\tilde{X}} \) in (9) becomes
The Laplace transform of \( \tilde{y} \) in (9) becomes
Lemma 1
[26] Meyer-Kalman-Yokubovic (MKY) If a proper transfer function \( H(S) = C^{T} (SI - A)^{ - 1} B \) with \( A \) a Hurwitz matrix is SPR (strictly positive real), then for any given \( Q = Q^{T} > 0 \), there exist a \( P = P^{T} > 0 \) such that
Lemma 2
[26] Consider the linear time-invariant system in the form
with \( x(t) \in R^{n} \),\( u(t) \in R^{m} \) and the matrices \( A \in R^{n \times n} \),\( B \in R^{n \times m} \). Then, every solution \( x(t) \) of the system is such that
with \( k_{1} \) decaying exponentially to zero and \( k_{2} \) a positive constant that depends on the eigenvalues of \( A \).
For the great advantage of neural network in dealing with nonlinear systems, a RBF neural network is adopted to approximate the unknown function \( f_{m} \).
The structure of a RBF network is a three-lawyer feed forward network. The input layer passes input signals without any operation; the hidden layer performs activation function in each node of the layer and the output layer gives the output. The structure of a RBF network is shown in Fig. 2.

Architecture of a RBF network
The output of the NN can be described as
where \( \omega = [\omega_{1} {\kern 1pt} {\kern 1pt} {\kern 1pt} \omega_{2} {\kern 1pt} \ldots {\kern 1pt} {\kern 1pt} {\kern 1pt} \omega_{n} ]^{T} \) is the weight vector and \( \omega_{n} \) is the neural weight connecting the nth neuron in the hidden layer and the output neuron. \( \phi \) represents the activation function that is performed in every node in the hidden layer; \( \phi = [\phi_{1} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} \phi_{2} {\kern 1pt} \ldots {\kern 1pt} \phi_{n} ]^{T} \) is the output vector of the hidden layer. Gaussian function is usually chosen as the activation function and the output of the nth node in the hidden layer is given by
where \( c_{n} \) and \( b_{n} \) are the center and the width of the Gaussian function respectively.
The \( f_{m} \) can be expressed as
where \( W \) is the optimal weight of the network, \( \sigma (X) \) is the Gaussian function in terms of the states \( X \), \( \varepsilon (X) \) is the approximation error.
We assume that the approximation error and the weight are bounded by known bounds, such as \( \left| {\varepsilon (X)} \right| \le \varepsilon_{d} \), \( \left\| W \right\|_{F} \le W_{M} \), where \( \varepsilon_{d} \),\( W_{M} \) are positive constants.
Let the estimation of \( f_{m} \) be given by
where the input of the Gaussian function is the states estimation instead of the states of the gyroscope for the purpose of avoiding to use the gyroscope states.
Substituting (15) and (16) into (10) yields
Define the Gaussian function error as
Substituting (18) into (17) yields
where the weight error is given by \( \tilde{W} = W - \hat{W} \), the disturbance term is defined as \( W_{{}}^{T} \tilde{\sigma }(X) = \rho \), and \( \rho \) is bounded such as \( \left\| \rho \right\| \le \beta \), where \( \beta \) is a positive constant.
Substituting \( \hat{f}_{m} \) in (16) into the observer in (7), we can get
Substituting \( \tilde{f}_{m} \) in (17) into the states estimation error in (9) yields
Substituting (17) into (12), the output estimation error becomes
where \( H(S) \) is a transfer function with stable poles which are realized by \( (A - KC^{T} ,B,C) \).
The output estimation error (22) can be rewritten as
where \( L^{ - 1} (S) \) is a transfer function with stable poles and the over bar means that all the signals are filtered by \( L^{ - 1} (S) \),such as \( \bar{\sigma } = L^{ - 1} (S)\sigma \), \( \bar{\rho } = L^{ - 1} (S)\rho \), \( \bar{\varepsilon } = L^{ - 1} (S)\varepsilon \), \( \bar{d}_{u} = L^{ - 1} (S)d_{u} \), \( \bar{v} = L^{ - 1} (S)v \).
And in (23), the term \( \delta \) is defined as
Rewrite \( \delta \) in the form \( \delta = L^{ - 1} (S)(\tilde{W}_{{}}^{T} \sigma ) - \tilde{W}_{{}}^{T} L^{ - 1} (S)\sigma \), it can be concluded that \( \delta \) is bounded such as \( \left\| \delta \right\| \le c_{1} \left\| {\tilde{W}} \right\|_{F} \), where \( c_{1} \) is a computable positive constant.
