
Abstract
The present study is aimed at producing landslide susceptibility map of a landslide-prone area (Anfu County, China) by using evidential belief function (EBF), frequency ratio (FR) and Mahalanobis distance (MD) models. To this aim, 302 landslides were mapped based on earlier reports and aerial photographs, as well as, carrying out several field surveys. The landslide inventory was randomly split into a training dataset (70%; 212landslides) for training the models and the remaining (30%; 90 landslides) was cast off for validation purpose. A total of sixteen geo-environmental conditioning factors were considered as inputs to the models: slope degree, slope aspect, plan curvature, profile curvature, the new topo-hydrological factor termed height above the nearest drainage (HAND), average annual rainfall, altitude, distance from rivers, distance from roads, distance from faults, lithology, normalized difference vegetation index (NDVI), sediment transport index (STI), stream power index (SPI), soil texture, and land use/cover. The validation of susceptibility maps was evaluated using the area under the receiver operating characteristic curve (AUROC). As a results, the FR outperformed other models with an AUROC of 84.98%, followed by EBF (78.63%) and MD (78.50%) models. The percentage of susceptibility classes for each model revealed that MD model managed to build a compendious map focused at highly susceptible areas (high and very high classes) with an overall area of approximately 17%, followed by FR (22.76%) and EBF (31%). The premier model (FR) attested that the five factors mostly influenced the landslide occurrence in the area: NDVI, soil texture, slope degree, altitude, and HAND. Interestingly, HAND could manifest clearer pattern with regard to landslide occurrence compared to other topo-hydrological factors such as SPI, STI, and distance to rivers. Lastly, it can be conceived that the susceptibility of the area to landsliding is more subjected to a complex environmental set of factors rather than anthropological ones (residential areas and distance to roads). This upshot can make a platform for further pragmatic measures regarding hazard-planning actions.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Landslides is characterized as a natural hazard all over the world, most events occurred in North America and Southeast Asia (Eker et al. 2014; Ganapathy and Rajawat 2015), the destructiveness and damage of landslides is no less than hurricanes or earthquakes, because it is lack of effective comprehensive monitoring networks (Kirschbaum et al. 2015; Topal and Hatipoglu 2015; Zeybek et al. 2015). Therefore, establishing quantitative models of landslide evolution processes is an effective approach for achieving early warnings of landslides (Day et al. 2015). The modeling of landslides is based on continuous monitoring of landslide-related variables, such as climate, hydrological parameters, soil conditions, land use, etc. (Wood et al. 2015; Yao et al. 2015). What are landslide mechanisms and mapping areas susceptible to landslides? If we fix these questions, it is essential for land use planning and may be considered as a scientific standard measure that assists government personnel or decision-making activities (Gallo and Lavé 2014; Havenith et al. 2015). However, it is still a challenging and difficult task to produce a reliable spatial prediction map of landslides, because of the complex nature of landslides (Bièvre et al. 2015; Tien Bui et al. 2015b).
If there was no prior expert knowledge for evaluation and weighting of variables, then there would be a need to extend a data-driven landslide susceptibility mapping (LSM) method named geographically-weighted principal component analysis (Faraji Sabokbar et al. 2014). The trigger of landslide is also a complicated problem and still in debate now (Larsen and Montgomery 2012; Tomás et al. 2015). It is worth mentioning that rainfall is an important trigger factor in landslide development (Bordoni et al. 2015a; Zhou et al. 2015), with the extreme rainfall incensement (Bordoni et al. 2015b; Ramos-Cañón et al. 2015), the rate of occurrence of landslides and the scale of fatalities and property losses have raised year by year (Galve et al. 2014; Su et al. 2015). Earthquake is another factor in some mountain areas, it always combination with rainfall (Barlow et al. 2015; Fan et al. 2014; Lacroix et al. 2015; Xu et al. 2014). In addition to some common factors induce landslide, human activities is also an unexpected and potential induce factor (Meten et al. 2015), such as rapid development and land reform in different mountainous areas (Damm and Klose 2015; Gutiérrez et al. 2015), for example: mining,new roads and highway constructions, urbanization, building factory and house (Youssef 2015).
In most previous work, numerous comparisons of susceptibility modeling methods have been discussed (Tsangaratos et al. 2016); the freedom of choice to decide which modeling method is most suitable for a particular application is still a challenging task (Kritikos et al. 2015; Tsangaratos and Ilia 2015), however until now there is no best method for empirical susceptibility modeling (Mansouri Daneshvar 2014; Umar et al. 2014). The search for the optimal landslide susceptibility modeling method is a complicated one and should not only consider model accuracy (Goetz et al. 2015; Trigila et al. 2015; Yusof et al. 2015). With the development of computer science, geospatial technologies like the use of GIS (Shahabi and Hashim 2015), Global Positioning System (GPS) (Wang et al. 2015), and Remote Sensing (RS) are meaningful in the disaster assessment, risk identification, and hazard management for landslides (Ahmed 2014; Barker et al. 2009; Ciampalini et al. 2015; Elmoulat et al. 2015; Jebur et al. 2014; Scaioni et al. 2014; Shi et al. 2015).
Though data-driven multivariate classification techniques are very advanced and useful in landslide susceptibility (Meinhardt et al. 2015; Sharma et al. 2014), expert knowledge can also be applied to account for bias in the inventory information and deficits in the used susceptibility factor data (Günther et al. 2014), such as analytical hierarchy process (AHP) (Zhao et al. 2017), spatial multi criteria evaluation approach (Pourghasemi et al. 2014), weighted linear combination (Le et al. 2018),there are some new method applied to landslide susceptibility assessment from different area around the world, they all perform good result and high AUC in validation, such as fuzzy logic (Meten et al. 2015; Hong et al. 2016b), artificial neural network (ANN) (Conforti et al. 2014; Das et al. 2012; Liu et al. 2013), logistic regression (LR) (Althuwaynee et al. 2014; Poiraud 2014; Yalcin et al. 2011; Iovine et al. 2014), generalized additive model (Petschko et al. 2014), ensemble of fuzzy-Shannon entropy (Shadman Roodposhti et al. 2016), Bayes’ net (Chen et al. 2018a), decision tree (Pradhan 2013), support vector machine (Liu et al. 2013; Peng et al. 2014; Hong et al. 2017a, b), random forest (Chen et al. 2018b), etc.
