
Abstract
The restricted strong convexity is an effective tool for deriving globally linear convergence rates of descent methods in convex minimization. Recently, the global error bound and quadratic growth properties appeared as new competitors. In this paper, with the help of Ekeland’s variational principle, we show the equivalence between these three notions. To deal with convex minimization over a closed convex set and structured convex optimization, we propose a group of modified versions and a group of extended versions of these three notions by using gradient mapping and proximal gradient mapping separately, and prove that the equivalence for the modified and extended versions still holds. Based on these equivalence notions, we establish new asymptotically linear convergence results for the proximal gradient method. Finally, we revisit the problem of minimizing the composition of an affine mapping with a strongly convex differentiable function over a polyhedral set, and obtain a strengthened property of the restricted strong convex type under mild assumptions.
Similar content being viewed by others
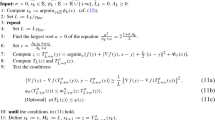

Avoid common mistakes on your manuscript.
1 Introduction
To obtain globally linear convergence rates of gradient-type methods for minimizing convex (not necessarily strongly convex) differentiable functions, we recently proposed the restricted strong convexity (RSC) [19, 20], which is a strictly weaker concept than the strong convexity. Up to now, it has been proved that the RSC property is a very powerful tool for analyzing descent methods including (in)exact gradient method, restarted nonlinear CG, BFGS and its damped limited memory variants L-D-BFGS [17, 20]. Almost parallel to work [19], the authors of [11, 18] defined the global error bound (GEB) property in the spirit of Hoffman’s celebrated result on error bounds for systems of linear inequalities [7, 10]. They showed that the GEB property also guarantees globally linear convergence results for descent methods. Moreover, they figured out a class of convex programs that frequently appear in machine learning obeying the GEB property. Very recently, the authors of [6, 9, 13] proposed the quadratic growth (QG) property with different names; it was called second order growth property in [13], optimal strong convexity in [9], and semi-strongly convex property in [6]. They showed that the QG property can guarantee globally linear convergence results for descent methods as well. Since each of these three notions contributes as a linear convergence guarantee, it should be interesting to see what is the relationship between them. With the help of Ekeland’s variational principle, we show that they are actually equivalent.
To deal with convex minimization over a closed convex and structured convex optimization, we propose a group of modified versions and a group of extended versions of these three notions by using gradient mapping and proximal gradient mapping separately [14] to replace the gradient notion. Similarly, the modified and extended versions can be used to derive globally linear convergence results for a large class of descent methods in convex minimization [3, 5, 6, 13]. If the objective function in convex program involves the gradient-Lipschitz-continuous property, we prove that the equivalence for the modified and extended versions still holds. Based on these equivalence notions, we establish new asymptotically linear convergence results for the proximal gradient method, that are complementary to recently appearing theory.
The equivalence results in this paper provide us with alternative ways to check whether a given convex minimization problem satisfies the RSC property; in some cases, to check one of the equivalence properties might be much easier than to check the others. As a case study, we investigate the problem of minimizing the composition of an affine mapping with a strongly convex differentiable function over a polyhedral set, which is very popular in machine learning. We prove that this problem enjoys a strengthened property of the RSC type and hence the modified GEB property without any compactness assumption of polyhedral sets.
At the time of writing this paper, the authors of [4] showed the equivalence between the error bound (corresponding to our growth property) and the Kurdyka-\({\L }\)ojasiewicz inequality for convex functions having a moderately flat profile near the set of minimizers. As the convex functions are differentiable, this paper might provide complementary results to that in [4]. When our paper was under review, the authors of [5] posted their paper concerning the equivalence between the error bound and quadratic growth properties on arXiv. They defined the error bound condition by using the proximal gradient mapping, that generalizes our modified error bound property and the global error bound from the beginning proposed in [18]. However, they did not discuss the equivalence to the RSC property. Besides, our convergence results for the proximal gradient method are new and might be of interest in themselves.
The rest of paper is organized as follows. In Sect. 2, we present the basic notations and concepts discussed in this paper. In Sect. 3, we analyze the relationship of different notions. In Sect. 4, we discuss the convergence of proximal gradient method implied by the equivalence notions. In Sect. 5 is devoted to a case study.