The error dynamics can be realized as
Remark 1
\( A_{c} \in R^{n \times n} \),\( B_{c} \in R^{n \times m} \), \( C_{c} = C \) is the minimal state space representation of \( H(S)L(S) \) such as
Define a Lyapunov function candidate as:
where \( P = P_{{}}^{T} > 0 \) , \( F = F_{{}}^{T} > 0 \).
Differentiating \( V_{1} \) with respect to time yields
Remark 2
Lemma 1 is referred to in the reasoning process of (27). For \( H(S)L(S) \) is SPR, according to Lemma 1, there exists a proper matrix \( P = P_{{}}^{T} > 0 \) such that \( A_{c}^{T} P + PA_{c} = - Q \),\( PB_{c} = C_{c} \),\( Q = Q_{{}}^{T} > 0 \) .
and \( \Delta = \tilde{W}_{{}}^{T} \bar{\sigma } + \bar{\delta } + \bar{\rho } + \bar{\varepsilon } + \bar{d}_{u} + \bar{v} \). Thus, the Eq. (27) is proved.
To make \( \dot{V}_{1} \le 0 \), we can choose the adaptive law as
Substituting (29) into (27) gives
where \( tr( - \tilde{W}_{{}}^{T} \bar{\sigma }\tilde{y}) = - \tilde{y}\tilde{W}_{{}}^{T} \bar{\sigma } \)
Remark 3
In the reasoning process of (30), the design of robust term in the observer in (7) is set as
where \( D \ge \beta \sigma_{M} \),\( \sigma_{M} = \sigma_{\hbox{max} } [L^{ - 1} (S)] \). And the result in (32) is derived to finish the proof of (30)
with \( \left\| \delta \right\| \le c\left\| {\tilde{W}} \right\|_{F} \) mentioned above. If \( \tilde{y} \) is 0, \( v \) is set as 0, (32) can still be derived to finish the proof of (30).
With the inequality derived in (32) and using the norm inequality below
(30) becomes
For \( \sigma_{M} = \sigma_{\hbox{max} } (L^{ - 1} (S)) \), \( \bar{\varepsilon } = L^{ - 1} (S)\varepsilon \), \( \bar{d}_{u} = L^{ - 1} (S)d_{u} \) and \( \varepsilon_{d} \), \( d_{ud} \) are the bounds of \( \varepsilon \), \( d_{u} \), we can get:
Substituting (34) into (33) yields
where
\( \alpha = W_{M} + \frac{c}{K}, \)
To make \( \dot{V}_{1} < 0 \), we get the following conditions to be satisfied
Or
\( \dot{V}_{1} \) is negative outside the set defined by (36) and (37). This demonstrates that \( \tilde{y} \), \( \tilde{W} \) are UUB (uniformly ultimately bounded); any excursion of \( \tilde{y} \), \( \tilde{W} \) beyond the bounds set by the conditions in (36) and (37) will cause decrease in the Lyapunov function. That is to say the bounds defined by the right side of Eqs. (36) and (37) can be taken as the bounds on \( \left| {\tilde{y}} \right| \) and \( \left\| {\tilde{W}} \right\|_{F}^{{}} \); and arbitrary small error bounds can be achieved by setting large \( K \) and small \( \sigma_{M} \).
Consider the estimation error dynamics in (21), according to Lemma 2, the bounds of \( \tilde{x} \) can be expressed such that \( \left\| {\tilde{x}(t)} \right\| \le m_{0} + m_{1} \left\| u \right\|_{2}^{\alpha } \). For \( \tilde{u} = \tilde{W}_{{}}^{T} \hat{\bar{\sigma }} + \bar{\delta } + \bar{\rho } + \bar{\varepsilon } + \bar{d}_{u} + \bar{v} \), it can be seen that all the terms in \( \tilde{u} \) are all bounded and mostly relative to the neural weight error \( \tilde{W} \), using Lemma 2 and norm inequality yields \( \left\| {\tilde{x}(t)} \right\| \le m_{0} + m_{1} (c_{1} + c_{2} \left\| {\tilde{W}_{F} } \right\|_{F}^{\alpha } ) \) with \( m_{0} \) decaying exponentially to zero and \( m_{1} \) a positive constant that depends on the eigenvalues of \( A \); \( c_{1} \), \( c_{2} \) are computable constants. It has been proven that \( \left\| {\tilde{W}} \right\|_{F}^{{}} \) is bounded, thus \( \left\| {\tilde{x}(t)} \right\| \) is also bounded.
4 Backstepping controller using states estimation
In this section, a backstepping controller is proposed using the states estimation. The control objective is to make the states \( X_{1} \) to track the reference trajectory \( X_{1d} \). And the novelty is that the controller is designed with the states estimation in stead of practical states.
The block diagram of the backstepping controller with neural states observer is depicted in Fig. 3. States estimation is incorporated in the controller to replace the states of the gyroscope. The design procedure of the backstepping controller using states estimation is investigated step by step as follows:

