
Abstract
In a recent paper, the unit-Gompertz (UG) distribution has been introduced and some of its properties have been studied. In a follow up paper, some of the subtle errors in the original paper have been corrected and some other interesting properties of this new distribution have been studied. In the present work, some more important properties are investigated. Moreover, to the best of our knowledge, no characterization results on this distribution have appeared in the literature. These are addressed in the present paper.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Data are generated in all branches of social, biological, physical and engineering sciences. They are modelled by means of probability distributions for better understanding. It is important and necessary that an appropriate probability distribution be fitted to empirical data, so that meaningful and correct conclusions can be drawn.
In this connection, characterization results have been used to test goodness of fit for probability distributions. Marchetti and Mudholkar [23] showed that characterization theorems can be natural, logical and effective starting points for constructing goodness-of-fit tests. Nikitin [27] observed that tests based on characterization results are usually more efficient than the other tests. Goodness-of-fit tests based on new characterizations results abound in the literature. Baringhaus and Henze [5] studied two new omnibus goodness of fit tests for exponentiality, each based on a characterization of the exponential distribution via the mean residual life function. Akbari [2] presented characterization results and new goodness-of-fit tests based on these new characterizations for the Pareto distribution. Earlier, Glänzel [10] derived characterization theorems for some families of both continuous and discrete distributions and used them as a basis for parameter estimation.
The main purpose of the present work is to present characterization results for the unit-Gompertz distribution introduced by Mazucheli et al. [25]. Essentially, this new distribution is derived from the Gompertz distribution. Recall that the density function of the Gompertz distribution is given by
where \( y>0; \) and \( \alpha > 0 \) and \( \beta >0 \) are the shape and the scale parameters, respectively. Using the transformation
this new distribution with support on \( \left( 0, 1\right) , \) which is referred to as the unit-Gompertz distribution, is obtained. For brevity, we shall refer to it subsequently as the UG distribution. Its pdf and cdf are given by
and
respectively.
Mazucheli et al. [25] used this new distribution to model the maximum flood level (in millions of cubic feet per second) for Susquehanna River at Harrisburg, Pennsylvania (reported in Dumonceaux and Antle [9]) and tensile strength of polyester fibers as given in Quesenberry and Hales [29]. Jha et al. [14] considered the reliability estimation in a multicomponent stress-strength based on an unit-Gompertz distribution. As an application, Jha et al. [15] discussed the problem of estimating multicomponent stress-strength reliability under progressive Type II censoring when stress and strength variables follow UG distributions with a common scale parameter.
Inferential issues have also been studied. In this connection, mention may be made of Kumar et al. [20] who were concerned with the inference for the unit-Gompertz model based on record values and inter-record times. Arshad et al. [4] were interested in the estimation of the parameters under the framework of the dual generalized order statistics. Anis and De [3] not only corrected some of the subtle errors in the original paper of Mazucheli et al. [25], but also discussed some reliability properties and stochastic ordering among others. However, no characterization results of this new distribution have been studied.
This paper attempts to fill in this gap and is organized as follows. At first some more properties—which were not investigated earlier—are presented in Sect. 2. The characterizations of the distribution are studied in Sect. 3. Section 4 concludes the paper.
2 Properties
Most of the important properties of this distribution were considered in Mazucheli et al. [25] and the complementary paper by Anis and De [3]. For completeness, we consider the \( L\textrm{-moments}, \) two new measures of entropy, aging intensity and reversed aging intensity functions.
2.1 \( L\textrm{-Moments} \)
\( L\textrm{-Moments} \) are summary statistics for probability distributions and data samples. These \( L\textrm{-moments} \) are computed from linear combinations of the ordered data values (hence the prefix L). Hosking [13] showed that the \( L\textrm{-moments} \) possess some theoretical advantages over ordinary moments. Moreover, they are less sensitive to outliers compared to the conventional moments. Computation of the first few sample \( L\textrm{-moments} \) and \( L\textrm{-moment} \) ratios of a data set provides a useful summary of the location, dispersion, and shape of the distribution, from which the sample was drawn. They can be used to obtain reasonably efficient estimates of parameters when a distribution is fitted to the data. As noted in Hosking [13], the main advantage of \( L\textrm{-moments} \) over conventional moments is that \( L\textrm{-moments}, \) being linear functions of the data, suffer less from the effects of sampling variability; are more robust than conventional moments to outliers in the data and enable more secure inferences to be made from small samples about an underlying probability distribution. \( L\textrm{-moments} \) sometimes yield more efficient parameter estimates than the maximum likelihood estimates.
