
Abstract
Saturated hydraulic conductivity (Ks) describes the water movement through saturated porous media. The hydraulic conductivity of streambed varies spatially owing to the variations in sediment distribution profiles all along the course of the stream. The artificial intelligence (AI) based spatial modeling schemes were instituted and tested to predict the spatial patterns of streambed hydraulic conductivity. The geographical coordinates (i.e., latitude and longitude) of the sampled locations from where the in situ hydraulic conductivity measurements were determined were used as model inputs to predict streambed Ks over spatial scale using artificial neural network (ANN), adaptive neuro-fuzzy inference system (ANFIS) and support vector machine (SVM) paradigms. The statistical measures computed by using the actual versus predicted streambed Ks values of individual models were comparatively evaluated. The AI-based spatial models provided superior spatial Ks prediction efficiencies with respect to both the strategies/schemes considered. The model efficiencies of spatial modeling scheme 1 (i.e., Strategy 1) were better compared to Strategy 2 due to the incorporation of more number of sampling points for model training. For instance, the SVM model with NSE = 0.941 (Strategy 1) and NSE = 0.895 (Strategy 2) were the best among all the models for 2016 data. Based on the scatter plots and Taylor diagrams plotted, the SVM model predictions were found to be much efficient even though, the ANFIS predictions were less biased. Although ANN and ANFIS models provided a satisfactory level of predictions, the SVM model provided virtuous streambed Ks patterns owing to its inherent capability to adapt to input data that are non-monotone and nonlinearly separable. The tuning of SVM parameters via 3D grid search was responsible for higher efficiencies of SVM models.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Artificial intelligence (AI) based approaches are increasingly being used nowadays for the purpose of determining spatial patterns of soil processes and many ecological variables (Kirkwood et al. 2016; Leuenberger and Kanevski 2015). The AI models have shown potential applications in various fields such as geography, geosciences, and demography. They are found applicable for spatial modeling of land use dynamics, spatial (environmental) processes that are non-stationarity, soil nutrient dynamics, air pollution exposure modeling, etc. (Forkuor et al. 2017; Grekousis et al. 2013; Reid et al. 2015). The AI-based models are known to model any spatial parameter based on their inherent ability to learn from complex input–output relationships even without considering any of the influencing physical factors.
There exist several studies using artificial intelligence (AI) algorithms for predicting soil parameters such as cation exchange capacity, soil temperature, hydraulic conductivity, soil organic carbon, and microbial diversity over spatial scales (Dai et al. 2014; Ghorbani et al. 2015; Twarakavi et al. 2009; Sanikhani et al. 2018). Several researchers indeed have successfully come up with models for estimating suspended sediment concentrations in rivers using novel data mining or AI techniques (Khosravi et al. 2018; Kisi and Yaseen 2019). Recently, by coupling ANNs with GIS, Gholami et al. (2018) modeled soil erosion at different time scales to furnish soil erosion rate maps of the hillslopes in Kasilian watershed, Iran. Here are a few literature examples related to soil hydraulic conductivity prediction using AI models. Soil physical and hydraulic properties such as particle-size distribution, bulk density, different pore sizes, field capacity, permanent wilting point, available water capacity etc. were used to develop using artificial neural network (ANN) and multiple linear regression models by Merdun et al. (2006) to predict soil water retention properties and saturated hydraulic conductivity of soil sampled within the Erzincan plain, Turkey. Twarakavi et al. (2009) taking the advantage of soil data that are easily obtainable such as textural information, bulk density, and retention points developed support vector machine (SVM)-based pedo-transfer function to predict soil hydraulic properties. Using terrain attributes such as slope gradient, elevation, profile curvature, slope aspect, and contour curvature as input variables, Motaghian and Mohammadi (2011) developed artificial neural network models to predict the spatial variation in saturated hydraulic conductivity. Zhao et al. (2016) evaluated the performance of multiple linear regression (MLR) and artificial neural network (ANN) models in the prediction of soil hydraulic conductivity (Ks) based on samples collected from Loess Plateau of China using bulk density, clay content, saturated soil water content, silt content (Silt), and latitude as input parameters. More and Deka (2018) employed hybrid structures such as neuro-fuzzy systems to model field-scale soil hydraulic conductivity sampled from murum soils of India.
