
Abstract
Type-2 diabetes mellitus (T2DM) is a chronic metabolic disorder affecting numerous people throughout the world. If untreated in the initial stages, diabetes-related complications such as retinopathy, neuropathy, and cardiac issues may arise in the body. This research introduces the efficient automatic T2DM identification method using photoplethysmography (PPG) signals. The tunable-Q wavelet transform (TQWT) is used to analyze the PPG signals which permit the PPG signal to be converted into predictable wavelets. Entropy features are then extracted by these wavelets for events of healthy controls and T2DM followed by statistical significance analysis and classification using least-square support vector machine (LS-SVM) classifier to identify the T2DM events. In addition, the majority voting-based feature selection method is applied for feature reduction and the most relevant feature selection. With top-ranked 20 relevant features, the LS-SVM classifier with radial basis function (RBF) kernel attained a maximum 98.51% classification accuracy, 98.64% sensitivity, 98.38% specificity, 98.61% area under the curve, 98.31% precision, and, 98.47% F-score. The results indicate that the suggested approach for T2DM identification has better classification performance than existing approaches.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Diabetes mellitus (DM) has become a dreadful non-communicable health condition that can cause significant morbidity and mortality. Its most prevalent form is type-2 diabetes mellitus (T2DM), also called non-insulin-dependent and adult-onset DM [1]. It needs to be detected at an early stage due to its asymptomatic nature, which can affect at any age, and cause many micro- and macrovascular complications even before its detection. It also brings a substantial financial burden not only on the individual/ family but on the whole health system and society [1, 2]. For the identification of T2DM, the prominent approaches such as hemoglobin test (Hb-A1C), fasting plasma glucose test (FPGT), oral glucose tolerance test (OGTT), and semi-invasive movable blood sugar meters are either costly or invasive due to which these approaches are not suitable for routine check-ups.
So, to overcome the above-mentioned limitation photoplethysmography (PPG) signal analysis has gained a lot of attention for T2DM detection in the last few years because of its simple, portable, inexpensive, and non-invasive nature. The PPG signal depicts blood volume fluctuations and contains information about blood vessels, arterial stiffness, and hemodynamic characteristics which are considered to be an early predictor of T2DM [3, 4]. Thus, the design of an automated technique to identify T2DM using the PPG signals is considered to be a thrust area of research.
1.1 Literature review
In the last several decades, the PPG signal has received great popularity to diagnose T2DM disease using machine learning techniques. Keikhosravi et al. [5] used bilateral PPG signals to assess endothelial dysfunction for T2DM identification and achieved 93.5% accuracy by naïve Bayes classifier. Similarly, Reddy et al. [6] used a support vector machine (SVM) with the weight fusion method for T2DM detection. They used multiple features from various domains of PPG signal to achieve an accuracy of 89%. In another study by applying an artificial neural network (ANN) along with time domain and physiological features, an accuracy of 85.5% was achieved [7]. After that, Nirala et al. [8] extracted different time-domain features from toe PPG signals and showed 97.87% accuracy using the SVM classifier with ten features. Prabha et al. [9] used physiological parameters along with Mel frequency cepstral coefficient-based features. Using a combination of principal component analysis and SVM classifier, they achieved 92.28% accuracy. In other studies, a smartphone-based PPG signal was utilized to develop T2DM detection systems [10, 11], but these systems obtained poor classification accuracy.
From literature review, it is observed that existing studies used the features based on morphology, time domain, and frequency domain to detect T2DM. However, the PPG morphological features are not highly accurate for the diagnosis of T2DM because it is highly influenced by motion artifacts in a nonstationary environment. Further, use of frequency domain, and time-domain methods for the PPG signal analysis is less accurate because of oscillatory (nonstationary) nature of these signals. Another study used empirical mode decomposition (EMD) to address these drawbacks. However, it suffers from mode mixing issues [12]. This motivated us to employ a time–frequency-based approach based on tunable-Q wavelet transform (TQWT) in oscillatory PPG signals for the diagnosis of T2DM. The TQWT permits flexible analysis for processing of the oscillatory and complex signals like PPG [13]. TQWT has been used in a variety of domains and a wide range of signal-processing fields. It has been also used for various disease identification using different biomedical signals [14,15,16].
