
Abstract
Land subsidence is mainly caused by excessive groundwater abstraction from aquifers. This study introduces Dynamic Subsidence Vulnerability Index (DSVI) by estimating possible land subsidence time variations by considering changes in groundwater level based on the ALPRIFT framework in Iran’s Hadishahr Plain, which is summarized in three modules. (i) Module I: mapping Subsidence Vulnerability Index (SVI) utilizing the ALPRIFT framework and optimization its weights by the Multiple Artificial Intelligence Models (MAIM) strategy; (ii) Module II: predicting groundwater level by Group Method of Data Handling (GMDH); and Module III: mapping DSVI by combining the results from Modules I and II. A two-pronged strategy is employed in MAIM: In Level 1, multiple models are derived from Sugeno Fuzzy Logic (SFL) and Support Vector Machin (SVM); and in Level 2, the outcomes of Level 1 models are combined by Artificial Neural Networks (ANN). According to the results: (i) ALPRIFT exhibits a correlation coefficient (r) of about 0.55 with corresponding measurements of land subsidence; (ii) using SVM and SFL to optimize the weights, r is raised to 0.83 and 0.74, respectively; (iii) the use of multiple models at Level 2 results in better performance than that of a single model at Level 1; and (iv) on the DSVI map, the central part of the plain is vulnerable at hotspot areas where groundwater is being improperly withdrawn from the Hadishahr Plain aquifer, increasing the risk of subsidence.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
A novel approach for mapping Subsidence Vulnerability Indices (SVIs) is developed by Nadiri et al. (2018). Three modules are used in this study to evaluate ALPRIFT’s usefulness for studying land subsidence in plains with sparse data.: Module I maps SVI using Multiple Artificial Intelligence Models (MAIM); Module II predicts groundwater levels (GWLs) based on Group Method of Data Handling (GMDH)- type neural networks; and subsidence evolution in Module III is based on the combined results from Modules I and II. There are seven data layers including Aquifer media (A), Land use (L), Pumping of groundwater (P), Recharge (R), Impacts induced by aquifer thickness (I), Fault distance (F) and water Table decline (T) in ALPRIFT framework, some of which are time-variant, while others are time-invariant. A novel aspect of this research is introducing Dynamic SVI (DSVI) mapping problems in order to enhance the accuracy of mapping. The three T, P, and R data layers could be changing during next 10-20 years or so. Based on the available data for study area, there is not enough evidence for variations in R; the P values for agricultural activities from the 1990 s are sparse; nevertheless, this layer plays an important role for DSVI mapping because it affects T values.
As an anthropogenic hazard, land subsidence has become a major environmental issue all around the world (Galloway et al. 1999; Hayashi et al. 2009; Saatsaz et al. 2013; Ye et al. 2015; Jafari et al. 2016; Nadiri et al. 2018; Rahmani et al. 2019; Malmir et al. 2021; Gharekhani et al. 2021). Land subsidence can result in the collapse of withdrawal wells, the need to divert rivers because of changes in elevation, and the damage to foundations, drainage systems, transportation networks, and underground pipelines caused by land subsidence (Kihm et al. 2007). In spite of extensive research on land subsidence, there are few studies on land subsidence triggered by over abstraction as an anthropogenic phenomenon. (Anumba and Scott 2001; Wang et al. 2018). These studies are also fragmented as land subsidence occurs in response to several causes such as: (i) the abstraction of groundwater, as happened in Thailand and Spain (Lorphensri et al. 2011); (ii) degrading organic soils, e.g. Venice, Italy (Tosi et al. 2013); (iii) dissolving limestone by karstification, e.g. Tampa in Florida (Beck 1986); (iv) extracting fossil fuel resources from underground reservoirs, e.g. Wilmington oil reservoir, California (Colazas and Strehle, 1995); (v) mining at subsurface, e.g. Bethlehem Mines Corporation in central Pennsylvania (Sossong, 1973); and (vi) meeting increased water demand from household, industry and agriculture.
Geogenic and anthropogenic activities inducing land subsidence can be categorized as follows: (i) variations in the thickness of compressible alluvium and distance from faults, as a result of geogenic activities (Avila-Olivera and Garduño-Monroy, 2008; Gu et al. 2018); and (ii) changes in land use caused by increasing groundwater abstraction because of anthropogenic activities (Galloway and Burbey 2011). Subsidence is controlled by one or more dimensions in each process which is effective in subsidence. In the state of the art, there are diverse techniques for different fields of study with no common concepts to bridge the gap; this is a flaw for SVI mapping, outlined below.
As a result of the lack of cross-cutting techniques, researchers used various methods to study and monitor subsidence and settlement, including field evidence and historical data (Psimoulis et al. 2007); (Interferometric Synthetic Aperture Radar (InSAR) (Ciampalini et al. 2019); Ground-Penetrating Radar (GPR) (Avila-Olivera and Garduño-Monroy 2008); Global Positioning System (GPS) (Sato et al. 2007). ALPRIFT, proposed by Nadiri et al. (2018), is also applicable for evaluating subsidence events triggered by both geogenic and anthropogenic processes. In this scoring system, the rate serves as a proxy for local variation, and the weight serves as a proxy for the importance of the underlying layer. As such, the scoring system is inherently subjective; however, a MAIM strategy is employed to minimize the level of subjectivity.
Previous studies on land subsidence using ALPRIFT have focused on reducing inherent subjectivities (e.g. Nadiri et al. 2018; Sadeghfam et al. 2020a) and indexing vulnerability into risk (e.g. Sadeghfam et al. 2020a, b). This research shows how MAIM practices can reduce subjectivity and integrate DSVI problems. In order to reduce subjectivity, modeling strategies have been developed; however, they are wide in choice without achieving any meaningful results. The MAIM modelling strategy used by the paper is an identical two levels of modeling as follows: at Level 1, multiple models are included Sugeno FL (SFL), and Support Vector Machine (SVM); (ii) at Level 2, the models at Level 1 are combined by Artificial Neural Networks (ANN); and (iii) each model involves learning from an appropriate set of target values.
