
Abstract
OFDM (ORTHOGONAL frequency-division multiplexing) is a well-known modulation scheme that has been widely employed in wireless broadband systems in the previous decade to combat frequency-selective type fading in wireless channels. In OFDM approaches, channel state information is critical for detecting and decoding coherent signals. Pilot tones are frequently included into the subcarriers of OFDM signals to perform channel estimation. The perceptron neural network (DNN) has shown to be an effective tool for channel estimation in wireless communication's suboptimal conditions. Prior to the demodulation of OFDM signals, a dynamic channel estimate is important. Depending on the channel types and circumstances, deep learning-based channel estimation outperforms classical channel estimation methods such as minimal mean-square error (MMSE) and least squares (LS). The simulation results validate the projected Perceptron model’s validity and demonstrate the use of our proposed Perceptron-based channel estimation in both nonlinear and linear signal models.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In order to identify in an OFDM system, we use deep learning along with channel estimation. Artificial neural networks (ANNs) and deep learning have a wide range of applications. It has been used successfully in communication systems for localization based on CSI [1], channel equalization [2], and channel decoding. We predict deep learning to find additional applications in communication systems as computing resources on devices improve and enormous amounts of data become available [2].
Channel estimation, channel state information (CSI), signal detection, and resource management, among other things, have all yielded fascinating findings for the physical layer or network layer of communications [3].
“ANNs have been shown to modify settings based on online pilot data for channel equalization with online training.” However, such approaches cannot be used directly since the number of parameters in deep neural networks (DNNs) has expanded dramatically, necessitating a huge amount of training data as well as a lengthy training period. To solve the problem, we train a DNN model that predicts transmitted data under a variety of channel circumstances. The model is then utilized to retrieve the sent data in an online deployment [4].
In addition to frequency selectivity, DNNs can learn and assess the properties of wireless channels that may suffer from nonlinear distortion and interference. To the best of our knowledge, this is the first attempt to deal with wireless channels using learning approaches without online training [3]. If there are enough pilots in OFDM systems, deep learning models can reach performance equivalent to classical approaches, and it can function better with restricted pilots, CP elimination, and nonlinear noise [3, 4].
Our contributions are listed as follows:
-
The performance of the Perceptron-based channel estimation was compared to that of the traditional least-squared (LS) and linear minimum mean-squared error (LMMSE) estimators. In the asymptotic limit of numerous training samples, we show that the Perceptron estimator based on DNNs can successfully resemble the minimal mean-squared error (MMSE) estimate [3].
-
We show that the Perceptron estimate scales polynomially rapidly with varied training sample sizes, whereas the MMSE estimator scales polynomially slowly. This result demonstrates the utility of our Perceptron estimator for channel estimation.
-
We show that when the statistics of training data do not match the deployed settings, the Perceptron estimator suffers severe performance loss and even fails to generate valid estimates.
This is how the rest of the paper is organized. Section II introduces the system concept and typical channel estimate methods. Section III examines the various DNN-based channel estimate algorithms. The training model data for perceptron-based channel estimation is supplied in Section IV. Section V presents the simulation findings, followed by Section VI’s conclusions.
Related work
The channel estimation techniques are adaptive estimators that may change the estimator’s parameters. In an OFDM wide area network, efficient channel estimate algorithms are necessary to function in rapid time changing channels. Either introducing pilot tones into all of the subcarriers of OFDM symbols with a specific time or inserting pilot tones into each OFDM symbol are common methods for channel estimation [5].
Because the radio channel is frequency selective and time-varying for wideband mobile communication systems, a dynamic channel estimate is required prior to demodulation of OFDM signals. Next-generation communication systems demand high data speeds. As a result of using MIMO channels, not only is the mobility of wireless communications boosted, but the algorithm is also more resistant to fading, making it efficient for the needs of next-generation wireless services.
One of the most common deep learning applications in wireless communication systems is channel estimation. For orthogonal frequency division multiplexing (OFDM) systems, the first attempt was made in [6] to use sophisticated deep learning algorithms to understand the properties of frequency selective wireless channels and battle nonlinear distortion and interference.
To solve challenges of both direction-of-arrival and channel estimates, a unique framework incorporates deep Learning algorithms into huge multiple-input multiple-output (MIMO) systems. In several instances, DL-based channel estimation has been extended to doubly selective channels and has quantitatively showed superior performance over traditional estimators [3].