The current work proposes a tunable-Q wavelet transform (TQWT) method for the automatic diagnosis of T2DM using PPG signals. The TQWT decomposes the PPG signal into various sub-bands (SBs) or wavelets. After the decomposition of PPG signals into useful sub-bands or wavelets, entropy features were extracted. After that, all extracted features were tested for being statistically significant. In addition, the majority voting-based feature selection method was employed to choose the most reliable features. Finally, the least-square support vector machine (LS-SVM) classifier with different kernels was tested for T2DM detection.
The rest of the article is arranged as follows: The overall proposed methodology is described in the second section. The third section explains the experimental results and discussion, and finally, the article is summarized with the conclusion in the fourth section.
2 Methodology
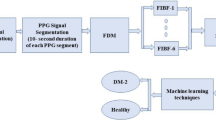
Figure 1 depicts the proposed methodology. Each section of the proposed methodology corresponding to Fig. 1 is explained below:

The flowchart of the proposed methodology for identification of T2DM
2.1 PPG dataset, pre-processing and segmentation
This study used Nirala et al. [8] PPG database. The PPG signal (5 min) was recorded from each participant at a sampling frequency of 1 kHz. To eliminate the noise present in the recorded PPG signals, a Butterworth bandpass filter was used with 0.5 and 20 Hz cut-off frequencies. After noise removal, the recorded PPG signals were segmented into ten small segments of 30-s each resulting in a total of 1510 samples (10 samples/subject) containing 770 samples of healthy controls and 740 samples of T2DM.
2.2 Tunable- Q wavelet transform (TQWT)
The most frequently used conventional wavelet transform (WT) is discrete wavelet transform (DWT) which has certain drawbacks, including fixed bandwidth of the filter bank and fixed oversampling rate. The fixed number of oscillations in the mother wavelet is another major limitation of DWT [17]. Unlike DWT, the TQWT is an effective transform because it overcomes the limitations as mentioned earlier by providing flexibility to adjust the Q-factor for any oscillatory signal. This choice does not exist in conventional WTs [15]. The TQWT analyzes the complex and oscillatory signals with the help of three adjustable parameters, namely redundancy, Q-factor, and the decomposition level which is denoted as r, Q, and, J, respectively. At each TQWT-based decomposition level, the input data series X(n) with sampling frequency (Fs) is represented as low-pass subband signals and high-pass subband signals along with their sampling frequencies denoted as αFs and βFs, respectively. Where α denotes the low-pass scaling factor and β denotes the high-pass scaling factor. The scaling of the signal spectrum is controlled by the parameters α and β. To produce a low-pass subband, the low-pass filter \(H_{0} (\varpi )\) and low-pass scaling (Lps α) are used. Likewise, by using high-pass filter \(H_{1} (\varpi )\) and high-pass scaling (Hps β), the high-pass subband is obtained. After Jth-level, the identical frequency response created for low-pass and high-pass subbands is expressed as \(H_{0}^{J} (\varpi )\) and \(H_{1}^{J} (\varpi )\), respectively, as [13, 15]:
where
\(\theta (\varpi )\) provides the frequency response of Daubechies filter that has two vanishing moments and it can be expressed as [13, 15]:
The values of Q and r are related to filter bank high-pass parameter α and low-pass parameter β, can be expressed as [13, 15]:
TQWT's parameters were selected based on the energy distribution of the PPG signal. The energy distribution curve helped us to identify the distribution of energy with respect to frequency for a defined decomposition level. Whereas the energy level of sub-bands helps us to visualize the distribution of energy in each band.
