
Abstract
This paper investigates different developments in non-expected utility theories. Our focus is to study the agent’s attitude towards risk in a context of monetary gambles. Based on simulated data of the “Deal or No Deal” TV game show, we first compare the performance of the expected utility model versus a loss-aversion model. We find that the loss-aversion model has a better performance compared to the expected utility model. We then study the attitude towards risk according to two parameters: the relative risk aversion coefficient defined over the value function and the probability weighting coefficient proposed by the Cumulative Prospect Theory. We find evidence for probability weighting being undertaken by contestants reflecting less risk aversion over large stakes. We also explore the performance of two models of rank-dependant utility: the Quiggin (1982) and the power probability weighting models. We find that the probability weighting coefficient is still significant for both models. Finally, we integrate initial wealth into the contestants’ preferences function and we show that the initial wealth level affects the estimates of risk attitudes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Recent financial literature highlights the relevance of the non-expected utility theory in explaining agents’ behavior towards monetary gambles (Epstein and Zin 1990; Rabin 2000; Barberis and Huang 2006; Barberis et al. 2006). This literature reveals that the expected utility model fails to describe the small stakes gambles,Footnote 1 as it provides for significant risk aversion, leading to the rejection of another type of gamble, namely the largeFootnote 2 stakes gamble.
A first area of research related to our work groups studies of non-expected utility. Different value functions and weighted probability functions were proposed in the literature. However, relevant behavioral finance literature outlines the prevalence of Prospect TheoryFootnote 3 of Kahneman and Tversky (1979) (Starmer 2000; Post et al. 2008; Chou et al. 2009). For instance, Starmer (2000) examines a set of non-expected utility theories and concludes that Prospect Theory constitutes a well grounded hypothesis departing from the standard theory of expected utility. Post et al. (2008) document that the loss-aversion value function proposed in Prospect Theory explains the agents’ choices substantially better than the expected utility does. Chou et al. (2009) confirm this finding and show strong and robust evidence supporting Prospect Theory.
A second area of behavioral finance literature focuses on non-deterministic approaches of choice under risk and uncertainty that address expected utility violations. These approaches are commonly grouped under the name of random utility maximization models.Footnote 4 Harless and Camerer (1994), Hey and Orme (1994) and Loomes and Sugden (1995) present the first studies integrating a stochastic specification in utility models. For instance, Hey and Orme (1994) find that an expected utility, with some additional structure of error terms, provides satisfactory predictions of individual choice. Recently, de Palma et al. (2008) highlighted the cross-fertilizations of random utility models with the study of decision making under risk and uncertainty, and recommended researchers to estimate people’s preferences based on the specification of a random utility model.
Finally, a growing number of studies use real monetary gambles provided by TV game shows to examine investors’ risky choices. Among the studied games, we cite Card Sharks (Gertner 1993), Jeopardy! (Metric 1995), Illinois Instant Riches (Hersch and McDougall 1997), Lingo (Beetsman and Schotman 2001), Hoosier Millionaire (Fullencamp et al. 2003), Who Wants to be a Millionaire? (Hartley et al. 2005) and Deal or No Deal (Post et al. 2006; Roos and Sarafidis 2006; Post et al. 2008; Van Den Assem 2008). The relevance of these studies is to provide estimates of the agents’ risk aversion based on real data of monetary gambles.
This paper investigates different developments in non-expected utility theories using the case of the Deal or No Deal game show. Our results complement those of Post et al. (2008) in two respects. First, we integrate non-linear probability weighting functions into the loss-aversion value function of Prospect Theory. Post et al. (2008) focus specifically on utility models which have a smooth probability weighting function. However, this study examines the rank-dependant utility model and the Cumulative Prospect Theory of Tversky and Kahneman (1992). Introducing different shapes of the probability weighting function improves the robustness of our results since it detects the investor’s sentiment of optimism (pessimism) that is not necessarily captured by the value functions. Second, our behavioral specifications are defined in a random utility model framework since we integrate a noise term into the contestants’ preferences, as in Hey and Orme (1994). In fact, the very reason for the interest in the random utility model is that the noise term could reflect errors in the contestants’ decisions that are not identified in the standard utility models. In addition, we separate the error in the stochastic model to consider positive and negative news. We also introduce a specific fixed effect into the contestants’ preferences, which conveys some of their personal characteristics and sources of their preferences’ heterogeneity. Hence, we estimate a random effect utility model using the maximum likelihood approach.
Using simulated data generated from the structure of the TunisianFootnote 5 version of the TV game show Deal or No Deal, we show the superiority of the loss aversion model to describe the contestants’ risky choice behavior. We also show that the agent, when according a subjective weight to the probability of occurrence of an outcome, overweights low probabilities and underweights high probabilities. This probability weighting is significant for different shapes of the rank-dependant utility models. Similar results are obtained when separating the error term of the random utility model for bad and good news. However, we find that the initial wealth level affects the estimates of risk attitudes.
