
Abstract
Recovering texture information from the aliasing regions has always been a major challenge for single image super-resolution (SISR) task. These regions are often submerged in noise so that we have to restore texture details while suppressing noise. To address this issue, we propose an efficient Balanced Attention Mechanism (BAM), which consists of Avgpool Channel Attention Module (ACAM) and Maxpool Spatial Attention Module (MSAM) in parallel. ACAM is designed to suppress extreme noise in the large-scale feature maps, while MSAM preserves high-frequency texture details. Thanks to the parallel structure, these two modules not only conduct self-optimization, but also mutual optimization to obtain the balance of noise reduction and high-frequency texture restoration during the back propagation process, and the parallel structure makes the inference faster. To verify the effectiveness and robustness of BAM, we applied it to 10 state-of-the-art SISR networks. The results demonstrate that BAM can efficiently improve the networks' performance, and for those originally with attention mechanism, the substitution with BAM further reduces the amount of parameters and increases the inference speed. Information multi-distillation network (IMDN), a representative lightweight SISR network with attention, when the input image size is 200 × 200, the FPS of proposed IMDN-BAM precedes IMDN {8.1%, 8.7%, 8.8%} under the three SR magnifications of × 2, × 3, × 4, respectively. Densely residual Laplacian network (DRLN), a representative heavyweight SISR network with attention, when the scale is 60 × 60, the proposed DRLN-BAM is {11.0%, 8.8%, 10.1%} faster than DRLN under × 2, × 3, × 4. Moreover, we present a dataset with rich texture aliasing regions in real scenes, named realSR7. Experiments prove that BAM achieves better super-resolution results on the aliasing area.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Single image super-resolution (SISR) is one of the popular computer vision research topics [1, 2], which aims to reconstruct a high-resolution (HR) image from a low-resolution (LR) image. With the success of deep learning prevailed in computer vision, many convolutional neural network (CNN)-based super-resolution (SR) methods have been proposed. According to their architectures, they can be categorized into linear [3,4,5,6,7,8], residual [9, 10], recursive [11,12,13], densely connected [14,15,16], multi-path [17], and adversarial [18] designs. To further improve the quality [19] of SR results while controlling parameter amounts, attention mechanisms [20, 21] were adopted in some SISR networks. At the same time, there exist quite a lot of excellent SISR networks [22,23,24,25,26] without the attention mechanism. One motivation of our work is to propose a plug-and-play attention mechanism for them so that their applications can be more extensive, and make it more fair to compare these networks with those with attention [27,28,29,30]. The attention mechanism [20, 21] was first applied to classification tasks. Due to its remarkable results in classification, great efforts have been made along this direction and expanded its application to SISR tasks. However, the SISR networks are so diverse that the attention module is usually designed solely for a specific network structure. These proposed attention mechanisms require a baseline to compare with in order to verify their effectiveness. Therefore, another motivation of our work is to propose a baseline of attention mechanism for SISR. Actually, our BAM is not only more efficient but also more lightweight than the attention mechanisms proposed in [27,28,29,30], which has been proved in our experiments. One major problem for the existing SISR networks is the information restoration in the texture aliasing area, so our biggest motivation is to overcome this problem. As shown in Fig. 1, IMDN-BAM has superior results in the texture aliasing area compared with IMDN.

Comparison of × 4 SR results of IMDN and IMDN-BAM on the realSR7 dataset. IMDN-BAM shows better super-resolution results on texture aliasing areas
The proposed BAM is plug-and-play for the majority of SISR networks. For those without attention, BAM can be easily inserted behind the basic block or before the upsampling layer. Only adding a few number of parameters, it can generally improve the SR results, validated by peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) [19] metrics. For those with attention, BAM can seamlessly replace their attention mechanism. Due to the simple structure and high efficiency of BAM, it can generally reduce the amount of parameters and improve the SR performance. We experimented on six networks without attention and four with attention to verify the effectiveness and robustness of BAM. Contributions are summarized as follows:
-
We propose a lightweight and efficient attention mechanism, for the SISR task. BAM can restore high-frequency texture information as much as possible while suppressing the extreme noise in the large-scale feature maps. Furthermore, the parallel structure can improve the inference speed.
-
We conduct comparative experiments on 10 state-of-the-art SISR networks [22,23,24,25,26,27,28,29,30]. The insertion or replacement of BAM generally improves the PSNR and SSIM values of final SR results and the visual quality, and for those [27,28,29,30] with attention, the replacement of BAM further reduces the amount of parameters and accelerates the inference speed. What is more, for lightweight SISR networks [23,24,25, 27, 31], the comparative experiments illustrate that BAM can generally improve their performance but barely increase or even decrease the parameters, which is significant for their deployment on terminals.
