
Abstract
Foggy weather reduces the quality of video capture and seriously affects the normal work of video surveillance, remote sensing monitoring, and intelligent driving. Many methods have been proposed to remove video haze. However, under the premise of ensuring real-time performance, their defogging effect needs to be further improved. This paper improves the dark channel prior (DCP) dehazing algorithm, and designs a defogging framework that takes into account good dehazing effect and real-time processing. First, an adaptive threshold segmentation algorithm is proposed, which can well solve the serious color cast problem in brighter areas in DCP. Second, an algorithm for preserving image details using gradients is proposed, which achieves a good balance between detail preservation and computational efficiency. Then, each frame of video is evenly divided into a plurality of sub-areas, and the sub-areas are sequentially processed in a pipeline manner, which improves calculation efficiency. Finally, a high-definition real-time video defogging framework with a resolution of 1920 × 1080 and 60 frames/s is realized on the ZYNQ 7035.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In the rapidly advancing information age, an abundance of diverse information permeates our surroundings, with visual information playing a crucial role in human production and daily life. However, during hazy weather conditions, light undergoes scattering and absorption by suspended airborne particles. This, combined with the reflected light from the observed target, results in the amalgamation of visual details in the collection system. Consequently, clarity and contrast diminish, significantly discounting the imaging effects. In video surveillance [1], fog obscures the picture and critical information may be lost. In remote sensing monitoring [2], aerial images are easily affected by fog, which makes the objects to be photographed unclear. In intelligent driving [3], foggy weather may weaken the display effect of obstacles, causing the driving system to misjudge, and then affect driving safety. In short, video defogging has practical significance. Therefore, improving the performance of video dehazing is very necessary and has practical significance.
While there has been considerable research on video dehazing [4, 5], there is a relative scarcity of studies focused on the hardware implementation of this process. In the realm of video dehazing research, the challenge lies in achieving effective dehazing while maintaining high resolutions and frame rates. Higher-resolution images can capture more intricate details, and a higher frame rate in videos contributes to a smoother visual experience. Due to constraints imposed by hardware resources and the need to balance frame rates with resolution requirements, existing research often involves an initial resolution reduction followed by super-resolution operations when designing dehazing architectures. However, such procedures frequently result in a significant loss of detailed information and a decrease in dehazing efficiency. In video defogging, in addition to the defogging effect, the computational efficiency of the algorithm is also an important point. To be smooth, video dehazing requires a lot of calculations in a short time. So, the complexity of the algorithm and the hardware circuit design play a decisive role in fluency. Besides, a good defogging effect must also be taken into account.
Most of the existing video defogging methods are derived from single-image defogging algorithms. However, most single-image defogging algorithms are designed for general-purpose serial processors, with complex logic and large calculation delays. When performing video defogging, FPGA [6] is often chosen. The parallel computing feature of FPGA is consistent with the large number of parallel computing operations in video processing, which can effectively improve computing efficiency.
The algorithm in this paper is improved on the dark channel prior dehazing (DCP) [7] algorithm, which solves the problem that it is prone to color cast in the sky area, and is finally applied to real-time dehazing of 1080p, 60 frames/s high-definition video. The main contributions of this paper are as follows:
1. An adaptive threshold segmentation method is proposed to separate brighter and non-brighter regions to make atmospheric light and transmittance estimation more accurate. The color cast in DCP is nicely solved with this method.
2. A method using gradients to preserve image details is proposed, which has a good balance on details preservation and computing efficiency.
3. A hardware structure for high-definition real-time video defogging is proposed. An efficient data interaction system is designed, which saves a lot of storage space while fully meeting the requirements of high-definition real-time video dehazing.
The rest of the paper is organized as follows: Sect. 2 introduces related works of image and video dehazing, Sect. 3 introduces DCP and the problems that need to be solved when using this method, Sect. 4 introduces the algorithm flow of this paper, Sect. 5 introduces the hardware architecture of this paper, Sect. 6 presents the results and compares them with other literatures, and Sect. 7 discusses the results.
2 Related works
Many single-image defogging algorithms have achieved good defogging effects [8, 9], which has a certain inspiration for the video dehazing.
At present, the dehazing algorithm is mainly based on the following three types of models:
1. Physical model.
2. Non-physical model.
3. Deep learning model.
Atmospheric scattering theory is the most widely used theoretical basis in physical models. The algorithm based on the atmospheric scattering model establishes a real physical imaging model, studies the cause of image degradation, and decomposes the fog-free image from the foggy image. Since the atmospheric light intensity and transmittance are unknown, the solution of this model is ambiguous.
