
Abstract
To overcome the limitations of the conventional medical service in terms of ageing and chronic diseases, AmI-based precision medicine has drawn particular attention. Precision medicine is a customized personal medical service using various information technologies such as personal health device, AI algorithm, image recognition, voice recognition, and natural language processing. In particular, the information technologies for follow-up care services for patients, such as context awareness, context information, and inference rules, are required. In PHD, contexts such as variable data include blood pressure, BMI, blood sugar, weather, and food. It has time-series characteristics, meaning that it changes often with time. Other kinds of health-related information, such as age, family history, smoking, and residential area, are intermittently changed. For inference that is highly related to a user, the context collected through AmI is presented with ontology. Ontology consists of a user’s ambient data, weather data, and lifelog. Context is changed along with a user’s ambient conditions and time. An inference engine is used to create the knowledge base and predict a change. This study proposes a neural-network based adaptive context prediction model for ambient intelligence. This is a learning model using neural network to calculate the similarity for recommendation in a mining lifecare platform. In a conventional prediction procedure, an error is used to update a weight. The proposed model learns the similarity weight of the users to become adapted to the user’s ambient. Based on the knowledge base, user clustering and deviation from mean are applied to calculate the similarity weight. Collaborative filtering technology is used to predict a user’s context and learn the similarity weight repeatedly using a neural network. According to the performance evaluation, the proposed neural-network based similarity weight method had the highest accuracy of prediction when the learning rate was 0.001. Consequently, we found that AmI is a new added-value technology to maintain a healthy lifestyle and contributes to developing the healthcare industry and improving the quality of life.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the development of context awareness computing technology and the convergence industry, ambient intelligence (AmI)-based lifecare advancement is investigated to overcome the limitations of the conventional medical service. In particular, increased chronic diseases and the super-ageing society have triggered more demands for constant healthcare. Owing to the IT-based paradigm of human–computer interaction and the development of pharmaceutical and medical technologies, new treatment methods have been developed to treat and prevent hard-to-treat chronic diseases. To examine a new treatment method, it is necessary to continue to observe and care for a patient who is to be cured. Accordingly, precision medicine applied to customized treatment and diagnosis using living habits, lifelog, and ambient intelligence has drawn particular attention. Precision medicine is customized healthcare using information technology and AmI. To recognize users and ambient context, and manage data, increased manpower and resources are required. Hence, AmI software able to recognize context and support advanced services for living conditions, actions, ageing preventions, habits, and emotions have drawn attention as the next-generation core technology. This enables multiple devices to be connected including IoT-based personal health devices (Atzori et al. 2010), voice recognition devices, and image recognition devices in the daily space via wired and wireless networks. In addition, context computing supports the recognition of presence and increases spatial efficiency.
Currently, a lifecare platform for healthcare and its promotion is developed through monitoring physical or mental conditions in real time and analyzing the potential health risk (Kim and Chung 2018; Yoo and Chung 2018). The platform includes precision medicine technology lifecare, wired and wireless network technology for reliable context transmission, cloud-based intelligence platform technology, medical information security technology (Jung et al. 2016a; Yao and Warren 2005), and ambient sensor technology for bio signal measurement. The components of AmI are ubiquity, awareness, intelligence, and natural interaction, which are complementary to the parts that a user fails to recognize. Ubiquity means that various devices are operated beyond a user’s recognition range. Awareness means that a user’s position, action, and intention are recognized, and its context is collected with the tracking function. Intelligence means that the collected context is used to predict the ambient condition or a user’s change (Adomavicius and Tuzhilin 2011). Natural interaction means the human–computer interaction between a user and a device through voice or gesture recognition. To materialize these components and apply them to daily life, a variety of information technologies, such as neural network, ontology, cloud, deep learning, IoT, sensor, and big-data mining are required.
With the emergence of the fourth industrial revolution, the advancement in AmI is investigated globally in various areas. Relevant studies have found the AmI solution for lifecare and a method of integrating, mining, and processing heterogeneous big data have been reported (Agrawal and Srikant 1995). While obtaining the data associations, hidden rules were discovered and were used to create the knowledge base for actual decision making (Jung et al. 2016). Chaib et al. (2018) developed the adaptive service model using multi-agents for the AmI context. Chen and Tsai (2018) applied AmI to the concept of industrial engineering to analyze its cost and convenience, and suggested its efficiency by applying it to a system. Orciuoli and Parente (2017) developed the NFS-based context awareness recommendation system using ontology and AmI in a semantic environment. Therefore, this study proposes a neural-network based adaptive prediction model for AmI. The proposed model uses a neural network model in a recommendation system to calculate a user’s similarity and adaptive weight, and thereby predicts the context based on of the AmI. The evolutionary prediction model considers the time series of the context existing in real life and applies a similarity weight using an error arising in the prediction.
