
Abstract
The drilling and blasting technique is among the common techniques for excavating tunnels with different shapes and sizes. Nevertheless, due to the dynamic energy involved, the rock mass around the excavation zone experiences damage and reduction in stiffness and strength. One of the most common and important issues that occurs during the tunneling process is the overbreak which is defined as the surplus drilled section of the tunnel. It seems that prediction of overbreak before blasting operations is necessary to minimize the possible damages. This paper develops a new hybrid model, namely, an artificial bee colony (ABC)–artificial neural network (ANN) to predict overbreak. Considering the most important parameters on overbreak, many ABC–ANN models were constructed based on their effective parameters. A pre-developed ANN model was also developed for comparison. In order to evaluate the obtained results of this study, a new system, i.e., the color intensity rating (CIR), was introduced and established to select the best ABC–ANN and ANN models. As a result, the ABC–ANN receives a high level of accuracy in predicting overbreak induced by drilling and blasting. The coefficients of determination (R2) for the ANN and ABC–ANN are 0.9121 and 0.9428, respectively, for training datasets. This revealed that the ABC–ANN model (as a new model in the field of this study) is the best one among the models developed in this study.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
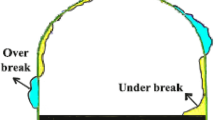
Tunnels are typically excavated for various applications such as road construction and water transfer in civil and mining works. Although new mechanized excavation techniques using tunnel boring machines (TBMs) have been used for tunnel excavation, traditional techniques such as drilling and blasting are still applicable for excavation of tunnels with different shapes and sizes (Bhandari 1997). In fact, due to its advantages of high flexibility and low cost, it is still considered as a common excavation technique (Raina et al. 2014). Nevertheless, damages to the peripheral rock mass around the excavation are inevitable because of the excessive dynamic energy associated with the blasting operation. After the blasting operation, the excavation cross section may have two major problems, namely, overbreak and under-break (Fig. 1). The overbreak is defined as the excavated area in excess of the final profile of the tunnel, and the under-break is defined as the portion of the rock that needs to be removed to reach the final tunnel profile.

Overbreak and under-break induced by drilling and blasting method
One of the most important issues that occurs in the excavation process of a tunneling project is always the overbreak phenomenon. Nowadays, with the progression and introduction of new technologies to tunneling industry, new methods are used instead of traditional methods (drilling and blast). Even with the use of more advanced equipment in the tunneling industry, overbreak is still common and reported. The main reasons for overbreak include unpredictability of the rock formation and the rock heterogeneity. In small tunnel projects with low excavation volumes, contractors are typically unwilling to invest in new mechanized equipment and rely on traditional methods. Therefore, it can be argued that for small- to medium-scale projects, the traditional methods, especially drilling and blasting, are the most common tunnel excavation methods. There is currently no existing experimental and analytical method for the determination of overbreak in the tunnels. Overbreak and under-break often are not measured in tunnels or underground mines, because existing methods are too complicated, expensive, inaccurate, or time-consuming (Maerz et al. 1996). There are currently three methods of actually measuring profiles: surveying techniques—manual or laser-based—and photographic light sectioning methods. The current state of the art for determination of the overbreak is to use predictive models. The prediction models, depending on the dataset being used for prediction, that can be used can have higher accuracy, lower cost and require less time.
Recently, artificial intelligence (AI) methods such as artificial neural networks (ANNs), fuzzy inference system (FISs) and adaptive neuro-fuzzy inference systems (ANFISs) have been employed in solving geotechnical problems (Hasanipanah et al. 2018; Koopialipoor et al. 2018b, d). AI methods were used to predict the uniaxial compressive strength (UCS) of rock by several researchers (Raina et al. 2004; Marto et al. 2014; Hajihassani et al. 2015; Jahed Armaghani et al. 2016). Alvarez Grima et al. (2000) developed an ANFIS to predict the penetration rate of TBMs. Momeni et al. (2015) applied the ANN technique to predict the bearing capacity of piles. In addition, this method was utilized to solve the problem of ground settlement induced by tunneling in the study carried out by Ocak and Seker (2013). Gordan et al. (2016) predicted the stability of homogeneous slopes combining particle swarm optimization (PSO) and an ANN.
