
Abstract
A reliable estimate of the crop production prior to harvest is important for determining the prices, import–export decisions, and various food procurement policies that would enable the Government to take advance action in terms of surplus or scarcity production. Crop yield forecasting models could potentially be applied to small areas where all the necessary data are available. For large area data availability becomes critical, and the techniques of regression modeling and remote sensing are favored over growth simulation modeling. In this study, various weather parameters based statistical models have been developed to forecast the sugarcane yield during autumn and spring planting for Muzaffarnagar District of Uttar Pradesh. Last 35 year historical weather data from 1981 to 2015 were used for analysis. Various weighted and un-weighted weather indices have been utilized in developing the statistical model. The developed model using regression techniques for the spring season (Model-S4) and autumn season (Model-A5) showed a good relationship between predicted and observed values of yield. Model-S4 error ranges from − 0.063 to + 5.81%, whereas Model-A5 error varying from − 3.54 to + 3.51%. In all the developed models, weighted weather indices have been found to be significantly more effective rather than un-weighted weather indices.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Sugarcane is a traditional commercial crop of India that plays a significant role in agriculture and industrial economy of the nation; therefore, a proper forecast of production of such crops is very important (Suresh and Krishna Priya 2011). The development of crop yield models to predict yields, i.e., production per unit area, is an important component in the production forecasting system. The present system of forecasting is based on eye estimate, which is totally subjective. A need was felt to develop a suitable objective methodology for the purpose of correct estimation of yield (Agrawal et al. 1980, 1986; Jain et al. 1980). Crop yield is affected by weather variability and technological change, such as genetic qualities of seed, pest control, improved management practices and increased or decrease fertilizer applications. The variability of weather parameters is the only uncontrollable source of variability in yields. The weather parameters effect during different growth stages of the crop helps to understand their responses on final yield and also provides yield forecast before harvest of the crop (Singh et al. 1976). The different crop yield models which are used for crop yield prediction utilizing remote sensing data, meteorological, and other collateral data are as follows in Fig. 1.

Crop yield forecasting models
In recent years, various yield forecasting methods have been utilized in India for different crops, such as wheat, rice, maize, soybean, etc., while a few studies have been done for sugarcane crop. However, all the methods (regression modeling, simulation modeling and remote sensing) were considered to have potential for sugarcane yield modeling. The yield forecasting regression models use information on yield and climate factors for recent years pertaining to locations under considerations. Generally, maximum temperature, minimum temperature, relative humidity, and precipitation, etc., during different phases of crop growth satisfy the criteria to be predictors. Regression models are based on weather parameters at various stages within a crop growth to the final yield. It is a simple, yet often effective technique for relating one or more climate variables to the final crop yield (Wisiol 1987). If the growth stage of a crop is sensitive to the climate prevailing at that time, then weighting factors can be used to make the model more sensitive to climate during that stage, thus rendering potentially greater accuracy in results. Minimum thresholds can also be used, for instance, to eliminate rainfall or temperature that does not contribute to growth (Stephens et al. 1994; Durling et al. 1995). For the best results, this model requires historical long duration good quality weather datasets. Historical data are often unreliable, especially within the small farm sector (Cane et al. 1994). They are also subject to socioeconomic, technological and management influences which distort the relationship between yields and climate (Martin et al. 2000). There is also the difficulty of applying regression models in circumstances not consistent with their development, as they are static in nature and cannot adapt to a new environment. Since these models are based on collected data, they reflect the response of the crop occurring in that specific area. As a result, the application of a model in a different area needs not necessarily produce good results (Horie et al. 1992).