-
We present a real-scene SISR dataset considering the practical texture aliasing issue. BAM can achieve better SR performance on this more realistic dataset.
2 Related works
In this section, 10 SISR networks used in control experiments will be introduced. The specific position where the BAM is inserted or replace the original attention module in each SISR network is shown in Fig. 2.

Structure diagram of six SISR networks without attention (where CARN and CARN-m have the same network structure but different number of channels) and four SISR networks with attention. BAM module is represented by a purple solid circle
2.1 SISR networks without attention mechanism
Enhanced deep residual super-resolution network (EDSR) [26] as the champion of NTIRE 2017 Challenge on Single Image Super-Resolution, removes the BN layer and the last activation layer in the residual network, allowing the residual structure originally designed for high-level problems to make a significant breakthrough in the low-level SISR problem. Our BAM module is inserted before the upsampling layer and marked with a purple solid circle in Fig. 2. To achieve real-time performance, Namhyuk Ahn proposed cascading residual network (CARN) [25] in which the middle part is based on ResNet. In addition, the local and global cascade structures can integrate features from multiple layers, which enables learning multi-scale information of the feature maps. Its lightweight variant, CARN-M, compromises the performance for speed. For these two networks, BAM is inserted behind each block. multi-scale residual network (MSRN) [22] combines local multi-scale features with global features to fully exploit the LR image, which solves the issue of feature disappearance during propagation. BAM will be concatenated to the end of each MSRN block.
Super lightweight super-resolution network (s-LWSR) [23] is specifically designed for the deployment of real-time SISR task on mobile devices. It borrows the idea of U-Net [31] and is the first attempt to apply the encoder–decoder structure for the SISR problem. The encoder part employs a similar structure with MobileNetV2 [32] and residual block as the basic building blocks of the network. To adapt to different scenarios, three networks of different size, s-LWSR16, s-LWSR32 and s-LWSR64, were proposed. Here, we choose the middle-size one, s-LWSR32. For s-LWSR32, the BAM will be inserted before the upsampling layer.
In recent years, many lightweight SR models have been proposed. Among them, adaptive weighted super-resolution network (AWSRN) [24] is a representative one. A novel local fusion block is designed in AWSRN for efficient residual learning, which consists of stacked adaptive weighted residual units and a local residual fusion unit. It can achieve efficient flow and fusion of information and gradients. Moreover, an adaptive weighted multi-scale (AWMS) module is proposed to not only make full use of the features in reconstruction layer but also reduce the amount of parameters by analyzing the information redundancy between branches of different scales. Different from the aforementioned networks, BAM will be inserted before the AWMS module.
2.2 SISR networks with attention mechanism
In the SISR field, the study focused on attention mechanism is relatively less than the ones on the network structure. The common attention mechanisms applied to SR are mainly the soft ones, including channel attention, spatial attention, pixel attention, and non-local attention. We introduce four networks with their own attention mechanism here.
LR input images contain rich low-frequency information, which is usually treated equally with high-frequency information across channels. This will hamper the network's learning ability. In order to solve the problem, residual channel attention network (RCAN) [29] was proposed. It leads the SISR model performance in terms of PSNR and SSIM metrics, thus is often used as the baseline by the following works. RCAN utilized a residual-in-residual (RIR) structure to construct the whole network, which allows the rich low-frequency information to directly propagate to the rear part through multiple skip connections. Thus, the network can focus on learning high-frequency information. What is more, a channel attention (CA) mechanism was utilized to adaptively adjusts features by considering the interdependence between channels. In our experiments, CA will be replaced with BAM.
IMDN is a representative lightweight SISR network with attention mechanism. It is constructed by the cascaded information multi-distillation blocks (IMDB) consisting of distillation and selective fusion parts. The distillation module extracts hierarchical features step-by-step, and fusion module aggregates them according to the importance of candidate features, which is evaluated by the proposed contrast-aware channel attention (CCA) mechanism.
Pixel attention network (PAN) [27] is the winning solution of AIM2020 VTSR Challenge. Although its amount of parameters is only 272 K, its performance is comparable to SRResNet [5] and CARN. PAN newly proposed a pixel attention (PA) mechanism, similar to channel attention and spatial attention. The difference is that PA generates 3D attention maps, which allows the performance improvement with fewer parameters.
