
Abstract
This paper proposes an optimized least mean absolute third (OPLMAT) algorithm to improve the capability of the adaptive filtering algorithm against Gaussian and non-Gaussian noises when the unknown system is a time-varying parameter system under low signal–noise rate. The optimal step size of the OPLMAT is obtained based on minimizing the mean-square deviation at the current time. In addition, the mean convergence and steady-state error of the OPLMAT algorithm are derived theoretically, and the computational complexity of OPLMAT is analyzed. Furthermore, the simulation experimental results of system identification presented illustrate the principle and efficiency of the OPLMAT algorithm. Simulation results demonstrate that the proposed algorithm performs much better than the LMAT and NLMAT algorithms.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Adaptive filter (AF) algorithms are frequently employed in equalization, active noise control, acoustic echo cancelation, biomedical engineering and many other fields [1]. The step size is a critical parameter in addressing the issue of obtaining either fast convergence rate or low excess mean-square error. Although a large step size responds quickly to plant changes, it may lead to a large MSD and even cause loss of convergence, while a small step size may degrade the tracking speed of the AF algorithm. To address this issue, a relatively large step size can be selected during the initial convergence of an AF algorithm and then a small step size used as the algorithm approaches its steady state. Selection of the step size should balance low steady-state error with a fast convergence rate. So the variable step size method attracts considerable attentions from scholars. There are various methods that can be adopted to get the step size formula. Shin et al. [2] made use of a special function to update step size. Kwong and Johnston [3] proposed a method based on the input data to obtain the step size. Ang [4] presented an approach based on squared instantaneous estimation errors to update the step size. step size parameter was selected in [5] such that the sum of the squares of the measured estimation errors was minimized at the current instant in time. Liu et al. [6] and Benesty et al. [7] utilized the various nonparametric variance estimates and proposed the nonparametric variable step size NLMS algorithms. In [8], Huang and Lee presented a method based on the mean-square error and the estimated system noise power to obtain the step size. Many of these algorithms were developed in a system identification context, and the reference signal is considered as the output of a time-invariant system, usually corrupted by additive noise. However, in practical engineering applications, the system is often non-stationary. Moreover, it makes more sense to minimize the system misalignment, instead of the classical error-based cost function. The approximating optimal step size is selected in [9] such that the MSD was minimized. Lee and Park [10] made use of mean-square deviation to update the step size of the APA algorithm. Zhi et al. [11] proposed the optimal step size of the PAP algorithm. Ciochină et al. [12] proposed an optimized NLMS algorithm which takes advantage of the joint optimization problem with both the normalized step size and regularization parameters. More recently, research has focused on AF algorithms based on high-order error power (HOEP) conditions [13,14,15]. Among HOEP algorithms, the LMAT algorithm can achieve the most robust against the unknown noise of several different probability densities [16]. For example, in [17, 18], impulsive