Our paper is organized as follows. Section 2 presents the value functions of expected utility theory and the loss-aversion model. Section 3 introduces the probability weighting functions of rank-dependant utility and Cumulative Prospect Theory. Section 4 is dedicated to a description of the game show and the simulated data. Section 5 details the methodology employed in this study. Section 6 contains the empirical results. Section 7 discusses the robustness of the results. We conclude in Section 8.
2 Value functions of preferences
Our study analyzes two types of value functions, namely the expected utility model (we consider here the form proposed by Lucas 1978) and the loss-aversion model as expressed in the Prospect Theory of Kahneman and Tversky (1979). Additionally, it is important to emphasize that our value functions do not integrate contestants’ initial wealth.
2.1 Expected utility function
The preference function of the expected utility that we consider is given by:
This is the fundamental equation of the Lucas asset pricing model (1978).Footnote 6
Where:
- U :
-
is the utility function
- γ i,r :
-
is the relative risk-aversion coefficient defined at the end of each round r (r varies from 1 to 7) and for each contestant i (i varies from 1 to N)
- \( {X}_{i,r}={\displaystyle {\sum}_{j=1}^{n_r}{x}_{j,i,r}}\times \frac{1}{n_r} \) :
-
is the average contestant’s prize obtained at the end of each round r
- x i,r :
-
are prizes in the remaining (unopened) boxes
- n r :
-
is the number of the remaining boxes at the end of each round r
The function described by Eq. (1) produces a constant relative risk aversion. This aversion is applied to the level of financial wealth created by the game X.
2.2 Loss-aversion function
Before presenting the loss-aversion function, we discuss theories developed under the name of non-expected utilities. The questioning of expected utility theory came about from experimental evidence, such as that presented by Allais (1953), Ellsberg (1961) and Tversky (1969). These authors found that investors systematically violate expected utility theory when choosing among risky assets. Theories of non-expected utility tried to explain this experimental evidence. Among them, we cite the weighting utility function (Chew and Mac Crimmon 1979; Chew 1989), implicit expected utility (Dekel 1986; Chew 1989), regret aversion theory (Bell 1982; Loomes and Sugden 1995), disappointment aversion theory (Gul 1991) and Prospect Theory (Kahneman and Tversky 1979).
Of all these non-expected utility theories, Prospect Theory seems to be the best at explaining the empirical results. Indeed, most theories are almost normative. They explain prizes’ formation by making the expected utility axioms less restrictive. However, Prospect Theory is a descriptive theory which models the agent’s behavior towards risky gambles.
In this paper, we have been inspired by the Prospect Theory of Kahneman and Tversky (1979) and we consider that the utility of an asset is generated by the following function:
Where:
- U :
-
is the utility function
- X :
-
is the average prize obtained at the end of each round and p is the probability of the realization of this prize
- V(X) and w(p):
-
are, respectively, the value and the probability weighting functions.
Let us present our value function V(X). This function is expressed in part by a term of loss aversion and narrow framing. We first study the loss aversion which we present in Fig. 1. We note that, unlike expected utility which defines the agent’s risk aversion over his overall wealth level, loss aversion expressed about gains and losses is defined around a reference point.Footnote 7 In particular, the loss-aversion function is concave with gains and convex with losses. The shape of the curve implies that the agent’s attitude towards risk is different: he is risk averse when he realizes a gain and becomes a risk lover if he loses.

The loss aversion function. This form of the loss aversion is defined by the following equation: \( \mathrm{U}\left(\mathrm{x}\right) = \left\{\begin{array}{c}\hfill \mathrm{x}\kern2.75em \mathrm{if}\kern0.75em \mathrm{x}>0\hfill \\ {}\hfill \lambda \mathrm{x}\kern2em \mathrm{if}\kern0.75em \mathrm{x}<0\hfill \end{array}\right. \); where:- x is an outcome defined around a reference point and; − λ is the coefficient of loss aversion
Our paper assumes that if the contestant evaluates a gamble X using the loss-aversion utility function, which we note υ(), he uses a proxy of realized gains/losses, which is the variable X i,r − E(xi,7). Where:
-
X i,r is the expected prize in a given round r. It is equal to \( {\displaystyle {\sum}_{j=1}^{n_r}{x}_{j,i,r}}\times \frac{1}{n_r} \).
-
E(xi,7): is the initial expected prize of the game. It is equal to \( {\displaystyle {\sum}_{j=1}^{24}{x}_{j,i,r}}\times \frac{1}{24} \).
-
X ir -E(xi,7) is an indicator of the performance realized during the game. It is defined as the expected prize in a given round r minus the initial expected prize. So, if X ir -E(xi,7) <0, the contestant registers a loss as his expected prize has decreased. However, if X ir -E(xi,7) ≥0, the player records a gain as his expected prize has increased. The loss-aversion function takes the following form :
Where: λ is the loss aversion coefficientFootnote 8 and α is a parameter. In our study, we set a value of λ equal to 2.5 and a value of α equal to 0.88. These are the experimental values used by Kahneman and Tversky (1979).
