
Abstract
Sediments accumulated in check dams are a valuable measure to estimate soil erosion rates. Here, geographic information systems (GIS) and three machine learning techniques (MARS-multivariate adaptive regression splines, RF-random forest and SVM-support vector machine) were used, for the first time, to predict sediment deposition rate (SR) in check-dams located in six watersheds in SW Spain. There, 160 dry-stone check dams (~ 77.8 check-dams km−2), accumulated sediments during a period that varied from 11 to 23 years. The SR was estimated in former research using a topographical method and a high-resolution Digital Elevation Model (DEM) (average of 0.14 m3 ha−1 year−1). Nine environmental-topographic parameters were calculated and employed as predictors of the SR. The ability of MARS, RF and SVM was evaluated by using a five-fold cross-validation, considering the entire area (ALL), the check dams on the hillslope (HILL) and the valley-bottoms (VALLEY), as well as the three catchments (B, C and D) with the highest number of check dams. The accuracy of the models was assessed by the relative root mean square error (RRMSE) and the mean absolute error (MAE). The results revealed that RF and SVM are able to predict SR with higher and more stable accuracy than MARS. This is evident for the datasets ALL, VALLEY and D, where errors of prediction exhibited by MARS were from 44 to 77% (RRMSE) and from 37 to 62% (MAE) higher than those achieved by RF and SVM, but it also held for the datasets HILL and B where the difference of RRMSE and MAE was 7–10% and 12–17%, respectively.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Soil erosion by water is considered one of the major issues of land degradation in a wide range of environments (Valentin et al. 2005; Zucca et al. 2006; Bou Kheir et al. 2007), including rangelands of southern Europe (e.g. dehesas in Spain). These landscapes are very sensitive to exogenous changes induced by anthropogenic factors such as climate change (with longer dry periods and more intense rainfall) or land use and vegetation cover changes (deforestation, overgrazing, fires, etc.). In this global change scene, dehesas landscapes are particularly susceptible to water erosion (Herguido Sevillano et al. 2017; Pulido et al. 2018). There are two main erosive processes in this landscape: sheetwash in hillslopes (Schnabel et al. 2010; Rubio-Delgado et al. 2017) and gully erosion in valley bottoms (Gómez-Gutiérrez et al. 2012; Schnabel et al. 2013). Several studies have quantified soil erosion rates produced by these processes, for example, Schnabel et al. (2010) estimated that soil erosion by non-concentrated flow in the hillslopes amounted to 0.63 t ha−1 year−1 for the period 1990–1997, while Gómez-Gutiérrez et al. (2012) estimated a soil erosion of 0.07 m3 ha−1 year−1 due to gullying for the period 2001–2007. A recent study estimated soil erosion rates in the order of 21–38 t ha−1 year−1 for a period between 50 and 90 years influenced by land-use pressure, with cultivation in the past and high stocking density since its abandonment (Rubio-Delgado et al. 2017).
In the last 30 years, several strategies have been carried out to restore the most degraded dehesas. Most of these restoration activities consist of (i) reforestation in places with poor vegetation cover and (ii) establishment of check dams in gullied channels. Check dams are among the most widespread methods to trap sediments and mitigate soil erosion effects in Mediterranean areas (Castillo et al. 2007; Bombino et al. 2009; Quiñonero-Rubio et al. 2016; Cucchiaro et al. 2019; Alfonso-Torreño et al. 2021). Check dams control sediment transport (Catella et al. 2005), stabilize slopes and torrential channels (Conesa 2004; Conesa García and García Lorenzo 2007; Romero, 2008); recharge aquifers (Conesa, 2004; Conesa García and García Lorenzo 2007), retain solid material (Martín-Rosales et al. 2003; Conesa 2004; Belmonte et al. 2005; Conesa García and García Lorenzo 2007), decrease water speed, consequently, reducing its erosive capacity (Belmonte et al. 2005; Romero 2008). Despite the clear benefits provided by check-dams, their efficiency is limited in time (Zhao et al. 2017), i.e. their lifespan can be short in headwater areas and steep slopes where soil erosion and sediment transport are intense (Martínez-Murillo and López-Vicente 2018). Sediments retained in check dams are the consequence of all erosion and sediment transport processes operating in a catchment. They may provide valuable information about the catchment sediment production and transport and have great value for environmental studies (Boix-Fayos et al. 2008; Vanmaercke et al. 2011). Catchment sediment yield can be estimated by measuring the sediment retained in check dams constructed at the outlet of a catchment (Verstraeten and Poesen 2002; Bellin et al. 2011; Sougnez et al. 2011; Baade et al. 2012).
The development of Unmanned Aerial Vehicles (UAV) platforms facilitates the acquisition of high-resolution aerial photos from which structure-from-motion (SfM) (Ullman 1979) photogrammetry together with multiview-stereo (MVS) algorithms can be applied to obtain point clouds, Digital Elevation Models (DEMs) and orthophotographs (Javernick et al. 2014; Woodget et al. 2015; Smith and Vericat 2015). SfM is a low-cost, user-friendly photogrammetric technique for obtaining high-resolution datasets at a range of scales with application in remote and large areas. Unlike conventional photogrammetric methods, the SfM method solves the camera pose and scene geometry simultaneously and automatically, using a highly redundant bundle adjustment based on matching features in multiple overlapping images (Westoby et al. 2012). DEMs produced using these technologies are suitable to quantify the volume of sediment retained behind check dams (Alfonso-Torreño et al. 2019). At the same time, numerous environmental parameters may be calculated from the cartographic datasets produced using the SFM-MVS workflow, such as vegetation cover, topographical and hydrological parameters. Numerous factors control the sediment discharge, including climate, topography, vegetation cover, land use, drainage network characteristics, and soil properties (Hovius 1998; Cerdà 2002). The quantification of sediments deposited and the extraction of variables obtained from the high-resolution DEM provide useful information for quantitative models of landscape evolution (Restrepo et al. 2006; Keesstra 2007; Keesstra et al. 2009). However, modelling sediment deposition rate is a complex task because of the nonlinearity of natural processes intervening at basin scale (Mutua et al. 2006; Keesstra et al. 2014; Borrelli et al. 2015). Sediment volume stored in dams has been used for distributed mathematical model validation (De Vente et al. 2008; Alatorre et al. 2010; Bussi et al. 2014; Mekonnen et al. 2015). Several attempts have been made to understand the role of factors influencing sediment yield and to develop hydrological distributed models in semi-arid regions (Tamene et al. 2006; Bouchnak et al. 2009; Bussi et al. 2013). Despite the fact that the approaches used in the previous studies represent innovative techniques for implementing distributed mechanistic models in sediment ungauged catchments, some drawbacks should be considered. For example, the errors in the estimation of the sedimentation volume and the availability of a few accumulated sediment volume values for calibrating and validating the models. Unlike previous researches, in this study, the dependent variable was calculated using topographic methods with centimeter precision at 160 different sites. The design and implementation of erosion control and sediment management strategies require a large amount of data on erosion rates and an understanding of the factors that control the delivery of sediment through the catchment system. The current study would help to fill the research gap because limited information is available on sediment deposition rates and on the factors controlling depositional processes on semi-arid micro-catchments.
In recent years, machine learning techniques supported by Geographical Information Systems have been applied successfully to model and predict different aspects of soil erosion and other geomorphological processes. Machine learning is a technique that employs advanced computer algorithms to model complex relationships in the training data and to provide predictions of the test data (Chen et al. 2018; Kavzoglu et al. 2019; Ma et al. 2020). For example, machine learning techniques have been used to predict spatial distribution of gully erosion (e.g., Gómez-Gutiérrez et al. 2009a, b, 2015; Conoscenti et al. 2014, 2018; Rahmati et al. 2016; Garosi et al. 2018; Conoscenti and Rotigliano 2020), to assess the landslide susceptibility (e.g., Vorpahl et al. 2012; Conoscenti et al. 2015; Rotigliano et al. 2019; Martinello et al. 2020) and to analyze climate change impacts on soil erosion (Wilby et al. 1999; Middelkoop et al. 2001; Nunes et al. 2008; Bangash et al. 2013).
