
Abstract
In the last few decades, metaheuristic algorithms that use the laws of nature have been used dramatically in numerous and complex optimization problems. The artificial hummingbird algorithm (AHA) is one of the metaheuristic algorithms that was invented in 2022 based on the foraging and migration behavior of the hummingbird for modeling and solving optimization problems. The algorithm initially starts with an initial random population of solutions. It then uses iterative processes and hummingbird position updates to balance exploration and exploitation toward the most optimal solutions. This paper has a detailed and extensive review of the AHA algorithm considering the aspects of hybrid, improved, binary, multi-objective, and optimization problems. In addition, a wide range of applications of AHA in various fields such as feature selection, image processing, scheduling, Internet of Things, classification, clustering, financial and economic issues, forecasting, wireless sensor networks, and many engineering challenges are explored. The statistical and numerical results showed that the AHA algorithm with deep learning methods, Levy flight, and opposition-based learning had the best performance. Also, the AHA algorithm is most widely used in solving multimodal optimization problems and continuous functions.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
An optimization problem aims to identify the most favorable solution from a set of available choices. An optimization problem is composed of three main elements: decision variables that define the problem, constraints that restrict the solution space, and an objective function that needs to be optimized [1]. As science and technology have advanced, the complexity of these problems has significantly increased, necessitating more sophisticated optimization techniques. These techniques are broadly classified into two groups: deterministic and stochastic [2]. Deterministic techniques are further categorized into gradient-based and non-gradient-based techniques. They are particularly efficient for linear, convex, or relatively simple problems. However, their effectiveness diminishes in the face of complex issues involving non-differentiable functions, nonlinear search spaces, non-convex challenges, and problems that are NP-hard, which are notoriously difficult to solve [3]. In contrast, stochastic methods, which have gained prominence due to their adaptability, utilize random operations, searches, and error-prone procedures. These methods are adept at navigating complex optimization problems that deterministic approaches often find too challenging [4]. In the realm of real-world applications, where problems are frequently too intricate for deterministic solutions, stochastic techniques, and particularly metaheuristic algorithms (MAs), are increasingly being recognized as viable and effective solutions [5]. These stochastic methods are valued for their ability to efficiently tackle complex optimization tasks that are commonplace in technique scenarios.
Traditional optimization techniques are not suitable for complex and combinatorial problems. Because complex problems contain scope and decision variables [6]. Traditional optimization techniques are defined in the form of a linear equation and are unable to find the appropriate value for the variables of the optimization problem. These techniques include the following disadvantages: (1) Increasing dimensionality: As the number of decision variables increases, traditional optimization techniques are not suitable for the search space due to the exponential growth of possible solutions [7]. (2) Sensitivity to initial conditions: Many traditional optimization techniques are sensitive to the initial settings of parameters, which can affect the convergence behavior and the quality of the obtained solutions [8]. (3) Multi-objective functions: Traditional optimization techniques have difficulty dealing with multi-objective or stochastic functions, leading to suboptimal solutions or premature convergence [9]. (4) Parallelization: Parallelization of traditional optimization techniques is challenging for effective use of modern computing problems and limits the scalability and performance of distributed systems. These techniques perform poorly when real-world problems are faced with uncertainties, outliers, or disordered data.
In contrast, MAs such as AHA are popular due to their simple concepts, easy implementation, and versatility in problem types. The goal of meta-heuristic algorithms is to explore the search space to find an almost optimal and efficient result. MAs use search techniques inspired by natural, biological, physical, team, social, or artificial systems. This process starts by generating a random number of candidate solutions within the range of global and local searches. Then the algorithm repeatedly updates the candidate solutions and the best candidate is presented as the optimal solution at the end of the meta-heuristic algorithm iterations.
Mas have gained considerable traction for their effectiveness in solving complex optimization problems [10]. Their popularity stems from a combination of factors: the simplicity of their underlying principles, the ease with which they can be implemented, and their proficiency in tackling problems that are high-dimensional and nonlinear. These algorithms initiate optimization issues by generating a set of feasible solutions at random within the designated problem space [11]. This process involves continuous iterations where the proposed solutions undergo systematic revisions and improvements, adhering to the specific rules of the algorithm. The ultimate goal of this iterative process is to identify the most suitable candidate solution that effectively addresses the problem at hand. However, it’s crucial to understand that MAs don’t always guarantee a globally optimal solution [12]. Owing to their reliance on random search techniques, they often converge on quasi-optimal solutions. While these solutions may not be the absolute best theoretically possible, they are generally very close to the optimal solution and are usually satisfactory for practical purposes.
Despite their seemingly straightforward approach, the efficiency and effectiveness of MAs can vary significantly. This variation is largely influenced by the distinct methods they employ for exploring the problem space and updating the candidate solutions [13]. Different MAs have different strategies for balancing the exploration and exploitation phases of the search process, which fundamentally affects their performance. Some may be better suited for certain types of problems or specific conditions within the problem space. As a result, selecting the right MA for a given optimization challenge is a critical decision that can greatly impact the quality of the solution and the efficiency of the problem-solving process.
Researchers can create appropriate solutions for different optimization problems by adjusting the structures and parameters of their algorithms. The inherent randomness in these algorithms enables them to thoroughly explore the entire search space. This helps in avoiding entrapment in local optimums and aids in finding favorable solutions. MAs stand out in solving a diverse array of optimization issues, particularly those that are complex, nonlinear, and non-differentiable, due to their versatility and adaptability. These algorithms have proven to be invaluable across various fields, benefiting both researchers and practitioners in their applications [14, 15].
There are metaheuristic algorithms with different versions: AHA [16], Genghis Khan shark (GKS) [17], Geyser inspired Algorithm (GEA) [18], Prairie Dog Optimization (PDO) [19], Dwarf Mongoose Optimization (DMO) [20], Gazelle Optimization Algorithm (GOA) [21], Lungs Performance-based Optimization (LPO) [22], Arithmetic Optimization Algorithm (AOA) [23], Reptile Search Algorithm (RSA) [24], Sinh Cosh Optimizer (SCHO) [25], Ebola Optimization Search Algorithm (EOSA) [26], Sine Cosine Algorithm (SCA) [27], Gorilla Troops Optimizer (GTO) [28], Moth-Flame Optimization (MFO) [29], Puma optimization (PO) [30], Slime Mould Algorithm (SMA) [31], Equilibrium Optimizer (EO) [32], Farmland Fertility Algorithm (FFA) [33], Electric Eel Foraging Optimization (EEFO) [34], African Vultures Optimization Algorithm (AVOA) [35], Beluga Whale Optimization (BWO) [36], and Tunicate Swarm Algorithm (TSA) [37].
While different MAs have their unique characteristics, they share two fundamental stages in their search process: exploration and exploitation. Exploration involves a wide-ranging and random examination of the solution space, while exploitation entails a more targeted search in the area identified during the exploration phase. As the algorithm enhances its exploitation skills, its precision increases and its randomness decreases. An algorithm with strong exploration capabilities can rapidly converge to a variety of solution sets through more random searching. On the other hand, an algorithm with effective exploitation skills can improve the quality and accuracy of solutions by focusing on local searches. However, enhancing exploration may diminish the effectiveness of exploitation and vice versa. Furthermore, striking the right balance between these two phases is often difficult and varies based on the specific optimization problem at hand.
The AHA [16] is an innovative bio-inspired optimization algorithm designed to address complex optimization challenges. Drawing inspiration from the extraordinary flight capabilities and intelligent foraging behaviors of hummingbirds in nature, this algorithm represents a significant advancement in the field of optimization. It uniquely simulates three specific flight maneuvers observed in hummingbird foraging—axial, diagonal, and omnidirectional. These maneuvers are intricately integrated into the algorithm, enhancing its ability to navigate through the problem space effectively. In addition to these flight patterns, the AHA also emulates three distinct foraging behaviors of hummingbirds: guided foraging, territorial foraging, and migrating foraging. Each of these behaviors contributes to the algorithm’s robustness and adaptability. The guided foraging behavior enables the AHA to initially focus on exploring the problem space extensively. As the algorithm progresses, this strategy gradually shifts towards more exploitation-oriented approaches. The territorial foraging behavior is specifically designed to intensify the exploitation process, allowing the algorithm to meticulously fine-tune solutions within a localized area. In contrast, the migrating foraging strategy is implemented to ensure a comprehensive exploration of the entire search area, preventing the algorithm from prematurely converging on suboptimal solutions.
A particularly novel aspect of the AHA is its incorporation of a ‘Visit Table (VT)’, a mechanism that mimics the memory of hummingbirds in recalling the locations of food sources. This feature allows each virtual ‘hummingbird’ within the algorithm to keep a position of its last visit to various points in the search space, akin to tracking food sources. This memory update mechanism is instrumental in guiding the algorithm towards more promising regions of the search area based on past experiences, thereby enhancing its efficiency in selecting optimal or near-optimal solutions. The combination of these unique flights and foraging strategies within the AHA framework marks a distinct departure from traditional optimization algorithms. Its approach to balancing exploration and exploitation, coupled with its memory-based strategy for tracking and revisiting solution spaces, positions the AHA as a potentially more effective and intelligent tool for solving a wide array of complex optimization problems.
The main contributions of this paper are as follows:
-
Hybridization, improved model types, and optimization problems are explored by the AHA algorithm.
-
AHA algorithm is analyzed with pseudocode and flowchart.
-
Analyze the effectiveness of AHA in solving different problems considering convergence rate, exploration, and exploitation aspects.
The general structure of this paper is as follows: In Sect. 2, the basic concepts of the AHA algorithm are stated. In Sect. 3, different methods of the AHA algorithm, including combinations, improved, binary mode, multi-objective mode, and optimization problems are described. In Sect. 4, the AHA algorithm is examined in terms of applications, advantages, and disadvantages, and finally, in Sect. 5, we discuss the conclusions and future works.
2 Artificial Hummingbird Algorithm (AHA)
In this section, a bio-inspired optimization algorithm called AHA, which draws inspiration from the intelligent behaviors of hummingbirds, is introduced. The three primary elements of the AHA algorithm are described in detail. An illustration (Fig. 1) is provided, depicting a hummingbird (agent) engaged in foraging.

A foraging hummingbird [16]
Food Sources: The agent operates as a complex biological organism in natural ecosystems, it has unique abilities in choosing its resources. Using its sharp senses and the experience it has gathered from previous times, this bird can identify and evaluate the different characteristics of resources. He not only examines the nectar quality and nutritional content of each flower but also the rate of nectar regeneration and the number of times the flowers have been visited before. In the AHA algorithm, it is assumed that each resource has the same number of flowers. This simplification is intended to reduce computational complexity and provide a standard analysis model. In this model, each resource is treated as a solution vector where the rate of nectar regeneration (i.e., the rate at which nectar is produced again) is represented by a fitness function. The amount of fitness indicates the quality of the resource; The higher this value, the better the source of food and the increase in the amount of regenerating nectar from that source.
Hummingbirds: In this method, each agent is systematically assigned to a specific feeding spot, meaning the bird and its chosen feeding area occupy the same space. These agents have the skill to remember their resource’s location and rate of nectar replenishment, and they can share this knowledge with fellow agents in the group. Additionally, every agent can recall the time elapsed since its last visit to each feeding location.
Visit Table: In the algorithm’s framework, there exists a crucial component known as the VT. This table meticulously tracks how often each resource is visited by various agents, also recording the time that has passed since a particular agent last frequented a certain resource. The unique aspect of this system is its prioritization mechanism: resources that have been neglected for a more extended period are given precedence for future visits by agents. This strategy is designed to optimize nectar collection efficiency. The VT serves a vital role for each agent. It acts as a guide, helping them to effectively pinpoint their next targeted resource based on various factors, including visit frequency and nectar availability. This targeted approach enhances the overall foraging efficiency of the agents. Moreover, the dynamic nature of the VT is crucial. With every iteration of the algorithm, the information within the table is updated. This continuous updating process ensures that the data remains current and reflective of the latest feeding patterns and preferences of the agents, thereby enabling them to make the most informed decisions about where to feed next.
The AHA algorithm, a swarm-based meta-heuristic approach, is crafted to address optimization issues. In this subsection, three mathematical models are introduced that replicate the foraging behaviors of agents: guided foraging, territorial foraging, and migrating foraging. These behaviors are illustrated in Fig. 2. Furthermore, the architecture of the AHA algorithm is segmented into three principal phases.

Three foraging behaviors of AHA
2.1 Mathematical Model and Algorithm
In Fig. 3, the cycle of the AHA algorithm is shown. The AHA algorithm for solving optimization problems contains five main cycles.

The cycle of the AHA algorithm
2.1.1 Initialization
A group of n agents is distributed across n resources, with their initial positions randomly determined as per Eq. (1) [38].
where “Low” and “Up” represent the lower and upper limits, respectively, for a problem with d dimensions. Here, “r” stands for a random vector within the range [0, 1], and “\({x}_{i}\)” denotes the position of the i th resource, which corresponds to the solution to the problem at hand. Also, the VT for the resources is set up initially as outlined in Eq. (2).
In cases where \(i\) equals j, the term \({VT}_{i,j}=null\) signifies that an agent is currently feeding at its designated resource. Conversely, when \(i\) is not equal to j, \({VT}_{i,j}=0\) illustrates that the \({i}{\mathrm{th}}\) the agent has just explored the \({j}{\mathrm{th}}\) resource in the ongoing iteration.
2.1.2 Guided Foraging
Each agent instinctively seeks out the resource containing the most nectar. This means that an ideal source should rapidly replenish its nectar and remain unvisited by the agent for a significant duration. In the AHA process, an agent aims to identify the resources that are most frequently visited for its purposeful foraging. Among these, the agent selects the source with the quickest nectar replenishment as its chosen resource. Once this target is established, the agent proceeds to fly towards it to feed.
In the AHA algorithm, the foraging process involves three types of flight skills: omnidirectional, diagonal, and axial flights. These are effectively represented by incorporating a direction switch vector. This vector dictates the availability of one or more directions in a d-dimensional space. As illustrated in Fig. 4, these flight behaviors are depicted in a 3-D space. Axial flight enables an agent to travel along any coordinate axis. Diagonal flight permits movement from one rectangle corner to its opposite, determined by any two of the three coordinate axes. Omnidirectional flight means an agent can fly in any direction, with the trajectory projected onto each of the three axes. While all birds are capable of omnidirectional flight, agents uniquely excel in both axial and diagonal flights.

Three flight behaviors of agents, a axial flight, b diagonal flight, c omnidirectional flight [16]
These flight behaviors can be extrapolated to a d-dimensional (d-D) space, where the axial flight is described by Eq. (3).
The diagonal flight is described as Eq. (4).
The omnidirectional flight is described as Eq. (5).
In Eq. (3), \(randi ([1,d])\) is a function that produces a random integer between 1 and d. Such functions are often used to introduce randomness or simulate variability in models. d is a parameter that sets the upper limit of the random integer range. \(randperm(k)\) generates a random sequence of integers from 1 to k. This could be used to create a randomized order or arrangement of numbers within a specified range, and r1 is a random number between (0, 1]. Diagonal flight within a d-dimensional space occurs within a hyperrectangle, defined by any 2 to d-1 coordinate axes. The movement of an agent in 3-D space, utilizing these three flight skills, is depicted in Fig. 5. In this figure, omnidirectional flight is indicated by red lines, diagonal flight by green lines, and axial flight by blue lines. The illustration shows an agent moving from (4, 4, 4) to (0, 0, 0). Using the three different flight skills, the agent reaches the target location in eight units of time. This demonstrates that the mathematical models for these flight skills can effectively simulate the searching behaviors of agents in both 3-D and multi-dimensional spaces.

