
Abstract
Detection and diagnosis of a disease with a single image can be tedious and difficult for doctors but with the adaptation of medical image fusion, a path for additional improvements can be paved. The objective of this research is to implement different fusion algorithms based on conventional and proposed hybrid techniques. Based on performance metrics it has been observed that the novel method, Discrete Component Wavelet Transform (DCWT) shows remarkable results in comparison to the traditional techniques. As per the enhancement methods, Binarization, Median Filter, and Contrast Stretching have been considered to compare the contrast performance with Contrast Limited Adaptive Histogram Equalization. Certain modifications to each enhancement method were made related to the selection of parameters. Thus, better qualitative and quantitative values were observed in Discrete Component Wavelet Transform. The different attributes were calculated from the fused images which were classified using various machine learning techniques. Maximum accuracy of 97.87% and 95.74% is obtained using Discrete Component Wavelet Transform for Support Vector Machine (SVM) and k Nearest Neighbor (kNN) (k = 4) respectively considering the combination of both features Grey Level Difference Statistics and shape.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Healthcare is one of the most popular fields in terms of collection and processing of data. With the advent of the digital era and advancement in technology, a large amount of multi-dimensional data is generated about patients, which includes hospital resources, clinical parameters, patients’ records, disease diagnostic details, and medical devices [1, 2]. The present-day medical science and health treatment, computer-assisted diagnostics, and rehabilitation are heavily dependent on image processing techniques. Biomedical imaging furnishes ways to improve the diagnosis process, augment disease identification, minimize error, and uncover new information about the concerned disease [3, 4]. The human body has complex, curve-like configurations such as the brain which is a highly structured and delicate organ. Radiologists have to know the position of activations leading to brain disease in functional data images to perceive the details accurately [5]. Brain anomalies are categorized depending on the position and form of tissues, which aids in the diagnosis of cancerous or non-cancerous abnormalities [6]. Infections, bleeding, hemorrhage, epilepsy, and cancers are a few of the examples of brain defects. Anatomical imageries like Computed Tomography (CT), Magnetic Resonance Image (MRI), Single Photon Emission Computed Tomography (SPECT), and Positron Emission Tomography (PET) can aid with this [7]. Medical image fusion is a technique that integrates the information, and complimentary features of two or more imaging modalities to enhance visualization and perception enabling the extraction and classification of vital features that may not be noticeable within each modality [8]. MRI and CT are among the most widely used radiology modalities for detecting neurodegenerative problems and diagnosing hemorrhage, acute stroke, and inflammation, with the assistance of image data processing. SPECT is also beneficial when there is a need to examine the activity of a few human body parts. A PET scan diagnoses certain health problems like cancer, neurology, and cardiology treatments and assesses the efficacy of a treatment by representing the appearance of an organ and how it functions [9,10,11]. MRI provides significant soft tissue visibility, contrast, and spatial resolution while avoiding the use of toxic ionized radiation. Because of these properties, MRI has become a valuable method in clinical and surgical settings for diagnosing tumors. Whereas, CT scans are most often used to distinguish between hemorrhage due to profuse bleeding and stroke when blood supply gets blocked in the brain. The CT scans enable vital details with faster scanning, making them more useful for detecting hemorrhage and stroke. The four commonly used MRI modalities are T1-weighted MRI (T1), T2-weighted MRI (T2), and FLAIR with contrast enhancement. Fluid Attenuated Inversion Recovery (FLAIR) [6, 7] as shown in figure 1.

MR imaging modalities: (a) T1-weighted MRI; (b) T2-weighted MRI; (c) FLAIR and (d) FLAIR with contrast enhancement (E5).
T1 and T2 are known as relaxation times measured in milliseconds, and tell how the brain reacts to electromagnetic energy. When having an MRI, the scanner sends radiofrequency waves to the brain. The energy of this signal is absorbed by brain tissue increasing its "magnetic momentum". When the radio frequency signal stops, the scan measures how long it takes for the tissue to give back this energy, or to "relax". This is T1. In contrast, T2 relaxation measures the time it takes for the magnetic momentum to lose coherence, after the RF signal has ceased, in a plane that is transversal to the main magnetic field of the scanner (which is head to toe) [5]. The time to give back energy (T1) and the time to lose coherence (T2) are biomarkers that characterize healthy tissue. Therefore, any abnormal values can be either identified by visual inspection (radiologist) or calculated (computer analysis). FLAIR is a particular type of medical image that is used to eliminate cerebrospinal fluid from the image. This is possible because we know the normal T1 for cerebrospinal fluid (CSF). The advantage of this technique is that lesions in regions close to the ventricles or in the cortical periphery where CSF is abundant are more easily identified [6]. Different diseases occur due to various disorders that affect the blood vessels, or blood supply to the brain. In this paper, the authors are working on cerebrovascular diseases.