These \( L\textrm{-moments} \) can be defined in terms of probability weighted moments (PWMs) by a linear combination. The probability weighted moments \( M_{p, r, s} \) are defined by
Observe that \( M_{p, 0, 0} \) represents the conventional noncentral moments. We shall use the quantities \( M_{1, r, 0} \) when the random variable x enters linearly. In particular, we define \( \tau _{r} = M_{1, r, 0}\) as the probability weighted moments. The \( \tau _{r}\mathrm {'s} \) find application, for example, in evaluating the moments of order statistics (discussed in Anis and De [3]). Hosking [13] showed that the linear combination between the \( L\textrm{-moments} \) (denoted by \( \lambda _{i} \)) and the PWMs \( \tau _{r}, \) for the first four moments, are as given below:
In the particular case of the unit-Gompertz distribution, after routine calculation, we find that the \( r\mathrm {-th} \) PWM is given by
where \( \Gamma \left( s;x\right) \) is the upper incomplete gamma function and is defined as
Hence, the the \( L\textrm{-moments} \) can be obtained. It should be noted that the algebraic expressions are rather involved; but for given values of the parameters \( \alpha \) and \( \beta , \) these \( L\textrm{-moments} \) can be easily obtained numerically. As an example, we give in Table 1, the \( L\textrm{-moments} \) for some specific values of the parameters \( \alpha \) and \( \beta \) of the unit-Gompertz distribution. Here we have chosen the parameter values \(\alpha =0.25, 0.50,0.75\) and \(\beta =1.0, 1.5, 2.0, 2.5, 3.0\). From Table 1, we can observe that as the value of parameter \(\alpha \) increases, the value of \(L\textrm{-moments}\) significantly increase. This is apparent from the expression of \(\tau _r\) because \(\alpha \) appears as a power of exponential.
2.2 Entropy
Entropy is used to measure the amount of information (or uncertainty) contained in a random observation regarding its parent distribution (population). A large value of entropy implies greater uncertainty in the data. Since its introduction by Shannon [31], it has witnessed many generalizations. Anis and De [3] discussed the popular Shannon and Rényi entropies for the unit-Gompertz distribution. For completeness, we list them below:
-
The Shannon entropy \( I_{S}: \)
$$\begin{aligned} I_{S}= & {} 1- \ln \left( \alpha \beta \right) - \left( 1+\beta \right) \frac{e^{\alpha }}{\beta }\Gamma \left( 0;\alpha \right) , \quad \alpha>0, \quad \beta >0; \end{aligned}$$ -
The Rényi entropy \( I_{R}\left( \gamma \right) : \)
$$\begin{aligned} I_{R}\left( \gamma \right)= & {} \frac{1}{1-\gamma }\left[ \alpha \gamma + \frac{\left( 1-\gamma \right) }{\beta } \ln \alpha - \left( 1-\gamma \right) \ln \beta +\frac{1}{\beta }\left\{ 1-\gamma \left( 1+\beta \right) \right\} \ln (\gamma )\right. \\{} & {} +\, \left. \ln \left( \Gamma \left( \gamma +\frac{1}{\beta }\left( \gamma -1\right) , \alpha \gamma \right) \right) \right] , \quad \alpha>0, \quad \beta>0; \quad \gamma >0. \end{aligned}$$
Next, we look at four other genralizations.
2.2.1 The Tsallis entropy
The Tsallis entropy was introduced by Tsallis [36] and is defined by
Clearly, the Tsallis entropy reduces to the classical Shannon entropy as \( \gamma \rightarrow 1.\) There are many applications of the Tsallis entropy. In physics, it is used to describe a number of non-extensive systems [12]. It has found application in image processing [43] and signal processing [34]. Zhang et al. [45] used a Tsallis entropy-based measure to reveal the presence and the extent of development of burst suppression activity following brain injury. Zhang and Wu [44] used the Tsallis entropy to propose a global multi-level thresholding method for image segmentation.
