
Abstract
Forecasting the electricity consumption has always played an important role in the management of power system management, which requires higher forecasting technology. Therefore, based on the principle of “new information priority”, combined with rolling mechanism and Markov theory, a novel grey power-Markov prediction model with time-varying parameters (RGPMM(λ,1,1)) is designed, which overcomes the inherent defects of fixed structure and poor adaptability to the changes of original data. In addition, in order to prove the validity and applicability of the prediction model, we have used the model to predict China’s total electricity consumption, and have compared it with the prediction results by a series of benchmark models. The result shows that the can better adapt to the characteristics of electricity consumption data, and it also shows the advantages of the proposed forecasting model. In this paper, the proposed forecasting model is used to predict China’s total electricity consumption in the next six years from 2018 to 2023, so as to provide certain reference value for power system management and distribution.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
China is a developing country and is in a period of rapid development. Electricity consumption forecast is an important part of Power Economic Planning, energy investment, and environmental protection (Lin and Liu 2016). Electricity consumption forecast has become an important research area in the operation and management of modern power systems (Kavousi-Fard et al. 2014). The high and low accuracy of electricity consumption forecasting (Amber et al. 2018) is of great significance to economic development and power planning. Accurate electricity consumption forecast is affected by a series of factors, such as population (Hussain et al. 2016), economic growth (Lin and Liu 2016), power facilities (Khosravi et al. 2012), and climate factors (Hernández et al. 2013), making the prediction problem a challenging and complex task. In order to solve these problems, in recent years, many domestic and foreign experts, scholars and related research institutions have done a lot of in-depth research on electricity consumption forecast models. The main methods are non-linear intelligent models (Bekiroglu et al. 2018; Hernandez et al. 2014), traditional statistical analysis models (Chui et al. 2009; Mohamed and Bodger 2005), and grey prediction models (Xiao et al. 2017).
Ghani and Ahmad (2010) used SPSS software to establish a linear regression model based on the multiple regression method to predict and analyze the fish landing to demonstrate the effectiveness and feasibility of the method. Wang J et al. (2018) used an autoregressive moving average (ARMA) model based on the time series algorithm to predict short-term wind power. Zhang et al. (2019) combined BP and RBF neural network methods to predict and analyze wind speed to verify the effectiveness and accuracy of the combined prediction model. The above models usually require a large amount of data, so it is difficult to get accurate results when dealing with limited data. Grey theory (Julong 1982) is used to solve the problem of uncertainty with limited data and poor information. It focuses on building a grey prediction model with a small amount of information. The grey theory is not to find the statistical law of time series data, but to associate the random process with time, and use the cumulative generation operation to process the original data. It reduces the inherent randomness of the data, transforms the irregular data into an exponential form, generates a sequence with strong regularity, and can predict the future direction of the data according to the theory. Grey systems are often used to discover the laws hidden in chaotic data. Wang et al. (1819) used the grey management degree and grey theory to establish a grey system model based on the basic data of urban heating and forecast its demand. Guo et al. (2013) proposed a new comprehensive adaptive grey model, CAGM(1,N), which can be applied to any actual forecasting issues and can obtain higher fitting and prediction accuracy compared with the traditional GM(1,N) model (Pai et al. 2008; Tien 2008).
These methods make predictions based on raw data by maximizing the fitting accuracy, but do not take into account the complex diversity of things themselves. The single grey model has a large error in the process of forecasting, and it is difficult to achieve the expected accuracy. The Markov model is suitable for the prediction of random problems, and it can better describe the dynamic trend of randomly changing objects and can make up for the shortcomings of the grey model. Therefore, two prediction models are combined. The grey model is used to forecast, and the predicted values are corrected by the Markov chain to effectively improve the accuracy of the prediction, so as to achieve the purpose of scientific prediction and analysis. So far, the combination of grey theory and Markov model has applied many areas of prediction, such as Yong and Yidan (1992) put forward the grey Markov model for the first time by combining the advantages of grey model and Markov theory, which has since been widely used in the prediction of traffic, natural disasters, energy consumption, and other fields. Kumar and models (2010) combined the grey Markov and time series model to ground breakingly predict energy consumption in India, which provided a feasible scheme for the prediction of India’s energy consumption. CAO Jian et al. (2019) explored the internal relationship among the accidents of road transport on hazardous chemical and the traffic accidents in China based on grey Markov model, and analyzed the grey Markov combined prediction model in the prediction of safety accident. The effectiveness and feasibility of the method had been verified by experiments.