2 Notation and definitions
We denote by \(d(x, \mathcal {Y})\) the distance from a point x to a nonempty closed set \(\mathcal {Y}\); that is, \(d(x, \mathcal {Y})=\inf _{y\in \mathcal {Y}}\Vert x-y\Vert \). When \(\mathcal {Y}\) is a single point set, i.e., \(\mathcal {Y}=\{y\}\), we use d(x, y) to replace \(d(x, \mathcal {Y})\) for simplicity. We will consider functions that take values in the extended real line \(\overline{\mathbb {R}}:=\mathbb {R}\bigcup \{+\infty \}\). The projection of x onto a nonempty closed convex set \(\mathcal {Y}\) is denoted by \([x]_\mathcal {Y}^+\). The spectral norm of a matrix X is given by \(\Vert X\Vert \). The terminology below follows from [14]. A convex differentiable function g is gradient-Lipschitz-continuous if there exists a positive scalar L such that
or equivalently,
and strongly convex if there exists a positive scalar \(\mu \) such that
2.1 Original versions for unconstrained convex program
Definition 1
Let \(f:\mathbb {R}^n\rightarrow \mathbb {R}\) be convex differentiable. Denote \(f^*=\min _{x\in \mathbb {R}^n} f(x)\) and \(\mathcal {X}=\arg \min _{x\in \mathbb {R}^n} f(x)\) and assume that \(\mathcal {X}\) is nonempty. Then the unconstrained convex program
obeys
-
(a)
the restricted strongly convex property with constant \(\nu >0\) if it satisfies the restricted secant inequality
$$\begin{aligned} \langle \nabla f(x), x-[x]_\mathcal {X}^+\rangle \ge \nu \cdot d^2(x,\mathcal {X}),\quad \forall x\in \mathbb {R}^n. \end{aligned}$$(4) -
(b)
the global error bound property with constant \(\kappa >0\) if it satisfies the error upper bound inequality
$$\begin{aligned} \Vert \nabla f(x)\Vert \ge \kappa \cdot d(x,\mathcal {X}),\quad \forall x\in \mathbb {R}^n. \end{aligned}$$(5) -
(c)
the quadratic growth property with constant \(\tau >0\) if it satisfies the second order growth of the function value
$$\begin{aligned} f(x)-f^*\ge \frac{\tau }{2}\cdot d^2(x,\mathcal {X}), \quad \forall x\in \mathbb {R}^n. \end{aligned}$$(6)
We use \(RSC(\nu )\), \(GEB(\kappa )\), and \(QG(\tau )\) to stand for the defined properties above respectively.
To ensure that \([x]_\mathcal {X}^+\) is well defined, we need \(\mathcal {X}\) to be closed; this is implied by the differentiable of f(x).
Remark 1
The RSC property first appeared in [8] as a restricted secant inequality. The authors of [19, 20] formally defined it and figured out a class of non-trivial RSC functions.
The authors of [11, 18] proposed the GEB property in the spirit of Hoffman’s error bounds [7]. The local version of GEB only implies asymptotic linear convergence rates [10].
The QG property appeared in a couple of papers [6, 9, 13] with different names. The equivalence between the RSC and the QG of convex differentiable functions was shown in [17, 20].
2.2 Modified versions for constrained convex program
To deal with constrained convex programs, we first introduce the gradient mapping [14].
Definition 2
Let \( \gamma >0\) be a fixed constant and Q be a closed convex set, and let \(\bar{x}\in \mathbb {R}^n\). Denote
We call \(G^f_Q(\bar{x};\gamma )\) the gradient mapping of function f on Q.
When \(Q=\mathbb {R}^n\), we have that
The latter implies that the gradient mapping generalizes the gradient notion.
