
Abstract
It is well known that a quadratic programming minimization problem with one negative eigenvalue is NP-hard. However, in practice one may expect such problems being not so difficult to solve. We suggest to make a single partition of the feasible set in a concave variable only so that a convex approximation of the objective function upon every partition set has an acceptable error. Minimizing convex approximations on partition sets provides an approximate solution of the nonconvex quadratic program that we consider. These minimization problems are to be solved concurrently by parallel computing. An estimation of the number of partition sets is given. The study presents a computational comparison with a standard branch-and-bound procedure.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Quadratic nonconvex programming has a wide range of applications and is an intensively studied field of global optimization. The number of publications devoted to this topic is quite impressive, see, for example, [1,2,3] and references therein. The main issue of the paper is connected to the result published in [4]. Namely, nonconvex quadratic programming problem with one negative eigenvalue in the objective is NP-hard. Properties of a quadratic function with one negative eigenvalue and the corresponding theoretical results can be found in [5, 6]. We get interested in how difficult on average the problem of global minimization of quadratic objective is with exactly one negative eigenvalue. We assume that the eigenvalues and eigenvectors of the matrix in the minimized function are known. Testing the problem from [4] showed that NP-hardness follows from exponential growth of the size of the feasible set. If the size is bounded then the problem can be solved in a reasonable time. The paper investigates this topic in details.
2 Problem formulation
We consider a quadratic programming problem
where Q is an indefinite \(n\times n\) matrix with exactly one negative eigenvalue, A is an \(m\times n\) matrix. The feasible set X is assumed to be nonempty and bounded. Here \(x^{\mathsf {T}}\) denotes the transpose of vector x.
Let us represent the matrix Q such that
where \(\lambda _1, \lambda _2, \ldots , \lambda _n\) are the eigenvalues of the matrix Q rearranged by increasing order, i.e. \(\lambda _1 \leqslant \ldots \leqslant \lambda _n\), \(\lambda _1<0\), \(\lambda _i \geqslant 0\), \(i=2,\ldots ,n\); W is a matrix, which columns are the eigenvectors of Q sorted according to its eigenvalues. \(\varLambda \) is a diagonal matrix with \(\lambda _1, \lambda _2, \ldots , \lambda _n\) as the diagonal elements. It is well known [7] that \(W^{-1} = W^{\mathsf {T}}\). The linear transformation
reduces the problem (1), (2) to the separable form, thus we get the following problem with the separable objective function:
where \(d = W^{\mathsf {T}}c\) and \(D = AW\). The problems (1), (2), and (5), (6) are equivalent in the sense that \(x^*\) is a solution of (1), (2) iff \(y^*= W^{\mathsf {T}} x^*\) solves (5), (6). Moreover values of the objectives also coincide. The further discussion refers mainly to the latter optimization statement since it is more convenient for analysis.