DRLN [30] employs cascading residual on the residual structure to allow the flow of low-frequency information so that the network can focus on learning high and mid-level features. Moreover, it proposes a Laplacian attention (LA) to model the crucial features to learn the inter-level and intra-level dependencies between the feature maps. In the comparative experiments, CA, CCA, PA, and LA will be replaced with BAM.
3 Proposed method
Some texture details in low-resolution images are often overwhelmed by extreme noises, which leads to a major difficulty to recover texture information from the texture aliasing area. To solve this problem, we proposed the BAM composed of ACAM and MSAM in parallel, where ACAM is dedicated to suppressing extreme noise in the large-scale feature maps and MSAM tries to pay more attention to the high-frequency texture details. Moreover, the parallel structure of BAM will allow not only self-optimization, but also mutual optimization of the channel and spatial attention during the gradient backpropagation process so as to achieve a balance between them. It can obtain the best noise reduction and high-frequency information recovery capabilities, and the parallel structure can speed up the inference process. The schematic of BAM is shown in Fig. 3. Since ACAM and MSAM generate vertical and horizontal attention weights for the input feature maps respectively, the dimension of their output is inconsistent. One is \(N \times C \times 1 \times 1\) and the other is \(N \times 1 \times H \times W\). Thus, we use broadcast multiplication to fuse them into an \(N \times C \times H \times W\) weight tensor, and then multiply it with the input feature maps element-wisely. Here, N is the batch size (N = 16 in our experiments), C is the number of channels of the feature maps, H and W are the height and width of the feature maps. In ACAM, avgpool operation is used to obtain the average value of each feature map, while in MSAM, maxpool operation is used to get the max value among the C channels for each position on the feature map, and they can be expressed as

BAM, consisting of ACAM and MSAM in parallel. The channel attention from ACAM and the spatial attention from MSAM will be fused by broadcast multiplication and then multiplied with the input feature maps element-wisely to obtain the final attention result. a ACAM. The channel attention information is extracted by avgpool. b MSAM. The spatial attention information is extracted by maxpool
where \(F \in {\mathbb{R}}^{N \times C \times H \times W}\) represents the input feature maps, max{} means to get the max value.
3.1 Avgpool channel attention module
Channel attention needs to find channels with more important information from the input feature maps and give them higher weights. It is highly likely for a channel with the dimension of \(H \times W\) (in our experiments, \(H = W \ge 64\)) to contain some abnormal extrema. Maxpool will pick these extreme values as noise and get the wrong attention information, which will make the texture recovery more difficult. Therefore, we only use avgpool to extract channel information so that it complies with Occam's razor principle when suppressing extreme noise and then pass it through a multi-layer perceptron (MLP) composed of two point-wise convolution layers. To increase the nonlinearity of MLP, PReLU [33] is used to activate the first convolution layer output. In addition, to reduce the parameter amount and computational complexity of ACAM, MLP adopts the bottleneck architecture [34]. The number of input channels is r times the number of output channels for the first convolution layer. After PReLU activation, the number of channels is restored by the second convolution layer. Finally, the channel weights are generated by a sigmoid activation function. The generation process of ACAM can be described by
where \({\mathcal{F}}_{n - > n/r}^{k \times k}\) represents the convolution layer with the kernel size of \(k \times k\) (for Eq. 3, \(k = 1\)), the input channel number of n and the output channel number of \(n/r\), r is set to 16 and n is determined by the channel numbers of the input feature maps in experiments. PReLU and Sigmoid are defined as
In the ablation experiments, in order to verify the minimalism of AvgPool for channel attention, a comparative experiment is carried out by adding MaxPool to ACAM, which is named as ACAM+, and the mathematical expression is
To reduce the parameter amount and the computational complexity, AvgPool and MaxPool share the MLP.
3.2 Maxpool spatial attention module
Spatial attention generates weights for the horizontal section of the input feature maps. Its goal is to find lateral areas which contribute most to the final HR reconstruction and give them higher weights. These areas usually contain high-frequency details in the form of extreme values in the channel. Thus, using maxpool operation for spatial attention is appropriate.