In 2014, there were 10,907 geological disasters in China, resulting in a total of 349 people death, 51 people missing and 218 people injured. The direct economic loss amounted to 5.41 billion Yuan. Among these geological disasters, 8125 were landslides, accounting for 74.5% of the total number. Jiangxi Province is located in the region of the south China; it belongs to the Subtropical warm and humid monsoon climate, in rainy season, there are many landslides in Jiangxi. Many studies show that global climate change is a major factor that impact ecological environment and human life(Lian et al. 2014). Changes in land use and precipitation extremes is two significant aspect of globe climate change(Xing et al. 2014), thus it is in particular could lead to a higher landslide susceptibility(Meinhardt et al. 2015).
The main difference between the present study and the previous works is the mere use of Mahalanobis distance, as probabilistic technique, for landslide susceptibility assessment where its result is compared with respect to bivariate statistical models. Also, we used a new topo-hydrological index (HAND) along with other geo-environmental factors for modeling which can bridge between landslide science and hydrological studies.
Description of study area
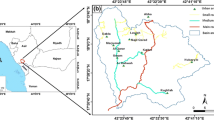
The Anfu area is located in the Central section of the Jiangxi Province, in the west of the Jian County and the east of the Lianhua County. The study area lies between latitude 27°04′N and 27°36′N, and longitude 114°00′E and 114°47′E. It covers an area of about 2800 km2. The altitude of the area ranges from 50.5 to 1914 m above sea level.
The study area belongs to a subtropical monsoon climate. According to report from the Jiangxi Province Meteorological Bureau (http://www.weather.org.cn), the average annual rainfall for the period 1960–2013 years is from 1542.0 mm. The average annual temperature is 17.7 °C. The rainy season is from Mar to Aug that accounts for 71.8% of the yearly rainfall. In May and June, the average rainfall varies between 200 mm and 250 mm per month. In the Anfu area, the high amount of rainfall is considered as the main triggering factor for the occurrence of landslides. However, until now, there were very few articles about forecasting their location and preventing their damages(Hong et al. 2015).
Methodology
Data used
Landslides inventory
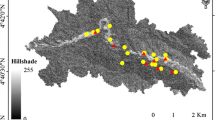
The landslide inventory map for study area was prepared based on aerial photograph, satellite images interpretation, and extensive field surveys. The landslides inventory database for the Anfu area is including 302 landslide events (Fig. 1) 212 landslide cases (70%) out of 302 detected landslides were randomly selected for modeling, and the remaining 90 (30%) landslide cases were used for the model validation purposes. The collected archive data confirmed that the area suffered similar landslides in historical and recent times. We have collected data relevant to independent and dependent variables in Anfu area. Daily meteorological records during 1960–2012 in Anfu area from the Jiangxi Provincial Meteorological Observatory were used in the study. The data included daily precipitation, daily temperature,rainy days etc. The DEM data comes from Aster Gdem Version2. Geological disaster data were provided by Department of Land and Resource of Jiangxi Province (http://www.jxgtt.gov.cn). Lithology data was obtained from the geological figure China land and resources data sharing (http://gsd.cgs.cn/download.asp). The Landsat 7 ETM+ data set is provided by Geospatial Data Cloud, Computer Network Information Center, Chinese Academy of Sciences (http://www.gscloud.cn) (Fig. 2).

The study area and spatial distribution of landslides

Flowchart of the developed methodology
Landslides conditioning factors
The selection of conditioning factors in the present study is mostly drawn on field surveys, expertise, availability of data, and literature reviews (see introduction) which follows: slope degree, slope aspect, plan curvature, profile curvature, HAND, average annual rainfall, altitude, distance from rivers, distance from roads, distance from faults, lithology, normalized difference vegetation index (NDVI), sediment transport index (STI), stream power index (SPI), soil texture, and land use/cover. Pradhan (2013) stated that identification of a suitable set of instability factors having a relationship with slope failures require a priori knowledge of main causes of landslides. These factors can embody the characteristics of landslide occurrence over Anfu area. Altitude has been considered as a vital factor that influences the occurrence and distribution of landslides, degree of weathering and human activities (Hong et al. 2016a) which was divided into five classes: < 400 m, 400–800 m, 800–1200 m, 1200–1600 m and > 1600 m (Fig. 3b). Slope angle is widely used in landslide susceptibility and slope stability assessment (Demir et al. 2013). Slope degree was divided into four classes: < 5°, 5°–15°, 15°–30° and > 30° (Fig. 3a). Slope aspect implies the variation in the intensity of the received sunlight which affects soil moisture, evaporation, erosion, and consequently different landslide episodes (Ilia and Tsangaratos 2016). Slope aspect was divided into nine primary and secondary classes: flat (−1°), north (337.5–360°, 0–22.5°), north-east (22.5–67.5°), east (67.5–112.5°), south-east (112.5–157.5°), south (157.5–202.5°), south-west (202.5–247.5°), west (247.6–292.5°) and north-west (292.5–337.5°) (Fig. 3c). The sediment transport index (STI) has been often used to reflect the erosive power of the overland flow (Pourghasemi et al. 2013a) following Eq. 1:
where β represents the slope at each pixel and As represents the upstream area (Pourghasemi et al. 2013b). STI can be easily produced as a function of standard terrain analysis in ESRI GIS. STI was divided into five classes (Fig. 3e). For plan curvature, positive, near zero, and negative values are representative for convex, flat, and concave curvature perpendicular to the main slope. Using SAGA-GIS, the plan curvature map was classified into the three classes mentioned above. Profile curvature, parallel to the main slope, was prepared with the same classification system and platform, yet with a reverse interpretation (Fig. 3g, h).



