
Abstract
We performed several machine-learning algorithms on a geochemical dataset including whole-rock (n = 1656) and glass (n = 1092) compositions of lavas and pyroclastics belonging to 8 volcanic fields along the South Aegean Active Volcanic Arc (SAAVA). We did not only test our trained model with the unknown distal tephras, but also controlled its performance using some known distal tephras (e.g., Nisyros-Kyra) from the easternmost part of the SAAVA. The different metrics and kappa values revealed that Naïve Bayes, Linear Discriminant Analysis, Artificial Neural Network, and Support Vector Machine (both probabilistic and non-probabilistic models) were the least performing algorithms; while the Random Forest and the gradient boosting algorithms (e.g., CatBoost, LightGBM) together with their average ensemble (Voting Classifier) were the best for the volcanic-source predictions of tephras. This also indicates that the latter algorithms give better results for the machine-learning applications on an imbalanced geochemical dataset, which was the main artifact in our training model. Despite the accurate prediction and training models especially for those having larger datasets (i.e., Santorini and Nisyros volcanoes), we here would like to express that the machine-learning can be as yet a time-saving tool (not an automatized decision-maker) in the tephrochronology studies providing a more efficient and rapid way of finding the possible volcanic sources for unknown tephras. In this regard, our freely-available Python codes would be easily implemented in further “tephra-hunting” studies in and around the SAAVA. However, there is a need for increasing the available geochemical (e.g., mineral chemistry) and also other interrelated datasets (e.g., geochronology) that should be as yet evaluated manually by the tephrochronologists to be able to improve the performances of machine-learning algorithms in the volcanic-source predictions.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The supervised machine-learning algorithms have become a helpful tool by providing an efficient way to better understand the complex processes in different aspects of earth sciences. Some examples can be given from the studies of seismology (e.g., DeVries et al. 2018; Corbi et al. 2019; Hulbert et al. 2019; Park et al. 2020), volcanology (e.g., Anzieta et al. 2019; Ren et al. 2020; Watson 2020; Witsil and Johnson 2020a, b), and petrology (e.g., Petrelli and Perugini 2016; Petrelli et al. 2020; Ouzounis and Papakostas 2021; Pignatelli and Piochi 2021; Valetich et al. 2021).
Tephrochronology is an interdisciplinary field where both proximal and distal tephra (i.e., ash in Greek) deposits are characterized and used as powerful remarks for various geological and environmental processes (e.g., Sarna-Wojcicki 2000; Lowe and Hunt 2001; Turney and Lowe 2002; Lowe 2011). Together with the recent analytical developments, geochemistry (glass, mineral, or whole-rock compositions) comes in possession of a widely used method in tephrochronology, especially when the geochronological data are missing or problematic. The conventional way of using geochemistry data for tephra correlation is mostly to draw a variety of binary diagrams including major oxides, trace elements, and their ratios. However, this can turn into a challenging task for the tephras of some geographic locations that have an identical geochemical affinity (e.g., South Aegean Active Volcanic Arc “SAAVA”; Francalanci et al. 2005). At this point, the multivariate statistical methods (e.g., principal component analysis) together with some of the machine-learning algorithms (e.g., support vector machine) serve as a more efficient and discriminating approach (Lowe et al. 2017) to not only better handle the geochemical datasets, but also better correlate the tephras using their compositions. Of those, the machine-learning applications have been significantly increasing for tephrochronology in recent years (e.g., Petrelli et al. 2017; Bolton et al. 2020).
In this study, we applied several machine-learning algorithms (e.g., random forest, gradient boosting decision tree) on a geochemical dataset representing 8 volcanic fields within the SAAVA to provide a case study for the usage of this approach in tephrochronology considering both known (controlling group) and unknown (test group) tephras around the eastern Mediterranean (Satow et al. 2015; Gençalioğlu-Kuşcu and Uslular 2018; Vakhrameeva et al. 2018). Our primary aim is to elucidate the performance of machine-learning on an easily handled geochemical dataset in comparison to widely used conventional binary plots that require various manually determined combinations and thereby high effort. Here we also discuss the pros and cons of the various machine-learning algorithms applied for an imbalanced compositional dataset to provide further insights into their usage in tephrochronology and related fields.
South Aegean active volcanic arc (SAAVA)
The volcanism along the SAAVA (Fig. 1) started at the lower Pliocene around the Sousaki in line with slab rollback of the Hellenic arc and continued until the present day with the historic activities of Methana, Milos, Santorini, and Nisyros volcanoes (e.g., Fytikas et al. 1984; Francalanci et al. 2005; Pe-Piper and Piper 2005; Francalanci and Zellmer 2019; Vougioukalakis et al. 2019). The western parts of the SAAVA are mostly represented by small volume monogenetic volcanism, while the central and eastern parts consist predominantly of composite volcanoes (e.g., Santorini and Nisyros calderas; Francalanci et al. 2005). The volcanics within the SAAVA display typical arc-related geochemical compositions mostly characterized by the calc-alkaline to high-potassium calc-alkaline affinity (e.g., Francalanci et al. 2005; Pe-Piper and Piper 2005) (Table 1) together with the influences of Aegean slab tear through the eastern to central parts of the arc (Klaver et al. 2016). The volcanological history of each volcanic sector is rather complex and the details are beyond the scope of our study. Hence the readers can refer to the comprehensive reviews in the literature (Innocenti et al. 1982; Fytikas and Vougioukalakis 2005; Francalanci and Zellmer 2019; Vougioukalakis et al. 2019) for further detailed information.

Digital elevation model (15 arc-second global relief, SRTM15 + V2.1) displaying the volcanic fields along the South Aegean Active Volcanic Arc (SAAVA) used in this study for the application of machine-learning algorithms. Trench locations are from Jongsma (1977). The map was created using the PyGMT tool (Uieda et al. 2021)
The products of explosive volcanism (aka tephra) along the SAAVA have been one of the important research aspects for both the understanding of volcanological evolution, the future risk assessment, and the paleoenvironmental/climatological construction of the eastern Mediterranean (e.g., Hamann et al. 2010; D'Antonio et al. 2016; Koutrouli et al. 2018; Wulf et al. 2018; Vakhrameeva et al. 2021). The distal tephras of Santorini (e.g., Minoan and Cape Riva), for example, have a widespread distribution found in the lake cores (e.g., Pearce et al. 2002) and the terrestrial settings of western Anatolia (Sulpizio et al. 2013) and marine cores of Aegean, Marmara, and even the Black Sea (e.g., Guichard et al. 1993; Wulf et al. 2002; Aksu et al. 2008; Satow et al. 2015). Nisyros volcano is another example that has mid-distal tephra records within the surrounding regions (e.g., Datça peninsula, Gençalioğlu-Kuşcu and Uslular 2018; Tilos island, Keller et al. 1990; Sterba et al. 2011). However, the distal tephra record of other volcanic fields along the SAAVA is almost absent and hence any evidence of non-correlated (or unknown) tephra layers within the eastern Mediterranean (documented and/or to be correlated) (e.g., Satow et al. 2015; Korkmaz et al. 2018; Vakhrameeva et al. 2018) needs some extra attention for the sake of better volcanological and paleoenvironmental reconstruction models.
