
Abstract
The tree species and its diversity are two critical components to be monitored for sustainable management of forest as well as biodiversity conservation. In the present study, we have classified the tree species and estimated its diversity based on hyperspectral remote sensing data at a fine scale level in the Saranda forest. This area is situated near the mining fields and has a dense forest cover around it. The forest surrounding the study area is exhibiting high-stress condition as evidenced by the dying and dry plant material, consequently affecting tree species and its diversity. The preprocessing of 242 Hyperion (hyperspectral) spectral wavebands resulted in 145 corrected spectral wavebands. The 21 spectral wavebands were selected through discrimination analysis (Walk’s Lambda test) for tree species analysis. The SVM (support vector machine), SAM (spectral angle mapper), and MD (minimum distance) algorithms were applied for tree species classification based on ground spectral data obtained from the spectroradiometer. We have identified six local tree species in the study area at the spatial level. The result shows that Sal and Teak tree species are located in the upper and lower hilly sides of two mines (Meghahatuburu and Kiriburu). We have also used hyperspectral narrow banded vegetation indices (VIs) for species diversity estimation based on the field-measured Shannon diversity index. The statistical result shows that NDVI705 (red edge normalized difference vegetation index) is having the best R2 (0.76) and lowest RMSE (0.04) for species diversity estimation. That is why we have used NDVI705 for species diversity estimation. The result shows that higher species diversity values are located in the upper and lower hilly sides of two mines. The linear regression between Hyperion and field measured Shannon index shows the R2 (0.72) and RMSE (0.15). This study will aid in effective geoenvironmental planning and management of forest in the hilltop mining areas.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The tree species and its diversity are the essential natural resources. In the study region, mining-related activities have shown a high potential for tree species growth and health problem. The tree species and its diversity have several ecological functions. Its disturbances directly affect the diversity, distribution, and abundance of forest, e.g., the effect of animals in forest protected areas (Bruce et al. 2008), land-use conversion (Fuller 2006), harvesting for fuelwood (Madubansi and Shackleton 2006) and mining activities (Obeng et al. 2019). Mining activities causes forest degradation, damage, and deterioration of biodiversity, as well as forest ecology (Raizada and Samra 2000; Morris 2010; Kayet et al. 2019a, b). Gibbs et al. (2016) have studied tree species and diversity in the Amazon forest area. They showed that 9% of tree species is lost by mining and allied activities between the years 2005 and 2015 in the Amazon forest.
However, hyperspectral remote sensing technology has shown the potential to identify the dynamics of tree species at spatial and regional scale level (Chambers et al. 2007; Plaza et al. 2009; Shen and Cao 2017). Hyperspectral compact airborne image (CASI) sensor data had been used for tree crowns and species identification (Bunting and Lucas 2006). They had developed an algorithm to delineate tree crown and species classification using ECognition expert, and ground spectral data. The hyperspectral remote sensing technology has provided higher accuracy to discriminate tree species by classifying it at a spatial scale level (ST.1). Kozoderov et al. (2015) had used BCC (Beiman cutler classification) algorithm in the R statistical program package for tree species classification based on hyperspectral data. They had shown that BCC method has better accuracy levels than other supervised classification methods (SVM and SAM). Dalponte et al. (2013) had used EHCS (efficient hierarchical clustering statistical) algorithm for identifying the Tamarisk tree species and their suitable wavebands using airborne hyperspectral (4 m) data combined with multispectral (0.5 m) data. Alonzo et al. (2014) had developed the ITC (individual tree crown) method based on hyperspectral data for classification of tree species. They had also used various threshold methods for full pixel tree species classification and compared that with the ITC method. The spectral behavior of tree species basically depends on leaves reflectance, absorption, and transmission properties. A spectral collection technique (SCT) is one of the significant elements in the discrimination analysis of tree species and identification (Adam et al. 2010; Delalieux et al. 2009). One airborne (HyMap) and one space-borne (Hyperion) hyperspectral satellite data (pixel resolution size of 8 and 30 m) based SMTs (Spectral measure techniques) algorithm had been used for tree species identification (Ghiyamat et al. 2013).
Hyperspectral narrow-banded VI–based tree species diversity estimation is a new task at a fine-scale level. Peng et al. (2018) studied the assessment of tree species diversity and mapping at regional scale level using hyperspectral narrow banded 37 VIs indices and 1st order derivation value for each wavelength from ground spectra. The combination of hyperspectral and multispectral (world view) data were used for species diversity mapping. The accuracy yielded by multispectral (70.5) has also been compared with hyperspectral (79.2) data (Cho et al. 2012). Some researchers have shown the relationship between spectral indices and plant diversity (Griffin et al. 2009; Tuanmu and Jetz 2015; Dudley et al. 2015). They had used the hyperspectral narrow banded indices, field spectra, and forest survey data for analysis of species diversity and had shown that it had higher accuracy for species diversity mapping. Hyperspectral narrow banded VIs were used for species diversity mapping with an error of 20% in the grassland forest of Sweden and temperate forest (27%) of Germany (Möckel et al. 2016; Leutner et al. 2012). They compared narrow-banded–derived Shannon index and field measured Shannon index. Assessment of species biodiversity has been carried out using airborne UAV (unmanned aerial vehicles) hyperspectral data in a subtropical forest (Getzin et al. 2012). They used a statistical correlation between narrow-banded VIs and 1st order derivation of each wavelength for this analysis. Hyperspectral images (airborne and spaceborne) had shown highest accuracy results for species biodiversity in different forest area, including rain (Ghazoul and Sheil 2010), tropical (Nagendra and Rocchini 2008) and mixed (Schneider et al. 2017), conifer (Nagendra 2001) and deciduous forest (Decocq et al. 2004). The airborne hyperspectral and thermal-infrared satellite imagery were applied for the detection of species diversity and vegetation species (Coates et al. 2015). They had used two statistical methods (standard deviation and linear regression) for species and diversity analysis at the regional scale level. The hyperspectral UAV (Getzin et al. 2012), airborne (Lassau and Hochuli 2005), and spaceborne (Nagendra and Rocchini 2008) data were used for estimation of forest biodiversity, and it had offered a very high accuracy results than multispectral.
