
Abstract
This paper proposes a multi-modal fusion algorithm for image filtering based on the guidance of local extrema maps. The image is subjected to a smoothing process using a locally extremal maps-guided image filter, and the difference from the original image forms the detail layer, while the smoothed image serves as the base layer. To preserve image details, both the base and detail layers undergo a resolution reduction process, establishing a multi-scale decomposition hierarchy. The base layer images at each level are decomposed using wavelet transform into low-frequency and high-frequency coefficients. For the low-frequency component, a region-energy fusion rule with adaptive weight allocation based on spatial and gradient information is employed, while the high-frequency component undergoes fusion using the AGPCNN fusion rule with neuron weight assignment initialized. The detail layer is fused using a weighted averaging fusion rule. Finally, the base layer images are fused through wavelet inverse transform. For the fusion of base and detail layers, a bottom layer employs the absolute maximum principle, while the top layer utilizes an average weighted fusion rule. Through subjective and objective analysis, experimental results indicate that the proposed fusion model algorithm not only effectively preserves edge and texture details but also maintains good color fidelity and spectral distortion control. Comparative analysis with eight other advanced fusion algorithms demonstrates superior fusion performance.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the advancement of modern remote sensing technology, various Earth observation satellites continuously provide remote sensing images with different spatial, temporal, and spectral resolutions [1]. Satellite remote sensing is unable to actively monitor changes, has low spatial resolution, and cannot meet high-precision requirements. The fixed orbit and observation frequency of satellites result in a low frequency of Earth observation, making it challenging to obtain timely information for sudden events, leading to slow data collection and low operational efficiency [2]. Different sensors highlight different information in images; PAN has higher spatial resolution, while MS provides more spectral information [3]. For research purposes, the characteristic information of a single image is insufficient to meet research objectives. High spatial and spectral resolution is essential for a range of image processing applications [4]. Therefore, the fusion of MS and PAN images, also known as pansharpening, is crucial for obtaining a comprehensive image with abundant spatial and spectral information [5].
Researchers commonly classify fusion methods into three levels based on the stage in the processing workflow and the abstraction level of information, namely pixel-level, feature-level, and decision-level fusion [6]. Pixel-level fusion methods directly manipulate pixels of source images, improving image quality and referentiality through different rules. Feature-level fusion methods extract objects of interest from source images, combining features using different fusion rules to create a multi-modal fusion image with highlighted features. Decision-level fusion extracts information using interpreted/labeled data. The principle of selection is linked to consolidated data. The main advantage of this approach is that higher-level representations make multi-modal fusion more robust and reliable [7].
Pixel-level image fusion methods can be categorized into three types: spatial domain-based, transform domain-based, and other methods. Spatial domain methods directly operate on the pixels of source images, such as Weighted average, PCA, and IHS. [8]. An example is the multi-scale exposure fusion method with detail enhancement in the YUV color space proposed by Qiantong Wang et al. [9]. Spatial domain fusion methods are simple, efficient, and computationally fast. However, the commonly used simple overlay operations for fusion rules often significantly reduce the signal-to-noise ratio and contrast of the resulting images. Classical transform domain operations include pyramid transforms and wavelet transforms [10]. Algorithms based on multi-scale transform methods, such as Laplacian pyramids [11, 12], wavelet transforms [13, 14], and hybrid methods, neural networks [15, 16], play a crucial role in image fusion and have been proven effective decomposition algorithms [17]. Fusion methods based on Multiscale Transform (MST) are the most common traditional methods. They typically apply traditional weighted fusion rules to base layers, overlooking global contrast [18]. To address these limitations, many scholars have proposed improvements. For instance, Yu Zhang et al. introduced a multi-modal brain image fusion method guided by local extreme value maps, using two guided image filters with local minimum and maximum mappings, respectively [19]. Veshki et al. presented a multi-modal image fusion method based on coupled feature learning [20], separating the images to be fused into relevant and irrelevant components using sparse representations with the same support and Pearson correlation constraints. However, their fusion images suffer from severe color loss. Jie et al. proposed a multi-modal medical image fusion method based on multiple dictionaries and truncated Huber filtering [21], using multiple dictionaries and truncated Huber filters to separate images at different layers. However, the color fidelity of the fused images is not high, and there is significant spectral loss.
Addressing the shortcomings of the aforementioned algorithms, this paper proposes a remote sensing image multi-scale fusion model based on locally extreme maps-guided image filters. The innovation lies in the following aspects:
-
(1)
The use of locally extreme maps-guided image filters to decompose the image into base and detail layers, combined with wavelet transforms for further extraction of details from the base layer.
