
Abstract
Accurately estimating evaporation is essential for water managers to formulate effective rules and policies. The complexity arising from intricate interactions within the soil-atmosphere system makes evaporation a challenging parameter to predict. In the past decade, Machine Learning techniques rooted in soft computing have emerged as potent tools for addressing the intricacies and non-linearities in hydrology. Surprisingly, there has been no prior research exploring the impact of reservoir water temperature on evaporation modeling. Consequently, this study aimed to employ a hybridized Adaptive Neuro-Fuzzy Inference System (ANFIS) integrated with four optimization algorithms: Genetic Algorithm (GA), Particle Swarm Optimization (PSO), Harris Hawks Optimization (HHO), and Salp Swarm Algorithm (SSA). The focus was on modeling the monthly evaporation of the Boukourdane Dam in Algeria for the period of September 1996 to August 2016 and examining how the reservoir's water temperature influences model performance based on four performance indicators, Root Mean Square Error (RMSE), Mean Absolute Error (MAE), scatter index (SI) and Correlation Coefficient (R). The findings underscored the significance of incorporating the water temperature parameter. Among the models, ANFIS-HHO demonstrated the highest accuracy with MAE, RMSE and R values of 1.28, 1.21 mm and 0.92, respectively during test period. Moreover, results revealing a notable impact of reservoir water temperature on evaporation forecasting and the addition of this parameter provide an increase in R and decrease in RMSE about 4.54% and 17.98% respectively.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Evaporation is the process of converting water from a liquid state to a vapor state (Feng et al. 2020; Singh et al. 2021; Moayedi et al. 2021), and it is a key component of the water budget for reservoirs (Duan and Bastiaanssen 2017; Moazenzadeh et al. 2018; Friedrich et al. 2018; Allawi et al. 2019; Seifi and Soroush 2020). Furthermore, evaporation plays an important role in reservoir management because it directly affects their storage efficiency (Piri et al. 2016a, b; Althoff et al. 2019; Zhao and Gao 2019). Therefore, it is imperative to consider the volume of water lost through evaporation when designing and operating reservoirs (Khosravi et al. 2019; Yaseen et al. 2020; Eshetu et al. 2023). In addition, providing an accurate estimation of evaporation is crucial for water managers to develop effective key rules and policies.
Evaporation is considered the most challenging parameter to estimate due to complex interactions between the components of the soil-atmosphere system (Wang et al. 2007; Rezaie-Balf et al. 2019; Shabani et al. 2020; Dong et al. 2021). The estimation of evaporation can be categorized into two main approaches. In the first one, i.e., the direct method, evaporation is measured directly using instruments such as the pan. However, this method has its drawbacks: operational difficulties (inaccessibility in some regions), limitations in instrument devices (a limited number of stations), and high installation and maintenance costs (Seifi and Soroush 2020; Shabani et al. 2020; Abed et al. 2021). The second approach is the indirect method, where evaporation is estimated through empirical equations based on meteorological variables such as air temperature, relative humidity, solar radiation, wind speed, and rainfall (Singh et al. 2021; Ahmadi et al. 2021; Mohamadi et al. 2020; Tikhamarine et al. 2019). However, also this method has limitations mainly based on climate variation and data availability (Seifi and Soroush 2020; Soroush et al. 2020; Malik et al. 2020; Dong et al. 2021).
In the last decade, Machine Learning (ML) techniques based on soft computing have been considered powerful tools to address the complexity and non-linearity in hydrology, in particular in the evaporation modeling problem (Deo et al. 2016; Ghorbani et al. 2018; Rezaie-Balf et al. 2019; Adnan et al. 2021a, b, 2022a; Cappelli et al. 2023; Sahoo et al. 2023; Mohammadi 2023 and Eshetu et al. 2023). These techniques, including Multilayer Perceptron (MLP), Support Vector Machines (SVM), Extreme Learning Machine (ELM), and Adaptive Neuro-Fuzzy Interface System (ANFIS), have shown their capability to develop reliable and robust intelligent predictive models of evaporation (Wang et al. 2017; Ghorbani et al. 2018; Tikhamarine et al. 2019; Wu et al. 2019; Shabani et al. 2020; Yaseen et al. 2020).
ANFIS is one of the powerful ML models adopted for implementing evaporation prediction. Based on the combination of Artificial Neural Networks (ANN) and fuzzy systems (FS), ANFIS has the advantage of including all factors not involved in an ideal model while eliminating certain factors considered in physically based models (Hundecha et al. 2001; Samanataray and Sahoo 2021). The capacity of ANFIS to learn and classify the input-target data is promising (Yaseen et al. 2017; Jasmine et al. 2022; Haznedar and Kilinc 2022; Adnan et al. 2022b). From the literature, many researchers have employed ANFIS in the modeling of evaporation (Kisi and Ozturk 2007; Shiri et al. 2011; Kisi et al. 2014; Keshtegar et al. 2018; Malik et al. 2017; Wang et al. 2017; Eray et al. 2018; Maroufpoor et al. 2018; Sanikhani et al. 2018). However, the drawback of ANFIS to get trapped in a local minimum during the training phase has a high probability (Mohamadi et al. 2020; Ghose et al. 2022; Haznedar and Kilinc 2022; Adnan et al. 2022a). Moreover, determining the best weights for membership functions has limitations (Khosravia et al. 2019; Dehghani et al. 2019 and Nou et al. 2020). Therefore, combining ANFIS with evolutionary and nature-inspired algorithms solves this weakness, enhances the model's performance, avoid the over parameterisation (Parsaie et al. 2019) and finds optimum parameters such as bias values, weight connections, linear and nonlinear parameters (Chen et al. 2017; Niu et al. 2019; Mosavi et al. 2018; Alizamir et al. 2020; Moghaddas et al. 2021; Riahi-Madvar et al. 2021; Pham et al. 2023).
The hybridization of ANFIS with various optimization algorithms has been employed in many research studies in the field of hydrological modeling, such as precipitation (Azad et al. 2019; Calp 2019; Phama et al. 2020; Chaudhury et al. 2022), flood prediction (Bui et al. 2018; Zhou et al. 2019; Sahoo et al. 2021; Tabbussum and Dar 2021; Ghose et al. 2022), and streamflow forecasting (Yaseen et al. 2017; Mohamadi et al. 2020; Riahi-Madvar et al. 2021; Samanataray and Sahoo 2021; Haznedar and Kilinc 2022; Adnan et al. 2022a).