Cerebrovascular disease is a term that encompasses a variety of illnesses, diseases, and disorders affecting the brain's blood vessels and blood supply. Brain damage may occur if a malformation, blockage, or hemorrhage prevents the brain cells from receiving enough oxygen. Stroke, transient ischemic attack (TIA), aneurysm, and vascular malformation are among them. A cerebrovascular occurrence necessitates immediate medical attention. A brain hemorrhage requires the attention of a neurosurgeon. Carotid endarterectomy is a procedure that involves cutting a hole in the carotid artery and extracting plaque. This re-establishes blood supply. The artery is then repaired with sutures or graft by the surgeon [12]. The most common form of cerebrovascular occurrence is a stroke. Stroke risk rises with age, particularly if a person or a close relative has previously experienced a cerebrovascular event. Between the ages of 55 and 85, this risk doubles every ten years. A stroke, on the other hand, can strike at any age, including infancy. Cerebrovascular disorders have eight main risk factors (CBVD) [13]. High blood pressure (hypertension), smoking, diet, high blood cholesterol, lack of exercise, becoming overweight or obese, diabetes, and excessive alcohol intake are some of the risk factors. Other cerebrovascular disease risk factors include (i) Moyamoya disease, a serious illness that can lead to a blocking of the cerebral arteries and their main branches, (ii) venous angiomas, which concern around 2% of the populace but rarely bleeds or cause symptoms, and (iii) a vein of Galen deformity, an arterial disorder that occurs in a fetus during pregnancy [14].
1.1 Related research
Previous literature in this field was directed to image enhancement and medical image fusion techniques concerning the brain. In [15] the proposed approach employs wavelet-based image fusion to generate a high-quality merged image with spatial and spectral detail. The method also detects brain tumors efficiently using ANN and determines the tumor's location and region. In [16] a new DCT-based image fusion algorithm is proposed. In multimodal medical images, it is extremely efficient at preserving tissue content, texture, and edges. Furthermore, the algorithm can generate high-quality fused images in a shorter amount of time. Instead of using the wavelet domain, a scheme [17] has been proposed for the fusion of multi-focus images in the MDCT domain. In terms of visual consistency and quantitative parameters, the MDCT domain performs similarly to wavelets, but with less computational complexity. In [18] a comparative analysis is conducted among different feature extraction methods: convolutional networks (ConvNet), SIFT codebook, HMAX, and color-texture codebook (CT). Lastly, a fusion algorithm is devised based on details acquired from each method's uncertainty matrix and further increases class-prediction performance. In [19], to improve the precision of feature extraction technique focus has been laid on locating abnormalities such as brain hemorrhage and brain tumor. The methodology includes the integration of patient's MRI or CT Dicom image slices into a single image, noise reduction by three different approaches, noise selection based on Peak Signal to Noise Ratio (PSNR) and Mean Squared Error (MSE) error metrics, skull removal, and image enhancement are all included in the brain image extraction and brain image transformation process. In [20] by employing significant image fusion methods, a pixel-dependent image fusion technique based on differential evolution—discrete wavelet transform (DE-DWT) is proposed. Images from CT and MRI were used in the simulations. The efficacy of the proposed DE-DWT method is indicated by performance indices such as entropy, MSE, PSNR, comparison, and homogeneity. In [21] a median filter was used to eliminate noise after image fusion using an intensity-based approach. It was concluded that the experimental SNR and CNR value improved on enhancing the contrast of fused images.
1.2 Contribution and objectives
The blur and noise in clinical images should be eliminated to improve the contrast and amount of information that can be retained. The need for improved diagnostic imaging has been raised to enable the experimenter to make an appropriate diagnosis. Broadly speaking, the task of improving medical pictures is to intensify an area of concern. The main consideration is to retain the specifics of the enlarged image. Because of such issues, image processing techniques like enhancement and fusion algorithms [22, 23] aid human visuals in making unbiased judgements of images. Unlike manually examining a site via biopsy or another method, medical imaging is non-invasive. The problem is that in comparison to manual verification techniques, imaging will always be less accurate in detection. Medical image processing is a subset of image processing, and with the above problem in mind, the objective of this paper is to utilize
-
1.
Improved noise removal of images (online data), enhanced resolution, etc.
-
2.
Enhanced image processing (diagnostics, object identification, etc.)
-
3.
Superior image display (generating 3D from 2D slices, etc.)
The paper focuses on the classification of cerebrovascular diseases. To assess regarding structures abnormality and the functionality of tissues, initially different medical imaging modalities were used for image fusion concerning both conventional techniques like Principal Component Analysis (PCA), Discrete Wavelet Transform (DWT), Discrete Cosine Transform (DCT), and proposed hybrid technique (DCT + PCA and Discrete Component Wavelet Transform) are utilized. The individual limitations of each fusion scheme helped in understanding how they can be curbed using a method which is less complex in methodology. The efficiency of each is then validated using feature extraction which extorts prominent features of the lesion and further, is employed to classifiers as inputs to add them to the category that they embody. The various shape and GLDS features obtained were then classified using different machine learning techniques.
The paper is structured as follows. Section 2 describes the materials and methodology of the proposed image fusion technique, feature extraction, and machine learning techniques. Section 3 elucidates the results of the proposed methodologies followed by concluding remarks in section 4.
2 Materials and methodology
While fusing two images, overlay means that the pixel values of one image replace the pixels of the second image whereas fused means that the pixel values are mixed. Image fusion is a process of extracting important information from multiple images, and their inclusion into fewer images, at times a single image [24, 25]. This single image is usually more informative and accurate than its source images. Image fusion has a wide range of applications [26, 27]. Multi-sensor fusion is a technique for achieving high spatial and spectral resolutions in remote sensing and astronomy by integrating data from two sensors, one of which has high spatial resolution and the other has high spectral resolution [28, 29]. In medical imaging, many fusion applications have emerged, such as the simultaneous assessment of CT, MRI, and/or PET images. In the military, defense, and surveillance fields, numerous applications use a multisensor fusion of visible and infrared images. In multi-sensor fusion, two sensors were used for high spatial and high spectral data. A benchmarked database is taken from Harvard Medical School, Whole Brain Atlas http://www.med.harvard.edu/aanlib/home.html [30] which provides a wide range of neuro imaging anatomies. When the brain is imaged, it is viewed in two-dimensional (2D) slices. These are typically viewed in three different planes: the sagittal, coronal, or axial planes. The fusion schemes fuse brain images of axial view (horizontal plane). This information resource of the central nervous system integrates clinical information with magnetic resonance (MR), computed tomography (CT), and nuclear medicine images. The Atlas project has been initiated by the Departments of Radiology and Neurology at Brigham and Women's Hospital, Harvard Medical School, the Countway Library of Medicine, and the American Academy of Neurology. This database consists of a total of over 100 CT and MR images of both the left and right sides of the brain.