The above research shows that the grey Markov model has better prediction accuracy and ability. However, the actual operation found that when faced with the prediction of small sample data, the model still has a certain degree of contingency. Therefore, according to the characteristics of China’s electricity consumption data, this paper optimizes and improves the traditional grey Markov model, and proposes RGPMM(λ,1,1) to predict China’s electricity consumption more accurately, so as to provide more accurate information for the rational distribution of energy.
objective
This article has carried out the work in the following aspects:
-
1)
Grey power prediction model (Wang et al. 2011). It is a new type of nonlinear grey prediction model. Its power index can reflect the nonlinear development characteristics of the data and is used to describe the development of things. The nonlinear situation has good prediction results.
-
2)
The power index λ is generally taken as integer in the traditional grey prediction models, such as λ = 2, which is called Verhulst model. In this paper, λ belongs to the real number R, that is, λ can be taken the fraction to establish the model and the value of can be estimated through optimization theory. Then a novel grey prediction model can be established. In the process of modeling, the robustness of λ is analyzed.
-
3)
The introduction of rolling mechanism (Akay and Atak 2007). In the forecasting process, because the data from the far past has little effect on the forecast, the Rolling Mechanism is introduced to continuously update the input information, which breaks the constraint of constant initial value in the classic grey prediction model and complies with the principle of “new information priority” (Julong 1989).
-
4)
In this paper, the relative error of the grey power model is used as the index, and the weighted Markov theory (Liu et al. 2018) is used to correct the grey power model, which further improves the prediction accuracy and adaptability of the model.
Organization
The rest of this article is organized as follows: the “Basic knowledge” section briefly introduces the historical background of the grey model and the traditional GM(1,1) model, Markov theory, rolling mechanism, and the grey development zone. The “Methodology of improved grey prediction model” section introduces how to build the RGPMM(λ,1,1). The “Case studies on forecasting the total electricity consumption in China” section illustrates the practicability of the RGPMM(λ,1,1) by experiment, and forecasts the total electricity consumption in the next few years by this model. The “Conclusion” section contains the conclusions and suggestions for future work.
Basic knowledge
Basic GM(1,1)
In 1982, Professor Deng Julong first proposed the concept of grey system and built the GM(1,1). The process of the GM(1,1) is as follows Julong (1982), Lin et al. (2012), and Zeng et al. (2020):
Step 1: Transforing the original data. Let a set of non-negative sequences is \(X^{\left (0\right )}=\left \{x^{\left (0\right )}\left (1\right ),\right . x^{\left (0\right )}\left (2\right ),\cdots ,x^{\left (0\right )}\) \(\left .\left (n\right )\right \},(n\geq 4)\). The 1-AGO sequence is given by
where, \(x^{\left (1\right )}\left (k\right )={\sum }_{i=1}^{k}x^{\left (0\right )}\left (i\right ), k=1,2,\cdots ,n.\)
Step 2: Based on the sequence \(X^{\left (1\right )}\), the whitening form equation of the prediction model can be established:
In Formula (2), a and b are the parameters to be estimated. The grey differential equation is:
where, \(z^{\left (1\right )}\left (k\right )=\frac {1}{2}\cdot \left [x^{\left (1\right )}\left (k\right )+x^{\left (1\right )}\left (k-1\right )\right ]\) is the background value and \(Z^{\left (1\right )}=\left \{z^{\left (1\right )}\left (2\right ),z^{\left (1\right )}\left (3\right ),\cdots ,z^{\left (1\right )}\left (n\right )\right \}\) is the mean sequence of \(X^{\left (1\right )}\) (Xiong et al. 2014).
Step 3: Estimating the model parameters. Set the parameters vector to be estimated as \(\begin {pmatrix}\hat {a}\\\hat {b}\end {pmatrix}\) and solve it according to the least squares method to obtain
where \(B=\left (\begin {array}{cc}-z^{\left (1\right )}\left (2\right )&1\\ -z^{\left (1\right )}\left (3\right )&1\\{\cdots } & {\cdots } \\ -z^{\left (1\right )}\left (n\right )&1 \end {array}\right )\), \(Y=(x^{\left (0\right )}\left (2\right ),x^{\left (0\right )}\left (3\right ),\) \(\cdots ,x^{\left (0\right )}\left (n\right ) )^{T}\).
Step 4: Obtaining the time response function. According to Eq. 4, solve (2), then the time corresponding equation is computed as:
Step 5: Obtaining the fitted and predicted values in the original domain. The simplified predicted value of the first-order accumulation operator sequence is \(\hat {x}^{\left (0\right )}\left (t\right )=\hat {x}^{\left (1\right )}\left (t\right )-\hat {x}^{\left (0\right )}\left (t-1\right ),\) namely,
where \(\hat {x}^{(0)}(t) (t\le n)\) are called fitted values, and \(\hat {x}^{(0)}(t)(t>n)\) are called predicted values.
The flow chart is shown in Fig. 1.

