
Abstract
Adaptive neuro-fuzzy inference system (ANFIS) has emerged as a synergic hybrid intelligent system. It combines the human-like reasoning style of fuzzy logic system (FLS) with the learning and computational capabilities of artificial neural networks (ANNs). ANFIS has several applications related to food processing and technology. The first part of this review provides a brief overview and discussion of ANFIS including: the general structure and topology, computational considerations, model development and testing. In the second part, two detailed examples are explained to demonstrate the capabilities of ANFIS in comparison with other modeling methods, followed by a brief but comprehensive discussion of ANFIS applications in different food processing and technology areas. The applications are divided into five main categories: food drying, prediction of food properties, microbial growth and thermal process modeling, applications in food quality control and food rheology. In all applications, the performance of ANFIS is compared to other methods such as ANNs, FLS and multiple regressions when available. It is concluded that, in most applications, ANFIS outperforms other modeling tools such as ANNs, FIS or multiple linear regression. Finally, some application guidelines, advantages and disadvantages of ANFIS are discussed.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Overview of Adaptive Neural Fuzzy Inference Systems (ANFIS)
Adaptive neural fuzzy inference system (ANFIS) was first proposed by Jang [11] as a synergic hybrid system that combines the advantages of artificial neural networks (ANNs) and fuzzy inference systems (FIS). It combines the human-like reasoning style of fuzzy logic systems with the learning and computational capabilities of neural networks. Jang [11] developed this novel architecture by introducing the learning procedure from neural network to the FIS to develop a set of fuzzy if–then rules with appropriate membership function (MFs) from the input–output data pairs. The procedure of constructing a FIS by utilizing the adaptive neural networks framework was then called adaptive network-based fuzzy inference system (ANFIS). ANFIS has been recognized as a powerful modeling tool as it is capable of combining pieces of information from several sources, including empirical models, heuristics and data. The knowledge that describes a process is usually contained in the data sets. Fuzzy inference systems (FIS) are normally incapable of learning the rules by themselves; they rather require an expert to derive the fuzzy if–then rules followed by an optimization process of the system parameters [8]. This process is usually complicated and time-consuming. Artificial neural networks (ANNs), on the contrary, have the advantage of self-learning from available data. Adaptive neural fuzzy inference system (ANFIS) was therefore developed to integrate the learning capabilities from ANNs with the reasoning capabilities from. The terminology “adaptive” means that some of the neurons in ANFIS have adjustable parameters that influence the outputs where the learning rules specify the magnitude of change in these parameters in order to achieve a predetermined minimum error [11]. Zheng et al. [36] reported that ANFIS has the advantages of offering simple learning algorithms with higher training speed and faster convergence results compared to other learning techniques. Although ANFIS is a powerful modeling platform, it is usually used when other conventional mechanistic modeling methods are simply inapplicable, too complicated, inefficient or inadequate.
Overview of Artificial Neural Networks (ANNs)
Artificial neural networks (ANNs) are distributed parallel processing systems which can mimic the living neurons. ANNs gained their popularity due to their ability to handle complex problems involving multi-input–output variables and nonlinear relationships. They can employ special functions called universal approximators that are able to model any inputs–outputs regardless of their complexity when adequate data and sufficient number of neurons are used. ANNs have been used in numerous applications involving prediction, control and classification tasks in food processing and technology. ANNs are classified according to learning method into either supervised or unsupervised ANNs. Supervised ANNs are the most common, since they are capable of learning from examples (such as measured output data sets) to guide the network learning process. Unsupervised ANNs, on the other hand, are more common in classification problems. In supervised learning process, the data sets are used to minimize the difference between predicted and measured (actual) outputs by employing a least-squares minimization algorithm called backward propagation (BP). In this process, neuron weights are adjusted backward from output to input layer at the end of each iteration, and a step repeated until a desired minimum error between predicted and measured outputs is attained [5]. The most common supervised ANNs are the feed-forward neural networks (FF-ANNs) and the radial basis function neural networks (RBF-ANNs). A detailed description of each type can be found in Marini [20]. Table 1 summarizes the main advantages and disadvantages of ANNs. It can be seen that while ANNs can model any function regardless of its level of complexity and has an excellent learning and generalization capacities, they have some limitations in terms of interpreting functionality (i.e., how the decision was made) and difficulty in selecting the proper number of layers and neurons within each layer.
Overview of Fuzzy Inference Systems (FIS)
Fuzzy inference systems (FIS) were developed on the basis of fuzzy logic (FL) to provide a method for expressing blurry attributes and permit the integration of data and information from experts in a specific field. A fuzzy system allows representing and integrating human heuristic knowledge in description of a certain system by utilizing fuzzy sets to implement a human-like way of thinking in soft computing. Due to their capability to tackle food-related problems by handling human reasoning in linguistic terms, they became an increasingly important approach in food modeling, control and classification [10]. The basic structure for FIS is made of three essential components [14]:
-
A rule base that contains a selection of fuzzy if–then rules
-
A data set that defines the membership functions (MF) of the fuzzy sets applied in the fuzzy rules.
-
A fuzzy reasoning mechanism, which can be used to perform the inference procedure on the fuzzy rules in order to derive the desired output.
Fuzzy logic is especially suitable in situations that involve dealing with fuzzy systems. For example, describing the concepts of food quality and their justifications in human mind are a common area of uncertainty, it is hard to make and adjust decisions on the basis of measurement results in terms of crisp values alone. In such situations, FL is used as a proper tool for dealing with such fuzzy relationships. FL can be helpful also in decision making since it helps in capturing any hidden uncertainty of operations or reasoning process. In conclusion, FL can be helpful in developing connections between numbers (crisp values) and words (linguistic terms) [12]. Fuzzy logic has been used in many applications related to food processing and technology including nonlinear modeling, expert systems, forecasting, descriptive sensory evaluation, developing quality measurement tools and process control [22]. Table 1 shows a summary of main advantages and disadvantages of FIS. It can be seen that FIS provides a useful platform for integrating human expertise to design problems using simple linguistic variables and provide a simple interpretation of the decisions made. Some limitations of FIS include the difficulty of selecting the proper fuzzy rules which often requires the expert knowledge of the field. They also lack the capability to be generalized into other cases.