To enhance the accuracy of evaporation prediction, numerous bio-inspired evolutionary algorithms are employed. Piri et al. (2016a, b) used the Cuckoo Algorithm (CA) to train both ANFIS and ANN for predicting daily pan evaporation in Iran. Zounemat-Kermani et al. (2019) integrated five metaheuristic algorithms with the ANFIS model in evaporation modeling. They reported that the Particle Swarm Optimization (PSO) and Genetic Algorithm (GA) were better at estimating evaporation compared to the Artificial Bee Colony (ABC), Firefly Algorithm (FA), and Continuous Ant Colony Optimization (CACO). Mohamadi et al. (2020) used Shark Algorithm (SA) and Firefly Algorithms (FFAs) to train ANFIS, Multilayer Perceptron (MLP) models, and Radial Basis Function (RBF) models for the prediction of monthly evaporation. They found that ANFIS-FFA provided more accuracy compared to the other hybrid models. Azar et al. (2021) hybridized ANFIS with the Harris Hawks Optimization (HHO) algorithm and demonstrated its superior performance in evaporation modeling compared to Least Square-Support Vector Regression (LS-SVR) and ANFIS models. Seifi et al. (2022) hybridized ANFIS with four meta-heuristic algorithms: Seagull Optimization Algorithm (SOA), Crow Search Algorithm (CA), Firefly Algorithm (FA), and PSO. They used them as inputs for employing ensemble Copula-based Bayesian Model Averaging (CBMA). Additionally, this technique yielded the highest prediction accuracy. Adnan et al. (2022a, b) combined ANFIS with Whale Optimization Algorithm (WOA) for predicting pan evaporation at three stations located in China. They found that the ANFIS-WOA models outperformed the Harris Hawks Optimization (HHO) and PSO algorithms. Jasmine et al. (2022) used the Firefly Algorithm (FFA) to train ANFIS for evaporation modeling in Arizona State, USA. They found that the ANFIS-PSO and ANFIS models were slightly better than ANFIS-FFA and ANFIS-GA. Kayhomayoon et al. (2022) investigated the effect of climate change on evaporation and optimized ANFIS using the Arithmetic Optimization Algorithm (AOA) and HHO. They concluded that this hybridization had more efficiency in predicting the amount of evaporation in other reservoirs.
The temperature of water in the reservoir influences considerably the evaporation. Reservoir characteristics such as area, depth, water quality, water temperature and water circulation, can affect the rate of evaporation (Terzi 2013 and Al Domany, 2017). Knapp et al. (1984) reported that the evaporation rate is influenced by water temperature. Therefore, in the higher water temperature, more molecules close to the liquid surface tend to escape to the layers of air, just above this surface (Cosandey and Robinson 2012). Thus, the process of evaporation has a positive correlation with air temperature and water temperature; in other words, in the case of higher temperature of air and water, a greater amount of the vaporized water is formed (Friedrich et al. 2018). By adding the parameter of the water temperature with those of the air temperature, sunny hours, and air pressure, Keskin and Terzi (2006) estimated in their study of daily evaporation modeling, on the Egirdir lake in western Turkey, that the best structure of the model were obtained based on these four input data. In addition, compared to the other models, which were based only on wind speed and relative humidity.
Despite its direct effect in the evaporation process, up to now, no research has investigated the influence of the reservoir’s water temperature in evaporation modelling. Hence, the main objective of this study was to use a hybridized ANFIS with four optimization algorithms including: Genetic Algorithm (GA), particle swarm optimization (PSO), Harris Hawks Optimization (HHO) and Salp Swarm Algorithm (SSA), in modeling the monthly evaporation of the Boukourdane Dam in Algeria and to investigate how the reservoir’s water temperature affects the performance of the models.
Materials and methods
The study area and the available data
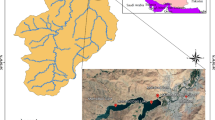
The Boukourdane dam is selected as case study. The study area is situated in the north of Algeria (latitude 36° 31’ N, longitude 2° 18’ E, and altitude 119.5 m). The reservoir storage and regulated volume of the Boukourdane dam are 105 and 50 MCM, respectively. The localization of the Boukourdane dam is shown in Fig. 1.

Localization of case study
The observed values of monthly meteorological data collected from the National Agency of dams (ANBT) in Algiers, for the period from September 1996 to August 2016, include Maximum temperature (Tmax, °C), Minimum temperature (Tmin, °C), Relative humidity (RH, %), Wind speed (W, km/h), Maximum temperature of water (Twmax, °C) and Minimum temperature of water (Twmin, °C). Such variables were considered as input in the modelling processes, whereas the target variable was the Evaporation (Ev, mm/day). Figure 2 shows the variation of the observed monthly evaporation in the Boukourdane dam.

Time series of observed evaporation
The statistical parameters of training and testing data for the both meteorological data are presented in the Table 1. The used data is divided into two different sets. The training dataset from September 1996 to August 2012 and the testing dataset from September 2012 to August 2016.
The investigated methodologies
Adaptive Neural-Fuzzy Inference System (ANFIS)
The approach of ANFIS consists on the hybridization of an adaptive ANN with a Fuzzy Inference System (FIS). Introduced by Jang (1993), the performances of the ANFIS are widely proved in many studies to solve nonlinear problems. By training the current input-output data, the mechanism of ANFIS provides the optimal parameters of the Membership Function (MFs).
The architecture of the ANFIS, as shown in Fig. 3, consists of five layers. In layer 1, which is called fuzzification, the inputs in each node j are transformed to a fuzzy membership function by an activation function μ (triangular, trapezoidal, sigmoidal, Gaussian, etc.), according Eqs. 1 and 2.
where x, y are the inputs, \({Q}_{j}^{1}\) is the membership function and Aj and Bj are the membership values of μ. For this study, Gaussian membership function, given in Eq. 3 has been utilized,

Architecture of ANFIS model
Cj and σj, which are the mean Gaussian curve and the standard deviation, are considered as the premise parameters of the membership functions.
The weights wk for the membership functions is calculated in layer 2 by the Eq. 4 and the firing strength of the rules are provided
The layer 3 normalizes the firing strengths using Eq. 5.
In layer 4, which is called defuzzification layer, the output for each node j are evaluated by Eq. 6, and the consequent parameters (p, q and r) of the firing strengths f are calculated.
The last layer calculate (using Eq. 7) the over-all output in a single node by assuming up all the incoming signals.
Genetic Algorithm (GA)
Invented by John Holland (1975), GA is basically inspired by the mechanisms of natural selection and genetic phenomena. The renewal of populations is essentially due to the best individuals of the species. This mechanism starts from an initial population of coded points and uses three operators (crossing, mutation for the exploration of the space with potential solutions and selection) evolves the population towards the optima of the problem. The decision to terminate the genetic algorithm’s execution is based on a number of criteria that depends on the problem types. The most frequently criteria used are: the convergence of the adaptation mean of a population, the time available for the execution of a single GA, and the maximum number of generations or the maximum number of evaluation functions in GA test. The arbitrary generation of a population chain could scan a limited space of the solution domain, thus making it possible to increase the probability of detecting the optimal solution and losing the neighborhood of the optimum during the search. For this reason, the execution of GA must be repeated several times with different sets of random starting points, to ensure a greater probability that the optimal solution is detected.
Particle swarm optimization (PSO)
Developed by Kennedy and Eberhart (1995), the algorithm of PSO is inspired from the nature social behavior and dynamic movements with communications of insects, birds and fish to combine self-experiences with social experiences. The optimal solution is obtained according the best position encountered by a particle and that of its neighbors, and a predefined fitness function measure the performance of each particle, which quantifies the performance of the optimization problem.
The update equation is:
where, t: the current iteration, i: ith solution,\({x}_{i}^{t}\): the position of ith solution in t th iteration, c1 and c2: acceleration coefficients and r1: random value, r2:random value, \(pbest\) :the best solution that ith particle obtained so far and gbest: the best position of the total swarm and \({V}_{i}^{t+1}\): the velocity of ith solution in t th iteration.