Landslides conditioning factor (a) Slope, (b) Altitude, (c) Aspect, (d) HAND, (e) STI, (f) SPI, (g) Plan curvature, (h) Profile curvature, (i) Distance to rivers, (j) Distance to faults, (k) Distance to roads, (l) Rainfall, (m) Lithology, (n) Landuse, (o) NDVI, (p) Soil
SPI measures the erosion power of the stream and is considered as a factor contributing to the stability states of the slopes in the study area, following Eq. 2 (Moore and Grayson 1991):
where As represents the specific catchment area and β (radian) is the slope gradient. Here, SPI was divided into five classes (Fig. 3f). The lithology map was obtained from the geological datasets of China (Fig. 3m and Table 1). The NDVI map was produced from RS imagery showing the surface vegetation coverage and density in an image. The NDVI value was computed using Eq. 3.
where R and IR stand for the spectral reflectance measurements acquired in the visible (red) and near-infrared regions, respectively. NDVI was classified into 10 classes (Fig. 3o). The land use/cover system in the Anfu area was divided into seven classes (Fig. 3n) including farmlands, forests, grasses, water bodies, residential areas, and bare lands. The map of distance to rivers was created using drainage map and categorized into (<100), (100–300), (300–500), (500–700), and (>700) classes (Fig. 3i). Distance to faults was calculated using a geological map of the study area. Also, distance to roads was prepared using a road map of the study area and classified into (<500), (500–1000), (1000–2000), (2000–3000), and (>3000) ranges, same as distance to faults map (Figs. 3j, k). All proximity maps were produced using an Euclidean function in ArcGIS 10.2. There is no doubt that rainfall is a most important triggered factor in landslide occurrence. Based on the rainfall data of the past 52 years (from 1960 to 2012), this area received an average annual rainfall of about 1435 mm. These observations signified the importance of correlating the initiations of landslide occurrences in Anfu area with rainfall infiltrations. The rainfall ranges from 627.6 to 1398.6 mm in the study area which was classified into 5 ranges (Fig. 3l). The HAND factor was obtained from DEM map using the new released ArcGIS extension (Rahmati et al. 2018), and classified into three hydrological zones of saturation, slope, and plateau. It is worth noting that all the classifications are based on expert knowledge of the study area and the interconnection of landslide localities and conditioning factors, since there is no consensus on how to deal with this issue. According to Süzen and Doyuran (2004) classification of continuous factors still remains unclear in landslide literature as most of the authors use their expert opinion for the boundaries of the classes. Overall, in order to classify continuous factors, expert knowledge does matter most, because there is not a standard framework to determine such classification strategy; hence, it is mainly up to the experts’ knowledge.
Method
Frequency ratio (FR) model
According to Bonham-Carter (1994), the frequency ratio is the probability of occurrence of a certain attribute. The frequency ratio method is based on the assumption that future landslides will happen at similar conditions to those in the past. The FR model is a simple and understandable probabilistic model, and it is the ratio of the area where landslides have occurred to the total study area and is also the ratio of the landslide occurrence probabilities to the non-occurrence for a given attribute. The landslide susceptibility map (LSM) was calculated by summation of each factor’s ratio value using Eq. 4:
The calculation steps for an FR for a class of the landslide-influencing factor are below (Eq. 5)
where, A is the number of pixels with landslide for each factor; B is the number of total landslides in study area; C is the number of pixels in the class area of the factor; D is the number of total pixels in the study area; and FR is the frequency ratio of a class for the factor.
Evidential belief function (EBF) model
Dempster-Shafer theory of evidence was first proposed by Dempster (Dempster 1967), and was developed by Shafer later on (Shafer 1976). There are four basic EBF functions, namely; degrees of belief (Bel), disbelief (Dis), uncertainty (Unc), and plausibility (Pls) (Dempster 1967). Unc represents ignorance of one’s belief in the proposition based on a given evidence and its value is Pls-Bel. Semantically, Dis is the belief that the proposition is not true based on the given evidence, which equals to 1- Pls or, equivalently, 1- Bel-Unc. The EBF method is applied in many fields, for instance: wildfire susceptibility assessment (Pourghasemi 2016), landslide modeling (Pradhan et al. 2014; Tien Bui et al. 2015a; Pourghasemi and Kerle 2016; Ding et al. 2017), and groundwater potential assessment (Mogaji et al. 2016). The data-driven estimation of evidential belief functions can be calculated by the following equations:
where, the numerator in Eq. (7) is the proportion of landslide pixels that occur within a factor class Aij, the numerator in Eq. (9) denotes the proportion of landslide pixels that does not occur within a factor class Aij, the denominator in Eq. (7) is the proportion of non-landslide pixels within a factor class Aij, and the denominator in Eq. (9) is the proportion of non-landslide pixels within other attributes outside the factor class Aij (Youssef et al. 2015).
Mahalanobis distance
Mahalanobis distance is a probabilistic distance which was proposed by Mahalanobis and is based on the relation between variants of which different features can be detected and analyzed (Mahalanobis 1936). It is a useful metric that can quantify the similarity between an unknown location and a known sample series. While, some properties differentiate this method from a simple Euclidian distance: 1) it maintains the correlation between data, 2) being insensitive to different measurement scales, and 3) interpretable from probabilistic standpoint. The Mahalanobis distance of an observation at a particular pixel within a factor vector \( \overrightarrow{x}={\left({x}_1,{x}_2,{x}_3,\dots, {x}_N\right)}^T \) by having a set of mean values of those factors at each landslide localities \( \overrightarrow{\upmu}={\left({\upmu}_1,{\upmu}_2,{\upmu}_3,\dots, {\upmu}_N\right)}^T \)and the covariance matrix S follows Eq. 12.
Models validation
Validation of three susceptibility maps was carried out using the ROC curve. The ROC plots the false-positive rate (the specificity) on the x-axis and the true-positive rate (the sensitivity) on the y-axis (Tahmassebip Swets 1988). To apply the ROC method to the study area, a concise and representative dataset was prepared using the randomly split landslide and non-landslide locations. The AUROC values vary from 0.5 to 1.0; the model with the higher AUC is considered to be the best in terms of predictive power and generalization capacity (Yesilnacar 2005).
