
Abstract
Land use/cover change (LUCC) simulation models are helpful tools for decision makers because of their capacity of predicting the landscape dynamics under various scenarios and thereby developing countermeasures. Developing LUCC models with high reliability still remains challenging due to complicated influencing of natural and anthropogenic factors. An adding/deleting approach is proposed in this study to explore whether and to what extent it can improve the accuracy of a hybrid LUCC model involved with cellular automata, Markov chain, and artificial neural network in the Qeshm Island, the biggest island in the Persian Gulf. The accuracy assessment was conducted by comparing the simulation results obtained from the models with the maps derived from Landsat image in 2014. The results revealed that the adding/deleting approach could improve the prediction accuracy of the model for the majority of land use classes as the area of the correctly predicted classes increased to 7.2 km2, which is greater than 6.09 km2 without using the approach. We further compared the results derived from the proposed approach with those from cellular automata-Markov chain-artificial neural network, Markov chain-artificial neural network, and cellular automata-Markov chain-logistic regression, resulting in the Figure of Merit index of 7.8 with this approach, compared to 6.7, 5.1, and 4.5 with the other three models mentioned above. This study demonstrates that the proposed approach is effective for improving the performance of LUCC modeling.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Land use/cover (LU/LC) and its underlying anthropogenic exploitation are crucial links between human activities and the natural environment on the Earth (Liu et al. 2017a, b; Muceku et al. 2016). Spatiotemporal LUCC simulations are beneficial and repeatable tools for studying and analyzing causes, trends, and consequences of alternative future landscape dynamics relative to socio-economic and natural environmental driving forces (Jia et al. 2018; Liu et al. 2017a, b; Verburg et al. 2004). The experimental modeling of land use changes is a complicated spatial dynamic and a nonlinear process (Verburg et al. 2002) to identify the patterns of changes and determine the effective variables that form the basis for modeling and prediction of future regional changes (Sangermano et al. 2012). Land change simulation is emphasized as the changing processes are accelerated due to socio-economic drivers or intense human activities.
Various approaches have been proposed to model LUCC including a multi-agent systems model (Tian and Qiao 2014; Castella and Verburg 2007), generalized linear models, unbalanced support-vector machines (Huang et al. 2009), or aggregated multivariate regression models (Yu et al. 2011; Zang and Huang 2006). The advantages and disadvantages of LUCC models have been discussed widely in the literature. For instance, the Markov chain approach can be used to predict land use changes (Liu et al. 2017a, b), but it fails to simulate the changes in the spatial distribution (Du et al. 2010). In addition, a Markov chain optimization procedure provides adequate information to support decisions; yet, it fails to present land use dynamic variations (Karimi et al. 2018; Yang et al. 2012). Hybrid models, obtained from integration of several individual models, have been recommended as a more viable modeling strategy (Marquez et al. 2019; Ghosh et al. 2017; Wang and Murayama 2017). For instance, the integration of the cellular automata (CA) and the Markov chain approaches has been used for simulation of LUCC, resulting in an improved modeling performance (Ghosh et al. 2017; Jokar Arsanjani et al. 2013). Moreover, to optimize probability maps of changes, genetic algorithm or neural network has been recently applied for LUCC modeling (Soares-Filho et al. 2013). The main goal behind integration of these models is to eliminate their defects while taking advantages of each of them.
Although integrated models are frequently and commonly used to study LUCC, there is still a limited understanding of the relationship between these factors and the causal chains constituting LUCC processes (Verburg et al. 2006). Generally, driving forces and variables of LUCC could be divided into two categories that include socio-economic and geographical factors (Jia et al. 2018). The first category often focuses on topography, location, and urban infrastructures, while the second category concentrates on GDP, amount, and density of population (Zhang et al. 2013). The selection of spatial and attribute variables for modeling and simulation procedures depends on such factors based on the objective of the study as well as the data availability. Location of a study area also affects the variables selection which specifies the parameters in the modeling procedure. But in addition to accessing the required data (Samardžić-Petrović et al. 2017), an important issue is which variables positively affect the final accuracy.
Improving the accuracy of modeling land use changes has always been a challenge in the field of land use change studies and researchers have explored different solutions for improving the accuracy of models (Shafizadeh-Moghadam et al. 2017; Kazemzadeh-Zow et al. 2017; Yirsaw et al. 2017; Chang-Martinez et al. 2015; Olmedo et al. 2015; Geri et al. 2011; Pontius and Malanson 2005). One option is to screen effective parameters by calibration procedure so as to improve the accuracy of models (Verstegen et al. 2014). In this view, it is expected that selection of effective variables, and excluding those that are considered less important, may improve the structure of a model and consequently enhance its performance (Wang et al. 2011). In addition, this approach can be effectively used to interpret and identify the factors that are important in land use changes. Given the difference in the causal-relationship patterns affecting LUCC processes in geographical regions, with the aid of this approach, we can advance our understanding of such differences and gain a better insight into the causal factors affecting the LUCC patterns. Furthermore, the analysis of the variable importance can help to reinforce the model structure, identify the critical inputs, and prioritize the tasks for updating, modifying, and simplifying a model (Ligmann-Zielinska 2013; Lilburne and Tarantola 2009). Moreover, according to the parsimony rule proposed by William of Ockham, the fourteenth-century philosopher, we should exclude factors that we do not have a proper understanding of and go straight forward to “the most accurate solution to a problem that is also the simplest and the shortest solution”. Hence, the inclusion of the variables that positively affect the accuracy of the results and the exclusion of the variables that are not important may contribute to end up with a parsimonious model and may also improve its accuracy.
In this sense, the main aim of this study is to explore whether and to what extent an adding/deleting approach can improve the accuracy of a hybrid LUCC model, in which cellular automata, Markov chain, and artificial neural network models are integrated. Adding/deleting approach is used as a technique for sensitivity analysis to measure the effect of parameters on different phenomena. To the best of our knowledge, this is the first time that an adding/deleting approach is developed for improving LUCC modeling. We have also applied special parameters for coastal regions such as “Distance to coastline”, “Distance to Mangrove forest”, and “Distance to Ports” as effective variables in LUCC modeling that could be considered as other innovations in this study. The result of the proposed approach has been compared with other commonly used hybrid modeling methods including CA_MC_ANN (cellular automata-Markov chain-artificial neural network), MC_ANN (Markov chain-artificial neural network), and CA_MC_LogReg (cellular automata-Markov chain-logistic regression) to validate the proposed method. Moreover, this study aims to obtain a sufficient understanding of the trend of LUCC in the Qeshm Island and identify the variables that have a positive impact on LUCC modeling process.
