
Abstract
Group independent component analysis (GICA) has been successfully applied to study multi-subject functional magnetic resonance imaging (fMRI) data, and the group independent component (GIC) represents the commonality of all subjects in the group. However, some studies show that the performance of GICA can be improved by incorporating a priori information, which is not always considered when looking for GICs in existing GICA methods. In this paper, we propose an improved multi-objective optimization-based constrained independent component analysis (CICA) method to take advantage of the temporal a priori information extracted from all subjects in the group by incorporating it into the computational process of GICA for group fMRI data analysis. The experimental results of simulated and real data show that the activated regions and the time course detected by the improved CICA method are more accurate in some sense. Moreover, the GIC computed by the improved CICA method has a higher correlation with the corresponding independent component of each subject in the group, which means that the improved CICA method with the temporal a priori information extracted from the group can better reflect the commonality of the subjects. These results demonstrate that the improved CICA method has its own advantages in fMRI data analysis.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In the past two decades, functional neuroimaging has become an important tool for studying various neural mechanisms in the brain. In particular, functional magnetic resonance imaging (fMRI) has drawn considerable attention due to being noninvasive and having high spatio-temporal resolution [1,2,3]. Many methods have been used for fMRI data analysis, and these methods are generally divided into model-based methods and data-driven methods [4,5,6]. The model-based methods require a priori information about the experimental paradigm, and usually only local brain area data are considered in these methods rather than data from the whole brain. On the contrary, data-driven methods do not depend on any a priori information, and several of these methods have been fruitfully applied to the field of fMRI data analysis, such as principle component analysis (PCA), independent component analysis (ICA), and clustering analysis (CA).
Among them, the purpose of ICA is to decompose the observed multivariate data into the source signals, which are assumed statistically independent and non-Gaussian. Since it was first introduced into this field for single-subject fMRI data analysis [7], it has become one of the most popular methods to analyze fMRI data [8,9,10]. Compared with univariate methods such as general linear model (GLM) methods based on the single voxel level [11], ICA is a multivariate method that considers the interactions between the voxels and is increasingly being applied to extract functional neural networks from the fMRI data of various cognitive activities without relying on any a priori information. Currently, ICA has been widely used for fMRI data analysis in a resting state [12, 13] or a specific cognitive task-related state [14, 15]. In many circumstances, ICA needs to be used for multiple-subject fMRI data analysis, which is usually referred to as group ICA (GICA) [16].
As a kind of purely data-driven blind source separation technique, ICA does not require any a priori information. However, many studies have shown that the capabilities of ICA can been greatly improved if some a priori information is incorporated into the estimation process when it is available [17,18,19]. This kind of method is usually called constrained ICA (CICA) or ICA with reference (ICA-R) [20, 21]. Compared with the classical ICA, CICA or ICA-R only extracts the sources of interest without extracting all the sources by introducing the a priori information into the calculation process, and this method avoids computing uninteresting sources, facilitates subsequent applications, and reduces the computation time and storage requirements [22, 23]. In addition, the separation quality and accuracy of interesting sources can also be improved through the incorporation of a priori information [24, 25]. On this basis, a great number of other extension methods have been proposed [26,27,28,29].
Currently, the existing methods with a priori information generally consider specific knowledge associated with the sources. For example, the spatial template of some mature networks, such as the visual network or the default mode network, and the specific experimental paradigms of some cognitive task experiments, such as block stimulation mode in a visual cognitive experiment, are considered [30,31,32]. However, this knowledge about the sources is not always known, especially in the case of complex cognitive activity. It is important to get available a priori information from the existing data itself. Recently, we proposed a method called GICA-IR to extract some intrinsic, spatial a priori information from data from groups of subjects. The results demonstrated that the group independent component (GIC) computed by GICA-IR is more representative of the commonality of the subjects in the group through incorporating this information into the GICA extraction procedure [33].
However, as far as we know, there are very few papers that study how to obtain temporal a priori information from the subjects in a group for multi-subject fMRI data analysis. In this paper, we propose a novel method to extract the temporal a priori information from the data from groups of subjects and then incorporate it into a GICA computational process for group fMRI data analysis using the improved multi-objective optimization-based CICA method. The experimental results showed that the GIC computed by the improved CICA method is more representative of the commonality of subjects in the group.
2 Methods
In this section, we first briefly introduce the relevant knowledge about ICA and GICA. Then, a detailed description of the proposed improved CICA method with temporal reference signal is presented. Finally, we provide a description of the experimental data and data processing.
2.1 Independent component analysis
Assume X = (x 1, x 2, …, x T )′ is a T × V matrix of observed fMRI data from a single subject, where T and V represent the number of time points and the number of voxels within the brain, respectively. Then, the classical spatial ICA can be formulated as the following linear generative model:
where S = (s 1, s 2, …, s N )′ is an N × V matrix in which each row represents a spatial source and N denotes the number of sources. These sources are assumed to be unobservable, independent, and non-Gaussian. M is a T × N unknown mixing matrix that mixes the N sources to generate the observed fMRI data, whose columns contain the associated time courses of the N source signals. Solving the ICA is estimating an N × T unmixing matrix W = (w 1, w 2, …, w N )′ such that Y = (y 1, y 2, …, y N )′ is a good approximation of the sources S according to the following equation:
Many algorithms can be used to solve the ICA model in (1), and currently the most widely used ICA algorithms include InfoMax [34] and FastICA [35].