The iron ore belt of the Saranda forest started facing trees species degradation due to mining activities for the last 25 years (FSI report). This resulted in the change in natural tree patterns and species biodiversity over the years. However, such changes are not yet well quantified, and its overall impacts on the future of the forest tree species are still not defined. Therefore, the effect of mining on tree species and species diversity must be adequately evaluated.
The major subobjectives of this paper include finding the suitable waveband for tree species classification using discriminant analysis; identify the spectral separability of different tree species using the J-M (Jeffries-Matusita) distance method; compare the accuracy performance of SVM, SAM, and MD algorithms for tree species classification; and compare the accuracy of narrow (Hyperion) and broad (Landsat OLI) band data for tree species classification. Mapping of species diversity is performed using hyperspectral narrow banded VIs and compared with the Shannon index (H) to draw the relationship between Hyperion and field derived Shannon index. Species diversity and tree species mapping will help in forest management, as well as in decision-making for forest landscapes.
Study area and tree species information
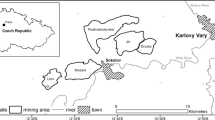
Kiriburu and Meghataburu are two major mines contributing to iron ore feed for Bokaro Steel Plant (SAIL) for the last four decades (Fig. 1). The study area has a latitudinal stretch from 22° 00′ 45″ to 22° 1′ 36″ N and longitudinal stretch from 85° 08′ 18.8″ to 85° 24.36′ 35″ E with mean elevation of 750 m from MSL. Saranda forest is characterized by hilly and steeply sloping with homogeneous forest cover (Ahmad et al. 2018). The soil of this region is mainly rocky, red, and black soil. This area comprises of two main varieties of forest, i.e., tropical moist deciduous and tropical dry deciduous and is also famous for the largest Sal forest of Asia. Sal and Teak trees are richly found in this region (FSI report 2015). The attributes of tree species of the study area are shown in Table 1. During summer, the temperature reaches to 43 °C. Yearly average temperature ranges between 25 and 32 °C. The average annual rainfall varies between 1200 and 1422 mm.

Location map of the study area
Material and methods
Data collection
The Hyperion (hyperspectral) and Landsat-8 OLI (multispectral) sensors satellite data were used for tree species identification and diversity mapping. Two satellite data sets, dated 16 Dec 2016 (Hyperion), and 9 Dec 2016 (Landsat OLI) were obtained from USGS (United States geological survey). Hyperion data were available only for the abovementioned period that is why we have used Landsat OLI of that period. Hyperion sensor captures very narrow banded data (Hyperion tutorial handbook). Field-based tree species spectral data were acquired by the spectroradiometer instrument in the study area for marching with satellite imagery spectra. The species phytosociological observation data were collected from the Chaibasa forest office, Saranda forest, for tree species identification. For species biodiversity analysis (Shannon index based), 18 plot data were collected from the study area. GPS (global positioning system) has recorded the tree species and its diversity locations (latitude and longitude) of the study area. The secondary data were (base map, toposheet, mining plan, and forest survey data) obtained from different concerned state government offices.
Field survey and analysis
The leaf reflectance spectra of tree species were recorded by field-based spectroradiometer during the time of field survey. A total of twenty spectra corresponding to six different tree species were recorded, and the mean spectra of each tree species were used for analysis and classification. GPS has measured the longitude and latitude for each sample of tree species (SF.1). We have measured in 10 × 10 m2 plots in the field for Shannon index analysis. A total of 18 plots were recorded during the field survey. The GPS position was acquired for the center of each diversity plot with the help of high-precision hand GPS. The species abundance cover, height, and habitat information were also acquired during field survey. The field survey photograph of tree species and its diversity are shown in Fig. 2.

Spectroradiometry field survey and laboratory analysis
Acquisition and preprocessing of field spectra
The spectroradiometer recorded the tree reflection spectra and their wavelength. This instrument recorded at spectral resolutions of VNIR (300–1000 nm) for 1.4 nm, NIR (1000–1700 nm) for 2 nm, and SWIR (1700–2500 nm) for 4-nm interval respectively. The different spectral wave ranges were resampled by the FWHM (Full width at half maximum) algorithm (Kayet et al., 2019). The spectra for different tree species were collected with the help of fiber optic source (300 to 2500 nm) and 180° FOV (field of view). For the measurement of white reference spectra, a standard reference panel (white) was used. Species leaf reflectance was measured with the help of a reflectance probe. The holder block of the reflectance probe was kept at sample distance 0–3/4″ and 90° angle was set. The raw field spectra of tree species in the study area are shown in the supplementary file (SF.2).