Methodology
Source dataset
A substantial part of the geochemical dataset including the whole-rock (n = 1656) and glass (n = 1092) compositions of Plio-Quaternary volcanics along the SAAVA was compiled from the GEOROC (Geochemistry of Rocks of the Oceans and Continents) database (Fig. 1; Supplementary Data S1). Data from some unpublished studies were also included (e.g., Bohla 1986; Rehren 1988). Here, the main idea of compiling all geochemical data including both lava flows and pyroclastics was that they could represent the main geochemical characteristics of each volcanic field. Otherwise, only available data for the tephra around the studied volcanic fields would not be enough for the application of machine-learning algorithms. A similar approach was followed by the relevant studies in the literature (e.g., Petrelli et al. 2017).
We classified the compiled geochemical dataset into 8 groups based on the spatial distribution of the volcanic fields (Table 1) and filtered the dataset by selecting the major oxides (SiO2, TiO2, FeOT, MgO, CaO, Al2O3, K2O, Na2O, MnO, and P2O5 in weight percentage–wt.%) and selected trace elements (Zr, Ba, Sr, Rb, Nb, La, and Ce in parts per million–ppm). The main reason for such a selection of trace elements was that these are the default elements in the whole-rock analysis (i.e., X-ray fluorescence–XRF and inductively coupled plasma mass spectrometry–ICP-MS) and the most common in glass (i.e., shard or inclusion) geochemistry analysis (e.g., electron microprobe–EPMA and laser ablation inductively coupled plasma mass spectrometry–LA-ICP-MS). Although our approach in selecting the distinct trace elements resulted in an optimum number of data (especially for trace element values), there were still some missing data in the dataset (see the descriptive statistics in the Supplementary Data S1). Thus, we applied one of the data imputing methods by replacing the blank parts with zero as the machine-learning algorithms require numerical inputs. Here, we did not calculate the mean/median values of the column to replace them with the missing values as the trace element compositions of different volcanic fields in the SAAVA can be unique for each specific volcanic field, and hence any generalization may create a bias for further interpretations. The data with a sum of the major oxides below 95 wt.% and high loss on ignition values (LOI > 5 wt.%) were removed from the dataset. In addition, we did not perform any further filtering to the dataset (e.g., age constraint).
Modelling
Preprocessing and experiments
Before the training step, the possible duplicates in the dataset were removed by comparing all the features with one another (Fig. 2). We then used the RobustScaler tool of the Scikit-learn Python library (Pedregosa et al. 2011; Kramer 2016) to scale the data based on the quantile range. The values outside of the 0.95-quantile (i.e., outliers) were extracted since they could potentially affect the performance of the model or corrupt the measurements (Fig. 2). The Box-Cox transformation (Box and Cox 1964) was applied to the data (Fig. 2). We performed feature engineering and did selection on the data using the SMOTE (synthetic minority oversampling technique; Chawla et al. 2002) since the dataset can be considered as imbalanced (Table 1; Supplementary Data S1).

Flowchart of machine-learning processing performed in this study
Hyper-parameter tuning is a common process in machine learning used to maximize the algorithm’s performance (e.g., Bardenet et al. 2013). The hyper-parameters can parameterize the learning algorithms that construct a training model with a given dataset (e.g., Claesen et al. 2014). To obtain the best hyper-parameters that yield the optimal model, we here employed the RandomizedSearchCV (Bergstra and Bengio 2012), which is better for the high-dimensional datasets with a larger extend in grid search (Paper 2020). The optimized tuning configurations for each algorithm can be found in our Python codes (https://github.com/guslular/ML_for_tephrochronology.git).
Classifiers
We implemented 10 different learning algorithms (Fig. 2 and Table 2) using the optimum tuning configurations in the Scikit-learn Python library (Pedregosa et al. 2011; Kramer 2016). These are Support Vector Machine (SVM) with the both probabilistic and non-probabilistic (raw) model (Cortes and Vapnik 1995; Li et al. 2010), Random Forest (RF; Breiman 2001), k-Nearest Neighbors (KNN; Laaksonen and Oja 1996), Naïve Bayes (Complement NB; Rennie et al. 2003), Artificial Neural Network (ANN, multi-layer perceptron; e.g., Gardner and Dorling 1998), Linear Discriminant Analysis (LDA; e.g., Balakrishnama and Ganapathiraju 1998; Izenman 2013), XGBoost (eXtreme Gradient Boosting; Chen and Guestrin 2016), LightGBM (Light Gradient Boosting Machine; Ke et al. 2017), CatBoost (Category Gradient Boosting; Prokhorenkova et al. 2017), and Voting Classifier (VC; the ensemble of XGBoost, LightGBM, and CatBoost) (Table 2). Most of the algorithms are all tree-based ensemble classifiers (except for the SVM) consisting of both averaging (e.g., Voting Classifier) and boosting (e.g., CatBoost) methods, which are widely considered as the most efficient classifiers for the tabular data due to their higher performance even in more complex algorithms (e.g., Dietterich 2000). However, the gradient boosting algorithms (e.g., XGBoost) were not much preferred in the literature of machine-learning applications on tephrochronology due to their rather long computational time (Bolton et al. 2020). The further details related to the algorithms are beyond the scope of this study and hence can be found in Python scikit-learn documentation (Pedregosa et al. 2011; Garreta and Moncecchi 2013) and the well-established literature.
Evaluation
We assessed the trained models with both accuracy (e.g., the accuracy score, Compute Area Under the Receiver Operating Characteristic Curve, ROC-AUC) and the Precision-Recall (F1 macro and weighted scores) metrics (Table 3). We also calculated the Cohen’s kappa (Cohen 1960) values (Table 3), which are used to express the degree of agreement between the algorithms and the training dataset (Altman 1990). For all metrics, the models were cross-validated with 10-folds of stratified splits (all contain 10% of total samples from each group) (Fig. 2). The goal of cross-validation was to evaluate and see how the model was generalized to unseen data. As the different splits can vary in the results, this might introduce bias to the predictions. The cross-validation divides the data into 10 equal parts and allows the model to train on all splits except one, then evaluates the model on this split. In order not to bring any bias to the splits and to use all available data, this method was repeated n-times, and the average was considered (https://github.com/guslular/ML_for_tephrochronology.git).
We also implemented a feature sensitivity analysis to understand the impacts of used major oxides and trace elements on our machine-learning model. We used the “shap” function in the Scikit-learn library, which is based on the Tree SHapley Additive exPlanations (SHAP) method (Lundberg and Lee 2017). This function allows a fast and exact computation of SHAP values, especially for the gradient boosting algorithms (e.g., XGBoost), owing to excluding sampling and background datasets (Lundberg and Lee 2017).