Harris Hawks Optimization (HHO)
Developed by Heidari et al. (2019), HHO is a novel algorithm based on swarm intelligence. Widely applied these recent years to solve complex nonlinear optimization problems, the mechanism of HHO mimics the hawk’s action searching their prey. HHO has two principal phases that are exploration and exploitation.
In the exploration phase, a set initial population of Harris hawks {X1, X2,……, Xn} is created randomly to track and detect the prey (rabbit) within the feasible space. According to the Eq. 10, both hawks and prey have the same chance q.
where X(t) and X(t+1) are the position of the Harris Hawk at the iteration t and t+1 respectively. Xrand is a randomly selected Harris Hawk among all available individuals, Xrabbit(t) is the position of the prey, q, r1, r2, r3 and r4 are random values varying between (0 and 1) and LB and UB are the lower and upper bands, respectively. Eq. 11 gives the mean position Xm (t) of the total number N of the Harris Hawk.
During the hunt process, the escaping energy E of the prey decreases, and the transition from the exploration to the exploitation phase can be expressed by Eq. 12.
where E0 is the initial energy of the prey, ranged between -1 and 1, and T is the maximum iteration
Exploitation is the second phase, which has the objective to improve the predefined solution that locally found. The attacked prey was surprised and tried to escape. Depending to the hawks’ chasing behavior, four scenarios can occur:
Soft Besiege
In the Soft Besiege case, the prey has energy, i.e. |E| > 0.5 and r >0.5, the soft Besiege can be occur following the Eq. 13.
where Δx represents the difference separating Hawk’s current and the prey position in the t iteration and J is the prey random jump in the escaping process, given by Eq. 14.
where r5 is a number ranged randomly between 0 and 1.
Hard Besiege
When the prey is tired, i.e. it energy decrease. |E| < 0.5, their position becomes:
Soft Besiege with Progressive Rapid Dive
This case has the condition that the prey has the energy to escape (|E| < 0.5). The formulation of the Soft Besiege with Progressive Rapid Dive is given by:
where S is a random vector, LF is levy flight function with D is dimension.
As consequence, the position of the hawks is updated following the Eq. 17.
Hard Besiege with Progressive Rapid Dive:
In the last case, the prey did not have chance to escape, due to its low energy, |E| < 0 and r < 0. The distance of the hawk and prey decrease and the stage of Hard besiege with progressive rapid dive occur as it follows:
Salp swarm Algorithm (SSA)
Salp swarm Algorithm (SSA) is a novel nature-inspired algorithm developed by Mirjalili (2017). SSA mimics the salps behavior’s during navigation and searching for food sources in the seas and oceans. In the mechanism of SSA, a set of initial population is created randomly and divided into two groups that are leader and followers. Leader salps are located at the top of the salp chain and lead the swarm towards the food location F (which considered as target). The rest of salps follow the leader during the aggregate phase.
The position of the salp leader xj1 is updated by Eq. 19.
Fj represents the best food solution in the jth dimension; ubj and lbj represent the upper and lower bounds in the jth dimension respectively, c2 and c3 are random numbers ranged between 0 and 1. c1 is a parameter that varied with the following expression (Eq. 20):
where t and T represent the current iteration and maximum number of iterations respectively.
Finally, the position of the followers xji is updated by Eq. 21.
where i ≥2 and xji represent the position of the ith follower at the jth dimension.
The steps of the SSA are listed in Fig. 4.

Pseudocode of the Salp swarm Algorithm (SSA)
Hybridization of the ANFIS
The main objective of the present study is to provide a model for Boukourdane dam evaporation forecasting with a high efficiency and accuracy. For this, four metaheuristic algorithms (GA, PSO, HHO and SSA) were utilized to train the ANFIS and optimize the both parameters: premise and consequent, given in the Eqs. 3 and 6 respectively. The flowchart of the hybrid ANFIS with the four metaheuristic algorithms optimization is shown in Fig. 5.

Flowchart of the hybrid ANFIS and the proposed algorithms optimization
The key steps of the ANFIS hybridization procedure are described as in the following: we start by classification of the inputs and output data into two parts, training and testing sets. In this study: maximal and minimal air temperature, relative humidity, wind speed and water temperature are selected as inputs variables, whereas the evaporation is selected as the single output. Secondly, we generate the initial fuzzy inference system (FIS) by the fuzzy c-mean (FCM) clustering approach to extract a set of initial rules and determinate the number of the membership function MF. The next step is the optimization of FIS parameters by different heuristic algorithms and training the ANFIS structure using the optimized parameters as it follows: (I)-Generate initial population for an algorithm optimization. (II)-Evaluate the optimal parameters of the algorithm by minimizing the objective function (OF). In this study, the Root Mean Square Error (RMSE) given in Eq. 22, is considered as OF. (III) Take the optimal parameters of the heuristic algorithm to form ANFIS structure. (IV) Run the algorithm till meeting the stop condition (i.e. maximum number of iterations) to obtain the optimal structure of ANFIS. If not, the algorithm returns to (II). The fourth step was carried out on the training of the best ANFIS with all algorithms optimization to generate the output data for train and test period. Finally, the statistical indexes such as RMSE, MAE, SI and R (expressed in Eqs. 22, 23, 24 and 25, respectively) was calculated based on the output data, to compare the performance of the hybridization.
-
Root Mean Square Error (RMSE):
$$RMSE=\sqrt{\frac{\sum_{i=1}^{N}{\left({Y}_{0i}-\widehat{{Y}_{ci}}\right)}^{2}}{N}}$$(22) -
Mean Absolute Error (MAE):
$$MAE=\sum\nolimits_{i=1}^{N}{(Y}_{0i}-{Y}_{ci})/N$$(23) -
Scatter Index (SI):
$$SI=\frac{RMSE}{\frac{1}{N} \sum_{i=1}^{N}{Y}_{oi}}$$(24)
According to Li et al. (2013), the model accuracy was characterized as following: SI<0.1 (excellent), 0.10<SI<0.20 (good), 0.20<SI<0.30 (fair) and SI>0.30 (poor).
-
Correlation Coefficient (R):
$$\begin{array}{cc}R=\frac{\sum_{i=1}^{N}\left({\widehat{Y}}_{Ci}-\overline{{Y }_{Oi}}\right)\left({Y}_{ci}-\overline{{Y }_{0i}}\right)}{\sqrt{\left(\sum_{i=1}^{N}{\left(Y-\overline{{Y }_{ci}}\right)}^{2}\right)\left(\sum_{i=1}^{N}{\left({Y}_{ci}-\overline{{Y }_{0i}}\right)}^{2}\right)}}& \left(-1<1\right)\end{array}$$(25)
where, Where Yc and Yo are calculated and observed values of evaporation and N is the quantity of data.
Also, radar charts and Taylor diagram radar charts were plotted to compare the prediction performance for all combination inputs. In particular, the Taylor diagram chart is a visual tool that provides comprehensive evaluation of the predicted evaporation results using three (criteria (standard deviation (SD), correlation (R) and RMSE) in a single diagram. The observed evaporation is plotted along the horizontal axis (based on the standard deviation) and model performance for such algorithm is spotted from the graph, more being closer to the reference point, more the model has the best accurate prediction.
