
Abstract
Twin-hypersphere support vector machine (THSVM) for binary pattern recognition aims at generating two hyperspheres in the feature space such that each hypersphere contains as many as possible samples in one class and is as far as possible from the other one. THSVM has a fast learning speed since it solves two small sized support vector machine (SVM)-type quadratic programming problems (QPPs). However, it only simply considers the prior class-based structural information in the optimization problems. In this paper, a structural information-based THSVM (STHSVM) classifier for binary classification is presented. This proposed STHSVM focuses on the cluster-based structural information of the corresponding class in each optimization problem, which is vital for designing a good classifier in different real-world problems. In addition, it also leads to a fast learning speed since this STHSVM solves a series of smaller-sized QPPs compared with THSVM. Experimental results demonstrate that STHSVM is superior in generalization performance to other classifiers.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Support vector machine (SVM) [1–3] finds the maximal margin between two classes [4] by solving a quadratic programming problem (QPP) in the dual space based on the structural risk minimization principle. Within a few years after its introduction SVM not only has a serious of improvements [5, 6], but also has already outperformed most other systems in a wide variety of applications [7–9]. However, classical SVM not only has the large computational cost, but also usually pays more attention to the separation between classes than the prior structural information within classes. In fact, for different real-world problems, different classes may have different underlying data structures.
Recently, a class of nonparallel hyperplane classifiers have been developed. For instance, TWSVM [10] aims at generating a pair of nonparallel planes such that each plane is as close as possible to the corresponding class and is at least one far from the other class. To this end, it solves a pair of smaller-sized QPPs, instead of a large one in SVM, making the learning speed of TWSVM be approximately four times faster than that of SVM in theory [10]. Some extensions to TWSVM include the least squares TWSVM (LSTWSVM) [11], nonparallel-plane proximal classifier (NPPC) [12], \(\nu\)-TWSVM [13], twin parametric-margin SVM (TPMSVM) [14], projection twin support vector machine (PTSVM) [15], nonparallel hyperplane SVM (NHSVM) [16], twin support vector regression (TSVR) [17], and twin parametric insensitive support vector regression (TPISVR) [18].
Different from TWSVM which seeks a hyperplane for each class using a SVM-type formulation, Peng and Xu [19] proposed a twin-hypersphere support vector machine (THSVM) classifier for binary classification, which aims at generating two hyperspheres in the feature space such that each hypersphere contains as many as possible samples in one class and is as far as possible from the other one. The THSVM not only has a faster learning speed than classical SVM since it solves two smaller sized QPPs instead of a large QPP as in classical SVM, but also successfully avoids the shortcomings in TWSVM [19], such as the matrix inversion problem. In this paper, we mainly focus on this THSVM.
As the relation between the structural information of data and SVM, it is desirable that an SVM classifier be adaptable to the discriminant boundaries to fit the structures in the data, especially for increasing the generalization capacities of the classifier. Fortunately, some algorithms have been developed to focus more attention on the structural information than SVM recently. They provide a novel view in which to design a classifier, that is, a classifier should be sensitive to the structure of data distribution [20]. These algorithms can be mainly divided into two kinds of approaches. The first one is manifold assumption-based, which assumes that the data actually lie on a sub-manifold in the input space. A typical model is Laplacian SVM (LapSVM) [21, 22]. LapSVM constructs a Laplacian graph for each class on top of the local neighborhood of each point to form the corresponding Laplacian (matrix) to reflect the manifold structure of individual-class data. They are then embedded into the traditional framework of SVM as additional manifold regularization terms. The second approach is cluster assumption-based [23], which assumes that the data contains clusters. For instance, structured large margin machine (SLMM) [20], ellipsoidal kernel machine (EKM) [24], minimax probability machine (MPM) [25], and maxi-min margin machine (\(\text {M}^4\)) [26]. However, the computational cost of these approaches is larger than classical SVM. More recently, Xue et al. [27] proposed a structural regularized SVM (SRSVM). This SRSVM embeds a cluster granularity into the regularization term to capture the data structure, Peng et al. [28] proposed a structural regularized PTSVM (SRPTSVM) for data classification in the spirit of this SRSVM.
THSVM only considers the relationship between two classes, i.e., it finds two hyperspheres to respectively cover the classes of points. In other words, it embeds the class granularity-based structural information [27] into the optimization problems, but not the covariance matrices of two classes. However, this structural information is too rough for real-world problems, which makes THSVM can not find the reasonable projection for each class, then reduce the generalization performance. To overcome this shortcoming, we present an improvement version for THSVM in this paper, called the structural-information-based THSVM (STHSVM) classifier. This STHSVM respectively embeds the data structures of two classes into the optimization problems based on the cluster granularity [27]. That is, in the pair of optimization problems of STHSVM, it considers the cluster-based structural-information constraints for each class, i.e., it introduces a series of hyperspheres but not a single hypersphere to respectively cover the corresponding class of points. Further, for each point in the opposite class, this STHSVM wishes it be as far as possible from the centers of all hypersphres under the given probability values. This STHSVM only needs to solve a series of much smaller sized QPPs compared with THSVM, indicating it has a much faster learning speed than THSVM for solving their QPPs. The experiment results show that this STHSVM obtains the better generalization than THSVM and the other classifiers.