2.2 Group independent component analysis
ICA was implemented on the multi-subject fMRI data, often referred to as GICA. Temporal concatenation GICA (TCGICA) is the most widely used method in the existing GICA approaches, which assumes that all subjects have common, spatially independent components (ICs). Specifically, assuming that there are K subjects in total, and X i is a T × V matrix that represents the fMRI data of each subject i (i = 1, ⋯ , K), the TCGICA concatenates the fMRI data of K subjects along the temporal dimension and then decomposes the KT × V group data as follows:
where \( \widehat{\boldsymbol{M}} \) is a KT × L group mixing matrix, \( \widehat{\boldsymbol{S}} \) is a L × V matrix in which each row represents a GIC, and L denotes the number of GICs.
2.3 The improved CICA with temporal reference signal
In this subsection, we first give the specific steps of the method for extracting the temporal reference signal from the group of subjects, and then we present a detailed description of the improved multi-objective optimization-based CICA method.
2.3.1 The extraction of the temporal reference signal
We assume there are a total of K subjects in the group, and all subjects have T time points and V voxels after normalization. First, we implemented ICA on each of the subjects in the group. For each subject i, ICA was defined as
where X i is a T × V fMRI observed data, \( {\boldsymbol{S}}_i={\left({\boldsymbol{s}}_{11},{\boldsymbol{s}}_{12},\dots, {\boldsymbol{s}}_{1{N}_i}\right)}^{\prime } \) is an N i × V matrix, and each row represents an IC of subject i. \( {\boldsymbol{M}}_i=\left({\boldsymbol{m}}_{11},{\boldsymbol{m}}_{12},\dots, {\boldsymbol{m}}_{1{N}_i}\right) \) is a T × N i mixing matrix. For the sake of simplicity, we only considered the case where each subject has just one IC of interest, and the correspondence of the ICs of different subjects could be obtained by the absolute value of the spatial correlation [36].
Now we denoted \( {\boldsymbol{s}}_{i{n}_i}\left(i=1,2,\dots, \mathrm{K}\right) \) as the n i st IC, which is the source of interest for the subject i, and \( {\boldsymbol{m}}_{i{n}_i}\left(i=1,2,\dots, \mathrm{K}\right) \) is the corresponding time course. Finally, these time courses were concatenated into a time course with greater length:
where m represents the temporal reference signal, which is a column vector of size KT × 1, and it is used as rt i in the following improved multi-objective optimization-based CICA method for group fMRI data analysis.
2.3.2 The improved multi-objective optimization-based CICA method
In this paper, the proposed improved CICA with temporal reference signal method was established with the multi-objective optimization framework as follows:
where J(w i ) is the negentropy of the estimated IC, \( {\widehat{\boldsymbol{s}}}_{\boldsymbol{i}}={\boldsymbol{w}}_{\boldsymbol{i}}^{\boldsymbol{T}}\widehat{\boldsymbol{X}} \). \( {\widehat{\boldsymbol{m}}}_{\boldsymbol{i}}={\boldsymbol{Z}}^{-1}{\boldsymbol{w}}_i \) denotes the time course corresponding to \( {\widehat{\boldsymbol{s}}}_{\boldsymbol{i}} \), and it is a column vector of size KT × 1. Z denotes the L × KT whitening matrix, which is obtained by eigenvalue decomposition, and L denotes the number of ICs. v is a Gaussian random variable with a zero mean and a unit variance. G(∙) is a non-quadratic function, and G(v) = log(cosh(v)) is used in this paper. rt i denotes a temporal reference signal, which is a column vector of size KT × 1, and \( {\varepsilon}_1\left({\boldsymbol{w}}_{\boldsymbol{i}}\right)= abs\left(E\left[{\widehat{\boldsymbol{m}}}_{\boldsymbol{i}}\bullet {\boldsymbol{rt}}_{\boldsymbol{i}}\right]\right) \) is specifically defined as the Pearson correlation coefficient to measure the closeness between \( {\widehat{\boldsymbol{m}}}_{\boldsymbol{i}} \) and rt i where both \( {\widehat{\boldsymbol{m}}}_{\boldsymbol{i}} \) and rt i have a zero mean and unit variance. Each solution of the multi-objective optimization problem in (6) corresponds to an optimal unmixing column vector w i that is constrained to ‖w i ‖2 = 1.