Movement of an agent in three-dimensional space utilizing three distinct flying abilities [16]
Possessing these flight capabilities, an agent reaches its chosen resource, thereby securing a potential resource. Consequently, an existing resource is refreshed and replaced by a new target resource, selected from all available sources. The mathematical formula that represents this guided foraging behavior and the acquisition of a candidate resource is formulated as Eq. (6).
In Eq. (6), the variable \({x}_{i}(t)\) signifies the location of the \({i}{\mathrm{th}}\) resource at a given time t, while \({x}_{i,{\text{tar}}}(t)\) corresponds to the location of the targeted resource which the \({i}{\mathrm{th}}\) agent intends to approach. The term ‘a’ act as a guidance factor, adhering to a normal distribution \(N(\mathrm{0,1})\), characterized by a mean value of 0 and a standard deviation of 1. Equation (6) is instrumental in revising the position of each existing resource relative to the targeted resource. This equation effectively simulates the directed foraging patterns of agents via diverse flying behaviors. The positional update for the \({i}{\mathrm{th}}\) resource is established in Eq. (8).
In Eq. (8), \(f(\cdot )\) represents the fitness value of the function. Equation (8) illustrates that if the nectar-refilling rate of the prospective resource surpasses that of the existing one, the agent will forsake its current resource and remain at the new one, as determined by Eq. (6), for feeding purposes.
In the AHA, the VT plays an essential role by recording the visitation history to various resources. During each iteration, agents consult this table to determine their preferred target resource. This table maintains a record of the time elapsed since a particular resource was last visited by the same agent, where longer durations of not being visited suggest an increased visit level. Agents exhibit a preference for resources that have the highest visit level. In situations where several sources are at an equivalent highest visit level, the choice falls on the source with a more favorable nectar refilling rate. Every agent in the group selects its resource according to Eq. (6). As the process unfolds, each agent, while engaging in directed foraging as per Eq. (6) towards its target, increments the visit levels of all alternate resources by 1, except for the one it is currently visiting, which is reset to 0. Post the directed foraging phase, an agent remains with its current resource until a better nectar refilling rate (or solution) is identified. Upon finding a superior solution, the agent transitions to this new source. The update of an agent’s residing resource mirrors the adjusted visit level for that source across the population. The new visit level is established as one plus the maximum level recorded among the other resources.
Figure 6 displays a VT for six resources, each with an agent assigned to it. The numbers in the VT represent the visit levels, indicating the duration for which an agent has not visited a particular resource. For instance, the number ‘8’ in blue signifies that agent x2 has not visited the resource where agent x5 is currently located for 8 time periods.

VT of a group of six agents [16]
The following example, a minimization problem, demonstrates how the VT is managed and how each agent selects its target resource in a guided foraging method. In this case, involving four agents, their starting positions and the VT are established using Eqs. (1) and (2). The first agent comes across three resources, all at the same high visit frequency. Of these, the one assigned to agent x4, with the fastest nectar refill, is selected by the first agent, after applying Eqs. (6) and (8) for this scenario, the visit frequencies for the resources of agents x2 and x3 increase by one, since they weren’t visited by agent x1, and the frequency for the chosen resource of x4 is reset to zero. The method of updating visit frequencies and choosing the resource for the first agent is shown in Fig. 7a.

Updating the VT and choosing the desired resource during a single iteration while executing a guided foraging strategy [16]
The second agent encounters three resources, each with the highest visit level. Among these, the resource of agent x4 offers the highest nectar-refilling rate, making it the target resource for the second agent. Following the execution of Eq. (6) and (8) for this agent, the visit levels for the resources of agents x1 and x3 are raised by 1, and the visit level for the target source x4 is reset to 0. The resource of agent x2 is replaced by the candidate v2, as v2’s nectar-refilling rate is superior to that of source x2. Consequently, the visit level for source x2 needs to be adjusted to the highest visit level plus one for each of the other agents, in their respective rows. The process of updating the visit level and choosing the target resource for the second agent is depicted in Fig. 7b.
For the third agent, it opts for the resource belonging to agent x2 as its target, attributed to its maximum visit level. This leads to an increment of 1 in the visit levels for the resources of agents x1 and x4, while resetting the visit level of the chosen target, source x2, to 0. These modifications in the visit level and the selection of the target resource for the third agent are depicted in Fig. 7c. In the case of the fourth agent, it selects the resource of agent x2 as its target, again due to its highest visit level. This action resets the visit level of source x2 to 0 and increases the visit levels of the sources of agents x1 and x3 by 1. Simultaneously, with the substitution of source x4 by its candidate v4, the visit level for source x4 is updated to the highest existing visit level plus one for each of the other agents. These alterations in visit level and the choice of target resource for the fourth agent are illustrated in Fig. 7d. After completing one iteration, the updated VT for the agents is showcased in Fig. 7.
2.1.3 Territorial Foraging
Once an agent has fed on the nectar at its chosen resource, it tends to look for a new resource rather than revisiting other existing ones. This behavior allows the agent to easily transition to a nearby area within its territory, where it might discover a new resource as a potential solution, possibly superior to its current one. The mathematical equation that models this local search behavior of agents during territorial foraging and identifies a candidate resource is formulated as Eq. (9).
In Eq. (9), ‘b’ represents a territorial factor that follows a normal distribution \(N(\mathrm{0,1})\), characterized by a mean of 0 and a standard deviation of 1. This equation enables any agent to efficiently locate a new resource in its immediate vicinity, based on its unique position and specialized flight abilities. Following the execution of the territorial foraging strategy, it’s necessary to update the VT (Fig. 8).

Refreshed VT of agents after single iteration [16]
2.1.4 Migration Foraging
When an agent frequently encounters an area lacking sufficient food, it generally moves to a more distant resource for nourishment. In the context of the AHA, a migration coefficient is defined. If the iteration count exceeds this coefficient’s predetermined threshold, the agent at the least efficient nectar-refilling site will shift to a randomly generated resource within the entire search area. At this point, the agent abandons its prior resource in favor of the new location for sustenance. Following this, the VT is updated accordingly. The mathematical expression that delineates an agent’s migratory foraging behavior, transitioning from the site with minimal nectar-refilling efficiency to a new, randomly selected source, is articulated in Eq. (11).
In Eq. (11), \({x}_{wor}\) is the resource with the worst nectar-refilling rate in the population.
In the guided foraging method, should there be no positional changes of any resource, agents are inclined to select various sources as their targeted resources. This tendency enhances exploration and diminishes the risk of prematurely converging on local optima. In contrast, the replacement of a resource with a new one increases its likelihood of being chosen as the target by agents at other resources, thus promoting increased exploitation. As outlined in Eq. (6), the initial phases of the iterations emphasize exploration due to the considerable distances between the resources. Nevertheless, as the iterations advance, these distances gradually reduce, thereby shifting the emphasis to exploitation. In the territorial foraging approach, an agent focuses on exploitation within its immediate vicinity. Moreover, the migratory foraging behavior of agents indicates their involvement in exploration over a larger search area.
In the AHA algorithm framework, there are three primary parameters: the size of the population, the maximum number of iterations, and a singular additional control parameter that determines the implementation of migration. In the most challenging scenario, where no resources are substituted during the guided and territorial foraging phases, an agent will methodically select each resource as its target in successive iterations, guided by the VT. Given a 50% likelihood of choosing between guided or territorial foraging, and a similar chance of selecting any other source during guided foraging, there is a possibility that an agent might revisit the same resource as its target after 2n iterations, representing a worst-case scenario. Under such circumstances, the migration foraging tactic becomes crucial to prevent stagnation and to improve exploration within the search space. Therefore, it is suggested that the migration coefficient be defined in correlation with the population size, as outlined in Eq. (12).
2.2 Flowchart and Pseudocode of AHA
AHA commences by initializing a random assortment of solutions along with a VT. Each iteration carries a probability of 50% to engage in either guided or territorial foraging. In guided foraging, agents gravitate towards their target resources, identified based on the VT and nectar-refilling rates. Territorial foraging encourages agents to inspect the vicinity around them. Following every 2n iterations, migration foraging is initiated. These foraging strategies integrate three distinct types of flight skills: omnidirectional, diagonal, and axial. The algorithm advances iteratively, executing a series of operations and computations, until it fulfills the predefined termination criteria. The outcome is the determination of the resource with the most favorable nectar-refilling rate, which approximates the global optimum. The flowchart detailing AHA is presented in Fig. 9.

The flowchart of AHA
The pseudocode of AHA is given in Algorithm 1.

Algorithm 1. The pseudocode of AHA [16]
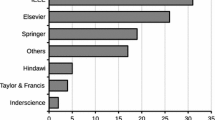
Since 2022, extensive research has been conducted in the area of optimization problem-solving using AHA. To ascertain the volume of AHA-related papers, an initial step involved downloading all AHA-related research papers. Subsequently, these papers were categorized based on the proportion of papers in various publications and the annual publication rate of AHA papers. In Fig. 10 shows the distribution of AHA papers across different journals. The breakdown is as follows: ScienceDirect (35%), IEEE (23%), Springer (16%), MDPI (18%), Tandfonline (4%), and other journals (4%). From Fig. 10, it’s evident that ScienceDirect holds the largest share of AHA paper publications.

Percentage of papers published with AHA in different publications
In Fig. 11, the number of AHA papers published per year is shown. The number of AHA papers published in 2022 was equal to 76.

Number of AHA papers published per year
The papers were carefully selected based on their titles, keywords, and abstracts. The investigation into these papers was conducted with meticulous precision, involving a thorough examination of every reliable and international database. Each paper underwent an in-depth review, focusing on its content and the algorithm type. Any duplicates were identified and eliminated during the screening process. In the end, papers related to the AHA algorithm were systematically categorized. Figure 12 illustrates the methodology of this search and displays the quantity of articles at various stages of the process.

The Procedure for extracting papers belongs to the AHA algorithm
To collect papers, a search was made in databases such as ScienceDirect, Springer, IEEE, MDPI, Tandfonline, and various journals in the field of computer engineering and applied engineering. Keywords are used for searching. The search terms to find articles related to AHA are shown in Fig. 13.

The search terms to find articles related to AHA
3 Methods of AHA
Figure 14 provides a detailed breakdown of the various classifications of AHA methods. This classification is systematically organized into four primary categories: Hybridization, Improved, Variants of AHA, and Optimization Problems.