After several experiments, the TQWT parameters Q, r and J were selected to be 1, 3, and 15, respectively, because, at these parameter values, most of the energy was confined to the frequency range of 0 to 15 Hz, i.e., the PPG frequency range as shown in Fig. 2 (a). Further, Fig. 2 (b) shows the energy level of SBs wherein SB1 and SB16 denote the highest and lowest frequency component of the PPG signal, respectively. It is observed from Fig. 2 (b) that at Q = 1, r = 3, and J = 15, the energy is distributed throughout over most of the SBs. So, based on this energy level distribution we selected the parameters of TQWT in our study. Figure 3 shows the decomposed components of the PPG signal for T2DM and healthy cases.

a The energy distribution versus frequency b The energy level of SBs at Q = 1, r = 3, and J = 15 of TQWT

Sub-bands of decomposed PPG signal using TQWT for two categories (Blue- T2DM PPG, Green- Healthy PPG, Black- SBs of T2DM, Red- SBs of healthy subject)
2.3 Feature extraction
After determining SBs using TQWT following features were extracted: -
2.3.1 Log energy entropy (LogEE)
The LogEE measures the randomness available in the signal. It is used to evaluate the complexity of the signal [17]. It is defined as the logarithm of the energy calculated for each SBs of the PPG segment [17]. Mathematically it can be formulated as [17]:
where Xi is an ith sample of decomposed SB of PPG signal and N is the length of decomposed SB.
2.3.2 Fuzzy entropy (FuzzyE)
Fuzzy entropy is used to measure the irregularity of the PPG signal [18]. For a finite database of n samples, fuzzy entropy is expressed as [19]:
where \(\phi^{A} \left( {B,C} \right)\) can be defined as [19]:
where Djk is the similarity degree between two distinct patterns of length A extracted from the signal and can be estimated using the fuzzy function [19]. The fuzzy similarity boundary is controlled by parameters C and B.
For fuzzy entropy calculation, we have selected the value of embedded dimension (A) = 2. The value of step (B) and width (C) of the fuzzy exponential function has taken 1 and 0.2*SD (SD is the standard deviation of data series), respectively [19, 20].
2.4 Statistical analysis
The Kolmogorov–Smirnov and Shapiro–Wilk tests were used to analyze the normality of all features. After that, based on the normality test, the Mann–Whitney U test (confidence range of 95%) was applied to analyze the statistical significance of extracted features.
2.5 Majority voting-based feature selection technique (MV-FST)
Feature selection techniques (FSTs) minimize the classifier model's complexity while improving classifier performance. The traditional feature selection methods use just one estimation criterion, resulting in a bias against the single criterion. Thus, we applied multi-criterion FSTs in this study. The combination of various FSTs was used through a majority vote to obtain the most significant feature. In our work, seven filter methods such as classifier attribute eval (Clas. AE), correlation attribute eval (Corel. AE), Info gain attribute (InfoG. A), gain ratio attribute (GainR. A), one R.A. attribute (1-RA. E), Relief-F attribute (Rel-FA. E), and symmetrical uncertainty attribute (SUA), and one wrapper method namely Cfs subsets eval (Cfs- SE) were used for selection of most relevant features. All filter-based FSTs organize the features rank-wise. In our work, a total of seven filter-based and one wrapper-based FST were applied independently and selected the top 20 features from each filter-based FST, and the wrapper-based FST (Cfs- SE) revealed only nine features. Based on the majority vote, the most optimal features were selected [8, 21]. To perform all FSTs, the Weka software version 3.9 was used.
2.6 Classification based on least-square support vector machine (LS-SVM)
As the name suggests, the least-square type of SVM [22]. The design of the LS-SVM classifier is based on kernel mapping theory and the marginal maximization principle. For solving optimization issues, the SVM uses quadratic equations, but LS-SVM uses linear equations [23]. The mathematical equation of the LS-SVM can be represented as [15]:
where yn and αn is the input data and Lagrange multipliers, respectively. The b and, \(k(x,x_{n} ) = k(\phi (x),\phi (x_{n} ))\) denotes the bias and kernel function, respectively. The \(x_{n}\) denotes the binary class target/ class label of input data.