Definition 3
Let \(f:\mathbb {R}^n\rightarrow \mathbb {R}\) be a convex differentiable function and let Q be a nonempty closed convex set. Denote \(\mathcal {X}=\arg \min _{x\in Q} f(x)\) and \(f^*=\min _{x\in Q} f(x)\) and assume that \(\mathcal {X}\) is nonempty. Let \(\gamma >0\) be a fixed constant. Then the constrained convex program
obeys
-
(a)
the modified restricted strongly convex property on Q with constant \(\nu >0\) if it satisfies the restricted secant inequality
$$\begin{aligned} \langle G^f_Q(y;\gamma ), y-[y]_\mathcal {X}^+\rangle \ge \nu \cdot d^2(y,\mathcal {X}),\quad \forall y\in Q. \end{aligned}$$(7) -
(b)
the modified global error bound property on Q with constant \(\kappa >0\) if it satisfies the error upper bound inequality
$$\begin{aligned} \Vert G^f_Q(y;\gamma )\Vert \ge \kappa \cdot d(y,\mathcal {X}), \quad \forall y\in Q. \end{aligned}$$(8) -
(c)
the modified quadratic growth property on Q with constant \(\tau >0\) if it satisfies the second order growth of the function value
$$\begin{aligned} f(y)-f^*\ge \frac{\tau }{2}\cdot d^2(y,\mathcal {X}), \quad \forall y\in Q. \end{aligned}$$(9)
We use \(mRSC(\nu )\), \(mGEB(\kappa )\), and \(mQG(\tau )\) to stand for the defined properties above respectively.
Again, the closedness of \(\mathcal {X}\) is guaranteed by the differentiable of f(x) and hence \([y]_\mathcal {X}^+\) is well defined.
Remark 2
The author of [17] also proposed a modified RSC by considering a convex constraint set Q. But they required that both \(X_f=\arg \min _{x\in \mathbb {R}^n} f(x)\) and \(Q\bigcap X_f\) are nonempty. Such assumptions are very strong conditions and many practical problems may fail to satisfy.
Remark 3
When \(Q=\mathbb {R}^n\), the modified versions return to the corresponding original versions since \(G^f_Q(\bar{x};\gamma )=\nabla f(\bar{x})\). Therefore, the modified Definition 3 can be viewed as a generalization of Definition 1.
2.3 Extended versions via proximal gradient mapping
To introduce extended versions of the previous notions for structure convex optimization, we need the concept of proximal gradient mapping [2].
Definition 4
Let \( \gamma >0\) be a fixed constant, \(f: \mathbb {R}^n\rightarrow \mathbb {R}\) be a differentiable function, \(g:\mathbb {R}^n\rightarrow \overline{\mathbb {R}}\) be a closed convex function, and \(\bar{x}\in \mathbb {R}^n\). Denote
We call \(G^f_g(\bar{x};\gamma )\) the proximal gradient mapping of functions f and g.
Let Q be a closed nonempty convex set. When g is the indicator function
we have that
This implies that the proximal gradient mapping generalizes the gradient mapping.
Definition 5
Let \(f:\mathbb {R}^n\rightarrow \mathbb {R}\) be a convex differentiable function and \(g:\mathbb {R}^n\rightarrow \overline{\mathbb {R}}\) be a closed convex function. Denote \(\mathcal {X}=\arg \min _{x} \varphi (x):= f(x)+g(x)\) and \(\varphi ^*=\min _{x} \varphi (x)\) and assume that \(\mathcal {X}\) is nonempty. Let \(\gamma >0\) be a fixed constant. Then the following convex program
obeys
-
(a)
the extended restricted strongly convex property with parameter \(\nu , \omega >0\) if it satisfies the restricted secant inequality
$$\begin{aligned} \langle G^f_g(y;\gamma ), y-[y]_\mathcal {X}^+\rangle \ge \nu \cdot d^2(y,\mathcal {X}),\quad \forall y\in [\varphi \le \varphi ^*+\omega ]. \end{aligned}$$(10) -
(b)
the extended global error bound property with parameter \(\kappa , \omega >0\) if it satisfies the error upper bound inequality
$$\begin{aligned} \Vert G^f_g(y;\gamma )\Vert \ge \kappa \cdot d(y,\mathcal {X}), \quad \forall y\in [\varphi \le \varphi ^*+\omega ]. \end{aligned}$$(11) -
(c)
the extended quadratic growth property with constant parameter \(\tau , \omega >0\) if it satisfies the second order growth of the function value
$$\begin{aligned} \varphi (y)-\varphi ^*\ge \frac{\tau }{2}\cdot d^2(y,\mathcal {X}), \quad \forall y\in [\varphi \le \varphi ^*+\omega ]. \end{aligned}$$(12)
We use \(eRSC(\nu , \omega )\), \(eGEB(\kappa , \omega )\), and \(eQG(\tau , \omega )\) to stand for the defined properties above respectively.