Finally, we employed the Discrepancy Ratio (DR), that is a statistic indicator proposed by White et al. (1973), expressed by Eq. 26, to perform the sensitivity analysis of the evaporation models performance.
where, Ypi and Yoi are the predicted and observed evaporation respectively. According to Eq. 26, if DR = 0, the predicted value is identical to the measured value. Otherwise, If the DR is larger than 0, the predicted value is overestimated, and if the DR is smaller than 0, it is underestimated. To avoid utilization of negative or zero observed values, Developed Discrepancy Ratio (DDR) was proposed, as given in Eq. 27:
Results
In this study, four metaheuristic algorithms (GA, PSO, HHO and SSA) were utilized to train ANFIS for forecasting the monthly evaporation of the Boukourdane dam in Algeria. In order to examinate the effect of the reservoir’s water temperature, two scenarios were considered. In the first one ‘‘scenario I’’, the temperature of the water in the reservoir Twmax and Twmin are added as input with the meteorological variables including: maximal and minimal air temperature, relative humidity and wind speed. While, in ‘‘scenario II’’, the reservoir’s water temperature is neglected. The inputs and output data utilized in this study were divided into two parts, training (80%) and testing (20%) sets. Moreover, four models were proposed for each scenario.
Table 2 resumes these models (M1, M2, M3 and M4 for each scenario) based on the combination of the variables’ inputs, while optimal algorithms parameters are listed in Table 3.
Table 4 reports the overall performance of the four hybridized algorithms in terms of the RMSE, MAE, SI and R, for the first scenario during the training and testing stages, while Table 5 reports the same information for the second scenario.
For the first scenario (Table 4), the results indicate that M1, which including all variables input, gave more accuracy of evaporation prediction than other models. The results show that among the algorithm applied, ANFIS-HHO model provided the best results in estimating the evaporation with an RMSE, MAE and R equal to 0.85 mm 1.09 and 0.88 respectively in the training, while in test period, RMSE, MAE and R are equal to 0.89 mm 0.73 and 0.92 respectively. Moreover, and according to Table 4, it can been seen a decrease in the accuracy for both M2 and M3, where in the training period, RMSE, MAE and R are equal to 0.98 mm 0.92 and 0.89 respectively, obtained by ANFIS-PSO for M2 while for M3, ANFIS-HHO models gives RMSE, MAE and R corresponding to 1.08 mm 0.91 and 0.89 respectively. In the test period. RMSE, MAE and R are equal to 1.21 mm 1.28 and 0.87 respectively obtained by ANFIS-GA for M2 while for M3, ANFIS-HHO models gives RMSE, MAE and R corresponding to 1.22 mm, 1.11 and 0.87 respectively. In addition, the lowest performance in the evaporation prediction is recorded for M4, where ANFIS-PSO model provided the best accuracy with an RMSE, MAE and R corresponding to 1.21 mm, 1.42 and 0.86 respectively in the training period, while in the test period, ANFIS-HHO provided the best accuracy with an RMSE, MAE and R corresponding to 1.22 mm, 1.05 and 0.85 respectively.
Finally, results of Table 4 indicate that among the all algorithms, ANFIS-HHO hybridization gives a good accuracy, where the value of SI is equal to 0.19 for the M1 model in the training period, and for the other algorithms the accuracy was fair. While in the test period, the accuracy was fair for the all algorithms. In addition, we can notice that the accuracy for M2, M3 and M4 models was fair in the training period, while in the test period, the accuracy was poor for these models.
For the second scenario (Table 5), similar results were found and the best accuracy of the evaporation prediction was obtained for the M1 model. The results indicate that among the algorithm applied, ANFIS-PSO model provided the best results with an RMSE and R corresponding to 1.03 mm and 0.89 respectively in the training period, while in the test period; they are corresponding to 1.05 mm and 0.89 respectively. In addition, according to Table 5, we can observe a decrease in the accuracy of the evaporation for the M2, M3 and M4 model. ANFIS-PSO model provided the best accuracy with an RMSE, MAE and R corresponding to 1.09 mm, 1.21 and 0.88 respectively in the training period for M2 model, while in the test period; ANFIS-GA provided the best accuracy with an RMSE, MAE and R corresponding to 1.24 mm, 1.89 and 0.85 respectively. For the M3 model, ANFIS-GA model provided the best accuracy with an RMSE, MAE and R corresponding to 1.15 mm, 1.32 and 0.87 respectively in the training period, while in the test period; ANFIS- PSO provided the best accuracy with an RMSE, MAE and R corresponding to 1.29 mm, 1.11 and 0.84 respectively. In addition, M4 had the worst performance in the evaporation prediction. From table 5, the results indicate that ANFIS-PSO model provided the best accuracy with an RMSE. MAE and R corresponding to 1.25 mm 1.57 and 0.83 respectively in the training period, while in the test period. ANFIS-HHO provided an RMSE, MAE and R corresponding to 1.32 mm, 1.07 and 0.83 respectively.
Finally, the values of SI presented in Table 5 indicate that, for all algorithms, the accuracy was fair in the training period for all models, while in the test period, except for the ANFIS-PSO hybridization where the accuracy was fair in M1 model, we notice that for the all models, the accuracy was poor.
The performance of the best models in the test period is presented on radar charts in Fig. 6 for the first scenario and in Fig. 7 for the second scenario. It is clear from Figs. 6 and 7 that radar plot illustrate graphically the results given in Tables 4 and 5 for the scenario I and scenario II respectively.

Radar chart for Scenario I

Radar chart for Scenario II
Figures 8 and 9 show the scatterplots of observed and predicted evaporation provided by the best hybrid algorithm in the test period for both scenario I and scenario II.

Scatterplots of observed and predicted evaporation for the best input combination in the test period – scenario I

Scatterplots of observed and predicted evaporation for the best input combination in the test period – scenario II
According to the results in Fig. 8 (scenario I), it can be seen that M1 model (including all input variables) had the least scattered predictions, followed by M2. M3 and M4. Furthermore, the hybridization ANFIS-HHO for M1 model provided the closest linear fit to the diagonal line compared to other models. The results in Fig. 9 were similar to those in Fig. 6, and the convergent tendency of 1:1 line was significantly spotted for M1 model compared to other models.
Figures 10 and 11 show the best predicted evaporation along the observed during the test period for both scenario I and scenario II. As displayed in Fig. 10, the predicted evaporation provided by M1 overlaps more with that observed compared to the other models. Similarly, with Scenario I, the predicted values of the evaporation for the M1 model in scenario II (Fig. 11) were much closer to the observed values in the time variation.

Predicted evaporation for the Scenario I in the: a) M1. b) M2. c) M3 and d) M4

Predicted evaporation for the Scenario II in the: a) M1. b) M2. c) M3 and d) M4
Concerning the model testing, Figs. 12 shows the results of the Taylor diagram analysis for the evaporation prediction in the test period, for both scenario I and scenario II, respectively.

