
Abstract
Accurate yield estimation of paddy crop plays an important role in forecasting paddy productivity for ensuring regional or national food security of the country. Although the crop growth models provide accurate yield forecasting, these models are difficult to implement in developing countries like India due to inhomogeneous or/and lack of required information about crop, soil, weather, etc. On the contrary, remotely sensed imagery available homogeneously provides valuable inputs for this purpose. Particularly, synthetic aperture radar (SAR) data proved to have great potential for paddy growth monitoring and biophysical parameters retrieval over optical data. Moreover, the effective use of artificial neural network (ANN) may enable us to understand the complex relation between parameters as well as improve the forecasting performance than using empirical-/semiempirical-based approaches. Thus, the study aims to analyze multi-temporal dual-polarization C-band Sentinel-1 SAR data for paddy yield forecasting using ANN model. In this study, smart sampling based on the normalized difference vegetation (NDVI) and normalized difference water index has been considered to obtain in situ yield measurements in the study area. The peak stage signature of backscattering coefficients is considered to estimate yield due to the maximum possibility of signal to interact with crop cover characteristics. It is observed that the VH-polarization-based ANN model provides better accuracy with coefficient of determination (R2) and root mean square error (RMSE) of 0.72 and 600.11 kg/ha, respectively, in comparison with VV polarization which has shown 0.26 and 948.46 kg/ha, respectively. Overall, the study demonstrates that the effective use of ANN model may provide reliable yield estimation accuracy from remotely sensed imagery alone.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Rice, Oryza sativa, is a globally important food for more than half the population and it has a notable influence on the global political and economic system. With the changes in global climate and increase in world population, it is utmost important and challenging to maintain the production and demand for rice, particularly in developing countries like India (Auffhammer et al., 2012; Guntukula, 2020; Mahajan et al., 2017). This may be addressed by effective monitoring of crop health status and accurate estimation of yield to maintain political and social stability and equity (Brisco et al., 1998). In contrast to conventional field-based approaches, remote sensing provides valuable inputs for this purpose by supplying coarse to high spatial and temporal resolution images at regional to global scales. The marginal 20–25 days temporal resolution with high spatial resolution datasets are generally acceptable and plentiful for agricultural crops monitoring because the average field size is very small in most of the developing countries including India (Sivasankar et al., 2018). Nonetheless, the spectral region used to acquire remotely sensed imagery has a significant impact on the potentials to retrieve crop characteristics including yield (Alebele et al., 2020; Ranjan & Parida, 2021).
Most early investigations were performed using multispectral optical remote sensing data to infer crop bio-geophysical parameters. For instance, Patel et al. (1991) proposed a semi-empirical based approach to estimate paddy yield from Landsat Multispectral Scanning System (MSS) and Indian Remote Sensing (IRS) Linear Imaging Self Scanning (LISS)-I datasets. In spite of potential capabilities and availability of multispectral remotely sensed imagery, operational applications of the data in this regard are limited due to its ability to acquire data only in clear weather conditions. This has made the radar remote sensing, operating in the microwave region of the electromagnetic spectrum, as a better alternative toward uninterrupted crop growth monitoring. Moreover, synthetic aperture radar (SAR) data is sensitive toward geometrical, structural and dielectric properties of various crop cover components which made the data as suitable to retrieve crop bio-geophysical parameters (Liao et al., 2018; Sivasankar, Kumar, et al., 2020; Sharifi and Hosseingholizadeh, 2020). However, it is necessary to choose proper SAR sensor parameters such as frequency, polarization and incidence angle of operation in enhancing the sensitivity of return signal toward crop cover (Sivasankar et al., 2018). Particularly, higher frequency like C-band and high incidence angle (> 30°) is identified as suitable for narrow leaf crops such as paddy and wheat (Ferrazzoli et al., 1997; Macelloni et al., 2001). Apart from SAR data sensitivity toward vegetation characteristics, it is also highly influenced by topographic characteristics like aspect and degree of slope in hilly terrain.