The rest of this paper is organized as follows: Sect. 2 briefly introduces the structural granularities of data and THSVM. Section 3 presents the proposed STHSVM. Experimental results both on the toy and real-world problems are given in Sect. 4. Some conclusions and possible further work are drawn in Sect. 5.
2 Background
In this paper, the training samples are denoted by a set \({\mathcal {D}}=\{( {x}_i,y_i)\}_{i=1}^l\), where \({x}_i\in {\mathcal {X}}\subset {\mathcal {R}}^m\) and \(y_i\in \{+1,-1\}\), \(i=1,\ldots ,l\). For simplicity, we use \({\mathcal {I}}_{\pm }\) to denote the sets of index \(i\) such as \(y_i=\pm\), \(k=1,2\), use the set \({\mathcal {I}}\) to denote all point indices, i.e., \({\mathcal {I}}= \mathcal {I}_+\cup {\mathcal {I}}_-\), and use the matrices \({C}\in {\mathcal {R}}^{m\times {l}}\), \({C}_+\in {\mathcal {R}}^{m\times {l_+}}\) and \({C}_-\in {\mathcal {R}}^{m\times {l_-}}\) to represent all training points, and points belonging to classes \(\pm 1\), respectively, where \(l_\pm =|{\mathcal {I}}_\pm |\).
2.1 Structural granularity
Let \({\mathcal {S}}_1,\ldots,{\mathcal {S}}_t\) be a partition of \({\mathcal {D}}\) according to some relation measure, where the partition characterizes the whole data in the form of some structures such as cluster, and \({\mathcal {S}}_1\cup \ldots \cup {\mathcal {S}}_t= {\mathcal {D}}\). Here \({\mathcal {S}}_i\), \(i=1,\ldots ,t\) is called structural granularity [27]. In general, four granularity layers can be differentiated:
Global granularity The granularity refers to the dataset \({\mathcal {D}}\). With this granularity, the whole data are characterized or enclosed by a single ellipsoid with center \(\mu\) and covariance matrix \(\Sigma\) obtained by minimizing its volume [24]:
The corresponding classifier, such as EKM [24], aims to utilize such global data structure, or more precisely, global data scatter in its design.
Class granularity The granularities are the class partitioned data subsets. Single ellipsoid can be used to describe an individual class to form the so called class structure. The covariance matrices of two classes are defined as
where \({J}_\pm =\frac{1}{\sqrt{l_\pm }} \left( {I}-\frac{1}{l_\pm }{e}{e}^T\right)\), \(\mu _\pm =\frac{1}{l_\pm } \sum _{i\in \mathcal {I}_\pm }x_i\) are the means of two classes, \({e}\) is the vector of ones with appropriate dimensions, and \({I}\) is the identity matrix with appropriate dimension. For example, PTSVM [15], respectively embeds the class granularities into the two optimization problems.
Cluster granularity The granularities are the data subsets within each class. The data structures within each class are depicted by a certain amount ellipsoids that are obtained by some clustering techniques. The corresponding covariance matrix in cluster \(i\) is: \(\Sigma _{{\mathcal {C}}_i}= {C}_{{\mathcal {C}}_i}{J}_{{\mathcal {C}}_i} {J}_{{\mathcal {C}}_i}^T {C}_{{\mathcal {C}}_i}^T\), where \({\mathcal {C}}_i\) is the index set of cluster \(i\) and \({J}_{{\mathcal {C}}_i}=\frac{1}{\sqrt{|{\mathcal {C}}_i|}}\left( {I}-\frac{1}{|{\mathcal {C}}_i|}{ee}^T\right)\). For example, SLMM [20] considers the cluster assumption about the data.
Point granularity The granularities are the neighborhoods \(ne( {x}_i)\) of each point \({x}_i\), which are described by overlapped local ellipsoids surrounding the data in each class, whose covariance matrix can be viewed as a kind of local generalized covariance \(\Sigma _i=\sum _{j\in {ne({x}_i)}}s_{ij}({x}_i- {x}_j)( {x}_i-{x}_j)^T\), where \(s_{ij}=\exp (-\gamma || {x}_i- {x}_j||^2)\), \(\gamma >0\). One of the most successful classifier under this granularity is LapSVM [21], which is successfully applied into semi-supervised problems.