The composition of this study is as follows. In Sect. 2, we describe a mining lifecare platform in the ambient intelligence. In Sect. 3, we propose the neural-network based adaptive context prediction model for the ambient intelligence. In Sect. 4, we present the experimental result. Finally, Sect. 5 concludes.
2 Mining lifecare platform in ambient intelligence
A mining lifecare platform for AmI integrates and processes heterogeneous data, including medical big data, bio big data, and lifelog big data. To support a patient’s decision-making and provide a proper health service, various types of large structured big data are integrated technically. Unstructured data that are not operable are preprocessing structurally using big-data computing technology (Agrawal and Srikant 1995). Big-data computing technology uses text mining, web mining, reality mining, and association rule mining (Chung and Park 2018; Agrawal and Srikant 1994).
Text mining uses natural language processing technology to extract meaningful disease patterns from unstructured data and structures them. To analyze the structure of unstructured web documents and web logs collected on the Internet, and to obtain patterns through search and integration, web mining is applied to structure them (Song et al. 2017). In a web document composed of unstructured data such as images, videos, and audios, meaningful knowledge of attributes and information association are found using semantic tags, and are then applied in decision-making. To analyze a user’s behavioral pattern and predict his/her health condition, reality mining collects the relevant information using healthcare IoT technology (Atzori et al. 2010), ambient sensors (Jung et al. 2016b), and wearable devices. It subsequently analyzes the information and structures it. Associated context mining (Jung et al. 2016; Kim and Chung 2017; Agrawal and Srikant 1994) infers the potential knowledge information through association rule mining in ontology-based context modeling, and generates rules with a semantic inference engine. From a context set frequently found in the ontology knowledge base, associations are extracted with using the Apriori algorithm (Agrawal and Srikant 1995). A context set with a high frequency means a potential disease risk, and the associations of diseases featuring the sharing of risks (Chung et al. 2016). The medical information of domestic patients with 10 major diseases leading to death, including diabetes, dyslipidemia, cardiovascular disease, and cerebrovascular disease, and the patient emergency complications data of the National Health Insurance Corporation (Medical Statistics Information 2017) are used to predict an individual’s disease occurrence risk rate. In terms of environmental and weather variables in a residential region, the processing of outlier data, missing values, and principal component analysis are conducted. Subsequently, the model for calculating the risk rates of cardiovascular disease and cerebrovascular disease is applied.
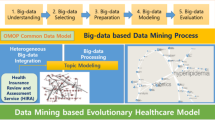
When structured and unstructured data are integrated with distributed-file-processing-based common data model through data mining, it can be used as an extended big-data gateway-system-based data warehouse and Common Data Model (CDM) known as the OMOP Common Data Model (ATHENA Standard Vocabulary 2018). Accordingly, for the integration of medical data and lifelog data and for the health service based on weather, diet, and environment data, a deep-learning-based evolutionary model is applied (Jung et al. 2013, 2016). The deep-learning-based evolutionary model uses integrated big data as input and performs unsupervised learning with using the deep belief network (DBN). In a distributed file framework that processes large data, a model can be created through training the learning data, and the created learning model is used for processing. A weight is adjusted depending on the heterogeneous input data and then repeated learning is performed. By setting the connection strength of the input layers for the integrated data input and multiple hidden layers connected with each other as the weight, nonlinear relationships can be learned and modeled. Further, for object classification and detection in unstructured data such as images, videos, and audios, a convolution neural network (CNN) is applied. Figure 1 illustrates the architecture of the mining lifecare platform in AmI.

Architecture of mining lifecare platform in ambient intelligence
It is possible to connect with a gateway system that is able to collect, express, and save hospital information and bio information as standard data. Using a lifelog data transmission interface module, the information is converted to the metadata for warehouse data distributed in a platform before transmission. In accordance with HL7 CCD/CCR and IEEE 101073, data are expressed and saved (Yao and Warren 2005, HL7 2018). The standard protocols are used to encrypt data. Therefore, it is possible to overcome the medical security issue of personal information data, which is difficult to understand even if leaked. For AmI, hidden knowledge is created with a semantic inference engine, and inference rules are additionally applied. The hidden knowledge added in the knowledge base is applied to the existing inference rules for updating. Entropy-based feedback is applied to adaptive decision in AmI to provide proper lifecare service to a user.
