
Abstract
We consider model-based clustering methods for continuous, correlated data that account for external information available in the presence of mixed-type fixed covariates by proposing the MoEClust suite of models. These models allow different subsets of covariates to influence the component weights and/or component densities by modelling the parameters of the mixture as functions of the covariates. A familiar range of constrained eigen-decomposition parameterisations of the component covariance matrices are also accommodated. This paper thus addresses the equivalent aims of including covariates in Gaussian parsimonious clustering models and incorporating parsimonious covariance structures into all special cases of the Gaussian mixture of experts framework. The MoEClust models demonstrate significant improvement from both perspectives in applications to both univariate and multivariate data sets. Novel extensions to include a uniform noise component for capturing outliers and to address initialisation of the EM algorithm, model selection, and the visualisation of results are also proposed.
Similar content being viewed by others

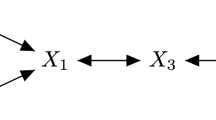
Avoid common mistakes on your manuscript.
1 Introduction
In many analyses using the standard mixture model framework, a clustering method is typically implemented on the outcome variables only. Reference is not made to the associated covariates until the structure of the produced clustering is investigated in light of the information present in the covariates. Therefore, interpretations of the values of the model parameters within each component are guided by covariates that are not actually used in the construction of the clusters. It is desirable to have covariates incorporated into the clustering process and not only into the interpretation of the clustering structure and model parameters, thereby making them endogenous rather than exogenous to the clustering model. This both exploits clustering capabilities and provides richer insight into the type of observation which characterises each cluster.
When each observation consists of a response variable \(\mathbf {y}_i\) on which the clustering is based and covariates \(\mathbf {x}_i\) there are, broadly speaking, two main approaches in the literature to having covariates guide construction of the clusters, neatly summarised by Lamont et al. (2016) and compared in Ingrassia et al. (2012). Letting \(\mathbf {z}_i\) denote the latent cluster membership indicator vector, where \(z_{ig}=1\) if observation i belongs to cluster g and \(z_{ig}=0\) otherwise, the first approach assumes that \(\mathbf {z}_i\) affects the distribution of \(\mathbf {x}_i\). In probabilistic terms, this means to replace the actual group-specific conditional distribution \(f\big (\mathbf {y}_i \,|\,\mathbf {x}_i, z_{ig} = 1\big )\mathrm {P}\big (z_{ig} = 1\big )\) with \(f\big (\mathbf {y}_i | \mathbf {x}_i, z_{ig} = 1\big )f\big (\mathbf {x}_i \,|\,z_{ig} = 1\big )\mathrm {P}\big (z_{ig} = 1\big )\). The name ‘cluster-weighted model’ (CWM) is frequently given to this approach, e.g. Dang et al. (2017) and Ingrassia et al. (2015); the latter provides a recent extension allowing for mixed-type covariates, with a further generalisation presented in Punzo and Ingrassia (2016). Noting the use of the alternative term ‘mixtures of regressions with random covariates’ to describe CWMs (e.g. Hennig 2000) provides opportunity to clarify that the remainder of this paper focuses on the second approach, with fixed potentially mixed-type covariates affecting cluster membership via \(f\big (\mathbf {y}_i \,|\,\mathbf {x}_i, z_{ig} = 1\big )\mathrm {P}\big (z_{ig} = 1 \,|\,\mathbf {x}_i\big )\).
This is achieved using the mixture of experts (MoE) paradigm (Dayton and Macready 1988; Jacobs et al. 1991) in which the parameters of the mixture are modelled as functions of fixed, potentially mixed-type covariates. We present, for finite mixtures of multivariate, continuous, correlated responses, a unifying framework combining all of the special cases of the Gaussian MoE model with the flexibility afforded by the covariance constraints in the Gaussian parsimonious clustering model (GPCM) family (Banfield and Raftery 1993; Celeux and Govaert 1995). This has, to date, been lacking for all but the mixture of regressions and the mixture of regressions with concomitant variables where the same covariates enter both parts of the model (Dang and McNicholas 2015).
Parsimony is obtained in GPCMs by imposing constraints on the elements of an eigen-decomposition of the component covariance matrices. For MoE models, reducing the number of covariance parameters in this manner can help offset the number of regression parameters introduced by covariates, which is particularly advantageous when model selection is conducted using information criteria with penalty terms involving parameter counts. The main contribution of this paper is the development of a framework combining GPCM constraints with all of the special cases of the Gaussian MoE framework whereby different subsets of covariates can enter either, neither, or both the component densities and component weights. We also consider the special cases of the MoE framework for univariate response data with equal and unequal variance across components. Thus, this paper addresses the aim of incorporating potentially mixed-type covariates into the GPCM family and the equivalent aim of bringing GPCM covariance constraints into the Gaussian MoE framework, by proposing the MoEClust model family. The name MoEClust comes from the interest in employing MoE models chiefly for clustering purposes. From both perspectives, MoEClust models show significant improvement in applications to both univariate and multivariate response data.
Other novel contributions include the addition of a noise component for capturing outlying observations, and proposed solutions to initialising the EM algorithm sensibly, addressing the issue of model selection, and a means for visualising the results of MoEClust models. We also expand the number of special cases in the MoE framework from four to six, by considering more parsimonious counterparts to the standard mixture model and the mixture of regressions by constraining the mixing proportions. In addition, a software implementation for the full suite of MoEClust models is provided by the associated R package MoEClust (Murphy and Murphy 2019), which is available from www.r-project.org (R Core Team 2019), with which all results were obtained. The syntax of the popular mclust package (Scrucca et al. 2016) is closely mimicked, with formula interfaces for specifying covariates in the gating and/or expert networks.
The structure of the paper is as follows. For both Gaussian mixtures of experts and MoEClust models, the modelling frameworks and inferential procedures are described, respectively, in Sects. 2 and 3. Section 3.3 describes the addition of a noise component for capturing outliers. Section 4 discusses proposals for addressing some practical issues affecting performance, namely the initialisation of the EM algorithm used to fit the models (Sect. 4.1), and issues around model selection (Sect. 4.2). The performance of the proposed models is illustrated in Sect. 5 with applications to univariate response CO2 emissions data (Sect. 5.1) and multivariate response data from the Australian Institute of Sports (Sect. 5.2). Finally, the paper concludes with a brief discussion in Sect. 6, with some additional results deferred to the Appendices.
2 Modelling
This section builds up the MoEClust models by first describing the mixture of experts (MoE) modelling framework in Sect. 2.1—elaborating on the special cases of the MoE model in Sect. 2.1.1—and then extending to the family of MoEClust models comprising Gaussian mixture of experts models with parsimonious covariance structures from the GPCM family in Sects. 2.2 and 2.3. Finally, a brief review of existing models and software is given in Sect. 2.4.
2.1 Mixtures of experts
The mixture of experts model (Dayton and Macready 1988; Jacobs et al. 1991) extends the mixture model used to cluster response data \(\mathbf {y}_i\) by allowing the parameters of the model for observation i to depend on covariates \(\mathbf {x}_i\). An independent sample of response/outcome variables of dimension p, denoted by \(\mathbf {Y}=\left( \mathbf {y}_1,\ldots ,\mathbf {y}_n\right) \), is modelled by a G-component finite mixture model where the model parameters depend on the associated covariate inputs \(\mathbf {X}=\left( \mathbf {x}_1,\ldots ,\mathbf {x}_n\right) \) of dimension d. The MoE model is often referred to as a conditional mixture model (Bishop 2006) because, given the set of covariates \(\mathbf {x}_i\), the distribution of the response variable \(\mathbf {y}_i\) is a finite mixture model:
Each component is modelled by a probability density function \(f\big (\mathbf {y}_i\,|\,\varvec{\theta }_g\left( \mathbf {x}_i\right) \big )\) with component-specific parameters \(\varvec{\theta }_g\left( \mathbf {x}_i\right) \) and mixing proportions \(\tau _g\left( \mathbf {x}_i\right) \); the latter are only allowed to depend on covariates when \(G\ge 2\). As usual, \(\tau _g\left( \mathbf {x}_i\right) > 0\) and \(\sum _{g=1}^{G}\tau _g\left( \mathbf {x}_i\right) =1\).
The MoE framework facilitates flexible modelling. While the response variable \(\mathbf {y}_i\) is modelled via a finite mixture, model parameters are modelled as functions of related covariates \(\mathbf {x}_i\) from the context under study. Both the mixing proportions and the parameters of component densities can depend on covariates. The terminology used to describe MoE models in the machine learning literature often refers to the component densities \(f\big (\mathbf {y}_i\,|\,\varvec{\theta }_g\left( \mathbf {x}_i\right) \big )\) as ‘experts’ or the ‘expert network’, and to the mixing proportions \(\tau _g\left( \mathbf {x}_i\right) \) as ‘gates’ or the ‘gating network’, hence the nomenclature mixture of experts. Given that covariates can be continuous and/or categorical with multiple levels, we let \(d + 1\) denote the number of columns in the corresponding design matrices, accounting also for the intercept term, in contrast to the number of covariates r.
