
Abstract
Wireless sensor network (WSN) clustering techniques play a crucial role in extending the network's lifespan through various methods. In WSN, the clustering techniques elect the best cluster heads (CHs) among the deployed sensor nodes in terms of their computational, energy, and link capabilities. The CHs nodes expend more energy than other sensor nodes due to a heavier workload, such as receiving messages from their cluster members and other cluster heads, aggregating all messages, and transmitting them to the base station with the help of non-cluster head nodes in the layered sensor network. Thus, there is a dire need to develop an efficient CHs election algorithm. In this paper, the modified particle swarm optimization (M-PSO) method, along with the Genetic algorithm (GA), is considered for selecting cluster heads and non-cluster heads. The proposed method computes the probability of choosing the best nodes as cluster heads, and the GA is employed to discover the optimum shortest path. The selection of the optimum route is based on the employed objective function. Additionally, the proposed method demonstrates superior performance compared to existing state-of-the-art techniques such as GAPSO-H, EC-PSO, and NEST. However, DMPRP performs 12% better than NEST, EC-PSO, and GAPSO-H overall.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
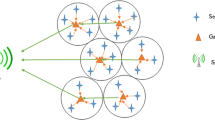
The sensor networks' lifespan can be extended by clustering techniques that reduce the quantity of radio emissions. The clustering approach may dynamically modify the lifespan of various sensor regions in network performance, reduce energy consumption, fault tolerance, low latency, and reliability [1]. The idea of clustering is to divide the network into several clusters, with one node in each cluster being chosen as the Cluster Head (CH). CHs are responsible for intra-cluster coordination, communication, and data aggregation among nodes within their cluster, as well as inter-cluster communication with external observers. Clustering is the process of grouping all of the network's sensors into groups with Non-Cluster Members (NCMs), Cluster Members (CMs), and CHs [2]. The cluster administrations control and transmit the gathered data to the Base Station (BS). In recent years, numerous clustering techniques have been introduced in WSNs. The distance from the BS to other nodes is computed based on the location of the BS, using the distance rate and the list of neighbors. The network's power consumption can be effectively lowered since the majority of the sensor nodes only need to send data over a short distance to the subsequent CH [3]. From NCMs to CH and from CH to BS, an optimal path may be chosen. Therefore, by applying an M-PSO method, DMPRP can be designed to increase the effectiveness of cluster selection [4]. The Genetic Algorithm (GA) is a global optimization approach based on the natural selection process [5, 6], which can be used to choose an optimized path. When constructing network paths, GA often optimizes a variety of factors. High-performance data network routing is suitable for optimization. The wireless sensor network in Fig. 1 is cluster-based. To communicate further, sensor nodes first monitor their surroundings, collect data, and then transfer it to the corresponding cluster head [7]. In Fig. 1, the performance of the cluster head collects data from cluster members and aggregates it to send directly or indirectly to the sink node and base station. Thus, the routing problem can be simplified through optimization [8]. This article examines the reliability of the genetic string while defining specific constraints on energy bandwidth, average inter-cluster distance, and cluster quality. Therefore, with the aid of GA, we are creating a routing plan to perform the best path [9].

Cluster based wireless sensor network
1.1 Contribution of Article
The contributions of the work are given as follows:
-
In this work, we have developed an effective dynamic multipath cluster optimization model that reduces energy consumption and increases the network lifetime through optimal cluster head (CH) selection in cluster-based sensor networks.
-
The M-PSO algorithm has been used to select the optimal cluster head based on probability computed using energy consumption rate (ECR).
-
The genetic algorithm (GA) is utilized to discover the optimum shortest path based on the M-PSO after the selection of CH.
-
By combining M-PSO and GA, the algorithm benefits from their complementary strengths. M-PSO may excel in efficiently exploring the solution space and quickly converging to promising regions, while GA can further refine the solutions and explore diverse search areas. This collaborative approach ensures a more robust and effective optimization process, leading to an end-to-end optimum solution from the source to the destination host in the wireless sensor network.
The remaining paper is set up as shown below. A literature review is included in Sect. 2. The network and energy models are presented in Sect. 3. In Sect. 4, we proposed a method for choosing the optimal cluster head by utilizing the M-PSO algorithm. Findings best cluster is using head selection M-PSO and the best cluster heads assist the genetic algorithm in determining the optimal shortest path in Sect. 5, which is all about genetic algorithms. The paper's experimental and performance evaluation for models and conclusion with the future work are offered in Sect. 6 and 7 respectively as a concluding point.
2 Literature Survey
The literature survey is divided into two parts namely traditional routing protocols and swarm intelligence-based routing protocols.
2.1 Traditional Routing Protocols
A well-known clustering methodology known as Low Energy Adaptive Clustering Hierarchy (LEACH) [10] adopts a hierarchy based on the idea of distributing traffic balance across the network's sensor nodes, which is a substantial contribution from LEACH. The LEACH protocol functions in multiple rounds, with some nodes acting as forwarders while others serve as CH nodes to balance the energy usage of nodes. The primary weakness of LEACH was the random selection of CH nodes, which could result in an uneven distribution of sensor nodes and cause an uneven distribution of power consumption among clusters in the network. The cluster head can perish earlier due to the LEACH protocol's primary focus on single-hop propagation, as it consumes energy more quickly [11]. Cognitive LEACH, an improved version of LEACH, distributes CHs more logically. It is largely focused on reducing the problem of power imbalance. Cog-LEACH, a centralized cognitive LEACH, was addressed by Latiwesh et al. [12]. This technique employs the remaining energy of sensor nodes and the addition of idle channels for head selection to manage the power burden on cluster nodes. However, this protocol was not suitable for scalable networks, single-hop routing transmission, or delivering data from source to destination [13]. Arumugam et al. [14] developed a novel protocol idea known as EE-LEACH. It suggests an effective way to create clusters and aggregate data, which reduces energy but increases network complexity as a result of integrating several technologies.