Classification of AHA methods
Hybridization: This category focuses on the integration of AHA with other methodologies, particularly MAs. It explores how AHA can be combined with these algorithms to enhance problem-solving capabilities.
Improved: Under this category, various sub-categories have been identified, each representing a different strategy to enhance the effectiveness of AHA. These sub-categories involve refining the original algorithms to produce more efficient and accurate solutions.
Variants of AHA: This classification includes the different forms of AHA, such as Binary and Multi-objective AHA. These variants are adapted to suit specific types of problems, with Binary AHA addressing binary decision problems and Multi-objective AHA dealing with problems involving multiple objectives.
Optimization Problems: In this section, the application of AHA in solving diverse optimization problems is highlighted. It demonstrates the versatility of AHA in finding the most optimal solutions in various fields, showcasing its practical utility in complex problem-solving scenarios.
3.1 Hybridization with other Meta-Heuristics
In this section, the combination of AHA with other algorithms is examined. AHA uses MAs to solve the problem of getting stuck in the local optimum. AHA used KHA, SA, PSO, CHOA, PBA, and AO algorithms.
In the study [39], the Binary Krill Herd-Adaptive Hummingbird Algorithm (BAHA-KHA) is introduced, integrating the Krill Herd Algorithm (KHA) with the Adaptive Agent Algorithm (AHA) specifically for task offloading. This hybrid model leverages KHA to bolster the efficiency of AHA. Additionally, BAHA-KHA tackles the challenge of local optimal task scheduling within Fog Computing (FC) contexts by utilizing the dynamic voltage and frequency scaling (DVFS) strategy. For sequencing task execution, it employs the Heterogeneous Earliest Finish Time (HEFT) technique. The core objective of the BAHA-KHA framework is to curtail resource usage and communication between interdependent tasks, while concurrently achieving a reduction in energy consumption. The model places a particular focus on workflow scheduling within the FC environment to diminish energy expenditure and shorten the total execution time (makespan) on fog computing resources. The effectiveness of this model was validated through tests involving five distinct workflows: Montage, CyberShake, LIGO, SIPHT, and Epigenomics. Comparative analyses indicate that BAHA-KHA surpasses the performance of other established algorithms like AHA, KHA, Particle Swarm Optimization (PSO), and Genetic Algorithm (GA). In terms of results, the BAHA-KHA demonstrated a notable decrease in makespan, approximately 18%, and a reduction in energy consumption by around 24% in comparison to the GA.
Model of [40] introduces an innovative adaptive algorithm, termed AHA–SA, which integrates Simulated Annealing (SA) with AHA, specifically for Infinite Impulse Response (IIR) systems. This model leverages the combined advantages of AHA and SA. The cohesive fusion of AHA and SA within the AHA–SA optimizer facilitates effective exploration of the search space, swift convergence, and the achievement of accurate solutions. Comprehensive experimental evaluations highlight the AHA–SA optimizer’s superior performance in comparison to other competing algorithms, particularly regarding the quality of solutions and the rate of convergence.
The model of [41] details a newly proposed hybrid model called AHA-PSO, designed to optimize the intricate composite shape-adjustable generalized cubic Ball curves. The algorithm integrates PSO to enhance the population variability of the base AHA algorithm. This improvement is targeted at avoiding local optima traps, thereby elevating the precision and acceleration of the AHA’s convergence process. The proficiency of the AHA-PSO model is evaluated using twenty-five benchmark test functions along with the CEC 2022 test suite. Statistical analysis of the results is conducted using the Friedman and Wilcoxon rank sum tests, demonstrating the AHA-PSO’s substantial competitive advantage and practical relevance compared to other contemporary optimization algorithms. Moreover, the research explores the creation of complex engineering curves by developing Composite Shape-adjustable Generalized Cubic Ball (CSGC-Ball) curves. These curves are derived from Shape-adjustable Generalized Cubic Ball (SGC-Ball) basis functions and are integrated with both broad-spectrum and focused shape modifiers, allowing for versatile adjustments to both the overall and localized shapes of the curves. A specialized optimization model for refining the shapes of these CSGC-Ball curves is formulated, concentrating on minimizing the energy value of the curve. The proposed AHA-PSO algorithm is applied to address this optimization problem. The efficacy and dominance of AHA-PSO in managing the optimization challenges of CSGC-Ball curve shapes are conclusively proven through two distinct numerical case studies.
Model of [42] presented a groundbreaking method known as the Deep Q-learning Network-based Hybrid Enhanced Chimp Artificial Hummingbird (DQN-Hybrid ECAH), specifically designed to overcome computational difficulties in the Internet of Things (IoT) environment. This method represents a significant leap forward in IoT, combining state-of-the-art strategies to effectively manage the intricate aspects of composite services in this area. The implementation of advanced chimp artificial hummingbird techniques ensures the efficiency and effectiveness of the DQN-Hybrid ECAH. Empirical testing demonstrates this approach’s superiority compared to other existing methods. It notably achieves impressive results in terms of Packet Delivery Ratio (PDR) and throughput, while simultaneously maintaining low jitter and reduced average end-to-end delay. These results highlight the DQN-Hybrid ECAH method’s ability to substantially improve the quality of composite services in IoT applications. Overall, the DQN-Hybrid ECAH represents a significant breakthrough in the IoT sector, offering a novel and proficient solution to the complexities of composite services in IoT. This method is not just beneficial for enhancing IoT application performance, but it also tackles the challenges associated with real-time adaptive sensing frequently found in these environments.
In a study [43], the innovative Artificial Hummingbird Pity Beetle Algorithm (AHPBA) is introduced for the selection of optimal features and weight parameters. The selected features are then inputted into Multi Cascaded \(Atrous\) based Deep Learning Schemes (MCA-DLS) for classification purposes. AHPBA further refines this process by optimizing the variance maximization within MCA-DLS. When compared to individual signal classification using One-Dimensional Convolutional Neural Networks (1DCNN), Long Short-Term Memory (LSTM), and Deep Neural Networks (DNN), MCA-DLS demonstrates superior performance, achieving an average accuracy of 94.51%. The application of AHPBA further enhances the average accuracy of MCA-DLS, boosting it to 96.4%. This represents a significant improvement over traditional optimization techniques, underscoring the effectiveness of AHPBA in optimizing deep-learning classification schemes.
In [44], the authors introduced a new variation of the Particle Swarm Optimization (PSO) algorithm. This innovative approach, inspired by AHA, aims to refine the algorithm’s search capabilities and increase the diversity within the algorithm’s population. To evaluate the performance of this modified PSO algorithm, dubbed PSO-AHA, the researchers utilized two sets of standard testing problems: the CEC-2010 and CEC-2013 benchmark suites. These benchmarks are widely recognized in the field for assessing algorithmic effectiveness. It also involved a comprehensive comparison of the PSO-AHA model with other well-known PSO variations. This comparison used shifted and rotated test functions derived from the CEC 2005 and CEC 2014 benchmark collections, allowing for a robust evaluation against established standards. The PSO-AHA algorithm demonstrated superior performance over seven others modified PSO algorithms. This research indicates that incorporating AHA patterns into the PSO framework could be a significant step forward in the development of more efficient and effective optimization algorithms.
Acknowledging the challenges such as slow search velocity, reduced optimization accuracy, and premature convergence inherent in the AHA, a novel variant named DGSAHA, integrating the golden sine factor, is proposed [45]. This advanced version of AHA initiates chaos mapping to create initial candidate solutions, enhancing the diversity of the population and paving the way for a broader scope of search. The method also involves introducing perturbations to individuals through differential variation within the population. This technique not only augments diversity but also aids in retaining superior individuals, eliminating weaker ones, and guiding the search toward the global optimum, thereby averting early convergence. To ascertain the efficacy of DGSAHA, it was tested against 25 classical functions, in addition to the CEC2014 and CEC2019 benchmark functions, and its performance was compared with various representative MAs and their advanced versions. The research further investigates the scalability of test functions with variable dimensions. Utilizing non-parametric statistical analysis and performance indices, it was shown that DGSAHA possesses exceptional comprehensive optimization capabilities, markedly improving search speed and convergence accuracy, and exhibiting a strong capacity to avoid local optima. Furthermore, the practicality and efficacy of DGSAHA are substantiated through three engineering case studies concentrating on plane and space truss topology optimization issues, demonstrating its applicability in engineering contexts.
In the model [46], an innovative feature selection (FS) optimization algorithm named AHA-AO, which integrates the AHA with Aquila Optimization, is introduced. The primary function of AHA-AO is to selectively identify the most pertinent features, thereby enhancing the overall efficacy of model classification. The performance of this methodology was assessed using four distinct datasets: ISIC-2016, PH2, \(Chest-XRay\), and Blood-Cell. The effectiveness of the AHA-AO algorithm was benchmarked against five other widely recognized FS optimization algorithms. The results demonstrated impressive accuracy rates: 87.30% for the ISIC-2016 dataset, 97.50% for the PH2 dataset, 86.90% for the \(Chest-XRay\) dataset, and 88.60% for the Blood-Cell dataset. These outcomes indicate that AHA-AO surpassed the other optimization techniques in performance. Furthermore, AHA-AO exhibited a faster capability in identifying relevant features compared to other FS models. This accelerated feature selection process contributed to the overall improvement in performance and efficiency of the deep learning models being used. Thus, the proposed AHA-AO algorithm not only advanced the accuracy of the models but also enhanced their operational speed.
Model of [47] introduced a new hybrid named HAHA-SA, which combines the AHA with simulated annealing to enhance AHA’s performance. The efficacy of HAHA-SA was tested through its application to three constrained engineering design problems. For a comprehensive assessment, the outcomes of these applications were benchmarked against those obtained using established optimizers. Statistical analyses of these results underscored the superiority of HAHA-SA in efficiently tackling complex, multi-constrained design optimization challenges.
Table 1 shows the main motivation of algorithms with AHA combination. Each algorithm has specific advantages and they enhance AHA.
In Fig. 15, the advantages of combining the algorithm with AHA are shown.

The advantages of combining the algorithm with AHA
The goal of hybrid algorithms is to balance the stages of exploration and exploitation and discover optimal solutions. According to the studies, it can be concluded that the best results are achieved by the combined models for complex and complicated problems. This means that the power of the population of agents in the search space increases and each agent finds the best optimal points.
3.2 Improved
In this section, chaotic, crossover, data mining, deep learning, Lévy flight, opposition-based learning (OBL), and quantum models are reviewed.
3.2.1 Chaotic
Model of [48] introduces an innovative fault detection method for three-phase transmission lines, combining the AHA with the Chaotic Concept. This integration enhances the quality of solutions. The paper presents a new algorithm, termed the Chaotic AHA, inspired by the flight mechanics of hummingbirds and chaotic systems. This algorithm aims to precisely identify fault locations in transmission lines. It has been tested using a Simulink model in MATLAB for a 400 kV, 300 km transmission line. Voltage and current data are collected from both ends of the transmission line for analysis. The proposed algorithm is effective in handling different types of symmetric and asymmetric faults.
The study in [49] introduces an Enhanced AHA (EAHA) for identifying parameters in the control systems of pumped storage units. This algorithm incorporates two main strategies to augment its optimization capabilities. Initially, a Chebyshev chaotic map is utilized to set up the artificial hummingbirds, thereby boosting the global search proficiency of the initial group. Furthermore, Lévy Flight (LF) is incorporated during the guided foraging stage to broaden the exploration area and prevent early convergence. The effectiveness of the EAHA method is assessed against four other algorithms using 23 standard test functions, demonstrating that EAHA outperforms these algorithms in terms of accuracy and speed of convergence. The application of EAHA in the parameter identification of control systems in pumped storage units further confirms its capability to address real-world challenges.
3.2.2 Crossover
Model of [50] discusses a new variant of the AHA, named Modified AHA (MAHA), which integrates genetic operators. The study reveals that MAHA enhances convergence speed and yields more effective search outcomes. This innovation was applied for the first time in identifying the global maximum power point (MPP) in photovoltaic (PV) systems, particularly those affected by shading. Typically, PV systems have a single MPP under uniform irradiance, easily located using standard tracking systems. However, shading alters this, resulting in multiple MPPs, including local and global MPPs. Traditional MPP tracking methods fail to differentiate between these, often settling on local MPPs. Therefore, an advanced MPPT technique utilizing a metaheuristic algorithm is essential to pinpoint the global MPP. Most MPPT strategies rely on multiple sensors (like those for voltage, current, irradiance, and temperature), increasing control system costs. This research proposes a cost-effective global MPPT method for PV systems under shadow conditions, using just a single sensor. The efficacy of MAHA is demonstrated through two shadow scenarios, with results indicating the superiority of this single-sensor-based MPPT approach for PV systems.
In [51], a novel technique known as the Crossover Boosted AHA-based AX-\(RetinaNet\) (CAHA-\(AXRNet\)) for identifying rice plant diseases is presented. This method emphasizes the effective detection and classification of diseases in rice plants. It utilizes the CAHA optimization algorithm to refine the hyperparameters within the AX-\(RetinaNet\) framework. The effectiveness of this approach is evaluated using three distinct disease detection datasets, including rice plant, rice leaf, and rice disease datasets, to distinguish between healthy and diseased rice plants. The method’s proficiency in disease detection is gauged using critical performance metrics such as precision, FF1 score accuracy, specificity, and recall. Demonstrating superior performance over existing methods for detecting rice plant diseases, the CAHA-\(AXRNet\) methodology achieves a notable accuracy rate of 98.1%.
3.2.3 Data Mining
In [52], an Enhanced AHA (EAHA) is used to optimize the parameters of a Support Vector Machine (SVM) for classifying the safety levels of environments by integrating various environmental factors. The EAHA addresses the original AHA’s limitations, namely its inadequate global exploration capability and slow convergence. This is achieved through a combination of strategies: initializing the population with Tent chaos mapping and backward learning, employing a Lévy Flight (LF) strategy for enhanced search capacity during the guided foraging phase, and utilizing a simple method to update the worst value at each iteration’s end. Utilizing this improved algorithm, the EAHA-SVM safety warning model is developed to categorize and forecast the safety of coal mine environments into four distinct classes. Separate simulations of the EAHA algorithm and the EAHA-SVM model demonstrate that the EAHA algorithm shows enhanced convergence speed and search accuracy, and the performance of the EAHA-SVM model is significantly better.
Model of [53] introduces a machine learning model designed to forecast the impact of Al2O3 nanoparticle concentration on the wear rates of Cu-Al2O3 nanocomposites, created through an in situ chemical method. This model is an advanced version of the Random Vector Functional Link (RVFL) algorithm, enhanced by the AHA. The AHA’s role is to optimize the RVFL configuration, thereby improving the prediction accuracy for Al2O3 nanoparticles. The modified RVFL-AHA model demonstrates high proficiency in predicting wear rates for various composites under different wear loads and speeds. It achieves remarkable accuracy levels, nearing 100% in training and 99.5% in testing, as measured by the coefficient of determination R2.
3.2.4 Deep Learning
Model of [54] introduces the HCNN + EHOA + KH-AES algorithm for effective attack detection in IoT. It aims to improve the detection of attacks promptly. This method improves security and accuracy in identifying IoT attacks in urban areas using an Intrusion Detection System (IDS) equipped with Hybrid Convolutional Neural Networks (HCNN). The process involves pre-processing and feature selection (FS) using the Entropy-Hummingbird Optimization Algorithm (EHOA). For secure data exchanges, the Krill Herd-Advanced Encryption Standard (KH-AES) algorithm is employed. The NSL-KDD dataset was used for implementing the IDS. Data classification covered six attack types: U2R, DoS, R2L, Probing, normal, and unknown. The classification accuracy is significantly influenced by the weights in the HCNN layers. This proposed method was compared with existing methods in terms of FS, classification, and data share security, demonstrating notable results.
Article [55] presents a hybrid machine learning model that merges a Long Short-term Memory (LSTM) neural network with AHA optimization to forecast the permeate flow and energy efficiency of a Reverse Osmosis (RO) unit. For predicting energy savings, the model uses recovery ratio and system pressure as inputs, while system pressure alone is used for permeate flow predictions. The AHA algorithm enhances the LSTM’s performance by fine-tuning its parameters. The improved model showed a notable increase in prediction accuracy over the standard LSTM model. In the power saving prediction test phase, the LSTM-AHA model achieved a coefficient of determination of 0.997, compared to 0.981 for the standalone LSTM. For permeate flow prediction, these figures were 0.992 for LSTM-AHA and 0.97 for LSTM. Furthermore, it was observed that the RO unit’s power consumption decreased as the recovery ratio increased, with the most significant power savings of over 85% occurring at a recovery ratio of 10%.
Figure 16 shows the flowchart of LSTM-AHA.

The flowchart of LSTM-AHA
The model of [56] introduced a novel approach combining a hybrid convolutional neural network-recurrent neural network with AHA (HCNNRNN-AHB). This technique is adept at categorizing fundus images into two groups: exudates and non-exudates. Initially, to reduce false positives, optic discs are eliminated using the Hough transform technique. Following this, the system extracts color and texture features from the fundus images to distinguish between exudates and non-exudates. The HCNNRNN-AHB approach, which merges CNN and RNN models with AHB optimization, then conducts the classification. The inclusion of the AHB algorithm optimizes CNN and RNN parameters, thus improving the model’s predictive accuracy. Simulation tests are carried out to evaluate the method’s effectiveness using various metrics, including accuracy, sensitivity, specificity, F-score, and area under the curve score. The results demonstrate that the HCNNRNN-AHB method attains a high classification accuracy of approximately 97.4%.
Model of [57] suggested a three-part approach for developing an advanced intelligent video surveillance system through the use of hybrid deep learning methods. The approach begins with a Modified Barnacles Mating Optimization (MBMO) algorithm, designed to segment objects from video frames while tackling issues of redundancy and temporal complexity. Next, a Chaotic Hummingbird Optimization (CHO) algorithm is applied to enhance feature optimization, addressing problems related to data dimensionality. The key innovation is the integration of a Hybrid Convolutional Neural Network (CNN) with a Supreme Gradient Boosting (hybrid CNN-\(SGboost\)) classifier, aimed at achieving accurate object prediction and detection. This system is tested against benchmark datasets such as Penn-Fudan pedestrians, Daimler pedestrian segmentation, and \(Inria\) person. It’s compared with leading alternatives using standard evaluation metrics. The simulation results underscore the hybrid model’s effectiveness, marking a notable improvement in precise object detection for video surveillance systems.
Model of [58] introduced a new technique for hyperparameter optimization (HPO) of a CNN designed for arrhythmia classification, employing a modified metaheuristic algorithm. This method features a unique variant of the MH algorithm, called the memory-enhanced AHA. It includes an additional memory unit that stores solution evaluations, significantly cutting down computation time. Furthermore, the research introduces a novel fitness function that takes into account both the accuracy rate and the total parameter count of each candidate network. The method was tested using raw ECG data from the MIT-BIH arrhythmia database. When compared to five other MH methods, the proposed approach demonstrated competitive or superior performance, achieving a classification accuracy of up to 98.87%.
The model of [59] introduced a novel meta-heuristic algorithm, the AHA, designed for waste classification based on feature selection (FS). However, AHA faces challenges like potential entrapment in local optima and slow convergence rates. To address these issues, the paper presents two enhanced versions: AHA with Random Opposition-Based Learning (AHA-ROBL) and AHA with Opposition-Based Learning (AHA-OBL). These variants improve the exploitation phase by employing ROBL and OBL techniques, respectively, to avoid local optima and quicken convergence. The primary goal of this research is to apply AHA-ROBL and AHA-OBL for selecting pertinent deep features from two pre-trained CNN models, VGG19 and \(ResNet20\), for efficient waste classification. The \(TrashNet\) dataset serves as the benchmark for testing the performance of these proposed methods. The performance of AHA-ROBL and AHA-OBL is assessed through various metrics. The experimental results validate the superiority of these proposed algorithms over the compared ones, especially in producing the optimal number of selected features with the highest precision.
Model of [60] introduced a novel model, AHA-CNN, designed for extracting features and classifying cancer diseases. This model, AHB-CNN, determines the likelihood of cancer in patients based on data gathered from sensors. The outcomes of this analysis are subsequently transmitted to hospital management for further evaluation. A significant focus of this study is on the application of the Rivest-Shamir-Adleman (RSA) encryption method. The choice of RSA is attributed to its key advantages, including asymmetric encryption capabilities, user-friendliness, straightforward implementation, and the high level of security it offers, particularly due to the complexity involved in factoring large prime numbers.
Figure 17 shows the advantages of combining AHA with deep learning networks.

