
Abstract
Background/Introduction
Due to the complexity and uncertainty of socioeconomic environments and cognitive diversity of group members, the cognitive information over alternatives provided by a decision organization consisting of several experts is usually uncertain and hesitant. Hesitant fuzzy preference relations provide a useful means to represent the hesitant cognitions of the decision organization over alternatives, which describe the possible degrees that one alternative is preferred to another by using a set of discrete values. However, in order to depict the cognitions over alternatives more comprehensively, besides the degrees that one alternative is preferred to another, the decision organization would give the degrees that the alternative is non-preferred to another, which may be a set of possible values. To effectively handle such common cases, in this paper, the dual hesitant fuzzy preference relation (DHFPR) is introduced and the methods for group decision making (GDM) with DHFPRs are investigated.
Methods
Firstly, a new operator to aggregate dual hesitant fuzzy cognitive information is developed, which treats the membership and non-membership information fairly, and can generate more neutral results than the existing dual hesitant fuzzy aggregation operators. Since compatibility is a very effective tool to measure the consensus in GDM with preference relations, then two compatibility measures for DHFPRs are proposed. After that, the developed aggregation operator and compatibility measures are applied to GDM with DHFPRs and two GDM methods are designed, which can be applied to different decision making situations.
Results and Conclusions
Each GDM method involves a consensus improving model with respect to DHFPRs. The model in the first method reaches the desired consensus level by adjusting the group members’ preference values, and the model in the second method improves the group consensus level by modifying the weights of group members according to their contributions to the group decision, which maintains the group members’ original opinions and allows the group members not to compromise for reaching the desired consensus level. In actual applications, we may choose a proper method to solve the GDM problems with DHFPRs in light of the actual situation. Compared with the GDM methods with IVIFPRs, the proposed methods directly apply the original DHFPRs to decision making and do not need to transform them into the IVIFPRs, which can avoid the loss and distortion of original information, and thus can generate more precise decision results.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Decision making is a fairly common activity in people’s daily life, whose purpose is to find an optimal alternative from multiple alternatives based upon the provided decision information [1–3]. Nowadays, because of the high complexity and uncertainty of socioeconomic environments, most decision making problems require the participation of multiple decision makers to conduct a group decision making (GDM) since the cognitive ability of a single decision maker is very limited and it is not possible for him/her to consider all important aspects of the problem and make a desirable decision. Social cognitive processes have a significant influence on GDM. Recently, Lee and Harris [4] reviewed the person perception and decision making literature to show that social cognition can inform the social decision making, and examined the benefits of integrating social psychological theory with behavioral economic theory. Yang and Jiang [5] discussed the influence of social cognitive activities on the GDM consistency convergence rate and the group’s consensus level. Brabec et al. [6] examined the relationships among measures that assess emotional intelligence, social cognition and emotional decision making through an experiment. To describe the cognitive information of human beings in social cognitive processes accurately, many techniques have been developed [7–9]. Among them, preference relations have turned out to be very useful in representing human beings’ cognitive information when a set of objects are compared.
Up to now, many different types of preference relations have been proposed, such as the fuzzy preference relation [10], the multiplicative preference relation [11], the intuitionistic fuzzy preference relation (IFPR) [12], the interval-valued intuitionistic fuzzy preference relation (IVIFPR) [13] and the hesitant fuzzy preference relation (HFPR) [14]. The HFPR is developed based upon the concept of the hesitant fuzzy set (HFS) [15], which models the decision makers’ hesitant cognitions by allocating to each element in a universe several different membership values. As a new tool for representing the cognitive information, HFPRs are able to well cope with such situations where a decision organization is hesitant among several possible values when providing the degrees to which one alternative is preferred to another. For example, suppose that a decision organization composed of several experts is required to provide the degrees that the alternative x i is superior to the alternative x j , and the experts prefer to use the values between 0 and 1 to express their cognitions [14]. Some experts in the decision organization provide 0.4, some provide 0.5, and the others provide 0.6, and these three parts cannot persuade each other; thus, the degrees that the alternative x i is superior to x j (i ≠ j) can be regarded as a hesitant fuzzy element (HFE) a ij = {0.4, 0.5, 0.6}. Here the decision organization is considered as a whole which provides all the possible preference values about x i over x j . A HFPR can be constructed when all the possible preference values over the set of alternatives are provided.
Since the HFS was introduced, several famous extensions have been developed, one of which is the dual hesitant fuzzy set (DHFS) [16], whose membership degrees and non-membership degrees are presented by a set of possible values, respectively. The DHFS differs from the other extensions of the HFS for it handles the hesitations both on the assignment of the membership degree and on the non-membership degree, while the others model the hesitations on membership degrees which are not exactly defined, but expressed by interval values (IVHFS [17, 18]), intuitionistic fuzzy sets (GHFS [19]), or triangular fuzzy numbers (TFHFS [20]). Since the proposal in 2012, the DHFS has attracted great attention and many research results have been obtained, which can be mainly classified into the following parts: basic definitions and operations over DHFSs [16, 21], information fusion techniques with DHFSs [22–24], measures of DHFSs [25, 26] and methods for decision making with dual hesitant fuzzy cognitive information [27, 28]. Nevertheless, to our knowledge, no scholars have studied the preference relation based on DHFSs. Therefore, the focus of this paper is to investigate the dual hesitant fuzzy preference relation (DHFPR) based upon the concept of DHFSs, which is needed in the real world since when a decision organization consisting of several experts provides the cognitive information over alternatives, they may give the degrees that one alternative is preferred and non-preferred to another, which are expressed by two sets of possible values. The main superiority of the DHFPR over other preference relations [10–14] is that it can capture more cognitive information by depicting the possible degrees that one alternative is preferred to another, and the possible degrees that the alternative is non-preferred to another, simultaneously.
During the GDM process, it is impossible for group members to cognitively view the involved problem in the same way since they usually come from different fields or departments and have different assumptions and interpretations on the problem [29]. Therefore, some dissimilar or even conflicting cognitions may appear. Usually, it is expected to reconcile these cognitions through interaction and discussion until a satisfactory consensus is obtained. In the course of consultation, the decision makers often confront the tricky issues surrounding the measurement of cognitive consensus of group members. One approach to measure the cognitive consensus is to ask group members to individually complete a questionnaire measuring that has been developed to assess assumptions, categories, dimensions and/or content domains [30, 31]. Furthermore, variation measures such as the interrater agreement index [32], the coefficient of variation [33] and the standard deviation [34] can be used to assess the degree of (dis)agreement within a group. Recently, a combination of questionnaire measuring and variation measures has been applied to measure the cognitive consensus of a group [31]. Besides, compatibility is a very efficient tool to measure the consensus of opinions of group members. The lack of acceptable compatibility, which indicates that there are significant differences among the opinions, can result in the unsatisfied or even incorrect decision results. Saaty and Vargas [35] came up with the compatibility to judge the difference between two multiplicative preference relations. Xu [36] defined the compatibility index between two interval fuzzy preference relations. Later, Xu [12] introduced some compatibility measures for IFPRs and IVIFPRs, and developed two consensus reaching procedures based on the proposed compatibility measures. Jiang et al. [37] defined the compatibility index between two intuitionistic multiplicative preference relations, on the basis of which they developed two different consensus models. Chen et al. [38] proposed the compatibility measure of uncertain additive linguistic preference relations. Due to the importance of compatibility in GDM, another focus of this paper is to study the compatibility measures between DHFPRs and investigate their applications in GDM with DHFPRs. Firstly, two different formulas are developed to calculate the compatibility degrees between DHFPRs. Furthermore, the importance weights of decision organizations are determined and the group’s consensus level is analyzed by using the developed compatibility formulas.
After a satisfactory consensus is reached, the next thing we need to do is to conduct a selection process, which refers to obtaining a final solution of alternatives, and encompasses two steps: the aggregation of individual preference relations and the exploitation of the group preference relation [39]. To date, many aggregation methods have been proposed for fusing the dual hesitant fuzzy cognitive information. Wang et al. [23] proposed some fundamental dual hesitant fuzzy aggregation operators in terms of the arithmetic and geometric operations. Afterward, Yu [24] and Wang et al. [40] extended Wang et al.’s aggregation operators [23] and presented a family of generalized dual hesitant fuzzy aggregation operators. Based on the Hamacher t-norm and t-conorm, Ju et al. [22] put forward some dual hesitant fuzzy Hamacher aggregation operators. For fusing the correlative dual hesitant fuzzy cognitive information, Ju et al. [41] developed some dual hesitant fuzzy Choquet aggregation operators, and Zhang [42] proposed the dual hesitant fuzzy Hamacher correlated geometric operator. In addition, considering that there may exist some interactions between the membership functions and the non-membership functions of different DHFSs, Xu et al. [43] presented a class of dual hesitant fuzzy interaction operators. Analyzing the above-mentioned dual hesitant fuzzy aggregation operators, it can be easily seen that these operators carry out different operations on the membership and non-membership information of DHFSs. However, in most circumstances, we are neutral and the membership and non-membership information should be treated fairly [44]. So, the third aim of this paper is to introduce a neutral aggregation operator for the dual hesitant fuzzy cognitive information.
The remainder of this paper is organized as follows: “Preliminaries” section reviews some basic definitions and operations of DHFSs. “Aggregation Operators and Compatibility Measures for Dual Hesitant Fuzzy Information” section develops a neutral aggregation operator for the dual hesitant fuzzy cognitive information and then introduces the concept of DHFPRs and proposes two different compatibility measures to calculate the compatibility degrees between DHFPRs. “Two Methods for GDM with DHFPRs” section applies the proposed aggregation operator and compatibility measures to GDM with DHFPRs and proposes two GDM methods. “Illustrative Example” section provides an example to illustrate the applicability and implementation processes of the proposed methods, and conducts comparative analyses to demonstrate their advantages. “Conclusions” section concludes the paper.
Preliminaries
Recently, Zhu et al. [16] defined the DHFS, which allows the membership and non-membership degrees of an element to a given set to be several different values, respectively, shown as follows:
Definition 1 [16]
Let X be a fixed set, then a DHFS on X is defined as:
where h(x) and g(x) are two sets of several values in [0, 1], representing the possible membership degrees and non-membership degrees of the element x ∊ X to the set D, respectively, with the conditions:
where \( \gamma \in h(x),\;\eta \in g(x),\;\gamma^{ + } = \cup_{\gamma \in h(x)} {\text{max\{ }}\gamma {\text{\} }} \) and \( \eta^{ + } = \cup_{\eta \in g(x)} {\text{max\{ }}\eta {\text{\} }} \) for all x ∊ X.
Similar to the definition of the degree of indeterminacy of an element to an intuitionistic fuzzy set [12],
is defined as the average degree of indeterminacy of the element x to the DHFS D, where #h(x) and #g(x) are the numbers of elements in h(x) and g(x), respectively. For convenience, Zhu et al. [16] called the pair d = (h(x), g(x)) a dual hesitant fuzzy element (DHFE), denoted by d = (h, g), satisfying the conditions: 0 ≤ γ, η ≤ 1 and γ + + η + ≤ 1, where \( \gamma \in h,\;\eta \in g,\;\gamma^{ + } = \hbox{max} \{ \gamma |\gamma \in h\} \) and \( \eta^{ + } = \hbox{max} \{ \eta |\eta \in g\} \). Here, h and g are called the set of membership degrees and the set of non-membership degrees of the DHFE d, respectively. The physical interpretation of the DHFE d = (g, h) can be given as follows: For example, if d = {{0.1, 0.2}, {0.4, 0.6}}, then it can be interpreted as “in a multi-criteria decision making problem, some decision makers think that the possible values for the membership degree of x to the set D are 0.1 and 0.2, for the non-membership degree are 0.4 and 0.6, and the average indeterminacy degree of x to the set D is 0.35 reflecting the average extent to which these decision makers are indeterminate about whether x belongs to the set D.”
Note that for a DHFE, d = (h, g), if h = ϕ and g = ϕ, then at this time d makes no sense; if h ≠ ϕ and g = ϕ, then in this case d is simplified to a HFE [14]; if #h = #g = 1, then in this case d is simplified to an intuitionistic fuzzy value (IFV) [12]. To better study the properties of DHFEs and distinguish DHFEs from HFEs, the paper thereinafter will only focus on the DHFEs d = (h, g) with h ≠ ϕ and g ≠ ϕ without explicitly mentioning them.