noise is modeled by an \(\alpha \)-stable random process. Besides, some algorithms for impulsive noise environments are introduced. The LMAT algorithm is based on the minimization of the mean of the absolute error value of the third power. The error function is a perfect convex function with respect to filter coefficients, so there is no local minimum for the LMAT algorithm. The feature of unknown system, the characteristics of the additive noise, SNR and the input excitation govern the effectiveness of the LMAT-type algorithm. However, in practical engineering applications, the measurement noise of an unknown system is non-Gaussian, and the system is often non-stationary with low SNR. So on the basis of work presented in [9,10,11,12, 16], the optimal step size rather than approximating optimal step size is selected in this paper such that the MSD at the current in time is minimum. The purpose of the OPLMAT algorithm is to deal with the Gaussian, uniform, Rayleigh and exponential noise distributions, which is different from the literature [17, 18]. The mean convergence and MSD of the OPLMAT algorithm are also derived. The computational complexity of the OPLMAT algorithm is analyzed theoretically. Finally, we have carried out four system identification simulation experiments to illustrate significant superiorities of the OPLMAT algorithm over the LMAT and NLMAT algorithms.
The main contributions of this work are as follows: (a) an OPLMAT algorithm based on minimizing the MSD at the current in time; (b) the step size of the OPLMAT algorithm can achieve minimum steady-state error; (c) the stability of the proposed algorithm is studied; (d) the steady-state errors are derived from both Gaussian and non-Gaussian noises; and (e) the obtained results may also have some potential value in practical applications.
Briefly, this paper is organized as follows. The proposed OPLMAT algorithm is introduced in Sect. 2. The performance of the OPLMAT algorithm is studied in Sect. 3. The numerical simulations are carried out in Sect. 4, and conclusions are presented in Sect. 5.
2 Proposed OPLMAT algorithm
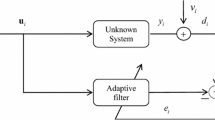
The coefficient vector of the unknown system is defined as \(\mathbf{W}_\mathrm{opt} =[w_0 ,w_1 ,\ldots ,w_{L-1} ]^{\mathrm{T}}\). L is the filter length. \(\mathbf{X}(n)=[x(n),x(n+1),\ldots ,x(n+L-1)]^{\mathrm{T}}\) denotes the input data vector of the unknown system at times instant n, and d(n) denotes the observed output signals, respectively.
where \(\xi (n)\) is a stationary additive noise with zero mean and variance of \(\sigma _\xi ^2\). In addition, \(\xi (n)\) is assumed to be uncorrelated with any other signal. \(\mathbf{X}(n)\) is also stationary with zero mean, a variance of \(\sigma _{x}^2\), and \(\mathbf{X}(n)\) is Gaussian with a definite positive autocorrelation matrix.
The cost function used for obtaining the OPLMAT algorithm is given by
where
The corresponding filter output is
Assuming
So
The updated recursion of coefficients vectors can be derived as Eq. (7):
In Eq. (7), \(\hbox {sgn}\left( {e(n)} \right) \) denotes the sign function of the variable e(n) [13].
The following assumptions are used in the subsequent analysis [15, 19].
Assumption A1
\(\mathbf{W}(n)\) is independent of \(\mathbf{X}(n)\).
Assumption A2
the error sequence e(n) conditioned on the weight vector \(\mathbf{V}(n)\) is a zero mean and Gaussian.
Based on Assumption A2, the distribution function of \(Y=e^{2}(n)\) is shown as Eq. (9).
Based on Eq. (9), the probability density function of \(Y=e^{2}(n)\) is shown as Eq. (10).
So