Result
Application of frequency ratio model
The results of the FR analysis for each identified class are summarized in Table 2. In Table 2, slope angle classes showed that >30° class has higher frequency ratio weight (4.36) followed by class 15–30° with FR of 1.52. In terms of slope aspect, most landslides occurred facing south, south-east and southwest (2.41, 2.24, and 1.82, respectively). In the case of altitude, the 800–1200 class had the highest FR of 4.23, indicating a high probability of landslide occurrence in within this altitude. In the case of plan curvature, in convex and flat classes, the FR is high and low (values of 1.07 and 0.00), respectively. The results of FR for profile curvature showed that < (0.001) class had the highest FR (1.18). Therefore, this class has the most probability for landslide occurrence. The results of HAND, showed that >281 and 162–281 classes had higher probability for landslide occurrence with the FR of 3.74, and 1.91 respectively. Landslides are most abundant in the >20 class of STI (FR = 2.95). The results of SPI, showed that 150–200 and 100–150 classes had higher probability for landslide occurrence with the FR of 2.43, and 2.42 respectively. In case of lithology, the highest value of FR is for class of B (2.16). In the case of NDVI, it can be seen that the class of (−0.001) - (0.00) has an FR value of 6.15, indicating that the probability of occurrence of landslides in this NDVI class is very high. Considering the case of the relationship between landslide occurrence and distance to rivers, the FR is 2.25 and 1.47 for >700 and 500–700 classes which shows abundant of landslide in these classes. In the case of distance to faults, classes of 2000–3000 and > 3000 m yield the highest landslide occurrence probabilities with FR values of 0.95 and 1.25, respectively. In the case of distance to roads, most of the landslides occurred in class of 1000–2000 with FR value of 1.24. In the case of precipitation, 1105.3–1398.5 yields an FR value of 1.26, thus it has the highest probability for landslide occurrence. In the case of Land use,it can be seen that the class of Forest and Grass has an FR value of (1.42, 1.14), indicating that the probability of occurrence of Human activity in this land use type is very high. The final landslide susceptibility map was developed using the Eq. 13 as follow:
The landslide susceptibility mapping using FR model was calculated using ArcGIS® 10.2 to calculate, and according to the Jenks natural breaks method, the degree of vulnerability of the area is divided into five categories: very low, low, moderate, high and very high (Fig. 5a).
The landslide susceptibility map achieved from the FR method, which covered of the total area, was designated to be a moderate LSM class with an percentage of 24.76%, and 25.54%, 26.94%, 16.88%, and 5.88% of the total area are related to very low, low, high, and very high LSM zones, respectively (Fig. 4a and Table 3). The classification scheme is based on natural break classifier.

Landslide susceptibility map by (a) FR model, (b) EBF model (c) Mahalanobis distance
Application of EBF model
To produce LSM and consider the relation between landslides and influencing factor, the EBF model was used. Table 2 shows the (Bel), disbelief (Dis), uncertainty (Unc), and plausibility (Pls) that was calculated for each class of each landslide conditioning factor. A comparatively high Bel value shows a higher probability of landslide occurrence, while a low Bel value shows a lower probability of groundwater occurrence.
As shown in Table 2, in the case of slope degree, it can be seen that the 15–30 and > 30 had higher Bel of 0.26 and 0.74. For altitude, 800–1200 had highest value of Bel (0.52). In the case of slope aspect, the south had the highest value of Bel (0.29). For HAND, >281 had the highest value of Bel (0.62). In the case of STI, >20 had the highest value of Bel (0.63). In the case of SPI, 100–150 and 150–200 had the highest value of Bel (0.25). For plan curvature, convex had the highest value of Bel (0.52). In the case of profile curvature, < (−0.001) had the highest value of Bel (0.59). For the distance to rivers, >700 had the highest value of Bel (0.40). In the case of distance to faults, >3000 had the highest value of Bel (0.28). In the case of distance to roads, 1000–2000 had the highest value of Bel (0.30). In the case of precipitation, 1105.3–1398.5 had the highest value of Bel (0.30). In the case of NDVI, (−0.001) -(0.00) had the highest value of Bel (0.63). For soil, Alh had the highest value of Bel (0.52). In the case of lithology, B had the highest value of Bel (0.29). In the case of landuse, forest had the highest value of Bel (0.42). The final landslide susceptibility map was developed using the Eq. 14 as follows:
The landslide susceptibility map EBF model was prepared in ArcGIS 10.2 and classified into to five classes (very low to very high) with respective percentages of 13.57%, 29.63%, 25.8%, 20.76%, and 10.24%, based on natural break classification scheme (Fig. 4b, Table 3).
Application of Mahalanobis distance model
In order to implement Mahalanobis distance model, extension of Land Facet Corridor Tools was used in ArcGIS 10.2 environment. The landslide susceptibility map EBF model was prepared in ArcGIS 10.2 and classified into to five classes (very low to very high) with respective percentages of 59.7%, 13.39%, 9.81%, 8.66%, and 8.44%, based on natural break classification scheme (Fig. 4c, Table 3).
Validation of landslide susceptibility maps
Results of prediction curves are exhibited in Fig. 5. The results show that for the landslide susceptibility map using the EBF model, the AUC is 0.7863, which corresponds to a relatively high prediction accuracy. The landslide susceptibility map using MD gives an AUC of approximately 0.7850, which also corresponds to a high prediction accuracy. The FR model clearly has higher AUC value of 0.8498 than that of the other models, which corresponds to a high prediction accuracy. Therefore, according to the results, FR givers a fairly better response with high generalization capacity, followed by EBF, and MD. Thus, the FR model was introduced as the premier model.

ROC curves success rate for the FR, EBF and Mahalanobis distance models
Discussion
This study undertook a comparative assessment of the application of the EBF and FR statistical methods and MD in landslide susceptibility. The AUROC analysis shows that the results of the landslide susceptibility obtained from the three models are reliable, although MD gave an underperformed prediction skill compared to EBF and FR. Therefore, a simple statistical equation termed FR proved to be brief but meaningful once again in landslide studies, which makes the use of other complicated models more questionable. However, the products of each model also matters. For instance, EBF supports a series of mass functions including belief, disbelief, uncertainty and plausibility that clarifies more aspects of the landslide occurrence and modeling aspects in the study area. Thus, the results can adequately represent quantitative relationships between landslide occurrences and conditioning factors by modeling the degree of uncertainty (Park 2011). On the other hand, the simple assumptions on which the FR is based, makes its results more sensitive to different model configurations such as inputs, either landslide inventory partitioning methods or different sets of conditioning factors. In this regard, EBF and MD hold more robust mathematical functions. This can be of interest for future works.