The grid-based protocols divide the network situation into several rectangles, with an odd number of grids from the rectangle region, and the sensor nodes forming clusters in each row [15]. This approach lengthens the life of the network and considerably reduces energy exploitation. Even if the grids are working inconsistently for each rectangle, there is an excessive amount of forwarding across all the tiers. This processing occurs when top-layer nodes have expired, and lower-layer nodes are unable to transfer data, which uses a lot of energy. The hotspot problem is successfully solved using several protocols, known as "Energy-Efficient and Balanced-Cluster-based Data Aggregation" (EE-BCDA) multi-hop [16]. In an effort to reduce the network's energy consumption, authors present the grid-based clustering algorithm EEMRP in transmission management (CM) [17]. They distribute multi-hop data transfer, which spreads the burden of CH nodes.
2.2 Swarm Intelligence Based Routing Protocols
Self-organization and self-association provide the optimum answer in optimizing several technological domains such as the position of nodes or localization, efficient data packet routing, cluster creation, CH selection, and many more, and are at the core of swarm intelligence (SI). ABCSD, known as the artificial bee colony search features protocol that Ari et al. created for cluster-based energy-efficient routing [18], was utilized to build the cluster, which uses less energy. While setting the threshold power is used in the protocol approach to pick CHs, a distributed method is used to choose CHs. No further cluster heads have been chosen when the cluster's total energy falls below the energy threshold [19]. Yalçin et al. [20] have presented two approaches based on bacterial interaction. The first is known as the cognitive-routing algorithm for power save, and the second is known as communication limits for cluster head selection. This method selects the number of hops between source to destination for communicating information. Karaboga et al. [21] proposed a routing protocol for clustering systems that uses the artificial bee colony (ABC) method to lengthen the network's lifespan. This approach uses a different quality of service system to reduce delay time between clusters receiving communication signals. This procedure was reacting to unequal energy consumption in the dispersion of cluster heads not taken into account.
Rao et al. proposed an "Energy-Efficient Cluster-Head Selection Algorithm" based on particle swarm optimization (PSOECHS) [22]. They select Cluster Head nodes by taking into account several variables, such as intra-cluster distance, BS distance, and the remaining energy of the sensors. Some nodes that are further away from the Cluster Head nodes fail prematurely. Due to a number of circumstances, it is necessary to exercise caution simultaneously when the cluster head node picked by nodes includes residual energy but is farther from such a node. Kuila et al. [23] employed clustering approaches based on particle swarm optimization. The cluster creation in this approach is dependent on two factors: first, the average cluster distance, and second, the lifespan of the gateway. The fitness amounts of each particle in the system are determined using a fitness function approach. The system quality is conditioned by this fitness value. Particularly higher value functions in the network structure helped the fitness to improve.
With the use of the PSO approach, Latiff et al. [24] suggested a clustering technique in energy-aware for WSN, which established an actual value function to minimize network energy reduction and reduce intra-cluster distance. The cluster-head sends data to the BS during routing. A method of PSO was proposed by Singh et al. for the formation of energy-aware clusters through the selection of an ideal cluster head. Particle swarm optimization enables the final cost reduction for the best placement of both cluster-head nodes in such a cluster. Instead of employing BS, a Semi-Distributed Particle Swarm Optimization (PSOSD) technique has been created using the Particle Swarm Optimization-based methodology inside clusters. However, because the protocol does not take into consideration the distance between nodes and the base station, it could result in CHs using excessive amounts of energy to send data to the base station [25]. The hybrid energy-efficient distributed clustering (HEED) protocol is another well-known clustering protocol that is discussed. The cost of intra-cluster data exchange and the residual energy of a hybrid node is taken into account while choosing the CHs on a periodic basis [26]. This method of clustering connects cost with re-selection, lowers head network, and can rule out the possibility of several CHs in the area. Additionally, HEED uses the multi-hop communication concept, allowing cluster heads to collectively send data to the base station through many hops [27]. Table 1 shows the comparative analysis of the various existing metaheuristics.
The authors introduce a hybrid GA-inspired greedy mutation strategy for IoT-enabled WSNs in a smart city, focusing on a weighted fitness function with node density, energy levels, and distance, alongside a 3-tier heterogeneity and energy-efficient node deployment to extend network longevity [32]. The proposed GM-WOA model, integrating genetic mutation with whale optimization, optimizes cluster node selection in heterogeneous SDN-enabled WSNs by using self-adaptive inertia weights, a fitness function, and genetic mutation for dynamic selection and energy-efficient transmission, ensuring even CN distribution for load balancing, and is implemented on the ONOS controller and tested with the ns-3 simulator [33]. This study introduces an AI-based green routing for ICPS utilizing a cluster-based approach with CH election via the AI-inspired ESHLFO algorithm and tackles the energy hole issue using four peripheral, energy-unlimited data collection nodes [34]. The papers [35, 36] explore methods to extend the lifetime of IoT networks.
3 Network Model
The methodology suggested in this study aims to establish a flexible structure of cluster heads, improving scalability for diverse network scenarios. It seeks to maintain enhanced energy efficiency in an ideal manner using wireless sensor networks. The energy is utilized to extend the life of the networks. The clustering process, which offers an algorithm for choosing CH nodes, and the routing algorithm are the main focus. The aforementioned network assumptions apply to the proposed DMRP. All sensor nodes are uniform. These nodes are immobile when processing and sending data. In this protocol, routing entails route discovery and route management [37]. The source node initiates the route recovery process to send messages known as route request and route reply (RREP). The destination node is the only node that can send an RREP message back to the sender node. The best route between the sender and the destination is used. Multiple data channels should be provided to ensure load balancing, reduced latency, and improved network performance. Several routing protocols might offer an alternative path in the event that any route fails [38].