Parameters influencing the overbreak can be classified into three groups: (a) rock mass characteristics; (b) geometric properties of the explosion pattern; and (c) blasting operation properties (Mandal and Singh 2009). Several researches have worked on overbreak in mines and tunnels. Monjezi and Dehghani (2008) considered the ratio of stemming to burden, charge of the last row to total charge, special charge, special charge per delay and the number of explosion rows in each stage as the most influential factors for overbreak in the GOL-GOHAR mine, Iran. Jang and Topal (2013), by using ANNs, predicted the overbreak of the Gyby tunnel in South Korea with a correlation coefficient (R) of 0.945 between the output of the model and the actual data. The correlation coefficient (R) is a measure of the difference between the overbreak computed through a certain functional and the measured (observed) overbreak. The inputs in this model included the UCS of the rock mass, quality index of rock mass, rock weathering conditions, groundwater conditions, and geomechanical classification index values of rock mass.
To develop a comprehensive ANN model, Monjezi et al. (2013) used parameters of UCS, special drilling, underground water content, burden, hole spacing, stemming, the diameter of the hole, stair height, and special charge and consumer charge in every delay as model inputs. They performed a sensitivity analysis on the mentioned parameters and concluded that burden and underground water content are the most important and least important parameters, respectively. Ebrahimi et al. (2016) demonstrated that the most influential parameters on overbreak are burden, spacing and charge per delay. By developing an ant colony optimization algorithm, Saghatforoush et al. (2016) concluded that the optimum values of overbreak and flyrock can be reduced significantly.
Gates et al. (2005) demonstrated that insufficient delay time and number of explosive rows are the most effective factors for overbreak. Esmaeili et al. (2014) suggested that the last row of charge and special charge are the most important factors for overbreak, while the ratio of burden to spacing, stiffness and density are the least important ones. Ibarra et al. (1996) reported that the charge factor of an environment from explosives can create under-break, and poor quality of rock may cause overbreak in tunnels. Mandal and Singh (2009) showed that in addition to the rock conditions, in situ stress influences significantly the overbreak. Several empirical models have been suggested by researchers to estimate overbreak (Lundborg 1974; Roth 1979). Singh and Xavier (2005) carried out a series of small experiments on the physical scale models to predict the blast damage. The most effective parameters for overbreak in their assumption was the characteristics of the rock mass [UCS and rock mass rating (RMR)] and the explosive material (special charge, burden and spacing). Recently, Koopialipoor et al. (2017) proposed a genetic algorithm (GA)-ANN model to predict overbreak induced by tunneling operations.
It can be concluded from the existing literature that due to the multiplicity of effective factors as well as the complex relationship between these parameters, there is a need to develop a new technique to predict and control tunnel overbreak. Therefore, it is necessary to evaluate the probability of an overbreak phenomenon for each project before conducting blasting operations. The present study attempts to predict overbreak induced by drilling and blasting operations at Gardaneh Rokh tunnel, Iran by using an artificial bee colony (ABC)–ANN approach. Note that several researchers have used ANN and ABC approaches for prediction and optimization purposes (Ebrahimi et al. 2016; Saghatforoush et al. 2016; Ghaleini et al. 2018; Koopialipoor et al. 2018a). The work presented in this paper is a new combination that has not been used/developed for prediction of overbreak in tunnels. To demonstrate the capabilities of the proposed hybrid model, an ANN model is also constructed and compared with the hybrid model. Finally, an examination of the ABC–ANN model is conducted to predict overbreak in a tunnel.
Case study and collected data
The Gardaneh Rokh tunnel is an important strategic tunnel in West Iran, connecting Esfahan and Chaharmahal-Bakhtiari provinces. The road on which the tunnel is located is a critical highway from economic and strategic aspects. This tunnel has a length of 1300 m and width of 13 m. The location of the area studied in this work is shown in Fig. 2. Excavation of this tunnel, as shown in Fig. 3, was performed in two sections; the top one was excavated using the drilling and blasting method, and the bottom one was excavated using hydraulic hammers.

Location of the study area

Cross section of the studied tunnel
Similar explosive patterns were used to excavate the top section of the tunnel. Although some minor changes were made in the pattern of explosions in this project, the changes were not varied enough to be considered in different arrangements for each stage of the explosion. Table 1 shows general specifications of excavation at the top section of the tunnel.
In this study, eight parameters were selected as model inputs for prediction of overbreak. A total of 255 datasets of RMR, advanced length, special charge, hole periphery burden, end row burden, periphery spacing, end row spacing, and number of applied delays were used for this analysis. A simple description of these parameters (input and output) is provided in Table 2.
