
Abstract
Traditional mining methods damage the cultivated land and produce gangue waste that often contaminates the environment. Yet, these problems can be mitigated by transforming the waste into gangue-based cemented backfill material (GCBM), whose mechanical properties are crucial for surface protection. Therefore, in this study, an intelligent model based on laboratory tests was developed to evaluate the GCBM’s mechanical properties. The strength tests and polynomial response surface model (PRSM) were used to analyze the non-linear correlation between the influencing factors and the uniaxial compressive strength (UCS). Meanwhile, the importance of multidimensional factors was analyzed by the mean impact value, revealing that concentration and gangue proportion are the most sensitive factors. In addition, an intelligent response surface model (IRSM) based on support vector regression model was constructed by enhancing an optimization algorithm with chaotic mapping and adaptive methods. The performance of the traditional PRSM and the novel IRSM was compared, and the IRSM was validated. The IRSM can predict UCS more efficiently and effectively than the traditional PRSM under high-dimensional factors, with R2 of 0.96 and MBE of 0.05. This indicated that the IRSM has the potential to promote coal mine waste reduction and environmental protection.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
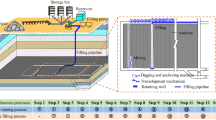
Underground coal mining leads to three significant environmental issues: surface subsidence, cultivated land occupation, and waste discharge (Gao et al. 2021). As shown in Fig. 1a and b, after sorting the raw coal, the remaining gangue is usually stacked on the surface. This leads to arable land occupation and environmental pollution (Czech et al. 2020). Moreover, when the coal is extracted, the rock above will sink, resulting in surface cracks and subsidence (Huang et al. 2022; Zhang et al. 2023), as shown in Fig. 1c. These issues pose a severe threat to the environment. In contrast, cemented paste backfill (CPB) can consume waste (Tariq and Yanful 2013) and avoid the overlying rock movement by backfilling the waste into the mined-out areas (Yilmaz et al. 2014). This technology has been used in China (Yang et al. 2021), Germany (Ermolovich et al. 2022), Canada (Jafari et al. 2021; Correia et al. 2021), Australia (Doherty et al. 2015), India (Behera et al. 2020), Russia (Khayrutdinov et al. 2020), and Turkey (Cavusoglu et al. 2021). Coal mines in China have adopted a gangue-based cemented paste backfill (GCPB) technology, whose principle Fig. 1 illustrates. After the raw coal is transported from the short wall working face, the fine coal and gangue are separated through underground beneficiation system. The fine coal is transported to the surface through the shaft, while the gangue is crushed and returned to the short wall working face (red line in Fig. 1). Meanwhile, the slurry is mixed with fly ash, cement, and additives on the surface and transported underground through the pipeline (blue line in Fig. 1), then mixed with gangue and filled into the short wall working face. Therefore, there is no need to lift the gangue to the surface and it can be reused in situ. This technology can decrease coal mine waste emissions, reduce the power consumption required for gangue lifting, and limit surface subsidence to safeguard the mine environment.

(a) Basic principle of GCPB applied in coal mines. (b) Waste accumulation. (c) Surface cracks and subsidence
After solidification, GCBM provides support for the rock, and its mechanical properties determine the support effectiveness. Therefore, optimizing the mechanical properties of GCBM is necessary (Li et al. 2022). In engineering applications, the load-bearing capacity of GCBM on rock is typically represented by uniaxial compressive strength (UCS) (Chen et al. 2022b; Jagadesh et al. 2023). However, determining the UCS of a large number of specimens is both time consuming and costly (Qi et al. 2020). Therefore, some scholars have proposed predicting the mechanical properties of backfilling material at different ratios using available experimental data. For example, Xiu et al. (2021) and Jiang et al. (2022) investigated the effect of time on the strength of cemented paste backfill material using linear regression. Sun et al. (2022) analyzed the strength of the paste using a PRSM. Zhu et al. (2021) constructed the quadratic polynomial regression models to study yield stress and plastic viscosity. Dong et al. (2023) used an improved response surface methodology (RSM) to prepare waste gangue-based geopolymer. Sadrossadat et al. (2022) predicted the cost, yield stress, and strength of CPB by metaheuristics. Miao et al. (2022) and Shaswat (2022) used neural networks and deep learning to predict tailings-based materials, respectively. In summary, there are two main methods for predicting the strength of backfilling material: mathematical models and machine learning. The former mainly includes PRSM (or polynomial regression models), and the latter mainly involves neural networks. However, both methods have their own limitations: (1) PRSM have to be modified every time there is a change in the input variables, which creates uncertainty in practical applications (Hu et al. 2022). (2) PRSM has weak generalization ability and cannot fit complex structures. Moreover, PRSM is also not suitable for handling high-dimensional data. (3) Neural networks require large amounts of data, which is a challenge in the case of GCPB due to the complex nature of UCS influence factors and limited experimental data. Therefore, it is a challenging issue to evaluate the mechanical properties of GCBM by dealing with the complex connections between high-dimensional variables.