where \(\mathbf{R}_{xx} =\hbox {E}\left[ {\mathbf{X}(n)\mathbf{X}^{\mathrm{T}}(n)} \right] \) and \(\mathbf{R}_{xx} =\sigma _{x}^2 \mathbf{I}\). \(\mathbf{I}\) denotes the identity matrix of proper dimension.
Ultimately, it is easy to show that the mean behavior of the weight vector converge to the optimal weight vector \(\mathbf{W}_\mathrm{opt}\) if \(\mu (n)\) is bounded by:
where \(\lambda _{\mathrm{max}}\) represents the maximum eigenvalue of the regressor covariance matrix \(\mathbf{R}_{xx}\).
As seen from Eq. (11), we will get \(\hbox {E}\left[ {\mathbf{V}(\infty )} \right] \) when \(n\rightarrow \infty \).
Now we will derive the optimal \(\mu (n)\).
Assuming \(\hbox {tr}\left( {\mathbf{R}_{xx}}\right) \) is the trace of the \(\mathbf{R}_{xx}\) and when \(L\gg 1\), then \(\hbox {tr}\left( {\mathbf{R}_{xx}}\right) =L\sigma _x^2\) [7].
Taking the statistical expectation of both sides with (14), Eq. (15) can be obtained.
Based on Eqs. (9), (10) and Eqs. (11), (16) can be obtained.
Based on Eq. (6),
Combining Assumption A1–Assumption A2 with Eq. (17), we get Eq. (18).
Substituting Eqs. (16) and (18) into Eq. (15), we get Eq. (19).
Substituting Eq. (20) into Eq. (19), we obtain Eq. (21).
The MSD at times instant n is defined as \(\hbox {MSD}\left( n \right) =\hbox {E}\left[ {\left\| {\mathbf{V}\left( n \right) } \right\| ^{2}} \right] \). So Eq. (21) can be derived as Eq. (22).
When the algorithm tends to be stable, \(\hbox {MSD}(n)\) is very small. So, Eq. (22) can be rewritten as Eq. (23) when discarding \(\hbox {MSD}^{2}(n)\).
where
In the real practical world, \(\sigma _e^2(n)\) and \(\sigma _x^2 (n)\) are unknown; however, we can estimate \(\sigma _e^2(n)\) and \(\sigma _x^2(n)\) by using Eq. (26) [8].
where \(\mathbf{p}(n)=\hbox {E}\left[ {e(n)\mathbf{X}(n)} \right] \), \(\rho \) is a small positive number to guarantee that the denominator of Eq. (26) remains finite when \(\sigma _{x}^2 (n)=0\).
Although in Eq. (26), \(\mathbf{p}(n)\) is also unknown, we can estimate this parameter by using Eq. (27).
Based on NPVSS-NLMS algorithm [7], we can get \(( {1-\frac{1}{2L}})\le \chi <1\).
The result from Eq. (23) illustrates a “separation” between the convergence and misadjustment components. Therefore, the term \(f\left( {L,\mu (n),\sigma _x^2 ,\sigma _{e} ,\sigma _\xi ^2 } \right) \) influences the convergence rate of the algorithm. It can be noticed that the fastest convergence mode is obtained when the function of Eq. (24) reaches its minimum.
The stability condition can be found by imposing \(\left| {f\left( {L,\mu (n),\sigma _x^2 ,\sigma _{e} ,\sigma _\xi ^2 } \right) } \right| <1\) which leads to Eq. (29).
There are two important issues to be considered: (1) in the context of system identification, it is reasonable to follow a minimization problem in terms of the system misalignment and (2) we have main parameters \(\mu (n)\) which influences the overall performance of the OPLMAT algorithm.
Thus, based on Eq. (23),
Substituting Eqs. (23), (24) and (25) into Eq. (30), the optimal step size is then given by
Using Eq. (31) in Eq. (23), followed by several straight forward computations, it results in
Denoting \(\lim \limits _{n\rightarrow \infty } \hbox {MSD}\left( n \right) =\hbox {MSD}\left( \infty \right) \) and developing Eq. (32), we obtain Eq. (33).
Based on Eq. (33), we know \(\hbox {MSD}\left( \infty \right) =0\). It means that our aforementioned step size adjusting mechanism can achieve zero steady-state mean-square deviation. For a Gaussian desired signal, \(\hbox {E}\left[ {\xi ^{4}(n)} \right] =3\sigma _\xi ^4\) [15]. For a uniform desired signal, \(\hbox {E}\left[ {\xi ^{4}(n)} \right] ={9\sigma _\xi ^4 }/5\) [15]. For a Rayleigh desired signal, \(\hbox {E}\left[ {\xi ^{4}(n)} \right] =8\sigma _\xi ^4\) [20]. For an exponential desired signal, \(\hbox {E}\left[ {\xi ^{4}(n)} \right] =3\sigma _\xi ^4\) [20].