3 Neural network based adaptive context prediction
3.1 Context configuration using ontology in ambient intelligence
Precision medicine focusing on individuals requires a variety of patient information. To collect, analyze, and manage the information, context-based AmI is required. In AmI, lifecare considers the data rules and relationships defined by CDM and consist of the PHD, PHR, weather data, and lifelog. The PHD is composed of personal health record that includes region, age, sex, drinking, smoking, high blood pressure, cholesterol, and medical record, and the EMR collected by a medical institution. The weather data include the observation information provided by the Korean Meteorological Administration, such as the ambient temperature, humidity, and fine dust based on the user’s position. Lifelog includes the information collected by personal health devices or IoT devices, such as the BMI, blood pressure, heart rate, sleeping hours, moving distance, and blood sugar. Based on the health context, ontology is presented using a rule-based inference engine. To apply ontology to various healthcare domains, the upper-level ontology is established. The upper-level ontology includes people, place, device, weather, and time, which are generally used in the healthcare domain. A lower class includes age, sex, BMI, drinking, blood sugar, blood pressure, heart rate, and sleeping hours. Figure 2 shows part of the health context presented with ontology.

Part of health context with ontology
In the health context created with ontology, the information on a different user who has a similar context with a target user is collected. In the model, the internal and external context relationships influencing health are used for decision making. The rules inferred from ontology are saved in the knowledge base. Using the inference rules in the knowledge base, the knowledge fitting a user’s context is searched, and then the information for decision making is provided depending on the health condition. To increase the accuracy in the knowledge-based decision making, it is necessary to predict the missing values and a user’s condition change. For such predictions, the collaborative filtering technique is primarily applied (Chung et al. 2016). It uses the context of a group that has a similar context with a user. Collaborative filtering predicts the users’ values based on the information collected from multiple users (Linden et al. 2003). Figure 3 illustrates the collaborative filtering based prediction in the knowledge base.

Collaborative filtering based prediction in knowledge base
3.2 Neural-network based adaptive context prediction model
Context changes often with time. Precision medicine predicts a user’s condition and change through the analysis. As an individual intensive healthcare method, precision medicine uses all of the information on personal health. Health change and prediction are related to a variety of context information. A user’s health condition continues to change with time and the change must be considered. The adaptive context prediction model proposed in this study is an evolutionary prediction model that adjusts the similarity depending on a user’s context change. It applies a neural network structure in which a weight is adjusted based on the difference between an actual value and a predictive value in a conventional prediction method used in a recommendation system. A conventional collaborative filtering structure can be presented in the similar structure as that of a neural network. The proposed neural-network based collaborative filtering has the predictive value of the user a’s context as an output and the context value of the user k in a cluster as an input. The similarity between the different users in the cluster is set as the weight “w” in a neural network, and the difference between a predictive value and a measured real value is set as an error. Figure 4 shows the neural-network based collaborative filtering structure.

Neural-network based collaborative filtering structure
In the neural network structure, back propagation is used to adjust the weight “w”. In a conventional neural network, numerous operations are executed to adjust a weight, and if an error value is lower than a setup value, the learning is complete. The proposed neural-network based collaborative filtering has many input values and changes often. Further, depending on the context of comparative users created as input nodes, a new node can be created or an existing node can be deleted. Therefore, in AmI, neural network learning does not occur once, but continues to occur based on the time series. Formula (1) shows a method of calculating the similarity of users in collaborative filtering (Sarwar et al. 2001). In formula (1), Ua means the user “a” as an active user. Uk is a different user in the cluster. w(Ua, Uk) represents the similarity weight of the user “a” and the user “k”. Ua,i is an actual value for the user a’s context i. i means the user’s context, including blood pressure, BMI, blood sugar, weather, weight, and temperature. \(\overline {{{U_a}}}\) means the mean of the user a’s context:
Formula (2) is a prediction method of context in AmI through collaborative filtering (Sarwar et al. 2001). In formula (2), \({U_{a,i - p(prediction)}}\) represents a predictive value for the user a’s context i. \(\overline {{{U_a}}}\) is the mean of the user a’s context. \(\overline {{{U_k}}}\) is the mean of the context i of the user k in the cluster. \(k \in u\)’s group means all users in the user group, and the group number is given sequentially from the number 1 according to a transaction number:
Formula (3) presents an adaptive similarity weight of the difference between a predictive value and an actual value through neural-network based learning. In formula (3), \(({U_{a,i}} - {U_{a,i - p}})\) means the difference between an actual value and a predictive value for the user a’s context i. Uk,i is an actual value for the context i of the different user k in the same cluster. α is the learning rate that is determined in repeated evaluations:
4 Experimental result
A neural-network based adaptive context prediction model provides feedback on the similarity weight of users based on the time-series context in AmI. Hence, a user’s health condition and change are predicted by the AmI-based precision medicine. In a mining lifecare platform, all of a user’s health data are collected. Based on the collected data, context is presented with ontology. Further, an inference engine is used to create the knowledge base. In an ambient network, users with similar contexts are sought based on the inference rules.