In this section, the proposed scheme of brain diseases is classified and detected. Figure 2 depicts the proposed framework of the overall architecture.

The proposed methodology for the detection of cerebrovascular disease. .
In the preprocessing phase, CT and MR images are imported, resized, and enhanced using the CLAHE method to eliminate the noise and irrelevant details from the entire dataset. The source images are then fused to produce a more detailed image which would aid in the detection and classification of cerebrovascular diseases utilizing different medical fusion techniques. To obtain significant results, before the fusion of images, they are individually pre-processed to remove artefacts, noise and improve the contrast. It makes the complex details of each image appear more refined and then decomposed into features which help in correct diagnosis. The CT and MR scans depict different information about the structure in and around the brain. Thus, the fusion of modified modalities is preferred rather than extracting the features and then merging because the former approach gives collective details which are easy to assess.
In this paper conventional (PCA, DCT, DWT, PCA-DWT) and proposed (DCT + PCA and Discrete Component Wavelet Transform) fusion techniques are implemented. The performance is examined using RMSE, PSNR, and SNR quality metrics. The work represents that Discrete Component Wavelet Transform performs better fusion, in terms of PSNR and SNR, when compared to other conventional methods. Dimensionality reduction is one of PCA's advantages yet leads to loss of content and incorporates most of the information from only one source image. Problems like visible blocking artifacts and a dull appearance in output images were in the DCT method. DWT method provides a better comprehension of details except that the fused images were low in contrast. In PCA-DWT, the contrast of output images was less and hindered the analysis. Further on implementing DCT-PCA, the representation of details in output images were better with the use of CLAHE and reduced artifacts but gave poor PSNR and SNR values. To overcome these limitations and provide a better fusion scheme, authors proposed the Discrete Component Wavelet Transform. It yields better PSNR and SNR values, acquired crucial details from source images, visibility of artifacts and noise was reduced to some extent. The statistical texture features and shape features are extracted from the fused images. Following that, kNN and SVM-based classifier is used to determine if the stroke is acute, or fatal established on the extracted features. Finally, the performance is assessed. The following subsections go through each of these approaches in greater depth. All the experimentations were conducted in MATLAB 2019b software with Pentium dual-core CPU @ 3.60 GHz processor, 64-bit operating system.
2.1 Image acquisition and pre-processing
The acquired data images are aligned to superimpose the corresponding features and details, properly. They are then preprocessed by examining the color frames and resizing to size 256 × 256. Enhancement Technique aims at noise suppression and improvement of contrast in source images. There are different enhancement techniques namely Binarization, median filtering, Contrast stretching, and Histogram Equalization. It depends on transformation functions to increase the contrast of the images. The transformation function transfers the pixel intensity levels from the given range to the required range [31]. Histogram equalization is a method to modify the dynamic range and contrast of the image by altering the shape of the histogram. Unlike contrast stretching operations, histogram equalization employs non-linear functions to map intensities from the input image to the output image. In this paper, authors processed images using different enhancement algorithms like Binarization/Median Filter/Contrast Stretching, and Contrast Limited Adaptive Histogram Equalization (CLAHE). CLAHE is a widely used image enhancement technique that utilizes histogram equalization. CLAHE is simple and the computational load is minimal. It can also be utilized for colored images. CLAHE is the development of the AHE technique in which all pixels adjacent to all functions will be converted [32, 33]. The AHE differs from CLAHE because CLAHE limits or restricts the contrast, use the maximum available value present on the clip, and returns it to the greyscale. The fundamental algorithm for enhancing individual image regions by using the CLAHE technique is described briefly in figure 3.

Flowchart of steps involved in CLAHE algorithm.
2.2 Image fusion
When localization of the disease is uncertain from within a single modality, fusion techniques are utilized to access more medical detail by synthesizing the complementary and contrasting characteristics of source images into a single one. Conventional medical image fusion approaches can not produce high-resolution images. As a result, there is indeed a significant need to employ hybrid fusion techniques to achieve the objective. The hybrid technique's basic purpose is to amplify the efficiency of the fusion method and fused image quality.
Conventional image fusion techniques:
-
i.
Principal Component Analysis (PCA): It is used to condense a huge number of variables into a small number that also contains the majority of the information that was previously present in the large set. Since medical images are of considerable amount, PCA will enable analysis and interpretation easy from the reduced data.
-
ii.
Discrete Wavelet Transform (DWT): Wavelet is defined by two functions: wavelet function called mother wavelet \(\psi \left(t\right)\) and scaling function is known as father wavelet \(\varphi (t)\). By translating and dilating mother wavelets \(\psi \left(x\right)\), diverse forms can be developed by using Eq. (1). DWT algorithm used for this research uses Daubechies/db2 wavelet [34, 35].
$$ \psi_{a,b} \,\left( x \right)\, = \,\frac{1}{{\sqrt {a\,} }}\psi \,\left( {\frac{x\, - b}{a}} \right) $$(1)where a represents the scaling parameter and b represents the shifting parameter.