In this paper, we also study the narrow framing mechanism. This mechanism was proposed by Tversky and Kahneman (1981) and implies that the utility function depends on each choice itself rather than its contribution to total wealth. Thus, while modeling loss aversion, we hypothesize that the contestant evaluates some of his performance in the game separately from his total wealth. This means that only a part of the gamble X is evaluated by the loss-aversion function. The other part is evaluated by the expected utility function. In our study, we note k as the narrow framing parameter. Its value is equal to 0.1 as in Barberis and Huang (2006).
Finally, we express the contestant’s value function of loss aversion as follows:
3 Probability weighting functions of preferences
The probability weighting of outcomes is a theory which states that the probability function is subject to a transformation during the investor’s decision making. That is, to match every probability, there is a weighting that may be lower or higher than the original probability.
Our paper examines different forms of probability weighting functions proposed in the financial literature.Footnote 9 These forms are studied in rank-dependant expected utility theory and Cumulative Prospect Theory.
3.1 The rank-dependant expected utility model
Rank-dependant expected utility was developed by Quiggin (1981, 1982). It is a generalization of expected utility theory, as it preserves the standard properties of continuity, transitivity and stochastic dominance of first order. However, it stipulates that the outcome is weighted according to its rank. It also applied w, the weighting function, to the cumulative probability, not to the individual probability. Thus, the weight of the probability p i , w(p i ) is expressed as follows:
Where: F is the cumulative function of probabilities.
According to the rank-dependant model, extreme events must be over/under-weighted. Indeed, low probability events should be overweighted while higher probability events should be underweighted. The probability weighting function of Quiggin (1982) is expressed as follows:
Where: δ is the probability weighting coefficient. This coefficient conveys the contestant’s attitude towards risk induced by the distribution of the events’ probabilities. Thus, two measures of risk aversion are possible. The first is the risk aversion coefficient γ of the value function and the second is the probability weighting coefficient δ, which reflects the sentiment of optimism (pessimism) expressed respectively over low (high) probabilities of high (low) gains. Indeed, the expression of Eq. (6) shows that the agent overweights low probabilities and underweights high probabilities.
In this paper, we also study the power probability weighting function. This function is expressed as follows:
According to this function, the concavity (the convexity) of the curve reflects the individual’s risk aversion (risk loving). In this case, the attitude towards risk is static and does not depend on the probabilities.
3.2 Cumulative prospect theory
Based on the rank-dependant model of Quiggin (1982), Tversky and Kahneman (1992) define their probability weighting function using a non-linear transformation. According to Cumulative Prospect Theory, the weight of an outcome i is expressed as follows:
Where: w + and w − are the probability weighting functions respective of gains and losses, and n are lottery outcomes. The functional formFootnote 10 proposed by Tversky and Kahneman (1992) is:
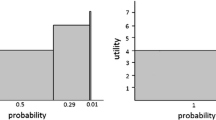
δ, the probability weighting coefficient of Tversky and Kahneman (1992), expresses optimism (pessimism) over low (high) probabilities. In their empirical results, Tversky and Kahneman (1992) found that δ + = 0.61 and δ − = 0.69. Thus, the weighting functions for gains and for losses are quite close, although the former is slightly more curved than the latter. Figure 2 presents the probability weighting function for δ equal to 0.69.Footnote 11 It shows that, for a given outcome i, people overweight low probabilities and underweight moderate and high probabilities.

Probability weighting function of Tversky and Kahneman: δ equal to 0.69. The curve in Fig. 2 is a probability weighting function, assuming a linear value function. It is fitted using the following functional form: \( w\left({p}_i\right)=\frac{{p_i}^{0.69}}{{\left({p_i}^{0.69}+{\left(1-{p}_i\right)}^{0.69}\right)}^{1/0.69}} \); Where :-pi is the probability of occurrence of an outcome i; −w(pi) is the probability weighting function
Table 1 summarizes the value functions and the probability weighting functions of the expected utility versus the loss aversion model and the rank-dependant utility models. It also compares the pros and cons of each model.
4 Description of the game show and simulated data
4.1 Description of the Tunisian game show
The TV game show Deal or No Deal is developed by the Dutch production company “Endemol” and was adapted to different countries. Our paper reproduces the Tunisian version of the Deal or No Deal game framework. This version is called “Dlilek Mlak” which means in Arabic “your heart is the king”. It is adapted by the production company “CactusProd” and was aired on Tunisian National Television between 2005 and 2007. Each year, 30 episodes were broadcast during the holy month of Ramadan, a month generally associated with festive market behavior reflecting positive investor sentiment (see Al-Hajieh et al. 2011).