The excess mean-square error (EMSE) at times instant n is given by Eq. (34).
Finally, the steady-state \(\hbox {EMSE}_{\mathrm{EMSE}\left( \infty \right) }\) is given by using Eqs. (33) and (34).
A summary of the procedure for the OPLMAT algorithm based on the analysis presented above is given in Table 1.
3 Computational complexity
The updated step size and \(\sigma _{e}\) formulas are added to the OPLMAT algorithm compared to the LMAT algorithm, meaning that the computational complexity of OPLMAT algorithm is greater than that of the LMAT algorithm. Furthermore, unlike the NLMAT algorithm, there is also no recursion required to compute \(\mathbf{X}^{\mathrm{T}}(n)\mathbf{X}(n)\) in OPLMAT algorithm. The computational complexity of the OPLMAT algorithm is slightly greater than that of the LMAT algorithm. However, the computational complexity of the OPLMAT algorithm is less than the complexity of the NLMAT algorithm when L is large. From Table 2, the OPLMAT algorithm has a considerable complexity advantage over NLMAT when \(L > 4\). Besides, the NLMAT algorithm also needs to estimate \(\sigma _{e}\). So compared to the NLMAT algorithm, there is no recursion to compute \(\mathbf{X}^{\mathrm{T}}(n)\mathbf{X}(n)\) and there are no comparisons. For convenience, the computational complexity of the OPLMAT algorithm and that of other existing LMAT-type algorithms are listed in Table 2.
4 Simulation results
This section presents the results of simulations in the context of system identification using various noise distributions of both stationary and non-stationary systems to illustrate the accuracy of the OPLMAT algorithm. The length of the unknown coefficient vector \(\mathbf{W}_\mathrm{opt}\) is L. The input signal x(n) is a Gaussian white noise with zero mean and \(\sigma _{x}^2 =1\). The correlated input signal y(n) is calculated by using \(y(n)=0.5y(n-1)+{x}(n)\). In all of our experiments, the coefficient vectors are initialized as zero vectors. Four different noise distributions (Gaussian, uniform, Rayleigh and exponential) are used in the experiments. \(\hbox {MSD}\left( n \right) =10\log _{10} \left( {\left\| {\mathbf{W}\left( n \right) -\mathbf{W}_\mathrm{opt}} \right\| _2^2 } \right) \) is used to measure the performance of algorithms. In addition, MSD error equals the absolute of simulation values and theory value (Eq. 23). The results are obtained via Monte Carlo simulation using 20 independent run sets and an iteration number of 5000. The values of steady-state error of the three algorithms are recognized in Table 3.
Experiment 1
The system noise is Gaussian white noise, and the input signal is x(n) with SNR \(=\) 3 dB. A time-varying system is modeled, and its coefficients are varied from a random walk process defined by \(\mathbf{W}_\mathrm{opt} (n)=\mathbf{W}_\mathrm{opt} +{\varvec{\upsilon }}(n)\), where \({\varvec{\upsilon }}(n)\) is an independent identically distributed (i.i.d.) Gaussian sequence with \(m_v =0\) and \(\sigma _v^2 =0.01\). \(\mathbf{W}_\mathrm{opt} =\left[ {0.8,0.2,0.7,0.2,0.1} \right] ^{\mathrm{T}}\). The MSD curves for the LMAT (\(\mu =0.02\)), NLMAT (\(\mu =0.02\)), and OPLMAT (\(\chi =0.98)\) algorithms with the uncorrelated input signal are shown in Fig. 1. Figure 2 depicts the MSD error curves for the OPLMAT algorithm. In order to make case of the OPLMAT algorithm more persuasive, we provide a plot elucidating the evolution of \(\mu (n)\) as a function of the number of iterations in Fig. 3.