With the advancements in remote sensing, GIS, computer science and computation techniques collectively enhanced the accuracy and precision to retrieve crop cover distribution and characteristics. Several previous studies (Patel et al., 2006; Inoue et al., 2014a, 2014b; Setiyono et al., 2019; Mandal and Rao 2020) have proposed various approaches to effectively retrieve crop yield within season from SAR data. These techniques range from simple empirical based to more complex models like radiative transfer, artificial intelligence, machine learning and deep learning-based approaches. Patel et al. (2006), is one of the notable studies in this area, proposed Interaction Factor (IF) from volume, moisture, height for each of the components and density of plant to determine the influence of various crop components on SAR backscatter. Moreover, Chauhan et al. (2018) reported that the IF provides valuable information as a crop descriptor to simulate SAR backscatter using water cloud model. Since 1990, the utilization of artificial neural networks (ANNs), a machine learning approach, over conventional methods have been significantly increased for remote sensing analysis (Atkinson & Tatnall, 1997). This is due to its ability to integrate different types of data for understanding complex patterns by incorporating realistic physical constraints (Carpenter et al., 1997; Lek & Guégan, 1999; Mas & Flores, 2008). Thus, several studies have attempted to analyze the performance of ANNs for agricultural applications which includes classification (Kumar et al., 2016; Murthy et al., 2003), crop biophysical parameters estimation (Chauhan et al., 2018; Jiang et al., 2004; Prasad et al., 2012). However, limited studies like Jing et al. (2013) have assessed the applicability of ANNs for yield estimation from SAR data. The literature clearly demonstrates the importance and research scope of ANNs in developing a robust model to improve the accuracy and precision of crop yield prediction from remotely sensed imagery.
Most of the previous studies (Maki et al., 2017; Setiyono et al., 2017, 2019) have attempted to analyze the integrated use of remotely sensed imagery (optical or/and SAR) in crop growth models to predict yield. However, the necessary information about weather and soil properties may not be available accurately over developing countries. Moreover, few studies (Li et al., 2003; Patel et al., 2006) attempted to retrieve yield based on remote sensing imagery alone, mostly exploring the potentials using empirical/semiempirical approach. Therefore, the study aims to assess the potentials of dual-polarization (VV + VH) Sentinel-1 SAR data using ANN-based approach. Further details about the study area, ground-truth data collection and methodology are given in the following sections.
Study Area and Datasets Used
Study Area
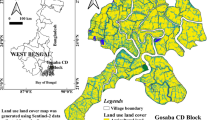
The study is carried over Cuttack district located in the mid-eastern part of Odisha. It extends over an area of 3,932 sq. km, between 84.85° E to 86.28° E longitudes and 20.04° N to 20.70° N latitudes as shown in Fig. 1. This region is situated at an altitude of about 15 m above MSL (Mean Sea Level) and covered with deltaic sediments of the Mahanadi River (Antaryami & Jyotsnarani, 2013). In Cuttack district, the temperature typically varies between 15 °C and 39 °C with an average annual rainfall of about 1501.3 mm. The area is dominated by agricultural fields, majorly cultivating paddy crop in the kharif season extended between June and December.

Location map of the study area. Red dots on the map represent the locations selected for CCE experiments
Satellite Data
Remotely sensed imagery acquired from Sentinel-1 and Sentinel-2 missions was used for estimating crop yield and site selection process for ground-truth data collection, respectively. These two missions are a constellation of two satellites, developed by European Space Agency (ESA) on behalf of the joint ESA/European Commission initiative Copernicus. Sentinel-1 provides the C-band (center frequency of 5.405 GHz) SAR datasets acquired in single or dual polarization, i.e., VV (vertical transmitting, vertical receiving) or HH (horizontal transmitting, horizontal receiving) or VV + VH (vertical transmitting, horizontal receiving) or HH + HV (horizontal transmitting, vertical receiving) in four different modes such as stripmap, Interferometric Wide swath (IW), extra wide swath and wave modes. In IW mode, Sentinel-1 acquires SAR data at spatial resolution (range × azimuth) of 5 m × 20 m with a wide swath width of 250 km at a look angle ranging from 29.1° (near range) to 46.0° (far range), whereas Sentinel-2 provides optical data in 13 spectral bands with four, six and three bands at 10 m, 20 m and 60 m spatial resolution, respectively. In this study, multi-temporal C-band dual-polarization (VV + VH) Sentinel-1A Level-1 Ground Range Detected (GRD) SAR imagery acquired in IW mode between 13 August 2019 and 11 December 2019 as well as cloud-free Level-1C Sentinel-2 optical data acquired on 15 November 2019 are used for analysis. The detailed specifications of the datasets used are given in Table 1. These datasets are freely available for researchers to download from the ESA Copernicus open access hub.
Ground-Truth Data
Two ground-truth data collection campaigns were carried over the study area during paddy crop growing season. The first campaign was done during the initial crop growth stage, i.e., between 20 and 23 September 2019 to collect necessary information for paddy crop mapping. During this campaign, field boundaries and tracks were recorded using handheld GPS along with the crop type and health status details.