Among the algorithms based on this model, the dark channel prior (DCP) proposed by He et al. has a good defogging effect. The DCP not only has a profound impact on image defogging [10,11,12], but is also widely used in other image processing fields [13, 14]. However, in the bright areas of the foggy image, dehazing by DCP is prone to color cast. In order to eliminate the color cast, many literatures adopt the idea of splitting the sky area. Li et al. [15] proposed the prior knowledge of sky area, which was obtained from thousands of image experiments. Then, the prior is used for atmospheric light estimation. Salazar-Colores et al. [16] proposed an algorithm based on dark channel depth approximation, local Shannon entropy and fast guided filter, which reduces the artifact in the sky area while reducing the computation time. Li et al. [17] proposed a threshold-based sky region segmentation algorithm, which can calculate quickly but lost many details.
Zhu et al. [18] proposed color attenuation prior algorithm, which is also one of the most widely used algorithms in physical models. According to the experimental statistics, the algorithm reputes that the difference between the brightness and saturation of the image is positively correlated with the fog density. Although the algorithm has a natural color after dehazing, the picture is blurry.
The non-physical model algorithm uses traditional image processing technology, focusing on the contrast and texture information of the image. Commonly used dehazing methods based on non-physical model include histogram equalization [19], Retinex theory, wavelet transform, and homomorphic filtering. KIM et al. [20] proposed an adaptive histogram equalization (AHE) algorithm. Although this algorithm achieves good results locally through image segmentation, the image is prone to block effects. In addition, the contrast limited adaptive histogram equalization (CLAHE) algorithm has been widely studied because it can effectively solve the problem of excessive contrast enhancement [21,22,23,24]. Retinex believes that scene imaging is not only related to the illumination of the object, but also related to the color around the object. The single-scale Retinex and multi-scale Retinex [25] algorithms based on this theory have achieved good results in the field of dehazing. However, dehazing algorithms based on non-physical models will lose image details, and there are few studies in recent years.
There are two ideas of defogging algorithm based on the deep learning. The first, using the deep learning model to restore the fog-free image directly. The second, using the deep learning model to estimate the transmittance and atmospheric light, and then combining the atmospheric scattering model to restore the fog-free image. Cai et al. [26] proposed a convolutional neural network based on architecture Dehaze-Net. The Max-Out layer is used for feature extraction to generate almost all features related to haze. In addition, the article also proposed a bilateral correction linear unit to improve the quality of fog-free images. Li et al. [27] performed equivalent transformation on the atmospheric scattering model, fused the transmittance and the atmospheric light into a parameter, then estimated the parameter using the convolution neural network model, and finally restored the fog-free image using the transformed formula. Song et al. [31] proposed DehazeFormer. The network improves multiple structures and effectively improves the dehazing effect. For image dehazing, methods based on deep learning have good performance. However, limited by the training set, their applicable scenarios are narrow. Besides, intensive computation makes it difficult to apply neural networks to video dehazing.
General-purpose serial processing is incompetent for the task of defogging real-time video, and many researchers deploy their algorithms into FPGA or ASIC. The real-time video defogging system proposed by Kumar et al. [28] consumed less resources and lower power consumption compared with others while maintaining a high throughput rate. The system achieves 3840 × 2160, 72 frames/s and 1920 × 1080, 289 frames/s on FPGA and ASIC, respectively. Shiau et al. [29] alternately uses weighting technology and edge preservation technology to refine the factor in the process of dehazing. Using TSMC 0.13-um technology, the design yields a processing rate of approximately 200 Mpixels/s.
3 Background
Algorithms based on deep learning are computationally intensive, and algorithms based on non-physical models are less effective. Various methods based on physical model have achieved good results, such as those in [16, 25]. Among the physical models, the atmospheric scattering model is commonly used, as shown in Eq. 1:
where I is the foggy image, J is the fog-free image, A is the atmospheric light, and t is the transmittance. The t satisfies Eq. 2:
where β is the incident light scattering rates, and d(x) is depth of the scene. To prevent excessive dehazing, the minimum transmittance is taken as t0, and the clear image can be obtained from Eq. 3:
In [7], the DCP points out that in a clear image, the gray value of at least one channel in RGB is close to 0. The dark channel prior model is shown in Eq. 4:
where Ω represents the patch of the pixel x, and c is a certain color channel. In summary, t satisfies Eq. 5
DCP first selects the top 0.1% dark channel pixels, and takes the maximum intensity of the original fog image corresponding to these pixels as A. This results in the misjudgment of particularly bright non-atmospheric pixels, resulting in a severe high atmospheric light. And it will increase the calculation delay because the transmittance needs to be calculated after the brightness of all pixels is counted.