MSD comparisons under this condition of Experiment 1

Learning curves of MSD error under this condition of Experiment 1

Evolution of \(\mu (n)\) as a function of iteration number under the condition of Experiment 1
Experiment 2
The system noise is a uniformly distributed noise over the interval (−3, 3) and the input signal is correlated input signal y(n) with SNR \(=\,-\)5 dB. A time-unvarying system is modeled, and its coefficients vector of the unknown system is \(\mathbf{W}_\mathrm{opt} =\left[ {0.8,0.2,0.7,0.2,0.1} \right] ^{\mathrm{T}}\). The MSD curves for the LMAT (\(\mu =0.05\)), NLMAT (\(\mu =0.05\)), and OPLMAT (\(\chi =0.98)\) algorithms with the uncorrelated input signal are shown in Fig. 4. Figure 5 shows the MSD error curves for the OPLMAT algorithm. In order to make case of the OPLMAT algorithm more persuasive, we provide a plot describing the evolution of \(\mu (n)\) as a function of the number of iterations in Fig. 6.

MSD comparisons under this condition of Experiment 2

Learning curves of MSD error under this condition of Experiment 2

Evolution of \(\mu (n)\) as a function of iteration number under the condition of Experiment 2
Experiment 3
The system noise is a Rayleigh distribution with 3, and the input signal is correlated input signal y(n) with SNR \(=\) 14 dB. A time-varying system is modeled, and its coefficients are varied from a random walk process defined by \(\mathbf{W}_\mathrm{opt} (n)=\mathbf{W}_\mathrm{opt} +{\varvec{\upsilon }}(n)\), where \({\varvec{\upsilon }}(n)\) is an i.i.d. Gaussian sequence with \(m_v =0\) and \(\sigma _v^2 =0.01\). \(\mathbf{W}_\mathrm{opt} =\left[ {0.8,0.2,0.7,0.2,0.1} \right] ^{\mathrm{T}}\). The MSD curves for the LMAT (\(\mu =0.01\)), NLMAT (\(\mu =0.01\)) and OPLMAT (\(\chi =0.98)\) algorithms with the uncorrelated input signal are shown in Fig. 7. Figure 8 plots the MSD error curves for the OPLMAT algorithm. In order to make case of the OPLMAT algorithm more persuasive, we provide a plot showing the evolution of \(\mu (n)\) as a function of the number of iterations in Fig. 9.

MSD comparisons under this condition of Experiment 3

Learning curves of MSD error under this condition of Experiment 3

Evolution of \(\mu (n)\) as a function of iteration number under the condition of Experiment 3
Experiment 4
The system noise is an exponential distribution with 2, and the input signal is correlated input signal y(n) with SNR \(=\) 14 dB. A time-varying system is modeled, and its coefficients are varied from a random walk process defined by \(\mathbf{W}_\mathrm{opt} (n)=\mathbf{W}_\mathrm{opt} +{\varvec{\upsilon }}(n)\), where \({\varvec{\upsilon }}(n)\) is an i.i.d. Gaussian sequence with \(m_v =0\) and \(\sigma _v^2 =0.01\). \(\mathbf{W}_\mathrm{opt} =\left[ {0.8,0.2,0.7,0.2,0.1} \right] ^{\mathrm{T}}\). The MSD curves for the LMAT (\(\mu =0.005\)), NLMAT (\(\mu =0.005\)) and OPLMAT (\(\chi =0.98)\) algorithms with the uncorrelated input signal are shown in Fig. 10. Figure 11 shows the MSD error curves for the OPLMAT algorithm. In order to make case of the OPLMAT algorithm more persuasive, we provide a plot showing the evolution of \(\mu (n)\) as a function of the number of iterations in Fig. 12.
Figures 1, 4, 7 and 10 show the OPLMAT algorithm has a smaller misalignment than the LMAT and NLMAT algorithms in steady-state stage. The reason for this observation is small \(\mu (n)\) in steady-state stage. From Fig. 1 and Table 3, the improvement due to implementation of the LMAT and NLMAT algorithms can nearly approach 14.32 and 10.62 dB, respectively. Thus, compared to the LMAT and NLMAT algorithms, the OPLMAT algorithm can perform better in identifying the unknown coefficients under this condition. From the other experimental results, the same conclusion can be obtained.