The channel matrix is treated as an image, and the channel is estimated using a DL-based image super-resolution and denoising algorithm. Furthermore, in huge MIMO systems, a sparse complex-valued neural network structure is expected to be used for channel estimation. Another line of study is attempting to develop a revolutionary end-to-end deep neural network (DNN) architecture that would replace all modules at the transmitter and receiver, rather than bolstering only a few [3].
Despite deep learning's enormous success, the DNN embedded wireless communication system is still regarded as a black box for signal transmission and receiving. There are few analytical interpretations available to corroborate the advantages and disadvantages of DL approaches when used to communications [3, 6], and there are few experimental evaluations accessible to verify the capabilities of DL in learning important functional components of wireless systems.
For future performance enhancement and expansion to other situations, it is required to understand why deep learning approaches deliver excellent results for a wide variety of jobs. Furthermore, knowing the limitations of DL approaches in wireless communication systems is critical for determining which scenarios are appropriate for DL embedded communication systems. Another relevant question is how well newly developed data-driven DL approaches in the field of wireless communications compare to older expert-designed algorithms [3, 7].
Deep learning approaches have overturned standard signal processing methods, allowing for adequate performance even in the absence of expert knowledge. So far, there has been little study on how deep learning methods learn from data and how the lack of expert knowledge impacts DL embedded communication systems [6].
The universal approximation of DNNs was proved in the initial findings, demonstrating that any continuous function specified on a compact set may be estimated with any precision using a DNN [8, 9]. As DNNs with rectified linear units (ReLU DNNs) have grown in popularity in recent years, the focus of research has switched to examining ReLU DNNs’ remarkable capabilities at function representation, and ReLU DNNs have also been shown to be universal approximations to a broad family of functions [3].
Despite the universal approximation, DNNs can compete with standard signal processing approaches in communication networks. More and more research has recently shown that DL approaches are especially well suited to channel estimation, and ReLU DNNs have grown more widespread in communication systems [2, 6].
The practical success of ReLU DNNs necessitates a thorough knowledge of their behaviour on estimating channels, which will serve as direction and inspiration for future deep learning-based estimation applications. The perceptron approach for channel estimation in multiple-input multiple-output (MIMO) systems is presented in this study [8].
LMMSE channel estimation
This section highlights on the system model considered in our study, besides the mathematical representation of both accurate and adaptive LMMSE channel estimation schemes.
System description
We consider an OFDM transmitter that employs K subcarriers, and a cyclic prefix (CP) of length Kcp used to combat the inter symbol interference between two successive transmitted OFDM symbols. Each transmitted frame consists of a preamble at the beginning, which is used for channel estimation at the receiver, followed by OFDM symbols that contain the transmitted data [9].
The input–output relation between the transmitted and the received OFDM frame at the receiver can be expressed as follows:
S[k, I], H [k, I] R[k, I], and N[k, I] are the transmitted preamble symbol, frequency domain channel gain, received preamble symbol, and noise symbol of the k-th sub-carrier of the i-th OFDM symbol, respectively. Out of the K sub-carriers in each OFDM symbol, the OFDM transmitter employs K on active sub-carriers in general. The remaining subcarriers are guard subcarriers. The p-th preamble signal may be stated as follows, assuming that the channel is static during frame transmission:
where r˜p = R[Kon, p], Sp = diag {S[Kon, p]}, and h˜ p = H˜ [Kon, p] are the frequency domain responses of the channel at the preamble that needs to be estimated at the receiver.
B. Accurate LMMSE: In general, the LMMSE channel estimation is given by:
where W LMMSE denotes the LMMSE channel estimation matrix, which is expressed as:
Channel estimation and detection based on deep learning
Deep learning methods
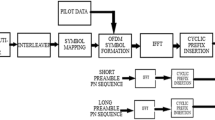
Deep learning has been effectively utilized in a broad range of applications, including natural language processing, computer vision [4], speech recognition, and so on, with considerable performance improvements. [1] provides a thorough introduction to deep learning and machine learning. Figure 1 depicts the structure of a typical deep learning model.

A Normal Deep learning model
DNNs, in general, are more complex variants of ANNs that increase the number of hidden layers to enhance representation or recognition capabilities. As illustrated in Fig. 1, each layer of the network is made up of numerous neurons, each of which has an output that is a nonlinear function of the weighted sum of the neurons in the layer before it.
The nonlinear function might be either the Sigmoid or Relu functions, which are defined as fS(a) = 1 1+ea and fR(a) = max(0, a), respectively. As a result, the network’s output z is a cascade of nonlinear transformations of input data I, mathematically represented as = f(I,)
where L signifies the number of layers and weights denote the neural network’s weights. The weights for the neurons are the model’s parameters, which must be tuned before the online deployment. On a training set with known desired outputs, the optimal weights are generally learnt.