2.2 Twin-hypersphere support vector machine
For binary pattern recognition, the THSVM uses a pair of hyperspheres, one for each class, to describe the samples in two classes, and classifies points according to which hypersphere a given point is relatively closest to. To this end, it obtains two optimization problems, and each one has an SVM-type formulation. Specifically, the THSVM is obtained by solving the following pair of optimization problems:
where \(\gamma _\pm >0\) and \(\nu _\pm >0\) are pre-specified penalty factors, and \({c}_\pm \in \mathcal {H}\) and \(R_\pm\) are the centers and radiuses of the hyperspheres, respectively.
Clearly, the first term of (3) or (4) minimizes the squares radius of the hypersphere to keep the hypersphere as compact as possible. The second term in the objective function of (3) or (4) maximizes the sum of squared distances from the center of hypersphere to the points of the opposite class, which leads to keep the center of this hypersphere far from the samples of the opposite class. The constraints require that the samples of the corresponding class be covered by this hypersphere. Otherwise, a set of error variables is used to measure the errors wherever these points are not covered by this hypersphere. The last term of (3) or (4) minimizes the sum of error variables, thus attempting to minimize misclassification due to points belonging to the opposite class.
Introducing the Lagrangian functions for the problems (3) and (4) and considering the Karush–Kuhn–Tucker (KKT) necessary and sufficient optimality conditions, we obtain their dual problems
where \(\alpha _i\)’s are the nonnegative Lagrangian multipliers, and \(k(u,v)\) is a kernel function: \(k(u,v)=u^Tv\) for the linear case, and \(k(u,v)=\varphi (u)^T\varphi (v)\) for the nonlinear case, such as the Gauss kernel \(k(u,v)=\exp \{-\sigma ||u-v||^2\},\sigma >0\).
After solving (5) and (6), we will obtain the two hyperspheres \(\left| \left| \varphi ({x})-{c}_\pm \right| \right| ^2\le R^2_\pm\), where the \(c_\pm\) and \(R^2_\pm\) values are computed by the KKT necessary and sufficient optimality conditions, which are:
where the index sets \(\mathcal {I^\prime}_\pm =\bigg \{i\Big |0<\alpha _i<\frac{c_\pm }{l_\pm },\,i\in \mathcal {I}_\pm \bigg \}\).
Then, a new test sample \({x}\) is assigned to the class \(+\) or \(-\), depending on which of the two hyperspheres it lies relatively closest to, i.e.:
3 Structural information-based twin-hypersphere support vector machine
Following the line of the cluster granularity model, the structural information-based twin-hypersphere support vector machine (STHSVM) classifier has two steps: clustering and learning. STHSVM first adopts some clustering techniques to capture the data distribution within classes, then respectively embeds the minimization of the compactness between the estimated clusters into the objective functions. In the following subsections, we will discuss these steps concretely.
3.1 Clustering
In this step, many clustering methods, such as \(k\)-means [29], nearest neighbor clustering [30], and fuzzy clustering [31], can be employed. The aim of clustering is to investigate the underlying data distribution within classes in SRPTSVM. After clustering, the structural information is introduced into the optimization problem by the covariance matrices of the clusters. So the clusters should be compact and spherical for the computation. Following this objective, we consider the following Wards linkage clustering (WLC) technique [32]. Here we only show the linear case, while this clustering method can also be applicable in the kernel space.
Concretely, if \(\mathcal {C}_1\) and \(\mathcal {C}_2\) are two clusters, also are the index sets of the points in the two clusters, then their Wards linkage \(W(\mathcal {C}_1, \mathcal {C}_2)\) can be calculated as
where \({\mu }_{\mathcal {C}_1}\) and \({\mu }_{\mathcal {C}_2}\) are the means of the two clusters, respectively.
Initially, each sample is a cluster in the clustering algorithm. The Wards linkage of two samples \({x}_i\) and \({x}_j\) is defined as \(W( {x}_i, {x}_j)=|| {x}_i- {x}_j||^2/2\). During clustering, the two clusters with the smallest Wards linkage value are merged. When two clusters \(\mathcal {C}_1\) and \(\mathcal {C}_2\) are being merged to a new cluster \(\mathcal {C^\prime}\), the linkage \(W(\mathcal {C^\prime},\mathcal {C})\) of \(\mathcal {C^\prime}\) and other cluster \(\mathcal {C}\) can be conveniently derived from \(W(\mathcal {C}_1,\mathcal {C})\), \(W(\mathcal {C}_2,\mathcal {C})\), and \(W(\mathcal {C}_1,\mathcal {C}_2)\) by
To simply determine the cluster number, this WLC uses kernels to measure the similarity between clusters. Salvador and Chan [33] provided a method to automatically determine the number of clusters that selects the number corresponding to the knee point, i.e., the point of maximum curvature, on the curve.