-
(2)
For low-frequency coefficients of the base layer, an improved regional energy fusion rule is applied, enhancing pixel connectivity within regions to maintain color consistency.
-
(3)
For high-frequency coefficients of the base layer, an improved AGPCNN rule.
2 Multiscale theory
In this section, we will introduce the general multiscale models.
Scale-space image processing is a fundamental technique in computer vision for object recognition and low-level feature extraction [22]. The term "scale-space" was introduced by Witkin when proposing a method for one-dimensional signal processing through convolution with a Gaussian kernel [23]. Scale-space can be considered as an alternative to traditional statistical smoothing methods [24].
Li et al. proposed an Image Fusion Algorithm based on Laplacian Pyramid and Principal Component Analysis Transforms [12]. The Laplacian pyramid model reduces the resolution of the image through downsampling, forming a multi-scale transformation space to better extract image features. The Principal Component Analysis method adopts a dimensionality reduction approach to rank and reduce the complex data information, seeking coordinate systems that reflect patterns to the maximum extent. Both the Laplacian pyramid and Principal Component Analysis methods used in their work are multi-scale spatial transformation techniques. The multi-scale spatial transformation model employed in this paper also involves downsampling to enhance the extraction of image features.
The fundamental idea behind multiscale analysis is to map points in high-dimensional space coordinates to low-dimensional space while preserving similarity between the two as much as possible.
The general steps of multiscale analysis are as follows:
-
(1)
Evaluate the nature of the data and, considering the data acquisition method, choose an appropriate analysis approach.
-
(2)
Determine the appropriate dimension based on the criteria for evaluation.
-
(3)
Assess the effectiveness and reliability of the results obtained from multiscale analysis.
-
(4)
Name the coordinate axes and classify objects based on the spatial map of the data.
The general steps of multiscale analysis are illustrated in Fig. 1.

The general flow of multi-scale analysis theory
3 Proposed fusion model
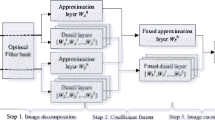
This section introduces the fusion model proposed in this paper, termed the local extrema maps-guided fusion model (LEMG). The fusion process of LEMG is outlined as follows:
-
(1)
Smooth the source image using an image filter guided by local extrema maps. Generate a detail layer by subtracting the smoothed image from the source image, where the smoothed image serves as the base layer.
-
(2)
Perform multi-scale decomposition on both the base and detail layers of two source images to extract additional details.
-
(3)
The base layer incorporates the global information of the source image to minimize spectral loss, ensuring the fused image retains the color fidelity of the source image, decompose the base layers of multiple scales using wavelet transform into low-frequency and high-frequency components. Apply an improved regional energy fusion rule to merge the low-frequency components of each layer and an enhanced AGPCNN rule to merge the high-frequency parts. For the detail layers, use a weighted average fusion rule to create multiple levels of merged detail layers.
-
(4)
For each base layer, the wavelet inverse transform is applied to form the fused base layers. The fused 3rd to 4th layers of base layers and the corresponding detail layers are fused using the rule of taking the absolute value of the maximum to highlight the features of each image. The fused images of the 1st and 2nd layers are blended using an average weighting rule to smooth the final fused image, achieving the optimal fusion effect.
The schematic diagram of the fusion model is depicted in Fig. 2.

Frame diagram of image fusion
3.1 Local extreme maps-guided image filter
Classical filters are based on the concept proposed by the Fourier transform. Filters separate useful signals from noise, thereby improving the signal's resistance to interference and signal-to-noise ratio. At the same time, filters can filter out uninteresting signal frequencies, achieving the goal of filtering signal frequencies and improving analysis accuracy. For images that require smoothing and highlighting edges, bilateral filters are commonly used to achieve this goal. The main idea is to construct a Gaussian kernel based on color intensity distance and spatial distance. However, bilateral filters tend to cause gradient reversal and produce artifacts when processing edges, and the computation time is too long. Therefore, Kaiming He and others proposed the concept of guided filters [25]. Figure 3 illustrates the distinct filtering outcomes of bilateral and guided filters. From left to right, the filtered images of the bilateral filter and the guide filter. The left column shows the filtering results of the bilateral filter, and the right column shows the filtering results of the guided filter.

Comparison of filter results
Guided filters are essentially an optimization algorithm that constructs an energy function and then minimizes it using optimization strategies such as least squares and Markov random fields. The energy function is usually defined as follows:
where U is the data term, V is the smoothing term.