Materials and methods
Study area
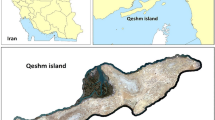
Qeshm Island with an area of approximately 1500 km2, is located in the south of Iran as the biggest island in the Persian Gulf from 55°14′58″E to 56°17′27″E and from 27°00′00″N to 26°32′04″N (Fig. 1). Qeshm is a large and diverse landscape that represents great ecological richness due to its geomorphology, climate, and hydrology. We can also see a diverse architecture and culture in this coastal zone that contains active ports, which play an effective role in connecting the island, as Free Zone Area, to the other commercial centers in the region for trading purposes. In addition, fisheries, tourism, and energy are related activities that have shown to highly impact the economic performance of the area (Bayani 2016). Furthermore, Mangrove Forests in this island shaped the largest mangrove community in Iran’s coasts that turned this island into a very important area in terms of environmental resources.

Location of the study area in the south of Iran in the north of Strait of Hormuz between the Persian Gulf and Oman
Data preparation
Landsat data, in particular, are an irreplaceable source of satellite images, as they offer an extensive archive for retrospective Land Use/Land Cover (LULC) studies (Shafizadeh-Moghadam et al. 2017). We used Landsat images (the following table-totally 6 Scenes) from USGS Landsat Archive-Level-1 (Table 1):
The topographic map of the Qeshm Island, generated by Iran’s National Cartographic Centre at the scale of 1:25,000 and the Google Earth software were used to extract training data (Keshtkar et al. 2017).
In this research, changes were detected using the post-classification method. First, cloud-free Landsat images were selected (level 1 products) and downloaded from the USGS archive as the dates of the images were close to the plant growth season (in the spring). The study area was identified and masked on the images and to use all of the image bands in the classification process, all bands (except for the thermal bands due to the spatial resolution) of each image were combined using the Layer-Stacking command and the mosaic of images was created for further processing. In the processing stage, first, the following six classes were defined in the classification phase: built-up, agricultural, dense vegetation, mangrove, water body, and barren land (Table 2).
Given the importance of the two classes, “Built-up” and “Agriculture”, we used an on-screen digitizing method to draw their boundaries using high-resolution satellite images derived from Google Earth software, in conjunction with topographic maps and pan-shaped images to make the identification of these classes more efficient. The remaining four land use classes were detected using the maximum likelihood (ML) method given the training samples from those classes. The maximum likelihood procedure is the most widely used classifier of remotely sensed imagery and is based on Bayesian probability theory (Eastman 2015, Ozturk 2015). We then merged the output of the classifier to the two classes, extracted from the on-screen digitizing, to obtain the final land use maps consisting of six classes. In order to evaluate the accuracy of the maps, 300 control points were randomly drawn from the study area for each year, and the true classes were identified at each location using the visual interpretation of the corresponding high-resolution images derived from Google Earth and also the pan-shaped Landsat images. By comparing the true classes with the generated land use maps, several accuracy metrics were calculated including the overall, user and producer accuracy as well as the kappa coefficient (Table 3).
Figure 2 illustrates the classification results using the combination of on-screen digitizing and supervised classification-ML on the Qeshm Island in the form of Land use maps prepared in six classes.

Land use maps of Qeshm Island for 2002–2014
Simulation of LUCC
Cellular automata
Cellular automata, defined in a raster space, is a modeling technique that is widely used in simulations of natural and synthetic processes due to its discrete dynamic nature. In a model based on the cellular automata, space is defined as a raster lattice and each unit is called a cell. This model is developed based on interactions between the following components: (1) the network space, which is known as the lattice; (2) cells that constitute the lattice; (3) the cell state that represents the quality and the states of the cell; and (4) the transition rules that control the changes of the cell state (Mitsova et al. 2011). The transition rules can be either global or local. In this study, the Markov chain and artificial neural network (ANN) models were adopted in our hybrid model as a data-driven approach to generate global and local rules. The cellular automata then updated the lattice cells discretely and simultaneously according to the local and global rules. The value of each new cell is determined based on the values of a set of variables at the cell, as well as at the neighboring cells, as the output of the modeling process. The cellular automata model is obtained using eq. 1:
where S denotes the limited and discrete cell state and N is the cell context. Further, t and t + 1 stand for the two different times, and f denotes the transition rules of the cell states in the local space (Sang et al. 2011).
Markov chain model
The Markov chain (MC) turned to be an important prediction method in the field of geographical research that can be used in the prediction of geographical features with no aftereffect (Sang et al. 2011). A model based on the Markov chain can express land use transitions between two periods of times that will be used to map the changes. The transitions are generated and put in a probability matrix of transitions that provides a basis for predicting and mapping future changes. The Markov chain model uses the conditional probability of Bayes’ formula to predict the land use changes (eq. 2):
where S(t) and S(t + 1) are the system states at times t and t + 1, respectively. In addition, p(ij) is the transfer probability matrix for one state, which is obtained using eq. (3) (Sang et al. 2011):
The Markov chain models are considered effective means of modeling land use evolution and provide indices for determining the directions and changes in land uses (Eastman 2015; Benito et al. 2010).