Assessment of streambed hydraulic conductivity profiles at fine spatial and temporal resolution is necessary for river corridor studies related to stream–aquifer interaction, streambed-induced infiltration, solute retention, and contaminant transport along the streambed (Wu et al. 2015). Literature that documents the importance of streambed hydraulic conductivity and its role in surface and groundwater interactions is comprehensively reviewed in Naganna et al. (2017). Successive erosion and deposition of sediments all along the stream course affect sediment distribution profiles and the streambed hydrogeological properties. In situ measurement of streambed hydraulic conductivity all along the length of the stream may not be an ideal and cost-effective way. Hence, the applicability of the AI approaches could be tested to induce a rule-based relationship for estimating the values of streambed hydraulic conductivity at unmeasured locations using representative georeferenced neighborhood data. Limited or no studies are available in the literature related to the artificial intelligence (AI)-based spatial modeling schemes to predict the spatial patterns of streambed hydraulic conductivity. Also, several studies in the literature use various soil properties and terrain attributes as inputs to simulate soil hydraulic conductivity. In reality, if the data of such predictor variables are unavailable then the application of soil hydraulic conductivity estimation may not be possible from such models. Hence, in the present study the geographical coordinates (i.e., latitude and longitude) of the sampling locations (points) from where the in situ hydraulic conductivity measurements were made were used as model inputs to predict streambed hydraulic conductivity (Ks) over spatial scale using artificial neural network (ANN), adaptive neuro-fuzzy inference system (ANFIS) and support vector machine (SVM) paradigms. Additionally, the potential of several AI approaches in predicting streambed hydraulic conductivity was evaluated comparatively.
Theoretical overview
Artificial neural network (ANN)
The multilayer perceptron (MLP) neural network is an extremely versatile technique capable of learning most complex nonlinear interrelationships between a set of dependent and independent variables (Cross et al. 1995; Kohonen 1988). A three-layered perceptron network with one hidden layer is as shown in Fig. 1. The network is trained on a set of reference data by adjusting the parameters of the MLP network with the assistance of a Levenberg–Marquardt backpropagation (BP) algorithm. The network architecture involving a set of processing units (neurons), a specific topology of weighted links connecting the neurons, and the learning paradigm that updates the connection weights determine the efficiency of MLP neural networks (Jain et al. 1996). The activation function has to be chosen based on the type of application. In the case of nonlinear mapping, the normally used activation functions are sigmoidal and hard-limiting functions. Sigmoidal functions are continuous and differentiable; however, the hard-limiting functions are non-continuous but differentiable.

Multilayer perceptron (MLP) neural network architecture
Every single input (Xn), weighted by an element (wij) of the weight matrix (W), is summated and provided to the transfer function or activation function (φ) along with a bias (B) term. The activation function constructs a nonlinear decision boundary via linear combinations of the weighted inputs and then applies a threshold to transform the net inputs from all the neuronal units into an output signal. The Levenberg–Marquardt backpropagation learning rule is a variation of Newton’s method which incrementally adjusts the weight and bias terms to minimize the mean square error (MSE) of the network. The quantum of progressions made in adjusting the synaptic weights and biases at every epoch is determined by the learning rate parameter. Smaller learning rates end up in longer training time, however, warrant stability that steers to minimum errors (Sivanandam and Paulraj 2009).