Crop yield estimation under Indian sub-continent conditions using meteorological parameter is very important from various perspectives. Agrawal et al. (1980) developed the yield models for rice yield using weather parameters and principle components of weather parameters for the Raipur District of Madhya Pradesh. Jain et al. (1980) investigated the individual effect of weather variables on rice yield, whereas Agrawal et al. (1983) forecast the rice yield utilizing the joint effect of weather parameters. Mall and Gupta (2000) have used 28 years weather parameters (temperature, rainfall, sunshine) and yield data (1970–1998) to develop the regression equations for wheat crop in the Varanasi District of Uttar Pradesh. The predicted wheat yield model was within + 15% of actual district yield. Mehta et al. (2000) developed the composite forecast models for sugarcane, combining bio-metrical characters and weather variables for Kohlapur District of Maharashtra. Khistaria et al. (2004) established a stepwise regression method using 29 years (1970–1998) weather and yield data for wheat forecasting models of Rajkot District, Gujarat. The percent deviations between the actual and predicted wheat yields ranging from 0 to 7.51%. Varmola et al. (2004) also give the forecast of wheat yield on the basis of weather variables using 30 years (1970–1998) data for the Mehsana District of Gujarat. This model was fitted based on stepwise regression techniques. The R2 value was (0.943) and simulated forecast error was less than 6%. Mallick et al. (2007) investigated the crop weather regression model for rice crop over the central region of Punjab using 29 years (1970–1998) historical datasets. They developed the basic model (linear, exponential, and power regression) and modified model (obtained with multiple correlation coefficient). Panwar et al. (2010) successfully reported a wheat yield weather model using 40 years (1970–2010) yield and weather data (Tmax, Tmin, rainfall, relative humidity) for the Allahabad District of Uttar Pradesh. The 38 years data (1970–2008) were used for developing the model and last 2 years (2009–2010) data are used for validation. The two-step nonlinear model (RMSE = 1.79) was found to be better as compared to the linear model (RMSE = 1.91). Pandey et al. (2013) forecast the rice yield for Faizabad District of Eastern Uttar Pradesh. The weather variables, such as rainfall, wind-velocity and sunshine hours, have been used over a span of the 21 years (1989–2009) along with the rice yield data. The technique of stepwise regression is utilized to screen out the significant climate factors, while multiple regression is consequently used to assess model parameters. The minimum RMSE value of 0.733 is found in the best fit model. Parbat et al. (2015) created the statistical yield model about a month before the harvesting time for rice (38 districts) and jute (6 districts) crop over the Bihar region using 25 years (1990–2014) rice yield and weather data. Their models were based on the correlation and regression approach in which weather factors are incorporated along with the technological trend at different stages of rice and jute crop. Panwar et al. (2018) developed the wheat yield forecast model for Aligarh District of Uttar Pradesh using the two-step nonlinear and linear regression model based on weather indices approach. They have utilized the last 40 years (1970–2010) wheat crop yield data and weather data. The nonlinear wheat yield forecast model was found superior (RMSE = 2.35) to the linear model (RMSE = 2.40). Das et al. (2020) forecast the coconut yield using last 15 years (2000–2015) weather and coconut yield data for west coast of India (14 districts). Simple and weighted (single and combination of two variables), two types of weather indices were computed for stepwise multiple linear regression technique. The data from 2000 to 2014 were used for model calibration while 2015 data are used for model validation.
The present study was done in Muzaffarnagar District of Uttar Pradesh to carry out assessment of sugarcane crops. Sugarcane is one of the major crops in the district, occupying about 70–75% of the sown area, whereas the other crops grown are wheat, mustard, sorghum, fodder, and paddy. Sugarcane requires about 25–32 °C temperature for good germination, and this temperature requirement is met twice in North India, i.e., in the month of September–October and also in the months of February–March. Spring (February–March) and autumn (September–October) are therefore two planting seasons of sugarcane in the northern part of India. Further, the duration of this crop ranges from 10 to 18 months. The spring planted sugarcane is harvested from February to March, not before the end of January otherwise the ratoon will be gappy because of poor sprouting of the stable due to low temperature. The autumn planted sugarcane is harvested after the mid-November. In this research work, different weather parameters are taken as input in stepwise regression technique and generated various weather indices (weighted and un-weighted) for developing the sugarcane yield forecasting models. A total of nine models (four for spring season and five for autumn season) are developed for sugarcane crop.