Multi-layer perceptron neural network
We used an artificial neural network (ANN) algorithm with a multi-layer perceptron (MLP) setting to calculate the probability of potential changes for the land uses in our study area. ANN is a learning algorithm, composed of several interconnected networks of processing units (artificial neurons) that is inspired by the biological neural network. This algorithm can learn from data and detect patterns with nonlinear structure by converting the system inputs to the user’s desired outputs. In ANN, artificial neurons are organized into layers. An MLP is a form of ANN with at least three layers that can be used to estimate the inherent relationships between the inputs and outputs of a model. It is also the most commonly used network model for image classification in RS (Yuan et al. 2009). The combination of the MLP approach and the back-propagation learning algorithms (or BP which is used in ANN to calculate the error contribution of each neuron after a batch of data is processed; for example, in image recognition multiple images) is one of the most common models of neural networks (Kazemzadeh-Zow et al. 2017). A typical MLP network is composed of an input layer, one or several hidden layers, and an output layer (Eastman 2015) which are used for entering data, processing data, analyzing data, and producing outputs, respectively (Yuan et al. 2009). In this research, the transition potential maps (TPM) values based on the land use changes between two time periods, 2002 and 2008, are used as the output layer (also called response variable), and the factors (also called the predictors) that derive the changes are organized in the input layer. In addition, the hidden layer was used to identify the relationships between the modified pixels and the criteria.
The MLP neural network links the response variable to the predictors using two procedures, forward and backward propagation steps, which are taken to make the corrective changes to the neuron connection weights. In the training stage, each sample is added to the model input layer and the receptor node collects all of the weight signals transmitted from all of the nodes to the node connected to the previous layer. Equation4 is utilized to calculate the input received by a simple node, j, in MLP.
Where netj refers to the input that a single node j receives; wj represents the weight between node i and node j and oi is the output from node i. The output from a node i was calculated through eq. (5):
It must be noted that the f function is normally a sigmoidal nonlinear function used to calculate the total input weight before the signal reaches the next layer. During this process, after forwarding the signals, the activity of the output nodes is compared to the expected activity. However, under special conditions, the actual output of the modeling process differs from the target output due to the network errors. In this case, eq. 6, which is known as the delta rule, can be used to backward the errors so as to correct the relationships between the network components.
In this relation, η is the learning speed, ais the stimulus factor, and δis the calculation error. The forward and backward transmission process continues until the features of all land use classes are taught to the network with the aim of obtaining the proper weight for the accurate relationship between the input layer and the hidden layer(s) as well as between the hidden layer(s) and the output layer. Equation (7) is used to calculate the number of hidden nodes.
where Nh, Ni, and NO show the number of the hidden nodes, input nodes, and output nodes of the network, respectively (Eastman 2015).
Sensitivity analysis through adding/deleting approach
A challenging problem in modeling land use changes is the calibration of the models (Van Vliet et al. 2016; Wang et al. 2012; Wang et al. 2011; Silva and Clarke 2002). To achieve more accurate models, integrated methods are proposed with various algorithms (Yirsaw et al. 2017; Chang-Martinez et al. 2015; Muceku et al. 2015). Sensitivity analysis can be used for a better understanding of components on modeling procedure, identifying of errors, and performance of variables (Li et al. 2014). In order to improve the calibration of a land use change model, the present study utilizes a procedure to select the effective variables in the modeling and explores whether this procedure improves the accuracy of the model.
We used the adding/deleting procedure through the repetitive model calibration to examine the effect of the input variables that may also be considered as a sensitivity analysis procedure. This method measures the sensitivity of the model to various combinations of the variables by deleting and adding variables to the model (Ligmann-Zielinska 2013). Through a repetitive model calibration, every time a variable is excluded from the model to measure its impact on the performance of the model. Finally, the variables that have no positive effects on the accuracy of the model will be excluded from the model structure. This will result in a parsimonious model that is expected to also improve the accuracy of the modeling results.
CA-Markov
There are various approaches to modeling LULC, such as equation-based models, system models, statistical techniques, expert models, evolutionary models, cellular models (including cellular automata and Markov chain) multi-agent (Parker et al. 2003), and hybrid models including CA-Markov (Yirsaw et al. 2017; Chang-Martinez et al. 2015). In this study, a hybrid model based on coupling cellular automata and Markov chains (hear after CA-Markov) was used which is a multi-criteria evaluation method that simultaneously uses CA and Markov chain modules. Using the expected value of change through Markov chain analysis, CA–Markov applies a contiguity kernel to ‘grow out’ a land use map to a later time period using a CA function (Jokar Arsanjani et al. 2011). Thus, this method has the ability to convert the results of the Markov chain by means of a CA function to spatially explicit outcomes (Pontius et al. 2004).
CA–Markov model is a robust approach due to its ability to employ Geographic Information Systems (GIS) and remote sensing (RS) data and quantity estimating as well as modeling the spatial and temporal dynamics of LUCC (Jokar Arsanjani and Kainz 2011). In the CA-Markov, the CA approach is used to control Markov’s strict function for considering both the spatial and temporal changes at the same time. A range of data including demographic, biophysical, and socio-economic data can be used in the model to determine the initial conditions, and then parameterize the model to generate the probability of transitions, that can be used to define the neighborhood rules and preparing the transition potential maps (TPM) (Kamusoko et al. 2009). Figure 3 illustrates the overall process of this study.

Flowchart of the methodology and main steps in the study
Validation
In order to validate the modeling results, the produced maps by different approaches have been compared with land use map in 2014. To describe the difference between predicted maps and real map, disagreement parameters recommended by Pontius and Millones have been used in this study. According to this method, quantification error and allocation error are presented to explain the accuracy of the modeling process. Quantification error or quantity disagreement is defined as the number of pixels of a category in the predicted map which are not matched with the corresponding cells in the original map. Likewise, location error or allocation disagreement would happen when the position of a class in predicted maps is not compatible with a real map. In this method, the Figure of Merit (FOM) is derived through eq. (5) to show compatibility between changes in predicted and observed maps which range from 0 to 100% (Tajbakhsh et al. 2018; Pontius and Millones 2011).
where A is the amount of observed change projected as persistence; B is the area of observed change predicted as change correctly; C is the observed change projected as change but in an incorrect class; and D is the area of error because of the observed persistence projected as change (Tajbakhsh et al. 2018; Pontius and Millones 2011).
In addition to the above method, the kappa coefficient which is still used in many similar studies (Alilou et al. 2018; Rimal et al. 2018) was used to validate the results of this study.