Regarding the EBF, the belief map was considered to be the landslide susceptibility map as it indicated the landslide-prone areas better than other functions. The disbelief map, showed the opposite distribution from that of the belief map. The plausibility map was similar to the belief map, but the contrast between lower degrees and the higher degrees was not much clear. The uncertainty map indicated a lack of information or the presence of insufficient evidential data layers for landslide susceptibility assessment. The FR model can reflect the spatial relationship between landslide occurrence and conditioning factors and also closely matches the objective of susceptibility assessment. As aforementioned, In FR model, the input, calculation, and output processes are very simple and easy to understand which makes it a good choice for a practical landslide susceptibility assessment when facing short amount of time. There are many studies comparing and validating FR and EBF models in landslide susceptibility mapping. Hong et al. (2016b), evaluated and compared FR and EBF methods with random forest and logistic regression models. The results were quite interesting as indicates a higher accuracy for FR than that of the EBF. Also, another study by Mohammady et al. (2012) also shows a higher accuracy for FR compared to EBF. Zhang et al. (2016), Ding et al. (2017), and Chen et al. (2017a) also attest such outperformance.
The results regarding the percentage of susceptibility classes can speak through a fact termed as practicality, which was recently proposed, by Kornejady et al. (2017a, b), Chen et al. (2017b), Pourghasemi et al. (2017), Termeh et al. (2018). This feature relies on being focused in addressing highly susceptible area to landsliding. For instance, a model that introduces half of an area, or even more, as highly susceptible to landslide occurrence cannot be taken seriously or, in other words, is not practical when there is a urgent need to go straight to management stage and spatial allocation of mitigation measures. The same applies to FR model in this study, which can roots from those simple mathematical assumptions and naïve data integration strategy. MD represents a high practicality, while EBF stands somewhere in the middle. This implies that choosing between an outperformed model and a practical one can be a matter of expertise, time and the budget one owns. It also indicates the need for more data and evaluation tests to choose the model that is reliable in more aspects, not only focused on one. Integrated evaluation tests can be helpful in this area.
Although the three used models in this study achieved good results in landslide susceptibility mapping, we encountered some limitations which opens an area for further assessments in future works: (1) the effect of landslide types on the results of the models should be addressed since each type can be subjected to a particular set of conditioning factors and might own different occurrence process, (2) different sets of conditioning factors should be engaged in modeling process, and 3) different sample partitioning techniques should be examined in order to assess the sensitivity of the models to altered inputs.
Conclusion
This study aimed at landslide susceptibility assessment by using statistical and probabilistic models in Anfu County, China. The take home inferences are as follows:
-
I.
FR model shows high predictive power and generalization capacity for modeling landslide susceptibility in our study area; however, the drawbacks of owning simple statistical assumptions and mathematical functions emerges with producing an unauthentic map to some extent. Where, almost half of the study area is introduced as highly susceptible to landsliding, which makes the allocation of mitigation measures much harder and defeats the purpose of having a practical outcome. MD shows more practical results in this regard, but choosing the best model will be up to the decision makers and their purpose to whether have a predictive model or a practical one. EBF shows moderate results in both area. We suggest an effort to make an ensemble model that performs well in both features mentioned above.
-
II.
According to FR, as the model with the highest AUROC, five factors are introduced as responsible for landslide occurrence in the area: NDVI, soil texture, slope degree, altitude, and HAND. This reveals that natural cause rather than anthropological agents mostly induce the landslides. Since changing the natural factors is not a logical option and sometimes impossible, undertaking “adaptation and avoidance strategies” could be a good choice to put on the agenda.
-
III.
HAND, as factor that bears on both hydrological and topological properties, shows promising results in landslide susceptibility assessment where it can be a good replacement for other ad hoc indices.
Lastly, we suggest using different novel data mining methods with different model structures, parameter configurations, better data resolutions, and different set of predictors in future to compare the results with this study. The results of this study is a good primary evaluation of landslide susceptibility in the study area which could be of prime interest to those who are dealing with land use planning and risk management.
References
Ahmed B (2014) Landslide susceptibility mapping using multi-criteria evaluation techniques in Chittagong Metropolitan Area, Bangladesh. Landslides
Althuwaynee OF, Pradhan B, Park H-J, Lee JH (2014) A novel ensemble bivariate statistical evidential belief function with knowledge-based analytical hierarchy process and multivariate statistical logistic regression for landslide susceptibility mapping. Catena 114:21–36
Barker DM et al (2009) Longitudinal distributions of river flood power: the combined automated flood, elevation and stream power (CAFES) methodology. Earth Surf Process Landf 34:280–290
Barlow J et al (2015) Seismically-induced mass movements and volumetric fluxes resulting from the 2010 Mw=7.2 earthquake in the Sierra Cucapah, Mexico. Geomorphology 230:138–145
Bièvre G, Jongmans D, Goutaland D, Pathier E, Zumbo V (2015) Geophysical characterization of the lithological control on the kinematic pattern in a large clayey landslide (Avignonet, French Alps). Landslides