Taylor’s diagram for the predicted evaporation in the test period using hybrided ANFIS techniques for the: a) Scenario I and b) Scenario II
As seen from the Fig. 12a, the results showed that ANFIS-HHO model performs better than the other models for the evaporation forecasting with considering water temperature inputs (first scenario), by providing higher SD and correlation coefficient (R superior to 0.9) and lower RMSE. In addition, among the other hybrid ANFIS models, the results provided by ANFIS-HHO were closer to the observed point. For the second scenario (where the water temperature is neglected). Figure 12b shows that the ANFIS-GA model had the greatest correlation coefficient and SD and the least RMSE, which indicates higher accuracy of this model. Moreover, the results found by ANFIS-GA are nearer to the observed one in comparison with the other hybrid ANFIS models.
Finally, concerning the Developed discrepancy ratio statistic (DDR), Table 6 presents the statistical indices of the DDR values in test period for the best model.
According to Table 6, results indicate that the lower value of the variance in scenario I (equal to 0.0789) is provided by ANFIS-HHO, while in scenario II, the lower value of the variance (equal to 0.0580) is provided by ANFIS-GA.
The value of DDR for all algorithms in scenario I and scenario II are presented in Fig. 13.

The DDR values in test period for: a) Scenario I and b) Scenario II
Discussion
In this study, the reservoir’s water temperature (TW) influence on the evaporation prediction was investigated. Combining four heuristic algorithms (GA, PSO, HHO and SSA) with ANFIS, the comparison between scenario I (with TW) and scenario II (without TW) (see Tables 4 and 5) show an increase in R about 4.54, 2.35, 3.57 and 2.41% corresponding to M1, M2, M3 and M4 respectively. In addition, we noticed a decreasing in RMSE about 17.98, 5.74, 3.57 and 8.19% corresponding to M1, M2, M3 and M4 respectively. This demonstrates the effect of the TW parameter on the prediction performance.
On the other hand, it can be concluded that the number of variables input affect the prediction performance. It was found that decreasing the number of inputs from M1 model, with all variables input, to M4 model with only two inputs, passing by M2 and M3 models, with three variables input, both for the scenario I and scenario II, reduces the prediction accuracy. The results resumed in Table 4 (scenario I) show a decrease of about 5.43% of R for M2 and M3 models, and 8.23% for M4 model respectively, compared to M1 model and also an increase of RMSE of about 35.95% for M2 and M3 models, and 37.08% for M4 model respectively, compared to M1 model. Similarly, results in Table 5 (scenario II) show a decrease of about 4.94% of R for M2 and M3 models, and 7.22% for M4 model respectively, compared to M1 model and also an increase of RMSE of about 22.86% for M2 and M3 models, and 20.45% for M4 model respectively, compared to M1 model. This demonstrates that the evaporation prediction is more accurate when using more input parameters. Same results are noticed in the researches of Wang et al. (2017), Ghorbani et al. (2018), Moazenzadeh et al. (2018), Khosravia et al. (2019), Shabani et al. (2020), Abed et al. (2021), and Adnan et al. (2022a, b).
As been reported previously, the application of ML has been shown as a powerful tool for evaporation modeling. As well as, training ANFIS using heuristic algorithms optimization algorithms provides better performances and enhance the prediction accuracy. The findings of this research report that during the test period, ANFIS-HHO proved the best accuracy in three models (M1. M3 and M4) for the scenario I and two models (M3 and M4) for the scenario II. Followed by ANFIS-GA, which proved two best models (M2 for both scenario I and II) and finally ANFIS-PSO, which proved one best model (M1 for the scenario II). This emphasizes the superiority of ANFIS-HHO model compared to the others models. The findings of this study were also in close agreement with the study performed by Azar et al. (2021) which found that hybridized ANFIS with HHO algorithm had superior performance in evaporation modeling at the Doroudzan dam in the central of Iran compared to ANFIS and LS-SVR (least square-support vector regression) models. Also, Kayhomayoon et al. (2022) concluded that hybridization of ANFIS with HHO had more efficiency in predicting the amount of evaporation at the Mahabad dam in the Northwestern of Iran compared to ANFIS and ANFIS-AOA (Arithmetic Optimization Algorithm) algorithms. Moreover. Adnan et al. (2022a, b) trained ANFIS with several algorithms optimization and found that the ANFIS-HHO and ANFIS-WOA (Whale Optimization Algorithm WOA) models (with an R2 > 0.81 and RMSE < 1.04 mm) outperformed the ANFIS and ANFIS-PSO algorithms in forecasting the pan evaporation at three stations located in China. Finally, the results of Khosravia et al. (2019) reported that the ANFIS-GA model performance was superior in the evaporation prediction at two meteorological stations in Iraq compared to ANFIS. ANFIS-ICA (Imperialistic competitive algorithm) and ANFIS-DE (Differential evolution algorithm) models.
Based on the SI indicator, our results reveal that the accuracy of the models was fair during the test period, for the all algorithms applied, when considering the reservoir water temperature, and was poor in the case where this parameter has neglected. As recommendation to overcome this gap, other technical was proposed in order to enhance the evaporation prediction accuracy. In this point, we can suggest the application in the future studies, the proposed methods: Gene Expression Programming (GEP), Least Squares Support Vector Regression (LSSVR) or the Long- Short Term Memory (LSTM).
Conclusions
Accurate prediction of evaporation is one of the key problems in reservoir management. The knowledge of the effect of the reservoir’s water temperature on evaporation is important in deriving the best reservoir operating rules. Therefore, in this study, we have investigated the influence of the reservoir’s water temperature (TW) on the evaporation prediction. Four heuristic algorithms namely GA, PSO, HHO and SSA were combined with ANFIS to derive the best model for evaporation forecasting of the Boukourdane Dam in Algeria. The results revealed that the addition of TW parameter affect the evaporation forecasting performance with an increase in R and a decrease in RMSE about 4.54% and 17.98% respectively. Comparing the models’ performance, the results indicated that the performance of the ANFIS-HHO model in the test period with RMSE = 0.89 mm. MAE = 0.73 and R = 0.92 demonstrated best performance with more accuracy in comparison to ANFIS-GA. ANFIS-PSO and ANFIS-SSA models. The findings illustrated that the number of variables input affect the prediction performance. Decreasing the number of inputs reduces the prediction accuracy. Finally, among the models. ANFIS-HHO demonstrated the highest accuracy, followed closely by ANFIS-GA.
Data availability
Data are available on request from Authors.