The life cycle of an adaptive context prediction model consists of four steps. In the first step, users with similar situations are clustered according to their health context based on the knowledge base. In the second step, with the context of the clustered users, the deviation from mean is used to calculate the similarity weight. In the third step as a predictive one, the similarity weight is used to predict a user’s weight, BMI, blood pressure, exercise amount, fasting blood sugar, and other numeric data. In the fourth step, when context is updated after the prediction, an adaptive similarity weight of the difference between a predictive value and an actual value through neural-network based learning is calculated. To apply the time-series characteristic meaning the frequent changes with time, the third step and the fourth step are repeatedly performed to learn the similarity weight. Figure 5 shows the life cycle of the adaptive context prediction model.

Life cycle of the adaptive context prediction model
For the performance evaluation, the transaction related to lifecare is used to predict a user’s weight in an adaptive context prediction model. For a user’s weight, its actual value is changed less and is measured easily. In each method, the difference between a predictive value and an actual value is compared. Table 1 shows the transaction related to lifecare. For a more convenient calculation, the data are collected from a total of 10 persons including the users for 10 days. A transaction is composed of easy-to-collect data, such as weight, BMI, blood pressure, exercise amount, blood sugar before meal, and heart rate. In addition, for consistency, such data are measured at 8:00 every morning. In Table 1, TID means the transaction ID, and UID the user ID. FBS means the fasting blood sugar with units of mg/dL. HR represents the heart rate with units of HR/min (Rho et al. 2016).
With the collected transaction, the error of the predicted result is evaluated by the neural-network based similarity (NNS), neural-network based median similarity (NNMS), median simple similarity (MSS), and daily simple similarity (DSS). NNS and NNMS are predictive methods using the proposed neural-network based collaborative filtering. NNS uses a user’s 1-day average value for prediction. NNMS uses the user average value of all transactions for prediction. This is because the frequent changes in context with time are considered. Depending on the learning rate, NNS is classified into NNS1 (learning rate = 0.001), NNS2 (learning rate = 0.01), and NNS3 (learning rate = 0.1). The MSS uses the similarity weight calculated using the average value of all transactions by the user. The DSS uses the similarity weight calculated using the daily collected context in AmI. Table 2 presents the sequence change in the similarity weight. In Table 2, s1 means sequence 1. When sequence 1 goes to sequence 2, the DSS has a small change in the similarity weight and a changing similarity weight depending on the input situation. The MSS calculates the similarity weight once based on all the transactions. Regardless of the sequence, the similarity weight remains constant. In the NNS and NNMS methods, the similarity weight is changed differently depending on the learning rate. The lower the learning rate is, the less the similarity weight changes; the higher the learning rate is, the more the similarity weight changes. Depending on the error, a difference exists in the weight change, and the input value of a different user is not influential.
Table 3 presents the error of a user’s weight predicted in each method. According to the evaluation of the methods, the MSS and DSS methods contain an irregular error depending on the data. The proposed NNS and NNMS methods overall improved the error. Regarding the mean of errors for 10 days, NNS1 showed 0.59 (the most excellent) and an accurate prediction. When the proposed NNS method has a learning rate of 0.001, the prediction of the context collected in AmI is the most accurate. Figure 6 shows the error graphs depending on the prediction method.

Error graphs depending on a prediction method
5 Conclusion
An AmI-based intelligence system has a large difference in the predictive value depending on the similarity weight. To express and infer knowledge in a changing context, an evolutionary model is required. This study proposed the neural-network based adaptive context prediction model for AmI. This is the prediction method of context in AmI by calculating the user’s similarity and the adaptive weight using a neural learning model in a recommendation system. Context changes in real life with time. The evolutionary prediction model learns the similarity weight using the prediction error. A performance evaluation is conducted in the knowledge base presented with ontology, which is created with the context collected in AmI by an inference engine. The MSS and DSS methods calculate the similarity coefficient depending on the learning rate and their predicted weight values are compared. According to the performance evaluation, a similarity coefficient calculated in MSS and DSS method is different each time with no special rules. The proposed prediction method using NNS gradually improved the overall error graphs in the down-right direction. According to the performance comparison with an existing method, the proposed method had an excellent value, or 0.59, on average. In the proposed adaptive prediction model, lifecare in AmI applies a user’s condition and change.
