
Abstract
This paper proposes a hybrid air relative humidity prediction based on preprocessing signal decomposition. New modelling strategy was introduced based on the use of the empirical mode decomposition, variational mode decomposition, and the empirical wavelet transform, combined with standalone machine learning to increase their numerical performances. First, standalone models, i.e., extreme learning machine, multilayer perceptron neural network, and random forest regression, were used for predicting daily air relative humidity using various daily meteorological variables, i.e., maximal and minimal air temperatures, precipitation, solar radiation, and wind speed, measured at two meteorological stations located in Algeria. Second, meteorological variables are decomposed into several intrinsic mode functions and presented as new input variables to the hybrid models. The comparison between the models was achieved based on numerical and graphical indices, and obtained results demonstrate the superiority of the proposed hybrid models compared to the standalone models. Further analysis revealed that using standalone models, the best performances are obtained using the multilayer perceptron neural network with Pearson correlation coefficient, Nash–Sutcliffe efficiency, root-mean-square error, and mean absolute error of approximately ≈0.939, ≈0.882, ≈7.44, and ≈5.62 at Constantine station, and ≈0.943, ≈0.887, ≈7.72, and ≈5.93 at Sétif station, respectively. The hybrid models based on the empirical wavelet transform decomposition exhibited high performances with Pearson correlation coefficient, Nash–Sutcliffe efficiency, root-mean-square error, and mean absolute error of approximately ≈0.950, ≈0.902, ≈6.79, and ≈5.24, at Constantine station, and ≈0.955, ≈0.912, ≈6.82, and ≈5.29, at Sétif station. Finally, we show that the new hybrid approaches delivered high predictive accuracies of air relative humidity, and it was concluded that the contribution of the signal decomposition was demonstrated and justified.
Graphical Abstract

Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Air relative humidity (RH) can be defined as the quantity of water available in the air, and it is one of the most critical weather variables for hydrological and climatic studies, and it was also included in various climatic change investigations (Gunawardhana et al.2017; Sein et al. 2022). One of the most important uses of RH in water resource management is its inclusion in the standard Penman–Monteith method for reference evapotranspiration (ET0) calculation (Eccel 2012). Air temperature and RH are considered the most important factors of the thermal environment (Kuang 2020), and their accurate estimation is of great importance. The RH is a highly sensitive weather variable, and it affects several other processes especially the agro-food and the biological items, and it is highly influenced by several other weather variables especially air temperature, precipitation, and solar radiation (Shrestha et al. 2019). During the last few years, the application of machine learning for water resources planning and management has received great importance and several application can be found in the literature, i.e., modelling pan evaporation (Kisi et al. 2022), predicting solar radiation in semi-arid regions (Jamei et al. 2023), modeling average grain velocity for rectangular channel (Kumari et al. 2022), and also for watershed prioritization (Sarkar et al. 2022). The RH data can be obtained from direct in situ measurement; however, alternatives methods based on modelling approaches can be a good alternative and several applications can be found in the literature.
Tao et al. (2022) used several weather variables collected at two meteorological stations in Irak, i.e., maximum air temperature (Tmax), minimum air temperature (Tmin), reference evapotranspiration (ET0), sunshine hours (SS), and wind speed (U2) for modelling monthly air relative humidity (RH). The authors used the extreme gradient boosting (XGBoost) algorithm for better input variables selection, and they compared the performances of three machines learning models, i.e., support vector regression (SVR), random forest regression (RFR), and multivariate adaptive regression spline (MARS), according to several input variables combinations. According to the obtained results, the RFR was the most accurate at Kut station, exhibiting root-mean-square error (RMSE), mean absolute error (MAE), and Nash–Sutcliffe efficiency (NSE) values of approximately ≈4.92%, ≈3.89%, and 0.916, respectively, while at Mosul station, MARS model was the most accurate exhibiting RMSE, MAE, and NSE values of ≈3.80%, ≈2.86%, and 0.967, respectively. Yasar et al. (2012) compared between multilayer perceptron neural networks (MLPNN) and multiple linear regression (MLR) in modelling monthly RH in Turkey. For calibrating the models, they used five input variables, namely, monthly precipitation (P), latitude, longitude, altitude, and the month number. It was found that the MLPNN was more accurate exhibiting a correlation coefficient (R) values ranging from ≈0.96 to ≈0.99, and from ≈0.73 to ≈0.94 for the MLPNN and MLR, respectively, while the mean absolute percentage error (MAPE) was ranged from ≈1.56 to ≈3.32% and from 3.88 to 8.56%, respectively, showing the high contribution of the topographical information, i.e., latitude, longitude, and altitude in improving the forecasting accuracies of the monthly RH. Hanoon et al. (2021) compared between gradient boosting tree (GBT), RFR, linear regression (LR), MLPNN, and radial basis function neural network (RBFNN) in predicting daily and monthly RH in Malaysia. For developing the models, the authors used the RH measured at previous lags times from (t − 1) to (t − 6) without the inclusion of other climatic variables. From the obtained results, it was found that (i) at daily time scale, the MLPNN was more accurate exhibiting R, RMSE, and MAE values of approximately ≈0.634, ≈2.6%, and ≈3.9%, and (ii) at monthly time scale, the RBFNN was the most accurate with R, RMSE, and MAE values of approximately ≈0.713, ≈1.6%, and ≈2%, respectively. Adnan et al. (2021) compared between MARS and M5Tree model for predicting daily RH using P, solar radiation (SR), and mean temperature (Tmean) measured at the Hunza River basin, Pakistan. Obtained results revealed that MARS model was more accurate compared to the M5Tree exhibiting RMSE, MAE, and coefficient of determination (R2) ranging from ≈5.86 to ≈6.58%, ≈4.97 to ≈5.43%, and ≈0.806 to ≈0.815, respectively, compared to the value of ≈6.08 to ≈6.19%, ≈5.46 to ≈5.58%, and ≈0.762 to ≈0.783 obtained using the M5Tree. In addition, they reported that the best forecasting accuracies were obtained using RH and Tmean measured at three previous lags as input variables. Shi et al. (2018) applied the MLPNN model for forecasting RH at 6 h, 24 h, and 72 h in advance. High forecasting accuracy was obtained with R2 values ranging from ≈0.654 to ≈0.977.