The main energy-consuming processes of sensor nodes can be divided into three categories: transmission, energy amplification, and reception operations. One of the most important characteristics for radio sensors is the distance between the transmitter and receiver nodes. The system chooses a free-space or multipath fading communication channel for the propagation distance in Eq. (1). Energy consumption is directly proportional to \({d}^{2}\) if the propagation distance is less than the threshold distance \({t}_{0}\), else it is proportional to \({d}^{4}\). The first equation establishes the highest energy required to transmit a l-bit packet over a d-distance from the transmitter to the receiver:
For transmitting one-bit data of sensor node use, the \({E}_{con}\) energy and system in Eq. (1) uses two versions of energy model amplifier coefficients, first free-space, and second multipath fading, indicated by \({E}_{fs}\) and \({E}_{mp}\), respectively. Determined using the second equation the threshold distance:
In Eq. (2), \({E}_{fs}\) and \({E}_{mp}\) are both parameters for amplifiers. The sensor nodes employ the multipath fading energy model amplifier parameter \({E}_{mp}\) when \(d<{t}_{0}\) and the free-space energy model amplifier parameter \({E}_{fs}\) when \(d = {t}_{0}\) and \(d > {t}_{0}\), respectively [30]. The proposed dynamic multipath clustering system based on uneven dynamic M-PSO is guaranteed to be able to communicate with nodes in clusters since the maximum transmission distance of sensor nodes in this study is not greater than \({t}_{0}\).
4 Proposed Mechanism
The working of the proposed mechanism consists of the cluster creation and formation, and cluster head selection.
4.1 Cluster Creation and Formation
Cluster members, cluster heads, and non-cluster heads all play roles in the development of clusters employing cluster-based designs. A cluster head node controls the cluster and collects data from cluster members to send to the base station. The ability of nodes to handle additional tasks is considered in relation to their proximity to the base station or their number of neighbors when choosing the cluster head. Node residual energy is assessed using characteristics such as cluster member, neighbor node, neighbor-ID, cluster head-IP, and neighbor cluster (NCH-IP), cluster gateway-IP. Using distance values and the base station location as reference points, we estimated the distance from the base station to other nodes and identified the list of nearby nodes. The multi-objective function of a network is taken into consideration to identify k-optimal clusters in mathematical form. The query that employs the k-means algorithm is referred to as expectation–maximization. The closest cluster is giving a data point’s assignment by the E-step in Eq. (3).
The centroid of each cluster will be determined using the M-step in Eq. (4).
The mathematical solution is described below. It encompasses the following objectives:
Equation (5) presents data point \({{\text{x}}}^{{\text{i}}}\), where \({{\text{w}}}_{{\text{ik}}}=1\) indicates that \({{\text{x}}}^{{\text{i}}}\) belongs to cluster \(k\), and \({{\text{w}}}_{{\text{ik}}}=0\) otherwise. The centroid of cluster \(k\), to which \({{\text{x}}}^{{\text{i}}}\) belongs, is also referred to as \(k\). This represents a dual minimization problem. First, we treat the set \(k\) and then minimize \({\text{J}}\) with respect to \({{\text{w}}}_{{\text{ik}}}\). Next, we fix \({{\text{w}}}_{{\text{ik}}}\) and minimize \({\text{J}}\) in relation to \(k\). In practice, we first identify \({\text{J}}\) with respect to \({{\text{w}}}_{{\text{ik}}}\) and monitor cluster assignments in the E-step. After determining the cluster assignments from the previous M-step, we split \({\text{J}}\) with respect to \(k\) and then recalculated the centroid. The data point \({{\text{x}}}^{{\text{i}}}\) is assigned to the closest cluster based on its distance from the overall cluster's centroid, as detailed in Eq. (6).
4.2 Cluster Head Selection
The following factors are primarily considered when selecting a cluster head: Cluster Head IP, Neighbour Node-IP, Neighbour Cluster-IP, Cluster Member-IP, NCH IP, and Cluster Gateway-IP. Dynamic multipath routing protocols used for cluster selection perform a minimal amount of calculation to determine the Energy Consumption Ratio (ECR) for each Cluster Head's selection:
After determining the ECR, the DMPRP calculates the Residual Energy Transfer Ratio (RETR) as shown in Eq. (7):
where \({{\text{d}}}_{{\text{toBS}}}\) represents the distance between the \({CLN}_{m}\) and the BS. Incorporating the ECR equation, the RETR is presented in Eq. (8):
The aggregate values of ECR and RETR in Eq. (9) for several nodes over a given period are determined by DMPRP for the current round. Since the rate of energy consumption equals \(P= {{\text{E}}}_{{\text{r}}}/T\), the total power dissipation over time is calculated using the Riemann sum. This approach allows for estimating the duration of an instance over time (\({E}_{instance}\)) in Eq. (10).
\({E}_{instance }- ECR\) works only in the presence of R in Eqs. (10) and (11). Over time, the energy usage is incorporated into Eq. (10) as follows:
The prior instance RETR is also calculated using DMPRP with the aforementioned formulas. In consideration of this, the BS selects a set of nodes with the lowest energy usage and highest residual energy. The choice of a CLN as a CH node is significantly influenced by the distance between factors. The following pseudo-code demonstrates the steps taken to select DMPRP cluster heads. The Algorithm 1 outlines the work steps that will be followed to choose cluster heads and non-cluster heads using the M-PSO Algorithm.