Methods
This section describes the methods used in this study. As discussed earlier, AI techniques are used in this research for application in the field of tunnel engineering and determination of overbreak. Given the fact that various parameters influence the overbreak, finding a new solution can be useful for researchers and engineers in this technical field. Therefore, developing a relationship to accurately predict the overbreak is essential. These models are coded in the software and output files on different devices (mobile and computer), and can be used as an application. Further details are provided in the following sections.
Artificial neural network
The artificial neural network (ANN) was developed by McCulloch and Pittsin (1943). This flexible technique is a type of AI system which can solve problems faster with a high degree of accuracy. Furthermore, it can be used to solve nonlinear problems where input and output parameters are considered unknown (Garrett 1994). The ANN is an imitation of the mechanism of data analysis of biological cells. The brain is a high complex network which can act as a parallel processor. Such networks are designed mainly for a series of nonlinear mapping between inputs and outputs. ANNs learn from previous experiences and are generalized using training samples. These techniques can change their behavior based on the environment and are appropriate for the required algorithms for mapping. In ANN systems, the data used to create models are known as training data. In other words, ANNs use training data to learn patterns in the data which can prepare them to achieve different outputs (Fausett and Fausett 1994). The structure of ANNs is created by processor units (neurons or nodes), which are responsible for the organization. These neurons can be combined with each other to form a layer. There are different ways to link neurons in an ANN. Feed-forward (FF)–back-propagation (BP) is a common procedures in ANNs and has been successfully implemented and reported by many researchers (Engelbrecht 2007; Momeni et al. 2015). Each neuron has multiple inputs. These inputs are combined and then the combination provides an output after processing. Network cells are connected to each other according to which output of each cell is considered as the next cell input. The first layer on the left side of the input layer does not play any role in processing, and only inputs that are imported in this section are sent to the next layer of the process through existing communications. The end layer (right layer) is the output layer that provides network response. The layers between the input and output layers are called hidden or intermediate layers (Haykin and Network 2004).
One of the most widely used learning algorithms in ANNs is the learning algorithm of error BP (Jahed Armaghani et al. 2015). The algorithm works on the basis of the error correction learning rule, which can be considered an extended algorithm of least average. In general, learning propagation consists of two steps: forward step and back step. In the forward stage, the inputs are forward layer by layer in the network, and, finally, a series of network outputs will be obtained as predicted values. During the forward stage, synaptic weights will be achieved. On the other hand, in the backward stage, the error of weights are set by the error regulating laws. The difference between predicted response and network response (expected), which is called the error signal, will be released in the opposite direction of network connections, and the weights change in a way that predicted response becomes closer to favorable response. Since the recent distribution is made in contrast to the weighted connections, error back-propagation is chosen to explain the modification behavior of the network. Different performance indices can be used in order to evaluate system results (Fausett and Fausett 1994):
-
(A)
The correlation coefficient (R2)
-
(B)
The root mean square error (RMSE)
Artificial bee colony (ABC)
The ABC optimization algorithm, developed by Karaboga (2005), is inspired by the social life of bees. In an ABC, each bee is a simple component. If these simple components form a colony of bees together, they will have a coherent and complex behavior which is be able to create an integrated system for discovering and exploiting the nectar of flowers. Each colony of bees consists of three bee colonies which have a duty. The first group of bees are scouts. These bees are tasked with discovering new sources. The scout bees will randomly search the peripheral environment, and after finding a food source, they store it in their memory. After each bee returns to the hive, the hive will share the source information in a waggle dance with other bees in the hive and hire some of them to exploit the sources. The second group consists of bees in a hive which are called employed bees. The employed bees are responsible for exploiting preset food sources. The third group of hive bees is onlooker bees. These bees in the hive await other bees, and after exchanging information with other bees in the waggle dance, choose one resource based on the fitness of the answer for exploitation.
This algorithm can solve many engineering, industrial and mathematical issues, such as optimization of the location of wells in oil reservoirs (Nozohour-Leilabady and Fazelabdolabadi 2016), optimization of water discharge from dams (Ahmad et al. 2016), data clustering (Zhang et al. 2010), scheduling of machines (Rodriguez et al. 2012), accidental failure of a nuclear power plant (de Oliveira et al. 2009). Also, with its hybrid combined with ANNs, it solves additional issues, such as prediction of the pressure at the bottom of a well along a network (Irani and Nasimi 2011). The only observed application of this algorithm in geotechnical engineering is to predict and optimize the back-break caused by blasting (Ebrahimi et al. 2016; Gordan et al. 2018; Koopialipoor et al. 2018c).