There are 24 boxes corresponding to 24 governorates. These boxes contain unknown prizes drawn randomly by contestants. The lowest prize is 0.08 dollar and the highest prize is 775,254 dollars. Table 2 presents an overview of these prizes.
The game begins with a simple general question. The contestant who is the fastest to answer the question correctly is selected to play. Every contestant has a box containing an unknown prize assigned by the bailiff of the show and can play up to seven rounds. At the end of the first six rounds, the contestant is given an offer by the banker, which he can either accept or refuse. Notably, as the game progresses and more boxes are opened, more information will be revealed about the prize distribution, inducing the contestant to change his final estimation of the potential gain and leading to the acceptance or refusal of the bank’s offers. Table 3 summarizes the number of initial and opened boxes for each round.
4.2 Description of the simulated data
We simulate 1000 games corresponding to 1000 contestants. For each game and each round, the player compares the utility of the bank offer to the utility of prizes in the remaining boxes. He then decides to continue the game if the utility of the bank offer is lower than that of the game. Conversely, if the bank offer has greater utility than the prizes in the remaining boxes, the contestant stops playing.
We consider the function bo (i, r) as the bank offer where i and r respectively denote the contestant and the round, which is a deterministic function known by all contestants. Recent literature in Deal or No Deal games assesses that the bank offer is governed by three strategies. First, it is closely dependant on the round r. Indeed, the banker becomes more generous as the game progresses since he encourages contestants to continue playing, which increases the excitement of the game. Second, the bank’s offer is a function of the contestant’s performance in a given round r. The trend observed in the game stipulates that if the contestant opens the bad boxes, the bank offer increases. However, if the contestant opens the right boxes, lowering his expected prize average, the banker decreases his offer. Third, the bank’s offer is likely to be related to the past performance of the contestant in a given round r. We expect the banker to be more generous with past losers.
Our function of the bank offer is modeled as follows:
Where:
- E(bo i,r ) :
-
is the expected bank offer for a given contestant i and a round r
- E(xi,7):
-
is the initial expected prize in the game
- for i,r : E(x i,r )/E(xi,7):
-
is defined as the expected prize in a given round r divided by the initial expected prize. It is the proxy of the contestant’s performance realized in a given round r.
- for i,r-1 : E(x i,r )/E(xS,7):
-
measure contestant performance in round r-1.
Based on the choices of 90 contestants from the Tunisian game show broadcast from 2005 to 2007, we find the valuesFootnote 12 of 9.46, 0.03, 0.058 and −0.016 for, respectively, α 0, α 1, α 2, and α 3. We use these values to generate bank offer data for every round of the simulated games.
Our simulated sample then concerns 1000 programs. For each program, we use data of the remaining boxes at the end of each round, the bank offer(s), the stop decision round, the prize won and the prize in the contestant’s box. Table 4 shows that the average of the stop decision rounds is 5.5. This significant average reflects that many contestants reject all bank offers and play until the last round. In fact, players who finish the game represent 1/3 of the total sample. Additionally, the average prize won in the game is equal to 52,894 dollars. This earning is larger than the average real prize in boxes and represents 71.76 % of the bank offers.
5 Methodology
In our study, we estimate the relative risk aversion and the probability weighting coefficient using the maximum likelihood approach. This approach has the advantage of allowing us to estimate the general trend in preferences, and also to detect the heterogeneity of preferences, which can produce high volatility in the contestants’ risk aversion. That is why we propose to introduce a noise term in the contestants’ preferences as modeled by Hey and Orme (1994). This noise could reflect errors in the contestants’ decisions or errors in our modeling of preferences. We also introduce a specific fixed effect in the contestants’ preferences, which conveys some of their personal characteristics and sources of their preferences’ heterogeneity. We thus obtain a random effect utility model.
Let V i,r denote the difference between the utility of the bank offer and that of the gamble X i,r :
Let also U the contestant utility take different forms: the expected utility model, the loss aversion and narrow framing model, the probability weighting model, the Quiggin (1982) model and the power probability weighting model. We will denote:
-
ε, the noise term of Hey and Orme (1994). ε ∼ F(.);
-
φ, the contestant specific fixed effect. φ ∼ G(.);
The difference in utility between the bank offer and the gamble X i,r becomes a stochastic function whose form is:
y i,r : the decision of a contestant i in a round r. y takes the value 1 if the contestant accepts the bank offer and 0 otherwise:
6 Empirical results
6.1 Results of the expected utility model versus the loss-aversion model
When estimating the value models, we assume that the probability weighting function is linear. The estimated functions of the expected utility and the loss aversion are expressed respectively by Eqs. (1) and (4).