Results
Model configuration
In this study, the CA_Markov_ANN hybrid model integrated with adding/deleting applied to screen variables has been used to simulate LU/LC of 2014 based on LU/LC maps of 2002 and 2008. Markov chain and ANN output have been used as inputs of the CA model in order to predict LUCC. The initial required data for LUCC modeling are LU/LC and variables which affect LU/LC changes (Yang et al. 2015). To this end, at first, LU/LC maps were extracted for three time intervals (2002, 2008, and 2014), and effective variables on land changes were prepared according to the literature survey, previous studies carried out in this field and available information for the study area. Based on the former studies considering modeling LUCC, two types of information should be generated from the initial data for modeling process: (1) quantity of changes and (2) transition potential maps-TPM (Jia et al. 2018; Xu et al. 2018; Kazemzadeh-Zow et al. 2017; Zhai et al. 2016; Brown et al. 2013). For this purpose, Markov chain was used to generate “quantity of changes” for each class separately. In fact, based on the changes that took place between 2002 and 2008, the probability of a possible change has been estimated for 2014 through using MLP. At this stage, in order to improve the accuracy of the modeling results, the disturbing variables were identified by using the sensitivity analysis (adding/deleting approach) method and were eliminated from the model.
In this study, 17 variables were used in the study area (Table 5). It has been tried that these variables be selected from 4 mainly categories include utilities, socio-economic, physical, and finally environmental factors that were earlier considered by Aburas et al. in their study. First, all 17 variables (listed in Table 5) were introduced into the model and the model was run. To validate the result of modeling, the produced map was compared with observed LU/LC map of 2014. Each time, one variable was removed and the model was run to simulate LUCC for every class separately, and each time, the result was compared with the real map of 2014 and accuracy of the result was compared with the case where all variables have been used. Indeed, the variables which deletion increased the accuracy of the results were known as disturbing variables and were excluded from the model in the final model. This process was repeated for all six classes. Comparison between the results of the final and initial models demonstrated that the accuracy of the modeling improved by identifying and eliminating the disturbing variables.
Predicting LUCC was done through using the land change modeler (LCM) which is developed by Clark University in IDRISI-TerrSet software. Transition potential map (TPM) and the quantity of changes in land use maps were used to assess the simulation in 2014 (Tajbakhsh et al. 2018). Markov chain as the most common stochastic method (Kazemzadeh-Zow et al. 2017) was used to obtain TPM. The summary of Markov probability matrix (Table 4) shows that the highest probability is related to the transitions of different classes to “Built_up”. Among these classes, “Agriculture” has the highest probability to be changed into the “Built-up” areas, and then “Dense_Vegetation”, “Bare_Land”, “Water_Body”, and “Mangrove” were in the next ranks, respectively.
Modeling the transition potential maps using MLP neural network
Modeling of the potential land use change transitions links the changes between different classes in a time period to the variables that may derive the changes (such as slope, proximity to the road, and other variables). For example, it can show the potential of transition from barren-land to built-up at each cell in the form of probability. Switching from one land use class to another is introduced with the aid of sub-models known as the transition models which is a key parameter for MC (Zhai et al. 2016). Selection of the sub-models was also assessed in this research based on the dominance of the changes that had occurred in one region in different scenarios. In this regard, the scenarios containing variation prediction sub-models were selected using trials and errors, and eventually, the scenario offering the best description of the regional changes from 2008 to 2014 was used to predict the changes. In this study, in order to predict the changes in the land use map of 2014, 23 sub-models of the transitions from barren-land to built-up and agriculture, and also the transitions from agriculture to built-up were fitted using MLP-ANN. Figure 4 shows the rate of potential change of each class to other classes for 2014.

Changes potential maps based on land use classes for 2014. Agriculture (a), Barren_land (b), Built_up (c), Dense_vegetation (d), Mangrove (e), Water body (f)
Using adding/deleting approach to improve the model performance
In this study, through a repetitive modeling process, one of the variables was removed at each run, and its performance was compared with the model used all the variables. Figure 5 shows the final predicted map for 2014.

Land cover simulation for 2014
Table 5 shows the results of adding/deleting procedure in evaluating the effects of different variables on the model performance for each land use class. Therefore, in this process, the impact of each variable was measured on the modeling process and in order to increase the accuracy of the simulation, the inclusion of variables with a negative impact were prevented in the model. Out of the 17 variables used in the models, “Elevation”, “Distance to Mangrove forest”, and “Distance to the road” were the only variables that were involved in the modeling of the changes of all the six classes. Elevation which is known as a geographical driver was used to develop a new approach for LUCC simulation in China (Xu et al. 2018) and the positive impact of “Distance to Mangrove forest” as one of the specific variables in coastal areas was considerable. However, “Distance to Vegetation”, “Distance to built-up areas”, “Distance to coastline”, and “Soil Condition” had a positive effect on improving the accuracy of the models for only three land use classes.
According to the results of this section, the correctly predicted land use changes increased from 6.09 to 7.2 km2 after applying the adding/deleting procedure. Increasing the accuracy of modeling has predominantly occurred in Barren lands and Mangrove classes (Table 5).
Table 6 shows the level of accuracy for each land use class before and after using the adding/deleting procedure. The results revealed that, with the exception of the “Dense Vegetation” class, the accuracy of the predicted changes for all the land use classes increased after calibrating the model by adding/deleting procedure. For “Dense_Vegetation class”, the accuracy was reduced by approximately 0.01 km2, which is not a big number in comparison with the size of the study area. This class, which is much affected by the annual precipitation, suffered from large changes. In total, the areas that were correctly predicted increased by more than 1.1 km2 overall after using our approach, which represents more than 18% of the study area that has been changed.
Among all the classes of the land use maps, the highest increment in the level of accuracy was attributed to Bare_Land, Mangrove, and Agriculture. In addition, the highest and the lowest numbers of the variables that had a positive effect on the accuracy of a class belonged to the prediction by the Water_Body class (i.e., 15 variables) and the Dense_Vegetation class (i.e., 10 variables), respectively (Fig. 6).

