
Abstract
We adapt the quasi-monotone method, an algorithm characterized by uniquely having convergence quality guarantees for the last iterate, for composite convex minimization in the stochastic setting. For the proposed numerical scheme we derive the optimal convergence rate of \(\text{ O }\left( \frac{1}{\sqrt{k+1}}\right)\) in terms of the last iterate, rather than on average as it is standard for subgradient methods. The theoretical guarantee for individual convergence of the regularized quasi-monotone method is confirmed by numerical experiments on \(\ell _1\)-regularized robust linear regression.
Similar content being viewed by others
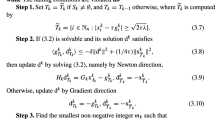


Avoid common mistakes on your manuscript.
1 Introduction
In the minimization of nonsmooth convex functions, typically, algorithms generate a sequence of iterates using subgradients or estimates thereof. The convergence rates are then derived for some linear combination of the iterates, rather than for the last estimate computed. Obtaining guarantees on the last iterate per se is often a challenging task. A significant contribution in that direction – sometimes also refered to as individual convergence – was given in [5] with the quasi-monotone subgradient method. The corresponding analysis was simplified and extended to solving minimization problems on decentralized networks in [4]. In this paper we extend the work of [5] in two important directions, first we consider a composite minimization problem with a simple additive function (usually a regularizer), and second we consider the stochastic case. We develop the Lyapunov-like analysis from [4] to handle the new elements and present numerical experiments confirming the performance guarantees. We obtain the convergence rate of order \(\text{ O }\left( \frac{1}{\sqrt{k+1}}\right)\) in expectation of function evaluations, which is optimal for nonsmooth convex optimization.
Let us briefly comment on the related literature. In [6] the authors introduce an adaptation of mirror descent in order to attain the optimal individual convergence. They successively apply the latter for regularized nonsmooth learning problems in the stochastic setting. As shown in [7], the Nesterov’s acceleration alternatively provides the individual convergence of projected subgradient methods as applied to nonsmooth convex optimization. Especially, the suggested methodology guarantees the regularization structure while keeping an optimal rate of convergence. Our contribution to individual convergence consists in theoretically justifying that also the initially proposed quasi-monotone subgradient method from [5] can be successively adjusted for composite minimization in the stochastic setting. We note that the setting we consider is distinct from the specialized algorithms that also adapt mirror descent for the important case wherein there are separable linear constraints, e.g., the classical [3] or more recent alternating minimization [2] and proximal point based method [1], but extending to this setting could be an interesting topic to pursue for future work.
2 Regularized quasi-monotone method
We consider the composite minimization problem
where \({\bar{f}}, g: {\mathbb {R}}^n \rightarrow {\mathbb {R}} \cup \{+\infty \}\) are closed convex functions. Moreover,
for some f closed and convex in the first argument and \(\xi\) is a sample from some random space \(\varXi\). We assume that \(\text{ dom }(f(\cdot ,\xi )) \subset \text{ dom }(g)\) for a.e. \(\xi\), and \(\text{ dom }(g)\) is closed. Usually, \({\bar{f}}\) plays the role of a loss function, whereas g is used for regularization. In our setting, f need not to be differentiable, but unbiased finite variance estimates of its subgradients, i.e. \(w(x,\xi )\sim \nabla f(x,\cdot )\) with \({\mathbb {E}}\left[ w(x,\xi )\right] \in \partial {{\bar{f}}}(x)\), should be available. Here, we use \(\nabla {{\bar{f}}}(x)\) to denote an element of the convex subdifferential \(\partial {{\bar{f}}}(x)=\partial {\mathbb {E}}[f(x,\xi )]\), i.e.
In addition, g has to be simple. The latter means that we are able to find a closed-form solution for minimizing the sum of g with some simple auxiliary functions. For that, we assume that for the effective domain of g there exists a prox-function \(\varPsi :{\mathbb {R}}^n \rightarrow {\mathbb {R}} \cup \{+\infty \}\) w.r.t. an arbitrary but fixed norm \(\Vert \cdot \Vert\). The prox-function \(\varPsi\) has to fulfil:
-
(i)
\(\varPsi (x) \ge 0\) for all \(x \in \text{ dom }(g)\).