Materials and Methods
Weather Parameters
Weekly weather average data, namely maximum temperature (Tmax), minimum temperature (Tmin), rainfall data, relative humidity at 8:30 IST (RH I) and relative humidity at 14:30 IST (RH II) have been used for this study. This study was conducted using the meteorological dataset of 1981–2015. The data from the period of 1981–2012 are used for model fitting and the remaining three years data (2013–2015) are used to validate the models. The weather data were collected from the weather station of Sugarcane Development Centre, Muzaffarnagar, and the District level sugarcane yield data were obtained from the Directorate of Agriculture, Lucknow, Uttar Pradesh (Fig. 2). The figure shows previous 35 years (1981–2015) of officially reported sugarcane acreage and yield statistics of Muzaffarnagar District. It represents the variability and trend of sugarcane over the years, and indicates that in the last 5 years, the sugarcane crop area is either constant or slightly decreasing, while productivity is increasing which may be probably due to technological advancements and crop genotype improvement.

Muzaffarnagar District last 35 years sugarcane productivity and acreage
The sugarcane yield could efficiently be forecasted 8–10 weeks in advance of the harvest using statistical modeling within the acceptable limit of errors (Suresh and Priya 2009; Bhatla et al. 2018); therefore in the present study the weather parameters ahead of 2½ months of harvesting are taken for the analysis. The study focuses on the pre-harvest forecast of sugarcane productivity, which is a crucial input to import/export policy-making decisions to decide the procurement prices from farmers, and exercise measures for storage and marketing. Therefore, the productivity forecast has been made considering only one variable (biomass) of the crop; however, the second variable (sugar recovery), which is amenable to changes even 1 week prior to harvesting is not considered which may be a limitation of the study.
Statistical Regression Technique
The simplest regression techniques rely on regression equation between one or more agro-meteorological parameters and crop yield (NASS 2006; Lobell et al. 2009). Beyond their simplicity, the main advantage is requiring less time to run the model with limited data requirement and easy calculations. The disadvantages lie in the fact that sometimes they perform unrealistic forecast when the greater priority is not given to the agronomic significance as compare to statistical significance. They also do not take into consideration the soil–plant–atmosphere continuum, which is important in the regions having different types of soil. These models involved simple regression analysis using weighted and un-weighted averages that require at least 20 years of actual yield data and weekly weather data during the crop period of the respective years. Regression models do not include other parameters like soils, and management practices data, and therefore, it is less reliable as compared to simulation models which incorporate soil management data along with weather data. The statistical regression method involves some steps which are presented in the flow diagram (Fig. 3).

Yield forecasting process using regression method
Yield Forecasting Weather Indices Approach
Relationship of crop yield with several weather parameters, such as minimum and maximum temperature, rainfall and relative humidity are of a complex nature. The following models are described as:
where Y = crop yield (q/ha); A0, aij, aii′j (ii′ = 1, 2, …, p) and c are constants; p = number of weather variables used, T = year number included to correct for the long-term upward or downward trend in yield, e = random error distributed as N (0, s2). Summation extended over j with the values (a) 0 and 1; (b) 1 and 2; and (c) 0, 1 and 2; to incorporate variation to the model I defined as model Ia, Ib and Ic, respectively. Zij and Zii′j are generated first and second-order variables defined as:
Here, n = number of weeks of weeks up to the time of forecast, w = week of identification, Xiw is the value of the ith weather variable in the wth week. Here, i = 1, 2, 3 and 4 refers to total rainfall, relative humidity, maximum and minimum temperature, respectively. The model I is similar to the model used by Hendricks and Scholl (1943). Further, some modification in the model I, as suggested by Agrawal et al. (1980) and Jain et al. (1980) were made by expressing the effect of changes in weather variable on yield in the wth week by replacing week number as weight (wj) by respective correlation coefficients (r jiw or rii¢ jw ) between yield and weather variables/interactions and the modified model, named as model II, as given below:
where
Here, riw is the correlation coefficient of Y with the ith weather variable in the wth week, rii′w is the correlation coefficients of Y with the product of the ith and the i¢th weather variables in the wth week, the rest of the notations have the same meaning as in the model I.