References
Adomavicius G, Tuzhilin A (2011) Context-aware recommender systems. In: Recommender systems handbook, pp 217–253
Agrawal R, Srikant R (1994) Fast algorithms for mining association rules. In: Proceedings of the 20th international conference on very large data bases, VLDB 1215, pp 487–499
Agrawal R, Srikant R (1995) Mining sequential patterns. In: Proceedings of the eleventh international conference on data engineering, USA, pp 3–14
ATHENA Standard Vocabulary (2018) Observational health data sciences and informatics [online]. https://www.ohdsi.org. Accessed 16 Apr 2018
Atzori L, Iera A, Morabito G (2010) The internet of things: a survey. Comput Netw 54(15):2787–2805
Chaib A, Boussebough I, Chaoui A (2018) Adaptive service composition in an ambient environment with a multi-agent system. J Ambient Intell Humaniz Comput 9(2):367–380
Chen T, Tsai HR (2018) Application of industrial engineering concepts and techniques to ambient intelligence: a case study. J Ambient Intell Humaniz Comput 9(2):215–223
Chung K, Park RC (2018) Chatbot-based healthcare service with a knowledge base for cloud computing. Clust Comput. https://doi.org/10.1007/s10586-018-2334-5
Chung K, Kim JC, Park RC (2016) Knowledge-based health service considering user convenience using hybrid Wi-Fi P2P. Inf Technol Manag 17(1):67–80
HL7 (2018) Health Level Seven International [online]. http://www.hl7.org. Accessed 16 Apr 2018
Linden G, Smith B, York J (2003) Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput 7(1):76–80
Jung H, Chung K (2016a) Knowledge-based dietary nutrition recommendation for obese management. Inf Technol Manag 17(1):29–42
Jung H, Chung K (2016b) Life style improvement mobile service for high risk chronic disease based on PHR platform. Clust Comput 19(2):967–977
Jung EY, Kim JH, Chung K, Park DK (2013) Home health gateway based healthcare services through U-health platform. Wirel Pers Commun 73(2):207–218
Jung H, Yoo H, Chung K (2016) Associative context mining for ontology-driven hidden knowledge discovery. Clust Comput 19(4):2261–2227
Kim JC, Chung K (2017) Emerging risk forecast system using associative index mining analysis. Clust Comput 20(1):547–558
Kim JC, Chung K (2018) Mining health-risk factors using PHR similarity in a hybrid P2P network. Peer-to-Peer Netw Appl. https://doi.org/10.1007/s12083-018-0631-7
Medical Statistics Information (2017) Health insurance review and assessment service (HIRA) [online]. http://opendata.hira.or.kr. Accessed 2017
Orciuoli F, Parente M (2017) An ontology-driven context-aware recommender system for indoor shopping based on cellular automata. J Ambient Intell Humaniz Comput 8(6):937–955
Rho MJ, Kim HS, Chung K, Choi IY (2016) Factors Influencing the Acceptance of Telemedicine for Diabetes Management. Cluster Comput 18(1):321–331
Sarwar B, Karypis G, Konstan J, Riedl J (2001) Item-based collaborative filtering recommendation algorithms. In: Proceedings of the 10th international conference on World Wide Web, ACM, pp 285–295
Song CW, Jung H, Chung K (2017) Development of a medical big-data mining process using topic modeling. Clust Comput. https://doi.org/10.1007/s10586-017-0942-0
Yao J, Warren S (2005) Applying the ISO/IEEE 11073 standards to wearable home health monitoring systems. J Clin Monit Comput 19(6):427–436
Yoo H, Chung K (2018) Mining-based lifecare recommendation using peer-to-peer dataset and adaptive decision feedback. Peer-to-Peer Netw Appl. https://doi.org/10.1007/s12083-017-0620-2
Acknowledgements
This work was supported by Kyonggi University Research Grant 2017.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kim, JC., Chung, K. Neural-network based adaptive context prediction model for ambient intelligence. J Ambient Intell Human Comput 11, 1451–1458 (2020). https://doi.org/10.1007/s12652-018-0972-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-018-0972-3