The flow chart of GM(1,1)
Markov process
Markov process (Zhao et al. 2014) is a theory that studies the state of things and their transition. A Markov process in which time and state are both discrete is called a Markov chain. Markov chain analysis is a statistical analysis method based on the probability theory and stochastic process theory, using stochastic mathematical models to analyze the quantitative relationship of objective objects in the development and change process. Its characteristic is no after-effect, that is, the current state of the system is only related to the previous state, and has nothing to do with the subsequent state.
Transition probability and transition probability matrix
In Markov process, the transition probability and the transition probability matrix of states need to be calculated, which are defined as follows:
Definition 1
Let {Xn, n ∈ T} be a Markov chain, and call the conditional probability pij(n,T) = P(Xn+ 1|Xn = i),i,j ∈ T the one-step transition probability of the Markov chain {Xn, n ∈ T} at time n, which is referred to as the transition probability. That is, the conditional probability that the particle is in state i at time n and then is in state j after one step. The matrix composed of transition probability is the transition probability matrix. In a Markov chain, the system state transition can be represented by the transition probability matrix P as follows:
The steps of Markov process
Markov process is introduced to obtain the transition probability of residual state, so as to determine the state of the residual when t > n. The steps are as follows:
Step 1: Determine the residual state;
Step 2: Calculate the state transition probability matrix P according to the residual state;
Step 3: Determine the initial state vector;
Step 4: According to the state transition formula, calculate the result of the t th state transition, and take the one with higher probability of occurrence status.
Methodology of improved grey prediction model
The grey power model
The GPM(λ,1,1) is an extension of the traditional GM(1,1). In this paper, the power exponent of GPM(λ,1,1) is analyzed according to the information covering principle of grey system, and the following definitions are given.
Definition 2
(The grey power model) Assuming \(X^{\left (0\right )}\) is a non-negative unimodal raw data sequence, \(X^{\left (1\right )}\) is the 1 − AGO sequence of \(X^{\left (0\right )}\). \(Z^{\left (1\right )}\) is a sequence generated next to the mean of the \(X^{\left (1\right )}\). Then, there is the following non-linear model which meets the three conditions of gray modeling, and the grey power model is
The whitening equation of the grey power model is
Solving the above model by the solution method of GM(1,1), we can get the solution of the whitening equation is
Parameters analysis of G P M(λ,1,1)
Parameter λ estimation method
The parameter λ is an important coefficient in the GPM(λ,1,1). According to the above formulas, since \(x^{\left (1\right )}\neq 0\), divide both sides of Eq. 5 by \(\left [x^{\left (1\right )}\right ]^{\lambda }\) and then take the deriation about t to get (7) as follows:
According to the information coverage principle of grey derivative, we cover \(\frac {dx^{\left (1\right )}}{dt}\) and \(\frac {d^{2}x^{\left (1\right )}}{dt^{2}}\) in Eq. 7 with the first grey derivatives and the second grey derivatives of \(x^{\left (1\right )}\), then we will get
Dividing the Eq. 8 with t = k by the Eq. 8 with t = k + 1, we can eliminate the unknown parameter a and get
It follows from Eq. 9 that
From the expression of λ, we can see that it can not only reflect the grey derivative of the original data, but also reflect the role of grey integral. When k = 2,3,⋯ ,n − 1, the corresponding \(\left (n-2\right )\) values of λ can be computed, which is {λk}.
Let \(g\left (\lambda \right )=\sum \limits _{k=2}^{n-1}{\left (\lambda -\lambda _{k}\right )^{2}}\), the value of λ that makes \(g\left (\lambda \right )\) take the minimum value is the constant value to be determined.
Since \(g\left (\lambda \right )\) is a parabola with an opening upward, according to the first order condition of unconditional extremum, the optimal value of λ is
In this case, \(g\left (\hat {\lambda }\right )\) takes the minimum value.
Estimates of parameters a and b
After the optimal value of λ is determined, the parameters a and b can be estimated directly according to the least square method. Then, we can get the theorem 1.
Theorem 1
Assuming \(X^{\left (0\right )}\), \(X^{\left (1\right )}\) and \(Z^{\left (1\right )}\) are as defined in Definition 1, then the least squares estimate of the parameter sequence in GPM(λ,1,1) is
where \(B=\begin {pmatrix}-z^{\left (1\right )}\left (2\right )&\left [z^{\left (1\right )}\left (2\right )\right ]^{\hat {\lambda }}\\ -z^{\left (1\right )}\left (3\right )&\left [z^{\left (1\right )}\left (3\right )\right ]^{\hat {\lambda }}\\{\cdots } & {\cdots } \\ -z^{\left (1\right )}\left (n\right )&\left [z^{\left (1\right )}\left (n\right )\right ]^{\hat {\lambda }}\end {pmatrix}\), \(Y=x^{\left (0\right )}\left (2\right ),x^{\left (0\right )}\) \(\left (3\right ),\cdots ,x^{\left (0\right )}\left (n\right )^{T}\).
Solution of G P M(λ,1,1)
According to Eq. 12 and the estimation results of parameters, we can simplify it to get \(\hat {x}^{\left (1\right )}\left (t+1\right )=\left [c\cdot e^{-\left (1-\hat {\lambda }\right )\hat {a}t}+\left . \hat {b} \middle / \hat {a} \right .\right ]^{\frac {1}{1-\hat {\lambda }}}\). If the initial value \(\hat {x}^{\left (1\right )}\left (1\right )=x^{\left (0\right )}\left (1\right )\), then the solution of GPM(λ,1,1) is
Rolling modeling mechanism
It is easy to produce some unacceptable errors in practical applications. In order to reduce the errors, rolling mechanism is proposed. The length of training data set is set as c, and the predicted period of rolling modeling is set as d. The steps are as follows:
Step 1: The original sequence \(\left \{x^{\left (0\right )}\left (1\right ),x^{\left (0\right )}\right .\left (2\right ),\cdots ,\) \(\left .x^{\left (0\right )}\left (c\right )\right \}\) is used to model and the d-period prediction value \(\left \{\hat {x}^{\left (0\right )}\left (c+1\right ),\hat {x}^{\left (0\right )}\left (c+2\right ),\cdots ,\hat {x}^{\left (0\right )}\left (c+d\right )\right \}\) is obtained;
Step 2: When predicting the sequence \(\{\hat {x}^{\left (0\right )}(c+d+1),\hat {x}^{\left (0\right )}\left (c+d+2\right ),\cdots ,\hat {x}^{\left (0\right )}\left (c+2d\right )\}\), we use the latest c data points \(\left \{\hat {x}^{\left (0\right )}\left (d+1\right ),\hat {x}^{\left (0\right )}\left (d+2\right ),\cdots ,\hat {x}^{\left (0\right )}\left (d+c\right )\right \}\) to predict;
Step 3: Repeat step 2 and use the latest sequence to predict the next set of d data points until the required data points are predicted.
The flow chart is shown in Fig. 2.