This algorithm consists of the following steps (Karaboga and Basturk 2007):
-
Initialize
-
Repeat
-
Send employed bees to food sources
-
Send onlooker bees to food sources
-
Send scout bees to search for new food sources
-
Up to (the desired situation is obtained).
Step 1 In the ABC algorithm, for the first time, half of the population of bees are employed bees and the other half are non-employed bees. For each food source, there is only one bunch of employed bees. In other words, the number of employed bees is equal to the number of food sources around the hive. Therefore, an employed bee is assigned to each food source, which means that within the scope of the answer, the number of food sources create an initial solution. After creating the initial solutions, the value of each solution must be calculated using the relationship of the problem.
Step 2 In this section, for each problem solution, a new answer is created using the relationship:
where xi,j is the parameter j from the answer i, vi,j is the parameter j in the new answer, i is the number of one to the number of solution problems, φ is a random number in a range of [−1, 1], k is a random number of one the number of answers to the problem, BN is the number of initial answers for the problem, and D is the number of optimization parameters.
After creating a new answer, if the value of this answer is more than the value of the previous answer, it will be replaced; otherwise, this answer will be forgotten.
Step 3 In this stage, the probability of receiving bees from each site is calculated by the following equation:
where \({\text{fi}}{{\text{t}}_i}~\) is the source of the fitness of source i and \({p_i}\) is the probability of choosing the source i by the onlooker bees. Considering the fitness of each item, a number of bees are allocated. In this step, all the bees may be assigned to a food site according to fitness. After calculating the value of each source, using the relation (1), a new answer is generated for the selected answers. If this answer receives more value than the previous answer, this answer will replace the previous answer or otherwise it will be fined. The purpose of the fine is to count the number of failures to improve the response, and if the answer is not improved, one unit will be added to it.
Step 4 In this stage, if the counter of non-improvement answers reaches the preset limit (Cmax), this answer will be replaced by a random answer. Also, at this stage, the conditions for the end of repetitions are also checked. If the conditions for the end of the algorithm are established, repetitions will end; otherwise, it will return to step two. More explanations regarding ABC structure and how it works can be found in similar studies (Karaboga 2005; Karaboga and Akay 2007; Karaboga and Basturk 2007). Figure 4 illustrates a general view of the ABC algorithm.

General view of the ABC algorithm to optimize the overbreak in tunnels
Developing the ANN model
In the current study, based on the complex nature of the problem, the perceptron ANNs were used to solve the problem. Herein, the Levenberg–Markvart (LM) learning function was used to teach the ANN. The number of layers of a neural network model was selected in accordance with several researches (e.g., Hornik et al. 1989). These layers include an input layer with nine nodes and an output layer with one output and a hidden layer. A hidden layer can solve any nonlinear function according to Hornik et al. (1989). Several studies explored the number of hidden layer neurons and there is a need to do trial and error to obtain the appropriate values for hidden neuron number. In Table 3, six relationships are presented to determine the number of hidden neuron numbers. In this table, Ni is the number of inputs, and No is the number of outputs of the model.
According to the values of relationships presented in Table 3, for all neural network learning algorithms, between 2 and 18 neurons for hidden neuron number was considered. Considering the importance of R2 and RMSE of each series of training and testing models, a comparison was made among them to select the best model. This comparison is based on a technique proposed by Zorlu et al. (2008), where each section is evaluated and assigned a score. Based on this method, every performance index (R2 or RMSE) was calculated in its own class, and the best of them received the highest rating. For instance, values of 0.913, 0.913, 0.904, 0.908, 0.902, 0.912, 0.912, 0.913, 0.913, 0.902, 0.898, 0.931, 0.925, and 0.915 were obtained for section of R2 training dataset for models 1–14, respectively. Ranking results of the mentioned 12 models were respectively obtained as 31, 31, 27, 28, 26, 30, 30, 31, 31, 26, 25, 40, 37, and 32. It should be noted that scores are generated for 42 models, the highest score of which is assigned to the best section, and if the two section are the same, the same score is awarded to them. Finally, the score of each row is aggregated from the models and is considered as a total score. Table 4 presents the results of this neural network. As shown in Table 4, model no. 6 created with the LM learning algorithm was selected as the best model based on the highest score. As it can be seen, R2 values of 0.910 and 0.893 for training and testing show the ability of the ANN model in predicting overbreak. In fact, the ANN model can provide a high level of prediction capacity for estimation of overbreak with low error.