In the original formulation of the MoE model for continuous data (Jacobs et al. 1991), the mixing proportions (gating network) are modeled using multinomial logistic regression (MLR), though this need not strictly be the case; Geweke and Keane (2007) impose a multinomial probit structure here instead. The mixture components (expert networks) are generalised linear models (GLM; McCullagh and Nelder 1983). Thus:
for some link function \(\psi \left( \cdot \right) \), with a collection of parameters in the component densities (comprising a \(\left( d + 1\right) \times p\) matrix of expert network regression parameters \(\hat{\varvec{\gamma }}_g\) and the \(p\times p\) component covariance matrix \(\widehat{\varvec{\Sigma }}_g\)), a \(\left( d + 1\right) \)-dimensional vector of regression parameters \(\smash {\hat{\varvec{\beta }}}_g\) in the gates, and \(\tilde{\mathbf {x}}_i = \left( 1, \mathbf {x}_i\right) \). Note that expert network covariates influence only the component means, and not the component covariance matrices. Henceforth, we restrict our attention to continuous outcome variables as per the GPCM family. Therefore, component densities are assumed to be the p-dimensional multivariate Gaussian \(\phi \left( \cdot \right) \), and the link function \(\psi \left( \cdot \right) \) is simply the identity, such that covariates are linearly related to the response variables, i.e.:

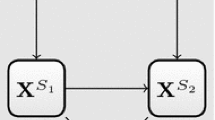
The graphical model representation of the mixture of experts models. The differences between the special cases are due to the presence or absence of edges between the covariates \(\mathbf {X}\) and the latent variable \(\mathbf {Z}\) and/or response variable \(\mathbf {Y}\). Note that different subsets of the covariates in \(\mathbf {X}\) can enter these two different parts of the full MoE model in (d)
2.1.1 The MoE family of models
It is possible that some, none, or all model parameters depend on the covariates. This leads to the four special cases of the Gaussian MoE framework shown in Fig. 1, with the following interpretations, due to Gormley and Murphy (2011):
-
(a)
in the mixture model the distribution of \(\mathbf {y}_i\) depends on the latent cluster membership variable \(\mathbf {z}_i\), the distribution of \(\mathbf {z}_i\) is independent of the covariates \(\mathbf {x}_i\), and \(\mathbf {y}_i\) is independent of \(\mathbf {x}_i\) conditional on \(\mathbf {z}_i\): \(f\big (\mathbf {y}_i\big ) = \sum _{g=1}^{G}\tau _g \phi \big (\mathbf {y}_i\,|\,\varvec{\theta }_g=\big \{\varvec{\mu }_g,\varvec{\Sigma }_g\big \}\big ).\)
-
(b)
in the expert network MoE model the distribution of \(\mathbf {y}_i\) depends on the covariates \(\mathbf {x}_i\) and the latent cluster membership variable \(\mathbf {z}_i\), and the distribution of \(\mathbf {z}_i\) is independent of \(\mathbf {x}_i\): \(f\big (\mathbf {y}_i\,|\,\mathbf {x}_i\big ) = \sum _{g=1}^{G}\tau _g \phi \big (\mathbf {y}_i\,|\,\varvec{\theta }_g\big (\mathbf {x}_i\big ) = \big \{\tilde{\mathbf {x}}_i \varvec{\gamma }_g, \varvec{\Sigma }_g\big \}\big ).\)
-
(c)
in the gating network MoE model the distribution of \(\mathbf {y}_i\) depends on the latent cluster membership variable \(\mathbf {z}_i\), \(\mathbf {z}_i\) depends on the covariates \(\mathbf {x}_i\), and \(\mathbf {y}_i\) is independent of \(\mathbf {x}_i\) conditional on \(\mathbf {z}_i\): \(f\big (\mathbf {y}_i\,|\,\mathbf {x}_i\big ) = \sum _{g=1}^{G}\tau _g\big (\mathbf {x}_i\big ) \phi \big (\mathbf {y}_i\,|\,\varvec{\theta }_g=\big \{\varvec{\mu }_g,\varvec{\Sigma }_g\big \}\big ).\)
-
(d)
in the full MoE model, given by (2), the distribution of \(\mathbf {y}_i\) depends on both the covariates \(\mathbf {x}_i\) and on the latent cluster membership variable \(\mathbf {z}_i\), and the distribution of the latent variable \(\mathbf {z}_i\) depends in turn on the covariates \(\mathbf {x}_i\).
For models (c) and (d), \(\mathbf {z}_i\) has a multinomial distribution with a single trial and probabilities equal to \(\tau _g\left( \mathbf {x}_i\right) \). The full MoE model thus has the following latent variable representation: \(\big (\mathbf {y}_i\,|\,\mathbf {x}_i,z_{ig} = 1\big )\sim \phi \big (\mathbf {y}_i\,|\,\varvec{\theta }_g\left( \mathbf {x}_i\right) = \big \{ \tilde{\mathbf {x}}_i \varvec{\gamma }_g, \varvec{\Sigma }_g\big \}\big ),\mathrm {P}\left( z_{ig} = 1\,|\,\mathbf {x}_i\right) = \tau _g\left( \mathbf {x}_i\right) \).
The MoE family can be expanded further, from four to six special cases, by considering the models in (a) and (b), under which covariates do not enter the gating network, by constraining the mixing proportions to be equal, i.e. \(\tau _g=\nicefrac {1}{G}\,\,\forall \,\,g\). This leads, respectively, to the equal mixing proportion mixture model and equal mixing proportion expert network MoE model. Such models are more parsimonious than their counterparts with unconstrained \(\varvec{\tau }\), as they require estimation of \(G-1\) fewer parameters. Note that the size of a cluster is proportional to \(\tau _g\), which is distinct from its volume (Celeux and Govaert 1995). Thus, situations where \(\tau _{ig}=\tau _g\left( \mathbf {x}_i\right) \), \(\tau _{ig}=\tau _g\), or \(\tau _{ig}=\nicefrac {1}{G}\) can all be accomodated. The six special cases of this MoE framework can be applied to both univariate and multivariate response data.
It is worth noting that CWMs most fundamentally differ from MoE models in their handling of the mixing proportions \(\tau _g\) and in how the joint density \(f\left( \mathbf {x}_i,z_{ig} = 1\right) \) is treated, either as \(\mathrm {P}\left( z_{ig} = 1\,|\,\mathbf {x}_i\right) =\tau _g\left( \mathbf {x}_i\right) \) (MoE) or \(f\left( \mathbf {x}_i\,|\,z_{ig} = 1\right) \mathrm {P}\left( z_{ig} = 1\right) \) (CWM). In other words, the direction of the edge between \(\mathbf {X}\) and \(\mathbf {Z}\) in the full MoE model in Fig. 1d is reversed under CWMs (Ingrassia et al. 2012). By virtue of modelling the distribution of the covariates, CWMs are also inherently less parsimonious. The same covariate(s) can enter both parts of full MoE models, in principle. Such models can provide a useful estimation of the conditional density of the outcome given the covariates, but the interpretation of the clustering model and the effect of the covariates becomes more difficult in this case. Conversely, allowing different covariates enter different parts of the model further differentiates MoE models from CWMs. It is common to distinguish among the overall set of covariates between concomitant gating network variables and explanatory expert network variables. Thus, for clarity, \(\smash {\mathbf {x}_i^{\left( G\right) }}\) and \(\smash {\mathbf {x}_i^{\left( E\right) }}\) will henceforth refer, respectively, to the possibly overlapping subsets of gating and expert network covariates, such that \(\smash {\mathbf {x}_i = \big \{\mathbf {x}_i^{(G)}\,\cup \,\mathbf {x}_i^{(E)}\big \}}\), with the dimensions of the associated design matrices given by \(d_G + 1\) and \(d_E + 1\). Higher order terms, transformations, and interaction effects between covariates are also allowed in both networks.
2.2 Gaussian parsimonious clustering models
Parsimony has been considered extensively in the model-based clustering literature. In particular, the volume of work on Gaussian and/or parsimonious mixtures has increased hugely since the work of Banfield and Raftery (1993) and Celeux and Govaert (1995). These works introduced the family of GPCMs, which are implemented in the popular R package mclust (Scrucca et al. 2016). The influence of GPCMs is clear on many other works which obtain parsimony in the component covariance matrices; e.g., using constrained factor-analytic structures (McNicholas and Murphy 2008), the multivariate t-distribution and associated tEIGEN family (Andrews and McNicholas 2012), and the multivariate contaminated normal distribution (Punzo and McNicholas 2016).