In this study, we focus on predicting sediment deposition rate by using three machine learning techniques that were selected because of their ability to model non-linear relationships between explanatory and target variables. These techniques are: (i) multivariate adaptive regression splines (MARS; Friedman 1991), (ii) random forest (RF; Breiman 2001), and (iii) support vector machine (SVM; Vapnik 1998). MARS, RF and SVM have been applied to different fields of geosciences, including detection of flood-prone areas (Tehrany et al. 2015; Mojaddadi et al. 2017) and prediction of landslide (e.g., Pourghasemi et al. 2013; Jebur et al. 2014; Trigila et al. 2015; Chen et al. 2017; Rotigliano et al. 2019; Martinello et al. 2020) and gully occurrence (e.g., Rahmati et al. 2017; Garosi et al. 2019; Gayen et al. 2019; Conoscenti and Rotigliano 2020; Pourghasemi et al. 2020). In regard to the prediction of sediment yield, very few applications of these modelling techniques exist in the literature. MARS has been employed to model sediment delivery at catchment scale in Canada (Sarangi et al. 2005) and Turkey (Yilmaz et al. 2018). RF was adopted to predict data of suspended sediment load, measured over a two-year period in a small catchment (3.3 ha) located in Panama (Zimmermann et al. 2012) and during three months in a medium-sized (44,500 ha) catchment of Spain (Francke et al. 2008). Çimen (2008) used SVM to estimate daily suspended sediment yield of two rivers in the USA whereas Buyukyildiz and Kumcu (2017) applied SVM for the same purpose in Turkey. However, none of the studies found in the literature have employed MARS, RF and SVM for the assessment of the average annual sediment production. Indeed, all the papers cited above aimed at predicting daily or monthly sediment yield. Moreover, these studies employed water discharge as the only predictor, except for Zimmermann et al. (2012) who used also day of year and antecedent rainfall data, and for Sarangi et al. (2005) who included also topographic attributes and parameters reflecting channel network and catchment geometry.
MARS, RF and SVM were employed to predict the sediment deposition rate measured at 160 dry-stone check dams, located within six small catchments of a dehesa landscape, in the SW of the Iberian Peninsula. The volume of sediment retained during time intervals of 11–23 years by the check dams was assessed by using a high-resolution DEM, produced by applying SfM photogrammetry to UAV-acquired imagery (see Alfonso-Torreño et al. 2019 for a detailed description of the procedure). The estimated sediment deposition rate, measured in m3 per ha per year, is considered as reflecting the average annual area-specific sediment yield (SSY) from each of the 160 sub-basins drained by the check dams.
Study area
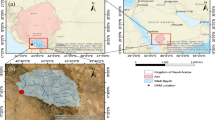
The study was conducted in six catchments, with a total surface of 239 ha, located in a communal farm in the Spanish region of Extremadura (Fig. 1a). The catchments belong to an extensive wavy erosion surface featured by Ediacaran slates and greywackes. The highest parts of the catchments have an undulated topography with slope gradients increasing to the south. The whole study area shows an average elevation of 327 m a.s.l. with a mean slope gradient of 19%. The study area is composed of six low-order catchments with channels draining (ephemeral flows) to the south where they join the Almonte River, tributary of the Tagus River (Fig. 1b). Soils in the area are very shallow and can be classified as Cambisols and Leptosols (Schnabel et al. 2013). Climate is the Mediterranean, with a mean annual temperature of 16 ºC and an annual average rainfall around 500 mm, with high seasonality and high interannual variations. The rainiest seasons are the autumn and winter, while the summer is dry. Due to the lack of herbaceous vegetation in late summer, the first rainfall events during the autumn erode the soil and contribute to the generation of runoff and sediment yield in the catchments. The area is representative of wooded rangelands that extent approximately 4 million of hectares in the Iberian Peninsula (Fig. 1c). The vegetation cover is composed of Mediterranean oak (Quercus ilex) and herbaceous plants in the understory. Livestock rearing of goats, cattle, pigs, and horses is the main land use with a livestock density of 0.97 LU ha−1 (livestock unit). The farm has not been cultivated since 1953. Other activities in the area are hunting, beekeeping, and recreational use.

a Location of the study area in the Iberian Peninsula, c study area including the location of the six catchments (from A to F), the dry-stone check-dams and the Ground Control Points (GCPs) (Alfonso-Torreño et al. 2019), c some views of the dehesa land-use system characterized by undulating topography and d an example of dry-stone check dam in the study area
The study area shows evidence of sheet erosion and, in some places, gully erosion. To mitigate the consequences of soil erosion by water, 269 dry-stone check dams were built in different topographic positions (i.e. valley bottom and hillslopes) (Fig. 1d). In a previous study, Alfonso-Torreño et al. (2019) calculated the sediment deposited behind 160 of these check dams. The results showed high spatial variability in the sediments deposited, with large volumes of sediment accumulated in the lower areas of the catchment than in the upper parts. The average volume of sediment trapped in the check dams located in the lower areas was 5.3 m3 with a standard deviation of 16.7 m3 and in the upper areas was 0.9 m3 with a standard deviation of 2.2 m3. A high spatial variability was also observed at catchment-scale. Valley bottom check dams retained more sediments than hillslope check dams.
Materials and methods
Dependent variable
Machine learning models were fed with a database that included the sediment deposition rate measured in the dry-stone check dams as a dependent variable or target and a set of environmental variables that were used as explanatory variables or predictors (i.e. independent variables).
Alfonso-Torreño et al. (2019) estimated the volume of sediment trapped by 160 check dams located in the study area, by using a high-resolution DEM (0.2 m pixel size) produced by means of SfM photogrammetry and aerial images. The aerial photographs were acquired using a fixed-wing UAV (Sensefly) (Fig. 2a) carrying on board a Sony WX220 sensor (18 Mpx) that resulted in a Ground Sample Distance (GSD) of 4 cm. The UAV was operated autonomously by using an external PC and a pre-programmed flight plan (Fig. 2b). A set of 1257 images was captured at an approximate altitude of 60 m on the terrain. A total of 13 GCPs were surveyed with a Leica GPS 1200 system (with RTK and Post-Processed solutions using GPS + GLONNASS satellites) and used to scale and georeference the 3D model (Fig. 2c). The photographs and GCPs were used as input in the SfM photogrammetry workflow. Pix4Dmapper Pro software (v. 3.1.18) was used to process the dataset and to produce a point cloud, a high-resolution DEM and an orthophotograph (Fig. 2d). The point cloud was projected in the ETRS89 UTM-29N coordinate system. The average root-mean-square error (RMSE) during the SfM processing was 0.007 m showing centimeter-level accuracies in the resulting cartographic products.

taken from the UAV using Pix4Dmapper Pro software
Field survey: a UAV taking off in the study area, b external PC with a pre-programmed flight plan c registration of GCPs by RTK survey with LoRa corrections and two antennas: Base (not shown in the picture) and Rover and d photogrammetric processing of RGB images
Two DEMs were necessary to estimate the volume of trapped sediments using a DEMs of Difference (DoD) approach (Wheaton et al. 2010). The first DEM represents the current topography and is the SfM-derived DEM. The second one represents the initial topography, i.e. the surface just before check dam construction. The initial topography was obtained digitizing the sediment deposit in each dry-stone check dam, removing points in the cloud within that polygon, and interpolating the surface using the surrounding points and the ANUDEM algorithm in ArcMap (topo to raster tool). To discriminate real topographic change, the root-mean-square error (RMSE) of the SfM-MVS workflow and the interpolation errors associated to the antecedent surface were incorporated in the DoD analysis as a minimum level of detection. This interpolation error was variable depending on (1) topographic position of check dams, i.e., valley bottom or hillslope and (2) check dam size. In addition, the depth of the sediment deposit estimated by this method was validated by sampling the depth of deposit at 28 locations using an auger. More details about the DoD approach and sediment volume estimation may be found in Alfonso-Torreño et al. (2019). The sediment deposition rate (SR) for each dry-stone check dam was calculated by using the contributing drainage area, the volume of sediments retained and the age of each check dam. The sediments accumulated in the check dams located upstream of a specific check dam were also considered. All check dams are located along channels and drain a relatively small area (mean 6.3 ha). This restoration measures have performed for 20 years on average and we may assume that sediments deposited upstream a specific dam would have reached the check dam in the absence of the upstream barriers. More details in Alfonso-Torreño et al. (2019) and Fig. 3.

a Work flow diagram of the method used to estimate the sediment deposition rate (SR) (i.e. the dependent variable) using the volume of sediments retained behind check dams (through a DEMs of Difference approach, see Alfonso-Torreño et al. (2019) for more details), contributing area and age of the check dams, b work flow diagram for the acquisition of a set of topographic and environment attributes (i.e. the independent variables) and c SR in check-dams using three data mining techniques
Explanatory variables
Numerous factors may influence the sediment dynamics in watershed basins. In this study, a set of nine environmental variables, which relate to topography, hydrology, and land cover, were selected as predictors of sediment deposition rate. The explanatory variables were derived from different source data, namely: the SfM-derived DEM with 0.2 m pixel size (DEM_02) and the SfM-derived orthophotograph with a resolution of 0.04 m (ORTHO). Calculation of the predictors was performed for the catchments of each check dam, including the area drained by any dams located upstream. ArcGIS 10.5 (www.esri.com) and SAGA GIS (www.saga-gis.org) were employed to calculate topographic and hydrologic attributes.