The paper highlights a set of novelties as follows: (i) dynamic vulnerability mapping by developing DSVI; (ii) formulating a three module strategy, in which Module I for SVI mapping employ MAIM practices and Module II for a predictive groundwater model employ Group Method of Data Handling (GMDH)-type neural networks. The formulated modelling strategy is applied in the Hadishahr Plain, a region in northwest Iran that is part of the East Azerbaijan province. The following reasons reveal the necessity for identifying hotspots in the study area: (i) East Azerbaijan’s GWL has dropped by more than 4 m at a rate of 31 cm/year on average for the past 14 years (from 2004 to 2018) based on the East Azerbaijan Regional Water Authority (ERWA) reports. (ii) This region has had a strong agricultural economy, but it has also undertaken changes without any management plan since the availability of abstraction wells in 2000, resulting in an over-extraction of aquifer. The Hadishahr Plain is one of the sub-basins of the Aras river basin with extensive groundwater storage, all of which are declining.
Study area
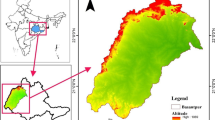
The study area extends over 55.5 km2 (Fig. 1) and contains Hadishahr Plain in East Azerbaijan province. The aquifer lies in the Dareh Diz basin, which lies south of the Kiamaki Mountain and drains to the Aras River. The main tributaries of Dareh Diz include Livarjan and Gargar rivers. As of 1986-2017, the mean annual precipitation and temperature are 192.1 mm and 14.2 °C, respectively, based on data from Jolfa Synoptic Station.

Geological and geographic location of Hadishahr sub-basin
(Hydro)geological setting of the study area
Hadishahr Plain (see Fig. 1) is mainly covered with alluvium made up of sand, silt and clay, causing subsidence in an over-extraction region. Different geological formations are detected in the basin. The regional igneous rocks as the oldest rock (Devonian) located in the southern part and Red sandstone, marl limestone and red shale formation mostly occurred in the Permian period, and associated with dolomite and limestone formations (Triassic) located in the southern and western parts. Most of the area’s southeast is covered by conglomerate (Eocene) and sandstone (Jurassic) formations, while the region’s north is covered by Quaternary alluvium.
Due to the northwest-southeast faults running along the southern part of the region, the Triassic and Eocene deposits are driven on separate units in this part of the region. Additionally, in this part of the region Paleozoic deposits were exposed in the fault direction that formed the Qaragoz-Divandaghi Mountains, as well as several long terraces in the southeast. The faults in the area include the Hadishahr fault along the direction of northwest to southeast and it is covered by bedded dolomite in the surface.
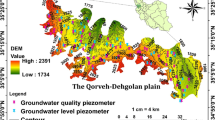
Hadishahr aquifer is an unconfined type, and it has ten observation wells (OWs), which allow GWLs to be monitored continuously. Figure 1 illustrates the distribution of their locations across the plain. As a result of high withdrawal rates around Hadishahr city because of the agricultural and drinking water demands, this region produces the highest cone of depression. According to the records in the Hadishahr observation wells, GWLs have declined at a rate of roughly 31 cm/year (between 2004 and 2018). The thicknesses of alluvium in the plain are often low at the margins, but become greater towards its middle. Thus, the thickest deposition is typically found in the middle and western parts. The groundwater in the aquifer is extracted from 65 withdrawal wells, 10 natural springs, and 38 qanats.
Land use
With a population of 34 thousand, Hadishahr is the largest city in the study area. In this region, agricultural activity is the main economic activity, due to its fertile soil. The next section discusses the classification of land use.
Materials and methods
Figure 2 presents the flowchart of the developed methodology and some details of the three modules. Module I includes mapping SVI for Hadishahr Plain by applying a strategy at two Levels based on the ALPRIFT framework and constricting a model for predicting water table at a specified time in Module II. Finally, Module III presents the evolution maps of SVI during next years by combining the results from Modules I and II. Notably, the Multiple Artificial Intelligence Modelling (MAIM) strategy is constructed at two levels. Multiple models, such as Sugeno FL (SFL) and Support Vector Machin (SVM), are used at the first level in order to optimize the weights of ALPRIFT, and at the second level, the models at Level 1 are combined using the GMDH algorithm.

The flowchart of methodology used in this study
Module description
Module I
The modelling strategy for Module I is presented in Fig. 2 and the various models/algorithms used by the module are outlined below.
Basic ALPRIFT Framework (BAF)
ALPRIFT was developed to calculate Subsidence Vulnerability Indices (SVIs) within the context of any aquifer or plain system (Nadiri et al. 2018). The framework brings together seven data layers and processes them through a scoring and weighting system. The data layers comprise: Aquifer media (A), Land use (L), Pumping of groundwater (P), Recharge (R), Impacts induced by aquifer thickness (I), Fault distance (F) and water Table decline (T). Even though the variations in these layers are presumed to be independent of one another, correlative relationships between them should be expected. Thus, BAF (Basic ALPRIFT Framework -BAF) does not help in identifying in-built correlations in the data. It merely evaluates a set of predetermined values, resulting in subjectivity issue.
In order to estimate SVI by BAF, the following steps are taken: (i) Utilize the GIS tool to divide the study domain into grid cells (pixels); (ii) Array each pixel with seven corresponding raw data layers, each of which contains the prescribed value, as per raw data; (iii) assign rate values at each pixel to the raw values; (iv) and give each data layer a weighting value. SVI can be described as follows:
Where, a subscript ‘r’ denotes rate and a subscript ‘w’ refers to weight; SVI stands for Subsidence Vulnerability Index while ALPRIFT data layers are represented by uppercase acronyms. Data layers are based on weights and rates used by Nadiri et al. (2018).