Adaptive neuro-fuzzy inference system (ANFIS)
Jang (1993) introduced adaptive neuro-fuzzy inference system (ANFIS), a hybrid machine learning approach that involves a fuzzy inference system (FIS) and a backpropagation algorithm to tune the membership function parameters of FIS. Depending on the complexity of the problem addressed, sometimes the backpropagation gradient descent method in combination with the least squares method is used to adjust the parameters of FIS (Jang et al. 1997). The fuzzy inference system, based on the number of input parameters, encompasses a set of fuzzy IF–THEN rules or conditional statements to approximate nonlinear functions. ANFIS is a multilayer feedforward five-layer architecture as illustrated in Fig. 2. The fixed nodes are represented by circular outline, and the square outlines are adaptive nodes presided by parameter settings. Each node performs a particular function on incoming signals. Every node in layer 1 (adaptive node) is associated with a node function governed by premise parameters. The output of every single node of layer 2 (fixed node) represents the firing strength of a rule which is nothing but the product of all incoming signals. Similarly, the output of every single node of layer 3 (fixed node) represents the normalized firing strength. Every node in the layer 4 is an adaptive node associated with a node function governed by consequent parameters. The final fixed node in layer 5 labeled as (Σ) computes the overall output as the summation of all incoming signals (Abraham 2005). The premise and consequent parameters of ANFIS are tuned in the learning process by means of a hybrid technique which involves the gradient descent backpropagation method coupled with a least squares optimization algorithm to provide optimal outputs. Soon after the training converges, the values of the premise parameters of membership function are fixed in the search space and the overall output is expressed as a linear combination of the consequent parameters (Jang 1992). Herein, grid partitioning (GP) type of the ANFIS model was employed in the streambed hydraulic conductivity modeling scheme. The performance of the ANFIS model is greatly affected by the type and number of membership functions, which are usually ascertained by trial-and-error procedure.

ANFIS architecture
Support vector machine (SVM)
SVM belongs to the category of supervised learning method proposed by Vladimir Vapnik and his team (Vapnik 2000). Using suitable kernel functions, SVM maps the nonlinear datasets of the input space into a higher-dimensional feature space, to transform them into linear ones. By avoiding or else minimizing over fitting and under fitting of the data, SVM offers maximum predictive accuracy. The structural risk minimization principle of SVM takes the advantage of convex optimization algorithm to simultaneously account for both the empirical risk and the confidence interval of the learning machine by maximizing the geometric margin. SVM is known to perform efficiently in both linear and nonlinear regression tasks with the assistance from Kernel trick. The efficiency of SVM modeling is entirely dependent over the optimal selection of hyper-parameters (i.e., cost, kernel parameter, and loss function). Usually, a three-dimensional fine grid search will be sufficient for finding the optimal values of the SVM parameters. Figure 3 presents the general SVM architecture. For further details regarding SVM, its formulations and applications, one may refer to following literature (Cortes and Vapnik 1995; Cristianini and Shawe-Taylor 2000; Raghavendra and Deka 2014; Vapnik 1999).

(adopted from Raghavendra and Deka 2014)
General SVM architecture
Study area and data analysis
The study pertains to a part of the Pavanje River originating in the Western Ghats of India. The study is focused on the stream reach obstructed by two vented dams in sequence. The streambed hydraulic conductivity data were collected from the study reach as shown in Fig. 4 for assessing the spatial and temporal variations in streambed hydraulic conductance. The hydraulic conductivity tests using Guelph permeameter were conducted along 40 transects across the channel covering the upstream and downstream reaches of each vented dam. The spacing between each transect was 50 m and in each transect, for every 5-meter interval, streambed hydraulic conductivity (Ks) was determined (refer to Fig. 5). The details related to physiography, geological details of the basin along with streambed sampling scheme, and frequency can be referred from Naganna and Deka (2018). This study uses the data of the streambed hydraulic conductivity of two time periods (2016 and 2017) presented in Naganna and Deka (2018) for the development of AI-based spatial prediction models.