For multi-objective optimization problems, there is no global solution that makes all of the cost functions achieve the optimum simultaneously. Therefore, a trade-off solution is needed to balance the optimality of all cost functions. Among the methods of solving the multi-objective optimization problem, the weighted summing method is simple and efficient, and it is achieved by optimizing the weighted sum function of the objective functions on the condition that the weight value of each objective function is positive and the sum of all weights is 1 [37]. Therefore, this method was adopted to solve the multi-objective optimization problem of (6) in our study. To avoid the calculation process being controlled by the objective function with a larger value, the arc-tangent function was used to normalize the objective function J(w i ) in (6):
where c i in (7) is automatically determined so that the possible values of f 1(w i ) and ε 1(w i ) range from 0 to 1 [36]. Then, the reformulated linear weighted objective function is
where a i (i = 1, 2) is the weight parameters and a 1 + a 2 = 1. Then, the iteration algorithm for optimizing f(w i ) can be derived as follows:
where g(∙) is the derivative of G(∙), sog(v) = tanh(v). E(∙) can be estimated as the mean of all samples. Once the gradient of the weighted sum function in (8) is calculated, the steepest ascent iteration formula can be set up as follows:
where w i (k) denotes the value of w i after the kth iteration. d i (k) = ∇f(w i (k))/‖∇f(w i (k))‖, and μ(k) denotes the step-length. Finally, the corresponding time course can be calculated by using the following formula when the IC \( {\widehat{\boldsymbol{s}}}_{\boldsymbol{i}} \) is obtained:
where w i is the unmixing column vector corresponding to \( {\widehat{\boldsymbol{s}}}_{\boldsymbol{i}}. \)
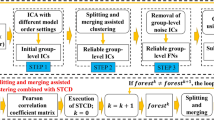
In the last subsection, the whole process for the proposed method is summarized as a flowchart (see Fig. 1).

The flowchart of the proposed method. X i (i = 1, 2, …, K) represents the fMRI data of subject i. M i (i = 1, 2, …, K) and S i (i = 1, 2, …, K) represent the temporal and spatial components of subject i, respectively, which are obtained using ICA. m represents the temporal reference rt i . \( \widehat{\boldsymbol{M}} \) and \( \widehat{\boldsymbol{S}} \) represent the group temporal and spatial components, respectively, which are obtained using the improved CICA method
2.4 Experimental data
In this subsection, the simulated and real fMRI data were used to evaluate the performance of the improved CICA method at the group level for fMRI data analysis.
2.4.1 Simulated data
The simulated fMRI data were obtained using the code downloaded from http://mlsp.umbc.edu/simulated_fmri_data.html [38], where a set of spatial sources with different simulated hemodynamic time courses were designed to generate the data through linear superposition. Specifically, the data for each simulated subject were produced by mixing the eight original sources with their corresponding time courses, and a total of 100 sample images were included in the data, where each source image had 60 × 60 pixels with 100 time points (see Fig. 2). The eight original sources were designed such that source 1 was task related, source 2 and source 6 were transiently task related, source 5 was function related, and source 3–source 4 and source 7–source 8 were artifact related. In particular, the task-related source 1 had a time course similar to the block-like shape that is often used to imitate an experimental paradigm.

The simulated original sources and their corresponding time courses, which are all normalized to have a mean of zero and a unit variance. Specifically, source 1 represents task-related information, source 2 and source 6 represent transiently task-related information, source 5 represents function-related information, and the others four sources (source 3–source 4 and source 7–source 8) represent artifact-related information
In this experiment, 20 groups of simulated datasets were produced from the same original sources/TCs by adding specific variability to each subject, and each simulated dataset included five subjects. The spatial variation in the sources of each subject was portrayed by adding Gaussian noise with a different signal-to-noise ratio (SNR) to the source images, and the signal-to-noise ratios ranged from 0.3 to 0.4 and were randomly determined for different subjects. The temporal variation in time courses was simulated by applying time delay and amplitude modulation, which were also randomly determined with the time courses.
2.4.2 Real fMRI data
A real fMRI dataset from five subjects who completed a visual task was included in this study. All five subjects were notified about the aim of this study, and they signed a written consent letter. The block pattern of OFF-ON-OFF-ON-OFF-ON was used as the experimental paradigm, and each block lasted 20 s. In the “ON” state, the visual stimulus corresponded to a radial blue/yellow checkerboard that reversed at 7 Hz. In the “OFF” state, the participants were required to focus on a cross at the center of the screen. The BOLD fMRI data from two subjects were acquired using single-shot SENSE gradient echo EPI with 37 slices, providing whole-brain coverage and 70 volumes, a TR of 2.0 s, and a scan resolution of 64 × 64. The in-plane resolution was 4 mm × 4 mm, and the slice thickness was 4 mm. The other three subjects were acquired using single-shot SENSE gradient echo EPI with 40 slices, providing whole-brain coverage and 70 volumes, a TR of 2.0 s, and a scan resolution of 80 × 80. The in-plane resolution was 3 mm × 3 mm, and the slice thickness was 3 mm.
2.5 Data processing
All of the calculations in this study were implemented on a workstation whose operation system platform was Windows 7 Unlimited Service Pack 1, with an Intel(R) Xeon(R) E5-1620 3.60 GHz processor and 40 GB RAM. The preprocessing and calculation steps from FastICA and the improved CICA methods were run using Matlab (Matlab, 2012b, MathWorks Inc., Sherborn, MA, USA) [39].