Preprocessing of spectra consisted of temperature drift correction, water absorption, noise bands removal, and spectral smoothing. The temperature drift errors were coming from 1001 to 1831 nm wavelength due to sensor detector changing (Lenhard et al. 2005). We have used a splice correction algorithm for temperature drift correction. The collected spectra had shown error of water vapor and noise (2350 to 2500, 1790 to 1960, and 1350 to 1460 nm wavelength) due to atmospheric components and instruments’ self-generation (Staenz et al. 2002). We have just removed two types of spectral errors from wavelength bands. Some researchers have used linear and nonlinear smoothing filter for spectral data smoothing. Savitzky-Golay algorithm based filter smoothing yields high accuracy (Savitzky and Golay 1964; Vaiphasa 2006). So, we have used the Savitzky-Golay filter for spectral data smoothing. The average spectra of tree species were calculated after spectral smoothing. This spectral has been used for spectral library development and applied for classification.
Preprocessing of satellite data
Pre-processing correction (geometric, radiometric, and terrain) of Hyperion and Landsat 8-OLI data were done by image processing software. The atmospheric correction was carried out by the FLAASH (fast line-of-sight atmospheric analysis of the hypercubes) model in image processing software (SF.3a and b). The location of the study area in the hilly region induces a shadow effect on the satellite imagery. We have used a band ratio algorithm for shadow effect removal from satellite images. The projection of two images at WGS (world geodetic system) 84 and zone 450 north, on UTM (universal transverse mercator coordinate system) projection system were performed.
Tree species discriminant analysis
For the band’s selection, we have used Hyperion wavebands obtained from the discriminant analysis. This analysis found a set of prediction equations based on independent variables that have been used to classify individuals into groups (Somers and Asner 2014). The discriminant analysis records the lowest Wilks lambda (L) values. The value of L lies between 0 to 1, with the value 1 or close to 1 indicates that the mean of the group is not different. Value of 0 or close to 0 indicates that the mean of the group is different. Green and Caroll developed the L statistic in 1978 (Eq. 1).
where, Seffect denotes a sum of squares matrix and Serror denotes cross products matrix. The classification of tree species were performed using selected spectral bands obtained from the L test.
Spectral separability analysis of tree species
For spectral characteristics of tree species, six different wavelength locations were selected for species spectral separability analysis. Jeffries-Matusita distance method is a method that was selected to estimate the spectral range for different species (Murakami et al., 2001). The value obtained from J-M method varies between 0 and √2. The value lying close to 0 indicates identical distribution whereas value close to √2 indicates dissimilar distribution. The Eq. 2 calculates the J-M distance method.
where, a & b are two target spectral signatures under comparison, μ represents the average vector of spectral signature, C represents the covariance matrix of spectral signature, T represents the transposition role and |C| is the determinant of C (Richards and Jia 2005). The selected end-members spectral wavebands of two datasets (Hyperion and Landsat OLI) were processed with J-M distance method for calculation of spectral separability.
Data dimensionality and spectral similarity analysis
Atmospherically corrected Hyperion data were used in MNF (minimum noise fraction) transformation for data dimensionality. MNF rotation transforms to determine the inherent dimensionality of image data, to segregate noise in the data, and to reduce the computational requirements for subsequent processing (Boardman 1993).We have analyzed noisy data in the MNF tool of image processing software, and outcome bands were used for the classification of tree species. The spectral analysis is based on spectral matching or similarity techniques. The satellite imagery–based derived end-member spectra were compared with field mean spectra using spectral similarity algorithms (Somers and Asner 2014). We have used SFF (spectral feature fitting) algorithm for spectral similarity analysis. A high spectral similarity score denotes the closest match and exhibits maximum value.
Tree species classification and accuracy assessment
The tree species located in Saranda forest are homogeneous, so we have used the full pixel supervised classification methods. Some researchers have used supervised classification algorithms (SAM and MD) for full pixels classification based on trained data (Petropoulos et al. 2013; Richards and Jia 2006). In the present study, supervised classification (SAM, SVM, and MD) algorithms have been used for full pixels classification for Landsat OLI, and Hyperion data based on training tree spectral data. The species classification accuracy matrixes were generated on the basis of ground locations spectra data. Equation 3 computes the accuracy of kappa statistic (K).
where r denotes the number of rows, xii denotes the number of observation in the ith column and row. N indicates the total observations. The xi + and x + i indicates the total number of observation in the ith row and column. A comparison was drawn between these algorithms on classified images based on accuracy assessment for the selection of the best classification algorithm.
Species diversity estimation based on narrow-banded VIs
Species diversity basically means the occurrence of different species of trees represented in a given community (Wang et al. 2003). Some researchers have used hyperspectral narrow banded VIs correlated with field measured Shannon index (H) values for plant diversity mapping at the regional scale level (Peng et al. 2018; Dudley et al. 2015; Mapfumo et al. 2016). The H index is a statistical method that classifies the species diversity by assuming that the sample represents all species (Peng et al. 2018). H index is calculated by following Eq. 3.
where p represents the ratio (n/N), “n” is the number of individual species and total number of different species is “N”. The ln is the natural log, Σ is the sum of the calculations, and s denotes the different types of species. We have used 13 hyperspectral VIs (ST. 2) extracted from Hyperion data correlated with Shannon index (H) values for the estimation of tree species diversity in the study area. The best correlated (higher R2 and lower RMSE) vegetation index was selected for this estimation.