Thapliyal et al. (2014) used a linear regression model for RH retrieval showing good predictive accuracy with R-value of approximately ≈0.91. Lu and Viljanen (2009) used the nonlinear autoregressive with external input (NNARX) model for predicting RH using Tmean and RH measured at previous lags times from (t − 1) to (t − 5) as input variables showing high predictive accuracy with R value of approximately ≈0.99. Bregaglio et al. (2010) investigated the feasibility of thirteen hourly air relative humidity modelling solutions based on different empirical formula and showing high to moderate correlation between measured and calculated RH with R-values ranging from ≈0.660 to ≈0.858. Hussein et al. (2021) compared between five machines learning models, namely, RFR, MLPNN, MLR, XGBoost, and the k-nearest neighbor (KNN) for predicting RH using monthly image data. The image data collected and used were available from NASA GESDISC data archive, and several climatic variables are available, namely, rainfall, evaporation, humidity, temperature, and wind speed. From the obtained results, it was found that the proposed models were able to accurately predict RH with R2 ranging from ≈0.960 to ≈0.999. Suradhaniwar et al. (2021) developed one-step and multi-step ahead forecasting frameworks for RH using suite of machines learning models. They applied the recurrent neural networks (RNN), the long-short term memory (LSTM), the support vector regression (SVR), the seasonal autoregressive integrated moving average (SARIMA), and the MLPNN models. Based on the RMSE values, it was found that the SVR and SARIMA models were more accurate than the MLPNN and the two deep learning models, i.e., the LSTM and RNN. Taking into account the RMSE values, it was found that the SARIMA (RMSE ≈ 1.87) and SVR (RMSE ≈ 1.97) outperformed the MLPNN (RMSE ≈ 2.83), LSTM (RMSE ≈ 2.12), and RNN (RMSE ≈ 2.13) for one-step and multi-step ahead forecasting: SARIMA (RMSE ≈ 11.31%) and SVR (RMSE ≈ 11.30%), MLPNN (RMSE ≈ 18.11%), LSTM (RMSE ≈ 12.02%), and RNN (RMSE ≈ 14.74%), respectively. Qadeer et al. (2021) used RFR and SVR for modelling RH using two predictors, namely, dry-bulb temperature and wet-bulb temperature, and they reported slightly and negligible difference between the two models. Arulmozhi et al. (2021) selected a large number of predictors for modelling RH, namely, wind direction (WD), U2, Tmean, air pressure (Pa), P, SR, and net radiation, and they compared between MLR, MLPNN, RFR, SVR, and decision tree regression (DTR). From the obtained results, the RFR was found to be more accurate and outperformed all others models with R2, RMSE, and MAE of 0.954, 2.429%, and 1.470%, respectively.
According to the literature discussed above, it is clear that several attempts have been made for better prediction of RH based on machine learning models. The above listed models, i.e., SVR, MLPNN, DTR, and RNN, have been used in RH modelling studies, whereas many other methods have not. Furthermore, we can argue about the advantages and limitations of each model were governed by the type of data and varied from one region to another. Because air relative humidity and meteorological variables were characterized by linear and nonlinear properties, it become particularly challenging to directly builds robust single machine learning models. In order to overcome the limitations of some single machine learning models, the hybridization based on preprocessing signal decomposition has become very popular lately because it can be easily used and their robustness has been demonstrated. Furthermore, to the best of the author’s knowledge; no study has reported the application of the preprocessing signal decomposition for predicting RH using climatic variables as predictors. Consequently, there is stillroom to investigate new modelling framework and to compare their performances relative to those of already reported in the literature, in an attempt to improve our understanding of the RH prediction. This study is the first to use a number of algorithms, i.e., the empirical mode decomposition (EMD), variational mode decomposition (VMD), and the empirical wavelet transform (EWT) for improving the predictive accuracy of the RH. In this study, we conduct also a comprehensive comparison of the performances of three different machine learning models (MLPNN, extreme learning machine (ELM), and RFR) with and without combination with the EMD, VMD, and EWT algorithms, which make the present study a deeply comparison between single and hybrid models.
Through these intercomparisons, the present investigation could be a sound argument for the judgment of the real benefit and the added utility of the signal decomposition in improving the retrieval of the RH. The paper is organized as follow. "Introduction" is an introduction with in depth literature review. In "Materials and methods", we present the case study, data used, and the mathematical description of the proposed models. "Study area and data" is reserved to the presentation of the results and discussion. Finally, the conclusion is provided in "Performance assessment of the models".
Materials and methods
Study area and data
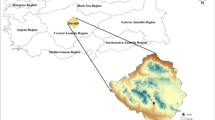
The present investigation was carried out in two sites areas in the East of Algeria, where meteorological information are available, as it is detailed in the following paragraphs. The selected two stations were the following (see Fig. 1): (i) Constantine station (Latitude: 36.374°, longitude: 6.562°, and altitude: 698 m) and (ii) Sétif (latitude: 36.374°, longitude: 5.312°, and altitude: 1094 m). For each station, we use data for a total period of 10 years ranging from 2000 to 2009, with total patterns of 3653. For each station, 70% of the data are used for model calibration (training) and 30% for model validation. The meteorological data sets used in the present study are composed from five predictors combined for better prediction of air relative humidity (RH). The selected variables are (i) solar radiation (SR: MJ/m2), (ii) the precipitation (P: mm), (iii) the wind speed (U2: m/s), and (iv) the maximal and minimal air temperature (Tmax and Tmin: °C). The RH is measured in percent (RH: %). Descriptive statistics parameters for all variables are calculated and provided in Table 1 for the two stations, with the mean, maximal, minimal, standard deviation, coefficient of variation, and the coefficient of correlation calculated between each variable and the RH, which have help in selecting the best input combination, and in total six were selected having various input variables starting from five and ending by two (Table 2). Furthermore, all variables used in the present study were standardized using the Z-score method by subtracting the mean and dividing by the standard deviation.

Location map showing the two stations in the east of Algeria
Performance assessment of the models
In the present study, four performance metrics were selected for model comparison and evaluation: the root-mean-square error (RMSE), mean absolute error (MAE), correlation coefficient (R), and Nash–Sutcliffe efficiency (NSE).
\({\overline{RH} }_{\mathrm{obs}}\) and \({\overline{RH} }_{\mathrm{pre}}\) are the mean measured, and mean forecasted air relative humidity, respectively;\({RH}_{\mathrm{obs}}\) and \({RH}_{\mathrm{pre}}\) specifies the observed and forecasted air relative humidity; and N shows the number of data points.
Machine learning models
ANN model
Artificial neural networks (ANN) are mathematical models biologically inspired from the function of the human brain. The ANN model is composed from an ensemble of units called neurons and arranged in a successive parallel layers. In the present paper, we use the multilayer perceptron neural network (MLPNN) model reported as universal approximator (Fig. 2). The basic element of the ANN model is called the neuron, and it can play a key dual role in providing the final response of the model: the summation, and the activation using an activation function. The summation is calculated based on the weighted sum of the inputs variables, while the activation is calculated using an activation function, generally the sigmoidal function (Eq. 5).

The multilayer perceptron neural network (MLPNN) architecture
The neurons from the input to the output layers are connected among them through an ensemble of parameters called weights similar to the biological neurons (Haykin 1999; Hornik 1991). The structure of the MLPNN model is determined based on the number of neurons in each layer and the total number of layers. For the input and the output layers, the total number of neurons corresponds exactly to the number of input and output variables, while the number of the neuron in the hidden layer is determined by trial and error. The success of the MLPNN comes from the backpropagation training algorithm, which was developed for improving the capability of the model in handling a nonlinear function approximation. During the training process, the cost function calculated between the actual (i.e., measured) and the calculated outputs is minimized. In addition, during the training process, there is a continuous updating of all model parameters (i.e., weights and biases) in both directions: forward and backward propagation of the gradient. More detail about the ANN can be found in Haykin (1999) and Hornik (1991).