The rolling mechanism
Building the R G P M M(λ,1,1)
Due to the complexity of the real situation, there will always be a certain difference between the fitting value obtained by GPM(λ,1,1) and the real value. Then, the accuracy index of grey fitting is random and non-stationary. In order to correct the predictable result and improve the prediction accuracy of GPM(λ,1,1), the fluctuation of grey fitting accuracy index is analyzed and predicted by Markov theory in this paper. Combined with the rolling mechanism, the electricity consumption is forecasted in the future. The steps of RGPMM(λ,1,1) are as follows and the flow chart is shown in Fig. 3.

The flow chart of RGPMM(λ,1,1)
Step 1: Calculate fitted values and predicted values
According to the time series \(X^{\left (0\right )}=\{x^{\left (0\right )}\left (1\right ),x^{\left (0\right )}\left (2\right ),\cdots ,x^{\left (0\right )}\) \(\left (n\right )\}\), GPM(1,1) is established to obtain
where \(\hat {x}^{(0)}(t) (t\le n)\) are called fitted values, and \(\hat {x}^{(0)}(t)(t>n)\) are called predicted values.
Step 2: Calculate the grey fitting accuracy index
The grey fitting accuracy index is set to \(Y\left (t\right )=\left . x^{\left (0\right )}\left (t\right ) \middle / \hat {x}^{\left (0\right )}\left (t\right ) \right .\), which reflects the deviation degree of the data fitted by model from the original data.
Step 3: Division of state interval
Considering that \(Y\left (t\right )\) is divided into m state \(E_{i}=\left [\otimes _{1i}, \otimes _{2i}\right ], i=1,2,\cdots ,m\). The grey elements ⊗1i and ⊗2i are the lower bound and the upper bound of the i th state, where \(\otimes _{1i}=Y\left (t\right )+a_{i}\overline {Y}\), \(\otimes _{2i}=Y\left (t\right )+b_{i}\times \overline {Y}\), \(\overline {Y}=\frac {1}{n}\cdot {\sum }_{i=1}^{n}Y(i)\). The ai and bi are constants that need to be determined based on experience and data.
Considering the limited amount of electricity consumption data in this paper, it is more appropriate to use the cluster analysis to determine the number of classification classes and the classification interval.
Step 4: Establish a state transition matrix
The transition probability of state Ei to state Ej is
where, \(M_{ij}\left (\omega \right )\) is the number of samples \(Y\left (t\right )\) transferred from the state of Ei to the state of Ej through ω steps; Mi is the total number of occurrences of Ei, and satisfies \({\sum }_{j=1}^{m}p_{ij}\left (\omega \right )=1\), i,j = 1,2,⋯ ,m. Therefore, \(p_{ij}\left (\omega \right )\) reflects the probability of transition from Ei to Ej through ω steps.
The state transition probability matrix is
The \(R\left (\omega \right )\) reflects the transfer law between the various states of the system. By examining \(R\left (\omega \right )\) and the current state, we can predict the future development and change of the system.
The autocorrelation coefficient of each order is
By normalizing rω, the Markov weight of each order is
where, 𝜃ω is the Markov weight of the ωth order, and the ωth order generally is the maximum order when |rω|≥ 0.3.
Step 5: Calculate more accurate the predicted value
The transition probability matrix is used to predict the state interval Ei of the grey fitting precision index. The interval interpolation is used to determine the predicted value. Therefore, \(\tilde {x}^{\left (0\right )}(n+1)=\hat {x}^{(0)}(n+1)\ast \widehat {Y}\left (n+1\right )\), where
Step 6: Calculate more accurate predicted values in the next few years
Through a rolling mechanism, the input data is updated and the RGMM(λ,1,1) is established to forecast the next year’s value. Continue the above process until the desired data forecasted.
Evaluation metrics
Here are three kinds of evaluation metrics to evaluate the prediction accuracy. Only when the three metrics are all passed, the RGPMM(λ,1,1) can be used to predict, and its predicted values have reference significance. There are three kinds of evaluation metrics as follows:
A: The residual test
The three statistical indicators are determined, namely MAE (Mean Absolute Error) (Hamzaçebi 2007), MAPE (Mean Absolute Percentage Error) (Azadeh et al. 2008), and RMSE (The Root Mean Squared Error) (Geem and Roper 2009). The formulas for MAE,MAPE and RMSE are as follows:
where x(0)(i) is the original value at time i, and the \(\hat {x}^{(0)}(i)\) is the fitted value at time i. Table 1 shows criteria of forecasting performance.
B: The correlation degree
The test method of correlation degree is γg:
where, ρ = 0.5, \({\Delta }(i)=\left |\hat {x}^{(0)}(i)-x^{(0)}(i)\right |\), i = 1,2,⋯ , n, n is the number of samples.
C: The posterior error test
The process of posterior error test is as follows:
Step 1: Calculate \(S_{0}=\sqrt {\frac {{\sum }_{i=1}^{n}(X^{(0)}(i)-\overline {X}^{(0)})^{2}}{n-1}}\) of {X(0)(i)} and \(S_{1}=\sqrt {\frac {{\sum }_{i=1}^{n}(\varepsilon ^{(0)}(i)-\overline {\varepsilon }^{(0)})^{2}}{n-1}}\) of {ε(0)(i)}, where \(\overline {X}^{(0)}=\frac {1}{n}\cdot {\sum }_{i=1}^{n}X^{(0)}(i)\), \(\varepsilon ^{(0)}(i)=x^{(0)}(i)-\hat {x}^{(0)}(i)\), \(\overline {\varepsilon }^{(0)}=\frac {1}{n}\cdot {\sum }_{i=1}^{n}\varepsilon ^{(0)}(i)\), i = 1,2,⋯ ,n
Step 2: The standard deviation ratio \(C=\frac {S_{1}}{S_{0}}\);
Step 3: The error probability \(P=\{|\varepsilon ^{(0)}(i)-\overline {\varepsilon }^{(0)}(i)|<0.6745\times S_{0}\}\);
Step 4: The discrimination rules are shown in Table 2.
Case studies on forecasting the total electricity consumption in China
Since forecasting electricity consumption is important for the dispatch and operation of the power system, the total electricity consumption forecast at the national level is put forward. To prove the prediction accuracy of RGPMM(λ,1,1) in the “Methodology of improved grey prediction model section”, it is compared with GM(1,1), GM(1,1,Xn) (Bahrami et al. 2014; Dang et al. 2004), OICGM(1,1) (Akdi et al. 2020), and NOGM(1,1) models (Ding et al. 2018).
Experimental data
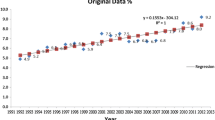
The experimental data is from the China Statistical Yearbook published by the National statistics Bureau of China (Bureau, 2019). The experimental data set includes the total amount of electricity consumption from 2008 to 2017, as shown in Table 3.
Selecting the input data set and determining the length of the input data set are the prerequisites to affect the accuracy of the prediction model. In this paper, the optimized subset method proposed by Wang (Wang et al. 2011) is used to determine the optimal length of the input data set, and c = 8 can be obtained. Eight data points are used as input data points, and the data of the last two years are used to test the prediction effect of the model.
The prediction results of experiment
In Table 3, the original sequence is X(0) = (3.45414, 3.70322, 4.19345, 4.70009,v4.97626, 5.42034, 5.63837, 5.80200,6.12971,6.48210). The flow chart of using the RGPM(λ,1,1) model to predict China’s electricity consumption is shown in Fig. 4.