Relationship between species diversity, distance from mines, and concentration of foliar dust
Saranda forest has some of the largest iron ore deposits of India. Mining activities are causing damage to tree species as well as its diversity. In this study, we have shown the relationship between species diversity and distance from mines with leaf dust concentration. We have calculated distance from two mines (Kiriburu and Meghataburu) based on field survey points location using GPS measurement tool. PCE instrument was used for the collection of leaf dust at field location points (Kayet et al. 2019a, b). We have then correlated three parameters (outcome species diversity values, distance from mines, and concentration of leaf dust values) for their relationship.
Results and discussion
Tree species discrimination
The tree species discrimination result is displayed in Table 2. The value of Wilks’ lambda ranged between 0 and 0.0099. The smaller value indicates that the group’s mean of the wavelength bands are different and have high separability between different tree species. From this analysis, 21 optimal wavebands were obtained. From 21 bands, 07 bands fall in the VIR region, 08 bands in the NIR region, and 06 bands in the SWIR region. These wavebands were used for tree species analysis and its classification.
Spectral separability of tree species
The J-M distance method–based spectral separability values were derived from Hyperion and Landsat 8-OLI satellite imagery (Table 3). The values thus obtained by J-M-distance method from Hyperion data ranged between 1.25 and 1.87, which indicates that it has high spectral separability between tree species. The value ranged between 1.107 and 1.392 indicates that it has moderate to low spectral separability between tree species. The spectral separability value of different tree species derived from Hyperion data is higher than Landsat 8 OLI data.
Data dimensionality and similarity
After performing data dimensionality, the eigenvalues lay between 103.88 and 1.07 (ST.3). The first 34 MNF bands had shown good result and exhibited better spectral information. These bands were used for tree species classification. The spectral similarity result (field spectra vs. Hyperion image spectra) is shown in Table 4. The similarity scores indicated that spectral similarity ranged between high to medium. The spectral similarity score for Sal and Teak trees were found highest than the other trees. Sal and Teak trees covers around 65% of the study area (FSI report 2015). The spectral variations of different tree species in the study area are shown in Fig. 3.

Visual comparison of resampled field average reflectance spectra for different tree species at the study area
Tree species classification and accuracy assessment
We have classified tree species of the study area into six different categories based on SVM, SAM, and MD algorithms using Hyperion and Landsat 8 OLI (SF.4). The enlarged view of the mines and its surrounding region classified by the SVM algorithm on Hyperion data is shown in Fig. 4. Sal and Teak trees covered most of the area. These trees were located at higher altitudes (700 to 900 m) on the hilly side of the study region. Other trees are dominant at lower altitude (300 to 400 m), northeast, and southeast parts of the study region. Classification accuracy estimation based on ground species spectra data shown that Hyperion image–based SVM algorithm provided better accuracy results (overall accuracy = 85.16, kappa = 0.78), than SAM algorithm (overall accuracy = 7828, kappa = 0.76) and MD algorithm (overall accuracy = 75.58, kappa = 0.73). Also, Landsat 8OLI image–based species classifications carried out by SVM algorithm; show an overall accuracy of 68.71% and a Kappa statistic of 0.66. The accuracy comparison (Hyperion-based SVM, SAM, MD, and Landsat 8 OLI–based SVM) matrix is shown in Table 5.

Spatial distribution of tree species mapped by SVM algorithm based on Hyperion data
Species diversity estimation and mapping
We have correlated 13 VIs with field measured Shannon index values. The regression analysis results (SSE,R2, Adj.R2, and RMSE) is shown in Table 6. The NDVI705 had shown best linear fitting (R2=0.76, RMSE = 0.04)) with Shannon index values. Since, NDVI 705 correlated well with waned chlorophyll content (Kumar et al. 2015), so we have used this index for diversity estimation. The linear regression plot between narrow-banded VIs and species diversity is shown in Fig. 5. The NDVI705-derived species diversity map is shown in SF.5. Enlarged view of the species diversity map for the mines and its surrounding region is shown in Fig. 6. The linear regression between fields measured Shannon index, and Hyperion derived Shannon index gave the R2 value of 0.72 and RMSE value of 0.15 (Fig. 7). The correlation between Hyperion and field derived Shannon index had shown better relationship (R2 0.68).

Regression between hyperspectral narrow-banded VIs and field measured Shannon index of 18 sampling plots

Species diversity mapped by Shannon index based on hyperspectral narrow-banded VIs

Regression between Hyperion imagery derived by Shannon index and field measured Shannon index
Relationship between species diversity, distance from mines, and foliar dust concentration
For each sample point, values of species diversity, distance from either mines (Kiriburu and Meghataburu), and foliar dust concentration are shown in ST.4. Those values were used for correlations analysis using three different correlation methods (Spearman, Pearson, and Kendall). The correlation results thus obtained by the abovementioned methods are shown in Table 7, (for Meghahatuburu mine) and for Kiriburu mine in ST.5. The correlations results thus obtained show that there exists a good negative correlation between foliar dust concentration, species diversity, and the distance from mines (Fig. 8).