-
iii.
Discrete Cosine Transform (DCT): Multi-scale techniques require more processing time and energy due to their complex computational algorithm in contrast to DCT. It uses a cosine function to translate a signal from spatial to frequency representation. After quantization, in the decomposition process, the most important frequencies that remain are used to recover the image. “DC coefficients” and “AC coefficients” are two types of DCT coefficients. AC coefficients are the remaining 63 coefficients with non-zero frequencies, while DC coefficients have zero frequency in both dimensions [36]. The DCT phase can focus the majority of the signal in the lower spatial frequencies. In this paper, the algorithm is based on taking the mean of all DC components and the largest frequency band of energy value is chosen to correspond to AC coefficients. Numerically, in general, the two-dimensional DCT for an input image size of N × N is shown in Eq. (2).
$$ D\,\left( {i,j} \right)\, = \,\frac{1}{{\sqrt {2N} }}\,C\left( i \right)\,C\left( j \right)\,\sum\limits_{y\, = \,0}^{N - 1} {P\left( {x,\,y} \right)} \,\cos \,\left( {\frac{{\left( {2x\, + 1} \right)\,i\,\pi }}{2N}} \right)\cos \,\left( {\frac{{\left( {2y\, + 1} \right)\,i\,\pi }}{2N}} \right) $$(2)where, P(x, y) represents a matrix of the input image of size N × N, (x, y) are the coordinates of the elements of the matrix, and (i, j) are coefficients of coordinates.
-
iv.
PCA–DWT: It is a method that is a combination of DWT and PCA. It uses the advantages provided by each method, making fusion performance better than its efficiency. PCA retains an acceptable degree of resolution and generates less abrupt spectral features, while DWT provides directional information in its decomposition stages. As a result, more spectral information and spatial features are retained, and fusion results obtained using this method are better [32].
Proposed image fusion techniques:
-
i.
DCT-PCA: A hybrid fusion technique formed by combining two conventional methods namely DCT and PCA. Considering DCT produces large quantized coefficients in which some are localized in low frequencies and edges contribute to high-frequency coefficients; is integrated with PCA. The algorithm implemented is based on the selection of the largest energy value of the frequency band since DCT possess excellent energy compactness. On the other hand, PCA will contribute to dimensionality reduction and aid in pattern recognition. Thus, analyzing the advantages of each technique, the procedural steps involved are given in Algorithm 1.

-
ii.
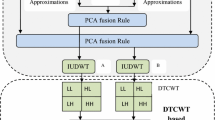
Discrete Component Wavelet Transform (DCT-PCA-DWT): The major purpose of this paper is to determine the performance of the proposed hybrid fusion technique as shown in figure 4.


Steps involved in Discrete Component Wavelet Transform.
It exploits the fusion properties of principal component analysis, discrete wavelet transforms, and discrete cosine transform. In the case of DCT, though a conventional method has the property of concentrating information making it useful for fusion. Apart from possessing dimensionality reduction characteristics, PCA transforms the original domain's features into a PCA domain in which the features are grouped in order of their variance. Finally, DWT has properties such as directional detail, orthogonality, and compactness that make it suitable for extracting key features at different stages of decomposition and it reduces spectral distortion as well.
The overall benefits of the proposed hybrid approach were observed to have improved image visual quality, high frequency resolution, refined edge details, reduced image artifacts and noise while the complex details being more comprehensive, dimensionality reduction, reasonable compression without losing much information and better accuracy. Algorithm 2 explains the proposed methodology steps.

2.3 Feature extraction
An image is a 3-dimensional matrix with dimensions of red, green, and blue color channels. Two main steps in image processing to decide which are image features to be considered are Feature detection and Feature extraction [37]. It is possible to differentiate between feature detection techniques that generate local decisions when features are identified in terms of local neighborhood operations applied to an image (known as feature extraction) [38]. The output from a feature detection step does not require a binary image. In the feature extraction module, for extracting the features two methods are employed (1) Morphological Features, (2) Texture-based features. The texture-based features are categorized as Statistical Methods, Signal Processing Methods (Laws’ Features) and Transform Domain Methods. First Order Statistics (FOS), Second-Order Statistics-GLCM Features, Higher-Order Statistics-GLRLM Features and other statistical features like Gray Level Difference Statistics (GLDS), Edge Features (Absolute Gradient), Neighborhood Gray Tone Difference Matrix (NGTDM) Features, and Statistical Feature Matrix (SFM) are some Statistical Methods. In this paper, the authors have computed GLDS and shape-based (morphological) features [39]. GLDS features compute contrast, energy, entropy, homogeneity, and mean based on the co-occurrence of a pixel pair that have a difference in gray levels separated by a particular distance. Morphological methods include the shape-based properties which include Area (calculates the area of the lesion), Perimeter, Convexity (ratio of the perimeter of the convex hull to the overall contour), Eccentricity (ratio of the minor axis to the major axis. Its value always lies between the 0 and 1), Extent, Euler No, Hole Area Ratio (HAR), Major Axis (longest diameter), Minor Axis (smallest diameter) and Solidity (the extent to which the given shape is convex or concave) [40, 41] are calculated. Each feature set is normalized by using min-max normalization.