For the unit-Gompertz distribution, the Tsallis entropy is given by
where \( \Gamma \left( s; x\right) \) is defined in (3).
2.2.2 The Mathai–Haubold entropy
Mathai and Haubold [24] introduced a new measure of entropy. It is defined by
The entropy \( I_{MH}\left( \gamma \right) \) is an inaccuracy measure through disturbance or distortion of systems. As \( \gamma \rightarrow 1, \) the entropy \( I_{MH}\left( \gamma \right) \) reduces to the Shannon entropy. In case of the unit-Gompertz distribution, the Mathai-Haubold entropy is given by
where \( \Gamma \left( s; x\right) \) is defined in (3).
2.2.3 The Varma entropy
Varma [38] introduced a new measure of entropy, indexed by two parameters, \( \gamma \) and \( \delta , \) which make this new measure of entropy much more flexible, thereby enabling several measurements of uncertainty within a given distribution. It plays a major role as a measure of complexity and uncertainty in different areas such as coding theory and electronics, engineering and physics to describe many chaotic systems. To understand the use of entropy in information theory, one can refer to Cover and Thomas [8]. The Varma entropy is defined as
When \( \delta \rightarrow 1 \) and \( \gamma \rightarrow 1,\) then \(I_{V}\left( \gamma , \delta \right) \rightarrow I_{S}\left( \gamma \right) , \) the Shannon entropy. For the unit-Gompertz distribution, the Varma entropy is given by
where \( \Gamma \left( s; x\right) \) is defined in (3).
2.2.4 The Kapur entropy
Kapur [18] proposed another measure of entropy. It is defined as
Clearly, if \( \delta =1 \), then the Kapur entropy reduces to the Rényi entropy. Furthermore, if \( \delta =1 \) and \( \gamma \rightarrow 1, \) then the Kapur entropy converges to the Shannon entropy. It has varied uses. For example, Upadhyay and Chhabra [37] used Crow Search Algorithm based on the Kapur entropy to estimate optimal values of multilevel thresholds. Specifically, for the unit-Gompertz distribution, the Kapur entropy is given by
where \( \Gamma \left( s; x\right) \) is defined in (3).
2.3 Aging intensity and reversed aging intensity functions
The reliability related functions like the hazard rate function, mean residual life function, reversed hazard rate function and expected inactivity time of the unit-Gompertz distribution were discussed in Anis and De [3]. For completeness, we shall simply list down the final expressions of these functions for the unit-Gompertz distribution.
-
Hazard rate function:
$$ h(x)= \frac{\alpha \beta \exp \left[ -\alpha \left( 1/x^{\beta }-1\right) \right] }{x^{1+\beta }\left\{ 1-\exp \left[ -\alpha \left( 1/x^{\beta }-1\right) \right] \right\} }; $$ -
Mean Residual Life function:
$$e\left( t\right) = \frac{1}{\bar{F}\left( t\right) } \left\{ e^{\alpha }\alpha ^{1/\beta }\left[ \Gamma \left( 1-\frac{1}{\beta }; \alpha \right) - \Gamma \left( 1-\frac{1}{\beta }; \frac{\alpha }{t^{\beta }}\right) \right] \right\} -t,$$where \( \Gamma \left( s, x\right) \) is the upper incomplete gamma function defined in (3);
-
Reversed hazard rate function:
$$\begin{aligned} r\left( x\right) =\frac{\alpha \beta }{x^{1+\beta }}; \end{aligned}$$ -
Expected inactivity time function:
$$I\left( x\right) =\frac{e^{\alpha /x^{\beta }}\alpha ^{1/\beta }}{\beta }\Gamma \left( \frac{-1}{\beta };\frac{\alpha }{x^{\beta }}\right) ,$$where \( \Gamma \left( s, x\right) \) is the upper incomplete gamma function defined in (3).
Next, we shall discuss two relatively new but important functions.