Test dataset
We used the model to predict the original test dataset (not used in the training model) consisting of the whole-rock and glass geochemistry data of known and unknown Quaternary tephra (n = 439) from the eastern Mediterranean (Supplementary Data S2). The example of known tephra was selected as a controlling group from Datça peninsula (southwestern Anatolia, Turkey) where the distal deposits of the Nisyros Kyra unit (133.5 ± 3.4 ka; U-Th/He, Ar-Ar) were documented (Gençalioğlu-Kuşcu and Uslular 2018; Gençalioğlu-Kuşcu et al. 2020). Here, the idea was to validate our machine-learning model that will be used for the prediction of unknown tephras (test group), which were chosen from the studies of Satow et al. (2015) and Vakhrameeva et al. (2018). In addition to the Kyra tephra as a controlling group, we also used the known tephra samples from the aforementioned studies.
Results and discussion
Classification performance
The mean training accuracy of each algorithm used in this study was above 0.89 (except for the NB and the LDA) based on the results of both accuracy and Precision-Recall metrics (Table 3; Figs. 3a-c). The SVM performed the least accurate training results (0.89–0.97) among the other algorithms (e.g., RF, XGBoost) that have relatively higher accuracy scores (0.93–0.99; Table 3). In addition, the accuracy values of KNN and ANN have higher ranges revealed by their larger quartile intervals in the box plots (Figs. 3a-c). The mean Cohen’s kappa values for each algorithm were above 0.80, again except for the NB and LDA (Fig. 3d). Similar to the results of the accuracy metrics, the kappa values were the lowest in the SVM (0.80) and the highest in the gradient boosting algorithms (0.89; Fig. 3d) that correspond to the scale of “very good” agreement (Altman 1990) with the training dataset. The processing times (in seconds) of each algorithm for the training and testing models were also listed in Table 3, revealing that the computational cost of these algorithms is rather reasonable.

Box and whisker plots of model performance (mean values) on cross-validations a. Accuracy score; b. F1 score (average weighted); c. Compute Area Under the Receiver Operating Characteristic Curve (ROC-AUC) score; d. The Cohen’s kappa values
The RF, which is also known as a reliable probabilistic algorithm especially for the compositional data (Bolton et al. 2020 and references therein), and the gradient boosting algorithms with their average ensemble (VC) provided the best accuracy results and hence will be considered in further interpretations throughout the manuscript. Other than NB and LDA, the SVM (both probabilistic and non-probabilistic) has the lowest accuracy and kappa values among the algorithms (Fig. 3 and Table 3). There are different claims on the accuracy/performance of the different versions of the SVM algorithm for the labeled compositional data within the literature (e.g., Petrelli and Perugini 2016; Petrelli et al. 2017; Bolton et al. 2020). The non-probabilistic model of this algorithm was successfully performed to predict the possible tectonic regimes of the volcanic fields (Petrelli and Perugini 2016), or to discriminate the volcanic fields within the same province using the major, trace, and isotope geochemistry data (Petrelli et al. 2017; Ouzounis and Papakostas 2021). However, its probabilistic model provided the poorest performance in the source correlation of some Alaskan tephras (Bolton et al. 2020). The latter study, which applied several machine learning algorithms using the R package “caret” (Kuhn et al. 2020), highlighted this discrepancy and indicated the problematic parts of this algorithm in the probabilistic model, especially for the multi-class datasets as in the case of our study. However, we could not detect any difference between different versions of the SVM implemented using the Python Scikit-learn library. This might be related to the possible distinctions in the machine learning libraries of different programming languages (i.e., R and Python) or the optimization configurations. However, it is at least clear that the performance of the SVM algorithm is relatively lower than the RF and the gradient boosting algorithms (Table 3; Fig. 3). In addition, as stated by Bolton et al. (2020), we here like to re-express the imbalanced behavior of geochemical datasets in terms of both data distributions among the volcanic fields and also within the data itself (i.e., the abundance of major element data compared to the trace elements, especially for the glass geochemistry).
Classification scores of the machine learning algorithms applied on a geochemical dataset representing 8 volcanic fields along the SAAVA are shown in Fig. 4. The ANN with the optimum final architecture (100 hidden layers) failed in the training model and predicted all groups as either Nisyros or Santorini that have larger datasets (Fig. 4). However, other algorithms provided successful predictions in the confusion matrices (Fig. 4). The classification scores were above 0.80 for half of the volcanic fields that can be explained mostly by the imbalanced behavior of the data (Table 1) together with the geochemical similarities between some groups (e.g., the significant portions of Yali volcanics were predicted as Nisyros). Santorini, Nisyros, Kos, and Antiparos were the well-trained volcanic fields predicted by most of the algorithms (Fig. 4). Of these, Santorini and Nisyros that have the largest number of data in our dataset have also the highest classification scores (> 0.94; Fig. 4). This also highlighted the importance of the total amount of data in a geochemical dataset for the successful application of machine learning algorithms. In addition to these volcanic fields, Milos and Methana have also higher classification scores in some algorithms (up to 0.76 and 0.84, respectively) (Fig. 4).

Classification scores of machine-learning algorithms applied for the SAAVA volcanics. Algorithms from upper left to the lower right: ANN, KNN, SVM (probability), RF, CatBoost, LightGBM; XGBoost, and Voting Classifier
On the other hand, we applied a feature sensitivity analysis to one of the gradient boosting algorithms that gave the best results (i.e., XGBoost; Fig. 5). The summary box plot indicates that the Sr seems to be the most prominent element (except for Antiparos) affecting the predictions in all volcanic fields (especially Methana and Santorini, Fig. 5). Furthermore, the major/minor elements have a dominant impact on the machine-learning models. The possible explanations would be either the higher numbers of major-element data compared to the trace elements in our compiled dataset, or any petrological implications (e.g., magma affinity). For example, the K2O contents are especially important for the Antiparos and Kos volcanic fields (Fig. 5) that could not be definitely discriminated in our predictions (Fig. 4).

Summary box plots of feature sensitivity analysis applied on XGBoost algorithm
The main problem in the training model was the effect of larger datasets (i.e., Santorini and Nisyros) on the classification of other volcanic fields (Fig. 4). That is especially obvious in the ANN algorithm in which all the groups were correlated either by Nisyros or Santorini (Fig. 4). In addition, there are some strong similarities between the geochemical affinities of volcanic fields, such as between Nisyros and Yali (Fig. 4), which was also stated by a petrology-oriented study (Popa et al. 2019). This might show that the machine learning algorithms could help us to determine such geochemical similarities among the volcanic fields (if exist) in a more efficient and less time-consuming way than the manually created geochemical diagrams.
The source predictions of unknown Tephras: Conventional vs. machine learning approach
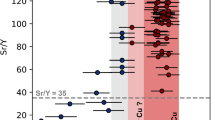
We report an example of binary discrimination plots used for the correlation of known and unknown tephras from the eastern Mediterranean (Satow et al. 2015; Gençalioğlu-Kuşcu and Uslular 2018; Vakhrameeva et al. 2018) with the volcanic fields in our dataset in Fig. 6. These diagrams can be varied using the different combinations of major oxides and trace elements, but the most common ones in our dataset were illustrated in Fig. 6. More detailed information can be found in the original studies.