It is easy to see that \(\varphi (x)\) is lower semicontinuous over \(\mathbb {R}^n\) and hence \(\mathcal {X}\) is closed; see e.g. Lemma 2.6.3 in [16]. This ensures that \([y]_\mathcal {X}^+\) is well defined.
Remark 4
The eQG appeared in [6] under the name of semi-strongly convex property. The authors of [21] proposed an analog of the eGEB property and exploited it by borrowing tools from set-valued analysis. The authors of [5] introduced the eGEB and proved that it is equivalent to the eQG. Our novelty here lies in the definition of eRSC.
3 Equivalence analysis
3.1 Equivalence among the original versions
In what follows, we prove that the notions defined in Definition 1 are actually equivalent. The idea of proof is mainly inspired by the seminal paper [1] and heavily relies on the well-known Ekeland’s variational principle in Lemma 1.
Theorem 1
Under the setting of Definition 1, the restricted strongly convex property, the global error bound property, and the quadratic growth property are equivalent in the following sense:
Proof
The implication of \(QG(\nu )\Rightarrow RSC(\frac{\nu }{2})\) has been shown in [17, 20]. The implication \(RSC(\frac{\nu }{2})\Rightarrow GEB(\frac{\nu }{2})\) is a direct consequence after applying the Cauchy-Schwartz inequality. It only needs to prove \(GEB(\nu ) \Rightarrow QG(\frac{\nu }{2})\). Now assume that f has the GEB property with constant \(\nu >0\). It suffices to prove that for all \(0\le \alpha <\frac{1}{4}\), the following holds:
If this is not true, then there must exist \(z_0\in \mathbb {R}^n\) such that
Clearly, \(z_0\notin \mathcal {X}\) and hence \(d(z_0, \mathcal {X})>0\) since \(\mathcal {X}\) is a nonempty closed set. Let \(\lambda =\frac{1}{2}d(z_0, \mathcal {X})\). By Ekeland’s variational principle with \(\epsilon =\alpha \nu \cdot d^2(z_0,\mathcal {X})=4\alpha \nu \lambda ^2\), there exists \(x_0\in \mathbb {R}^n\) such that \(d(x_0,z_0)\le \lambda \) and
Then, \(x_0\) minimizes the convex function \(f(x)+4\alpha \nu \lambda \cdot d(x,x_0)\). By the first-order optimality condition, we get
where \(\mathcal {Y}=\{y\in \mathbb {R}^n: \Vert y\Vert \le 1\}\) [16]. Hence, we can find \(y_0\in \mathcal {Y}\) such that \(\nabla f(x_0)=-4\alpha \nu \lambda y_0\). Since
we have \(d(x_0, \mathcal {X})\ge \lambda \). Therefore,
which contradicts the GEB property. This completes the proof. \(\square \)
3.2 Equivalence among the modified and extended versions
In this part, we deduce the equivalence among the modified and extended versions.
Theorem 2
Let \(f:\mathbb {R}^n\rightarrow \mathbb {R}\) be a convex differentiable function whose gradient is Lipschitz-continuous with positive scalar L and \(g:\mathbb {R}^n\rightarrow \overline{\mathbb {R}}\) be a closed convex function. Let \(\gamma \ge L\) be a fixed constant. Then the extended versions are equivalent in the following sense
and
where \(\omega \in (0, +\infty ]\) is a fixed constant and the other parameters satisfy \(\kappa _1=\tau _1=\nu _1\) and
In particular, the equivalence among the modified versions also holds in the same way by letting \(\omega =+\infty \).
Proof
The equivalence of \(eGEB(\kappa , \omega )\) and \(eQG(\tau ,\omega )\) has been shown in [5] recently; see Lemma 2. Applying the Cauchy-Schwartz inequality to the left-hand side term of eRSC gives the eGEB property. It remains to prove that eGEB implies eRSC. By using Lemma 3 with \(x=[y]_\mathcal {X}^+\) and \(\bar{x}=y\), we get
Noticing that \(\varphi (p^f_g(y;\gamma )) - \varphi ([y]_\mathcal {X}^+)=\varphi (p^f_g(y;\gamma )) - \varphi ^*\ge 0\) and applying the eGEB property, we obtain
which completes the proof. \(\square \)
4 Convergence analysis
In this section, we discuss asymptotically linear convergence of the proximal gradient method, based on the equivalence notions defined before.
