
Abstract
One of the most widespread disorders in childhood is called autism spectrum disorder (ASD), which affects the brain's function. Previously, many efforts have been made to develop an intelligent system to detect disease using brain activity. However, accurate diagnosis of ASD remains a challenging issue among scientists. The purpose of this study was to diagnose ASD at an early age using a low computationally algorithm based on electroencephalography (EEG) signal. In this study, we classified two groups of normal and autistic children using brain signals at resting-state. Two brain channels (C3 and C4) of 61 children including 27 normal children and 34 autistic children in the age range of 4 to 8 years were studied. For the first time, we characterized the EEGs using innovative polar-based lagged state-space indices. The classification was performed using the support vector machine (SVM). The results demonstrated the highest average accuracy of 81.96% using the indices of two EEG channels. Using single-channel EEG measures, the maximum average classification rate of 78.68% was achieved using C4. To sum up, the results revealed that despite the limited number of brain channels and computational simplicity, the proposed algorithm was able to distinguish the two groups of normal and autistic children with satisfactory accuracy.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Autism spectrum disorder (ASD) is a type of neurodevelopmental disorder [1, 2] characterized by impairments in verbal and nonverbal behaviors and symptoms like stereotyped behaviors, repetitive games, lack of eye contact, and the like. These symptoms appear almost before the age of three years old [2, 3]. As the prevalence rate of this disorder is increasing in recent years [4], it is important to diagnose the disease as soon as possible to improve the behavioral performance of the child [5]. The diagnostic process is usually based on behavioral observations and clinical interviews. However, it is difficult to evaluate clinical methods such as how the child plays, communicating with the environment, and learning a language at an early age [3, 6].
There has been a great deal of research on paraclinical approaches as a complement or replacement for clinical methods to diagnose and evaluate the brain function of these children. Studies in the field of neuroimaging on autistic people [7, 8] have concluded that this group's functional-behavioral abnormalities may be due to disorders in some brain areas such as the amygdala [9, 10], fusiform gyrus [11], and the prefrontal [7].
In the Sadeghi study [12], a functional magnetic resonance imaging (fMRI)-based technique was used. Two groups including 31 normally control (NC) and 29 ASD were classified using region-based features. The highest accuracy of 92% was obtained by using support vector machine (SVM). Also, in the Kazeminejad and Sotero study [13], a total of 816 NC and ASD individuals based on FMRI images were investigated. The accuracy of 95% was achieved using an SVM classifier. Note that the methods and features were similar to the previous article.
Recently, electroencephalography (EEG) has been the focus of many researchers to diagnose the disease. Despite the low spatial resolution of EEG recordings over MRI and fMRI, EEG signals have several advantages, including simplicity, lower cost, wider availability and high temporal resolution [14], which is why they are commonly used to study the dynamics of information flows in the brain. MRI devices are also scary and frightening for children because of their structure and function.
In the research performed by Ibrahim et al. [14], various features, including Shannon entropy (SE), discrete wavelet transform (DWT), band power (BP), largest Lyapunov exponent (LLE), and standard deviation were extracted. This investigation was performed over 10 NC and 9 ASD aged 9–16 years. The most encouraging result with the accuracy of 94.2% was obtained by using the k-nearest neighbors (KNN) classifier and combining SE and DWT features. In the Kang et al. study [15], both NC and ASD groups consisted of 52 members with an average age of 4.5 years classified using SVM. By using power spectrum analysis and coherence features, the accuracy was 91.38%. In Heunis et al. [16], two groups of NC and ASD with 7 members per each group and mean age of 2–6 years were classified. Using the recurrence quantification analysis (RQA) and SVM classifier, the accuracy of 92.9% was accomplished. In the Askari et al. paper [17], a 14-channel EEG module was evaluated employing the SVM classifier. The signals were analyzed based on the state and weight values of cellular neural networks (CNNS). The scheme was tested on two categories, including NC groups with 94 members and the ASD group with 84 members with a mean age of 9.5 years. The accuracy of 95.1% was achieved. Bajestani et al. [18] evaluated two-brain channel data. Their framework incorporated a visibility graph and KNN classifier. A total of 60 members of NC and ASD children in the age range of 4–8 years old attended the analysis. They reported the accuracy of 81.67%.