Tephra-fall deposits found in Datça peninsula and correlated with the Nisyros Kyra unit (Gençalioğlu-Kuşcu and Uslular 2018; Gençalioğlu-Kuşcu et al. 2020) mostly plot with the Nisyros and Yali samples in Fig. 6. As the age (133.5 ± 3.4 ka) and other characteristics (e.g., depositional, glass and mineral chemistry) of the Kyra tephra are well documented, it is relatively easy to link these with the Kyra eruptions of Nisyros volcano occurred before Yali volcanism (e.g., upper pumice unit, 45 ± 10 ka, Guillong et al. 2014). In our machine learning model (Table 4 and Supplementary Data S2), we could predict the Datça distal tephras as Nisyros tephra with the higher scores of various algorithms (65 to 100%).
On the other hand, it is notable that the significant amounts of tephra samples found in the sediment cores around the SE Aegean Sea (Satow et al. 2015) are mainly correlated with Santorini (Fig. 6). However, it is a challenging task to ensure that they are only correlated with the Santorini as there are some similarities with other volcanic fields in some diagrams (e.g., Kos, Milos, and Antiparos). The ones that were already correlated with Santorini (Satow et al. 2015) were also predicted as Santorini in our machine learning model with the higher scores ranging from 68% to 100% (Table 4; Supplementary Data S2). Here, except for the RF algorithm, other higher accuracy algorithms have scores greater than 90% (up to 100%; Supplementary Data S2). Our machine learning model can suggest some supporting corrections for the distal tephras, which were correlated using the conventional geochemical plots. For example, Satow et al. (2015) claimed that the tephra layer of LC21–2005 is mostly correlated with the Santorini, except for three samples that do not resemble within the geochemical plots. However, the results of our machine learning model revealed that all the samples belonging to this tephra are well correlated with the Santorini (Table 4; Supplementary Data S2). A similar example can be given for the following tephra layers named LC21–3225 and LC21–3775. The former is mostly correlated with Santorini as suggested by Satow et al. (2015) apart from one sample that did not plot together with others. Here, we suggest that there might be more samples that are not correlated with Santorini, and Nisyros would be a candidate for these tephras based on our machine learning model (Supplementary Data S2). Satow et al. (2015) provided an age interval for this sample between 21.7 ± 0.6 ka and 21.8 ± 0.6 ka that might result in the reconsideration of the available ages of the youngest Nisyros tephra (upper pumice, < 70 ± 24 ka; Guillong et al. 2014). As for the sample of LC21–3775 that could not be correlated with any volcanic source by Satow et al. (2015), we here proclaim that Santorini can be the best candidate for the volcanic source of this tephra layer based on our model (Supplementary Data S2).
Besides, Satow et al. (2015) could not exactly correlate some of the tephras (e.g., LC21–12625, LC21–13485 with the age of >128–121 ka) and marked them with a question mark (i.e., Kos- Nisyros-Yali?) in their study (Supplementary Data S2) even after using various geochemical combinations and other proxies (e.g., geochronological data). Despite the relatively lower performance scores compared to the predictions for Santorini, the source predictions of these uncorrelated tephras obtained by our model seem to be promising (Table 4; Supplementary Data S2). The five higher accuracy algorithms with various scores mostly address either Kos or Antiparos as a possible volcanic source (Table 4; Supplementary Data S2). However, since the last known volcanic activity in Antiparos was around the Pliocene (Innocenti et al. 1982; Hannappel and Reischmann 2005), these tephras could be correlated with the Kos Plateau Tuff (or Kos ignimbrite), which is one of the most voluminous ignimbrite deposits in the region with the age of 160–165 ka (Smith et al. 1996; Bachmann et al. 2010).
There are also some unknown tephras/cryptotephras together with those that have mostly correlated with the Santorini in the sediment core around Tenaghi Philippon (SE Balkan Peninsula; Vakhrameeva et al. 2018). The conventional binary plots also indicated that some of the tephras were correlated with the Santorini samples (Fig. 6). However, some tephras could not be correlated with any volcanic field around the Aegean arc (e.g., POP4 and POP5). or example, POP4 was geochemically correlated with either Kos or Milos (Vakhrameeva et al. 2018). However, our machine learning model predicted the volcanic source of this tephra as either Kos (up to 47%) or Yali (up to 100%). Here, two important geological facts falsify our prediction of Yali for this tephra dated as 358 ka: the first one is that the age of Yali volcanism significantly postdated the formation of this tephra; and the second one is that our machine learning model did not successfully train the Yali volcanics (Fig. 4) due to their similarities with some of the Nisyros volcanics, which have been stated in the literature as well (e.g., Popa et al. 2019). Therefore, we suggest that the older volcanics on Kos Island (i.e., Kefalos Tuff; Dalabakis and Vougioukalakis 1993) would be the best candidate for the possible volcanic source of POP4 tephra. Certainly, this claim desires some further analysis (e.g., mineral chemistry, etc.) and also the integration of different volcanic fields from the eastern Mediterranean (e.g., central Italy, central Anatolia) into the machine learning models to provide a better constraint on this prediction.
Tephra layers called POP5 could also not be correlated with the volcanic fields around the eastern Mediterranean even after employing various geochemical plots with the datasets of different volcanic fields (e.g., central Anatolia). Vakhrameeva et al. (2018) stated that an unknown eruption of Campanian volcanoes could be the possible candidate for these so-called unknown tephras mostly based on their identical age data (> 128–121 ka). Considering that the Campanian or other volcanoes around the eastern Mediterranean were not included in our machine learning model, we correlated POP 5 tephras of Vakhrameeva et al. (2018) mostly with the Kos (up to 77%), Milos (up to 98%), and Yali (up to 93%) (Table 4, Supplementary Data S2). As mentioned above, the temporal evolution of Yali volcanism is not appropriate for these tephras that have ages ranging from 419 ka to 438 ka (Vakhrameeva et al. 2018). Therefore, we here assert that Kos (i.e., Kefalos Tuff; Dalabakis and Vougioukalakis 1993) and Milos would be the best candidates for the possible volcanic sources of these tephras (Supplementary Data S2).
Concluding remarks
Our recent findings in this study enabled us to conclude that:
-
The Random Forest together with the gradient boosting algorithms (e.g., XGBoost, LightGBM) provided the best performance for the imbalanced geochemical dataset, while the Naïve Bayes, Linear Discriminant Analysis, Support Vector Machine, and the Artificial Neural Network were the poorest performing algorithms.
-
According to the feature sensitivity analysis on XGBoost algorithm, the Sr and some major elements (e.g., K2O, MnO) have higher impacts on the prediction models that can be linked with the petrological characteristics of the volcanic fields. However, this needs some further investigations for a better clarification.