From Definition 1, it can be noticed that for different DHFEs, the numbers of elements in the sets of membership degrees or the sets of non-membership degrees may be different. To operate correctly in computation, such as developing the distance or similarity measures, Zhu and Xu [21] proposed the following method to normalize DHFEs:
Definition 2 [21]
Assume that d = (g, h) is a DHFE, then \( \overline{\gamma } = \varsigma \gamma^{ + } + (1 - \varsigma )\gamma^{ - } \) and \( \overline{\eta } = (1 - \varsigma )\eta^{ + } + \varsigma \eta^{ - } \) are called the added membership degree and non-membership degree, respectively, where γ + and γ − are the maximum and minimum elements in h, respectively, η + and η − are the maximum and minimum elements in g, respectively, and ς(0 ≤ ς ≤ 1) is a parameter provided by the decision maker according to his/her risk preference.
Thus, for two DHFEs, when the numbers of elements in the sets of membership degrees or the sets of non-membership degrees are different, we can use ς to add the membership degrees or the non-membership degrees to a set of membership degrees or a set of non-membership degrees so that the two sets of membership degrees or the sets of non-membership degrees have the same number of elements. For example, for two DHFEs d 1 = {{0.1, 0.2}, {0.4, 0.5, 0.6}} and d 2 = {{0.2, 0.3, 0.4, 0.6}, {0.3, 0.4}}, obviously, \( \# h_{{d_{1} }} \ne \# h_{{d_{2} }} \) and \( \# g_{{d_{1} }} \ne \# g_{{d_{2} }} \). Then by Definition 2, d 1 can be extended as d 1 = {{0.1, 0.2, 0.2, 0.2}, {0.4, 0.5, 0.6}} and d 2 can be extended as d 2 = {{0.2, 0.3, 0.4, 0.6}, {0.3, 0.3, 0.4}}. At this time, the two DHFEs have the same numbers of membership degrees and non-membership degrees. Clearly, ς = 1 indicates that the decision makers are optimistic, ς = 0 indicates that the decision makers are pessimistic, and ς = 0.5 indicates that the decision makers are indifferent. This paper only considers the case in which the decision makers are optimists for other cases can be studied in a similar way.
In order to compare DHFEs, Zhu et al. [16] gave the following comparison laws:
Definition 3 [16]
Let d i = (h i , g i ), i = 1, 2 be two DHFEs, \( s(d_{i} ) = (1/\# h_{i} )\sum\nolimits_{{\gamma_{i} \in h_{i} }} {\gamma_{i} } - (1/\# g_{i} )\sum\nolimits_{{\eta_{i} \in g_{i} }} {\eta_{i} } \) the score function of d i (i = 1, 2), and \( p(d_{i} ) = (1/\# h_{i} )\sum\nolimits_{{\gamma_{i} \in h_{i} }} {\gamma_{i} } + (1/\# g_{i} )\sum\nolimits_{{\eta_{i} \in g_{i} }} {\eta_{i} } \) the accuracy function of d i (i = 1, 2), where #h i and #g i are the numbers of elements in h i and g i , respectively, i = 1, 2, then
-
(i)
if s(d 1) > s(d 2), then d 1 is superior to d 2, denoted by d 1 ≻ d 2;
-
(ii)
if s(d 1) = s(d 2), then
-
(1)
if p(d 1) = p(d 2), then d 1 is indifferent to d 2, denoted by d 1 ∼ d 2;
-
(2)
if p(d 1) > p(d 2), then d 1 is superior to d 2, denoted by d 1 ≻ d 2.
-
(1)
However, the above comparison laws cannot effectively differentiate two DHFEs in some cases.
Example 1
Let d 1 = {{0.05, 0.15, 0.7}, {0.3}} and d 2 = {{0.2, 0.4}, {0.1, 0.2, 0.6}} be two DHFEs, then from Definition 3, it can be derived that
Since s(d 1) = s(d 2) and p(d 1) = p(d 2), then in this case d 1 and d 2 cannot be distinguished. In fact, such cases are common in reality. Thus, it is very necessary to introduce a new comparison method.
Definition 4
For a DHFE d = (h, g), \( v(d) = \frac{1}{\# h}\sqrt {\sum\nolimits_{{\gamma_{i} ,\gamma_{j} \in h}} {(\gamma_{i} - \gamma_{j} )^{2} } } + \frac{1}{\# g}\sqrt {\sum\nolimits_{{\eta_{i} ,\eta_{j} \in g}} {(\eta_{i} - \eta_{j} )^{2} } } \) is called the variance degree of d, where #h and #g are the numbers of elements in h and g, respectively.
Obviously, \( \frac{1}{\# h}\sqrt {\sum\nolimits_{{\gamma_{i} ,\gamma_{j} \in h}} {(\gamma_{i} - \gamma_{j} )^{2} } } \) represents the deviation degree of all elements in the membership degree set h and reflects the extent to which these elements agree with each other. The smaller \( \frac{1}{\# h}\sqrt {\sum\nolimits_{{\gamma_{i} ,\gamma_{j} \in h}} {(\gamma_{i} - \gamma_{j} )^{2} } } \) is, the higher consistency these elements have, which means that there are less differences among the opinions of the decision makers about the assignment of the membership degree. For \( \frac{1}{\# g}\sqrt {\sum\nolimits_{{\eta_{i} ,\eta_{j} \in g}} {(\eta_{i} - \eta_{j} )^{2} } } \), the similar conclusion can be got. During the decision making process, it is usually expected that the differences among the opinions of the decision makers are as few as possible. Therefore, the smaller v(d) is, the more preferred the DHFE d is. Conversely, d is less preferred.
Based on the above analysis, in comparing two DHFEs, when the score and accuracy functions cannot differentiate them, the variance degree can be considered as the third criterion, that is to say, for two DHFEs d 1 and d 2, when s(d 1) = s(d 2) and p(d 1) = p(d 2), we should compute their variance degrees, and compare them by the regulation: if v(d 1) < v(d 2), then d 1 ≻ d 2; if v(d 1) = v(d 2), then d 1 ∼ d 2. Then from Definition 4, it can be derived that in Example 1:
Then, v(d 1) < v(d 2), that is, the variance degree of d 1 is smaller than that of d 2. Therefore, d 1 ≻ d 2.
Aggregation Operators and Compatibility Measures for Dual Hesitant Fuzzy Information
This section first develops a neutral aggregation operator for dual hesitant fuzzy information and then defines DHFPRs and studies the compatibility measures between DHFPRs.
Symmetric Dual Hesitant Fuzzy Weighted Averaging (SDHFWA) Operator
In this subsection, a neutral aggregation operator for fusing DHFEs will be developed. Before that, the existing main operational laws of DHFEs are first recalled [16]:
Let d i = (h i , g i ), i = 1, 2 be two DHFEs and λ ≥ 0, then
-
(i)
\( d_{1} \oplus d_{2} = \cup_{{\gamma_{1} \in h_{1} ,\eta_{1} \in g_{1} ,\gamma_{2} \in h_{2} ,\eta_{2} \in g_{2} }} \{ \{ \gamma_{1} + \gamma_{2} - \gamma_{1} \gamma_{2} \} ,\{ \eta_{1} \eta_{2} \} \} ; \)
-
(ii)
\( d_{1} \otimes d_{2} = \cup_{{\gamma_{1} \in h_{1} ,\eta_{1} \in g_{1} ,\gamma_{2} \in h_{2} ,\eta_{2} \in g_{2} }} \{ \{ \gamma_{1} \gamma_{2} \} ,\{ \eta_{1} + \eta_{2} - \eta_{1} \eta_{2} \} \} ; \)
-
(iii)
\( \lambda d_{1} = \cup_{{\gamma_{1} \in h_{1} ,\eta_{1} \in g_{1} }} \{ \{ 1 - (1 - \gamma_{1} )^{\lambda } \} ,\{ \eta_{1}^{\lambda } \} \} ; \)
-
(iv)
\( d_{1}^{\lambda } = \cup_{{\gamma_{1} \in h_{1} ,\eta_{1} \in g_{1} }} \{ \{ \gamma_{1}^{\lambda } \} ,\{ 1 - (1 - \eta_{1} )^{\lambda } \} \} . \)
Based upon the above operational laws, Wang et al. [23] developed the following dual hesitant fuzzy aggregation operators:
Let d = (d 1, d 2, …, d n ) be a collection of DHFEs with d i = (h i , g i ), i = 1, 2, …, n, and w = (w 1, w 2, …, w n )T be the weight vector of them, with w i ∊ [0, 1], i = 1, 2, …, n and \( \sum\nolimits_{i = 1}^{n} {w_{i} } = 1 \), then
-
(1)
The dual hesitant fuzzy weighted averaging (DHFWA) operator is defined as:
$$ {\text{DHFWA}}_{w} (d_{1} ,d_{2} , \ldots ,d_{n} ) = \mathop \oplus \limits_{i = 1}^{n} (w_{i} d_{i} ) = \cup_{{\gamma_{i} \in h_{i} ,\eta_{i} \in g_{i} }} \left\{ {\left\{ {1 - \prod\limits_{i = 1}^{n} {(1 - \gamma_{i} )^{{w_{i} }} } } \right\},\left\{ {\prod\limits_{i = 1}^{n} {\eta_{i}^{{w_{i} }} } } \right\}} \right\}; $$(1) -
(2)
The dual hesitant fuzzy weighted geometric (DHFWG) operator is defined as:
$$ {\text{DHFWG}}_{w} (d_{1} ,d_{2} , \ldots ,d_{n} ) = \mathop \otimes \limits_{i = 1}^{n} (d_{i} )^{{w_{i} }} = \cup_{{\gamma_{i} \in h_{i} ,\eta_{i} \in g_{i} }} \left\{ {\left\{ {\prod\limits_{i = 1}^{n} {\gamma_{i}^{{w_{i} }} } } \right\},\left\{ {1 - \prod\limits_{i = 1}^{n} {(1 - \eta_{i} )^{{w_{i} }} } } \right\}} \right\}. $$(2)
Note that the aforementioned operational laws and the aggregation operators perform different operations on the membership and non-membership information of DHFEs. However, in most circumstances, we are neutral and the membership and non-membership information should be treated in a fair manner [44]. Therefore, it needs to develop some new operations and aggregation operators for DHFEs.
Definition 5
Let d i = (h i , g i ), i = 1, 2 be two DHFEs and λ ≥ 0, then
-
(i)
\( d_{1} { + }d_{2} = \cup_{{\gamma_{1} \in h_{1} ,\eta_{1} \in g_{1} ,\gamma_{2} \in h_{2} ,\eta_{2} \in g_{2} }} \left\{ {\left\{ {\frac{{\gamma_{1} \gamma_{2} }}{{\gamma_{1} \gamma_{2} { + (}1 - \gamma_{1} ) (1 - \gamma_{2} )}}} \right\},\left\{ {\frac{{\eta_{1} \eta_{2} }}{{\eta_{1} \eta_{2} { + }\left( {1 - \eta_{1} } \right)\left( {1 - \eta_{2} } \right)}}} \right\}} \right\}; \)
-
(ii)
\( \lambda \otimes d_{1} = \cup_{{\gamma_{1} \in h_{1} ,\eta_{1} \in g_{1} }} \left\{ {\left\{ {\frac{{\gamma_{1}^{\lambda } }}{{\gamma_{1}^{\lambda } + (1 - \gamma_{1} )^{\lambda } }}} \right\},\left\{ {\frac{{\eta_{1}^{\lambda } }}{{\eta_{1}^{\lambda } + (1 - \eta_{1} )^{\lambda } }}} \right\}} \right\}. \)
Theorem 1
Let d 1 and d 2 be two DHFEs and λ ≥ 0, then d 1 + d 2 and λ ⊗ d 1 are also DHFEs.
Proof
Similar proof of Theorem 1 can be found in Ref. [44].
Based on the operational laws in Definition 5, the symmetric dual hesitant fuzzy weighted averaging operator is defined below:
Definition 6
Let d = (d 1, d 2, …, d n ) be a collection of DHFEs, then a symmetric dual hesitant fuzzy weighted averaging (SDHFWA) operator is defined as:
where w = (w 1, w 2, …, w n )T is the weight vector of d = (d 1, d 2, …, d n ), with w i ∊ [0, 1], i = 1, 2, …, n and \( \sum\nolimits_{i = 1}^{n} {w_{i} } = 1 \). In particular, if w = (1/n, 1/n, …, 1/n)T, then the symmetric dual hesitant fuzzy averaging (SDHFA) operator is achieved:
Clearly, the SDHFWA operator generalizes the well-known weighted averaging (WA) operator [45], which first weights all the given dual hesitant fuzzy arguments and then aggregates all the weighted dual hesitant fuzzy arguments into a collective one. The SDHFA operator is a special case of the SDHFWA operator, which assigns each dual hesitant fuzzy argument the same importance in the aggregation of dual hesitant fuzzy information. Moreover, suppose that d i = (h i , g i ), i = 1, 2, …, n, then it can be easily proven that:
Theorem 2
Assume that d = (d 1 , d 2 , …, d n ) is a collection of DHFEs with d i = (h i , g i ), i = 1, 2, …, n, and w = (w 1 , w 2 , …, w n ) T is the weight vector of them, with w i ∊ [0, 1], i = 1, 2, …, n and \( \sum\nolimits_{i = 1}^{n} {w_{i} } = 1 \), then
where \( \underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{ \prec } = \; \prec \cup \,\; \sim \).