The second campaign was carried out between 9 and 23 December 2019 during the harvesting phase of the paddy crop. Field level paddy yield data are collected from selected fields, well distributed in the study area, using the Crop Cutting Experiment (CCE) approach. The dimension of CCE size (5 m × 5 m) for the field level yield estimation was selected on the basis of government state rule.
These fields are identified using the smart sampling techniques, detailed procedure is given in the following section. This enables the study to be comprehensive by considering the wide range of variations in the paddy crop patterns which includes early, mid and late sown crops. During the ground-truth data collection, an Android-based mobile application developed by Amnex Infotechnologies Pvt. Ltd., was used for CCE sample collection. The information collected through CCE mobile app consists of geographic coordinates (latitude & longitude), district, taluk, gram panchayat/ village name, date of CCE, farmer name, farmer contact number, crop name, crop variety, CCE size detail, land details, biomass weight, grain wet weight, grain dry weight, moisture percentage, photographs, other remarks (stress, disease, pest), etc. The plot-wise measured paddy grain weight and moisture content are used to estimate actual yield (dry grain weight). In this study, a total 137 CCE sample points have been collected over the parts of Cuttack District.
Methodology
Initially, multi-temporal SAR datasets are preprocessed and co-registered with cloud-free optical data in order to minimize shifts between images. The preprocessed multi-temporal Sentinel-1 SAR data are integrated with ground-truth data collected during the first campaign for paddy crop mapping, based on the workflow proposed by Sivasankar, Sharma, et al. (2020). Further analyses are carried over paddy fields using cloud-free optical data for the selection of locations to carry out CCE experiments. The detailed process of the smart sampling method used in this study is given in the following subsection. Later, field boundaries, locations and tracks recorded during the ground-truth data collection are overlaid on SAR imagery to extract the backscattering coefficients (\(\sigma_{{{\text{VV}}}}^{0}\) and \(\sigma_{{{\text{VH}}}}^{0}\)) signature from sampled agricultural fields. These multi-temporal backscatter signatures are analyzed with a polynomial curve fitting approach to obtain the peak stage signature of paddy crop patterns which includes early, mid and late sown crops. This peak stage signature of backscattering coefficients is related to in situ paddy yield (collected during the second ground-truth data collection campaign) to train and validate the ANN as well as to test the same. The detailed flowchart of the methodology is given in Fig. 2. As the sampled fields are considered over flat terrain, the influence of topographic characteristics is neglected in the study.

Flowchart of the methodology
Sentinel-1 SAR Data Preprocessing
The C-band dual-polarization (VV + VH) Sentinel-1A Level-1 GRD SAR imagery are preprocessed using Sentinel Application Platform (SNAP), an open-source software developed by Brockmann Consult, SkyWatch, Sensar and C-S. At first, Sentinel-1 SAR data applied a precise orbit of acquisition and thermal noise removal. Then, radiometric calibration was carried to convert digital number (DN) values of raw data into sigma nought backscatter (\({\sigma }^{0}\)) values which are proportional to the intensity of backscattered signal from a unit area on ground. This is followed by removal of speckle (black and pepper) noise, which is inherently in SAR images due to the coherent nature of the acquisition, using a refined Lee filter with window kernel size of 5 × 5 pixels. Later, it was applied to Range Doppler terrain correction using the Shuttle Radar Topography Mission (SRTM) digital elevation model at a spatial resolution of 1 arc second (30 m) as reference. These datasets are converted to dB logarithmic units, co-registered and resampled to 20 m pixel spacing before utilizing them for crop classification and yield estimation purposes.
Remote Sensing-Based CCE Sampling
The sampling fields for in situ yield data collection are identified using the smart sampling technique based on stratification of normalized difference vegetation index (NDVI) and normalized difference water index (NDWI), proposed by Kriegler et al. (1969) and Gao (1996), respectively, generated from cloud-free Sentinel-2 optical data acquired on 15 November 2019 (see Fig. 3a, b). Among these indices, NDVI measured using near-infrared (NIR) and red bands indicates the photosynthetically active biomass, whereas NDWI measured using NIR and short-wave infrared (SWIR) bands represents the water content of leaves. Thus, these two indices provide a better indicator to assess the spatial distribution of crop health status across the study area. The paddy crop in the study area is initially categorized into five different classes based on the NDVI and NDWI values. Then, the sampling fields (as given in Fig. 3c) are identified using a stratified sampling approach based on the crop health status by keeping in mind the accessibility and possibility to measure in situ yield data. Therefore, this enables the study to be comprehensive by considering the wide range of variations in paddy crop patterns.