-
Despite the recent developments and various configurations of the machine learning algorithms, the imbalanced behavior of a dataset, which is a common problem in earth sciences, is still one of the important debugs for successful training and testing models.
-
The testing model was successful to predict the known or unknown tephras when they corresponded to the volcanic field that has larger data in our dataset (e.g., Nisyros, Santorini). However, there is no clear difference between the conventional plotting and the machine learning application for the source prediction of unknown tephras that possibly correlate with the volcanic fields including relatively less amount of geochemical data.
-
The idea of geochemical similarity between some volcanics of Yali and Nisyros was also supported by our machine learning model. Despite a need for further analyses and corrections, we here suggested possible volcanic sources for POP4 (as Kefalos tuff) and POP5 (as Kos or Milos) samples of Vakhrameeva et al. (2018) and also for some samples (e.g., LC21–12625, LC21–13485) of Satow et al. (2015), which are correlated mostly with the Kos ignimbrites.
-
Our freely accessible Python code established in this study together with the extensible geochemical dataset to implement the machine learning algorithms can be easily used for further tephrochronology studies around the eastern Mediterranean as a regular tool to predict or at least to decrease the number of possible volcanic sources before elaborating the common correlation methods.
-
The machine learning applications in tephra correlation can be as yet considered as a fast and helpful tool (not a decision-maker) that eliminates the possible candidates and suggests a quantitatively best correlation. Here, there is still a need for an expert opinion to decide the possible volcanic sources for the unknown tephras considering the available geological and geochronological data. The accuracy of such applications will possibly be improved in the future together with the integration of region-based current tephra databases (e.g., Lowe et al. 2015; Tomlinson et al. 2015), the increasing amount of geochemical and interrelated datasets (e.g., mineral chemistry, geochronology), and the recent analytical and statistical developments on the tephra correlations (e.g., Lowe et al. 2017).
Code availability
The machine learning analysis was performed on a Windows computer with Intel ® Xeon ® CPU E5–2640 v4@ 2.40 GHz i7 processor and 32 GB memory. The Python code is available for downloading at the link: https://github.com/guslular/ML_for_tephrochronology.git.
References
Aksu AE, Jenner G, Hiscott RN, İşler EB (2008) Occurrence, stratigraphy and geochemistry of Late Quaternary tephra layers in the Aegean Sea and the Marmara Sea. Mar Geol 252(3–4):174–192
Allen SR, McPhie J (2000) Water-settling and resedimentation of submarine rhyolitic pumice at Yali, eastern Aegean. Greece. J. Volcanol. Geotherm. Res. 95(1–4):285–307
Allen SR, Stadlbauer E, Keller J (1999) Stratigraphy of the Kos plateau tuff: product of a major quaternary explosive rhyolitic eruption in the eastern Aegean. Greece Int J Earth Sci 88(1):132–156
Altman DG (1990) Practical statistics for medical research. Chapman and Hall/CRC, London, 611p
Anzieta JC, Ortiz HD, Arias GL, Ruiz MC (2019) Finding possible precursors for the 2015 Cotopaxi volcano eruption using unsupervised machine learning techniques. Int J Geophys 2019:1–8
Bachmann O, Schnyder C (2006) The pre-Kos plateau tuff volcanic rocks on Kefalos peninsula (Kos Island, Dodecanese, Greece): crescendo to the largest eruption of the modern Aegean Arc, Trans. Am. Geophys. Union 87(52), Fall Meet. Suppl., Abstract V33C-0680
Bachmann O, Schoene B, Schnyder C, Spikings R (2010) The 40Ar/39Ar and U/Pb dating of young rhyolites in the Kos-Nisyros volcanic complex, eastern Aegean arc, Greece: age discordance due to excess 40Ar in biotite. Geochem Geophys Geosys 11(8):Q0AA08. https://doi.org/10.1029/2010gc003073
Balakrishnama S, Ganapathiraju A (1998) Linear discriminant analysis-a brief tutorial. Ins Sig Inf Process 18:1–8
Bardenet R, Brendel M, Kégl B, Sebag M (2013) Collaborative hyperparameter tuning. In international conference on machine learning. PMLR, pp 199–207
Bergstra J, Bengio Y (2012) Random search for hyper-parameter optimization. J Mach Learn Res 13:281–305
Bohla M (1986) Vulkanologische untersuchung der jungen pyroklastite auf Tilos (dodekanes, greichenland) (PhD thesis). Diploma Thesis. University of Freiburg, Germany
Bolton MS, Jensen BJ, Wallace K, Praet N, Fortin D, Kaufman D, De Batist M (2020) Machine learning classifiers for attributing tephra to source volcanoes: an evaluation of methods for Alaska tephras. J Quat Sci 35:81–92
Box GE, Cox DR (1964) An analysis of transformations. J Roy Stat Soc B Met 26:211–243
Breiman L (2001) Random forests. Mach Learn 45:5–32
Buettner A, Kleinhanns IC, Rufer D, Hunziker JC, Villa IM (2005) Magma generation at the easternmost section of the Hellenic arc: Hf, Nd, Pb and Sr isotope geochemistry of Nisyros and Yali volcanoes (Greece). Lithos 83(1–2):29–46
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) SMOTE: synthetic minority over-sampling technique. JArtif Intell Res 16:321–357
Chen T, Guestrin C, (2016) XGBoost. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining; San Francisco, California. USA: Association for Computing Machinery, pp 785–794
Claesen M, Simm J, Popovic D, Moreau Y, De Moor B (2014) Easy hyperparameter search using optunity. arXiv preprint arXiv:1412.1114
Cohen J (1960) A coefficient of agreement for nominal scales. Educ Psychol Meas 20:37–46
Corbi F, Sandri L, Bedford J, Funiciello F, Brizzi S, Rosenau M, Lallemand S (2019) Machine learning can predict the timing and size of analog earthquakes. Geophys Res Lett 46(3):1303–1311
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–297
Dalabakis P, Vougioukalakis G (1993) The Kefalos tuff ring (W. Kos): depositional mechanisms, vent position and model of the evolution of the eruptive activity. Bull Geol Soc Greece 28:259–273