Let f, F and \( \bar{F}=1-F \) be the pdf, cdf and survival function of the random variable X. Jiang et al. [16] defined the aging intensity function (AIF), denoted by \( L\left( x\right) ,\) as
Though \( L\left( x\right) \) is related to the failure rate function, it does not determine the distribution uniquely. Numerically, \( L\left( x\right) >1, \) if the failure rate is increasing; \( L\left( x\right) =1, \) if the failure rate is constant and \( L\left( x\right) <1, \) if the failure rate is decreasing. The larger the value of \( L\left( x\right) , \) the stronger is the tendency of aging and vice versa. Thus, it describes the aging property quantitatively. It can also be interpreted as the percentage the cdf changes (decreases) when the lifetime x changes (decreases) by a small amount. Jiang et al. [17] used the AIF for parameter estimation when the data are heavily censored. For the UG distribution, we have
where \( H\left( \alpha , \beta \right) =\exp \left[ -\alpha \left( 1/x^{\beta }-1\right) \right] . \)
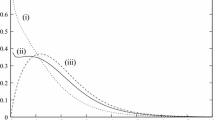
Figure 1 shows the plots of the AIF for different values of \(\alpha \) and \(\beta \). These plots clearly show that the AIF is bathtub-shaped.

Plots of aging intensity function for different values of \(\alpha \) and \(\beta \)
The dual concept of reversed aging intensity function \( \widetilde{L} \left( x\right) \) is defined by
The larger the numerical value of the reversed aging intensity function, the weaker is the tendency of aging. The aging intensity function L and the reversed aging intensity function \( \widetilde{L}\) do not characterize the family of distribution uniquely. See Szymkowiak [32] and Buono et al. [6] for details.
For the UG distribution, we get
Observe that the first derivative of \(\widetilde{L}\left( x\right) \) is
For \(x\in (0,1)\), \(\widetilde{L}^{'}\left( x\right) >0\) implies that the reversed aging intensity function is always non-decreasing and this can be visualised from Fig. 2. It can also be observed from Fig. 2 that the value of \(\widetilde{L}(x)\) increases as the value of \(\beta \) increases and is an asymptote at \(x=1\) for all values of \(\beta >0\).

Plot of reversed aging intensity function for different values of \(\beta \)
3 Characterizations
We shall now give characterizations of the unit-Gompertz distribution based on (i) truncated first moment; (ii) hazard function; (iii) reversed hazard function; (iv) Mills ratio and (v) elasticity function.
3.1 Characterizations based on the truncated first moment
We shall begin with characterizations based on the truncated first moment. To prove the characterization results, we shall need two lemmas and an assumption, which are presented first.
Assumption
\(\mathcal {A}\): Assume that X is an absolutely continuous random variable with the pdf given in (1) and the corresponding cdf given in (2). Assume that \( E\left( X\right) \) exits and the density \( f\left( x\right) \) is differentiable. Define \( \eta = \sup \left\{ x: F\left( x\right) <1\right\} \) and \( \zeta = \inf \left\{ x: F\left( x\right) >0\right\} . \)
Lemma 3.1
Under Assumption \(\mathcal {A}\), if \(E\left( X\mid X \le x\right) = g\left( x\right) \tau \left( x\right) , \) where \( g\left( x\right) \) is a continuous differentiable function of x with the condition that \(\int _{\zeta }^{x}\frac{u-g^{\prime }(u)}{g(u)}du\) is finite for all \( x> \zeta , \) and \( \tau \left( x\right) =\frac{f\left( x\right) }{F\left( x\right) } \), then
where the constant c is determined by the condition \(\int _{\zeta }^{\eta }f\left( x\right) dx=1.\)
Lemma 3.2
Under Assumption \(\mathcal {A}\), if \(E\left( X\mid X \ge x\right) = h\left( x\right) r \left( x\right) , \) where \( h\left( x\right) \) is a continuous differentiable function of x with the condition that \(\int _{\zeta }^{x}\frac{u-h^{\prime }(u)}{h(u)}du\) is finite for all \( x>\zeta , \) and \( r\left( x\right) =\frac{f\left( x\right) }{1- F\left( x\right) } \), then
where c is a constant determined by the condition \(\int _{\zeta }^{\eta }f\left( x\right) dx=1.\)
See Ahsanullah [1] for the details of proofs of Lemmas 3.1 and 3.2.
3.1.1 Characterization theorems
We shall now state and prove two characterization theorems based on the truncated first moment.