ELM
Suppose we have N observations with input variables xi and its corresponding output yi. We do not know any possible relation between x and y variables, and we suppose that the xi can provide some useful information’s for predicting yi with an acceptable accuracy level. In order to solve the approximation function linking the input (xi) to the output (yi), Huang et al. (2006a, b) propose an extreme learning machine algorithm (ELM) for training the single layer feedforward neural network (SLFN) having three layers: input layer (xi), one hidden layer, and one output layer (yi) as shown in Fig. 3. Compared to the standalone ANN for which all parameters were updated during the training process, in the ELM model, the input weights and the hidden layer biases were “randomly” selected (i.e., the wij and bj), and the output weights linking the hidden layer to the output layer were analytically determined (i.e., the βj) using the Moore Penrose generalized inverse operation, making the training algorithm a simple linear system.

The extreme learning machine (ELM) architecture
Suppose that the hidden layer is composed with L hidden neurons, it is assumed that there exist a series of models parameters designated as: wij, bj, βj, and a nonlinear transformation function G for which the following formulation can be drawn:
where f is the final response of the ELM model, the xn are the input variables, βj is the output weights matrix, wij is the weights linking the input to the hidden layers, bj is the bias of the hidden layer neuron j, and G is the sigmoid activation function. H is called the hidden layer output matrix (Huang et al. 2006a, b).
RFR
Random forest regression (RFR) is an ensemble method composed of several decision trees models (DT) introduced by Breiman (2001). Each DT is constructed based on a recursive splitting strategy of the input training data (Fig. 4). It is important to note that for each root node, the calibration datasets are arranged into a unique partition, and each DT is induced by an out-of-bag (OOB) approach, which is a sampling with replacement. The OOB leads to two kind of data: a part will be “left out,” while the second part will be repeated in the sample. By achieving the training of all DT, RFR model uses an average or majority vote depending on whether a classification or regression task is handled form all the predictions of the single trees.

The random forest regression (RFR) architecture
Signal decomposition methods
In the present paper, three-signal decomposition were used, namely, the empirical mode decomposition (EMD), the variational mode decomposition (VMD), and the empirical wavelet transform (EWT). An example of the application of the three algorithms for maximal air temperature decomposition is provided in Fig. 5.

An example of maximal air temperature (Tmax) signal decomposition using a the EMD, b the VMD. and c the EWT
Empirical mode decomposition
Empirical mode decomposition (EMD) was proposed by Huang et al. (1998). The EMD algorithm is a preprocessing signal decomposition mainly used for filtering any nonlinear signal and making it as a series of sub signal called intrinsic mode functions (IMFs). In order to be an IMF oscillatory component, some conditions should be respected as the phase and amplitude of each one changes slowly: (i) only one zero value is attributed to one IMF between two consecutive extremes and (ii) the local average of the IMF is equal to zero (Alaodolehei et al. 2020; Abdulhay et al. 2020). Decomposition of nonlinear signal using the EMD, i.e., the “sifting” process, involves several stages, which can be summarized as follows (Abdollahpoor and Lotfivand 2020):
-
1.
The calculated IMFs should be ordered from lower scale to higher scale.
-
2.
The process of extracting the IMF will start by calculating the local maxima and minima if the signal x (t).
-
3.
The obtained local maxima and minima are used by the cubic spline curve for setting the upper and lower envelopes, and their average value, i.e., the m1 (t), is then calculated.
-
4.
Calculates the first component, i.e., C1(t) as follow:
$${C}_{1}\left(t\right)=x\left(t\right)-{C}_{1}\left(t\right)$$(7) -
5.
This process (i.e., the “sifting” process) is iterative and will continue until the first IMF is extracted.
-
6.
While the process is iterative, there is a shutoff parameter for stopping the “sifting” process, i.e., the standard deviation (SD) calculated as follows (Abdollahpoor and Lotfivand 2020):
$$SD=\sum\limits_{t=0}^{T}\left[\frac{{\left|{h}_{k-1}\left(t\right)-{h}_{k}\left(t\right)\right|}^{2}}{{h}_{k-1}^{2}\left(t\right)}\right]$$(8) -
7.
Finally, the original signal x(t) can be reformulated as follow:
$$x\left(t\right)=\sum\nolimits_{i=1}^{N}{IMF}_{i}\left(t\right)+{R}_{N}\left(t\right)$$(9)
where N is the number of IMF and the RN is called the residue (El Bouny et al. 2019).
VMD
Dragomiretskiy and Zosso (2014) propose the variational mode decomposition (VMD) for signal decomposition. The VMD uses an adaptive decomposition process for extracting a series of intrinsic mode functions (IMFs) characterized by specific sparsity properties (Li et al. 2022). The VMD estimates the modes, i.e., the IMFs and their respective center frequencies using an adaptively and concurrently algorithm (Peng et al.2020). Each mode calculated using the VMD could be formulated as follow:
where uk (t) is the kth mode component, Ak (t) is a non-negative envelope, and ϕk (t) is instantaneous phase, respectively (Li et al. 2022). Using the VMD, we suppose that each calculated mode corresponds to an IMF having a finite bandwidth and a central frequency, which were determined using an iterative searching process for an optimal solution (Zhang et al. 2020). Given any nonlinear and nonstationarity signal f (t), the VMD can be seen as a minimization of a constrained optimization problem and the VMD can be constructed a follows:
where uk (k = 1, 2, 3, …, K) represents the K IMFs using VMD, wk is the corresponding center frequencies of each IMF, t is the time script, K represents the total number of sub-signals, δ(t) is the Dirac distribution, j is the imaginary unit, and ⊗ is the convolution operator, and finally the expression \(\left(\delta \left(t\right)+\frac{j}{\pi t}\right)\) corresponds to the Hilbert transform of uk (t) (Liu et al. 2021; Li et al. 2022; Peng et al.2020).
EWT
The empirical wavelet transform (EWT) was introduced by Gilles (2013). The EWT was formulated based on the assumption that a signal x(t) results from the sum of the individual subcomponents characterized by a compact support in Fourier spectrum (Liu et al. 2020). The EWT is used for providing a series of sub signal called multiresolution analysis (MRA) (Wang and Hu 2015). The EWT uses two distinguished functions, namely: (i) empirical wavelet functions \(({\widehat{\varnothing }}_{n}\left(\omega \right))\) (i.e., the band-pass filters) and (ii) empirical scale function \({\widehat{\varphi }}_{n}\left(\omega \right)\) (i.e., the low-pass filters). The two functions are defined by Eqs. (12) and (13), respectively (Hu et al. 2015; Si et al. 2019):
and
For the two above equations, (ω) is the nth maxima of the Fourier spectrum. The selection of the best (τ) value should be proportional to (ωn) for which (τn = γ.ωn) where (0 < γ < 1). The function β (x) ∈ Ck ([0, 1]) is an arbitrary function and expressed as follows (Liu et al. 2020; Hu et al. 2015; Si et al. 2019):
Results and discussion
Model development
This study compares between single models, i.e., MLPNN, ELM, and RFR, and hybrid models based on signal decomposition, i.e., the EMD, VMD, and EWT. Hence, the hybrid models were designated hereafter as MLPNN_EMD, MLPNN_VMD, and MLPNN_EWT, and this is identical with the ELM and RFR models. For each single and hybrid models, six input combinations were tested and compared for showing the effect of varying the models structure on the predictive accuracy (Table 3). Furthermore, in this section, we try to investigate if we can obtain accurate RH prediction values and range, and more precisely, if the signal decomposition algorithms can help in rendering the predictive results more accurate. A series of evaluation metrics was used for comparison and to determine whether the hybrid models were better than the single models, i.e., the R, NSE, RMSE, and MAE. In addition, a graphical comparison using the scatterplot, boxplot, violin plot, and Taylor diagram between measured and predicted data was provided, and the results were presented for each station separately. The flowchart of the proposed modeling framework is depicted in Fig. 6.