In the following, the ABC–ANN model for prediction of overbreak in the tunnels will be described.
Prediction of overbreak by the ABC–ANN model
An ABC algorithm was used to improve the performance of the ANN in this study. In general, the BP algorithm is used to train the ANN. This algorithm has some defects that can reduce the ANN’s performance. One of the most important problems is the trapping of local minima in the search space. When a local minimum is reached, it announces to the system that these coefficients are the best coefficients, while this is a bug in a BP algorithm. In this situation, optimization algorithms are used to find the best minimum which is also the global minimum. In this research, an ABC algorithm is used to optimize network coefficients to reduce the RMSE error.
In this algorithm, after generating the initial coefficients for each solution, using Eq. (1), a series of new coefficients was created. After calculating the prediction and error values, in case of improvement, the new coefficients will replace the previous ones. Otherwise, the coefficients will be fined and the new coefficients will be forgotten. After calculating the probability of choosing coefficients, new items were created around the coefficients with greater merit. In this case, if the error rate is reduced, new coefficients will be replaced; otherwise, new coefficients will be forgotten. The reason for this procedure is that in the next few queries, the search does not arrive at space and no more time is spent. By doing this, finding speed is improved and the ABC internal system is also optimized. In the last step of the algorithm, when the penalty amount of each of the coefficients reaches a predetermined value, new coefficients will be generated randomly. In Fig. 5, a comparison can be seen between BP and ABC algorithms for finding optimal coefficients. As it can be seen, Fig. 8 shows part of the system space that BP is able to locate, while the ABC is able to find the global minimum. For this reason, an intelligent hybrid of the ABC–ANN model was used and developed to predict overbreak induced by drilling and blasting.

A comparison between the results of the BP and ABC algorithms to find the minimum for ANN models
Considering a proposed ANN model with seven neurons (obtained from the developed ANN), many ABC–ANN models were built. Here, the ABC algorithm attempts to find suitable weights and optimize them in the search space. By increasing the number of bees, they can, in fact, cover a larger search space. This process continues until reaching the lowest level of error. Each time the choices take place, the values will remain constant until a better result is obtained for the network weights. In this study, different models were constructed with 500 repetition numbers and different number of bees, ranging from 10 to 80 (see Fig. 6).

The best costs of overbreak
From all these iterations, the number of bees was equal to 30, which has a very little difference in comparison with others, and produced the best optimum pattern in this research. In other words, 30 bees is the optimum number of bees that will also reduce the computation time needed for the analysis. Moreover, based on RMSE results, 200 iterations can be utilized instead of 500 iterations to optimize the analysis time. Utilizing the determined values for the number of bees and iterations, five ABC–ANN models were built, and further discussion in this regard is provided in the following section.
Evaluation of the results
In this research, various ABC–ANN and ANN models were constructed to evaluate/predict overbreak in tunnels. Here, all 330 sets of data were selected randomly and classified into 5 different parts. These sets were randomly assigned 20% and 80% for training and testing, respectively. Then, five ANN models and five ABC–ANN models were constructed and evaluated based on R2 and RMSE results. These values are rated according to the new system. Here, the authors assigned an exclusive color to each of the rows of models. In this way, the model with the higher score is assigned a higher red color intensity in each column. The lesser the color intensity (lighter colors), the lower rate (weight) of the parameters/factors. For example, the no. 4 ABC–ANN model (see Table 5) receives the highest intensity of red in the R2 column of the training section. In this way, the best are specified in each column and in the last column, a case that is collectively better (in terms of the intensity of the red color) is selected. In this way, the new method is used to select the best models. It should be noted that the same result can be obtained by rating. However, this new way of finding the best models can be a new and smart solution for selecting and categorizing models. This categorization method is called the color intensity rating (CIR) system. In order to evaluate the proposed CIR system, a published study by Jahed Armaghani et al. (2016) was considered and the CIR system was applied to their ranking method (see Table 6). Based on the obtained results of CIR, it was found that there is a match between ranking technique and the CIR system. Therefore, it can be concluded that the proposed CIR system is implemented correctly, and it can be introduced as a new technique to select the best model.