Study area—stream reach obstructed by vented dams

Streambed hydraulic conductivity sampling scheme
The descriptive statistics of in situ measured streambed hydraulic conductivity (Ks) along the three segments of the study reach measured at two different time periods (dry periods of 2016 and 2017) are presented in Table 1 to illustrate the overall variation in the Ks distribution. The magnitude of Ks with reference to the three segments varied by two orders of magnitude.
Methodology and performance evaluation
For spatial modeling of streambed hydraulic conductivity, two diverse schemes/strategies were adopted. In Strategy 1, the training and testing datasets were chosen in such a pattern that the Ks data along a transect were estimated by considering the Ks data of two neighborhood transects both upstream and downstream. Figure 6 shows the scheme of selection of training and testing transects along the study reach. The Ks data measured at transect locations—2, 3, 5, 6, 8, 9, 11, 12, 13, 15, 16, 18, 19, 21, 22, 24, 25, 27, 28, 30, 31, 33, 34, 36, 37, 39, 40—were considered as training features, and the models were calibrated to estimate the Ks values at transects—1, 4, 7, 10, 14, 17, 20 m 23, 26, 29, 32, 35, 38. The predicted Ks values were evaluated against the observed Ks values at those transects. The sample size considered for training and testing of AI models was, respectively, 134 and 53 Ks point samples in the case of Strategy 1. During model development, the point location details (i.e., the geographical information—latitude and longitude) from where the Ks values were sampled along each transect were considered as model inputs by targeting measured Ks. Specifically, the geographical coordinates were the predictors and the Ks values serve as predictand. The testing transects were considered to be the unknown locations where there is a necessity for prediction. While model testing, the Ks values were estimated at those testing transect locations by entering only geographical coordinates as inputs so that it becomes easier to validate the model predictions based on the observed Ks values.

Spatial modeling schemes
Similarly, in Strategy 2, the alternate transects—one after the other—were considered as training and testing transects. The scheme of Strategy 2 is as shown in Fig. 6. In this case, the samples of upstream transects are considered for training the models. The sample size considered for training and testing of AI models was, respectively, 96 and 91 Ks point samples in the case of Strategy 2. The proposed AI models have been developed using Matlab software.
The spatial prediction performance of all the models was evaluated by computing error and efficiency statistics as given below.
Statistical criteria | Value | Inference |
|---|---|---|
Root-mean-square error, RMSE = \(\sqrt {\frac{{\left( {O_{i} - P_{i} } \right)^{2} }}{N}}\) | A value below half of the standard deviation | Satisfactory |
Relative RMSE, RRMSE = \(\frac{RMSE}{{\sigma_{obs} }}\) | 0.00 ≤ RRMSE ≤ 0.10 0.10 ≤ RRMSE ≤ 0.30 0.30 ≤ RRMSE ≤ 0.50 RRMSE > 0.70 | Very good Good Satisfactory Poor |
Mean absolute error, MAE = \(\frac{{\sum\nolimits_{i = 1}^{N} {\left| {P_{i} - O_{i} } \right|} }}{N}\) | A value below half of the standard deviation | Satisfactory |
Nash–Sutcliffe efficiency, NSE = \(1 - \frac{{\sum\nolimits_{i = 1}^{N} {\left( {P_{i} - O_{i} } \right)^{2} } }}{{\sum\nolimits_{i = 1}^{N} {\left( {O_{i} - \overline{O} } \right)^{2} } }}\) | 0.75 < NSE < 1.00 0.65 < NSE ≤ 0.75 0.50 < NSE ≤ 0.65 0.4 < NSE ≤ 0.50 NSE ≤ 0.4 | Very good Good Satisfactory Acceptable Unsatisfactory |
where O and P signpost the observed and predicted Ks values, respectively. \(\overline{O}\) and \(\overline{P}\) are the mean of observed and forecasted values, \(\sigma_{o}\) and \(\sigma_{p}\) are the standard deviation of observed and forecasted values, respectively. N represents the total number of data samples.