References
Abed M, Imteaz MA, Ahmed AN, Huang YF (2021) Application of long short-term memory neural network technique for predicting monthly pan Evaporation. Sci Rep 11:20742. https://doi.org/10.1038/s41598-021-99999-y
Adnan RM, Mostafa RR, Elbeltagi A, Yaseen ZM, Shahid S, Kisi O (2022a) Development of new machine learning model for streamflow prediction: case studies in Pakistan. Stoch Env Res Risk Assess 36:999–1033. https://doi.org/10.1007/s00477-021-02111-z(0123456789)
Adnan RM, Jaafari A, Milan SG, Kisi O, Heddam S, Zounemat-Kermani M (2022b) Hybridized Adaptive Neuro-Fuzzy Inference System with Metaheuristic Algorithms for Modeling Monthly Pan Evaporation. Water 14:3549. https://doi.org/10.3390/w14213549
Adnan RM, Petroselli A, Heddam S, Guimarães Santos CA, Kisi O (2021a) Comparison of different methodologies for rainfall-runoff modeling: machine learning vs conceptual approach. Nat Hazards 105:2987–3011. https://doi.org/10.1007/s11069-020-04438-2
Adnan RM, Petroselli A, Heddam S, Guimarães Santos CA, Kisi O (2021b) Short term rainfall-runoff modelingusing several machine learning methods and a conceptual event-based model. Stoch Env Res Risk A 35:597–616. https://doi.org/10.1007/s00477-020-01910-0
Ahmadi F, Mehdizadeh S, Mohammadi B, Pham QB, Doan TN, Vo ND (2021) Application of an artificial intelligence technique enhanced with intelligent water drops for monthly reference evapotranspiration estimation. Agric Water Manag 244:106622. https://doi.org/10.1016/j.agwat.2020.106622
Al Domany M (2017) L’évaporation dans le bilan hydrologique des étangs du Centre-Ouest de la France (Brenne et Limousin). Thèse de doctorat, Université d’Orléans, p 332
Alizamir M, Kisi O, Adnan RM, Kuriqi A (2020) Modelling reference evapotranspiration by combining neuro-fuzzy and evolutionary strategies. Acta Geophysica 68(3):14. https://doi.org/10.1007/s11600-020-00446-9
Allawi MF, Othman FB, Afan HA, Ahmed AN, Hossain MS, Fai CM, El-Shafie A (2019) Reservoir Evaporation Prediction Modeling Based on Artificial Intelligence Methods. Water 11:1226. https://doi.org/10.3390/w11061226
Althof D, Rodrigues LN, Silva DD (2019) Evaluating Evaporation Methods for Estimating Small Reservoir Water Surface Evaporation in the Brazilian Savannah. Water 11:1942. https://doi.org/10.3390/w11091942
Azad A, Manoochehri M, Kashi H, Farzin S, Karami H, Shiri J (2019) Comparative evaluation of intelligent algorithms to improve adaptive neuro-fuzzy inference system performance in precipitation modelling. J Hydrol 571:214–224. https://doi.org/10.1016/j.jhydrol.2019.01.062
Azar A, Milan NG, Kayhomayoon Z (2021) Predicting monthly evaporation from dam reservoirs using LS-SVR and ANFIS optimized by Harris hawks optimization algorithm. Environ Monit Assess 193:695. https://doi.org/10.1007/s10661-021-09495-z
Bui T, Khosravi K, Li S, Shahabi H, Panahi M, Singh VP, Chapi K, Shirzadi A, Panahi S, Chen W et al (2018) New Hybrids of ANFIS with Several Optimization Algorithms for Flood Susceptibility Modeling. Water 10:1210. https://doi.org/10.3390/w10091210
Calp MH (2019) A Hybrid ANFIS-GA approach for estimation of regional rainfall amount. GU J Sci 32(1):145–162
Cappelli F, Tauro F, Apollonio C, Petroselli A, Borgonovo E, Grimaldi S (2023) Feature importance measures to dissect the role of sub-basins in shaping the catchment hydrological response: a proof of concept. Stoch Env Res Risk A 37(4):1247–1264. https://doi.org/10.1007/s00477-022-02332-w
Chaudhury S, Samantaray S, Sahoo A, Bhagat B, Biswakalyani C, Satapathy DP (2022) Hybrid ANFIS-PSO Model for Monthly Precipitation Forecasting. In: Bhateja V, Tang J, Satapathy SC, Peer P, Das R (eds) Evolution in Computational Intelligence. Smart Innovation, Systems and Technologies, 267th edn. Springer, Singapore. https://doi.org/10.1007/978-981-16-6616-2_33
Chen W, Panahi M, Pourghasemi HR (2017) Performance evaluation of GIS-based new ensemble data mining techniques of adaptive neuro-fuzzy inference system (ANFIS) with genetic algorithm (GA), differential evolution (DE), and particle swarm optimization (PSO) for landslide spatial modelling. Catena 157:310–324. https://doi.org/10.1016/j.catena.2017.05.034
Cosanday C, Robinson M (2012) Hydrologie continentale. Armand Colin, Paris
Dehghani M, Akram Seifib A, Hossien Riahi-Madvar H (2019) flow prediction by combining ANFIS and grey wolf optimization. Journal of Hydrology 576:698–725. https://doi.org/10.1016/j.jhydrol.2019.06.065
Deo RC, Samui P, Kim D (2016) Estimation of monthly evaporative loss using relevance vector machine, extreme learningmachine andmultivariate adaptive regression spline models. Stoch Env Res Risk Assess 30(6):1769–1784. https://doi.org/10.1007/s00477-015-1153-y
Dong L, Zeng W, Wu L, Lei G, Chen H, Srivastava AK, Gaiser T (2021) Estimating the Pan Evaporation in Northwest China by Coupling CatBoost with Bat Algorithm. Water 13:256. https://doi.org/10.3390/w13030256
Duan Z, Bastiaanssen WGM (2017) Evaluation of three energy balance-based evaporation models for estimating monthly evaporation for five lakes using derived heat storage changes from a hysteresis model. Environ Res Lett 12:024005. https://doi.org/10.1088/1748-9326/aa568e
Eray O, Mert C, Kisi O (2018) Comparison of multi-gene genetic programming and dynamic evolving neural-fuzzy inference system in modeling pan evaporation. Hydrol Res 49(4):1221–1233. https://doi.org/10.2166/nh.2017.076. nh2017076
Eshetu KD, Alamirew T, Ayele T, Woldesenbet D (2023) Interpretable machine learning for predicting evaporation from Awash reservoirs. Earth Science Informatics, Ethiopia. https://doi.org/10.1007/s12145-023-01063-y
Feng W, Lu H, Yao T, Yu Q (2020) Drought characteristics and its elevation dependence in the Qinghai-Tibet plateau during the last half-century. Sci Rep 10:14323. https://doi.org/10.1038/s41598-020-71295-1
Friedrich K, Grossman RL, Huntington J, Blanken PD, Lenters J, Holman KD, Gochis D, Livneh B, ErikSkeie PJ, Healey NC, Dahm K, Pearson C, Finnessey T, Hook SJ, Kowalski T (2018) Reservoir evaporation in the Western United States: current science, challenges, and future needs. Bull Am Meteorol Soc.https://doi.org/10.1175/BAMS-D-15-00224.1
Ghorbani MA, Deo RC, Yaseen ZM, Kashani MH, Mohammadi B (2018) Pan evaporation prediction using a hybridmultilayer perceptron-firefly algorithm (MLP-FFA) model: Case study in North Iran. Theor Appl Climatol 133(3):1119–1131. https://doi.org/10.1007/s00704-017-2244-0