The output of maxpool passes a convolution layer with large receptive field of \(k \times k\) (for Eq. 7, k = 7), and then gets activated by the sigmoid function to obtain the spatial attention weights. This design effectively controls the amount of parameters. It can be expressed by
Similarly, to verify the minimalism of MSAM, AvgPool will be added to MSAM to form a new structure named as MSAM+ in ablation experiments. It can be written as
3.3 Balanced attention mechanism
There are two innovations in the design of BAM. One is that the ACAM tries to suppress the extreme noise and the MSAM tries to maintain the texture information. The other is the parallel structure, which makes the generation process of channel attention and spatial attention independent of each other and allows the mutual optimization of two attentions during the backpropagation. The combination of these two innovations enables BAM to recover as much high-frequency information as possible from the texture aliasing area. Ablation experiments prove that the current design of BAM can effectively control the parameter amount and obtain better performance than the original networks, evaluated by PSNR and SSIM metrics. The formula of BAM is
where \(\otimes\) means broadcast multiplication and \(\odot\) stands for Hadamard multiplication. Because the outputs of ACAM and MSAM have different dimensions, we utilize broadcast multiplication to fuse them and then element-wisely multiply it with the input feature maps to obtain the final attention results. ACAM and MSAM are self-optimized in their respective gradient backpropagation process. To reveal the mutual optimization of ACAM and MSAM in the gradient backpropagation process of BAM, we give the partial derivative of BAM concerning the input feature maps F as follows:
As illustrated in Eq. 10, not only is ACAM and MSAM related to each other but also related to each other’s first-order partial differentials (The gradient), which means ACAM and MSAM can optimize mutually in the gradient backpropagation process of BAM.
To show that BAM is minimally effective, we replace ACAM and MSAM with ACAM+ and MSAM+ to form a new structure BAM+ in the ablation comparative experiments. BAM+ can be expressed as
3.4 Parameter amount analysis
Moreover, to study the effect of BAM insertion on the original network parameter amount, we calculate the parameters of BAM, which depend on the parameters of ACAM and MSAM. First, we calculate the parameter amount of the convolutional layer without bias term using
where k is the size of the convolution kernel, \(n_{{{\text{in}}}}\) and \(n_{{{\text{out}}}}\) is the number of input and output channels of the convolutional layer, respectively.
Based on Eq. 3 and Eq. 12, the parameter amount of ACAM can be obtained by
where k is the kernel size which is equal to 1 in Eq. 13, r is the scale factor between the number of input and output channels (in our experiments, r is set to 16) and the last item is the parameter amount of PReLU. Based on Eq. 7 and Eq. 12, the parameter amount of MSAM is
In Eq. 14, \(k = 7\), \(n_{{{\text{in}}}} = n_{{{\text{out}}}} = 1\). And we can see that MSAM only has 49 parameters.
4 Experiments and discussions
To demonstrate the effectiveness and robustness of BAM, we select six existing SISR networks without attention [22,23,24,25,26] and four with attention [27,28,29,30] for control experiments. How BAM is inserted or replaces the original attention module has been elaborated in Sect. 2. Also, to further improve the effectiveness of BAM, IMDN is selected as the base model for the ablation experiments. Its CCA module is replaced with CA, SE, CBAM and BAM sequentially.
4.1 Datasets and metrics
As shown in Table 1, the training sets for different SISR networks are different, and for the deep learning task, the richer the data is, the better the results would be. Therefore, to fully verify the efficient performance of the proposed BAM, we choose the smallest training set for training. Following [24, 25], we use 800 high-quality (2 K resolution) images from DIV2K [35] as the training set, and evaluate on Set5 [36], Set14 [37], BSD100 [38], and Manga109 [39] with the PSNR and SSIM metrics under the upscaling factors of × 2, × 3, and × 4, respectively, for ablation experiments we add Urban100 [40] for validation. In all the experiments, bicubic interpolation is utilized as the resizing method. Referring to [41], we calculate the metrics on the luminance channel (Y channel of the YCbCr channels converted from the RGB channels).
4.2 Implementation details
During the training, we use the RGB patches with size of 64 × 64 from the LR input together with its corresponding HR patches. We only apply data augmentation to the training data. Specifically, the 800 image pairs in training set are cropped into five pairs from the four corners and center of the original image so that the training set is expanded by five times to 4000 image pairs. In addition, we randomly rotate and flip them during the training process.
For optimization, Adam is used and its initial learning rate is set as 0.0001, which will be halved at every 200 epochs. The batch size is set as 16. We train for a total of 1000 epochs. The loss function for training is L1 loss function, which can be expressed as
where ILR and IHR are the input LR image and the target HR image respectively, \({\mathcal{L}}^{{{\text{SR}}}}\) represents the SISR network using the upsampling scale of SR, h, w and c are the height, width and channels of the HR image, respectively, and \(||_{1}\) is the L1 norm.
We adopt pytorch 1.1.0 framework to implement experiments on the desktop computer with 3.4 GHz Intel Xeon-E5-2643-v3 CPU, 64G RAM, and two NVIDIA GTX 2080Ti GPUs.