We have used different kernel functions, namely linear (Lin), polynomial (Poly), and radial basis function (RBF) in the LS-SVM classifier. Each kernel's formulation is explained in [23]. The kernel's regularization parameters and optimal values were calculated by a procedure that associates a simplex and coupled simulated annealing (CSA) method as demonstrated at www.esat.kuleuven.be/sista/lssvmlab/. LS-SVM was used to identify alcoholism [15], and septal defects [14]. In Refs [12], LS-SVM was also used to classify T2DM using RR interval.
3 Results and discussion
A total of 151 participants including 77 healthy controls and 74 T2DM participants were utilized in this study. Subjects who suffered from lower limb amputation, excessive limb movement, leg inflammation, suffering from cardiac pacemakers, and being affected by cardiac arrhythmia were not included in the study. Detailed information about the dataset can be acquired from Nirala et al. [8]. Table 1 represents the demographic information of all participants. The proposed method for the detection of T2DM is a step-by-step process including TQWT, extraction of features, selection of features, and classification. All experiments were implemented using MATLAB 2018a software. An input PPG (30-s duration) signal was decomposed into 16 SBs, namely SB-1 to SB-16 using TQWT. Two entropy-based features namely Log energy entropy (LogEE) and Fuzzy entropy (FuzzyE) were extracted from all 16 SBs. We denote these features as LogEE-SB1 to LogEE-SB16 and FuzzyE-SB1 to FuzzyE-SB16, respectively. Initially, 32 features were extracted, then Kolmogorov–Smirnov and Shapiro–Wilk tests were applied to check the normality. Out of 32 features, only nine features were found normal and non-homogeneous. The rest features were non-normal. Therefore, the non-parametric Mann–Whitney U test was applied to all 32 features. The results of the statistical analysis are shown in Table 2. The probabilistic values (p-value) of the Mann–Whitney U test were used to perform the discriminative analysis of the resulting features. Table 2 shows that out of 32 features, the majority of features continuously obtained lower p-value except for only two SBs (FuzzyE-SB2 and FuzzyE-SB9).
The p-value, median, 25 percentile, and 75 percentile values for LogEE and FuzzyE are shown in Table 2. We can observe from Table 2, that the LogEE feature reveals a lower value for the healthy class in all SB signals which indicates that the T2DM group has higher energy as compared to the healthy group. Also, the lower value of LogEE shows that the PPG signal is less random (high rhythmic) in the healthy class than T2DM class. FuzzyE estimates similarity in the time series. The estimation of similarity is based on the exponential function mentioned in [18]. In Table 2, the FuzzyE value for T2DM subjects is lower than healthy subjects for low-frequency SB signals (SB9 to SB16). The FuzzyE value for T2DM subjects is higher than healthy subjects for high-frequency SB signals (SB2 to SB8) except SB1. All the SB signals presented good discrimination capability for both groups except FuzzyE-SB2 and FuzzyE-SB9. The smaller value of FuzzyE in the T2DM class indicates that the diabetic PPG signals have more regularity as compared to healthy PPG signals.
Classification of healthy and T2DM was carried out in two ways. Firstly, all statistically significant features (30 features) were used for classification, and secondly, classification using features selected by MV-FST. In our study, feature vector contained a total of 32 features that were extracted from various frequency scales of SBs and supplied to different FSTs. Each FST provided ranks of features based on their criteria. A majority vote was conducted on the features obtained from each FST. The results of the voting score of features are shown in Table 3. Features with maximum voting score of eight and a minimum voting score of five were further selected in this study.