Cluster Head Selection
Here, a brief description of the packet scheduling using modified particle swarm optimization is discussed. Route selection is based on the condition of node fitness. To organize efficient route selection, we introduced the MPSO scheduling packets method, which generated a dynamic multipath routing protocol. We briefly describe MPSO before providing the projected algorithm. PSO essentially chooses an appropriate number of nodes to communicate with multiple nodes, with distance and fitness values entered into an N-dimensional space. Each node's fitness and distance are updated using Eqs. (12) and (13), respectively:
where \({n}_{i}\) stands for a node's fitness and \({s}_{i}\) for a node's distance. The category of the node route is the optimal solution to determine PSO using the best dynamic multipath routing in three distinct objectives of packet scheduling. PSO classifies the best cluster head as the optimal outcome. The best non-cluster head is presented as the best point among non-clustering nodes, while the best cluster member represents the accurate point among certain nearby nodes. Positions of all cluster members, the best cluster head, and the non-cluster head are shown in Eqs. (12) and (13), where \({n}_{i}\) represents the \({i}^{th}\) node's fitness and \({s}_{i}\) represents the \({i}^{th}\) node's distance. PSO creates the optimum dynamic multipath routing for packet scheduling that categorizes the node route's optimal solution into three different scopes: \({CH}_{best}\), \({CM}_{best}\), and \({NCH}_{best}\). It displays the best cluster head (\({CH}_{best}\)) as the ideal result. The top cluster participant, the best point among certain surrounding nodes, is represented by \({CM}_{best}\), while the best point among non-clustering nodes is represented by \({NCH}_{best}\), a non-cluster head.
The positions of the best cluster head, cluster member, and non-cluster head, are displayed respectively in Eqs. (14), (15), and (16):
There are following updates which are made to the \(n+1\) nodes' fitness and distance for the next node, respectively in Eqs. (17) and (18):
where \(i=1, 2,\) and \(j = 1, 2, ..., {n}_{p}\). After several iterations, \({n}_{p}\) represents the number of nodes,\(w\), which ranges from 0 to 1. These are random parameters given between 0 and 1, and the nodes will find the best solution in the search space. The search space is determined by the previous average solution and the population.
The pseudo code modified packet scheduling using MPSO is discussed in this subsection as Algorithm 2. There are the following inputs used nodes, fitness value, distance, and time for finding the best cluster head selection. We are using the following steps to find out the best cluster head selection:

Modified MPSO
The description of the cluster selection flow using the MPSO algorithm as follows. A DMPRP is first used to create and establish clusters. After the clusters are formed, we must choose the best cluster heads, which aggregate the data and send it to the base station. The base station computes the optimal choice based on probability. Using the MPSO approach from Eq. (7), the likelihood of the energy consumption ratio is calculated for CHs (Cluster Heads) and NCHs (Non-Cluster Heads). Figure 2 depicts a working flow diagram for the PSO (Particle Swarm Optimization) algorithm's cluster selection process. If a cluster head produced at random falls below the threshold value, choose it as a CH; otherwise, choose it as an NCH. Based on the best probability and fitness value, the BS (Base Station) selects the clusters using the MPSO Algorithm shown in Fig. 2. If the fitness function is lower than the options for CHs and NCHs, select the best applicable option. Repeat this process until the best selection scheduling is completed. The optimal shortest path is then determined using GA (Genetic Algorithm) by computing the cluster heads' selection using the M-PSO algorithm.

Data flow process of PSO Cluster Selection
5 Genetic Algorithm (GA)
The underlying concept of GAs for evolution closely resembles the ideas put forth by Charles Darwin. The concept of natural selection provides the foundation for the hypothetical search algorithm known as GA. Genetic crossover significantly improves the algorithm's capacity to locate and identify the ideal outcome. Holland had two additional objectives: first, to better understand the process of natural selection; and second, to create an artificial framework that functions similarly to the natural system. Through optimization, the best response can be derived from the parameters. The objective function is set up for optimization. Instead of aiming for the largest production to optimize, it means striving for the best quality that most closely satisfies the criteria. GAs are most useful for applications that require optimization.
5.1 GA Operations
The efficacy of GAs is dependent on its operators, which determine the mode of operation of the GA, as shown in Fig. 2. The following are numerous GA procedures:
-
1.
Selection The chromosomes are picked in the selection process either from the population or based on the significance of their intended function. The most important node for assessing whether a chromosome will persist is the Objective function. A chromosome with a higher fitness value is more likely to produce one or more offspring in the next generation.
-
2.
Crossover In general, it is similar to other optimization methods. At the bottom and top of the crossing, the selected parent crosses across a 1-point or 2-point mechanism. Following the parents' marriage, further children are born.
-
3.
Mutation A genetic algorithm's decision-making process includes a supporting role for mutation. Due to the possibility of genetic information being lost during reproduction and crossover processes, the mutation is crucial. Rotating bits at a rate of Mutation is a common method for achieving mutation. The main objective is to diversify the population [39].
5.2 Algorithm Representation of String
A numerical sequence represents the real chromosome across the population. Each number represents one of the network's nodes, whereas the text indicates a network path. Figure 3 depicts the length of the genetic string. There is no defined length for chromosomes; they can vary in length. Then, more hops occur the more nodes there are throughout the genome. Transport data will be present. Instead, they make up a significant section of the population and have the same origin and destination. Random sampling is done from that population count. The remaining chromosomes are not taken into account.

Genetic representation of string
5.3 Proposed Genetic Outline
The generic outlines of the proposed work as given as follows:
-
1.
Population initialization 33% of the population is picked after 30 rounds of randomization for n chromosomes.
-
2.