2.4 Machine learning techniques
Classification of diseases is a majorly focused challenge in medical data mining. Machine learning is a branch of Artificial Intelligence itself [34]. Artificial intelligence involves the creation of algorithms that can change themselves without human help to produce certain output by providing itself through relevant data [42, 43]. Many algorithms, like, Artificial Neural Network, Support Vector Machine (SVM), Bayesian Classifier, Random forest, kNN, etc. have different means to derive the machine learning model. In this paper, K Nearest Neighbors (kNN) and SVM algorithms are used as machine learning techniques.
-
i.
The k-NN algorithm is a classification algorithm used in Data Science and Machine Learning. kNN has no complex parameters, regulation task, easy to implement, less nonlinear, and where all data points are well defined. The goal is to classify a new data point/observation into one of the multiple existing categories. So, several neighbors ‘k's are selected, and the k closest data points are identified (either using Euclidean or Manhattan distances). Of the k closest data points (or ‘neighbors’), the category with the highest number of k-close neighbors is the category assigned to the new data point [44, 45]. There are various methods to choose the best k in KNN. The first is dividing the data into training and validation (tuning) set and tune k till it works for the problem.
-
ii.
SVM or Maximum Margin Classifiers maximizes the geometric margin while minimizing the empirical classification error [46]. It uses the kernel trick to effectively perform non-linear classification. As data points of the type, named training data is provided. After transforming the input vectors into a decision value, the SVM classifier performs classification using an acceptable threshold value. SVM must be tuned, with the cost "C" and the use of a kernel and its variables being important hyper-parameters [47]. SVM is a set of similar supervised learning methods for classification and regression in medical diagnosis [48]. SVM's are very powerful learning Algorithms with well-defined theory.
In this paper, the authors have used SVM with RBF Kernel as they can approximate any target function as long as it is measurable. SVMs are equivalent to shallow neural network architecture. While SVMs can not go deep, neural networks can. Going deep essentially means adding more hidden layers to your network. For simulation using SVM, gamma and C parameter is considered. The gamma parameter is the maximum distance between the separating line and the data points, and C is how much care about outliers (points that are on the wrong side of the line) is considered.
2.5 Performance parameter
Medical image reliability must be assessed for medical practitioners to make correct and impartial diagnoses. In this work, the objective analysis is accomplished by using reference image approaches like Peak Signal to Noise Ratio (PSNR) and Signal to Noise Ratio (SNR) [32] while accuracy is calculated for classification. A higher SNR result represents that the source and fused images are similar, while a higher PSNR value shows the effectiveness of the fusion method.
3 Results and discussion
The biggest challenge in medical image processing is the number of samples of the class trying to model will be far fewer in number compared to every other image. For example, if trying to detect cancerous cells, gets only a fraction of the total dataset having cancerous cells because it is a rare phenomenon. The size of the datasets goes into gigabytes and sometimes terabytes if trying to capture 3D images. The proposed technique, Discrete Component Wavelet Transform and DCT-PCA is compared to existing techniques, such as PCA, DCT, DWT, and PCA-DWT, using different sets of CT and MR images concerning the brain. The application of the proposed framework is based on CT and MR images of brain collected from the brain atlas, Harvard medical school. In future, author will incorporate the framework with practical aspects as well. Authors have processed the images by different enhancement algorithms like Binarization, Median Filter, Contrast Stretching, and CLAHE. Due to constraint of space, only four pair of images and experimental findings considering CLAHE is shown in figure 5. CLAHE is simple and the computational load is minimal.

Fusion results of different sets of images.
SET I, represents the patient being diagnosed with Myocardial Infarction, with corresponding fused results obtained from the proposed and other fused techniques. SET II, represents the patient suffering from a fatal stroke, with corresponding fused results obtained from proposed and other fused techniques. SET III shows a section of the left hemisphere containing a wide area of unusual lesion which led to an acute stroke. The corresponding fused results, obtained from proposed and other fused techniques are displayed as well. SET IV, represents the patient suffering from multiple embolic infarcts and corresponding fused results, obtained from proposed and other fused techniques are displayed as well.
Figure 5 shows the fused CT and MR images using conventional and proposed techniques. The advantages of DWT, DCT, and PCA can be incorporated and utilized as: Using DWT, the enhanced source images are decomposed into their equivalent frequency sub-bands. The details contained in these sub-bands are then fused by DCT as it possesses a good proportion of preserving information and computational complexity. The fused sub-bands are then converted to the PCA domain such that features with significant variances are maintained and those with little variation are removed. This minimizes processing time since only the components consisting of the majority of the original data set will be reconstructed. Problems like blocking artifacts and poor spatial resolution will be resolved by the usage of DWT providing a superior resolution of the fused image.
On datasets 1, 2, 3, and 4, table 1 shows the performance metrics experimental results of conventional fusion algorithms and hybrid fusion algorithms. MRI and CT images are used as input source multimodal medical images to analyze the output of the proposed image fusion approach.