Analysis of vegetation indices for stratification of paddy crop: a NDVI, b NDWI and c CCE sampling points
ANN for Crop Yield Estimation
A two-layer feedforward neural network comprising one hidden layer with sigmoid neurons and one output layer with linear neurons, available in the MATLAB software is employed for the study analysis. The typical structure of this type of ANN is illustrated in Fig. 4. The neural network operates based on the weights and biases between layers (as given in Eq. 1) to minimize errors during the training phase of the model. In this study, the model was attempted twice with backscattering coefficients (first attempt with \(\sigma_{{{\text{VV}}}}^{0}\) whereas second attempt with \(\sigma_{{{\text{VH}}}}^{0}\)) as inputs and one hidden layer with 10 neurons to infer paddy yield. The total of 137 samples are randomly divided into three independent sets, i.e., 95 samples (≈ 70%) for training the model whereas two different sets of 21 samples (≈ 15%) for validation and testing purposes. Among these sets, training samples are basically used during training and further corrections in the network based on the error calculated from validation samples, whereas the testing samples provide an independent measure of network performance during and after training. This study considered the Levenberg–Marquardt algorithm for network training process and mean squared error (MSE) is the average squared difference between estimated and actual yield, for assessing the performance. The ANN model automatically adjusts weights and biases during each training iteration to provide an optimum trained model based on the performance.
where ‘y’ and ‘x’ represent the output and input of the model, respectively; f(.) indicates the complex neural network function; ‘w’ and ‘b’ indicate weights and bias, respectively; and ‘i’ and ‘j’ indicate the number of inputs and neurons in hidden layer, respectively.

Structure of a two-layer feedforward neural network
Results and Discussion
In this study, the maximum likelihood supervised classification was used for paddy crop classification using multi-temporal dual-polarized (VV + VH) Sentinel-1A SAR data. During this process, the ground-truth information collected over 65 locations during the first campaign is randomly divided into two sets in which 46 (≈ 70%) are used for training and 19 (≈ 30%) are used for validation purposes. It is well known that the pixel-based classification methods like maximum likelihood commonly observe ‘salt and pepper’ or speckled appearance which limits its accuracy (Lu & Weng, 2007). Thus, the classification output underwent post-classification processing in ArcGIS software which includes filtering, smoothening and generalization. The final paddy crop map (given in Fig. 5) has significantly improved the classification performance with overall accuracy of 91.25% and observed an area of about 97,000 ha.

Paddy classification map of the study area
As discussed in ‘Remote Sensing-Based CCE sampling’ section, ground-truth sampling fields are identified for paddy yield data collection. The study analysis observed that the study area is majorly covered by good and excellent crop health status with an area of about 12,270.49 ha (which contributes 12.56% of total paddy area). Table 2 provides the area (ha) under each category of crop health status and number of CCE samples taken in the corresponding category. The statistical analysis of in situ yield data observes mean and standard deviation of 5286.55 kg/ha and 1115.21 kg/ha, respectively. It is also observed that the kurtosis of 0.45 and 0.51 indicates the data is most closely representing the normal distribution (see Fig. 6). This clearly shows that the data is not having influential outliers or extreme values for further analysis. Thus, the ground-truth paddy yield data has been considered for prediction modeling using multi-temporal SAR data.

Analysis of ground-truth data: a histogram of yield data with normal distribution curve and b normal probability plot
The time-series backscattering coefficients (\({\sigma }^{0}\)), as given in Fig. 7, show the various paddy crop growth patterns in the study area. It is observed that the increase in backscatter (\({\sigma }_{\mathrm{VV}}^{0}\) and \({\sigma }_{\mathrm{VH}}^{0}\)) during the crop growth from initial stage to mature stage whereas the backscatter is decreased between mature stage and harvesting. Several previous studies (Choudhury & Chakraborty, 2006; Patel & Srivastava, 2013; Yang et al., 2014) have also observed similar trends of SAR backscatter with paddy crop growth. During the peak crop growth stages, the microwave signal interacts more with crop cover than the underneath soil. This enables the remotely sensed data at peak crop growth stages as a crucial input to infer the crop bio-geophysical parameters including grain yield (Brandão et al., 2015; Liu et al., 2019). Thus, the study estimated the highest value of \({\sigma }_{\mathrm{VV}}^{0}\) and \({\sigma }_{\mathrm{VH}}^{0}\) during the crop growing season from each sampled plot for further analysis. The study observed that the peak mature stage of paddy crop with mean and standard deviation of -8.9 dB and 1.48 dB, respectively, for VV polarization whereas − 14.22 dB and 1.2 dB, respectively, for VH polarization.