Results and discussion
Performance of ANN prediction models
Based on trial-and-error scheme, the number of hidden neurons of the multilayer perceptron neural network (ANN) was determined. The tansig and purelin were employed as input and output transfer functions along with Levenberg–Marquardt backpropagation learning rule. The model structure and performance statistics of the ANN model for each strategy are presented in Table 2 along with the performance statistics of the ANN model for each strategy. From the statistical indices, it is evident that the performance of ANN models during the testing phase was satisfactory but not up to the mark. For instance, the MAE of all the models was sufficiently high and the RRMSE values above 0.4 signpost that the spatial Ks predictions were not so accurate but fall under the satisfactory category. With reference to Strategy 1 model of 2017, even though the training results were good with an NSE = 0.835, the test performance was merely acceptable with an NSE = 0.75.
Performance of ANFIS prediction models
The adaptive neuro-fuzzy inference system (ANFIS) with grid partitioning method was calibrated by selecting the shape and optimal number of membership functions. The optimal ANFIS architectures calibrated based on trial-and-error approach for spatial modeling of streambed Ks are presented in Table 3. The ‘hybrid’ training algorithm which includes the backpropagation gradient descent method in combination with a least squares method was used for fitting the training data set. The performance statistics of ANFIS model for each strategy are presented in Table 4.
From the statistical indices, it is evident that the performance of all the ANFIS models during the testing phase has acceptable accuracy measures. For instance, the MAE of all the models was sufficiently less and the RRMSE values less than 0.4 and 0.3 signpost that the spatial Ks predictions were decently and highly accurate, respectively. Strategy 1 model of 2017 had a higher prediction accuracy compared to other ANFIS models with a test NSE = 0.949. The Gaussian and Gbell membership functions were found to provide better prediction accuracy for the spatial modeling strategies 1 and 2, respectively.
Performance of SVM prediction models
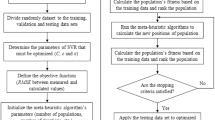
The support vector machine (SVM) with radial basis kernel function was employed in this study to predict the spatial streambed hydraulic conductivity. The optimal parameters of SVM (i.e., the cost, kernel, and the ε-insensitive loss function) were identified via 3D Grid Search. Table 5 presents the optimal values of SVM parameters. Hypothetically, a logarithmic grid ranging between 2−12 and 212 is usually sufficient for arriving at the best parameter combination. In the event that the best parameters lie on the limits of the grid, the further search could be extended in that direction in a subsequent search. The performance statistics of the SVM model for each strategy are presented in Table 6.
From the statistical indices, it is evident that the performance of all the SVM models during the testing phase was of relatively higher accuracy. The MAE of all the model predictions was sufficiently less, and the RRMSE values less than 0.3 signpost superior spatial Ks predictions. Strategy 1 model of 2016 had a higher prediction accuracy compared to other SVM models with a test NSE = 0.941.
Comparative evaluation of AI models
The three AI models, namely the ANN, ANFIS, and SVM, provided more or less satisfactory spatial predictions with respect to both the strategies considered. Both SVM and ANFIS prediction models performed much better than the ANN models, and based on the error indices the SVM models performed relatively better than the ANFIS prediction models. For a comparative evaluation of all the models, Table 7 presents the evaluated statistical indices of the test phase. Figure 7 illustrates the scatter plots based on the observed vs predicted streambed Ks values of Strategy 1—ANN, ANFIS, and SVM models during the test phase. Similarly, Fig. 8 illustrates the scatter plots of Strategy 2—ANN, ANFIS, and SVM models during the test phase. The scatter plot displays the strength, direction, and form of the relationship between the observed and predicted streambed Ks values. The prediction performance or the relative skill of different AI models is graphically summarized via Taylor diagrams as presented in Figs. 9 and 10.