Block diagram of the backstepping controller with neural states observer
We consider the Eq. (4) as the system model, the states are defined as \( X_{1} = q \) and \( X_{2} = \dot{q} \). The system model can be rewritten in state-space form as
The output is expressed as
Consider the model with parameter variation and external disturbances, according to (4), the system model can be rewritten as
Step 1. Define the tracking error as
Differentiating the tracking error with respect to time yields
Define the tracking error of \( \hat{X}_{2} \) as
where \( \hat{X}_{2d} \) is the virtual control force
The virtual control \( \hat{X}_{2d} \) is chosen as
where \( a_{1} \) is a positive constant.
Substituting (44) into (42) gives
Choose the first Lyapunov function as
and the derivative of \( V_{2} \) is
If \( e_{2} \to 0 \), then
\( \dot{V}_{2} = - a_{1} e_{1}^{2} < 0 \).
As can be seen in (7), the observer is designed as
Step 2. Differentiating \( e_{2} \) with respect to time and using (48), we obtain
Define the second Lyapunov candidate as
and the derivative of \( V_{3} \) is expressed as
According to (51), to make \( \dot{V}_{3} \) negative, the control law can be designed as
where \( a_{2} \) is a non-zero positive constant.
Theorem 1
If the control force in (52) is applied to gyroscope model described in (40), the entire system is stable.
Proof
Substituting the controller (52) into (51) gives
This implies that \( \dot{V}_{3} \) is a negative semi-definite function; \( \dot{V}_{3} \) is negative semi-definite ensures that \( e_{1} \), \( e_{2} \) are bounded. For \( \dot{V}_{3} \le 0 \), the integral of \( \dot{V}_{3} \) is \( \int\limits_{0}^{t} {\dot{V}_{3} (t)} dt = V_{3} (t) - V_{3} (0) \le 0 \). Since \( V_{3} (0) \) is bounded and \( V_{3} (t) \) is a non-increasing and bounded function, \( e_{1} \), \( e_{2} \) are bounded. So, \( {\ddot{V}}_{3} (t) = - 2a_{1} e_{1} \dot{e}_{1} - 2a_{2} e_{2} \dot{e}_{2} \) is also bounded.\( {\ddot{V}}_{3} (t) \) is bounded implies that \( \dot{V}_{3} \) is uniformly continuous in the time domain. According to Barbalat lemma, it can be concluded that \( \dot{V}_{3} (t) \) will converge to zero, which means that \( e_{1} \), \( e_{2} \) will converge to zero. Thus, with arbitrary small error between gyroscope states and their estimation, the trajectory tracking object can be achieved and the tracking error will converge to zero.
5 Simulation study
According to the proposed observer based backstepping control approach, the simulation is performed in MATLAB/Simulink software. The parameters of the MEMS gyroscope are set as follows:
choose the reference length \( q_{0} = 1 \) μm, the reference frequency \( \omega_{0} = 1\;{\text{kHz}} \), and the angular velocity \( \varOmega_{z} = 100\;{\text{rad/s }} \). Through non-dimensional transform, the parameters can be obtained:
The control objective is to make the system states to track the desired trajectory given by:
We choose the initial states as \( X_{0} = \left[ {\begin{array}{*{20}c} 0 & 0 & 0 & 0 \\ \end{array} } \right] \), the external disturbances as \( d = \left[ {\begin{array}{*{20}c} {d_{1} } \\ {d_{2} } \\ \end{array} } \right] = \left[ {\begin{array}{*{20}c} {10\sin (\omega_{1} t)} \\ {10\sin (\omega_{2} t)} \\ \end{array} } \right] \). For comparison, another case is provided where the disturbance is chosen as \( d = \left[ {\begin{array}{*{20}c} {d_{1} } \\ {d_{2} } \\ \end{array} } \right] = \left[ {\begin{array}{*{20}c} {10{\text{random}}(1)} \\ {10{\text{random}}(1)} \\ \end{array} } \right] \).
Parameters of the observer are set as follows:
The gain of the observer \( K = \left[ \begin{aligned} K_{1} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 0 \hfill \\ 0{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} K_{2} \hfill \\ \end{aligned} \right] = \left[ \begin{aligned} 900{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 0 \hfill \\ 0{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 900 \hfill \\ \end{aligned} \right] \), gain of the robust part \( D = \left[ \begin{aligned} D_{1} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 0 \hfill \\ 0{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} D_{2} \hfill \\ \end{aligned} \right] = \left[ \begin{aligned} 900{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 0 \hfill \\ 0{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 900 \hfill \\ \end{aligned} \right] \), and the transfer function with stable pole is set as \( L^{ - 1} (s) = \frac{1}{S + 3}. \)
Parameters in the backstepping control are set as:\( a = \left[ \begin{aligned} a_{1} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 0 \hfill \\ 0{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} a_{2} \hfill \\ \end{aligned} \right] = \left[ \begin{aligned} 5{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 0 \hfill \\ 0{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 5 \hfill \\ \end{aligned} \right] \)
In the design of the adaptive neural network part, the parameters are set as: \( F = \left[ \begin{aligned} F1{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} 0 \hfill \\ 0{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} F2 \hfill \\ \end{aligned} \right] = \left[ {\begin{array}{*{20}c} {0.01} & 0 \\ 0 & {0.01} \\ \end{array} } \right] \). The center and width of the Gaussian function of the neural network is chosen as \( c = 0.1*{\text{ones}}\;(1,{\text{node}}) \) and \( b = 0.3*ones(1,node) \) and node is the number of neurons in the hidden layer where \( node = 40 \).
Figures 4, 5, 6, 7, 8, 9 are simulation results where the disturbance is chosen as \( d = 10*\sin (\omega t) \) and Figs. 10, 11, 12, 13 present tracking and estimation performance where a random signal with zero mean and unity variance is chosen as the disturbance.