The rolling mechanism
According to Theorem 1 and Formula (11) in the “Methodology of improved grey prediction model” section, the parameters of λ and \(\left (\begin {array}{cc} a\\b \end {array}\right )\) are estimated twice by MATLAB software programming to predict the total electricity consumption in 2016, 2017. Its calculation and results are as follows:
In 2016, the estimates calculated by MATLAB are \(\hat {\lambda }=0.2539\) and \(\left (\begin {array}{cc} \hat {a}\\\hat {b} \end {array}\right )= \left (\begin {array}{cc} 0.0041\\2.4323 \end {array}\right )\).
Substitute the parameter estimates into Eq. 13, the time response sequence function by RGPM(λ,1,1) model in 2016 is
Similarly, by entering the new initial value, the estimated values of parameters in 2017 are \(\hat {\lambda }=-0.0035\) and \(\left (\begin {array}{cc} \hat {a}\\\hat {b} \end {array}\right )=\left (\begin {array}{cc} -0.0587\\4.0794 \end {array}\right )\).
Then, the time response sequence function of 2017 is
The different parameter values of each step indicate that the RGPM(λ,1,1) can make the prediction result dynamic according to the characteristics of the input data. Figure 5 intuitively shows that the forecast results by RGPM(λ,1,1) are in good agreement with the real values.

The predicted value of RGPM(λ,1,1)
The prediction values of each grey model are shown in Table 4 and Figs. 6 and 7.

Comparison of the original data and the predicted values of each model

The histogram of actual values and predicted values for each model
The related parameters and run time of each grey model are shown in Table 5.
Through Table 4 and Figs. 6 and 7, it can be intuitively shown that the fitting degree between the predicted results of RGPM(λ,1,1) and the real values is better than that of GM(1,1), GM(1,1,Xn), OICGM(1,1), and NOGM(1,1). This result can also be verified by using the experimental test indicators mentioned in the “Evaluation metrics” section. The prediction effect and the detection results of each grey model are shown in Table 6.
Through Table 6, the values of 6 detection indexes by GM(1,1) are MAE = 0.6041, MAPE = 10.9339%, RMSE = 0.7006, rg = 0.4991, P = 0.9000, and C = 0.3870. Since MAPE = 10.9339% ∈ [10%,20%], it indicates that the prediction ability of GM(1,1) is weaker than other 4 grey prediction models. Moreover, its P = 0.9000 < 1.0000, which further indicates that the predictive ability of GM(1,1), is weaker than that of GM(1,1,Xn), OICGM(1,1), NOGM(1,1), and RGPM (λ,1,1). This result further shows that the grey model with non-integer power is more suitable for the prediction of total electricity consumption, and the intervention of the rolling mechanism further improves the accuracy of the prediction results.
In summary, RGPM(λ,1,1) is superior to other four grey models in all detection indices. That is, its prediction performance is better than other four models. MAE and MAPE are increased by several percentage points respectively, indicating that the prediction accuracy of RGPM(λ,1,1) is greatly improved compared with other four grey models. So, RGPM(λ,1,1) is a better choice to analyze the forecast value of the country’s total electricity consumption. However, the more accurate the prediction of national electricity consumption, the better it can provide more accurate forecast information for power workers. In order to improve the prediction performance of the grey power model, the weighted Markov model is used to modify it.
The prediction results of R G P M M(λ,1,1)
The RGPM(λ,1,1) is used to get the fitted value \(\hat {x}^{(0)}(t)\), t = 1,2,⋯ ,8 in each year, where 1-8 denote the 2008-2015, respectively. The accuracy index of grey fitting is obtained according to \(Y(t)=\frac {x^{(0)}(t)}{\hat {x}^{(0)}(t)}\) presented in the “Methodology of improved grey prediction model” section, as shown in Table 7.
From Table 7, it can be found that the grey fitting accuracy index has a strong volatility, and the weighted Markov model can be used to predict the state of the grey fitting accuracy.
The Q-type clustering (Narasimhan et al. 2005) is used to divide the state. The clustering result is shown in Fig. 8. According to the cluster diagram, the accuracy indices of grey fitting can be divided into 5 states, which are denoted as {E1, E2, E3, E4, E5}. The clustering results are shown in Fig. 8 and Table 8. Then, the Markov state interval can be obtained as follows:

The figure of Q-cluster for 2008–2015
According to the grey fitting accuracy index sequence, the autocorrelation coefficients of each order can be calculated as r0 = 1.0000,r1 = 0.2306,r2 = − 0.0694,r3 = − 0.0412,r4 = − 0.4134,r5 = − 0.1910,r6 = − 0.0172, r7 = 0.0016. The autocorrelation diagram is shown in Fig. 9 and Table 8.

The each order of autocorrelation coefficient
According to Fig. 10, it is found that when m is taken as 4, the condition of \(\left |r_{\omega }\right |\ge 0.3\) is satisfied, and there are r1 = 0.2306,r2 = − 0.0694,r3 = − 0.0412,r4 = − 0.4134. Then the Markov weights of each order are obtained as follows:

The figure of Q-cluster for 2008-2015
The Markov transition probability matrixes of each step are calculated as follows:
The accuracy index of grey fitting is in the state of E3 in 2015, so we can get:
The one-step transition probability vector is (0.5,0,0, 0,0.5), and the corresponding Markov weight is 𝜃1 = 0.3056;
The two-step transition probability vector is (0,0.5,0, 0.5,0), and the Markov weight is 𝜃2 = 0.0920;
The three-step transition probability vector is (0,0,0.5, 0.5,0), and the Markov weight is 𝜃3 = 0.0546;
The four-step transition probability vector is (0,0,1, 0,0), and the Markov weight is 𝜃4 = 0.5478.
According to \(p_{i}=\sum \limits _{\omega =1}^{m}{\theta _{\omega }p_{i}(\omega )}\), the weighted Markov prediction probability is calculated, as shown in Table 9.
From Table 9, the weighted probability value of the transition probability can be obtained. Based on results, max{pi} = p3 = 0.5751, that is, the probability of being in the state of E3 in 2016 is the largest. And its adjacent states are E2 and E4. According to Formula (15), perform linear interpolation on the interval of state E3, and the predicted value of grey fitting accuracy is
Through the correction of the grey fitting accuracy index, the more accurate predicted value in 2016 can be obtained as follows:
In modeling process, the introduction of rolling mechanism makes the established model make full use of the latest information to forecast the electricity consumption in 2017. Then using the latest data from 2009 to 2016, the proposed RGPMM(λ,1,1) model can be built to obtain the predicted value in 2017. The results are as follows:
The grey fitting accuracy index in 2017 is in Table 10.
The clustering result and the autocorrelation diagram are shown in Table 11 and Figs. 10 and 11.

The each order of autocorrelation coefficient
After the correction by Markov blanket, the more accurate prediction value in 2017 is 6.5258.
Comparing the forecasting performance of R G P M(λ,1,1) and R G P M M(λ,1,1)
The predicted performance of RGPMM(λ,1,1) model is compared with the RGPM(λ,1,1) model. MSE and MAPE are selected to evaluate the predictive performance of the models, and their expressions are respectively as follows:
MSE and MAPE of each model are calculated. The result is in Table 12.
In Table 12, it is found that the values of MSE and MAPE by RGPMM(λ,1,1) are smaller than RGPM(λ,1,1). The result shows that the RGPMM(λ,1,1) further improves the accuracy.
Forecast the total electricity consumption in the next 6 years
Because that RGPMM(λ,1,1) has been shown to provide accurate prediction, we use it to forecast China’s electricity consumption from 2018 to 2023. During the process, the results by Q-cluster and the correlation coefficients of each year are in Tables 13, 14, 15, 16, 17, and 18 and Figs. 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, and 23.

The figure of Q-cluster during 2010-2017

Each order of autocorrelation coefficient for 2018

The figure of Q-cluster during 2011–2018

The each order of autocorrelation coefficient for 2019

The figure of Q-cluster during 2012–2019

The each order of autocorrelation coefficient of 2020

The figure of Q-cluster during 2013–2020

The each order of autocorrelation coefficient for 2021

The figure of Q-cluster during 2014-2021

The each order of autocorrelation coefficient for 2022

The figure of Q-cluster during 2015–2022

The each order of autocorrelation coefficient for 2023
The prediction results are modified by Markov theory during 2018-2023 are shown in Figs. 24, 25, 26, 27, 28, and 29.