The relation amongst species diversity indices (Shannon index), distance from mines (Kiruburu and Meghataburu) and foliar dust concentration
Discussion
As per the result obtained in this study, we could infer that, hyperspectral (Hyperion) data has more capability in tree species mapping and diversity assessment when coupled with field spectral data, than any other multispectral data (Landsat). Some researchers studied on tree species classification and diversity estimation based on hyperspectral and multispectral data at a fine-scale level. Dalponte et al. 2014 had studied on tree crown and classification using airborne hyperspectral data in boreal forest area. They had shown that hyperspectral data has better accuracy for tree species classification than other multispectral data. Shen and Cao (2017) worked on tree species classification using hyperspectral and Lidar data in subtropical forest area. They had used random forest classification algorithm to differentiate five tree species and provided a relatively higher accuracy (85.4%). This study has displayed a stepwise discrimination test for the identification of wavebands, which is significant for tree species classification. As obtained from the tree species discrimination analysis, 21 different spectral wavebands were selected for tree species classification, of which six belongs to the visual infrared region; eight to the near-infrared, and seven to shortwave infrared region (ST.6). Vyas et al. (2011) studied on tree species discrimination analysis, and they found 22 wavebands, of which seven falls in VIR, eight in NIR, and six bands in the SWIR region. Peerbhay et al. (2013) worked on tree species discrimination analysis in Natal, South Africa. They found a total of 27 wavebands (8-VIR, 12-NIR, and 7-SWIR) from discrimination analysis, and they used those bands for tree species classification. In this work, the result obtained from J-M distance method had shown that Hyperion data–based species spectral separability value (1.25 to 1.87) was higher than Landsat 8 OLI data (1.10 to 1.39). Puletti et al. (2016) had applied the J-M method for spectral separability analysis of tree species. They found that the spectral separability value obtained from hyperspectral data (1.17–1.93) was higher than multispectral data (1.20–1.67). Hao et al. (2014) had used Landsat data for spectral separability analysis of tree species based on the J-M distance method. They found that the spectral separability value lay between 1.27 and 1.73 for different tree species. Some previous studies have reported that the tree species classification performed on hyperspectral data had shown better result than multispectral data. This study has shown that tree species classification based on hyperspectral data (85.16%) provided better classification accuracy than multispectral data (68.71%,). Vyas and Krishnayya (2014) had compared species classification accuracy based on Hyperion (accuracy 85.25%) and Landsat ETM data (accuracy 65.25%) in Western Himalaya region, India. Lim et al. (2019) studied on tree species classification using Hyperion and Sentinel-2 satellite imagery in South Korea and China and compared the accuracy level also (Hyperion-67% and Sentinel-2–51%). In the study, we have used hyperspectral VIs data for species diversity estimation based on Shannon index values. NDVI705 has shown best correlated value (R2 = 0.72) with field-based Shannon index data as it has good sensitivity to chlorophyll content, leaf pigment, canopy structure, and canopy water content (Gitelson et al. 2005; Croft et al. 2014). So we have used the NDVI705 index for species diversity estimation. Other vegetation indices were not matched perfectly with field-based Shannon index due to low canopy structure, canopy water content, and chlorophyll content in the study area (Tuominen et al. 2009; Sims and Gamon 2002). Some researchers had shown that SD and CV NDVI were best correlated with Shannon index values for plant diversity estimation (Peng et al. 2018; Peng et al. 2019). Onyia et al. (2018) studied plant diversity in oil-polluted regions using NDVVI (normalized difference vegetation vigour index) on hyperspectral data. They found that NDVVI was best correlated with Shannon index values. In this study, we have correlated Hyperion and field derived Shannon index values for result validation. The correlation results show that R2 is 0.72, and RMSE is 0.15. These values are not matched well due to noise content in the hyperspectral data and forest canopy problem in the study area. Jha et al. (2019) had performed correlation between AVIRIS-NG (airborne visible/infrared imaging spectrometer-next generation) and field measured Shannon diversity index values and found that R2 was 0.86. Onyia et al. (2019) had correlated two species diversity results (Hyperion and Shannon index diversity) and obtained a R2 value of 0.67. In this study, the correlation between species diversity, foliar dust concentration, and distance from mines had shown a strong negative relationship. Kayet et al. (2019a, b) showed a better negative relationship between forest health, distance from mines, and foliar dust deposition. Tuominen et al. (2009) had shown a clear negative relationship between leaf reflectance and trees distance from mines.
This study involved the tree species classification and diversity estimation. Some errors obtained in the study are shown in regression analysis graph. Many reasons are contributing to the error in tree species classification and diversity estimation. Hyperion data exhibits higher noise ratio and get affected by atmospheric components. It could have induced some error to the study results (Shaw and Burke 2003). The spatial resolution of the Hyperion image is 30 m, so the mixed pixel problem arose for species classification and diversity estimation (Lee and Lathrop 2005). The spectroradiometer instrument collected some self-generated noise during field spectra collection. It may have effect on the results (Vaiphasa 2006). Due to the location of the study area on the hills, the satellite imagery gets infected with shadow error (Adler-Golden et al. 2005). Forest canopy can induce the problem of image spectral segregation (Ustin et al. 2004). The study area has a canopy density cover of about 30 to 40 %.