An insight into ALPRIFT data layers
A single ALPRIFT data layer provides detailed information about soil texture and structure within a study area as a function of the physical characteristics of aquifer area. However, closer attention to the data layers shows that a set of them are time invariant and these comprise ALRIF which is intrinsic characteristics of study area for subsidence process. The P data layer, the time variability of which is driven by water abstraction due to anthropogenic activities and the T data layer, the time variability of which is driven by complex hydrogeological processes.
Using InSAR data
The study uses interferometric synthetic aperture radar (InSAR) technique and Sentinel-1 A images for the detection of land subsidence. The period under investigation is from April 2016 to April 2017. We have used two single look complex (SLC) Sentinel-1 images (interferometric wide mode) from ascending orbit 174 (2016.04.16 and 2017.04.16) to produce a deformation map of the region. Due to the short vegetation of the study area and semi-arid to arid climate of Iran, differential InSAR (DInSAR) analysis can produce acceptable deformation maps for land subsidence (An example of simple DInSAR for long temporal baselines are given in http://utie.ir/en/2019/11/07/land-deformation-maps-in-tehran-detected-by-synthetic-aperture-radar-sar-interferometry/). We can obtain further information about the subsidence behavior of land by incorporating further analyses, such as SBAS (small baseline subset) or PS-InSAR (permanent scatterer); however, there is less uncertainty inherent in such approaches. The required procedures to InSAR processing include as follows: coregistration; forming an interferogram and estimating coherence; topographic phase removal; phase filtering; phase unwrapping; terrain correction; taking line-of-sight displacement and converting it to vertical distance and absolute distance. Further information about these procedures is available by Hanssen (2001).
The measured subsidence by InSAR data used to condition the SVI, as:
Where, CSVI represents Conditioned SVI at pixel i; Si is subsidence at grid cell i (in cm), Smax denotes maximum of subsidence value; and Smin is minimum of subsidence value. It is noteworthy that the minimum and maximum SVI indices are 24 and 240, respectively.
Multiple Artificial Intelligence Models (MAIM)
A sufficient level of accuracy should be achieved in mapping SVIs for both Module I and Module II to be incorporated into an analysis of land subsidence variation in a plain. Nadiri et al. (2014) critique the use of advanced artificial intelligence modeling methods for constructing innovative models, but existing practices are criticized for accepting one from multiple models as “superior” and eliminating the rest. They proposed Multiple Artificial Intelligence Modeling (MAIM) approach so that many modelling strategies can be unified in order to improve accuracy through learning from multiple models. As per Nadiri et al. (2019); Khatibi et al. (2020), Khatibi and Nadiri (2021), models used through MAIM practices are defensible for enhancing their accuracy through strategies. To achieve defensible models, the strategies are needed and the paper uses the following procedure for Module I. The modelling strategy processes at different levels are as follows:
-
Level 1: Modules I construct multiple models using the following Sugeno Fuzzy Logic (SFL) (Nadiri et al. 2013; 2020) and Support Vector Machine (SVM) models (Nadiri et al. 2017a). The fuzzy sets theory assigns partial membership ranging from 0 to 1 to input and output data sets by selecting an appropriate \(Membership \ Functions \ (MF\)e.g. trapezoidal, Z-shape, S-shape, sigmoid, triangular, and Gaussian,). It is possible to extract membership functions and clustering functions from inputs utilizing clustering algorithms, like the Subtractive Clustering (SC) method (Chiu 1994; Li et al. 2001), which makes use of SFL modeling to eliminate redundant clustering and provide if-then rules. By using a trial-and-error method to select the radius of the ideal number of clusters and fuzzy if-then rules, the ideal cluster radius is determined. Clustering radius varies from 0 to 1, as does the number of rules, and it determines how many clusters there are in the SC method. Based on the ALPRIFT scoring system site data, SFL calculates the weight values using the SC method (Li et al. 2001). Support Vector Machine (SVM) is a highly-established kernel-based machine learning approach and the paper uses its regression capabilities. In the feature space, the kernel functions for prediction are derived by utilizing linear high dimensional hypothesis spaces. SVM in the paper further uses the Least-Squares method to learn the values of two of its training parameters (i.e. σ and γ).
-
Level 2: The Artificial Neural Network (ANN) is used to incorporate the models including SFL and SVM at Level 1. In other words, the ANN model as a combiner model reuses outputs of both models at Level 1 as its inputs at Level 2 for Module I. A class of ANN namely multilayer perceptron (MLP) network is used in this study which is made up of an input layer, one or more hidden layers, and one output layer. MAIM is expressed mathematically as follows:
Where, \({SVI}_{MI.1-SFL}\) and \({SVI}_{MI.1-SVM}\) are the output from Module I at Level 1 and both SFL and SVM are used in the sense of: “is a function of.” where, \({SVI}_{MI.2}\) is the output from Module I at Level 2 and ANN is used in the sense of: “is a function of.”
Module II
Module II is implemented to predict GWL using Group Method of Data Handling (GMDH)- type neural networks. It is one brand of implementing neural networks, developed by Ivakhnenko (1978), which uses Volterra-Kolmogorov-Gabor polynomial (Ivakhnenko 1968). Generally, GMDH can typically be applied for modeling complicated systems and its topography utilizes feed-forward connections between layers of neurons with similar spatial alignment arranged in pairs connected by quadratic polynomials, producing new neurons within the layer following. As part of GMDH, the direct relationship between multiple inputs and outputs is represented by a Volterra series, as follows (Ivakhnenko 1968):
Where, X = (x1, x2, …, xn) are the inputs data, \( \overset\frown{y}\) is the output of model and A = (a0, a1, …, an) are the values of polynomial coefficients. A polynomial of the second degree with two variables such as the Volterra series can be analyzed using Eq. 4.