Adaptive Neural Fuzzy Inference System (ANFIS)
ANFIS General Structure
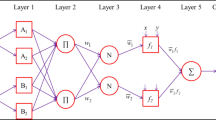
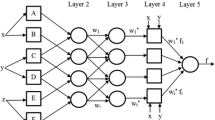
ANFIS in its simplest form is a fuzzy reasoning system with parameters trained by ANN-based algorithms. The linear parameters are usually estimated by using the conventional least-squares (LS) algorithms, while the membership functions (MFs) parameters are adjusted using a hybrid neural network learning method. A systematic approach was developed by a Sugeno fuzzy model [known as Takagi–Sugeno–Kang (TSK)] [11] to generate the fuzzy rules on the basis of available input–output data (Fig. 1). ANFIS in its simplest form is a two-input model using the following fuzzy rule:
where a and b are fuzzy sets in the antecedent, x and y are linguistic variables, and g = f(x, y) represents the crisp function in the consequent. The function g can be any function which can appropriately describe the model outputs within the fuzzy region determined by the antecedent of the rule. A polynomial with input variables x and y is the most common. When g = f(x, y) is a constant, the FIS is called a zero-order Sugeno fuzzy model, while a first-order Sugeno fuzzy model is represented by first-order polynomial (i.e., px + qy + r) [3]. The basic structure of ANFIS is composed of the following parts: a TSK fuzzy inference system and a feed-forward neural network with a learning algorithm such as backpropagation (BP). The learning algorithm adjusts the parameters of the TSK system [17]. A simple first-order Sugeno fuzzy model with two inputs (x and y) and one output (z) fuzzy inference system (FIS) is explained below. The model contains a set of four fuzzy if–then rules as follows:

A typical two-input first-order TSK model
The typical architecture of a two-input ANFIS is shown in Fig. 2. It shows five layers of squares or circles. The squares represent adaptive nodes, while the circles denote fixed nodes. The function of each layer is explained below.

A typical architecture of two-input ANFIS
Layer 1 This layer is composed of square i nodes (i.e., all nodes are adaptive). The output of this layer represents the fuzzy membership grade of the inputs x and y given as follows:
Any fuzzy membership function (such as bell-shape function) with values between 0 and 1 can be assigned to µ Ai (x), µ Bj (y) as follows:
Layer 2 This layer is composed of circle i nodes denoted as ∏ (i.e., all nodes are fixed). Each node in this layer calculates the firing strength of a rule by multiplication:
Layer 3 This layer is composed of circle i nodes denoted as N (i.e., all nodes are fixed). The ith circle node in this layer calculates a ratio of that node firing strength to the total firing strength of all nodes as follows:
where \( \overline{w}_{i} \) represents the normalized firing strengths.
Layer 4 This layer is composed of square i nodes (i.e., all nodes are adaptive). Outputs from each node at this layer are the product of the first-order Sugeno-type polynomial and the normalized firing strength:
where \( \overline{w}_{i} \) is the output of layer 3 and {pi, qi, ri} is the set of parameters.
Layer 5 This layer includes a single fixed node, labeled ∑. It calculates the overall output as a summation of all incoming signals as follows:
ANFIS Model Development, Testing and Computational Considerations
ANFIS has two sets of adjustable parameters, the premise parameters in the first layer and the consequent parameters in the fourth layer. The learning process involves adjusting the premise and the consequent parameters separately until the intended response of the FIS is achieved. This process involves rapid training and adapting of FIS using a hybrid learning algorithm, which combines the least-squares (LS) and the backpropagation (BP) algorithms. In the first step, the premise membership function parameters are fixed and the ANFIS output is expressed as a linear combination of the consequent parameters. At this point, the LS method is used to estimate the optimal values of the consequent parameters. Fixing the premise parameters at this stage will help reducing the search space and therefore speeding up the convergence during training process. The hybrid learning algorithms use a two-step process to achieve this goal. In the first step, the premise parameters are held fixed, the signals are propagated forward from layer 1 to layer 4 and the consequent parameters are found by the LS method. In the second step, the consequent parameters are fixed, while the error signals are propagated backward from the output to the input end, where the premise parameters are updated by the standard BP algorithm [11]. Backpropagation algorithm uses the gradient-descent method to obtain premise parameters. Several nonlinear least-squares algorithms, however, are used to estimate the consequent parameters such as Gauss–Newton, Levenberg–Marquardt algorithm or conjugate gradient method. A summary of the advantages and disadvantages of main algorithms used in ANFIS are shown in Table 2 [19]. As can be seen, each algorithm has advantages as well as limitations in terms of computational complexity, speed and convergence. Nevertheless, the Levenberg–Marquardt algorithm (LMA) has gained the most popularity in solving nonlinear problems. Identifying a good ANFIS structure requires the implementation of efficient gradient-descent learning to the membership function parameters. This will allow specifying the I/O space partition, consequent variables and rule premise, the initial positions and number of the membership functions as well as the number of if–then rules. The dimensionality of input variables in FIS structure is usually reduced by using the clustering techniques such as subtractive clustering. Using the clustering techniques to find FIS rules has the advantage of being more tailored to the input data than when FIS is generated without using clustering. This can help eliminate the problem of combinatorial explosion of rules especially with higher-dimensional input data. Clustering can be used to identify the large data set groups in a given data set to produce a concise representation of the system’s behavior. When little or no prior knowledge of the data exists, the fuzzy clustering approach can be used to develop the fuzzy model. The membership functions and associated fuzzy rules can be determined with the help of some clustering methods by classifying the data sets to clusters or subsets. This will result in a set of cluster centers that act as prototypical data points which describe a specific characteristic mode of the system and represent the nucleus of the fuzzy if–then rule. In subtractive clustering, an efficient, one-pass algorithm estimates the cluster number and centers in a specific data set. The cluster centers can then be used to generate the primary Sugeno-type fuzzy inferences system which is capable of modeling the data behavior. Finally, ANFIS fine-tunes the parameters of the neuro-fuzzy model [14].
Applications of Adaptive Neural Fuzzy Inference Systems in Food Processing and Technology
Demonstrating the Use of ANFIS: Case Studies
To demonstrate the use of ANFIS in food process modeling, two case studies are discussed in details. The first case exemplifies the use of ANFIS in modeling a complex and nonlinear time-dependent intermittent drying of spouted grains. The second case demonstrates the use of ANFIS in modeling fuzzy sensory attributes of espresso coffee by pod.
Case Study 1: Using ANFIS in Modeling Nonlinear Time-Dependent Intermittent Drying of Spouted Grains
Modeling intermittent drying of spouted corn using ANFIS was discussed by Jumah and Mujumdar [14]. They reported that intermittent drying is a multivariable, time-varying, highly nonlinear and strongly interactive process. Such complexities render the process too difficult to be modeled using conventional mechanistic modeling techniques which are more or less a simplification of the reality. The authors used MATLAB to develop an overall ANFIS model for this process that consisted of two sub-models as follows:
Step 1: Assigning Governing Equations, Input and Output Variables
The authors used six different sub-models to predict solid temperature and solid moisture content. Three sub-models were used for predicting solid temperature (T s) and the other three for predicting the solid moisture content (X). The first three sub-models are named the T-Models which yield the solid temperature (T s) as the output variable as follows:
-
T-Model (1) with two input variables: T in(t), T s(t − 1) and 2 membership functions per input and two fuzzy rules.