Parsimonious covariance matrix parameterisations are obtained in GPCMs by means of imposing constraints on the components of an eigen-decomposition of the form \(\varvec{\Sigma }_g=\lambda _g\mathbf {D}_g\mathbf {A}_g\mathbf {D}_g^\top \), where \(\lambda _g\) is a scalar controlling the volume, \(\mathbf {A}_g\) is a diagonal matrix, with entries proportional to the eigenvalues of \(\varvec{\Sigma }_g\) with \(\det (\mathbf {A}_g) = 1\), specifying the shape of the density contours, and \(\mathbf {D}_g\) is \(p\times p\) orthogonal matrix, the columns of which are the eigenvectors of \(\varvec{\Sigma }_g\), governing the corresponding ellipsoid’s orientation. Imposing constraints reduces the number of free covariance parameters from \(Gp\left( p+1\right) {/}2\) in the unconstrained (VVV) model. This is desirable when p is even moderately large. Thus, GPCMs allow for intermediate component covariance matrices lying between homoscedasticity and heteroscedasticity. Table 1 summarises the geometric characteristics of the GPCM constraints, which are then shown in Fig. 2.
Note for models with names ending in I that the number of parameters is linear in the data dimension p. Thus, the diagonal models are especially parsimonious and useful in \(n\le p\) settings. While there are 2 variance parameterisations for mixtures of univariate response data, and 14 covariance parameterisations for mixtures of multivariate response data, considering the equal mixing proportion constraint doubles the number of models available in each of these cases.
2.3 The MoEClust family of models
Interest lies in bringing parsimonious covariance structures to Gaussian MoE models:
where \(\varvec{\Sigma }_g\) can follow any of the GPCM constraints outlined in Table 1. It is equivalent to say that interest lies in incorporating covariate information into the GPCM model family. Using the covariance constraints, combined with the six special cases of the MoE model described in Sect. 2.1.1, yields the MoEClust family of models, which are capable of dealing with correlated responses and offering additional parsimony in the component densities compared to current implementations of Gaussian MoE models, by virtue of allowing the size, volume, shape, and/or orientation to be equal or unequal across components. For MoE models, every continuous covariate added to the gating and expert networks introduces \(G-1\) and Gp additional regression parameters, respectively. Parsimonious MoEClust models allow the increase in the number of regression parameters to be offset by the reduction in the number of covariance parameters. This can be advantageous when model selection is conducted using information criteria which include penalty terms based on parameter counts (see Sect. 4.2).
2.4 Existing models and software
A number of tools for fitting MoE models are available in the R programming environment (R Core Team 2019). These include flexmix (Grün and Leisch 2007, 2008), mixtools (Benaglia et al. 2009), and others. Tools for fitting GPCMs without covariates include mclust (Scrucca et al. 2016) and Rmixmod (Lebret et al. 2015).
The flexmix package (Grün and Leisch 2007, 2008) can accommodate the full range of MoE models outlined in Sect. 2.1.1, excluding those for which \(\varvec{\tau }\) is constrained to be equal, in the case of univariate \(\mathbf {y}_i\), though only models with unequal variance can be fitted. The user can specify the form of the GLM and covariates (if any) to be used in the gating and expert networks, for which the package has a similar interface to the (glm) functions within R. In the case of a multivariate continuous response, there is functionality for multivariate Gaussian component distributions though only for models without expert network covariates. Furthermore, only the VVI and VVV constraints and models with unequal mixing proportions or gating concomitants are facilitated.
For univariate data, the mixtools package (Benaglia et al. 2009) can accommodate the expert network MoE model with equal or unequal variance; it can also accommodate the full MoE model, though only for \(G=2\), with unequal variance, and with the restriction that all covariates enter both part of the model. The package allows for nonparametric estimation of the functional form for the mixing proportions (gating networks) and the component densities (expert networks), so it offers further flexibility beyond flexmix in these cases. However, the multivariate models in mixtools use the local independence assumption, so it does not directly offer the facility to model multivariate Gaussian component densities with non-diagonal covariance. Furthermore, multivariate response models in mixtools do not yet incorporate covariates in any way, and the equal mixing proportions constraint is not facilitated in any way either.
The mclust package (Scrucca et al. 2016) and Rmixmod package (Lebret et al. 2015) can accommodate the full range of covariance constraints in Table 1, and are thus examples of existing software which can fit GPCMs, but only using the standard finite mixture model (model (a) in Fig. 1) or the equal mixing proportions mixture model; i.e., they do not facilitate dependency on covariates in any way.

Ellipses of isodensity for each of the 14 parsimonious eigen-decomposition covariance parameterisations for multivariate data in GPCMs, with three components in two dimensions
Another important contribution in this area is by Dang and McNicholas (2015). This work introduces eigen-decomposition parsimony to the MoE framework, though only for the expert network MoE model and the full MoE model. However, for the full MoE model, all covariates are assumed to enter into both parts of the model. Thus, the MoEclust model family completes the work of Dang and McNicholas (2015) by considering all six special cases of the MoE framework, whereby different subsets of covariates can enter either, neither, or both the component densities and/or component weights, as well as models with equal mixing proportions. In addition, our unifying MoEClust framework also incorporates such parsimonious models for univariate response data.
Finally, it should be noted that eigen-decomposition parsimony has been introduced to the alternative CWM framework, in which all covariates enter the same part of the model, by Dang et al. (2017), for the multivariate Gaussian distributions of both the response variables and the covariates, assuming only continuous covariates; see also Punzo and Ingrassia (2015) for eigen-decomposition parsimony applied to the covariates only. The flexCWM package (Mazza et al. 2018) allows GPCM covariance structures in the distribution of the continuous covariates only, though only univariate responses are accommodated. It also allows, simultaneously or otherwise, covariates of other types, as well as omitting the distribution for the covariates entirely, leading to non-parsimonious mixtures of regressions, with or without concomitant variables.
3 Model fitting via EM
To estimate the parameters of MoEClust models, we focus on maximum likelihood estimation using the EM algorithm (Dempster et al. 1977). This is outlined first for MoE models in Sect. 3.1 and then extended to MoEClust models in Sect. 3.2. Model fitting details are described chiefly for the full MoE model only, for simplicity. A simple trick involving the residuals of the weighted linear regressions in the expert network assists fitting when using GPCM constraints. A uniform noise component to capture outlying non-Gaussian observations is added in Sect. 3.3. When gating concomitants are present, the noise component is treated in two different ways.
3.1 Fitting MoE models
For the full mixture of experts model, the likelihood is of the form:
where \(\tau _g\big (\mathbf {x}_i^{\left( G\right) }\big )\) and \(\varvec{\theta }_g\big (\mathbf {x}_i^{\left( E\right) }\big )\) are as defined by (1). The data are augmented by imputing the latent cluster membership indicator \(\smash {\mathbf {z}_i=\left( z_{i1},\ldots ,z_{iG}\right) ^\top }\). Thus, the conditional distribution of \(\big (\mathbf {y}_i,\mathbf {z}_i\,|\,\mathbf {x}_i\big )\) is of the form:
Hence, the complete data likelihood is of the form:
and the complete data log-likelihood has the form:
The iterative EM algorithm for MoE models follows in a similar manner to that for standard mixture models. It consists of an E-step (expectation) which replaces for each observation the missing data \(\mathbf {z}_i\) with their expected values \(\hat{\mathbf {z}}_i\), followed by a M-step (maximisation), which maximises the expected complete data log-likelihood, computed with the estimates \(\smash {\hat{\mathbf {Z}} = \left( \hat{\mathbf {z}}_1,\ldots ,\hat{\mathbf {z}}_n\right) }\), to provide estimates of the component weight parameters \(\smash {\hat{\tau }_g\big (\mathbf {x}_i^{\left( G\right) }\big )}\) and the component parameters \(\smash {\hat{\varvec{\theta }}_g\big (\mathbf {x}_i^{\left( E\right) }\big )}\). Aitken’s acceleration criterion is used to assess convergence of the non-decreasing sequence of log-likelihood estimates (Böhning et al. 1994). Parameter estimates produced on convergence achieve at least a local maximum of the likelihood function. Upon convergence, cluster memberships are estimated via the maximum a posteriori (MAP) classification. The E-step involves computing:
where \(\smash {\big \{\hat{\varvec{\beta }}^{\left( t\right) },\hat{\varvec{\gamma }}^{\left( t\right) },\widehat{\varvec{\Sigma }}^{\left( t\right) }\big \}}\) are the estimates of the parameters in the gating and expert networks on the t-th iteration of the EM algorithm.