3.2 STHSVM classifier
Without loss of generality, we denote the clusters in two classes as \(\mathcal {P}_1,\ldots , \mathcal {P}_{c_1}\) and \(\mathcal {N}_1,\ldots ,\mathcal {N}_{c_2}\), respectively. To find the hyperspheres for each class, which show the compactness within classes, i.e., the clusters that cover the different structural information in different classes, the STHSVM classifier optimizes the following two optimization problems:
where \(\gamma _\pm ,\nu _\pm\), \(k=1,2\) are penalty factors given by users, \(l_{+,s}=|\mathcal {P}_s|\), \(s=1,\ldots ,c_1\) and \(l_{-,t}=|\mathcal {N}_t|\), \(t=1,\ldots ,c_2\) denote the sizes of the clusters \(\mathcal {P}_s\) and \(\mathcal {N}_t\), \(l_+=\sum _{s=1}^{c_1}l_{+,s}\), \(l_-=\sum _{t=1}^{c_2}l_{-,t}\), \(c_{+,s}, R_{+,s}\), \(s=1,\ldots ,c_1\) and \(c_{-,t},R_{-,t}\), \(t=1,\ldots ,c_2\), are the centers and radiuses of clusters \(\mathcal {P}_s\) and \(\mathcal {N}_t\), respectively. In addition, \(p_{j,s}\), \(s=1,\ldots ,c_1\), \(j\in \mathcal {I}_-\) are the probabilities of \(x_j\) belonging to clusters \(\mathcal {P}_s\), and \(p_{i,t}\), \(t=1,\ldots ,c_2\), \(i\in \mathcal {I}_+\) are the probabilities of \(x_i\) belonging to clusters \(\mathcal {N}_t\). In this work, we define them as
and
where \(\kappa (u)=\exp (-\tau {u^2})\), \(\tau >0\), \(\mu _{+,s}\), \(s=1,\ldots ,c_1\) and \(\mu _{-,t}\), \(t=1,\ldots ,c_2\) are the means of clusters \(\mathcal {P}_s\) and \(\mathcal {N}_t\), respectively. We have \(\sum _{t=1}^{c_2}p_{i,t}=1\) for all \(i\in \mathcal {I}_+\) and \(\sum _{s=1}^{c_1}p_{j,s}=1\) for all \(j\in \mathcal {I}_-\). Obviously, for any point \(x_i\), \(i\in \mathcal {I}_+\), we have a larger value \(p_{i,t}\) if \(x_i\), \(i\in \mathcal {I}_+\) is nearer to cluster \(t\) than the other clusters in Class \(-\).
First of all, we consider the illustrations of the optimization problems (12) and (13) before optimizing them. First, the constraints require that the samples in a cluster of the corresponding class be covered by one hypersphere. Otherwise, a set of error variables \(\{\xi _i,i\in \mathcal {I}_+\}\) or \(\{\xi _j,j\in \mathcal {I}_-\}\) is used to measure the errors wherever these points are not covered by this hypersphere. Compared with the corresponding term of THSVM, this term makes STHSVM pay more attention to the cluster granularity-based structure information, which are more reasonable for real-world problems. Clearly, for many real-world problems, it is not suitable to use one hypersphere to only cover the points in one class. The last term of the objective function of (12) or (13) minimizes the sum of error variables, thus attempting to minimize misclassification due to points belonging to the opposite class. Second, the first term in the objective function of (12) or (13) minimizes the squares radiuses of the hyperspheres. Hence, minimizing them tends to keep these hyperspheres as compact as possible, i.e., makes these hyperspheres be as small as possible. Note that this term gives the different weights for these hyperspheres according to the sizes of clusters. This definition for weights is reasonable since the clusters with larger sizes should have larger influence than those with smaller sizes. Last, the second term in the objective function of (12) or (13) maximizes the sum of squared distances from the centers of hyperspheres to the points of the opposite class, which leads to keep the centers of this hyperspheres far from the samples of the opposite class. However, by considering the cluster granularity-based structure information, this term introduces the different weights \(p_{j,s}\) or \(p_{i,t}\). In fact, if one point in Class \(-\) is nearer to a cluster of Class \(+\), we will hope it is as far as possible from the corresponding hyperphere’s center of this cluster than the other centers. In this STHSVM, we use (14) or (15) to depict this end, which can describe the above design.
We now consider to optimize the primal optimization problems (12) and (13). The corresponding Lagrangian function of the problem (12) is
where \(\lambda _s\ge 0\), \(s=1,\ldots ,c_1\), \(\alpha _i\ge 0,\,\beta _i\ge 0,\,i\in {\mathcal {I}}_+\) are the Lagrangian multipliers. Differentiating the Lagrangian function () with respect to \({c}_{+,s},\,R^2_{+,s}\), and \(\xi _i,\,i\in \mathcal {I}_+\) yields the following Karush–Kuhn–Tucker (KKT) necessary and sufficient optimality conditions:
Note that \(R_{+,s}^2>0\) will hold in the optimality result of problem (12) if the suitable parameters \(\nu _+\) and \(\gamma _+\) are given. Then, we have \(\sum _{i\in \mathcal {P}_s}\alpha _i=\frac{l_{+,s}}{l_+}\), \(s=1,\ldots ,c_1,\) according to the KKT conditions (18) and (23), and
Substituting (18), (19) and (24) into (16), we obtain the dual optimization problem of (12) as following:
where the constant term does not influence the solution of this optimization problem. Hence we can omit this term in the optimization process.