Theorem 3.3
Suppose that the random variable X satisfies Assumption \(\mathcal {A}\) with \(\zeta =0\) and \(\eta =1.\) Then, \(E\left( X\mid X \le x\right) = g\left( x\right) \tau \left( x\right) , \) where \(\tau (x)=\frac{f(x)}{F(x)}\) and
where \( \Gamma \left( s; x\right) \) is defined in (3), if and only if
Proof
Suppose
We have
Since \(\tau (x)=\frac{f(x)}{F(x)},\) it follows that
where \( \Gamma \left( s;x\right) \) is the upper incomplete gamma function defined in (3). Hence, after simplifying, we obtain
Conversely, suppose that \( g\left( x\right) \) is given by (4). Differentiating \(g\left( x\right) \) with respect to x, and simplifying, we obtain
Hence,
By Lemma 3.1, we have
Integrating both sides of (5) with respect to x, we obtain
where k is a constant. Using the condition \( \int _{0}^{1} f\left( x\right) dx=1,\) we get
This completes the proof. \(\square \)
Theorem 3.4
Suppose that the random variable X satisfies Assumption \(\mathcal {A}\) with \(\zeta =0\) and \(\eta =1.\) Then, \(E\left( X\mid X \ge x\right) = h\left( x\right) r \left( x\right) , \) where \(r(x)=\frac{f(x)}{1-F(x)}\) and
where \( \Gamma \left( s;x\right) \) is the upper incomplete gamma function defined in (3), if and only if
Proof
Suppose
We have
Since \(r(x)=\frac{f(x)}{1-F(x)},\) it follows that
where \( \Gamma \left( s;x\right) \) is the upper incomplete gamma function defined in (3). Hence,
Conversely, suppose that \( h\left( x\right) \) is given by (6). Differentiating \(h\left( x\right) \) with respect to x, and simplifying, we obtain
Hence,
By Lemma 3.2, we have
Integrating both sides of (7) with respect to x, we obtain
where k is a constant. Using the condition \( \int _{0}^{1} f\left( x\right) dx=1,\) we get
This completes the proof. \(\square \)
3.2 Characterization based on the hazard function
Mazucheli et al. [25] obtained the hazard rate function of the UG distribution. Specifically, it is given by
Anis and De [3] discussed the shape of the hazard function.
We shall now use it to provide a characterization result for this distribution. It is well known that the hazard function uniquely determines the distribution. More specifically, the hazard function, \( h_{F}, \) of a twice differentiable distribution function, F, satisfies the first order differential equation
where \( f\left( x\right) = \frac{dF\left( x\right) }{dx}.\) The next theorem establishes a characterization of the UG distribution based on the hazard rate function.
Theorem 3.5
The pdf of X is given by (1) if and only if its hazard function, \( h_{F}, \) satisfies the first order differential equation
Proof
If the random variable X has the pdf (1), then it is easy to check that the differential equation (8) holds.
Conversely, suppose the differential equation in (8) is true. Then, it is easy to see that the left hand side of (8) can be rewritten as \( \frac{d}{dx}\left[ h_{F}\left( x\right) \left\{ 1-\exp \left[ - \alpha \left( \frac{1}{x^{\beta }} -1\right) \right] \right\} \right] ; \) while the right hand side is just \( \frac{d}{dx}\left[ \frac{\alpha \beta \exp \left[ -\alpha \left( \frac{1}{x^{\beta }} -1\right) \right] }{x^{1+\beta }} \right] . \) Hence, we have
Thus, we have
which is the hazard function of the UG distribution. \(\square \)
3.3 Characterization based on the Mills ratio
The Mills ratio \( M\left( x\right) \) was introduced into the statistical literature by Mills [26]. Essentially, it is the reciprocal of the hazard function. The convexity of the Mills ratio of continuous distributions has important applications in monopoly theory, especially in static pricing problems. Xu and Hopp [42] used the convexity of Mills ratio to establish that the price is a sub-martingale. Like the hazard function, the Mills ratio \( M\left( x\right) , \) of a twice differentiable distribution function, F, satisfies the first order differential equation
where \( f\left( x\right) = \frac{dF\left( x\right) }{dx}.\) The next theorem establishes a characterization of the UG distribution based on the Mills ratio.
Theorem 3.6
The pdf of X is given by (1) if and only if its Mills ratio \( M\left( x\right) \) satisfies the first order differential equation
Proof
If the random variable X has the pdf (1), then routine but elaborate calculations show that the differential equation (9) holds.