Table 5 displays the results for the maximum likelihood approach applied to our stochastic preference model. We find that the estimates of the contestants’ relative risk aversion are respectively 0.212 for the expected utility model (see Panel A) and 0.196 for the loss-aversion model (see Panel B). This finding is different from previous studies’ results which document much higher risk aversion estimates. For instance, Fullencamp et al. (2003) study the contestants’ risk aversion for the game show “How is the millionaire?” and document a coefficient ranging from 0.64 to 1.76 depending on the level of initial wealth studied. Post et al. (2006) and Anderson et al. (2006) are interested in the game “Deal or No Deal”. On a sample of Dutch and Australian data ranging from 2002 to 2005, Post et al. (2006) find an average relative risk aversion of 1.01 for an initial wealth equal to zero and 1.61 for an initial wealth equal to 25,000 Euros. Anderson et al. (2006) integrate the wealth created by the game into the initial wealth of the contestants and report a relative risk aversion of 0.85 on a sample of simulated data. The lower values of our risk aversion estimates can be explained by the fact that we do not integrate initial wealth into our preference models. Integrating initial wealth into the contestants’ preferences may capture investor behavior aspects that are not necessarily detected in our models. This issue will be discussed later in our results robustness check.
In addition, we note that the higher relative risk aversion of our sample’s contestants is consistent with the empirical evidence of Rabin (2000) who argues that expected utilities have difficulty explaining behavior for both small and large stakes. This result is close to that reported by Post et al. (2008) who examine data from Germany, the United States and the Netherlands over the period 2002–2007 and show that strong risk aversion is needed in order to explain the behavior of losers who reject generous bank offers and continue to play, even with tens of thousands of Euros at stake.
Comparing the two models, we find that the loss aversion model provides a lower relative risk aversion estimate than expected utility. This drop in estimating risk aversion can be explained by the loss-aversion term, which implies risk-seeking behavior after losses. Hence, we need a higher relative risk aversion to compensate for this risk seeking. Post et al. (2008) also study Prospect Theory and outline that contestant losers are risk-seekers and have a strong incentive to look ahead multiple game rounds to allow for the possibility of winning the largest remaining prize. Panel A and Panel B of Table 5 also report a mean likelihood statistic of −7.886*10−4 and −2.347*10−3 for, respectively, the expected utility and the loss-aversion model. This finding provides evidence for the superiority of the loss-aversion model to describe the contestant’s risky choice behavior. This confirms the finding of Chou et al. (2009), who show strong and robust evidence supporting Prospect Theory over the period 1984–2003 using COMPUSTAT data.
Table 5 reports the results of the heterogeneity in contestants’ preferences estimates. We show that no matter which utility model we have, the standard deviations of the contestant specific fixed effect σ ϕ and of the noise term \( {\upsigma}_{\upvarepsilon} \) are statistically significant and of the same magnitude. This finding highlights the importance of studying expected and non-expected utilities in a discrete choice model. Relevant related literature outlines that the noise term could reflect specification errors, omitted factors, non-observable factors, and unobserved heterogeneity of preferences (de Palma et al. 2008). Hence, implementing a noise term improves the significance of choice models’ estimates involving risk. Our finding also suggests that the individual heterogeneity term has the same importance as the contestants’ specific characteristics. Furthermore, Table 5 shows a negative correlation between relative risk aversion and the noise term. This evidence reflects more pronounced mistakes for risk-loving contestants.
6.2 Results of the rank-dependant utility models
6.2.1 Results of the cumulative prospect model
When estimating the Cumulative Prospect Model,Footnote 13 we use the utility function defined in Eq. (2). The value function and the probability weighting function of the cumulative prospect model are, respectively, expressed by Eqs. (4) and (9).
Panel A of Table 6 displays the results of the estimation. Two observations stand out. First, we find that the probability weighting coefficient δ is statistically significant and has a value of 0.596. This finding provides evidence that the agent, when according a subjective weight to the probability of occurrence of an outcome, overweights low probabilities and underweights high probabilities. Similar results are reported by related literature on TV game show data. For instance, Anderson et al. (2006) find evidence for probability weighting being undertaken by contestants, particularly in the domain of gains. Roos and Sarafidis (2006) document the relevance of using the rank-dependant model when modeling preferences in a natural experiment. Botti et al. (2006) also show that the rank-dependant model always fits the natural data best since it captures the players’ psychological attitude to overvalue and to undervalue extreme outcomes.
Second, Panel A of Table 6 reports a drop in the relative risk aversion estimate compared to its values in Table 5. This drop is explained by the correlation between the probability weighting and the relative risk aversion coefficients. In fact, a decrease in the weighting probability coefficient (relative to the expected utility model, where δ =1) implies optimistic behavior (lower risk aversion) over large stakes (big prizes) and pessimistic behavior over small stakes (low prizes). As the amount of big prizes is relatively more important than low prizes in the Deal or No Deal game, we need a higher relative risk aversion to compensate for the lower probability weighting coefficient. It is for this reason that we find that the correlation coefficient between the two parameters of risk attitudes is positive (see Panel A of Table 6).