The next step was to feed features to the machine learning classifier to classify healthy and T2DM events. The classification was performed by LS-SVM using tenfold cross-validation (CV) to prevent overfitting. Here the whole data is divided into ten equal parts. For each of the tenfold, one part (10%) of the data is used for testing and the remaining nine parts (90%) are used for training. Also, for each fold, a different 10% of data is chosen as a test set. The final testing accuracy is calculated by averaging the accuracies of all ten iterations. The classification was performed using four (got the highest majority vote value 8), seven (got majority vote value 8 and 7), eleven (got majority vote value 8, 7, and 6), and 20 (got majority vote value 8, 7,6 and,5) top-ranked features. To evaluate the classification model with different kernels, various performance measures (PM) such as accuracy (Ac), specificity (Sp), sensitivity (Sen), area under the receiving operating characteristics curve (AUC), precision (Pr), and F-score were calculated. These performance measures are computed from the confusion matrix in which TP, TN, FP, and FN expresses true positive, true negative, false positive, and false negative samples, respectively [8].
Tables 4 and 5 present the obtained classification results. From Table 5, we can observe that using 20 top-ranked features, the LS-SVM classifier along with the RBF kernel showed the highest average performance such as 98.51% accuracy, 98.64% sensitivity, 98.38% specificity, 98.61% AUC, 98.331% precision, and 98.47% F-score after 10 times trails. In Tables 4 and 5 the highest classification results are marked in bold.
During optimization with RBF kernel, the average value of obtained optimal kernel parameters sig 2 (σ) and gamma (ϒ) are 1.409 and 30.51, respectively, after 10 trials. The LS-SVM with poly and linear kernel showed an accuracy of 97.23% and 72.7%, respectively. The LS-SVM classifier with a linear and poly kernel demonstrated poor performance compared to the RBF kernel, hence, were avoided in Table 4. Using 11 features with RBF kernel, LS-SVM also obtained 97.23% average accuracy. Table 5 shows that using 30 statistically significant features the LS-SVM with RBF kernel showed average accuracy of 98.49%, a sensitivity of 98.65%, a specificity of 98.33%, an AUC of 98.49%, a precision of 98.25%, an F-score of 98.45% and the average value of obtained optimal kernel parameters sig 2 (σ) and gamma (ϒ) are 4.79 and 173.23, respectively, after 10 times iteration. As compared to polynomial and RBF kernels, the linear kernel presented the poorest classification performance in both cases with MV-FST (20 features) and without FST (30 features). The reason is that due to its underlying constraint, the linear kernel is incapable of managing the nonlinearity comprised in its input. From Tables 4 and 5, we can observe that there is no huge difference in the accuracy of the LS-SVM classifier with RBF kernel either by using 30 statistically significant features or by using the top 20 features obtained by MV- FST. Even if we increase the number of features to more than 20, there was no change in accuracy. This means that the top 20 ranked features selected by MV-SVT are relevant features.
The main objective of applying the MV-FST was to reduce the number of features and minimize the computational time and load of classification. Figure 4 shows the area under the receiving operating characteristic curve (ROC) of the various LS-SVM classifiers using the top-ranked 20 features. A large area under the ROC expresses the high classification performance [24]. The obtained results indicated that the LS-SVM classifier with RBF kernel is the most appropriate machine learning classifier to distinguish T2DM from healthy PPG signals.

The ROC plot and values of AUC for LS-SVM classifier with RBF kernel using top 20 ranked features
We now compare the proposed study to the previous PPG-based T2DM detection techniques. The results are shown in Table 6. Keikhosravi et al. [5] used bilateral PPG signals for T2DM screening by using an improved model of the upper vascularity of the human body. Singular value decomposition (SVD) was employed for the feature reduction and the Naïve Bayes was applied for classification. Ramu Reddy et al. [6] extracted time, frequency, nonlinear, shape, and heart rate variability-based features from the PPG signal. SVM with a weighted fusion was applied for T2DM classification. For comparison purposes, another research utilized time-domain features with the SVM classification algorithm [8]. Furthermore, smartphone-recorded PPG signals were utilized for the analysis of T2DM by a 34-layer CNN deep learning algorithm [11]. In addition, for the analysis of T2DM the demographic parameter age and four-time-domain features were used that correlated with the HbA1C test, and a neural network was applied for classification [7]. Recently, the PPG signal's features were extracted from smartphone fingertip videos, and classification was done using a Gaussian SVM classifier for T2DM identification Gaussian fitting-based feature extraction approach was used to extract time and frequency domain features [10]. However, Table 6 shows that the proposed TQWT method with MV-FST + LS-SVM + RBF kernel classification-based T2DM identification system was a more accurate technique compared to the earlier methods. In Table 6 the results of proposed method are highlighted in bold.