The selected explanatory variables are: catchment area (CA), catchment slope (SLO), upstream channel slope (UCS) and length (UCL), connectivity index (CI), tree frequency (TF), canopy cover (TC), bare ground (BG) and animal paths density (PAT). Most of the selected predictors are frequently used in water erosion studies. Table 1 reports descriptive statistics and source data of the predictor variables, calculated for the entire study area (dataset ALL), as well as for each individual catchment (datasets A, B, C, D, E and F).
CA reflects the area drained by each check dam. Drainage area has been largely employed in regression equations as the only explanatory variable of sediment yield from catchments (Alatorre et al. 2010, and references therein). Area-specific sediment production usually decreases as basin size increases, since with increasing drainage area, average slope steepness decreases and more sediment accumulation sites may occur (Van Rompaey et al. 2001). SLO is the average slope gradient of the area upstream of each dam. Slope gradient is considered an important predictor of soil erosion as it controls flow velocity and thus its erosive power and sediment transport capacity. Similarly, UCS and UCL are expected to be related to erosivity and transport capacity of concentrated flow. The CI reflects the potential of sediment transfer between two positions within a catchment. In this experiment, CI was calculated according to the equation proposed by Borselli et al. (2008) and modified by Cavalli et al. (2013), who suggested a weighting factor based on surface roughness (Conoscenti et al. 2018; Alfonso-Torreño et al. 2019). TF and TC are calculated as the number of trees per hectare and as the percentage of catchment occupied by the vertical projection of the tree canopy, respectively. Both TF and TC are expected to reflect the protective role of trees against soil erosion and sediment transport. BG is the percentage of surface not covered by vegetation and, thus, directly exposed to water erosion. Finally, PAT is calculated as the length of pathways created by the livestock transit (km·ha−1).
Modelling of sediment deposition rate
The analysis was performed in three steps. First, The Pearson’s correlation coefficient (r) and the variance inflation factor (VIF) were calculated. The Pearson correlation coefficient was employed to explore bivariate relationships between covariates and sediment deposition rate whereas VIF was calculated in order to detect collinearity among the predictor variables. Following the “rule of 10” (Heckmann et al. 2014; Vargas-Cuervo et al. 2019), predictors with VIF > 10 were removed from the analysis. Then, after removing collinear predictors, three different machine learning methods were trained and tested in the entire study area, by using a k-fold cross-validation strategy. Finally, the same models and validation strategy were applied individually to the three catchments with the highest number of check dams in order to explore differences of the predictive performance.
All statistical analysis and calculations were carried out in R open source software (R Development Core Team 2018), by using the packages “corrplot” (Wei and Simko 2017), “usdm” (Naimi et al. 2014), “caret” (Wing and Kuhn 2018), “PerformanceAnalytics” (Peterson and Carl 2020).
Machine learning models
In this experiment, the following machine learning methods were employed in order to compare their ability to predict sediment deposition rate: multivariate adaptive regression splines (MARS; Friedman 1991); random forest (RF; Breiman 2001), and support vector machine (SVM; Vapnik 1998).
MARS is a non-parametric regression technique, which is able to establish relationships between both categorical and continuous dependent and independent variables. It is considered an extension of generalized linear models. However, differently from linear models, MARS is able to model complex non-linear relationships by splitting the range of the covariates into regions and fitting to each of them a linear regression. MARS equations include an intercept and a number of terms, which reflect individual linear functions or combinations of two or more linear functions (known as interaction terms) (Leathwick et al. 2006; Garosi et al. 2018). In order to avoid overfitting and reduce the complexity of the model, the maximum number of terms and the maximum degree of interactions were set equal to 20 and 2, respectively.
RF is also a non-parametric regression technique able to predict both categorical and continuous variables. It operates by constructing in parallel an ensemble (“forest”) of regression trees and providing the average prediction of the individual trees. The philosophy basis of RF is that by combining weak learners (i.e. the individual trees), strong learners can be obtained. Individual trees are trained on samples of cases, which are selected randomly with a bootstrapping technique. At each node of the trees, the best split is selected among the binary splits provided by a small group of independent variables, which are selected at random from all predictors. The outcome is the average (or weighted average) of the terminal nodes (Vorpahl et al. 2012). The number of trees (ntree) and number of independent variables (mtry) selected at each node are important parameters for RF model training. In our study, ntree was set to 500 whereas the RMSE was used to select the optimal model using the smallest value of mtry.
SVM is a machine learning technique that can be used for both classification and regression tasks. When used in regression, SVM is also known as “support vector regression”. In contrast to linear regression, which aims at minimizing the sum of squared errors, SVM tries to fit the error within a certain threshold. In other words, SVR models consider an acceptable error and try to identify the best hyperplane that fits the data. A kernel function is used to transform the data into a higher dimensional feature space where hyperplanes can be applied. Key parameters for SVM models are ε (insensitive error constant) and C (regulatory factor). The ε parameter delimits the bandwidth where the error is considered acceptable, while the C parameter regulates the complexity of the model. In this study, the Radial Basis Function was employed as kernel function. Tuning of ε and C was performed automatically by R caret package, aiming at finding the simplest model with the lowest RMSE value.
Calibration and validation of the models
The ability of MARS, RF and SVM models to predict the sediment deposition rate at the dry-stone check dams of the study area was evaluated by using a k-fold cross-validation approach. This operates by randomly splitting the dataset into k samples, each containing the same number of observations, and by using k − 1 combined samples at a time for training and the remaining sample for testing. The process is repeated k times thus generating k accuracy estimates. In our study k was set equal to 5.
The accuracy of the models was assessed by calculating the relative root mean square error (RRMSE) and the mean absolute error (MAE) of the predicted values of SR at the check dams. RRMSE is obtained by normalizing the RMSE, which is the square root of the average of squared errors. Normalization facilitates the comparison of RMSE calculated from datasets with different scale and unit of measure. MAE is the average absolute difference between predicted and observed values.
RRMSE and MAE were calculated as follows:
in which n is the number of check dams, Oi is the observed sediment deposition rate (m3 ha−1 year−1) and Pi is the predicted sediment deposition rate (m3 ha−1 year−1).
Cross-validation of MARS, RF and SVM models was performed using the entire study area (dataset ALL), as well as the individual catchments B, C and D (datasets B, C and D), which contains the largest number of check dams (43, 29 and 49, respectively). Moreover, the same validation approach was applied separately to the check dams located on hillslopes (dataset HILL) and on valley bottom (dataset VALLEY).
To evaluate the robustness of the models, the k-fold cross-validation (with k = 5) was repeated ten times, thus obtaining 50 RRMSE values and 50 MAE values for each model on each of the datasets. Variability of the predictive skill was assessed by means of box plots and by calculating the mean and the standard deviation of both the metrics. The significance of the difference between groups of RRMSE and MAE values was explored by performing the Wilcoxon signed-rank test with p < 0.01.
To further evaluate the ability of MARS, RF, and SVM to predict the sediment deposition rate, a “final model” was identified by the “caret” R package for each of these techniques. This was done by selecting the models with the smallest RMSE, choosing from the ten repetitions of the fivefold cross-validation, performed on the six analyzed datasets (i.e. ALL, HILL, VALLEY, B, C and D). The final models were employed to predict the 160 SR values of the six datasets; R2 was used to evaluate their performance.
Results
Correlation analysis
The correlation plot of Fig. 4 reports the values of Pearson’s correlation coefficient (r), with p-value < 0.01, calculated among variables. The degree and sign of correlation are indicated by circles of different size and color. The sediment deposition rate is moderately correlated only to CA (r = 0.49), UCL (r = 0.48) and CI (r = 0.45). As regards collinearity among predictors, the r coefficient reveals a perfect correlation of CA and UCL (r = 1) and a very high level of correlation between SLO and UCS (r = 0.88). A high degree of correlation (r > 0.6) exists between CI and CA (r = 0.64) and UCL (r = 0.62).

Plot showing significant (p-value < 0.01) Pearson’s correlation coefficient (r) values between dependent (sediment deposition rate -SR-) and independent variables (catchment area -CA-, catchment slope -SLO-, upstream channel slope -UCS- and length -UCL-, connectivity index -CI-, tree frequency -TF-, canopy cover -TC-, bare ground -BG- and animal paths density -PAT-)
The values of VIF, which are reported in Table 2 indicated CA and UCL as strongly correlated (VIF ≫ 10). As the correlation coefficient (r) calculated between sediment deposition rate and CA is slightly higher than that calculated with UCL, we decided to discard the latter from the analysis and keep CA. In this way, VIF values were all below the threshold of 10 (Table 2) and thus only UCL was omitted for modelling the sediment deposition rate, although r values indicated a moderate to high level of correlation between some of the remaining predictors.