Generation of Weather Indices
For each weather parameter, two types of indices were developed. One, as simple total values of weather parameters in different weeks (un-weighted indices: Zi0) and the other one as, weighted total, weights being correlation coefficients between detrended yield and weather variable in respective weeks (weighted indices: Zi1). Similarly, for the joint effect of weather variables, weekly interaction variables were generated using weekly products of weather variables taking two at a time. Weather indices denoted as Z; un-weighted indices are 0 and weighted indices are 1. The weather indices are as follows:
-
(a)
Un-weighted weather indices = Sum (each weather variable)
Generated un-weighted weather indices for each variable are: Tmin = Z20, Z21; Rain = Z30, Z31; RHI = Z40, Z41; RHII = Z50, Z51
-
(b)
Weighted weather indices = Sum (each week variable * correlation coefficient)
Generated indices based on combinations of each weather variable are: Tmax * Tmin = Z120, Z121; Tmax * Rain = Z130, Z131; Tmax * RHI = Z140, Z141; Tmax * RHII = Z150, Z151; Tmin * Rain = Z230, Z231; Tmin * RHI = Z240, Z241; Tmin * RHII = Z250, Z251; Rain * RHI = Z340, Z341; Rain * RHII = Z350, Z351; RHI * RHII = Z450, Z451
The stepwise regression (Draper and Smith 1981) method was utilized for the selection of significant generated variables (Zij and Zii′j) and then, further analysis was implemented only including these significant variables (Agrawal et al. 2001; Mehta et al. 2000). The thirty weather indices were generated for spring and autumn planted sugarcane.
Results and Discussions
Sugarcane Model Based on Generated Weather Indices for Spring Planted Sugarcane
The weekly data from 15th February (7th standard week) to 15th November (46th standard week) period from 1981 to 2012 were utilized for weather indices generation. In the model development, the starting data were taken, a fortnight before planting (15th February) as this period is expected to have an effect on the establishment phase of the crop. Data after 15th November were not taken, as the main objective is to forecast the yield before two and half months in advance of harvesting. By this time duration the grand growth phase of the crop is also completed and the sugarcane crop may not be affected too much by weather factors ahead of two and half month of harvesting, but in case of extreme weather condition may affect the crop even at maturity, i.e., extreme rainfall at maturity may cause flood like situation, hot and dry weather at maturity may cause stress to the crop by reducing juice (sucrose accumulation in sugarcane stalks) content while heavy rain during ripening may reduce the total sugarcane (Cardozo and Sentelhas 2013). The correlation between various weather indices and sugarcane yield were computed and its significance was tested using the t test method. Various statistical parameters are shown in Table 1 and forecast model summary is shown in Table 2. In Table 2 Time (T) indicates years. As the weather parameters and yield data for model development is used from the year 1981–1982 to 2015–2016 therefore, in the model these years (1981–82, 1982–1983, 1983–1984… 2014–2015, 2015–2016) values will be 1, 2, 3 ….. 34, 35, respectively.
Sugarcane Model Based on Generated Weather Indices for Autumn Planted Sugarcane
The weekly data from 30th September (39th standard week), a fortnight before planting, to the next year of 30th August (35th standard week) period from 1981 to 2012 were used to produce weather indices for autumn planted sugarcane. Data beyond 30th August were not considered, at this time duration the grand growth development phase of sugarcane is additionally completed. The results of t test along with the regression coefficients and the forecast model summary are presented in Tables 3 and 4, respectively.
Model Validation and Performance Analysis
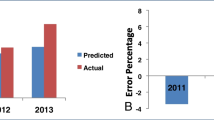
The developed models were validated by the successive 3 years actual observed yield of Muzaffarnagar District of Uttar Pradesh from 2013 to 2015. The adequacy of the models is examined by using the value of the coefficient of determination (R2). The result reveals that the Model-S4 was found suitable (R2 = 0.907) for spring season sugarcane with least percent deviation of + 5.81, − 0.063, + 0.97 for the year 2013, 2014, and 2015, respectively (Tables 5, 6). This model was created with individual weather indices viz. Tmax, Time, Rain as well as a jointed product of Tmin and Rain. For autumn planted sugarcane Model-A5 was found best (R2 = 0.942) with least percentage variance of + 1.20, − 3.54, + 3.51 during 2013, 2014, and 2015, respectively (Tables 7, 8). This model was created utilizing the Tmax, Time, Tmin, Rain and Joint impact of Tmin and Rain weather indices.