-
(ii)
\(\varPsi\) is strongly convex on \(\text{ dom }(g)\) with convexity parameter \(\beta >0\), i.e. for all \(x,y \in \text{ dom }(g)\) and \(\alpha \in [0,1]\) it holds:
$$\begin{aligned} \varPsi \big (\alpha x + (1-\alpha )y\big ) \le \alpha \varPsi (x) + (1-\alpha ) \varPsi (y) - \frac{\beta }{2} \alpha (1-\alpha ) \Vert x-y\Vert ^2. \end{aligned}$$ -
(iii)
The auxiliary minimization problem
$$\begin{aligned} \min _{x} \left\{ \langle s,x\rangle + g(x) + \gamma \varPsi (x)\right\} \end{aligned}$$is easily solvable for \(s \in {\mathbb {R}}^n\) and \(\gamma > 0\).
In our analysis, we consider that g is strongly convex with convexity parameter \(\sigma \ge 0\) w.r.t. the norm \(\Vert \cdot \Vert\). Note that \(\sigma =0\) corresponds to the mere convexity of g.
For stating our method, we choose a sequence of positive parameters \((a_k)_{k \ge 0}\), which is used to average the subdifferential information of f. We set:
Equivalently, it holds:
Another sequence of positive parameters \((\gamma _k)_{k \ge 0}\) controls the impact of the prox-function \(\varPsi\). We assume:
Now, we are ready to formulate the regularized quasi-monotone method for solving the composite minimization problem (1):
Regularized Quasi-Monotone Method (RQM) | |
|---|---|
0. Initialize \(\displaystyle x_{0} = \text{ arg } \min _{x} \left\{ A_{0} g(x) + \gamma _{0}\varPsi (x)\right\}\), \(s_{-1}=0\). | |
1. Sample \(\xi _k\sim \varXi\). | |
2. Compute \(w\left( x_k,\xi _k\right)\) and set \(\displaystyle s_{k}=s_{k-1} + a_{k} w\left( x_k,\xi _k\right)\). | |
3. Forecast \(\displaystyle x^+_{k} = \text{ arg } \min _{x} \left\{ \left\langle s_{k}, x \right\rangle + A_{k+1} g(x) + \gamma _{k+1}\varPsi (x)\right\}\). | |
4. Update \(\displaystyle x_{k+1} = \frac{A_{k}}{A_{k+1}} x_k + \frac{a_{k+1}}{A_{k+1}} x^+_{k}\). |
It is clear that iterates of (RQM) are convex combinations of forecasts:
In order to achieve convergence rates for RQM, the control parameters \(\left( a_k\right) _{k\ge 0}\) and \(\left( \gamma _k\right) _{k\ge 0}\) should be properly specified. How to do this, will be clear from our convergence analysis in the next section, cf. possible choices in (18), (21) and (22) below.
3 Convergence analysis
Before performing the convergence analysis of (RQM), let us deduce some useful properties of the following auxiliary function:
Since \(A_{k} g + \gamma _{k}\varPsi\) is strongly convex with convexity parameter
the convex function \(\varphi _{k}\) is differentiable and its gradient \(\nabla \varphi _k\) is \(\frac{1}{\mu _{k}}\)-Lipschitz continuous. The latter property means:
Moreover, it holds:
Let us derive the convergence rate of (RQM). For that, we set:
where \(\Vert \cdot \Vert _*\) denotes the dual norm of \(\Vert \cdot \Vert\). We shall denote, as standard, the filtration \(\sigma\)-algebra corresponding to the sequence of iterates as \(\{\mathcal {F}_k\}\).
Theorem 1
Let \(x_* \in \text{ dom }(g)\) solve the composite optimization problem (1), and the sequence \(\left( x_k\right) _{k\ge 0}\) be generated by (RQM). Then, it holds for \(k \ge 0\) that:
Proof
Let us define the stochastic Lyapunov function:
We consider the expected difference:
Let us estimate the expressions I-IV from above.
Estimation of I We split:
Due to convexity of f, the definitions of \(A_{k}\) and \(x_{k}\), we obtain:
By using convexity of g, it also follows:
Overall, we deduce:
Estimation of II First, in view of the definitions of \(\varphi _k\), \(A_k\), and \(x^+_{k}\), we obtain:
Second, due to Lipschitz continuity of \(\nabla \varphi _k\) and definitions of \(s_k\) and \(x_k^+\), we have:
By using these two auxiliary inequalities, we are ready to estimate:
Estimation of III
The definitions of \(s_k\) and \(A_k\) provide:
Estimation of IV
Here, we have:
Altogether, we can see that
Since \(x^+_k\) is defined given \(\mathcal {F}_k\), we have:
By additionally using that the sequence \((\gamma _k)_{k \ge 0}\) is by assumption nondecreasing, and \(\varPsi (x) \ge 0\) for all \(x \in \text{ dom }(g)\), we obtain:
Hence, we get by induction and taking total expectations:
It turns out that the expectation of \(V_0\) is nonnegative. For that, we first estimate due to the choice of \(x_0\):
This gives:
where again the last inequality is due to the assumptions on \(\gamma _0\) and \(\varPsi\). Additionally, it holds by definition of \(\varphi _k\):
Hence, we obtain:
The assertion (11) then follows.