Green bars show the correct predicted changes after adding/deleting and the red bars show correct predicted changes before adding/deleting (a left, unit: km2)- ). The number of variables used to model in every class (b right)
Results of validation
To validate the methods of modeling in this study, the 3D method which is suggested by Pontius-Millones has been used. This technique has been recently used in similar studies (Varga et al. 2019; Tajbakhsh et al. 2018; Yao et al. 2017). In this method, the FOM is derived through the percentage of “change simulated correctly” dividing on all agreement/disagreements. As seen in Table 7, the main sector of the study area (more than 96%) is simulated correctly as persistence in four methods. It has also been reported in a study conducted by Tajbakhsh et al. (2018), and due to its extensive range, this section is removed from the graph in Fig. 7. According to table, the “change simulated correctly” range and the FOM factor (as the final factor for accuracy evaluation in 3D method) in the proposed method of this study are more than other methods used for comparison. Also, the percentage of “Persistence simulated as change” as one of the disagreements is lower than others. Details of this comparison are also evident in the diagram shown in Fig. 7.

Agreement and disagreement components in 1-CA_MC_LogReg, 2-MC_ANN, 3-CA_MC_ANN, and 4-CA_MC_ANN_SA
In addition to the Pontius-Millones method, in this research, the standard Kappa index, which is also used in many other modeling LUCC studies (Yulianto et al. 2018; Kazemzadeh-Zow et al. 2017; Zhai et al. 2016; Han et al. 2015) was used to measure the accuracy of the model predictions and verify the validation of the modeling. In this approach, the general correction is the proportion of the similar pixels to the total number of pixels which is being compared. Therefore, in order to validate the results of the CA-Markov combinational model, the simulated maps from 2014 were compared with the real map and the Kappa standard coefficient for the results was 0.94. The results of the comparison by the differentiation of the land use classes are shown in Table 8. As illustrated in the table, the maximum of the Kappa coefficient is related to the barren land and water body which have a larger area in comparison with other classes. Also, a visual comparison between simulated map from 2014 after adding/deleting with the simulated map before adding/deleting demonstrates increment of accuracy in the simulated map using adding/deleting approach (Fig. 8).

Comparison of the simulated map after adding/deleting (top) with the simulated map before adding/deleting (down)
Discussion
In general, the accuracy has always been an important issue in studies whose purpose is to model and predict changes of phenomena or their behaviors including LUCC. This is even more important in modeling and simulation of land use changes (Olmedo et al. 2015) as achieving such the model with high accuracy is a difficult task, and using the suitable modeling approach in order to achieve the goals, is essential (Brown et al. 2013). Cellular automata (CA) has been widely used to simulate spatiotemporal properties of complex systems and environments (Yang et al. 2012; Clancy et al. 2010). Recently, hybrid models in which CA was integrated with other models such as Markov chains, logistic regression, neural network, etc. have been developed to simulate and predict LUCC (Rimal et al. 2018; Yirsaw et al. 2017; Chang-Martinez et al. 2015). Each of these models individually has capabilities and also can act as a complementary of others. More or less, CA-Markov modeling has given promisingly accurate and reliable results in most of their applied fields in the geographic and spatial domain (Ghosh et al. 2017), such a way that it can be said CA-Markov has become the most common method for LUCC simulation (Yulianto et al. 2018). In fact, it can be claimed that the result of modeling using this method is comparable to actual LULC changes (Halmy et al. 2015). Nevertheless, attempts to increase the accuracy of this model and other LUCC modeling approaches are followed by the scientific community (Brown et al. 2013).
In this study, CA-Markov was used to model LUCC in the Qeshm Island. In addition, the ANN was used to simulate the behavior of the pixels due to its ability to model nonlinear relationships in complex systems (Yang et al. 2015; Pijanowski et al. 2014). Although the ANN can determine the locations of the changes, it has low efficiency for determining the amount and type of changes. The empirical and dynamic methods are used to solve this problem. The Markov model can depict the direction of LUCC shifts and predict the future land requirements for land use categories by taking into account the influence of related factors on land use requirements (Han et al. 2015). Therefore, a hybrid model, which combines these three parts, can increase the modeling efficiency. The high accuracy of this hybrid method was mentioned by Zhai et al., but this does not mean that this model is perfect (Zhai et al. 2016) and improving the efficiency of this method is still required.
Variables used for LUCC modeling can help us to understand the causes of change and are also an important part of the simulation (Zhai et al. 2016). Furthermore, identifying and determining the variables affecting the pattern of land use changes is one of the issues that help us ameliorate the performance of the model (Aburas et al. 2016; Mishra et al. 2014). Given that the pattern of land use changes varies from region to region and depends on geographical conditions and characteristics, it is difficult to come up with a list of definite and identical variables. Different set of variables have been employed for modeling LUCC in various studies (Zeng et al. 2015; Chowdhury and Maithani 2014). Previously, efforts have been made to identify the variables that are more appropriate for the modeling process of LUCC (Zhai et al. 2016). For example, in a study by Dubovyk et al., two sets of factors were introduced including firstly, the factors determined by the experts and secondly, the factors that could be selected through the literature (Dubovyk et al. 2011). Aburas et al. (2017) also mentioned that variables could be selected based on experts’ experiences (). In our study, however, we used the adding/deleting approach that is also useful to explore the contribution of different variables to account for the changes in the models. We argue that incorporating such the approach in studies can help us identify the effective or useless variables, and consequently, improve the model calibration.
Analyzing and comparing the simulated with the observed maps for the year 2014 shows that the CA-Markov model is generally reliable for modeling and predicting the LUCC in the Qeshm Island. However, as also discussed by Zhou et al. (2012) in their study, for classes that are highly sensitive to environmental or socioeconomic factors (i.e., the changes in these factors can lead to notable changes in the classes), we may need further information or appropriate incorporations of additional variables in the modeling process. For example, a Built-Up class is affected by management decisions and regional development plans. Thus, we need to incorporate the management policies into the modeling process to obtain more accurate results for this class. While the CA-Markov model implements the contiguity rule to simulate changes in a land use class due to the proximity of the class to a similar class within the scope of the study (Kamusoko et al. 2009) and does not consider socio-economic factors and policies in modeling process. This issue has also been highlighted in a study performed by Jokar Arsanjani et al. (2011).