The proposed work is focused on the application of TQWT-based time–frequency characteristics of the PPG signal for classification of healthy and T2DM patients. The primary reason for the good performance of our approach is appropriate selection of relevant subbands using TQWT and further using those subbands for feature extraction. We used the nonlinear features that are useful to depict the dynamic behavior of the PPG signal for healthy and T2DM subjects. Also, the LS-SVM classifier with RBF and Poly kernel provides excellent performance for the classification of nonlinear data. Hence, the proposed method achieved good performance due to the appropriate selection of parameters (Q = 1, r = 3, and J = 15) of TQWT and the kernel for the LS-SVM classifier. High classification performance was obtained using 1510 samples. The primary reason of increasing the sample size using segmentation was to improve the generalization of our proposed methodology. Also, previous studies such as Ramu Reddy et al. [6], Nirala et al. [8], Qawqzh et al. [7], Zhang et al. [10] used much lesser number of samples compared to our study. In TQWT, the tuning of the Q-factor provides an accurate decomposition of an oscillating signal with the least information loss. TQWT's time–frequency distributions provide accurate time and frequency localization. The proposed approach utilizing entropy features extracted from TQWT SBs of PPG signal with an LS-SVM classifier can be a promising non-invasive technique for the identification of T2DM.
Along with advantages, our study suffers from some limitations. First, our data size is very small, we used the PPG signal of only 151 participants acquired by Nirala et al. [8]. However, the sample size used in this study is much more than those in previous studies. In addition, this research aimed to make a non-invasive approach to T2DM identification that can differentiate between healthy and T2DM patients. Thus, this system is unable to estimate glucose levels. In future, optical approach for non-invasive glucose level detection can be developed. Further, we used only three kernel functions of the LS-SVM classifier. In future, it is possible to design new kernel functions and utilize them with the LS-SVM to improve the classifier's performance. Although, TQWT requires parameter adjustment. This limitation can be solved by employing an optimization method to select the parameters of TQWT for a specific signal automatically. Another limitation of TQWT is that extracting features from the long duration of the PPG signal takes a very long time. In the future, we can overcome this limitation by using some more advanced wavelet transforms like flexible analytical wavelet transform and Fourier–Bessel series expansion. This research yields encouraging results and makes the groundwork for the evolution of intelligent non-invasive T2DM identification technology that plays a significant role in the treatment of T2DM.
4 Conclusions
This study proposed a photoplethysmography-based automatic type-2 diabetes (T2DM) detection technique using tunable-Q wavelet transform and least-square support vector machine (LS-SVM) classifier with RBF kernel. The extracted features are evaluated using classifiers like LS-SVM to classify normal and T2DM groups. The main findings of the suggested work are as follows. (1) TQWT-based entropy features can be useful for diagnosis of type-2 diabetes with high accuracy, (2) the LS-SVM classifier along with RBF kernel achieves high classification performance in detecting T2DM, (3) the proposed technique classifies two events healthy and type-2 diabetes with classification performance Ac 98.51%, Sen 98.64%, and Sp 98.38%. (4) The proposed automatic type-2 diabetes diagnosis technique can be useful in routing clinical scenario and telemedicine applications. This technique can be utilized for the diagnosis and analysis of other heart diseases using PPG signals in future.