Cross-validation on the datasets ALL, HILL and VALLEY
The results of the five-fold cross-validation performed ten times on the datasets ALL, HILL and VALLEY are revealed by the three top box plots of Fig. 5, which show the variability of the metrics RRMSE and MAE calculated for the models MARS, RF and SVM. The box plots display the first and third quartiles, the median and the highest and the lowest data falling within the distance of 1.5 times the inter-quartile range (IQR) from the third and first quartiles, respectively. The observed points outside this range are plotted as outliers. Moreover, the mean and standard deviation values of the same data are reported in Table 3.

Box plots showing the variability of relative root mean squared error (RRMSE) and mean absolute error (MAE) calculated for ten repetitions of fivefold cross-validation performed on the datasets ALL, HILL, VALLEY, B, C and D
Mean and median values of both RRMSE and MAE indicate that MARS performs worse than RF and SVM on the datasets ALL and VALLEY, whereas a smaller difference of predictive skill occurs on the dataset HILL. Moreover, MARS data are largely dispersed and skewed to the higher values of RRMSE and MAE, especially on the datasets ALL and VALLEY. On the other hand, RF and SVM models exhibit a similar performance on the three datasets. Only MAE values calculated on the dataset HILL indicate a significantly better performance of SVM. However, performance metrics calculated for SVM appear slightly more dispersed and skewed towards the higher values on the datasets ALL and VALLEY.
As regards the predictive skill observed on the datasets ALL, HILL and VALLEY, any significant difference of RRMSE and MAE values were found for the MARS models. On the other hand, RF enables to predict the sediment deposition rate of the VALLEY check dams with significantly better accuracy than that achieved on the datasets ALL and HILL. Moreover, RF reaches significantly lower RRMSE and MAE values on the dataset ALL than on the dataset HILL. Accordingly, the selected significance test (i.e. Wilcoxon signed-rank test) revealed that the accuracy of the SVM models on the dataset VALLEY is better than that achieved on the dataset ALL, which in turn is better than that measured for the hillslope check dams. Only the difference of RRMSE values observed on the dataset ALL and VALLEY are slightly above the selected significance threshold (p = 0.0136).
Figure 6 shows the scatter plots of the SR values observed and predicted on the datasets ALL, HILL and VALLEY by using the final MARS, RF, and SVM models. The linear regression lines and the R2 values are reported on the graphs of Fig. 6. These plots confirm that the models exhibit the best predictive performance on the dataset VALLEY and that they are able to predict SR of the dataset ALL with better accuracy than the sediment deposition rate of check dams located on hillslopes. RF final models achieve the best performance on the three datasets, whereas, surprisingly, SVM final models show lower accuracy than MARS final models, with the exception of the dataset HILL, where MARS generates an intercept-only model with R2 = 0.

Scatter plots of the sediment deposition rate (SR) values observed and predicted on the datasets ALL, HILL, and VALLEY, by using the final MARS, RF, and SVM models
Finally, an analysis of the predictor importance was performed using the final RF models, which exhibited the best fitting on the datasets ALL, HILL, and VALLEY. The three top bar plots of Fig. 7 reveal the importance of the predictors, which was estimated on these three datasets by means of the index IncNodePurity (also known as Mean Decrease Gini). This index measures the quality (purity) of a split for each node (predictor) of a tree by using the Gini Index. It is measured separately for each tree of the forest and then averaged over all the trees; higher values of the index correspond to the greater importance of the variable (Kuhn et al. 2008). The ranking of variable importance is similar for the datasets ALL and VALLEY, where CI and CA are the highest-ranked predictors; the remaining variables reach substantially lower importance than CI and CA and are ranked similarly. On the other hand, the ranking of the variable importance was greatly different on the dataset HILL, where the percentage of BG exhibits the highest IncNodePurity value while TF and PAT are less important than other predictors.

Importance of the predictors evaluated for RF models on the datasets ALL, HILL, VALLEY, B, C and D, by using the parameter IncNodePurity
Cross-validation on the individual catchments B, C and D
The variability of the 50 RRMSE and MAE values calculated by executing ten times the fivefold cross-validation on the individual catchments B, C and D is depicted in the bottom box plots of Fig. 5 Table 4 reports the mean and standard deviation calculated for the same groups of data.
MARS, RF and SVM clearly achieve the best predictive ability on the catchment D, where values of RRMSE and MAE are largely below those calculated on the catchments B and C. Accordingly, data of both the metrics are markedly less dispersed on the dataset D than on the datasets B and C. Mean, median and dispersion of RRMSE and MAE values measured on the catchment D are also significantly below those calculated on the datasets ALL, HILL and VALLEY. Figure 6 shows a similar predictive performance of MARS, RF and SVM models on the catchments B and C. Accordingly, the Wilcoxon signed-rank test reveals only two significant differences of RRMSE (SVM models) and MAE (RF models). However, mean and standard deviation values of RRMSE and MAE (Table 4) measured on catchment C are largely below those calculated on catchment B, where data are more dispersed and a number of outliers occur (Fig. 5).
According to cross-validation on catchment D, no significant difference of accuracy between RF and SVM is observed, whereas both these techniques perform largely better than MARS. The three modelling techniques achieve very similar performance on catchment C whereas SVM exhibits the best ability to predict the sediment deposition rate measured on the check dams of the catchment B.
The final MARS, RF and SVM models were employed to predict the SR values plotted in Fig. 8 versus the rates of sediment deposition observed in the catchments B, C and D. As also revealed by Fig. 5 and Table 4, SR values measured on the check dams of the catchment D are predicted with higher accuracy than that those observed on the catchments B and C. RF final models exhibit the best performance on the three catchments, achieving very high R2 values. Figure 8 also reveals a better ability of MARS final models to fit the training data if compared to that demonstrated by SVM.

Scatter plots of the sediment deposition rate (SR) values observed and predicted on the catchments B, C and D, by using the final MARS, RF and SVM models
Figure 7 shows the ranking of variable importance of the final RF models trained on the catchments B, C and D. CI and CA are clearly the most important predictors, with CI achieving the highest-ranking position on the catchments B and C, whereas CA is the highest-ranked variable on the catchment D.
Discussion
The Pearson’s correlation coefficient (r) revealed a moderate correlation between the measured SR and CA, UCL and CI, whereas no significant correlation does exist with the other predictors. A relationship between SR and CA was expected, as well as that with UCL, which strongly depends on CA, as it was calculated on a drainage network automatically derived by using this attribute. Drainage area is indeed largely recognized in the literature as one of the most important explanatory variable of area-specific sediment yield (e.g., de Vente and Poesen 2005; Grauso et al. 2008; Alatorre et al. 2010; Bachiller et al. 2019), although this relationship is usually negative whereas our data reveal a positive correlation. A negative relationship is explained in the literature considering that erosion mainly occurs on the steepest slopes of a catchment and that average catchment steepness decreases with increasing CA (Boyce 1975; Van Rompaey et al. 2001; Verstraeten and Poesen 2001; Delmas et al. 2009). However, the check dams show small drainage areas (average of 6.3 ha) with relatively homogeneous steep-slopes. According to literature (Boyce 1975; Van Rompaey et al. 2001; Verstraeten and Poesen 2001; Delmas et al. 2009; Nadal-Romero et al. 2011), deposition of sediments in small catchments is less probable than in large catchments, where slope commonly decreases and intermediate sinks are more frequent. In small catchments, an increase in the specific sediment yield may be explained by active erosion processes and high connectivity typical of first or second-order catchments. Under these circumstances, the occurrence of gullies is frequent in the SW of the Iberian Peninsula and evidences a threshold phenomenon that requires a minimum discharge (or drainage area) and slope gradient Gómez-Gutiérrez et al. (2009a).
As sediment yield is related to the degree of connectivity between sediment sources and catchment outlet, the positive relationship of SR and CI was expected and confirms the reliability of the employed CI and that of the procedure followed to calculate the volume of sediments trapped by the check dams in the study area. On the other hand, the absence of a significant linear relationship between SR and the other selected predictors may indicate that these relationships are not linear and thus, if they exist, could be detected by using more complex modelling approaches.
The cross-validation performed on the datasets ALL, HILL and VALLEY revealed that RF and SVM are able to predict the sediment deposition rate with substantially better and more stable accuracy than MARS models. On the other hand, a very small difference of performance between RF and SVM models was detected. The same results were found by applying the cross-validation of MARS, RF and SVM to catchment D whereas the three modelling techniques achieved approximately the same accuracy in predicting the SR measured at the check dams of the catchments B and C.