In table 1, PSNR 1 and SNR 1 indicate the experimental results between source image 1 and the corresponding fused image. Similarly, PSNR 2 and SNR 2 indicate the experimental results between source image 2 and corresponding fused image, for all datasets. SNR is a metric for determining the information-to-noise ratio of a fused image. The higher the value, the more identical the reference and fused images are, whereas, in the case of PSNR, it is a common metric that is calculated by dividing the number of grey levels in the image by the pixel values in the source and fused images. The fused and reference images are identical when the value is high. A higher value means better fusion. On comparing, the outcomes of the proposed hybrid technique, in terms of performance metrics, are superior to those of other existing conventional techniques. It can be perceived in SET III that PCA and DCT fusion performance with PSNR 2 values as 8.90 dB and 11.80 dB was not satisfactory. The corresponding values 13.37 dB, 12.56 dB, 13.33 dB obtained for DWT, PCA-DWT, and DCT-PCA, respectively were observed to be producing improved but not acceptable fusion results. One of the objectives of our work is to determine a better fusion algorithm. It has been observed that DWT algorithm alone provides superior results than DWT + PCA. This analysis is not only based on the experimental values but also on the pictorial representation of the fused images. From figure 5, authors have observed that images from DWT + PCA give a washed-off appearance which can hinder the assessment and extraction of the desired features. On the other hand, the results of DWT represent the details with higher resolution comparatively.
On the other hand, the Discrete Component Wavelet Transform furnished the highest experimental value of 19.80 dB. Thus, not only does the proposed algorithm retain edge information, but it also enhances spatial detail information. As a result, both quantitative and qualitative evaluation criteria demonstrate that the Discrete Component Wavelet Transform (proposed method) of multimodal medical image fusion is more reliable. PCA possesses dimensionality reduction property such that it removes redundant features from the anatomical images and DCT preserves frequency information which is seen as a limitation in DWT, and less computational complexity. Issues like blocking artifacts and poor spatial resolution are further resolved by DWT. When implementing a fusion algorithm on a large dataset of medical images, its storage and processing time might hamper its efficiency. Thus, to mitigate this issue we initiate the use of novel Discrete Component Wavelet Transform. There exists a variety of techniques in the literature however, the implementation of DCWT furnishes better qualitative and quantitative results with comprehensible and less complex methods.
After fusion, different feature descriptors were evaluated. In this paper, the authors have considered only GLDS and shape features where the different attributes are calculated as shown in table 2.
Additionally, to detect the type of brain strokes or Cerebrovascular disease in the resultant images, texture-based analysis is employed which leads to the extraction of useful features. The algorithm collected a total of 62 features, including twenty texture features and forty two shape features, which were then used to evaluate output and fed the acquired statistics to kNN and SVM classifier. In this work, emphasis has been laid on examining the attributes of GLDS features and descriptors based on shape features. The descriptions of the feature extracted (based on Discrete Component Wavelet Transform fused images) through statistical analysis of the MR and CT images are shown in table 3.
It is observed in the results that the out of obtained features Homogeneity, Mean, Contrast, Energy and Entropy gave superior values in contrast to other methods. In this paper, all the features were used for the classification process using kNN and SVM. KNN is more intuitive but it might also be slower to use in case K's value is to be kept high, or a total number of points is high. (This might be made better using KD-tree or other such algorithms). Table 3 shows the classification accuracy of different fusion techniques considering GLDS, shape, and combination of GLDS and shape features using kNN.
Maximum accuracy of 95.74% was obtained using Discrete Component Wavelet Transform for k = 4 using a combination of both feature GLDS and shape. The kNN technique is slower and the performance breaks down in high dimensional spaces. One major reason that KNN is slow is that it requires directly observing the training data elements at evaluation time. A naive KNN classifier looks at all the data points to make a single prediction, while many machine learning methods have no dependence on the number of training data points for evaluation run time. kNN's ability to solve nonlinear problems in low dimensional spaces with such simplicity is incredible, but runtime (and performance) on larger and high dimensional problems is certainly a downside. The performance breaks down in high dimensional spaces because the distance between points becomes less meaningful of a quantity. To overcome the disadvantage of using kNN, SVM is used for further processing. The SVM searches for a separating hyperplane between the data points of different classes. The idea of the SVM is now, to seek the hyperplane which maximizes the margin between the data points and itself. The SVM can be extended to be a non-linear classifier by using kernel methods. However, it is difficult to know which kernel is best for a specific problem. In the Support Vector Machine, the choice of different parameters namely kernel, Gamma parameter, and C parameter to optimize the algorithm is necessary. The table shows the accuracy considering different parameters using the LiBSVM library. The simulations were carried out on all fusion techniques but table 4 tabulates the results of the proposed image fusion techniques using SVM.
In table 4, obj = optimal objective value of the dual SVM problem, rho = bias term in the decision function sgn(wTx - rho), nSV = number of support vectors, and nBSV are number of bounded support vectors (αi = C). nu-SVM is a comparable structure of C-SVM where C is swapped by nu. For a large value of C, the model considers more data points of support vector to obtain a higher variance and lower bias leading overfitting problem. If the value is small then it selects fewer data points as a support vector and has low variance or high bias. The maximum accuracy is achieved considering the hybridization of GLDS and shape-based feature for the proposed image fusion technique. 97.87% accuracy is achieved using the proposed discrete component wavelet transform, 95.74% is achieved using DWT + PCA, and 91.49% is for DCT + PCA fusion method. 95.68%, accuracy is obtained using GLDS features for the discrete component wavelet transform and DWT + PCA fusion techniques while 87.62% accuracy has been observed for DCT + PCA fusion technique. 81.81%, 89.32%, and 85.71% accuracy is obtained using shape features for all the three proposed fusion techniques (DCWT, DWT + PCA and DCT + PCA respectively).
Authors also tried for other machine learning technique like Random forest, Neural network but the obtained accuracy is less than the SVM and KNN as tabulated in table 5.