The advantages of combining AHA with deep learning networks
One of the common applications of AHA algorithm in deep learning techniques is to optimize hyperparameters. Deep learning techniques, especially LSTM and CNN models, have many meta-parameters such as learning rate, batch size, number of layers, etc. The AHA algorithm can effectively find the best value for meta-parameters in the high-dimensional search space, which potentially leads to better performance of LSTM and CNN models [61]. To process the image data by CNN, the AHA algorithm can select the optimal feature. The AHA algorithm helps to find a subset of similar features to train CNN layers, thus reducing the dimensionality of the input space and improving computational efficiency. AHA algorithm can help optimal configuration for LSTM or CNN models. These settings include number of layers, size of layers, number of activation functions, etc.
3.2.5 Lévy Flight
Lévy Flight (LF) is a type of random walk where the lengths of steps adhere to the Lévy distribution. This distribution stands apart from normal and Cauchy distributions due to its heavy-tailed nature, implying a greater likelihood of retaining the same position. Under similar conditions, LF, guided by the Lévy distribution, covers a substantially broader search area compared to Brownian motion, which operates under a uniform distribution. The AHA is recognized as a population optimization algorithm noted for its rapid computation, minimal parameters, and ease of implementation. Nonetheless, its broader application is somewhat constrained due to two primary shortcomings: a tendency towards premature convergence and the risk of getting trapped in local minima. To address these issues, numerous enhancements have been proposed and implemented by researchers. Incorporating LF into the AHA enhances its efficiency in exploring the search space, effectively mitigating these limitations.
Model of [62] introduced an enhanced version of the AHA, termed Adaptive Levy AHA (ALAHA). This new variant incorporates adaptive search strategies and LF. The algorithm begins by employing Kent mapping in its initial phase to distribute the hummingbird agents. Subsequently, LF is integrated as an adaptive weighting factor. This integration serves to modify the step size during the AHA’s guided and regional search phases, thereby augmenting the global search capabilities of the population. Furthermore, the algorithm implements an adaptive distance search around individual hummingbirds based on the convergence of the population, aiming to refine the search accuracy. To evaluate the performance of ALAHA, 10 classical benchmark test functions are utilized. The algorithm’s effectiveness is then compared with other algorithms from various perspectives. The outcomes of these tests indicate notable enhancements in ALAHA, particularly in terms of superior search capability, stability, and robustness. This improvement suggests that the ALAHA algorithm represents a significant advancement in optimization techniques.
Model of [63] presented an Improved AHA (IAHA) model, designed specifically to minimize total fuel generation costs, environmental pollution, and overall power losses in AC-Multi-Terminal Direct Current (AC-MTDC) power systems. This advanced IAHA incorporates various Territorial Foraging Tactics (TFTs) along with a Linear Control Process (LCP), effectively enhancing both local and global search capabilities. In contrast to the traditional AHA, the IAHA was tested on the modified IEEE 57-bus and 30-bus hybrid AC and multi-terminal HVDC power systems for assessment. The simulation results highlighted the IAHA’s considerable economic, environmental, and technical advantages. Particularly, within the IEEE 57-bus hybrid AC-MTDC power system, IAHA realized a notable reduction in fuel costs, emissions, and losses by 22%, 59.51%, and 71.83%, respectively, compared to the baseline scenario. Similarly, for the IEEE 30-bus hybrid AC-MTDC system, IAHA demonstrated decreases in fuel costs, emissions, and losses by 17.01%, 16.04%, and 28.49%, respectively, relative to the original case. These findings emphasize the IAHA’s efficiency in enhancing performance in AC-MTDC power systems.
The AHA often struggles with a balance between exploration and exploitation abilities, leading to premature convergence and low precision. Model of [64] proposed a multi-strategy enhanced version of AHA, termed the LCAHA (Levy Chaotic AHA), which incorporates a sinusoidal chaotic map strategy, LF, and novel cross and update foraging strategies. Initially, the LCAHA employs the sinusoidal chaotic map strategy during initialization, enhancing the population’s ergodicity. The integration of LF then improves the population’s diversity, controls premature convergence, and increases stability. Furthermore, the introduction of two innovative strategies, cross-foraging and update foraging, further augments the algorithm’s exploratory and developmental capabilities. These three tactics collaboratively enhance the comprehensive efficacy of the AHA. The efficacy of LCAHA is rigorously tested on 23 classical benchmark test suites, including CEC2017, CEC2019, and CEC2020, as well as six engineering optimization scenarios. The quantitative empirical findings highlight LCAHA’s potential in addressing intricate optimization challenges. Notably, the algorithm is applied to two spacecraft trajectory optimization cases, where its practical applicability and potential are convincingly demonstrated through experimental results.
Model of [65] introduced a refined version of the improved AHA (IAHA), specifically designed to address the task scheduling problem. The IAHA incorporates a set of innovative initialization rules, including global selection, local selection, and random selection, which collectively aim to enhance the quality of the initial population. Furthermore, the algorithm employs LF to improve both guided and territorial foraging. Another key feature of IAHA is the integration of the Simplex Search Strategy (SSS), which is utilized to augment migration foraging, thereby boosting the algorithm’s capability to seek optimal solutions. To fine-tune the IAHA, orthogonal tests are conducted to identify the most effective combination of parameters. Furthermore, the performance of IAHA is evaluated through comparative tests against various versions of AHA and other algorithms, using both a benchmark case and a simulated crowdsourcing scenario. The experimental findings demonstrate that the IAHA is capable of consistently obtaining superior solutions in many instances, showcasing its efficiency and economic viability as a solution to task scheduling challenges. Figure 18 shows the combination of LF and SSS with AHA.

The combination of LF and SSS with AHA
The model of [66] introduced a novel parameter estimation technique utilizing a recent metaheuristic algorithm known as the AHA. The simplicity and ease of implementation of AHA make it an attractive choice for addressing parameter estimation challenges. However, a notable drawback of AHA is its slow convergence speed, leading to an excessive number of function evaluations before achieving the desired results. To counteract these limitations, the study proposes two enhancements to the classical AHA, resulting in a new variant named Improved AHA (IAHA). This variant is specifically tailored to address the parameter estimation issues in Proton Exchange Membrane Fuel Cell (PEMFC) stacks. IAHA was utilized to determine unidentified parameters in six distinct PEMFC stacks, and its effectiveness was compared with 11 renowned optimizers. The criteria for comparison included accuracy of outcomes, convergence speed, stability, and CPU time. The empirical findings indicate that IAHA exceeds the performance of rival algorithms in all aspects, except for CPU time, where its performance is akin to that of other methods. This demonstrates IAHA’s effectiveness in enhancing parameter estimation in PEMFC stacks while maintaining reasonable computational efficiency.
The model of [67] addressed the complex issue of stochastic optimal reactive power dispatch (ORPD) in the context of renewable energy sources like solar PV, wind turbines, and hydropower generation systems, which are inherently uncertain. To represent the variability in time-varying load demand and power generation from these renewable sources, the study employs several probability density functions (PDFs), including normal, lognormal, Weibull, and Gumbel distributions. A Monte Carlo simulations-based method is then used to generate an appropriate number of scenarios, effectively reducing the complexity of these stochastic models. The second major contribution of this paper is the development of an enhanced version of the AHA, named Modified AHA (MAHA). This improved algorithm incorporates LF motion and distance bandwidth motion around the best solution. These additions are designed to augment both the exploratory and exploitative capabilities of the traditional AHA and prevent it from getting trapped in local minima. The efficacy of MAHA is rigorously tested on the IEEE 30-bus system, focusing on reducing active power loss, improving voltage profiles, and enhancing voltage stability. The results demonstrate that MAHA outperforms several well-known conventional algorithms like the original AHA, GWO, SCA, Dragonfly Optimization (DO), Black Widow Optimization (BWO), and other cutting-edge algorithms in solving the ORPD problem. This indicates the proposed MAHA’s effectiveness and superiority in this field.
Figure 19 shows the advantages of combining AHA with levy flight.

The advantages of combining AHA with levy flight
Table 2 shows the improvement of AHA by the LF. Items such as the advantages and disadvantages of levy flights have been analyzed.
3.2.6 Opposition-Based Learning
The novel oppositional chaotic AHA (OCAHA) was effectively employed for solving both single-objective (SOP) and multi-objective (MOP) design optimization challenges related to forced-draft counter-flow evaporative cooling towers [68]. For the SOP framework, Merkel’s method was utilized to determine the geometric dimensions of the cooling tower. This determination was based on correlations of the overall mass-transfer coefficient and the loss coefficient pertinent to the film packing within the tower fill. The algorithm focused on two primary decision variables: the mass flow rate of the cooling air and the cross-sectional area of the tower fill. The outcome was a notable average reduction of 2.37% in the total annual cost compared to the baseline study, achieved through enhanced convergence speed in all test scenarios. In the context of MOP, the algorithm concurrently optimized four critical performance metrics for wire-mesh-filled cooling towers. These metrics encompassed the cooling range, the tower characteristic ratio, the tower effectiveness, and the water evaporation rate, to maximize the overall efficiency. The decision variables in this scenario were the mass flow rates of water and air. OCAHA demonstrated superior performance in identifying the most optimized solution compared to other designs, achieving the most effective overall optimization results from previous research.
Model of [69] introduced an innovative method for designing a fractional order proportional-integral-derivative (FOPID) controller. This design is centered around a modified version of the elite opposition-based AHA (m-AHA), which is tailored for the optimal tuning of controller parameters. This novel approach has shown superior performance over existing optimization techniques in benchmark functions. Its effectiveness is further demonstrated in the application of cruise control systems, where it brings enhanced flexibility and precision. This research makes a significant contribution to the field of autonomous vehicle technology. It presents a new and efficient strategy for the design of FOPID controllers, which has the potential to improve the driving experience by ensuring greater safety and reliability. The integration of Opposition-Based Learning (OBL) with AHA, as illustrated in Fig. 20 of the study, is a key aspect of this advanced controller design approach.

The combination of OBL with AHA
In [70], a novel iteration of the AHA is presented, named CODA. This iteration enhances AHA by integrating Opposition-Based Learning (OBL), a chaos mechanism, and the Differential Evolution (DE) algorithm. The DE algorithm is particularly utilized to optimize the configuration of chaotic maps, and OBL is employed to determine the best initial population. CODA’s advanced capabilities enable it to effectively avoid local optima and improve the exploration of specific areas of interest. CODA’s application is demonstrated in the task scheduling of fog computing systems, where it is used in conjunction with the Analytic Hierarchy Process (AHP) to ascertain task priorities. The primary objectives of this task scheduling are to minimize energy consumption, duration, and costs. The results of these simulations indicate that CODA outperforms other established meta-heuristic algorithms in terms of energy efficiency, makespan (total completion time), and cost. Compared to existing algorithms such as AHA, Gravitational Search Algorithm (GSA), MFO, SOA, SSA, WOA, SCA, PSO, MVO, and DE, CODA demonstrates superior performance in meeting the demands of the task scheduling process. On average, the CODA-based task scheduling model surpasses other research studies, achieving a 46% improvement in makespan, an 8% reduction in cost, and a 41% decrease in energy consumption.
Model of [71] proposed an enhanced version of the AHA, named Adaptive Opposition AHA (AOAHA), which incorporates an adaptive opposition approach to decide the usage of opposition-based learning (OBL). This enhancement, featuring an adaptive updating mechanism, is designed to enable the original algorithm to achieve more precise results, especially when dealing with complex problems. The AOAHA underwent thorough assessment through 23 benchmark functions, where its performance was meticulously compared not only with the original AHA but also with other modern optimization algorithms. These comparisons included an evaluation against the Supply–Demand-Based Optimization (SDO), the Wild Horse Optimizer (WHO), and the TSA, offering a comprehensive analysis of the capabilities of both its predecessor and current contemporaries in the field. One of the key applications of the AOAHA was in the development of accurate models for solar cell systems, a crucial component in solar power plants, aiming to boost their overall efficiency. The research involved conducting experiments on both static and dynamic models of solar cell systems, ensuring that the proposed model accurately reflects real-world scenarios. The results of these applications were assessed using multiple methods, including comparisons with other advanced and effective optimization techniques. The AOAHA showed its potential through its impressive results in these applied tests, indicating its effectiveness in enhancing the accuracy and efficiency of complex system models.
3.2.7 Quantum
Model of [72] explored the synthesis of two machine-learning techniques, namely Random Vector Functional Link (RVFL) and Relevance Vector Machine (RVM), with two innovative optimization algorithms: the Quantum-based Avian Navigation Optimizer Algorithm (QANA) and the AHA. This integrative approach is deployed to forecast evapotranspiration data from two climatic stations situated in the semi-arid regions of Pakistan, utilizing the optimized machine learning models. The combined RVFL and RVM models, optimized with QANA and AHA, are deployed to forecast evapotranspiration data. To evaluate the precision of these models, the study employs four statistical measures: Root Mean Square Errors (RMSE), Mean Absolute Errors, the Determination Coefficient, and the Nash–Sutcliffe Efficiency. These metrics are used to assess the performance across different input combinations, which include variables like minimum temperature, maximum temperature, and extraterrestrial radiation. Additionally, the study investigates the effects of varying data segmentation strategies and periodicity on the models’ effectiveness. Amongst the tested models, the RVM-QANA, particularly when configured with a 75–25% training-to-test data split and incorporating a comprehensive range of inputs (including minimum temperature, maximum temperature, extraterrestrial radiation, and MN). This outcome highlights the RVM-QANA model’s capability for accurately predicting climatic data in semi-arid environments.
Model of [73] presented a refined version of the AHA for feature selection (FS), incorporating elements of Quantum-based optimization. The primary objective of this Quantum-enhanced AHA (QAHA) is to boost the population’s ability to explore and identify viable regions more effectively. To validate the effectiveness of the QAHA in FS, extensive experiments were carried out using eighteen datasets from the UCI machine learning repository. In these tests, QAHA was benchmarked against other FS methods, where its efficiency was firmly established. Furthermore, the study extended its examination to a real-world context by applying QAHA to four datasets from the Smart Internet of Things (SIoT). The performance results from these SIoT datasets demonstrated QAHA’s high efficiency in improving accuracy through the reduction of feature numbers. Specifically, in the UCI dataset experiments, QAHA achieved an impressive average accuracy of 93% across the eighteen datasets. For the SIoT datasets, QAHA showed accuracies of approximately 90.7%, 98.7%, 92.2%, and 84.6% for the Trajectory, GAS sensors, Hepatitis, and \(MovementAAL\) datasets, respectively. These results highlight QAHA’s potential in effectively handling both academic and real-world data scenarios.
Figure 21 shows the percentage of improved AHA based on different methods. The largest percentage belongs to deep learning. Deep learning has used AHA to improve parameters and training.