System architecture
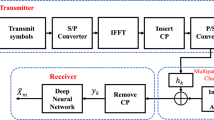
The architecture of the OFDM system with perceptron-based channel estimation and signal detection is illustrated in Fig. 2. The baseband OFDM system [1] is the same as the conventional ones. On the transmitter side, the transmitted symbols inserted with pilots are first converted to a paralleled data stream; then, the inverse discrete Fourier transform (IDFT) is used to convert the signal from the frequency domain to the time domain. After that, a cyclic prefix (CP) is inserted to mitigate the inter-symbol interference [2].

An OFDM System Models With Deep Learning Methods
The length of the CP should be no shorter than the maximum delay spread of the channel. We consider a sample-spaced multi-path channel described by complex random variables {h(n)} N−1 n=0.
The received signal after the perceptron can be expressed as
where * denotes the dot product while x(i) and b(i) represent the transmitted signal and the additive white Gaussian noise, respectively. After removing the CP and performing DFT, the received frequency domain signal is
where Y(k), X(k), H(k), and b(k) are the DFT of y(i), x(i), h(i), and b(i), respectively.
The pilot symbols are assumed to be in the first OFDM block, whereas the transmitted data is in the subsequent OFDM blocks. They create a frame when put together. The channel can be viewed as a constant that spans the pilot and data blocks, although it varies from frame to frame. In our initial investigation, the perceptron model takes as input received data consisting of one pilot block and one data block, and recovers the transmitted data end-to-end [10].
Two phases are incorporated, as illustrated in Fig. 2, to provide an efficient perceptron model for joint channel estimation and symbol detection. The model is trained offline using OFDM samples received from various information sequences and under a variety of channel settings with specified statistical qualities, such as a typical urban or hilly terrain delay profile. The perceptron model creates output in the online deployment stage that recovers the transmitted data without explicitly predicting the wireless channel.
Model training
Given the channel estimations acquired by LS estimation as input, DNN-aided perceptron estimation will learn the real channel information to minimize the MSE. The goal of perceptron estimation is to reduce the average MSE between the prediction and real channels; hence, the training phase's loss function is defined as disparities between actual and predicted values.
where N is the number of training realizations employed, and hn(t) denotes the actual channel corresponding to hn (t). All of the weights and biases are represented by W and B, respectively. The weights and biases are updated from a set of starting values by minimizing the loss function (7) with forward and backward propagation [10].
The loss function (7) represents supervised learning model training. It is predicated on the fact that genuine channels are accessible throughout the training phase, which is achieved if the pilot power or coherence interval is large enough. As a result, the learning-based perceptron presented beats LS estimation [11, 12].
For DNN-1, the number of neurons in each layer is 8, 16, 16, 16, and 8, correspondingly. In the meanwhile, for DNN-2, the numbers are 8, 32, 32, 32, and 8. It is worth noting that the number of neurons in the input and output layers is the same as the total number of real and picture portions for a four-path channel, which is eight. We train using 70% of the data, validate with 15% of the data, and test with 15% of the data. The two DNN models, DNN-1 and DNN-2, are suggested in this study for channel estimation with five layers (input layer, three hidden layers, and output layer) [13, 14].
Simulation results
This section examines the performance of the recommended perceptron-based estimator for channels. The setting and default parameters of the simulation system are illustrated first, followed by the training of a perceptron model with simulation data. The parameter selections of the perceptron estimator, as well as the structure of the input data, are then investigated [3, 16]. Finally, the performance of perceptron-based estimators is compared to that of traditional approaches in terms of bit-error rates (BERs) at various signal-to-noise ratios (SNRs)
Simulation setup
The proposed DL-based estimator is implemented on one computer with one central processing units and 32 GB of memory with MATLAB configuration. Unless otherwise specified, the parameters of the channel model follow the default setting as shown in Table 1.
The deep learning-based perceptron technique is shown to be more resilient than LS and MMSE in the following trials when the CP is missing or there is nonlinear clipping noise. An OFDM system with 64 subcarriers and a CP of length 16 is investigated in our experiments. The wireless channel is based on the wire-free world effort for a new radio model, with a carrier frequency of 2.6 GHz, 24 pathways, and typical urban channels with a maximum delay of 16 sample period [4].
The QPSK modulation technique is used, as well as a fading multi-path model channel. The simulations, on the other hand, LS and LMMSE estimations are also supplied as standards for comparison. The two distinct situations related to the velocity of mobiles are exploited [7] to analyse the performance of all the discussed channel estimates utilizing in the MIMO-OFDM system using the 5G channel model.