4.3 Comparisons with original SISR networks
For the convenience of discussion, we refer to the original networks as the control group, the BAM versions as the experimental group and add the “BAM” suffix to the networks’ original name. The control experiments’ results of without and with attention networks are summarized in Tables 2 and 3, respectively. The networks are listed in the order of their publication times, respectively [24]. It can be seen from Tables 2 and 3 that, except for RCAN-BAM and PAN-BAM at the × 3 and × 4 scaling factor on the Manga109 benchmark, all the other experimental groups outperform their corresponding control group on PSNR metric. Although the PSNR metric of RCAN-BAM is lower than the one of RCAN, its SSIM metric is still higher than that of RCAN. It reflects that BAM is more capable of restoring the fine structures than the color. In addition, for the three scale factors, the highest PSNR and SSIM metrics are all achieved by DRLN-BAM, and for × 4 upsampling scale, the PSNR/SSIM metrics improvements on four benchmarks are {0.03/0.0007, 0.17/0.0036, 0.95/0.0289, 0.55/0.0070} separately, meanwhile the reduction of the parameter amount is 266.7 K. Compared with the original attention mechanism of DRLN, BAM reduces the parameters, but obtains better performance.
Actually, some control experiments used additional data sets [35, 42,43,44] for training in their original papers, as shown in Table 1. In detail, CARN used extra [35, 43, 44]; PAN, DRLN used extra [42]; s-LWSR32, EDSR and MSRN used all the images in DIV2K [35]. For deep learning tasks, there is a universally used law, the richer the amount of data, the better the effect. Although our experimental groups have the disadvantage of a smaller training set, but can generally achieve a better PSNR/SSIM results than the corresponding control groups. For lightweight networks such as PAN and IMDN, it is traditionally quite difficult to further improve their performance. The proposal of BAM makes it possible to enhance these lightweight SISR networks even with reduced parameters, which is of great significance for their deployment in realistic cases.
The results of the comparative experiments in Tables 2 and 3 show that for the networks without attention, the incorporation of BAM can further increase their performance indicated by PSNR and SSIM metrics by only adding a small number of parameters. As illustrated in Fig. 4, for the original networks with attention, BAM not only reduces the number of parameters but also improves the model performance. This thoroughly proves the efficiency and robustness of BAM. The calculation of Param Decrement and PSNR Increment in Fig. 4 are expressed as following:

Under the × 2 and × 4 upsampling scales, the relationship between the parameter decrement and the PSNR increment of the four SISR networks with attention
where \(P_{{{\text{ori}}}}\) and \(P_{{{\text{BAM}}}}\) represent the parameter amounts of the control and experimental groups, respectively, \({\text{PSNR}}_{{{\text{ori}}}}\) and \({\text{PSNR}}_{{{\text{BAM}}}}\) stand for the PSNR results of the control and experimental groups separately.
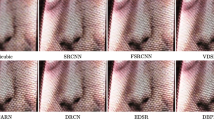
Figure 5 displays the × 4 SR results of five groups of SISR networks with or without BAM on a representative image selected from the BSD100 dataset. For the three networks without attention, EDSR, CARN and AWSRN, their BAM version only increases a few parameters but greatly improves the metrics. Especially for EDSR-BAM, which achieves a very obvious visual improvement compared to the control group. For the two lightweight networks with attention, IMDN and PAN, the BAM replacement increases the SR quality while reducing the number of parameters.

Comparative experiments of five SISR networks under scaling factors of × 4. The best two results are highlighted in red and blue colors, respectively. The red dashed ellipse is used to guide areas where the visual effect is not obvious improved. The improvement between EDSR-BAM and EDSR is significant
Figure 6 displays the visual perception comparison between the × 4 SR results of the experimental group and the control group for IMDN and DRLN. IMDN and DRLN can stand for the current lightweight and heavyweight top-level networks, respectively. As can be seen, the experimental group is capable of recovering more detailed information and has a significant improvement on the aliased texture areas, such as alphabet letters, Chinese characters, cloth textures, hairs, and even facial wrinkles. Whether for a lightweight network such as IMDN or a heavyweight network such as DRLN, the BAM replacement can further improve the visual quality of SR results with the reduced parameters. IMDN-BAM and DRLN-BAM can be utilized as baselines for the follow-up researches. And these two sets of figures thoroughly validate the effectiveness of BAM. Figure 7 illustrates the metrics improvement on four lightweight SISR networks of × 3 SR results. The SR results of experimental groups all make a great improvement compared to the control group on PSNR/SSIM metrics. For the two networks without attention, AWSRN and CARN, their BAM versions only increase a few parameters but greatly improves the metrics; for the two lightweight networks with attention, IMDN and PAN, the BAM replacement increases the SR quality while reducing the number of parameters.