Parents selection Fitness functions F(x) are used to choose parents. Based on the findings of an M-PSO algorithm, this value is determined for each X chromosome. As a parent, the big Fitness value chromosome is picked. The two chromosomal pairs that produce offspring that seem to thrive in natural selection are used for crossing over.
-
3.
Create a new population, and then continue the previous procedures until the new population is complete.
-
Selection Choose parents from either group based on objective characteristics such as the fitness value of CHs and NCHs.
-
Crossover: Creating new offspring by crossing parents.
-
Mutation Offspring are mutated based on mutation rate.
-
Case 1: Trace the recurring and missing nodes, denoted by R and M.
Case 2: If R and M is not present
Then randomly pick any two nodes and swap say as S. length of chromosome say L
Case 3: If (L≤2)
No mutation is performed.
Case 4: If (L≥3)
The middle value is changed with the missing node.
-
Acceptance If the current kids outperform the existing chromosomes, they are placed in the new population.
-
Then 'stop' if the stop condition is met, and the best solution from the current population is returned.
5.4 Data Flow of Cluster Selection Using Results of M-PSO with GA
Based on a random selection, the population is initially chosen as the best-fitted subset of the CHs (Cluster Heads) and NCHs (Non-Cluster Heads) created by the M-PSO algorithm. It is then determined which chromosomes will be transferred to the offspring based on their fitness values. Following the crossover procedure, a new offspring is generated, and then the mutation procedure is performed. A flow diagram for cluster selection using M-PSO and GA is shown in Fig. 4. In Case 1, during the mutation operation, it is necessary to identify the repeating and absent nodes to organize the data. If there are no repeating or missing nodes in Case 2, any random integer is selected and swapped. To decide whether a mutation is necessary in Case 3, the length of the chromosome must be examined. In the fourth case, if the length is greater than three, the chromosome with the missing node is flipped. Generation refers to the loop's repeated iteration. The population's initial repeat (Generation 0) is managed on randomly selected individuals. After reaching the final condition, the most promising outcome is selected based on the superiority of the path.

Data flow diagram of Cluster Selection using PSO with GA
5.5 Evaluating the Fitness Value of Mutated Off-Springs
Both mutant children' fitness values have been computed. The mutant progeny replaces the chromosomes that have the lowest fitness value. It is thought that the worst chromosomes are eliminated. The population is stable in size. The fitness function confirms the accessibility of a bandwidth first. The path disregards the Optimum-path unless the required bandwidth is unavailable. If not, it calculates the number of route hops and the delay factor. Each route's sustainability is assessed using the Objective Functions described below. Let f1 stand for an energy efficiency function and f2 for a fitness function of cluster quality and an average of intra-cluster distance. The f1 and f2 functions must be minimized, and this calls for the best possible choice of CHs. The 2-objective functions are normalized between 0 and 1, which effectively minimizes the linear combination of f1 and f2. f1 and f2 are used to generate the fitness function for the proposed modified PSO (M-PSO)-based strategy. The following is the linear programming formulation for choosing the best CHs. We take into account the three parameters: average Inter-cluster distance, existing energy, and cluster quality (CQ).
5.6 Derivation of the Fitness Function
5.6.1 Cluster Quality for CH and NCH
The objective is to maximize the energy consumption ratio (ECR) by improving the cluster quality between CHs and NCHs and their cluster members. Using the signal strength indicator (RSSI), it evaluates the amount of energy that the RF client is delivering. Calculating the receiver's low power and low voltage requires the CC2420 transceiver from an access point or router. The quality of a route may be measured accurately and simply using RSSI, according to numerous researches. Following is an estimation of the quality of the route link between local \({CH}_{j}\) and cluster member \({node}_{i}\):
Because the quality of the route connection is inversely related to the RQ, the value must be lowered in order to improve cluster quality.
To increase the cluster quality, the value must be decreased because the quality of the route connection is inversely connected to the RQ.
where is the number of cluster \(j\) members?
5.6.2 Average ICD
Average ICD (intra-cluster distance) is the average of all node distances from the specified CHs and may be computed as:
The energy consumption ratio (ECR) needs to be decreased because all nodes utilize energy when sending data to their respective CHs during intra-cluster communication. Consequently, a node is selected as a CH if it is close to all other nodes. The average cluster quality (CQ) and average inter-cluster distance (ICD) must be minimized to ensure a suitable CH range for all CHs. Consequently, we have the following first objective:
Objective 1:
where m denoted the number of CHs.
5.6.3 Energy Efficiency
Every existing energy is indicated as, where the total existing energy of all the currently chosen CHs, denoted by, may be calculated as
For the optimal selection of CHs, the total energy of all CHs must be maximized, meaning the reciprocal need should be minimized. This is because a node with greater battery capacity is better suited for data aggregation and cluster management, making a node's remaining energy a critical factor in deciding CHs. Furthermore, all sensor nodes receive an equal share of the absorbed energy. Consequently, the following is our second objective function:
Objective 2:
where \(j\) stands for initial and current energy values, respectively, and m stands for the number of CHs.
The proposed technique does not directly contradict any of the two objective functions indicated above. Therefore, it is preferable to reduce each of these goal functions linearly combined rather than individually. We utilize the fitness function shown below since it generates a distinct optimum solution.
Since a lower fitness value yields better particle positioning, which results in the best possible selection of CHs, minimizing the fitness value is our main objective.
6 Experimental and Performance Evaluation
We use Network Simulator Version 2 to simulate our experiment and evaluate the effectiveness of our proposed model, DMPRP (NS2). Using WSN features, we first set up a wireless sensor network in NS2, and then we develop a hybrid WSN model that accounts for sensor nodes with various energy rates, channels, and bandwidth rates. Each sensor node in a network is randomly placed and equipped with different wireless sensing capabilities. In this experiment, we altered a network with various nodes, topographies, energy rates, and communication ranges. The main goal is to assess how well the suggested strategy improves communication effectiveness in diverse contexts.