D'Antonio M, Mariconte R, Arienzo I, Mazzeo FC, Carandente A, Perugini D, Petrelli M, Corselli C, Orsi G, Principato MS, Civetta L (2016) Combined Sr-Nd isotopic and geochemical fingerprinting as a tool for identifying tephra layers: application to deep-sea cores from eastern Mediterranean Sea. Chem Geol 443:121–136
DeVries PM, Viégas F, Wattenberg M, Meade BJ (2018) Deep learning of aftershock patterns following large earthquakes. Nature 560(7720):632–634
Dietterich TG (2000) Ensemble methods in machine learning. In: International workshop on multiple classifier systems. Springer, Berlin, Heidelberg, pp 1–15
Druitt TH, Edwards L, Mellors RM, Pyle DM, Sparks RSJ, Lanphere M, Davies M, Barreirio B, (1999) Santorini Volcano. Geol Soc Lond Mem 19:1–176
Druitt TH, Pyle DM, Mather TA (2019) Santorini volcano and its plumbing system. Elements 15(3):177–184
Elburg MA, Smet I (2020) Geochemistry of lavas from Aegina and Poros (Aegean arc, Greece): distinguishing upper crustal contamination and source contamination in the Saronic gulf area. Lithos 358:105416
Francalanci L, Varekamp JC, Vougioukalakis GE, Defant MJ, Innocenti F, Manetti P (1995) Crystal retention, fractionation, and crustal assimilation in a convecting magma chamber, Nisyros volcano. Greece. Bull. Volcanol. 56:601–620
Francalanci L, Vougioukalakis G, Fytikas M, Beccaluva L, Bianchini G, Wilson M (2007) Petrology and volcanology of Kimolos and Polyegos volcanoes within the context of the South Aegean arc. Greece Spec Pap Geol Soc Am 418:33
Francalanci L, Vougioukalakis GE, Perini G, Manetti P (2005) A west-east traverse along the magmatism of the South Aegean volcanic arc in the light of volcanological, chemical and isotope data. In: Fytikas M, Vougioukalakis GE (eds) Developments in volcanology: the South Aegean active volcanic arc, present knowledge and future perspectives, vol 7. Elsevier, Amsterdam, pp 65–111
Francalanci L, Zellmer GF (2019) Magma genesis at the South Aegean volcanic arc. Elements: Int Mag Min Geochem Petrol 15:165–170
Fytikas M, Innocenti F, Kolios N, Manetti P, Mazzuoli R, Poli G, Rita F, Villari L (1986) Volcanology and petrology of volcanic products from the island of Milos and neighbouring islets. J VolcanolGeotherm Res 28(3–4):297–317
Fytikas M, Innocenti F, Manetti P, Peccerillo A, Mazzuoli R, Villari L (1984) Tertiary to quaternary evolution of volcanism in the Aegean region. Geol Soc Lond, Spec Publ 17:687–699. https://doi.org/10.1144/GSL.SP.1984.017.01.55
Fytikas M, Vougioukalakis G (2005) The South Aegean active volcanic arc: present knowledge and future perspectives. Developments in Volcanology 7, Elsevier, p 381
Gardner MW, Dorling SR (1998) Artificial neural networks (the multilayer perceptron)—a review of applications in the atmospheric sciences. Atmos Environ 32(14–15):2627–2636
Garreta R, Moncecchi G (2013) Learning scikit-learn: machine learning in python. Packt Publishing Ltd., Birmingham, p 103
Gençalioğlu-Kuşcu G, Uslular G (2018) Geochemical characterization of mid-distal Nisyros tephra on Datça peninsula (southwestern Anatolia). J Volcanol Geotherm Res 354:13–28
Gençalioğlu-Kuşcu G, Uslular G, Danišik M, Koppers A, Miggins DP, Friedrichs B, Schmitt AK (2020) U–Th disequilibrium, (U–Th)/he and 40Ar/39Ar geochronology of distal Nisyros Kyra tephra deposits on Datça peninsula (SW Anatolia). Quat. Geochron. 55:101033
Guichard F, Carey S, Arthur MA, Sigurdsson H, Arnold M (1993) Tephra from the Minoan eruption of Santorini in sediments of the Black Sea. Nature 363(6430):610–612
Guillong M, Sliwinski JT, Schmitt A, Forni F, Bachmann O (2016) U-Th zircon dating by laser ablation single collector inductively coupled plasma-mass spectrometry (LA-ICP-MS). Geostand Geoanal Res 40(3):377–387
Guillong MV, von Quadt A, Sakata S, Peytcheva I, Bachmann O (2014) LA-ICP-MS Pb–U dating of young zircons from the Kos–Nisyros volcanic Centre, SE Aegean arc. J Anal Atom Spectrom 29(6):963–970
Hamann Y, Wulf S, Ersoy O, Ehrmann W, Aydar E, Schmiedl G (2010) First evidence of a distal early Holocene ash layer in eastern Mediterranean deep-sea sediments derived from the Anatolian volcanic province. Quat Res 73(3):497–506
Hannappel A, Reischmann T (2005) Rhyolitic dykes of Paros Island, Cyclades. In: Fytikas M, Vougioukalakis GE (eds) The South Aegean Active Arc: Present Knowledge and Future Perspectives, Elsevier, Amsterdam, pp 305–328
Hulbert C, Rouet-Leduc B, Johnson PA, Ren CX, Rivière J, Bolton DC, Marone C (2019) Similarity of fast and slow earthquakes illuminated by machine learning. Nat Geosci 12(1):69–74
Innocenti F, Kolios N, Manetti P, Rita F, Villari L (1982) Acid and basic late Neogene volcanism in Central Aegean Sea: its nature and geotectonic significance. Bull Volcanol 45(2):87–97
Izenman AJ (2013) Linear Discriminant Analysis. In: Linear discriminant analysis. In modern multivariate statistical techniques (pp. 237–280). Springer, New York, NY
Jongsma D (1977) Bathymetry and shallow structure of the Pliny and Strabo trenches, south of the Hellenic Arc. Geol Soc Am Bull 88(6):797–805
Ke G, Meng Q, Finley T, Wang T, Chen W, Ma W, Ye Q, Liu T-Y (2017) LightGBM: a highly efficient gradient boosting decision tree. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R (eds) Advances in neural information processing systems 30. Curran Associates, Inc., pp 3146–3154
Keller J, Rehren TH, Stadlbauer E (1990) Explosive volcanism in the Hellenic Arc: a summary and review. In: Hardy DA, Keller J, Galanopoulos VP, Flemming NC, Druitt DH (eds) Thera and the Aegean World III, Earth Sciences, vol. 2, The Thera Foundation, London, pp 13–26
Klaver M, Davies GR, Vroon PZ (2016) Subslab mantle of African provenance infiltrating the Aegean mantle wedge. Geology 44(5):367–370
Korkmaz T, Ön ZB, Akçer-Ön S (2018) Preliminary results on tephrochronological record of Lake Acıgöl. VIII. In: Quaternary symposium of Turkey, 2-5 May. İstanbul Technical University, İstanbul, Turkey, p 84. Abstract book
Koutrouli A, Anastasakis G, Kontakiotis G, Ballengee S, Kuehn S, Pe-Piper G, Piper DJW (2018) The early to mid-Holocene marine tephrostratigraphic record in the Nisyros-Yali-Kos volcanic center, SE Aegean Sea. J Volcanol Geotherm Res 366:96–111
Kramer O (2016) Scikit-Learn. Study Big Data 20:45–53