This optimization problem can be broken down into a series of small-sized optimization problems by multiplying the objective functions by \(\left( {\frac{l_{+,s}}{l_+}-\frac{\nu _+}{l_-}\sum _{j\in \mathcal {I}_-}p_{j,s}}\right)\) for \(s=1,\ldots ,c_1\):
Next, notice that \(\left| \left| \varphi ({x}_i)-{c}_{+,s}\right| \right| ^2=R_{+,s}^2\) if \(0<\alpha _i<\frac{\gamma _+}{l_+},i\in \mathcal {P}_s\) according to the KKT conditions (19)–(23). Thus, we compute the square radiuses \(R_{+,s}^2\), \(s=1,\ldots ,c_1\) by the following formula:
where the index sets \(\mathcal {I}_{+,s}^{R}=\left\{ i\bigg |0<\alpha _i<\frac{\gamma _+}{l_+},\,i\in \mathcal {P}_s\right\}\), \(s=1,\ldots ,c_1\).
Similarly, we obtain the \(c_2\) simplified dual of problems (13) as following:
where \(\alpha _j,\,j\in \mathcal {I}_-\) are the nonnegative Lagrangian multipliers, and the centers \({c}_{-,t}\), \(t=1,\ldots ,c_2\) are
Also, the square radiuses \(R_{-,t}^2\), \(t=1,\ldots ,c_2\) are
where the index sets \(\mathcal {I}_{-,t}^{R}\), \(t=1,\ldots ,c_2\) are
Once the elements \(({c}_{+,s}, R^2_{+,s})\), \(s=1,\ldots ,c_1\) and \(({c}_{-,t},R^2_{-,t})\), \(t=1,\ldots ,c_2\) are calculated by (24), (27), (29) and (30), a series of hyperspheres
are obtained. A new test sample \({x}\) is assigned to the class \(+\) or \(-\), depending on which of these hyperspheres given by (31) it lies relatively closest to, i.e.,
In summary, our STHSVM algorithm for pattern recognition is listed as follows:
Algorithm 1
The STHSVM algorithm
-
1.
Set the parameters \(\nu _\pm\), \(\gamma _\pm\), and kernel function;
-
2.
Determine the clusters \(\mathcal {P}_1,\ldots ,\mathcal {P}_{c_1}\) for Class \(+\) and the clusters \(\mathcal {N}_1,\ldots ,\mathcal {N}_{c_2}\) for Class \(-\) according to some clustering technique;
-
3.
Optimize the optimization problems (26) and (28) by some optimization technique;
-
4.
Compute \(({c}_{+,s}, R^2_{+,s})\), \(s=1,\ldots ,c_1\) and \(({c}_{-,t},R^2_{-,t})\), \(t=1,\ldots ,c_2\) by (24), (27), (29) and (30);
-
5.
Predict the label for a new point \(x\) by (32).
4 Experiments
In this section, we run a series of experiments systematically on both toy and real-world classification problems to evaluate the proposed STHSVM algorithm. First, we present two synthetic datasets, i.e., the XOR and Hex datasets, to intuitively compare STHSVM with THSVM. On real-world problems, several datasets in the UCI database are used to evaluate the classification accuracies derived from STHSVM in comparison to some other algorithms, including the TWSVM [10], TPMSVM [14], SRSVM [27], SRPTSVM [28], and THSVM [19]. Remark that the regularization terms are introduced in the TPMSVM, which is helpful to the generalization performance. Here only Gaussian kernel is employed for nonlinear problems. For these classifiers, the kernel widths and the regularization parameters are selected from the set \(\{2^{-9},\ldots ,2^{10}\}\) by cross-validation. While the \(\nu /c\) values in TPMSVM are selected from the set \(\{0.05,0.1,\ldots ,0.95\}\). All methods are implemented in MATLABFootnote 1 on Windows XP running on a PC.
4.1 Toy datasets
In this part we compare our method with THSVM on the 2-D XOR and Hex problems, in which the points are randomly generated under Gaussian distributions in each class. Table 1 describes the corresponding attributes of the XOR and Hex problems. It can be easily seen that, for the two problems, the two classes are composed of some clusters and these clusters have totally different distributions. Thus, in these cases, the structural information within the classes may be more important than the discriminative information between the classes. For each cluster of the two problems, we randomly generate 100 training points and 500 test points, respectively.