The strong reliance of the Dense_Vegetation class on the precipitation, which can cause difficulty in the process of simulation and prediction of its changes, is a significant issue in this study. While in areas where precipitation is not considered a limiting factor (for example, in the eastern and southeastern parts of China), it is expected that socio-economic factors play a major role (Shi et al. 2018). This means that, due to the importance and influence of managerial factors and human decisions on land use changes in the region, the results showed in order to achieve a higher accuracy, we need to apply bio-physic, socio-economic and human variables in the modeling process (Guerrero et al. 2018; Jokar Arsanjani et al. 2011). For instance, multi-agent models have recently been developed to simulate land use changes; hence, taking human behavior into the expansion of built-up usage would certainly increase prediction accuracy (Jokar Arsanjani and Kainz 2011; Parker et al. 2003). Despite the problems mentioned above, the present study achieved its goal of identifying effective and disturbing variables using the adding/deleting technique and ultimately improved the accuracy of the results. With taking the achievements of this research into account, using the adding/deleting method can improve the accuracy of “Cellular Automata-Markov Chain-Artificial Neural Network” for land use changes modeling.
Conclusions
We developed an adding/deleting approach in this study as an innovation to improve efficiency of model and then applied it in the Qeshm Island to explore whether it could identify the effective and disturbing variables in the hybrid land change model and improve the accuracy of the simulation. We identified the disturbing variables using the proposed approach and then excluded them from the hybrid model, which ultimately resulting in an increased accuracy of the land use change predictions. The area of the correctly predicted classes increased to 7.2 km2, which was greater than 6.09 km2 without using the proposed approach. Among 17 variables that have been used in the modeling process, “Elevation”, “Distance to Mangrove forest”, and “Distance to the road” were introduced as the positive variables used to simulate all classes. Therefore, the significance of these variables is more than other variables.
The proposed adding/deleting approach and its integration with CA-Markov for screening the effective and disturbing variables can help to improve the performance of model. The findings confirmed the importance of model configuration and the appropriate framework of the effective elements in the modeling process in the study area since these elements can affect modeling outputs in different ways. Particularly, socioeconomic and managerial factors should be seriously taken into consideration when performing LUCC modeling. Due to the climatic conditions in the study area, which is located in a dry climate, the strong dependence of vegetation on annual precipitation is evaluated as a challenge in the modeling process. However, this issue is recommended to be assessed in similar climates. Furthermore, this article is limited to the Qeshm Island in the Persian Gulf and the implementation of the same approach for other regions especially in different climate zones and different countries is highly recommended.
References
Aburas MM, Ho YM, Ramli MF, Ash’aari ZH (2016) The simulation and prediction of spatio-temporal urban growth trends using cellular automata models: a review. Int J Appl Earth Obs Geoinf 52:380–389
Aburas MM, Ho YM, Ramli MF, Ash’aari ZH (2017) Improving the capability of an integrated CA-Markov model to simulate spatio-temporal urban growth trends using an analytical hierarchy process and frequency ratio. Int J Appl Earth Obs 59:65–78
Alilou H, Moghaddam Nia A, Keshtkar HR, Han D, Bray M (2018) A cost-effective and efficient framework to determine water quality monitoring network locations. Sci Total Environ 624:283–293
Bayani N (2016) Ecology and environmental challenges of the Persian Gulf. Iran Stud 49(6):1047–1063
Benito PR, Cuevas JA, Bravo R, Barrio JMGD, Zavala MA (2010) Land use change in a Mediterranean metropolitan region and its periphery: assessment of conservation policies through CORINE land cover data and Markov models. Forest Syst 19:315–328
Brown DG, Verburg PH, Pontius RG, Lange MD (2013) Opportunities to improve impact, integration, and evaluation of land change models. Curr Opin Environ Sustain 5(5):452–457
Castella JC, Verburg PH (2007) Combination of process-oriented and pattern-oriented models of land use change in mountain area of Vietnam. Ecol Model 202:410–420
Chang-Martinez LA, Mas JF, Valle NT, Torres PSU, Folan W (2015) Modeling historical land cover and land use: a review from contemporary modeling. ISPRS Int J Geo-Inf 4:1791–1812
Chowdhury PR, Maithani S (2014) Modelling urban growth in the indo-Gangetic plain using nighttime OLS data and cellular automata. Int J Appl Earth Obs 33:155–165
Clancy D, Tanner JE, McWilliam S (2010) Quantifying parameter uncertainty in a coral reef model using Metropolis-coupled Markov chain Monte Carlo. Ecol Model 221:1337–1347
Du YY, Wen W, Cao F, Ji M (2010) A case-based reasoning approach for land use change prediction. Expert Syst Appl 37:5745–5750
Dubovyk O, Sliuzas R, Flacke J (2011) Spatio-temporal modeling of informal settlement development in Sancaktepe district, Istanbul, Turkey. ISPRS J Photogramm Remote Sens 66(2):235–246
Eastman JR (2015) IDRISI TerrSet, guide to GIS and image processing, manual version 18.00. Clark University, Worcester
Geri F, Amici V, Rocchini D (2011) Spatially-based accuracy assessment of forestation prediction in a complex Mediterranean landscape. Appl Geogr 31(3):881–890