-
T-Model (2) with one input variable: T in(t) and 2 membership functions per input and two fuzzy rules.
-
T-Model (3) with two input variables: t, T in(t) and 4 membership functions per input and four fuzzy rules.
The second set of three sub-models is the X-Model which gives the solid moisture content (X) as the output variable as follows:
-
X-Model (1) with three input variables: T in(t), T s(t) and X(t − 1) and 3 membership functions per input with three fuzzy rules.
-
X-Model (2) with one input variable: T in(t), T s(t) and 3 membership functions per input with three fuzzy rules.
-
X-Model (3) with two input variables: t, T s(t) and 6 membership functions per input with six fuzzy rules.
The authors used data on intermittent drying of corn in a spouted bed. The data set is obtained from a previous study which they conducted [14]. They used continuous spouting air supply at u = 0.5 m/s with periodic heating. The inlet air temperature T in was varied accordingly to provide an intermittent drying scheme as follows:
where T h and T c are the higher and lower (cooler) temperatures, respectively,
τ is the drying cycle period, α is the intermittency (fraction of the drying cycle when T in = T h), and n denotes the number of heating cycles (n = 0, 1, 2, etc.). The following parameter values were specified: τ = 0.6 min, α = 0.25, T in = 80 °C, T c = 40 °C, T h = 80 °C.
The input and output data vectors are loaded into MATLAB and assigned a vector for each input and output. In total, 50 % of the total input–output data vectors (odd data rows: 1, 3, 5, etc.) are assigned to training data set, while the other 50 % (even data rows: 2, 4, 6, etc.) are assigned for testing.
Step 2: Assigning the Type and Number of Membership Functions and Number of Epoch
An intuitive approach which involves choosing most common type MF (Gauss-bell MF) and the smallest number of membership functions (i.e., two membership functions per input variable). The number of MFs per input variable is then increased to 4 or 6 to improve ANFIS prediction accuracy. Three hundred epochs are used to guarantee convergence to a good solution.
Step 3: Training and Testing of ANFIS
In this step, MATLAB function “genfis1” is used to train and test ANFIS. This function provides the training and testing of output vectors, training and testing errors, initial and tuned membership functions as well as the fuzzy if–then rule extracted.
Step 4: Extracting Outputs and Calculating ANFIS Prediction Accuracy
The training and testing results as well as selected statistical accuracy indicators (such as the root-mean-squared error (RMSE) and the correlation coefficient (R 2) used in this study) are applied to evaluate the overall performance of ANFIS. Based on the results obtained, steps 1–4 were repeated until the desired ANFIS performance was attained. This involved adding or removing inputs, changing the training to testing date partition ratio and changing the type and/or number of membership functions.
Final Results
The final results revealed that among the three solid temperature sub-models tested, the T-model (1) showed the best performance with lowest RMSE and highest R 2 values for both training and testing data (0.146 and 0.178, and 0.999 and 0.999, respectively). They also specified two Gauss-bell membership functions per input with two fuzzy rules. With regard to solid moisture content (X-model), they reported that X-model (1) showed the best accuracy among the three sub-models tested with highest R 2 and lowest RMSE (0.999 and 0.999, 0.00029 and 0.00026, for training and testing data sets, respectively). They used three Gauss-bell membership functions per input with three fuzzy rules.
Jumah et al. [13] reported the use of a diffusion-based model to solve coupled mass and heat transfer in intermittent drying of spouted grain. The study will be analyzed to demonstrate the advantage of using ANFIS over conventional diffusion-based models. In their study, they used key assumptions to facilitate the solution methodology and to compensate for the lack of adequate information. The assumptions included:
-
1.
Uniform, homogeneous and isotropic spherical shape of corn kernels.
-
2.
Perfect mixing of grains so that moisture content and temperatures of kernels are uniform throughout the grain bed.
-
3.
The internal mass transfer resistance to moisture in the grain is significantly larger than external resistance at the gas layer surrounding the grain kernel.
-
4.
Heat losses, particle shrinkage and both conduction and mass transfer between grains particles are negligible.
The intermittent drying problem involved solving a set of semi-discrete nonlinear ordinary differential equations with appropriate boundary conditions to predict grain surface temperature [T s(t)] and grain moisture content [X s(t)]. The authors reported that results showed a systematic discrepancy between predicted and experimentally measured grain surface temperature. They explained the observed discrepancy in terms of several factors including: neglecting heat loss from the bed, using of inappropriate heat transfer boundary conditions at the surface of grain kernel by assuming negligible drying during the off period leading to an assumption of zero concentration gradient at the surface of the grain particle. They reported that the use of such boundary conditions was driven by the lack of information about the heat and mass transfer processes for an aggregate of particles in zero flow static bed. They observed that such lack of information led to an overestimated heat and mass transfer coefficients (Nusselt and Sherwood numbers). They reported, however, a more reasonable agreement between experimental and predicted moisture content although it was difficult to compare them due to the difficulty in fitting the behavior of intermittent drying.
A comparison between ANFIS and diffusion-based model for the prediction of grain particle surface temperature and moisture content variation during intermittent drying demonstrates the clear advantages of using ANFIS over the diffusion-based, coupled heat and mass transfer analytical approach. ANFIS provided a grain particle surface temperature [T-model (1)] and moisture content model [X-model (1)] with almost a perfect fit between experimental and predicted data as observed by the high value of R 2 (0.999) for both surface temperature and moisture content predictions. This can be referred to the exceptional computational capability of ANFIS which implements a universal approximator function that can fit any functional relationship. The only requirement for ANFIS to perform well is the availability of a good data to learn from. ANFIS, therefore, can be an excellent choice when assumptions or approximations may reduce the performance or accuracy of the analytical mathematical models. This will be the case when the model is too complicated or essential information are missing such as the case with heat and mass transfer coefficients in the above example.