Flowchart of the modelling strategy for air relative humidity
Results at Constantine station
Table 3 lists the numerical performance of the three single models used in this study. Hereafter, we focus on the results during the validation stage.
According to Table 3, the MLPNN model yields better accuracy for all input combinations, but its numerical performances were slightly superior to those of the ELM and RFR, implying its superiority. First, using all five input variables, the MLPNN1 exhibited the high R (≈0.939) and NSE (≈0.882) values, and the lowest RMSE (≈7.44) and MAE (≈5.62) values, respectively. The ELM1 and the RFR1 yielded equally numerical performances slightly lower than the MLPNN1. The results in Table 3 show that in terms of the mean values, the MLPNN models yielded the biggest mean R (≈0.924) and NSE (≈0.851) values, and the lower mean RMSE (≈8.33) and MAE (≈6.43) values, followed by the ELM models, and the RFR models were found to be the less accurate.
More precisely, in terms of RMSE and MAE, the biggest improvement among all models are gained using the MLPNN models with ≈1.662% and ≈3.064% compared to the ELM models and ≈4.82% and ≈6.29% compared to the RFR models. Beyond the first input combination, it is clear from Table 3 that the models based on four input variables (i.e., combination two and three) exhibited slightly lower performances and it is clear that the inclusion of the precipitation plays minor role in models performances improvement. The MLPNN2 and ELM2 for which the P was excluded worked equally having the same numerical performances superior to the RFR2. Furthermore, using only three input variables, i.e., the fourth and fifth input combinations, it is clear that the performances of the models were significantly decreased from the first to the fifth combination and the inferiority of the RFR5 became more obvious. The MLPNN1 improve the MLPNN5 by decreasing the RMSE and MAE by approximately ≈17.119% and ≈19.611%, respectively, and the ELM1 improve the ELM5 by decreasing the RMSE and MAE by approximately ≈12.449% and ≈12.802%, respectively, while the RMSE and MAE of the RFR5 was improved by ≈15.949% and ≈19.124%, respectively.
Finally, our analysis revealed that the poorest performances among all proposed models were exhibited using the models having only two input variables for which the RMSE and MAE were significantly increased and the R and NSE values were dramatically decreased, and more precisely, the RFR6 is the only one for which the R and the NSE were decreased below the values of ≈0.900 and ≈0.800, respectively (Table 3).
In the second part of the present study, we tried to improve the RH predictive accuracy by applying the signal decomposition, and in total, three algorithms were compared, i.e., the EMD, VMD, and EWT. Obtained results are depicted in Table 4. A further discussion of the differences between the models with and without signal decomposition is warranted hereafter. An analysis of the ensemble results obtained using the EMD signal decomposition revealed that the contribution of the EMD in improving the performances of the ELM and RFR is too small; on the contrary, the numerical performances were slightly deteriorated.
The analysis show that the mean RMSE and MAE values of the single ELM models were relatively equal to those obtained using the ELM_EMD, while the mean R and NSE values remained unchangeable, from (≈0.921 and ≈0.845) to (≈0.920 and ≈0.846), respectively, showing the limitation of the EMD algorithm in improving the performances of the single ELM models. Regarding the RFR models, we can clearly see that mean RMSE and MAE were increased from (≈8.755 and ≈6.866) to (≈9.068 and ≈7.225), respectively. However, it is important to note that the performances of the single RFR5 and RFR6 were slightly improved using the EMD algorithm for which the values of RMSE and MAE were dropped from (≈9.424 and ≈7.53) to (≈9.209 and ≈7.302) between RFR5 and RFR_EMD5, and from (≈9.753 and ≈7.869) to (≈9.047 and ≈7.246) between RFR6 and RFR_EMD6. Concerning the MLPNN models, it is clear from the results reported in Table 4 that the MLPNN models are the only models for which significant improvement was gained using the EMD algorithm. All six models (i.e., from MLPNN1 to MLPNN6) showed their numerical performances improved by an increase in the R and NSE values and a decrease in the RMSE and MAE values. Overall comparison between models revealed that the mean RMSE and MAE values calculated using the MLPNN models were decreased from (≈8.332 and ≈6.433) to (≈7.371 and ≈5.795) exhibiting an improvement rates of approximately ≈11.532% and ≈9.917%, respectively. Among the six input combination, it is clear that the MLPNN_EMD1 is the unique model that benefit most from the EMD showing it performances significantly increased with an improvement rates of approximately ≈1.064%, ≈2.040%, ≈7.89%, and ≈4.47% in terms of R, NSE, RMSE, and MAE, respectively. As we can conclude that the EMD is an interesting algorithm for improving the MLPNN performances, but this cannot be generalized to the other machines learning models, i.e., the ELM and the RFR for which no improvement was gained.
It can be seen from Table 4 that when the VMD algorithm was used for signal decomposition, no improvement was gained and all machine-learning models have shown their performances decreased significantly, highlighting the limitation and the poor contribution of the VMD in improving the predictive accuracy of the RH. In order to evaluate the prediction performance of the proposed hybrid VMD models compared to the single models, the comparison between the mean four metrics, i.e., the R, NSE, RMSE, and MAE values, is discussed hereafter (Table 4). We can see that the mean R (≈0.908), NSE (≈0.823), RMSE (≈9.100), and MAE (≈7.211) of the ELM_VMD, the mean R (≈0.921), NSE (≈0.841), RMSE (≈8.555), and MAE (≈6.656) of the MLPNN_VMD, and the mean R (≈0.890), NSE (≈0.776), RMSE (≈10.259), and MAE (≈8.321) of the RFR_VMD were all less than the values obtained using the single ELM, MLPNN, and RFR models, which leads to the conclusion that further efforts are required to understand the very limitation and the poor contribution of the VMD in improving the accuracy of the RH estimation.
As shown in Table 4, compared with the VMD, the results of the EWT algorithm are more practical and can provide more support to the prediction of the RH. As shown in Table 4, it is obvious that the performances of the MLPNN and RFR models were improved and the used of the EWT leads to a significant increase in the mean R, NSE, RMSE, and MAE values, while the performances of the ELM models were decreased. Using the EWT, the mean R, NSE, RMSE, and MAE values of the MLPNN models were improved by ≈1.516%, ≈3.250%, ≈9.853% and ≈8.528%, respectively. Similarly, the mean R, NSE, RMSE, and MAE values of the RFR models were improved by ≈1.494%, ≈2.035%, ≈4.959%, and ≈3.442%, respectively. Among all proposed models, it is clear that the MLPNN_EWT1 was the best model showing its performances significantly improved compared to the single MLPNN1 model, exhibiting improvement rates of approximately ≈1.171%, ≈2.267%, ≈8.796%, and ≈6.876%, in terms of R, NSE, RMSE, and MAE values, respectively.