The preprocessing steps of the real-data experiment were implemented using SPM8 software (http://www.fil.ion.ucl.ac.uk/spm/), which included slice timing, motion correction, spatial normalization, and smoothing with a Gaussian kernel of 8 mm. In all experiments, FastICA, the newly published method [39] (which is denoted as CICA in this paper), and the improved CICA method were used. Specifically, FastICA was implemented using GIFT software (v2.0e) (http://mialab.mrn.org/software/) for the purpose of comparison. Moreover, ICASSO [40] with 20 runs of ICA was used to obtain reliable ICs, and MDL [41] was used to estimate the number of ICs. Furthermore, the positioning and display of the spatial networks were implemented using MRIcro software (http://www.mricro.com).
3 Results
In this section, the advantages of the improved CICA method are demonstrated by comparing the experimental results obtained with the improved CICA method with those obtained with FastICA and CICA for the group fMRI data analysis. Specifically, the spatial a priori information in CICA was obtained using a previously described method [33], and a detailed description is presented in Appendix 1.
First, a power analysis of the receiver operating characteristic (ROC) curve was adopted to evaluate the spatial detection ability of these methods in the simulated experiment, which is denoted by the area surrounded by the ROC curve, and a larger area under the curve (AUC) is usually better [42]. Second, the correlations among the time courses computed by FastICA, CICA, and the improved CICA methods with the true time course were used to measure the temporal performance, which can be calculated using the following formula:
where TTC represents the true time course and TC represents the time courses computed by each method. Finally, the correlations among the GICs computed by FastICA, CICA, and the improved CICA methods with the corresponding IC of each subject were used to evaluate the group-level analysis, which can be calculated as follows:
where GIC represents the group independent component and IC i represents the corresponding independent component of subject i.
In the experiments in this paper, the weighting parameter “a” of the improved CICA method was a value from 0.1 to 0.9 with a step length of 0.1, and then we decided which “a” to use according to the evaluation of the experimental results of each “a.” The corresponding results were the final experimental results. Specifically, in order to guarantee the consistency of the selection of the optimal weighting parameters for the simulated data and real data experiments, the index obtained by the following formula (14) was used to select the best situation. We first calculated the average of the correlation coefficients between the GIC and the corresponding IC of each subject across all subjects and then combined this average with the correlation coefficient between the true time course and the time course calculated with a new average, which was used as the quantitative indicator to select the weighting parameter of the improved CICA method:
where K denotes the number of subjects in the group and K = 5 for both simulated data and real data experiments in this paper.
3.1 Simulated data results
In this experiment, we focused on the task-related source 1, and its corresponding time course had a block-like shape that closely matched the experimental paradigm. The results of using weighting parameter a = 0.6 for dataset 8, a = 0.1 for dataset 14, and a = 0.9 for other datasets are presented according to formula (14).
Figure 3 shows the AUCs of the ROC curves of the GICs that were computed by FastICA, CICA, and the improved CICA methods on the 20 simulated datasets. It can be seen clearly from the figure that the AUCs of CICA were significantly higher than those of the improved CICA, except dataset 14, and those of FastICA across all datasets, and the AUCs of the improved CICA are significantly higher than those of FastICA, except dataset 8. These significant differences were verified by T test with a confidence level of 95%, which demonstrated that CICA has the best source recovery ability, and the improved CICA method with the temporal reference signal extracted from the group of subjects had better source recovery ability compared with FastICA.

The AUCs of FastICA, CICA, and the improved CICA methods on the 20 simulated datasets
Figure 4 shows the correlation coefficients (CCs) among the true time course and the group time courses computed by FastICA, CICA, and the improved CICA methods on the 20 simulated datasets. It can be seen from the figure that the CCs of the improved CICA are significantly higher than those of CICA and FastICA across all simulated datasets using T tests with a confidence level of 95%, while the CCs between CICA and FastICA were not significantly different. These results demonstrate that the improved CICA method had better temporal detection performance compared with CICA and FastICA methods.

The CCs among the true time course and the time courses computed by FastICA, CICA, and the improved CICA methods on the 20 simulated datasets
Figure 5 shows the average CCs of the GIC with the corresponding IC of each subject in the group across the 20 simulated datasets and their standard deviations, which are obtained using GICs computed by FastICA, CICA, and the improved CICA methods. We can see from the figure that the CCs calculated by CICA and the improved CICA methods were significantly higher than those of FastICA, which was verified by T tests at a confidence level of 95%. At the same time, the CCs of the improved CICA were slightly higher than those of CICA, but they were not significantly different. These results demonstrate that the GIC computed by the improved CICA method was more representative of the commonality of subjects in the group. That is, the temporal reference signal extracted from the group of subjects improved the analysis of the group data.

The average CCs of the 20 simulated datasets among the GIC and the corresponding IC of each of the five subjects and their standard deviations, which are obtained using GICs computed by FastICA, CICA, and the improved CICA methods
3.2 Real data results
In this section, only the task-related independent component is considered. The performance of the improved CICA method was compared with FastICA and CICA for fMRI data analysis at the group level. The results using weighting parameter a = 0.9 with the improved CICA method are presented according to formula (14).
Figure 6 shows the visual regions detected by FastICA, CICA, and the improved CICA methods. We can see from the figure that the regions of the improved CICA method are better than those of FastICA and similar to those of CICA, which means that the improved CICA method is superior to FastICA in source recovery using the temporal reference signal from the group of subjects and has the same performance as the CICA method.