Data availability and materials
The data used to support the findings of this study are taken from Nirala et al. [8] (https://doi.org/10.1016/j.bbe.2018.09.007). This dataset is not publicly available. The dataset generated during the current study are available from the corresponding author on reasonable request after publication of this article.
References
Himsworth, H.P., Kerr, R.B.: Insulin-sensitive and insulin-insnsitive types of diabetes mellitus. Clin. Sci. 4, 119–152 (1939)
Kopita, L., Kocbek, P., Cilar, L., Sheikh, A., Stiglic, G.: Early detetion of type 2 diabetes mellitus using machine learning-based prediction models. Sci. Rep. 10(1), 1–12 (2020)
Pilt, K., Ferenets, R., Meigas, K., Lindberg, L.G., Temitski, K., Viigimaa, M.: New photoplethysmographic signal analysis algorithm for arterial stiffness estimation. Sci. World J. (2013). https://doi.org/10.1155/2013/169035
Muhammad, I.F., Borné, Y., Östling, G., Kennbäck, C., Gottsäter, M., Persson, M., Engström, G.: Arterial stiffness and incidence of diabetes: a population-based cohort study. Diabetes Care 40(12), 1739–1745 (2017)
Keikhosravi, A., Aghajani, H., Zahedi, E.: Discrimination of bilateral finger photoplethysmogram responses to reactive hyperemia in diabetic and healthy subjects using a differential vascular model framework. Physiol. Measure. 34(5), 513 (2013). https://doi.org/10.1088/0967-3334/34/5/513
Reddy, V.R., Choudhury, A.D., Jayaraman, S., Thokala, N.K., Deshpande, P., Kaliaperumal, V.: PerDMCS: weighted fusion of PPG signal features for robust and efficient diabetes mellitus classification. HEALTHINF (2017). https://doi.org/10.5220/0006297205530560
Qawqzeh, Y.K.: Neural network-based diabetic type II high-risk prediction using photoplethysmogram waveform analysis. Int. J. Adv. Comput. Sci. Appl. 10(12), 1–5 (2019)
Nirala, N., Periyasamy, R., Singh, B.K., Kumar, A.: Detection of type-2 diabetes using characteristics of toe photoplethysmogram by applying support vector machine. Biocybern. Biomed. Eng. 39(1), 38–51 (2019). https://doi.org/10.1016/j.bbe.2018.09.007
Prabha, A., Yadav, J., Rani, A., Singh, V.: Non-invasive diabetes mellitus detection system using machine learning techniques. In: 2021 11th International Conference on Cloud Computing, Data Science and Engineering (Confluence) (pp. 948–953). IEEE. https://doi.org/10.1109/confluence51648.2021.9377138.
Zhang, G., Mei, Z., Zhang, Y., Ma, X., Lo, B., Chen, D., Zhang, Y.: A non-invasive blood glucose monitoring system based on smartphone PPG signal processing and machine learning. IEEE Trans. Ind. Inform. 16(11), 7209–7218 (2020). https://doi.org/10.1109/TII.2020
Avram, R., Tison, G., Kuhar, P., Marcus, G., Pletcher, M., Olgin, J.E., Aschbacher, K.: Predicting diabetes from PHOTOPLETHYSMOGRAPHY using deep learning. J. Am. Coll. Cardiol. 73(9S2), 16–16 (2019). https://doi.org/10.1016/s0735-1097(19)33778-7
Pachori, R.B., Kumar, M., Avinash, P., Shashank, K., Acharya, U.R.: An improved online paradigm for screening of diabetic patients using RR-interval signals. J. Mech. Med. Biol. 16(01), 1640003 (2016). https://doi.org/10.1142/S0219519416400030
Selesnick, I.W.: Wavelet transform with tunable Q-factor. IEEE Trans. Signal Process. 59(8), 3560–3575 (2011). https://doi.org/10.1109/TSP.2011.2143711
Patidar, S., Pachori, R.B., Garg, N.: Automatic diagnosis of septal defects based on tunable-Q wavelet transform of cardiac sound signals. Expert Syst. Appl. 42(7), 3315–3326 (2015). https://doi.org/10.1016/j.eswa.2014.11.046