6.1 Performance Analysis
In this experiment, we compared the proposed DMPRP's performance with that of the NEST [3], EC-PSO [28] and GAPSO-H [29] techniques using the following metrics: the amount of energy used, the routing overhead, the end-to-end latency, communication delay, packet delivery ratio, and throughput.
The energy consumption metric refers to the total power expenditure incurred by a network in executing its operations, including the processing and transmission of data across its nodes. This parameter is pivotal for evaluating the efficiency and sustainability of networks, especially in environments where energy resources are limited.
Network overhead refers to the amount of traffic or data being transmitted through a network infrastructure at any given time. It is a measure of the utilization of network resources and indicates the level of demand placed on the network by various applications, devices, and users. Understanding and managing network load is essential for maintaining network performance, reliability, and quality of service.
The end-to-end latency is also known as network latency. Network latency is the time it takes for data to travel from the source node to the destination node in a network. It is a crucial metric in assessing the responsiveness and efficiency of a communication system, including wireless sensor networks (WSNs), Internet of Things (IoT) devices, and other networked systems.
The communication delay also referred to as transmission delay, is the time required for data to be transmitted from the sender to the receiver in a communication system. It is one of the components of end-to-end latency and is a critical factor in determining the overall responsiveness and efficiency of the communication network.
The packet delivery ratio (PDR) is a metric used to evaluate the effectiveness of data transmission in a network, particularly in wireless communication systems like wireless sensor networks (WSNs). It represents the ratio of successfully delivered packets to the total number of packets sent by a source node.
Throughput in the context of networking, refers to the rate at which data is successfully transmitted from a source to a destination within a network over a specified period of time. It is a key performance metric that measures the efficiency and capacity of a network to deliver data packets between devices or nodes.
In our first experiment nodes are varying from 50, 100, 150, and 200 nodes with respect to the amount of energy used, the routing overhead, the end-to-end latency, communication delay, and packet delivery ratio in Fig. 5. The following are some examples of the metrics used to determine the effectiveness of the routing technique and compare it with the approach based on the NEST-sites selection process: NEST, EC-PSO, GAPSO-H, and EC-PSO, which are acronyms for Energy Centers Searching employing PSO. We looked into two options: the number of nodes and the number of rounds [29]. The results presented above show how well the suggested protocols DMPRP, NEST, EC-PSO, and GAPSO-H perform for different numbers of nodes. The findings showed that using additional Cluster Heads improved the distribution of data from the zones of non-cluster members to the closest Cluster Head. The number of nodes affects how much energy is used by the total system. Figure 5A and B show how many packets were successfully sent to the base station and how the packet delivery ratio fell as the number of nodes and rounds increased. The overall delivery ratio varied with the number of rounds, as seen in Fig. 5C. The overhead rises with the quantity of nodes and rounds, as seen by the overhead results in Figs. 5D and 6E. More routing was completed, which had a higher impact on control packets as more nodes distributed data.

A represents ratio between nodes and packet delivery, B represents ratio between nodes and network overhead, C represents ratio between nodes and energy consumption, D represents ration between nodes and end-to-end delay and E represents ratio between nodes and throughput

A represents ratio between rounds and packet delivery, B represents ratio between rounds and network ahead, C represents ratio between rounds and energy consumption, D represents ratio between rounds and end-to-end delay and E represents ratio between rounds and throughput
Additionally, the number of rounds is considered with respect to the packet delivery ratio, network overhead, energy consumption, end to end delay, and throughput in simulation results. Figure 6C and B show that when the number of sensors increases, the energy consumption rises, and the cluster head establishes connectivity with both non-cluster and cluster members. The cluster head consumes extra energy based on the designated energy level, and the suggested model improves communication by limiting the routing packets for the number of rounds in Fig. 6A. Figure 6D shows the end-to-end delay performance of DMPRP, NEST, EC-PSO, and GAPSO-H compared in Fig. 6A–E. According to the findings, the suggested protocol DMPRP's end-to-end delay rate is higher because there are more players and cluster heads, which impacts packet delay. As a result, DMPRP performs 12% better overall than NEST, EC-PSO, and GAPSO-H. Figures 5 and 6 depict the throughput fluctuation with regard to the number of nodes and rounds in the throughput scenario. According to the determined results, the throughput rate was marginally lower, although it was higher in relation to the volume of packets transmitted over the network when compared to NEST, EC-PSO, and GAPSO-H.
6.2 Discussions
In our initial study, we varied node counts at 50, 100, 150, and 200 to assess their impact on energy usage, routing costs, delay times, communication delay, and successful message transmissions, as seen in Fig. 5. We measured the efficiency of different routing methods, including proposed DMPRP, NEST [3], EC-PSO [28], and GAPSO-H [29], based on metrics like energy consumption and delivery success rates. These methods were compared against a background of varying node and operational cycle numbers. Our findings indicate that increasing the number of Cluster Heads enhances data distribution efficiency from non-cluster zones to their nearest Cluster Heads, impacting the system's overall energy footprint. Figure 5A and B highlight the correlation between node/round numbers and packet delivery success, showing a decline in delivery rates with higher node and round counts. This trend also influenced routing overhead and control packet distribution as node and cycle numbers grew, as detailed in Figs. 5D and 6E.