Conversely, suppose the differential equation in (9) is true. Then, the above differential equation can be rewritten as
or equivalently,
and hence
which represents the Mills ratio for the UG distribution. \(\square \)
3.4 Characterization based on the reversed hazard rate function
The reversed hazard rate function \( r_{F}\left( x\right) \) is an important characteristic of a random variable and has found many applications. Lagakos et al. [21] used the reversed hazard rate function to analyze right-truncated data. Cheng and Zhu [7] used the reverse hazard rate function to characterize the best strategy for allocating servers in a tandem system. Kijima [19] used the reversed hazard rate function to study continuous time Markov Chains. Gupta et al. [11] used the reversed hazard rate function to calculate the Fisher information. Townsend and Wenger [35] used the reversed hazard rate function to model information processing capacity. Razmkhah et al. [30] used the reversed hazard rate function to calculate the Shannon entropy.
Anis and De [3] showed that for the UG distribution, \(r_{F}\left( x\right) =\frac{\alpha \beta }{x^{1+\beta }}. \)
The reversed hazard rate function can be used to characterize a random variable. More precisely, the reversed hazard rate function, \( r_{F}, \) of a twice differentiable distribution function, F, satisfies the first order differential equation
where \( f\left( x\right) = \frac{dF\left( x\right) }{dx}.\) The next theorem establishes a characterization of the UG distribution based on the reversed hazard rate function.
Theorem 3.7
The pdf of X is given by (1) if and only if its reversed hazard function, \( r_{F}, \) satisfies the first order differential equation
Proof
If the random variable X has the pdf (1), then it is easy to check that the differential equation (10) holds.
Conversely, suppose the differential equation in (10) is true. Then, the above differential equation can be rewritten as
This implies \( r_{F}\left( x\right) =\frac{\alpha \beta }{x^{1+\beta }}, \) which is essentially the reversed hazard rate function of the UG distribution. \(\square \)
3.5 Characterization based on the elasticity function
The elasticity function of a random variable is a relatively new concept. Veres-Ferrer and Pavía [39,40,41] studied this function and its relationship with other stochastic functions. Essentially, the elasticity function \( e\left( x\right) \) of a random variable is defined by \( e\left( x\right) = \frac{x f\left( x\right) }{F\left( x\right) }. \) As an example of its application, mention may be made of Pavía et al. [28] who used these concepts to study risk management in business. Szymkowiak [33] used it to characterize a parent distribution uniquely. Lariviere and Porteus [22] adopted this concept and applied it to the supply chain management. For the UG distribution, the elastic function is given by \( e\left( x\right) = \frac{\alpha \beta }{x^{\beta }}. \) The elasticity function satisfies the first order equation
The following theorem establishes a characterization of the UG distribution based on the elasticity function.
Theorem 3.8
The pdf of X is given by (1) if and only if its elasticity function \( e\left( x\right) \) satisfies the first order differential equation
Proof
If the random variable X has the pdf (1), then routine, but elaborate calculation shows that the differential equation (11) holds.
Conversely, suppose the differential equation in (11) holds. Then, the above differential equation can be simplified as
and hence \( e\left( x\right) = \frac{\alpha \beta }{x^{\beta }}, \) which is the elastic function of the UG distribution. \(\square \)
4 Conclusion
In this work, we have presented five characterizations of the recently-introduced unit-Gompertz distribution. To the best of our knowledge, this is the only work on the characterizations of this distribution available in the literature till date. We hope this will enable researchers to understand whether the given data at hand can be modeled by this distribution. We also looked at the L-moments, four measures of entropy, aging intensity and reversed aging intensity functions.