Percentage diagram of Improved AHA based on different methods
3.3 Variants of AHA
3.3.1 Binary
In [74], the AHA demonstrated superior performance compared to several traditional techniques when analyzed using the Wilcoxon test. This algorithm has been successfully applied to various practical problems, particularly in the energy sector. The study is motivated by the binary codes of various optimization algorithms provided by different researchers, leading to the development of a binary version of the AHA specifically for tackling discrete optimization problems. The effectiveness of this binary AHA is assessed through benchmark functions, and its results are juxtaposed with those of the original AHA across various dimensions. This comparative analysis serves to highlight the strengths and applications of the binary AHA in solving discrete optimization challenges.
Model of [75] introduced the Pareto-Discrete Hummingbird Algorithm (PDHA), a novel approach specifically designed to effectively solve the Partial Sequence-Dependent Disassembly Line Balancing Problem (PSD-DLBP). The PDHA operates in two key stages: a self-searching stage and an information-interacting stage. These stages are structured to create a balance between the algorithm’s exploration and exploitation capabilities. The performance and superiority of the PDHA were thoroughly evaluated by comparing it with four other models across two examples of varying scales. Furthermore, it was demonstrated that the PDHA excels in addressing the challenges of the PSD-DLBP, indicating its effectiveness and potential for practical applications in this domain.
3.3.2 Multi-Objective
In many real-world scenarios, particularly in science and engineering, there is a need to address problems involving multiple objectives simultaneously. These objectives often conflict with each other, making it challenging to achieve a balanced resolution for each goal. Such problems are known as multi-objective optimization problems (MOOPs). In MOPs, solutions that are not outperformed on all objectives by other solutions are referred to as Pareto optimal solutions. In the context of multi-objective optimization (MOO), the ideal solution represents a compromise among various feasible options. This solution is a trade-off, meaning it might not be the absolute best for any single objective but is optimal when considering all objectives collectively. Typically, a mathematical formulation of a MOO problem involves m objectives, n variables, q equality constraints, and p inequality constraints. This formulation is generally encapsulated in what is referred to as Eq. (13).
Owing to the fragmented nature of the Pareto front (PF) and the intricacy of the objective, locating precise solutions within a limited timeframe can be an expensive endeavor. In such cases, seeking an approximate solution is often more feasible for practical purposes. These types of challenges can be effectively addressed through population-based optimization techniques, which are capable of generating a set of equilibrium solutions.
This section describes the MOAHA method for Multi-Objective Optimization (MOO) problems. It incorporates three primary components [76]:
-
1.
An external archive is integrated into MOAHA to preserve the best non-dominated (ND) solutions found at each search step.
-
2.
During the optimization, the archive is efficiently managed using the Dynamic Elimination-Based Crowding Distance (DECD) method. This technique, known for its effectiveness and lack of need for additional parameters, is employed to enhance solution diversity. It involves removing fewer essential solutions with lower crowding distances to maintain a constant-sized Evolutionary Algorithm (EA). When a solution with the smallest current crowding distance is taken out of the Pareto optimal set (PS), only the crowding distances of adjacent solutions need updating, while the rest remain the same. Before removing the \({i}{\mathrm{th}}\) solution, which has the latest lowest crowding distance, the crowding distances of the solutions immediately before and after this solution are recalculated according to Eq. (14) and Eq. (15) [77].
$$\left\{\begin{array}{l}{d}_{k}\left({x}_{i-1}\right)=\left|{f}_{k}\left({x}_{i}\right)-{f}_{k}\left({x}_{i-2}\right)\right|\\ max\left({f}_{k}\right)-min\left({f}_{k}\right)\\ D\left({x}_{i-1}\right)=\sum_{k=1}^{m} {d}_{k}\left({x}_{i-1}\right)\end{array}\right.$$(14)$$\left\{\begin{array}{l}{d}_{k}\left({x}_{i+1}\right)=\mid \begin{array}{c}\left|{f}_{k}\left({x}_{i}\right)-{f}_{k}\left({x}_{i+2}\right)\right|\\ max\left({f}_{k}\right)-min\left({f}_{k}\right)\end{array}\\ D\left({x}_{i+1}\right)=\sum_{k=1}^{m} {d}_{k}\left({x}_{i+1}\right)\end{array}\right.$$(15)After the \({i}{\mathrm{th}}\) solution, which has the most recently calculated lowest crowding distance (CD), is removed, the CDs of the solutions immediately before and after it are modified. These modifications are carried out ibyEq. (16) for the solution preceding the \({i}{\mathrm{th}}\) solution and Eq. (17) for the solution succeeding it [77].
$$\left\{\begin{array}{l}{d}_{k}\left({x}_{i-1}\right)=\mid \begin{array}{c}\left|{f}_{k}\left({x}_{i+1}\right)-{f}_{k}\left({x}_{i-2}\right)\right|\\ max\left({f}_{k}\right)-min\left({f}_{k}\right)\end{array}\\ D\left({x}_{i-1}\right)=\sum_{k=1}^{m} {d}_{k}\left({x}_{i-1}\right)\end{array}\right.$$(16)$$\left\{\begin{array}{l}{d}_{k}\left({x}_{i+1}\right)=\left|{f}_{k}\left({x}_{i-1}\right)-{f}_{k}\left({x}_{i+2}\right)\right|\\ max\left({f}_{k}\right)-min\left({f}_{k}\right)\\ D\left({x}_{i+1}\right)=\sum_{k=1}^{m} {d}_{k}\left({x}_{i+1}\right)\end{array}\right.$$(17)This \(D\left({x}_{i-1}\right)\) is the crowding distance of the \({(i-1)}{\mathrm{th}}\) solution and \({d}_{k}\left({x}_{i-1}\right)\) is the side length of the cuboid of the \({(i-1)}{\mathrm{th}}\) solution.
-
3.
In the phase of updating solutions, the refinement of non-dominated solutions is carried out using a strategy that employs the non-dominated sorting (NDS) technique. This method is vital in improving the convergence rate of the solutions.
In the context of a MOO problem, the Multi-Objective AHA (MOAHA) initially establishes an Efficient Archive (EA) with a set number and creates a random population of Hummingbird Behaviors (HBs). Following this, a VT is initiated, and all non-dominated solutions from the initial population are recorded in the archive. During each iteration, MOAHA randomly chooses between territorial and directed foraging with a 50% probability. In guided foraging, each HB alters its location based on the target Feature Set (FS) determined by the VT and dominance relation. Conversely, in territorial foraging, an HB searches within its local neighborhood. After completing a foraging round, the solution is updated by refreshing the VT using the non-dominated sorting (NDS) method. In migrating foraging, solutions at the worst non-dominated (ND) points are randomly reinitialized within the search area, and the VT is modified accordingly. At the end of each iteration, ND solutions from the new population are added to the archive. If the archive size exceeds its predetermined limit, the Efficient Archive technique based on dynamic elimination-based crowding distance (DECD) is employed.
The aforementioned procedures are iteratively executed until they fulfill the pre-established limit of iterations. Consequently, this results in the creation of an archive that encompasses the Pareto Front (PF), featuring the optimum non-dominated solutions. Figure 21 illustrates the fundamental workflow of MOAHA-DECD for a single MOOP, with each MOOP generating a unique Pareto front. The Pareto optimal solutions are sets of non-dominated or equally good solutions that improve one objective function and lead to a trade-off with another. A comparative analysis of MOOPs in different scenarios, particularly in reducing energy consumption, was conducted. This analysis provides decision-makers with a range of solutions, enabling them to apply their industrial insight to select the most “preferred” solution for their specific context.
Figure 22 shows the basic working flowchart of MOAHA-DECD.

The basic working flowchart of MOAHA-DECD [77]
The model of [78] introduced an innovative multi-objective AHA method designed to enhance antenna isolation through the optimization of each antenna’s geometric parameters. It employs an efficient chaotic sampling technique for generating discrete random samples. The effectiveness of this tuning approach is demonstrated using an antenna array as a case study. Findings indicate that this proposed method successfully improves antenna isolation without the need for extra decoupling mechanisms.
The model of [79] introduced a novel Multi-Objective AHA (MOAHA) algorithm. This algorithm mimics the unique flight abilities and smart foraging strategies of hummingbirds in nature. It utilizes three distinct types of flight maneuvers; axial, oblique, and all-around in its food search methodologies. The MOAHA is evaluated through five practical engineering case studies. To assess its performance, various metrics like spacing (S), Inverted Generational Distance (IGD), and Maximum Spread (MS) are employed, comparing MOAHA with other algorithms like MOPSO, MOWOA, and MOHHO. The results indicate that the proposed algorithm is capable of generating high-quality Pareto fronts, exhibiting notable precision, uniformity, and highly competitive results in both qualitative and quantitative terms.
The model of [80] introduces a new Multi-objective AHA (MOAHA) based approach for optimizing the allocation and sizing of Renewable Distributed Generators (RDG) and the operation strategy of Battery Energy Storage Systems (BESS) to improve the Voltage Stability Margin (VSM). This method underwent rigorous testing on three different electrical systems: the IEEE 33-bus system, the IEEE 69-bus system, and the distribution grid on \(Masirah\) Island in Oman. The Pareto fronts produced by this approach demonstrated superior effectiveness when compared with results from four contemporary metaheuristic techniques in this domain. These techniques include the Multi-objective Multi-verse Optimization (MOMVO), the Multi-objective Equilibrium Optimization Technique (MOEOT), the Multi-objective Particle Swarm Optimization (MOPSO), and the Non-dominated Sorting Genetic Algorithm-III (NSGA-III). The comparative analysis showcased this method’s enhanced efficiency in optimizing multiple objectives simultaneously. The results demonstrated that the optimal Pareto solution candidates (PSC) generated by MOAHA successfully met the VSM constraints and cost objectives across all three test systems. Additionally, they facilitated substantial energy transfer during both peak and off-peak times. Moreover, all PSCs successfully prevented voltage violations, and there was a notable reduction in active power losses during each optimization period and total energy losses overall.
The model of [81] presented an Integrated Energy Management System (IEMS) framed as a mixed-integer nonlinear problem, addressed using a Multi-objective AHA (MOAHA). This IEMS is designed to handle the variability and uncertainty of Renewable Energy Sources (RES) and is evaluated under four distinct scenarios: good, bad, average weather, and a forecast based on a stochastic RES model. The efficacy of this IEMS is compared in-depth with the traditional energy management strategy (CEMS), both with and without the inclusion of the Home Hybrid Battery (HHB) storage system and Demand Response (DR). Furthermore, the performance of MOAHA is compared against the advanced Multi-objective PSO (MOPSO). The assessment employs four quality metrics to measure the advantages of the proposed IEMS: Renewable Contribution Factor (RCF), Greenhouse Gas (GHG) emissions, Loss of Power Supply Probability (LPSP), and Saving Cost (SC). The findings indicate that the MOAHA model outperforms the other models in these comparisons.
This study proposes a method for stabilizing a nonlinear ball-wheel system using a fuzzy fractional-order adaptive robust feedback linearization control technique [82]. In this method, a controller utilizing feedback linearization adopts a decoupled sliding mode to determine the sliding surfaces and adjust the adaptive coefficients. Following this, the controller’s efficiency is further improved by incorporating fractional-order calculus and systems based on fuzzy logic. Additionally, the multi-objective AHA (MAHA) is employed to optimize the control coefficients. This optimization process involves two key objective functions: the integral of the absolute values of the control efforts and the errors within the system.
The model of [83] introduced an updated version of the multi-objective red kite optimization algorithm (MOROA), designed to optimize both targeted fitness functions. This research was conducted using two standard distribution networks: the IEEE-33 bus and the IEEE-69 bus. The effectiveness of the proposed ROA is evaluated by comparing it with various optimization algorithms, including the dung beetle optimizer (DBO), African vulture’s optimization algorithm (AVOA), bald eagle search (BES) algorithm, Bonobo optimizer (BO), GWO, multi-objective MVO (MOMVO), multi-objective GWO (MOGWO), and multi-objective AHA (MOAHA). In the case of the IEEE-33 bus network, the new ROA significantly reduced power loss by 58.24% and voltage deviation by 90.47%. Similarly, the IEEE-69 bus network, achieved reductions in power loss and voltage deviation by 68.39% and 93.22%, respectively. These results demonstrate the efficiency and robustness of the proposed ROA in addressing the challenges of integrating Renewable Energy Sources (RESs) and Flexible Charging Stations (FCSs) into electrical networks.
In research [77], the Multi-Objective AHA with Dynamic Elimination-Based Crowding Distance (MOAHA-DECD) is applied within an ASPEN Plus–MATLAB framework to optimize energy efficiency in the production of low-density polyethylene (LDPE). The study tackles three distinct objectives: Problem 1 (P1) focuses on minimizing energy costs while maximizing productivity; Problem 2 (P2) aims at minimizing energy costs and maximizing conversion; and Problem 3 (P3) involves minimizing energy costs, maximizing productivity, and maximizing conversion. Key decision variables in the process include the inlet pressure, and the mass flow rates of two initiators, tert-butyl \(peroxypivalate\) (TBPPI) and tert-butyl 3,5,5-trimethyl-peroxy hexanoate (TBPIN), specifically in reacting zones 3 and 5. The Pareto solutions generated exhibit a comprehensive and evenly distributed coverage across the entire Pareto front (PF), featuring diverse points. The outcomes indicate that the optimal results include the highest productivity at 554.958 million, the lowest energy cost, and the highest conversion rate.
The study in [84] applies three different optimization techniques to a self-supplied thermodynamic system: the Non-Dominated Sorting Genetic Algorithm II (NSGA-II), PSO, and the Multi-Objective AHA (MOAHA), which is inspired by hummingbird foraging behavior. According to the findings, the MOAHA model demonstrates superior performance, particularly in optimizing energy consumption.
In a study [76], a specialized Multi-Objective AHA (MOAHA) is developed to tackle intricate multi-objective optimization tasks, particularly in the realm of engineering design. MOAHA incorporates an external repository designed to record Pareto optimal solutions. It also introduces a groundbreaking technique known as Dynamic Elimination-Based Crowding Distance (DECD) for efficient archive management. This innovative strategy guarantees the preservation of solution variety within the population, enhancing the robustness of the optimization process. Moreover, MOAHA integrates a sophisticated non-dominated sorting mechanism, fostering a solution update process that refines Pareto optimal solutions and thereby enhances the algorithm’s convergence capabilities. The efficacy of MOAHA is further evidenced through its application to five complex, real-world engineering design challenges. This demonstrates MOAHA’s adeptness in resolving elaborate multi-objective problems in real-world scenarios, where true Pareto optimal solutions and fronts are not pre-identified.
Model of [85] introduced a novel AHA designed for identifying the optimal sites and capacities of biomass-based Distributed Generators (DGs) in radial distribution networks. This method is characterized by improved exploration and exploitation phases, enhancing its search efficiency and averting the risk of being ensnared in local optima. The primary goals are to reduce network active power loss and voltage fluctuations. A specialized adaptation of the AHA algorithm is developed to effectively address a dual-objective task, aiming to concurrently mitigate both issues. This modified methodology is rigorously evaluated across three different radial distribution networks, specifically the IEEE 33-bus, IEEE 69-bus, and IEEE 119-bus systems. In this process, it is benchmarked against various other optimization techniques, including but not limited to the fractal search algorithm, PSO, GA, WOA, sperm swarm optimization, tunicate swarm algorithm, pathfinder algorithm, SOA, SCA, multi-objective water cycle algorithm, multi-objective GWO, and multi-objective sparrow search algorithm. To further substantiate the effectiveness of the proposed strategy, comprehensive statistical assessments are conducted. These include the Wilcoxon test, Friedman test, Analysis of Variance (ANOVA), and Kruskal Wallis tests, providing a robust evaluation of the approach’s performance. The results from this extensive analysis strongly support the superiority and efficiency of the modified AHA-based method, especially in its application to integrate biomass-based Distributed Generators (DGs) into radial distribution networks.
In a study [86], an innovative method utilizing the AHA is presented for addressing the optimal reactive power dispatch (ORPD) challenge. This AHA-inspired model leverages the dynamic flight and foraging behaviors of hummingbirds to optimally adjust control variables. These variables encompass generator bus voltages, settings of on-load tap-changing transformers (OLTCs), and the magnitude of switchable shunt VAR compensators, to minimize key performance metrics. Moreover, the research introduces a multi-objective optimal reactive power dispatch framework (MO-ORPD), designed to concurrently optimize individual objectives. This framework takes into consideration the integration of renewable energy sources (RES) and the variability in power demands. The efficiency and resilience of the AHA-based model are confirmed through empirical tests conducted on the IEEE 14-bus and IEEE 39-bus systems, specifically focusing on solving the ORPD problem. The outcomes are then benchmarked against other well-established optimization methods in the field. To substantiate the model’s effectiveness, box plots, and statistical evaluations using SPSS software are utilized.
Figure 23 shows the percentage of variants of AHA based on two different methods. Figure 23 shows that the percentages of Binary and Multi-objective are 15% and 85%, respectively.