For the M-step, we notice that the complete data log-likelihood in (3) can be considered as a separation into the portion due to the gating network and the portion due to the expert network. Thus, the expectated complete data log-likelihood (4) can be maximised separately under the EM framework:
The first term is of the same form as MLR, here written with component 1 as the baseline reference level, for identifiability reasons:
Thus, methods for fitting such models can be used to maximise this term and estimate the parameters in the gating network. The second term is of the same form as fitting G separate weighted multivariate linear regressions, and thus methods for fitting such models can be used to estimate the expert network parameters. Note that these are multivariate in the sense of a multivariate outcome \(\mathbf {y}_i\); the associated design matrix having \(d_E + 1\) columns means these regressions are possibly also multivariate in terms of the explanatory variables. Thus, fitting MoE models is straightforward in principle.
3.2 Fitting MoEClust models
Maximising the second term in (4), corresponding to the expert network, gives rise to the following expression:
When the same set of regressors are used for each dependent variable, as is always the case for MoEClust models, or when \(\varvec{\Sigma }_g\) is diagonal, it can be shown that \(\varvec{\gamma }_g\) does not depend on \(\varvec{\Sigma }_g\), much like a Seemingly Unrelated Regression model (SUR; Zellner 1962). We first estimate \(\hat{\varvec{\gamma }}_g\) and then \(\widehat{\varvec{\Sigma }}_g\). Fitting G separate multivariate regressions (weighted by \(\hat{z}_{ig}\)), yields G sets of \(n \times p\) SUR residuals \(\smash {\hat{\mathbf {r}}_{ig} = \mathbf {y}_i -\tilde{\mathbf {x}}_i^{\left( E\right) } \varvec{\gamma }_g}\), which, crucially, satisfy \(\sum _{i=1}^{n}\hat{z}_{ig}\hat{\mathbf {r}}_{ig}=0\). Thus, maximising (5) is equivalent to minimising:
which is of the same form as the criterion used in the M-step of a standard Gaussian finite mixture model with component covariance matrices \(\widehat{\varvec{\Sigma }}\), component means equal to zero, and new augmented data set \(\hat{\mathbf {R}}\). Thus, when estimating the component covariance matrices via (6), the same M-step function as used within mclust can be applied to augmented data, constructed so that each observation is represented as follows:
-
1.
Stack the G sets of SUR residuals into the \(\left( n \times G\right) \times p\) matrix \(\hat{\mathbf {R}}\):

-
2.
Create the \(\left( n \times G\right) \times G\) block-diagonal matrix \(\hat{\varvec{\zeta }}\) from the columns of \(\hat{\mathbf {Z}}\):



Structuring the model in this manner allows GPCM covariance structures to be easily imposed on Gaussian MoE models with gating and/or expert network covariates, hence the nomenclature MoEClust. In the end, the M-step involves three sub-steps, each using the current estimate of \(\hat{\mathbf {Z}}\): i) estimating the gating network parameters \(\smash {\hat{\varvec{\beta }}}_g\) and hence the component weights \(\smash {\hat{\tau }_g\big (\mathbf {x}_i^{\left( G\right) }\big )}\) via MLR, ii) estimating the expert network parameters \(\hat{\varvec{\gamma }}_g\) and hence the component-specific means via weighted multivariate multiple linear regression, and iii) estimating the constrained component covariance matrices \(\widehat{\varvec{\Sigma }}_g\) using the augmented data set comprised of SUR residuals, as outlined above.
In the absence of covariates in the gating and/or expert networks, under the special cases outlined in Sect. 2.1.1, their respective contribution to (4) is maximised as per the corresponding term in a standard GPCM. In other words, the gating and expert networks, without covariates, can be seen as regressions with only an intercept term. Thus, the augmented data structure is not required when there are no expert covariates and the formula for estimating \(\varvec{\tau }\) in the absence of concomitant variables is \(\hat{\tau }_g = n^{-1}\sum _{i=1}^n \hat{z}_{ig}\), rather than (1). As described in Sect. 2.1.1, it is sometimes useful to expand the model family further by considering more parsimonious alternatives to the special cases of models (a) and (b) in Fig. 1, where gating network concomitants are omitted, by constraining the mixing proportions to be equal and fixed, i.e. \(\tau _g=\nicefrac {1}{G}\,\,\forall \,\,g\). Similarly, removing the corresponding regression intercept(s) from the part(s) of the model where covariates enter can yield further parsimony in appropriate settings.
3.3 Adding a noise component
For models with expert network covariates, and/or when the volume and/or shape differ across components, the mixture likelihood is unbounded. We restrict our interest only to solutions for which the log-likelihood at convergence is finite. As per the eps argument to the mclustR package’s emControl function (Scrucca et al. 2016), we monitor the conditioning of the covariances and add a tolerance parameter (set to the relative machine precision, i.e. 2.220446e-16 on IEEE compliant machines) to the M-step estimation of the component covariances to control termination of the EM algorithm on the basis of small eigenvalues. For models with unconstrained \(\varvec{\Sigma }_g\), each cluster must contain at least \(p + 1\) units to avoid computational singularity. Thus, in practice, such spurious solutions with infinite likelihood occur especially for higher G values, whereby either solutions with empty components reduce to ones with fewer components, or uninteresting solutions with degenerate components containing too few units or even singletons are found. Sensible initial allocations (see Sect. 4.1) and/or the equal mixing proportion constraint, which help avoid empty or otherwise poorly populated clusters, can help to alleviate this problem. García-Escudero et al. (2018) offer an excellent discussion of the notions of spurious solutions and degenerate components.
Further extending MoEClust models via the inclusion of an additional uniform noise component can also help in addressing these issues, by capturing outlying observations which do not fit the prevailing pattern of Gaussian clusters and thus would otherwise be assigned to (possibly many) small clusters. In particular, the noise component for encompassing clusters with non-Gaussian distributions is here distributed as a homogeneous spatial Poisson process, as per Banfield and Raftery (1993). Such a noise component can be included regardless of where covariates (if any) enter, and regardless of the GPCM constraints employed. Model-fitting via the EM algorithm is not greatly complicated by the addition of a noise component, though it is required to estimate V, the hypervolume of the region from which the response data have been drawn, or to consider V as an independent tuning parameter as per Hennig and Coretto (2008), especially if \(n\le p\). For univariate responses V is given by the range of \(y_1,\ldots ,y_n\). For multivariate data, V can be estimated by the hypervolume of the convex hull, ellipsoid hull, or smallest hyperrectangle enclosing the data. We focus on the latter method.
For initialisation, a column in which each entry is \(\tau _0\) (the guess of the prior probability that observations are noise) is appended to the starting \(\mathbf {Z}\) matrix, with the other columns corresponding to non-noise components then multiplied by \(1-\tau _0\). The initial \(\tau _0\) should not be too high; it is set to 0.1 here. For models with a noise component and no gating concomitants, the mixing proportions can be, as before, either constrained or unconstrained. In the latter case, we estimate \(\tau _0\) and then constrain the remaining proportions. We add the extension that concomitants, when present, are allowed to affect (7) or not affect (8) the mixing proportion of the noise component. Henceforth, for clarity, we refer to these settings as the gated noise (NG) and non-gated noise (NGN) models, respectively. The NGN model assumes \(\tau _0\) is constant across observations and covariate patterns. It is thus the more parsimonious model; it requires only 1 extra gating network parameter, rather than \(d_G + 1\) under the GN model, relative to models without a noise component, though it is only defined for \(G\ge 2\).
4 Practical issues
In this section, factors affecting the performance of MoEClust models are discussed; namely, the necessity of a good initial partition to prevent the EM algorithm from converging to a suboptimal local maximum (Sect. 4.1), and the necessity of model selection with regard to where and what covariates (if any) enter the model to yield further parsimony by reducing the number of gating and/or expert network regression parameters (Sect. 4.2). Novel strategies for dealing with both issues are proposed.
4.1 EM initialisation
With regards to initialisation of the EM algorithm for \(G>1\) MoEClust models, model-based agglomerative hierarchical clustering and quantile-based clustering have been found suitable for multivariate and univariate data, respectively. Both flexmix and mixtools randomly initialise the allocations, despite the obvious computational drawback of the need to run the EM algorithm from multiple random starting points. However, when explanatory variables \(\smash {\mathbf {x}_i^{\left( E\right) }}\) enter the expert network, it is useful to use them to augment the initialisation strategy with extra steps. Algorithm 1 outlines the proposed initialisation strategy, similar to that of Ning et al. (2008). It takes the initial partition of the data (whether obtained by hierarchical clustering, random initialisation, or some other method) and iteratively reallocates observations in such a way that each subset can be well-modelled by a single expert.