Conclusions
This work promotes the development of methods for tree species mapping and species diversity estimation using hyperspectral and field data. The species classification was carried out by comparing three different classifiers algorithms (SAM, SVM, and MD) of hilly terrain mining effected forest region. Hyperion-based SVM produced better accuracy (85.16% overall accuracy) followed by SAM (79.55% overall accuracy) and MD (76.58% overall accuracy). The classification accuracy is obtained by hyperspectral (Hyperion) data over multispectral (Landsat OLI) data (68.71% overall accuracy). The tree species diversity carried out by hyperspectral narrow-banded VIs which is correlated with field measured Shannon index. The NDVI705 shows better fit for species diversity estimation. Also, the good correlation result (R = 0.72) was observed between fields measured Shannon index and Hyperion-derived Shannon index. The output maps and statistics had shown that hyperspectral data has the good capability to monitor the tree species and its diversity. The study results also showed that, the effects of mining decreasing the tree species and its diversity as well. The tree diversity results showed a reduction in their species number and ecosystem. So, the monitoring of tree species and its diversity are important for forest and its management. Our work mainly focused on tree species classification, compared different classification algorithms, and identified the best classifier and species diversity mapping at hilly terrain mining effected forest region. We believe that it can be applied to other forest near mining effected regions. Future work will be exceptionally good when Hyperspectral data sources combines with Lidar and UAV data sources.
References
Adam E, Mutanga O, Rugege D (2010) Multispectral and hyperspectral remote sensing for identification and mapping of wetland vegetation: a review. Wetl Ecol Manag 18(3):281–296
Adler-Golden SM, Acharya PK, Berk A, Matthew MW, Gorodetzky D (2005) Remote bathymetry of the littoral zone from AVIRIS, LASH, and QuickBird imagery. IEEE Trans Geosci Remote Sens 43(2):337–347
Ahmad F, Uddin MM, Goparaju L (2018) An evaluation of vegetation health and the socioeconomic dimension of the vulnerability of Jharkhand state of India in climate change scenarios and their likely impact: a geospatial approach. Environ Socio-Econ Stud 6(4):39–47
Alonzo M, Bookhagen B, Roberts DA (2014) Urban tree species mapping using hyperspectral and lidar data fusion. Remote Sensing of Environment 148:70–83
Boardman JW (1993) Automating spectral unmixing of AVIRIS data using convex geometry concepts
Bruce PG, Scrosati B, Tarascon JM (2008) Nanomaterials for rechargeable lithium batteries. Angew Chem Int Ed 47(16):2930–2946
Bunting P, Lucas R (2006) The delineation of tree crowns in Australian mixed species forests using hyperspectral Compact Airborne Spectrographic Imager (CASI) data. Remote Sens Environ 101(2):230–248
Chambers JQ, Asner GP, Morton DC, Anderson LO, Saatchi SS, Espírito-Santo FD et al (2007) Regional ecosystem structure and function: ecological insights from remote sensing of tropical forests. Trends Ecol Evol 22(8):414–423
Cho MA, Mathieu R, Asner GP, Naidoo L, van Aardt J, Ramoelo A, Debba P, Wessels K, Main R, Smit IPJ, Erasmus B (2012) Mapping tree species composition in South African savannas using an integrated airborne spectral and LiDAR system. Remote Sens Environ 125:214–226
Coates AR, Dennison PE, Roberts DA, Roth KL (2015) Monitoring the impacts of severe drought on southern California chaparral species using hyperspectral and thermal infrared imagery. Remote Sens 7(11):14276–14291
Croft H, Chen JM, Zhang Y (2014) The applicability of empirical vegetation indices for determining leaf chlorophyll content over different leaf and canopy structures. Ecol Complex 17:119–130
Dalponte M, Orka HO, Gobakken T, Gianelle D, Næsset E (2013) Tree species classification in boreal forests with hyperspectral data. IEEE Trans Geosci Remote Sens 51(5):2632–2645
Dalponte M, Ørka HO, Ene LT, Gobakken T, Næsset E (2014) Tree crown delineation and tree species classification in boreal forests using hyperspectral and ALS data. Remote Sens Environ 140:306–317
Decocq G, Aubert M, Dupont F, Alard D, Saguez R, Wattez-Franger ANNIE et al (2004) Plant diversity in a managed temperate deciduous forest: understorey response to two silvicultural systems. J Appl Ecol 41(6):1065–1079
Delalieux S, Somers B, Verstraeten WW, Van Aardt JAN, Keulemans W, Coppin P (2009) Hyperspectral indices to diagnose leaf biotic stress of apple plants, considering leaf phenology. Int J Remote Sens 30(8):1887–1912
Dudley KL, Dennison PE, Roth KL, Roberts DA, Coates AR (2015) A multi-temporal spectral library approach for mapping vegetation species across spatial and temporal phenological gradients. Remote Sens Environ 167:121–134
Forest Survey of India (2015) Trees outside forest (urban) (tof-u) report
Fuller DO (2006) Tropical forest monitoring and remote sensing: a new era of transparency in forest governance? Singap J Trop Geogr 27(1):15–29