When DCP selects a larger patch for calculation, the halo effect will appear. The method proposed by [30] can not only solve the above problem, but also preserve the edge details of the image. According to the guided filtering algorithm, there is a local linear relationship between the filtered image and the guided image, and the gradient of the output image is approximately consistent with the gradient of the reference image, as shown in Eq. 6:
where I is the reference image, and q is the output image. The ωk is the neighborhood corresponding to pixel k. Both ak and bk in the patch of ωk are constants. This method defines the difference between the filtered image and original image as noise N, and aims to optimize N to minimum, and finally obtains Eq. 7:
where (Ii − µk) can be regarded as image texture information, and \(\mathop {p_{k} }\limits^{\_\_}\) is the background information of the local area. Assume that ωk is a flat area, satisfying covk(p, I) → 0, vark(I) → 0, vark(I) ≪ ε, so qi ≈\(\mathop {p_{k} }\limits^{\_\_}\), which has a smoothing filtering effect. Assuming that ωk is the edge area of the object, satisfying vark(I) ≫ ε, the image texture information occupies an important proportion, which maintains the edge.
However, the calculation of the guided filtering algorithm is complex and time-consuming. Video defogging requires not only good defogging effect, but also high video frame rate. So, this method is not suitable for video defogging.
4 Proposed method
Using DCP in the brighter area or sky area directly will cause color cast. This paper defines the brighter area and sky area as P, and the rest as \(\mathop P\limits^{\_\_}\), and deals with them separately. Unlike DCP which adopts the complex guided filtering, this paper designs a more convenient image detail preservation method in transmission’s estimation.
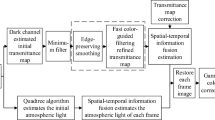
Figure 1 shows the flow of the defogging algorithm proposed in this paper. The process is divided into 7 steps. In Step. 1, the image is decomposed into many sub-areas. In Step. 2, the dark channel map of the sub-region is calculated. In Step. 3, the gradients and the maximum gray value T of sub-region is calculated simultaneously. In Step. 4, the atmospheric light is calculated. In Step. 5, the initial transmittance is calculated. In Step. 6, the final transmittance is calculated. In Step. 7, the fog-free sub-region is restored.

Dehazing process
4.1 Atmospheric light estimation
For the purpose of saving hardware resources and shortening the calculation delay, an image is decomposed into several n × n sub-areas, each of which is defined as O. The sub-areas are calculated in raster manner, as indicated by the purple arrow in step.1.
There is a clear difference between the pixels of P and \(\mathop P\limits^{\_\_}\). When O slides in the image, it can perceive the difference. If the maximum value T in O and A satisfies Eq. 8:
it means that O contains pixels belonging to P. The ∆ is a tunable parameter. Only the sky area in P contributes to the update of A, so considering the non-sky area in P will cause A to be too large. The areas that are bright but not sky, such as street lights, are significantly brighter than other areas and occupy relatively few pixels. When T of a few continuous sub-areas all satisfies Eq. 8, it means that these areas include the bright but not sky region. The number of continuous is defined as Γ which is a tunable parameter. If Γ is large, it means that these areas include the sky region.
In this paper, the judgment of brighter pixel in non- atmospheric light is divided into two cases. In case 1, when A increases fast, the combination of Γ1 and ∆1 is used. In case 2, when A increases slowly, the combination of Γ2 and ∆2 is used. The Cnt is used to count the number of times that Eq. 8 is continuously satisfied.
To prevent the video from flickering due to the fast update of A, this paper only updates it when Λ frame images are refreshed. The Fcnt is used to count the number of refreshed frames. When it is the first sub-area to be processed, A = T. The FtCnt is used to count the number of O that has been processed.
4.2 Transmission Estimation
The A is constantly updated, and we can use αA as a threshold to divide P and \(\mathop P\limits^{\_\_}\), avoiding inaccurate segmentation caused by using the same threshold for different images. The transmittance of P is determined by α and ω0, and the transmittance of \(\mathop P\limits^{\_\_}\) is determined by DCP.
The initial transmittance t1 of the \(\mathop P\limits^{\_\_}\) is Eq. 9:
and the t1 of the P is Eq. 10:
the ω0 is a tunable parameter. The t0 is the minimum transmittance to suppress noise. The pixel value of P is fixed to αA, Eq. 10 can be obtained by replacing I(x) in Eq. 9 with αA. This step calculates the transmittance of P and \(\mathop P\limits^{\_\_}\) separately, avoiding color cast. Next, the transmittance is redistributed according to the gradient to achieve the effect of preserving the image details.