Guided filters require two source images, namely the guided image and the input image to be processed. The function is defined as follows:
where Oi and Gi are the output and guided images, ak and bk are unique constant linear functions in the \(M \times M\) window \(\omega_{k}\).
The energy function is defined as follows:
where \(I_{i}\) is the input image, \(\theta\) is a constant to prevent \(a_{k}\) from becoming too large.
Yu Zhang et al. introduced a guided filter based on a locally extreme value map as the guided image for the input image, thereby significantly suppressing the salient features of the input image. First, the input image is filtered using the following formula:
In the equations presented, \(I_{F} ,I,{\text{I}}_{{{\text{min}}}} ,M\) represents the post-filtered image, the input image, the local minimum map of the input image, and the window size. The calculation formula for Imin is given by:
Here, \(ime\) denotes the morphological erosion operator, and s represents a disk-shaped structuring element.
Subsequently, the filtered image is further processed through a local maximum value mapping, with the calculation formula given by:
Here, \(I_{f} ,I_{max}\) represents the post-filtered image and the local maximum image of IF. The calculation for Imax is as follows:
Here, \(imd\) denotes the morphological dilation operator.
The formula for the guided image filter based on local extreme maps is given by:
Here, Iout is the filtered output image, and \(LG\) represents the guided image filter based on local extreme maps.
Prominent bright and dark features are removed from the input image to obtain a smooth image. Subsequently, significant features are obtained by subtracting the smoothed image from the input image, according to the following formulas:
In the following, Ib, Id denotes the bright feature map and the dark feature map, with \(\max ,\min\) representing the maximum and minimum values, respectively.
The results of image filtering using local extreme maps-guided image filter on the experimental data of this paper are presented in Fig. 4. The images are the first to fourth filtered images from left to right, with the left column showing the filtering results of Image 1 and the right column showing the filtering results of Image 2.

The results of image filtering using local extreme maps-guided image filter
3.2 Fusion rule for low-frequency coefficients
The energy algorithm involves calculating the energy of an image or pixel region. In the context of an image, the grayscale value corresponds to the energy, with higher grayscale values indicating higher energy. Generally, energy calculation involves summing the squared grayscale values of each pixel within an image or region.
Conventional region energy algorithms typically select a window region and employ a fixed weight multiplied by the region's pixels to compute the energy of the central pixel. Iterating through the image matrix yields an energy matrix of equal size to the image matrix. However, traditional region energy algorithms employ a fixed weight matrix that cannot be adjusted based on varying region features. Consequently, these algorithms fail to adapt to diverse image characteristics, limiting the enhancement of fusion effects. This paper introduces an improved region energy algorithm that elevates the fusion effect of the region energy fusion strategy by constructing a weight matrix adaptable to each region's features.
Initially, gradient information for each region is computed to construct the weight matrix, as given by the following formula:
Subsequently, the spatial weight matrix for the region is created using the following formula:
The variables are defined as follows: \(\varepsilon\) embodies the standard deviation of the Gaussian kernel associated with the spatial weight matrix, x represents a \(M \times M\) matrix configuration where each row encompasses M values between elements of [− 1,1] within the window size, y signifies a \(M \times M\) matrix setting where each column comprises \(M\) values within the window size between elements of [− 1,1], \(W_{s^{\prime}}\) stands for the preliminary spatial weight matrix, and \(W_{s}\) denotes the normalized spatial weight matrix, serving as the conclusive spatial weight matrix.
Finally, the formula for the adaptive weight matrix is as follows:
Here, F1, F2 denotes the outcome of convolution between the spatial weight matrix and the gradient matrices of the two input images, with conv symbolizing the convolutional operation.
Figure 5 compares the results of low-frequency fusion and high-Frequency Coefficients in this paper with traditional region-based energy fusion rules. The left column is the result image of the traditional fusion rule, and the right column is the result image of the fusion rule proposed in this paper.

Compare images with traditional fusion rules
3.3 Fusion rules for high-frequency coefficients
The pulse coupled neural network (PCNN) is an artificial neural network inspired by physiological stimuli, providing the ability to establish a highly adaptable physiological filter. PCNN models various aspects of the primate visual cortex, including pulse duration, inter-pulse duration, and neural interconnections. This network not only meets the filtering requirements of visual models but also generates essential connections and pulses for simulating state modulation and temporal synchronization. However, due to the considerable number of parameters in the PCNN model, the AGPCNN model is introduced. This model features a simplified structure with fewer parameters and employs Gaussian filters for distributing weights among neurons.