Percentage of variants of AHA based on two different methods
3.4 Optimization
Optimization is a fundamental principle focused on identifying the most advantageous decision variables to achieve either the minimum or maximum outcome of a specified objective function. Optimization techniques operate by systematically exploring the search space to uncover the optimal solution for complex problems. The optimization process initiates a series of improvements in alignment with the objective function, considering various constraints and parameters. When this process is applied in conjunction with the target objective function, aiming for minimization leads to achieving the optimal value for the desired decision variables. The intricacy of optimization challenges is on an exponential rise. Many complex real-world optimization issues present a formidable structure that requires resolution through gradient-free optimization methods, beyond the scope of classical algorithms. The limitations of these traditional optimization algorithms in tackling tough optimization problems have spurred researchers to develop or refine nature-inspired optimization algorithms. Furthermore, the increasing computational complexity in this field has prompted researchers to innovate and create new, advanced nature-inspired optimization algorithms, underlining the necessity for such developments in the realm of optimization.
Table 3 shows a general review of AHA papers in the field of optimization in 2023.
In the design of Wireless Sensor Networks (WSNs), energy consumption is a crucial parameter as it determines the lifespan of individual sensor nodes and, consequently, the entire network. Balancing energy limitations with the resource constraints of the sensors is vital for optimal network performance. However, in networks with numerous nodes, conventional direct routing tends to be energy-intensive, potentially shortening the network’s lifespan significantly. Drawing from traditional wired networks, hierarchical or cluster-based routing methods are commonly employed in large WSNs, offering benefits like scalability, efficient communication, and fault tolerance. In such hierarchical structures, the network is divided into smaller units called clusters, each overseen by a Cluster Head (CH). The CH is responsible for collecting or merging data from nodes within its cluster. This routing technique often involves both inter-cluster and intra-cluster communications, functioning in a multi-hop manner. Here, a sensor node is designed to communicate only with its closest neighbor, conserving its energy by avoiding attempts to reach far-off nodes. Other clustering strategies focus on achieving a balance between reliable sensing and the minimization of communication overhead, often through unsupervised learning processes. In this regard, the AHA has introduced effective routing and clustering rules. The application of AHA has led to reduced energy consumption and extended network lifetime, showcasing its efficacy in optimizing WSNs.
Cloud computing encompasses a variety of resources such as storage, computing power, and networking capabilities. These resources are effectively transformed into services accessible to users through the process of virtualization. However, there is a notable interplay between the quality of these services and factors like the rate of resource utilization, as well as the relationship between service quality and energy consumption. Consequently, when it comes to the optimization of resource deployment and scheduling, a comprehensive approach is required that considers and jointly manages all available resources. In this regard, it’s essential to aim for an optimization that not only enhances the Quality of Service (QoS) but also simultaneously reduces energy consumption and costs. The AHA has been utilized for task scheduling and resource allocation in cloud computing environments. When compared to other algorithms such as PSO, GA, Ant Colony Optimization (ACO), and Artificial Bee Colony (ABC), AHA has demonstrated greater efficiency, highlighting its effectiveness in optimizing cloud computing resources.
Table 4 shows a general review of AHA papers in the field of optimization in 2022.
Control engineering is intricately linked to the exploration and development of dynamic systems, aiming to design controllers that are efficient, reliable, and effective. With the advent of PID control, there has been a surge of interest in tuning methods that enhance the performance of PID controllers. However, the PID control strategy, especially for nonlinear systems, faces certain challenges. These include the difficulty in selecting appropriate controller gains, a process known as tuning. If the controller gains are set too low, the system may fail to meet its control objectives. Conversely, overly high controller gains can lead to system instability, despite being a feasible choice. Therefore, one of the primary concerns in control engineering is the precise tuning of controller parameters. The aim is to adjust these variables to not only stabilize the closed-loop control system but also to meet various objectives. These objectives encompass stability, longevity, performance tracking and measurement, noise reduction, disturbance rejection, and robustness against environmental uncertainties. In this regard, the AHA emerges as an apt choice for determining control parameters in both engineering and scientific domains. Its suitability stems from its ability to effectively navigate the complexities of parameter tuning in control systems.
4 Discussion
The AHA incorporates a migration strategy that is particularly formulated to prevent local stagnation, a key feature in optimization scenarios where there is a significant risk of settling on a local optimum instead of reaching the global optimum. This strategy is vital in such contexts. By moving towards a more distant resource when a frequently visited area becomes exhausted, the AHA emulates a tactic that improves its capacity to thoroughly explore the solution space. This approach effectively decreases the chances of the algorithm becoming trapped in local optima.
The effectiveness of Artificial Neural Networks (ANNs) is largely influenced by two critical factors: the structure of the network and its training methodology. The key to unlocking the full potential of ANNs lies in selecting an optimal network structure and an effective training algorithm. This involves making informed decisions about the number of neurons, their arrangement, connection weights, hidden layers, and biases. The challenge of finding the best network structure is a complicated task, often characterized by non-differentiability and multimodality. Training algorithms for ANNs can be broadly categorized into two types: gradient-based and metaheuristic-based. The gradient-based approach, one of the earliest methods for optimizing ANNs, is known for its proficient local search capabilities. However, its effectiveness heavily relies on the initial parameter values and starting positions. This method tends to require extensive exploration and longer learning times and suffers from slow convergence rates. It is particularly prone to getting stuck at local optima in complex scenarios, especially in flat regions with minimal gradient changes. On the other hand, the metaheuristic-based approach leverages heuristic search strategies, excellent exploration abilities, and the inclusion of randomness operators. This approach shows great promise in developing effective algorithms capable of solving real-world optimization problems across various applications. In this context, the AHA stands out as a powerful tool for training ANNs. It addresses and overcomes many of the limitations inherent in the gradient-based approach, positioning itself as a robust and reliable solution for complex optimization challenges in ANN training.
The combination of AHA with KHA, known as the AHA–KHA hybrid, enhances the performance of AHA by boosting population diversity and mitigating the issue of becoming ensnared in local optima [39]. In this hybrid approach, a vector is integrated into AHA to record the most effective solutions found, specifically the best local solution achieved by each agent and the best global solution achieved by the entire swarm. The techniques from KHA are then applied, utilizing these stored local and global best positions. KHA introduces its mutation method to the target vector, leveraging both the local and global best solutions to attain an improved position. This collaborative strategy combines the strengths of both AHA and KHA, leading to more effective optimization outcomes.
The AHA is employed for global search due to its strong exploration capabilities, while Differential Evolution (DE) is integrated for local search to enhance exploitation, thereby boosting the precision of the solutions. In each iteration, the first step involves calculating the average fitness of the entire population. Following this, for every search agent, a determination is made: if the agent’s fitness is below the average fitness, its position is updated using AHA’s step and position vectors. Conversely, if the agent’s fitness is above the average, the position is revised through DE’s mutation, crossover, and selection processes. This dual approach effectively combines the strengths of both AHA and DE, optimizing both the exploration and exploitation aspects of the search process.
An enhancement to the AHA has been developed by incorporating opposition-based learning (OBL), aimed at boosting the algorithm’s efficiency. This enhancement focuses on improving the exploitation phase of AHA, thereby achieving a more balanced interplay between exploration and exploitation. Once the positions of the agents are updated, OBL is applied to half of the population. This involves evaluating whether the agent’s position is superior to its opposite counterpart, with the fitter of the two being selected as the agent’s position. Furthermore, OBL is utilized to refine the initialization process of the population. This results in initial solutions that exhibit better fitness, contributing to a more accurate convergence towards the global optimum. During the initialization phase of an agent’s position in AHA, OBL is used to determine the opposite of the position. The fitter of these two positions is then selected as a member of the initial population. Figure 24 illustrates the distribution of AHA methods across four different areas, showcasing the application of this enhanced approach.

Percentage of AHA methods based on four different areas
Researchers have used the AHA as applicable and useful methods for optimizations in various disciplines. Figure 25 shows the division of the AHA-based optimization domain in 2022 papers. The division is based on six different (biomedical engineering, electrical engineering, water engineer, network engineering, data engineering, industrial engineering) fields. The percentage results show that the AHA algorithm is the most used in electrical engineering. Also, medical engineering is in second place for processing patient images. The deterministic approaches used for parameter estimation in industrial engineering suffer from various limitations. These include being prone to getting stuck in local optimal solutions, sensitivity to initial conditions, high computational demands, vulnerability to noise and outliers, tendency to converge to suboptimal solutions, inability to handle complex nonlinear models, non-differentiable functions, and multi-objective optimization challenges. These shortcomings are addressed by AHA, which not only overcomes local minima but also provides more reliable results compared to other methods. Utilizing population-based techniques, AHA ensures consistency in parameter estimation for industrial engineering tasks.

Segmentation of the AHA-based optimization domain in 2022 papers
Figure 26 shows the division of the AHA-based optimization domain in 2023 papers. The division is based on six different (biomedical engineering, electrical engineering, water engineer, network engineering, data engineering, industrial engineering) fields. The percentage results show that the AHA algorithm is the most used in electrical engineering. Also, water engineering is in the second place for predicting rain, precipitation, flood forecasting, etc.