In the above papers, it has been attempted to classify the two groups of NC and ASD with high accuracy using fMRI and EEG data analysis. The neural imaging methods such as fMRI are costly. Additionally, although nonlinear methods are more convenient for evaluating the brain's performance as a nonlinear and chaotic system and they gain a high capability in signal processing [19], they often involve complex and time-consuming computation.
The articles mentioned above may have achieved considerable accuracy by examining the high number of channels, but due to the difficulty of signal recording from the autistic children and being noisy the recorded data, it is better to try to obtain a satisfactory result by investigating a more limited number of channels and thus smaller feature dimensions.
In addition, since it is relatively easier to obtain high accuracy of classification at an older age due to the obvious manifestation of autism symptoms, it is important to detect this disorder at an early age. In this study, we tried finding a way to classify NC and ASD children with high accuracy and high speed by examining fewer channels. Therefore, it was attempted to classify the rest EEG of two groups using innovative polar-based lagged state space. The benefits of this research include:
-
(1)
A low number of EEG channels (two channels).
-
(2)
Low-aged children.
-
(3)
Nonlinearity of features.
-
(4)
Simple, high-speed computing algorithm (less than 3 s)
Other sections of this article are as follows. Section 2 provides a brief overview of the data, the method used, and the features extracted for classification. Section 3 presents experimental results. Section 4 discusses the results. Finally, Sect. 5 concludes the paper.
2 Materials and methods
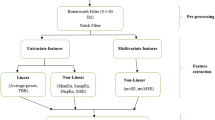
Figure 1 shows an overview of the proposed algorithm. It comprises of four main parts, including data selection, pre-processing, feature extraction, and classification. In this study, the EEG signals of 27 normal children and 34 autistic ones were analyzed. First, the EEG time series were segmented and normalized in the pre-processing module. Then, feature extraction was performed managing the polar-based lagged state-space-based indices. Ultimately, the SVM classifier was used for data classification.

Overall view of the methodology
2.1 Data selection
This work was implemented on the EEG dataset of Bajestani’s research [18] that was contained totally of 61 right-handed children aged in the range of 4–8 years (6 ± 2). Explicitly, 34 belonged to the ASD group, and 27 were in the NC group. Recording the data was done from two channels: C3 & C4. Bajestani mentioned in his article [18] that "Research has shown that the C3 and C4 areas relate to voluntary movement, long-term attention, and memory and that the central area of the brain is related to the areas of mood control, performance, and actuator performance. Of course, the temporal area is one of the disorder's critical areas. However, because of the child's shaking and consequently the high probability of the electrode separating, recording took place in the central area." In addition, the signals were recorded using a 10-channel Flexcomp Infinity device with a sampling rate of 256 Hz and 24-bit resolution. Signals were recorded in three steps in an acoustic room. First, two minutes of baseline recording (without any auditory or visual stimulation) were accomplished. In the second step, an animation was displayed for 5 min and at last, the animation was replayed silently for 5 min. In this study, we only used the 60 s of baseline recording.
2.2 Pre-processing
At this stage, initially, the data were segmented into the 60 s, 30 s and 15 s lengths to examine the impact of the windowing on classification results. The data were then normalized into the interval [−1, 1]. Normalization is a common mean to reduce the computational complexity of the particular method. The normalization formula is described as follow.
2.3 Feature extraction
In this study, two geometric properties were extracted from the state space. Each state of the system is represented as a point in the state space based on its variables [20]. For transmitting a time series to an m-dimensional state space and creating its trajectory, we need “m” coordinates for each point in the trajectory. These m coordinates are obtained by considering the number of n samples separated by time delay “L”. Figure 2a shows the time series points of the signal selected at intervals L. The amplitude of points determine the coordinates of a system state in the state space. Since m = 2 is considered in the present study, the system is defined by two variables (two-dimensional state space). Based on the two points in the time series, a trajectory is created in the state space (Fig. 2b). This trajectory is being investigated in the following. If L ˃ 1, the state space is delayed.