Proof
From the lemma that \( \prod\nolimits_{i = 1}^{n} {x_{i}^{{\lambda_{i} }} } \le \sum\nolimits_{i = 1}^{n} {\lambda_{i} x_{i} } \) with equality if and only if x 1 = x 2 = ··· = x n , where x i > 0, λ i > 0 for i = 1, 2, …, n, and \( \sum\nolimits_{i = 1}^{n} {\lambda_{i} } = 1 \) [46], it can be derived that
where γ i ∊ h i , η i ∊ g i for i = 1, 2, …, n. Then it can be easily proven that
Furthermore, it can be derived that
Then by Definition 3, it can be concluded that \( {\text{DHFWG}}_{w} (d_{1} ,d_{2} , \ldots ,d_{n} )\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{ \prec } {\text{SDHFWA}}_{w} (d_{1} ,d_{2} , \ldots ,d_{n} )\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{ \prec } {\text{DHFWA}}_{w} (d_{1} ,d_{2} , \ldots ,d_{n} ). \)
Theorem 2 demonstrates that the developed SDHFWA operator can generate more neutral aggregation results.
Example 2 [23]
There is a panel with five emerging technology enterprises A 1, A 2, …, A 5. The experts select four attributes to evaluate the five enterprises: (1) G 1 is the technical advancement; (2) G 2 is the potential market and market risk; (3) G 3 is the industrialization infrastructure, human resources and financial conditions; (4) G 4 is the employment creation and the development of science and technology. In order to avoid affecting each other, the experts are required to evaluate the five possible emerging technology enterprises under the above four attributes in anonymity. The decision matrix D = (d ij )5×4 is presented in Table 1, where d ij (i = 1, 2, …, 5; j = 1, 2, …, 4) is a DHFE, and the weight vector of attributes is w = (0.2, 0.15, 0.35, 0.3)T. To get the ranking orders of the five technology enterprises, the DHFWA, DHFWG [23] and SDHFWA operators (Eqs. 1–3) are here adopted to aggregate the attribute values of each enterprise, respectively. Table 2 shows the score values of the obtained aggregation results and ranking orders of five enterprises.
From Table 2, it can be seen that the ranking of the five emerging technology enterprises derived by the SDHFWA operator is identical to that obtained by the DHFWA operator, and slightly differs from that obtained by the DHFWG operator, but the values obtained by the SDHFWA operator are smaller than those obtained by the DHFWA operator, and are bigger than those obtained by the DHFWG operator, which indicates that the proposed SDHFWA operator can generate more neutral results.
Compatibility Measures of DHFPRs
The purpose of this subsection is to introduce the concept of DHFPRs and develop the compatibility measures between DHFPRs. First of all, DHFPRs are defined as follows:
Definition 7
Let A = {a 1, a 2, …, a m } be a fixed set, a DHFPR R on A is presented by a matrix \( R = (d_{ij} )_{m \times m} \subset {\text{A}} \times {\text{A}} \), where for all i, j = 1, 2, …, m, d ij = (h ij , g ij ) is a DHFE with h ij indicating all the possible degrees to which a i is preferred to a j and g ij representing all the possible degrees to which a i is non-preferred to a j . In addition, d ij should satisfy the following characteristics:
-
(i)
For all i = 1, 2, …, m, h ii = {0.5}, g ii = {0.5};
-
(ii)
For all i, j = 1, 2, …, m, i ≠ j,
-
(1)
if h ij ≠ ϕ and g ij ≠ ϕ, then h ji = g ij and g ji = h ij ;
-
(2)
if h ij ≠ ϕ and g ij = ϕ, then \( \gamma_{ij}^{\sigma (t)} + \gamma_{ji}^{{\sigma (\# h_{ji} - t + 1)}} = 1,\;\# h_{ji} = \# h_{ij} ,g_{ji} = \phi, \) where \( \gamma_{ij}^{\sigma (t)} \) is the tth smallest element in h ij and \( \gamma_{ji}^{{\sigma (\# h_{ji} - t + 1)}} \) is the \( \# h_{ji} - t + 1{\text{th}} \) smallest element in h ji ;
-
(3)
if h ij = ϕ and g ij ≠ ϕ, then \( h_{ji} = \phi ,\;\eta_{ij}^{\sigma (t)} + \eta_{ji}^{{\sigma (\# g_{ji} - t + 1)}} = 1,\;\# g_{ji} = \# g_{ij} ,\) where \( \eta_{ij}^{\sigma (t)} \) is the tth smallest element in g ij and \( \eta_{ji}^{{\sigma (\# g_{ji} - t + 1)}} \) is the \( \# g_{ji} - t + 1{\text{th}} \) smallest element in g ji .
-
(1)
From Definition 7, it can be easily seen that DHFPRs can capture more cognitive information than other types of preference relations [10–14] since they can simultaneously describe the possible degrees that one alternative is preferred to another and the possible degrees that the alternative is non-preferred to another.
In what follows, an example derived from a real decision making problem (adapted from Ref. [14]) is provided to illustrate the construction of DHFPRs:
Example 3
Consider a problem of selecting a loading–hauling system for a hypothetical iron ore open pit mine. Three potential transportation system alternatives are evaluated:
-
x 1: shovel–truck system;
-
x 2: shovel–truck-in-pit crusher-belt conveyor system;
-
x 3: loader truck system.
In order to obtain more objective results, a decision organization containing several experts is asked to provide their preferences over these three systems. The experts in the decision organization make paired comparisons of these three systems and give their preference values. For example, when discussing the degree to which x 1 is superior to x 2, some experts deem it as 0.1, some deem it as 0.3, and the others deem it as 0.4, and these three parts cannot persuade each other, which indicates that the possible values for the degree that x 1 is superior to x 2 are 0.1, 0.3 and 0.4. On the other hand, when discussing the degree to which x 1 is inferior to x 2, some consider it as 0.5, and the rest consider it as 0.6, which states that the possible values for the degree that x 1 is inferior to x 2 are 0.5 and 0.6. Tables 3 and 4 present the preferences over the three systems provided by the decision organization.
At this time, DHFEs can be used to collect the preferences over the three systems of the decision organization. For example, the preferences over the systems x 1 and x 2 can be represented by a DHFE {{0.1, 0.3, 0.4}, {0.5, 0.6}}. Then according to Tables 3 and 4, the following DHFPR is constructed:
For the above-mentioned decision making problem, the existing indirect approaches can be also chosen to deal with the preferences of the decision organization. Here the arithmetic averaging operator can be adopted to aggregate the preferences over each pair of systems, and in this case, the derived average value of the preferences can be seen as the average preference of the decision organization over these two systems. For instance, for the systems x 1 and x 3, (0.2 + 0.3)/2 = 0.25 can be seen as the average degree that x 1 is superior to x 3, and (0.6 + 0.7)/2 = 0.65 can be seen as the average degree that x 1 is inferior to x 3; thus, the preferences over the systems x 1 and x 3 can be represented by the IFV (0.25, 0.65). Following this idea, based on Tables 3 and 4, the following matrix is constructed, which is an IFPR [12].
Moreover, Tables 3 and 4 can be transformed into Tables 5 and 6, respectively [14].
Then by Tables 5 and 6, the following matrix is constructed, which is an IVIFPR [12].
From the above results, it can be clearly seen that the constructed IFPR and IVIFPR contain little original preference information of the decision organization, while the constructed DHFPR involves all original preference information. Our method employs DHFEs to directly collect the preferences of the decision organization over each pair of systems and excludes the aggregation or transformation step on the preferences, which avoids the possible loss of information in the aggregation or transformation process. It can be also observed that DHFPRs are both helpful and effective in the practical GDM process because they can objectively model the hesitant situation in which a decision organization has several possible values when establishing the preference and non-preference degrees of one alternative over another.
Theorem 3
Let R = (R (1), R (2), …, R (n)) be a collection of DHFPRs with \( R^{(k)} = (d_{ij}^{(k)} )_{m \times m} \), k = 1, 2, …, n, where for i, j = 1, 2, …, m, \( d_{ij}^{(k)} = (h_{ij}^{(k)} ,g_{ij}^{(k)} ) \) and λ = (λ 1, λ 2, …, λ n )T be the weight vector of R = (R (1), R (2), …, R (n)), where λ k ≥ 0, k = 1, 2, …, n and \( \sum\nolimits_{k = 1}^{n} {\lambda_{k} } = 1 \) , then by the SDHFWA operator (Eq. 3 ), the aggregation result is also a DHFPR, denoted by R′ = (d ij ) m×m , and for all i, j = 1, 2, …, m,
Proof
The results can be derived from an easy calculation.
Compatibility is a very useful tool to measure the consensus of viewpoints within a group. Below the compatibility between DHFPRs is investigated:
Definition 8
Let \( R^{(k)} = (d_{ij}^{(k)} )_{m \times m} \) and \( R^{(l)} = (d_{ij}^{(l)} )_{m \times m} \) be two DHFPRs. Suppose that for i, j = 1, 2, …, m, \( d_{ij}^{(k)} = (h_{ij}^{(k)} ,g_{ij}^{(k)} ) \) and \( d_{ij}^{(l)} = (h_{ij}^{(l)} ,g_{ij}^{(l)} ) \), the compatibility degree between R (k) and R (l) is defined as:
where for a = k, l, \( \overline{{\pi_{ij}^{(a)} }} = 1 - \sum\nolimits_{t = 1}^{{\# h_{ij}^{(a)} }} {(h_{ij\sigma (t)}^{(a)} )} /\# h_{ij}^{(a)} - \sum\nolimits_{s = 1}^{{\# g_{ij}^{(a)} }} {(g_{ij\sigma (s)}^{(a)} )} /\# g_{ij}^{(a)}, \) \( h_{ij\sigma (t)}^{(a)} \) is the tth smallest element in \( h_{ij}^{(a)} \), \(g_{ij\sigma (s)}^{(a)}\) is the sth smallest element in \( g_{ij}^{(a)} \),\( \;\# h_{ij} = {\text{max\{ }}\# h_{ij}^{(k)} ,\# h_{ij}^{(l)} {\text{\} }} \) and \( \# g_{ij} = {\text{max\{ }}\# g_{ij}^{(k)} ,\# g_{ij}^{(l)} {\text{\} }} \) (\( \# h_{ij}^{(a)} \) and \( \# g_{ij}^{(a)} \) are the numbers of elements in \( h_{ij}^{(a)} \) and \( g_{ij}^{(a)} \), respectively).
Remark
From Eq. (2), a compatibility formula of IFPRs can be derived when the considered DHFPRs \( R^{(k)} = [(h_{ij}^{(k)} ,g_{ij}^{(k)} )]_{m \times m} \) and \( R^{(l)} = [(h_{ij}^{(l)} ,g_{ij}^{(l)} )]_{m \times m} \) are simplified to the IFPRs, i.e., for all i, j = 1, 2, …, m, \( \# h_{ij}^{(k)} = \;\# g_{ij}^{(k)} = 1 \), and \( \;\# h_{ij}^{(l)} = \;\# g_{ij}^{(l)} = 1 \). At this time, the derived compatibility formula of IFPRs is different from that developed by Xu [12]. In the definition of compatibility formula, Xu [12] used the max operation (for more details, please see Ref. [12]), while we here adopt the square root operation. Obviously, the results derived from Xu’s formula [12] are easily affected by the arguments with too high or too low values, while our formula can reduce the impact of these arguments by the square root operation.
Theorem 4
The compatibility degree derived from Eq. ( 2 ) satisfies the following properties:
-
(i)
0 ≤ c 1(R (k), R (l)) ≤ 1;
-
(ii)
\( c_{1} (R^{(k)} ,R^{(l)} ) = 1 \Leftrightarrow R^{(k)} = R^{(l)} ; \)
-
(iii)
c 1(R (k), R (l)) = c 1(R (l), R (k));
-
(iv)
If c 1(R (k), R (l)) = 1 and c 1(R (l), R (z)) = 1, then c 1(R (k), R (z)) = 1;
-
(v)
Especially, if for all i, j = 1, 2, …, m, \( \# h_{ij}^{(k)} = \# h_{ij}^{(l)} \) and \( \# g_{ij}^{(k)} = \# g_{ij}^{(l)} \), then \( c_{1} (R^{(k)} ,R^{(l)} ) = c_{1} ((R^{(k)} )^{\text{T}} ,(R^{(l)} )^{\text{T}} ) \), where \( (R^{(a)} )^{\text{T}} \) is the transposition of R (a)(a = k, l).