Kuhn M, Wing J, Weston S, Williams A, Keefer C, Engelhardt A, Cooper T, Mayer Z, Kenkel B, Team RC et al (2020) Package ‘caret’. R J. 2020. Available online: http://cran.r-project.org/web/packages/caret/ caret.pdf
Laaksonen J, Oja E (1996) Classification with learning k-nearest neighbors. In: Proceedings of international conference on neural networks (ICNN'96), IEEE International Conference, Vol. 3, pp 1480–1483
Li CH, Lin CT, Kuo BC, Ho HH (2010) An automatic method for selecting the parameter of the normalized kernel function to support vector machines. International Conference on Technologies and Applications of Artificial Intelligence (TAAI), IEEE, pp 226–232
Lowe DJ (2011) Tephrochronology and its application: a review. Quat. Geochron. 6(2):107–153
Lowe DJ, Hunt JB (2001) A summary of terminology used in tephra-related studies. In: Juvigne, E.T.; Raynal, J-P. (Eds), “Tephras: chronology, archaeology”, CDERAD editeur, Goudet. Les Dossiers de l’Archeo-Logis 1:17–22
Lowe DJ, Pearce NJ, Jorgensen MA, Kuehn SC, Tryon CA, Hayward CL (2017) Correlating tephras and cryptotephras using glass compositional analyses and numerical and statistical methods: review and evaluation. Quat Sci Rev 175:1–44
Lowe JJ, Ramsey CB, Housley RA, Lane CS, Tomlinson EL, Associates R, Team R et al (2015) The RESET project: constructing a European tephra lattice for refined synchronisation of environmental and archaeological events during the last c. 100 ka. Quat Sci Rev 118:1–17
Lundberg SM, Lee SI (2017) A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems 30:4768–4777. http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions.pdf
Morris A (2000) Magnetic fabric and palaeomagnetic analyses of the Plio–quaternary calc-alkaline series of Aegina Island, South Aegean volcanic arc. Greece Earth Planet Sci Lett 176:91–105
Ouzounis AG, Papakostas GA (2021) Machine learning in discriminating active volcanoes of the Hellenic volcanic arc. Appl Sci 11(18):8318
Paper, D (2020) Scikit-learn classifier tuning from simple training sets. In: Hands-On Scikit-Learn for Machine Learning Applications; Apress: Berkeley, pp 137–163
Park Y, Mousavi SM, Zhu W, Ellsworth WL, Beroza GC (2020) Machine-learning-based analysis of the Guy-Greenbrier, Arkansas earthquakes: A tale of two sequences. Geophys Res Lett 47(6):e2020GL087032
Parks MM, Biggs J, England P, Mather TA, Nomikou P, Palamartchouk K, Papanikolaou X, Paradissis D, Parsons B, Pyle DM, Raptakis C, Zacharis V (2012) Evolution of Santorini volcano dominated by episodic and rapid fluxes of melt from depth. Nat Geosci 5:749–754
Pe G (1973) Petrology and geochemistry of volcanic rocks of Aegina. Greece Bull Volcanol 37:491–514
Pearce NJ, Eastwood WJ, Westgate JA, Perkins WT (2002) Trace-element composition of single glass shards in distal Minoan tephra from SW Turkey. J Geol Soc 159(5):545–556
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E (2011) Scikit-learn: machine learning in Python. J Mach Learn Res 12:2825–2830
Pe-Piper G, Piper D, Reynolds P (1983) Paleomagnetic stratigraphy and radiometric dating of the Pliocene volcanic rocks of Aegina. Greece Bull Volcanol 46:1–7
Pe-Piper G, Piper DJ (2013) The effect of changing regional tectonics on an arc volcano: Methana. Greece J Volcanol Geotherm Res 260:146–163
Pe-Piper G, Piper DJW (2005) The South Aegean active volcanic arc: relationships between magmatism and tectonics. In: Fytikas M, Vougioukalakis GE (eds) Developments in volcanology: the South Aegean active volcanic arc, present knowledge and future perspectives, vol 7. Elsevier, Amsterdam, pp 113–133
Petrelli M, Bizzarri R, Morgavi D, Baldanza A, Perugini D (2017) Combining machine learning techniques, microanalyses and large geochemical datasets for tephrochronological studies in complex volcanic areas: new age constraints for the Pleistocene magmatism of Central Italy. Quat Geochron 40:33–44
Petrelli M, Caricchi L, Perugini D (2020) Machine Learning Thermo-Barometry: Application to Clinopyroxene-Bearing Magmas. J Geophys Res Solid Earth 125(9):e2020JB020130
Petrelli M, Perugini D (2016) Solving petrological problems through machine learning: the study case of tectonic discrimination using geochemical and isotopic data. Contrib Min Pet 171(10):1–15
Pignatelli A, Piochi M (2021) Machine learning applied to rock geochemistry for predictive outcomes: the Neapolitan volcanic history case. J Volcanol Geotherm Res 415:107254
Popa RG, Bachmann O, Ellis BS, Degruyter W, Tollan P, Kyriakopoulos K (2019) A connection between magma chamber processes and eruptive styles revealed at Nisyros-Yali volcano (Greece). J Volcanol Geotherm Res 387:106666
Popa RG, Dietrich VJ, Bachmann O (2020) Effusive-explosive transitions of water-undersaturated magmas. The case study of Methana Volcano, South Aegean Arc. J Volcanol Geotherm Res 399:106884
Prokhorenkova L, Gusev G, Vorobev A, Dorogush AV, Gulin A (2018) CatBoost: unbiased boosting with categorical features. Advances in Neural Information Processing Systems (2018), pp 6637–6647
Rehren TH (1988) Geochemie und Petrologie von Nisyros (Ofstliche Agais). Ph.D. thesis, Dep. of Geol., Univ. of Freiburg, Freiburg, Germany
Ren CX, Peltier A, Ferrazzini V, Rouet-Leduc B, Johnson PA, Brenguier F (2020) Machine learning reveals the seismic signature of eruptive behavior at Piton de la Fournaise volcano. Geophys Res Lett 47(3):e2019GL085523
Rennie JD, Shih L, Teevan J, Karger DR (2003) Karger Tackling the poor assumptions of Naive Bayes text classifiers, Proc. Twent. Int. Conf. Mach. Learn. ICML, pp 616–623
Sarbas B (2008) The GEOROC database as part of a growing geoinformatics network. In: BradySR et al (eds) Geoinformatics 2008—Data to knowledge, proceedings: U.S. Geological Survey Scientific Investigations Report 2008–5172, pp 42–43
Sarna-Wojcicki A (2000) Tephrochronology. In: Noller JS, Sowers JM, Lettis WR, William R (eds) Quaternary geochronology: methods and applications, AGU reference shelf, vol 4, pp 357–377
Satow C, Tomlinson EL, Grant KM, Albert PG, Smith VC, Manning CJ, Ottolini L, Wulf S, Rohling EJ, Lowe JJ, Blockley SPE, Menzies MA (2015) A new contribution to the Late Quaternary tephrostratigraphy of the Mediterranean: Aegean Sea core LC21. Quat Sci Rev 117:96–112
Smith PE, York D, Chen Y, Evansen NM (1996) Single crystal 40Ar–39Ar dating of Late Quaternary paroxysm on Kos, Greece: concordance of terrestrial and marine ages. Geophys Res Lett 23:3047–3050