Segmentation of the AHA-based optimization domain in 2023 papers
The AHA algorithm, while beneficial, faces challenges with operational compatibility in complex scenarios, often leading to unsatisfactory solution accuracy within a given timeframe. Conversely, the PSO algorithm is heavily reliant on the number of iterations and is characterized by a high number of initial parameters, alongside the complexity of its physical and mathematical underpinnings. However, a notable strength of the AHA algorithm is its minimal dependency on parameters, possessing the least possible number of parameters, which stands out as a unique advantage. To address these issues, a hybrid AHA-PSO algorithm has been developed [44]. This hybrid algorithm aims to resolve AHA’s limitations in exploitation and prevent it from getting trapped in local optima. By combining AHA with PSO, the hybrid algorithm enhances the exploitation capabilities of AHA, thereby reducing the likelihood of converging to local optima. The hybrid algorithm operates on an iterative level, initially applying AHA followed by PSO. This strategy utilizes AHA’s exploration strengths and PSO’s exploitation advantages. The optimal position identified by AHA is leveraged as the global best position for PSO, which then proceeds to further exploit the search space for an improved position. Consequently, the velocity and position update equations of PSO are integrated into AHA, enhancing the overall effectiveness and efficiency of the algorithm in navigating complex search spaces.
Table 5 shows the general advantages and disadvantages of the AHA algorithm.
The AHA outperforms traditional optimization methods in terms of rapid convergence and enhanced search capabilities, owing to its minimal reliance on algorithmic parameters. Furthermore, AHA achieves a more effective equilibrium between exploration and exploitation compared to other algorithms. This balance is crucial for the algorithm’s performance: exploration involves venturing into new areas of the search space, while exploitation focuses on thoroughly investigating areas around previously visited points. Furthermore, AHA’s versatility allows it to be effectively combined with other AI-related techniques, enhancing its applicability and efficiency in various computational contexts. This adaptability of AHA, paired with its balanced approach to exploring and exploiting the search space, contributes significantly to its overall effectiveness as an optimization tool.
Numerous research efforts have demonstrated that the AHA is effective in addressing a wide range of standard problems, including real-world applications and both constrained and unconstrained issues. Nonetheless, AHA is not without its minor shortcomings. There are instances where the algorithm may become trapped in local optima, experience premature convergence, or require an extended period to converge [44]. These limitations, however, can be effectively mitigated through the use of hybrid models and the implementation of beneficial operators. Enhancements to AHA can be achieved by fine-tuning the balance between exploratory search and exploitation, ensuring the diversity of the search is maintained, and facilitating faster convergence. These adjustments can significantly improve the overall performance and effectiveness of the AHA in solving complex problems.
In the AHA, a high exploration rate can lead to rapid convergence. This results in a more random search of the solution space, yielding a diverse array of solutions. To enhance the quality and precision of these solutions, AHA tends to focus its search within a more localized area when the opportunity for effective exploitation is at its peak. However, there is a trade-off between exploration and exploitation capabilities: as one improves, the other tends to diminish, and this effect is reciprocal. An additional challenge within AHA is finding the optimal blend of these two capabilities, exploration and exploitation, as the ideal mix is not uniform across all problem types [96]. Consequently, striking a balance between these two phases that is universally effective for all optimization problems is a complex task. This inherent difficulty in achieving a universally applicable equilibrium between exploration and exploitation in AHA makes it challenging to optimize its performance across diverse problem sets.
The literature shows that the AHA algorithm often has a low convergence rate. This slowness in reaching optimal solutions can be a significant problem in optimization problems. To solve the problem, two strategies can be used. In the first step, the crowding method is diverse, which includes strategic selection and generation of new solution candidates in a way that optimally expands the search space. This approach ensures that the algorithm does not prematurely converge to sub-optimal solutions and explores a wider set of solutions. Second, the implementation of mechanisms such as chaos and quantum to maintain population diversity. Such mechanisms ensure that a wide and diverse set of solutions is always present in the algorithm’s population set. This diversity prevents the AHA algorithm from getting stuck in local optima and encourages the exploration of different spaces. By integrating these methods, the efficiency and effectiveness of AHA can be significantly increased, leading to faster and more accurate convergence to the optimal solution.
5 Conclusion and Future Works
The AHA is innovative in the field of meta-heuristic algorithms that was developed in 2022. This algorithm is inspired by the unique search and migration behaviors of hummingbirds. The AHA algorithm has been used for a wide variety of optimization problems, including continuous, discrete, and multi-objective problems. In this paper, a comprehensive and complete review of AHA and its applications in various optimization scenarios was reviewed. The search procedures were carried out systematically through search engines and authoritative databases such as Google Scholar, IEEE, ScienceDirect, Springer, MDPI, Tandfonline, etc. The advantages, limitations and challenges of the AHA algorithm was investigated in various practical problems. The effectiveness of the AHA is significantly influenced by its ability to balance exploration and exploitation. The AHA algorithm with hybrid approaches has been able to improve the extensive search capabilities and refinement capabilities to find a more robust solution. The AHA algorithm has attracted the attention of researchers due to its strong performance. AHA has been used in a wide range of applications in control engineering, clustering, water engineering, image processing, industrial engineering, structural engineering, and other applications. In addition, the AHA is presented to solve mathematical optimization problems such as unconstrained optimization, constrained optimization, scheduling problems, and forecasting problems. AHA research has shown significant results, especially in the areas of multi-objective optimization and optimization. Key advantages of AHA include robustness in solution quality, ability to maintain an optimal balance between exploration and exploitation, scalability for high-dimensional problems, and simple design. These features make the AHA algorithm a versatile and powerful tool in optimization problems.
According to the investigations, it was concluded that the AHA includes the following limitations: (1) One of the limitations of the AHA algorithm is premature convergence. Employing strategies such as combining population diversity mechanisms or adaptive inertia weight strategies are suitable to reduce premature convergence. (2) The AHA may have scalability issues when dealing with high-dimensional optimization problems or large datasets. In the area of AHA scalability, hybrid optimization approaches can be used to increase efficiency. (3) AHA’s balance between exploration and exploitation may not always be optimal, leading to suboptimal solutions. Development of dynamic adaptive mechanisms to adjust the rate of exploration and exploitation is a beneficial strategy. (4) The AHA algorithm may not adapt well to dynamic optimization environments where the objective function or constraints change over time. It is fruitful to propose an adaptive AHA to adjust operators to change in response to dynamic environments.
To consider future directions, the following key aspects will be focused on:
-
1.
Multi-objective optimization using AHA: Multi-objective optimization is very important in scenarios where decisions require balancing different conflicting objectives. The AHA algorithm is capable of finer and more efficient solutions and can provide more comprehensive results.
-
2.
Hybrid optimization with AHA: Hybrid optimization includes a wide range of applications such as scheduling and resource allocation. The application of AHA to these types of problems can significantly increase the usefulness and effectiveness, especially in scenarios where the nature of the problem variables plays an important role in the complexity and accuracy of the solutions.
References
Turgut OE, Turgut MS, Kırtepe E (2023) A systematic review of the emerging metaheuristic algorithms on solving complex optimization problems. Neural Comput Appl 35(19):14275–14378
Zamani H et al (2024) A critical review of moth-flame optimization algorithm and its variants: structural reviewing, performance evaluation, and statistical analysis. Arch Comput Methods Eng 2024(1):1–49
Abdulsalami AO et al (2024) An improved heterogeneous comprehensive learning symbiotic organism search for optimization problems. Knowl Based Syst 285(1):1–45
Gharehchopogh FS (2022) Advances in tree seed algorithm: a comprehensive survey. Arch Comput Methods Eng 29(5):3281–3304
Gharehchopogh FS et al (2023) A multi-objective mutation-based dynamic Harris Hawks optimization for botnet detection in IoT. Internet Things 24:100952
Shehab M et al (2020) Moth–flame optimization algorithm: variants and applications. Neural Comput Appl 32(14):9859–9884
Gharehchopogh FS (2023) An improved Harris Hawks optimization algorithm with multi-strategy for community detection in social network. J Bionic Eng 20(3):1175–1197
Abualigah L, Diabat A (2020) A comprehensive survey of the Grasshopper optimization algorithm: results, variants, and applications. Neural Comput Appl 32(19):15533–15556
Gharehchopogh FS et al (2024) Advances in Manta ray foraging optimization: a comprehensive survey. J Bionic Eng 21(2):953–990
Özbay E (2023) An active deep learning method for diabetic retinopathy detection in segmented fundus images using artificial bee colony algorithm. Artif Intell Rev 56(4):3291–3318
Gharehchopogh FS et al (2023) Slime mould algorithm: a comprehensive survey of its variants and applications. Arch Comput Methods Eng 30(4):2683–2723
Gharehchopogh FS, Ibrikci T (2024) An improved African vultures optimization algorithm using different fitness functions for multi-level thresholding image segmentation. Multimed Tools Appl 83(6):16929–16975
Özbay E, Özbay FA, Gharehchopogh FS (2023) Peripheral blood smear images classification for acute lymphoblastic leukemia diagnosis with an improved convolutional neural network. J Bionic Eng 2023:1–17
Gharehchopogh FS et al (2023) Cqffa: a chaotic quasi-oppositional farmland fertility algorithm for solving engineering optimization problems. J Bionic Eng 20(1):158–183
Sharma S et al (2023) Non-dominated sorting advanced butterfly optimization algorithm for multi-objective problems. J Bionic Eng 20(2):819–843
Zhao W, Wang L, Mirjalili S (2022) Artificial hummingbird algorithm: a new bio-inspired optimizer with its engineering applications. Comput Methods Appl Mech Eng 388:114194
Hu G et al (2023) Genghis Khan shark optimizer: a novel nature-inspired algorithm for engineering optimization. Adv Eng Inform 58:102210
Ghasemi M et al (2024) Geyser inspired algorithm: a new geological-inspired meta-heuristic for real-parameter and constrained engineering optimization. J Bionic Eng 21(1):374–408
Ezugwu AE et al (2022) Prairie dog optimization algorithm. Neural Comput Appl 34(22):20017–20065
Agushaka JO, Ezugwu AE, Abualigah L (2022) Dwarf mongoose optimization algorithm. Comput Methods Appl Mech Eng 391:114570
Abdollahzadeh B et al (2022) Mountain gazelle optimizer: a new nature-inspired metaheuristic algorithm for global optimization problems. Adv Eng Softw 174:103282
Ghasemi M et al (2024) Optimization based on performance of lungs in body: lungs performance-based optimization (LPO). Comput Methods Appl Mech Eng 419(1):116582
Abualigah L et al (2021) The arithmetic optimization algorithm. Comput Methods Appl Mech Eng 376:113609
Abualigah L et al (2022) Reptile search algorithm (RSA): a nature-inspired meta-heuristic optimizer. Expert Syst Appl 191:116158
Bai J et al (2023) A sinh cosh optimizer. Knowl Based Syst 282:111081
Ovelade ON, Ezugwu AE (2021) Ebola optimization search algorithm: a new nature-inspired metaheuristic algorithm for global optimization problems. In: 2021 international conference on electrical, computer and energy technologies (ICECET)
Mirjalili S (2016) SCA: a sine cosine algorithm for solving optimization problems. Knowl Based Syst 96(1):120–133
Abdollahzadeh B, Soleimanian Gharehchopogh F, Mirjalili S (2021) Artificial gorilla troops optimizer: a new nature-inspired metaheuristic algorithm for global optimization problems. Int J Intell Syst 36(10):5887–5958
Mirjalili S (2015) Moth-flame optimization algorithm: a novel nature-inspired heuristic paradigm. Knowl Based Syst 89(1):228–249
Abdollahzadeh B et al (2024) Puma optimizer (PO): a novel metaheuristic optimization algorithm and its application in machine learning. Cluster Comput 2024:1–49
Li S et al (2020) Slime mould algorithm: a new method for stochastic optimization. Futur Gener Comput Syst 111:300–323
Faramarzi A et al (2020) Equilibrium optimizer: a novel optimization algorithm. Knowl Based Syst 191:105190
Shayanfar H, Gharehchopogh FS (2018) Farmland fertility: a new metaheuristic algorithm for solving continuous optimization problems. Appl Soft Comput 71:728–746
Zhao W et al (2024) Electric eel foraging optimization: a new bio-inspired optimizer for engineering applications. Expert Syst Appl 238(1):122200
Abdollahzadeh B, Gharehchopogh FS, Mirjalili S (2021) African vultures optimization algorithm: a new nature-inspired metaheuristic algorithm for global optimization problems. Comput Ind Eng 158:107408
Zhong C, Li G, Meng Z (2022) Beluga whale optimization: a novel nature-inspired metaheuristic algorithm. Knowl Based Syst 251(1):109215
Kaur S et al (2020) Tunicate swarm algorithm: a new bio-inspired based metaheuristic paradigm for global optimization. Eng Appl Artif Intell 90:103541
Storn R, Price K (1997) Differential evolution—a simple and efficient heuristic for global optimization over continuous spaces. J Global Optim 11(4):341–359
Abdalrahman AO et al (2023) The application of hybrid krill herd artificial hummingbird algorithm for scientific workflow scheduling in fog computing. J Bionic Eng 20(5):2443–2464
Ekinci S, Izci D, Yilmaz M (2023) Simulated annealing aided artificial hummingbird optimizer for infinite impulse response system identification. IEEE Access 11(3):88627–88636
Chen K, Chen L, Hu G (2023) PSO-incorporated hybrid artificial hummingbird algorithm with elite opposition-based learning and cauchy mutation: a case study of shape optimization for CSGC–Ball curves. Biomimetics 8:1–20. https://doi.org/10.3390/biomimetics8040377
Vallidevi K, Jothi S, Karuppiah SV (2023) HO-DQLN: hybrid optimization-based deep q-learning network for optimizing QoS requirements in service oriented model. Expert Syst Appl 227(1):120188
Aswath S, Sundaram VRS, Mahdal M (2023) An adaptive sleep apnea detection model using multi cascaded atrous-based deep learning schemes with hybrid artificial humming bird pity beetle algorithm. IEEE Access 11(1):113114–113133
Zare M et al (2023) A modified particle swarm optimization algorithm with enhanced search quality and population using hummingbird flight patterns. Decis Anal J 7(1):100251
Wang J et al (2022) An enhanced artificial hummingbird algorithm and its application in truss topology engineering optimization. Adv Eng Inform 54(1):101761
Elaziz MA et al (2022) AHA-AO: artificial hummingbird algorithm with aquila optimization for efficient feature selection in medical image classification. Appl Sci 12:28–37. https://doi.org/10.3390/app12199710
Yildiz BS et al (2022) A new hybrid artificial hummingbird-simulated annealing algorithm to solve constrained mechanical engineering problems. Mater Test 64(7):1043–1050
Verma S et al (2023) Fault location optimisation for transmission line using chaotic artificial hummingbird algorithm. In: 2023 IEEE world conference on applied intelligence and computing (AIC)
Wang L et al (2022) Parameter identification of a governing system in a pumped storage unit based on an improved artificial hummingbird algorithm. Energies 15:22–36. https://doi.org/10.3390/en15196966
Alhumade H et al (2023) Modified artificial hummingbird algorithm-based single-sensor global MPPT for photovoltaic systems. Mathematics 11:1–18. https://doi.org/10.3390/math11040979
Sankareshwaran SP et al (2023) Optimizing rice plant disease detection with crossover boosted artificial hummingbird algorithm based AX-RetinaNet. Environ Monit Assess 195(9):1–22
Li Z, Feng F (2023) A safety warning model based on IAHA-SVM for coal mine environment. Sensors. https://doi.org/10.3390/s23146614
Sadoun AM et al (2022) Utilization of improved machine learning method based on artificial hummingbird algorithm to predict the tribological behavior of Cu-Al2O3 nanocomposites synthesized by in situ method. Mathematics 10:25–42. https://doi.org/10.3390/math10081266
Akshaya V, Mandala V, Anilkumar C, VishnuRaja P, Aarthi R (2023) Security enhancement and attack detection using optimized hybrid deep learning and improved encryption algorithm over Internet of Things. Meas Sens 30(2):100917
Essa FA et al (2023) Performance prediction of a reverse osmosis unit using an optimized long short-term memory model by hummingbird optimizer. Process Saf Environ Prot 169(1):93–106
Dhiravidachelvi E et al (2023) Artificial humming bird optimization-based hybrid CNN-RNN for accurate exudate classification from fundus images. J Digit Imaging 36(1):59–72
Dhevanandhini G, Yamuna G (2023) An optimal intelligent video surveillance system in object detection using hybrid deep learning techniques. Multimed Tools Appl 2023(1):1–15
Kıymaç E, Kaya Y (2023) A novel automated CNN arrhythmia classifier with memory-enhanced artificial hummingbird algorithm. Expert Syst Appl 213(1):119162