Polynomial curve fit plot: a–c VH-backscatter and d–f VV-backscatter
The peak crop growth backscatter signatures in VV and VH polarization are analyzed to retrieve the paddy yield using ANN algorithm. It is observed that cross-polarization (\({\sigma }_{\mathrm{VH}}^{0}\)) has better performance for paddy yield estimation than the like polarization (\({\sigma }_{\mathrm{VV}}^{0}\)) data (see Fig. 8) due to the multiple scattering within the crop canopy at the peak stage and less influence by the crop surface condition (Ranson, & Sun, 1994; Wang et al., 2019). The training results for the \({\sigma }_{\mathrm{VH}}^{0}\) backscatter show that the overall values are greater than 0.72 with the validation and test results also showed the good coefficient of determination (R2), 0.75 and 0.70, respectively, between estimated yield and observed yield. But in case of \({\sigma }_{VV}^{0}\) backscatter, the training result shows the poor ‘R2’ value of 0.26 with the validation and test result also showed poor ‘R2,’ 0.36 and 0.14 in comparison of VH polarization. Moreover, the best validation performance was observed for \({\sigma }_{\mathrm{VH}}^{0}\) at epoch 4 whereas the \({\sigma }_{\mathrm{VV}}^{0}\) at epoch 14. This clearly indicates that the cross-polarization (VH) backscattering coefficients are more suitable for paddy yield estimation than the like polarization (VV). The study results support the previous studies (Inoue et al., 2014a, 2014b; Parida & Singh, 2021; Patel & Srivastava, 2013) in observing the cross-polarization for retrieving crop bio-geophysical parameters due to the multiple scattering in crop cover.

Training, validation and test results for VV polarization and VH polarization between observed paddy yield and estimated yield a VV polarization and b VH polarization
The study further analyzed the error distribution during training, testing and validation process for each ANN model. Error histograms (difference between actual and predicted yield value) given in Fig. 9 represents the error value, error frequency and zero error for \({\sigma }_{\mathrm{VV}}^{0}\) and \({\sigma }_{\mathrm{VH}}^{0}\) backscattering coefficients. It is observed that the zero error is illustrated with a yellow line in the middle with 12 instances for \({\sigma }_{\mathrm{VH}}^{0}\) and 5 instances for \({\sigma }_{\mathrm{VV}}^{0}\) in the training set. It is also observed that the errors in training, test and validation sets are more inclined to zero meaning, indicating that these ANN models have a high degree of generalizability. The detailed study results about the performance of \({\sigma }_{\mathrm{VV}}^{0}\) and \({\sigma }_{\mathrm{VH}}^{0}\) for paddy yield forecasting are given in Table 3 and spatial distribution of paddy yield derived from \({\sigma }_{\mathrm{VH}}^{0}\) using ANN is given in Fig. 10.

Error histogram with 20 bins for the training, validation and test steps: a \(\sigma_{{{\text{VV}}}}^{0}\) and b \(\sigma_{{{\text{VH}}}}^{0}\)

Paddy yield map derived from VH-backscattering using ANN
The study was used the ANN model to predict paddy yield and build a spatial map of the study area. The spatial map (Fig. 10) depicts the distribution of minimum, mean and maximum paddy yields across the research area. The minimum, mean and maximum yield values were found to be 394 kg/ha, 4791 kg/ha and 8498 kg/ha, respectively. Also, it has been observed that distribution of low yields pixels ranging from 394 kg/ha to 1743 kg/ha, is very low in comparison with distribution of mean and maximum yield pixels. We have verified with optical data as well and found that total 2.99 ha of very low yield value pixel due to the very low density of paddy crop. The results also indicate the overestimation of grain yield pixels, ranging 6646 kg/ ha to 8498 kg/ha, near to the river and coastal area, as well as a low land area with high moisture availability regions with total area of 2203.657 ha of very high yield pixels.
The study results show comparable accuracy obtained from previous studies (Maki et al., 2017; Setiyono et al., 2017) where remote sensing data integrated with climate variables and crop growth models. It is also demonstrated that the proper choice of input data and effective use of ANN may provide reasonable accuracy and precision that is observed from integrated use of remotely sensed imagery and crop growth models.