When using a deterministic approach to obtain the starting partition for Algorithm 1, initialisation can be further improved by considering information in the expert network covariates to find a good clustering of the joint distribution of \(\smash {\big (\mathbf {y}_i, \mathbf {x}_i^{\left( E\right) }\big )}\). When \(\smash {\mathbf {x}_i^{\left( E\right) }}\) includes categorical or ordinal covariates, the model-based approach to clustering mixed-type data of McParland and Gormley (2016) is employed at this stage.


Initial 2-component partitions on univariate data clearly arising from a mixture of two linear regressions, obtained using a agglomerative hierarchical clustering, b random allocation, and c Algorithm 1 applied to the initialisation in (b), demonstrating the improvement achieved by incorporating expert network covariates into the initialisation strategy. Allocations are distinguished using black points and red triangles. Corresponding fitted lines are also shown
If at any stage a level is dropped from a categorical variable in subset \(\varvec{\Omega }_g\) the variable itself is dropped from the corresponding regressor for the observations with missing levels. Convergence of the algorithm is guaranteed and the additional computational burden incurred is negligible. By using the Mahalanobis distance metric (Mahalanobis 1936), each observation is assigned to the cluster corresponding to the Gaussian ellipsoid to which it is closest. This has the added advantage of potentially speeding up the running of the EM algorithm. The estimates of \(\eta _g\big (\varvec{\gamma }_g,\cdot \big )\) at convergence are used as starting values for the expert network. The gating network is initialised by considering the partition itself at convergence as a discrete approximation of the gates.
Figure 3 illustrates the necessity of this procedure using a toy data set, with a single continuous covariate and a univariate response clearly arising from a mixture of two linear regressions, which otherwise would not be discerned without including the covariate in the initialisation routine via Algorithm 1. A further demonstration of the utility of this strategy is shown in “Appendix B”.
Our initialisation strategy has the same limitation that the result may represent a suboptimal local maximum. However, the problem is transferred from the difficult task of initialising the EM algorithm to initialising Algorithm 1. Thus, it is feasible to repeat the algorithm with many different partitions and choose the best result to initialise the EM algorithm, since it converges very quickly, requires much less computational effort than the EM itself, and generally reduces the number of required EM iterations.
4.2 Model selection
Whether a variable should be considered as a covariate or part of the response is usually clear from the context of the data being clustered. However, within the suite of MoE models outlined in Sect. 2.1.1, it is natural to question which covariates, if any, are to be included, and if so in which part(s) of the MoE model. Unless the manner in which covariates enter is guided by the question of interest in the application under study, this is a challenging problem as the space of MoE models is potentially very large once variable selection for the covariates entering the gating and expert networks is considered. Thus, only models where covariates enter all mixture components or all component weights in a linear manner are typically considered in practice in order to restrict the size of the model search space. However, even within this reduced space, there are \(2^r\) models to consider when \(G=1\) and \(2^{2r}\) models to consider otherwise. Thus, the model space increases further if the number of components G is unknown.
Model comparison for the MoEClust family is even more challenging, especially for multivariate response data for which there are potentially 14 different GPCM covariance constraints to consider for models with \(G \ge 2\) and 3 otherwise. When \(p=1\), there are 2 covariance constraints to consider when \(G \ge 2\) and 1 otherwise. Considering constraints on the mixing proportions further increases the model search space. However, model selection can still be implemented in a similar manner to other model-based clustering methods: the Bayesian Information Criterion (BIC; Schwarz 1978) and Integrated Completed Likelihood (ICL; Biernacki et al. 2000) have been shown to give suitable model selection criteria, both for the number of component densities (and thus clusters) required and for selecting covariates to include in the model. The number of free parameters in the penalty term for these criteria of course depends on the included gating and expert network covariates and the GPCM constraints employed.
For MoEClust models involving mixtures of GLMs, stepwise variable selection approaches can be used to find the optimal covariates for inclusion in either the multinomial logistic regression (gating network) or the multivariate weighted linear regression (expert network). Indeed, more parsimony can be achieved using variable selection, as there are a total of \(G\left( d_G + 1\right) + Gp\left( d_E + 1\right) \) intercept and regression coefficients to estimate for a \(G > 1\) full MoE model. However, the selected covariates may only be optimal for the given G and the given set of GPCM covariance matrix constraints. MoEClust models also allow for covariates entering only one part of the model. Thus, the recommend approach is a greedy stepwise search whereby each step could involve adding/removing a component or adding/removing a single covariate, in either the gating or expert network. Backward selection can be particularly cumbersome when r is large. Thus, the recommended forward search algorithm proceeds as follows:

While one could consider changing the GPCM constraints as another potential action in Step 2 of Algorithm 2, our experience suggests that increasing G or adding covariates (especially in the expert network) can radically alter the covariance structure. Thus, we advise changing the GPCM constraints simultaneously and identifying the optimum action by first finding the optimum constraints for each action. While this is more computationally intensive than altering the GPCM constraints as a step in itself, this makes the search less likely to miss optimal models as it traverses the model space. See “Appendix A” for an example of how to conduct such a stepwise search using code from the MoEClustR package (Murphy and Murphy 2019).
In certain special instances, some extra steps can be considered. When there are no gating network concomitants, a choice can be made, for each action, between fitted models with equal or unequal mixing proportions. We distinguish between G-component models without a noise component and models with \(\left( G-1\right) \) Gaussian components plus an additional noise component. Thus, we recommend treating models with a noise component differently, by running a stepwise search for models excluding the possibility of a noise component, running a separate stepwise search starting from a \(G=0\) noise-only model, and ultimately choosing between the optimal models with and without a noise component identified by each search. In the presence of a noise component, one can also fit the GN and NGN models, in (7) and (8) respectively, when evaluating every action involving models with gating network concomitants.
When r is not so prohibitively large as to render an exhaustive search infeasible, Gormley and Murphy (2010) demonstrates how model selection criteria such as the BIC can be employed to choose the appropriate number of components and guide the inclusion of covariates across the six special cases of the MoE model described in Sect. 2.1.1. Adapting this approach to MoEClust models where GPCM constraints must also be chosen requires fixing the covariates to be included in the component weights and densities and finding the G value and GPCM covariance structure which together optimise some criterion. Different fits with different combinations of covariates are then compared according to the same criterion. However, due to the highlighted computational difficulties when r is large, Algorithm 2 remains the recommended approach.
5 Results
The clustering performance of the MoEClust models is illustrated by application to two well-known data sets: univariate CO2 data (Sect. 5.1) and multivariate data from the Australian Institute of Sports (Sect. 5.2). Additional results are provided for each data set in the Appendices. In particular, code examples (“Appendix A”) and details of the initialisation (“Appendix B’) for the CO2 data and results of the stepwise search (“Appendix C”) for the AIS data are given.
Hereafter, any mention of methods for initialising the allocations, when covariates enter the expert network, refers to finding a single initial partition for Algorithm 1. The BIC and the stepwise search strategy outlined in Algorithm 2 were used to find the optimal number of components, choose the covariance type, and select the best subset of covariates, as well as where to put them. Results of exhaustive searches are also provided for demonstrative purposes. All results were obtained using the R package MoEClust (Murphy and Murphy 2019).
5.1 CO2 data
As a univariate example of an application of MoEClust, data on the CO2 emissions of \(n=28\) countries in the year 1996 (Hurn et al. 2003) are clustered, with Gaussian component densities. Studying the relationship between CO2 and the covariate Gross National Product (GNP), both measured per capita, is of interest. As consideration is only being given to inclusion/exclusion of a single covariate in the gating and/or expert networks, an exhaustive search is feasible. A range of models (\(G\in \{1,\ldots ,9\}\)) are fitted, with either the equal (E) or unequal variance (V) models from Table 1. Quantile-based clustering of the CO2 values is used to initialise Algorithm 1 when the expert network excludes GNP, otherwise hierarchical clustering of both CO2 and GNP is used.
Table 2 gives BIC and ICL values for the top model under each of the six special cases of the MoE framework. The chosen model had \(G=3\), equal variances (i.e. the E constraint), equal mixing proportions, and GNP in the expert network; thus, this is an equal mixing proportion expert network MoE model. This model maximised both the BIC and ICL criteria, and was also identified by the forward stepwise search described in Algorithm 2, starting from a \(G=1\) model (BIC\(=-163.90\)), adding a component (BIC\(=-163.16\)), adding GNP to the expert network and changing to the V model type (BIC\(=-157.20\)), and finally adding a further component, constraining the mixing proportions, and changing back to the E model type (BIC\(=-155.20\)). Thereafter, neither adding a component nor adding GNP to the gating network improved the BIC. Code to reproduce both the exhaustive and stepwise searches using the MoEClustR package is given in “Appendix A”.