Case Study 2: Using ANFIS in Modeling Sensory Attributes of Espresso Coffee
The second case study will discuss the use of ANFIS to design and optimize espresso coffee quality as reported by Russo et al. [26]. The previous case involved predicting intermittent drying using ANFIS and comparing the results with analytical methods. It was observed that input–output relationship was modeled analytically at a reasonable accuracy. Sensory analysis, however, is very difficult to model analytically. This is mainly due to the unreliability and subjectivity in measuring sensory attributes and the nature of interactions among those attributes. Sensory panel evaluation of coffee quality is usually subjective; therefore, a computerized method is needed to design the quality characteristics of optimal coffee blend by mimicking the role of sensory panel but in a less subjective way. Russo et al. [26] proposed an approach to optimize coffee blend composition, extraction time and temperature to produce a high-quality espresso coffee by using ANFIS and simulated annealing. In their study, the expert system capabilities of ANFIS were combined with multi-criteria heuristic approach (sensory expert’s evaluation) to optimize coffee quality. In other words, ANFIS was used to optimize the output sensory quality attributes such as taste and aroma in a way similar to sensory experts by manipulating the input variables (coffee blend, extraction time and temperature). In their study, the authors first used the predefined attributes of a good-quality espresso including a balanced bitter and acid taste, a strong body, persistent hazelnut foam, a potent and fine aroma, and a compact texture. They also specified the input factors that affect the presence and intensity of each specific sensory attribute in espresso coffee including coffee blend, extraction temperature and time during the percolation process. Based on that, they constructed a computerized ANFIS model that is capable of designing the optimal espresso coffee attributes on the basis of the predefined sensory evaluation results. They specified the desired ANFIS input–output vector as follows:
Input Variables
-
Five different roasted coffee blends’ combinations: pure Arabica from Coffee Arabica (A), pure Robusta from Coffee Canephora (R) and Arabica Robusta blends at three different percentage [A20:R80, A80:R20 and A40:R60)]
-
Four extraction temperatures (80, 90, 100 and 110 °C)
-
Five extraction times (10, 15, 20, 25 and 30 s).
Output Variables
Those were selected as eight specific sensory attributes measured using a variation in the quantitative descriptive analysis (QDA) method. The optimal output sensory attributes were obtained on a scale from 1 to 10 as follows:
-
(1) color intensity = 7, (2) acidity = 7, (3) olfactive intensity = 9, (4) body = 9, (5) bitterness = 5, (6) texture = 9, (7) roast intensity = 7, (8) astringency = 3.
The next step involved constructing ANFIS model to map the input–output data vectors for training data (70 % of total data set). They used three triangular membership functions for each input variable and then derived the rule base which included 27 Tagaki–Sugeno if–then rules. The derived network was then tested (cross-validated) with the remaining 30 % data sets. A backpropagation algorithm was used for this purpose to assure no over-fitting occurs.
ANFIS was then utilized to obtain the optimal quality attributes. For example, the best color intensity was obtained at extraction time around 20 s and extraction temperature around 100 °C. Other quality attributes such as bitterness and olfactive intensity which are related to coffee aroma were found to be optimal at temperatures ranging from 95 to 100 °C and extraction time near 20 s with a coffee blend containing 60–70 % of Arabica.
Next, the results obtained from ANFIS were used to perform inverse optimization using simulated annealing. This involves working backward to obtain the best input conditions (coffee blend, extraction time and temperature) for a desired output (optimal coffee quality). For example, if the optimal extraction time which is related to the desired volume of the coffee is known, what would be the optimum extraction temperature, time and coffee blend? ANFIS will provide the needed information: The best quality coffee achieved at 15 s extraction time should be extracted at 92 °C extraction temperature and 67 % Arabica and 33 % Robusta coffee blend. Simulated annealing reverse optimization will rephrase the question in the reversed order as follows: If the optimal composition of coffee mixture (obtained from ANFIS) is given, what would be the best extraction temperature and time to get the best coffee quality? To give an example, if the coffee blend was prepared from 10 % Arabica and 90 % Robusta, then the best coffee can be obtained at extraction time and temperatures equal to 22 s and 95 °C, respectively.
This case study on the application of ANFIS in coffee quality optimization demonstrates the superior capabilities of ANFIS in solving highly complicated and practical food industry problems that would be difficult to be solved by any other method. The authors concluded that ANFIS utilized a synergy between the outstanding computational capabilities of artificial neural networks and the human-like reasoning heuristic approach of fuzzy sets in addition to simulated annealing reverse optimization to solve a difficult food quality problem. In addition, they reported that they were the first to use this approach in optimizing food processes.
Further applications of ANFIS in food processing and technology are grouped into five categories and discussed briefly by focusing on the main objectives for using ANFIS as well as a brief discussion on inputs–outputs, performance indicators as well as a comparison with the performance of other modeling methods when applicable (such as artificial neural networks, multivariate regression). The five categories include food drying, prediction of food properties, microbial growth and thermal process modeling, applications in food quality control and food rheology.
Food Drying
The application of ANFIS in food drying is reported by several researchers as shown in Table 3. Yüzgeç et al. [35] used ANFIS in fluidized bed drying to model Baker’s yeast production to predict the yield of dry product and product temperature. It was found that the overall performance of ANFIS model was better than the three other conventional modeling tools based on heat and mass transfer, diffusion in granules and artificial neural networks. The performance measures showed a higher R 2 for both yeast yield (0.985) and temperature (0.815) when using ANFIS compared to other models. In another study by Prakash and Anil Kumar [23], ANFIS was applied successfully to model jaggery drying in a greenhouse dryer. It was used to model the moisture ratio, jaggery temperature and thermal performance of the greenhouse. When compared to conventional thermal modeling, ANFIS was found to provide better model fit in terms of R 2 and root mean error deviation E % (0.999 and 0.7 % compared to 0.98 and 2.47 %) for ANFIS and thermal modeling, respectively. Rami and Mujumdar [12] reported the use of ANFIS in modeling nonlinear complex intermittent drying of grains in a spouted bed, which is normally difficult to model using conventional drying models. They used drying air temperature and grain moisture content to predict grains temperature and drying rate over time. ANFIS was found to model both grains temperature and drying rate with high precision (R 2 = 0.999 and RMSE = 0.178). Al-Mahasneh et al. [2] used ANFIS in comparison with conventional thin-layer drying models to predict moisture ratio in open sun drying of roasted green wheat. ANFIS showed superior performance in comparison with two-term exponential mode with RMSE = 1.2 × 10−6 and R 2 = 0.999 and RMSE = 0.038 and R 2 = 0.988, respectively. Nikrooz et al. [21] reported the use of ANFIS in predicting energy efficiency in leafy vegetables solar dryer using various climatic conditions and design parameters. They observed higher performance of ANFIS prediction compared to empirical thermal models (R 2 = 0.99 vs. 0.68).