In [30], reference images are required to preserve image edge details, which greatly increase hardware resources consumption. Therefore, this paper obtains image edge information through gradients. The adjustable parameter G is used to distinguish between flat and edge areas. If the gradient is smaller than G, it means that the pixel belongs to the flat area. The final transmittance in flat area is the mean of initial transmittance in O. In the edge area, the gradient is larger than G, and the final transmittance equals to initial transmittance. The gradient is sum of absolute values of the difference between adjacent pixel values in step.3.1 in Fig. 1.
After the above calculation, both A and t are estimated relatively accurately, and J can be obtained by combining Eq. 3. When a frame of video is calculated, it will be handed over to the display unit.
5 Hardware architecture
The hardware architecture of proposed dehazing method consists of three parts: video player end, defogging end, and display end. The video player end plays the real foggy video, the defogging end performs dehazing processing, and the display end displays the processed data. As shown in Fig. 2, the interface between each end adopts HDMI. In defogging end, there mainly includes HDMI Input, Input FIFO, Input BUFFER, Computing Unit, Ping-Pong BUFFER, DMA, DDR, Output FIFO, HDMI Display Unit, and Clock Wizard.

Hardware structure
The circuit structure of the defogging end is shown in Fig. 3. The structure is divided into a − k modules. Where module a belongs to the clock domain I, module c − i belongs to the clock domain II, and module k belongs to the clock domain III. The module b syncs data from clock domain I to clock domain II. The module j syncs data from clock domain II to clock domain III. The 3 clock domains, which work at 148.5 MHz, 200 MHz, and 148.5 MHz respectively, are asynchronous in the system. The video resolution is 1920 × 1080, it is 2200 × 1125 after adding blanking pixels, and the video frame rate is 60 frames/s. As above reasons, the HDMI interface needs to work at 2200 × 1125 × 60, which is 148.5 MHz. Although the two HDMI interfaces work at the same frequency, they have no clear phase relationship, they are asynchronous. In order to process data in a timely manner, the frequency of clock domain II needs to be greater than I and III. Therefore, the clock domain II works at 200 MHz.

Circuit structure of defogging end
Each frame is divided into many sub-areas which are called O. There are 20 cycles for each O to calculate. The transfer of data from module c to module d marks the beginning of the calculation. The transfer of data from module h to module i marks the end of the calculation. The data of the frame enters Input BUFFER along the direction of the purple arrow in module c, and the O needs 4 × 4 pixels to start calculating, so some data entered in advance will not be used temporarily. The calculation of O is one time, and the new data can flush out the old data, so there is no need to buffer the whole frame. 4 groups of buffers are set up, and the polling method is used to alternately cache the entire image. The round-robin priority is used in write arbiter, which ensures the sequential consistency of the buffers when reading and writing data. The round-robin priority is used in read arbiter for the same reason. When a group of buffers is full, the write priority is lowered and a readable signal is given. Similarly, when a group of buffers is empty, the read priority is lowered and a writable signal is given. The write arbiter routes data to buffer with the highest write priority and a writable flag. The read arbiter takes out data from buffer with the highest read priority and a readable flag.
Figure 4 shows the storage principle of Input BUFFER. The Input BUFFER consists of 4 groups, each group consists of 4 RAMs. One RAM can store a row of a frame which height is H and width is W. Every 4 adjacent pixels of a row are stored in the same address of Input BUFFER. In one pixel, there are 3 channels that are R, G, B, respectively. So, one pixel is 24 bits. But each pixel occupies 32 bits in this paper for two reasons. First, the bit width of FIFO IP core used in the article must be 32 bits or a multiple of it. The write bit width of Input FIFO is configured as 32 bits and the read bit width is configured as 128 bits. Second, regardless of whether the bit width of the input BUFFER is 24 or 32, the number of block RAM used is the same. Therefore, to simplify the data access process, the bit width of each RAM of Input BUFFER is 32 × 4, that is, 128 bits.

Storage principle of Input BUFFER
Whenever the Input BUFFER initiates a read data request to the Input FIFO, W pixels will be written into the Input BUFFER, so the depth of Input BUFFER is W/4. To prevent data loss, the depth of Input FIFO is at least W/2. Because the FIFO in this article is composed of block RAM, and the number used of block RAM with a depth less than 2048 is the same, the depth of the Input FIFO is 2048. In Fig. 3, the purple arrow in module c indicates the Input BUFFER writing direction, and the dotted line indicates that each line needs to be written from the beginning of the next line after the current line is full. When reading, 4 RAMs are read simultaneously. In each cycle, the bit width of read data is 128 × 4, that is, 512 bits.