In order to remedy the above deficiencies, this paper proposed an IRSM based on laboratory tests. The model integrated an improved intelligent optimization algorithm with SVR. It is used to deal with the effects of high-dimensional factors on UCS. The study also evaluated the importance of each factor, the model’s convergence and prediction performance, and compared the performances of PRSM and IRSM.
Materials and mechanical tests
Materials
In this study, the materials include fly ash, gangue, and binder. Gangue is a waste product generated after sorting raw coal into fine coal. The gangue is from the Nantun coal mine and is crushed to less than 10 mm. The percentage of gangue less than or equal to 5 mm in the whole is the fine gangue rate. Fly ash is a waste collected from flue gas. Secondary fly ash was used in the test. It has a sieve residue of less than 20% (0.045 mm square hole sieve) and a burnt vector of less than 8%. Adding fly ash to the backfilling material can reduce the binder requirement, enhance the compatibility of the backfilling material, and effectively reduce the cost of GCBM. The binder used in this study is ordinary Portland cement (Type PO 42.5R, based on Chinese Standard GB175-2007 Common Portland Cement).
Mechanical tests
Referring to the Box–Behnken design method in PRSM, we designed a test with three factors: mass concentration (X1), gangue proportion (X2), and fly ash proportion (X3). Based on the experience of Nantun coal mine, the engineering requirements for the strength and fluidity of GCBM can be met when the concentration is 81–84%, the gangue proportion is 30–50%, and the fly ash proportion is 35–50%. Table 1 shows the experimental scheme. We tested the UCS after 28 days of curing, as it best reflects the bearing effect of GCBM (Yang et al. 2022; Chen et al. 2022a), and took it as the response value (Y).
The test procedure is presented in Fig. 2. Initially, the materials were mixed with water and stirred for 5 min with a mixer. Then, the resulting slurry was poured into a mold measuring 70.7 × 70.7 × 70.7 mm and adequately vibrated to enhance its compactness. The samples were then allowed to cure for 28 days at 20 °C and 98% humidity in an oven. Following the curing period, the UCS test was conducted using a servo press (WAW-2000D) with a loading rate of 0.5 mm/min.

GCBM’s mechanical testing process
Mechanical test results
The relationship between the factors and UCS obtained through the PRSM is shown in Eq. 1. This is a ternary quadratic regression equation, where the primary and secondary terms of factors, as well as the interaction between them, all exert varying degrees of influence on the UCS. The primary term of each factor exerts the strongest influence, while the concentration of the secondary term has the greatest degree of influence. In contrast, gangue (X2) and fly ash (X3) have the least degree of influence in the interaction. The relationship between multiple factors affecting the UCS is complex and non-linear. While this complexity may be presented through an explicit function such as a polynomial, the polynomial will become excessively lengthy as the number of factors increases.
The p-value of PRSM is 0.0032 with an R2 of 0.9269, indicating a very significant fit. Figure 3 shows the relationship between the residuals and the predicted values from the model, which can be used to detect outliers (Kermani et al. 2023). As shown in the figure, none of the internally studentized residual exceed ± 3, and the data points are scattered irregularly, suggesting that the residuals are acceptable and there are no outliers.

Prediction results of PRSM. (a) The distribution of residuals. (b) Correlation between predicted and measured values
The response surface in Fig. 4 illustrates how the factors are coupled and influence the dependent variable. The slope of each factor on the response surface reflects the significance of the results, and the top view indicates the significance of the coupling effect between factors. By examining the coupling relationship between mass concentration and gangue proportion, it is observed that as gangue proportion increases and concentration decreases, UCS initially decreases and then increases. With every 1% change in concentration and 4% change in gangue proportion, the average change in UCS is 2 MPa, indicating that the slopes of the two factors are not the same. The coupling relationship between concentration and fly ash proportion exhibits an inconsistent trend in their influence on UCS. As fly ash proportion increases and concentration decreases, UCS initially decreases and then increases. The slope of concentration in the response surface is larger than that of fly ash proportion. Regarding the coupling relationship between gangue proportion and fly ash proportion, the two have the same trend of influence on UCS. With every 5.5% change in gangue proportion and 5% change in fly ash proportion, the average change of UCS is 1.2 MPa. With the increase of fly ash proportion and gangue proportion, UCS increases exponentially. In summary, the factors exhibit different degrees of interaction and have a strong non-linear influence on UCS.

The coupling effect of influencing factors to UCS. (a) Mass concentration and gangue proportion. (b) Mass concentration and fly ash proportion. (c) Gangue proportion and fly ash proportion
The analysis above indicates a complex non-linear relationship between the influencing factors and UCS. In the PRSM, incorporating more factors leads to a more complex relationship between them and UCS. As the number of factors increases, the workload grows exponentially, and the number of tests and the terms of equations increase (Ottoni et al. 2018; Bhattacharya 2021). In addition, when independent variable data changes, equations must also change, leading to uncertainties in engineering applications. It can be seen that PRSM has limitations when dealing with complex relationships between high-dimensional variables. Therefore, in the next section, an intelligent response surface model is proposed to deal with this challenge.