Food Properties
The application of ANFIS in modeling various food properties is reported by several researchers as shown in Table 4. In a study by Sagdic et al. [27], ANFIS was used to model antibacterial activities of Turkeys’ grape pomace powders and pomace extracts at different concentrations against Staphylococcus aureus and Escherichia coli in vegetable soup. The results showed that ANFIS model performed better than both artificial neural networks (ANN) and multiple linear regressions (MLR) for predicting antibacterial effects. ANFIS provided fitting results much better than MLR and slightly better than ANN with RMSE = 0.0023, mean absolute errors (MAE) = 0.0215 and determination coefficient (R 2) = 0.999. Taghadomi-Saberi et al. [30] reported the use of ANFIS with triangular and two-term Gaussian membership functions and ANNs with two hidden layer networks architectures to model antioxidant activity and anthocyanin content of sweet cherry at different ripening stages. They reported better performance of ANNs with the lowest error and highest correlation coefficients values for predicting antioxidant activity and anthocyanin content (R = 0.93 and 0.98, respectively). ANFIS models, however, performed slightly worse than ANNs with R = 0.87 and 0.90 for antioxidant activity and anthocyanin content, respectively. Shahbazikhah et al. [29] used ANFIS to develop a quantitative structural property relationship for the prediction of the partition coefficient K in various food packaging. The model used two packaging materials, four food simulants and six migrants to predict the partition coefficient. They reported that ANFIS was applied for the first time in this field as a new modeling technique. They observed that ANFIS model outperformed the conventional MLR with a root-mean-square error (RMSE) = 0.0006 and 0.024 and correlation coefficient (R 2) of 0.992 and 0.904, respectively. Yalcin et al. [32] used ANFIS and artificial neural networks (ANNs) to model the fatty acid composition of seven vegetable oils including hazelnut, soybean, sunflower, olive, canola, corn and cotton seed. They used shear rate, shear stress and oil type as inputs and the fatty acids C16:0 and C18:2 percentages as outputs. The root-mean-square error (RMSE), mean absolute error (MAE) and determination coefficient (R 2) were 0.729, 0.539, 0.983 and 1.996, 1.671, 0.890, respectively. ANFIS not only performed better than ANNs but also replaced the complicated chromatography methods for evaluating fatty acid profile. Rahman et al. [25] reported the use of ANFIS and ANNs to predict thermal conductivity of various fruits and vegetables. The inputs were temperature, apparent porosity and water content of foods. They noticed that the use of a wide temperature range including those below freezing points made it difficult to predict thermal conductivity by conventional models. On the contrary, ANFIS was able to predict thermal conductivity quite well with values that closely matched experimental date (mean square error = 0.011) compared to 0.021 and 0.011 for ANN and MLR, respectively, and R 2 = 0.978 compared to 0.951 and 0.931 for ANN and MLR, respectively. They also reported that ANFIS alleviated the problem associated with defining the hidden structure of ANN by trial and error.
Microbial Growth and Thermal Processing of Food
The application of ANFIS in modeling microbial growth and thermal processing is reported by several researchers as shown in Table 5. Yolmeh et al. [34] used ANFIS and genetic algorithm–artificial neural network (GA-ANN) models to model the effect of annatto dye on Salmonella enteritidis population in mayonnaise using three inputs (annatto dye concentration at 0, 0.1, 0.2 and 0.4 %, storage time of 1–20 days and storage temperatures at 4 and 25 °C). Both ANFIS and GA-ANN were able to predict S. enteritidis population with high accuracy of 0.998 and 0.999, respectively. They also reported that sensitivity analysis of the input factors revealed that storage temperature was the most important factor for the prediction of S. enteritidis population in mayonnaise. Amiryousefi et al. [3] reported the use of ANFIS and self-organizing map (SOM) clustering to predict mass transfer kinetics in deep-fat frying of ostrich meat. They used ANFIS to predict fat and moisture content as the most important quality parameters in fried foods. The data set of each mass transfer parameter was classified into two clusters using SOM, and each cluster was then fed into a separate ANFIS model that was capable of extracting the rule base by data tuning by using a triangular membership function (MF) in training ANFIS. The results demonstrated that the optimized ANFIS model with SOM clustering was able to improve the prediction performance of ANFIS and successfully describe mass transfer during deep-fat frying compared to ANFIS alone with a 12.46 % improvement and with R = 0.96 in MC prediction and 5.46 % improvement with R = 0.92 for FC prediction. They concluded that the described methodology can also be applied in optimizing the operating conditions of the deep-fat frying process. Qin et al. [24] reported the use of neuro-fuzzy-based approach to predict the risk factors for Salmonella Typhimurium infections in various food types (green salad, fruit juices, eggs, burgers), contact types (such as living on a livestock farm) and other factors (such as taking any anti-diarrheal medicines). The neuro-fuzzy model was used to choose and tune the membership functions and the parameters associated with them rather than using the trial and error procedure used in conventional fuzzy logic. The ANFIS model was trained with 80 % of the training data and tested (validated) with the rest 20 % unexposed data. The results showed better performance of the proposed neuro-fuzzy approach when compared to the conventional fuzzy logic model with an accuracy of 69.45 and 54.67 %, respectively. They concluded that neuro-fuzzy model proposed a good mean that can help evaluating the risks associated with Salmonella Typhimurium infections in various food and nonfood factors. Escaño et al. [7] used a neuro-fuzzy model to predict the temperature variation in batch sterilization autoclave with time [T(t)] using the positions of the steam valve, drain and purge valves, temperature of steam and previous samples for the temperature inside the retort (T(t − 1); T(t − 2)) as inputs. They observed that ANFIS was able to accurately predict the measured autoclave temperature. They reported an important advantage of neuro-fuzzy control strategy as it can be integrated on industrial PLC, which may save a considerable cost on commercial hardware setups. In addition, the neuro-fuzzy modeling was relatively simple, making it an attractive choice in industrial environments.