The visual areas from slices 28 to 43 are detected by FastICA, CICA, and the improved CICA methods. All the spatial maps are z-scored with the same threshold of 2
Figure 7 shows the prior block and the time courses computed by FastICA, CICA, and the improved CICA methods as well as the CCs between the prior block and the time course of each method. It can be clearly seen from the figure that the CC of the improved CICA method is higher than those of CICA and FastICA, which means that the time course computed by the improved CICA method is more accurate than those of FastICA and CICA and further demonstrates its better temporal performance.

The prior block (black) and time courses computed by FastICA (blue), CICA (green), and the improved CICA method (red), and the CCs between the prior block and the time course of each method, including corrcoef1 for FastICA, corrcoef2 for CICA, and corrcoef3 for the improved CICA method (color figure online)
Figure 8 shows the CCs between the GIC and the corresponding IC of each subject in the group. The results were obtained using GICs computed by FastICA, CICA, and the improved CICA methods. We can see from the figure that the GICs computed by CICA and the improved CICA methods have a higher correlation with the corresponding IC of each subject than with that of FastICA. These significant differences were found using T tests at a confidence level of 95%. Although the CCs of the improved CICA were slightly lower than those of CICA, they were not significantly different. This result indicates that the GIC calculated by the improved CICA method can better reflect the commonality of subjects in the group.

The CCs between the GIC and the corresponding IC of each subject in the group. The results were obtained using GICs computed by FastICA, CICA, and the improved CICA methods
4 Discussion
In this study, the improved CICA method with the temporal a priori information extracted from the group data had better performance in detecting brain functional connectivity through the experimental results with the simulated and real fMRI data. First, the results in Figs. 3 and 6 show that the spatial source recovery of the improved CICA method was better than that of FastICA, but it was not as good as CICA. Second, the results in Figs. 4 and 7 show that the time courses of the corresponding sources computed by the improved CICA method were more accurate than those of the FastICA and CICA methods. Finally, the results in Figs. 5 and 8 demonstrate that the correlation between the GIC computed by the improved CICA method and the corresponding IC of each subject in the group was improved in comparison with that of FastICA, but there was no significant difference with CICA, which means that the GIC computed by the improved CICA method was more representative of the commonality of the subjects in the group.
In this paper, in order to imitate the situation of noise contained in the real fMRI data, noises with different SNRs that ranged from 0.3 to 0.4 were added to the simulated data, which were used for the evaluation of the performance of the different methods. However, if the SNR of the added noise was too small, all methods showed poor performance in signal detection and thus lost the significance of evaluation. On the contrary, if the SNR of the added noise was too large, all methods produced better detection results and that there was no obvious comparability between the different methods. The SNR range adopted in this paper was a trade-off between these two situations, and it was much closer to the noise found in real data.
In the classical CICA method, the a priori reference signal was incorporated using a constraint condition g(y) = ε(y, r) − ξ ≤ 0, where y denotes the output signal, r denotes a reference signal, ε(y, r) is a distance criterion, and ξ is a threshold parameter that needs to limit the distance such that the desired output signal should be the only one satisfying the inequality constraint. However, it is difficult to predetermine the threshold parameter ξ in practical application because the ICs are blind, so the choice of a suitable ξ is quite dependent on the applied CICA. Improper ξ often leads to two possible consequences. When ξ is beyond the upper bound of the feasible range, the output may produce an undesired IC. On the other hand, when ξ is smaller than the lower bound of the range, the output cannot produce any IC. Therefore, special effort has to be made to determine a proper parameter. In this paper, the multi-objective optimization strategy was applied to estimate ICs with the CICA method, which circumvents the selection of threshold parameter ξ, and the results demonstrated its improved performance.
In this paper, the weighted summation method was used to solve the multi-objective optimization problem of Eq. (6). The weight parameters “a 1” and “a 2” in formula (8) reflect the importance of the corresponding objective function f 1(w i ) and ε 1(w i ) in the summation function f(w i ). The goal of the weighted summation method is to seek a balance between the independence of the output signal and the similarity with the reference signal and then to obtain a source signal that is the closest to the reference signal with the largest independence. According to theory, applying the linear weighted summation method to solve the multi-objective optimization problem in [37] was proposed by Klamroth et al. As long as the weight parameters satisfied the conditions that they were strictly positive and added to 1, then one point of the Pareto optimal set can be found with one choice of such weights [43].