Intelligent response surface model
Support vector regression model
Support vector machine (SVM) can be used to construct response surface models (Shin and Cho 2006; Gao and Bai 2015), which can be used to explore the relationship between multiple explanatory variables and one or more response variables. The advantage of SVM is that it can deal with non-linear and high-dimensional data and has good generalization ability. As a variant of SVM, support vector regression model (SVR) also can be used as a response surface model to predict the effects of multidimensional variables on the mechanical properties of cemented backfill materials (Shin and Cho 2008).
SVR is based on VC theory and is effective at constructing relationships between high-dimensional variables through implicit functions (Moges et al. 2023). Unlike the traditional PRSM, it uses kernel functions instead of only a polynomial function to fit the response surface, which improves the fitting accuracy and flexibility (Bouchehed et al. 2023). SVR only uses the support vectors to determine the classifier, and the number of support vectors is usually much smaller than the total number of samples, which reduces the computational complexity and data size requirements. Moreover, the optimization goal of SVR is to minimize structural risk rather than empirical risk, and thus is able to eliminate the need for data volumes of millions or more, as is required for neural networks. Therefore, when the number of samples is limited, SVR demonstrates good small sample learning and generalization abilities in comparison to neural networks (El Bilali et al. 2023).
The principle of SVR is to construct an interval zone between different data points and achieve prediction by narrowing the interval zone. This paper uses the Gaussian radial basis kernel function to construct the response surface, and the width parameter and loss parameter of this kernel function affect the performance of SVR (Liu et al. 2021), which require optimization.
Improved intelligent optimization algorithm
White Shark Algorithm
The White Shark Algorithm (WSO) proposed in 2022 is a bio-inspired optimization method that mimics the hunting and tracking behavior of white sharks (Braik et al. 2022). Each population consists of several white sharks, and the position of each white shark represents a potential solution. White sharks can use their sense of sight and smell to find prey and track individuals with high-foraging ability. By simulating the hunting and tracking process, the positions are continuously updated and compared with the previous positions to select the optimal solution. The core of the white shark population speed and position update is shown in Eqs. (2) and (3).
where k = 1, 2, …, n represents every white shark in population, \({v}_{i+1}^{k}\) and \({v}_{i}^{k}\) denote the velocity of the current population movement and the velocity after the next iteration, respectively, \({x}_{t}\) is the current position, \({x}_{t-{\text{best}}}\) is the optimal position, \({x}_{t-{\text{gbest}}}\) is the current global optimal position, p stands for the individuals drawing on their own experiences, and g represents individuals drawing on group experiences. μ defines the contraction factor used to analyze the convergence behavior in WSO, and it indicates how much the next iteration depends on the previous one; τ denotes the acceleration coefficient.
Chaos mapping initialization
The quality of the initial population diversity affects the subsequent optimization process (Arora and Anand 2019). The initialized population of the WSO is generated randomly, as depicted in Fig. 5a. This method may produce null values in some domains and cause uneven and discontinuous population, which may impair the later iterations. However, chaotic mapping offers randomness, ergodicity, and regularity (Pan et al. 2022; Yıldız et al. 2022), which can enhance the population initialization. Some common chaotic mapping methods are logistic mapping, tent mapping, and circle mapping (Rezaee Jordehi 2015). Among them, circle mapping is more stable and has a higher coverage, as Eq. (4) and Fig. 5b demonstrate. Therefore, circle mapping was used to improve the population initialization quality in this paper.

(a) Randomly generated population distribution. (b) The distribution using circle mapping
Adaptive convergence
In practical applications, WSO suffers from slow convergence and the tendency to fall into local solutions (Lakshmanan et al. 2023). To improve its iterative performance, this paper adopted an adaptive approach. The original WSO employed a constant τ, implying that each iteration drew from the preceding generation in a uniform manner. However, in reality, the population’s iterative process is non-linear and dynamic (Iiduka 2022). The population initially explores randomly in a broad range; once the optimal individual emerges, others learn from its experience. Consequently, assigning different inertia weights, denoted by μ, based on the exploration’s progress is crucial. Currently, main adjustment methods include random, linear, and non-linear adjustments. This study employed the non-linear method, considering the iterative experience (Yan et al. 2022). The specific principle is shown in Eq. (5). This adaptive adjustment guarantees global exploration and smooth non-linear convergence in the early stage, followed by faster non-linear convergence after the population reaches a better fitness value.
Intelligent response surface modeling
Figure 6 illustrates the basic principle of enhancing WSO with circle chaotic mapping and adaptive adjustment (CA-WSO). First, circle mapping is used to enhance the initialized population, after which the initialized fitness value is calculated and ranked. Then, based on the behavior of white sharks, the algorithm updates the positions of individuals adaptively and non-linearly, and adjusts the learning factor dynamically to increase the convergence rate. Subsequently, the algorithm calculates and compares the fitness value of each generation with the best value of the previous generation, and selects the best value so far. This process repeats until the algorithm obtains the global optimum.