Food Quality Control
The field of food quality control received much attention in food industry. Some applications of neuro-fuzzy system in food quality control are given in Table 6. ANFIS was used by Zheng et al. [36] in detecting bruises of Chinese bayberries. They used different input membership functions (MFs) for this purpose and showed that the “gauss2mf” MF performed much better than other types of MFs in terms of bruises detection. They reported a classification accuracy of 78.57 and 100 % for bruised and healthy fruits, respectively, with a 90 % total correct classification rate. They concluded that ANFIS provides a good potential for developing a useful classification tool on the basis of FD and RGB values for detecting bruises in other fruits during handling, processing and storage. ANFIS was reported by Atsalakis et al. [4] to forecast the yearly production of five fruits including cherries, lemons, olives, oranges and pistachios by estimating the optimal food forecast parameters for the individual year. The model used the time series of yearly data as input variables. ANFIS results were compared to an autoregressive moving average (ARMA) and an autoregressive (AR) model. The results were compared on the basis of root-mean-square error (RMSE) and mean absolute percentage error (MAPE). In all five fruits production forecasting, ANFIS gave better results than both ARMA and AR models. They concluded that the suggested neuro-fuzzy model could be used to efficiently forecast yearly fruit production using time series data for the studied fruits. Russo et al. [26] used a combination of neuro-fuzzy technique with simulated annealing as a nonlinear modeling methodology to design and optimize espresso coffee quality. They used three input variables that have a strong influence on the sensory quality of the coffee including the extraction time between 10 and 30 s, the coffee blends (100 % Arabica, 100 % Robusta and Arabica Robusta: A20R80, A80R20 and A40R60) and the extraction temperatures from 80 to 110 °C. The output was measured as the sensory quality of the coffee measured using the quantitative descriptive analysis method (QDA) which is based on acidity, astringency, bitterness, body, olfactive intensity, color intensity, roast intensity and texture. They reported that based on the results obtained, the optimal blend composition with respect to sensorial values was found by using 70 % Arabica and 30 % Robusta extracted at 93 °C and 15 s. Davidson et al. [6] developed an ANFIS model to recognize consumer preferences for biscuits as part of an automated bakery inspection system. They used digital images to estimate some physical features of chocolate chip cookies (biscuits) such as baked dough color, fraction of top surface area, size and shape. ANFIS was then used in order to predict consumer ratings based on the three features extracted from digital images. Two of the fuzzy models based on Mamdani and Sugeno ANFIS gave satisfactory results of average consumer ratings. They reported that feature extraction can be combined with high-level information processing method such as ANFIS to integrate features in a way that enables automated prediction of average consumer ratings of the biscuit quality. They concluded that fuzzy inference system was also simple in terms of inference methods and the number of rules used. ANFIS was used by Madadlou et al. [18] to model sono-disruption process of re-assembled casein micelles which influences the acid-induced gelation time. ANFIS model utilized four inputs (sonication time, pH value of casein solution, ultrasonic frequencies (ultrasonic bath and probe) and acoustic power dissipated to the medium) and one output (the size of re-assembled micelles). Two primary networks were obtained by both subtractive clustering and grid partition. Grid partitioning provided an ANFIS with higher recognition capability (RMSE = 10.66) compared to subtractive clustering (RMSE = 16.64). However, subtractive clustering was able to describe the process by using much fewer rules. When the number of epochs (iterations) was increased, a model with higher recognition capability with simpler structure was obtained with a small fuzzy rules number (16 rules). When ANFIS was generated using a lower range of influence (0.2 vs. 0.5), a higher recognition capability was observed but with a relatively more complex fuzzy rule base (41 rules). Khalifa et al. [16] developed an efficient walnut sorting system by combining (ANFIS) classifier and principle component analysis (PCA) with acoustic emissions analysis. The system was used to classify walnuts into two classes (empty and fill walnuts). The system was trained and validated with 281 sample data points. Some statistical indicators of the sound impact signals in time domain were chosen as sorting features, and PCA was used for feature reduction to decrease the dimensionality of input variables. The selected statistical features were then used as input to ANFIS. The system used 27 rules with excellent classification accuracy (100 % accurate). They concluded that ANFIS-PCA classification system proposed in the study demonstrated massive advantages such as nondestructiveness, high-speed operation and low cost. The authors proposed using the system for commercial walnut classifications although they suggested a wider study involving more cases for more efficient cross-validation.
Food Rheology
Some applications of neuro-fuzzy systems in food rheology are shown in Table 7. Toker et al. [31] investigated the effect of temperature (60, 70 and 80 °C), starch concentration (5, 7.5 and 10 %) and time on the creep and recovery behavior of the grape molasses using ANFIS and ANN. ANFIS model was established to predict the compliance value [J(t)] obtained from creep and recovery analyses. Comparison based on the statistical parameters (R 2 value, mean absolute error and root-mean-square error) showed that ANFIS outperformed ANN model for the desired output. R 2 fitted values of J(t) varied between 0.987 and 0.999 and between 0.075 0.159 for ANFIS and ANN, respectively. Karaman and Kayacier [15] reported using ANFIS to study the effect of temperature on rheological characteristics of apricot and date molasses. The rheological properties were evaluated in the temperature range from 10 to 40 °C and shear rates from 0.1 to 100 s−1. Both ANFIS and conventional power law model were able to calculate apparent viscosity of apricot and date molasses with high prediction capabilities (R 2 = 0.979–0.999 and RMSE = 0.12–0.46). Yilmaz [33] reported the use of ANFIS to accurately model the compliance (J) for linear creep and recovery properties of model meat emulsions using the effect of creep test time, oil level and temperature. He reported that it is impossible to perform mathematical modeling of structure or to interpret the results obtained from meat emulsion systems using the conventional molecular perspective due to their complexity and the ill-defined viscoelastic nature in both creep and recovery behavior. ANFIS with “trimf” input membership function (MF) was observed to perform better than other types of MFs. The results obtained from ANFIS were compared with both ANN and (MLR). It was found that ANFIS was superior to both MLR and ANN models with R 2 = 0.990, 0.984 and 0.441, respectively. Al-Mahasneh et al. [1] used ANFIS along with ANNs to model apparent viscosity of eight Jordanian honeys using shear rates between 2.2 and 47 s−1, temperatures between 28 and 58 °C and water content from 16.1 to 17.3 %. They reported that both ANFIS and ANNs were able to predict apparent viscosity with good accuracy (R 2 = 0.956 and 0.978 for ANFIS and ANNs, respectively). The two models were observed to have an extra advantage over conventional mathematical models, since they can predict honey viscosity as a function of all input variables, offering a wider range of viscosity prediction. In addition, they concluded that ANFIS can be used to model rheological properties of more complex liquid foods where conventional rheological models often fail or can be too complicated to describe such properties. Ghoush et al. [9] reported the use of ANFIS to model and identify the rheological and emulsification properties (viscosity and emulsion stability) of a model egg yolk mayonnaise prepared from wheat protein (WP) at 4 % and iota-carrageenan (IC) at 0.1 % as an alternative emulsifier. ANFIS was used to compare several mayonnaise treatments based on emulsion stability and viscosity at 4, 23 and 40 °C. They reported that ANFIS used 27 nodes and 8 fuzzy rules to model the mayonnaise viscosity and emulsion stability with high prediction accuracy = 96 % and an estimated prediction error of output properties close to 4 %. They reported that ANFIS can be used efficiently for predicting many other food properties related to food industry. Samhouri et al. [28] reported the use of ANFIS to model the color parameters (lightness and yellowness) of the mayonnaise formulation system studied in Ghoush et al. [9] which represents a model egg yolk mayonnaise prepared from wheat protein (WP) at 4 % and iota-carrageenan (IC) at 0.1 % as an alternative emulsifier. ANFIS was used to compare several mayonnaise treatments based on the color parameters (lightness and yellowness) at 4, 23 and 40 °C. They reported that ANFIS used also 27 nodes and 8 fuzzy rules to model the mayonnaise lightness and yellowness with high prediction accuracy = 96–97 % and an estimated prediction error of output properties close to 3–4 %.
Advantages and Disadvantages of Using ANFIS
Advantages
-
1.
ANFIS has the ability to handle large amounts of noisy or ill-behaved data from nonlinear or complex dynamic systems.
-
2.
ANFIS is especially useful in modeling system with unknown or not fully understood underlying physical relationships between inputs and outputs.