Furthermore, if all models were compared one by one, the mean RMSE and MAE values of the MLPNN6 having only the Tmax and P as input variables were decreased by approximately ≈15.215% and ≈13.665%, respectively, which constitute the high improvement rates among all proposed models. From Tables 3 and 4, the numerical values of the performances metrics lead to conclude that the performances of the hybrid models based on signal decomposition are generally higher than the single models except the VMD algorithm who failed to give any improvement in terms of predictive accuracy. In addition, the experimental results show that the RMSE and MAE values of the EWT based models are the lowest, while the R and NSE values were the highest compared to the values obtained using the EMD algorithm. In conclusion, the hybrid EWT–based models have the best predictive performance and the relatively better air relative humidity estimation.
The models were further compared based on graphical comparison as shown in Figs. 7 and 8. In Fig. 7, we drawn the scatterplot of measured and predicted air relative humidity for the best single and hybrid models for which we can conclude that plotted data were less scattered using the MLPNN models with and without decomposition and the models based on the EWT were the best accurate models. According to the boxplot (Fig. 8a) and the violin plot (Fig. 8b), the models based on EWT were the most accurate and the MLPNN with and without decomposition improve all other models showing the high similarity with the measured one. However, according to the Taylor diagram (Fig. 8c), the RFR_VMD was the poorest model among all proposed models.

Scatterplot of measured against predicted RH using the best single and hybrid models for the Constantine station: validation stage

Graphs showing the comparison between measured and predicted air relative humidity during the validation stage: a boxplot, b violin plot, and (c) Taylor diagram
Results at Sétif station
Table 5 shows the predictive results for the training and validation data using the different singles methods and based on the six input combinations for Sétif station. When comparing the three single models (ELM, MLPNN, and RFR) taking into account the mean values of the performances metrics, it is obvious that the RFR models were worse than the ELM and the MLPNN models.
The ELM models yielded an R and NSE values ranging from ≈0.905 to ≈0.938 (mean ≈ 0.924), and from ≈0.818 to ≈0.879 (mean ≈ 0.854), the MLPNN models yielded an R and NSE values ranging from ≈0.908 to ≈0.943 (mean≈0.926), and from ≈0.824 to ≈0.887 (mean ≈ 0.857), while the values obtained using the RFR were ranged from ≈0.902 to ≈0.933 (mean ≈ 0.919), and from ≈0.800 to ≈0.871 (mean ≈ 0.834). Using the MLPNN instead of the ELM and RFR allows achieving better performances, however, it shows generally slightly better performances compared to the ELM in terms of the mean R, NSE, RMSE, and MAE for which the difference was completely negligible. Overall, among all proposed models, it is clear that the MLPNN1 was the most accurate, followed by the ELM1 the RFR2, respectively. Regarding our analysis based on the number of input variables included, we can conclude that the use of more input leads to more reliable prediction. In fact, the fifth and six input combination appear the poorest and more precisely, the lowest accuracy was obtained with the MLPNN6 having an R ≈ 0.908, NSE ≈ 0.824, RMSE ≈ 9.660, and MAE ≈ 7.588, followed by the ELM6 R ≈ 0.905, NSE ≈ 0.818, RMSE ≈ 9.839, and MAE ≈ 7.521, while the RFR6 was the poorest with R ≈ 0.902, NSE ≈ 0.800, RMSE ≈ 10.316, and MAE ≈ 7.719, respectively. We conduct a systematic analysis of the model performance based on signal decompositions algorithms. According to Table 6, using the VMD algorithm, only the MLPNN models have shown their performances improved, while the performances of the ELM and RFR have significantly deteriorated. First, the mean R, NSE, RMSE, and MAE values of the MLPNN were slightly improved using the VMD algorithm showing improvement rates of ≈0.66%, ≈1.342%, ≈3.858%, and ≈1.806%, respectively. The improvement begin to be considered as significant beyond the third (MLPNN_VMD3) until the last input combinations (MLPNN_VMD6), for which the most significant improvement was gained exhibiting an improvement rates of approximately ≈1.762%, ≈3.641%, ≈8.820%, and ≈8.448%, respectively (MLPNN_VMD6 compared to the MLPNN6).
The performances and effectiveness of the hybrid models based on EMD algorithm are presented and discussed. Based on the results in Table 6, the improved percentages of each single model by the proposed hybrid models have been calculated as follow: (i) the mean R, NSE, RMSE, and MAE of the ELM models were decreased by ≈0.25%, ≈0.53%, ≈1.685%, and ≈3.957%, respectively, showing the limitation of the EMD algorithm improving the single ELM models; (ii) the mean R, NSE, RMSE, and MAE of the MLPNN models were increased by ≈2.753%, ≈5.583%, ≈13.975%, and ≈14.51%, respectively, showing the significant contribution of the EMD in improving the performances of the MLPNN models; and (iii) the mean R, NSE, and RMSE of the RFR models were enhanced by ≈0.363%, ≈0.280%, and ≈0.455, respectively, exhibiting a negligible improvement of the single RFR models.
From Table 6, it can be found that (a) compared with the single models, the MLPNN_EMD1 to MLPNN_EMD4 have obtained the highest prediction accuracy, and the MLPNN_EMD1 shows better performances that all other models exhibiting the highest R (≈0.949) and NSE (≈0.901) values, and the lowest RMSE (≈7.268) and MAE (≈5.609) values; (b) the prediction accuracies of the hybrid MLPNN_EMD1 to MLPNN_EMD4 are little difference and the ELM-based hybrid models have a little better prediction performances than the RFR-based hybrid models. This indicate that the ELM is more appropriate to building robust predictive models; (c) using only two input variables for all the predictive models, the MLPNN_EMD6 shows the best prediction performances with R (≈0.933) and NSE (≈0.870), RMSE (≈8.310), and MAE (≈6.487) exhibiting improvement rates of approximately ≈2.753%, ≈5.583%, ≈13.975%, and ≈14.510%, compared to the MLPNN6.