The difference in predictive performance of the employed modelling techniques is hard to explain. A possible reason may be that, compared to MARS, RF and SVM are able to detect more complex relationships between target variables and predictors. In the literature, we did not find any study comparing the ability of these modelling techniques in predicting sediment yield. The only comparison among the three models in the field of erosion that we found was carried out by Gayen et al. (2019), in a study aiming to predict gully occurrence in an Indian catchment, where RF achieved the best accuracy, followed by MARS and SVM. In similar analyses, Arabameri et al. (2018) measured a slightly better performance of RF compared to MARS, whereas Garosi et al. (2019) and Pourghasemi et al. (2020) found that RF achieves a slightly better performance than SVM. In a study applying machine learning algorithms to model catchment-scale erosion pin measurement, Nguyen et al. (2020) also estimated a better accuracy of RF with respect to SVM models. These erosion studies agree that RF is able to achieve the best predictive performance. This does not contrast with the results of our experiment. Indeed, if cross-validation revealed a similar predictive ability of RF and SVM, the fit to the data of the final models is substantially different, with RF achieving the highest accuracy on all the datasets (Figs. 4 and 7).
The results of the cross-validation revealed that RF and SVM achieved the best accuracy in predicting the sediment deposition rate measured on the valley bottoms (dataset VALLEY), whereas the worst performance was observed on the dataset HILL. The performance of MARS on the three datasets is instead not significantly different. The final MARS, RF and SVM models also show the best fit to the VALLEY dataset. These results agree with those found by validating the models on the individual catchments, which revealed that RF, SVM, and MARS, obtained the best accuracy on the dataset D. The latter is indeed mainly made of dry-stone check dams located on valley bottoms (45 out of 49), whereas catchments B and C include a lower percentage of VALLEY check dams (43% and 65%, respectively). The poorer ability of the models to predict the sediment deposition rate measured at the hillslope check dams could be explained considering that dams located on hillslopes retained the sediments with less efficiency than those located on valley bottoms. The latter are indeed characterized by larger walls than those forming the check dams located on hillslopes (Alfonso-Torreño et al. 2019).
As the RF final models achieved the best fit to all the datasets, they were employed to assess the relative importance of the independent variables. The IncNodePurity index revealed that CI and CA are the most important predictors on the datasets ALL and VALLEY, as well on the analyzed individual catchments, with CI achieving the highest-ranking position except for the catchment D, where CA is the most important predictor. On the other hand, the variables are ranked very differently on the dataset HILL, where the percentage of BG reaches the best-ranking position. However, in light of the poorer performance of the models observed on the dataset HILL with respect to the other ones, we consider this ranking less significant than those observed on the other datasets. Overall, the ranking of the variables importance confirms the results of the correlation analysis, which revealed that SR has a significant linear correlation only with CI and CA. The other variables are not linearly correlated with SR and show low importance also for the more complex models generated by MARS, RF, and SVM algorithms.
Measuring the volume of sediments retained by check dams placed at various locations along a drainage network allows the estimation of SR from the upstream portions of the catchment. As shown in this study, these data can be used to calibrate and validate machine learning algorithms which are able to provide reliable predictions of SR by using as predictors a set of environmental variables which can be derived from DEMs and remotely sensed images. This approach may help to predict the spatial variability of soil erosion, thus providing useful information to design effective erosion control measures in areas where sedimentological data are not available.
However, it is worth noting that the machine learning algorithms used in this study are strongly influenced by the quality and reliability of the input data. The results of this study indeed reveal that the models trained using the data measured on the valley bottom dams clearly achieve higher accuracy than those calibrated with the data estimated on the hillslopes. The latter in fact are probably less reliable because, as mentioned above, they were measured using smaller walls than those of the valley bottoms. Moreover, assuming that the amount of sediment accumulated on each DEM_02 pixel located upstream of the check-dams is estimated with the same error across the study area, the error of volume estimation is expected to be higher in percentage for HILL dams compared to VALLEY dams, where the volume of retained sediments is, on average, an order of magnitude greater than that assessed for the hillslope dams (Alfonso-Torreño et al. 2019). Finally, it is worth highlighting that exporting these models to other areas with different environmental conditions is certainly complicated and requires further investigation as also detected by Gómez-Gutiérrez et al. (2009b), as highlighted by some attempts to export the models from one basin to another, which were performed in the framework of this study.
Concluding remarks
In this study, the ability of three machine learning techniques (i.e. MARS, RF, and SVM) to predict the SR at the outlets of 160 sub-basins (mean area = 6.3 ha) of six small catchments, was evaluated and compared. A fivefolds cross-validation was used to assess the performance of the models on the entire study area (dataset ALL), on the hillslope (dataset HILL) and valley bottom (dataset VALLEY) check dams, as well as on three catchments (B, C and D) with the highest number of check dams. SR was calculated by using the volume of sediments retained by the check dams, their age and drained area. The following conclusions can be drawn from the results of this experiment.
-
RF and SVM are able to predict SR with substantially higher and more stable accuracy than MARS models. This holds for the datasets ALL, VALLEY and for the catchment D. A smaller difference of accuracy was instead observed for the dataset HILL, whereas no significant difference was revealed by cross-validating the models on catchments B and C.
-
RF and SVM achieved approximately the same performance on all the datasets. However, when validating the final models on all the check dams of the datasets, RF exhibited a substantially better predictive performance compared to SVM.
-
RF and SVM predicted SR of the valley bottom check dams with higher accuracy than that estimated for the hillslope sub-basins.
-
The performance of the three modelling techniques observed on the catchment D was clearly better than that achieved on the catchments B and C. This can be explained by considering that most (92%) of the check dams of catchment D are located on valley bottoms, where RF, SVM, and to a minor extent MARS, exhibited a better ability to predict SR with respect to hillslope check dams.
The sediment deposition rate measured at the 160 check dams provides valuable information to understand the magnitude and the spatial variability of the soil erosion and sedimentation rates and processes in dehesa landscapes. Efficient modelling of deposition rates at micro-basin scale may assist in the suitable location of check dams and, thus, in reducing the effects on flow and deposition areas. The modelling approach described in this paper enables to achieve, without any hydrological measures (i.e. water discharge), a reliable prediction of mean annual area-specific sediment yield by using environmental data that can be easily extracted from high-resolution DEMs and aerial imagery, which are increasingly available for large sectors of the world.