Bonham-Carter GF (1994) Geographic Information Systems for Geoscientists. Computer Methods in the Geosciences 4(4):1–2
Bordoni M, Meisina C, Valentino R, Bittelli M, Chersich S (2015a) Site-specific to local-scale shallow landslides triggering zones assessment using TRIGRS. Nat Hazards Earth Syst Sci 15:1025–1050
Bordoni M et al (2015b) Hydrological factors affecting rainfall-induced shallow landslides: From the field monitoring to a simplified slope stability analysis. Eng Geol 193:19–37
Chen Z, Liang S, Ke Y, Yang Z, Zhao H (2017a) Landslide susceptibility assessment using evidential belief function, certainty factor and frequency ratio model at Baxie River basin, NW China. Geocarto International:1–20
Chen W, Pourghasemi HR, Panahi M, Kornejady A, Wang J, Xie X, Cao S (2017b) Spatial prediction of landslide susceptibility using an adaptive neuro-fuzzy inference system combined with frequency ratio, generalized additive model, and support vector machine techniques. Geomorphology 297:69–85
Chen W, Peng J, Hong H, Shahabi H, Pradhan B, Liu J, Zhu AX, Pei X, Duan Z (2018a) Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci Total Environ 626:1121–1135
Chen W, Xie X, Peng J, Shahabi H, Hong H, Bui DT, Duan Z, Li S, Zhu AX (2018b) GIS-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. Catena 164:135–149
Ciampalini A et al (2015) Remote sensing as tool for development of landslide databases: The case of the Messina Province (Italy) geodatabase. In: Geomorphology
Conforti M, Pascale S, Robustelli G, Sdao F (2014) Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy). Catena 113:236–250
Damm B, Klose M (2015) The landslide database for Germany: Closing the gap at national level. Geomorphology 249(15):82–93
Das HO, Sonmez H, Gokceoglu C, Nefeslioglu HA (2012) Influence of seismic acceleration on landslide susceptibility maps: a case study from NE Turkey (the Kelkit Valley). Landslides 10:433–454
Day S et al (2015) Submarine landslide deposits of the historical lateral collapse of Ritter Island, Papua New Guinea. Mar Pet Geol 67:419–438
Demir G et al (2013) A comparison of landslide susceptibility mapping of the eastern part of the North Anatolian Fault Zone (Turkey) by likelihood-frequency ratio and analytic hierarchy process methods. Nat Hazards 65(3):1481–1506
Dempster AP (1967) Upper and lower probabilities induced by a multivalued mapping. Ann Math Stat:325–339
Ding Q, Chen W, Hong H (2017) Application of frequency ratio, weights of evidence and evidential belief function models in landslide susceptibility mapping. Geocarto International 32:619–639
Eker AM, Dikmen M, Cambazoğlu S, Düzgün ŞHB, Akgün H (2014) Evaluation and comparison of landslide susceptibility mapping methods: a case study for the Ulus district, Bartın, northern Turkey. Int J Geogr Inf Sci 29:132–158
Elmoulat M, Brahim LA, Mastere M, Jemmah AI (2015) Mapping of Mass Movements Susceptibility in the Zoumi Region Using Satellite Image and GIS Technology (Moroccan Rif). International Journal of Scientific & Engineering Research 6:210–217
Fan X, Rossiter DG, van Westen CJ, Xu Q, Görüm T (2014) Empirical prediction of coseismic landslide dam formation. Earth Surf Process Landf 39:1913–1926
Faraji Sabokbar H, Shadman Roodposhti M, Tazik E (2014) Landslide susceptibility mapping using geographically-weighted principal component analysis. Geomorphology 226:15–24
Gallo F, Lavé J (2014) Evolution of a large landslide in the High Himalaya of central Nepal during the last half-century. Geomorphology 223:20–32
Galve JP, Cevasco A, Brandolini P, Soldati M (2014) Assessment of shallow landslide risk mitigation measures based on land use planning through probabilistic modelling. Landslides 12:101–114
Ganapathy GP, Rajawat AS (2015) Use of hazard and vulnerability maps for landslide planning scenarios: a case study of the Nilgiris, India. Nat Hazards 77:305–316
Goetz JN, Brenning A, Petschko H, Leopold P (2015) Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput Geosci 81:1–11
Günther A, Van Den Eeckhaut M, Malet J-P, Reichenbach P, Hervás J (2014) Climate-physiographically differentiated Pan-European landslide susceptibility assessment using spatial multi-criteria evaluation and transnational landslide information. Geomorphology 224:69–85
Gutiérrez F et al (2015) Large landslides associated with a diapiric fold in Canelles Reservoir (Spanish Pyrenees): Detailed geological–geomorphological mapping, trenching and electrical resistivity imaging. Geomorphology 241:224–242
Havenith HB et al (2015) Tien Shan Geohazards Database: Landslide susceptibility analysis. Geomorphology
Hong H, Pradhan B, Xu C, Tien Bui D (2015) Spatial prediction of landslide hazard at the Yihuang area (China) using two-class kernel logistic regression, alternating decision tree and support vector machines. Catena 133:266–281
Hong H, Naghibi SA, Pourghasemi HR, Pradhan B (2016a) GIS-based landslide spatial modeling in Ganzhou City, China. Arab J Geosci 9(2):112
Hong H, Pourghasemi HR, Pourtaghi ZS (2016b) Landslide susceptibility assessment in Lianhua County (China): a comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 259:105–118
Hong H, Liu J, Zhu AX, Shahabi H, Pham BT, Chen W, Pradhan B, Bui DT (2017a) A novel hybrid integration model using support vector machines and random subspace for weather-triggered landslide susceptibility assessment in the Wuning area (China). Environ Earth Sci 76(19):652
Hong H, Chen W, Xu C,Youssef A M, Pradhan B, Dieu T B. (2017b) Rainfall-induced landslide susceptibility assessment at the Chongren area (China) using frequency ratio, certainty factor, and index of entropy. Geocarto International 32(2):139–154
Ilia I, Tsangaratos P (2016) Applying weight of evidence method and sensitivity analysis to produce a landslide susceptibility map. Landslides
Iovine G, Greco R, Gariano SL, Pellegrino AD, Terranova OG (2014) Shallow-landslide susceptibility in the Costa Viola mountain ridge (Southern Calabria, Italy) with considerations on the role of causal factors. Nat Hazards 73(1):111–136. https://doi.org/10.1007/s11069-014-1129-0