The basic principle of IRSM
The intelligent response surface model (IRSM) comprises CA-WSO and SVR, denoted as CA-WSO-SVR. The process of IRSM is segregated into two parts, as depicted in Fig. 6. The first part’s core is the WSO algorithm, which iteratively determines the optimal hyperparameters with SVR as the objective function. This part is based on the training dataset and uses cross-validation to find the optimal parameters. On the other hand, the second part’s core is SVR. Based on the model and test set trained in first part, it uses the trained model for establishing the non-linear correlation between the high-dimensional factors and UCS. Finally, the model’s performance was assessed via evaluation metrics and iteration curves.
Dataset and evaluation indicators
In total, 373 datasets were utilized to train the SVR. Out of these, 44 data were obtained through laboratory tests and 329 data were sourced from literature (Jiang et al. 2019; Shi et al. 2021; Sun et al. 2022, 2019; Wang et al. 2018; Zhang et al. 2021, 2017; Yin 2018; Yu 2017; Yang 2011; Ouyang 2019; Niu 2014; Zhao 2018, 2014; Deng 2017; Guo 2013; Chen 2017; Gao 2021). The cited and experimental data constitute a diverse dataset that includes different fly ash types, fine gangue rates, and concentrations under different working conditions, for a total of nine variables.
Since SVR is based on statistical theory and does not rely on extensive experience (Rahmati et al. 2019), these amounts of data are feasible. The data were split into a training part and a test part in an 8:2 ratio, with 298 data used for training and 75 data for testing. In addition, 30 individuals were chosen from the WSO population, and the model was iterated 100 times.
To evaluate the reliability of IRSM, four indicators are used in this paper: the squared correlation coefficient (R2) (Van den Hove et al. 2020), the mean absolute error (MAE), the mean bias error (MBE), and the root-mean-square error (RMSE). R2 indicates the correlation between measured and predicted values, determining whether they are consistent. MBE and RMSE reflect the direction of deviation and dispersion between the predicted and measured values, respectively. MAE has better robustness to anomalous data, so it is used as an aid in measuring residuals between data. The formulas for these metrics are shown in Eqs. (6) to (9).
where \(n\) is the number of data, and \({y}_{i}\) and \({\widehat{y}}_{i}\) denote the measured and predicted, respectively. \(\overline{y }\) and \(\overline{{\widehat{y} }_{i}}\) refer to the average of the measured and predicted values, respectively.
Results and discussion
Verification and performance analysis of IRSM
Convergence performance analysis of IRSM
Figure 7 shows the iterations of WSO and CA-WSO. The optimal value and mean value of the objective function fluctuated during the WSO iteration, resulting in a longer convergence time of 145 s for 100 iterations. In contrast, the CA-WSO converged faster, taking only 84 s, which is 42% faster than the WSO. These results demonstrate that the improved CA-WSO algorithm completes iterations more smoothly and efficiently.

Convergence of the models. (a) The convergence diagram of WSO. (b) The convergence of CA-WSO
Predictive performance analysis of IRSM
This section compares the prediction effect of the unoptimized SVR, WSO-SVR, and CA-WSO-SVR, as shown in Fig. 8. Figure 8a, c, and e shows the comparison between the measured and predicted values, and Fig. 8b, d, and f shows a linear fit to the measured and predicted values.

Comparison of measured and predicted values of SVR (a, b), WSO-SVR (c, d), and CA-WSO-SVR (e, f)
As Fig. 8a, c, and e illustrates, SVR produces the largest error, with a maximum residual of 6.5 MPa and an average absolute residual of 0.8 MPa. WSO-SVR yields a moderate error, with a maximum residual of 3.2 MPa and an average absolute residual of 0.6 MPa. CA-WSO-SVR generates the smallest error, with a maximum residual of 3 MPa and an average absolute residual of 0.4 MPa. This indicates that CA-WSO-SVR has the least prediction deviation and the predicted values are most consistent with the measured values.
Figure 8b, d, and f indicates that the majority of the predicted values for the three models are distributed within the 95% prediction interval. The R2 for the three linear fits are 0.82, 0.91, and 0.96, respectively. This indicates a strong correlation between the measured and predicted values of CA-WSO-SVR, while the correlation of SVR is weak. Both SVR and WSO-SVR have wide confidence intervals, while CA-WSO-SVR has the narrowest confidence interval, suggesting high uncertainty for the former two. Moreover, the fitted line of CA-WSO-SVR approximates the ideal fitted line more closely, and the data dispersion is minimal. This indicates that the improved model has a better prediction.
The comparison of the four evaluation indexes (R2, RMSE, MAE, and MBE) is shown in Fig. 9a. The prediction effect improves gradually from SVR to WSO-SVR and then to CA-WSO-SVR, as indicated by the increasing R2 (16% increase). The prediction error also decreases, with a 55% reduction of RMSE. CA-WSO-SVR has the smallest RMSE (0.66), MAE (0.44), MBE (0.05), and the largest R2 (0.9576). Therefore, comprehensively, CA-WSO-SVR has the best prediction performance, followed by WSO-SVR and SVR.