Ali MAS, Fathimathul-Rajeena PP, Salama-Abd-Elminaam D (2022) A feature selection based on improved artificial hummingbird algorithm using random opposition-based learning for solving waste classification problem. Mathematics 10:32–46. https://doi.org/10.3390/math10152675
Jacob TP, Pravin A, Kumar RR (2022) A secure IoT based healthcare framework using modified RSA algorithm using an artificial hummingbird based CNN. Trans Emerg Telecommun Technol 33(12):e4622
Abualigah L et al (2024) Fake news detection using recurrent neural network based on bidirectional LSTM and GloVe. Soc Netw Anal Min 14(1):40
He Y, Li XF (2022) An artificial hummingbird optimization algorithm incorporating adaptive search and levy flight. In: 2022 3rd international conference on computer science and management technology (ICCSMT)
Moustafa G et al (2023) Economic environmental operation in bulk AC/DC hybrid interconnected systems via enhanced artificial hummingbird optimizer. Electr Power Syst Res 222(1):109503
Hu G et al (2023) LCAHA: a hybrid artificial hummingbird algorithm with multi-strategy for engineering applications. Comput Methods Appl Mech Eng 415(1):116238
Zhu G, Liu D (2023) Modeling and IAHA solution for task scheduling problem of processing crowdsourcing in the context of social manufacturing. Systems. https://doi.org/10.3390/systems11080383
Abdel-Basset M, Mohamed R, Abouhawwash M (2023) On the facile and accurate determination of the highly accurate recent methods to optimize the parameters of different fuel cells: Simulations and analysis. Energy 272(1):127083
Jamal R et al (2023) Solution to the deterministic and stochastic optimal reactive power dispatch by integration of solar, wind-hydro powers using modified artificial hummingbird algorithm. Energy Rep 9(1):4157–4173
Bhattacharjee V, Roy PK, Chattoraj C (2023) Optimal design of forced-draft counter-flow evaporative-cooling towers through single and multi-objective optimizations using oppositional chaotic artificial hummingbird algorithm. Therm Sci Eng Prog 46(1):102178
Abualigah L et al (2023) Modified elite opposition-based artificial hummingbird algorithm for designing FOPID controlled cruise control system. Intell Autom Soft Comput 2023(1):1–20
Ghafari R, Mansouri N (2023) An efficient task scheduling in fog computing using improved artificial hummingbird algorithm. J Comput Sci 74(5):102152
Ramadan A et al (2022) Accurate photovoltaic models based on an adaptive opposition artificial hummingbird algorithm. Electronics 11:1–16. https://doi.org/10.3390/electronics11030318
Mostafa RR et al (2023) Modeling potential evapotranspiration by improved machine learning methods using limited climatic data. Water. https://doi.org/10.3390/w15030486
Elaziz MA et al (2023) Quantum artificial hummingbird algorithm for feature selection of social IoT. IEEE Access 11(1):66257–66278
Dhapola P, Kumar V (2023) Binary artificial hummingbird algorithm: a binary version of artificial hummingbird algorithm for optimization problems. In: 2023 IEEE international conference on contemporary computing and communications (InC4)
Yin T, Zhang Z, Jiang J (2021) A Pareto-discrete hummingbird algorithm for partial sequence-dependent disassembly line balancing problem considering tool requirements. J Manuf Syst 60:406–428
Zhao W et al (2022) An effective multi-objective artificial hummingbird algorithm with dynamic elimination-based crowding distance for solving engineering design problems. Comput Methods Appl Mech Eng 398(1):115223
Rohman FS et al (2023) Artificial hummingbird-based optimisation with advanced crowding distance of energy reduction in the polyethylene reactors. Process Integr Optim Sustain 2023(1):1–14
Qin PF et al (2022) Optimization of antenna isolation using an enhanced multi-objective artificial hummingbird algorithm based on chaotic sampling. In: 2022 IEEE MTT-S international microwave workshop series on advanced materials and processes for RF and THz applications (IMWS-AMP)
Khodadadi N et al (2023) Multi-objective artificial hummingbird algorithm. In: Biswas A, Kalayci CB, Mirjalili S (eds) Advances in swarm intelligence: variations and adaptations for optimization problems. Springer, Cham, pp 407–419
Abid MS et al (2023) Multi-objective architecture for strategic integration of distributed energy resources and battery storage system in microgrids. J Energ Storage 72:108276
Yousri D et al (2023) Integrated model for optimal energy management and demand response of microgrids considering hybrid hydrogen-battery storage systems. Energ Convers Manage 280(1):116809
Arbatsofla SM et al (2023) Fuzzy fractional-order adaptive robust feedback linearization control optimized by the multi-objective artificial hummingbird algorithm for a nonlinear ball–wheel system. J Braz Soc Mech Sci Eng 45(11):575
Alshareef SM, Fathy A (2023) Efficient red kite optimization algorithm for integrating the renewable sources and electric vehicle fast charging stations in radial distribution networks. Mathematics 11:10–23. https://doi.org/10.3390/math11153305
Sun W et al (2023) A heat source self-supplied thermodynamic system using liquefied natural gas: performance evaluation and three-objective optimization. J Clean Prod 429(1):139545
Fathy A (2022) A novel artificial hummingbird algorithm for integrating renewable based biomass distributed generators in radial distribution systems. Appl Energy 323(1):119605
Waleed U et al (2022) A multiobjective artificial-hummingbird-algorithm-based framework for optimal reactive power dispatch considering renewable energy sources. Energies. https://doi.org/10.3390/en15239250
Mahadeva R et al (2023) Water desalination using PSO-ANN techniques: a critical review. Digit Chem Eng 9(2):100128
Iliadis LA et al (2023) Triple-band modified printed inverted-F antenna design for WI-FI-7 applications. In: 2023 17th European conference on antennas and propagation (EuCAP)
Zhang L, Guo S, Qi J (2023) The determination of the strongest attributes of high-performance concrete featuring innovative admixtures via optimal regression-based methodologies. Multiscale Multidiscip Model Exp Des 2023(1):1
Wang M et al (2023) SPOAHA: spark program optimizer based on artificial hummingbird algorithm. In: Knowledge science, engineering and management: 16th international conference, KSEM 2023, Guangzhou, August 16–18, 2023, proceedings, Part III, Springer, pp 317–331, numpages = 15
Ayyarao TSLV, Kishore GI (2023) Parameter estimation of solar PV models with artificial humming bird optimization algorithm using various objective functions. Soft Comput 2023(1):1–19
Mohan R et al (2023) OralNet: fused optimal deep features framework for oral squamous cell carcinoma detection. Biomolecules. https://doi.org/10.3390/biom13071090
Rajwar D, Sankar MM (2022) Optimal siting and sizing of distributed generation in radial distribution system using artificial hummingbird algorithm. In: 2022 IEEE 2nd international symposium on sustainable energy, signal processing and cyber security (iSSSC)
Jamal R et al (2023) Optimal scheduling of short-term hydrothermal with integration of renewable energy resources using Lévy spiral flight artificial hummingbird algorithm. Energy Rep 10(1):2756–2777
Choudhury S, Sahoo GK (2023) Optimal mitigation of power quality uncertainty in a grid tied microgrid through robust artificial hummingbird algorithm. In: 2023 international conference in advances in power, signal, and information technology (APSIT)
Ramadan A et al (2023) Optimal allocation of renewable DGs using artificial hummingbird algorithm under uncertainty conditions. Ain Shams Eng J 14(2):101872
Mohamed EA et al (2023) Optimal 1+PDDF/FOPIT frequency regulator for developing robust multi-microgrid systems with employing EV energy storage batteries. J Energy Storage 73(1):109088
Pervez I et al (2023) NeuralPV: a neural network algorithm for PV power forecasting. In: 2023 IEEE international symposium on circuits and systems (ISCAS)
Boursianis AD et al (2023) Modified bow-tie antenna design using artificial hummingbird algorithm for wireless power transfer IoT applications. In: 2023 17th European conference on antennas and propagation (EuCAP)
Kusla V et al (2023) Meta-heuristic artificial humming bird algorithm based energy efficient cluster head selection (MAHA-EECHS) in wireless sensor networks. In: 2023 international conference on emerging smart computing and informatics (ESCI)
Kumar R, Sharma VK (2023) Interconnected power control on unequal, deregulated multi-area power system using three-degree-of-freedom-based FOPID-PR controller. Electr Eng 2023(1):1–20
Sharma M, Dhundhara S, Singh Sran R (2023) Impact of hybrid electrical energy storage system on realistic deregulated power system having large-scale renewable generation. Sustain Energy Technol Assess 56(1):103025
Li Y et al (2023) Hybrid energy storage power allocation strategy based on parameter-optimized VMD algorithm for marine micro gas turbine power system. J Energy Storage 73(1):109189
Franklin RV, Fathima AP (2023) Frequency regulation for state-space model-based renewables integrated to multi-area microgrid systems. Sustainability 15:1–17. https://doi.org/10.3390/su15032552
Lim YK et al (2023) Fairness-aware unmanned aerial vehicle-mounted base station placement with quality of service provisioning. In: 2023 international conference on computer, control, informatics and its applications (IC3INA)
Benghanem M et al (2023) Evaluation of the performance of polycrystalline and monocrystalline PV technologies in a hot and arid region: an experimental analysis. Sustainability 15:1–18. https://doi.org/10.3390/su152014831
Ekinci S, Izci D (2023) Enhancing IIR system identification: harnessing the synergy of gazelle optimization and simulated annealing algorithms. e-Prime Adv Electr Eng Electr Energy 5(5):100225
El-Sehiemy R et al (2023) Electrical parameters extraction of PV modules using artificial hummingbird optimizer. Sci Rep 13(1):9240
Lokhannadh C et al (2023) Electric vehicles (EV) route optimization using artificial hummingbird algorithm, 508–512
Fathy A (2023) Efficient energy valley optimization approach for reconfiguring thermoelectric generator system under non-uniform heat distribution. Renew Energy 217(3):119177
Das S et al (2023) Effects of emission reduction and rework policy in a production system of green products: an interval valued optimal control theoretic approach. Comput Ind Eng 179(3):109212
Priyanka JH, Parveen N (2023) DeepSkillNER: an automatic screening and ranking of resumes using hybrid deep learning and enhanced spectral clustering approach. Multimed Tools Appl 2023(1):1
Arumugam SR (2023) Conditional random field-recurrent neural network segmentation with optimized deep learning for brain tumour classification using magnetic resonance imaging. Imaging Sci J 71(3):199–220
Ekinci S, Izci D, Kayri M (2023) Artificial hummingbird optimizer as a novel adaptive algorithm for identifying optimal coefficients of digital IIR filtering systems. Int J Model Simul 20(1):1–15
Chu S-C et al (2023) Artificial hummingbird algorithm with parallel compact strategy. In: Advances in smart vehicular technology, transportation, communication and applications. Springer, Singapore
Malibari AA et al (2023) Artificial hummingbird algorithm with transfer-learning-based mitotic nuclei classification on histopathologic breast cancer images. Bioengineering. https://doi.org/10.3390/bioengineering10010087
Ebrahim MA et al (2023) Artificial hummingbird algorithm based optimal secondary control for islanded microgrid. In: 2022 23rd international middle east power systems conference (MEPCON)
Waleed U, Ashraf MM, Arshad A (2023) Artificial hummingbird algorithm based dynamic generation expansion planning considering renewable energy sources. In: 2023 international conference on emerging power technologies (ICEPT)
Bhagat SK, Saikia LC (2023) Application of inertia emulation control strategy with energy storage system in multi-area hydro-thermal system using a novel metaheuristic optimized tilt controller. Electric Power Syst Res 222:109522
Sarkhani Benemaran R (2023) Application of extreme gradient boosting method for evaluating the properties of episodic failure of borehole breakout. Geoenergy Sci Eng 226(2):211837
Bhagat SK, Saikia LC, Babu NR (2023) Application of artificial hummingbird algorithm in a renewable energy source integrated multi-area power system considering fuzzy based tilt integral derivative controller. e-Prime Adv Electr Eng Electr Energy 4(1):100153
Sadoun AM et al (2023) An enhanced dendritic neural algorithm to predict the wear behavior of alumina coated silver reinforced copper nanocomposites. Alex Eng J 65(1):809–823
Talha A, Bouayad A, Malki MOC (2023) An enhanced artificial hummingbird algorithm for workflow scheduling in cloud. In: Artificial intelligence and smart environment. Springer, Cham
Pervez I et al (2023) An electrostatic discharge algorithm for electric vehicle li ion battery parameters estimation. In: 2023 IEEE international symposium on circuits and systems (ISCAS)
Anand A, Yadav S, Saha SK (2022) An approach for linear phase FIR low pass and high pass filter design using AHA algorithm. In: 2022 6th international conference on computing, communication, control and automation (ICCUBEA)
Nour M et al (2023) A new two-stage controller design for frequency regulation of low-inertia power system with virtual synchronous generator. J Energy Storage 62(1):106952
Omar A et al (2023) A new optimal control methodology for improving MPPT based on FOINC integrated with FPI controller using AHA. Electr Power Syst Res 224(1):109742
Shi X, Wang J, Zhang B (2024) A fuzzy time series forecasting model with both accuracy and interpretability is used to forecast wind power. Appl Energy 353(1):122015
Lakhina U et al (2023) A cost-effective multi-verse optimization algorithm for efficient power generation in a microgrid. Sustainability. https://doi.org/10.3390/su15086358
Jaballah MS, Harzallah S, Nail B (2023) Vibration control and seismic damages reduction for structural buildings based on optimal fractional-order controller and a graphical user interface development. J Vib Eng Technol 11(8):4349–4370
Shaheen A et al (2022) Representations of solar photovoltaic triple-diode models using artificial hummingbird optimizer. Energy Sources Part A: Recovery Util Environ Effects 44(4):8787–8810
Hamida MA et al (2022) Parameter identification and state of charge estimation of Li-Ion batteries used in electric vehicles using artificial hummingbird optimizer. J Energy Storage 51(1):104535
Demirtas M, Koc K (2022) Parameter extraction of photovoltaic cells and modules by INFO algorithm. IEEE Access 10(1):87022–87052
Haddad S et al (2022) Parameter estimation of solar modules operating under outdoor operational conditions using artificial hummingbird algorithm. IEEE Access 10(1):51299–51314
Wang M et al (2022) Optimal UAVs placement for localization based on artificial hummingbird algorithm. In: 2022 IEEE international conference on signal processing, communications and computing (ICSPCC)
Ramzi K, Souhil M (2022) Optimal power flow incorporating stochastic wind power using artificial gorilla troops optimizer. In: 2022 19th international multi-conference on systems, signals and devices (SSD)
Abid MS et al (2022) Optimal planning of multiple renewable energy-integrated distribution system with uncertainties using artificial hummingbird algorithm. IEEE Access 10:40716–40730
Duong TL et al (2022) Optimal operation of electric power system incorporating renewable energy source based on artificial hummingbird algorithm. Int J Electr Eng Inf 14(4):841–855
Mohamed EA, Aly M, Watanabe M (2022) New tilt fractional-order integral derivative with fractional filter (TFOIDFF) controller with artificial hummingbird optimizer for LFC in renewable energy power grids. Mathematics 10:20–35. https://doi.org/10.3390/math10163006
Mohseni S, Khalid R, Brent AC (2022) Metaheuristic-based isolated microgrid sizing and uncertainty quantification considering EVs as shiftable loads. Energy Rep 8(1):11288–11308
Morgan EF et al (2022) Load frequency control of interconnected power system using artificial hummingbird optimization. In: 2022 23rd international middle east power systems conference (MEPCON)
Kotb MF, El-Fergany AA, Gouda EA (2022) Estimation of electrical transformer parameters with reference to saturation behavior using artificial hummingbird optimizer. Sci Rep 12(1):19623
Boursianis AD et al (2022) Dual-band frequency selective surface design using artificial hummingbird algorithm. In: 2022 IEEE international symposium on antennas and propagation and USNC-URSI radio science meeting (AP-S/URSI)
Alamir N et al (2022) Developing an artificial hummingbird algorithm for probabilistic energy management of microgrids considering demand response. Front Energy Res 10:905788
Singh H et al (2022) Design and synthesis of circular antenna array using artificial hummingbird optimization algorithm. J Comput Electron 21(6):1293–1305
Kumar S, Singh H (2023) Design and synthesis of circular antenna array for low side lobe level and high directivity using artificial hummingbird optimization algorithm. Recent Adv Electr Electr Eng 16(1):1–1
Hamdi M et al (2022) Chicken swarm-based feature subset selection with optimal machine learning enabled data mining approach. Appl Sci. https://doi.org/10.3390/app12136787
El-Sattar HA et al (2022) An effective optimization strategy for design of standalone hybrid renewable energy systems. Energy 260(1):124901
Bhat SJ, Santhosh KV (2022) An artificial hummingbird algorithm based localization with reduced number of reference nodes for wireless sensor networks. Phys Commun 55(1):101921
Kansal V, Dhillon JS (2022) Ameliorated artificial hummingbird algorithm for coordinated wind-solar-thermal generation scheduling problem in multiobjective framework. Appl Energy 326(1):120031
Acknowledgements
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Research Project under grant number RGP2/283/45. The authors extend their appreciation to TAIF University, Saudi Arabia, for supporting this work through project number (TU-DSPP-2024-258).
Funding
The research was funded by TAIF University, TAIF, Saudi Arabia (TU-DSPP-2024-258).
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Hosseinzadeh, M., Rahmani, A.M., Husari, F.M. et al. A Survey of Artificial Hummingbird Algorithm and Its Variants: Statistical Analysis, Performance Evaluation, and Structural Reviewing. Arch Computat Methods Eng (2024). https://doi.org/10.1007/s11831-024-10135-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11831-024-10135-1