Sterba JH, Steinhauser G, Bichler M (2011) On the geochemistry of the Kyra eruption sequence of Nisyros volcano on Nisyros and Tilos. Greece Appl Radiat Isotopes 69(11):1605–1612
Stewart AL, McPhie J (2006) Facies architecture and late Pliocene–Pleistocene evolution of a felsic volcanic island, Milos. Greece. Bull. Volcanol. 68:703–726
Sulpizio R, Alçiçek MC, Zanchetta G, Solari L (2013) Recognition of the Minoan tephra in the Acigöl Basin, western Turkey: implications for inter-archive correlations and fine ash dispersal. J Quat Sci 28:329–335
Tomlinson EL, Smith VC, Albert PG, Aydar E, Civetta L, Cioni R, Çubukçu E, Gertisser R, Isaia R, Menzies MA, Orsi G, Rosi M, Zanchetta G (2015) The major and trace element glass compositions of the productive Mediterranean volcanic sources: tools for correlating distal tephra layers in and around Europe. Quat Sci Rev 118:48–66
Turney C, Lowe J (2001) Tephrochronology. In: Last WM, Smol JP (eds) Tracking Environmental Changes in Lake Sediments: Physical and Chemical Techniques, Kluwer Academic, Dordrecht (2001), pp 451–471
Uieda L, Tian D, Leong WJ, Toney L, Schlitzer W, Grund M, Newton D, Ziebarth M, Jones M, Wessel P (2021) PyGMT: A Python interface for the Generic Mapping Tools (version v0.4.0), Zenodo. https://doi.org/10.5281/zenodo.4978645
Vakhrameeva P, Koutsodendris A, Wulf S, Fletcher WJ, Appelt O, Knipping M, Gertisser R, Trieloff M, Pross J (2018) The cryptotephra record of the marine isotope stage 12 to 10 interval (460–335 ka) at Tenaghi Philippon, Greece: exploring chronological markers for the middle Pleistocene of the Mediterranean region. Quat Sci Rev 200:313–333
Vakhrameeva P, Koutsodendris A, Wulf S, Portnyagin M, Appelt O, Ludwig T, Trieloff M, Pross J (2021) Land-sea correlations in the eastern Mediterranean region over the past c. 800 kyr based on macro-and cryptotephras from ODP site 964 (Ionian Basin). Quat Sci Rev 255:106811
Valetich MJ, Le Losq C, Arculus RJ, Umino S, Mavrogenes J (2021) Compositions and classification of fractionated boninite series melts from the Izu–Bonin–Mariana arc: a machine learning approach. J Petrol 62(2):egab013
Van Hinsbergen D, Snel E, Garstman S, Mărunţeanu M, Langereis C, Wortel M, Meulenkamp J (2004) Vertical motions in the Aegean volcanic arc: evidence for rapid subsidence preceding volcanic activity on Milos and Aegina. Mar Geol 209:329–345
Vanderkluysen L, Volentik A, Hernandez J, Hunziker JC, Bussy F, Principe C (2005) The petrology and geochemistry of lavas and tephras of Nisyros volcano (Greece). In: Hunziker JC, Marini L (eds) The geology, geochemistry and evolution of Nisyros volcano (Greece), Implications for the volcanic hazards, vol 44. Lausanne, Mémoires de Géologie, pp 79–99
Vespa M, Keller J, Gertisser R (2006) Interplinian explosive activity of Santorini volcano (Greece) during the past 150,000 years. J Volcanol Geotherm Res 153(3–4):262–286
Volentik A, Vanderkluysen L, Principe C, Hunziker JC (2005) Stratigraphy of Nisyros volcano, (Greece). In: Hunziker JC, Marini L (eds) The geology, geochemistry and evolution of Nisyros volcano (Greece), Implications for the volcanic hazards, vol 44. Lausanne, Mémoires de Géologie, pp 26–66
Vougioukalakis GE, Satow CG, Druitt TH (2019) Volcanism of the South Aegean volcanic arc. Elements: An International Magazine of Mineralogy, Geochemistry, and Petrology 15(3):159–164
Watson LM (2020) Using unsupervised machine learning to identify changes in eruptive behavior at Mount Etna. Italy J Volcanol Geotherm Res 405:107042
Witsil AJ, Johnson JB (2020a) Analyzing continuous infrasound from Stromboli volcano, Italy using unsupervised machine learning. Comput Geosci 140:104494
Witsil AJ, Johnson JB (2020b) Volcano video data characterized and classified using computer vision and machine learning algorithms. Geosci Front 11(5):1789–1803
Wulf S, Hardiman MJ, Staff RA, Koutsodendris A, Appelt O, Blockley SP, Lowe JJ, Manning CJ, Ottolini L, Schmitt AK, Smith VC, Tomlinson EL, Vakhrameeva P, Knipping M, Kotthoff U, Milner AM, Müller UC, Christanis K, Pross J (2018) The marine isotope stage 1–5 cryptotephra record of Tenaghi Philippon, Greece: towards a detailed tephrostratigraphic framework for the eastern Mediterranean region. Quat Sci Rev 186:236–262
Wulf S, Kraml M, Kuhn T, Schwarz M, Inthorn M, Keller J, Kuscu I, Halbach P (2002) Marine tephra from the cape Riva eruption (22 ka) of Santorini in the sea of Marmara. Mar Geol 183:131–141
Zhou X, Kuiper K, Wijbrans J, Boehm K, Vroon P (2021) Eruptive history and 40Ar/39Ar geochronology of the Milos volcanic field, Greece. Geochronology 3(1):273–297
Acknowledgments
We would like to thank the GEOROC database (Sarbas 2008) to provide a comprehensive and open-access database for the community. We also greatly acknowledge the valuable comments by the editor Hassan A. Babaie and the anonymous reviewers.
Author information
Authors and Affiliations
Contributions
Uslular G.: Conceptualization, Methodology, Implementing ML algorithms, Writing-Original Draft. Kıyıkçı, F.: Methodology, Writing Code, Implementing ML algorithms. Karaarslan, E.: Supervision, Review&Editing. Gençalioğlu-Kuşcu, G.: Supervision, Review&Editing.
Corresponding author
Ethics declarations
Ethics Approval
Not applicable.
Additional information
Communicated by: H. Babaie
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary Data S1
The whole-rock and glass geochemistry dataset of the SAAVA volcanics (together with the descriptive statistics of each volcanic field) used for the machine-learning application (XLSX 326 kb)
Supplementary Data S2
The prediction results of the test and control data based on the different algorithms that have relatively higher accuracy results (XLSX 152 kb)
Rights and permissions
About this article

Cite this article
Uslular, G., Kıyıkçı, F., Karaarslan, E. et al. Application of machine-learning algorithms for tephrochronology: a case study of Plio-Quaternary volcanic fields in the South Aegean Active Volcanic Arc. Earth Sci Inform 15, 1167–1182 (2022). https://doi.org/10.1007/s12145-022-00797-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-022-00797-5