The comparison of the evaluation indexes
Performance comparison of PRSM and IRSM
Based on the study conducted, the comparison between PRSM and IRSM is presented in Table 2 and Fig. 9. The R2 of the novel IRSM is higher than that of the traditional PRSM, and the residuals are smaller. In addition, when there is a complex non-linear relationship between the influencing factors, PRSM, being an explicit polynomial function, can only reflect the coupling effect between the factors by continuously adding interaction terms. This results in a lengthy polynomial, which is prone to overfitting and exhibits weak generalization performance. On the contrary, IRSM, using implicit functions to construct response surfaces, is not limited by data dimensionality. When data quality is ensured and hyperparameters are optimized, its generalization performance is significantly better than that of PRSM. In summary, IRSM has a better prediction effect and a wider application range than PRSM.
Relative importance analysis of the factors
As discussed earlier, the mechanical properties of GCBM depend on various factors. However, the importance of each factor is unclear and requires further study. To measure the relative importance of the factors, this paper employs the mean impact value (MIV) based on the SVR (Yan et al. 2020). The principle of MIV is as follows: First, the control variables method is used to increase and decrease each variable of the training set by 10%, resulting in two new training parts. Next, the CA-WSO-SVR predicts the two parts and calculate the difference. Finally, the MIV of each sample is calculated, as shown in Eq. (9), and the importance of each factor is obtained by the MIV in order.
Figure 10 presents the importance analysis of each factor. The results indicate that concentration is the most critical factor with an importance fraction of 0.0461. This is due to the fact that concentration represents a comprehensive combination of various materials in GCBM. Gangue proportion is also a highly significant factor, with an importance score of 0.0341, mainly because gangue is the most vital component in GCBM. Notably, concentration and gangue proportion contribute to over 50% of the importance, indicating their dominant role in GCBM. In addition, cemented material proportion, fly ash proportion, fine gangue rate, and fly ash type are also essential factors that require attention. In addition, the importance fractions of water-reducing agents and early-strength agents are relatively small, at 0.0031 and 0.0016, respectively. Although these materials are important for early solidification and flow performance during transport, they have minimal impact on the later strength.

The importance of each factor
Conclusions
In this paper, we address the demand for reducing mine waste by developing GCBM. We first analyze the relationship between the three primary factors and UCS by laboratory strength tests and PRSM. In addition, we employ MIV to analyze the relative importance of factors. To predict the mechanical properties of GCBM under high-dimensional factors, we improve an intelligent optimization algorithm and establish an IRSM, which is then validated. The main findings are as follows:
-
1.
The effects of various factors on UCS exhibit complex non-linear characteristics. For instance, the UCS increases exponentially with the increase of fly ash proportion and gangue proportion. In addition, the MIV was used to study the relative importance of multidimensional factors, suggesting that concentration and gangue proportion are the most sensitive factors, with importance fraction of 0.0461 and 0.0341, respectively.
-
2.
The initialization and iterative processes of the WSO algorithm was improved by circle chaotic mapping and adaptive methods, respectively. The improved algorithm was then combined with SVR to form an intelligent response surface model. Empirically, the improved algorithm enhanced initialization quality and increased convergence speed by 42%. Consequently, it can optimize SVR more efficiently and effectively.
-
3.
By comparing the traditional PRSM and the improved IRSM, the prediction accuracy, in decreasing order, is CA-WSO-SVR, PRSM, WSO-SVR, and SVR, with R2 of 0.9576, 0.9269, 0.9094, and 0.8247, respectively. Thus, the improved IRSM exhibits better prediction performance, facilitating the reuse and reduction of mine waste.
Data availability
The data presented in this study are available on request from the corresponding author.
References
Arora S, Anand P (2019) Chaotic grasshopper optimization algorithm for global optimization. Neural Comput & Applic 31:4385–4405. https://doi.org/10.1007/s00521-018-3343-2
Behera SK, Ghosh CN, Mishra DP et al (2020) Strength development and microstructural investigation of lead-zinc mill tailings based paste backfill with fly ash as alternative binder. Cement Concr Compos 109:103553. https://doi.org/10.1016/j.cemconcomp.2020.103553
Bhattacharya S (2021) Central composite design for response surface methodology and its application in pharmacy. In: Kayaroganam P (ed) Response Surface Methodology in Engineering Science. IntechOpen. https://doi.org/10.5772/intechopen.95835