Where, A = (a0, a1, …, an) are unknown coefficients in the Volterra series.These coefficients are estimated by the least squares method by using a set of input and output values. General steps required for implementation of GMDH-type neural networks are available in the literature, see for example: Ivakhnenko (1978); Farlow (1984); Hiashi and Tanaka (1990]) Kim and Park (2005); Ebtehaj et al. (2015) and Sfidari et al. (2018).
As shown in Fig. 1, the model structure employs time-series as an input variable. The lagged values of GWL selected by Non-dominated Sorting Genetic Algorithm-II (NSGA-II) that presented in Table 2. NSGA-II is a widely used multi-objective optimization algorithm that provides three advantages, including fast sorting that does not dominate, a fast comparison procedure, and an easy way to estimate the distance between two objects that are crowded. (Deb et al. 2002). An overview of NSGA-II can be summed up as follows: (i): Step 1: Establish a population and constraint based on the problem domain, ii) Sorting based on the initial population’s nondomination criteria, iii) As soon as the sorting is completed, the crowding distance value is allocated and ranking and crowding distance determine which individuals in the population are selected, iv) Binary tournament selection using a crowded comparison is used to select individuals, v) Using simulated binary crossovers and polynomial mutations for real-coded GA, vi) Combined with the current generation, the new generation is selected based on the offspring of the current generation. After selecting delay of input data, the GMDH is constructed which is expressed mathematically as follows:
Where, GWLGMDH is the output from the GMDH model; GWL t0-1 is GWL at the before one-time step at OWs; GWL t0-3 is GWL at the before three-time step at OWs and so on.
Module III
The results from Modules I and II are combined in Module III to produce DSVI maps. Module III use prediction of the water table for future time as a results of the prediction model at Module II to provide a map for a particular time, expressed as:
Where, DSVI is Dynamic Subsidence Vulnerability Index; SVI MI.2 is the output from Module I at Level 2; GWLMII is the output from Module II.
Dataset preparation
GWLs are monitored with 10 observation wells, and geological logs are recorded in 15 wells. Besides, there are 65 pumping wells in the Hadishahr palin. The data preparation processes and formulation by Basic ALPRIFT Framework are presented in detail by Nadiri et al. 2018, 2020. In this section, we will provide some details to ensure reproducibility.
Data layers for Module I
In detail, Nadiri et al. (2018) describe seven data layers in ALPRIFT, including best practices associated with them. A description of the data layers is provided in Fig. 2 and Appendix A (Table A1), as well as the sources of data.
Validation
In definition, a framework cannot be subjected to theory, empirical analysis or measurement. However, measuring performance with quantitative data should be carried out in order to set a quantitative basis for its evaluation. Using a local global positioning system (GPS) dataset can be used to measure subsidence as has been shown (Moiwo and Tao, 2015); however, GPS is unavailable due to financial limitations for the study area. Land subsidence can be assessed by using satellite images taken by remote sensing. In this research, satellite images are used to employ a technique designed to detect ground subsidence by using Interferometric Synthetic Aperture Radar (InSAR) images. InSAR results were obtained for April 2016 to April 2017 to meet this goal. The data processed from April 2016 to April 2017 illustrated maximum subsidence of 16 cm (Fig. 5c), with an accuracy of about 10 mm associated with deformation. In the absence of more info, this information indicates that the area is facing increased concerns about subsidence.
Training and testing data for Module I
A grid of 200 m × 200 m was generated from the ALPRIFT spatial models, thus discretizing the spatial data into 903 pixels. Each pixel is represented by a set of fields comprising 7 ALPRIFT data layers, a measured value, and one field for each modelled SVI value. There was no measurement for all of the pixels, so the Condition Subsidence Vulnerability Indices (CSVI) were applied according to Eq. 2. A total of 903 pixels were generated with CSVI values and are used during the training and testing stages of the model. Data for training and testing phases is divided randomly, where data points from 80% of the dataset are used for developing model in training stage and the remaining 20% are used for testing the developed model.
Data requirements for Module II
There are ten OWs in Hadishahr Plain. An available report from EARWA, Unknown (2018), reported 16 years (2002-2018) of recorded GWLs. In Fig. 3, the annual average of GWLs in ten OWs is shown from 2002 to 2018. 198 GWL values for each OW were used as raw data for this module. In terms of data sets, 80% of the GWL data was used for training, and 20% about testing.

Annually average of GWL in the Hadishahr Plain aquifer from 2002 to 2018
Performances creterion
Root Mean Squared Error (RMSE), coefficient of determination (R2), correlation coefficient (r) and Receiver Operating Characteristics (ROC) (Swets 1988) are used to measure the performance of the model. R2 and RMSE metrics determine the overall goodness-of-fit between the simulated and observed values. If the RMSE value is close to 0, then it means the prediction is more accurate. Coefficient of determination (\(-{\infty }\le {R}^{2}\le 1\)) is the proportion of variance explained by a model in the observation data. The high R2 values indicate that the predictions and the observed values agree better (Legates and McCabe 1999). The correlation coefficient range is between +1 and −1. Zero value represents no correlation, 1 value is a total positive correlation, and −1 is a total negative linear correlation.
Receiver Operating Characteristic (ROC) is an analysis tool based on the “Signal Detection Theory” and is used for spatial goodness-of-fit for correlation of two images. As measured by the Area Under Curve (AUC), the ROC curve accuracy represents the probability of correct diagnosis when the value is 1, however, when it is 0.5, it represents a strong correlation between two images.
Results
The results for Modules 1, 2 and 3 are presented in this section.