As shown in Fig. 3, look-up table and shifting are used to simplify the circuit. Look-up table is used to simplify the circuits of division involved in Eqs. 3 and 9. Taking Eq. 9 as an example, A is the address of the look-up table, and \(W_{0} /A\) is the content. The A is 8 bits, so the depth of the table is 256. For saving resources, the width of \(W_{0} /A\) is 16 bits, so the width of table is 16 bits. When the divisor is an integer multiple of 2, it is done by shifting.
To display video stably, 3 defogged frames need to be buffered in DDR before being transferred to the HDMI Display Unit. DMA is responsible for moving the defogged frames to DDR. The interface between the DMA controller and the DDR is AXI4. To improve the AXI4 bus transfer efficiency, the Ping-Pong BUFFER needs to buffer some sub-areas before sending a write request to the DMA. In Fig. 3, module i shows the storage principle of Ping-Pong BUFFER. The purple arrows indicate the direction from which data are read. In writing state, the 4 buffers of each Ping-Pong BUFFER proceed simultaneously. The Ping-Pong BUFFER consists of 2 groups, each group consists of 4 RAMs. Each group of Ping-Pong BUFFER buffers W/4 sub-areas, that is, a total of 4 rows and W columns of pixels. The width of Ping-Pong BUFFER is 128 bits and the depth is W/4.
Because DDR and HDMI Display Unit are in different clock domains, pixels in DDR need to be synchronized by Output FIFO before being transferred to HDMI Display Unit. According to the HDMI protocol, the HDMI Display Unit only reads one pixel from the FIFO per cycle, so the write bit width of Output FIFO is configured as 128 bits, the read bit width is configured as 32 bits. Same as the setting principle of Input FIFO, the depth of Output FIFO is configured as 2048.
6 Experimental results
We compare with the work of He et al. [7], Zhu et al. [18], H. Land et al. [19], Li et al. [27], Kumar et al. [28], and Song et al. [31]. The dataset is SOTS, from B. Li et al.’s work [32]. In addition, we also select some commonly used foggy images and foggy video screenshots as test data.
The objective metrics PSNR (peak signal to noise ratio) and SSIM (structural similarity index measurement) are used to judge quality of the proposed method.
The simulation tool for algorithm is MATLAB R2021B, the EDA tool is Vivado2021.1, the processor of PC is Intel 12,400@2.5 GHz and RAM is 32G.
The hardware platform selected is ZYNQ7035, the number of LUTs is 171,900, the number of flip-flops is 343,800, the block RAM’s capacity is 17.6 Mb, and the DDR’s capacity is 1 GB. The resource utilization of the framework is shown in Table 1. As indicated in this table, this article employs relatively few hardware resources, demonstrating practical significance.
6.1 Running time comparison
Table 2 presents the results of the model runtime tests. During the experiments, we selected outdoor foggy images with a resolution of 1920*1080 for testing. All models were run on the same machine (Intel Core i5-12,400 CPU@2.5 GHz and 32 GB memory) without GPU acceleration. Overall, the proposed algorithm in this paper achieved the shortest runtime in hardware implementation, taking only about 17 ms per image. In terms of algorithm runtime comparison, [27] performed the best. It is a deep learning-based dehazing algorithm that exhibits excellent results for single-image dehazing. However, its computational complexity makes hardware implementation challenging. The algorithm proposed in this paper has a short runtime, with [7, 18] having slightly longer runtimes compared to our algorithm. In comparison to other models [19, 28], the runtime is longer. In conclusion, the algorithm presented in this paper not only performs well in software runtime but also excels in hardware implementation.
6.2 Computational complexity comparison
Computational complexity can be estimated and compared by evaluating the number of operations required to process a single frame of an image, including addition, subtraction, multiplication, division, and calculations involving maximum and minimum values. These calculations are helpful for qualitatively comparing our proposed method with [7, 18, 19, 27, 28]. As shown in Table 3, the algorithmic complexity of our proposed method is the lowest, not only compared to traditional dehazing algorithms [7, 18, 19], but also lower than existing hardware methods [28]. According to Table 3, it is evident that the algorithm proposed in this paper is significantly lower in complexity compared to deep learning-based research [27].
6.3 Parameters selection
There are 8 parameters of the model in this paper which are n, Λ, α, ∆, Γ, ω0, G and t0. When the single-image defogging, all parameters except Λ are used. When the video defogging, all parameters are used. The following experiments are carried out with the parameters of this section.
Figure 5 shows that the image is relatively blurry without using gradients. Figure a does not use gradients, and the side length n is 4. Figure 5b−d all use gradients, and the n of O is 3, 4, 5, respectively. When n is larger, the image details are richer, but the difference is not large. In addition, in circuits, larger n consumes more resources. Under comprehensive consideration, n is 4.