In addition, Panel A of Table 6 shows a drop in the standard deviations of the contestant specific fixed effect σ ϕ and of the noise term σ ε compared to Table 5. This suggests a better performance of Cumulative Prospect Theory and corroborates the finding of de Palma et al. (2008) who support the use of the probability weighting function form of Tversky and Kahneman (1992) in a random utility model framework.
6.2.2 Comparing between rank-dependant utility models
In this study, we explore whether other models of rank-dependant utility have better performance than the Cumulative Prospect Model. We study the Quiggin (1982) and the power probability weighting functions modeled respectively by Eqs. (6) and (7). The value function we consider here is the loss-aversion model expressed by Eq. (4). Results in Panel B and Panel C of Table 6 report a mean likelihood statistic of −2.987and −2.745*10−3 for, respectively, the Quiggin (1982) and the power function. Even if the absolute values of these estimates are lower than the absolute value of the likelihood statistic of the Cumulative Prospect Model, which is equal to −3.897*10−3 (see Panel A of Table 6), the power function has a better performance than the expected utility model. We also note that the probability weighting coefficient δ is still significant for both models of rank-dependant utility. This confirms the relevance of including this preferences parameter when describing the agent’s attitude towards risk.
7 Robustness check
Our conclusions regarding the level of risk aversion depend on assumptions about initial wealth and the expression of the stochastic function we estimate. To check for robustness of our results, we integrate initial wealth into the cumulative prospect utility model since relevant related literature highlights that risk aversion estimates decrease if we lower the initial wealth level and increase if we raise the initial wealth level (Post et al. 2006; Van Den Assem 2008). We examine several levels of initial wealth, namely: 5000, 15,000, 19,394 and 38,788 US dollars. The first two values reflect medium and higher average incomes of Deal or No Deal Tunisian contestants while the two last values are the values used by Post et al. (2006) (respectively 25,000 and 50,000 Euros) and which we convertFootnote 14 into US dollars. The aim of considering these values of initial wealth is to compare our finding to those reported by Post et al. (2006). We also separate the error term in the stochastic model to consider positive and negative news. The model is then estimated via the maximum likelihood approach.
Table 7 displays the results of the estimations. We show that both the relative risk aversion and the probability weighting coefficient increase as initial wealth increases. Indeed, Panel A shows that for an initial wealth equal to 5000 dollars, there is a relative risk aversion estimate of 0.372 and a weighting coefficient of 0.616; while Panel B presents, for an initial wealth equal to 15,000 dollars, a relative risk aversion of 0.994 and a probability weighting estimate of 1.217. This finding provides evidence that the initial wealth level affects the estimates of risk attitudes. In addition, Panel C reports, for an initial wealth equal to 19,394 dollars (25,000 Euros), the value of 1.194 for relative risk aversion, while Panel D presents, for an initial wealth equal to 38,788 dollars, a relative risk aversion equal to 1.584. Hence, our estimates are lower than those reported by Post et al. (2006) and Post et al. (2008), even with the same values of initial wealth. This suggests that the Tunisian contestants are more risk averse than other contestants and can be explained by several social reasons which influence their decisions of risky choices.
Additionally, similar results of the Cumulative Prospect Model are obtained when decomposing the error in the stochastic model into positive error (for good news) and negative error (for bad news). Indeed, results in Table 7 do not show a significant variation in the mean likelihood statistics.
8 Discussion and conclusions
This work investigates different non-expected utility theories based on simulated data of the Deal or No Deal TV game show. The results of the maximum likelihood approach applied to our random preference model show that the agent’s attitude toward risk is highly sensitive to behavioral specifications. Indeed, we find a better performance of the loss-aversion model compared to the expected utility model. We also find a significant probability weighting coefficient of the Cumulative Prospect Model, which supports evidence that an agent overweights large stakes and underweights small stakes. This finding is consistent with further findings of the Quiggin (1982) and the power function models’ estimates. A robustness check of our results reports a negative relationship between measures of risk aversion and initial wealth level.
Our results complement those recently obtained by Post et al. (2008). However, our contestants’ preferences model is completely different since we integrate non-linear probability functions in a random utility framework. Hence, our findings are different from those reported by recent literature on non-expected utility theories.
This study has focused on simulated data derived from episodes of the Tunisian TV game show because the insufficient number of episodes makes the use of real data unfeasible. For further research, it would be interesting to include episodes from developing countries which have a very similar game format (for example, Lebanon and Morocco) in order to examine the role of the cultural, social and economic background of the contestants in their decisions about risky choices. It would also be interesting to collect international data in order to obtain more degrees of freedom to analyze the effect of initial wealth on measures of risk aversion in greater detail, especially on the probability weighting coefficient.
Notes
Modeled as follows: GS: \( \left(550,\frac{1}{2},-500,\frac{1}{2}\right) \).
Modeled as follows GL: \( \left(20000000,\frac{1}{2},-10000,\frac{1}{2}\right) \).
See Barberis (2012) for a complete review of Prospect Theory.