Jebur MN, Pradhan B, Tehrany MS (2014) Optimization of landslide conditioning factors using very high-resolution airborne laser scanning (LiDAR) data at catchment scale. Remote Sens Environ 152:150–165
Kirschbaum D, Stanley T, Zhou Y (2015) Spatial and temporal analysis of a global landslide catalog. Geomorphology
Kornejady A, Ownegh M, Bahremand A (2017a) Landslide susceptibility assessment using maximum entropy model with two different data sampling methods. Catena 152:144–162
Kornejady A, Ownegh M, Rahmati O, Bahremand A (2017b) Landslide susceptibility assessment using three bivariate models considering the new topo-hydrological factor: HAND. Geocarto International:1–68
Kritikos T, Robinson TR, Davies TRH (2015) Regional coseismic landslide hazard assessment without historical landslide inventories: A new approach. J Geophys Res Earth Surf 120:711–729
Lacroix P, Berthier E, Maquerhua ET (2015) Earthquake-driven acceleration of slow-moving landslides in the Colca valley, Peru, detected from Pléiades images. Remote Sens Environ 165:148–158
Larsen IJ, Montgomery DR (2012) Landslide erosion coupled to tectonics and river incision. Nat Geosci 5:468–473
Le QH, Van Nguyen TH, Do MD, Le TCH, Nguyen HK, Luu TB (2018) TXT-tool 1.084–3.1: Landslide Susceptibility Mapping at a Regional Scale in Vietnam, In Landslide Dynamics: ISDR-ICL Landslide Interactive Teaching Tools (pp. 161–174). Springer, Cham
Lian C, Zeng Z, Yao W, Tang H (2014) Extreme learning machine for the displacement prediction of landslide under rainfall and reservoir level. Stoch Env Res Risk A 28:1957–1972
Liu Z, Shao J, Xu W, Chen H, Shi C (2013) Comparison on landslide nonlinear displacement analysis and prediction with computational intelligence approaches. Landslides 11:889–896
Mahalanobis PC (1936) On the generalised distance in statistics. Proceedings of the National Institute of Sciences of India 1936:49–55
Mansouri Daneshvar MR (2014) Landslide susceptibility zonation using analytical hierarchy process and GIS for the Bojnurd region, northeast of Iran. Landslides 11:1079–1091
Meinhardt M, Fink M, Tünschel H (2015) Landslide susceptibility analysis in central Vietnam based on an incomplete landslide inventory: Comparison of a new method to calculate weighting factors by means of bivariate statistics. Geomorphology 234:80–97
Meten M, Bhandary NP, Yatabe R (2015) Application of GIS-based fuzzy logic and rock engineering system (RES) approaches for landslide susceptibility mapping in Selelkula area of the Lower Jema River Gorge, Central Ethiopia. Environ Earth Sci 74:3395–3416
Mogaji K, Omosuyi G, Adelusi A, Lim H (2016) Application of GIS-Based Evidential Belief Function Model to Regional Groundwater Recharge Potential Zones Mapping in Hardrock Geologic Terrain. Environmental Processes 3:93–123
Mohammady M, Pourghasemi HR, Pradhan B (2012) Landslide susceptibility mapping at Golestan Province, Iran: a comparison between frequency ratio, Dempster–Shafer, and weights-of-evidence models. J Asian Earth Sci 61:221–236
Moore ID, Grayson RB (1991) Terrain-based catchment partitioning and runoff prediction using vector elevation data. Water Resour Res 27(6):1177–1191
Park N-W (2011) Application of Dempster-Shafer theory of evidence to GIS-based landslide susceptibility analysis. Environ Earth Sci 62(2):367–376
Peng L et al (2014) Landslide susceptibility mapping based on rough set theory and support vector machines: A case of the Three Gorges area, China. Geomorphology 204:287–301
Petschko H, Brenning A, Bell R, Goetz J, Glade T (2014) Assessing the quality of landslide susceptibility maps - case study Lower Austria. Nat Hazards Earth Syst Sci 14:95–118. https://doi.org/10.5194/nhess-14-95-2014
Poiraud A (2014) Landslide susceptibility–certainty mapping by a multi-method approach: A case study in the Tertiary basin of Puy-en-Velay (Massif central, France). Geomorphology 216:208–224
Pourghasemi HR (2016) GIS-based forest fire susceptibility mapping in Iran: a comparison between evidential belief function and binary logistic regression models. Scand J For Res 31:80–98
Pourghasemi HR, Kerle N (2016) Random forests and evidential belief function-based landslide susceptibility assessment in Western Mazandaran Province, Iran. Environ Earth Sci 75:1–17
Pourghasemi H, Moradi H, Aghda SF (2013a) Landslide susceptibility mapping by binary logistic regression, analytical hierarchy process, and statistical index models and assessment of their performances. Nat Hazards 69(1):749–779
Pourghasemi HR et al (2013b) Landslide susceptibility mapping using support vector machine and GIS at the Golestan Province, Iran. J Earth Syst Sci 122(2):349–369
Pourghasemi HR, Moradi HR, Aghda SF, Gokceoglu C, Pradhan B (2014) GIS-based landslide susceptibility mapping with probabilistic likelihood ratio and spatial multi-criteria evaluation models (North of Tehran, Iran). Arab J Geosci 7(5):1857–1878
Pourghasemi HR, Yousefi S, Kornejady A, Cerdà A (2017) Performance assessment of individual and ensemble data-mining techniques for gully erosion modeling. Sci Total Environ 609:764–775
Pradhan B (2013) A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput Geosci 51:350–365
Pradhan B, Abokharima MH, Jebur MN, Tehrany MS (2014) Land subsidence susceptibility mapping at Kinta Valley (Malaysia) using the evidential belief function model in GIS. Nat Hazards 73:1019–1042
Rahmati O, Kornejady A, Samadi M, Nobre AD, Melesse AM (2018) Development of an automated GIS tool for reproducing the HAND terrain model. Environ Model Softw 102:1–12
Ramos-Cañón A, Prada-Sarmiento L, Trujillo-Vela M, Macías J, Santos-R A (2015) Linear discriminant analysis to describe the relationship between rainfall and landslides in Bogotá. Colombia Landslides 13(4):671–681
Scaioni M, Longoni L, Melillo V, Papini M (2014) Remote Sensing for Landslide Investigations: An Overview of Recent Achievements and Perspectives. Remote Sens 6:9600–9652
Shadman Roodposhti M, Aryal J, Shahabi H, Safarrad T (2016) Fuzzy Shannon Entropy: A Hybrid GIS-Based Landslide Susceptibility Mapping Method. Entropy 18(10):343
Shafer G (1976) A mathematical theory of evidence. Technometrics 20:242
Shahabi H, Hashim M (2015) Landslide susceptibility mapping using GIS-based statistical models and Remote sensing data in tropical environment. Sci Rep 5:9899