It can be seen from Table 6 that (a) the improved percentages of the three models using the EWT algorithm are almost relatively equal just except that the mean values of the R (≈0.939), NSE (≈0.875), RMSE (≈8.159), and MAE (≈6.468) obtained using the RFR_EWT were slightly superior to those obtained using the ELM_EWT (R ≈ 0.931, NSE ≈ 0.867, RMSE ≈ 8.421, MAE ≈ 6.670), and those of the MLPNN_EWT (R ≈ 0.932, NSE ≈ 0.865, RMSE ≈ 8.400, MAE ≈ 6.662), respectively, which indicates that the proposed EWT algorithm has obviously enhanced the prediction accuracy; (b) among all proposed models, the MLPNN_EWT1 yielded the best prediction performances improvement for which the R and NSE values were remarkably increased from (≈0.943 and ≈0.887) to (≈0.955 and ≈0.912) exhibiting an improvement rates of approximately ≈1.273% and ≈2.818%, and the RMSE and MAE values were dramatically decreased from (≈7.729 and ≈5.933) to (≈6.820 and ≈5.293) exhibiting an enhancement rates of approximately ≈11.761% and ≈10.787%, respectively; (c) using only two input variables, we can see that the RFR_EWT6 was the best model showing and improvement rates of approximately ≈3.659%, ≈8.625%, ≈19.038%, and ≈14.251% compared to the single RFR6, which is the high improvement rate gained using all three signal decomposition algorithms. The scatterplots of the measured and predicted air relative humidity for the best single and hybrid models are depicted in Fig. 9. The boxplot, violin plot, and the Taylor diagram are depicted in Fig. 10.

Scatterplot of measured against predicted RH using the best single and hybrid models for Sétif station: validation stage

Graphs showing the comparison between measured and predicted air relative humidity for Sétif station during the validation stage: a boxplot, b violin plot, and c Taylor diagram
Discussion
This section further discusses the results of the above experiments with already published works. To prove that the presented combined models based on signal decomposition indeed improves the air relative humidity prediction accuracy, the values of the performances indices obtained using our approach are compared with those reported in the literature in a similar studies. In comparison to our study, Tao et al. (2022) produce higher correlations between the measured and predicted RH (R ≈ 0.984) using the MARS model at Mosul station, Irak, compared to the best value obtained in our study (R ≈ 0.955) at Sétif Station, but produce lower correlation between the measured and predicted RH at Kut station with values ranging from R ≈ 0.890 to R ≈ 0.946, compared to the values of R ≈ 0.955 obtained using the MLPNN_EWT proposed in our study. Relative to our study, Yasar et al. (2012) have higher correlation between measured and predicted RH, exhibiting excellent correlation coefficient ranging from R ≈ 0.960 to R ≈ 0.999. Again, this leads them to conclude a significant and critical role of the latitude, longitude, and altitude in increasing the predictive accuracy. In the investigation conducted by Hanoon et al. (2021), they certainly downplayed the potential advantage of machine leaning models, i.e., the MLPNN and the RBFNN used for modelling RH (the R values were ranged from ≈0.634 to ≈0.713), and therefore reported a lesser role of the modelling scenario based only on the inclusion of the RH measured at several time lags.
The motivation of Adnan et al. (2021) study was to investigate whether the inclusion of the RH measured at previous lag combined with mean air temperature can yielded high predictive accuracy. They obtained a correlation coefficients ranging from ≈0.898 to ≈0.903 using the MARS model, and ranging from ≈0.873 to ≈0.885 using the M5Tree model; hence, our correlation coefficients are likely more accurate (R ≈ 0.955). For instance, Shi et al. (2018) simulate the RH at three different time scale, i.e., 6, 24, and 72 h. Depending on the time scale, they show that there is a significant decrease in the MLPNN model performances, and more precisely, the high R value (≈0.988) obtained for 6-h interval of time was dropped to be (≈0.852) for the model based on 24 h, and further deteriorated to be very low (≈0.806) for the model at 72-h interval of time, which are less than the values achieved in our present study. Finally, the modelling strategy proposed by Hussein et al. (2021) for which the RH was predicted using monthly image data, it was found that excellent predictive accuracy can be achieved with R values ranging from ≈0.980 to ≈0.999; however, their approach was criticized for employing high precision satellite images, which are not always available for the majors part of the world.
The significant improvements in air relative humidity prediction have made the proposed signal decomposition to be more attractive tool. As the needs for continuous measurement of air relative humidity continue to increase, the issues caused by some single and standalone machine learning models have become more relevant, which have motivated the introduction of new robust modelling frameworks. In this context, the improvement of air relative humidity estimation has boosted the development of new modelling strategy based on the combination of two paradigms: machine learning and signal decomposition. However, despite the increasing number of published paper from different countries, making generalization and conclusions more difficult because the obtained results from one study to another varied according to the type of data, the extent of data, how the models were evaluated, and how the modelling strategy was formulated. Based on the idea that air relative humidity variability is governed by the fluctuation of various weather variables, our approach was based on testing various input combination. In summary, to introduce an accurate air relative humidity prediction, a novel combined model based on EMD, VMD, EWT, and machine leaning models is proposed. Among the proposed decomposition algorithms, the EWT was found to be the most significant algorithm for improving the estimation of the air relative humidity, and this was confirmed for all machine-learning models. Meanwhile, the VMD was found to be the poorest algorithm compared to the EMD and EWT. Ultimately, the results obtained using the MLPNN was clearly superior to those obtained using the RFR and the ELM models based on all decomposition algorithms. At Constantine station, the MLPNN_EWT1 showed significantly better performances than the MLPNN_EMD1 and the MLPNN_VDM1 with R, NSE, RMSE, and MAE of ≈0.950, ≈0.902, ≈6.791, and ≈5.241, respectively. At Sétif station, the same hybrid model, i.e., the MLPNN_EWT1, exhibited the high performances with R, NSE, RMSE, and MAE of ≈0.955, ≈0.912, ≈6.820, and ≈5.293, respectively. In summary, the above experiments show that hybrid model based on EWT algorithm predicts the air relative humidity accurately with more precision and it leverages the strong correlations between measure and calculated data for different sites and they significantly enhance the single models and they have demonstrated to be more suitable for ensuring better generalization ability than single machine learning models.
Conclusion
In this paper, we propose a new data driven approaches for better prediction of air relative humidity (RH) based on signal decomposition algorithms and standalone machine learning hybrid models. While the use of signal decomposition algorithms is broadly reported in the literature for hydrological modelling studies and agrometeorological variables prediction, few investigations were related to their application for RH prediction. Our hybrid models have demonstrated their suitability in improving the performances of the standalone models especially using fewer input variables, and it was found that the VMD was the less accurate algorithm exhibiting poor performances compared to the EMD and EWT algorithms. Further analysis revealed that while the two studied stations were located in the same climatic zone, i.e., the semi-arid climate, the proposed standalone and hybrid models worked differently depending on the input variables combinations. In overall, it was demonstrated that the MLPNN model was more accurate compared to the ELM and RFR with and without signal decomposition, and it takes full advantages from the EMD and EWT rather than the VMD. More precisely, the improvements rates gained from the application of the signal decomposition were more obvious using the MLPNN compare to the ELM and RFR models.
According to the obtained results, we can report the following finding for futures studies:
-
1.
In the future, we plan to extend the present modeling framework to a large dataset located in different climate regions.
-
2.
This investigation provides a clear discussion about the factors affecting air relative humidity and the significant input combinations were selected. It is identified that, solar radiation, the minimal and maximal temperatures are the major’s factors affecting relative humidity. Therefore, the predictive accuracy of the proposed models can be certainly improved by using optimizations algorithms and better selection of the studied input variables.
-
3.
We also plan to investigate the possible other factors that can help in improving the predictive accuracies, especially the possible inclusion of other weathers variables.