On applying Median filter, low contrast images reduce the visibility of finer complex details. CLAHE is simple and the computational load is minimal. Considering the time and speed constraints, pipeline of this research thus, prefers CLAHE for precise detection of tumor. Also, SVM classifier is preferable to a Random Forest classifier. The latter classifies based on the probability of the object belonging to a class. But when dealing with biomedical images, especially Brain images, there can be a high number of random features. For such non-linear cases, SVM is more robust as it uses the kernel trick and an optimal margin-based classifier. Table 6 shows the Sensitivity and Specificity of the different machine learning techniques employing Discrete Component Wavelet Transform with GLDS + Shape features and CLAHE technique.
The highest accurate results providing 97.87% accuracy are observed for SVM classifier to distinguish between the classes and decide its class labels depending upon its immediate neighbors making it best suitable for classification problem.
4 Conclusion and future work
Image processing techniques allow a doctor to make better decisions by image classification and detection of ailments that may be obscure with current technology. Doctors can incorrectly diagnose patient information due to the imprecision of the image data. So, there is a demand for the development of a model that when used can make therapeutic judgements more precise leading to the correct identification and treatment of diseases. The different medical images were collected, pre-processed; registration and enhancement techniques are applied. The medical Image Processing field was confined to reformatting and volume rendering of image data along with superimposing MR image data upon CT data. The medical imaging modalities were used for image fusion namely PCA, DWT, DCT, and proposed fusion technique (PCA + DCT and Discrete Component Wavelet Transform). The various morphological and GLDS features were extracted from the fused images which were further used in the detection of Cerebrovascular disease using different machine learning techniques. The efficiency of each is then validated using feature extraction which would extort prominent features of the lesion and further, be employed to classifiers as inputs to add them to the category that they embody. Medical imaging is a colossal field, open to new additions and improvements. Therefore, our future work will be directed toward the use of deep learning techniques for medical images.
References
https://www.internationalstudentinsurance.com/india-student-insurance/healthcare-system-in-india.php
Smeulders A W, Worring M, Santini S, Gupta A and Jain R 2000 Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 22: 1349–1380
Eisenhauer E A, Therasse P, Bogaerts J, Schwartz L H, Sargent D, Ford R, Dancey J, Arbuck S, Gwyther S, Mooney M, Rubinstein L, Shankar L, Dodd L, Kaplan R, Lacombe D and Verweij J. 2009 New response evaluation criteria in solid tumours: revised RECIST guideline (version 1.1). Eur. J. Cancer 45: 228–247
Vijan A, Dubey P and Jain S 2020 Comparative analysis of various image fusion techniques for brain magnetic resonance images. Proc. Comput. Sci. 167: 413–422
Dogra J, Jain S and Sood M 2019 Glioma extraction from MR images employing GBKS graph cut technique. Vis. Comput. 35(10): 1–17
Dogra J, Jain S and Sood M 2020 Gradeint based kernel selection technique for tumor detection and extraction from medical images using graph cut. IET Image Process. 14(1): 84–93
Lanaras C, Baltsavias E and Schindler K Estimating the relative spatial and spectral sensor response for hyperspectral and multispectral image fusion. https://ethz.ch/content/dam/ethz/special-interest/baug/igp/photogrammetry-remote-sensing-dam/documents/pdf/Papers/LanarasACRS16.pdf
Davis M E 2016 Glioblastoma: overview of disease and treatment. Clin. J. Oncol. Nurs. 20: S2
Arikan M, Fröhler B, and Möller T 2016 Semi-automatic brain tumor segmentation using support vector machines and interactive seed selection. In: Proceedings of the MICCAI-BRATS Workshop, pp. 1–3
Corso J J, Sharon E, Dube S, El-Saden S, Sinha U and Yuille A 2008 Efficient multilevel brain tumor segmentation with integrated bayesian model classification. IEEE Trans. Med. Imaging 27: 629–640
Clinical Methods: The History, Physical, and Laboratory Examinations. 3rd edition.Ch 55 ,https://www.ncbi.nlm.nih.gov/books/NBK378/
https://www.aans.org/en/Patients/Neurosurgical-Conditions-and-Treatments/Cerebrovascular-Disease
Ambily P K, James S P and Mohan R R 2015 Brain tumor detection using image fusion and neural network. Int. J. Eng. Res. Gen. Sci. 3(2): 1383–1388
Wang M and Shang X 2020 A fast image fusion with discrete cosine transform. IEEE Signal Process. Lett. 27: 990–994
Kumar B K S, Swamy M N S and Ahmad M O 2013 Multiresolution DCT decomposition for multifocus image fusion. In: Proceedings of Canadian Conference on Electrical and Computer Engineering (CCECE), Regina, Canada, pp. 1–4
Wang Z, Cui P, Li F, Chang E and Yang S 2014 A data-driven study of image feature extraction and fusion. Inform. Sci. 1–23
Snehkunj R, Jani A N and Jani N N 2018 Brain MRI/CT images feature extraction to enhance abnormalities quantification. Indian J. Sci. Technol. 11(1): 1–10