References
Ahsanullah, M.: Characterizations of Univariate Distributions. Atlantis Press, Paris (2017)
Akbari, M.: Characterization and goodness-of-fit test of Pareto and some related distributions based on near-order statistics. J. Probab. Stat. 2020, 4262574 (2020). https://doi.org/10.1155/2020/4262574
Anis, M.Z., De, D.: An expository note on the unit-Gompertz distribution with applications. Statistica (Bologna) 80(4), 469–490 (2020)
Arshad, M., Azhad, Q.J., Gupta, N., Pathak, A.K.: Bayesian inference of unit-Gompertz distribution based on dual generalized order statistics. Commun. Stat.—Simul. Comput. 52(8), 3657–3675 (2023). https://doi.org/10.1080/03610918.2021.1943441
Baringhaus, L., Henze, N.: Tests of fit for exponentiality based on a characterization via the mean residual life function. Stat. Pap. 41, 225–236 (2000)
Buono, F., Longobardi, M., Szymkowiak, M.: On generalized reversed aging intensity functions. Ricer. Math. 71, 85–108 (2021). https://doi.org/10.1007/s11587-021-00560-w
Cheng, D.W., Zhu, Y.: Optimal order of servers in a tandem queue with general blocking. Queue. Syst. 14, 427–437 (1993)
Cover, T., Thomas, J.A.: Elements of Information Theory, 2nd edn. Wiley, Hoboken (2006)
Dumonceaux, R., Antle, C.E.: Discrimination between the log-normal and the Weibull distributions. Technometrics 15(4), 923–926 (1973)
Glänzel, W.: A characterization theorem based on truncated moments and its application to some distribution families. In: Bauer, P., Konecny, F., Wertz, W. (eds.) Mathematical Statistics and Probability Theory. Springer, Dordrecht (1987). https://doi.org/10.1007/978-94-009-3965-3_8
Gupta, R.D., Gupta, R.C., Sankaran, P.G.: Some characterization results based on factorization of the (reversed) hazard rate function. Commun. Stat.—Theory Methods 33, 3009–3031 (2004)
Hamity, V.H., Barraco, D.E.: Generalized nonextensive thermodynamics applied to the cosmical background radiation in Robertson–Walker universe. Phys. Rev. Lett. 76, 4664–4666 (1996)
Hosking, J.R.: L-Moments: analysis and estimation of distributions using linear combinations of order statistics. J. R. Stat. Soc. Ser. B (Methodol.) 52, 105–124 (1990). https://doi.org/10.1111/rssb.1990.52.issue-1
Jha, M.K., Dey, S., Tripathi, Y.M.: Reliability estimation in a multicomponent stress-strength based on unit-Gompertz distribution. Int. J. Qual. Reliab. Manag. 37, 428–450 (2019)
Jha, M.K., Dey, S., Alotaibi, R.M., Tripathi, Y.M.: Reliability estimation of a multicomponent stress-strength model for unit Gompertz distribution under progressive Type II censoring. Qual. Reliab. Eng. Int. 36, 965–987 (2020)
Jiang, R., Ji, P., Xiao, X.: Aging properties of unimodal failure rate models. Reliab. Eng. Syst. Saf. 79, 113–116 (2003)
Jiang, R., Cao, Y., Faqun, Q.: An aging-intensity-function-based parameter estimation method on heavily censored data. Qual. Reliab. Eng. Int. 39(8), 3484–3501 (2022)
Kapur, J.N.: Generalized entropy of order \( \alpha \) and type \( \beta \). Math. Semin. 4, 79–84 (1967)
Kijima, M.: Hazard rate and reversed hazard rate monotonicities in continuous-time Markov chains. J. Appl. Probab. 35, 545–556 (1998)
Kumar, D., Dey, S., Ormoz, E., MirMostafaee, S.M.T.K.: Inference for the unit-Gompertz model based on record values and inter-record times with an application. Rendicont. Circolo Mat. Palermo. 69, 1295–1319 (2020). https://doi.org/10.1007/s12215-019-00471-8
Lagakos, W., Barraj, L.M., Gruttola, V.: Nonparametric analysis of truncated survival data, with application to AIDS. Biometrika 75(3), 515–523 (1988)
Lariviere, M.A., Porteus, E.L.: Selling to the newsvendor: an analysis of price-only contracts. Manuf. Serv. Oper. Manag. 3(4), 293–305 (2001)
Marchetti, C.E., Mudholkar, G.S.: Characterization theorems and goodness-of-fit tests. In: Huber-Carol, C., Balakrishnan, N., Nikulin, M.S., Mesbah, M. (eds.) Goodness-of-Fit Tests and Model Validity. Statistics for Industry and Technology. Birkhäuser, Boston (2002). https://doi.org/10.1007/978-1-4612-0103-8_10