Module I results
Module I: ALPRIFT data layers
Each data layer are shown in Fig. 4 which indicates that they are largely independent of each other but some correlation between the data layers may be expected at individual pixels. These are the basis for formulating modelling strategies to learn inherent correlations.

Rated BAF data layers; (a) Aquifer media; (b) Land use; (c) Pumping of groundwater; (d) Recharge; (e) Impacts in terms of thickness; (f) Fault distance; (g) water Table decline, (h) predicted water Table decline
Module I: Basic ALPRIFT Framework (BAF)
The ALPRIFT data layers, shown in Fig. 3, are arranged in a geospatial database in ArcGIS software to index its spatial vulnerability by the Basic ALPRIFT Framework (BAF) using Eq. 1 through the procedure illustrated in Fig. 1. The level of SVI varies from 24 to 240, and its range can be categorized into four classes (class 1: 24-78, class 2: 78-132, class 3: 132-186, and class 4: 186-240). In Fig. 5a, rates and weights are mapped to SVI values from Nadiri et al. (2018). The SVI values range between 78 and 186 for Hadishahr Plain; According to the above-mentioned classifications, the percentage area of each class is as follows: class 1 — 0%; class 2 — 55.6%; class 3 — 44.4%; class 4 — 0%.

Subsidence mapping to identify hotspots: (a) BAF; (b) MAIM-ANN; (c) measured subsidence; (d) AUC/ROC performance metrics (BAF, MI.1-SFL, MI.1-SVM and MI.2-ANN)
BAF performances are measured by the comparison of its SVI values (Fig. 5a) with measured subsidence (Fig. 5c). Clearly, convergences and divergences between the results can be seen, which is to be expected. A statistical test at a 95% level demonstrates the significance of this performance metric, which is established by r for BAF of 0.55. The above findings are strikingly similar to those presented in the authors’ DRASTIC vulnerability index studies (Nadiri et al. 2017a, b, c) and in the BAF study (Nadiri et al. 2018). The MAIM strategy highlighted above thus proves to be a necessary tool for improving correlation values.
Module I - Level 1: Sugeno Fuzzy Logic (SFL) and Support Vector Machine (SVM)
Level 1 models (SFL and SVM) are created based on their clustering radii and the if-then rules they use, which are set as they increase from 0 to 1. Using the lowest RMSE as an indicator, a clustering radius of 0.9 was found to generate 27 ‘if-then’ rules. The SVM type of Least Square (SVM-LS) is used at Level 1. The model has two training parameters σ and γ, the values of which are presented in Table 1. Both SFL and SVM are compared using three metrics, r, R2 and RMSE, during both the training and testing phases, which indicate whether the results are fit-for-purpose.
Module I - Level 2: MAIM model combiner using Artificial Neural Networks (ANN)
ANN, the combiner model at Level 2, incorporates the outputs from SFL and SVM models at Level 1 as inputs, and uses CSVI as its target value. In the ANN model, the MLP structure is used in conjunction with the Levenberg–Marquardt (LM) training algorithm. In this structure, an input layer is composed of two neurons and an output layer is composed of one neuron. The hidden layer consists of four neurons. Neurons of the hidden layer use the tangent sigmoid (TANSIG) transfer function whereas those in the output layer use a linear PURELIN function. Following 1500 epochs, the RMSE is 0.085 based on the LM algorithm. The r value for MAIM-ANN prediction in the test step is 0.92.
In addition to its training and testing phases performance given in Table 1, MAIM-ANN’s mapping can also be seen in Fig. 5b. Based on the results obtained, a value increment of 0.37 was observed for the performance metrics, making the results of this study tenable. Figure 5b delineates the proportion of vulnerable of areas within each class (class 1 —70.9%; class 2 —12.6%; class 3 —11.8%; class 4 —4.2%; class 3 —0.5%).
Overview of Module I
With learning from Level 1 models, the paper aims not to rank models based on their performance but to increase accuracy at Level 2 by applying what was learned from Level 1. Nonetheless, better performance of MAIM-ANN against BAF and SFL and SVM is evident from Table 1. For instance, the r = 0.55 of BAF is enhanced to r = 0.92 by MAIM-ANN. The inter-comparison of the performance of BAF and MAIM-ANN in terms of ROC/AUC, are 0.871 and 0.893, respectively, which shows that the signal in BAF is quite strong in the first place but this is quite enhanced by MAIM-ANN.
Module II: GWL prediction
Based on the GMDH neural network, GWLs in the Hadishahr aquifer were predicted in the study. NSGA-II is applied for delay selection of input GWL data. The optimal delay selection for each OW is given in Table 2. Utilizing the GMDH-type neural network, 198 input–output datasets were employed for the development of a polynomial meta-model. GWLs at various lag times were considered as inputs and the GWL at t0 (present time) was predicted by GMDH neural networks. 80% of the data out of 198 input–output data pairs is used for training the model and the remaining 20% for testing the prediction abilities of GMDH-type neural networks.
The designed structure of the evolved 4-hidden layer GMDH-type neural network for OW1 is depicted in Fig. 6. The structure of GMDH model in other OWs is similar to OW1 but the inputs are different for each OW. The performance of GMDH model in both training and testing phases is presented in Table 3 for OW1- OW10 in terms of RMSE and R2 metrics. The results of GWL simulation using GMDH model show that the model has acceptable performance. Therefore, GMDH model was carried out to forecast the monthly GWL. In addition to the GWL, the decline in groundwater is calculated according to the forecast for the one-year period (from 2016 to 2017). A glance through Table 3 indicates that GMDH performs remarkably well at OW1 in terms of RMSE.