3 Minimization procedure
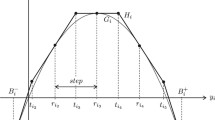
The objective function (5) is concave in \(y_1\) and is convex in other variables. Therefore the main idea of the minimization procedure for problem (5), (6) is a partition of the feasible set Y in variable \(y_1\) only. Let
be a projection of the set Y onto the \(y_1\)-axis. Divide the set \({\widetilde{Y}}\) into p intervals:
where \(\alpha \leqslant \alpha _i < \beta _i \leqslant \beta \), \(\beta _i = \alpha _{i+1}\) for \(i = 1,\ldots ,p-1\), and \(\alpha _1 = \alpha \), \(\beta _p = \beta \). Then we define a partition \(\{Y_1,Y_2, \ldots ,Y_p\}\) of Y as follows:
For every partition set \(Y_i\) we underestimate the concave part \(\lambda _1 y_1^2\) of the objective by an affine function \(l_i\) such that \(\lambda _1 y_1^2\) and \(l_i\) intersect at points \(\alpha _i\) and \(\beta _i\):
From (9) we obtain a convex approximation of g:
This inequality can be presented in the following equivalent form:
It is known [8] that
which results in the following estimation of the approximation error upon the entire feasible set:
Theorem 1
For a given \(\varepsilon > 0\), let the partition (7) satisfy
and \(y^*\) be a minimum point of \(\varphi \) upon Y. Then the following inequality holds:
Proof
The inequalities (11) are equivalent to
As \(\varphi (y^*) \leqslant \varphi (y)\) for every \(y\in Y\), (12) directly follows from (10) and (13).\(\square \)
From (10) to (13) we have that for every given tolerance \(\varepsilon >0\) we may define a partition of Y with sufficiently small widths of intervals in \(y_1\), so that
Underestimation of g by \(\varphi \) in that manner allows us to perform the partition (8) only once such that the inequality (14) holds. By Theorem 1, every minimizer of \(\varphi \) upon Y is an approximate solution of (5), (6). In order to minimize \(\varphi \), we solve p convex quadratic programming problems
Let \(y^{*i}\) be a solution of the ith problem in (15). Then
and a minimum point of \(\varphi \) is the corresponding vector among \(y^{*1}, \ldots , y^{*p}\). The optimization problems (15) are suggested to solve concurrently by parallel computing, since they are independent of each other.
As every partition set implies solving a convex quadratic program, the number of partition intervals p has a significant impact on how fast the set of problems (15) would be solved. For a particular problem (5), (6), one can compute the value of p satisfying (11) by
where \(\lceil a \rceil \) is the least integer greater than or equal to a number a. Additionally, an upper estimation of p needed to meet (11) may be established. Since X is bounded, there exists a box constrained set \({\widehat{X}} = \left\{ x\in {\mathbb {R}}^n \mid x^{\min } \leqslant x \leqslant x^{\max } \right\} \) such that \(X \subseteq {\widehat{X}}\). It is better to choose \({\widehat{X}}\) so that it has the minimal diameter.
Theorem 2
For a given \(\varepsilon >0\), there exists a positive integer p satisfying
such that the partition (7) meets (11).
Proof
Inscribe \({\widehat{X}}\) in a ball \(B = \left\{ x\in {\mathbb {R}}^n \mid \Vert x - x_0 \Vert \leqslant r \right\} \), where \(x_0 = \frac{1}{2}(x^{\min } + x^{\max })\), \(r = \Vert x^{\max } - x_0 \Vert \), and \(\Vert \cdot \Vert \) is the 2-norm. As \(W^{\mathsf {T}} W = I\), where I is the identity matrix, the projection of B onto the \(y_1\)-axis after the transformation (4) has the length equal to the diameter 2r of B. Since \(X\subset B\), there exist an integer p and bounds \((\alpha _i, \beta _i)\), \(i=1,\ldots ,p\), such that (11) holds and \(p \leqslant \lceil 2r / l \rceil \), where \(l = 2\sqrt{ \varepsilon / |\lambda _1| }\). The latter inequality directly implies (17). \(\square \)
It follows from Theorem 2 that, if \(X \subseteq {\widehat{X}}\) and \(\lambda _1\), \(x^{\min }\), \(x^{\max }\) do not depend on n, then the number of intervals p(n) has growth rate \(\sqrt{n}\). In the next section we consider an example, where the first component of \(x^{\max }\) grows rapidly as n increases.
4 Computational experiment
The proposed method with a single partition was computationally compared with a standard branch-and-bound procedure [9]. Let denote the former method by SP and the latter one by BB. In BB algorithm, partitioning is performed by bisection and, additionally, partition sets that certainly do not admit a solution are excluded from the consideration. More precisely, a partition set should be neglected if its lower bound of the objective exceeds the best known objective value (the record). For a particular partition set \(Y_i\) in BB procedure, lower bound is a minimum of \(\varphi _i\) on \(Y_i\).