Feature extraction of polar-based lagged state space. a Signal time series. b The trajectory in state space. To transmit the signal to the 2D state-space separates two points from the time series with an arbitrary delay and considers the amplitude of the first point (red point) as X coordinate and the second dot amplitude (white point) as Y coordinate. For each point in the trajectory, two polar feature θ (angle of each point from the horizontal axis x) and r (the distance of each point to the origin) have been defined. According to part b, the angles of the two points n_i and n_(i + 3) are equal, with different distances
In Fig. 3, delayed phase space (L = 4) and non-delayed phase space are plotted for both NC and ASD groups. The attractor of the non-delayed phase space is more stretched out, whereas the attractor of the delayed phase space is more extended. This is true for both NC and ASD groups. Here, it is important to select the appropriate L. There are different ways to determine the optimal delay. We used mutual information [21] to determine the optimal delay in this study. The best delay was four (Fig. 4).

Representation of the non-delayed state space and delayed state space for both NC and ASD groups

Selecting the best delay based on the first local minimum in the mutual information chart. The selected delay is 4
Many investigations have emphasized the proper performance of delayed phase space in the study of various clinical and psychological applications [22,23,24,25,26,27,28,29,30,31]. Most of them used state-space Cartesian indices to quantify it. The oval is typically mounted on it and large and small oval diameters are extracted as features. Phase space is an indicator that can be studied both qualitatively and quantitatively and it's a new kind of reconstruction of temporal data, which is the reason for calling it a state-space. Various methods have been used to quantify it, such as feature extraction in the form of automatic regression (AR) and amplitude-frequency analysis (AFA) [35, 36]. In addition to amplitude information, it can be useful to examine the phase information by how each point in the phase space is distributed. In this experiment, we intended using phase information instead. Therefore, for the first time, we investigated the polar characteristics of the state space.
The features extracted from the state space are the angle of each point in the trajectory from the horizontal axis x and the distance of each point to the origin (Fig. 2). Figure 2 symbolically explains the polar-based lagged state-space indices and Eq. (2) formulates them.
where i is the point counter in the trajectory. Also, \(x_{i}\) and \(y_{i}\) are the coordinates of each point in the state space.
Of these two types of features, θ reveals the quality of a point and r reveals its quantity. Since two points in a trajectory with different lengths (r) may appear to be independent, if they had equal angles (θ), actually they are identical in nature because θ is a qualitative property and r is a quantitative property.
2.4 Statistical features
As mentioned in the previous section, θ and r values of all points were obtained for each trajectory in the state space. At present, the statistical properties including mean, mode and variance were calculated for θ and r values of each trajectory. Ultimately, 12 features were created that were named according to Table 1.
These simple statistical properties can show us phase space differences between ASD and NC groups. Totally, r indices represent the longitudinal changes of points in the phase space and θ indices characterize the transverse changes of points in the phase space. For example, in relation to θ features, the mode can show the angle of the major points of the phase space relative to the horizon and whether this value changes under the disease or not. The variance of the theta demonstrates the scatter of data points with respect to the mean values.
2.5 Classification
After determining the input features, SVM classifier was used to classify autism and normal data using 12 features extracted from two channels. SVM [32] is a supervised machine learning algorithm that models directly the decision boundary, and this boundary is specified by the support vectors. When a linear decision boundary cannot separate data from different classes, SVM loses its function. Therefore, it maps data to a more robust feature space, containing nonlinear features. So, the data again become separable with a hyper-plane using this mapping.
In these situations, kernel functions are used. We used the radial basis function (RBF) kernel function in this paper. And SVM has been run 50 times and the highest average results have been announced. For validating the model constructed with the abovementioned features, K-fold cross-validation was used. At each run, this method randomly divides all samples into k sections of equal size, with a subset of k parts used for testing and the rest for the train. This process is repeated k times. The size of training and test data are presented in Table 2. In this table, the left number represents the number of samples and right number represents the features."
In this study, we set k = 5. To evaluate the overall performance of the classifier, accuracy, specificity, and sensitivity were calculated according to the following equations.
where TP is identified as true positive; TN as true negative; FP as false positive and FN as false negative.
3 Results
If we divide Fig. 3 into four parts by the coordinates (0, 0), the accumulation of points in the delayed phase space (L = 4) for the NC sample is more likely to occur in the first quarter. While points accumulation in the ASD sample is in the third quarter. In general, the delayed phase space of the NC attractor is larger and wider. Before data classification, the Kruskal–Wallis and multiple comparison tests were used to find the significance level of the extracted features. The test compares each feature between two groups of NC and ASD to investigate the significance level. Figure (5a) shows the graph of changes in the statistical features of "r" and Fig. (5b) shows the graphs of changes in the statistical features of "θ" in both groups.