Structure of generalized GMDH neural network for OW1
Module III: mapping dynamic SV
Dynamic Subsidence Vulnerability Indices (DSVI) framework construct using the results of models at both Modules I and II. As per decision support system, the results of Modules I and II are combined for mapping DSVI (Fig. 7) in Module III. Therefore, in DSVI mapping, the decline in water table is predicted by simulating the results of the GMDH model of Module II in a future year (from 2017 to 2018), which is substituted in the procedure for Module I to render its DSVI map given in Fig. 7. This figure also gives the proportions of areas within each class (class 1 —40.1%; class 2 —37.5%; class 3 —11.3%; class 4 —8.6%; class 5 —2.4%). Evidently, for any period, the T data layer can be predicted and this can potentially serve as a tool to map out the evolution of land subsidence of a study area. The SVI maps in Fig. 8 show the SVI for 2008, 2013, 2018 (simulated), and 2023 (simulated). As the GWL in Hadishahr Plain has declined over the last 15 years, subsidence’s likelihood has increased.

Dynamic subsidence vulnerability mapping to identify hotspots in the future

Subsidence vulnerability mapping from 2008 to 2023 (The average water table decline in 2008, 2013, 2018 and 2023 years is 0.37, 0.39, 0.46 and 0.58 m, respectively)
Discussion
Using the research results, one can understand how land subsidence takes place as GWLs decline. In light of these results, the proof-of-concept can be considered valid. Subsidence of land in plains has been the focus of last year’s studies. There is a great deal of research on land subsidence and simulations of its effects (see, Chen et al. 2020; Nappo et al. 2021; Luo and Zeng 2011; Galloway and Burbey 2011). Main focus is often on the identification of location and values of land subsidence in plains. Several studies have used GPS and remote sensing data to identify land subsidence. Also, other research used numerical models in the aquifers to predict/forecast of land subsidence (Gambolati 1975; Ye et al. 2016; Wu et al. 2010; Candela et al. 2020). In these studies, the goal is to manage the impacts of subsidence, mitigate its effects, and recover the impacted lands before further physical, social, cultural, and economic damage occurs. Groundwater resource overuse for agricultural activities is often responsible for subsidence in plains. Artificial recharges of aquifers and basin management plans are the most commonly used remediation methods. The use of sustainable drainage systems to recharge aquifers has also become an option in the last few decades. The BAF method applied by Nadiri et al. (2018, 2020) can also be used for subsidence management by creating an accurate map of Hadishahr Plain subsidence, as given in Fig. 5a. By adopting a management plan, the dual objective of equitable water allocations and protecting the GWL would be more economically and environmentally feasible. On the other hand, without a plan, permanent damage can almost be guaranteed. According to Fig. 7, there is an increased risk of land subsidence for the coming year based on the DSVI map. The main limitations of DSVI include limited data and increased noise as prediction into the future time span increases which is a well-known problem of prediction problems. It is confirmed that MAIM model is better suited to forecast the outcome of a BAF-MAIM model than using prescribed weight values.
Conclusions
We present a methodology to map Dynamic Subsidence Vulnerability Indices (DSVI) in plains. We developed the methodology by using ALPRIFT (Nairi et al. 2020) and applied it to Hadishahr Plain, in the province of East Azerbaijan, situated in northwest Iran, where GWLs dropped by approximately 4 m during 2004-2018. The objectives of this research are done in three Modules: (i) Module I, mapping Subsidence Vulnerability Indices (SVI) by applying the basic ALPRIFT framework and optimization weights by Multiple Artificial Intelligence Models (MAIM); and (ii) Module II, predicting GWLs by GMDH model; Module III: combining the results from Modules I and II to generate dynamic DSVI maps. Module I employs a single modelling strategy at two levels: at Level 1, multiple models are constructed by Sugeno Fuzzy Logic (SFL) and Support Vector Machine (SVM) models. (ii) At Level 2, the outputs of models at Level 1 are combined by Artificial Neural Network (ANN).
Although the ALPRIFT framework produces a statistically significant signal, it is not sufficiently convincing to be used to produce land subsidence maps of the Hadishahr Palin. Modelling results from module I indicate that the MAIM accuracy is defendable. DSVI's module III indicates that the Hadishahr Plain is vulnerable to subsidence. The greater the decline of GWL, the more subsidence occurs.
Abbreviations
- SVI:
-
Subsidence Vulnerability Indices
- TSVI:
-
Dynamic SVI
- GWL:
-
Groundwater Level
- FL:
-
Fuzzy Logic
- SFL:
-
Sugeno Fuzzy Logic
- InSAR:
-
Interferometric Synthetic Aperture Radar
- GPR:
-
Ground-Penetrating Radar
- OW:
-
Observation well
- CSVI:
-
Conditioned SVI
- MF :
-
Membership Function
- BAF :
-
Basic ALPRIF framework
- RMSE:
-
Root Mean Squared Error
- r:
-
Correlation coefficient
- SVM:
-
Support Vector Machine
- MMs:
-
Multiple Models
- GMDH:
-
Group Method of Data Handling
- ANN:
-
Artificial Neural Networks
- AUC:
-
Area Under Curve
- MAIM:
-
Multiple Artificial Intelligence Models
- GPS:
-
Global Positioning System
- SC:
-
Subtractive Clutering
- MLP :
-
Multi layer perceptron
- SLC :
-
single look complex
- NSGA-II:
-
Non-dominated Sorting Genetic Algorithm-II
- R2 :
-
Coefficient of determination
- ROC:
-
Receiver Operating Characteristics
References
Anumba CJ, Scot DT (2001)Performance evaluation of a knowledge-basedsystem for subsidence management. Struct Surv 19:222–232
Avila-Olivera JA, Garduño-Monroy VH (2008)A GPR study of subsidence-creep -faultprocesses in Morelia, Michoacán, Mexico. Eng Geol 100(1–2):69–81
Beck BF (1986)A generalized genetic framework for the development of sinkholes and Karst in Florida, U.S.A. Environ Geol Water Sci 8:5. https://doi.org/10.1007/BF02525554
Candela T, Koster K, Stafleu J, Visser W, Fokker P (2020) Towards regionally forecasting shallow subsidence in the Netherlands. Proc. IAHS 382:427–431. https://doi.org/10.5194/piahs-382-427-2020
Chen B, Gong H, Chen Y, Li X, Zhou C, Zhu L, Duan L, Zhao X (2020) Land subsidence and its relation with groundwater aquifers in Beijing Plain of China. Science of The Total Environment 735:139111
Chiu S (1994)Fuzzy model identification based on cluster estimation. Intell Fuzzy Syst 2:267–278
Ciampalini A, Solari L, Giannecchini R, Galanti Y, Moretti S (2019)Evaluation of subsidence induced by long-lastingbuildings load using InSAR technique and geotechnical data: The case study of a Freight Terminal (Tuscany, Italy). Appl Earth Obs Geoinf 82:101925
Colazas XC, Strehle RW (1995)Subsidence in theWilmington Oil Field, Long Beach, California, USA. Dev Pet Sci 41:285–335
Deb K, Pratap A, Agarwal S, Meyarivan T (2002)A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput 6(2):182–197
Unknown (2018) Report and available data. published by East Azerbaijan Regional Water Authority (EARWA), Iran.