The receiver travels slowly in the first scenario, with a maximum Doppler frequency of 36 Hz. The pilot symbols, as well as data in the frequency and time domains, are added. The pilot spacing in the time domain is Dt = 4 and in the frequency domain is Df = 2 since the channel changes slowly over time.
The technology provides high-speed mobility in the second scenario, resulting in a maximum Doppler frequency of 200 Hz. The Dt = Df = 2 arrangement is used in this case to deal with a fast change of channels over time [15, 16].
Figure 3 demonstrate the MSE of different channel predictions for the first and second cases, respectively. The transmitted data is modulated using QPSK in the simulation.

The MSE with SNR of the channel estimate level
As seen in Fig. 3, all channel estimate approaches result in MSE decreasing as the SNR increases. Because it ignores statistical channel information when performing channel estimation, LS estimation produces the poorest MSE performance in both circumstances. LMMSE estimation, on the other hand, makes use of the mean and covariance matrices, resulting in superior MSE performance than the LS counterpart [17].
The MSE performance of our suggested perceptron approaches is the best, especially at low and medium SNR levels. When the SNR rises over 13 dB, deep learning-based techniques perform worse than LMMSE estimate in terms of MSE. This might be because the DNN models’ structure is still not ideal at high SNR levels, requiring more careful tuning of the hyper-parameters. Despite the fact that the DNN-2 model contains more neurons in each hidden layer than the DNN-1 model, the findings are very similar. This indicates that a more complicated DNN structure does not automatically imply greater precision. The MSE of all four channel estimate techniques is worse than those of the first scenario due to the severity of Doppler effects, despite the fact that the pilot symbols are inserted more densely in time domain in the second situation with the high receiver speed.
In Fig. 4, we show the BER performance of the various situations using different channel estimate approaches. The BER performance does not show the differences between the channel estimate approaches. However, in all circumstances, we find that LS estimation has the poorest performance among the four ways, while the BER performance of the remaining methods is nearly identical. Even while LS estimate performs worse than the others, the difference in performance is minor. This can be explained by the fact that the loss function, rather than the BER measure, has been constructed to reduce channel estimate errors. In addition, Fig. 4 illustrate how increasing the SNR level successfully combats Doppler effects, resulting in large improvements in the BER. For example, if the SNR level is 10 times higher at fD = 36 Hz, the BER improves by 10%. For example, increasing the SNR level from 5 to 10 dB improves the BER by 10 for fD = 36 Hz.

The BER versus the SNR level of the channel estimate
Conclusion
We have shown our early efforts to use DNNs for channel estimation and symbol identification in an OFDM system in this study. The simulated data is used to train the perceptron model. To aid channel estimation in a MIMO-OFDM system with two alternative scenarios of fading multi-path channel models, a deep neural network with two benchmarks dubbed DNN-1 and DNN-2 has been presented. With the channel estimate from least squares estimation and the matching perfect channels, the suggested perceptron channel estimation techniques are trained. The suggested estimations are compared to the standard LS and LMMSE estimations in terms of channel estimation errors and bit error ratio as a function of SNR levels using the QPSK modulation method. We found better improvements in the proposed DNN-aided perceptron estimation in lowering channel estimate errors due to efficient learning of channel parameters.
Future work
5G is the future of telecommunications; with ever-increasing internet traffic and the demand for high data rates, the arrival of 5G is a requirement of the day. Furthermore, the frequency bands utilized for 2G, 3G, and 4G communications have grown overcrowded, necessitating the allocation of new frequency bands, which are later allotted by the Federal Communication Commission (FCC) [18]. These frequencies are allocated for 5G communication, and the suggested artwork is to design a MIMO antenna that works in one of the FCC-reserved 5G channels. Because MIMO generation can already handle high transmission rates, a surge in records site visits can also be supported by the MIMO system [19].