When using the linear weighted summation method to solve the multi-objective optimization problem, the summation function will contain the corresponding weight parameters that are usually determined manually according to artificial experience, and this process means that the experimental results obtained by this approach will contain many kinds of situations. Therefore, it is necessary to choose the best situation according to certain evaluation indicators from these results by additional post-processing steps. In the experiments in this paper, the weighting parameter “a” of the improved CICA method was a value from 0.1 to 0.9 with a step length of 0.1, thus making the results include nine kinds of situations. To guarantee the consistency of the selection of the optimal weighting parameters for the simulated data and real data experiments, the index obtained by formula (14) was used to select the best situation, and the evaluation results of all situations obtained by formula (14) are shown in Appendix Tables 1 and 2, which correspond to simulated-data and real-data experiments, respectively, and are presented in Appendix 2. However, sometimes the final evaluation results may be different when adopting a different evaluation index. For example, in the simulated data experiment in this paper, if we use the average of AUCs (see Fig. 3) and CCs (see Fig. 4) to choose the optimal weighting parameter, the best situation is a = 0.9 for dataset 18, which is different from the results obtained by formula (14). The evaluation results of all situations obtained by this approach are shown in Appendix Table 3, which is also presented in Appendix 2.
In addition, tensor decomposition (TD) has also shown better performance with multi-subject fMRI data analysis in recent years due to its ability to retain multi-way linkages and interactions presented in the data [44], and it can be used to obtain common spatial maps (SMs), common time courses (TCs), and subject-specific intensities [45, 46]. However, the TD method sometimes may converge to a local optimal solution because of the noise in the fMRI data, such as canonical polyadic decomposition (CPD), which is a popular TD method. To improve the robustness of CPD with respect to noise, some additional properties have been efficiently incorporated into CPD as modality constraints [47]. For example, Beckmann and Smith proposed a solution using the statistical independence as a spatial modality constraint in TD by combining ICA with CPD [45]. Recently, Kuang et al. propose a new combined ICA and CPD method by incorporating TC delays into a CP model as the temporal constraint to obtain the shared TC, and then estimated the shared SM using a least-square fit post shift-invariant CPD [48]. Therefore, how to extract a priori information from the data itself and how to introduce it into the TD method to improve fMRI data analysis will be questions worth studying in the future.
5 Conclusions
In this paper, we proposed a multi-objective optimization-based improved CICA method with temporal a priori information extracted from group subject data and then used it for group fMRI data analysis. The experimental results of simulated and real fMRI data showed that the group data analysis using the improved CICA method was better than that of FastICA in both spatial and temporal domains, and it not only increased the accuracy of spatial sources and time courses but also improved the correlation of the GIC with the corresponding IC of each subject in the group. Compared to the CICA method, it only performed better temporally, and there was a slight deficiency in spatial source signal recovery. On the whole, it has its own advantages in fMRI data analysis as a blind source separation method.
References
Logothetis NK (2008) What we can do and what we cannot do with fMRI. Nature 453:869–878
Im CH (2007) Dealing with mismatched fMRI activations in fMRI constrained EEG cortical source imaging: a simulation study assuming various mismatch types. Med Bio Eng Comput 45:79–90
Vargas ER, Mitchell DGV, Greening SG, Wahl LM (2016) Network analysis of human fMRI data suggests modular restructuring after simulated acquired brain injury. Med Bio Eng Comput 54:235–248
Li KM, Guo L, Nie JX, Li G, Liu T (2009) Review of methods for functional brain connectivity detection using fMRI. Comput Med Imaging Graph 33:131–139
Li Z, Zang YF, Ding J, Wang Z (2017) Assessing the mean strength and variations of the time-to-time fluctuations of resting-state brain activity. Med Bio Eng Comput 55:631–640
Sun F, Morris D, Babyn P (2009) The optimal linear transformation-based fMRI feature space analysis. Med Bio Eng Comput 47:1119–1129
McKeown MJ, Makeig S, Brown GG, Jung TP, Kindermann SS, Bell AJ, Sejnowski TJ (1998) Analysis of fMRI data by blind separation into independent spatial components. Hum Brain Mapp 6:160–188
Zhang S, Tsai SJ, Hu S, Xu J, Chao HH, Calhoun VD, Li CR (2015) Independent component analysis of functional networks for response inhibition: Inter-subject variation in stop signal reaction time. Hum Brain Mapp 36:3289–3302
Long Z, Chen K, Wu X, Reiman E, Peng D, Yao L (2009) Improved application of independent component analysis to functional magnetic resonance imaging study via linear projection techniques. Hum Brain Mapp 30:417–431
Long Z, Li R, Hui M, Jin Z, Yao L (2013) An improvement of independent component analysis with projection method applied to multi-task fMRI data. Comput Biol Med 43:200–210
Friston KJ, Frith CD, Turner R, Frackowiak RSJ (1995) Characterizing evoked hemodynamics with fMRI. NeuroImage 2:157–165
Damoiseaux JS, Rombouts S, Barkhof F, Scheltens P, Stam CJ, Smith SM, Beckmann CF (2006) Consistent resting-state networks across healthy subjects. Proc Natl Acad Sci U S A 103:13848–13853
Mantini D, Perrucci MG, Del Gratta C, Romani GL, Corbetta M (2007) Electrophysiological signatures of resting state networks in the human brain. Proc Natl Acad Sci U S A 104:13170–13175
Calhoun VD, Kiehl KA, Pearlson GD (2008) Modulation of temporally coherent brain networks estimated using ICA at rest and during cognitive tasks. Hum Brain Mapp 29:828–838
Schmithorst VJ (2005) Separate cortical networks involved in music perception: Preliminary functional MRI evidence for modularity of music processing. NeuroImage 25:444–451