The proximal gradient method, also known as the forward-backward splitting method, is fundamental for the following structured optimization problem
where f is a convex function with the gradient-Lipschitz-continuous property and g is a closed convex function. It can be stated as
where the constant \(\gamma >0\) is appropriately chosen. Based on the eGEB property, the authors of [5] observed that an asymptotically Q-linear convergence in function values can be assured for this method, and moreover, if the iterates \(x_k\) have some limit point \(x^*\), then \(x_k\) asymptotically converge R-linearly. Motivated by the arguments in [20], we have established below an asymptotically Q-linear convergence in the distance values \(d(x_{k},\mathcal {X})\), and proved that \(x_k\) themselves asymptotically converge R-linearly to a limit point \(x^*\) under a compactness assumption on the minimizer set \(\mathcal {X}\). The following result is complimentary to that of [5] and might be of interest in itself.
Theorem 3
Let \(f:\mathbb {R}^n\rightarrow \mathbb {R}\) be a convex differentiable function whose gradient is Lipschitz-continuous with positive scalar L and \(g:\mathbb {R}^n\rightarrow \overline{\mathbb {R}}\) be a closed convex function. Denote \(\mathcal {X}=\arg \min _{x} \varphi (x):= f(x)+g(x)\) and \(\varphi ^*=\min _{x} \varphi (x)\) and assume that \(\mathcal {X}\) is nonempty. Let \(\gamma \ge L\) be a fixed constant. Suppose that \({{\mathrm{minimize}}}_{x} \varphi (x)\) satisfies the \(eQG(\tau ,\omega )\) property (equivalently, the \(eGEB(\kappa , \omega )\) property). Then, the iterates \(x_k\) generated by the proximal gradient method asymptotically converge Q-linearly, that is there exists an index m such that the inequality
holds for all \(k\ge m\). Moreover, if \(\mathcal {X}\) is compact, then the iterates \(x_k\) asymptotically converge R-linearly to some limit point \(x^*\in \mathcal {X}\) in the sense that
holds for all \(k\ge 1\), where \(m>\frac{L}{2\omega }d^2(x_0,\mathcal {X})\) and \(C=\frac{2(\varphi (x_m)-\varphi ^*)}{\gamma }\left( \sum _{i=0}^\infty (1-\frac{\kappa }{2\gamma })^{\frac{i}{2}}\right) ^2\).
The proof idea below is partially inspired by [5, 20].
Proof
Let \(m= \lceil \frac{L}{2\omega }d^2(x_0,\mathcal {X})\rceil \) where \(\lceil x \rceil \) denotes the smallest integer larger than x. By using the standard sublinear estimate [2]
we deduce that \(\varphi (x_k)-\varphi ^*\le \omega \) holds for all \(k\ge m\). Denote the projection point of x onto \(\mathcal {X}\) by \(x^{\prime }\). By invoking Lemma 3 with \(x=x_k^{\prime }\) and \(\bar{x}=x_k\), we have that
Now, together with the \(eQG(\tau ,\omega )\) property, we derive that for all \(k\ge m\)
which yields the asymptotically Q-linear convergence of \(x_k\).