As shown in Table 5, in general, the ABC–ANN values are darker red, which indicates the superiority of this method compared to the ANN. The best model according to Table 6 is model no. 4 of the ABC–ANN models, where the R2 and RMSE values for training and testing model no. 4 were 0.9428 and 0.0628, and 0.9396 and 0.0696, respectively. Therefore, the use of the ABC–ANN method is recommended to improve the overbreak prediction results in tunnels. Finally, the values of R2 and RMSE for ANN and ABC models for five data sets are plotted in Figs. 7 and 8.

Values of R2 for ANN and ABC–ANN models

Values of RMSE for ANN and ABC–ANN models
The results of selected ANN and ABC–ANN models are presented in Figs. 9, 10, 11 and 12. By implementing the ABC algorithm, the performance of the network can be increased significantly, especially in results of training datasets.

Prediction values of overbreak for training model no. 6 using the ANN

Prediction values of overbreak for testing model no. 6 using the ANN

Prediction values of overbreak for training model using the ABC–ANN

Prediction values of overbreak for testing model using the ABC–ANN
Conclusions
In the present study, using AI models, prediction of overbreak in tunnels was conducted. After identifying the effective parameters in the overbreak phenomenon, eight input parameters were used to create a neural network of three types of learning functions. A rating system was applied to identify and select the best model for optimization. The R2 and RMSE values of the best selected ANN model were 0.921 and 0.4820, and 0.923 and 0.4277 for training and testing, respectively. The ABC algorithm, one of the new optimization algorithms, was used to optimize the weights of the ANN. Considering that overbreak is one of the main problems in tunneling, the accurate prediction of this amount can contribute to a more efficient and economical tunnel excavation.
Different models of the ABC–ANN network were created. Subsequently, considering that the number of bees to determine the optimum value of errors and finding the global minimum are important, the number of effective bees was evaluated. Thirty bees were selected as the optimum number of bees. Finally, the developed ANN and ABC–ANN models were utilized for five data sets. In this situation, model no. 3 was chosen as the best prediction model. The values of R2 and RMSE for the training and testing of model no. 3 were 0.9428 and 0.0628, and 0.9396 and 0.0696, respectively. To evaluate the developed models, the CIR method was implemented. The improved results of the ABC–ANN compared to the ANN showed that the use of hybrid algorithms could provide better results for prediction of overbreak in tunnels.
References
Ahmad A, Razali SFM, Mohamed ZS, El-shafie A (2016) The application of artificial bee colony and gravitational search algorithm in reservoir optimization. Water Resour Manag 30:2497–2516
Armaghani DJ, Mohamad ET, Narayanasamy MS et al (2017) Development of hybrid intelligent models for predicting TBM penetration rate in hard rock condition. Tunn Undergr Sp Technol 63:29–43. https://doi.org/10.1016/j.tust.2016.12.009
Bhandari S (1997) Engineering rock blasting operations. A A Balkema 388:388
de Oliveira IMS, Schirru R, de Medeiros J (2009) On the performance of an artificial bee colony optimization algorithm applied to the accident diagnosis in a pwr nuclear power plant. In: 2009 International nuclear Atlantic conference (INAC 2009)
Ebrahimi E, Monjezi M, Khalesi MR, Armaghani DJ (2016) Prediction and optimization of back-break and rock fragmentation using an artificial neural network and a bee colony algorithm. Bull Eng Geol Environ 75:27–36
Engelbrecht AP (2007) Computational intelligence: an introduction. Wiley, Hoboken
Esmaeili M, Osanloo M, Rashidinejad F et al (2014) Multiple regression, ANN and ANFIS models for prediction of backbreak in the open pit blasting. Eng Comput 30:549–558
Fausett L, Fausett L (1994) Fundamentals of neural networks: architectures, algorithms, and applications. Prentice-Hall, Upper Saddle River
Garrett JH (1994) Where and why artificial neural networks are applicable in civil engineering. J Comput Civil Eng 8(2):129–130
Gates WCB, Ortiz LT, Florez RM (2005) Analysis of rockfall and blasting backbreak problems, US 550, Molas Pass, CO. In: Alaska Rocks 2005, the 40th US symposium on rock mechanics (USRMS). American Rock Mechanics Association