Visual perception comparison of the SR results from IMDN versus IMDN-BAM and DRLN versus DRLN-BAM on the Manga109 dataset under the scale factor of × 4. Comparing their results, we can see that the SISR networks with BAM can generally better restore the fine structures, including cloth textures, alphabet letters, facial wrinkles, hairs and Chinese characters

Metrics comparison of the × 3 SR results of 4 lightweight SISR networks, the best results are marked in bold red. The highest PSNR and SSIM scores are all achieved by AWSRN-BAM
4.4 Ablation experiments
4.4.1 Comparison with another four attention mechanisms
To verify the efficiency of BAM, we conduct ablation experiments on three scaling factors of × 2, × 3, and × 4 based on the IMDN. Its original attention module, CCA, is replaced with CA, SE, CBAM and BAM, respectively. We evaluate on the five benchmarks of Set5, Set14, BSD100, Urban100 and Manga109 with PSNR and SSIM metrics.
From the results of ablation experiments in Table 4, it can be found that under three scaling factors, all the networks using BAM obtain the highest SSIM and PSNR metrics on five benchmark datasets. Moreover, after replacing CCA with SE or CBAM, the performance of the model is worse than the original version, reflecting that the effective attention mechanism on classification tasks does not necessarily have the same effect on the SISR task. Moreover, Fig. 8 shows the × 4 SR results of five attention mechanisms used in Table 4, where we can see that BAM maintains a great balance between noise suppression and high-frequency texture detail recovery. BAM is the best one to recover the texture aliasing area among the five attention mechanisms.

Comparison of × 4 SR results by five attention mechanisms on the realSR7 dataset proposed in this paper
4.4.2 Minimization verification
To verify the minimalism of BAM and its two basic modules, ACAM and MSAM, and the efficiency of the parallel structure of BAM, we conduct ablation experiments on three scaling factors of \(\times 2\), \(\times 3\), and \(\times 4\) based on the lightweight network IMDN. Its original attention module, CCA, is replaced with ACAM, ACAM+, MSAM, MSAM+, BAM, BAM+, and CBAM, respectively. We evaluate on the four benchmarks of Set5, Set14, BSD100, and Manga109 with PSNR and SSIM metrics.
To show the minimalism of ACAM and MSAM, their results are compared with the ones of ACAM+ and MSAM+, respectively. As for BAM, we compare it with BAM+. To verify that the parallel structure is more balanced than the series structure so as to generate attention more reasonably, BAM is compared with CBAM which cascades channel and spatial attentions. From the results of ablation experiments in Table 5, it can be found that under three scaling factors of \(\times 2\), \(\times 3\), and \(\times 4\), all the experiments using BAM obtain the highest SSIM and PSNR metrics on four benchmarks. Compared with ACAM+ and MSAM+, the networks with ACAM and MSAM are more lightweight but achieve higher PSNR and SSIM. This verifies that the use of only AvgPool to extract channel attention information and only MaxPool to extract spatial attention information is effective for the SISR task. The comparison between BAM and BAM+ shows the minimalism of BAM.
4.4.3 Quantitative verification
To quantitatively verify that the insertion of BAM improves the network's SR performance, we conduct further experiments on IMDN-BAM. We randomly select one of the six BAMs in IMDN-BAM, extract its input and output feature maps, and then calculate the definition evaluation function SMD2 [45] values for each feature map in input and output feature maps separately, finally, obtain the average values of these two sets of data. The larger the SMD2 value, the richer the texture. The expression of SMD2 is as follows:
in which, H and W are the pixel height and width of each feature map, and \(f(h,w)\) is the gray value of the feature map at pixel coordinate \((h,w)\). Figure 9 shows the SMD2 values of each feature map in input and output feature maps in a certain BAM layer of IMDN-BAM, after the input feature maps are assigned attention by BAM, the average SMD2 indicators of the output feature maps are all improved, and the improvements are {0.0136, 0.0143, 0.0274,0.0189, 0.0244, 0.0242, 0.0128, 0.0364}, respectively. The experiment results reflect that BAM has indeed improved the clarity and texture richness of feature maps, and quantitatively verify the efficient performance of BAM.