To prove the convergence of \(\{x_k\}\) themselves, we first consider the sequence \(\{x^{\prime }_k\}\subseteq \mathcal {X}\), which must have a subsequence, denoted by \(\{x^{\prime }_{k_i}\}\), converging to some point \(x^*\in \mathcal {X}\) due to the compactness assumption on \(\mathcal {X}\). We claim that \(x^{\prime }_k\rightarrow x^*\) as \(k\rightarrow \infty \). Otherwise, there must exist another subsequence of \(\{x_k\}\), denoted by \(\{x^{\prime }_{k_j}\}\), converging to a different point \(\hat{x}\in \mathcal {X}\). Notice that
and \(d(x^{\prime }_{k_i}, x^{\prime }_{k_j})\le d(x_{k_i}, x_{k_j}),\) where the latter follows from the nonexpansive property of projection operator. We get that
Denote \(\ell _1=\min \{k_i, k_j\}\) and \(\ell _2=\max \{k_i,k_j\}\); then
By invoking Lemma 3 with \(x=\bar{x}=x_i\), we have that
On the other hand, inequality (15) implies
Applying the \(eGEB(\kappa , \omega )\) property to (19) and combining with (18), we get that
Let \(\ell _1\ge m\) and \(i\ge m\); then
and hence
where \(D=\sqrt{\frac{2(\varphi (x_m)-\varphi ^*)}{\gamma }}\sum _{i=0}^\infty \left( 1-\frac{\kappa }{2\gamma }\right) ^{\frac{i}{2}}<\infty \). Together with the fact that \(x^{\prime }_{k_i}\rightarrow x^*\) as \(k_i\rightarrow \infty \) and \(x^{\prime }_{k_j}\rightarrow \hat{x}\) as \(k_j\rightarrow \infty \), we immediately get \(d(x^*,\hat{x})=0\) by using (17) with \(k_i\rightarrow \infty \) and \(k_j\rightarrow \infty \), which contradicts \(x^*\ne \hat{x}\). Therefore, \(x^{\prime }_k\rightarrow x^*\) as \(k\rightarrow \infty \) indeed holds. Finally, in light of the asymptotically Q-linear convergence of \(x_k\), we have that
which implies that the iterates \(x_k\) converge to \(x^*\in \mathcal {X}\). The asymptotically R-linear convergence of \(\{x_k\}\) follows by setting \(k_i=\ell _1=k+m\) and letting \(k_j\rightarrow +\infty \) in (22). This completes the proof. \(\square \)
Remark 5
Although (22) implies that \(\{x_k\}\) is a Cauchy sequence and hence converges, it can not ensure its convergence to a point belonging to \(\mathcal {X}\) without the compactness assumption on \(\mathcal {X}\).
5 A case study: composition minimization with constraints
The authors of [21] presented a unified framework for establishing error bounds for a class of structured convex optimization problems. By the equivalence between the error bound condition and quadratic growth, the authors of [5] streamlined and illuminated the arguments in [21] and also extended their results to a wider setting. Here, in a transparent way we derive a strengthened property of the RSC type for the following constrained convex program
where Q is a polyhedral set in the n-dimensional Euclidean space, and f is the composition of an affine mapping with a strongly convex differentiable function. We assume that f and Q are of the special form:
where E is some \(m\times n\) matrix, A is some \(k\times n\) matrix, \(b\in \mathbb {R}^k\) is some vector, and g is strongly convex and gradient-Lipschitz-continuous with positive scalars \(\mu \) and L respectively.
The convex program (23) has been extensively studied for its wide applications in data networks and machine learning.
Theorem 4
Under the setting of Definition 3 and letting \(\gamma \ge L\Vert EE^T\Vert \), we have that the constrained convex program (23) obeys the strengthened property of the RSC type:
and the modified quadratic growth property:
where \(C_i, i=1,2\) are positive constant depending on matrices E and A and the positive scalar \(\mu \).
Proof
By using (29) in Lemma 5 with \(x=[y]_\mathcal {X}^+, \bar{x}=y\) and noticing that \(f(x_Q(y;\gamma ))\ge f([y]_\mathcal {X}^+)=f^*\), we get
Since g is strongly convex, there must exist a unique vector \(t^*\) such that \( Ex=t^*, \forall x\in \mathcal {X}\); please refer to [10, 18]. Thus,
Due to the result of Hoffman’s error bound in Lemma 6, there must exist a constant \(\theta >0\) depending on matrices E and A such that for any \(y\in Q=\{x|Ax\le b\}\) it holds
Thus, the strengthened property of the RSC type follows from this and the inequality (26).
By Lemma 7, for any \(x^*\in \mathcal {X}\) we have \(G^f_Q(x^*;\gamma )=0\) and hence \(x^*=x_Q(x^*;\gamma )\). Therefore, using (29) Lemma 5 with \(\bar{x}=[y]_\mathcal {X}^+\) and the fact of \(\Vert Ey-E[y]_\mathcal {X}^+\Vert ^2\ge \theta \cdot d^2(y,\mathcal {X})\), we get the modified quadratic growth property. This completes the proof. \(\square \)
Remark 6
By Lemma A.8 in [18], we get
Thus, using this and applying the Cauchy-Schwartz inequality to (24), we get
Or, equivalently there exists a constant \(C_3>0\) such that
On the contrast, the authors of [18] derived the following error bound
for \(f(x)=g(Ex)+q^Tx\). Although this bound enables the incorporation of the additional linear term, the constant \(\kappa _3\) depends on the positive parameter M and hence on the variable y. To avoid such dependence, the authors of [3] derived the quadratic growth property
for \(f(x)=g(Ex)+q^Tx\) by assuming that Q is compact, where \(\kappa _4>0\) is a constant. Here, we can drop the compactness assumption by neglecting the linear term \(q^Tx\).