Now, let us show that the convergence rate of (RQM) derived in Theorem 1 is optimal for nonsmooth optimization, i.e. it is of order \(\text{ O }\left( \frac{1}{\sqrt{k+1}}\right)\). For that, we exemplarily consider the following choice of control parameters:
We also assume that the subgradients’ estimates of f have uniformly bounded second moments, i.e. there exists \(G >0\) such that
Corollary 1
Let \(x_* \in \text{ dom }(g)\) solve the composite optimization problem (1), and the sequence \(\left( x_k\right) _{k\ge 0}\) be generated by (RQM) with control parameters from (18). Then, it holds for all \(k\ge 0\):
Proof
In order to obtain (20), we estimate the terms in (11) which involve control parameters:
\(\square\)
From the proof of Corollary 1 we see that also other choices of control parameters guarantee the optimal convergence rate of RQM. E.g., we may have chosen:
We show that the convergence rate of (RQM) derived in Corollary 1 can be improved to \(\text{ O }\left( \frac{\ln k}{k}\right)\) if the regularizer g turns out to be strongly convex. Additionally, an estimate in terms of generated iterates can be obtained. For that, consider the control parameters as follows:
Corollary 2
Let \(x_* \in \text{ dom }(g)\) solve the composite optimization problem (1), and the sequence \(\left( x_k\right) _{k\ge 0}\) be generated by (RQM) with control parameters from (22). Additionally, let g be strongly convex with convexity parameter \(\sigma >0\). Then, it holds for all \(k\ge 0\):
Proof
In order to obtain (23), we estimate the terms in (11) which involve control parameters:
For (24), we use the assumption that g is strongly convex, hence, also F is. In particular, we obtain:
Since \(x_*\) solves (1), we have \(0 \in \partial F(x_*)\) and it follows:
By taking expectation and recalling (23), we are done. \(\square\)
Finally, we note that estimating convergence rates for the generated sequence of iterates itself is a hard task in the framework of subgradient methods. We refer e.g. to [8], where the dual averaging methods were adjusted for stochastic composite minimization. There, just the boundedness of iterates could be in general shown. If g is strongly convex, an estimate was nevertheless provided. This is also the case for RQM as we have shown in Corollary 2.
4 Numerical experiments
We performed numerical experiments on two representative synthetic problems with various parameters for the data generation and observed two general patterns in regards to the relative performance of solvers.
For each problem instance we ran one hundred trials of (RQM) in order to investigate the robustness and spread of the performance. Note that the initial \(x_0\) set by (RQM) is the zero vector. First, we compare the parameter choice Parameters A as in (18), i.e. \(a_k=1\) and, thus, \(A_k=k+1\), with \(\gamma _k=\sqrt{k+1}\), to the choice of \(a_k=k\) and, thus, \(A_k = \frac{k(k+1)}{2}\), with the more aggressive constant step-size \(\gamma _k= 10\) Parameters B.
We also compare (RQM) to the stochastic regularized subgradient (SRSG) with Nesterov’s extrapolation from [7]. There, by choosing control parameters
the authors iterate:
Finally, we also compare the procedure to the standard mirror descent algorithm, in this case the update becomes,
In the experiments we use the Euclidean dual map \(\varPsi (x)=\frac{1}{2}\Vert x\Vert ^2_2\) and the theoretically optimal rate \(\gamma _k=\sqrt{k+1}\).
4.1 Huber loss and \(\ell _1\)-regularization
Consider linear regression with a robust Huber loss and \(\ell _1\)-regularization, i.e.
where
Here, we expect the number N of data samples to be large. The \(\ell _1\)-regularization on the parameters encourages sparsity, i.e. most of the parameters to become zero. The Huber loss is a means of mitigating the impact of outliers on the stability of the regression estimate, i.e. by enforcing linear as opposed to quadratic growth of the loss beyond the influence boundary \(\delta\). We take the subgradients
Denoting \(x=(\mathbf {a},b)\) and choosing as prox-function \(\varPsi (x)=\frac{1}{2}\Vert x\Vert ^2_2\), the subproblem in (RQM) admits an explicit solution:
The explicit solution of the subproblem in (25) is
Now we describe the generation of the synthetic data used to generate the problem for comparison. We let \(\mathbf {a}\in {\mathbb {R}}^{10}\), \(\delta =2\), and \(N=10000\) and conduct the following procedure:
-
1.