Ebtehaj I, Bonakdari H, Zaji H, Azimi AH, Khoshbin F (2015)GMDH-typeneural network approach for modeling the discharge coefficient of rectangular sharp-crestedside weirs. Eng Sci Technol 18:746–757
Farlow SJ (1984)Self-organizingmethods in modeling: GMDH type algorithms. Marcel Dekker Inc, CrC Press
Galloway DL, Burbey TJ (2011)Regional land subsidence accompanying groundwater extraction. Hydrogeol 19(8):1459–1486
Galloway D, Jones D, Ingebritsen SE (1999)Land subsidence in the United State. U.S. Geological Survey, Circular 1182
Gambolati G (1975)Numerical models in land subsidence control. Comput Methods Appl Mech Eng 5(2):227–237
Gharekhani M, Nadiri AA, Khatibi R, Sadeghfam S (2021)An investigation into time-variantsubsidence potentials using inclusive multiple modelling strategies. J Environ Manage 294:112949
Gu K, Shi B, Liu C, Jiang H, Li T, Wu J (2018)Investigation of land subsidence with the combination of distributed fiber optic sensing techniques and microstructure analysis of soils. Eng Geol 240(5):34–47
Hanssen RF (2001)Radar Interferometry: Data Interpretation and Error Analysis. Springer Science & Business Media, Berlin
Hayashi T, Tokunag T, Aichi M, Shimada J, Taniguchi M (2009)Effects of human activities and urbanization on groundwater environments: an example from the aquifer system of Tokyo and the surrounding area. Sci Total Environ 407(9):3165–3172
Hiashi I, Tanaka H (1990)The fuzzy GMDH algorithm by possibility models and its application. Fuzzy Sets Syst 36(2):245–258
Ivakhnenko AG (1968)The Group Method of Data Handling –a rival of the Method of Stochastic Approximation. Soviet Automatic Control c/c of Avtomatika 1(3):43–55
Ivakhnenko AG (1978)The Group Method of Data Handling in Long-RangeForecasting. Technol Forecast Soc Change 12:213–227
Jafari F, Javadi S, Golmohammadi G, Karimi N, Mohammadi K (2016)Numerical simulation of groundwater flow and aquifer-systemcompaction using simulation and InSAR technique: Saveh basin, Iran. Environ Earth Sci 75(9):833
Khatibi R, Nadiri AA (2021)Inclusive Multiple Models (IMM)for predicting groundwater levels and treating heterogeneity. Geosci Front 12(2):713–724
Khatibi R, Ghorbani MA, Naghshara S, Aydin H, Karimi V (2020)Framework for ‘Inclusive Multiple Modelling’ with Critical Views on Modelling Practices -Applications to Modelling Water Levels of Caspian Sea and Lakes Urmia and Van. Hydro 587:124923
Kihm JH, Kim JM, Song SH, Lee GS (2007)Three-dimensionalnumerical simulation of fully coupled groundwater flow and land deformation due to groundwater pumping in an unsaturated fluvial aquifer system. J Hydrol 335(1–2):1–14
Kim D, Park GT (2005)GMDH-typeneural network modeling in evolutionary optimization, vol 3533. IEA/AIE, pp 563–570
Legates DR, McCabe CJ (1999)Evaluation the use of goodness-of-fitmeasures in hydrologic and hydro climate model validation. Water Resour Res 35(1):233–241
Li H, Philip CL, Huang HP (2001)Fuzzy neural intelligent systems: mathematical foundation and the applications in engineering. CRC Press, Boca Rato, p 392
Lorphensri O, Ladawadee A, Dhammasarn S (2011)Review of groundwater management and land subsidence in Bangkok, Thailand. In: Taniguchi M (eds)Groundwater and Subsurface Environments. Springer, Tokyo
Luo ZJ, Zeng F (2011)Finite element numerical simulation of land subsidence and groundwater exploitation based on visco-elastic-plasticbiot’s consolidation theory. J Hydrodynam 23(5):615–624
Malmir M, Javadi S, Moridi A, Neshat A, Razdar B (2021)A new combined framework for sustainable development using the DPSIR approach and numerical modeling. Geosci Front 12(4):101169
Moiwo JP, Tao F (2015)Satellite signal shows storage-unloadingsubsidence in North China. Hydrol Earth Syst Sci 12:6043–6075
Nadiri AA, Chitsazan N, Tsai FTC, Moghaddam AA (2014)Bayesian artificial intelligence model averaging for hydraulic conductivity estimation. J Hydrol Eng 19:520–532
Nadiri AA, Fijani E, Tsai FTC, Moghaddam AA (2013)Supervised committee machine with artificial intelligence for prediction of fluoride concentration. Hydroinformatics 15(4):1474–1490
Nadiri AA, Gharekhani M, Khatibi R, Moghaddam A (2017)Assessment of groundwater vulnerability using supervised committee to combine fuzzy logic models. Environ Sci Pollut Res 24(9):8562–8577
Nadiri AA, Gharekhani M, Khatibi R, Sadeghfam S, Asghari Moghaddam AA (2017)Groundwater vulnerability indices conditioned by Supervised Intelligence Committee Machine (SICM). Sci Total Environ 574:691–706