Remark 7
There is an alternative way in [13] to prove the modified QG property. Indeed, By the strong convexity of g and the fact of \(\Vert Ey-E[y]_\mathcal {X}^+\Vert ^2\ge \theta \cdot d^2(y,\mathcal {X})\), we derive for \(\forall y\in Q\) that
Thus, by Theorem 2 we immediately get the mRSC property
where \(C_4\) is some positive constant.
References
Aragón Artacho, F.J., Geoffroy, M.H.: Characterization of metric regularity of subdifferentials. J. Convex Anal. 15(2), 365–380 (2008)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2(1), 183–202 (2009)
Beck, A., Shtern, S.: Linearly convergent away-step conditional gradient for non-strongly convex functions (2015). arXiv:1504.05002v1 [math.OC]
Bolte, J., Nguyen, T.P., Peypouquet, J., Suter, B.W.: From error bounds to the complexity of first-order descent methods for convex functions (2015). arXiv:1510.08234v1 [math.OC]
Drusvyatskiy, D., Lewis, A.S.: Error bounds, quadratic growth, and linear convergence of proximal methods (2016). arXiv:1602.06661v1 [math.OC]
Gong, P.H., Ye, J.P.: Linear convergence of variance-reduced stochastic gradient without strong convexity (2015). arXiv:1406.1102v2 [cs.NA]
Hoffman, A.J.: On approximate solutions of systems of linear inequalities. J. Res. Natl. Bureau Stand. 49, 263–265 (1952)
Lai, M.J., Yin, W.T.: Augmented \(\ell _1\) and nuclear-norm models with a globally linearly convergent algorithm. SIAM J. Imaging Sci. 6(2), 1059–1091 (2013)
Liu, J., Wright, S.J.: Asynchronous stochastic coordinate descent: parallelism and convergence properties. SIAM J. Optim. 30, 351–376 (2015)
Luo, Z.Q., Tseng, P.: On the linear convergence of descent methods for convex essentially smooth minimization. SIAM J. Optim. 117, 408–425 (1992)
So, A.M.-C.: Non-asymptotic convergence analysis of inexact gradient methods for machine learning without strong convexity (2013). arXiv:1309.0113v1 [math.OC]
Mangasarian, O.L., Shiau, T.-H.: Lipschitz continuity of solutions of linear inequalities, programs and complementarity problems. SIAM J. Control Optim. 25(3), 583–595 (1987)
Necoara, I., Nesterov, Y., Glineur, F.: Linear convergence of first order methods for non-strongly convex programming (2015). arXiv:1504.06298v3 [math.OC]
Nesterov, Y.: Introductory Lectures on Convex Optimization: A Basic Course. Kluwer Academic, New York (2004)
Robinson, S.M.: Bounds for error in the solution set of a perturbed linear program. Linear Algebra Appl. 6(69–81), 1–38 (1973)
Ruszczyński, A.P.: Nonlinear Optimization, vol. 13. Princeton university press, New Jersy (2006)
Sch\(\ddot{o}\)pfer, F.: Linear convergence of descent methods for the unconstrained minimization of restricted strongly convex functions. SIAM J. Optim. (2015) (submitted)
Wang, P., Lin, C.: Iteration complexity of feasiable decent methods for convex optimization. J. Mach. Learn. Res. 15, 1523–1548 (2014)
Zhang, H., Yin, W.T.: Gradient methods for convex minimization: better rates under weaker conditions. Technical report, CAM Report 13-17, UCLA (2013)
Zhang, H., Cheng, L.Z.: Restricted strong convexity and its applications to convergence analysis of gradient-type methods. Optim. Lett. 9(5), 961–979 (2015)
Zhou, Z.R., So, A.M.-C.: A unified approach to error bounds for structured convex optimization problems (2015). arXiv:1512.03518v1 [math.OC]
Acknowledgments
We would like to thank anonymous reviewers for their valuable comments, with which great improvements have been made in this manuscript. The work is supported by the National Science Foundation of China (Nos. 11501569 and 61571008).