Conclusions
The developed sugarcane model for spring plantation (Model-S4) and autumn plantation (Model-A5) showed a good relationship between predicted and observed values. Model-S4 error ranges from − 0.063 to + 5.81%, whereas Model-A5 error varying from − 3.54 to +3.51%. The model created with the least data set (Tmax or Z11 only) predicted the worst yield as compare to the other model. The impact of relative humidity was not reflected in any of the models. The prediction of sugarcane yield using regression equation is more reliable when weather parameters were taken together instead of individual parameters. In all the models, weighted weather indices have been found significantly more effective rather than un-weighted weather indices. The proposed model by incorporating statistical indicators along with weighted weather indices was found suitable for sugarcane yield forecasting for Muzaffarnagar District. This study concluded that the stepwise regression technique can be successfully used for forecasting sugarcane yield using weather variables before two and half months of harvest.
References
Agrawal, R., R.C. Jain, and M.P. Jha. 1983. Joint effects of weather variables on rice yield. Mausam 34(2): 189–194.
Agrawal, R., R.C. Jain, and M.P. Jha. 1986. Models for studying rice crop-weather relationship. Mausam 37(1): 67–70.
Agrawal, R., R.C. Jain, M.P. Jha, and D. Singh. 1980. Forecasting of rice yield using climatic variables. Indian Journal of Agricultural Sciences 50(9): 680–684.
Agrawal, R., R.C. Jain, and S.C. Mehta. 2001. Yield forecast based on weather variables and agricultural inputs on agroclimatic zone basis. Indian Journal of Agricultural Sciences 71(7): 487–490.
Bhatla, R., B. Dani, and A. Tripathi. 2018. Impact of climate on sugarcane yield over Gorakhpur District, UP using statistical model. Vayu Mandal 44(1): 11–22.
Cane, M.A., G. Eshel, and R.W. Buckland. 1994. Forecasting Zimbabwean maize yield using eastern equatorial Pacific sea surface temperature. Nature 370(6486): 204–205.
Cardozo, N.P., and P.C. Sentelhas. 2013. Climatic effects on sugarcane ripening under the influence of cultivars and crop age. Scientia Agricola 70(6): 449–456.
Das, B., B. Nair, V. Arunachalam, K.V. Reddy, P. Venkatesh, D. Chakraborty, and S. Desai. 2020. Comparative evaluation of linear and nonlinear weather-based models for coconut yield prediction in the west coast of India. International Journal of Biometeorology 64: 1111–1123.
Draper, N.R., and H. Smith. 1981. Applied regression analysis, 2nd ed. New York: Wiley.
Durling, J.C., O.B. Hesterman, and C.A. Rotz. 1995. Predicting first-cut alfalfa yields from preceding winter weather. Journal of Production Agriculture 8(2): 254–259.
Hendricks, W.A., and J.C. Scholl. 1943. Technique in measuring joint relationship: The joint effects of temperature and precipitation on crop yield. North Carolina Agriculture Experiment Station Technical Bulletin, No. 74.
Horie, T., M. Yajima, and H. Nakagawa. 1992. Yield forecasting. Agricultural Systems 40(1–3): 211–236.
Jain, R.C., R. Agarwal, and M.P. Jha. 1980. Effects of climatic variables on rice yield and its forecast. Mausam 31(4): 591–596.
Khistaria, M.K., S.L. Vamora, S.K. Dixit, A.D. Kalola, and D.N. Rathod. 2004. Pre-harvest forecasting of wheat yield from weather variables in Rajkot district of Gujarat. Journal of Agrometeorology 6: 197–203.