See McFadden (2001) for a review of random utility models.
Certainly, the risky choice is highly sensitive to the context of the country and the amount of the stakes in the game. However, expanding the database to include other editions of other countries is only useful to study differences in risky choices and reduces the need for fully specified structural models such as those employed in this paper.
This model displays the expected utility function of Von Newman and Morgenstern (1947).
When modeling the loss-aversion function, we consider a fixed reference point. However, Mulino et al. (2009) document a special case of the framing effect. Indeed, using data from the Australian version of the TV game show Deal or No Deal, they explore whether risk aversion varies with a change in the reference point.
We choose a preference framework where the loss-aversion coefficient is static. A possible extension of our work is to consider the house money effect of Thaler and Johnson (1990) which stipulates that prior outcomes affect risky choices. Ko and Huang (2012) also explored contestants’ preferences in a multi-period betting game and found that subjects took more risk after losses.
Along with the studies of subjective weighted probabilities, another area of research examines the probability of returns using the entropy principle. This principle consists of generating probabilities based on limited information. See Smimou et al. (2007) for a literature review on the entropy applications. See also Myerson (2005) for an introduction of the use of probability models in analyzing risks and economic decisions.
Unlike the rank-dependant utility model, which has a symmetric probability function, Cumulative Prospect Theory, with its asymmetry, can explain the certainty effect: a greater sensitivity to probability variation at high levels of probabilities. Therefore, it resolves the paradox of Allais (1953).
The parameters’ estimation significance level is 1 percent.
Incorporating probability weighting into a loss aversion value function is a common assumption in many applications of Prospect Theory and Cumulative Prospect Theory. Examples are Levy and Levy (2004), Bernard and Ghossoub (2010), De Giorgi et al. (2010), He and Zhou (2011) and De Giorgi and Legg (2012).
We use an exchange rate of 1 Euro =0.7757 US dollar.
References
Abdellaoui M (2000) Parameter-free elicitation of utilities and probability weighting functions. Manag Sci 46:1497–1512
Al-Hajieh H, Redhead K, Rodgers T (2011) Investor sentiment and calendar anomaly effects: a case study of the impact of Ramadan on Islamic Middle Eastern markets. Res Int Bus Financ 25(3):345–356
Allais M (1953) Le comportement de l’homme rationnel devant le risque, critiques des postulats et axiomes de l’école américaine. Econometrica 21:503–546
Anderson S, Harrison GW, Lau MI and Rutstrom E (2006) Dynamic choice in a natural experiment. Working paper 06–10, Department of Economics, College of Business administration, University of Central Florida
Barberis N (2012) Thirty years of prospect theory in economics: a review and assessment. NBER Working paper 18621
Barberis N and Huang M (2006) The loss aversion/narrow framing approach to equity premium puzzle. Working paper, Yale University
Barberis N, Huang M, Thaler R (2006) Individual preferences, monetary gambles, and stock market participation: a case for narrow framing. Am Econ Rev 96(4):694–712
Beetsman R, Schotman P (2001) Measuring risk attitudes in a natural experiment: data from the television game show Lingo. Econ J 111:821–848
Bell D (1982) Regret in decision making under uncertainty. Oper Res 30:961–981
Bernard C, Ghossoub M (2010) Static portfolio choice under cumulative prospect theory. Math Finan Econ 2:277–306
Botti F, Conte A, Di Cagno D and Ippoliti CD’ (2006) Risk attitude in real decision problem. http://eprints.luiss.it/103/1/DiCagno_2007_01_OPEN.pdf
Camerer C (2000) Prospect theory in the wild: evidence from the field. Choices, values and frames (D. Kahneman and A. Tversky, eds.), 288–300
Camerer C, Ho T (1994) Nonlinear weighting of probabilities and violations of the betweenness axiom. J Risk Uncertain 8:167–196
Chew S (1989) Axiomatic utility theories with between ness property. Ann Oper Res 19:273–98
Chew S and Mac Crimmon K (1979) Alpha-nu choice theory: an acclimatization of expected utility. Working Paper, University of British Columbia
Chou PH, Chou RK, Ko KC (2009) Prospect theory and the risk-return paradox: some recent evidence. Rev Quant Finan Acc 33(3):193–208
De Giorgi E, Legg S (2012) Dynamic portfolio choice and asset pricing with narrow framing and probability weighting. J Econ Dyn Control 36:951–972
De Giorgi EG, Hens T, Rieger MO (2010) Financial market equilibria with cumulative prospect theory. J Math Econ 46(5):633–651