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Lemma 1
(Ekeland’s variational principle, [1]) Let \((X, d(\cdot ,\cdot ))\) be a complete metric space and let \(f:\mathbb {R}^n\rightarrow \overline{\mathbb {R}}\) be a lower semicontinuous function bounded from below, where d(x, y) stands for the Euclidean distance. Suppose that for some \(\epsilon >0\) and \(z\in X\), \(f(z)<\inf f +\epsilon \). Then for any \(\lambda >0\) there exist \(y\in X\) such that \(d(z,y)\le \lambda \) and
Lemma 2
(Corollary 3.6, [5]) Let f be gradient-Lipschitz-continuous with positive scalar L and \(g:\mathbb {R}^n\rightarrow \overline{\mathbb {R}}\) be a closed convex function. Then the \(eQG(\tau , \omega )\) implies \(eGEB(\kappa , \omega )\) with \(\kappa =\frac{\tau \gamma ^2}{(2\gamma +\tau )(\gamma +L)}\). Conversely, the \(eGEB(\kappa , \omega )\) implies the \(eQG(\tau , \omega )\) with any \(\tau \in (0, \kappa )\).
The following result describes an important property of the proximal gradient mapping.
Lemma 3
([2]) Let f(x) be gradient-Lipschitz-continuous with positive scalar L, \(g:\mathbb {R}^n\rightarrow \overline{\mathbb {R}}\) be a closed convex function, \(\gamma \ge L\), and \(\bar{x}\in \mathbb {R}^n\). Denote \(\varphi (x)=f(x)+g(x)\). Then, for any \(x\in Q\) we have
Lemma 4
Let \(f(x)=g(Ex)\) with g satisfying the properties (1) and (3), and denote \(\hat{L}=L\Vert EE^T\Vert \). Then, we have
and
Proof
By applying integration, we derive \(\forall x, y\in \mathbb {R}^n\) that
Thus, by the strong convexity we get
and by the Lipschitz property and the Cauchy-Schwartz inequality we have
both of which complete the proof. \(\square \)
To deal with the gradient mapping of \(f(x)=g(Ex)\), we need the following result which is motivated by Theorem 2.2.7 in [14].
Lemma 5
Let \(f(x)=g(Ex)\) with g satisfying the properties (1) and (3), and let \(\gamma \ge \hat{L}(=L\Vert EE^T\Vert )\) and \(\bar{x}\in \mathbb {R}^n\). Then, for any \(x\in Q\) we have
Proof
Denote \(x_Q=x_Q(\bar{x};\gamma ), G=G^f_Q(\bar{x};\gamma )\) and let
Then, \(\nabla \phi (x)=\nabla f(\bar{x})+\gamma (x-\bar{x})\) and for any \(x\in Q\) we have
With this inequality and by Lemma 4, we derive that
where the last inequality follows from \(f(x)\le \phi (x)\) since \(\gamma \ge \hat{L}\). Hence, the desired result holds. \(\square \)
Lemma 6
(Hoffman’s error bound, [7, 12, 15]) Let E be an \(m\times n\) matrix and A be a \(k\times n\) matrix, and let b be a vector in \(\mathbb {R}^k\). Then, there exists a scalar \(\theta >0\) depending on E and A only such that, for any y satisfying \(Ax\le b\) and any \(t^*\in \mathbb {R}^m\) such that the linear system \(Ex=t^*, Ax\le b\) is consistent, there is a point \(\bar{y}\in \{u: Eu=t^*, Au\le b\}\) satisfying \(\theta \Vert y-\bar{y}\Vert ^2\le \Vert Ey-t^*\Vert ^2\).
Lemma 7
Let \(\gamma >0\). Then \(\bar{x}\in Q\) is optimal for (23) if and only if \(G^f_Q(\bar{x};\gamma )=0\)
The proof is identical to the proof of Lemma A.6 in [18]. Hence we omit the arguments.
Rights and permissions
About this article

Cite this article
Zhang, H. The restricted strong convexity revisited: analysis of equivalence to error bound and quadratic growth. Optim Lett 11, 817–833 (2017). https://doi.org/10.1007/s11590-016-1058-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11590-016-1058-9