Sharma LP, Patel N, Ghose MK, Debnath P (2014) Development and application of Shannon’s entropy integrated information value model for landslide susceptibility assessment and zonation in Sikkim Himalayas in India. Nat Hazards 75:1555–1576
Shi X, Zhang L, Balz T, Liao M (2015) Landslide deformation monitoring using point-like target offset tracking with multi-mode high-resolution TerraSAR-X data. ISPRS J Photogramm Remote Sens 105:128–140
Su C, Wang L, Wang X, Huang Z, Zhang X (2015) Mapping of rainfall-induced landslide susceptibility in Wencheng, China, using support vector machine. Nat Hazards 76:1759–1779
Süzen ML, Doyuran V (2004) Data driven bivariate landslide susceptibility assessment using geographical information systems: a method and application to Asarsuyu catchment, Turkey. Eng Geol 71(3):303–321
Tahmassebip Swets JA (1988) Measuring the accuracy of diagnostic systems. science, 240(4857), 1285-1293. oor, N., Rahmati, O., Noormohamadi, F., Lee, S., 2016. Spatial analysis of groundwater potential using weights-of-evidence and evidential belief function models and remote sensing. Arab J Geosci 9:1–18
Termeh SVR, Kornejady A, Pourghasemi HR, Keesstra S (2018) Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci Total Environ 615:438–451
Tien Bui D et al (2015a) A novel hybrid evidential belief function-based fuzzy logic model in spatial prediction of rainfall-induced shallow landslides in the Lang Son city area (Vietnam). Geomatics. Natural Hazards and Risk 6:243–271
Tien Bui D, Tuan TA, Klempe H, Pradhan B, Revhaug I (2015b) Spatial prediction models for shallow landslide hazards: a comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides
Tomás R, Li Z, Lopez-Sanchez JM, Liu P, Singleton A (2015) Using wavelet tools to analyse seasonal variations from InSAR time-series data: a case study of the Huangtupo landslide. Landslides
Topal T, Hatipoglu O (2015) Assessment of slope stability and monitoring of a landslide in the Koyulhisar settlement area (Sivas, Turkey). Environmental Earth Sciences
Trigila, A., Iadanza, C., Esposito, C., Scarascia-Mugnozza, G., 2015. Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology
Tsangaratos P, Ilia I (2015) Landslide susceptibility mapping using a modified decision tree classifier in the Xanthi Perfection, Greece. Landslides
Tsangaratos P, Ilia I, Hong H, Chen W, Xu C (2016) Applying information theory and GIS-based quantitative methods to produce landslide susceptibility maps in Nancheng county, China. Landslides, 1–21. https://doi.org/10.1007/s10346-016-0769-4
Umar Z, Pradhan B, Ahmad A, Jebur MN, Tehrany MS (2014) Earthquake induced landslide susceptibility mapping using an integrated ensemble frequency ratio and logistic regression models in West Sumatera Province, Indonesia. Catena 118:124–135
Wang G et al (2015) A methodology to derive precise landslide displacement time series from continuous GPS observations in tectonically active and cold regions: a case study in Alaska. Nat Hazards 77:1939–1961
Wood JL, Harrison S, Reinhardt L (2015) Landslide inventories for climate impacts research in the European Alps. Geomorphology 228:398–408
Xing AG et al (2014) Dynamic analysis and field investigation of a fluidized landslide in Guanling, Guizhou, China. Eng Geol 181:1–14
Xu C, Xu X, Shyu JBH, Zheng W, Min W (2014) Landslides triggered by the 22 July 2013 Minxian–Zhangxian, China, Mw 5.9 earthquake: Inventory compiling and spatial distribution analysis. J Asian Earth Sci 92:125–142
Yalcin A, Reis S, Aydinoglu AC, Yomralioglu T (2011) A GIS-based comparative study of frequency ratio, analytical hierarchy process, bivariate statistics and logistics regression methods for landslide susceptibility mapping in Trabzon, NE Turkey. Catena 85:274–287
Yao W, Zeng Z, Lian C, Tang H (2015) Training enhanced reservoir computing predictor for landslide displacement. Eng Geol 188:101–109
Yesilnacar EK (2005) The application of computational intelligence to landslide susceptibility mapping in Turkey: University of Melbourne, Department, 200
Youssef AM (2015) Landslide susceptibility delineation in the Ar-Rayth area, Jizan, Kingdom of Saudi Arabia, using analytical hierarchy process, frequency ratio, and logistic regression models. Environ Earth Sci 73:8499–8518
Youssef AM, Pourghasemi HR, El-Haddad BA, Dhahry BK (2015) Landslide susceptibility maps using different probabilistic and bivariate statistical models and comparison of their performance at Wadi Itwad Basin, Asir Region, Saudi Arabia. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-015-0734-9
Yusof NM, Pradhan B, Shafri HZM, Jebur MN, Yusoff Z (2015) Spatial landslide hazard assessment along the Jelapang Corridor of the North-South Expressway in Malaysia using high resolution airborne LiDAR data. Arab J Geosci
Zeybek M, Şanlıoğlu İ, Özdemir A (2015) Monitoring landslides with geophysical and geodetic observations. Environ Earth Sci
Zhang Z et al (2016) GIS-based landslide susceptibility analysis using frequency ratio and evidential belief function models. Environ Earth Sci 75(11):948
Zhao H, Yao L, Mei G, Liu T, Ning Y (2017) A Fuzzy Comprehensive Evaluation Method Based on AHP and Entropy for a Landslide Susceptibility Map. Entropy 19(8):396
Zhou S, Fang L, Liu B (2015) Slope unit-based distribution analysis of landslides triggered by the April 20, 2013, Ms 7.0 Lushan earthquake. Arab J Geosci
Acknowledgements
The authors would like to acknowledge the anonymous reviewers and the editor for their helpful comments on a previous version of the manuscript. Also, the authors wish to express their sincere thanks to Universiti Teknologi Malaysia (UTM) based on Research University Grant (Q.J130000.2527.17H84) for their financial supports in this research.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Communicated by: H. A. Babaie
Rights and permissions
About this article

Cite this article
Hong, H., Kornejady, A., Soltani, A. et al. Landslide susceptibility assessment in the Anfu County, China: comparing different statistical and probabilistic models considering the new topo-hydrological factor (HAND). Earth Sci Inform 11, 605–622 (2018). https://doi.org/10.1007/s12145-018-0352-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-018-0352-8