de Palma A, Ben-Akiva M, Brownstone D, Holt C, Magnac T, McFadden D, Moffatt P, Picard N, Train K, Wakker P, Walker J (2008) Risk, uncertainty and discrete choice models. Springer Sci Bus Media Mark Lett. doi:10.1007/s11002-008-9047-0
Dekel (1986) An axiomatic characterization of preferences under uncertainty: weakening the independence axiom. J Econ Theory 40:304–18
Diecidue E, Wakker P (2001) On the intuition of rank-dependent utility. J Risk Uncertain 23:281–298
Ellsberg D (1961) Risk, ambiguity, and the savage axioms. Q J Econ 75:686–696
Epstein LG and Zin SE (1990) First-order’ risk aversion and the equity premium puzzle. J Monet Econ, 387–407
Fullencamp C, Tenorio R, Battalio R (2003) Assessing individual risk attitudes using fields data from lottery games. Rev Econ Stat 85(1):218–225
Gertner R (1993) Game show and economic behavior: risk taking on cards sharks. Q J Econ 108(2):507–521
Gonzalez R, Wu G (1999) On the shape of the probability weighting function. Cogn Psychol 38:129–166
Gul F (1991) A theory of disappointment aversion. Econometrica 59(3):667–686
Harless DW, Camerer CF (1994) The predictive utility of generalized expected utility theories. Econometrica 62(6):1251–1289
Hartley R, Gauthier L, Walker I (2005) Who really wants to be a millionaire? Estimates of risk aversion from gameshow data, working paper. Department of Economics, University of Warwick
He XD, Zhou XY (2011) Portfolio choice under cumulative prospect theory: an analytical treatment. Manag Sci 57:315–331
Hersch P, McDougall G (1997) Decision making under uncertainty when the stakes are high: evidence from a lottery game show. South Econ J 64(1):75–84
Hey JD, Orme C (1994) Investigating generalizing expected utility theory using experimental data. Econometrica 62(6):1292–1326
Kahneman D, Tversky A (1979) Prospect theory: an analysis of decision under risk. Econometrica 47:263–291
Ko KJ, Huang Z (2012) Time-inconsistent risk preferences in a laboratory experiment. Rev Quant Finan Acc 39(4):471–484
Levy H, Levy M (2004) Prospect theory and mean-variance analysis. Rev Financ Stud 17:1015–1041
Loomes G, Sugden R (1995) Incorporating a stochastic element into decision theories. Eur Econ Rev 39:641–648
Lucas R (1978) Asset prizes in an exchange economy. Econometrica 46:1429–1446
McFadden D (2001) Economic choices. Am Econ Rev 91(3):351–378
Metric A (1995) A natural experiment in “Jeopardy”. Am Econ Rev 85(1):240–253
Mulino D, Schellings R, Brooks R, Faff R (2009) Does risk aversion vary with decision-frame? An empirical test using recent game show data. Rev Behav Finance 1:44–61
Myerson R (2005) Probability models for economic decisions. Duxbury Press
Post T, Baltussen G and Van den Assem M (2006) Deal or no Deal? Decision making under risk in a large-payoff game show. Tinbergen Institute Discussion Paper 009(2)
Post T, Vandenassem M, Baltussen G, Thaler R (2008) Deal or no Deal? Decision making under risk in a large payoff game show. Am Econ Rev 98(1):38–71
Quiggin J (1981) The theory of multiproduct firm under uncertainty. Australian National University, B.EC Honors thesis
Quiggin J (1982) A theory of anticipated utility. J Econ Behav Organ 3:232–343
Rabin M (2000) Risk aversion and expected utility theory: a calibration theorem. Econometrica 68:1281–1292
Roos N and Sarafidis Y (2006) Decision making under risk in deal or no deal. working paper, Scholl of economics and political science, University of Sydney
Smimou K, Bector CR, Jacoby G (2007) A subjective assessment of approximate probabilities with a portfolio application. Res Int Bus Finance 21(2):134–160
Starmer C (2000) Developments in non-expected utility theory: the hunt for a descriptive theory of choice under risk. J Econ Lit 38(2):332–382
Thaler R, Johnson E (1990) Gambling with the house money and trying to break even: the effects of prior outcomes on risky choice. Manag Sci 36:643–660
Tversky A (1969) Intransitivity of preferences. Psychogical Rev 79:281–299
Tversky A, Kahneman D (1981) The framing of decisions and the psychology of choice. Science 211:453–458
Tversky A, Kahneman D (1992) Advances in prospect theory: cumulative representation of uncertainty. J Risk Uncertain 5:297–323
Van Den Assem M (2008) Deal or No Deal? Decision making under risk in a large-stake TV game show and related experiments. ERIM PhD, series in research in management 138, Erasmus Research Institute of Management (ERIM)
Von Newman J and Morgenstern O (1947) Theory of games and economics behavior. Princeton University Press
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Aissia, D.B. Developments in non-expected utility theories: an empirical study of risk aversion. J Econ Finan 40, 299–318 (2016). https://doi.org/10.1007/s12197-014-9305-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12197-014-9305-3
Keywords
- Non-expected utility theories
- Agent’s attitude towards risk
- Deal or No Deal TV game show
- Loss-aversion model
- Rank-dependant utility