Calhoun VD, Adali T, Pearlson GD, Pekar JJ (2001) A method for making group inferences from functional MRI data using independent component analysis. Hum Brain Mapp 14:140–151
Wang Z, Xia MG, Jin Z, Yao L, Long Z (2014) Temporally and spatially constrained ICA of fMRI data analysis. PLoS One 9:e94211
Ma X, Zhang H, Zhao X, Yao L, Long Z (2013) Semi-blind independent component analysis of fMRI based on real-time fMRI system. IEEE Trans Neural Syst Rehabil Eng 21:416–426
Liu H, Xie X, Xu S, Wan F, Hu Y (2013) One-unit second-order blind identification with reference for short transient signals. Inf Sci 227:90–101
Lu W, Rajapakse JC (2005) Approach and applications of constrained ICA. IEEE Trans Neural Netw 16:203–212
Lu W, Rajapakse JC (2006) ICA with reference. Neurocomputing 69:2244–2257
Barros AK, Vigario R, Jousmaki V, Ohnishi N (2000) Extraction of event related signals from multi-channel bioelectrical measurements. IEEE Trans Biomed Eng 47:583–588
Lin QH, Zheng YR, Yin FL, Liang H, Calhoun VD (2007) A fast algorithm for one unit ICA-R. Inf Sci 177:1265–1275
Calhoun VD, Adali T, Stevens MC, Kiehl KA, Pekar JJ (2005) Semi-blind ICA of fMRI: A method for utilizing hypothesis-derived time courses in a spatial ICA analysis. NeuroImage 25:527–538
Lin QH, Liu JY, Zheng YR, Liang H, Calhoun VD (2010) Semiblind spatial ICA of fMRI using spatial constraints. Hum Brain Mapp 31:1076–1088
Sun ZL, Shang L (2010) An improved constrained ICA with reference based unmixing matrix initialization. Neurocomputing 73:1013–1017
Li CL, Liao GS, Shen YL (2010) An improved method for independent component analysis with reference. Digit Signal Process 20:575–580
Mi JX (2014) A novel algorithm for independent component analysis with reference and methods for its applications. PLoS One 9:e93984
Mi JX, Xu Y (2014) A comparative study and improvement of two ICA using reference signal methods. Neurocomputing 137:157–164
Valente G, De Martino F, Filosa G, Balsi M, Formisano E (2009) Optimizing ICA in fMRI using information on spatial regularities of the sources. Magn Reson Imaging 27:1110–1119
Zhang ZL (2008) Morphologically constrained ICA for extracting weak temporally correlated signals. Neurocomputing 71:1669–1679
James CJ, Gibson OJ (2003) Temporally constrained ICA: an application to artifact rejection in electromagnetic brain signal analysis. IEEE Trans Biomed Eng 50:1108–1116
Shi YH, Zeng WM, Wang NZ, Chen DTL (2015) A novel fMRI group data analysis method based on data-driven reference extracting from group subjects. Comput Methods Prog Biomed 122:362–371
Bell AJ, Sejnowski TJ (1995) An information maximization approach to blind separation and blind deconvolution. Neural Comput 7:1129–1159
Hyvarinen A, Oja E (1997) A fast fixed-point algorithm for independent component analysis. Neural Comput 9:1483–1492
Du YH, Fan Y (2013) Group information guided ICA for fMRI data analysis. NeuroImage 6:157–197
Klamroth K, Tind J (2007) Constrained optimization using multiple objective programming. J Glob Optim 37:325–355
Correa N, Adali T, Li YO, Calhoun VD (2005) Comparison of blind source separation algorithms for FMRI using a new Matlab toolbox: Gift. IEEE Int Conf Acoust Speech Signal Process 5:401–404
Shi YH, Zeng WM, Wang NZ, Zhao L (2017) A new method for independent component analysis with priori information based on multi-objective optimization. J Neurosci Methods 283:72–82
Himberg J, Hyvarinen A, Esposito F (2004) Validating the independent components of neuro- imaging time series via clustering and visualization. NeuroImage 22:1214–1222
Li YO, Adali T, Calhoun VD (2007) Estimating the number of independent components for functional magnetic resonance imaging data. Hum Brain Mapp 28:1251–1266
Wang NZ, Zeng WM, Chen L (2013) SACICA: a sparse approximation coefficient-based ICA model for functional magnetic resonance imaging data analysis. J Neurosci Methods 216:49–61
Marler RT, Arora JS (2004) Survey of multi-objective optimization methods for engineering. Struct Multidiscip Optim 26:369–395
Andersen AH, Rayens WS (2004) Structure-seeking multilinear methods for the analysis of fMRI data. NeuroImage 22:728–739
Beckmann CF, Smith SM (2005) Tensorial extensions of independent component analysis for multi-subject fMRI analysis. NeuroImage 25:294–311
Kuang LD, Lin QH, Gong XF, Cong FY, Calhoun VD (2013) Multi-subject fMRI data analysis: shift-invariant tensor factorization vs. group independent component analysis. In: 2013 I.E. China summit and international conference on signal and information processing, 269–272
Cichocki A, Mandic D, Phan AH, Caiafa C, Zhou G, Zhao Q, Lathauwer L (2015) Tensor decompositions for signal processing applications from two-way to multiway component analysis. IEEE Signal Process Mag 32:145–163
Kuang LD, Lin QH, Gong XF, Cong F, Sui J, Calhoun VD (2015) Multi-subject fMRI analysis via combined independent component analysis and shift-invariant canonical polyadic decomposition. J Neurosci Methods 256:127–140
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grants No. 31470954, No. 61271446), the Research Foundation from Shanghai Science and Technology Project (Grant No. 14590501700), the Innovation Program of Shanghai Municipal Education Commission (Grant No.15ZZ079), the Programs for Graduate Special Endowment Fund for Innovative Developing (Grant No. 2015ycx081), and Excellent Doctoral Dissertation Cultivation (Grant No. 2015bxlp005) of Shanghai Maritime University.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1
In this section, we provide a detailed description of extracting spatial a priori information from group data [33]. Similar to extracting temporal a priori information from group data as described in this paper, we first need to implement ICA at the single-subject level. Now assuming that we have obtained the ICs, S i (i = 1, 2, …, K), of each subject in the group using formula (6), then these ICs will be used to extract the spatial a priori information by principal component analysis (PCA). For simplicity, we consider the situation in which each subject in the group has one IC of interest corresponding to the group IC (GIC). The correspondence of the ICs across different subjects corresponding to the GIC can be measured using the absolute value of the spatial correlation [36].