MSD comparisons under this condition of Experiment 4

Learning curves of MSD error under this condition of Experiment 4

Evolution of \(\mu (n)\) as a function of iteration number under the condition of Experiment 4
Figures 2, 5, 8 and 11 show the MSD error. We observe an excellent match between predictions provided by our newly designed algorithm and results given by Monte Carlo simulations.
From Figs. 3, 6, 9 and 12, we know that \(\mu (n)\) has a large value in the initial stage, which results in a high convergence rate as expected. After the algorithm converges on the point where a low misalignment is desired, \(\mu (n)\) automatically decreases.
5 Conclusions
In the context of system identification using the LMAT-type algorithm, this paper described a way to derive the optimal variable step size of the LMAT based on mean-square deviation analysis. The OPLMAT algorithm is developed in this paper in order to addresses both stationary and non-stationary unknown systems in the presence of several types of noise under low SNR. The optimal step size leads the proposed algorithm to achieve the lowest steady-state error theoretically. The step size can be updated based on the number of iteration. In addition, the computational complexity of this algorithm is less when \(L>4\). Simulation results showed that the proposed algorithm performed better than the LMAT and NLMAT algorithms. The analytical result corroborated the simulations.
References
Sayed, A.H.: Adaptive Filters. Wiley, Hoboken (2008)
Shin, H.C., Sayed, A.H., Song, W.J.: Variable step size NLMS and affine projection algorithms. IEEE Signal Process. Lett. 11(2), 132–135 (2004)
Kwong, R.H., Johnston, E.W.: A variable step size LMS algorithm. IEEE Trans. Signal Process. 40(7), 1633–1642 (1992)
Ang, W.P., Farhang-Boroujeny, B.: A new class of gradient adaptive step size LMS algorithms. IEEE Trans. Signal Process. 49(4), 805–810 (2001)
Wang, P., Kam, P.-Y.: An automatic step size adjustment algorithm for LMS adaptive filters and an application to channel estimation. Phys. Commun. 5, 280–286 (2012)
Liu, J.C., Yu, X., Li, H.R.: A nonparametric variable step size NLMS algorithm for transversal filters. Appl. Math. Comput. 217(17), 7365–7371 (2011)
Benesty, J., Rey, H., Vega, L.R., et al.: A nonparametric VSSNLMS algorithm. IEEE Signal Process. Lett. 13(10), 581–584 (2006)
Huang, H.-C., Lee, J.: A new variable step size NLMS algorithm and its performance analysis. IEEE Trans. Signal Process. 60(4), 2055–2060 (2012)
Zhao, S., Jones, D.L., Khoo, S., et al.: New variable step sizes minimizing mean-square deviation for the LMS-type algorithms. Circuits Syst. Signal Process. 33(7), 2251–2265 (2014)
Lee, C.H., Park, P.G.: Optimal step size affine projection algorithm. IEEE Signal Process. Lett. 19(7), 431–434 (2012)
Zhi, Y.F., Shang, F.F., Zhang, J., et al.: Optimal step size of pseudo affine projection algorithm. Appl. Math. Comput. 273, 82–88 (2016)
Ciochină, S., Paleologu, C., Benesty, J.: An optimized NLMS algorithm for system identification. Signal Process. 118, 115–121 (2016)
Lee, Y.H., Mok, J.D., Kim, S.D., Cho, S.H.: Performance of least mean absolute third (LMAT) adaptive algorithm in various noise environments. IET Electron. Lett. 34(2), 241–243 (1998)
Walach, E., Widrow, B.: The least mean fourth (LMF) adaptive algorithm and its family. IEEE Trans. Inf. Theory 30(2), 275–283 (1984)
Eweda, E., Bershad, N.J.: Stochastic analysis of a stable normalized least mean fourth algorithm for adaptive noise canceling with a white Gaussian reference. IEEE Trans. Signal Process. 60(12), 6235–6244 (2012)
Zhao, H., Yu, Y., Gao, S., et al.: A new normalized LMAT algorithm and its performance analysis. Signal Process. 105(12), 399–409 (2014)
Arikan, O., Cetin, A.E., Erzin, E.: Adaptive filtering for non-Gaussian stable processes. IEEE Signal Process. Lett. 2(11), 1400–1403 (1995)
Aydin, G., Arikan, O., Cetin, A.E.: Robust adaptive filtering algorithms for \(\alpha \)-stable random processes. IEEE Trans. Circuits Syst. II Analog Digit. Signal Process. 46(2), 198–202 (1999)
Price, R.: A useful theorem for nonlinear devices having Gaussian inputs. IRE Trans. Inf. Theory 4(2), 69–72 (1958)
Spiegel, M.R.: Mathematical Handbook of Formulas and Tables. McGraw-Hill, New York (2012)
Acknowledgements
This work was supported by National Natural Science Foundation of China (61074120, 61673310) and the State Key Laboratory of Intelligent Control and Decision of Complex Systems of Beijing Institute of Technology.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Guan, S., Li, Z. Optimal step size of least mean absolute third algorithm. SIViP 11, 1105–1113 (2017). https://doi.org/10.1007/s11760-017-1064-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-017-1064-0