Proof
According to the well-known Cauchy–Schwarz inequality, (i) and (ii) can be easily proven. Furthermore, the other three properties can be derived from a simple deduction.
Clearly, R (k) and R (l) are perfectly compatible if and only if R (k) = R (l), i.e., c 1(R (k), R (l)) = 1. On the contrary, R (k) and R (l) have the worst compatibility if c 1(R (k), R (l)) = 0. As a result, the larger the value of c 1(R (k), R (l)), the better the compatibility between R (k) and R (l).
In the following, a different formula is designed to compute the compatibility degree between DHFPRs.
Definition 9
Let \( R^{(k)} = (d_{ij}^{(k)} )_{m \times m} \) and \( R^{(l)} = (d_{ij}^{(l)} )_{m \times m} \) be two DHFPRs. Suppose that for i, j = 1, 2, …, m, \( d_{ij}^{(k)} = (h_{ij}^{(k)} ,g_{ij}^{(k)} ) \), \( d_{ij}^{(l)} = (h_{ij}^{(l)} ,g_{ij}^{(l)} ) \), and for a = k, l, \( h_{ij\sigma (t)}^{(a)} \) is the tth smallest element in \( h_{ij}^{(a)} \), \( g_{ij\sigma (s)}^{(a)} \) is the sth smallest element in g (a) ij , \( \# h_{ij} = {\text{max\{ }}\# h_{ij}^{(k)} ,\# h_{ij}^{(l)} {\text{\} }} \) and \( \# g_{ij} = {\text{max\{ }}\# g_{ij}^{(k)} ,\# g_{ij}^{(l)} {\text{\} }} \) (\( \# h_{ij}^{(a)} \) and \( \# g_{ij}^{(a)} \) are the numbers of elements in \( h_{ij}^{(a)} \) and \( g_{ij}^{(a)} \), respectively), then the compatibility degree between R (k) and R (l) is defined as:
where \( \Delta h_{ij\sigma (t)} = |h_{ij\sigma (t)}^{(k)} - h_{ij\sigma (t)}^{(l)} | \) for t = 1, 2, …, #h ij , \( \Delta h_{\hbox{max} }^{ij} = \max_{t} \{ \Delta h_{ij\sigma (t)} \} \), \( \Delta h_{\hbox{min} }^{ij} = \min_{t} \{ \Delta h_{ij\sigma (t)} \} \), \( \Delta g_{ij\sigma (s)} = |g_{ij\sigma (s)}^{(k)} - g_{ij\sigma (s)}^{(l)} | \) for s = 1, 2, …, #g ij , \( \Delta g_{\hbox{max} }^{ij} = \max_{s} \{ \Delta g_{ij\sigma (s)} \} \), and \( \Delta g_{\hbox{min} }^{ij} = \min_{s} \{ \Delta g_{ij\sigma (s)} \} \).
Theorem 5
The compatibility degree derived from Eq. ( 3 ) possesses the properties listed in Theorem 4.
Proof
The proof of Theorem 5 is easy.
Analyzing the proposed formulas, it can be found that Formula (2) involves three aspects of information of DHFEs, i.e., the membership degrees, the non-membership degrees and the average indeterminacy degree, while Formula (3) only considers the first two kinds of information. Furthermore, it can be easily observed that the results got by Formula (2) tend to be influenced by single arguments, especially those with too high or too low values, while Formula (3) is capable of alleviating the influence of these arguments by means of dealing with the considered arguments as a whole.
Let A = {a 1, a 2, …, a m } be a set of alternatives, and \( R^{(k)} = (d_{ij}^{(k)} )_{m \times m} \) be a DHFPR on the set A, where for i, j = 1, 2, …, m, \( d_{ij}^{(k)} = (h_{ij}^{(k)} ,g_{ij}^{(k)} ) \), then the ith row vector \( \{ (h_{ij}^{(k)} ,g_{ij}^{(k)} )|j = 1,2, \ldots ,m\} \) of R (k), denoted by \( V_{i}^{(k)} \), depicts the pairwise comparison preferences of the alternative a i over all alternatives in A. In the following, two different compatibility formulas are developed to calculate the compatibility degree between two row vectors of DHFPRs:
Definition 10
Let \( V_{i}^{(k)} = \{ (h_{i1}^{(k)} ,g_{i1}^{(k)} ),(h_{i2}^{(k)} ,g_{i2}^{(k)} ), \ldots ,(h_{im}^{(k)} ,g_{im}^{(k)} )\} \) and \( V_{i}^{(l)} = \{ (h_{i1}^{(l)} ,g_{i1}^{(l)} ),(h_{i2}^{(l)} ,g_{i2}^{(l)} ), \ldots ,(h_{im}^{(l)} ,g_{im}^{(l)} )\} \) be the ith row vectors of the DHFPRs \( R^{(k)} = (d_{ij}^{(k)} )_{m \times m} \) and \( R^{(l)} = (d_{ij}^{(l)} )_{m \times m} \), respectively. Suppose that for a = k, l; j = 1, 2, …, m, \( h_{ij\sigma (t)}^{(a)} \) is the tth smallest element in \( h_{ij}^{(a)} \), \( g_{ij\sigma (s)}^{(a)} \) is the sth smallest element in \( g_{ij}^{(a)} \), \( \# h_{ij} = {\text{max\{ }}\# h_{ij}^{(k)} ,\# h_{ij}^{(l)} {\text{\} }} \) and \( \# g_{ij} = {\text{max\{ }}\# g_{ij}^{(k)} ,\# g_{ij}^{(l)} {\text{\} }} \) (\( \# h_{ij}^{(a)} \) and \( \# g_{ij}^{(a)} \) are the numbers of elements in \( h_{ij}^{(a)} \) and \( g_{ij}^{(a)} \), respectively), then the compatibility degree between \( V_{i}^{(k)} \) and \( V_{i}^{(l)} \) is defined as:
or
where \( \Delta h_{ij\sigma (t)} = |h_{ij\sigma (t)}^{(k)} - h_{ij\sigma (t)}^{(l)} | \) for \( t = 1,2, \ldots ,\# h_{ij} \), \( \Delta h_{\hbox{max} }^{ij} = \max_{t} \{ \Delta h_{ij\sigma (t)} \} \), \( \Delta h_{\hbox{min} }^{ij} = \min_{t} \{ \Delta h_{ij\sigma (t)} \} \), \( \Delta g_{ij\sigma (s)} = |g_{ij\sigma (s)}^{(k)} - g_{ij\sigma (s)}^{(l)} | \) for \( s = 1,2, \ldots ,\# g_{ij} \), \( \Delta g_{\hbox{max} }^{ij} = \max_{s} \{ \Delta g_{ij\sigma (s)} \} \) and \( \Delta g_{\hbox{min} }^{ij} = \min_{s} \{ \Delta g_{ij\sigma (s)} \} \).
Clearly, the larger the value of \( c_{r} (V_{i}^{(k)} ,V_{i}^{(l)} )(r = 1,2) \), the better the compatibility between \( V_{i}^{(k)} \) and \( V_{i}^{(l)} \). Furthermore, the compatibility degree \( c_{r} (V_{i}^{(k)} ,V_{i}^{(l)} ) \) derived from Eq. (7) or (8) possesses the following properties:
-
(i)
\( 0 \le c_{r} (V_{i}^{(k)} ,V_{i}^{(l)} ) \le 1; \)
-
(ii)
\( c_{r} (V_{i}^{(k)} ,V_{i}^{(l)} ) = 1 \Leftrightarrow V_{i}^{(k)} = V_{i}^{(l)}; \)
-
(iii)
\( c_{r} (V_{i}^{(k)} ,V_{i}^{(l)} ) = c_{r} (V_{i}^{(l)} ,V_{i}^{(k)} ); \)
-
(iv)
If \( c_{r} (V_{i}^{(k)} ,V_{i}^{(l)} ) = 1 \) and \( c_{r} (V_{i}^{(l)} ,V_{i}^{(z)} ) = 1 \), then \( c_{r} (V_{i}^{(k)} ,V_{i}^{(z)} ) = 1 \).
Two Methods for GDM with DHFPRs
To date, although there have been many methods designed to solve the GDM problems with various types of preference relations [11–14, 47], no methods have been proposed to deal with the GDM problems with DHFPRs. Below we intend to investigate the GDM problems with DHFPRs and develop some solving methods.
The GDM problem considered in this section can be described as follows: Let A = {a 1, a 2, …, a m } be a set of alternatives and O = {o 1, o 2, …, o n } be a set of decision organizations. Suppose that for any two alternatives a i and a j (i ≠ j, i, j = 1, 2, …, m), each decision organization o k , which has several experts, offers some values to describe the degrees that a i is superior to a j , and several values to depict the degrees to which a i is inferior to a j . Then in this case, the preference information for the two alternatives provided by o k can be viewed as a DHFE \( d_{ij}^{(k)} \) and all \( d_{ij}^{(k)} \), i, j = 1, 2, …, m can constitute a DHFPR \( R^{(k)} = (d_{ij}^{(k)} )_{m \times m} \).
In the process of GDM with DHFPRs, it is necessary to integrate the individual DHFPRs into a collective one. At this time, the relative importance weights of decision organizations need to be taken into account and incorporated into each individual DHFPR, which have a great influence on the aggregation result. However, in many practical situations, the information about the importance weights of decision organizations is usually unknown or is very difficult to obtain. Therefore, how to assign reasonable weights to the decision organizations in light of their DHFPRs is an issue that needs to be solved first. During the decision making process, it is usually expected that the differences or contradictions among the preference relations provided by the decision makers are as few as possible [37]. Note that c r (R (k), R (l))(r = 1, 2) measures the compatibility degree between R (k) and R (l), and the larger the value of c r (R (k), R (l))(r = 1, 2), the better the compatibility between R (k) and R (l). Thus, the larger the average compatibility degree between R (k) and the others, the more reliable the information provided by the decision organization o k . At this time, a larger weight should be assigned to this decision organization.
Since compatibility is a very valid tool to measure the agreement of opinions, the developed compatibility measures can be used to analyze the group’s consensus level during the process of GDM. Based on the above analysis, the following GDM method is proposed.
Method 1
-
Step 1 If the importance weights of decision organizations are completely unknown, then the weight λ k of the decision organization o k is determined by the following equation:
$$ \lambda_{k} = \frac{{c(R^{(k)} )}}{{\sum\nolimits_{l = 1}^{n} {c(R^{(l)} )} }},\quad k = 1,2, \ldots ,n. $$(9)Here,
$$ c(R^{(k)} ) = \frac{1}{n - 1}\sum\limits_{l = 1,l \ne k}^{n} {c(R^{(k)} ,R^{(l)} )} ,\quad k = 1,2, \ldots ,n, $$where c(R (k), R (l)) is the compatibility degree between R (k) and R (l) calculated by Eq. (2) or (3).
-
Step 2 For all k = 1, 2, …, n, let \( R_{I}^{(k)} = (d_{ijI}^{(k)} )_{m \times m} = R^{(k)} \), where for all i, j = 1, 2, …, m, \( d_{ijI}^{(k)} = (h_{ijI}^{(k)} ,g_{ijI}^{(k)} ) \) and I = 0. Suppose that the desirable consensus level is δ*.
-
Step 3 Use Eq. (1) to aggregate all individual DHFPRs \( R_{I}^{(k)} \), k = 1, 2, …, n into the collective DHFPR R I = (d ijI ) m×m , where
$$ d_{ijI} = \cup_{{\gamma_{ijI}^{(k)} \in h_{ijI}^{(k)} ,\eta_{ijI}^{(k)} \in g_{ijI}^{(k)} }} \left\{ {\left\{ {\frac{{\prod\nolimits_{k = 1}^{n} {(\gamma_{ijI}^{(k)} )^{{\lambda_{k} }} } }}{{\prod\nolimits_{k = 1}^{n} {(\gamma_{ijI}^{(k)} )^{{\lambda_{k} }} } + \prod\nolimits_{k = 1}^{n} {(1 - \gamma_{ijI}^{(k)} )^{{\lambda_{k} }} } }}} \right\},\left\{ {\frac{{\prod\nolimits_{k = 1}^{n} {(\eta_{ijI}^{(k)} )^{{\lambda_{k} }} } }}{{\prod\nolimits_{k = 1}^{n} {(\eta_{ijI}^{(k)} )^{{\lambda_{k} }} } + \prod\nolimits_{k = 1}^{n} {(1 - \eta_{ijI}^{(k)} )^{{\lambda_{k} }} } }}} \right\}} \right\},\quad i,j = 1,2, \ldots ,m. $$(10) -
Step 4 Compute the compatibility degree \( c(R_{I}^{(k)} ,R_{I} ) \) between the individual DHFPR \( R_{I}^{(k)} \) (k = 1, 2, …, n) and the collective DHFPR R I by Eq. (2) or (3).