References
Alatorre LC, Beguería S, García-Ruiz JM (2010) Regional scale modeling of hillslope sediment delivery: a case study in the Barasona Reservoir watershed (Spain) using WATEM/SEDEM. J Hydrol 391:109–123. https://doi.org/10.1016/j.jhydrol.2010.07.010
Alfonso-Torreño A, Gómez-Gutiérrez Á, Schnabel S, Lavado-Contador JF, de Sanjosé Blasco JJ, Sánchez Fernández M (2019) sUAS, SfM-MVS photogrammetry and a topographic algorithm method to quantify the volume of sediments retained in check-dams. Sci Total Environ 678:369–382. https://doi.org/10.1016/j.scitotenv.2019.04.332
Alfonso-Torreño A, Gómez-Gutiérrez Á, Schnabel S (2021) Dynamics of erosion and deposition in a partially restored valley-bottom gully. Land 10:62. https://doi.org/10.3390/land10010062
Arabameri A, Pradhan B, Pourghasemi HR, Rezaei K, Kerle N (2018) Spatial modelling of gully erosion using GIS and R programing: a comparison among three data mining algorithms. Appl Sci 8:1369. https://doi.org/10.3390/app8081369
Baade J, Franz S, Reichel A (2012) Reservoir siltation and sediment yield in the Kruger National Park, South Africa: a first assessment. Land Degrad Dev 23:586–600. https://doi.org/10.1002/ldr.2173
Bachiller AR, Rodríguez JLG, Sánchez JCR, Gómez DL (2019) Specific sediment yield model for reservoirs with medium-sized basins in Spain: an empirical and statistical approach. Sci Total Environ 681:82–101. https://doi.org/10.1016/j.scitotenv.2019.05.029
Bangash RF, Passuello A, Sanchez-Canales M, Terrado M, López A, Elorza FJ, Ziv G, Acuña V, Schuhmacher M (2013) Ecosystem services in Mediterranean river basin: climate change impact on water provisioning and erosion control. Sci Total Environ 458–460C:246–255. https://doi.org/10.1016/j.scitotenv.2013.04.025
Bellin N, Vanacker V, van Wesemael B, Solé-Benet A, Bakker MM (2011) Natural and anthropogenic controls on soil erosion in the Internal Betic Cordillera (southeast Spain). CATENA 87:190–200. https://doi.org/10.1016/j.catena.2011.05.022
Belmonte Serrato F, Romero Díaz A, Martínez-Lloris M (2005) Erosión en cauces afectados por obras de corrección hidrológica (Cuenca del Río Quípar, Murcia). Papeles De Geografía 41–42:71–83
Boix-Fayos C, de Vente J, Martínez-Mena M, Barberá GG, Castillo V (2008) The impact of land use change and check-dams on catchment sediment yield. Hydrol Process 22:4922–4935. https://doi.org/10.1002/hyp.7115
Bombino G, Gurnell AM, Tamburino V, Zema DA, Zimbone SM (2009) Adjustements in channel form, sediment calibre and vegetation around check-dams in the headwater reaches of mountain torrents, Calabria, Italy. Earth Surf Process Landf 34(7):1011–1021. https://doi.org/10.1002/esp.1791
Borrelli P, Märker M, Schütt B (2015) Modelling post-tree-harvesting soil and sediment deposition potential in the Turano river basin (Italian Central Apennine). Land Degrad Dev 26(4):356–366. https://doi.org/10.1002/ldr.2214
Borselli L, Cassi P, Torri D (2008) Prolegomena to sediment and flow connectivity in the landscape: a GIS and field numerical assessment. CATENA 75:268–277. https://doi.org/10.1016/j.catena.2008.07.006
Bou Kheir R, Wilson J, Deng Y (2007) Use of terrain variables for mapping gully erosion susceptibility in Lebanon. Earth Surf Process Landf 32:1770–1782. https://doi.org/10.1002/esp1501
Bouchnak H, Felfoul MS, Boussema MR, Snane MH (2009) Slope and rainfall effects on the volume of sediment yield by gully erosion in the souar lithologic formation (Tunisia). CATENA 78(2):170–177. https://doi.org/10.1016/j.catena.2009.04.003
Boyce RC (1975) Sediment routing with sediment delivery ratios. In Present and prospective technology for predicting sediment yields and sources. US Department of Agriculture, Publication ARS-S-40:61–65
Breiman L (2001) Random forests. Mach Learn 45:5–32
Bussi G, Rodríguez-Lloveras X, Francés F, Benito G, Sánchez-Moya Y, Sopeña A (2013) Sediment yield model implementation based on check dam infill stratigraphy in a semiarid Mediterranean catchment. Hydrol Earth Syst Sci 17:3339–3354. https://doi.org/10.5194/hess-17-3339-2013
Bussi G, Francés F, Horel E, López-Tarazón JA, Batalla RJ (2014) Modelling the impact of climate change on sediment yield in a highly erodible Mediterranean catchment. J Soils Sediment 14(12):1921–1937. https://doi.org/10.1007/s11368-014-0956-7
Buyukyildiz M, Kumcu SY (2017) An estimation of the suspended sediment load using adaptive network based fuzzy inference system, support vector machine and artificial neural network models. Water Resour Manag 31:1343–1359. https://doi.org/10.1007/s11269-017-1581-1
Castillo VM, Mosch WM, Conesa García C, Barberá GG, Navarro Cano JA, López-Bermúdez F (2007) Effectiveness and geomorphological impacts of check dams for soil erosion control in a semiarid Mediterranean catchment: El Cárcavo (Murcia, Spain). CATENA 70(3):416–427. https://doi.org/10.1016/j.catena.2006.11.009
Catella M, Paris E, Solari L (2005) Case study: efficiency of slit-check dams in the Mountain region of Versilia Bain. J Hydraul Eng. https://doi.org/10.1061/(ASCE)0733-9429(2005)131:3(145)
Cavalli M, Trevisani S, Comiti F, Marchi L (2013) Geomorphometric assessment of spatial sediment connectivity in small Alpine catchments. Geomorphology 188:31–41. https://doi.org/10.1016/j.geomorph.2012.05.007
Cerdà A (2002) The effect of season and parent material on water erosion on highly eroded soils in eastern Spain. J Arid Environ 52:319–337. https://doi.org/10.1006/jare.2002.1009
Chen W, Xie X, Wang J, Pradhan B, Hong H, Bui DT, Duan Z, Ma J (2017) A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. CATENA 151:147–160. https://doi.org/10.1016/j.catena.2016.11.032
Chen W, Xie X, Peng J et al (2018) GIS-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. CATENA 164:135–149. https://doi.org/10.1016/j.catena.2018.01.012
Çimen M (2008) Estimation of daily suspended sediments using support vector machines. Hydrol Sci J 53:656–666. https://doi.org/10.1623/hysj.53.3.656
Conesa C (2004) Los diques de retención en cuencas de régimen torrencial: diseño, tipos y funciones. Nimbus 16–14:125–132
Conesa García C, García Lorenzo R (2007) Litofacies de relleno y modelo de sedimentación de los diques de retención en el tramo inferior de la Rambla del Cárcavo (Cuenca del Segura). Cuaternario y Geomorfología 21(3–4):77–100
Conoscenti C, Rotigliano E (2020) Predicting gully occurrence at watershed scale: comparing topographic indices and multivariate statistical models. Geomorphology 359:107123. https://doi.org/10.1016/j.geomorph.2020.107123
Conoscenti C, Angileri S, Cappadonia C, Rotigliano E, Agnesi V, Märker M (2014) Gully erosion susceptibility assessment by means of GIS-based logistic regression: a case of Sicily (Italy). Geomorphology 204:399–411. https://doi.org/10.1016/j.geomorph.2013.08.021
Conoscenti C, Ciaccio M, Caraballo-Arias NA, Gómez-Gutiérrez Á, Rotigliano E, Agnesi V (2015) Assessment of susceptibility to earth-flow landslide using logistic regression and multivariate adaptive regression splines: a case of the Belice River basin (western Sicily, Italy). Geomorphology 242:49–64. https://doi.org/10.1016/j.geomorph.2014.09.020
Conoscenti C, Agnesi V, Cama M, Caraballo-Arias NA, Rotigliano E (2018) Assessment of gully erosion susceptibility using multivariate adaptive regression splines and accounting for terrain connectivity. Land Degrad Dev 29:724–736. https://doi.org/10.1002/ldr.2772
Cucchiaro S, Cavalli M, Vericat D, Crema S, Llena M, Beinat A, Marchi L, Cazorzi F (2019) Geomorphic effectiveness of check dams in a debris-flow catchment using multi-temporal topographic surveys. CATENA 174:78–83. https://doi.org/10.1016/j.catena.2018.11.004
De Vente J, Poesen J (2005) Predicting soil erosion and sediment yield at the basin scale: scale issues and semi-quantitative models. Earth-Sci Rev 71:95–125. https://doi.org/10.1016/j.earscirev.2005.02.002
De Vente J, Poesen J, Verstraeten G, Van Rompaey A, Govers G (2008) Spatially distributed modelling of soil erosion and sediment yield at regional scales in Spain. Glob Planet Change 60:393–415. https://doi.org/10.1016/j.gloplacha.2007.05.002
Delmas M, Cerdan O, Mouchel JM, Garcin M (2009) A method for developing a large-scale sediment yield index for European river basins. J Soils Sediment 9:613–626. https://doi.org/10.1007/s11368-009-0126-5
Francke T, López-Tarazón JA, Schröder B (2008) Estimation of suspended sediment concentration and yield using linear models, random forests and quantile regression forests. Hydrol Process 22:4892–4904. https://doi.org/10.1002/hyp.7110