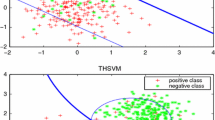
For the XOR and Hex problems, we use the linear and kernel STHSVM and kernel THSVM classifiers to find the decision bounds. Remark that the linear THSVM can not successfully obtain the suitable separating bound for this problem, Figs. 1 and 2 show the one-run training results obtained by the linear and kernel STHSVM and kernel THSVM on these two problems. Due to the formal neglect of the structural information within the classes, kernel THSVM cannot differentiate the different data occurrence trends, i.e., the clusters in each class. Then, the derived hyperspheres for two classes only as possibly as cover the points in the corresponding classes. Specifically, it can be found from Figs. 1a and 2a that the obtained hyperspheres cover the same area, i.e., they can not successfully depict the data, since the structural information under cluster granularity is ignored. Different to the THSVM classifier, STHSVM embeds the structure information within the classes into the optimization problems. Then, STHSVM should get more reasonable discriminant boundaries than THSVM which basically accord with the data occurrence trend, and thus has the best classification performance than the other classifiers in theory. Figures 1b, c and 2b, c confirm this conclusion, in which the results show that it obtains a better separating bound than THSVM. To further explain the conclusion, we make ten independent runs on the XOR and Hex problems and compare with the results of the two classifiers, listed in Table 2. It can be found that our linear and kernel STHSVM obtains the better performance than the kernel THSVM classifier.

Training results of kernel THSVM (a), linear STHSVM (b), and kernel STHSVM (c) on the XOR problem. The two classes of points are marked by “\(\times\)” and “\(+\)”, the decision bounds of these classifiers are marked by solid curves in black, and the hyperspheres of these classifiers marked by solid curves in blue and red, respectively

Training results of kernel THSVM (a), linear STHSVM (b), and kernel STHSVM (c) on the Hex problem. The two classes of points are marked by “\(\times\)” and “\(+\)”, the decision bounds of these classifiers are marked by solid curves in black, and the hyperspheres of these classifiers marked by solid curves in blue and red, respectively
To further explain the performance of the proposed STHSVM classifier, in Figs. 3 and 4, we depict the two-dimensional scatter plots for kernel THSVM and linear/nonlinear STHSVM on the XOR and Hex problem with \(100+100\) and \(150+150\) test points, respectively. The plots are obtained by plotting test points with coordinates \((d_1, d_2)\). Here, \(d^i_+\) and \(d^i_-\) are the relative ‘distances’ of a test point \({x}_i\) to the centers of the positive and negative hyperspheres for the THSVM, i.e., \(d^i_\pm = ||{\varphi }({x}_i)-{c}_\pm || /R_\pm\) for the THSVM. While \(d^i_+\) and \(d^i_-\) are the minimum relative ‘distances’ of a test point \({x}_i\) to the centers of the positive and negative hyperspheres for the STHSVM, i.e., \(d^i_+=\min _{s}\left[ {\sqrt{l_+}||\varphi ({x}_i)-{c}_{+,s}||}/{\sqrt{l_{+,s}}R_{+,s}}\right]\) and \(d^i_-=\min _{t}\left[ {\sqrt{l_-}||\varphi ({x}_i)-{c}_{-,t}||}/{\sqrt{l_{-,t}}R_{-,t}}\right]\) for the STHSVM. In short, the point \({x}_i\) is assigned to class \(+1\) if the value of \(d_+^i\) is less than \(d_-^i\) and vice versa. In Figs. 3 and 4, each point is marked as “\(\circ\)” if its class label is \(+1\) and “\(\Box\)” otherwise. Obviously, the two-dimensional projections for test points indicate how well the classification criterion is able to discriminate between the two classes. It can be seen that for the kernel THSVM, most points are covered by the corresponding hyperspheres and are far from the opposite hyperspheres, i.e., the corresponding \(d_+^i\)’s or \(d_-^i\)’s are not larger than one. This indicates the hyperspheres in the THSVM can effectively depict the data characteristic of classes. However, for the linear and kernel STHSVM, it not only can be found that most points are covered by the corresponding hyperspheres and are far from the opposite hyperspheres, but also is more robust than the THSVM. In fact, this is because the STHSVM embeds the structure information within the classes into the optimization problems.

Two-dimensional projections for test points from the XOR dataset with the kernel THSVM (a), linear STHSVM (b), and kernel STHSVM (c)

Two-dimensional projections for test points from the Hex dataset with the kernel THSVM (a), linear STHSVM (b), and kernel STHSVM (c)
4.2 Benchmark datasets
In this section, we compare with the performance of TWSVM, TPMSVM, SRSVM, SRPTSVM, THSVM, and STHSVM on the 13 benchmark datasets [34] in that order: Banana (B), Breast Cancer (BC), Diabetes (D), Flare (F), German (G), Heart (H), Image (I), Ringnorm (R), Splice (S), Thyroid (Th), Titanic (T), Twonorm (Tw), and Waveform (W). In particular, we use in each problem the train-test splits given in that reference (100 for each dataset except for Image and Splice, where only 20 splits are given).