Further analysis into the effects of operational cycles on delivery success, network costs, energy use, delay times, and overall throughput revealed a direct relationship between sensor count and energy demand, with Cluster Heads playing a pivotal role in connecting different network segments, as documented in Fig. 6C and B. This setup necessitated additional energy, especially for Cluster Heads, to maintain effective communication across rounds, as illustrated in Fig. 6A. Moreover, our comparison in Fig. 6D and E showed that DMPRP, despite causing higher end-to-end delays due to the increased number of elements in the network, still outperformed other models by 12% in overall efficiency. Figures 5 and 6 collectively demonstrate how network performance metrics like throughput react to changes in node and cycle counts, underlining a slight throughput reduction but an overall higher packet transmission rate when compared to other evaluated protocols.
7 Conclusion and Future Work
In this article, the suggested dynamic multi-path routing protocol enhances network performance by using a modified particle swarm optimization technique for the optimum cluster and cluster head selection. Improvements in packet delivery ratio, network overhead, energy consumption, end-to-end delay, and throughput all contribute to better overall performance. In order to obtain a more efficient energy-consumption ratio, the network field structure is divided into numerous groups (clusters) based on node architecture. This will balance the load and improve performance by choosing the cluster head. The proposed work has further enhanced a route path from NCH to CH based on the cluster head selected. The results are used to find the best shortest path using the Genetic Algorithm. Comparing DMPRP's overall performance to NEST, EC-PSO, and GAPSO-H, it is becoming more effective.
Future research in wireless sensor networks (WSNs) will focus on enhancing load balancing through advanced location techniques and Bacterial Foraging Optimization (BFO). Efforts will also be made to improve energy efficiency using Managed Diffusion and Load Aggregation. The integration of WSN clustering with technologies like machine learning, edge computing, and IoT will address challenges in data processing, security, and scalability. Collaborations across various fields and real-world testing of clustering techniques will provide insights into their application effectiveness and scalability. However, challenges like computational complexity from integrating Modified Particle Swarm Optimization (M-PSO) and Genetic Algorithm (GA), and resource constraints in WSNs, will need addressing to optimize network performance.
Data availability
This work is based on simulator so there is no need of database.
References
Singh, D., Kumar, B., Singh, S., & Chand, S. (2019). SMAC-AS: MAC based secure authentication scheme for wireless sensor network. Wireless Personal Communications, 107(2), 1289–1308.
Prakash, V., & Pandey, S. (2021). Best cluster head selection and route optimization for cluster based sensor network using (M-pso) and GA algorithms.
Singh, S., Nandan, A. S., Malik, A., Kumar, R., Awasthi, L. K., & Kumar, N. (2022). A GA-based sustainable and secure green data communication method using IoT-enabled WSN in healthcare. IEEE Internet of Things Journal, 9(10), 7481–7490.
Hamida, E. B., & Chelius, G. (2008). A line-based data dissemination protocol for wireless sensor networks with mobile sink. In Proceedings of the 2008 IEEE International Conference on Communications, Beijing, China.
Ruan, D., & Huang, J. (2019). A PSO-based uneven dynamic clustering multi-hop routing protocol for wireless sensor networks. Sensors, 19, 1835.
Nandan, A. S., Singh, S., Malik, A., & Kumar, R. (2021). A green data collection & transmission method for IoT-based WSN in disaster management. IEEE Sensors Journal, 21(22), 25912–25921.
Goldberg, D. E. (1989). Genetic algorithms in search, optimization & machine learning. Addison-Wesley Longman Publishing Co., Inc.
Wang, Z. X., Chen, Z. Q., & Yuan, Z. Z. (2004). QoS routing optimization strategy using genetic algorithm in optical fiber communication networks. Journal of Computer Science and Technology, 19, 213–217.
Nandan, A. S., Singh, S., Kumar, R., & Kumar, N. (2022). An optimized genetic algorithm for cluster head election based on movable sinks and adjustable sensing ranges in IoT-based HWSNs. IEEE Internet of Things Journal, 9(7), 5027–5039.
Eletreby, R. M., Elsayed, H. M., Khairy, M. M. (2014) CogLEACH: A spectrum aware clustering protocol for cognitive radio sensor networks. In Proceedings of the 9th International Conference on Cognitive Radio Oriented Wireless Networks and Communications (CROWNCOM), Oulu, Finland.
Latiwesh, A., & Qiu, D. Energy efficient spectrum aware clustering for cognitive sensor networks: CogLeach-C. In Proceedings of the 10th International Conference on Communications and Networking in China (ChinaCom), Shanghai, China, 2015.
Arumugam, G. S., & Ponnuchamy, T. (2015). EE-Leach: Development of energy-efficient LEACH protocol for data gathering in WSN. EURASIP Journal on Wireless Communication and Networks, 2015, 1–9.
Huang, J., Hong, Y., Zhao, Z., & Yuan, Y. (2017). An energy-efficient multi-hop routing protocol based on grid clustering for wireless sensor networks. Cluster Computing, 20, 3071–3083.
Yuea, J., Zhang, W., Xiao, W., Tang, D., & Tang, J. (2012). Energy efficient and balanced cluster-based data aggregation algorithm for wireless sensor networks. Procedia Engineering, 29, 2009–2015.
Pant, M.; Dey,B.; Nandi, S. A multi-hop routing protocol for wireless sensor network based on grid clustering. In Proceedings of the 2015 Applications and Innovations in Mobile Computing (AIMoC), Kolkata, India, pp. 137–140 (2015).
Ari, A. A. A., et al. (2016). A power efficient cluster-based routing algorithm for wireless sensor networks: Honeybees swarm intelligence based approach. Journal of Network and Computer Applications, 69, 77–97.
Yalçın, S., & Erdem, E. (2019). Bacteria interactive cost and balanced-compromised approach to clustering and transmission boundary-range cognitive routing in mobile heterogeneous wireless sensor networks. Sensors, 19(4), 867.