Friedman JH (1991) Multivariate adaptive regression splines. Ann Stat 19:1–141
Garosi Y, Sheklabadi M, Porghasemi HR, Besalatpour AA, Conoscenti C, Van Oost K (2018) Comparison of differences in resolution and sources of controlling factors for gully erosion susceptibility mapping. Geoderma 330:65–78. https://doi.org/10.1016/j.geoderma.2018.05.027
Garosi Y, Sheklabadi M, Conoscenti C, Pourghasemi HR, Van Oost K (2019) Assessing the performance of GIS-based machine learning models with different accuracy measures for determining susceptibility to gully erosion. Sci Total Environ 664:1117–1132. https://doi.org/10.1016/j.scitotenv.2019.02.093
Gayen A, Pourghasemi HR, Saha S, Keesstra S, Bai S (2019) Gully erosion susceptibility assessment and management of hazard-prone areas in India using different machine learning algorithms. Sci Total Environ 668:124–138. https://doi.org/10.1016/j.scitotenv.2019.02.436
Gómez-Gutiérrez Á, Schnabel S, Felicísimo ÁM (2009a) Modelling the occurrence of gullies in rangelands of southwest Spain. Earth Surf Process Landf 34:1894–1902. https://doi.org/10.1002/esp1881
Gómez-Gutiérrez Á, Schnabel S, Lavado Contador F (2009b) Using and comparing two nonparametric methods (CART and MARS) to model the potential distribution of gullies. Ecol Model 220:3630–3637. https://doi.org/10.1016/j.ecolmodel.2009.06.020
Gómez-Gutiérrez Á, Schnabel S, De Sanjosé JJ, Lavado Contador JF (2012) Exploring the relationships between gully erosion and hydrology in rangelands of SW Spain. Z Geomorphol Suppl Issues 56:27–44. https://doi.org/10.1127/0372-8854/2012/S-00071
Gómez-Gutiérrez Á, Conoscenti C, Angileri SE, Rotigliano E, Schnabel S (2015) Using topographical attributes to evaluate gully erosion proneness (susceptibility) in two mediterranean basins: advantages and limitations. Nat Hazards 79:291–314. https://doi.org/10.1007/s11069-015-1703-0
Grauso S, Pagano A, Fattoruso G, De Bonis P, Onori F, Regina P, Tebano C (2008) Relations between climatic-geomorphological parameters and sediment yield in a mediterranean semi-arid area (Sicily, southern Italy). Environ Geol 54:219–234. https://doi.org/10.1007/s00254-007-0809-4
Heckmann T, Gegg K, Gegg A, Becht M (2014) Sample size matters: investigating the effect of sample size on a logistic regression susceptibility model for debris flows. Nat Hazards Earth Syst Sci 14:259–278. https://doi.org/10.5194/nhess-14-259-2014
Herguido Sevillano E, Lavado Contador JF, Pulido M, Schnabel S (2017) Spatial patterns of lost and remaining trees in the Iberian wooded rangeland. Appl Geogr 87:170–183. https://doi.org/10.1016/j.apgeog.2017.08.011
Hovius N (1998) Controls on sediment supply by large rivers, relative role of eustasy, climate and tectonismin continental rocks. Society of Sedimentray Geology. Special Publication 59:3–16. https://doi.org/10.2110/pec.98.59.0002
Javernick L, Brasington J, Caruso B (2014) Modeling the topography of shallow braided rivers using Structure-from-Motion photogrammetry. Geomorphology 213:166–182. https://doi.org/10.1016/j.geomorph.2014.01.006
Jebur MN, Pradhan B, Tehrany MS (2014) Optimization of landslide conditioning factors using very high-resolution airborne laser scanning (LiDAR) data at catchment scale. Remote Sens Environ 152:150–165. https://doi.org/10.1016/j.rse.2014.05.013
Kavzoglu T, Colkesen I, Sahin EK (2019) Machine learning techniques in landslide susceptibility mapping: a survey and a case study. In: Pradhan S, Vishal V, Singh T (eds) Landslides: theory, practice and modelling. Advances in natural and technological hazards research, vol 50. Springer, Cham. https://doi.org/10.1007/978-3-319-77377-3_13
Keesstra SD (2007) Impact of natural reforestation on floodplain sedimentation in the Dragonja basin, SW Slovenia. Earth Surf Proc Land 32(1):49–65. https://doi.org/10.1002/esp.1360
Keesstra SD, van Dam O, Verstraeten G, van Huissteden J (2009) Changing sediment dynamics due to natural reforestation in the dragonja catchment, SW Slovenia. Catena 78(1):60–71. https://doi.org/10.1016/j.catena.2009.02.021
Keestra SD, Maroulis J, Argaman E, Voogt A, Wittenberg L (2014) Effects of controlled fire on hydrology and erosion under simulated rainfall. Cuad Investig Geogr 40(2):269–293. https://doi.org/10.18172/cig.2532
Kuhn S, Egert B, Neumann S, Steinbeck C (2008) Building blocks for automated elucidation of metabolites: machine learning methods for NMR prediction. BMC Bioinform 9:1–19. https://doi.org/10.1186/1471-2105-9-400
Leathwick JR, Elith J, Hastie T (2006) Comparative performance of generalized additive models and multivariate adaptive regression splines for statistical modelling of species distributions. Ecol Model 199:188–196. https://doi.org/10.1016/j.ecolmodel.2006.05.022
Ma Z, Mei G, Piccialli F (2020) Machine learning for landslides prevention: a survey. Neural Comput Appl. https://doi.org/10.1007/s00521-020-05529-8
Martinello C, Cappadonia C, Conoscenti C, Agnesi V, Rotigliano E (2020) Optimal slope units partitioning in landslide susceptibility mapping. J Maps. https://doi.org/10.1080/17445647.2020.1805807
Martínez-Murillo JF, López-Vicente M (2018) Effect of salvage logging and check dams on simulated hydrological connectivity in a burned area. Land Degrad Dev 29:701–712. https://doi.org/10.1002/ldr.2735
Martín-Rosales W, Pulido-Bosch A, Gisbert J, Vallejos A (2003) Sediment yield estimation and check dams in a semiarid area (Sierra de Gádor, southern Spain), in Erosion Prediction in Ungauged Basins: integrating methods and techniques. IAHS Publ 279:51–58
Mekonnen M, Keesstra SD, Baartman JE, Ritsema CJ, Melesse AM (2015) Evaluating sediment storage dams: structural off-site sediment trapping measures in northwest Ethiopia. Cuad Investig Geogr 41(1):7–22. https://doi.org/10.18172/cig.2643
Middelkoop H, Daamen K, Gellens D, Grabs W, Kwadijk JCJ, Lang H, Parmet BWAH, Schädler B, Schulla J, Wilke K (2001) Impact of climate change on hydrological regimes and water resources management in the Rhine Basin. Clim Change 49:105–128. https://doi.org/10.1023/A:1010784727448
Mojaddadi H, Pradhan B, Nampak H, Ahmad N, Ghazali AH (2017) Ensemble machine-learning-based geospatial approach for flood risk assessment using multi-sensor remote-sensing data and GIS. Geomat Nat Hazards Risk 8:1080–1102. https://doi.org/10.1080/19475705.2017.1294113
Mutua BM, Klik A, Loiskandl W (2006) Modelling soil erosion and sediment yield at a catchment scale: the case of Masinga catchment, Kenya. Land Degrad Dev 17(5):557–570. https://doi.org/10.1002/ldr.753
Nadal-Romero E, Martínez-Murillo JF, Vanmaercke M, Poesen J (2011) Scale-dependency of sediment yield from badland areas in Mediterranean environments. Prog Phys Geogr Earth Environ 35:297–332. https://doi.org/10.1177/0309133311400330
Naimi B, Hamm N, Groen TA, Skidmore AK, Toxopeus AG (2014) Where is positional uncertainty a problem for species distribution modelling. Ecography (cop) 37:191–203. https://doi.org/10.1111/j.1600-0587.2013.00205.x
Nguyen KA, Chen W, Lin B-S, Seeboonruang U (2020) Using machine learning-based algorithms to analyze erosion rates of a watershed in northern Taiwan. Sustainability 12(5):2022. https://doi.org/10.3390/su12052022
Nunes JP, Seixas J, Pacheco NR (2008) Vulnerability of water resources vegetation productivity and soil erosion to climate change in Mediterranean watersheds. Hydrol Process 22:3115–3134. https://doi.org/10.1002/hyp.6897
Peterson BG, Carl P (2020) PerformanceAnalytics: econometric tools for performance and risk analysis. R package version 2.0.4. https://CRAN.R-project.org/package=PerformanceAnalytics
Pourghasemi HR, Jirandeh AG, Pradhan B, Xu C, Gokceoglu C (2013) Landslide susceptibility mapping using support vector machine and GIS at the Golestan Province. Iran J Earth Syst Sci 122:349–369. https://doi.org/10.1007/s12040-013-0282-2
Pourghasemi HR, Sadhasivam N, Kariminejad N, Collins AL (2020) Gully erosion spatial modelling: role of machine learning algorithms in selection of the best controlling factors and modelling process. Geosci Front. https://doi.org/10.1016/j.gsf.2020.03.005
Pulido M, Schnabel S, Lavado Contador JF, Lozano-Parra J, González F (2018) The impacto of heavy grazing on soil quality and pasture production in rangelands of SW Spain. Land Degrad Dev 29(2):219–230. https://doi.org/10.1002/ldr.2501