We consider three groups of test problems. For every group, the result of the computation for both SP and BB algorithms is presented in a separate table. The names of columns are as follows. n is the number of variables, m is the number of linear constraints in (2) excluding box constraints, SP Int. is the number of intervals p computed by (16), SP Th.Int. is the theoretical estimation of p computed by (17), SP Time is the time of SP algorithm in seconds, BB Int. is the number of convex problems solved in BB algorithm, BB Time is the time of BB algorithm in seconds, Rel.Err. stands for an actual relative error computed after the solution is obtained. In all tables, every row corresponds to a single randomly generated problem. All random values were chosen from specific intervals according to a uniform distribution. To compute the right hand side of (17), we took box constraints of the problems’ definitions as the set \({\widehat{X}}\).
The program was implemented in AIMMS 4.66 modelling environment [10], problems (15) in both methods were solved by IBM ILOG CPLEX 12.9 solver [11]. In the SP method, we solved problems (15) concurrently in parallel using AIMMS GMP library facilities and, additionally, the number of threads used by one CPLEX session was limited to 1. In BB, problems of type (15) were solved sequentially, however the number of threads used by one CPLEX session was not limited so that every convex problem in BB was solved by multiple threads. We used default values for all other CPLEX parameters. Computation was performed on a computer with AMD Ryzen 7 1700X @ 3.4GHz CPU (8 cores, 16 threads), 16 Gb RAM. Preliminary experiments showed that the time of SP is minimal when the method uses 8 threads on this computer. Hence, for the SP algorithm, the number of simultaneous solution of convex problems was limited to 8.
Example 1
In problem (1), (2), set \(c = - (Q - \lambda _1 I ) x^*\), \(x^*= (1, -1,\ldots ,1,-1)^{\mathsf {T}}\), \(X = \{ x\in {\mathbb {R}}^n \mid -1 \leqslant x \leqslant 1 \}\). Vector \(x^*\) is a solution of (1), (2) [12]. Values of \(\lambda _1\), \(\lambda _i\), \(i=2,\ldots ,n\), and of elements of W were randomly chosen from intervals \([-11,-7]\), [0, 20], \([-10,10]\) respectively. Eigenvectors of Q were computed by applying the Gram–Schmidt process to columns of W. Then we defined Q by (3). For these problems, we set \(\varepsilon = 10^{-2}\), because it provided an acceptable relative error in a solution point. The computational results of SP and BB methods are in Table 1. We did not apply the SP algorithm to problems with \(n > 500\) due to considerable time of computation, more than 10 minutes per one problem. In all instances both algorithms found the solution \(x^*\). As there are box constraints only, \(m=0\) for all problems. The number of intervals turns out to be close to its theoretical estimation (17) and grows in accordance with it as n increases. On the other hand, in the BB algorithm, the number of convex problems solved by the method is small and is approximately constant for all dimensions we considered. The “bottleneck” in this case is the time CPLEX spends for solving one quadratic programming problem.
Example 2
In this case of (1), (2) all parameters of the objective function were generated randomly in the same way as in Example 1, except for vector c, the elements of which were randomly chosen from \([-30,30]\). Elements of A were generated from \([-15,15]\). Vector b was computed such that every constraint in (2) defined a tangent hyperplane to a ball with the radius 4 and random center, the elements of which were from \([-5,5]\). In order to guarantee the boundedness, we added box constraints \(-10\leqslant x \leqslant 10\). We set \(\varepsilon = 10^{-2}\). Table 2 contains the result of experiment. It shows that the number of intervals in SP is significantly larger than in Example 1. The reason for it is that variables have a larger bounds so that the length of projection \({\widetilde{Y}}\) increases. Inspite of the promising estimation (17), large number of intervals together with a significant time of solving convex QP leads to considerable time of the SP method. The number of convex problems solved in BB slightly exceeds that in Example 1, but still is nearly constant as n increases. The number m of non-box linear constraints increases the time CPLEX needs to solve a QP problem. One can observe this effect if we compare the columns BB Int. and BB Time for problems with the same n. For example, the problem with \(n=1000\), \(m=1500\) takes more than 1.5 times of computation time compared with the problem with the same n and \(m=800\). For the SP algorithm, the similar result takes place.