Ghaleini EN, Koopialipoor M, Momenzadeh M, Sarafraz ME, Mohamad ET, Gordan B (2018) A combination of artificial bee colony and neural network for approximating the safety factor of retaining walls. Eng Comput. https://doi.org/10.1007/s00366-018-0625-3
Gordan B, Jahed Armaghani D, Hajihassani M, Monjezi M (2016) Prediction of seismic slope stability through combination of particle swarm optimization and neural network. Eng Comput. https://doi.org/10.1007/s00366-015-0400-7
Gordan B, Koopialipoor M, Clementking A, Tootoonchi H, Mohamad ET (2018) Estimating and optimizing safety factors of retaining wall through neural network and bee colony techniques. Eng Comput. https://doi.org/10.1007/s00366-018-0642-2
Grima MA, Bruines PA, Verhoef PNW (2000) Modeling tunnel boring machine performance by neuro-fuzzy methods. Tunn Undergr Sp Technol 15:259–269
Hajihassani M, Jahed Armaghani D, Monjezi M et al (2015) Blast-induced air and ground vibration prediction: a particle swarm optimization-based artificial neural network approach. Environ Earth Sci 74:2799–2817. https://doi.org/10.1007/s12665-015-4274-1
Hasanipanah M, Armaghani DJ, Amnieh HB, Koopialipoor M, Arab H (2018) A risk-based technique to analyze flyrock results through rock engineering system. Geotech Geol Eng 36(4):2247–2260. https://doi.org/10.1007/s10706-018-0459-1
Haykin S, Network N (2004) A comprehensive foundation. Neural Netw 2:41
Hecht-Nielsen R (1989) Kolmogorov’s mapping neural network existence theorem. In: Proceedings of the international joint conference in neural networks, pp 11–14
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Netw 2:359–366
Ibarra JA, Maerz NH, Franklin JA (1996) Overbreak and under-break in underground openings part 2: causes and implications. Geotech Geol Eng 14:325–340
Irani R, Nasimi R (2011) Application of artificial bee colony-based neural network in bottom hole pressure prediction in underbalanced drilling. J Pet Sci Eng 78:6–12
Jahed Armaghani D, Hajihassani M, Monjezi M et al (2015) Application of two intelligent systems in predicting environmental impacts of quarry blasting. Arab J Geosci 8:9647–9665. https://doi.org/10.1007/s12517-015-1908-2
Jahed Armaghani D, Tonnizam Mohamad E, Hajihassani M et al (2016) Evaluation and prediction of flyrock resulting from blasting operations using empirical and computational methods. Eng Comput. https://doi.org/10.1007/s00366-015-0402-5
Jang H, Topal E (2013) Optimizing overbreak prediction based on geological parameters comparing multiple regression analysis and artificial neural network. Tunn Undergr Sp Technol 38:161–169
Kaastra I, Boyd M (1996) Designing a neural network for forecasting financial and economic time series. Neurocomputing 10:215–236
Kanellopoulos I, Wilkinson GG (1997) Strategies and best practice for neural network image classification. Int J Remote Sens 18:711–725
Karaboga D (2005) An idea based on honey bee swarm for numerical optimization. Technical report-tr06, Erciyes University, Engineering Faculty, Computer Engineering Department
Karaboga D, Akay B (2007) Artificial bee colony (ABC) algorithm on training artificial neural networks. In: Signal processing and communications applications, 2007. SIU 2007. IEEE 15th. IEEE, pp 1–4
Karaboga D, Basturk B (2007) A powerful and efficient algorithm for numerical function optimization: artificial bee colony (ABC) algorithm. J Glob Optim 39:459–471
Koopialipoor M, Armaghani DJ, Haghighi M, Ghaleini EN (2017) A neuro-genetic predictive model to approximate overbreak induced by drilling and blasting operation in tunnels. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-017-1116-2
Koopialipoor M, Armaghani DJ, Hedayat A et al (2018a) Applying various hybrid intelligent systems to evaluate and predict slope stability under static and dynamic conditions. Soft Comput. https://doi.org/10.1007/s00500-018-3253-3
Koopialipoor M, Fallah A, Armaghani DJ et al (2018b) Three hybrid intelligent models in estimating flyrock distance resulting from blasting. Eng Comput. https://doi.org/10.1007/s00366-018-0596-4
Koopialipoor M, Ghaleini EN, Haghighi M, Kanagarajan S, Maarefvand P, Mohamad ET (2018c) Overbreak prediction and optimization in tunnel using neural network and bee colony techniques. Eng Comput. https://doi.org/10.1007/s00366-018-0658-7
Koopialipoor M, Nikouei SS, Marto A, Fahimifar A, Armaghani DJ, Mohamad ET (2018d) Predicting tunnel boring machine performance through a new model based on the group method of data handling. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-018-1349-8