-
Step 5 If for all k = 1, 2, …, n, \( c(R_{I}^{(k)} ,R_{I} ) \ge \delta^{*} \), then go to Step 7; otherwise, there must exist at least one k 0 such that \( c(R_{I}^{{(k_{0} )}} ,R_{I} ) < \delta^{*} \); then, at this time go to the next step.
-
Step 6 Let \( R_{I + 1}^{{(k_{0} )}} = (d_{ijI + 1}^{{(k_{0} )}} )_{m \times m} \), where for all i, j = 1, 2, …, m, \( d_{ijI + 1}^{{(k_{0} )}} = (h_{ijI + 1}^{{(k_{0} )}} ,g_{ijI + 1}^{{(k_{0} )}} ) \) and
$$ h_{ijI + 1\sigma (t)}^{{(k_{0} )}} = \frac{{(h_{ijI\sigma (t)}^{{(k_{0} )}} )^{1 - b} (\overline{{h_{ijI} }} )^{b} }}{{(h_{ijI\sigma (t)}^{{(k_{0} )}} )^{1 - b} (\overline{{h_{ijI} }} )^{b} + (1 - h_{ijI\sigma (t)}^{{(k_{0} )}} )^{1 - b} (1 - \overline{{h_{ijI} }} )^{b} }},\quad i,j = 1,2, \ldots ,m, $$(11)$$ g_{ijI + 1\sigma (s)}^{{(k_{0} )}} = \frac{{(g_{ijI\sigma (s)}^{{(k_{0} )}} )^{1 - b} (\overline{{g_{ijI} }} )^{b} }}{{(g_{ijI\sigma (s)}^{{(k_{0} )}} )^{1 - b} (\overline{{g_{ijI} }} )^{b} + (1 - g_{ijI\sigma (s)}^{{(k_{0} )}} )^{1 - b} (1 - \overline{{g_{ijI} }} )^{b} }},\quad i,j = 1,2, \ldots ,m, $$(12)where b(0 ≤ b ≤ 1) is an adjustment parameter determined by the decision maker, representing the decision maker’s preference to some degree, \( h_{ijI + 1\sigma (t)}^{{(k_{0} )}} \) and \( h_{ijI\sigma (t)}^{{(k_{0} )}} \) are the tth smallest values in \( h_{ijI + 1}^{{(k_{0} )}} \) and \( h_{ijI}^{{(k_{0} )}} \), respectively,\( g_{ijI + 1\sigma (s)}^{{(k_{0} )}} \) and \( g_{ijI\sigma (s)}^{{(k_{0} )}} \) are the sth smallest values in \( g_{ijI + 1}^{{(k_{0} )}} \) and \( g_{ijI}^{{(k_{0} )}} \), respectively, \( \overline{{h_{ijI} }} = \frac{1}{{\# h_{ijI} }}\sum\nolimits_{{\gamma_{ijI} \in h_{ijI} }} {\gamma_{ijI} } \) and \( \overline{{g_{ijI} }} = \frac{1}{{\# g_{ijI} }}\sum\nolimits_{{\eta_{ijI} \in g_{ijI} }} {\eta_{ijI} } \), in which d ijI = (h ijI , g ijI ), i, j = 1, 2, …, m are the DHFEs in the collective DHFPR R I = (d ijI ) m×m in the Ith iteration. Let I = I + 1, and return to Step 3.
-
Step 7 Let R = (d ij ) m×m = R I , then for the alternative a i (i = 1, 2, …, m), employ the SDHFA operator to fuse all the corresponding dual hesitant fuzzy preference values d ij = (h ij , g ij ), j = 1, 2, …, m into the collective dual hesitant fuzzy preference value d i , where
$$ d_{i} = \cup_{{\gamma_{ij} \in h_{{_{ij} }} ,\eta_{ij} \in g_{ij} }} \left\{ {\left\{ {\frac{{\prod\nolimits_{j = 1}^{m} {(\gamma_{ij} )^{1/m} } }}{{\prod\nolimits_{j = 1}^{m} {(\gamma_{ij} )^{1/m} } + \prod\nolimits_{j = 1}^{m} {(1 - \gamma_{ij} )^{1/m} } }}} \right\},\left\{ {\frac{{\prod\nolimits_{j = 1}^{m} {(\eta_{ij} )^{1/m} } }}{{\prod\nolimits_{j = 1}^{m} {(\eta_{ij} )^{1/m} } + \prod\nolimits_{j = 1}^{m} {(1 - \eta_{ij} )^{1/m} } }}} \right\}} \right\}. $$(13) -
Step 8 Compare d i , i = 1, 2, …, m according to Definitions 3 and 4, and then get the priority of the alternative a i according to the ranking of d i (i = 1, 2, …, m).
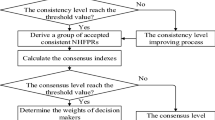
The above GDM process can be depicted by the flowchart shown in Fig. 1.

Overall GDM process by Method 1
In the above-mentioned method, Steps 2–6 constitute a consensus improving procedure which requires the experts to converge to a uniform opinion by adjusting their preference values. However, in real life, there exist some situations where the experts do not expect their opinions to be modified or they do not have to agree in order to reach a consensus. For example, in the process of judging figure skating, there are no expectations that all experts finally reach an agreement. Oppositely, it is expected that the experts could generate various opinions and the usual procedure is to rule out the high and low extreme opinions and average the remainder [48]. In what follows, another method for GDM with DHFPRs is designed in which the group’s consensus level is improved without altering the opinions of the experts, but by modifying their weights and the alternatives are ranked based upon the rationale of TOPSIS [49]. Before doing so, the following definition is first introduced:
Definition 11
Let \( V_{i}^{(k)} \) and V i be the ith row vectors of the individual DHFPR R (k) and the collective DHFPR R, respectively, then the consensus level of the alternative a i is defined as:
and the group consensus level is defined as:
where λ = (λ 1, λ 2, …, λ n )T is the weight vector of decision organizations with λ k ≥ 0, k = 1, 2, …, n and \( \sum\nolimits_{k = 1}^{n} {\lambda_{k} } = 1 \), and \( c(V_{i}^{(k)} ,V_{i} ) \) is the compatibility degree between \( V_{i}^{(k)} \) and V i computed by Eq. (7) or (8).
Method 2
-
Step 1 Suppose that λ = (λ 1, λ 2, …, λ n )T is the known weight vector of decision organizations, where λ k ≥ 0, k = 1, 2, …, n and \( \sum\nolimits_{k = 1}^{n} {\lambda_{k} } = 1 \).
-
Step 2 For all k = 1, 2, …, n, let \( R_{I}^{(k)} = (d_{ijI}^{(k)} )_{m \times m} = R^{(k)} \), where for i, j = 1, 2, …, m, \( d_{ijI}^{(k)} = (h_{ijI}^{(k)} ,g_{ijI}^{(k)} ) \), λ kI = λ k and I = 0. Suppose that the desirable consensus level is δ*.
-
Step 3 Use Eq. (1) to aggregate all individual DHFPRs \( R_{I}^{(k)} \), k = 1, 2, …, n into the collective DHFPR R I = (d ijI ) m×m , where
$$ d_{ijI} = \cup_{{\gamma_{ijI}^{(k)} \in h_{ijI}^{(k)} ,\eta_{ijI}^{(k)} \in g_{ijI}^{(k)} }} \left\{ {\left\{ {\frac{{\prod\nolimits_{k = 1}^{n} {(\gamma_{ijI}^{(k)} )^{{\lambda_{kI} }} } }}{{\prod\nolimits_{k = 1}^{n} {(\gamma_{ijI}^{(k)} )^{{\lambda_{kI} }} } + \prod\nolimits_{k = 1}^{n} {(1 - \gamma_{ijI}^{(k)} )^{{\lambda_{kI} }} } }}} \right\},\left\{ {\frac{{\prod\nolimits_{k = 1}^{n} {(\eta_{ijI}^{(k)} )^{{\lambda_{kI} }} } }}{{\prod\nolimits_{k = 1}^{n} {(\eta_{ijI}^{(k)} )^{{\lambda_{kI} }} } + \prod\nolimits_{k = 1}^{n} {(1 - \eta_{ijI}^{(k)} )^{{\lambda_{kI} }} } }}} \right\}} \right\},\;i,j = 1,2, \ldots ,m. $$(16) -
Step 4 For k = 1, 2, …, n; i = 1, 2, …, m, Eq. (7) or (8) is used to compute the compatibility degree \( c(V_{iI}^{(k)} ,V_{iI} ) \) between the ith row vectors of \( R_{I}^{(k)} \) and R I , and then calculate the consensus level \( C_{i}^{I} \) of the alternative a i by Eq. (14) and the group consensus level C I by Eq. (15).
-
Step 5 If C I ≥ δ*, then the group members reach an acceptable consensus, and go to Step 8; otherwise, go to the next step.
-
Step 6 Measure the contribution of the decision organization o l . Firstly, the consensus level \( C_{{i\overline{l} }}^{I} \) of the alternative a i excluding the decision organization o l is computed by
$$ C_{{i\overline{l} }}^{I} = \sum\limits_{k = 1,k \ne l}^{n} {\lambda_{kI}^{'} c(V_{iI}^{(k)} ,V_{iI}^{'} )} , $$(17)where \( \lambda_{kI}^{'} = \lambda_{kI} /\sum\nolimits_{t = 1,t \ne l}^{n} {\lambda_{tI} } \), and \( V_{iI}^{'} \) is the ith row vector of the new collective DHFPR \( R_{I}^{'} \) derived by Eq. (16) after excluding the decision organization o l . Then the contribution \( D_{il}^{I} \) of the decision organization o l to the alternative a i is computed by
$$ D_{il}^{I} = C_{i}^{I} - C_{{i\overline{l} }}^{I} , $$(18)where \( D_{il}^{I} \) indicates the difference between the consensus levels of the alternative a i including and excluding the decision organization o l . Finally, the contribution measure \( D_{l}^{I} \) of the decision organization o l is achieved by
$$ D_{l}^{I} = \sum\limits_{i = 1}^{m} {D_{il}^{I} } . $$(19)Obviously, the smaller the \( D_{l}^{I} \) is, the less contribution that the decision organization o l makes toward the group decision. On the contrary, the larger \( D_{l}^{I} \) is, the more contribution that the decision organization o l does to the group decision.
-
Step 7 Update the weights of decision organizations. When the group’s consensus level is lower than the desired value, which implies that there exists enough discrepancy among the decision organizations’ opinions, the weights of decision organizations should be modified by using the following equations:
$$ p_{k}^{I + 1} = \lambda_{kI} \left( {1 + \frac{{D_{k}^{I} }}{m}} \right)^{\partial } ,\quad k = 1,2, \ldots ,n, $$(20)$$ \lambda_{kI + 1} = \frac{{p_{k}^{I + 1} }}{{\sum\nolimits_{t = 1}^{n} {p_{t}^{I + 1} } }},\quad k = 1,2, \ldots ,n, $$(21)where λ kI is the weight of the decision organization o k in the Ith iteration. Parameter ∂ indicates the effect of the decision organization’s contribution on its weight. The larger the value of ∂, the faster the group reaches the desired consensus level. Let I = I + 1, go to Step 3.
-
Step 8 Rank the alternatives. Let R = R I . Suppose that a + and a − are the positive and negative ideal alternatives, respectively, then V + = {(1, 0), (1, 0), …, (1, 0)} and V − = {(0, 1), (0, 1), …, (0, 1)} can be used to describe the pairwise comparison preferences of a + and a − over all alternatives in A, respectively. According to the implications of compatibility, the optimal alternative should have the compatibility degree with a + as large as possible and have the compatibility degree with a − as small as possible. Thus, the alternative a i can be ranked by the following formula:
$$ V(a_{i} ) = \frac{{c(V_{i} ,V^{ + } )}}{{c(V_{i} ,V^{ + } ) + c(V_{i} ,V^{ - } )}}, $$(22)where V i is the ith row vector of R, c(V i , V +) is the compatibility degree between V i and V +, and c(V i , V −) is the compatibility degree between V i and V −, which are computed by Eq. (7) or (8). Notice that the larger the value of V(a i ), the better the alternative a i . Consequently, the ranking orders of alternatives can be achieved.