Repeating both the exhaustive and stepwise searches with the addition of a noise component for all models also failed to yield any model with an improved BIC. The fourth row of Table 2 corresponds to a full MoE, with GNP included in both parts of the model; its sub-optimal BIC highlights the benefits of the model selection approach. The parameters of the optimal model are given in Table 3. Its fit is exhibited in Fig. 4, showing the relationship between CO2 and GNP is clustered around three different linear regression lines; one cluster of eight countries with a large slope value and two equally-sized clusters, each with different intercepts but near-zero slope values.

Scatter plots of GNP against CO2 emissions for \(n=28\) countries with three linear regression components from the optimal MoEClust model with equal variances and mixing proportions
The optimal model contains GNP in the expert network and has constraints on the component variances and mixing proportions. These are features of MoEClust, which neither MoE nor GPCM models can fully accommodate. While flexmix and mixtools can fit the sub-optimal expert network MoE model in row four of Table 2, with unequal variances and mixing proportions (which achieves the second highest BIC value), our initialisation strategy ultimately leads to the same or higher BIC estimates. Across 50 random starts, BIC values of \(-157.29\) and \(-157.20\) are achieved using flexmix and mixtools, respectively. Among these random starts, BIC values as low as \(-163.67\) are obtained. However, the MoEClustR package, with Algorithm 1 invoked, achieves a BIC of \(-157.20\) with only a single initial partition. Using MoEClust without this initialisation strategy also yields the lower BIC value of \(-163.67\). A further demonstration of the advantages of our initialisation strategy, using instead the optimal model for the the CO2 data, is provided in “Appendix B”.
5.2 Australian institute of sport (AIS) data
Various physical and hematological (blood) measurements were made on 102 male and 100 female athletes at the Australian Institute of Sport (AIS; Cook and Weisberg 1994). The thirteen variables recorded in the study are detailed in Table 4.
MoEClust models are used to investigate the clustering structure in the athletes’ hematological measurements and investigate how covariates may influence these measurements and the clusters. Cluster allocations are initialised using model-based agglomerative hierarchical clustering. Results of the forward stepwise model search described in Algorithm 2, with all covariates considered for inclusion, are given in “Appendix C”. The optimal model (BIC\(=-4010.14\)) is a 2-component EVEequal mixing proportion expert network MoE model, which thus has clusters of equal size, volume, and orientation, and unequal shape. Notably, the only covariate (Sex), only enters in one part of the model, the expert network. The sub-optimal BIC values for the best model with all covariates in both parts of the model (\(G=1\), EEE, BIC\(=-4234.79\)), which is the same as the best model with all covariates in the expert network only (regardless of \(\varvec{\tau }\) being constrained or not), and all covariates in the gating network only (\(G=2\), VEE, BIC\(=-4092.79\)), highlight the need for the model selection strategy employed. As the optimal model uses the EVE constraints, it has 19 covariance parameters; an otherwise exactly equivalent VVV model, having 30 such parameters, yields a lower BIC of \(-4056.19\), thus showcasing the benefits of the parsimonious covariance constraints. The difference of 11 covariance parameters between these models is exactly one more than the number of regression parameters introduced by the expert network covariate.
Subsequently, and purely for the purposes of comparing certain special cases of interest, an exhaustive search over a range of MoEClust models is conducted, with \(G \in \{1,\ldots ,9\}\). This is rendered feasible by only considering the covariates BMI and Sex; allowing either, neither, or both to enter either, neither, or both of the gating and expert networks. Note that BMI is itself computed using the covariates measuring weight (Wt) and height (Ht). With 3 permissible covariance parameterisations for the single component models, and 14 otherwise, 16 possible combinations of gating and/or expert network covariate settings, and consideration also being given to models with equal mixing proportions, this still requires fitting 2, 252 MoEClust models. However, some spurious solutions were found, particularly for higher values of G, in the sense that models with empty components or degenerate components with few observations reduced to equivalent models with fewer non-empty components (see Sect. 3.3). Table 5 gives the BIC and ICL values of a selection of these fitted models, representing the optimal models for certain special cases of interest.
The inclusion of covariates improves the fit compared to GPCM models. Similarly, using GPCM covariance constraints improves the fit compared to standard Gaussian MoE models. The top three models according to BIC all have 2 components, the EVE covariance constraints, and the covariate Sex in the expert network; they differ only in their treatment of the gating network. Models with equal and unequal mixing proportions, and with BMI as a gating concomitant, have zero, one, and two associated gating network parameters, respectively. The optimal model has equal mixing proportions and was also identified above via Algorithm 2. The full MoE model with BMI in the gating network and Sex in the expert network is an interesting case as it does not fit the framework of Dang and McNicholas (2015), which assumes that when covariates enter the model, they enter in both parts. The best such model has ‘Sex’ in both networks (\(G=2\), EVE) and achieves a BIC of \(-4020.22\) with a corresponding rank of 8.
Up to now, models with a noise component have not yet been considered for the AIS data. Thus, another stepwise search is conducted, including a noise component for all candidate models and starting from a \(G=0\) noise-only model (see “Appendix C”). Consideration was also given to both the GN and NGN model types, in (7) and (8) respectively, where models included gating concomitants, and to models with equal/unequal mixing proportions for the non-noise components for models without gating concomitants. The optimal model thus found has two EEE Gaussian clusters and an additional noise component. The covariate ‘Sex’ enters the expert network (see Table 6). Both ‘SSF’ and ‘Ht’ enter the gating network, though not for the noise component, which has a constant mixing proportion (\(\hat{\tau }_0\approx 0.08\)), as per the NGN model in (8). Thus, the Gaussian clusters have equal volume, shape, and orientation, but unequal size. This model achieves a BIC value of \(-3989.83\), which compares favourably to simply adding a noise component to the previously optimal model from Table 5 (BIC=\(-3992.81\)) and to models with a noise component but no variable selection (or no covariates at all).
The gating network has an intercept of 10.60 and slope coefficients of 0.04 (SSF) and \(-0.08\) (Ht). Thus, higher SSF values increase the probability of belonging to the second Gaussian cluster, to which taller athletes are less likely to belong, and the probability of belonging to the noise component is constant. Though every observation has its own mean parameter in the presence of expert covariates, given by the fitted values of the expert network (shown in Table 6), the means are summarised in Table 7 by the posterior mean of the fitted values of the model according to (9). The noise component is accounted for by \(\bar{\varvec{\mathcal {V}}}\), the p-dimensional centroid of the region used to estimate V.
Given that there exists a binary variable, ‘Sex’, in the expert network for the optimal MoEClust model, there are effectively four Gaussian components plus an additional noise component. By virtue of the EEE constraint on the Gaussian components, all four components and thus both clusters in fact share the same covariance matrix. Components 1 and 2, corresponding to females and males in Cluster 1, share the same covariance matrix but differ according to their means. The same is true for females and males (Components 3 and 4) in Cluster 2. Table 7 gives the means and average gates in terms of both components and clusters, as well as the common \(\widehat{\varvec{\Sigma }}\) matrix.
Though the plots in Fig. 4 are suitable for univariate data with a single continuous expert network covariate, visualising MoEClust results for multivariate data with \(r>1\) mixed-type covariates constitutes a much greater challenge. For the optimal model fitted to the AIS data, the data and clustering results are shown using a generalised pairs plot in Fig. 5. This plot depicts the pairwise relationships between the hematological response variables, the included gating and expert network covariates, and the MAP classification, coloured according to the MAP classification. The marginal distributions of each variable are given along the diagonal. For the hematological response variables, ellipses with axes related to the within-cluster covariances are drawn. For the purposes of visualising Fig. 5, owing to the presence of an expert network covariate in the fitted model, the MVN ellipses in panels depicting two response variables are centered on the posterior mean of the fitted values, as described in (9). The shape and size of the ellipses are also modified for the same reason: they are derived by adding the extra variability in the component means to \(\widehat{\varvec{\Sigma }}_g\). Thus, the depicted ellipses do not conform to the EEE covariance constraints of the optimal model.

Generalised pairs plot for the optimal MoEClust model fit to the AIS data, depicting pairwise relationships between the hematological response variables, the expert network covariate Sex, the gating concomitants SSF and Ht, and the MAP classification. Colours and plotting symbols correspond to the MAP classification: blue circles and red squares for the two Gaussian clusters; grey crosses for the 4 female and 9 male outlying observations assigned to the uniform noise component. Mosaic plots are used to depict two categorical variables, scatter plots are used for panels involving two continuous variables, and a mix of box-plots and jittered strip-plots are used for mixed pairs (colour figure online)
It is clear from Fig. 5 that the variables ‘Hematocrit’ (Hc), ‘Hemoglobin’ (Hg), and ‘plasma ferritin concentration’ (Fe), and the gating network concomitants ‘SSF’ and ‘Ht’, are driving much of the separation between the clusters. On the other hand, the expert network covariate ‘Sex’ is driving separation within the Gaussian clusters. The correspondence between the MAP cluster assignment and the Sex label is notably poor, with an adjusted Rand index (Hubert and Arabie 1985) of just 0.11. This index is higher for models where Sex does not enter the expert network, especially when it instead enters the gating network, though such fitted models all have sub-optimal BIC values (see Table 5). This is because, under the optimal model, the athletes’ size in terms of their SSF and height measurements, rather than their Sex, influences the probability of cluster membership, and athletes are divided by Sex within each cluster rather than the clusters necessarily capturing their Sex.