Conclusions
The study focuses on analyzing the potentials of dual-polarization (VV + VH) C-band Sentinel-1 SAR data for paddy yield forecasting using ANN model. A completely remotely sensed imagery (optical + SAR) has been proposed in this work to properly select the locations for ground-truth data collection as well as paddy yield estimation. In this study, the artificial neural network model has been used for estimating the paddy yield from VV and VH polarization signatures during the peak stage of paddy crop growth. It is observed that the VH polarization is highly sensitive and provides better accuracy than the VV polarization. This is because of the cross-polarization sensitivity toward the multiple scattering of microwave signals in crop cover. The study results exhibit that the effective use of ANN model integrated with remotely sensed imagery may provide comparable accuracy that is observed from crop growth models which require a lot of information regarding crop, soil, weather, etc. However, the proposed methodology needs to be further analyzed over different study areas to understand its applicability for operational applications as well as influence of weather parameters and others.
References
Alebele, Y., Zhang, X., Wang, W., Yang, G., Yao, X., Zheng, H., Zhu, Y., Cao, W., & Cheng, T. (2020). Estimation of canopy biomass components in paddy rice from combined optical and SAR data using multi-target Gaussian regressor stacking. Remote Sensing, 12(16), 2564.
Antaryami, M., & Jyotsnarani, S. (2013). Soils of Cuttack District. Odisha Review, 69(11), 51–57.
Atkinson, P. M., & Tatnall, A. R. (1997). Introduction neural networks in remote sensing. International Journal of Remote Sensing, 18(4), 699–709.
Auffhammer, M., Ramanathan, V., & Vincent, J. R. (2012). Climate change, the monsoon, and rice yield in India. Climatic Change, 111(2), 411–424.
Brandão, Z. N., Sofiatti, V., Bezerra, J. R., Ferreira, G. B., & Medeiros, J. C. (2015). Spectral reflectance for growth and yield assessment of irrigated cotton. Australian Journal of Crop Science, 9(1), 75–84.
Brisco, B., Brown, R. J., Hirose, T., McNairn, H., & Staenz, K. (1998). Precision agriculture and the role of remote sensing: A review. Canadian Journal of Remote Sensing, 24(3), 315–327.
Carpenter, G. A., Gjaja, M. N., Gopal, S., & Woodcock, C. E. (1997). ART neural networks for remote sensing: Vegetation classification from Landsat TM and terrain data. IEEE Transactions on Geoscience and Remote Sensing, 35(2), 308–325.
Chauhan, S., Srivastava, H. S., & Patel, P. (2018). Wheat crop biophysical parameters retrieval using hybrid-polarized RISAT-1 SAR data. Remote Sensing of Environment, 216, 28–43.
Choudhury, I., & Chakraborty, M. (2006). SAR signature investigation of rice crop using RADARSAT data. International Journal of Remote Sensing, 27(3), 519–534.
Ferrazzoli, P., Paloscia, S., Pampaloni, P., Schiavon, G., Sigismondi, S., & Solimini, D. (1997). The potential of multifrequency polarimetric SAR in assessing agricultural and arboreous biomass. IEEE Transactions on Geoscience and Remote Sensing, 35(1), 5–17.
Gao, B. C. (1996). NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sensing of Environment, 58(3), 257–266.
Guntukula, R. (2020). Assessing the impact of climate change on Indian agriculture: Evidence from major crop yields. Journal of Public Affairs, 20(1), e2040.
Inoue, Y., Sakaiya, E., & Wang, C. (2014a). Capability of C-band backscattering coefficients from high-resolution satellite SAR sensors to assess biophysical variables in paddy rice. Remote Sensing of Environment, 140, 257–266.
Inoue, Y., Sakaiya, E., & Wang, C. (2014b). Potential of X-band images from high-resolution satellite SAR sensors to assess growth and yield in paddy rice. Remote Sensing, 6(7), 5995–6019.
Jiang, D., Yang, X., Clinton, N., & Wang, N. (2004). An artificial neural network model for estimating crop yields using remotely sensed information. International Journal of Remote Sensing, 25(9), 1723–1732.
Jing, Z., Zhang, Y., Wang, K., & Shi, R. (2013). Retrieving rice yield and biomass from Radarsat-2 SAR data with artificial neural network (ANN). In Remote sensing and modeling of ecosystems for sustainability X (Vol. 8869, p. 88690X). International Society for Optics and Photonics.