Comparison of details without gradients and details with gradients. a Is not using gradient to preserve details n is 4, b−d all use gradient information, n are 3, 4, 5, respectively
Incorporating the similarity between adjacent frames, Λ is used to avoid dividing lines and flickering. Because A is constantly changing, the difference between the A used by the upper and lower adjacent sub-areas is relatively large, which may cause the dividing line as shown in the Fig. 6b. Figure 6a is the original image, and Fig. 6b is the dehazed image. Besides, there may be video flicker caused by a large difference in the value of A between adjacent frames. For these reasons, A is calculated every Λ frames. If the value of Λ is too large, it may update A untimely. In this paper, Λ is 100.

Dehazed image appears dividing line. a is the original, b is the dehazed image
As an adaptive threshold segmentation parameter, α has a crucial impact on the results. We find that PSNR and SSIM become smaller as α increases. Figure 7 illustrates the above phenomenon. However, objective indicators cannot fully express the performance of the algorithm. Figure 8 shows the defogged images when α is 0.65, 0.735, and 0.9, respectively. The first row of comparisons show that when α is larger, the degree of defogging tends to be greater and the details are richer. The second row of comparisons shows that a too large α may cause color cast. Considering the actual application requirements, α is 0.735.

The change trend of the objective evaluation index when α takes different values. a is PSNR, b is SSIM

The change trend of the objective evaluation index when α takes different values
For avoiding the bright area from interfering with the update of A, we use two groups of ∆ and Γ to extract bright area. The first group adapts to regions where pixel values change rapidly, corresponding to the smaller bright regions. The second group adapts to regions where pixel values change slowly, corresponding to the larger bright regions. Therefore, ∆1 is 15, ∆2 is 5, Γ1 is 10, Γ2 is 50.
The ω0 and t0 are derived from DCP, ω0 is used to adjust the degree of defogging, and t0 is used to suppress noise. The larger ω0, the larger the degree of dehazing, but if the degree of defogging is too high, it may cause some areas to be extremely dark. So, ω0 is 0.85. Consistent with DCP, t0 is 0.1. G is used to extract edges. If G is too large, the edges may not be clear, and if G is too small, it may contain noise. So, G is 25.
6.4 Objective evaluation
Synthetic foggy graphs are selected from the SOTS for testing. Tables 4 and 5 list the test results of PSNR and SSIM, respectively. In the comparison, [31] performs the best, and [27] also performs well, both of which are dehazing algorithms based on deep learning. Good dehazing effect of [27, 31] on the single image but difficult to be applied to video defogging due to large amount of calculation. In addition, limited by the training set, the dehazing effect of real images is poor as shown in Fig. 12. This article also performs well. It surpasses [7] and, in the majority of cases, outperforms both [18, 19]. The algorithms in this paper and [28] are both improved on DCP, and both are designed for video defogging, but the dehazing effect of this paper is better. Because the color cast of DCP is solved by using adaptive threshold segmentation, and the image details are preserved using gradient information, the indexes are better than [28].
6.5 Subjective evaluation
The adaptive threshold segmentation proposed by this paper solves color cast well. In Fig. 9, (a) is the original image, (b) uses DCP only, and (c) uses DCP with adaptive threshold segmentation. Both Fig. 9b, c has a good degree of dehazing. However, color cast appeared in Fig. 9b, while there is no color cast in Fig. 9c.

The comparison of the dehazing effect with using DCP only and DCP with adaptive threshold segmentation. a Is the original image, b uses DCP only, c uses DCP with adaptive threshold segmentation
A subjective comparison between the proposed and state-of-the-art methods using natural images is depicted in Fig. 10. The fog removal in [7] is complete, but color cast is serious in deep part of the fog. The defogging effect of [31] on the real foggy image is not obvious, the main reason is that the training of the neural network is insufficient, which leads to the limitation of the application scenarios of this method. The method of [18] maintains a natural color while ensuring a high degree of dehazing. However, this method does not perform well in detail preservation, and the dehazed image is relatively blurry. The method of [19] achieves a favorable visual effect after dehazing, with a relatively clear image. But it tends to excessively enhance the contrast of the processed image, resulting in an unnatural appearance and potential loss of details. The method of [27] can maintain normal colors and rich details, and has stable performance in various scenes. But its dehazing ability is relatively weak, and there is still a lot of fog left in defogged image. The method of [28] is derived from DCP, and its halo effect has been improved, but it does not solve color cast either. The proposed method has good effect in image color, detail, and dehazing degree.