Texture richness comparison between Input and Output feature maps of BAM based on IMDN-BAM, under × 2 upsampling scales. We draw the SMD2 value curves of each feature map in Input (red) and Output (blue) feature maps of BAM, and use the average SMD2 value of each curve to measure their texture richness, the higher the better, the improvement of SMD2 index before and after BAM operation quantitatively illustrate the effectiveness of our proposed BAM
4.5 Speed comparison
To further prove the minimalism and efficiency of BAM, we select IMDN and DRLN as the representatives of lightweight and heavyweight SISR networks respectively, and compare the FPS between the experimental group and the control group with multiple input scales. Under each input scale, we count the average inference time of 700 images to calculate FPS, and it can be expressed as following
where Frames is the number of images, and \({\text{Time}}_{{{\text{Frames}}}}\) is the total time utilized for inference.
Figure 10 shows the FPS curves of IMDN-BAM and IMDN, DRLN-BAM and DRLN under different input scales on 2080Ti. It can be seen that the experimental group has the advantage in inference speed as well, and the speed advantage gets more obvious when the scale of the input image is smaller. When the input image size is 200 × 200, the FPS of proposed IMDN-BAM exceeds IMDN {8.1%, 8.7%, 8.8%} under the three SR magnifications of × 2, × 3, and × 4, respectively. When the input image scale is 60 × 60, the FPS of proposed DRLN-BAM exceeds DRLN {11.0%, 8.8%, 10.1%} under × 2, × 3, and × 4. The above experimental results illustrate that BAM can accelerate the inference speed while improving network performance indicators, which has significant application value for the landing of lightweight networks on mobile terminals.

Speed comparison between IMDN-BAM and IMDN, DRLN-BAM and DRLN on 2080Ti under × 2, × 3, and × 4 upsampling scales. As shown in Fig. 9, experimental groups are faster than the control groups under each input scale and each upsampling factor
5 Conclusion
Aiming at the problem that textures are often overwhelmed by extreme noise in SISR tasks, we propose an attention mechanism BAM, consisting of ACAM and MSAM in parallel. ACAM can well suppress extreme noise in large-scale feature maps, while MSAM focuses more on high-frequency texture details. The overall parallel structure of BAM enables ACAM and MSAM to optimize each other during the back propagation process, so as to obtain an optimal balance between noise suppression and texture restoration. In addition, the parallel structure brings in a faster inference speed. BAM is a universal attention mechanism research for SISR tasks. This research can improve the performance of SISR networks without attention, and provide a strong baseline for the subsequent attention mechanism works for SISR. The control experimental results strongly prove that BAM can efficiently improve the performance of state-of-the-art SISR networks and further reduce the parameter amounts and improve the inference speed for those originally with attention. The ablation experimental results illustrate the efficiency of BAM. What’s more, BAM demonstrates higher capability to restore the texture aliasing area in real scenes on the realSR7 dataset proposed in this paper.
Availability of code and data
The source code is released at https://github.com/dandingbudanding/BAM.
References
Wang, Z., Chen, J., Hoi, S.: Deep learning for image super-resolution: a Survey. IEEE Trans. Pattern Anal. Mach. Intell. 1–1, 99 (2020)
Anwar, S., Khan, S., Barnes, N.: A deep journey into super-resolution: a survey. arXiv, preprint arXiv:1904.07523 (2019)
Zhang, K., Zuo, W., Chen, Y., Meng, D., Zhang, L.: Beyond a gaussian denoiser: residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 26, 3142–3155 (2017)
Zhang, K., Zuo, W., Gu, S., Zhang, L.: Learning deep CNN denoiser prior for image restoration. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE (2017)
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. 38, 295–307 (2016)
Shi, W., Caballero, J., Huszár, F., Totz, J., Wang, Z.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: CVPR (2016)
Chao, D., Chen, C.L., Tang, X.: Accelerating the super-resolution convolutional neural network. In: ECCV (2016)
Kim, J., Lee, J.K., Lee, K.M.: Accurate image super-resolution using very deep convolutional networks. In: CVPR (2016)
Jiao, J., Tu, W.C., Liu, D., He, S., Lau, R., Huang, T.S.: FormNet: formatted learning for image restoration. IEEE Trans. Image Process. 29(99), 6302–6314 (2020)
Fan, Y., Shi, H., Yu, J., Ding, L., Huang, T.S.: Balanced two-stage residual networks for image super-resolution. In: CVPRW (2017)
Ying, T., Jian, Y., Liu, X.: Image super-resolution via deep recursive residual network. In: CVPR (2017)
Tai, Y., Yang, J., Liu, X., Xu, C.: MemNet: a persistent memory network for image restoration. In: IEEE Computer Society (2017)