Kriegler, F. J., Malila, W. A., Nalepka, R. F., & Richardson, W. (1969). Preprocessing transformations and their effects on multispectral recognition. Remote Sensing of Environment, VI, 97–132.
Kumar, P., Prasad, R., Mishra, V. N., Gupta, D. K., & Singh, S. K. (2016). Artificial neural network for crop classification using C-band RISAT-1 satellite datasets. Russian Agricultural Sciences, 42(3), 281–284.
Lek, S., & Guégan, J. F. (1999). Artificial neural networks as a tool in ecological modelling, an introduction. Ecological Modelling, 120(2–3), 65–73.
Li, Y., Liao, Q., Li, X., Liao, S., Chi, G., & Peng, S. (2003). Towards an operational system for regional-scale rice yield estimation using a time-series of Radarsat ScanSAR images. International Journal of Remote Sensing, 24(21), 4207–4220.
Liao, C., Wang, J., Shang, J., Huang, X., Liu, J., & Huffman, T. (2018). Sensitivity study of Radarsat-2 polarimetric SAR to crop height and fractional vegetation cover of corn and wheat. International Journal of Remote Sensing, 39(5), 1475–1490.
Liu, J., Shang, J., Qian, B., Huffman, T., Zhang, Y., Dong, T., Jing, Q., & Martin, T. (2019). Crop yield estimation using time-series MODIS data and the effects of cropland masks in Ontario, Canada. Remote Sensing, 11(20), 2419.
Lu, D., & Weng, Q. (2007). A survey of image classification methods and techniques for improving classification performance. International Journal of Remote Sensing, 28(5), 823–870.
Macelloni, G., Paloscia, S., Pampaloni, P., Marliani, F., & Gai, M. (2001). The relationship between the backscattering coefficient and the biomass of narrow and broad leaf crops. IEEE Transactions on Geoscience and Remote Sensing, 39(4), 873–884.
Mahajan, G., Kumar, V., & Chauhan, B. S. (2017). Rice production in India. In B. S. Chauhan, K. Jabran, & G. Mahajan (Eds.), Rice production worldwide (pp. 53–91). Springer.
Maki, M., Sekiguchi, K., Homma, K., Hirooka, Y., & Oki, K. (2017). Estimation of rice yield by SIMRIW-RS, a model that integrates remote sensing data into a crop growth model. Journal of Agricultural Meteorology, 73(1), 2–8.
Mandal, D., & Rao, Y. S. (2020). SASYA: An integrated framework for crop biophysical parameter retrieval and within-season crop yield prediction with SAR remote sensing data. Remote Sensing Applications: Society and Environment, 20, https://doi.org/10.1016/j.rsase.2020.100366.
Mas, J. F., & Flores, J. J. (2008). The application of artificial neural networks to the analysis of remotely sensed data. International Journal of Remote Sensing, 29(3), 617–663.
Murthy, C. S., Raju, P. V., & Badrinath, K. V. S. (2003). Classification of wheat crop with multi-temporal images: Performance of maximum likelihood and artificial neural networks. International Journal of Remote Sensing, 24(23), 4871–4890.
Parida, B. R., & Singh, S. (2021). Spatial mapping of winter wheat using C-band SAR (Sentinel-1A) data and yield prediction in Gorakhpur district, Uttar Pradesh (India). Journal of Spatial Science. https://doi.org/10.1080/14498596.2021.1896393
Patel, N. K., Ravi, N., Navalgund, R. R., Dash, R. N., Das, K. C., & Patnaik, S. (1991). Estimation of rice yield using IRS-1A digital data in coastal tract of Orissa. International Journal of Remote Sensing, 12(11), 2259–2266.
Patel, P., & Srivastava, H. S. (2013). RADARSAT-2 announcement of opportunity project on soil moisture, surface roughness and vegetation parameter retrieval using SAR polarimetry. In SAC/EPSA/MPSG/CVD/TDP R& D/01/13, SOAR International Closing and Reporting–2013.
Patel, P., Srivastava, H. S., & Navalgund, R. R. (2006). Estimating wheat yield: an approach for estimating number of grains using cross-polarised ENVISAT-1 ASAR data. In Microwave remote sensing of the atmosphere and environment V (Vol. 6410, p. 641009). International Society for Optics and Photonics.
Prasad, R., Pandey, A., Singh, K. P., Singh, V. P., Mishra, R. K., & Singh, D. (2012). Retrieval of spinach crop parameters by microwave remote sensing with back propagation artificial neural networks: A comparison of different transfer functions. Advances in Space Research, 50(3), 363–370.