Ghose DK, Sahoo A, Tanaya K, Kumar U (2022) Performance Evaluation of hybrid ANFIS model for Flood Prediction. In: 8th International Conference on Advanced Computing and Communication Systems (ICACCS), pp 772–777. https://doi.org/10.1109/ICACCS54159.2022.9785002
Haznedar B, Kilinc HC (2022) A Hybrid ANFIS-GA approach for estimation of hydrological time series. Water Resour Manag 36:4819–4842. https://doi.org/10.1007/s11269-022-03280-4
Heidari AA, Mirjalili S, Faris H, Aljarah I, Mafarja M, Chen H (2019) Harris hawks optimization: algorithm andapplications. Future Gener Comput Syst 97:849–872. https://doi.org/10.1016/j.future.2019.02.028
Holland JH (1975) Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control and artificial intelligence. University Michigan Press, Ann Arbor
Hundecha Y, Bardossy A, Werner H (2001) Development of a fuzzy logic-based rainfall-runoff model. Hydrol Sci J 46(3):363–376. https://doi.org/10.1080/02626660109492832
Jang JSR (1993) Anfis: Adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23(3):665–685
Jasmine M, Mohammadian A, Bonakdari H (2022) On the prediction of evaporation in arid climate using machine learning model. Math Comput Appl 27:32. https://doi.org/10.3390/mca27020032
Kayhomayoon Z, Naghizadeh F, Malekpoor M, Arya-Azar N, Ball J, Ghordoyee-Milan S (2022) Prediction of evaporation from dam reservoirs under climate change using soft computing techniques. Environ Sci Pollut Res 30:27912–27935. https://doi.org/10.1007/s11356-022-23899-5
Kennedy J, Eberhart R (1995) Particle swarm optimization. In: Proceedings of the IEEE international conference on neural networks, Perth, 1942–1945
Keshtegar B, Kisi O, Ghohani H, Zounemat-Kermani M (2018) Subset modeling basis ANFIS for prediction of the reference evapotranspiration”. Water Resour Manage 32(3):1101–1116. https://doi.org/10.1007/s11269-017-1857-5
Keskin ME, Terzi O (2006) Evaporation estimation models for Lake E˘girdir, Turkey. Hydrol Process 20:2381–2391. https://doi.org/10.1002/hyp.6049
Khosravia K, Daggupatia P, Alamib MT, Awadhc SM, Gharebd MI, Panahii M, Phamf BT, Rezaiee F, Qig C, Yaseen ZM (2019) Meteorological data mining and hybrid data-intelligence models for reference evaporation simulation: A case study in Iraq. Comput Electron Agric 167:105041. https://doi.org/10.1016/j.compag.2019.105041
Kisi O, Ozturk O (2007) Adaptive neuro-fuzzy computing technique for evapotranspiration estimation. J Irrig Drain Eng 133(4):368–379. https://doi.org/10.1061/(ASCE)0733-9437(2007)133:4(368)
Kisi O, Sanikhani H, Zounemat-Kermani M (2014) Comparison of two different adaptive Neuro-Fuzzy inference system in modelling daily reference evapotranspiration. Water Resour Manag 28:2655–2675. https://doi.org/10.1007/s11269-014-0632-0
Knapp HV, Yu YS, Pogge EC (1984) Monthlyevaporation for Milford Lake in Kansas". J Irrig Drain Eng 110(2):138–148
Li MF, Tang XP, Wu W, Liu HB (2013) General models for estimating daily global solar radiation for different solar radiation zones in mainland China. Energy Convers Manag 70:139–148
Malik A, Kumar A, Kisi O (2017) Monthly pan evaporation estimation in Indian central Himalayas using different heuristic approaches and climate based models. Comput Electron Agric 143:302–313. https://doi.org/10.1016/j.compag.2017.11.008
Malik A, Kumar A, Kim S, Kashani MH, Karimi V, Sharafati A, Ghorbani MA, Al-Ansari N, Salih SQ, Yaseen ZM, Chau K-W (2020) Modeling monthly pan evaporation process over the Indian central Himalayas: Application ofmultiple learning artificial intelligence model. Eng Applic Comput Fluid Mech 14(1):323–338. https://doi.org/10.1080/19942060.2020.1715845
Maroufpoor E, Sanikhani H, Emamgholizadeh S, Kişi Ö (2018) Estimation of wind drift and evaporation losses from sprinkler irrigation systems by different data-driven methods. Irrig Drain 67(2):222–232
Mirjalili S, Gandomi AH, Mirjalili SZ, Saremi S, Faris H, Mirjalili SM (2017) Salp swarm algorithm: a bio-inspired optimizer for engineering design problems. Adv Eng Softw 114:163–191. https://doi.org/10.1016/j.advengsoft.2017.07.002
Moayedi M, Ghareh S, Foong LK (2021) Quick integrative optimizers for minimizing the error of neural computing in pan evaporation modeling. Eng Comput 38:1331–1347. https://doi.org/10.1007/s00366-020-01277-4
Moazenzadeh R, Mohammadi B, Shamshirband S, Chau KW (2018) Coupling a firefly algorithm with support vector regression to predict evaporation in northern Iran. Eng Applic Comput Fluid Mech 12(1):584–597. https://doi.org/10.1080/19942060.2018.1482476
Mohammadi B (2023) Modeling various drought time scales via a merged artificial neural network with a firefly algorithm. Hydrology 10(3):58. https://doi.org/10.3390/hydrology10030058
Mohamadi S, Ehteram M, El-Shafie A (2020) Accuracy enhancement formonthly evaporation predictingmodel utilizing evolutionary machine learningmethods. Int J Environ Sci Technol 17(7):3373–3396. https://doi.org/10.1007/s13762-019-02619-6
Moghaddas F, Kabiri-Samani A, Zekri M, Azamathulla HM (2021) Combined APSO-ANN and APSO-ANFIS models for prediction of pressure loss in air-water two-phase slug flow in a horizontal pipeline. J Hydroinform 23:1. https://doi.org/10.2166/hydro.2020.300
Mosavi A, Ozturk P, Chau K (2018) Flood prediction using machine learning models: literature review. Water 10:1536. https://doi.org/10.3390/w10111536
Niu W, Feng Z, Cheng C, Zhou J (2019) Forecasting daily runoff by extreme learning machine based on quantum-behaved particle swarm optimization. J Hydrol Eng 23(3). https://doi.org/10.1061/(ASCE)HE.1943-5584.0001625
Nou MRG, Zolghadr M, Bajestan MS, Azamathulla MH (2020) Application of ANFIS–PSO hybrid algorithm for predicting the dimensions of the downstream scour hole of ski-jump spillways. Iran J Sci Technol Trans Civ Eng 45:1845–1859. https://doi.org/10.1007/s40996-020-00413-w
Parsaie A, Haghiabi AH, Emamgholizadeh S, Azamathulla HM (2019) Prediction of discharge coefficient of combined weir-gate using ANN, ANFIS and SVM. Int J Hydrol Sci Technol 9(4)
Piri J, Mohammadi K, Shamshirband S, Akib S (2016a) Assessing the suitability of hybridizing the Cuckoo optimization algorithm with ANN and ANFIS techniques to predict daily evaporation. Environ Earth Sci 75(3):246. https://doi.org/10.1007/s12665-015-5058-3
Pham QB, Mohammadi B, Moazenzadeh R, Heddam S, Zolá RP, Sankaran A, Gupta V, Elkhrachy I, Khedher KM, Anh DT (2023) Prediction of lake water-level fluctuations using adaptive neuro-fuzzy inference system hybridized with metaheuristic optimization algorithms. Appl Water Sci 13:13. https://doi.org/10.1007/s13201-022-01815-z