Sivakumar P, Velmurugan S P, and Sampson J 2020 Implementation of differential evolution algorithm to perform image fusion for identifying brain tumor. 3C Tecnología. In: Glosas de innovaciónaplicadas a la pyme. Edición Especial, Marzo, pp. 301–311
Maya A T, Suryono S and Anam C 2021 Image contrast improvement in image fusion between CT and MRI images of brain cancer patients. Int. J. Sci. Res. Sci. Technol. 8(1): 104–110
Masood S, Sharif M, Yasmin M, Shahidnd M A and Reh A 2017 Image fusion methods: a survey. J. Eng. Sci. Technol. Rev. 10(6): 187–191
Jain S, Sachdeva M, Dubey P and Vijan A 2019 Multi-sensor image fusion using intensity hue saturation technique. In: Luhach A, Jat D, Hawari K, Gao XZ., Lingras P (eds) Advanced Informatics for Computing Research. ICAICR 2019. Communications in Computer and Information Science, vol 1076. Springer, Singapore, pp. 147–157
Pal B, Mahajan S and Jain S 2020 Medical image fusion employing enhancement techniques. In: 2020 IEEE International Women in Engineering (WIE) Conference on Electrical and Computer Engineering (WIECON-ECE), Bhubaneswar, India, pp. 223–226
Rajalingam B and Priya R 2017 A novel approach for multimodal medical image fusion using hybrid fusion algorithms for disease analysis. Int. J. Pure Appl. Math. 117(15): 599–619
Salau A O, Jain S and NnennaEneh J 2021 A review of various image fusion types and transform. Indonesian J. Electr. Eng. Comput. Sci. 24(3): 1515–1522
Li Y, Liu X, Wei F, Sima D M, Cauter S V, Himmelreich U, Pi Y, Hu G, Yao Y and Huffel S V 2017 An advanced MRI and MRSI data fusion scheme for enhancing unsupervised brain tumor differentiation. Comput. Biol. Med. 8(1): 121–129
Yong Y, Huang S, Gao J and Qian Z 2014 Multi-focus image fusion using an effective discrete wavelet transform based algorithm. Meas. Sci. Rev. 14(2): 102–108
Zitová B and Jan F 2003 Image registration methods: a survey. Image Vis. Comput. 21(11): 977–1000
Mohideen S K, Perumal S A and Sathik M M 2018 Image de-noising using discrete wavelet transform. IJCSNS Int. J. Comput. Sci. Netw. Sec. 8(1): 213–214
Pal B, Mahajan S and Jain S 2020 A comparative study of traditional image fusion techniques with a novel hybrid method. In: International Conference on Computational Performance Evaluation (ComPE) North-Eastern Hill University, Shillong, Meghalaya, India, pp. 820–825
Bhardwaj C, Jain S and Sood M 2019 Automatic blood vessel extraction of fundus images employing fuzzy approach. Indonesian J. Electr. Eng. Inform. 7(4): 757–771
Prashar N, Sood M and Jain S 2020 A novel cardiac arrhythmia processing using machine learning techniques. Int. J. Image Graph. 20(3): 2050023
Jain S 2018 Classification of protein kinase B using discrete wavelet transform. Int. J. Inf. Technol. 10(2): 211–216
Winarno A, Setiadi D R I M, Arrasyid A A, Sari C A and Rachmawanto E H 2017 Image watermarking using low wavelet subband based on 8×8 sub-block DCT. In: 2017 International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, pp. 11–15
Salau A O and S Jain 2019 Feature extraction: a survey of the types, techniques and applications. In: 5th International Conference on Signal Processing and Communication (ICSC-2019), Jaypee Institute of Information Technology, Noida (INDIA), pp. 158–164
Sharma S, Jain S and Bhusri S 2017 Two class classification of breast lesions using statistical and transform domain features. J. Glob. Pharma Technol. 9(7): 18–24
Bhusri S, Jain S and Virmani J 2016 Classification of breast lesions using the difference of statistical features. Res. J. Pharm. Biol. Chem. Sci. 7(4): 1365–1372
Bhusri S, Jain S and Virmani J 2016 Breast Lesions Classification using the Amalagation of morphological and texture features. Int. J. Pharma BioSci. 7(2B): 617–624
Rana S, Jain S and Virmani J 2016 SVM-Based characterization of focal kidney lesions from B-Mode ultrasound images. Res. J. Pharm. Biol. Chem. Sci. 7(4): 837
https://www.sas.com/en_in/insights/analytics/data-mining.htnl
https://hackernoon.com/deep-learning-vs-machine-learning-a-simple-explanation-47405b3eef08
Jain S and Chauhan D S 2020 Instance-based learning of marker proteins of carcinoma cells for cell death/survival. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 8(3): 313–332
Dogra J, Jain S and Sood M 2019 Glioma classification of MR brain tumor employing machine learning. Int. J. Innov. Technol. Explor. Eng. 8(8): 2676–2682
Jain S 2020 Computer aided detection system for the classification of non small cell lung lesions using SVM. Curr. Comput. Aided Drug Des. 16(6): 833–840
Li R, Zhang W, Suk H I, Wang L, Li J, Shen D and Ji S 2014 Deep learning based imaging data completion for improved brain disease diagnosis. In: Proceedings of the Medical Image Computing and Computer-Assisted Intervention MICCAI-BRATS, pp. 305–312
Jain S and Paul S 2020 Recent Trends in Image and Signal Processing in Computer Vision. Switzerland AG: Springer Nature
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Authors declare that no funding was received for this research and they have no conflict of interest.
Rights and permissions
About this article

Cite this article
Pal, B., Jain, S. Novel Discrete Component Wavelet Transform for detection of cerebrovascular diseases. Sādhanā 47, 237 (2022). https://doi.org/10.1007/s12046-022-02016-9
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12046-022-02016-9