Getzin S, Wiegand K, Schöning I (2012) Assessing biodiversity in forests using very high-resolution images and unmanned aerial vehicles. Methods Ecol Evol 3(2):397–404
Ghazoul J, Sheil D (2010) Tropical rain forest ecology, diversity, and conservation (No. 577.34 G4)
Ghiyamat A, Shafri HZM, Mahdiraji GA, Shariff ARM, Mansor S (2013) Hyperspectral discrimination of tree species with different classifications using single-and multiple-endmember. Int J Appl Earth Obs Geoinf 23:177–191
Gibbs HK, Munger J, L'Roe J, Barreto P, Pereira R, Christie M, Amaral T, Walker NF (2016) Did ranchers and slaughterhouses respond to zero-deforestation agreements in the Brazilian Amazon? Conserv Lett 9(1):32–42
Gitelson AA, Vina A, Ciganda V, Rundquist DC, Arkebauer TJ (2005) Remote estimation of canopy chlorophyll content in crops. Geophys Res Lett 32(8). https://doi.org/10.1029/2005GL022688
Griffin JN, Jenkins SR, Gamfeldt L, Jones D, Hawkins SJ, Thompson RC (2009) Spatial heterogeneity increases the importance of species richness for an ecosystem process. Oikos 118(9):1335–1342
Hao P, Wang L, Niu Z, Aablikim A, Huang N, Xu S, Chen F (2014) The potential of time series merged from Landsat-5 TM and HJ-1 CCD for crop classification: a case study for Bole and Manas Counties in Xinjiang, China. Remote Sens 6(8):7610–7631
Jha CS, Singhal J, Reddy CS, Rajashekar G, Maity S, Patnaik C et al (2019) Characterization of species diversity and forest health using AVIRIS-NG hyperspectral remote sensing data. Curr Sci 116(7):00113891
Kayet N, Pathak K, Chakrabarty A, Kumar S, Chowdary VM, Singh CP (2019a) Forest health assessment for geo-environmental planning and management in hilltop mining areas using Hyperion and Landsat data. Ecol Indic 106:105471
Kayet N, Pathak K, Chakrabarty A, Kumar S, Chowdary VM, Singh CP, Basumatary S (2019b) Assessment of foliar dust using Hyperion and Landsat satellite imagery for mine environmental monitoring in an open cast iron ore mining areas. J Clean Prod 218:993–1006
Kozoderov V, Kondranin T, Dmitriev E, Kamentsev V (2015) Bayesian classifier applications of airborne hyperspectral imagery processing for forested areas. Adv Space Res 55(11):2657–2667
Kumar SS, Manoj P, Giridhar P (2015) Fourier transform infrared spectroscopy (FTIR) analysis, chlorophyll content and antioxidant properties of native and defatted foliage of green leafy vegetables. J Food Sci Tech 52(12):8131–8139
Lassau SA, Hochuli DF (2005) Wasp community responses to habitat complexity in Sydney sandstone forests. Austral Ecol 30(2):179–187
Lee S, Lathrop RG (2005) Sub-pixel estimation of urban land cover components with linear mixture model analysis and Landsat Thematic Mapper imagery. Int J Remote Sens 26(22):4885–4905
Lenhard K Schaepman ME, Purves R, Gege P, Hüni A (2005) Improving the calibration of airborne hyperspectral sensors for earth observation
Leutner BF, Reineking B, Müller J, Bachmann M, Beierkuhnlein C, Dech S, Wegmann M (2012) Modelling forest α-diversity and floristic composition—On the added value of LiDAR plus hyperspectral remote sensing. Remote Sens 4(9):2818–2845
Lim J, Kim KM, Jin R (2019) Tree species classification using hyperion and sentinel-2 data with machine learning in South Korea and China. ISPRS International Journal of Geo-Information 8(3):150
Madubansi M, Shackleton CM (2006) Changing energy profiles and consumption patterns following electrification in five rural villages, South Africa. Energy Policy 34(18):4081–4092
Mapfumo RB, Murwira A, Masocha M, Andriani R (2016) The relationship between satellite-derived indices and species diversity across African savanna ecosystems. Int J Appl Earth Obs Geoinf 52:306–317
Möckel T, Dalmayne J, Schmid BC, Prentice HC, Hall K (2016) Airborne hyperspectral data predict fine-scale plant species diversity in grazed dry grasslands. Remote Sensing 8(2):133
Morris RJ (2010) Anthropogenic impacts on tropical forest biodiversity: a network structure and ecosystem functioning perspective. Philos Trans Royal So B Biol Sci 365(1558):3709–3718
Nagendra H (2001) Using remote sensing to assess biodiversity. Int J Remote Sens 22(12):2377–2400
Nagendra H, Rocchini D (2008) High resolution satellite imagery for tropical biodiversity studies: the devil is in the detail. Biodivers Conserv 17(14):3431–3442
Obeng EA, Oduro KA, Obiri BD, Abukari H, Guuroh RT, Djagbletey GD, Appiah-Korang J, Appiah M (2019) Impact of illegal mining activities on forest ecosystem services: local communities’ attitudes and willingness to participate in restoration activities in Ghana. Heliyon 5(10):e02617
Onyia NN, Balzter H, Berrio JC (2018) Normalized difference vegetation vigour index: a new remote sensing approach to biodiversity monitoring in oil polluted regions. Remote Sens 10(6):897
Onyia NN, Balzter H, Berrio JC (2019) Spectral diversity metrics for detecting oil pollution effects on biodiversity in the Niger Delta. Remote Sens 11(22):2662