Scatter plots of Strategy 1—ANN, ANFIS and SVM models during the test period

Scatter plots of Strategy 2—ANN, ANFIS and SVM models during the test period

Taylor diagrams plotted for comparative evaluation of Strategy 1—ANN, ANFIS and SVM models of test phase

Taylor diagrams plotted for comparative evaluation of Strategy 2—ANN, ANFIS and SVM models of the test phase
With reference to Strategy 1 model for 2016 Ks data, the SVM model provides relatively better predictions than other two based on the NSE statistic. The RRMSE = 0.24 indicates relatively good spatial Ks predictions. The instances of underestimation and overestimation of observed Ks values were better captured in scatter plots presented in Fig. 7 wherein the Ks predictions by SVM model were quite closer to the observed values. In Taylor diagram as presented in Fig. 9, three statistical indices, namely the correlation coefficient (R), the standard deviation (σ) and the root-mean-square difference (RMSD), are used to characterize the statistical relationship between the modeled and reference fields. In this case, both ANFIS and SVM predictions were analogous to each other. For a comparative evaluation of RRMSE and NSE statistic, Fig. 11 presents the pictographic representation via bar chart. The model efficiencies of spatial modeling scheme 1 (i.e., Strategy 1) were better compared to Strategy 2 due to the incorporation of more number of sampling points for model training.

Plot of RRMSE and NSE statistic of all the AI models
Pertaining to Strategy 1 model for 2017 Ksdata, the performance of ANFIS prediction model was found to be relatively superior to the SVM model. The ANN model underperformed as compared to ANFIS and SVM predictions. From the scatter plots presented in Fig. 7, it can be observed that both ANFIS and SVM models were analogous in capturing the spatial variations of streambed Ks. From the Taylor diagram as presented in Fig. 9, it can be observed that the standard deviation of ANN predictions significantly differs from that of the observed Ks data. Here, the RMSD, standard deviation, and correlation coefficient of ANFIS predictions were superior to SVM predictions.
Comparing the statistical indices with regard to Strategy 2 models for 2016 and 2017 Ks data, it was evident that the SVM predictions outperform the other two models in terms of all the indices considered. The scatter plots presented in Fig. 8 portray the ability of individual AI models to fit the observed Ks data. From the Taylor diagrams as presented in Fig. 10, it could be seen that the standard deviation of ANFIS predictions was closer to the standard deviation curve of observed Ks data. However, the SVM predictions had better RMSD and R statistics, reaffirming the better accuracy over its comparison counterparts. Henceforth, based on NSE, RMSD and R values, the SVM model predictions were considered to be efficient even though the ANFIS predictions were less biased compared to SVM predictions.
It is always not possible to collect dense data of any variable of interest by sampling through experiments from the area of interest. In such cases, with limited data obtained through coarse sampling could be employed to predict data samples to enhance the database. For instance, in the present study, with the help of neighborhood streambed Ks data samples, the AI models provided reliable predictions of streambed Ks at two different spatial scales. The streambed Ks being an important parameter for assessing the surface water seepage into aquifers needs to be studied to identify potential recharge zones along the length/stretch of the river.
Summary and conclusions
The artificial intelligence (AI) based spatial modeling schemes were tested to predict the spatial patterns of streambed hydraulic conductivity. The geographical coordinates (i.e., latitude and longitude) of the sampled locations from where the in situ hydraulic conductivity measurements were made were used as model inputs to predict streambed Ks over spatial scale using an artificial neural network (ANN), adaptive neuro-fuzzy inference system (ANFIS), and support vector machine (SVM) paradigms. The statistical measures computed by using the actual versus predicted streambed Ks values of individual models were comparatively evaluated. The spatial modeling schemes/strategies proposed were found suitable for predicting streambed Ks patterns. With such spatial modeling schemes that incorporate the neighborhood data to predict the variable of interest, one can easily predict at unknown point locations at significant confidence levels. The AI-based spatial models provided more or less satisfactory spatial Ks prediction efficiencies with respect to both the strategies/schemes considered. Although ANN and ANFIS models provided a satisfactory level of predictions, the SVM model was found to provide more accurate streambed Ks patterns due to its inherent capability to adapt to input data that are non-monotone and nonlinearly separable. The tuning of SVM parameters via 3D grid search was responsible for higher efficiencies of SVM models. The present study involved the prediction of streambed hydraulic conductivity at shorter spans or intervals. Even with limited field experimental data, the study discloses the potential of data-driven models to predict streambed Ks patterns by presenting two spatial modeling schemes. In the future, one can test the similar strategies for longer spatial scales/spans with sufficient data collected from an extensive stretch of the river.