Real foggy image dehazing comparison
Because the algorithm in this paper is improved from DCP, the dehazing effect is obvious. This paper proposes an adaptive threshold segmentation algorithm, which effectively solves the color cast, so the color of the defogged image is natural. In addition, since the image details are preserved using gradient information in this paper, the defogged image is clear.
To save resources, limited bit width is used, and there are errors between the parameters in the hardware and the actual values. Figure 11 shows the comparison between algorithm-level and hardware-level simulation results. Both have a good degree of dehazing. Both results are almost the same. This shows that limited bit width has practical application significance.

Screenshot of fog removal from real foggy video
Figure 12 shows the real-time dehazing effect of the foggy video. The smaller screen shows the original video, while the larger one shows the defogged video. The dehazed video is obviously clearer than the original video, and many originally unclear areas are highlighted, as shown in the green circle in the figure. The framework has a good dehazing effect.

Real-time dehazing effect of the foggy video
Figure 13 shows a comparison of the dehazing effect of several adjacent frames. Figure 13a−c are the 1st, 9th, and 10th frames of the video, respectively. The color of dehazed video is natural, and the objects that were originally unclear are also displayed more clearly. The effect is stable in video dehazing.

Dehazing results on dash cam video. The left display is before defogging, the right is after defogging
7 Conclusion
In this paper, a dehazing framework suitable for high-definition real-time video is implemented on FPGA, which does a good job of keeping colors normal and detailing.
We devised a method for adaptive threshold segmentation. The method can find not only a suitable threshold to split sky area and non-sky area, but also the most suitable transmittance for sky area. This method solves the color cast in DCP well. This paper uses gradients to preserve image details, which simplifies computation while having good retention.
The dehazing performance of this paper stands out in the PSNR and SSIM tests. In the comparison of these two metrics, the proposed method in this paper significantly outperforms non-physical model algorithms and competes favorably with deep learning-based methods in most scenarios. In terms of execution time, the algorithm in this paper exhibits outstanding performance. Its processing speed far surpasses non-physical model- based dehazing algorithms, with a dehazing runtime of 3.265 s per image in MATLAB and only 0.017 s per frame on the hardware platform FPGA. It is worth noting that the computational complexity of this algorithm is much lower than that of non-physical model-based and deep learning-based dehazing algorithms, with a computational complexity of only 47 * h * w per frame image.
Data availability
Please email the corresponding author to request access to the experimental data.
References
Zahra, G., Imran, M., Qahtani, A.M., Alsufyani, A., Almutiry, O., Mahmood, A., Alazemi, FEid: Visibility enhancement of scene images degraded by foggy weather condition: an application to video surveillance. Comput. Mater. Continua 68(9), 3465–3481 (2021)
Hu, T., Jin, Z., Yao, W., Lv, J., Jin, W.: Cloud image retrieval for sea fog recognition (CIR-SFR) using double branch residual neural network. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 16, 3174–3186 (2023)
Liu, Z., He, Y., Wang, C., Song, R.: Analysis of the influence of foggy weather environment on the detection effect of machine vision obstacles. Sensors 20(2), 349 (2020)
Akshay, J., Vijay, K., Kumar, S.S.: Aethra-net: Single image and video dehazing using autoencoder. J. Vis. Commun. Image Represent. 94, 103855 (2023)
Ren, W., Zhang, J., Xu, X., Ma, L., Cao, X., Meng, G., Liu, W.: Deep video dehazing with semantic segmentation. IEEE Trans. Image Process. 28(4), 1895–1908 (2019)
Lee, S., Ngo, D., Kang, B.: Design of an FPGA-based high-quality real-time autonomous dehazing system. Remote Sens. 14(8), 1852 (2022)
He, K., Sun, J., Tang, X.: Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 33(12), 2341–2353 (2011)
Zhang, X., Xu, S.: Research on image processing technology of computer vision algorithm. In: 2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL), pages 122–124, (2020)
Parihar, A.S., Gupta, Y.K., Singodia, Y., Singh, V., Singh, K.: A comparative study of image dehazing algorithms. In: 2020 5th International Conference on Communication and Electronics Systems (ICCES), pages 766–771, (2020)