The AGPCNN model comprises five components: feedforward input, connectivity input, neuron internal state, binary output, and dynamic threshold. The respective computational formulas are as follows:
In the provided excerpt, (i, j) signifies the position of neurons, n represents the iteration count, \(G_{\sigma }\) denotes a Gaussian filter with a standard deviation of \(\sigma\) and a 3 × 3 kernel, \(\alpha\) stands for adaptive estimation of connection strength, \(d_{\Theta }\) is the decay constant, and \(a_{\Theta }\) corresponds to the normalization constant. The computational formula of \(\alpha\) is articulated as follows:
\(I_{s} (i,j)\) represents the spatial frequency of the \(3 \times 3\) local window of neurons for (i, j), \(I_{r} (i,j)\) represents row frequency, and \(I_{l} (i,j)\) represents column frequency. The calculation is performed as follows:
\(M \times N\) is the size of the regional window.
The calculation of pulse time for the AGPCNN model after n iterations is as follows:
The AGPCNN model employed in this study has transitioned from the prior Gaussian filter-weighted allocation for neighboring neurons to an allocation using He initialization. This adjustment, which takes into account the properties of \({\text{Re}} LU\), effectively mitigates the problem of gradient vanishing, resulting in an enhanced fusion effect.
4 Experimental results and comparisons
This section presents the experimental comparative results between the algorithm model proposed in this paper and eight other existing algorithms.
4.1 Experimental setup
In order to validate the effectiveness of the proposed algorithm model, comparisons were made against eight other state-of-the-art algorithm models. The experimental data comprised four sets of remote sensing images, namely, panchromatic images and multispectral images. The experiments were conducted in the Matlab2022a environment using NVIDIA GeForce RTX 4060 Laptop GPU. Refer to Fig. 6 for the data images utilized in this study. The eight compared algorithm models are as follows:

Image of the experimental data
-
C1: Detail-Enhanced Multi-Scale Exposure Fusion in YUV Color Space (DEMEF) [9].
-
C2: Medical image fusion by adaptive Gaussian PCNN and improved Roberts operator (AGPRO) [13].
-
C3: NSCT-DCT based Fourier Analysis for Fusion of Multi-modal Images (NDFA) [14].
-
C4: Medical image fusion based on extended difference-of-Gaussians and edge-preserving (EDGEP) [15].
-
C5: Fusion of Multi-modal Images using Parametrically Optimized PCNN and DCT based Fourier Analysis (PODFA) [16].
-
C6: Local extreme map guided multi-modal brain image fusion (LEGFF) [19].
-
C7: Multi-modal image fusion via coupled feature learning (CCFL) [20].
-
C8: Multi-modal medical image fusion via multi-dictionary and truncated Huber filtering (MDHU) [21].
4.2 Experimental results
Figure 7 illustrates the fusion images obtained from the experiments. From top to bottom are the fusion image results of the first to fourth experimental groups. From left to right, they are C1 ~ C8 and the proposed algorithm are, respectively. Tables 1, 2, 3 and 4 provide the parameter data for evaluation. The data with the highest rankings in the evaluation parameters are marked with underlines.

Image of the result of the experimental fusion
From a subjective perspective, the fusion images between the first and third groups, as well as the fourth group of experiments reveal that C1, C4, C5, C6, C7, and the proposed fusion model algorithm exhibit superior color restoration, edge contour retention, and detail texture preservation. However, C2, C3, and C8, while maintaining good contour texture, suffer from severe color distortion and exhibit a significant color gap from the original multispectral images, resulting in poor fusion performance. The fused image results of the second group of experiments are similar to those of the first group of experiments. C1, C4, C5, C6, C7, and the proposed fusion model algorithm demonstrate commendable image fusion effects, while C2, C3, and C8 show subpar fusion results.
In the objective evaluation of fusion effects, this study utilizes eight fusion assessment parameters, namely mean squared error (MSE), color consistency index (CCI), peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), distortion degree (DD), similarity measure (SM), correlation coefficient (CC), and mutual information (MI). MSE measures the expected value of the squared difference between estimated and true parameter values, indicating the degree of data variation. A smaller MSE implies better accuracy in describing experimental data. CCI gages the perceptual color difference between two colors, with higher CCI values indicating smaller color differences between the fusion and source images. PSNR represents the mean squared error between the fusion and original images, with higher values signifying lower image distortion. SSIM quantifies the similarity between two images, where larger SSIM values indicate greater similarity between the fusion and source images. DD assesses image distortion, with smaller values denoting less distortion in fusion images. SM measures image similarity, with larger values indicating better fusion effects. CC reflects the statistical indicator of the closeness of the relationship between variables, with larger values indicating a stronger correlation. MI measures the distance (similarity) between two distributions, with larger values indicating higher similarity between the fusion and source images.