In this article, significance values of features "\(R_{3}\)", "\(R_{6}\)", "\(T_{4}\)", "\(T_{6}\)" were less than 0.001. As shown in Fig. (5a), the mean value of the NC group was higher in features \(R_{3}\) and \(R_{6}\) than in the ASD group and was lower in the other features. And in Fig. (5b), the largest mean difference was between the NC and ASD groups in features \(T_{4}\) and \(T_{6}\). The classification results are reported in Table 3. The results showed the classification performances based on the 60 s windowing were better than those of the 15 s and 30 s. In addition, the highest average accuracy of 81.96% was obtained utilizing the two-channel information, and 78.68% for a single channel of C4.

Graph of changes in statistical features. Mean and standard deviation of the statistical features, including mean, mode and variance in the two brain channels, i.e., C3 and C4. a r, and b θ. Note: The red line is belonged to the ASD group and the blue line is belonged to the normal group. Using multiple comparison test, significantly different features have been identified with asterisk. “*” means that significances between the two groups are less than 0.001 (p < 0.001)
4 Discussion
We designed a system that classifies two groups of normal and autism using two brain channels. For this purpose, for the first time, we used polar-based lagged state-space indices. This simple method is fast and based on brain signal dynamics. In addition, it maintains low computational costs. To characterize these features, we used statistical indices of mean, mode, and variance. Finally, we formulated the diagnostic algorithm with a conventional and popular SVM classifier.
Table 4 compares the results of various studies in the field of NC and ASD classification, in terms of numbers of EEG channels, features, and classifiers.
As it can be observed, the data investigated in the studies [14, 33, 34] are relatively in older ages. It should be considered diagnosis is simpler at an older age and classification would be done easier. On the other hand, if the disorder is diagnosed after a certain age, it does not have a favorable outcome in the process of remission and treatment, and it is ideal to be diagnosed at a very early age to provide a suitable treatment for these children [18].
Using nonlinear and holistic methods are more preferred for examining a complex and chaotic system such as the brain. Most of the papers [14, 15, 17, 33] have employed a combination of linear and nonlinear features, that the calculation of these nonlinear methods is complex and time-consuming, like visibility graph method used in the Bajestani et al. article [18]. Since in this study, the features were extracted from the state space, the calculations are simpler and shorter. Also, the number of analyzed data in this study was more than that of the other studies [14, 16, 31, 33]. Consequently, it can be concluded that the results are more generalizable. In addition, in most similar articles, at least 14 EEG channels have been investigated, whereas in this paper by using only two EEG channels (C3 and C4), superior accuracy, sensitivity, and specificity in classification’s performances have been obtained. It is notable the results of this research are superior to the results obtained by the same data in the previous experiment [18].
Former studies have shown symptoms of the disorder appear in many areas of the brain. Consequently, a more considerable number of channels may provide more comprehensive brain changes. However, one of the problems is the difficulty of recording all the brain channels from autistic children. Therefore, it is desirable to provide a more accurate algorithm to diagnose the disease with fewer brain channels, and thus lower financial and time costs. Reducing the number of brain channels to two channels and simultaneously increasing the performance of the classification, confirm the superiority of our proposed approach to pave the way for designing an online diagnosis system.
5 Conclusion
Diagnosis of ASD at an early age before clinical-behavioral observations is important to initiate treatment as soon as possible. In this study, in spite of a limited number of EEG channels (C3, C4), it was attempted to present a method that in addition to simplicity and incredible speed of computation, could distinguish between two groups of NC and ASD with high accuracy. r and θ polar features were extracted from the lagged state space. Additionally, significant differences between the features were revealed using the Kruskal–Wallis test. The results showed that using the window length of the 60 s, the accuracy of the SVM classifier was 82% for two-channel (C3, C4), and 80.3% for a single-channel EEG (C4). Due to the simplicity and high speed, the proposed scheme can be used in online applications.