References
Van Chien, T., & Björnson, E. Massive MIMO communications. In: 5G Mobile communications (pp. 77–116). Springer, cham. (2017). https://doi.org/10.3390/s20102753
H. Ye, G.Y. Li, B.H. Juang, Power of deep learning for channel estimation and signal detection in OFDM systems. IEEE Wire Commun Lett 7(1), 114–117 (2017). https://doi.org/10.1109/LWC.2017.2757490
Q. Hu, F. Gao, H. Zhang, S. Jin, G.Y. Li, Deep learning for channel estimation: Interpretation, performance, and comparison. IEEE Trans. Wire. Commun. 20(4), 2398–2412 (2020). https://doi.org/10.1109/TWC.2020.3042074
X. Yi, C. Zhong, Deep learning for joint channel estimation and signal detection in OFDM systems. IEEE Commun. Lett. 24(12), 2780–2784 (2020). https://doi.org/10.1109/LCOMM.2020.3014382
T. Van Chien, T.N. Canh, E. Björnson, E.G. Larsson, Power control in cellular massive MIMO with varying user activity: A deep learning solution. IEEE Trans. Wireless Commun. 19(9), 5732–5748 (2020). https://doi.org/10.1109/TWC.2020.2996368
C.J. Chun, J.M. Kang, I.M. Kim, Deep learning-based channel estimation for massive MIMO systems. IEEE Wireless Commun. Lett. 8(4), 1228–1231 (2019). https://doi.org/10.1109/LWC.2019.2912378
Le Ha, A., Van Chien, T., Nguyen, T. H., & Choi, W. Deep learning-aided 5G channel estimation. In 2021 15th international conference on ubiquitous information management and communication (IMCOM) (2021, Jan). (pp. 1–7). IEEE https://doi.org/10.1109/IMCOM51814.2021.9377351.
Y. Yang, F. Gao, X. Ma, S. Zhang, Deep learning-based channel estimation for doubly selective fading channels. IEEE Access 7, 36579–36589 (2019). https://doi.org/10.1109/ACCESS.2019.2901066
T. O’shea, J. Hoydis, An introduction to deep learning for the physical layer. IEEE Trans. Cognitive Commun. Net. 3(4), 563–575 (2017). https://doi.org/10.1109/TCCN.2017.2758370
Y. Yang, F. Gao, G.Y. Li, M. Jian, Deep learning-based downlink channel prediction for FDD massive MIMO system. IEEE Commun. Lett. 23(11), 1994–1998 (2019). https://doi.org/10.1109/TCOMM.2020.3019077
D. Neumann, T. Wiese, W. Utschick, Learning the MMSE channel estimator. IEEE Trans. Signal Process. 66(11), 2905–2917 (2018). https://doi.org/10.1109/TSP.2018.2799164
Q. Yuan, D. Li, Z. Wang, C. Liu, C. He, Channel estimation and pilot design for uplink sparse code multiple access system based on complex-valued sparse autoencoder. IEEE Access. (2019). https://doi.org/10.1109/ACCESS.2019.2904990
K. Koufos, K. Haloui, M. Dianati, M. Higgins, J. Elmirghani, M. Imran, R. Tafazolli, Trends in intelligent communication systems: review of standards, major research projects, and identification of research gaps. J. Sens. Actuator Netw. 10(4), 60 (2021). https://doi.org/10.3390/jsan10040060
Mei, K., Liu, J., Zhang, X., & Wei, J. Machine learning based channel estimation: A computational approach for universal channel conditions. (2019). arXiv preprint arXiv:1911.03886https://doi.org/10.13140/RG.2.2.12584.11527.
H. Huang, J. Yang, H. Huang, Y. Song, G. Gui, Deep learning for super-resolution channel estimation and DOA estimation based massive MIMO system. IEEE Trans. Veh. Technol. 67(9), 8549–8560 (2018). https://doi.org/10.1109/TVT.2018.2851783
H. Ye, G.Y. Li, B.H. Juang, Power of deep learning for channel estimation and signal detection in OFDM systems. IEEE Wireless Commun. Lett. 7(1), 114–117 (2017). https://doi.org/10.1109/LWC.2017.2757490
H. Ye, L. Liang, G.Y. Li, B.H. Juang, Deep learning-based end-to-end wireless communication systems with conditional GANs as unknown channels. IEEE Trans. Wireless Commun. 19(5), 3133–3143 (2020). https://doi.org/10.1109/TWC.2020.2970707
S. Dörner, S. Cammerer, J. Hoydis, S. Ten Brink, Deep learning based communication over the air. IEEE J. Selected Topics Signal Process. 12(1), 132–143 (2017). https://doi.org/10.1109/JSTSP.2017.2784180
Ye, H., Li, G. Y., Juang, B. H. F., & Sivanesan, K. Channel agnostic end-to-end learning based communication systems with conditional GAN. In 2018 IEEE globecom workshops(2018, Dec). (GC Wkshps) (pp. 1–5). IEEE https://doi.org/10.1109/GLOCOMW.2018.8644250.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Rani, M., Singal, P. Perceptron for channel estimation and signal detection in OFDM systems. J Opt 52, 69–76 (2023). https://doi.org/10.1007/s12596-022-00924-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12596-022-00924-x