Mathai, A.M., Haubold, H.J.: Pathway model, superstatistics, Tsallis statistics and a generalized measure of entropy. Phys. A 375, 119–122 (2007)
Mazucheli, J., Menezes, A.F., Dey, S.: Unit-Gompertz distribution with applications. Statistica (Bologna) 79(1), 25–43 (2019)
Mills, J.P.: Table of the ratio: area to bounding ordinate, for any portion of normal curve. Biometrika 18(3), 395–400 (1926)
Nikitin, Y.: Test based on characterizations, and their efficiencies: a survey. Acta Comment. Univer. Tartu. Math. 21, 3–24 (2017)
Pavía, J.M., Veres-Ferrer, E.J., Foix-Escura, G.: Credit card incidents and control systems. Int. J. Inf. Manage. 32(6), 501–503 (2012)
Quesenberry, C., Hales, C.: Concentration bands for uniformity plots. J. Stat. Comput. Simul. 11(1), 41–53 (1980)
Razmkhah, M., Morabbi, H., Ahmadi, J.: Comparing two sampling schemes based on entropy of record statistics. Stat. Pap. 53, 95–106 (2012)
Shannon, C.E.: A mathematical theory of communication. Bell Syst. Tech. J. 27, 379–423 (1948)
Szymkowiak, M.: Generalized aging intensity functions. Reliab. Eng. Syst. Saf. 178, 198–208 (2018)
Szymkowiak, M.: Measures of ageing tendency. J. Appl. Probab. 56, 358–83 (2019)
Tong, S., Bezerianos, A., Paul, J., Zhu, Y., Thakor, N.: Nonextensive entropy measure of EEG following brain injury from cardiac arrest. Physica A 305, 619–628 (2002)
Townsend, J.T., Wenger, M.J.: A theory of interactive parallel processing: new capacity measures and predictions for a response time inequality series. Psychol. Rev. 111, 1003–1035 (2004)
Tsallis, C.: Possible generalization of Boltzmann–Gibbs statistics. J. Stat. Phys. 52(1), 479–487 (1988)
Upadhyay, P., Chhabra, J.K.: Kapur’s entropy based optimal multilevel image segmentation using Crow Search Algorithm. Appl. Soft Comput. 97, 105522 (2020). https://doi.org/10.1016/j.asoc.2019.105522
Varma, R.S.: Generalization of Rényi’s entropy of order \( \alpha \). J. Math. Sci. 1, 34–48 (1966)
Veres-Ferrer, E.J., Pavía, J.M.: Properties of the elasticity of a continuous random variable A special look at its behavior and speed of change. Commun. Stat.—Theory Methods 46(6), 3054–3069 (2017). https://doi.org/10.1080/03610926.2015.1053943
Veres-Ferrer, E.J., Pavía, J.M.: On the relationship between the reversed hazard rate and elasticity. Stat. Pap. 55, 275–284 (2014)
Veres-Ferrer, E.J., Pavía, J.M.: Elasticity function of a discrete random variable and its properties. Commun. Stat.—Theory Methods 46(17), 8631–8646 (2017). https://doi.org/10.1080/03610926.2016.1186190
Xu, X., Hopp, W.J.: Price trends in a dynamic pricing model with heterogeneous customers: a martingale perspective. Oper. Res. 57(5), 1298–1302 (2009)
Yu, M., Zhanfang, C., Hongbiao, Z.: Research of automatic medical image segmentation algorithm based on Tsallis entropy and improved PCNN. In: IEEE Proceedings on ICMA, pp. 1004–1008 (2009)
Zhang, Y., Wu, L.: Optimal multi-level thresholding based on maximum Tsallis entropy via an artificial bee colony approach. Entropy 13, 841–859 (2011)
Zhang, D., Jia, X., Ding, H., Ye, D., Thakor, N.V.: Application of Tsallis entropy to EEG: quantifying the presence of burst suppression after asphyxial cardiac arrest in rats. IEEE Trans. Biomed. Eng. 57(4), 867–874 (2010)
Acknowledgements
Thanks are due to the learned reviewer whose suggestions lead to an improvement in the presentation.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There is no Conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Anis, M.Z., Bera, K. The unit-Gompertz distribution revisited: properties and characterizations. Rend. Circ. Mat. Palermo, II. Ser 73, 1921–1936 (2024). https://doi.org/10.1007/s12215-024-01021-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12215-024-01021-7