In this study, we investigated the EEG of the groups in the rest condition. Future works should carefully appraise the effect of visual stimulation on the EEG signals of the autistic children. Since in this study, two-channel EEG data previously recorded in [18] were used, we could not assess the role of electrode selection. Therefore, to improve the accuracy of classification, it is recommended to carefully evaluate the performance of the proposed algorithm on the most appropriate location of brain electrodes. Given that in almost all articles, NC groups have been compared to ASD, it can be useful if we investigate classification between ASD and non-ASD cases. Therefore, it is suggested that the performance of the framework in discrimination between ASD and non-ASD is examined in the future.
References
Sparks, B. F., et al.: Brain structural abnormalities in young children with autism spectrum disorder. Neurology 59(2), 184–192 (2002)
Coben, R.: Connectivity-guided neurofeedback for autistic spectrum disorder. Biofeedback 35(4), 131–135 (2007)
Wöhr, M., Scattoni, M.L.: Neurobiology of autism (preface). Behav. Brain Res. 251, 1–4 (2013)
Christensen, D.L., et al.: Prevalence and characteristics of autism spectrum disorder among children aged 8 years—autism and developmental disabilities monitoring network, 11 Sites, United States, 2012. MMWR. Surveill. Summ. 65(13), 1–23 (2018)
Landa, R.J.: Diagnosis of autism spectrum disorders in the first 3 years of life. Nat. Clin. Pract. Neurol. 4(3), 138–147 (2008)
Gray, D.E.: Lay conceptions of autism: parents’ Explanatory Models. Med. Anthropol. 16(1–4), 99–118 (1994)
Park, H.R., Lee, J.M., Moon, H.E., Lee, D.S., Kim, B-N., Kim, J., Kim, D.G., Paek, S.H.: A short review on the current understanding of autism spectrum disorders, Exp. Neurobiol. 25(1), 1–13 (2016). https://doi.org/10.5607/en.2016.25.1.1
Hadjikhani, N., et al.: Activation of the fusiform gyrus when individuals with autism spectrum disorder view faces. Neuroimage 22(3), 1141–1150 (2004)
Liston, C., Cohen, M.M., Teslovich, T., Levenson, D., Casey, B.J.: Atypical prefrontal connectivity in attention-deficit/hyperactivity disorder: pathway to disease or pathological end point? Biol. Psychiatry 69(12), 1168–1177 (2011)
Schumann, C.M., Barnes, C.C., Lord, C., Courchesne, E.: Amygdala Enlargement in Toddlers with Autism Related to Severity of Social and Communication Impairments. Biol. Psychiatry. 66(10), 942–949 (2009)
Dziobek, I., Bahnemann, M., Convit, A., Heekeren, H.R.: The role of the fusiform-amygdala system in the pathophysiology of Autism. Arch. Gen. Psychiatry 67(4), 397–405 (2010)
Sadeghi, M., Khosrowabadi, R., Bakouie, F., Mahdavi, H., Eslahchi, C., Pouretemad, H.: Screening of autism based on task-free fMRI using graph theoretical approach. Psychiatry Res. Neuroimag. 263, 48–56 (2017)
Kazeminejad, A., Sotero, R.C.: Topological properties of resting-state FMRI functional networks improve machine learning-based autism classification. Front. Neurosci. 13, 1–10 (2019)
Ibrahim, S., Djemal, R., Alsuwailem, A.: Electroencephalography (EEG) signal processing for epilepsy and autism spectrum disorder diagnosis. Biocybern. Biomed. Eng. 38(1), 16–26 (2018)
Kang, J., Zhou, T., Han, J., Li, X.: EEG-based multi-feature fusion assessment for autism. J. Clin. Neurosci. 56, 101–107 (2018)
Heunis, T., et al.: Recurrence quantification analysis of resting state EEG signals in autism spectrum disorder - a systematic methodological exploration of technical and demographic confounders in the search for biomarkers. BMC Med. 16(1), 1–17 (2018)
Askari, E., Setarehdan, S.K., Sheikhani, A., Mohammadi, M.R., Teshnehlab, M.: Modeling the connections of brain regions in children with autism using cellular neural networks and electroencephalography analysis. Artif. Intell. Med. 89(40–50), 2018 (2017)