The above GDM process can be described by the flowchart shown in Fig. 2.

Overall GDM process by Method 2
From the solving steps of Methods 1 and 2, it can be easily observed that the consensus improving procedures involved in the two methods are markedly different. In Method 1, the consensus level of each decision organization is got by computing the compatibility degree between the individual DHFPR and the collective DHFPR by Eq. (2) or (3). If the consensus level is less than the desired consensus level, it is required to adjust the DHFPR according to the adjustment parameter provided by the decision maker. However, in Method 2, the consensus level of each alternative is first achieved by aggregating the compatibility degrees between the row vectors of the DHFPR and the collective DHFPR, which are computed by Eq. (7) or (8). Then, the consensus level of the group is computed by averaging the consensus levels of all alternatives. If the consensus level is less than the desired consensus level, it is needed to modify the weights of decision organizations according to their contributions to the group decision.
Illustrative Example
In this section, an example concerning the evaluation of causes of students’ disruptive behavior (adapted from Ref. [50]) is adopted to validate the practicality and effectiveness of the proposed methods in solving the GDM problems with DHFPRs.
Description of the Problem and the Analysis Process
One of the biggest problems presented today in the classroom is misbehavior. To find out the causes of this misbehavior and the influence these exert on it is of interest to teachers and, in general, to anyone involved in education (the Education Department, parents, students, etc.). Now three decision organizations o 1, o 2 and o 3 composed of teachers, parents and students, respectively, are asked to rate some given causes of disruptive behavior. Among these causes are
-
a 1: lack of interest in subject or general disinterest in school;
-
a 2: unsettled home environment;
-
a 3: pupil psychological or emotional instability;
-
a 4: lack of self-esteem;
-
a 5: dislike of teacher;
-
a 6: use of drugs.
The opinions about the six causes given by the three organizations are presented in Matrices U (1)–U (3), all of which are DHFPRs:
In order to solve the above-mentioned GDM problem with DHFPRs, the following steps are given based upon Method 1:
-
Step 1 By Eq. (2), the compatibility degrees c 1(U (k), U (l)) between U (k) and U (l) are computed, listed in the following matrix:
$$ C = (c_{kl} )_{3 \times 3} = \left( {\begin{array}{*{20}l} 1 \hfill & {0.9585} \hfill & {0.9403} \hfill \\ {0.9585} \hfill & 1 \hfill & {0.9324} \hfill \\ {0.9403} \hfill & {0.9324} \hfill & 1 \hfill \\ \end{array} } \right), $$where c kl = c 1(U (k), U (l)), for k, l = 1, 2, 3. Then by Eq. (9), the weights of decision organizations are determined:
$$ w_{1} = 0.3346,\quad w_{2} = 0.3338,\quad w_{3} = 0.3316. $$ -
Step 2 For all k = 1, 2, 3, let \( U_{0}^{(k)} = U^{(k)} \). Then by Eq. (10), all DHFPRs \( U_{0}^{(k)} \), k = 1, 2, 3 are fused into the collective DHFPR U 0. Suppose that U 0 = (d ij0)6×6, where for i, j = 1, 2, …, 6, d ij0 = (h ij0, g ij0). Due to the limited space, only some elements in U 0 are listed here:
$$ \begin{aligned} h_{120} & = \{ 0.1861,0.2635,0.2667,0.2871,0.3627,0.3679,0.3865,0.3903,0.4806,0.5005,0.5061,0.6197\} , \\ g_{120} & = \{ 0.1692,0.2129,0.215,0.2558,0.2667,0.3134,0.3161,0.3804\} . \\ \end{aligned} $$ -
Step 3 By Eq. (2), the compatibility degrees \( c_{1} (U_{0}^{(k)} ,U_{0} ) \) between \( U_{0}^{(k)} \), k = 1, 2, 3 and U 0 are calculated:
$$ c_{1} (U_{0}^{(1)} ,U_{0} ) = 0.933,\quad c_{1} (U_{0}^{(2)} ,U_{0} ) = 0.9321,\quad c_{1} (U_{0}^{(3)} ,U_{0} ) = 0.9135. $$ -
Step 4 Suppose that the desired consensus level is 0.93. Since \( c_{1} (U_{0}^{(3)} ,U_{0} ) < 0.93 \), then it is needed to repair the DHFPR U (3). By Eqs. (11) and (12) (where b = 0.5), the new DHFPR is constructed:
$$ \begin{aligned} U_{1}^{(3)} & = \left( {\begin{array}{*{20}l} {\{ \{ 0.5\} ,\{ 0.5\} \} } \hfill & {\{ \{ 0.2086,0.3411,0.5187\} ,\{ 0.1672,0.3065\} \} } \hfill & {\{ \{ 0.1836,0.3064\} ,\{ 0.3044,0.508\} \} } \hfill \\ {\{ \{ 0.1672,0.3065\} ,\{ 0.2086,0.3411,0.5187\} \} } \hfill & {\{ \{ 0.5\} ,\{ 0.5\} \} } \hfill & {\{ \{ 0.3865,0.4904,0.6581\} ,\{ 0.1587,0.1834\} \} } \hfill \\ {\{ \{ 0.3044,0.508\} ,\{ 0.1836,0.3064\} \} } \hfill & {\{ \{ 0.1587,0.1834\} ,\{ 0.3865,0.4904,0.6581\} \} } \hfill & {\{ \{ 0.5\} ,\{ 0.5\} \} } \hfill \\ {\{ \{ 0.0904,0.221\} ,\{ 0.3197,0.5352,0.5895\} \} } \hfill & {\{ \{ 0.192,0.4161,0.5877\} ,\{ 0.2249\} \} } \hfill & {\{ \{ 0.2986,0.3469\} ,\{ 0.2995,0.4609,0.5115\} \} } \hfill \\ {\{ \{ 0.4363,0.5133\} ,\{ 0.2053,0.311\} \} } \hfill & {\{ \{ 0.3146,0.462\} ,\{ 0.18,0.3013,0.3497\} \} } \hfill & {\{ \{ 0.1246,0.2888,0.4866\} ,\{ 0.3295\} \} } \hfill \\ {\{ \{ 0.1077,0.1533\} ,\{ 0.3891,0.5746,0.6881\} \} } \hfill & {\{ \{ 0.209,0.3417,0.5477\} ,\{ 0.1525,0.2611\} \} } \hfill & {\{ \{ 0.1549,0.3099\} ,\{ 0.2046,0.3865,0.4859\} \} } \hfill \\ \end{array} } \right. \\ & \quad \left. {\begin{array}{*{20}l} {\{ \{ 0.3197,0.5352,0.5895\} ,\{ 0.0904,0.221\} \} } \hfill & {\{ \{ 0.2053,0.311\} ,\{ 0.4363,0.5133\} \} } \hfill & {\{ \{ 0.3891,0.5746,0.6881\} ,\{ 0.1077,0.1533\} \} } \hfill \\ {\{ \{ 0.2249\} ,\{ 0.192,0.4161,0.5877\} \} } \hfill & {\{ \{ 0.18,0.3013,0.3497\} ,\{ 0.3146,0.462\} \} } \hfill & {\{ \{ 0.1525,0.2611\} ,\{ 0.209,0.3417,0.5477\} \} } \hfill \\ {\{ \{ 0.2995,0.4609,0.5115\} ,\{ 0.2986,0.3469\} \} } \hfill & {\{ \{ 0.3295\} ,\{ 0.1246,0.2888,0.4866\} \} } \hfill & {\{ \{ 0.2046,0.3865,0.4859\} ,\{ 0.1549,0.3099\} \} } \hfill \\ {\{ \{ 0.5\} ,\{ 0.5\} \} } \hfill & {\{ \{ 0.1946,0.2404\} ,\{ 0.316,0.5308,0.5853\} \} } \hfill & {\{ \{ 0.2128,0.3984\} ,\{ 0.2139,0.3999\} \} } \hfill \\ {\{ \{ 0.316,0.5308,0.5853\} ,\{ 0.1946,0.2404\} \} } \hfill & {\{ \{ 0.5\} ,\{ 0.5\} \} } \hfill & {\{ \{ 0.3292,0.4882,0.5886\} ,\{ 0.0887,0.2572\} \} } \hfill \\ {\{ \{ 0.2139,0.3999\} ,\{ 0.2128,0.3984\} \} } \hfill & {\{ \{ 0.0887,0.2572\} ,\{ 0.3292,0.4882,0.5886\} \} } \hfill & {\{ \{ 0.5\} ,\{ 0.5\} \} } \hfill \\ \end{array} } \right). \\ \end{aligned} $$ -
Step 5 By Eq. (10), the DHFPRs \( U_{0}^{(1)} \), \( U_{0}^{(2)} \) and \( U_{1}^{(3)} \) are aggregated into the new collective DHFPR U 1. Suppose that U 1 = (d ij1)6×6, where d ij1 = (h ij1, g ij1) for i, j = 1, 2, …, 6. Because of the limited space, only some elements in U 1 are listed here:
$$ \begin{aligned} h_{121} & = \{ 0.2335,0.2759,0.3263,0.327,0.349,0.3773,0.4014,0.4359,0.4602,0.461,0.5161,0.5763\} , \\ g_{121} & = \{ 0.1986,0.2436,0.25,0.3021,0.2476,0.2995,0.3068,0.365\} . \\ \end{aligned} $$ -
Step 6 By Eq. (2), the following compatibility degrees are calculated:
$$ c_{1} (U_{0}^{(1)} ,U_{1} ) = 0.9378,\quad c_{1} (U_{0}^{(2)} ,U_{1} ) = 0.9376,\quad c_{1} (U_{1}^{(3)} ,U_{1} ) = 0.9629. $$Obviously, \( c_{1} (U_{0}^{(1)} ,U_{1} ) \ge 0.93 \), \( c_{1} (U_{0}^{(2)} ,U_{1} ) \ge 0.93 \) and \( c_{1} (U_{1}^{(3)} ,U_{1} ) \ge 0.93 \). Thus, the group reaches the desired consensus level.
-
Step 7 Let U = U 1, then by Eq. (13), the dual hesitant fuzzy preference values with respect to each alternative a i are fused into the collective dual hesitant fuzzy preference value d i , and then according to Definition 3, the score values of d i , i = 1, 2, …, 6 are calculated:
$$ s(d_{1} ) = 0.1494,\quad s(d_{2} ) = - 0.0011,\quad s(d_{3} ) = 0.0127,\quad s(d_{4} ) = - 0.0806,\quad s(d_{5} ) = 0.1273,\quad s(d_{6} ) = - 0.2043 $$by which the ranking orders of the alternatives a 1, a 2, …, a 6 are achieved: a 1 ≻ a 5 ≻ a 3 ≻ a 2 ≻ a 4 ≻ a 6.
In the above solving process, if the compatibility measure shown in Eq. (3) is used to measure the agreement of preferences, the following computational results can be achieved:
In Step 1, the calculated weights of decision organizations by Eqs. (3) and (9) are listed as follows:
In Step 3, the calculated compatibility degrees c 2(U (k)0 , U 0) between U (k)0 , k = 1, 2, 3 and U 0 by using Eq. (3) are listed as:
In Step 6, the derived compatibility degrees \( c_{2} (U_{1}^{(k)} ,U_{1} ) \) between \( U_{1}^{(k)} \), k = 1, 2, 3 and U 1 by using Eq. (3) are listed as:
In Step 7, the derived score values of d i , i = 1, 2, …, 6 by Definition 3 are listed as:
by which the ranking orders of the alternatives a 1, a 2, …, a 6 are achieved: a 1 ≻ a 5 ≻ a 3 ≻ a 2 ≻ a 4 ≻ a 6.
From the above results, it can be seen that by using different compatibility measures, the yielded ranking orders of weights of decision organizations are the same, i.e., w 1 > w 2 > w 3, and the same conclusion can be drawn for the ranking orders of compatibility degrees between the individual DHFPRs and the collective DHFPR, and for the ranking orders of the alternatives, which demonstrate the effectiveness of the proposed compatibility measures shown in Eqs. (2) and (3).