In Table 3, we report the training time of one-run and the average test accuracies of linear TWSVM, TPMSVM, SRSVM, SRPTSVM, THSVM, and STHSVM on these benchmark datasets. For the linear SRPTSVM classifier, we adopt the recursive strategy to find the best prediction performance. Table 4 lists the training time of one-run and the average test accuracies of nonlinear TWSVM, TPMSVM, SRSVM, SRPTSVM, THSVM, and STHSVM with Gaussian kernels. From these results, we can find that STHSVM obtains the best learning results than THSVM and other classifiers for most datasets. In fact, this is because STHSVM embeds the structural information of each class under cluster granularity into its two optimization problems, which is more helpful to further improve the learning performance. In addition, it can be found that compared with the other methods, SRSVM and SRPTSVM obtain better generalization performance than TWSVM and TPMSVM for many datasets. This is also because the two methods successfully embed the data structural information into their optimization problems. However, the results in Tables 3 and 4 show that our method outperforms SRSVM and SRPTSVM for many datasets. A possible reason is that it uses a more reasonable strategy to depict the data structure than the latter. In order to find out whether STHSVM is significantly better than the other algorithms, we perform the \(t\) test on the classification results to calculate the statistical significance of STHSVM. The null hypothesis \(H_0\) demonstrates that there is no significant difference between the mean numbers of patterns correctly classified by STHSVM and the other algorithms. If the hypothesis \(H_0\) of each dataset is rejected at the 5 % significance level, i.e., the \(t\) test value is more than 1.734, the corresponding results in Tables 3 and 4 is denoted “*”. Consequently, as shown in Tables 3 and 4, it can be clearly found that STHSVM possesses significantly superior classification performance compared with the other classifiers on the most datasets. This just accords with our conclusions. As for the learning time of these methods, remark that it need find the cluster-based structural information through some clustering technique, which leads to some extra learning time compared with THSVM. However, it can be seen that, for most datasets, the proposed STHSVM with different kernels has a comparable speed with THSVM. In fact, this is because this proposed STHSVM only needs to optimize a series of smaller-sized optimization problems compared with THSVM, which leads it to have a much faster speed than THSVM. Tables 3 and 4 also confirm this conclusion. In fact, the time for clustering in this STHSVM is listed in tables indicates this method is much efficient. In summary, these simulation results show that our STHSVM not only obtains a better generalization performance than these related methods, but also has a fast learning speed.
5 Conclusions
The twin-hypersphere support vector machine (THSVM) [19] for binary classification seeks two hypersphres by solving two SVM-type problems, one for each class, to make the points in each class are covered as many as possibly by one hyperphere. Then, it classifies a new point according to which hypersphere is relatively closest to. However, it only considers the global structure information of each class, which leads to hardly extend to real-world problems.
In this paper, under the structural granularity [27], which characterizes a series of data structures involved in the various classifier design ideas, we have introduced an improved THSVM named the structural information-based THSVM (STHSVM) classifier. In each optimization problem of STHSVM, a data structural-information derived from the cluster granularity [27] is absorbed into the learning process. Further, STHSVM introduces a different probability sum of projected center for each point to depict the cluster granularity-based structural information. The experiments have confirmed that this STHSVM successfully embeds into the cluster granularity-based structural information and obtains the good performance. The idea in this method can be easily extended to some other TWSVM classifiers. There still exists some future work. For example, we only apply our method into the middle-scale classification problems since it has a large cost to cluster large-scale datasets. In addition, another problem is to discuss the relationship between the performance and the cluster number. Also, the parameter-selection problem is an important further problem.
Notes
Available at: http://www.mathworks.com.