References
Abraham A (2005) Adaptation of fuzzy inference system using neural learning. In: Nedjah N, Macedo Mourelle L (eds) Fuzzy systems engineering. Studies in fuzziness and soft computing, vol 181. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11339366_3
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–297. https://doi.org/10.1007/BF00994018
Cristianini N, Shawe-Taylor J (2000) An introduction to support vector machines and other kernel-based learning methods. Cambridge University Press, Cambridge
Cross SS, Harrison RF, Kennedy RL (1995) Introduction to neural networks. Lancet 346:1075–1079. https://doi.org/10.1016/S0140-6736(95)91746-2
Dai F, Zhou Q, Lv Z, Wang X, Liu G (2014) Spatial prediction of soil organic matter content integrating artificial neural network and ordinary kriging in Tibetan Plateau. Ecol Indic 45:184–194. https://doi.org/10.1016/j.ecolind.2014.04.003
Forkuor G, Hounkpatin OKL, Welp G, Thiel M (2017) High resolution mapping of soil properties using remote sensing variables in south-western Burkina Faso: a comparison of machine learning and multiple linear regression models. PLoS One 12:e0170478. https://doi.org/10.1371/journal.pone.0170478
Gholami V, Booij MJ, Nikzad Tehrani E, Hadian MA (2018) Spatial soil erosion estimation using an artificial neural network (ANN) and field plot data. Catena 163:210–218. https://doi.org/10.1016/j.catena.2017.12.027
Ghorbani H, Kashi H, Hafezi Moghadas N, Emamgholizadeh S (2015) Estimation of soil cation exchange capacity using multiple regression, artificial neural networks, and adaptive neuro-fuzzy inference system models in Golestan Province. Iran. Commun Soil Sci Plant Anal 46:763–780. https://doi.org/10.1080/00103624.2015.1006367
Grekousis G, Manetos P, Photis YN (2013) Modeling urban evolution using neural networks, fuzzy logic and GIS: the case of the Athens metropolitan area. Cities 30:193–203. https://doi.org/10.1016/j.cities.2012.03.006
Jain AK, Mao Jianchang, Mohiuddin KM (1996) Artificial neural networks: a tutorial. Computer (Long Beach Calif) 29:31–44. https://doi.org/10.1109/2.485891
Jang J-SR (1992) Neuro-fuzzy modeling: architectures, analyses, and applications. University of California, Berkeley
Jang JSR (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23:665–685. https://doi.org/10.1109/21.256541
Jang J-SR, Sun C-T, Mizutani E (1997) Neuro-fuzzy and soft computing: a computational approach to learning and machine intelligence. Prentice Hall, New Jersey
Khosravi K, Mao L, Kisi O, Yaseen ZM, Shahid S (2018) Quantifying hourly suspended sediment load using data mining models: case study of a glacierized Andean catchment in Chile. J Hydrol 567:165–179
Kirkwood C, Cave M, Beamish D, Grebby S, Ferreira A (2016) A machine learning approach to geochemical mapping. J Geochemical Explor. https://doi.org/10.1016/j.gexplo.2016.05.003
Kisi O, Yaseen ZM (2019) The potential of hybrid evolutionary fuzzy intelligence model for suspended sediment concentration prediction. Catena 174:11–23
Kohonen T (1988) An introduction to neural computing. Neural Networks 1:3–16. https://doi.org/10.1016/0893-6080(88)90020-2
Leuenberger M, Kanevski M (2015) Extreme learning machines for spatial environmental data. Comput Geosci 85:64–73. https://doi.org/10.1016/j.cageo.2015.06.020