-
3.
ANFIS can integrate information from several sources such as expert systems, human reasoning (heuristics), empirical models and data for effective model development.
-
4.
ANFIS is capable of reducing the dimensionality of the problem by using a subtractive clustering technique which prevents the combinatorial explosion of fuzzy rules when input data sets involve higher dimensions. Subtractive clustering methods are especially useful for building the fuzzy model when no prior knowledge of the fuzzy rules exists. The cluster produced is then utilized to produce the initial Sugeno-type fuzzy inference system that best models the behavior of the given data. Backpropagation in ANFIS can be used after that to tune the parameters of the neuro-fuzzy model.
Disadvantages
-
1.
Since ANFIS is a data-driven modeling technique, it is extremely important to select the appropriate input variables which provide the essential information needed for successful modeling. In other words, it is important to avoid losing key information when omitting one or more key input variables and to prevent the inclusion of redundant or irrelevant input variables that can confuse the training process. While this applies to any modeling technique, it is more crucial in ANFIS as it depends heavily on input–output data for modeling compared to other methods.
-
2.
The number of fuzzy rules increases exponentially with the increase in the number of input variables as given by the formula: p n where p is the number of fuzzy membership functions and n is the number of input variables. This means a high number of membership functions and/or input variables will yield an excessively high number of fuzzy rules, making ANFIS too difficult to apply for new unseen data and increasing the computational time significantly. Prior experience and knowledge of the user and the use of a clustering tool for input variables may help reducing this problem.
-
3.
The successful implementation of ANFIS requires the availability of a relatively large data set for training and cross-validation. In several cases, however, it may be difficult to generate adequate amount of data for various reasons such as cost, difficulty in measurements or simply unavailability. Adequate data sets are needed to prevent model under-fitting (a model with poor generalization capability for unseen data).
General Guidelines for Using ANFIS
There are general guidelines that can be followed for successful development of ANFIS.
-
(a)
Selecting appropriate input variables selecting adequate input variables is important to avoid model under-fitting. In other words, to avoid missing important information about the system is being modeled. This is considered an important primary task. Inclusion of irrelevant or highly correlated input variables may degrade the reliability of model training and validation process. On the other hand, model over-fitting which occurs when too many input variables are used to build the model can adversely affect the usefulness and generalization capabilities of the model. In ANFIS, this depends on the experience and knowledge of the user in a specific process. In addition, some tools such as subtractive culturing, by combining the highly related (correlated) input variables to one or more clusters and therefore reducing the dimensionality of the input variables, can improve the reliability of the model developed and reduce the computational burden.
-
(b)
Choosing appropriate number and type of membership functions prior experience and knowledge of the user can help choosing the appropriate type and number of membership functions in addition to data partition scheme (splitting the data for training and validation) and selecting the best type of optimization algorithm.
-
(c)
The successful implementation of ANFIS this requires a relatively large data set for training and validation which is sometimes needed to prevent model under-fitting and to yield a good generalization of the results for unseen data. A general guideline would be to increase the size of data set as the number of model inputs is increased.
When to Use ANFIS?
ANFIS is a hybrid intelligent modeling technique with outstanding modeling capabilities which can be applied in several areas of food industry. Nevertheless, it would be inefficient it in applications where analytical modeling or other more straightforward statistical modeling techniques are applicable and adequate. Some applications where the application of ANFIS is recommended include:
-
Problems which involve fuzzy or blurred attributes such as in descriptive sensory testing.
-
Problems that involve complex or ill-conditioned systems such as multivariable, time-varying processes or highly complex functional relationships such as such as intermittent drying.
-
Problems that involve noisy data from dynamic or nonlinear systems such as time series forecasting.
-
Problems which involve physical relationships that may not be fully understood or difficult to predict accurately such as modeling microbial growth.
Concluding Remarks
This review explains the applications of ANFIS in food processing and technology. The paper discussed ANFIS in comparison with fuzzy logic systems (FLS) and artificial neural network (ANNs) in terms of structure, function, complexity and applications in the food industry. It was found that ANFIS prediction and modeling capabilities of various food processing and technology applications such as drying, food properties prediction, quality control and rheology were almost always better or similar to the other modeling methods such as ANNs, FLS or multiple regressions (MR). However, ANFIS implementation may yield high number of fuzzy rules rendering it more complex than other methods. In addition it requires a relatively large data set for training and validation to yield a generalized model and prevent over-fitting. Nevertheless, application of ANFIS has gained increasing attention in various modeling and control applications in food processing and technology. Finally, ANFIS is best utilized in situation where no alternative mechanistic conventional modeling techniques are feasible or when the modeling problem is too complicated to be solved otherwise such as fuzzy systems. Even if ANFIS was used in such situations, a compromise should be made between a sophisticated model structure which is capable of predicting outputs accurately and generalizing to unseen data but has the potential to be complicated and to include a large set of fuzzy rules, with a simple model structure but yet incapable of capturing the whole picture and missing essential information and therefore providing poor prediction and generalization results. Such compromise is normally attained by the user knowledge and experience in both the nature of problem and the skill in using ANFIS.