Bouchehed A, Laouacheria F, Heddam S, Djemili L (2023) Machine learning for better prediction of seepage flow through embankment dams: Gaussian process regression versus SVR and RVM. Environ Sci Pollut Res 30:24751–24763. https://doi.org/10.1007/s11356-023-25446-2
Braik M, Hammouri A, Atwan J et al (2022) White Shark Optimizer: a novel bio-inspired meta-heuristic algorithm for global optimization problems. Knowl-Based Syst 243:108457. https://doi.org/10.1016/j.knosys.2022.108457
Cavusoglu I, Yilmaz E, Yilmaz AO (2021) Sodium silicate effect on setting properties, strength behavior and microstructure of cemented coal fly ash backfill. Powder Technol 384:17–28. https://doi.org/10.1016/j.powtec.2021.02.013
Chen L (2017) The laws of overlying strata movement and deformation with high-concentration cemented backfilling in coal mine. Dissertation, China University of Mining and Technology-Beijing
Chen G, Ye Y, Yao N et al (2022a) Deformation failure and acoustic emission characteristics of continuous graded waste rock cemented backfill under uniaxial compression. Environ Sci Pollut Res 29:80109–80122. https://doi.org/10.1007/s11356-022-23394-x
Chen Q, Luo K, Wang Y et al (2022b) In-situ stabilization/solidification of lead/zinc mine tailings by cemented paste backfill modified with low-carbon bentonite alternative. J Market Res 17:1200–1210. https://doi.org/10.1016/j.jmrt.2022.01.099
Correia L, Cothill B, Antunes P, James S (2021) Case study: Paste plant retrofit. Minefill 2020–2021. CRC Press-Balkema, Leiden, pp 360–374
Czech T, Marchewicz A, Sobczyk AT et al (2020) Heavy metals partitioning in fly ashes between various stages of electrostatic precipitator after combustion of different types of coal. Process Saf Environ Prot 133:18–31. https://doi.org/10.1016/j.psep.2019.10.033
Deng X-J (2017) Ground control mechanism of mining extra-thick coal seam using upward slicing longwall roadway cemented backfilling technology. Dissertation, China University of Mining and Technology (in Chinese)
Doherty JP, Hasan A, Suazo GH, Fourie A (2015) Investigation of some controllable factors that impact the stress state in cemented paste backfill. Can Geotech J 52:1901–1912. https://doi.org/10.1139/cgj-2014-0321
Dong C, Zhou N, Zhang J et al (2023) Optimized preparation of gangue waste-based geopolymer adsorbent based on improved response surface methodology for Cd(II) removal from wastewater. Environ Res 221:115246. https://doi.org/10.1016/j.envres.2023.115246
El Bilali A, Abdeslam T, Ayoub N et al (2023) An interpretable machine learning approach based on DNN, SVR, Extra Tree, and XGBoost models for predicting daily pan evaporation. J Environ Manage 327:116890. https://doi.org/10.1016/j.jenvman.2022.116890
Ermolovich EA, Ivannikov AL, Khayrutdinov MM et al (2022) Creation of a nanomodified backfill based on the waste from enrichment of water-soluble ores. Materials 15:3689. https://doi.org/10.3390/ma15103689
Gao H, Bai G (2015) Vibration reliability analysis for aeroengine compressor blade based on support vector machine response surface method. J Cent South Univ 22:1685–1694. https://doi.org/10.1007/s11771-015-2687-3
Gao H, Huang Y, Li W et al (2021) Explanation of heavy metal pollution in coal mines of China from the perspective of coal gangue geochemical characteristics. Environ Sci Pollut Res 28:65363–65373. https://doi.org/10.1007/s11356-021-14766-w
Gao X-Y (2021) Experimental study on filling material properties of powdered coal ash paste in goaf. Dissertation, North China University of Science and Technology (in Chinese)
Guo X-Y (2013) The study of influencing factors of paste filling performance. Dissertation, Taiyuan University of Technology (in Chinese)
Hu Y, Li K, Zhang B, Han B (2022) Investigation of the strength of concrete-like material with waste rock and aeolian sand as aggregate by machine learning. J Comput Design Eng 9:2134–2150. https://doi.org/10.1093/jcde/qwac101
Huang Y, Wang J, Li J et al (2022) Ecological and environmental damage assessment of water resources protection mining in the mining area of Western China. Ecol Indic 139:108938. https://doi.org/10.1016/j.ecolind.2022.108938
Iiduka H (2022) Appropriate learning rates of adaptive learning rate optimization algorithms for training deep neural networks. IEEE Trans Cybern 52:13250–13261. https://doi.org/10.1109/TCYB.2021.3107415
Jafari M, Shahsavari M, Grabinsky M (2021) Drained triaxial compressive shear response of cemented paste backfill (CPB). Rock Mech Rock Eng 54:3309–3325. https://doi.org/10.1007/s00603-021-02464-5
Jagadesh P, de Prado-Gil J, Silva-Monteiro N, Martínez-García R (2023) Assessing the compressive strength of self-compacting concrete with recycled aggregates from mix ratio using machine learning approach. J Market Res 24:1483–1498. https://doi.org/10.1016/j.jmrt.2023.03.037
Jiang H, Fall M, Li Y, Han J (2019) An experimental study on compressive behaviour of cemented rockfill. Constr Build Mater 213:10–19. https://doi.org/10.1016/j.conbuildmat.2019.04.061