In the above, Method 1 has been adopted to solve the GDM problem concerning the evaluations of causes of students’ disruptive behaviors, in which the consensus level of each decision organization is improved by adjusting the preference values of the decision organization. Nonetheless, sometimes, the decision organizations do not expect their opinions to be modified. In what follows, Method 2 will be used to resolve the aforementioned GDM problem, in which the group’s consensus level is improved without altering the opinions of the decision organizations but by modifying their weights. It is worthwhile to point out that in order to make a fair comparison with Method 1, here the importance weight vector of the three organizations is assumed as \( w = (0.3346,0.3338,0.3316)^{\text{T}} \), and the desired consensus level is assumed as δ * = 0.93. Then, according to Method 2, the following steps are given:
-
Step 1 For all k = 1, 2, 3, let \( U_{I}^{(k)} = U^{(k)} \) and w k0 = w k . Then by Eq. (16), all DHFPRs \( U_{0}^{(k)} \), k = 1, 2, 3 are aggregated into the collective DHFPR U 0. Suppose that U 0 = (d ij0)6×6, where d ij0 = (h ij0, g ij0) for i, j = 1, 2, …, 6. Due to the limited space, only some elements in U 0 are listed here:
$$ \begin{aligned} h_{120} & = \{ 0.1861,0.2635,0.2667,0.2871,0.3627,0.3679,0.3865,0.3904,0.4806,0.5005,0.5061,0.6197\} , \\ g_{120} & = \{ 0.1692,0.2129,0.215,0.2558,0.2667,0.3134,0.3161,0.3803\} . \\ \end{aligned} $$ -
Step 2 By Eq. (7), the compatibility degrees \( c_{1} (V_{i0}^{(k)} ,V_{i0} ), \), k = 1, 2, 3 between the ith row vectors of \( U_{0}^{(k)} \), k = 1, 2, 3 and U 0 are calculated, listed in the following matrix:
$$ C = (c_{ki} )_{3 \times 6} = \left( {\begin{array}{*{20}c} {0.9415} & {0.9163} & {0.9364} & {0.9232} & {0.966} & {0.9173} \\ {0.9237} & {0.9288} & {0.917} & {0.935} & {0.9522} & {0.9511} \\ {0.9491} & {0.9241} & {0.9366} & {0.9025} & {0.9187} & {0.8557} \\ \end{array} } \right), $$where \( c_{ki} = c_{1} (V_{i0}^{(k)} ,V_{i0} ) \), for k = 1, 2, 3; i = 1, 2, …, 6. Then by Eqs. (14) and (15), the consensus level \( C_{i}^{0} \) of the alternative a i (i = 1, 2, …, 6) and the group consensus level C 0 are, respectively, computed:
$$ C_{1}^{0} = 0.9381,\quad C_{2}^{0} = 0.923,\quad C_{3}^{0} = 0.93,\quad C_{4}^{0} = 0.9203,\quad C_{5}^{0} = 0.9457,\quad C_{6}^{0} = 0.9081,\quad C^{0} = 0.9275. $$ -
Step 3 Since C 0 < 0.93, then it is needed to update the weights of decision organizations. Firstly, it is required to calculate the contribution of each decision organization to the group decision. By using Eq. (17), the new consensus level of each alternative excluding one decision organization is calculated, as given in Table 7.
Table 7 New consensus levels excluding one specific decision organization
By Eqs. (18) and (19), the contribution of each decision organization to the group decision is achieved:
Then, by means of Eqs. (20) and (21) [let ∂ = 7 in Eq. (20)], the new weights of the decision organizations can be obtained. Table 8 shows the weights of decision organizations and the group consensus level in each iteration.
From Table 8, it can be easily observed that during the iterations, the weights of decision organizations o 1 and o 2 increase, while the weight of the decision organization o 3 decreases. This is the consequence of the decision organization o 3 contributing less to the group decision. Furthermore, it can be also found that in the iteration process, the group consensus level gradually increases until it is not less than the desired consensus level 0.93. To provide a better view of the change process, the changes in the decision organizations’ weights as the group consensus level changes from 0.9275 to 0.9301 are presented in Fig. 3 (Fig. 3 is formed according to the data obtained by setting ∂ = 1 in Eq. (20). Different parameters ∂ do not influence the changing tendencies of the weights with the changing of the group consensus level since they just affect the speed that the group reaches the desired consensus level).

Weights of decision organizations with the change in the group consensus level
It can be easily seen from Fig. 3 that in order to improve the group consensus level, the weights of decision organizations o 1 and o 2 gradually increase, while the weight of the decision organization o 3 gradually decreases. These conclusions are consistent with those derived from Table 8.
-
Step 4 According to Eqs. (7) and (4), the following results are computed:
$$ V(a_{1} ) = 0.5252,\quad V(a_{2} ) = 0.4961,\quad V(a_{3} ) = 0.5008,\quad V(a_{4} ) = 0.4896,\quad V(a_{5} ) = 0.525,\quad V(a_{6} ) = 0.4633 $$by which the ranking orders of the alternatives a 1, a 2, …, a 6 are achieved: a 1 ≻ a 5 ≻ a 3 ≻ a 2 ≻ a 4 ≻ a 6.
In the above solving process, if the compatibility measure shown in Eq. (8) is adopted to measure the agreement of preferences, the following computational results can be obtained:
In Step 2, by Eqs. (8), (14) and (15), the derived consensus level \( C_{i}^{0} \) of the alternative a i (i = 1, 2, …, 6) and the group consensus level C 0 are listed as:
In Step 3, the weight vector of the decision organizations obtained in the final iteration is \( w = ( 0. 5 3 2 3, 0. 3 5 8 8, 0. 1 0 8 9)^{\text{T}} \), and in this case, the obtained group consensus level is 0.9302, which is larger than the desired consensus level.
In Step 4, by Eqs. (8) and (4), the following results are computed:
by which the ranking orders of the alternatives a 1, a 2, …, a 6 are achieved: a 1 ≻ a 5 ≻ a 3 ≻ a 2 ≻ a 4 ≻ a 6.
From the above results, it can be seen that by using different compatibility measures, the obtained ranking orders of consensus levels of alternatives in the 0th iteration are the same, i.e., C 05 ≻ C 01 ≻ C 03 ≻ C 02 ≻ C 04 ≻ C 06 , and the same conclusion can be drawn for the ranking orders of weights of decision organizations obtained in the final iteration, and for the ranking orders of the alternatives. Therefore, it can be concluded that the proposed compatibility measures shown in Eqs. (7) and (8) are applicable and effective. Furthermore, it can be also observed that no matter which compatibility measure is used to compute the degree of agreement of preferences in the decision making process, the ranking orders of the alternatives derived from Methods 1 and 2 are the same, i.e., a 1 ≻ a 5 ≻ a 3 ≻ a 2 ≻ a 4 ≻ a 6, which demonstrates the practicability and effectiveness of the proposed methods in dealing with the GDM problems with DHFPRs.
Comparative Analyses and Discussions
In this subsection, with the same decision making problem as mentioned in “Description of the Problem and the Analysis Process” section, comparison analyses are conducted to show the advantages of the proposed methods in solving the GDM problems with DHFPRs.
More recently, Xu [12] and Liao et al. [13] investigated the consensus improving procedures for GDM with IVIFPRs. Since the DHFEs’ envelopes are the interval-valued intuitionistic fuzzy values (IVIFVs) (for details, please refer to Ref. [21]), and considering that within the dual hesitant fuzzy context, there have been no investigations similar to our methods proposed in “Two Methods for GDM with DHFPRs” section, we here make comparisons with the GDM methods developed by Xu [12] and Liao et al. [13], which are close to our methods. Since both Xu’s [12] and Liao et al.’s [13] methods are designed to deal with the situations where the weight values need to be provided in advance, in order to make the comparisons fair, here the weight vector is assumed as \( w = (0.3346,0.3338,0.3316)^{\text{T}} \), which is the same as that used in the solving processes in “Description of the Problem and the Analysis Process” section. The detailed solving steps of the two methods are presented in “Appendix.”
In order to facilitate the comparisons of different methods, the ranking orders of alternatives derived from different methods are listed in Table 9 (where Method k (Eq. (t)) denotes that the compatibility measure in Eq. (t) is used to compute the degree of agreement of preferences when Method k is adopted to solve the GDM problem).
From Table 9, it can be easily seen that the ranking orders of the alternatives obtained by Xu’s [12] or Liao et al.’s [13] method are different from those obtained by Method 1 or Method 2. The main reason may be that the proposed methods directly apply the original DHFPRs to GDM and do not need to transform them into IVIFPRs, which can avoid the loss and distortion of original information. However, when adopting Xu’s [12] or Liao et al.’s [13] method, the given DHFPRs are not fully utilized and just transformed into IVIFPRs, which leads to the loss and distortion of original information and may further result in inaccurate decision results.
Furthermore, analyzing the solving steps of different methods, it can be easily seen that when Xu’s method [12] is applied to solve the GDM problem described in “Description of the Problem and the Analysis Process” section, there are no consensus improving procedures involved since the calculated compatibility degree between each initial IVIFPR and the collective IVIFPR is not less than the desired consensus level. Notably, when the compatibility degree between the individual IVIFPR and the collective IVIFPR is less than the desired consensus level, Xu [12] recommended to return the IVIFPR (together with the collective IVIFPR and some elements with the smallest compatibility degrees as a reference) to the decision maker for re-evaluation and to construct a new IVIFPR according to his/her new comparisons until it reaches the desired consensus, which is not easy to implement especially when a lot of IVIFPRs need to be re-evaluated, and wastes plenty of time and resources. Although in Liao et al.’s method [13], the consensus improving procedures are automatic, the desired consensus level is reached by adjusting the IVIFPRs of the decision makers, and thus, Liao et al.’s method [13] cannot deal with the situations where the decision makers do not expect their opinions to be modified. In addition, in both Xu’s [12] and Liao et al.’s [13] methods, it is required that the weight values are provided in advance and no methods for deriving weights are provided.
Therefore, compared with Xu’s [12] and Liao et al.’s [13] methods, Methods 1 and 2 have some desirable advantages, which are summarized as follows:
-
(1)
Both Methods 1 and 2 can avoid the loss and distortion of original information, and generate more precise decision results since they directly employ the original DHFPRs during the decision making process, which are able to objectively represent the hesitant preference and non-preference degrees of one alternative over another, and do not need to transform the DHFPRs into the IVIFPRs.
-
(2)
Both Methods 1 and 2 can integrate more useful information into the decision making process by considering the situation that all pairwise comparison judgments for alternatives from the decision makers are DHFEs and thus can better deal with the practical uncertain decision situations.
-
(3)
Method 1 can well deal with such GDM problems in which the weights of group members are completely unknown, because by using Step 1, the weights can be objectively determined based upon the provided DHFPRs, which is very important in solving a decision making problem. Furthermore, in Method 1, when repairing the DHFPRs that do not reach the desired consensus, it is not needed to interact with the group members to spend much time adjusting the DHFEs in the DHFPRs one by one, but just give the adjustment parameter, which can greatly improve the efficiency of decision making.
-
(4)
Method 2 can well handle such situations where the group members do not agree to compromise for reaching the desired consensus level since it improves the consensus level of the group without altering the opinions of the group members, but by modifying their weights according to their contributions to the group decision.
Conclusions
In this paper, the GDM problems in which the cognitive information of group members is expressed by DHFPRs have been investigated. Firstly, a new operator to aggregate dual hesitant fuzzy cognitive information has been developed, which treats the membership and non-membership information fairly, and can generate more neutral results than the existing dual hesitant fuzzy aggregation operators. Since compatibility is a very effective tool to measure the consensus in GDM with preference relations, then two compatibility measures for DHFPRs have been proposed. After that, the developed aggregation operator and compatibility measures have been applied to GDM with DHFPRs and two GDM methods have been designed, which can be applied to different decision-making situations. Each method involves a consensus improving model with respect to DHFPRs. The model in the first method reaches the desired consensus level by adjusting the group members’ preference values, and the model in the second method improves the group consensus level by modifying the weights of group members according to their contributions to the group decision, which maintains the group members’ original opinions and allows the group members not to compromise for reaching the desired consensus level. In actual applications, we may choose a proper method to solve the GDM problems with DHFPRs in light of the actual situation. Compared with the GDM methods with IVIFPRs [12, 13], the proposed methods directly apply the original DHFPRs to decision making and do not need to transform them into the IVIFPRs, which can avoid the loss and distortion of original information and thus can generate more precise decision results.
References
Meng F, Chen X. Correlation coefficients of hesitant fuzzy sets and their application based on fuzzy measures. Cogn Comput. 2015;7(4):445–63.
Meng F, Wang C, Chen X. Linguistic interval hesitant fuzzy sets and their application in decision making. Cogn Comput. 2016;8(1):52–68.
Xu ZS, Zhao N. Information fusion for intuitionistic fuzzy decision making: an overview. Inf Fusion. 2016;28:10–23.
Lee VK, Harris LT. How social cognition can inform social decision making. Front Neurosci. 2013;7:259.