Ghosh P, Mukhopadhyay A, Chanda A, Mondal P, Akhand A, Mukherjee S, Nayak SK, Ghosh S, Mitra D, Ghosh T, Hazra S (2017) Application of cellular automata and Markov-chain model in geospatial environmental modeling- a review. Remote Sens Appl Soc Environ 5:64–77
Guerrero P, Haase D, Albert C (2018) Locating spatial opportunities for nature-based solutions: a river landscape application. Water 10(12)
Halmy MWA, Gessler PE, Hicke JA, Salem BB (2015) Land use/land cover change detection and prediction in the northwestern Coastal Desert of Egypt using Markov-CA. Appl Geogr 63:101–112
Han H, Yang C, Song J (2015) Scenario simulation and the prediction of land use and land cover change in Beijing-China. Sustainability 7:4260–4279
Huang B, Xie C, Tay R, Wu B (2009) Land-use-change modeling using unbalanced support-vector machines. Environ Plann B Plann Des 36:398–416
Jia Z, Ma B, Zhang J, Zeng W (2018) Simulating spatial-temporal changes of land-use based on ecological redline restrictions and landscape driving factors: a case study in Beijing. Sustainability 10(4)
Jokar Arsanjani J, Kainz W (2011) Integration of agent based modeling and Markov model in simulation of urban sprawl. Proceeding of AGILE 2011 Conference, Utrecht
Jokar Arsanjani J, Kainz W, Mousivand AJ (2011) Tracking dynamic land use change using spatially explicit Markov chain based on cellular automata: the case of Tehran. Int J Image Data Fusion 2(4)
Jokar Arsanjani J, Helbich M, Kainz W, Boloorani AD (2013) Integration of logistic regression, Markov chain and cellular automata models to simulate urban expansion. Int J Appl Earth Obs Geoinf 21:265–275
Kamusoko C, Aniya M, Adi B, Manjoro M (2009) Rural sustainability under threat in Zimbabwe – simulation of future land use/cover changes in the Bindura district based on the Markov-cellular automata model. Appl Geogr 29(3):435–447
Karimi H, Jafarnezhad J, Khaledi J, Ahmadi P (2018) Monitoring and prediction of land use/land cover changes using CA-Markov model: a case study of Ravansar County in Iran. Arab J Geosci 11:592
Kazemzadeh-Zow A, Shahraki SZ, Salvati L, Samani NN (2017) A spatial zoning approach to calibrate and validate urban growth models. Int J Geogr Inf Sci 31(4):763–782
Keshtkar H, Voigt W, Alizadeh E (2017) Land-cover classification and analysis of change using machine-learning classifiers and multi-temporal remote sensing imagery. Arab J Geosci 10:154
Li X, Liu X, Le Y (2014) A systematic sensitivity analysis of constrained cellular automata model for urban growth simulation based on different transition rules. Int J Geogr Inf Sci 7:1317–1335
Ligmann-Zielinska A (2013) Spatially-explicit sensitivity analysis of an agent-based model of land use change. Int J Geogr Inf Sci 27:1764–1781
Lilburne L, Tarantola S (2009) Sensitivity analysis of spatial models. Int J Geogr Inf Sci 23(2):151–168
Liu X, Liu X, Liang X, Li X, Xu X, Ou J, Chen Y, Li S, Wang S, Pei F (2017a) A future land use simulation model (FLUS) for simulating multiple land use scenarios by coupling human and natural effects. Landsc Urban Plan 168:94–116
Liu D, Zheng X, Zhang C, Wang H (2017b) A new temporal–spatial dynamics method of simulating land use change. Ecol Model 350:1–10
Marquez MA, Guevara E, Rey D (2019) Hybrid model for forecasting of changes in land use and land cover using satellite techniques. IEEE J Sel Top Appl Earth Obs Remote Sens 12(1):252–273
Mishra VN, Rai PK, Mohan K (2014) Prediction of land use changes based on land change modeler (LCM) using remote sensing: a case study of Muzaffarpur (Bihar), India. J Geogr Instit Jovan Cvijic 64(1):111–127
Mitsova D, Shuster W, Wang X (2011) A cellular automata model of land covers change to integrate urban growth with open space conservation. Landsc Urban Plan 99(2):141–153
Muceku Y, Reçi H, Kaba F, Kuriqi A, Shyti F, Kruja F, Kumbaro R (2015) A case study: Integrated Geotechnical and Geophysical-ERT Investigation for Bridge Foundation of Tirana Bypass. International Congress on Roads. AACE, Tirana
Muceku Y, Korini O, Kuriqi A (2016) Geotechnical analysis of hill's slopes areas in heritage town of Berati, Albania. Period Polytech Civil Eng 60(1):61–73
Olmedo MTC, Pontius RG Jr, Paegelow M, Mas JF (2015) Comparison of simulation models in terms of quantity and allocation of land change. Environ Model Softw 69:214–221
Ozturk D (2015) Urban growth simulation of Atakum (Samsun, Turkey) using cellular automata-Markov chain and multi-layer perceptron-Markov chain models. Remote Sens 7:5918–5950
Parker DC, Manson SM, Janssen MA, Hoffmann MJ, Deadman P (2003) Multi-agent systems for the simulation of land use and land-cover change: a review. Ann Assoc Am Geogr 93:314–337
Pijanowski BC, Tayyebi A, Doucette J, Pekin BK, Braun D, Plourde J (2014) A big data urban growth simulation at a national scale: configuring the GIS and neural network based land transformation model to run in a high performance computing (HPC) environment. Environ Model Softw 51:250–268
Pontius RG Jr, Malanson J (2005) Comparison of the structure and accuracy of two land change models. Int J Geogr Inf Sci 19(2):243–265
Pontius RG Jr, Millones M (2011) Death to kappa: birth of quantity disagreement and allocation disagreement for accuracy assessment. Int J Remote Sens 32(15):4407–4429
Pontius RG Jr, Shusas E, McEachern M (2004) Detecting important categorical land changes while accounting for persistence. Agriculture. Ecosyst Environ 101(2–3):251–268
Rimal B, Zhang L, Keshtkar H, Haack B, Rijal S, Zhang P (2018) Land use/land cover dynamics and modeling of urban land expansion by the integration of cellular automata and Markov chain. ISPRS Int J Geo-Inf 7(4):154
Samardžić-Petrović M, Kovačević M, Bajat B, Dragićević S (2017) Machine learning techniques for modeling short term land-use change, ISPRS. Int J Geo-Inf 6(12):387
Sang L, Zhang C, Yang J, Zhu D, Yun W (2011) Simulation of land use spatial pattern of towns and villages based on CA–Markov model. Math Comput Model 54(3):938–943