Jiang H, Ren L, Zhang Q et al (2022) Strength and microstructural evolution of alkali-activated slag-based cemented paste backfill: coupled effects of activator composition and temperature. Powder Technol 401:117322. https://doi.org/10.1016/j.powtec.2022.117322
Kermani F, Shoja Razavi R, Zangenemadar K et al (2023) Optimization of single-pass geometric characteristics of IN718 by fiber laser via linear regression and response surface methodology. J Mater Res Technol 24:274–289. https://doi.org/10.1016/j.jmrt.2023.02.212
Khayrutdinov AM, Kongar-Syuryun ChB, Kowalik T, Tyulyaeva YuS (2020) Stress-strain behavior control in rock mass using different-strength backfill. Min inf anal bull 2020:42–55. https://doi.org/10.25018/0236-1493-2020-10-0-42-55
Lakshmanan M, Kumar C, Jasper JS (2023) Optimal parameter characterization of an enhanced mathematical model of solar photovoltaic cell/module using an improved white shark optimization algorithm. Optim Control Appl Methods 44:2374–2425. https://doi.org/10.1002/oca.2984
Li Z, Guo L, Zhao Y et al (2022) A particle size distribution model for tailings in mine backfill. Metals 12:594. https://doi.org/10.3390/met12040594
Liu D, Wang C, Ji Y et al (2021) Measurement and analysis of regional flood disaster resilience based on a support vector regression model refined by the selfish herd optimizer with elite opposition-based learning. J Environ Manage 300:113764. https://doi.org/10.1016/j.jenvman.2021.113764
Miao X, Wu J, Wang Y et al (2022) Coupled effects of fly ash and calcium formate on strength development of cemented tailings backfill. Environ Sci Pollut Res 29:59949–59964. https://doi.org/10.1007/s11356-022-20131-2
Moges G, McDonnell K, Delele MA et al (2023) Development and comparative analysis of ANN and SVR-based models with conventional regression models for predicting spray drift. Environ Sci Pollut Res 30:21927–21944. https://doi.org/10.1007/s11356-022-23571-y
Niu L (2014) Study on physical and mechanical properties of gangue paste filling mining backfill. Dissertation, Hebei University of Engineering (in Chinese)
Ottoni ALC, Nepomuceno EG, de Oliveira MS (2018) A response surface model approach to parameter estimation of reinforcement learning for the travelling salesman problem. J Control Autom Electr Syst 29:350–359. https://doi.org/10.1007/s40313-018-0374-y
Ouyang S-Y (2019) Study on transportation and mechanical properties optimization of sand-based cemented filling materials. Dissertation, China University of Mining and Technology (in Chinese)
Pan Z, Lu W, Wang H, Bai Y (2022) Recognition of a linear source contamination based on a mixed-integer stacked chaos gate recurrent unit neural network–hybrid sparrow search algorithm. Environ Sci Pollut Res 29:33528–33543. https://doi.org/10.1007/s11356-022-18538-y
Qi C, Chen Q, Sonny Kim S (2020) Integrated and intelligent design framework for cemented paste backfill: a combination of robust machine learning modelling and multi-objective optimization. Miner Eng 155:106422. https://doi.org/10.1016/j.mineng.2020.106422
Rahmati O, Choubin B, Fathabadi A et al (2019) Predicting uncertainty of machine learning models for modelling nitrate pollution of groundwater using quantile regression and UNEEC methods. Sci Total Environ 688:855–866. https://doi.org/10.1016/j.scitotenv.2019.06.320
Rezaee Jordehi A (2015) Chaotic bat swarm optimisation (CBSO). Appl Soft Comput 26:523–530. https://doi.org/10.1016/j.asoc.2014.10.010
Sadrossadat E, Basarir H, Karrech A, Elchalakani M (2022) Multi-objective mixture design and optimisation of steel fiber reinforced UHPC using machine learning algorithms and metaheuristics. Eng Comput 38:2569–2582. https://doi.org/10.1007/s00366-021-01403-w
Shaswat K (2022) Concrete slump prediction modeling with a fine-tuned convolutional neural network: hybridizing sea lion and dragonfly algorithms. Environ Sci Pollut Res 29:43758–43769. https://doi.org/10.1007/s11356-020-12244-3
Shi J, Chen Z, Zheng B (2021) Experimental research on material and mechanical properties of rock-like filling materials in disaster prevention of underground engineering. Adv Mater Sci Eng 2021:1–14. https://doi.org/10.1155/2021/6691310
Shin H, Cho S (2006) Response modeling with support vector machines. Expert Syst Appl 30:746–760. https://doi.org/10.1016/j.eswa.2005.07.037
Shin H, Cho S (2008) Response modeling with support vector regression. Expert Syst Appl 34:1102–1108. https://doi.org/10.1016/j.eswa.2006.12.019
Sun Q, Tian S, Sun Q et al (2019) Preparation and microstructure of fly ash geopolymer paste backfill material. J Clean Prod 225:376–390. https://doi.org/10.1016/j.jclepro.2019.03.310
Sun Q, Wei X, Wen Z (2022) Preparation and strength formation mechanism of surface paste disposal materials in coal mine collapse pits. J Market Res 17:1221–1231. https://doi.org/10.1016/j.jmrt.2022.01.062
Tariq A, Yanful EK (2013) A review of binders used in cemented paste tailings for underground and surface disposal practices. J Environ Manage 131:138–149. https://doi.org/10.1016/j.jenvman.2013.09.039
Van den Hove A, Verwaeren J, Van den Bossche J et al (2020) Development of a land use regression model for black carbon using mobile monitoring data and its application to pollution-avoiding routing. Environ Res 183:108619. https://doi.org/10.1016/j.envres.2019.108619