Lobell, D.B., K.G. Cassman, and C.B. Field. 2009. Crop yield gaps: their importance, magnitudes, and causes. Annual Review of Environment and Resources 34: 179–204.
Mall, R.K., and B.R.D. Gupta. 2000. Wheat yield models based on meteorological parameters. Journal of Agrometeorology 2(1): 83–87.
Mallick, K., J. Mukherjee, S.K. Bal, S.S. Bhalla, and S.S. Hundal. 2007. Real time rice yield forecasting over Central Punjab region using crop weather regression model. Journal of Agrometeorology 9(2): 158–166.
Martin, R.V., R. Washington, and T.E. Downing. 2000. Seasonal maize forecasting for South Africa and Zimbabwe derived from an Agro climatological model. Journal of Applied Meteorology 39(9): 1473–1479.
Mehta, S.C., R. Agrawal, and V.P.N. Singh. 2000. Strategies for composite forecast. Journal of the Indian Society of Agricultural Statistics 53(3): 262–272.
National Agricultural Statistics Service. 2006. The yield forecasting program of NASS by the Statistical Methods Branch. Estimates Division, National Agricultural Statistics Service, U.S. Department of Agriculture, Washington, D.C., NASS Staff Report No. SMB 06-01.
Pandey, K.K., V.N. Bharti, and K.C. Gairola. 2013. Pre-harvest forecast models based on weather variable and weather indices for Eastern UP. Advances in Bioresearch 4(2): 118–122.
Panwar, S.A., A.N. Kumar, K.N. Singh, R.K. Paul, B. Gurung, R. Ranjan, N.M. Alam, and A.B. Rathore. 2018. Forecasting of crop yield using weather parameters-two step nonlinear regression model approach. Indian Journal of Agricultural Sciences 88(10): 1597–1599.
Panwar, S., K.N. Singh, A. Kumar, and A. Rathore. 2010. A non-linear approach based on weather variables. Advances in Applied Physical and Chemical Sciences 72(5): 72–77.
Parbat, S.K., R.K. Giri, K.K. Singh, and A.K. Baxla. 2015. Rice and jute yield forecast over Bihar region. International Research Journal of Engineering and Technology 2(3): 1636–1647.
Singh, D., H.P. Singh, and P. Singh. 1976. Pre harvest forecasting of wheat yield. Indian Journal of Agricultural Sciences 46(10): 445–450.
Stephens, D.J., G.K. Walker, and T.J. Lyons. 1994. Forecasting Australian wheat yields with a weighted rainfall index. Agricultural and Forest Meteorology 71(3–4): 247–263.
Suresh, K.K., and S.R. Krishna Priya. 2009. A study on pre-harvest forecast of sugarcane yield using climatic variables. Statistics and Applications 7&8(1&2) (New Series):1–8.
Suresh, K.K., and S.R. Krishna Priya. 2011. Forecasting sugarcane yield of Tamilnadu using ARIMA models. Sugar Tech 13(1): 23–26.
Varmola, S.L., S.K. Dixit, J.S. Patel, and H.M. Bhatt. 2004. Forecasting of wheat yields on the basis of weather variables. Journal of Agrometeorology 6(2): 223–228.
Wisiol, K. 1987. Choosing a basis for yield forecasts and estimates. In Plant growth modelling for resource management, vol. 1, ed. K. Wisiol and J.D. Hesketh, 75–103. Boca Raton: CRC Press.
Acknowledgements
The authors wish to acknowledge Director, Sugarcane Development Centre, Muzaffarnagar, for providing the meteorological dataset from 1981 to 2015. We are also grateful to the Director, Directorate of Agriculture, Lucknow, Uttar Pradesh, for the District level sugarcane yield data. Help and support received from farmers during field visits, is also acknowledged.
Funding
No funding was received.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Verma, A.K., Garg, P.K., Hari Prasad, K.S. et al. Sugarcane Yield Forecasting Model Based on Weather Parameters. Sugar Tech 23, 158–166 (2021). https://doi.org/10.1007/s12355-020-00900-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12355-020-00900-4