Indeed, Table 6 implies that males, on average, have elevated levels of all five blood measurements in both Gaussian clusters. However, the magnitude of this effect is more pronounced in Cluster 2, related to athletes with higher average SSF measurements (a proxy for body fat) and lower average height. Interestingly, Fig. 5 also shows that females have higher average SSF measurements and lower average height; this may explain why there are more males than females in Cluster 1, and the reverse in Cluster 2, given the signs of the gating network coefficients for SSF (0.04) and Ht (\(-0.08\)).
6 Discussion
The development of a suite of MoEClust models has been outlined, clearly demonstrating the utility of mixture of experts models for parsimonious model-based clustering where covariates are available. A novel means of visualising such models has also been proposed. The ability of MoEClust models to jointly model the response variable(s) and related covariates provides deeper and more principled insight into the relations between such data in a mixture-model based analysis, and provides a principled method for both creating and explaining the clustering, with reference to information contained in covariates. Their demonstrated use to cluster observations and appropriately capture heterogeneity in cross-sectional data provides only a glimpse of their potential flexibility and utility in a wide range of settings. Indeed, given that general MoE models have been used, under different names, in several fields, including but not limited to statistics (Grün and Leisch 2007, 2008), biology (Wang et al. 1996), econometrics (Wang et al. 1998), marketing (Wedel and Kamakura 2012), and medicine (Thompson et al. 1998), MoEClust models could prove useful in many domains.
Improvement over GPCM models has been introduced by accounting for external information available in the presence of potentially mixed-type covariates. Similarly, improvement over Gaussian mixture of experts models which incorporate fixed covariates has been introduced by allowing GPCM family covariance structures in the component densities. MoEClust models are thus Gaussian parsimonious MoE models where the size, volume, shape, and/or orientation can be equal or unequal across components. MoEClust models have been further extended to accomodate the presence of an additional uniform noise component to capture departures from Gaussianity, in such a way that observations are smoothly classified as belonging to Gaussian clusters or as outliers. In particular, two means of doing so have been proposed for models which include gating concomitants. Due to sensitivity of the final solution obtained by the EM algorithm to the initial values, an iterative reallocation procedure based on the Mahalanobis distance has been proposed to mitigate against convergence to suboptimal local maxima for models with expert network covariates. This initialisation algorithm converges quickly and also speeds up convergence of the EM algorithm itself.
Previous parsimonious Gaussian mixtures of experts (Dang and McNicholas 2015) accommodated only the cases where all covariates enter the expert network MoE model, or the full MoE model with the restriction that all covariates enter both parts of the model. MoEClust constitutes a unifying framework whereby different subsets of covariates can enter either, neither, or both the gating and/or expert networks of Gaussian parsimonious MoE models. Considering the standard mixture model (with no dependence on covariates), or the expert network MoE model, with the equal mixing proportion constraint expands the model family further.
On a cautionary note, care must be exercised in choosing how and where covariates enter when a MoEClust model is used as a clustering tool, as the interpretation of the analysis fundamentally depends on where covariates enter, which of the six special cases of the MoE framework is invoked, and on which GPCM constraints are employed. To this end, a novel greedy forward stepwise search algorithm has been employed for model/variable selection purposes. This strategy has the added advantage of introducing additional parsimony, by potentially reducing the number of regression parameters in the gating and/or expert networks.
Gating network MoEClust models may be of particular interest to users of GPCMs; while concomitants influence the probability of cluster membership, the correspondance thereafter between component densities and clusters has the same interpretation as in standard GPCMs. When covariates enter the component densities, we warn that observations with very different response values can be clustered together, because they are being modelled using the same GLM; similarly, regression distributions with distinct parameters do not necessarily lead to well-separated clusters.
MoEClust models allow the number of parameters introduced by gating and expert network covariates to be offset by a reduction in the number of covariance parameters. This is particularly advantageous when model selection is conducted using the BIC or ICL, which include a penalty term based on the parameter count. Thus, MoEClust models may tend to favour including covariates more than standard Gaussian MoE models would. This is particularly true for explanatory variables in the expert network, which tend to necessitate more regression parameters (Gp) than concomitant variables in the gating network (\(G-1\)) per additional continuous covariate or level of categorical covariates included. Thus, in cases where a MoE model might elect to include a concomitant variable in the gating network, a MoEClust model with fewer covariance parameters may elect to include it as an explanatory expert network variable instead. While this does lead to a better fit, it can complicate interpretation.
Possible directions for future work in this area include investigating the utility of nonparametric estimation of the gating network (Young and Hunter 2010), as well as exploring the use of regularisation penalties in the gating and expert networks to help with variable selection when the number of covariates r is large. Regularisation in another, Bayesian sense, by specifying a prior on the component variances/covariances in the spirit of Fraley and Raftery (2007), and/or component regression parameters, could also prove useful for avoiding spurious solutions due to computational singularity described in Sect. 3.3. MoEClust models could also be developed in the context of hierarchical mixtures of experts (Jordan and Jacobs 1994), and/or extended to the supervised or semi-supervised model-based classification settings, where some or all observations are labelled.
Beyond the family of GPCM constraints, MoEClust models could be extended to avail of parsimonious factor-analytic covariance structures for high-dimensional data (McNicholas and Murphy 2008). These could be incorporated into Gaussian mixture of experts models using residuals in an equivalent fashion to Sect. 3.2 above. Similarly, MoEClust models could benefit from the heavier tails of the multivariate t-distribution, and the robustness to outliers it affords, by considering the associated tEIGEN family of covariance constraints (Andrews and McNicholas 2012). However, our inclusion of a uniform noise component has the advantage of drawing a clearer distinction between observations belonging to clusters or designated as outliers.