References
Boser B, Guyon L, Vapnik VN (1992) A training algorithm for optimal margin classifiers. In: Proceedings of the 5th Annual Workshop on Computational Learning Theory, ACM Press, Pittsburgh, 1992, pp 144–152
Vapnik VN (1995) The natural of statistical learning theory. Springer, New York
Vapnik VN (1998) Statistical learning theory. Wiley, New York
He Q, Wu C (2011) Separating theorem of samples in Banach space for support vector machine learning. Int J Mach Learn Cybernet 2(1):49–54
Wang X, He Q, Chen D, Yeung D (2005) A genetic algorithm for solving the inverse problem of support vector machines. Neurocomputing 68:225–238
Wang X, Lu S, Zhai J (2008) Fast fuzzy multi-category SVM based on support vector domain description. Int J Pattern Recognit Artif Intell 22(1):109–120
Osuna E, Freund R, Girosi F (1997) Training support vector machines: an application to face detection. In: Proceedings of IEEE Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 1997, pp 130–136
El-Naqa I, Yang Y, Wernik M, Galatsanos NP, Nishikawa RM (2002) A support vector machine approach for detection of microclassification. IEEE Trans Med Imaging 21(12):1552–1563
Schölkopf B, Tsuda K, Vert J-P (2004) Kernel methods in computational biology. MIT Press, Cambridge
Jayadeva, Khemchandani R, Chandra S (2007) Twin support vector machines for pattern classification. IEEE Trans Pattern Anal Mach Intell 29(5):905–910
Kumar MA, Gopal M (2009) Least squares twin support vector machines for pattern classification. Expert Syst Appl 36(4):7535–7543
Ghorai S, Mukherjee A, Dutta PK (2009) Nonparallel plane proximal classifier. Signal Process 89(4):510–522
Peng X (2010) A \(\nu\)-twin support vector machine (\(\nu\)-TSVM) classifier and its geometric algorithms. Inform Sci 180(15):3863–3875
Peng X (2011) TPMSVM: a novel twin parametric-margin support vector machine for pattern recognition. Pattern Recognit 44(10–11):2678–2692
Chen X, Yang J, Ye Q, Liang J (2011) Recursive projection twin support vector machine via within-class variance minimization. Pattern Recognit 44(10–11):2643–2655
Shao YH, Chen WJ, Deng NY (2014) Nonparallel hyperplane support vector machine for binary classification problems. Inform Sci 263:22–35
Peng X (2010) TSVR: an efficient twin support vector machine for regression. Neural Netw 23(3):365–372
Peng X (2012) Efficient twin parametric insensitive support vector regression model. Neurocomputing 79:26–38
Peng X, Xu D (2013) A twin-hypersphere support vector machine classifier and the fast learning algorithm. Inform Sci 221(1):12–27
Yeung D, Wang D, Ng W, Tsang E, Zhao X (2007) Structured large margin machines: sensitive to data distributions. Mach Learn 68(2):171–200
Belkin M, Niyogi P, Sindhwani V (2004) Manifold regularization: a geometric framework for learning from examples, Dept. Comput. Sci., Univ. Chicago, Chicago, IL, Techique report, TR-2004-06, Aug 2004
Chen WJ, Shao YH, Hong N (2014) Laplacian smooth twin support vector machine for semi-supervised classification. Int J Mach Learn Cybernet 5(3):459–468
Rigollet P (2007) Generalization error bounds in semi-supervised classification under the cluster assumption. J Mach Learn Res 8:1369–1392
Shivaswamy PK, Jebara T (2007) Ellipsoidal kernel machines. In: Proceeding of 12th International Workshop on Artificial Intelligence Statistic, 2007, pp 1–8
Lanckriet GRG, Ghaoui LE, Bhattacharyya C, Jordan MI (2002) A robust minimax approach to classfication. J Mach Learn Res 3:555–582
Huang K, Yang H, King I, Lyu MR (2008) Maxi–min margin machine-learning large margin classifiers locally and globally. IEEE Trans Neural Netw 19:260–272
Xue H, Chen S, Yang Q (2011) Structural regularized support vector machine: a framework for structural large margin classifier. IEEE Trans Neural Netw 22:573–587
Peng X, Xu D (2014) Structural regularized projection twin support vector machine for data classification. Inform Sci 279:416–432
Hartigan JA, Wong MA (1979) A \(k\)-means clustering algorithm. Appl Stat 28(1):100–108
Lu S-Y, Fu KS (1978) A sentence-to-sentence clustering procedure for pattern analysis. IEEE Trans Syst Man Cybernet 8(5):381–389
Zadeh LA (1965) Fuzzy sets. Inform Control 8:338–353
Ward JH (1963) Hierarchical grouping to optimize an objective function. J Am Stat Assoc 58(301):236–244
Salvador S, Chan P (2004) Determining the number of clusters/segments in hierarchical clustering/segmentation algorithms. In: Proc. 16th IEEE Int. Conf. Tools Artif. Intell., Nov 2004, pp 576584
Rätsch G (2000) Benchmark repository, datasets available at http://ida.first.fhg.de/projects/bench/benchmarks.htm
Acknowledgments
The authors would like to genuinely thank the anonymous reviewers for their constructive comments and suggestions. This work is partly supported by the National Natural Science Foundation of China (61202156), the National Natural Science Foundation of Shanghai (12ZR1447100), and the program of Shanghai Normal University (DZL121).
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Peng, X., Kong, L. & Chen, D. A structural information-based twin-hypersphere support vector machine classifier. Int. J. Mach. Learn. & Cyber. 8, 295–308 (2017). https://doi.org/10.1007/s13042-014-0323-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-014-0323-4