Position tracking of X and Y axis (\( d = 10 \times \sin (\omega t) \))

Tracking errors of X and Y axis (\( d = 10 \times \sin (\omega t) \))

Position estimation of X and Y axis (\( d = 10 \times \sin (\omega t) \))

Position estimation error of X and Y axis (\( d = 10 \times \sin (\omega t) \))

Control inputs of X and Y axis (\( d = 10 \times \sin (\omega t) \))

Partial enlarged drawing of control inputs of X and Y axis (\( d = 10 \times \sin (\omega t) \))

Position tracking of X and Y axis (\( d = 10 \times {\text{random}}(1) \))

Tracking error of X and Y axis (\( d = 10 \times {\text{random(}}1) \))

Position estimation of X and Y axis (\( d = 10 \times {\text{random}}(1) \))

Position estimation error of X and Y axis (\( d = 10 \times {\text{random}}(1) \))
Figure 4 depicts the position tracking performance with backstepping control. It can be observed from Figs. 4 and 5 that the position in the \( X \),\( Y \) direction can track the given trajectory in a short time and the tracking error converges to zero asymptotically. That is to say that the designed backstepping controller can maintain the proof mass to oscillate in the \( X \), \( Y \) direction at the given frequency and amplitude.
Figure 6 depicts the position estimation performance and Fig. 7 depicts the estimation error in the \( X \), \( Y \) direction. It can be observed from Figs. 6 and 7 that the position estimation can track the gyroscope position in a short time and the tracking error is within a small bound. Thus, the states estimation can be adopted to replace the position of the gyroscope. Figures 8 and 9 depict the control force along the \( X \) axis and \( Y \) axis where the control force is very smooth.
Figures 10 and 11 depict the trajectory tracking and tracking error where the disturbance is chosen as \( d = 10*random(1) \). It can be observed form Fig. 10 that the system states can still track the desired trajectory although a random signal is a much stronger disturbance. But it can also been seen that the bound of tracking error becomes larger.
The states estimation and estimation error are shown in Figs. 12 and 13. It can be found form Fig. 12 that the states estimation(blue dotted line) almost overlap with system states(read line) which means that the states observer can correctly estimate the system states. And the bound of estimation error also becomes larger because the random signal disturbance is a stronger disturbance.
It can be concluded that the proposed estimator can correctly estimate gyroscope states in the presence of disturbance and estimation errors under different disturbances in Figs. 7 and 13 show that the proposed estimator has very good robustness. Tracking errors in Figs. 5 and 11 show that it is feasible to use states estimation in controller design.
6 Conclusion
In the paper, a backstepping control scheme with adaptive neural observer is proposed for MEMS gyroscopes. The states estimation is used to replace actual gyroscope states in the controller design. Thus, the control force can be derived without using gyroscope states and this can help to reduce the complexity of the system for not installing physical sensors in the system. Both the controller and the observer are designed in the sense of Lyapunov stability theory, so bounded states estimation error can be achieved and the stability of the entire control system is guaranteed.
Numerical simulations demonstrate that the gyroscope trajectory can track the command trajectory very well. Small estimation error and tracking error indicate that it is feasible to use states estimation in controller design procedure. Simulation results also show strong robustness to different disturbances.
References
Juan W, Fei J (2013) Adaptive fuzzy approach for non-linearity compensation in MEMS gyroscope. Trans Inst Meas Control 35(8):1008–1015
Fazlyab M, Pedram MZ (2013) Parameter estimation and interval type-2 fuzzy sliding mode control of a z-axis MEMS gyroscope. ISA Trans 52(6):900–911
Wang S, Fei J (2014) Robust adaptive sliding mode control of MEMS gyroscope using T–S fuzzy model. Nonlinear Dyn 77(1–2):361–371