Kim, J., Lee, J.K., Lee, K.M.: Deeply-recursive convolutional network for image super-resolution. In: CVPR (2016)
Abbass, M.Y.: Residual dense convolutional neural network for image super-resolution. Optik. (2020). https://doi.org/10.1016/j.ijleo.2020.165341
Haris, M., Shakhnarovich, G., Ukita, N.: Deep back-projection networks for super-resolution. In: CVPR (2018)
Tong, T., Li, G., Liu, X., Gao, Q.: Image super-resolution using dense skip connections. In: IEEE International Conference on Computer Vision (2017)
Park, S., Son, H., Cho, S., Hong, K., Lee, S.: SRFeat: single image super-resolution with feature discrimination, pp. 455–471. Springer International Publishing, Cham (2018)
Wang, X., Yu, K., Wu, S., Gu, J., Liu, Y., Dong, C., Loy, C.C., Qiao, Y., Tang, X.: ESRGAN: enhanced super-resolution generative adversarial networks. Springer, Cham (2018)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004)
Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: CBAM: convolutional block attention module. In ECCV, pp. 3–19 (2018)
Jie, H., Li, S., Gang, S., Albanie, S.: Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. 7132–7141 (2017)
Qin, J., Huang, Y., Wen, W.: Multi-scale feature fusion residual network for single image super-resolution. Neurocomputing 379, 334–342 (2020)
Li, B., Wang, B., Liu, J., Qi, Z., Shi, Y.: s-LWSR: super lightweight super-resolution network. IEEE Trans. Image Process. 1, 99 (2020)
Wang, C., Li, Z., Shi, J.: Lightweight image super-resolution with adaptive weighted learning network. arXiv preprint arXiv:1904.02358 (2019)
Ahn, N., Kang, B., Sohn, K.A.: Fast, accurate, and lightweight super-resolution with cascading residual network. In: ECCV (2018)
Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. In: CVPRW (2017)
Zhao, H., Kong, X., He, J., Qiao, Y., Dong, C.: Efficient image super-resolution using pixel attention. arXiv preprint arXiv:2010.01073 (2020)
Hui, Z., Gao, X., Yang, Y., Wang, X.: Lightweight image super-resolution with information multi-distillation network. In: ACM MM, pp. 2024–2032 (2019)
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.: Image super-resolution using very deep residual channel attention networks. In: ECCV, pp. 286–301 (2018)
Anwar, S., Barnes, N.: Densely residual Laplacian super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 99 (2020)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional Networks for Biomedical Image Segmentation. Springer, Cham (2015)
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: MobileNetV2: inverted residuals and linear bottlenecks. In: CVPR (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: surpassing human-level performance on ImageNet classification. In: CVPR (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR, pp. 770–778 (2016)
Agustsson, E., Timofte, R.: NTIRE 2017 challenge on single image super-resolution: dataset and study. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2017)
Bevilacqua, M., Roumy, A., Guillemot, C., Morel, A.: Low-complexity single image super-resolution based on nonnegative neighbor embedding. In: BMVC (2012)
Zeyde, R., Elad, M., Protter, M.: On single image scale-up using sparse-representations. In: International Conference on Curves and Surfaces (2010)
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: IEEE International Conference on Computer Vision (2002)
Narita, R., Tsubota, K., Yamasaki, T., and Aizawa, K.: Sketch-based manga retrieval using deep features. In: 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), pp. 49–53 (2017)
Huang J., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: CVPR, pp. 5197–5206 (2015)
Huang, G., Liu, Z., Laurens, V., Weinberger, K.Q.: Densely connected convolutional networks. In: CVPR, pp. 4700–4708 (2017)
Timofte, R., Agustsson, E., et al.: NTIRE 2017 challenge on single image super-resolution: methods and results. In: CVPRW, pp. 1110–1121 (2017)
Yang, J.W.J.H.: Image super-resolution via sparse representation. IEEE Trans. Image Process. 19, 2861–2873 (2010)
Arbeláez, P., Maire, M., Fowlkes, C., Malik, J.: Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. 33, 898–916 (2011)
Wang, F., Cao, P., Zhang, Y., Hu, H., Yang, Y.: A machine vision method for correction of eccentric error based on adaptive enhancement algorithm. IEEE Trans. Instrum. Meas. 70, 1–11 (2020)
Acknowledgements
The authors would like to thank the Associate Editor and the Reviewers for their constructive comments. This work is supported by OPPO Research Institute. And this work is pre-print at https://arxiv.org/abs/2104.07566
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, F., Hu, H., Shen, C. et al. BAM: a balanced attention mechanism to optimize single image super-resolution. J Real-Time Image Proc 19, 941–955 (2022). https://doi.org/10.1007/s11554-022-01235-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11554-022-01235-x