Phama BT, Le LM, Lec TT, Buid KTT, Le VM, Ly HB, Prakashe I (2020) Development of advanced artificial intelligence models for daily rainfall prediction. Atmos Res 237:104845. https://doi.org/10.1016/j.atmosres.2020.104845
Piri J, Mohammadi K, Shamshirband S, Akib S (2016b) Assessing the suitability of hybridizing the Cuckoo optimization algorithm with ANN and ANFIS techniques to predict daily evaporation. Environ Earth Sci 75:246
Riahi-Madvar H, Dehghani M, Memarzadeh R, Gharabaghi B (2021) Short to Long-Term Forecasting of River Flows by Heuristic Optimization Algorithms Hybridized with ANFIS. Water Resources Management 35:1149–1166. https://doi.org/10.1007/s11269-020-02756-5
Rezaie-Balf M, Kisi O, Chua LH (2019) Application of ensemble empirical mode decomposition based on machine learning methodologies in forecasting monthly pan evaporation. Hydrol Res 50:2. https://doi.org/10.2166/nh.2018.050
Sahoo BB, Panigrahi B, Nanda T, Tiwari MK, Sankalp S (2023) Multi-step Ahead Urban Water Demand Forecasting Using Deep Learning Models. SN Comput Sci 4(6):752. https://doi.org/10.1007/s42979-023-02246-6
Sahoo A, Samantaray S, Paul S (2021) Efficacy of ANFIS-GOA technique in flood prediction a case study of Mahanadi river basin in India. H2Open J 4(1):137–156
Samanataray S, Sahoo A (2021) A Comparative Study on Prediction of Monthly StreamflowUsing Hybrid ANFIS-PSO Approaches. KSCE J Civ Eng 25(10):4032–4043. https://doi.org/10.1007/s12205-021-2223-y
Sanikhani H, Kisi O, Maroufpoor E, Yaseen ZM (2018) Temperaturebased modeling of reference evapotranspiration using several artificial intelligence models: application of different modeling scenarios. Theor Appl Climatol 1–14. https://doi.org/10.1007/s00704-018-2390-z
Seifi A, Soroush F (2020) Pan evaporation estimation and derivation of explicit optimized equations by novel hybrid meta-heuristic ANN based methods in different climates of Iran. Comput Electron Agric 173:105418. https://doi.org/10.1016/j.compag.2020.105418
Seifi A, Ehteram M, Soroush F, Torabi A (2022) Multi-model ensemble prediction of pan evaporation based on the Copula Bayesian Model Averaging approach. Eng Appl Artif Intell 114:105124. https://doi.org/10.1016/j.engappai.2022.105124
Shabani S, Samadianfard S, Sattari MT, Mosavi A, Shamshirband S, Kmet T, Várkonyi-Kóczy AR (2020) Modeling Pan Evaporation Using Gaussian Process Regression K-Nearest Neighbors Random Forest and Support Vector Machines; comparative analysis. Atmosphere 11:66. https://doi.org/10.3390/atmos11010066
Shiri J, Dierickx W, Mohammed A, Ali B, Ghorbani A (2011) Estimating daily pan evaporation from climatic data of the State of Illinois USA using adaptive neurofuzzy inference system (ANFIS) and artificial neural network (ANN). Hydrol Res 42(6):491–502. https://doi.org/10.2166/nh.2011.020
Singh A, Singh RM, Kumar AR, Kumar A, Hanwat S, Tripathi VK (2021) Evaluation of soft computing and regression-based techniques for the estimation of evaporation. J Water Clim Change 12:1. https://doi.org/10.2166/wcc.2019.101
Soroush F, Fathian F, Khabisi FH et al (2020) Trends in pan evaporation and climate variables in Iran. Theor Appl Climatol 142:407–432. https://doi.org/10.1007/s00704-020-03262-9
Tabbussum R, Dar AQ (2021) Performance evaluation of artificial intelligence paradigms—artificial neural networks, fuzzy logic, and adaptive neuro-fuzzy inference system for flood prediction. Environ Sci Pollut Res 28(20):25265–25282
Terzi O (2013) Estimating daily pan evaporation using data mining process. Scientia Iranica A 20(4):1077–1084
Tikhamarine Y, Malik A, Kumar A, Souag-Gamane D, Kisi O (2019) Estimation of monthly reference evapotranspiration using novel hybrid machine learning approaches. Hydrol Sci J 64:1824–1842. https://doi.org/10.1080/02626667.2019.1678750
Wang L, Niu Z, Kisi O, Li C, Yu C (2017) Pan evaporation modeling using four different heuristic approaches. Comput Electron Agric 140:203–213. https://doi.org/10.1016/j.compag.2017.05.036
Wang RY, Yang XG, Zhang JL, Wang DM, Liang DS, Zhang LA (2007) Study of soil water and land surface evaporation and climate on Loess Plateau in the Eastern Gansu Province. Adv Earth Sci 22:625–635. https://doi.org/10.11867/j.issn.1001-8166.2007.06.0625
White WR, Milli H, Crabbe AD (1973) Sediment transport: an appraisal method. In: Performance of theoretical methods when applied to flume and field data. Tech. Rep. 1T119. Wallingford
Wu L, Huang G, Fan J, Ma X, Zhou H, Zeng W (2019) Hybrid extreme learning machine with meta-heuristic algorithms for monthly pan evaporation prediction. Comput Electron Agric 168(12):105115. https://doi.org/10.1016/j.compag.2019.105115
Yaseen ZM, Ebtehaj I, Bonakdari H, Deo RC, Danandeh MA, Mohtar WHM, Diop L, El-Shafie A, Singh VP (2017) Novel approach for streamflow forecasting using a hybrid ANFIS-FFA model. J Hydrol 554:. https://doi.org/10.1016/j.jhydrol.2017.09.007
Yaseen ZM, Al-Juboori AM, Beyaztas U, Al-Ansari N, Chau KW, Qi K, Ali M, Salih SQ, Shahid S (2020) Prediction of evaporation in arid and semi-arid regions: a comparative study using different machine learning models. Eng Applic Comput Fluid Mech 14(1):70–89. https://doi.org/10.1080/19942060.2019.1680576
Zhao G, Gao H (2019) Estimating reservoir evaporation losses for the United States: fusing remote sensing and modeling approaches. Remote Sens Environ 226(1):109–124. https://doi.org/10.1016/j.rse.2019.03.015
Zhou Y, Guo S, Chang FJ (2019) Explore an evolutionary recurrent ANFIS for modelling multi-step-ahead flood forecasts”. J Hydrol 570:343–355
Zounemat-Kermani M, Kisi O, Piri J, Meymand AM (2019) Assessment of artificial intelligence–Based models and metaheuristic algorithms in modeling evaporation. J Hydrol Eng Arch 24(10). https://doi.org/10.1061/(ASCE)HE.1943-5584.0001835
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
B.M: Data processing, conceptualization and writing, M.A.M: Methodology and writing, A.P: Supervision, Revising and writing.
Corresponding author
Ethics declarations
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Communicated by: H. Babaie
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Marouane, B., Mu’azu, M.A. & Petroselli, A. Prediction of reservoir evaporation considering water temperature and using ANFIS hybridized with metaheuristic algorithms. Earth Sci Inform 17, 1779–1798 (2024). https://doi.org/10.1007/s12145-024-01223-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-024-01223-8