Kumar Shukla, R., & Kumar Tiwari, A. (2021). Comparative analysis of machine learning based approaches for face detection and recognition. Journal of Information Technology Management, 13(1), 1–21.
Karaboga, D., et al. (2014). A comprehensive survey: Artificial bee colony (ABC) algorithm and applications. Artificial Intelligence Review, 42(1), 21–57.
Rao, P. C. S., Jana, P. K., & Banka, H. (2017). A particle swarm optimization based energy efficient cluster head selection algorithm for wireless sensor networks. Wireless Networks, 23(7), 2005–2020.
Kuila, P., & Jana, P. K. (2014). Energy efficient clustering and routing algorithms for wireless sensor networks: Particle swarm optimization approach. Engineering Applications of Artificial Intelligence, 33, 127–140.
Latiff, N. M. A. et al. Dynamic clustering using binary multi-objective particle swarm optimization for wireless sensor networks. In 2008 IEEE 19th International Symposium on Personal, Indoor and Mobile Radio Communications. IEEE, 2008.
Singhal, P., Srivastava, P. K., Tiwari, A. K., & Shukla, R. K. (2022). A survey: Approaches to facial detection and recognition with machine learning techniques. In Proceedings of Second Doctoral Symposium on Computational Intelligence (pp. 103–125). Springer, Singapore.
Kaswan, A., Singh, V., & Jana, P. K. (2018). A multi-objective and PSO based energy efficient path design for mobile sink in wireless sensor networks. Pervasive Mobile Computing, 46, 122–136.
Younis, O., & Fahmy, S. (2004). HEED: A hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Transactions on Mobile Computing, 3(4), 366–379.
Kumar Shukla, R., Das, D., & Agarwal, A. (2016). A novel method for identification and performance improvement of blurred and noisy images using modified facial deblur inference (FADEIN) algorithms. In 2016 IEEE Students' Conference on Electrical, Electronics and Computer Science (SCEECS), (pp. 1–7). IEEE.
Labraoui, N., Yenké, B. O., & Gueroui, A. Clustering algorithm for wireless sensor networks: The honeybee swarms nest-sites selection process based approach Ado Adamou Abba Ari.
Wang, J., et al. (2019). An improved routing schema with special clustering using PSO algorithm for heterogeneous wireless sensor network. Sensors, 19(3), 671.
Sahoo, B. M., Pandey, H. M., & Amgoth, T. (2021). GAPSO-H: A hybrid approach towards optimizing the cluster based routing in wireless sensor network. Swarm and Evolutionary Computation, 60, 100772.
Prakash, V., & Pandey, S. (2023). Metaheuristic algorithm for energy efficient clustering scheme in wireless sensor networks. Microprocessors and Microsystems, 101, 104898.
Singh, S., Nandan, A. S., Sikka, G., Malik, A., & Kumar, N. (2024). A genetic-algorithm-based dynamic transmission of data for communicable disease in IoMT environment. IEEE Internet of Things Journal, 11(1), 1427–1438.
Singh, S., Garg, D., & Malik, A. (2023). A novel cluster head selection algorithm based IoT enabled heterogeneous WSNs distributed architecture for Smart City. Microprocessors and Microsystems, 101, 104892.
Tyagi, V., & Singh, S. (2023). GM-WOA: A hybrid energy efficient cluster routing technique for SDN-enabled WSNs. The Journal of Supercomputing, 79, 14894–14922.
Verma, S., Kaur, S., Garg, S., Sharma, A. K., & Alrashoud, M. (2024). AGRIC: Artificial-intelligence-based green routing for industrial cyber-physical system pertaining to extreme environment. IEEE Internet of Things Journal, 11(3), 3749–3756.
Jain, A., Mehrotra, T., Sisodia, A., Vishnoi, S., Upadhyay, S., Kumar, A., Verma, C., & Illés, Z. (2023). An enhanced self-learning-based clustering scheme for real-time traffic data distribution in wireless networks. Heliyon, 9(7), e17530.
Nagaraj, S., Kathole, A. B., Arya, L., Tyagi, N., Goyal, S. B., Rajawat, A. S., Raboaca, M. S., Mihaltan, T. C., Verma, C., & Suciu, G. (2023). Improved secure encryption with energy optimization using random permutation Pseudo algorithm based on Internet of Thing in wireless sensor networks. Energies, 16(1), 1–16.
Tiwari, A. K., & Shukla, R. K. (2019). Machine learning approaches for face identification feed forward algorithms. In: Proceedings of 2nd International Conference on Advanced Computing and Software Engineering (ICACSE).
Vimalarani, C., Subramanian, R., & Sivanandam, S. N. (2016). An enhanced PSO-based clustering energy optimization algorithm for wireless sensor network. The Scientific World Journal, 2016, 8658760. https://doi.org/10.1155/2016/8658760
Shukla, R. K., Prakash, V., & Pandey, S. (2020). A perspective on Internet of Things: Challenges & applications. In 2020 9th International Conference System Modeling and Advancement in Research Trends (SMART), (pp. 184–189). IEEE.
Funding
The authors have received no financial support for this research authorship and publication of this article.
Author information
Authors and Affiliations
Contributions
All authors have contribution in this manuscript. We declare that all authors agreed with the content and that all gave explicit consent to submit and that we have obtained consent from the responsible authorities at the institute/organization where the work has been carried out, before the work is submitted.
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Prakash, V., Singh, D., Pandey, S. et al. Energy-Optimization Route and Cluster Head Selection Using M-PSO and GA in Wireless Sensor Networks. Wireless Pers Commun (2024). https://doi.org/10.1007/s11277-024-11096-1
Accepted:
Published:
DOI: https://doi.org/10.1007/s11277-024-11096-1