Patidar, S., Pachori, R.B., Upadhyay, A., Acharya, U.R.: An integrated alcoholic index using tunable-Q wavelet transform based features extracted from EEG signals for diagnosis of alcoholism. Appl. Soft Comput. 50, 71–78 (2017). https://doi.org/10.1016/j.asoc.2016.11.002
Nishad, A., Pachori, R.B., Acharya, U.R.: Application of TQWT based filter-bank for sleep apnea screening using ECG signals. J. Ambient Intell. Hum. Comput. (2018). https://doi.org/10.1007/s12652-018-0867-3
Sadiq, M.T., Akbari, H., Rehman, A.U., Nishtar, Z., Masood, B., Ghazvini, M., Too, J., Hamedi, N., Kaabar, M.K.: Exploiting feature selection and neural network techniques for identification of focal and nonfocal EEG signals in TQWT domain. J. Healthcare Eng. (2021). https://doi.org/10.1155/2021/6283900
Zarei, A., Asl, B.M.: Automatic detection of obstructive sleep apnea using wavelet transform and entropy-based features from single-lead ECG signal. IEEE J. Biomed. Health Informat. 23(3), 1011–1021 (2018). https://doi.org/10.1109/JBHI.2018.2842919
Chen, W., Wang, Z., Xie, H., Yu, W.: Characterization of surface EMG signal based on fuzzy entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 15(2), 266–272 (2007). https://doi.org/10.1109/TNSRE.2007.897025
Zhao, X., Sun, G.: A multi-class automatic sleep staging method based on photoplethysmography signals. Entropy 23(1), 116 (2021). https://doi.org/10.3390/e23010116
Singh, B.K.: Determining relevant biomarkers for prediction of breast cancer using anthropometric and clinical features: a comparative investigation in machine learning paradigm. Biocybern. Biomed. Eng. 39(2), 393–409 (2019)
Sani M, Norhazman H, Omar H, Zaini N, Ghani S (2014) Support vector machine for classification of stress subjects using EEG signals. In: Proc. IEEE Conf. Syst., Process Control (ICSPC), pp. 127–131
Pelckmans, K., et al.: LS-SVMlab: A MATLAB/C toolbox for least squares support vector machines. Tutorial KULeuven-ESAT Leuven Belgium 142(1–2), 1–2 (2002)
Khandoker, A.H., Lai, D.T., Begg, R.K., Palaniswami, M.: Wavelet-based feature extraction for support vector machines for screening balance impairments in the elderly. IEEE Trans. Neural Syst. Rehabil. Eng. 15(4), 587–597 (2007)
Acknowledgements
The authors would like to thank the National Institute of Technology Raipur, India for providing infrastructure and facilities to carry out this research work.
Funding
This research work has no funding support. It’s part of my PhD.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study's conception and design. Material preparation, data collection, and analysis were performed by Bhanupriya Mishra. Data collection was done by Neelam Shobha Nirala, and Figs. 1, 2, 3 and 4 were prepared by Bikesh Kumar Singh. The first draft of the manuscript was written by Bhanupriya Mishra, and all authors commented on previous versions of the manuscript and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Conflict of interest
The authors state that they have no conflict of interest.
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Ethical approval and informed consent
In this work, the dataset was used from the Institute whose ethical approval had already taken and mentioned in Nirala et. al. [8]. This work approved by Institutional Ethical Committee National Institute of Technology Raipur (Letter No- NITRR/IEC/3/2015).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mishra, B., Nirala, N. & Singh, B.K. Photoplethysmography signal-based automated diagnosis of type-2 diabetes using tunable-Q wavelet transform and least-square support vector machine classifier. SIViP 17, 2745–2754 (2023). https://doi.org/10.1007/s11760-023-02491-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-023-02491-5