Peerbhay KY, Mutanga O, Ismail R (2013) Commercial tree species discrimination using airborne AISA eagle hyperspectral imagery and partial least squares discriminant analysis (PLS-DA) in KwaZulu–Natal, South Africa. ISPRS J Photogramm Remote Sens 79:19–28
Peng Y, Fan M, Song J, Cui T, Li R (2018) Assessment of plant species diversity based on hyperspectral indices at a fine scale. Sci Rep 8(1):4776
Peng Y et al (2019) Identification of the best hyperspectral indices in estimating plant species richness in sandy grasslands. Remote Sens 11(5):588
Petropoulos GP, Vadrevu KP, Kalaitzidis C (2013) Spectral angle mapper and object-based classification combined with hyperspectral remote sensing imagery for obtaining land use/cover mapping in a Mediterranean region. Geocarto International 28(2):114–129
Plaza A, Benediktsson JA, Boardman JW, Brazile J, Bruzzone L, Camps-Valls G et al (2009) Recent advances in techniques for hyperspectral image processing. Remote Sens Environ 113:S110–S122
Puletti N, Camarretta N, Corona P (2016) Evaluating EO1-Hyperion capability for mapping conifer and broadleaved forests. Eur J Remote Sens 49(1):157–169
Raizada A, Samra JS (2000) Rehabilitation of an abandoned limestone mine in the lower western Himalayas-impact assessment on vegetation development and floristic diversity. Indian Forester 126(8):842–855
Richards JA, Richards JA (1999) Remote sensing digital image analysis (vol. 3, pp. 10–38). Berlin: Springer
Richards JA, Jia X (2005) Remote-sensing digital image analysis. Introduction/John A. Richards, Xiuping Jia.
Richards JA, Jia X (2006) Interpretation of hyperspectral image data. Remote Sensing Digital Image Analysis: An Introduction:359–388
Savitzky A, Golay MJ (1964) Smoothing and differentiation of data by simplified least squares procedures. Anal Chem 36(8):1627–1639
Schneider FD, Morsdorf F, Schmid B, Petchey OL, Hueni A, Schimel DS, Schaepman ME (2017) Mapping functional diversity from remotely sensed morphological and physiological forest traits. Nat Commun 8(1):1–12
Shaw GA, Burke HK (2003) Spectral imaging for remote sensing. Lincoln Lab J 14(1):3–28
Shen X, Cao L (2017) Tree-species classification in subtropical forests using airborne hyperspectral and LiDAR data. Remote Sens 9(11):1180
Sims DA, Gamon JA (2002) Relationships between leaf pigment content and spectral reflectance across a wide range of species, leaf structures and developmental stages. Remote Sens Environ 81(2-3):337–354
Somers B, Asner GP (2014) Tree species mapping in tropical forests using multi-temporal imaging spectroscopy: Wavelength adaptive spectral mixture analysis. Int J Appl Earth Obs Geoinf 31:57–66
Staenz K, Secker J, Gao BC, Davis C, Nadeau C (2002) Radiative transfer codes applied to hyperspectral data for the retrieval of surface reflectance. ISPRS J Photogramm Remote Sens 57(3):194–203
Tuanmu MN, Jetz W (2015) A global, remote sensing-based characterization of terrestrial habitat heterogeneity for biodiversity and ecosystem modelling. Global Ecology and Biogeography 24(11):1329–1339
Tuominen J, Lipping T, Kuosmanen V, Haapanen R (2009) Remote sensing of forest health. Geosci Remote Sens:30–52
Ustin SL, Roberts DA, Gamon JA, Asner GP, Green RO (2004) Using imaging spectroscopy to study ecosystem processes and properties. AIBS Bull 54(6):523–534
Vaiphasa C (2006) Consideration of smoothing techniques for hyperspectral remote sensing. ISPRS J Photogramm Remote Sens 60(2):91–99
Vyas D, Krishnayya NSR (2014) Estimating attributes of deciduous forest cover of a sanctuary in India utilizing Hyperion data and PLS analysis. Int J Remote Sens 35(9):3197–3218
Vyas D, Krishnayya NSR, Manjunath KR, Ray SS, Panigrahy S (2011) Evaluation of classifiers for processing Hyperion (EO-1) data of tropical vegetation. Int J Appl Earth Obs Geoinf 13(2):228–235
Wang G, Zhou G, Yang L, Li Z (2003) Distribution, species diversity and life-form spectra of plant communities along an altitudinal gradient in the northern slopes of Qilianshan Mountains, Gansu, China. Plant Ecol 165(2):169–181
Acknowledgements
The authors are thankful to Space Application Centre (SAC) ISRO, Ahmedabad for their financial support and providing necessary data. The authors are also thankful to DFO of Saranda forest, SAIL; Raw Material Division (RMD), Kolkata and Forest department of Jharkhand for their financial support and providing necessary data. The authors would like to thanks, Indian Institute of Technology, Kharagpur and Vidyasagar University for their constant support and providing the wonderful platform for research.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editor: Philippe Garrigues
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
ESM 1
(DOCX 7323 kb)
Rights and permissions
About this article

Cite this article
Kayet, N., Pathak, K., Chakrabarty, A. et al. Assessment of mining activities on tree species and diversity in hilltop mining areas using Hyperion and Landsat data. Environ Sci Pollut Res 27, 42750–42766 (2020). https://doi.org/10.1007/s11356-020-09795-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-020-09795-w