Quiñonero-Rubio JM, Nadeu E, Boix-Fayos C, Vente J (2016) Evaluation of the effectiveness of forest restoration and check dams to reduce catchment sediment yield. Land Degrad Dev 27(4):1018–1031. https://doi.org/10.1002/ldr.2331
R Core Team (2018) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna
Rahmati O, Haghizadeh A, Pourghasemi HR, Noormohamadi F (2016) Gully erosion susceptibility mapping: the role of GIS-based bivariate statistical models and their comparison. Nat Hazards 82:1–28. https://doi.org/10.1007/s11069-016-2239-7
Rahmati O, Tahmasebipour N, Haghizadeh A, Pourghasemi HR, Feizizadeh B (2017) Evaluation of different machine learning models for predicting and mapping the susceptibility of gully erosion. Geomorphology 298:118–137. https://doi.org/10.1016/j.geomorph.2017.09.006
Restrepo JD, Kjerfve B, Hermelin M, Restrepo JC (2006) Factors controlling sediment yield in a major south American drainage basin: the Magdalena river, Colombia. J Hydrol 316:213–232. https://doi.org/10.1016/j.jhydrol.2005.05.002
Romero A (2008) Los diques de corrección hidrológica como instrumentos de cuantificación de la erosión. Cuad Investig Geogr 34:89–99. https://doi.org/10.18172/cig.1208
Rotigliano E, Martinello C, Hernandéz MA, Agnesi V, Conoscenti C (2019) Predicting the landslides triggered by the 2009 96E/Ida tropical storms in the Ilopango caldera area (El Salvador, CA): optimizing MARS-based model building and validation strategies. Environ Earth Sci 78:210. https://doi.org/10.1007/s12665-019-8214-3
Rubio-Delgado J, Guillén J, Corbacho JA, Gómez-Gutiérrez Á, Baeza A, Schnabel S (2017) Comparison of two methodologies used to estimate erosion rates in Mediterranean ecosystems: 137Cs and exposed tree roots. Sci Total Environ 605–606:541–550. https://doi.org/10.1016/j.scitotenv.2017.06.248
Sarangi A, Madramootoo C, Enright P, Prasher S, Patel R (2005) Performance evaluation of ANN and geomorphology-based models for runoff and sediment yield prediction for a Canadian watershed. Curr Sci 89:2022–2033
Schnabel S, Ceballos Barbancho A, Gómez-Gutiérrez Á (2010) Erosión hídrica en la dehesa extremeña. In: Schnabel S, Lavado Contador JF, Gómez-Gutiérrez Á, García Marín R (eds) Aportaciones a la Geografía Física de Extremadura con especial referencia a las dehesas, Asociación Profesional para la Ordenación del Territorio, el Ambiente y el Desarrollo Sostenible, España, p 153–185
Schnabel S, Dahlgren RA, Moreno-Marcos G (2013) Soil and water dynamics. In: Campos P, Oviedo JS, Díaz M, Montero G (eds) Mediterranean oak woodland working landscapes. Dehesas of Spain and Ranchlands of California, Springer, Dordrecht, pp 91–122
Smith MW, Vericat D (2015) From experimental plots to experimental landscapes: topography, erosion and deposition in sub-humid badlands from Structure-from-Motion photogrammetry. Earth Surf Proc Land 40(12):1656–1671. https://doi.org/10.1002/esp.3747
Sougnez N, van Wesemael B, Vanacker V (2011) Low erosion rates measured for steep, sparsely vegetated catchments in southeast Spain. CATENA 84:1–11. https://doi.org/10.1016/j.catena.2010.08.010
Tamene L, Park SJ, Dikau R, Vlek PLG (2006) Analysis of factors determining sediment yield variability in the highlands of northern Ethiopia. Geomorphology 76:76–91. https://doi.org/10.1016/j.geomorph.2005.10.007
Tehrany MS, Pradhan B, Mansor S, Ahmad N (2015) Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. CATENA 125:91–101. https://doi.org/10.1016/j.catena.2014.10.017
Trigila A, Iadanza C, Esposito C, Scarascia-Mugnozza G (2015) Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology. https://doi.org/10.1016/j.geomorph.2015.06.001
Ullman S (1979) The interpretation of structure from motion. Proc R Soc B 203:405-426. https://doi.org/10.1098/rspb.1979.0006
Valentin C, Poesen J, Li Y (2005) Gully erosion: impacts, factors and control. CATENA 63:132–153. https://doi.org/10.1016/j.catena.2005.06.001
Van Rompaey AJJ, Verstraeten G, Van Oost K, Govers G, Poesen J (2001) Modelling mean annual sediment yield using a distributed approach. Earth Surf Process Landf 26:1221–1236. https://doi.org/10.1002/esp.275
Vanmaercke M, Poesen J, Verstraeten G, de Vente J, Ocakoglu F (2011) Sediment yield in Europe; spatial patterns and scale dependency. Geomorphology 130(3–4):142–161. https://doi.org/10.1016/j.geomorph.2011.03.010
Vapnik V (1998) Statistical learning theory. Wiley, New York
Vargas-Cuervo G, Rotigliano E, Conoscenti C (2019) Prediction of debris-avalanches and -flows triggered by a tropical storm by using a stochastic approach: an application to the events occurred in Mocoa (Colombia) on 1 April 2017. Geomorphology 339:31–43. https://doi.org/10.1016/j.geomorph.2019.04.023
Verstraeten G, Poesen J (2001) Factors controlling sediment yield from small intensively cultivated catchments in a temperate humid climate. Geomorphology 40:123–144. https://doi.org/10.1016/S0169-555X(01)00040-X
Verstraeten G, Poesen J (2002) Regional scale variability in sediment and nutrient delivery from small agricultural watersheds. J Environ Qual 31(3):870–879. https://doi.org/10.2134/jeq2002.8700
Vorpahl P, Elsenbeer H, Märker M, Schröder B (2012) How can statistical models help to determine driving factors of landslides? Ecol Model 239:27–39. https://doi.org/10.1016/j.ecolmodel.2011.12.007
Wei T, Simko V (2017) R package “corrplot”: visualization of a Correlation Matrix (Version 0.84). Available from https://github.com/taiyun/corrplot
Westoby MJ, Brasington J, Glasser NF, Hambrey MJ, Reynolds JM (2012) “Structure-from-Motion” photogrammetry: a low-cost, effective tool for geoscience applications. Geomorphology 179:300–314. https://doi.org/10.1016/j.geomorph.2012.08.021
Wheaton JM, Brasington J, Darby SE, Sear DA (2010) Accounting for uncertainty in DEMs from repeat topographic surveys: improved sediment budgets. Earth Surf Proc Landf 35:136–156. https://doi.org/10.1002/esp.1886
Wilby RL, Hay LE, Leavesley GH (1999) A comparison of downscaled and raw GCM output: implications for climate change scenarios in the San Juan River basin Colorado. J Hydrol 225:67–91. https://doi.org/10.1016/S0022-1694(99)00136-5
Wing J, Kuhn M (2018) caret: classification and regression training. https://cran.r-project.org/package=caret
Woodget AS, Carbonneau PE, Visser F, Maddock IP (2015) Quantifying submerged fluvial topography using hyperspatial resolution UAS imagery and structure from motion photogrammetry. Earth Surf Proc Landf 40:47–64. https://doi.org/10.1002/esp.3613
Yilmaz B, Aras E, Nacar S, Kankal M (2018) Estimating suspended sediment load with multivariate adaptive regression spline, teaching-learning based optimization, and artificial bee colony models. Sci Total Environ 639:826–840. https://doi.org/10.1016/j.scitotenv.2018.05.153
Zhao G, Kondolf GM, Mu X, Han M, He Z, Rubin Z, Wang F, Gao P, Sun W (2017) Sediment yield reduction associated with land use changes and check dams in a catchment of the Loess Plateau, China. CATENA 148:126–137. https://doi.org/10.1016/J.CATENA.2016.05.010
Zimmermann A, Francke T, Elsenbeer H (2012) Forests and erosion: insights from a study of suspended-sediment dynamics in an overland flow-prone rainforest catchment. J Hydrol 428–429:170–181. https://doi.org/10.1016/j.jhydrol.2012.01.039
Zucca C, Canu A, Della Peruta R (2006) Effects of land use and landscape on spatial distribution and morphological features of gullies in an agropastoral area in Sardinia (Italy). CATENA 68:87–95. https://doi.org/10.1016/j.catena.2006.03.015
Funding
This research was possible due to the financial support of the Spanish Ministry of Economy and Competitiveness (Project CGL2014-54822-R). Alberto Alfonso-Torreño was supported by a predoctoral fellowship (PD16004) from Junta de Extremadura and European Social Fund. Chiara Martinello was supported by a predoctoral fellowship from the Italian Ministry of Education, Universities and Research (MIUR). All authors have contributed equally to the realization of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of a Topical Collection in Environmental Earth Sciences on “Geosphere Anthroposphere Interlinked Dynamics: Geocomputing and New Technologies”, guest edited by Sebastiano Trevisani, Marco Cavalli, and Fabio Tosti.
Rights and permissions
About this article

Cite this article
Conoscenti, C., Martinello, C., Alfonso-Torreño, A. et al. Predicting sediment deposition rate in check-dams using machine learning techniques and high-resolution DEMs. Environ Earth Sci 80, 380 (2021). https://doi.org/10.1007/s12665-021-09695-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-021-09695-3