Choose 4 components of \(\mathbf {a}\) to be nonzero. Randomly sample these components and b.
-
2.
Choose 10000 input samples \(\{x_i\}\) uniformly in \([-5,5]\).
-
3.
With probability 0.95 generate \(y_i \sim \mathcal {N}\left( \mathbf {a}^T x_i+b,1\right)\), and otherwise \(y_i \sim \mathcal {N}\left( \mathbf {a}^T x_i+b,5\right)\).
-
4.
Run (RQM).
We set \(\lambda =0.1\). The trajectory of the objective value with the associated one standard deviation confidence interval is shown in Fig. 1. Note that for the Nesterov’s extrapolation algorithm we report the objective value on \({\hat{x}}_k\), as this is what the theoretical convergence guarantees in [7] are derived for. We see that SRSG with Nesterov’s extrapolation performs better that our method with the theoretically optimal choice of Parameters A. However, it is worth mentioning that alternative parameter choices (Parameter B) may work better in practice. In any case, all the methods produce convergent sequences w.r.t. the function value.

Evolution of the objective error with the iterations for Huber Loss and \(\ell _1\)-Regularization
4.2 \(\ell _1\)-regression and box constraint
Now, we present a problem and data generation parameters for which the theoretically optimal algorithm RQM exhibit the better comparative performance. The optimization problem is defined to be \(\ell _1\)-regression with an indicator of membership to a box constraint
where
In this case, the subproblem uses a stochastic subgradient of the loss term, i.e., for sample i, we have that s or w, respectively for the two algorithms is given by
Additionally, we use the same prox-function \(\varPsi (x)=\frac{1}{2}\Vert x\Vert ^2_2\). Finally, incorporating the indicator in the subproblem is simply projection onto the box C. We let \(\mathbf {a}\in {\mathbb {R}}^{5}\) and \(N=1000\) and generate the data as follows:
-
1.
Randomly sample \(\mathbf {a} \sim \mathcal {N}\left( 0,7\mathbf {I}\right)\) and \(b\sim \mathcal {N}(0,8)\).
-
2.
Choose 1000 input samples \(\{x_i\}\) uniformly in \([-15,15]\).
-
3.
Generate \(y_i \sim \mathcal {N}\left( \mathbf {a}^T x_i+b,1\right)\).
-
4.
Finally \(\mathbf {x}_l=x_l\mathbf {1}\) was chosen randomly uniformly in \([-20,0]\) and \(\mathbf {x}_u=x_u\mathbf {1}\) in [0, 20].
We can see now in Fig. 2 that in this case the theoretically optimal choice of Parameters A exhibit the best performance.

Evolution of the objective error with the iterations for \(\ell _1\)-Regression and Box Constraint
References
Bai, J., Zhang, H., Li, J.: A parameterized proximal point algorithm for separable convex optimization. Optim. Lett. 12(7), 1589–1608 (2018)
Bitterlich, S., Boţ, R.I., Csetnek, E.R., Wanka, G.: The proximal alternating minimization algorithm for two-block separable convex optimization problems with linear constraints. J. Optim. Theory Appl. 182(1), 110–132 (2019)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J., et al.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3(1), 1–122 (2011)
Liang, S., Wang, L., Yin, G.: Distributed quasi-monotone subgradient algorithm for nonsmooth convex optimization over directed graphs. Automatica 101, 175–181 (2019)
Nesterov, Y., Shikhman, V.: Quasi-monotone subgradient methods for nonsmooth convex minimization. J. Optim. Theory Appl. 165(3), 917–940 (2015)
Tao, W., Pan, Z., Wu, G., Tao, Q.: Primal averaging: a new gradient evaluation step to attain the optimal individual convergence. IEEE Trans. Cybern. 50, 835–845 (2020)
Tao, W., Pan, Z., Wu, G., Tao, Q.: Strength of Nesterov’s extrapolation in the individual convergence of nonsmooth optimization. IEEE Trans. Neural Netw. Learn. Syst. 31, 1–12 (2020)
Xiao, L.: Dual averaging methods for regularized stochastic learning and online optimization. J. Mach. Learn. Res. 11(88), 2543–2596 (2010)
Acknowledgements
The authors would like to thank the anonymous referees for their suggestions in improving the presentation and content of this work. Research Supported by the OP VVV project CZ.02.1.01/0.0/0.0/16\_019/0000765 “Research Center for Informatics”.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kungurtsev, V., Shikhman, V. Regularized quasi-monotone method for stochastic optimization. Optim Lett 17, 1215–1228 (2023). https://doi.org/10.1007/s11590-022-01931-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11590-022-01931-4