Nadiri AA, Khatibi R, Khalifi P, Feizizadeh B (2020) A study of subsidence hotspots by mapping vulnerability indices through innovatory ‘ALPRIFT’ using artificial intelligence at two levels. Bulletin of Engineering Geology and the Environment 79(8):3989–4003
Nadiri AA, Naderi K, Khatibi R, Gharekhani M (2019)Modelling groundwater level variations by learning from multiple models using fuzzy logic. Hydrol Sci J 64:210–226
Nadiri AA, Sedghi Z, Khatibi R, Gharekhani M (2017)Mapping vulnerability of multiple aquifers using multiple models and fuzzy logic to objectively derive model structures. Sci Total Environ 593:75–90
Nadiri AA, Taheri Z, Khatibi R, Barzegari G, Dideban K (2018)Introducing a new framework for mapping subsidence vulnerability indices (SVIs). Sci Total Environ 628:1043–1057
Nappoa N, Pedutob D, Polcaric M, Maria F, Ferrarioa F, Comercid V, Stramondoc S, Michettia AM (2021)Subsidence in Como historic centre (northern Italy): Assessment of building vulnerability combining hydrogeological and stratigraphic features, Cosmo-SkyMedInSAR and damage data. Int J Disast Risk Reduct 56:102115
Psimoulis P, Ghilardi M, Fouache E, Stiros S (2007)Subsidence and evolution of the Thessaloniki plain, Greece, based on historical leveling and GPS data. Eng Geol 90(1 2):55–70
Rahmani B, Javadi S, Shahdany MH (2019) Evaluation of aquifer vulnerability using PCA technique and various clustering methods. Geocarto International 36(1):1–24
Saatsaz M, Sulaiman WNA, Eslamian S, Javadi S (2013)Development of a coupled flow and solute transport modelling for Astaneh-Kouchesfahangroundwater resources, North of Iran. Int J Water 7(1–2):80–103
Sadeghfam S, Khatibi R, Dadashi S, Nadiri AA (2020)Transforming subsidence vulnerability indexing based on ALPRIFT into risk indexing using a new fuzzy-catastrophescheme. Environ Impact Assess Rev 82:106352
Sadeghfam S, Nourbakhsh Khiyabani F, Khatibi R, Daneshfaraz R (2020)A study of land subsidence problems by ALPRIFT for vulnerability indexing and risk indexing and treating subjectivity by strategy at two levels. Hydroinformatics 22(6):1640–1662
Sato PH, Abe K, Otaki O (2007)GPS-measuredland subsidence in Ojiya City, Niigata Prefecture, Japan. Eng Geol 67(3–4):379–390
Sfidari E, Kadkhodaie A, Ahmadi B, Ahmadi B, Faraji MA (2018)Prediction of pore facies using GMDH-typeneural networks: a case study from the South Pars gas field, Persian Gulf basin. Geopersia 8(1):43–60
Sossong AT (1973)Subsidence experience of Bethlehem Mines Corporation in Central Pennsylvania. In: Hargraves AJ (ed)Subsidence in mines-Proceedingsof symposium, 4th, Wollongong University, February 20-22, 1973. Australasian Institute of Mining and Metallurgy, pp 5.1–5.5
Swets JA (1988)Measuring the accuracy of diagnostic systems. Science 240(48–57):1285–1293
Tosi L, Teatini P, Strozzi T (2013)Natural versus anthropogenic subsidence of Venice. Sci Rep 3(1):1–9
Wang J, Deng Y, Ma R, Liu X, Guo Q, Liu S, Shao Y, Wu L, Zhou J, Yano T, Wana H, Huana X (2018)Model test on partial expansion in stratified subsidence during foundation pit dewatering. J Hydrol 557:489–508
Wu J, Shi X, Ye S, Xue Y (2010)Numerical Simulation of Viscoelastoplastic Land Subsidence due to Groundwater Overdrafting in Shanghai, China. J Hydrol Eng 15:3
Ye S, Luo Y, Wu J, Teatini P, Wang H, Jiao X (2015)Three dimensional numerical modeling of land subsidence in Shanghai. Proc IA372:443–448
Ye S, Luo Y, Wu J, Yan X, Wang H, Jiao X, Teatini P (2016)Three-dimensionalnumerical modeling of land subsidence in Shanghai, China. Hydrogeol J 24:695–709
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: H. Babaie.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Highlights
Dynamic Subsidence Vulnerability Indices (DSVI) is summarized in three Modules.
Module I: setting up an SVI and optimizing it by Multiple Artificial Intelligence Models (MAIM) strategy.
Module II: predicting groundwater level by Group Method of Data Handling (GMDH) model.
Module III: mapping DSVI by integrating the results from Modules I and II in Iran’s Hadishahr Plain aquifer.
Supplementary Information
Below is the link to the electronic supplementary material.
ESM 1
(DOCX 14.4 KB)
Rights and permissions
About this article

Cite this article
Nadiri, A.A., Habibi, I., Gharekhani, M. et al. Introducing dynamic land subsidence index based on the ALPRIFT framework using artificial intelligence techniques. Earth Sci Inform 15, 1007–1021 (2022). https://doi.org/10.1007/s12145-021-00760-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-021-00760-w