Wang Z, Wang Z, Zhao W (2018) Microscopic pore and filling performance of coal gangue cementitious paste. J Wuhan Univ Technol-Mat Sci Edit 33:427–430. https://doi.org/10.1007/s11595-018-1840-9
Xiu Z, Wang S, Ji Y et al (2021) An analytical model for the triaxial compressive stress-strain relationships of cemented pasted backfill (CPB) with different curing time. Constr Build Mater 313:125554. https://doi.org/10.1016/j.conbuildmat.2021.125554
Yan H, Zhang J, Zhou N, Li M (2020) Application of hybrid artificial intelligence model to predict coal strength alteration during CO2 geological sequestration in coal seams. Sci Total Environ 711:135029. https://doi.org/10.1016/j.scitotenv.2019.135029
Yan H, Zhang J, Zhou N et al (2022) Coal permeability alteration prediction during CO2 geological sequestration in coal seams: a novel hybrid artificial intelligence approach. Geomech Geophys Geo-Energ Geo-Resour 8:104. https://doi.org/10.1007/s40948-022-00400-7
Yang Z (2011) Research the solidification characteristics and floor stability of the backfilling materials with cement fly ash and waste rock. Dissertation, Qingdao University of Technology (in Chinese)
Yang K, Zhao X, Wei Z, Zhang J (2021) Development overview of paste backfill technology in China’s coal mines: a review. Environ Sci Pollut Res 28:67957–67969. https://doi.org/10.1007/s11356-021-16940-6
Yang L, Hou C, Zhu W et al (2022) Monitoring the failure process of cemented paste backfill at different curing times by using a digital image correlation technique. Constr Build Mater 346:128487. https://doi.org/10.1016/j.conbuildmat.2022.128487
Yıldız BS, Pholdee N, Panagant N et al (2022) A novel chaotic Henry gas solubility optimization algorithm for solving real-world engineering problems. Eng Comput 38:871–883. https://doi.org/10.1007/s00366-020-01268-5
Yilmaz E, Belem T, Benzaazoua M (2014) Effects of curing and stress conditions on hydromechanical, geotechnical and geochemical properties of cemented paste backfill. Eng Geol 168:23–37. https://doi.org/10.1016/j.enggeo.2013.10.024
Yin B (2018) Research on the fly ash cemented filling materials and its modification and further application. Dissertation, Taiyuan University of Technology (in Chinese)
Yu Y (2017) Development for the new backfilling cementing materials and research on its properties in coal mine. Dissertation, China University of Mining and Technology-Beijing (in Chinese)
Zhang X, Lin J, Liu J et al (2017) Investigation of hydraulic-mechanical properties of paste backfill containing coal gangue-fly ash and its application in an underground coal mine. Energies 10:1309. https://doi.org/10.3390/en10091309
Zhang F, Liu J, Ni H et al (2021) Development of coal mine filling paste with certain early strength and its flow characteristics. Geofluids 2021:1–14. https://doi.org/10.1155/2021/6699426
Zhang Y, Liu Y, Lai X et al (2023) Transport mechanism and control technology of heavy metal ions in gangue backfill materials in short-wall block backfill mining. Sci Total Environ 895:165139. https://doi.org/10.1016/j.scitotenv.2023.165139
Zhao Y-S (2014) Study on the transportation properties of cemented backfill slurry with high concentration in Xinyang coal mine. Dissertation, China University of Mining and Technology-Beijing (in Chinese)
Zhao Z-H (2018) Paste proportion test and pipeline transportation simulation in coal mining. Dissertation, Shandong University of Science and Technology (in Chinese). https://doi.org/10.27275/d.cnki.gsdku.2018.000442
Zhu L, Jin Z, Zhao Y, Duan Y (2021) Rheological properties of cemented coal gangue backfill based on response surface methodology. Constr Build Mater 306:124836. https://doi.org/10.1016/j.conbuildmat.2021.124836
Acknowledgements
The authors thank the Nantun coal mine for the experimental materials.
Funding
The work was supported by the National Natural Science Foundation of China (Grant No. 52130402), Ordos Science & Technology Plan (Grant No. 2022EEDSKJZDZX005), the Natural Science Foundation of Jiangsu Province (Grant No. BK20210510), and the Postgraduate Research & Practice Innovation Program of Jiangsu Province (Grant No. KYCX23_2781).
Author information
Authors and Affiliations
Contributions
PS: conceptualization and methodology, visualization and formal analysis, writing—original draft. JZ: resources, funding acquisition. HY: writing—review, supervision. NZ: resources, funding acquisition. GZ: writing—original draft preparation. YZ: writing—original draft preparation. PC: resources.
Corresponding author
Ethics declarations
Consent for publication
All authors approved the version to be published.
Conflict of interest
The authors declare no competing interests.
Additional information
Responsible Editor: Philippe Garrigues
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Shi, P., Zhang, J., Yan, H. et al. Mechanical properties evaluation of waste gangue-based cemented backfill materials based on an improved response surface model. Environ Sci Pollut Res 31, 3076–3089 (2024). https://doi.org/10.1007/s11356-023-31368-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-023-31368-w