Ranjan, A. K., & Parida, B. R. (2021). Predicting paddy yield at spatial scale using optical and Synthetic Aperture Radar (SAR) based satellite data in conjunction with field-based Crop Cutting Experiment (CCE) data. International Journal of Remote Sensing, 42(6), 2046–2071.
Ranson, K. J., & Sun, G. (1994). Mapping biomass of a northern forest using multifrequency SAR data. IEEE Transactions on Geoscience and Remote Sensing, 32, 388–396.
Setiyono, T. D., Holecz, F., Khan, N. I., Barbieri, M., Quicho, E., Collivignarelli, F., Maunahan, A., Gatti, L., & Romuga, G. C. (2017). Synthetic Aperture Radar (SAR)-based paddy rice monitoring system: Development and application in key rice producing areas in Tropical Asia. In IOP conference series: Earth and environmental science (Vol. 54, No. 1, p. 012015). IOP Publishing.
Setiyono, T. D., Quicho, E. D., Holecz, F. H., Khan, N. I., Romuga, G., Maunahan, A., Garcia, C., Rala, A., Raviz, J., Collivignarelli, F., Gatti, L., Barbieri, M., Phuong, D. M., Minh, V. Q., Vo, Q. T., Intrman, A., Rakwatin, P., Sothy, M., Veasna, T., … Mabalay, M. R. O. (2019). Rice yield estimation using synthetic aperture radar (SAR) and the ORYZA crop growth model: development and application of the system in South and South-east Asian countries. International Journal of Remote Sensing, 40(21), 8093–8124.
Sharifi, A., & Hosseingholizadeh, M. (2020). Application of Sentinel-1 data to estimate height and biomass of rice crop in Astaneh-ye Ashrafiyeh, Iran. Journal of the Indian Society of Remote Sensing, 48(1), 11–19.
Sivasankar, T., Kumar, D., Shanker Srivastava, H., & Patel, P. (2020). Wheat leaf area index retrieval using RISAT-1 hybrid polarized SAR data. Geocarto International, 35(8), 905–915.
Sivasankar, T., Kumar, D., Srivastava, H. S., & Patel, P. (2018). Advances in radar remote sensing of agricultural crops: A review. International Journal on Advanced Science, Engineering and Information Technology, 8, 1126.
Sivasankar, T., Sharma, P. K., Ramya, M. N. S., Venkatesh, P., & Bairagi, G. D. (2020b). Evaluation of multi-temporal Sentinel-1 dual polarization SAR data for crop type classification. In Spatial Information Science for Natural Resource Management (pp. 44–61). IGI Global.
Wang, J., Dai, Q., Shang, J., Jin, X., Sun, Q., Zhou, G., & Dai, Q. (2019). Field-scale rice yield estimation using Sentinel-1A Synthetic Aperture Radar (SAR) data in coastal saline region of Jiangsu Province, China. Remote Sensing, 11, 2274. https://doi.org/10.3390/rs11192274
Yang, Z., Li, K., Liu, L., Shao, Y., Brisco, B., & Li, W. (2014). Rice growth monitoring using simulated compact polarimetric C band SAR. Radio Science, 49(12), 1300–1315.
Acknowledgements
The study work has been carried out under the project, entitled ‘Gram Panchayat level crop yield estimation using the technology’ with collaboration of MNCFC. The authors would like to express their gratitude to the Mahalanobis National Crop Forecast Center (MNCFC), Delhi-110012, for their enthusiastic support. The satellite data provided by ESA (Sentinel-1/1A & Sentinel-2A) are thankfully acknowledged. The authors are grateful to Dr. V.N Sridhar—former scientists SAC (ISRO) for their advice on conducting this study and analyzing the results. Special thanks to Mr. Thamizh Vendhan, Senior lead Consultant, Amnex Technology, for his kind help and technical suggestion.
Funding
The data for this study come from a central government project called ‘Pilot Study on GP (Gram Panchayat) level Crop Yield Estimation using Advanced Technology’. The Mahalanobis National Crop Forecast Center (MNCFC) provided funding for the project with Reference ID (F.No.: 6/7(2)/PMFBY/2017-MNCFC).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
About this article

Cite this article
Sharma, P.K., Kumar, P., Srivastava, H.S. et al. Assessing the Potentials of Multi-temporal Sentinel-1 SAR Data for Paddy Yield Forecasting Using Artificial Neural Network. J Indian Soc Remote Sens 50, 895–907 (2022). https://doi.org/10.1007/s12524-022-01499-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12524-022-01499-7