The predicted value of RGPMM(λ,1,1) for 2018

The predicted value of RGPMM(λ,1,1) for 2019

The predicted value of RGPMM(λ,1,1) for 2020

The predicted value of RGPMM(λ,1,1) for 2021

The predicted value of RGPMM(λ,1,1) for 2022

The predicted value of RGPMM(λ,1,1) for 2023
The parameters and forecasted results are presented in Table 19.
It can be seen from experimental results in Table 19 that the total electricity consumption will maintain a growth trend. It is estimated that by 2023, electricity consumption will increase from 6.48210 ∗ 1012kwh in 2017 to 9.9826 ∗ 1012kwh, which is nearly 1013kwh, almost twice that of 2012. This prediction result is of great significance to energy planning and policy-making. In order to ensure secure and stable energy and power supply, it is necessary to accelerate the establishment and improvement of auxiliary services for the power allocation, continuously improve the capacity of power system, and ensure the perfection of power infrastructure in the supply chain. Meanwhile, it is worth noting that huge consumption will bring a heavy burden to energy planning and environmental protection. Therefore, the government needs to take appropriate actions and plans to meet the high energy demand in the future, so as to avoid the phenomenon of resource waste caused by unreasonable resource arrangement.
Conclusion
Electricity consumption forecast is of great significance to the economic development and the guarantee of people’s life. However, due to the increase in electricity demand and in the complexity of the power system, it is becoming more and more difficult to accurately predict the power consumption. Therefore, it is meaningful to design a prediction method which is suitable for the limited data.
Aiming at the problem of power demand under limited data, a grey power-Markov forecasting model based on rolling mechanism is proposed. It predicts the electricity consumption on the basis of grey theory by introducing rolling mechanism and Markov state prediction. According to the research results, the following conclusions can be drawn:
-
1)
In view of the problems faced by power system load forecasting, RGPMM(λ,1,1) is proposed. The example shows that it gets a better prediction effect than the traditional GM(1,1) models, and it improves the prediction accuracy to a certain extent. This model provides a new way to forecast electricity consumption. The structure of the new grey prediction model is simple, the modeling process is easy to operate, and it is easy to be applied in other fields.
-
2)
Total electricity consumption is not only an important indicator of economic development, but also an important indicator of formulating the energy strategy and related environmental protection policies. The forecast results of the total electricity consumption indicate that China’s total power consumption will continue to maintain a strong growth trend in the next few years. It has certain reference value for formulating the energy strategy and related environmental protection policies.
However, the grey prediction model proposed in this paper also has some defects. It only solves the univariate prediction problem, and no corresponding solution is proposed for the multivariate prediction problem. Therefore, there is still a lot of work to be done in the future. Future work: the forecasting model proposed in this article is for univariate, and multivariate gray models can be considered in the future. In addition, the new model proposed in this paper can also be used to forecast the industrial electricity consumption, the agricultural electricity consumption, the residential electricity consumption and other fields.
References
Azadeh A, Ghaderi SF, Sohrabkhani S (2008) A simulated-based neural network algorithm for forecasting electrical energy consumption in Iran[J]. Energy policy 36(7):2637–2644
Akay D, Atak M (2007) Grey prediction with rolling mechanism for electricity demand forecasting of Turkey[J]. Energy 32(9):1670–1675
Amber KP, Ahmad R, Aslam MW, et al. (2018) Intelligent techniques for forecasting electricity consumption of buildings[J]. Energy 157:886–893
Akdi Y, Gölveren E, Okkaoğlu Y (2020) Daily electrical energy consumption: periodicity, harmonic regression method and forecasting[J]. Energy 191:116524
Bekiroglu K, Duru O, Gulay E, et al. (2018) Predictive analytics of crude oil prices by utilizing the intelligent model search engine[J]. Appl Energy 228:2387–2397
Bahrami S, Hooshmand RA, Parastegari M (2014) Short term electric load forecasting by wavelet transform and grey model improved by PSO (particle swarm optimization) algorithm[J]. Energy 72:434–442
Chui F, Elkamel A, Surit R, et al. (2009) Long-term electricity demand forecasting for power system planning using economic, demographic and climatic variables[J]. Eur J Indu Eng 3(3):277–304
CAO Jian SHI, Shiliang CAO, et al. (2019) Huajuan Study on prediction and relationship of road transportation accidents of dangerous chemicals and traffic accidents based on GM (1, 1)-Markov model[J]. J Safety Sci Technol 15(1):26–31
China Statistical Yearbook of 2019
Ding S, Hipel KW, Dang Y (2018) Forecasting China’s electricity consumption using a new grey prediction model[J]. Energy 149:314–328
Dang Y, Liu SF, Liu B (2004) The GM models that x(n) be taken as initial value[J]. Kybernetes 33(2):247–254
Guo H, Xiao X, Forrest JA (2013) Research on a comprehensive adaptive grey prediction model CAGM (1, N)[J]. Appl Math Comput 225:216–227