References
Andrews JL, McNicholas PD (2012) Model-based clustering, classification, and discriminant analysis via mixtures of multivariate \(t\)-distributions: the \(t\)EIGEN family. Stat Comput 22(5):1021–1029
Banfield J, Raftery AE (1993) Model-based Gaussian and non-Gaussian clustering. Biometrics 49(3):803–821
Benaglia T, Chauveau D, Hunter DR, Young D (2009) mixtools: an R package for analyzing finite mixture models. J Stat Softw 32(6):1–29
Biernacki C, Celeux G, Govaert G (2000) Assessing a mixture model for clustering with the integrated completed likelihood. IEEE Trans Pattern Anal Mach Intell 22(7):719–725
Bishop CM (2006) Pattern recognition and machine learning. Springer, New York
Böhning D, Dietz E, Schaub R, Schlattmann P, Lindsay BG (1994) The distribution of the likelihood ratio for mixtures of densities from the one-parameter exponential family. Ann Inst Stat Math 46(2):373–388
Celeux G, Govaert G (1995) Gaussian parsimonious clustering models. Pattern Recogn 28(5):781–793
Cook RD, Weisberg S (1994) An introduction to regression graphics. Wiley, New York
Dang UJ, McNicholas PD (2015) Families of parsimonious finite mixtures of regression models. In: Morlini I, Minerva T, Vichi M (eds) Advances in statistical models for data analysis: studies in classification. Springer International Publishing, Switzerland, pp 73–84 data analysis, and knowledge organization
Dang UJ, Punzo A, McNicholas PD, Ingrassia S, Browne RP (2017) Multivariate response and parsimony for Gaussian cluster-weighted models. J Classif 34(1):4–34
Dayton CM, Macready GB (1988) Concomitant-variable latent-class models. J Am Stat Assoc 83(401):173–178
Dempster AP, Laird NM, Rubin DB (1977) Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc Ser B 39(1):1–38
Fraley C, Raftery AE (2007) Bayesian regularization for normal mixture estimation and model-based clustering. J Classif 24(2):155–181
García-Escudero LA, Gordaliza A, Greselin F, Ingrassia S, Mayo-Iscar A (2018) Eigenvalues and constraints in mixture modeling: geometric and computational issues. Adv Data Anal Classif 12(2):203–233
Geweke J, Keane M (2007) Smoothly mixing regressions. J Econ 138(1):252–290
Gormley IC, Murphy TB (2010) Clustering ranked preference data using sociodemographic covariates. In S. Hess & A. Daly, editors, Choice modelling: the state-of-the-art and the state-of-practice, chapter 25, pp 543–569. Emerald
Gormley IC, Murphy TB (2011) Mixture of experts modelling with social science applications. In: Mengersen K, Robert C, Titterington DM (eds) Mixtures: estimation and applications, chapter 9. Wiley, New York, pp 101–121
Grün B, Leisch F (2007) Fitting finite mixtures of generalized linear regressions in R. Comput Stat Data Anal 51(11):5247–5252
Grün B, Leisch F (2008) FlexMix version 2: finite mixtures with concomitant variables and varying and constant parameters. J Stat Softw 28(4):1–35
Hennig C (2000) Identifiability of models for clusterwise linear regression. J Classif 17(2):273–296
Hennig C, Coretto P (2008) The noise component in model-based cluster analysis. In: Preisach C, Burkhardt H, Schmidt-Thieme L, Decker R (eds) Data analysis. Springer, Berlin, pp 127–138 machine learning and applications: studies in classification, data analysis, and knowledge organization
Hubert L, Arabie P (1985) Comparing partitions. J Classif 2(1):193–218
Hurn M, Justel A, Robert CP (2003) Estimating mixtures of regressions. J Comput Graph Stat 12(1):55–79
Ingrassia S, Minotti SC, Vittadini G (2012) Local statistical modeling via the cluster-weighted approach with elliptical distributions. J Classif 29(3):363–401
Ingrassia S, Punzo A, Vittadini G, Minotti SC (2015) The generalized linear mixed cluster-weighted model. J Classif 32(1):85–113
Jacobs RA, Jordan MI, Nowlan SJ, Hinton GE (1991) Adaptive mixtures of local experts. Neural Comput 3(1):79–87
Jordan MI, Jacobs RA (1994) Hierarchical mixtures of experts and the EM algorithm. Neural Comput 6(2):181–214
Lamont AE, Vermunt JK, Van Horn ML (2016) Regression mixture models: does modeling the covariance between independent variables and latent classes improve the results? Multivariate Behav Res 51(1):35–52
Lebret R, Iovleff S, Langrognet F, Biernacki C, Celeux G, Govaert G (2015) Rmixmod: the R package of the model-based unsupervised, supervised, and semi-supervised classification mixmod library. J Stat Softw 67(6):1–29
Mahalanobis PC (1936) On the generalised distance in statistics. Proc Natl Inst Sci India 2(1):49–55
Mazza A, Punzo A, Ingrassia S (2018) flexCWM: a flexible framework for cluster-weighted models. J Stat Softw pp 1–27
McCullagh P, Nelder J (1983) Generalized linear models. Chapman and Hall, London
McNicholas PD, Murphy TB (2008) Parsimonious Gaussian mixture models. Stat Comput 18(3):285–296
McParland D, Gormley IC (2016) Model based clustering for mixed data: clustMD. Adv Data Anal Classif 10(2):155–169
Murphy K, Murphy TB (2019) MoEClust: Gaussian parsimonious clustering models with covariates and a noise component. R package version 1.2.3. https://cran.r-project.org/package=MoEClust
Ning H, Hu Y, Huang TS (2008) Efficient initialization of mixtures of experts for human pose estimation. In Proceedings of the international conference on image processing, ICIP 2008, October 12-15, 2008, San Diego, California, pp 2164–2167
Punzo A, Ingrassia S (2015) Parsimonious generalized linear Gaussian cluster-weighted models. In: Morlini I, Minerva T, Vichi M (eds) Advances in statistical models for data analysis: studies in classification. Springer International Publishing, Switzerland, pp 201–209 data analysis, and knowledge organization
Punzo A, Ingrassia S (2016) Clustering bivariate mixed-type data via the cluster-weighted model. Comput Stat 31(3):989–1030
Punzo A, McNicholas PD (2016) Parsimonious mixtures of multivariate contaminated normal distributions. Biom J 58(6):1506–1537
R Core Team. R: a language and environment for statistical computing. Statistical Computing, Vienna, Austria
Schwarz G (1978) Estimating the dimension of a model. Ann Stat 6(2):461–464
Scrucca L, Fop M, Murphy TB, Raftery AE (2016) mclust 5: clustering, classification and density estimation using Gaussian finite mixture models. R J 8(1):289–317
Thompson TJ, Smith PJ, Boyle JP (1998) Finite mixture models with concomitant information: assessing diagnostic criteria for diabetes. J Roy Stat Soc: Ser C 47(3):393–404
Wang P, Puterman ML, Cockburn I, Le N (1996) Mixed Poisson regression models with covariate dependent rates. Biometrics 52(2):381–400
Wang P, Puterman ML, Cockburn I (1998) Analysis of patent data: a mixed-Poisson regression-model approach. J Bus Econ Stat 16(1):27–41
Wedel M, Kamakura WA (2012) Market segmentation: conceptual and methodological foundations. International Series in Quantitative Marketing. Springer, US
Young DS, Hunter DR (2010) Mixtures of regressions with predictor-dependent mixing proportions. Comput Stat Data Anal 54(10):2253–2266
Zellner A (1962) An efficient method of estimating seemingly unrelated regression equations and tests for aggregation bias. J Am Stat Assoc 57(298):348–368
Acknowledgements
This work was supported by the Science Foundation Ireland funded Insight Centre for Data Analytics in University College Dublin under Grant Number SFI/12/RC/2289_P2.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: \(\hbox {CO}_{2}\) data: code examples
Code to reproduce both the exhaustive (Listing 1) and greedy forward stepwise (Listing 2) searches for the CO2 data described in Sect. 5.1, using the MoEClustR package (Murphy and Murphy 2019), is provided below. The code in Listing 1 can be used to reproduce the results in Table 2.


Appendix B: \(\hbox {CO}_{2}\) data: initialisation
The solutions for the optimal \(G=3\) equal mixing proportion expert network MoEClust model with equal component variances and the explanatory variable ‘GNP’ fit to the CO2 data with and without the initial partition being passed through Algorithm 1 are shown in Fig. 6. A BIC value of \(-155.20\) is achieved after 18 EM iterations with our proposed initialisation strategy compared to a value of \(-161.06\) in 30 EM iterations without. While the models differ only in terms of the initialisation strategy employed, Table 2 shows that the model would not have been identified as optimal according to the BIC criterion had Algorithm 1 not been used. The superior solution in Fig. 6a has one cluster with a steep slope and two clusters with near-zero slopes but different intercepts.

Scatter plots of GNP against CO2 emissions for \(n=28\) countries showing three linear regression components from the optimal MoEClust model, with equal variances and mixing proportions, with (a) and without (b) the initialisation strategy described in Algorithm 1 invoked
Appendix C: AIS data: stepwise model search
For the AIS data, Table 8 gives the results of the greedy forward stepwise model selection strategy described in Algorithm 2, showing the action yielding the best improvement in terms of BIC for each step. This forward search is less computationally onerous than its equivalent in the backwards direction. A 2-component EVEequal mixing proportion expert network MoE model is chosen, in which the mixing proportions are constrained to be equal and Sex enters the expert network. This same model was identified after an exhaustive search over a range of G values, the full range of GPCM covariance constraints, and every possible combination of the BMI and Sex covariates in the gating and expert networks (see Table 5). Note, however, that the remaining covariates in Table 4 are also considered for inclusion here.
To give consideration to outlying observations departing from the prevailing pattern of Gaussianity, a separate stepwise search is conducted, starting from a \(G=0\) noise-only model, with all candidate models having an additional noise component. Thus, a distinction is made between the model found by following the steps shown in Table 8 with \(G=2\)EVE Gaussian components, and the model found by the second stepwise search described in Table 9 with three, of which two are EEE Gaussian and one is uniform. Ultimately, the model with the noise component identified in Table 9 is chosen, based on its superior BIC. Aside from the noise component, it similarly includes ‘Sex’ in the expert network, but differs in its treatment of the gating network and the GPCM constraints employed for the Gaussian clusters. It is a full MoE model where the Gaussian clusters have equal volume, shape, and orientation, the expert network includes the covariate ‘Sex’, and the both ‘SSF’ and ‘Ht’ influence the probability of belonging to the Gaussian clusters but not the additional noise component, as per (8).
Rights and permissions
About this article

Cite this article
Murphy, K., Murphy, T.B. Gaussian parsimonious clustering models with covariates and a noise component. Adv Data Anal Classif 14, 293–325 (2020). https://doi.org/10.1007/s11634-019-00373-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11634-019-00373-8
Keywords
- Model-based clustering
- Mixtures of experts
- EM algorithm
- Parsimony
- Multivariate response
- Covariates
- Noise component