Example 3
As stated in [4], a specifically defined QP problem with one negative eigenvalue is equivalent to the maximum clique problem. For the graph with the set of vertices \(V=\{1,\ldots ,v\}\) and the set of edges E this QP is
where \(b=4\). Without loss of generality, we add the constraint \(y \leqslant 1\) to provide the boundedness. The key feature that makes this problem difficult to solve is that the length of projection \({\widetilde{Y}}\) onto w-axis (assuming \(y_1 = w\)) rapidly grows as v increases. Indeed, due to (18) this length may be estimated by \(b + b^2 + \cdots + b^v\). Inspite of this, we made some experiments to illustrate how behaviour of the methods differs from the previous two examples. We assume \(\varepsilon = 10^{-4}\). The set E was generated randomly in the form of a symmetric adjacency (0, 1)-matrix with zeros on its diagonal. We did not apply the SP algorithm due to a very large number of partition intervals in almost all problems we considered (see the column SP Int. in Table 3). This number exceeds \(10\,000\) even for the graph with 4 vertices. The number of convex problems in the BB procedure also increases fast. It is easy to see that problems (15) are linear for this statement, however large numbers in coefficients raise numerical issues with increasing of v.
5 Conclusion
We consider a quadratic programming problem with one negative eigenvalue. In general, it is NP-hard. However, if input parameters such as the negative eigenvalue and the feasible set do not depend on the number of variables, then a solution can be found by solving an acceptable number of convex quadratic programming problems. The experiment shows that, for the standard branch-and-bound procedure, the number of these convex problems is nearly constant for different dimensions.
References
Bomze, I.: Global optimization: a quadratic programming perspective. In: Di Pillo, G., Schoen, F. (eds.) Nonlinear Optimization. Lecture Notes in Mathematics, vol. 1989. Springer, Berlin (2010)
Murti, K.G.: Optimization for Decision Making: Linear and Quadratic Models. Springer, New York (2010)
Tuy, H.: Convex Analysis and Global Optimization. Springer, Berlin (2016)
Pardalos, P.M., Vavasis, S.A.: Quadratic programming with one negative eigenvalue is NP-hard. J. Glob. Optim. 1, 15–22 (1991)
Cambini, A., Martein, L.: Generalized Convexity and Optimization: Theory and Applications. Springer, Berlin (2009)
Mishra, S.K., Giorgi, G.: Invexity and Optimization. Springer, Berlin (2008)
Jeffrey, A.: Matrix Operations for Engineers and Scientists: An Essential Guide in Linear Algebra. Springer, Cham (2010)
Pardalos, P.M., Rosen, J.B.: Constrained Global Optimization: Algorithms and Applications. Springer, Berlin (1987)
Horst, R., Tuy, H.: Global Optimization: Deterministic Approaches. Springer, Berlin (1996)
https://www.aimms.com. Accessed 24 July 2019
https://www.ibm.com/products/ilog-cplex-optimization-studio. Accessed 24 July 2019
Pardalos, P.M.: Construction of test problems in quadratic bivalent programming. ACM Trans. Math. Softw. 17, 74–87 (1991)
Acknowledgements
We are grateful to two anonymous referees whose comments and suggestions helped us to essentially improve the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This study was funded by Russian Foundation for Basic Research according to the research Project No. 18-07-01432.
Rights and permissions
About this article

Cite this article
Minarchenko, I., Khamisov, O. On minimization of a quadratic function with one negative eigenvalue. Optim Lett 15, 1447–1455 (2021). https://doi.org/10.1007/s11590-020-01653-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11590-020-01653-5