Bajestani, G.S., Behrooz, M., Khani, A.G., Nouri-Baygi, M., Mollaei, A.: Diagnosis of autism spectrum disorder based on complex network features. Comput. Methods Programs Biomed. 177, 277–283 (2019)
Rodríguez-Bermúdez. G and García-Laencina, P.J.: Analysis of EEG signals using nonlinear dynamics and chaos: A review. Appl. Math. Inf. Sci., 9(5), 2309–2321 (2015)
Stam, C.J.: Chaos, continuous EEG, and cognitive mechanisms: a future for clinical neurophysiology. Am. J. Electroneurodiagnostic Technol. 43(4), 211–227 (2018)
Kim, H.S., Eykholt, R., Salas, J.D.: Nonlinear dynamics, delay times, and embedding windows. Phys. D Nonlinear Phenom. 127(1–2), 48–60 (1999)
Goshvarpour, A., Goshvarpour, A.: Rahati S 2011 analysis of Lagged poincaré plots in heart rate signals during meditation. Digit. Sig. Process 21(2), 208–214 (2011)
Goshvarpour, A., Goshvarpour, A.: A novel approach for EEG electrode selection in automated emotion recognition based on lagged Poincare’s indices and sLORETA. Cogn Comput (2019). https://doi.org/10.1007/s12559-019-09699-z
Goshvarpour, A., Goshvarpour, A.: Poincaré’s section analysis for PPG-based automatic emotion recognition. Chaos Soliton Fract 114, 400–407 (2018)
Goshvarpour, A., Goshvarpour, A.: Asymmetry of lagged Poincare plot in heart rate signals during meditation. J. Tradit. Complement Med. (2020). https://doi.org/10.1016/j.jtcme.2020.01.002
Goshvarpour, A., Goshvarpour, A.: Do meditators and non-meditators have different HRV dynamics? Cogn Syst Res 54, 21–36 (2019)
Goshvarpour, A., Goshvarpour, A.: Gender and age classification using a new Poincare section-based feature set of ECG. SIViP 13(3), 531–539 (2019)
Goshvarpour, A., Goshvarpour, A.: The potential of photoplethysmogram and galvanic skin response in emotion recognition using nonlinear features. Australas Phys. Eng. S (2019). https://doi.org/10.1007/s13246-019-00825-7
Goshvarpour, A., Abbasi, A., Goshvarpour, A.: Fusion of heart rate variability and pulse rate variability for emotion recognition using lagged poincare plots. Australas Phys Eng S 40(3), 617–629 (2017)
Goshvarpour, A., Abbasi, A., Goshvarpour, A.: Indices from lagged poincare plots of heart rate variability: an efficient nonlinear tool for emotion discrimination. Australas Phys Eng S 40(2), 277–287 (2017)
Goshvarpour, A., Goshvarpour, A.: Poincare indices for analyzing meditative heart rate signals. Biomed J 38(3), 229–234 (2015)
Subasi, A., Gursoy, M.I.: EEG signal classification using PCA, ICA, LDA and support vector machines. Expert Syst. Appl. 37(12), 8659–8666 (2010)
Djemal, R., AlSharabi, K., Ibrahim, S., & Alsuwailem, A.: EEG-based computer aided diagnosis of autism spectrum disorder using wavelet, entropy, and ANN. BioMed research international. 9816591 [9 pages], (2017). https://doi.org/10.1155/2017/9816591
Simões, M., et al.: A novel biomarker of compensatory recruitment of face emotional imagery networks in autism spectrum disorder. Front. Neurosci 12, 1–15 (2018)
Chen, M., Fang, Y., Zheng, X.: Phase space reconstruction for improving the classification of single trial EEG. Biomed. Signal Process. Control 11(1), 10–16 (2014)
Fang, Y., Chen, M., Zheng, X.: Extracting features from phase space of EEG signals in brain-computer interfaces. Neurocomputing 151(P3), 1477–1485 (2015)
Acknowledgements
The authors would like to extend their sincere thanks to Dr. Ghasem Sadeghi Bajestani for sharing data.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors”.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest".
Ethical approval
The files have been registered under the Ethics License #500685/95 from the Medical Sciences University of Mashhad [18].”
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ghoreishi, N., Goshvarpour, A., Zare-Molekabad, S. et al. Classification of autistic children using polar-based lagged state-space indices of EEG signals. SIViP 15, 1805–1812 (2021). https://doi.org/10.1007/s11760-021-01928-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-021-01928-z