Jackson, J., Kun, S., Agyekum, K.O., Oluwasanmi, A., Suwansrikham, P.: A fast single-image dehazing algorithm based on dark channel prior and rayleigh scattering. IEEE Access 8, 73330–73339 (2020)
Hassan, H., Bashir, A.K., Ahmad, M., Menon, V.G., Afridi, I.U., Nawaz, R., Luo, B.: Real-time image dehazing by superpixels segmentation and guidance filter. J. Real-Time Image Proc. 18(5), 1555–1575 (2021)
Lu, J., Dong, C.: DSP-based image real-time dehazing optimization for improved dark-channel prior algorithm. J. Real-Time Image Proc. 17(5), 1675–1684 (2020)
Cao, N., Lyu, S., Hou, M., Wang, W., Gao, Z., Shaker, A., Dong, Y.: Restoration method of sootiness mural images based on dark channel prior and retinex by bilateral filter. Heritage Sci. 9(1), 30 (2021)
Wang, M.-W., Zhu, F.-Z., Bai, Y.-Y.: An improved image blind deblurring based on dark channel prior. Opto-Electron. Lett. 17(1), 40–46 (2021)
Li, Y., Miao, Q., Song, J., Quan, Y., Li, W.: Single image haze removal based on haze physical characteristics and adaptive sky region detection. Neurocomputing 182, 221–234 (2016)
Salazar-Colores, S., Moya-Sánchez, E.U., Ramos-Arreguín, J.-M., Cabal-Yépez, E., Flores, G., Cortés, U.: Fast single image defogging with robust sky detection. IEEE Access 8, 149176–149189 (2020)
Li, W., Jie, W., Mahmoudzadeh, S.: Single image dehazing algorithm based on sky region segmentation. In: 2019 International Conference on Advanced Data Mining and Applications, pages 489–500, (2019_
Zhu, Q., Mai, J., Shao, L.: A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 24(11), 3522–3533 (2015)
Rafael C. Gonzalez and Richard E. Woods. Digital Image Processing, 3rd ed. Prentice Hall, Upper Saddle River, pp. 144–166 (2007)
Kim, T.K., Paik, J.K., Kang, B.S.: Contrast enhancement system using spatially adaptive histogram equalization with temporal filtering. IEEE Trans. Consum. Electron. 44(1), 82–87 (1998)
Reza, A.M.: Realization of the contrast limited adaptive histogram equalization (clahe) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 38(1), 35–44 (2004)
Yadav, G., Maheshwari, S., Agarwal, A.: Contrast limited adaptive histogram equalization based enhancement for real time video system. In: 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), pages 2392–2397, (2014)
Hitam, M.S., Awalludin, E.A., Jawahir Hj Wan Yussof, W.N., Bachok, Z.: Mixture contrast limited adaptive histogram equalization for underwater image enhancement. In: 2013 International Conference on Computer Applications Technology (ICCAT), pages 1–5, (2013)
Xu, Z., Liu, X., Chen, X.: Fog removal from video sequences using contrast limited adaptive histogram equalization. In: 2009 International Conference on Computational Intelligence and Software Engineering, pages 1–4, (2009)
Jobson, D., Rahman, Z., Woodell, G.: A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 6(7), 965–976 (1997)
Cai, B., Xu, X., Jia, K., Qing, C., Tao, D.: Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 25(11), 5187–5198 (2016)
Li, B., Peng, X., Wang, Z., Xu, J., Feng, D.: Aod-net: All-in-one dehazing network. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), Oct 2017.
Kumar, R., Balasubramanian, R., Kaushik, B.K.: Efficient method and architecture for real-time video defogging. IEEE Trans. Intell. Transp. Syst. 22(10), 6536–6546 (2021)
Shiau, Y.H., Kuo, Y.T., Chen, P.Y., Hsu, F.Y.: VLSI design of an efficient flicker-free video defogging method for real-time applications. IEEE Trans. Circuits Syst. Video Technol. 29(1), 238–251 (2019)
He, K., Sun, J., Tang, X.: Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 35(6), 1397–1409 (2013)
Song, Y., He, Z., Qian, H., Du, X.: Vision transformers for single image dehazing. IEEE Trans. Image Process. 32, 1927–1941 (2023)
Li, B., Ren, W., Fu, D., Tao, D., Feng, D., Zeng, W., Wang, Z.: Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 28(1), 492–505 (2019)
Author information
Authors and Affiliations
Contributions
In this paper, Xinchun Wu is in charge of algorithm research and overall framework design, Xiangyu Chen is in charge of circuit design, Xiao Wang is in charge of algorithm simulation, Xiaojun Zhang is in charge of circuit simulation, Shuxuan Yuan is in charge of data sorting, Biao Sun is in charge of drawing charts, and Xiaobing Huang is in charge of document sorting, Lintao Liu is in charge of circuit design.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wu, X., Chen, X., Wang, X. et al. A real-time framework for HD video defogging using modified dark channel prior. J Real-Time Image Proc 21, 55 (2024). https://doi.org/10.1007/s11554-024-01432-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11554-024-01432-w