Yang L, Jiang M. Dynamic group decision making consistence convergence rate analysis based on inertia particle swarm optimization algorithm. In: International joint conference on artificial intelligence, Hainan Island, 2009. p. 492–496.
Brabec CM, Gfeller JD, Ross MJ. An exploration of relationships among measures of social cognition, decision making, and emotional intelligence. J Clin Exp Neuropsychol. 2012;34(8):887–94.
Czubenko M, Kowalczuk Z, Ordys A. Autonomous driver based on an intelligent system of decision-making. Cogn Comput. 2015;7(5):569–81.
Hei YQ, Li WT, Li M, Qiu Z, Fu WH. Optimization of multiuser MIMO cooperative spectrum sensing in cognitive radio networks. Cogn Comput. 2014;7(3):359–68.
Haikonen POA. Yes and no: match/mismatch function in cognitive robots. Cogn Comput. 2014;6(2):158–63.
Orlovsky SA. Decision-making with a fuzzy preference relation. Fuzzy Sets Syst. 1978;1(3):155–67.
Herrera F, Herrera-Viedma E, Chiclana F. Multiperson decision-making based on multiplicative preference relations. Eur J Oper Res. 2001;129(2):372–85.
Xu ZS. Compatibility analysis of intuitionistic fuzzy preference relations in group decision making. Group Decis Negot. 2013;22(3):463–82.
Liao HC, Xu ZS, Xia MM. Multiplicative consistency of interval-valued intuitionistic fuzzy preference relation. J Intell Fuzzy Syst. 2014;27(6):2969–85.
Xia MM, Xu ZS. Managing hesitant information in GDM problems under fuzzy and multiplicative preference relations. Int J Uncertain Fuzzy Knowl Based Syst. 2013;21(6):865–97.
Torra V. Hesitant fuzzy sets. Int J Intell Syst. 2010;25(6):529–39.
Zhu B, Xu ZS, Xia MM. Dual hesitant fuzzy sets. J Appl Math. 2012;11:2607–45.
Chen N, Xu ZS, Xia MM. Interval-valued hesitant preference relations and their applications to group decision making. Knowl Based Syst. 2013;37:528–40.
Wei GW, Zhao XF. Induced hesitant interval-valued fuzzy Einstein aggregation operators and their application to multiple attribute decision making. J Intell Fuzzy Syst. 2013;24(4):789–803.
Qian G, Wang H, Feng XQ. Generalized hesitant fuzzy sets and their application in decision support system. Knowl Based Syst. 2013;37(4):357–65.
Yu DJ. Triangular hesitant fuzzy set and its application to teaching quality evaluation. J Inf Comput Sci. 2013;10(7):1925–34.
Zhu B, Xu ZS. Some results for dual hesitant fuzzy sets. J Intell Fuzzy Syst. 2014;26(4):1657–68.
Ju Y, Zhang W, Yang S. Some dual hesitant fuzzy Hamacher aggregation operators and their applications to multiple attribute decision making. J Intell Fuzzy Syst. 2014;27(5):2481–95.
Wang H, Zhao X, Wei G. Dual hesitant fuzzy aggregation operators in multiple attribute decision making. J Intell Fuzzy Syst. 2014;26(5):2281–90.
Yu D. Some generalized dual hesitant fuzzy geometric aggregation operators and applications. Int J Uncertain Fuzzy Knowl Based Syst. 2014;22(3):367–84.
Singh P. A new method for solving dual hesitant fuzzy assignment problems with restrictions based on similarity measure. Appl Soft Comput. 2014;24:559–71.
Ye J. Correlation coefficient of dual hesitant fuzzy sets and its application to multiple attribute decision making. Appl Math Model. 2014;38(2):659–66.
Ren ZL, Wei CP. A multi-attribute decision-making method with prioritization relationship and dual hesitant fuzzy decision information. Int J Mach Learn Cybern. 2015. doi:10.1007/s13042-015-0356-3.
Yu DJ, Li DF. Dual hesitant fuzzy multi-criteria decision making and its application to teaching quality assessment. J Intell Fuzzy Syst. 2014;27(4):1679–88.
Lehner P, Seyed-Solorforough MM, Connor MFO, Sak S, Mullin T. Cognitive biases and time stress in team decision making. IEEE Trans Syst Man Cybern A Syst Hum. 1997;27(5):698–703.
Mohammed S. Toward an understanding of cognitive consensus in a group decision-making context. J Appl Behav Sci. 2001;37(4):408–25.
Mohammed S, Ringseis E. Cognitive diversity and consensus in group decision making: the role of inputs, processes, and outcomes. Organ Behav Hum Decis Process. 2001;85(2):310–35.
James LR, Demaree RG, Wolf G. Estimating within-group interrater reliability with and without response bias. J Appl Psychol. 1984;69(1):85–98.
Allison PD. Measures of inequality. Am Sociol Rev. 1978;43:865–80.
Xu ZS, Cai X. Group consensus algorithms based on preference relations. Inf Sci. 2011;181(1):150–62.
Saaty TL, Vargas LG. Dispersion of group judgements. Comput Math Model. 2007;46(7):918–25.
Xu ZS. On compatibility of interval fuzzy preference relations. Fuzzy Optim Decis Mak. 2004;3(3):217–25.
Jiang Y, Xu ZS, Yu XH. Compatibility measures and consensus models for group decision making with intuitionistic multiplicative preference relations. Appl Soft Comput. 2013;13(4):2075–86.
Chen H, Zhou L, Han B. On compatibility of uncertain additive linguistic preference relations and its application in the group decision making. Knowl Based Syst. 2011;24(6):816–23.
Roubens M. Fuzzy sets and decision analysis. Fuzzy Sets Syst. 1997;90(90):199–206.
Wang C, Li Q, Zhou X. Multiple attribute decision making based on generalized aggregation operators under dual hesitant fuzzy environment. J Appl Math. 2014;2:2577–92.
Ju Y, Yang S, Liu X. Some new dual hesitant fuzzy aggregation operators based on Choquet integral and their applications to multiple attribute decision making. J Intell Fuzzy Syst. 2014;27(6):2857–68.
Zhang Y. Research on the computer network security evaluation based on the DHFHCG operator with dual hesitant fuzzy information. J Intell Fuzzy Syst. 2015;28(1):199–204.
Xu Y, Rui D, Wang H. Dual hesitant fuzzy interaction operators and their application to group decision making. J Ind Prod Eng. 2015;32(4):273–90.
Xia MM, Xu ZS. Entropy/cross entropy-based group decision making under intuitionistic fuzzy environment. Inf Fusion. 2012;13(1):31–47.
Harsanyi JC. Cardinal welfare, individualistic ethics, and interpersonal comparisons of utility. Netherlands: Springer; 1980.
Xu ZS. On consistency of the weighted geometric mean complex judgment matrix in AHP. Eur J Oper Res. 2000;126(3):683–7.
Xu ZS. A method based on linguistic aggregation operators for group decision making with linguistic preference relations. Inf Sci. 2004;166(1):19–30.
Ben-Arieh D, Chen Z. Linguistic-labels aggregation and consensus measure for autocratic decision making using group recommendations. IEEE Trans Syst Man Cybern A Syst Hum. 2006;36(3):558–68.
Hwang CL, Yoon K. Multiple attributes decision making methods and applications. Berlin: Springer; 1981.
Herrera-Viedma E, Herrera F, Chiclana F. A consensus model for multiperson decision making with different preference structures. IEEE Trans Syst Man Cybern A Syst Hum. 2002;32(3):394–402.
Acknowledgments
The work was supported by the National Natural Science Foundation of China (Nos. 61273209 and 71571123), the Fundamental Research Funds for the Central Universities (No. KYLX_0207) and the Scientific Research Foundation of Graduate School of Southeast University (No. YBJJ1527).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
Na Zhao, Zeshui Xu and Fengjun Liu declare that they have no conflict of interest.
Informed Consent
Informed consent was not required as no human or animals were involved.
Human and Animal Rights
This article does not contain any studies with human or animal subjects performed by any of the authors.
Appendix
Appendix
According to the fact that the envelope of the DHFE d = (h, g) is the IVIFV ([γ −, γ +], [η −, η +]), where γ − and η − are the minimum elements in h and g, respectively, and γ + and η + are the corresponding maximum elements [21], the DHFPRs U (1)–U (3) are transformed into the following IVIFPRs \( \widetilde{U}^{(1)} - \widetilde{U}^{(3)} \):
Then by Eq. (12) in Ref. [12], the transformed IVIFPRs are aggregated into the following collective IVIFPR:
Furthermore, by Eq. (11) in Ref. [12], the compatibility degrees \( c(\widetilde{U}^{(k)} ,\widetilde{U}) \) of \( \widetilde{U}^{(k)} ,k = 1,2,3 \) and \( \widetilde{U} \) are computed:
Since all \( c(\widetilde{U}^{(k)} ,\widetilde{U}) \ge 0.93,k = 1,2,3 \), then by Eq. (14) in Ref. [12], the overall preference values \( \widetilde{{r_{i} }},i = 1,2, \ldots ,6 \) corresponding to the alternatives a i , i = 1, 2, …, 6 are derived:
Finally, by Eq. (15) in Ref. [12], the closeness coefficients of the overall preference values are calculated:
by which the ranking orders of the alternatives a 1, a 2, …, a 6 are achieved: a 5 ≻ a 1 ≻ a 3 ≻ a 2 ≻ a 4 ≻ a 6.
In what follows, Liao et al.’s method [13] will be adopted to resolve the GDM problem described in “Description of the Problem and the Analysis Process” section. Before doing so, it should be pointed out that as Liao et al. [13] measured the consensus of each individual IVIFPR by calculating the distance between the IVIFPR and the collective IVIFPR, and the smaller the distance, the better the consensus of the IVIFPR, here the threshold value is assumed as τ * = 1 − 0.93 = 0.07 for facilitating comparisons with other decision making methods.
Firstly, by Algorithm 2 in Ref. [13], the following multiplicative consistent IVIFPRs \( \widetilde{U}_{*}^{(k)} \) from \( \widetilde{U}^{(k)} ,k = 1,2,3 \) are constructed:
Then, by the symmetric interval-valued intuitionistic fuzzy weighted averaging operator in Ref. [13], the multiplicative consistent IVIFPRs are aggregated into the following collective IVIFPR:
Furthermore, by Eq. (34) in Ref. [13], the deviation between each multiplicative consistent IVIFPR and the collective IVIFPR is computed:
Since \( d(\widetilde{U}_{*}^{(3)} ,\widetilde{U}_{ * } ) > 0.07 \), then by Eqs. (35–38) in Ref. [13] (where η = 0.5), the IVIFPR \( \widetilde{U}_{*}^{(3)} \) is modified as:
Then, the obtained new collective IVIFPR \( \widetilde{U}_{1 * } \) is
By Eq. (34) in Ref. [13], the deviations between the IVIFPRs \( \widetilde{U}_{*}^{(1)} \),\( \widetilde{U}_{*}^{(2)} \),\( \widetilde{U}_{1*}^{(3)} \) and the new collective IVIFPR \( \widetilde{U}_{1 * } \) are computed:
As \( d(\widetilde{U}_{*}^{(1)} ,\widetilde{U}_{1 * } ) \le 0.07 \), \( d(\widetilde{U}_{*}^{(2)} ,\widetilde{U}_{1 * } ) \le 0.07 \) and \( d(\widetilde{U}_{1*}^{(3)} ,\widetilde{U}_{1 * } ) \le 0.07 \), then by the symmetric interval-valued intuitionistic fuzzy averaging operator in Ref. [13], all the interval-valued intuitionistic fuzzy preference values corresponding to the alternatives a i , i = 1, 2, …, 6 are fused into the overall preference values \( \widetilde{{r_{i} }},i = 1,2, \ldots ,6 \):
Finally, according to the comparison laws of IVIFVs [13], the ranking orders of \( \widetilde{{r_{1} }},\widetilde{{r_{2} }}, \ldots ,\widetilde{{r_{6} }} \) are achieved: \( \widetilde{{r_{2} }} \succ \widetilde{{r_{1} }} \succ \widetilde{{r_{5} }} \succ \widetilde{{r_{3} }} \succ \widetilde{{r_{4} }} \succ \widetilde{{r_{6} }} \). Thus, the ranking orders of the alternatives a 1, a 2, …, a 6 are a 2 ≻ a 1 ≻ a 5 ≻ a 3 ≻ a 4 ≻ a 6.
Rights and permissions
About this article

Cite this article
Zhao, N., Xu, Z. & Liu, F. Group Decision Making with Dual Hesitant Fuzzy Preference Relations. Cogn Comput 8, 1119–1143 (2016). https://doi.org/10.1007/s12559-016-9419-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-016-9419-3