Ghani IMM, Ahmad S (2010) Stepwise multiple regression method to forecast fish landing[J]. Procedia-Soc Behav Sci 8:549–554
Geem ZW, Roper WE (2009) Energy demand estimation of South Korea using artificial neural network[J]. Energy policy 37(10):4049–4054
Hussain A, Rahman M, Memon JA (2016) Forecasting electricity consumption in Pakistan: the way forward[J]. Energy Policy 90:73–80
Hamzaçebi C (2007) Forecasting of Turkey’s net electricity energy consumption on sectoral bases[J]. Energy policy 35(3):2009–2016
Hernández L, Baladrón C, Aguiar JM, et al. (2013) Experimental analysis of the input variables’ relevance to forecast next day’s aggregated electric demand using neural networks[J]. Energies 6(6):2927–2948
Hernandez L, Baladron C, Aguiar JM, et al. (2014) A survey on electric power demand forecasting: future trends in smart grids, microgrids and smart buildings[J]. IEEE Commun Surv Tutorials 16(3):1460–1495
Yong HE, Yidan BAO (1992) Grey-markov forecasting model and its application[J]. Syst Eng-Theory Practice 12(4):59–63
Julong D (1982) Grey control system[J]. J Huazhong Univ Sci Technol 3(9):18
Julong D (1989) Introduction to grey system theory[J]. J Grey Syst 1(1):1–24
Khosravi A, Nahavandi S, Creighton D, et al. (2012) Interval type-2 fuzzy logic systems for load forecasting: a comparative study[J]. IEEE Trans Power Syst 27(3):1274–1282
Kavousi-Fard A, Samet H, Marzbani F (2014) A new hybrid modified firefly algorithm and support vector regression model for accurate short term load forecasting[J]. Expert Syst Appl 41(13):6047–6056
Kumar U, models Jain V K. (2010) Time series (Grey-Markov, Grey Model with rolling mechanism and singular spectrum analysis) to forecast energy consumption in India[J]. Energy 35(4):1709–1716
Lin B, Liu C (2016) Why is electricity consumption inconsistent with economic growth in China?[J]. Energy Policy 88:310–316
Liu T, Wang B, Yang C (2018) Online Markov Chain-based energy management for a hybrid tracked vehicle with speedy Q-learning[J]. Energy 160:544–555
Lin Z, Zhang Q, Liu H (2012) Parameters optimization of GM (1, 1) model based on artificial fish swarm algorithm[J] Grey Systems, Theory and Application
Mohamed Z, Bodger P (2005) Forecasting electricity consumption in New Zealand using economic and demographic variables[J]. Energy 30(10):1833–1843
Narasimhan M, Jojic N, Bilmes JA (2005) Q-clustering[j]. Advances in Neural Information Processing Systems 18:979–986
Pai TY, Chiou RJ, Wen HH (2008) Evaluating impact level of different factors in environmental impact assessment for incinerator plants using GM (1, N) model[J]. Waste Manag 28(10):1915–1922
Tien TL (2008) The indirect measurement of tensile strength for a higher temperature by the new model IGDMC (1, n)[J]. Measurement 41(6):662–675
Wang J, Zhu S, Zhao W, et al. (2011) Optimal parameters estimation and input subset for grey model based on chaotic particle swarm optimization algorithm[J]. Expert Syst Appl 38(7):8151–8158
Wang J, Zhou Q, Zhang X (2018) Wind power forecasting based on time series ARMA model[C] ∖∖ IOP Conference Series: Earth and Environmental Science. IOP Publish 199(2):022015
Wang S, Wang P, Zhang Y (1819) A prediction method for urban heat supply based on grey system theory[J]. Sustain Cit Soc 52(10):2020
Wang ZX, Dang Y, Pei LL (2011) Modeling approach for oscillatory sequences based on GM(1, 1) power model[J]. Syst Eng Electron 33(11):2440–2444
Xiong P, Dang Y, Yao T, et al. (2014) Optimal modeling and forecasting of the energy consumption and production in China[J]. Energy 77:623–634
Xiao X, Yang J, Mao S, et al. (2017) An improved seasonal rolling grey forecasting model using a cycle truncation accumulated generating operation for traffic flow[J]. Appl Math Model 51:386–404
Zeng B, Ma X, Shi J (2020) Modeling method of the grey GM(1, 1) model with interval grey action quantity and its application[J]. Complexity 2020
Zhang Y, Chen B, Pan G, et al. (2019) A novel hybrid model based on VMD-WT and PCA-BP-RBF neural network for short-term wind speed forecasting[J]. Energy Convers Manag 195:180–197
Zhao W, Wang J, Lu H (2014) Combining forecasts of electricity consumption in China with time-varying weights updated by a high-order Markov chain model[J]. Omega 45:80–91
Acknowledgements
The authors are grateful to the editor and reviewers for their valuable comments.
Funding
This work is financially supported by the National Natural Science Foundation of China (61573266) and Natural Science Basic Research Program of Shaanxi (Program No. 2021JM-133).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Responsible Editor: Philippe Garrigues
Author contribution
Liqin Sun contributed the idea. Liqin Sun and Youlong Yang performed the calculations. Jiadi Zhu checked the calculations. Liqin Sun wrote the main manuscript. Youlong Yang and Tong Ning made an improvement. All authors contributed to discussion and reviewed the manuscript.
Data availability
The data in this article are from: “’http://www.stats.gov.cn/tjsj/ndsj/2019/indexch.htm”.
Ethical approval
Not applicable
Consent to participate
Not applicable
Consent to publish
Not applicable
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Sun, L., Yang, Y., Ning, T. et al. A novel grey power-Markov model for the prediction of China’s electricity consumption. Environ Sci Pollut Res 29, 21717–21738 (2022). https://doi.org/10.1007/s11356-021-17016-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-021-17016-1