Merdun H, Çınar Ö, Meral R, Apan M (2006) Comparison of artificial neural network and regression pedotransfer functions for prediction of soil water retention and saturated hydraulic conductivity. Soil Tillage Res 90:108–116. https://doi.org/10.1016/j.still.2005.08.011
More SB, Deka PC (2018) Estimation of saturated hydraulic conductivity using fuzzy neural network in a semi-arid basin scale for murum soils of India. ISH J Hydraul Eng 24:140–146. https://doi.org/10.1080/09715010.2017.1400408
Motaghian HR, Mohammadi J (2011) Spatial estimation of saturated hydraulic conductivity from terrain attributes using regression, kriging, and artificial neural networks. Pedosphere 21:170–177. https://doi.org/10.1016/S1002-0160(11)60115-X
Naganna SR, Deka PC (2018) Variability of streambed hydraulic conductivity in an intermittent stream reach regulated by Vented Dams: a case study. J Hydrol 562:477–491. https://doi.org/10.1016/j.jhydrol.2018.05.006
Naganna SR, Deka PC, Ch S, Hansen WF (2017) Factors influencing streambed hydraulic conductivity and their implications on stream–aquifer interaction: a conceptual review. Environ Sci Pollut Res 24:24765–24789. https://doi.org/10.1007/s11356-017-0393-4
Raghavendra NS, Deka PC (2014) Support vector machine applications in the field of hydrology: a review. Appl Soft Comput 19:372–386. https://doi.org/10.1016/j.asoc.2014.02.002
Reid CE, Jerrett M, Petersen ML, Pfister GG, Morefield PE, Tager IB, Raffuse SM, Balmes JR (2015) Spatiotemporal prediction of fine particulate matter during the 2008 Northern California wildfires using machine learning. Environ Sci Technol 49:3887–3896. https://doi.org/10.1021/es505846r
Sanikhani H, Deo RC, Yaseen ZM, Eray O, Kisi O (2018) Non-tuned data intelligent model for soil temperature estimation: a new approach. Geoderma 330:52–64
Sivanandam S, Paulraj M (2009) Introduction to artificial neural networks. Vikas Publishing House, New Delhi
Twarakavi NKC, Šimůnek J, Schaap MG (2009) Development of pedotransfer functions for estimation of soil hydraulic parameters using support vector machines. Soil Sci Soc Am J 73:1443. https://doi.org/10.2136/sssaj2008.0021
Vapnik VN (1999) An overview of statistical learning theory. IEEE Trans Neural Netw 10:988–999. https://doi.org/10.1109/72.788640
Vapnik VN (2000) The nature of statistical learning theory. Springer, New York. https://doi.org/10.1007/978-1-4757-3264-1
Wu G, Shu L, Lu C, Chen X (2015) The heterogeneity of 3-D vertical hydraulic conductivity in a streambed. Hydrol Res 47(1):15–26. https://doi.org/10.2166/nh.2015.224
Zhao C, Shao M, Jia X, Nasir M, Zhang C (2016) Using pedotransfer functions to estimate soil hydraulic conductivity in the Loess Plateau of China. Catena 143:1–6. https://doi.org/10.1016/j.catena.2016.03.037
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Rights and permissions
About this article

Cite this article
Naganna, S.R., Deka, P.C. Artificial intelligence approaches for spatial modeling of streambed hydraulic conductivity. Acta Geophys. 67, 891–903 (2019). https://doi.org/10.1007/s11600-019-00283-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11600-019-00283-5