-
4.
It is highly recommended to explore new models and new signal decompositions algorithms to achieve the higher prediction accuracy.
However, at the end of the present study, some limitations of our methodology should be highlighted. It is worth mentioning that the performances of the hybrid models was significantly affected by the change in the meteorological input variables, and the high predictive accuracy was guaranteed with the inclusion of the variables having high coefficient of correlation with the air relative humidity. Secondly, it was found that the robustness and success of the signal decomposition algorithms could not be generalized and the results of each model will be different. For example, it was found that the VMD algorithm does not work accurately with all machine learning models. In summary, we argue that air relative humidity is affected by many external factors such as solar radiation, air temperature, and wind speed, making it highly nonlinear. It was demonstrated that single models often fail to correctly predict air relative humidity; consequently, it is worthwhile to explore the capability of the complex hybrid models in order to achieve high predictive accuracies.
Data availability
The data presented in this study will be available on interested request from the corresponding author.
Abbreviations
- ANN:
-
Artificial neural networks
- DT:
-
Decision trees
- DTR:
-
Decision tree regression
- ELM:
-
Extreme learning machine
- EMD:
-
Empirical mode decomposition
- EWT:
-
Empirical wavelet transform
- ET 0 :
-
Reference evapotranspiration
- GBT:
-
Gradient boosting tree
- IMFs:
-
Intrinsic mode functions
- KNN:
-
K-nearest neighbor
- LR:
-
Linear regression
- LSTM:
-
Long-short term memory
- M5Tree:
-
M5 model tree
- MAE:
-
Mean absolute error
- MAPE:
-
Mean absolute percentage error
- MARS:
-
Multivariate adaptive regression spline
- MLPNN:
-
Multilayer perceptron neural network
- MLR:
-
Multiple linear regression
- MRA:
-
Multiresolution analysis
- NNARX:
-
Nonlinear autoregressive with external input
- NSE:
-
Nash-Sutcliffe efficiency
- OOB:
-
Out-of-bag
- P:
-
Precipitation
- Pa:
-
Air pressure
- RH:
-
Air relative humidity
- R:
-
Correlation coefficient
- R 2 :
-
Determination coefficient
- RBFNN:
-
Radial basis function neural network
- RFR:
-
Random forest regression
- RMSE:
-
Root-mean-square error
- RNN:
-
Recurrent neural networks
- SARIMA:
-
Seasonal autoregressive integrated moving average
- SLFN:
-
Single-layer feedforward neural network
- SR :
-
Solar radiation
- SS :
-
Sunshine hours
- SVR:
-
Support vector regression
- T max :
-
Maximum air temperature
- T mean :
-
Mean temperature
- T min :
-
Minimum air temperature
- U 2 :
-
Wind speed
- VMD:
-
Variational mode decomposition
- WD:
-
Wind direction
- XGBoost:
-
Extreme gradient boosting
References
Abdollahpoor R, Lotfivand N (2020) Fully adaptive denoising of ECG signals using empirical mode decomposition with the modified indirect subtraction and the adaptive window techniques. Circ Syst Signal Process 39(8):4021–4046. https://doi.org/10.1007/s00034-020-01350-9
Abdulhay E, Alafeef M, Alzghoul L, Al Momani M, Al Abdi R, Arunkumar N, ... & de Albuquerque VHC (2020). Computer-aided autism diagnosis via second-order difference plot area applied to EEG empirical mode decomposition. Neural Comput Appl 32(15):10947–10956. https://doi.org/10.1007/s00521-018-3738-0.
Adnan M, Adnan RM, Liu S, Saifullah M, Latif Y & Iqbal M (2021). Prediction of relative humidity in a high elevated basin of western Karakoram by using different machine learning models. Weather Forecast 59:. https://doi.org/10.5772/intechopen.98226.
Alaodolehei B, Jafarian K, Sheikhani A, Beni HM (2020) Performance enhancement of an achalasia automatic detection system using ensemble empirical mode decomposition denoising method. J Med Biol Eng 40(2):179–188. https://doi.org/10.1007/s40846-019-00497-4
Arulmozhi E, Basak JK, Sihalath T, Park J, Kim HT, Moon BE (2021) Machine learning-based microclimate model for indoor air temperature and relative humidity prediction in a swine building. Animals 11(1):222. https://doi.org/10.3390/ani11010222
Bregaglio S, Donatelli M, Confalonieri R, Acutis M, Orlandini S (2010) An integrated evaluation of thirteen modelling solutions for the generation of hourly values of air relative humidity. Theoret Appl Climatol 102(3):429–438. https://doi.org/10.1007/s00704-010-0274-y
Breiman L (2001) Random Forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Dragomiretskiy K, Zosso D (2014) Variational mode decomposition. IEEE Trans Signal Process 62(3):531–544. https://doi.org/10.1109/TSP.2013.2288675
Eccel E (2012) Estimating air humidity from temperature and precipitation measures for modelling applications. Meteorol Appl 19(1):118–128. https://doi.org/10.1002/met.258
El Bouny L, Khalil M, Adib A (2019) ECG signal filtering based on CEEMDAN with hybrid interval thresholding and higher order statistics to select relevant modes. Multimedia Tools Appl 78(10):13067–13089. https://doi.org/10.1007/s11042-018-6143-x
Gilles J (2013) Empirical wavelet transform. IEEE Trans Signal Process 61(16):3999–4010. https://doi.org/10.1109/TSP.2013.2265222
Gunawardhana LN, Al-Rawas GA, Kazama S (2017) An alternative method for predicting relative humidity for climate change studies. Meteorol Appl 24(4):551–559. https://doi.org/10.1002/met.1641
Hanoon MS, Ahmed AN, Zaini NA, Razzaq A, Kumar P, Sherif M,... & El-Shafie A (2021). Developing machine learning algorithms for meteorological temperature and humidity forecasting at Terengganu state in Malaysia. Sci Rep 11(1):1-19.https://doi.org/10.1038/s41598-021-96872-w
Haykin S (1999) Neural networks a comprehensive foundation. Prentice Hall, Upper Saddle River
Hornik K (1991) Approximation capabilities of multilayer feedforward networks. Neural Netw 4(2):251–257. https://doi.org/10.1016/0893-6080(91)90009-T. 485
Hu J, Wang J, Ma K (2015) A hybrid technique for short-term wind speed prediction. Energy 81:563–574. https://doi.org/10.1016/j.energy.2014.12.074
Huang NE, Shen Z, Long SR, Wu MC, Shih HH, Zheng Q, Yen N, Liu HH (1998) The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proceed R Soc London: Series A: Math, Physical Eng Sci 454(1971):903–995
Huang GB, Chen L, Siew CK (2006a) Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans Neural Networks 17(4):879–892. https://doi.org/10.1109/TNN.2006.875977
Huang GB, Zhu QY, Siew CK (2006b) Extreme learning machine: theory and applications. Neurocomputing 70(1–3):489–501. https://doi.org/10.1016/j.neucom.2005.12.126
Hussein EA, Ghaziasgar M, Thron C, Vaccari M, Bagula A (2021) Basic statistical estimation outperforms machine learning in monthly prediction of seasonal climatic parameters. Atmosphere 12(5):539. https://doi.org/10.3390/atmos12050539
Jamei M, Bailek N, Bouchouicha K, Hassan MA, Elbeltagi A, Kuriqi A,... & El-Kenawy ESM (2023). Data-driven models for predicting solar radiation in semi-arid regions. Comput Mater Continua 74(1):1625–1640. https://doi.org/10.32604/cmc.2023.031406.