Lundborg N (1974) The hazards of flyrock in rock blasting. Swedish Detonic Research Foundation, Reports DS 12, Stockholm
Maerz NH, Ibarra JA, Franklin JA (1996) Overbreak and under-break in underground openings Part 1: measurement using the light sectioning method and digital image processing. Geotech Geol Eng 14:307–323
Mandal SK, Singh MM (2009) Evaluating extent and causes of overbreak in tunnels. Tunn Undergr Sp Technol 24:22–36
Marto A, Hajihassani M, Jahed Armaghani D, Tonnizam Mohamad E, Makhtar AM (2014) A novel approach for blast-induced flyrock prediction based on imperialist competitive algorithm and artificial neural network. Sci World J. https://doi.org/10.1155/2014/643715
Masters T (1993) Practical neural network recipes in C++. Morgan Kaufmann, Burlington
McCulloch WS, Pitts W (1943) A logical calculus of the ideas immanent in nervous activity. Bull Math Biophys 5:115–133
Momeni E, Jahed Armaghani D, Hajihassani M, Mohd Amin MF (2015) Prediction of uniaxial compressive strength of rock samples using hybrid particle swarm optimization-based artificial neural networks. Meas J Int Meas Confed. https://doi.org/10.1016/j.measurement.2014.09.075
Monjezi M, Dehghani H (2008) Evaluation of effect of blasting pattern parameters on back break using neural networks. Int J Rock Mech Min Sci 45:1446–1453
Monjezi M, Ahmadi Z, Varjani AY, Khandelwal M (2013) Backbreak prediction in the Chadormalu iron mine using artificial neural network. Neural Comput Appl 23:1101–1107
Nozohour-leilabady B, Fazelabdolabadi B (2016) On the application of artificial bee colony (ABC) algorithm for optimization of well placements in fractured reservoirs; efficiency comparison with the particle swarm optimization (PSO) methodology. Petroleum 2:79–89
Ocak I, Seker SE (2013) Calculation of surface settlements caused by EPBM tunneling using artificial neural network, SVM, and Gaussian processes. Environ Earth Sci 70:1263–1276
Paola JD (1994) Neural network classification of multispectral imagery. Master Tezi, Univ Arizona, USA
Raina AK, Haldar A, Chakraborty AK et al (2004) Human response to blast-induced vibration and air-overpressure: an Indian scenario. Bull Eng Geol Environ 63:209–214
Raina AK, Murthy V, Soni AK (2014) Flyrock in bench blasting: a comprehensive review. Bull Eng Geol Environ 73:1199–1209
Ripley BD (1993) Statistical aspects of neural networks. Netw Chaos Stat Probab Asp 50:40–123
Rodriguez FJ, García-Martínez C, Blum C, Lozano M (2012) An artificial bee colony algorithm for the unrelated parallel machines scheduling problem. In: International conference on parallel problem solving from nature. Springer, pp 143–152
Roth J (1979) A model for the determination of flyrock range as a function of shot conditions. US Bureau of Mines contract J0387242. Manag Sci Assoc Los Altos
Saghatforoush A, Monjezi M, Faradonbeh RS, Armaghani DJ (2016) Combination of neural network and ant colony optimization algorithms for prediction and optimization of flyrock and back-break induced by blasting. Eng Comput 32:255–266
Singh SP, Xavier P (2005) Causes, impact and control of overbreak in underground excavations. Tunn Undergr Sp Technol 20:63–71
Wang C (1994) A theory of generalization in learning machines with neural network applications. Doctoral Dissertation, University of Pennsylvania, Philadelphia, PA, USA
Zhang C, Ouyang D, Ning J (2010) An artificial bee colony approach for clustering. Expert Syst Appl 37:4761–4767
Zorlu K, Gokceoglu C, Ocakoglu F et al (2008) Prediction of uniaxial compressive strength of sandstones using petrography-based models. Eng Geol 96:141–158
Acknowledgements
The authors would like to extend their appreciation to the manager, engineers and personnel of Forum708 (Otagh-MEH), for providing the needed information and facilities that made this research possible. Additionally, the authors would like to express their sincere appreciation to reviewers because of their valuable comments that increased the quality of our paper.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Koopialipoor, M., Ghaleini, E.N., Tootoonchi, H. et al. Developing a new intelligent technique to predict overbreak in tunnels using an artificial bee colony-based ANN. Environ Earth Sci 78, 165 (2019). https://doi.org/10.1007/s12665-019-8163-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-019-8163-x