We denote the location set of voxels in the mask of subject i as VLS i ( i = 1, 2, …, K), and \( {\boldsymbol{s}}_{\boldsymbol{i}{\boldsymbol{n}}_{\boldsymbol{i}}}\left(\ i=1,2,\dots, K\right) \) denotes the n i th IC of subject i corresponding to the GIC of interest. Then, we can calculate the location set of common activated voxels in all \( {\boldsymbol{s}}_{\boldsymbol{i}{\boldsymbol{n}}_{\boldsymbol{i}}}\left(\ i=1,2,\dots, K\right) \) at the same threshold θ and denote it as CAVLS:
Let \( {\boldsymbol{s}}_{{\boldsymbol{i}\boldsymbol{n}}_{\boldsymbol{i}}}^{\boldsymbol{c}}\left(i=1,2,\dots, K\right) \) denote the common voxels from \( {\boldsymbol{s}}_{\boldsymbol{i}{\boldsymbol{n}}_{\boldsymbol{i}}} \) with regard to the index CAVLS where \( {\boldsymbol{s}}_{{\boldsymbol{i}\boldsymbol{n}}_{\boldsymbol{i}}}^{\boldsymbol{c}} \)is a column vector of size v × 1 and can be retrieved as
Here, the absolute value in \( {\boldsymbol{s}}_{\boldsymbol{i}{\boldsymbol{n}}_{\boldsymbol{i}}} \) is used in formula (s1) and formula (s2) due to the network of interest possibly having negative activation in the IC. Although it may mean that \( {\boldsymbol{s}}_{{\boldsymbol{i}\boldsymbol{n}}_{\boldsymbol{i}}}^{\boldsymbol{c}}\left(\ i=1,2,\dots, K\right) \) contains some noise, the spatial reference is extracted from all \( {\boldsymbol{s}}_{{\boldsymbol{i}\boldsymbol{n}}_{\boldsymbol{i}}}^{\boldsymbol{c}}\left(\ i=1,2,\dots, K\right) \) by PCA, which has the ability to reduce the noise.
Now we use PCA to calculate the spatial reference signal from the K × v matrix R which consists of all\( {\boldsymbol{s}}_{{\boldsymbol{i}\boldsymbol{n}}_{\boldsymbol{i}}}^{\boldsymbol{c}}\left(i=1,2,\dots, K\right) \):
Then, the eigenvalue λ k (k = 1, 2, …, K) such that λ 1 ≥ λ 2 ≥ ⋯ ≥ λ K ≥ 0, and the corresponding eigenvectors e k (k = 1, 2, …, K) of the covariance matrix C = E[RR ′] can be calculated, where e k is a column vector of size K × 1. Finally, we selected the first principal component as the spatial reference r:
where r is a row vector of size 1 × v and the corresponding contribution of r can be calculated by \( {c}_r={\lambda}_1/\sum_{k=1}^K{\lambda}_k \). In particular, if all subjects in the group have the same mask, then the spatial a priori information can be obtained directly through formulas (s3) and (s4).
Appendix 2
aThe bold numbers indicated the "index" values of the best situation obtained by formula (14) in each simulated dataset.
bThe bold number indicated the "index" value of the best situation obtained by formula (14) in the real-data experiment.
cThe bold numbers indicated the average of AUCs and CCs of the best situation in each simulated dataset.
Rights and permissions
About this article

Cite this article
Shi, Y., Zeng, W., Tang, X. et al. An improved multi-objective optimization-based CICA method with data-driver temporal reference for group fMRI data analysis. Med Biol Eng Comput 56, 683–694 (2018). https://doi.org/10.1007/s11517-017-1716-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11517-017-1716-9