Ashfaq RAR, Wang XZ, Huang JZX, Abbas H, He YL (2016) Fuzziness based semi-supervised learning approach for intrusion detection system. Inf Sci. doi:10.1016/j.ins.2016.04.019 (in press)
Gao S, Ning B, Dong H (2015) Adaptive neural control with intercepted adaptation for time-delay saturated nonlinear systems. Neural Comput Appl 26(8):1–9
Wang XZ, Ashfaq RAR, Fu AM (2015) Fuzziness based sample categorization for classifier performance improvement. J Intell Fuzzy Syst 29(3):1185–1196
Wang XZ (2015) Learning from big data with uncertainty—editorial. J Intell Fuzzy Syst 28(5):2329–2330
Gao S, Dong H, Ning B, Chen L (2015) Neural adaptive control for uncertain nonlinear system with input saturation: state transformation based output feedback. Neurocomputing 159(1):117–125
He YL, Wang XZ, Huang JZX (2016) Fuzzy nonlinear regression analysis using a random weight network. Inf Sci. doi:10.1016/j.ins.2016.01.037 (in press)
Gao S, Dong H, Ning B, Sun X (2015) Neural adaptive control for uncertain MIMO systems with constrained input via intercepted adaptation and single learning parameter approach. Nonlinear Dyn 82(3):1–18
Cui LZ, Yu FR, Yan Q (2016) When big data meets software-defined networking: SDN for big data and big data for SDN. IEEE Netw 30(1):58–65
Gao S, Dong H, Sun X, Ning B (2015) Neural adaptive chaotic control with constrained input using state and output feedback. Chin Phys B 24(1):170–176
Laurent, Matthieu F, Antoine F (2013) Adaptive controller and observer for a magnetic microrobot. IEEE Trans Robot 29(4):1060–1067
Wonhee K, Donghoon S, Daehee W (2013) Disturbance-observer-based position tracking controller in the presence of biased sinusoidal disturbance for electrohydraulic actuators. IEEE Trans Control Syst Technol 21(6):2290–2298
Jiang, Xu D, Shi P, Lim CC (2014) Adaptive neural observer-based backstepping fault tolerant control for near space vehicle under control effector damage. IET Control Theory Appl 8(9):658–666
Chen M, Ge S (2013) Direct adaptive neural control for a class of uncertain nonaffine nonlinear systems based on disturbance observer. IEEE Trans Cybern 43(4):1213–1225
Li Y, Tong S, Li T (2013) Adaptive fuzzy backstepping control of static var compensator based on state observer. Nonlinear Dyn 73(1–2):133–142
Choi J, Farrell J (2001) Adaptive observer backstepping control using neural networks. IEEE Trans Neural Netw 12(5):1103–1112
Yao Y, Jiao Z, Ma D (2014) Extended-state-observer-based output feedback nonlinear robust control of hydraulic systems with backstepping. IEEE Trans Industr Electron 61(11):6285–6293
Tong S, Li Y, Shi P (2012) Observer-based adaptive fuzzy backstepping output feedback control of uncertain MIMO pure-feedback nonlinear systems. IEEE Trans Fuzzy Syst 20(4):771–785
Boulkroune A, Bounar N, M’Saad, Farza M (2014) Indirect adaptive fuzzy control scheme based on observer for nonlinear systems: a novel SPR-filter approach. Neurocomputing 135(SI):378–387
Zhou Q, Shi P, Xu S, Li H (2013) Observer-based adaptive neural network control for nonlinear stochastic systems with time delay. IEEE Trans Neural Net Learn Syst 24(1):71–80
Ting, Chang Y (2013) Observer-based backstepping control of linear stepping motor. Control Eng Pract 21(7):730–739
Xu Y, Tong S, Li YM (2013) Observer-based fuzzy adaptive control of nonlinear systems with actuator faults and unmodeled dynamics. Neural Comput Appl 23(S1):391–405
Yoo S, Park J, Choi Y (2008) Output feedback dynamic surface control of flexible joint robots. Int J Control Autom Syst 6(2):223–233
Na J, Ren X, Zheng D (2013) Adaptive control for nonlinear pure-feedback systems with high-order sliding mode observer. IEEE Trans Neural Netw Learn Syst 24(3):370–382
Acknowledgments
The authors thank the anonymous reviewers for your constructive comments that improved the quality of the paper. This work is partially supported by National Science Foundation of China under Grant No. 61374100; Natural Science Foundation of Jiangsu Province under Grant No. BK20131136.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Lu, C., Fei, J. Backstepping control of MEMS gyroscope using adaptive neural observer. Int. J. Mach. Learn. & Cyber. 8, 1863–1873 (2017). https://doi.org/10.1007/s13042-016-0564-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-016-0564-5