References
Al-Mahasneh MA, Rababah TM, Ma’abreh AS (2013) Evaluating the combined effect of temperature, shear rate and water content on wild-flower honey viscosity using adaptive neural fuzzy inference system and artificial neural networks. J Food Process Eng 36(2013):510–520
Al-Mahasneh MA, Rababah TM, Bani-Amer MM, Al-Omari NM, Mahasneh MK (2013) Fuzzy and conventional modeling of open sun drying kinetics for roasted green wheat. Int J Food Prop 16:70–80
Amiryousefi MR, Mohebbi M, Khodaiyan F, Asadi S (2011) An empowered adaptive neuro-fuzzy inference system using self-organizing map clustering to predict mass transfer kinetics in deep-fat frying of ostrich meat plates. Comput Electron Agric 76(1):89–95
Atsalakis GS, Atsalakis IG (n.d.) Fruit production forecasting by neuro-fuzzy techniques (113th Seminar, September 3–6, 2009, Chania, Crete, Greece No. 57680). European Association of Agricultural Economists. https://ideas.repec.org/p/ags/eaa113/57680.html
Bishop MC (1994) Neural network and their applications. Rev Sci Instrum 64:1803–1831
Davidson VJ, Ryks J, Chu T (2001) Fuzzy models to predict consumer ratings for biscuits based on digital image features. IEEE Trans Fuzzy Syst 9(1):62–67. doi:10.1109/91.917115
Escaño JM, Bordons C, Vilas C, Garcña MR, Alonso AA (2009) Neurofuzzy model based predictive control for thermal batch processes. J Process Control 19(9):1566–1575. doi:10.1016/j.jprocont.2009.07.016
Garibaldi JM, Ifeachor EC (1999) Application of simulated annealing fuzzy model tuning to umbilical cord acid-base interpretation. IEEE Trans Fuzzy Syst 7(1):72–84
Ghoush MA, Samhouri M, Al-Holy M, Herald T (2008) Formulation and fuzzy modeling of emulsion stability and viscosity of a gum-protein emulsifier in a model mayonnaise system. J Food Eng 84(2):348–357. doi:10.1016/j.jfoodeng.2007.05.025
Guillaume S, Charnomordic B (2001) Knowledge discovery for control purposes in food industry databases. Fuzzy Sets Syst 122:487–497
Jang J-SR (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23:665–685
Jiang Q, Chen CH (2005) A multi-dimensional fuzzy decision support strategy. Decis Support Syst 38:591–598
Jumah R, Mujumdar A, Raghavan G (1996) A mathematical model for constant and intermittent batch drying of grains in a novel rotating jet spouted bed. Drying Technol 14(3,4):765–802
Jumah R, Mujumdar AS (2005) Modeling intermittent drying using an adaptive neuro-fuzzy inference system. Drying Technol 23(5):1075–1092. doi:10.1081/DRT-200059138
Karaman S, Kayacier A (2011) Effect of temperature on rheological characteristics of molasses: modeling of apparent viscosity using adaptive neuro-fuzzy inference system (ANFIS). LWT Food Sci Technol 44(8):1717–1725
Khalifa S, Komarizadeh MH (2012) An intelligent approach based on adaptive neuro-fuzzy inference systems (ANFIS) for walnut sorting. Aust J Crop Sci 6(2):183–187
Kosko B (1992) Neural networks and fuzzy systems: a dynamical system approach. Prentice-Hall, Englewood Cliffs
Madadlou A, Emam-Djomeh Z, Mousavi ME, Javanmard M (2010) A network-based fuzzy inference system for sonodisruption process of re-assembled casein micelles. J Food Eng 98(2):224–229. doi:10.1016/j.jfoodeng.2009.12.031
Madsen K, Nielsen HB, Tingleff O (2004) Methods for non-linear least squares problems, 2nd edn. Informatics and Mathematical Modelling Technical University of Denmark. April 2004
Marini F (2009) Artificial neural networks in food stuff analyses: trends and prospectivesAreviw. AnalyticaChemicaActa 635:121–131
Nikrooz B, Nazilla T, Hossein J (2015) Development and evaluation of an adaptive neuro-fuzzy interface models to predict performance of a solar dryer. AgricEngInt CIGR J 17(2):112–121. http://www.cigrjournal.org
Perrot N, Ioannou I, Allais I, Curt C, Hossenlopp J, Trystram G (2006) Fuzzy concepts applied to food product quality control: a review. Fuzzy Sets Syst 157:1145–1154
Prakash O, Kumar A (2014) ANFIS modelling of a natural convection greenhouse drying system for jaggery: an experimental validation. Int J Sustain Energ 33(2):316–335. doi:10.1080/14786451.2012.724070
Qin L, Yang SX (2011) An adaptive neuro-fuzzy approach to risk factor analysis of Salmonella Typhimurium infection. Appl Soft Comput 11(8):4875–4882. doi:10.1016/j.asoc.2011.06.012
Rahman MS, Rashid MM, Hussain MA (2012) Thermal conductivity prediction of foods by neural network and fuzzy (ANFIS) modeling techniques. Food Bioprod Process 90(2):333–340. doi:10.1016/j.fbp.2011.07.001
Russo L, Albanese D, Siettos CI, Di Matteo M, Crescitelli S (2012) A neuro-fuzzy computational approach for multicriteria optimisation of the quality of espresso coffee by pod based on the extraction time, temperature and blend. Int J Food Sci Technol 47(4):837–846. doi:10.1111/j.1365-2621.2011.02916.x
Sagdic O, Ozturk I, Kisi O (2012) Modeling antimicrobial effect of different grape pomace and extracts on S. aureus and E. coli in vegetable soup using artificial neural network and fuzzy logic system. Expert Syst Appl 39(2012):6792–6798
Samhouri M, Abughoush M, Herald T (2007) Fuzzy identification and modeling of a gum-protein emulsifier in a model mayonnaise color development system. Int J Food Eng 3(4). Article 11
Shahbazikhah P, Asadollahi-Baboli M, Khaksar R, Alamdari RF, Zare-Shahabadi V (2011) Predicting partition coefficients of migrants in food simulant/polymer systems using adaptive neuro-fuzzy inference system. J Braz Chem Soc 22(8):1446–1451. doi:10.1590/S0103-50532011000800007
Taghadomi-Saberi S, Omid M, Emam-Djomeh Z, Ahmadi H (2014) Evaluating the potential of artificial neural network and neuro-fuzzy techniques for estimating antioxidant activity and anthocyanin content of sweet cherry during ripening by using image processing. J Sci Food Agric 94(1):95–101. doi:10.1002/jsfa.6202
Toker OS, Dogan M (2013) Effect of temperature and starch concentration on the creep/recovery behaviour of the grape molasses: modelling with ANN, ANFIS and response surface methodology. Eur Food Res Technol 236(6):1049–1061. doi:10.1007/s00217-013-1959
Yalcin H, Toker OS, Ozturk I, Dogan M, Kisi O (2012) Prediction of fatty acid composition of vegetable oils based on rheological measurements using nonlinear models. Eur J Lipid Sci Technol 114(10):1217–1224. doi:10.1002/ejlt.201200040
Yilmaz MT (2012) Comparison of effectiveness of adaptive neuro-fuzzy inference system and artificial neural networks for estimation of linear creep and recovery properties of model meat emulsions. J Texture Stud 43(5):384–399. doi:10.1111/j.1745-4603.2012.00349.x
Yolmeh M, HabibiNajafi MB, Salehi F (2014) Genetic algorithm-artificial neural network and adaptive neuro-fuzzy inference system modeling of antibacterial activity of annatto dye on Salmonella enteritidis. Microb Pathog 67–68:36–40. doi:10.1016/j.micpath.2014.02.003
YüzgeçU Y Becerikli, Türker M (2009) Comparison of different modeling concepts for drying process of baker’s yeast. IEEE Trans Neural Netw 19(7):1231–1242
Zheng H, Jiang B, Lu H (2011) An adaptive neural-fuzzy inference system (ANFIS) for detection of bruises on Chinese bayberry (Myricarubra) based on fractal dimension and RGB intensity color. J Food Eng 104(4):663–667
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Al-Mahasneh, M., Aljarrah, M., Rababah, T. et al. Application of Hybrid Neural Fuzzy System (ANFIS) in Food Processing and Technology. Food Eng Rev 8, 351–366 (2016). https://doi.org/10.1007/s12393-016-9141-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12393-016-9141-7