Sangermano F, Toledano J, Eastman JR (2012) Land cover change in the Bolivian Amazon and its implications for REDD+ and endemic biodiversity. Landsc Ecol 27(4):571–584
Shafizadeh-Moghadam H, Asghari A, Taleai M, Helbich M, Tayyebi A (2017) Sensitivity analysis and accuracy assessment of the land transformation model using cellular automata. GISci Remote Sens 54(5):639–656
Shi G, Jiang N, Yao L (2018) Land Use and Cover Change during the Rapid Economic Growth Period from 1990 to 2010: A Case Study of Shanghai. Sustainability 10(2)
Silva EA, Clarke KC (2002) Calibration of the SLEUTH urban growth model for Lisbon and Porto, Portugal. Comput Environ Urban Syst 26:525–552
Soares-Filho BS, Rodrigues HO, Follador M (2013) A hybrid analytical-heuristic method for calibrating land-use change models. Environ Model Softw 43(5):80e87
Tajbakhsh SM, Memarian H, Moradi K, Aghakhani Afshar AH (2018) Performance comparison of land change modeling techniques for land use projection of arid watersheds. Glob J Environ Sci Manag 4(3):263–280
Tian G, Qiao Z (2014) Modeling urban expansion policy scenarios using an agent-based approach for Guangzhou metropolitan region of China. Ecol Soc 19(3):52
Van Vliet J, Bregt AK, Brown DG, Van Delden H, Heckbert S, Verburg PH (2016) A review of current calibration and validation practices in land-change modeling. 82:174–182
Varga GO, Pontius RG Jr, Singh KS, Szabó S (2019) Intensity analysis and the figure of Merit’s components for assessment of a cellular automata – Markov simulation model. Ecol Indic 101:933–942
Verburg PH, Soepboer W, Veldkamp A, Limpiada R, Espaldon V (2002) Modelingthe spatial dynamics of regional land use: the CLUE-S model. Environ Manag 30:391–405
Verburg PH, Schot PP, Dijst MJ, Veldkamp A (2004) Land use change modeling : current practice and research priorities. GeoJournal 61:309–324
Verburg PH, Kok K, Pontius Jr RG, Veldkamp A (2006) Modeling land use and land-cover change, part of the global change - the IGBP series book series (GLOBALCHANGE), pages 117–135
Verstegen JA, Karssenberg D, Hilst FVD, Faaij APC (2014) Identifying a land use change cellular automaton by Bayesian data assimilation. Environ Model Softw 53:121–136
Wang R, Murayama Y (2017) Change of land use/cover in Tianjin City based on the Markov and cellular automata models. ISPRS Int J Geo-Inf 6(5):150
Wang F, Hasbani JG, Wang X, Marceau DJ (2011) Identifying dominant factors for the calibration of a land use cellular automata model using rough set theory. Comput Environ Urban Syst 35:116–125
Wang SQ, Zheng XQ, Zang XB (2012) Accuracy assessments of land use change simulation based on Markov-cellular automata model. Procedia Environ Sci 13:1238–1245
Xu E, Zhang H, Lina Yao L (2018) An elevation-based stratification model for simulating land use change. 10(11)
Yang X, Zheng X, Lv L (2012) A spatiotemporal model of land use change based on ant colony optimization, Markov chain and cellular automata. Ecol Model 233:11–19
Yang X, Chen R, Zheng XQ (2015) Simulating land use change by integrating ANN-CA model and landscape pattern indices. Geomat Nat Haz Risk 7:918–932
Yao Y, Li J, Zhang X, Duan P, Li S, Xu Q (2017) Investigation on the Expansion of Urban Construction Land Use Based on the CART-CA Model. ISPRS Int J Geo-Inf 6(5)
Yirsaw E, Wu W, Shi X, Temesgen H, Bekele B (2017) Land use/land cover change modeling and the prediction of subsequent changes in ecosystem service values in a coastal area of China, the Su-xi-Chang region. Sustainability 9(1204):1–17
Yu W, Zang S, Wu C, Liu W (2011) Analyzing and modeling land use land cover change (LUCC) in the Daqing City, China. Appl Geogr 31:600–608
Yuan H, Van Der Wiele CF, Khorram S (2009) An Automated Artificial Neural Network System for Land Use/Land Cover Classification from Landsat TM Imagery. Remote Sens 1:243–265
Yulianto F, Maulana T, Khomarudin MR (2018) Analysis of the dynamics of land use change and its prediction based on the integration of remotely sensed data and CA-Markov model, in the upstream Citarum watershed, West Java, Indonesia. Int J Dig Earth, published online: 19
Zang S, Huang X (2006) An aggregated multivariate regression land use model and its application to land use change processes in the Daqing region (Northeast China). Ecol Model 193:503–516
Zeng C, Liu Y, Stein A, Jiao L (2015) Characterization and spatial modeling of urban sprawl in the Wuhan metropolitan area, China. Int J Appl Earth Obs 34:10–24
Zhai R, Zhang C, Li W, Boyer MA, Dean Hanink D (2016) Prediction of land use change in Long Island sound watersheds using nighttime light data. Land 5(4)
Zhang P, Liu YH, Pan Y, Yu ZR (2013) Land use pattern optimization based on CLUE-S and SWAT models for agricultural non-point source pollution control. Math Comput Model 58:588–595
Zhou D, Lin Z, Liu L (2012) Regional land salinization assessment and simulation through cellular automaton-Markov modeling and spatial pattern analysis. Sci Total Environ 439:260–274
Acknowledgments
Anonymous reviewers supplied constructive feedback that helped to improve this manuscript.
Funding
This research was partially supported by Chinese Government Marine Scholarship (Grant No: 2016SOA016).
Author information
Authors and Affiliations
Contributions
A.K. N., J. H., and A.K. conceived and designed the project; A.K.N. and A.K. executed analyses; A. K. N, J. H., A.K., and B. N. wrote the paper.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest. The funding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
Additional information
Editorial handling: C. Gokceoglu
Rights and permissions
About this article

Cite this article
Kourosh Niya, A., Huang, J., Kazemzadeh-Zow, A. et al. An adding/deleting approach to improve land change modeling: a case study in Qeshm Island, Iran. Arab J Geosci 12, 333 (2019). https://doi.org/10.1007/s12517-019-4504-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12517-019-4504-z