Tables 1, 2, 3 and 4 demonstrate that the proposed fusion model algorithm holds a dominant position in all four sets of experiments across the eight evaluation metrics. In comparisons with eight other algorithms, all the data are in the first place. The algorithm exhibits superior color retention in fusion images, coupled with lower spectral distortion, demonstrating outstanding image fusion performance and applicability to various image fusion scenarios.
5 Conclusion
The experimental results highlight the efficacy of the proposed fusion model algorithm in maintaining color accuracy and minimizing spectral losses within the domain of remote sensing image fusion. Additionally, it demonstrates a robust performance in preserving image edge contours and textures during the fusion process. Future research will focus on refining and enhancing the overall image fusion performance of this model.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
References
Zhang, P., Jiang, Q., Cai, L., Wang, R., Wang, P., Jin, X.: Attention-based F-UNet for Remote Sensing Image Fusion. In: IEEE 23rd Int Conf on High Performance Computing & Communications; 7th Int Conf on Data Science & Systems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys). Haikou, Hainan, China 2021, 81–88 (2021). https://doi.org/10.1109/HPCC-DSS-SmartCity-DependSys53884.2021.00038
Chu, F., Liu, H., Wang, Z., Cao, Z.: Super-resolution Reconstruction of Airborne Remote Sensing Images based on Multi-scale Fusion. In: 2022 3rd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Xi’an, China, pp. 648–651 (2022). https://doi.org/10.1109/ICBAIE56435.2022.9985886.
Ma, W., et al.: A multi-scale progressive collaborative attention network for remote sensing fusion classification. IEEE Trans. Neural Netw. Learn. Syst. 34(8), 3897–3911 (2023). https://doi.org/10.1109/TNNLS.2021.3121490
Tan, W., Xiang, P., Zhang, J., Zhou, H., Qin, H.: Remote sensing image fusion via boundary measured dual-channel PCNN in multi-scale morphological gradient domain. IEEE Access 8, 42540–42549 (2020). https://doi.org/10.1109/ACCESS.2020.2977299
Basheer, P. I., Prasad, K. P., Gupta, A. D., Pant, B., Vijavan, V. P., Kapila, D.: Optimal fusion technique for multi-scale remote sensing images based on DWT and CNN. In: 2022 8th International Conference on Smart Structures and Systems (ICSSS), Chennai, India, 2022, pp. 1–6. https://doi.org/10.1109/ICSSS54381.2022.9782239.
Li, S., Kang, X., Fang, L., Hu, J., Yin, H.: Pixel-level image fusion: A survey of the state of the art. Inform. Fusion, 33, 100–112, ISSN 1566–2535. https://doi.org/10.1016/j.inffus.2016.05.004.
Kumar, K. V., Sathish, A.: A comparative study of various multimodal medical image fusion techniques—A review. In: Seventh International conference on Bio Signals, Images, and Instrumentation (ICBSII). Chennai, India, pp 1–6 (2021). https://doi.org/10.1109/ICBSII51839.2021.9445149
Sebastian, J., King, G.R.G.: Fusion of multimodality medical images—a review. In: Smart Technologies, Communication and Robotics (STCR). Sathyamangalam, India, pp 1–6 (2021). https://doi.org/10.1109/STCR51658.2021.9588882
Wang, Q., Chen, W., Wu, X., Li, Z.: Detail-enhanced multi-scale exposure fusion in YUV color space. IEEE Trans. Circuits Syst. Video Technol. 30(8), 2418–2429 (2020). https://doi.org/10.1109/TCSVT.2019.2919310
Li, Y., Liu, M., Han, K.: Overview of multi-exposure image fusion. In: 2021 International Conference on Electronic Communications, Internet of Things and Big Data (ICEIB), Yilan County, Taiwan, 2021, pp. 196–198. https://doi.org/10.1109/ICEIB53692.2021.9686453.
Li, H., Wang, J., Han, C.: Image mosaic and hybrid fusion algorithm based on pyramid decomposition. In: 2020 International Conference on Virtual Reality and Visualization (ICVRV), Recife, Brazil, 2020, pp. 205–208. https://doi.org/10.1109/ICVRV51359.2020.00049.