Kisi O, Mirboluki A, Naganna SR, Malik A, Kuriqi A, Mehraein M (2022) Comparative evaluation of deep learning and machine learning in modelling pan evaporation using limited inputs. Hydrol Sci J 67(9):1309–1327. https://doi.org/10.1080/02626667.2022.2063724
Kuang W (2020) Seasonal variation in air temperature and relative humidity on building areas and in green spaces in Beijing, China. Chin Geogr Sci 30(1):75–88. https://doi.org/10.1007/s11769-020-1097-0
Kumari A, Kumar A, Kumar M, Kuriqi A (2022) Modeling average grain velocity for rectangular channel using soft computing techniques. Water 14(9):1325. https://doi.org/10.3390/w14091325
Li G, Chen K, Yang H (2022) A new hybrid prediction model of cumulative COVID-19 confirmed data. Process Saf Environ Prot 157:1–19. https://doi.org/10.1016/j.psep.2021.10.047
Liu H, Yu C, Wu H, Duan Z, Yan G (2020) A new hybrid ensemble deep reinforcement learning model for wind speed short term forecasting. Energy 202:117794. https://doi.org/10.1016/j.energy.2020.117794
Liu Y, Feng G, Tsui KL, Sun S (2021) Forecasting influenza epidemics in Hong Kong using Google search queries data: a new integrated approach. Expert Syst Appl 185:115604. https://doi.org/10.1016/j.eswa.2021.115604
Lu T, Viljanen M (2009) Prediction of indoor temperature and relative humidity using neural network models: model comparison. Neural Comput Appl 18(4):345–357. https://doi.org/10.1007/s00521-008-0185-3
Peng T, Zhang C, Zhou J, Nazir MS (2020) Negative correlation learning-based RELM ensemble model integrated with OVMD for multi-step ahead wind speed forecasting. Renew Energy 156:804–819. https://doi.org/10.1016/j.renene.2020.03.168
Qadeer K, Ahmad A, Qyyum MA, Nizami AS, Lee M (2021) Developing machine learning models for relative humidity prediction in air-based energy systems and environmental management applications. J Environ Manag 292:112736. https://doi.org/10.1016/j.jenvman.2021.112736
Sarkar P, Kumar P, Vishwakarma DK, Ashok A, Elbeltagi A, Gupta S, Kuriqi A (2022) Watershed prioritization using morphometric analysis by MCDM approaches. Ecol Inform 70:101763. https://doi.org/10.1016/j.ecoinf.2022.101763
Sein ZMM, Ullah I, Iyakaremye V, Azam K, Ma X, Syed S, Zhi X (2022) Observed spatiotemporal changes in air temperature, dew point temperature and relative humidity over Myanmar during 2001–2019. Meteorol Atmos Phys 134(1):1–17. https://doi.org/10.1007/s00703-021-00837-7
Shi X, Lu W, Zhao Y, Qin P (2018) Prediction of indoor temperature and relative humidity based on cloud database by using an improved BP neural network in Chongqing. IEEE Access 6:30559–30566. https://doi.org/10.1109/ACCESS.2018.2844299
Shrestha AK, Thapa A & Gautam H (2019). Solar radiation, air temperature, relative humidity, and dew point study: Damak, jhapa, Nepal. Int J Photoenergy 2019:. https://doi.org/10.1155/2019/8369231.
Si Y, Zhang Z, Kong L, Li S, Wang Q, Kong C, Li Y (2019) Aging condition identification of viscoelastic sandwich structure based on empirical wavelet transform and Hilbert envelope demodulation. Compos Struct 215:13–22. https://doi.org/10.1016/j.compstruct.2019.02.039
Suradhaniwar S, Kar S, Durbha SS, Jagarlapudi A (2021) Time series forecasting of univariate agrometeorological data: a comparative performance evaluation via one-step and multi-step ahead forecasting strategies. Sensors 21(7):2430. https://doi.org/10.3390/s21072430
Tao H, Awadh SM, Salih SQ, Shafik SS, Yaseen ZM (2022) Integration of extreme gradient boosting feature selection approach with machine learning models: application of weather relative humidity prediction. Neural Comput Appl 34(1):515–533. https://doi.org/10.1007/s00521-021-06362-3
Thapliyal PK, Shukla MV, Bisht JH, Pal PK, Navalgund RR (2014) Improvement in the retrieval of humidity profiles using hybrid regression technique from infrared sounder data: a simulation study. Meteorol Appl 21(2):301–308. https://doi.org/10.1002/met.1330
Wang J, Hu J (2015) A robust combination approach for short-term wind speed forecasting and analysis-Combination of the ARIMA (autoregressive integrated moving average), ELM (extreme learning machine), SVM (support vector machine) and LSSVM (least square SVM) forecasts using a GPR (Gaussian process regression) model. Energy 93:41–56. https://doi.org/10.1016/j.energy.2015.08.045
Yasar A, Simsek E, Bilgili M, Yucel A, Ilhan I (2012) Estimation of relative humidity based on artificial neural network approach in the Aegean Region of Turkey. Meteorol Atmos Phys 115(1):81–87. https://doi.org/10.1007/s00703-011-0168-2
Zhang Y, Pan G, Chen B, Han J, Zhao Y, Zhang C (2020) Short-term wind speed prediction model based on GA-ANN improved by VMD. Renew Energy 156:1373–1388. https://doi.org/10.1016/j.renene.2019.12.047
Author information
Authors and Affiliations
Contributions
Conceptualization: Khaled Merabet and Salim Heddam; data curation: Khaled Merabet and Salim Heddam; formal analysis: Khaled Merabet and Salim Heddam; validation: Khaled Merabet and Salim Heddam; supervision: Khaled Merabet and Salim Heddam; writing original draft: Khaled Merabet and Salim Heddam; visualization: Khaled Merabet and Salim Heddam; investigation: Khaled Merabet and Salim Heddam. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
All the authors have declared their consent to publish the manuscript.
Institutional Review Board statement
Not applicable.
Informed consent
Not applicable.
Conflict of interest
The authors declare no competing interests.
Additional information
Responsible Editor: Philippe Garrigues
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Highlights
• Predicting air relative humidity using three models, i.e., ELM, MLPNN, and RFR.
• Preprocessing signal decomposition for improving models performances.
• The EMD, VMD, and EWT were used and compared.
• Signal decomposition contributes to the models performances improvement.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Merabet, K., Heddam, S. Improving the accuracy of air relative humidity prediction using hybrid machine learning based on empirical mode decomposition: a comparative study. Environ Sci Pollut Res 30, 60868–60889 (2023). https://doi.org/10.1007/s11356-023-26779-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-023-26779-8