Li, D., Dong, X., Wang, K., Zhou, M., Chen, H., Su, J.: Image fusion algorithm based on Laplacian pyramid and principal component analysis transforms. In: 2022 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi'an, China, 2022, pp. 31–35. https://doi.org/10.1109/ICCNEA57056.2022.00018.
Vajpayee, P., Panigrahy, C., Kumar, A.: Medical image fusion by adaptive Gaussian PCNN and improved Roberts operator. SIViP 17, 3565–3573 (2023). https://doi.org/10.1007/s11760-023-02581-4
Jana, M., Basu, S., Das, A.: NSCT-DCT based Fourier Analysis for Fusion of Multimodal Images. In: 2021 IEEE 8th Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), Dehradun, India, 2021, pp. 1–6. https://doi.org/10.1109/UPCON52273.2021.9667618.
Jie, Y., Li, X., Wang, M., Zhou, F., Tan, H.: Medical image fusion based on extended difference-of-Gaussians and edge-preserving. Expert Syst. Appl. 227, 120301. ISSN 0957–4174 (2023). https://doi.org/10.1016/j.eswa.2023.120301
Jana, M., Basu, S., Das, A.: Fusion of Multimodal Images using Parametrically Optimized PCNN and DCT based Fourier Analysis. In: IEEE Delhi Section Conference (DELCON). New Delhi, India 2022, 1–7 (2022). https://doi.org/10.1109/DELCON54057.2022.9753411
Zhang, Y., Lee, H. J.: Infrared and visible image fusion based on multi-scale decomposition and texture preservation model. In: 2021 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shanghai, China, 2021, pp. 335–339 (2021). https://doi.org/10.1109/ICCEAI52939.2021.00067.
Wu, S., Zhang, K., Yuan, X., Zhao, C.: Infrared and visible image fusion by using multi-scale transformation and fractional-order gradient information. In: ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023, pp. 1–5 (2023). https://doi.org/10.1109/ICASSP49357.2023.10096652.
Yu, Z., Wenhao, X., Shunli, Z., Jianjun, S., Ran, W., Xiangzhi, B., Li, Z., Qing, Z.: Local extreme map guided multi-modal brain image fusion. Front. Neurosci. 16 (2022). https://doi.org/10.3389/fnins.2022.1055451.
Veshki, F. G., Ouzir, N., Vorobyov, S. A., Ollila, E.: Multimodal image fusion via coupled feature learning. Signal Process. 200, 108637. ISSN 0165–1684 (2022). https://doi.org/10.1016/j.sigpro.2022.108637.
Jie, Y., Li, X., Tan, H., Zhou, F., Wang, G.: Multi-modal medical image fusion via multi-dictionary and truncated Huber filtering. Biomed. Signal Process. Control 88(Part B), 105671. ISSN 1746–8094 (2024). https://doi.org/10.1016/j.bspc.2023.105671.
Lindeberg, T.: Scale-space theory in computer vision. Lecture Notes in Computer Science (1993)
Witkin A. P. Scale-space fltering. In: Proceedings of 8th Int. Joint Conf. Art. Intell., 1983, pp 1019–1022
Simonoff, J.S.: Smoothing Methods in Statistics (Springer Series in Statistics). Springer-Verlag, Berlin (1996)
He, K., Sun, J., Tang, X.: Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 35(6), 1397–1409 (2013). https://doi.org/10.1109/TPAMI.2012.213
Acknowledgements
This work is sponsored by Natural Science Foundation of Xinjiang Uygur Autonomous Region (Grant No. 2022D01C425), the Postgraduate Course Scientific Research Project of Xinjiang University (Grant No. XJDX2022YALK11)
Author information
Authors and Affiliations
Contributions
M.S. and X.Z. made significant contributions to conceptualization and methodology. M.S. , X.Z. and Y.N. were involved in the software development and validation. M.S. and X.Z. actively participated in the writing of the original draft. X.Z. , M.S. and Y.L. made substantial contributions to the writing, reviewing, and editing process. X.Z. provided research materials. X.Z. played a crucial role in supervision and funding acquisition. All authors critically reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no conflicts of interest regarding the publication of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sun, M., Zhu, X., Niu, Y. et al. Multi-modal remote sensing image fusion method guided by local extremum maps-guided image filter. SIViP 18, 4375–4383 (2024). https://doi.org/10.1007/s11760-024-03079-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-024-03079-3